![]()
TensorHive is an open source tool for managing computing resources used by multiple users across distributed hosts. It focuses on granting exclusive access to GPUs for machine learning workloads and consists of reservation, monitoring and job execution modules.
It's designed with simplicity, flexibility and configuration-friendliness in mind.
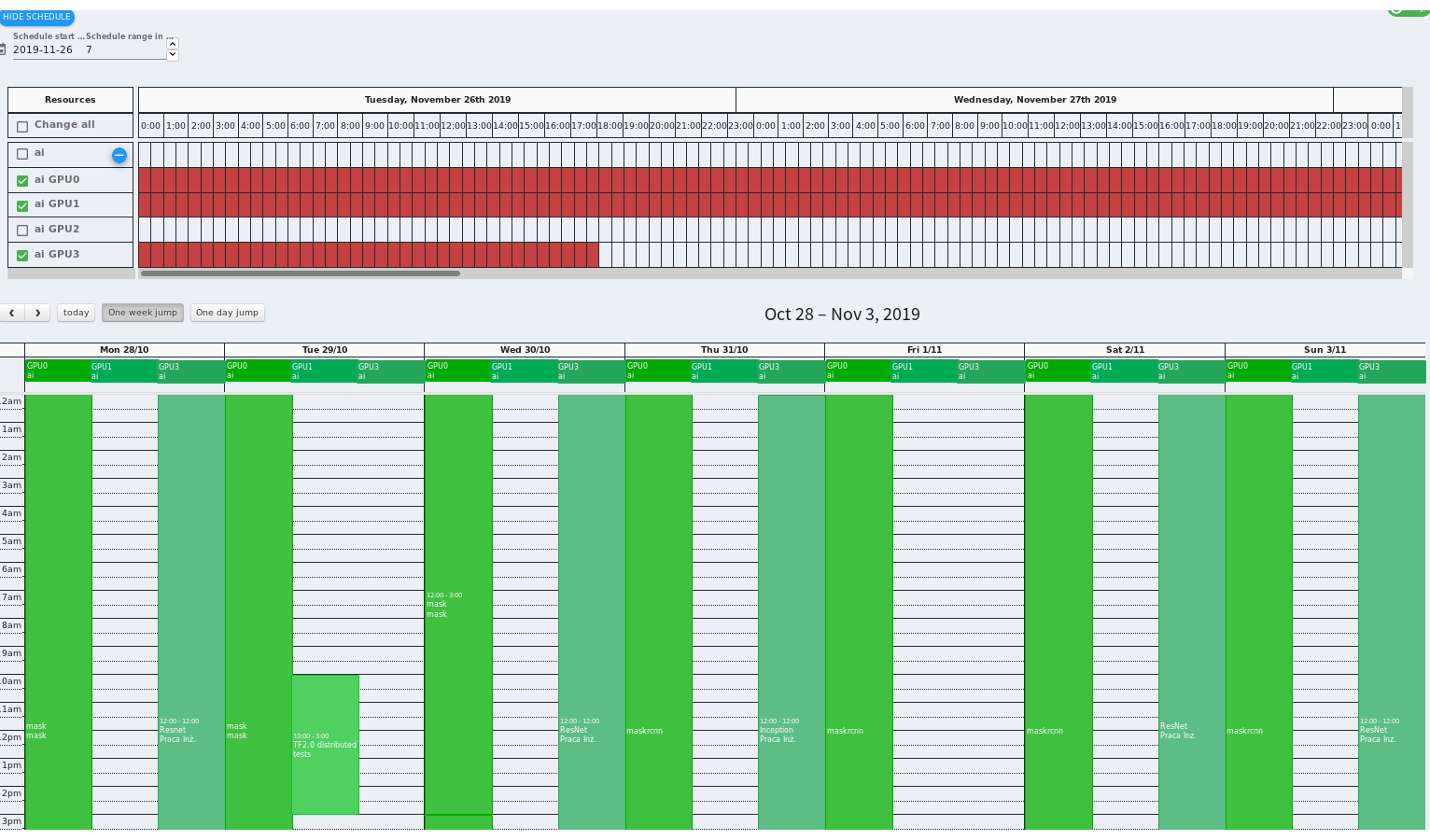
Each column represents all reservation events for a GPU on a given day.
In order to make a new reservation simply click and drag with your mouse, select GPU(s), add some meaningful title, optionally adjust time range.
If there are many hosts and GPUs in our infrastructure, you can use our simplified, horizontal calendar to quickly identify empty time slots and filter out already reserved GPUs.
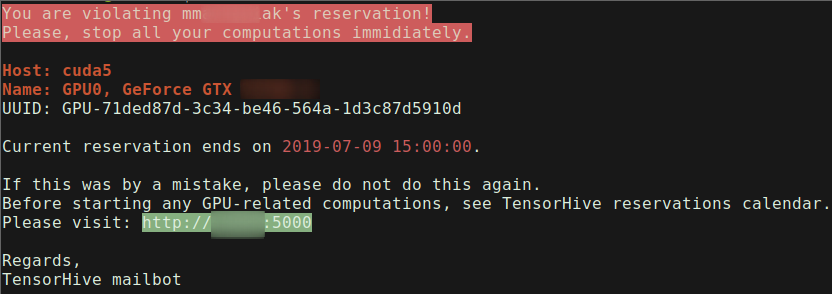
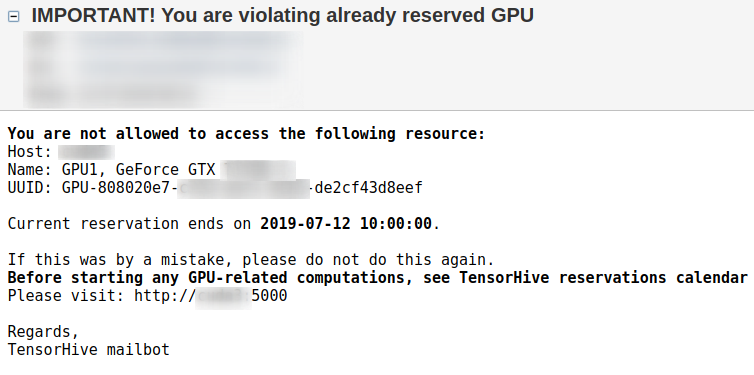
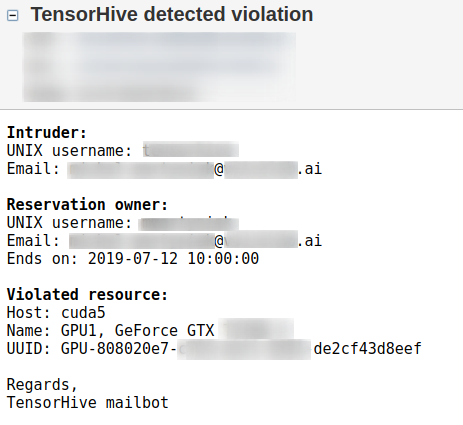
From now on, only your processes are eligible to run on the reserved GPU(s). TensorHive periodically checks if some other user has violated it. They will be spammed with warnings on all his PTYs, emailed every once in a while, additionally admin will also be notified (it all depends on the configuration).
| Terminal warning | Email warning | Admin warning |
|---|---|---|
 |
 |
 |
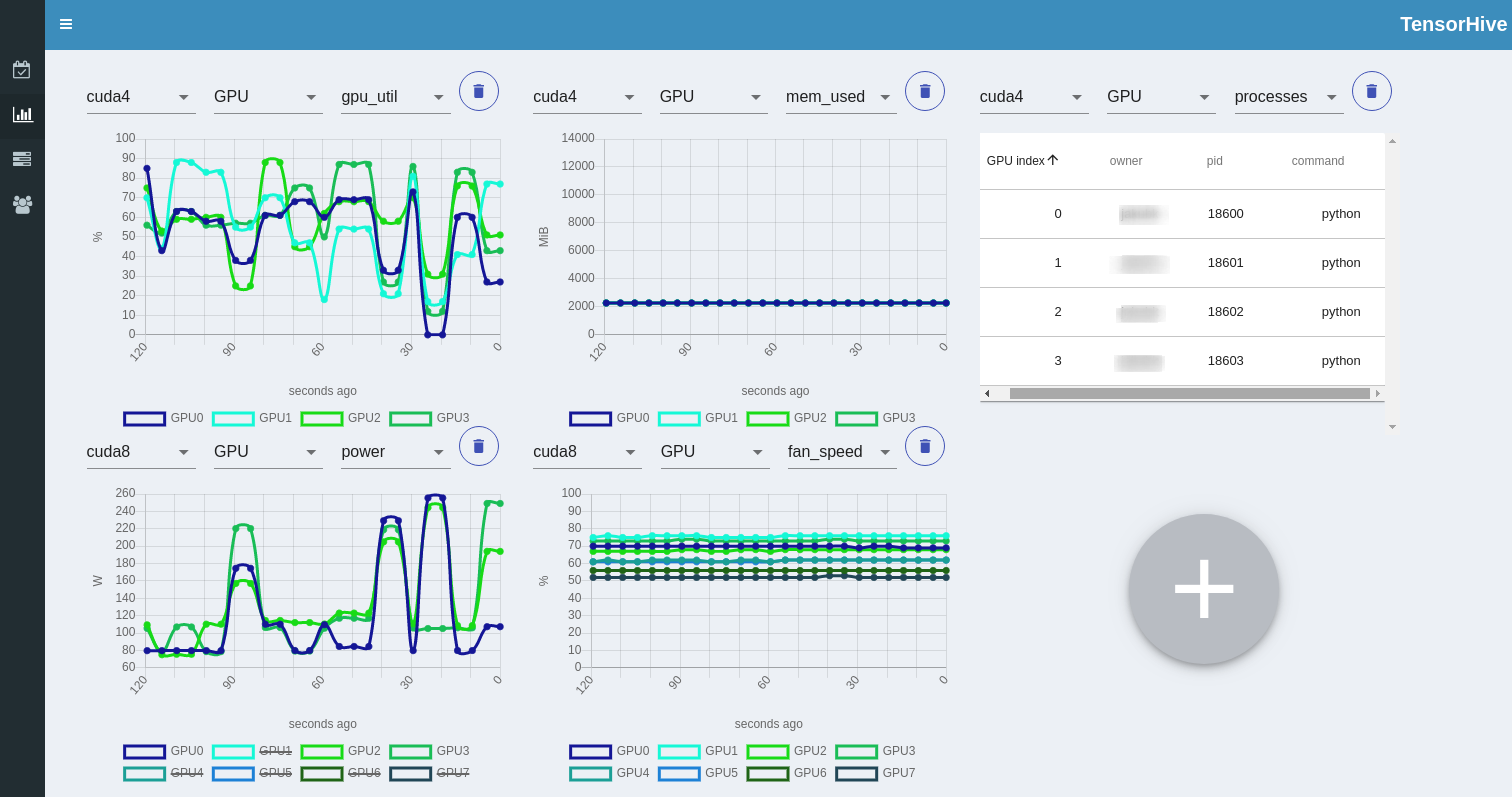
Accessible infrastructure can be monitored in the Nodes overview tab. Sample screenshot: Here you can add new watches, select metrics and monitor ongoing GPU processes and their owners.
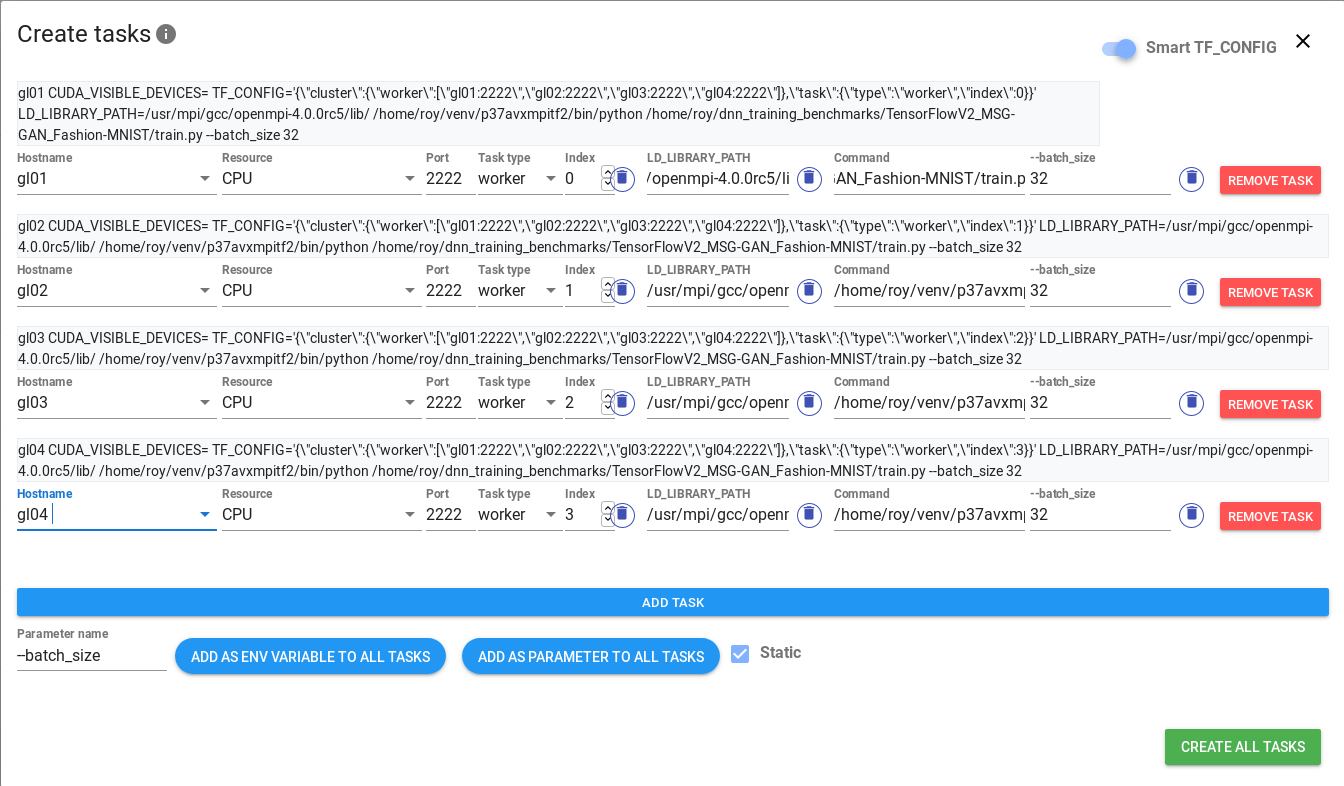
Thanks to the Job execution module, you can define commands for tasks you want to run on any configured nodes.
You can manage them manually, set specific spawn/terminate dates or add jobs to a queue, so that they are executed automatically
when the required resources are not reserved.
Commands are run within screen session, so attaching to it while they are running is a piece of cake.
It provides a simple, but flexible (framework-agnostic) command templating mechanism that will help you automate multi-node trainings.
Additionally, specialized templates help to conveniently set proper parameters for chosen well known frameworks. In the examples directory, you will find sample scenarios of using the Job execution module for various
frameworks (including TensorFlow and PyTorch) and computing environments.
TensorHive requires that users who want to use this feature must append TensorHive's public key to their ~/.ssh/authorized_keys on all nodes they want to connect to.
Our goal is to provide solutions for painful problems that ML engineers often have to struggle with when working with remote machines in order to run neural network trainings.
- You're an admin, who is responsible for managing a cluster (or multiple servers) with powerful GPUs installed.
- 😠 There are more users than resources, so they have to compete for it
- 🎤 The users require exclusive access to the GPUs, rather than a queuing system
- 🔮 You need to control which projects in your organization consume the most computing power
- 🌊 Other popular tools are simply an overkill, have different purpose or require a lot of time to spend on reading documentation, installation and configuration (Grafana, Kubernetes, Slurm)
- 🐧 People using your infrastructure expect only one interface for all the things related to managing computing infrastructure: monitoring, reservation calendar and scheduling distributed jobs
- 💥 Can't risk messing up sensitive configuration by installing software on each individual machine, prefering centralized solution which can be managed from one place
- You're a standalone user who has access to beefy GPUs scattered across multiple machines.
- 〽️ You want to keep the GPU utilization high, considering batch size, host to device data transfer etc. - charts with metrics such as
gpu_util,mem_util,mem_usedare great for this purpose - 📅 Visualizing names of training experiments using calendar helps you track how you're progressing on the project
- 🐍 Launching distributed trainings is essential for you, no matter what the framework is
- 😵 Managing a list of training commands for all your distributed training experiments drives you nuts
- 💤 Remembering to manually launch the training before going sleep is no fun anymore
0️⃣ Dead-simple one-machine installation and configuration, no sudo requirements
1️⃣ Users can make GPU reservations for specific time range in advance via reservation mechanism
➡️ no more frustration caused by rules: "first come, first served" or "the law of the jungle".
2️⃣ Users can prepare and schedule custom tasks (commands) to be run on selected GPUs and hosts
➡️ automate and simplify distributed trainings - "one button to rule them all"
3️⃣ Gather all useful GPU metrics, from all configured hosts in one dashboard
➡️ no more manual logging in to each individual machine in order to check if GPU is currently in use or not
4️⃣ Access to specific GPUs or hosts can be granted to specific users or groups
➡️ division of the infrastructure can be easily adjusted to the current needs of work groups in your organization
5️⃣ Automatic execution of queued jobs when there are no active GPU reservations
➡️ jobs that are not urgent can be added to a queue and automatically executed later
- All nodes must be accessible via SSH, without password, using SSH Key-Based Authentication (How to set up SSH keys - explained in Quickstart section)
- Only NVIDIA GPUs are supported (relying on
nvidia-smicommand) - Currently TensorHive assumes that all users who want to register into the system must have identical UNIX usernames on all nodes configured by TensorHive administrator (not relevant for standalone developers)
- (optional) We recommend installing TensorHive on a separate user account (for example
tensorhive) and adding this user to thettysystem group.
pip install tensorhive(optional) For development purposes we encourage separation from your current python packages using e.g. virtualenv, Anaconda.
git clone https://github.com/roscisz/TensorHive.git && cd TensorHive
pip install -e .TensorHive is already shipped with newest web app build, but in case you modify the source, you can can build it with make app. For more useful commands see our Makefile.
Build tested with Node v14.15.4 and npm 6.14.10
The init command will guide you through basic configuration process:
tensorhive init
You can check connectivity with the configured hosts using the test command.
tensorhive test
(optional) If you want to allow your UNIX users to set up their TensorHive accounts on their own and run distributed
programs through Job execution module, use the key command to generate the SSH key for TensorHive:
tensorhive key
Now you should be ready to launch a TensorHive instance:
tensorhive
Web application and API Documentation can be accessed via URLs highlighted in green (Ctrl + click to open in browser).
You can fully customize TensorHive behaviours via INI configuration files (which will be created automatically after tensorhive init):
~/.config/TensorHive/hosts_config.ini
~/.config/TensorHive/main_config.ini
~/.config/TensorHive/mailbot_config.ini
Serving TensorHive through reverse proxy requires proper configuration of URL parameters in the [api] section of
main_config.ini, including url_schema, url_hostname, url_port and url_prefix.
(see example)
Let's assume that the WebApp is served locally on http://localhost:5000, the API on http://localhost:1111 and we
want to serve TensorHive publicly at https://some-server/tensorhive. In such case the following main_config.ini:
url_schema = https
url_hostname = some-server
url_port = 443
url_prefix = tensorhive/api
should be used along with a reverse proxy similar to the following example for nginx:
location /tensorhive {
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-Host $host:$server_port;
proxy_set_header X-Forwarded-Server $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
add_header 'Access-Control-Allow-Origin' '*';
add_header 'Access-Control-Allow-Credentials' 'true';
add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS';
add_header 'Access-Control-Allow-Headers' 'DNT,X-CustomHeader,Keep-Alive,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type';
proxy_pass http://localhost:5000/tensorhive;
proxy_set_header SCRIPT_NAME /tensorhive;
}
location /tensorhive/api {
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-Host $host:$server_port;
proxy_set_header X-Forwarded-Server $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
add_header 'Access-Control-Allow-Origin' '*';
add_header 'Access-Control-Allow-Credentials' 'true';
add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS';
add_header 'Access-Control-Allow-Headers' 'DNT,X-CustomHeader,Keep-Alive,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type';
proxy_pass http://localhost:1111;
}
If you use TensorHive for a scientific publication, we would appreciate citations:
@article{JMLR:v22:20-225,
author = {Paweł Rościszewski and Michał Martyniak and Filip Schodowski},
title = {TensorHive: Management of Exclusive GPU Access for Distributed Machine Learning Workloads},
journal = {Journal of Machine Learning Research},
year = {2021},
volume = {22},
number = {215},
pages = {1-5},
url = {http://jmlr.org/papers/v22/20-225.html}
}We'd ❤️ to collect your observations, issues and pull requests!
Feel free to report any configuration problems, we will help you.
Currently we are gathering practical infrastructure protection scenarios from our users to extract and further support the most common TensorHive deployments.
If you consider becoming a contributor, please look at issues labeled as good-first-issue and help wanted.
Project created and maintained by:
- Paweł Rościszewski (@roscisz)
Michał Martyniak (@micmarty)
- Filip Schodowski (@filschod)
Top contributors:
- Jacek Szempliński (@jszemplinski)
- Mateusz Piotrowski (@matpiotrowski)
- Martyna Oleszkiewicz (@martyole)
- Tomasz Menet (@tomenet)
- Bartosz Jankowski (@brtjank)
TensorHive has been greatly supported within a joint project between VoiceLab.ai and Gdańsk University of Technology titled: "Exploration and selection of methods for parallelization of neural network training using multiple GPUs".