Transfer learning using pre trained objective detection model FCOS: Fully Convolutional One-Stage Object Detection architecture #5932
Comments
|
@santhoshnumberone The vision/torchvision/models/detection/fcos.py Line 162 in 2214acb Though it's possible to modify the entire network to replace all references of I'm going to close the issue, as I believe this answers your question but feel free to reopen if you face issues. |
I have an interesting finding to disprove your thinking of I did the same with Faster R-CNN ResNet-50 FPN Replacing prediction head with label I trained using Trained for 10 epochs Here's the output for first two epochs Here's the training result for first two epochs when trained head from scratch So you can see the difference here training from pre trained weights gives better result than when trained from scratch So request you to look into what the actual issue with this particular FCOS model implementation in pytorch |
|
@santhoshnumberone You are using optimizer configuration that I haven't tested but the 0.0 accuracies on the from scratch might indicate an issue of LR or initialisation. Note that 2 epochs are not nearly enough to get good results. Our recent refresh of the models used 400 epochs to get near SOTA results (see #5763 for details to copy the recipe and try it out). So far, I don't see any evidence that there is a problem with the implementation of FCOS. We have fully reproduced the result of the paper and thus I think it's more likely that the issue could be on the way you train or modify the model. I recommend trying the recipe posted above to see what kind of results you get between from scratch and pre-trained. |
I agree, I don't have resources(GPU or I could have achieved Could you please guide me as to how to overcome getting this error while trying to train with FCOS? |
Understood but it's very hard to provide much help if I can't reproduce the problem. I can only tell you what I believe is not but due to the lack of info I'm forced to guess.
As mentioned earlier, the |
Since Let me try it and get back with result. I wonder how come this is not the issue with the code of |
|
Hi, I have a question regarding this. I'm trying to do transfer learning using FCOS but with a completely different set of classes compared to the pre-trained case. I couldn't find any tutorial on how to modify the layers to accommodate for the custom classes. I still want to leverage the pre-trained weights. Could you please help @datumbox ? |
|
@santhoshnumberone and @datumbox - I figured out how to do this. Here's a way you can modify the FCOS to custom number of classes. |
🚀 The feature
FCOS architecture
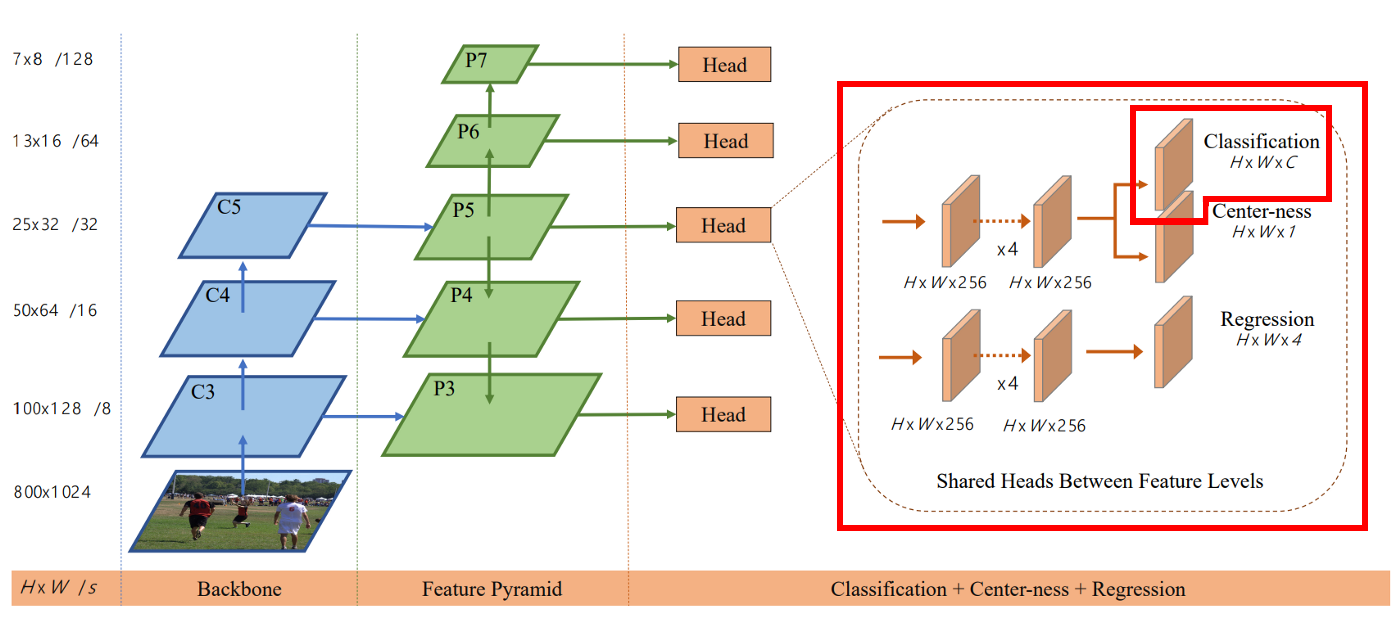
I used
requires_gradto freeze all the layers in the network and decided to train only the classification which used to predict90 classesto train onlyone classUsed the code below to replace the entire classification block and pick
77th labelonly, replaced entire weight and bais classification with 77th class.I got this output
Motivation, pitch
Following this script An Instance segmentation model for PennFudan Dataset and Building your own object detector — PyTorch vs TensorFlow and how to even get started?
There's no Predictor class for FCOS: Fully Convolutional One-Stage Object Detection architecture pytorch model /torchvision/models/detection/fcos.py like for faster-RCNN Predictor or MaskRCNN Predictor
When I started training the model, with the script below
I got this error
What do I do to alter this and get it working?
Alternatives
I have no idea how to correct the issue
Additional context
Looks like dimension mismatch but how do I correct it? and where do I correct it?
cc @datumbox @vfdev-5 @YosuaMichael
The text was updated successfully, but these errors were encountered: