Java Virtual Machine. Środowisko uruchomieniowe dla języka JAVA. Interpretuje JAVA Bytecode - język pośredni będący wynikiem kompilacji kodu JAVA.
Więcej: https://bottega.com.pl/pdf/materialy/jvm/jvm1.pdf
KRÓTKO: Garbage Collector składowa JVM odpowiadająca za zwalnianie nieużywanej pamięci.
W języku JAVA nie ma bezpośredniej możliwości "zwolnienia pamięci" z poziomu języka. Garbage Collector jest algorytmem za to odpowiedzialnym. Co jakiś czas podczas działania programu Garbage Collector zatrzymuje bieżący wątek i sprawdza, które obiekty na stercie nie mają żadnej referencji w programie. Jeśli nie mają referencji (znaczy, że nie są już używane) - zostają usuwane z pamięci. Więcej: https://bottega.com.pl/pdf/materialy/jvm/jvm2.pdf
- STOS - typy proste, wskaźniki do obiektów, wskaźniki powrotu z funkcji.
- STERTA - Obiekty i typy złożone
TYPY PROSTE
| typ | wielkość | opis |
|---|---|---|
| boolean | 1 bit | wartość logiczna |
| byte | 8 bit | liczba całkowita ze znakiem |
| short | 16 bit | liczba całkowita ze znakiem |
| int | 32 bit | liczba całkowita ze znakiem |
| long | 64 bit | liczba całkowita ze znakiem |
| float | 32 bit | liczba zmiennoprzecinkowa |
| double | 64 bit | liczba zmiennoprzecinkowa |
| char | 16 bit | litera |
Każdy typ prosty ma swój odpowiednik jako typ obiektowy w JAVIE, np. int => Integer.
- Boxing - pakowanie obiektu do typu obiektowego
int someInteger = 1234;
Integer boxedInteger = Integer.valueOf(someInteger);- Autoboxing - Automatyczne opakowanie typu przez kompilator:
int someInteger = 1234;
Integer boxedInteger = someInteger;- Unboxing - Odpakowanie typu obiektowego
Integer boxedInteger = Integer.valueOf(someInteger);
int integer = (int)boxedInteger;String - łańcuch znaków. Jest obiektem Immutable (niezmienialnym). Dodawanie łańcuchów za każdym razem tworzy nowy obiekt.
Aby dodawać do siebie wiele String'ów używamy klasy StringBuilder lub StringBuffer ze względu na wydajność.
StringBuffer ma wszystkie metody synchronized, jest thread safe, natomiast StringBuilder jest szybszy.
Nie zmieniają swojego stanu po utworzeniu. W celu zmienienia go, tworzy się nowy na jego podstawie. Przykład: klasa String, DataTime
ZALETY:
- Po utworzeniu obiektu możemy być pewni, że nie zmieni on swojego stanu. Możemy np. przekazać go innej metodzie bez obaw.
- Każda zmiana obiektu Immutable powoduje utworzenie nowego obiektu.
- Dzięki tym cechom są bezpieczniejsze w programowaniu wielowątkowym, kiedy wiele wątków może na raz utworzonym obiekcie pracować jednocześnie.
Dotyczą pól / klas / metod:
| klasyfikator | opis |
|---|---|
| public | dostęp publiczny |
| protected | dostęp tylko z poziomu klas dziedziczących |
| private | dostęp tylko z tej samej klasy |
| dostęp z obrębu pakietu |
obj1 == obj2- porównuje referencjeboolean result = obj1.equals(obj2)porównuje zawartość obiektów
Metodę .equals() należy zaimplementować (albo użyć do tego biblioteki).
Metodę int hashCode() należy zaimplementować.
Zwraca ona liczbę int specyficzną dla każdego obiektu.
Konrakt mówi, że jeśli wartości hashCode() obiektów są:
- takie same -> Obiekty mogą być identyczne
- różne -> Obiekty na pewno się różnią
Metody .equals() i .hashCode() są używane m.in w kolekcjach do wyszukiwania i porównywania obiektów.
Można je generować przy pomocy IDE lub kompilatora (używając np. @Data z biblioteki Lombok).
Udostępniają metody compare() / compareTo() pozwalające porównać obiekty.
Metody zwracają typ int o wartościach:
-1: mniejszy0: równy1: większy
PRZYKŁADY:
- Interfejs
Comparable:obj1.compareTo(obj2) - Interfejs
Comparator:comparatorInstance.compare(obj1, obj2)
"test" == "test" //taki kod zwrca true
"test" == new String("test") // A taki kod zwraca false?
new String("test") == new String("test") // I taki też zwraca false?Kompilator optymalizuje kod podczas kompilacji zapisując jawnie utworzone ciągi znaków w jednym obiekcie. Wszystkie wystąpienia "test" w przykłądzie wskazują na ten sam obiekt. Stąd operator == porównujący referencje w pierwszym przypadku zwraca true.
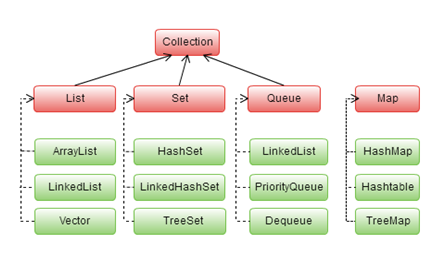
Sposobem implementacji.
- ArayList - przechowuje elementy w Arrayu bardzo szybkie operacje wstawiania na końcu / początku i losowy dostęp
- LinkedList w każdym elemencie posiada wskaźnik do następnego elementu, co umożliwia bardzo szybkie wstawianie na dowolną pozycję lecz powolny losowy dostęp do danych.
- HashSet
- nie gwarantuje kolejności wstawiania
- może przechowywać obiekty o wartości
null - gwarantuje szybkość działania
O(1), gdzieTreeSet, tylkolog(n)
HashMap przechowuje dane w postaciach: klucz-wartość.
Podczas zapisu map.put(key, value) implementacja HashMap wywołuje .hashCode() na kluczu key i wykorzystując ten hashcode znajduje indeks pod którym zapisany będzie obiekt(Entry<key, value>) w wewnętrznym Array'u. Każdy wpis (Entry) przechowuje zarówno klucz jak i wartość.
Wiele kluczy może zwrócić ten sam hashcode - stąd pod danym indeksem może być wiele zapisanych obiektów. Dana sytuacja nazywa się kolizją. A obiekty w tej sytuacji zapisywane są w strukturze LinkedList<Entry> w danym buckecie.
Podczas pobierania zasobu z map.get(key), znowu liczony jest hashcode, wybierany bucket. Jeśli nie ma kolizji - zwracany jest obiekt. Jeśli jest kolizja, wyszukiwany jest odpowiedni wpis na liście (korzystając z metody .equals()).
Zapewnia to osiągnięcie złożoności obliczeniowej przy pobieraniu obiektu: O(1).
Podstawowy podział:
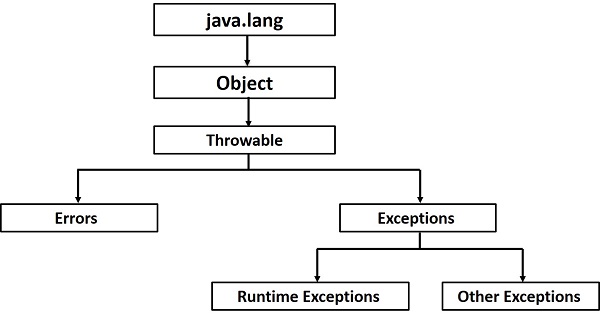
- Error zwykle nie zależy od programisty. Sygnalizuje awarię, której programista nie może / nie powinien obsługiwać w kodzie jak: StackOverflowError, czy OutOfMemoryError.
- Exception'y - mogą / powinny być obsługiwane przez programistę.
- checked - wyjątki sprawdzane w trakcie kompilacji. Program się nie skompiluje bez ich obsłużenia lub zadeklarowania.
- unchecked - nie są sprawdzane w trakcie kompilacji.
- Źródłem 2. pierwsze jest unchecked, drugie checked.
https://www.tutorialspoint.com/java/java_generics.htm
PROCESY:
- System operacyjny udostępnia aplikacjom procesy, które "opakowują" zasoby dostępne dla danej aplikacji, te zasoby to:
- Wątki (ciąg instrukcji procesora)
- Pamięć operacyjna
- Uchwyty do plików
- połączenia HTTP (port), urządzenia wejścia/wyjścia, itp.
- Proces zawsze posiada conajmniej jeden wątek.
- Każdy proces może mieć podprocesy
- proces-rodzic ma dostęp do wszystkich zasobów swoich podprocesów
- podproces ma dostęp tylko do swoich zasobów
WĄTKI:
- Jeden wątek -> Jeden ciąg instrukcji procesora
- Są Najmniejszą sekwencją instrukcji możliwą do zarządzania przez
Schedulersystemu operacyjnego. - Jednocześnie jeden rdzeń procesora może obsługiwać wiele wątków, lecz nie w tym samym czasie (sytem operacyjny przydziela ułamek czasu procesora na każdy z nich).
- Wszystkie wątki dzielą jedną pamięć w ramach tego samego procesu. Dlatego są łatwiejsze/szybsze do utworzenia / zamknięcia, niż procesy.
https://winterbe.com/posts/2015/04/07/java8-concurrency-tutorial-thread-executor-examples/ https://winterbe.com/posts/2015/04/30/java8-concurrency-tutorial-synchronized-locks-examples/
- wait() - zatrzymuje wątek w danym miejscu (celem synchronizacji)
- notify() - uruchamia zatrzymany wątek.
- notifyAll() - uruchamia wszystkie zatrzymane wątki
Mechanizmy umożliwiające programiście używać ogólnych nie zdefiniowanych w momencie pisania metod / klas, których wybór nastąpi później w trakcie kompilacji / uruchomienia programu.
Dodanie funkcjonalności do klasy poprzez jej rozszerzanie / nadpisanie.
Aby ograniczyć powiązania w aplikacji do minimum. Ułatwia to późniejsze utrzymanie kodu.
Tu jest wszystko: https://refactoring.guru/design-patterns/catalog
PRZYKŁADY:
- KREACYJNE (creational)
- Singleton
- Factory method
- Abstract factory
- Builder
- STRUKTURALNE (structural)
- Facade
- Proxy
- Decorator
- Composite
- CZYNNOŚCIOWE (behavioral)
- Observer
- Visitor
- Iterator
- Strategy
Niemutowalność, co za tym idzie obiekt jest thread safe. Dodatkowo przy dużej liczbie podobnych obiektów poprawia wydajność.
- Kompozycja - dodanie funkcjonalności do klasy wstawiając do niej pole innej klasy.
- Dziedziczenie - dodanie funkcjonalności do klasy poprzez skopiowanie i nadpisanie jej metod/pól Np.
class BaseClass {
void someMethod() {
//do something
}
}
// Dziedziczenie
class ExtendingClass extends BaseClass {
void myMethod() {
this.someMethod() // funkcjonalność z BaseClass poprzez dziedziczenie
}
}
// Kompozycja
class CompositionClass {
BaseClass base = new BaseClass();
void myMethod() {
base.someMethod() // funkcjonalność z BaseClass poprzez kompozycje
}
}- Interfejs nie jest klasą więc:
- nie może zawierać pól
- ma wszystkie metody publiczne
- nie można go instancjonować
- Przeznaczeniem:
- interfejs służy do zdefiniowania kontraktu,
- klasa abstrakcyjna do zaimplementowania wspólnej funkcjonalności
- Interfejs umożliwia wielodziedziczenie. (JAVA 8+)
https://hackernoon.com/solid-principles-made-easy-67b1246bcdf
-
Single Responsibility Principle - Każda klasa powinna posiadać dokładnie jedną odpowiedzialność i robić tę jedną rzecz najlepiej jak się da. Nigdy nie powinien istnieć więcej niż jeden powód do modyfikacji klasy.
-
Open-Closed Principle - Projekt powinien być otwarty na rozszerzanie i zamknięty na modyfikacje. Zamiast modyfikować klasę raczej powinniśmy ją rozszerzać, jednocześnie bazując na abstrakcji aniżeli konkretnych implementacjach.
-
Liskov Substitution Principle - Jeśli w danym miejscu programu oczekujemy jakiegośkonkretnego typu obiektu (np. Animal), to powinniśmy mieć możliwość użycia tam dowolnego jego podtypu np. Cat, Mouse itp.
-
Interface Segregation Principle - Krótko: Użytkownik nie powinien być zmuszony do implementowania metod których nie używa. Lepiej więcej małych Interfejsów niż jeden duży. Celem są proste i krótkie interfejsy przeznaczone do jednego celu (SRP). Ograniczy to powstawanie niepotrzebnych zależności w projekcie.
-
Dependency Inversion Principle - Opieraj się na abstrakcjach, zamiast konkretnych implementacjach. Moduły wysokopoziomowe NIE POWINNY zależeć od modułów niskopoziomowych.
Interfejsy powinny stać wyżej w hierarchii niż ich konkretne implementacje, które mogą się zmieniać. Ten wzorzec jest powszechnie implementowany przez kontenery Dependency Injection, gdzie w kodzie używa się nazw interfejsów, a za dostarczenie konkretnych instancji obiektów odpowiada centralnie kontener DI.
Keep It Simple, Stupid! KOD POWINIEN BYĆ:
- czytelny i zrozumiały (nie buduj hack'ów)
- możliwie najkrótszy (wszystkie nieużywane funkcje - do wyrzucenia )
- Jak coś nie jest konieczne w kodzie to tego ma tam nie być! 80% czasu przy programowaniu to czytanie (nie pisanie) kodu. Zadbaj, by było go jak najmniej.
Problem powstał w JAVA 8 i dotyczy wielodziedziczenia. Interfejsy w JAVA8 mogą posiadać domyślne implementacje. Jednocześnie można zaimplementować kilka interfejsów i przypadkowo podziedziczyć kilka implementacji funkcji o tej samej nazwie i parametrach np. boo(). Którą zatem wybrać? Można się odnieść beżpośrednio do konkretnej implementacji: Interface1.boo()
int silnia(int level) {
if (level < 0) {
throw new RuntimeException("Level should not be negative.")
}
if (level == 0) {
return 1;
}
int currentValue = 1;
for (i = 2; i <= level; i++) {
currentValue = currentValue * i;
}
return currentValue;
}[ZADANIE] Napisz algorytm liczący n-ty element ciągu fibonacciego (bez rekurencji). (wartość elementu to suma dwóch poprzednich, gdzie: fib(0) = 1, fib(1) = 1, fib(2) = 1, fib(3) = 2, fib(4) = 3, ...
function fib(n) {
if (n < 0) throw "argument should be 0 or higher, actual is " + n
if (n == 0) return 0;
if (n == 1) return 1;
let prevPrevValue = 0, prevValue = 1, currentValue
for (let i = 2; i <= n; i++) {
currentValue = prevPrevValue + prevValue
prevPrevValue = prevValue
prevValue = currentValue
}
return currentValue
}function isPowerOf2(n) {
for (i = 1; i<=n; i *=2) {
if (n === i) return true
}
return false
}Selenium udostępnia 8 rodzai, przy czym wszystkie można zastąpić albo CSS lub XPATH.
Dwa zupełnie odmienne rodzaje języka służącego do określenia elementów w drzewie DOM / XML.
- CSS - Selektory bardziej zwięzłe, bardziej zrozumiałe dla frontendowców. Natywna obsługa klas CSS.
- XPATH - daje największe możliwości. Umożliwia wyszukiwanie po zawartości tekstowej, poruszanie się po drzewie, itp.
Szybszy jest CSS, ponieważ nie wczytuje człego drzewa DOM podczas działania.
Generalnie - jak nie potrzebujemy ficzerów XPATH to CSS będzie szybszy i bardziej przejrzysty
- div#content
- .img
- .img.first
- .img .first
- .img:first-child
- .img > div
- .img[lol='xd']
- //*[@type='hidden']
- //div[0]
- //div[3]
- //div[div]
- //div//a
- //div/a
- //div/a[contains(text(), 'lol')]
- //div/a[contains(., 'lol')]
- //div/a/../..//div[name='lol']
- //div/a[contains(.,'loltext')]/..
- //div[@name='lol'][@id='lolId']
- //div[a[@id='lolId']]
[ZADANIE] Masz slider w postaci licznika samochodowego w kształcie półokręgu. Możesz przesuwać wskazówkę za pomocą "wajchy" po tym półokręgu myszką. Pod spodem jest licznik 0-100%, który wskazuje jak ustawiłeś wskazówkę(0% wskazówka z lewej, 50% wskazówka do góry, 100% wskazówka z prawej).
- Jak sprawdzić czy to działa używając Selenium ?
- Napisz komponent, który enkapsuluje działania na tym sliderze.
- Masz do dyspozycji funkcję dragAndDrop(x, y), gdzie x i y to współrzędne z układu zaczynającego się w lewym górnym rogu strony.
Nie* (z jednym zastrzeżeniem)
Są przede wszystkim obiekty. Dziedziczenie odbywa się przez prototypy.
W ES6 doszła składnia definicji class, która pod spodem niczym się nie różni od opierania się na prototypach.
this -> Aktualny kontekst wykonania. This jest przypisywany np. podczas tworzenia nowego obiektu poprzez operator new.
setTimeout(0, () => console.log("First"));
console.log("Second");ODPOWIEDŹ:
> Second
>
> First
W pierwszej linii wywołujemy funkcję setTimeout, która triggeruje dodanie do Event Loop funkcji () => console.log("First") po czasie 0 (od razu) na koniec event loop'a.
Jednak Zostanie ona wykonana, dopiero po zakończeniu wszystkich instrukcji z aktualnego kontekstu wykonania (tj. wklejonego kodu - drugiej linijki: console.log("Second")).
Można użyć funkcji bind()
API ułatwiające zarządzanie asynchronicznym kodem. Zmniejsza poziom skomplikowania kodu w porównaniu do używania callback'ów.
Zwraca Promise'a - obietnicę zwrócenia wyniku. Np.
async function abc() {
return "abc"; // return Promise<String>
}Czeka na rozwiązanie Promise i:
- Gdy się powiedzie (
resolved) zwraca jej wynik - Gdy się nie powiedzie (
rejected) wyrzuca Wyjątek
Typowanie, a dzięki temu:
- podpowiadanie składni -mniejsze prawdopodobieństwo błędów dzięki kompilacji
- zwiększa czystość kodu
- wymusza stosowanie typów i dzięki temu zmniejsza prawdopodobieństwo rzutowania / konwersji typów tam gdzie o nie jest pożądane / zamierzone.
Tak
Tak, z zastrzeżeniem, że
- korzysta z API środowiska(np. przeglądarki), które działają w innych wątkach i procesach np WEB API's timing API, fetch API itp.
- można w przeglądarce uruchomić service worker, który działa na innym wątku.
- można w Node.JS uruchomić podprocesy (child_process), każdy ma swój wątek.
[ZADANIE] Napisz funkcję hello(name) zwracającą obietnicę (Promise), która po 1 sekundzie rozwiązuje się do wartości name.
function hello(name) {
return new Promise((resolve, reject) => {
return setTimeout(() => resolve(name), 1000);
});
}Lub korzystając ze składni async:
async function hello(name) {
await sleep(1000);
return name;
}
//funkcja pomocnicza
function sleep(ms) {
return new Promise(res => setTimeout(res, ms))
}[ZADANIE] Za pomocą konsoli przeglądarki mając otwartą stronę wyników wyszukiwania z Google wypisz wszystkie znalezione linki.
Jedno z rozwiązań:
const links = document.querySelectorAll(".r > a:first-child");
links.forEach(link => console.log(link.href));[ZADANIE] Masz dwie wieże naprzeciw siebie, każda ma 3 okna po 1 na każdym piętrze - czyli razem 6 okien naprzeciw siebie. Można między dowolnymi oknami przerzucić 2 liny - w zależności od kombinacji mogą się przecinać albo nie.
Napisz logikę / zamodeluj problem odpowiadające na pytanie kiedy liny się przetną, a kiedy nie.
- Na wejściu masz informacje o tym, jak są zawieszone liny, na wyjściu odpowiedz czy się przecinają.
- Zamodeluj to używając klasy / klas.
- zaimplementuj metodę mówiącą czy liny się przecinają zwracającą
truelubfalse.
[ZADANIE] Proszę tutaj jest termometr zaokienny, zastanawiamy się czy zamawiać 1000000 sztuk. Jak byś go przetestował/a ?
Syllabus: https://sjsi.org/ist-qb/do-pobrania/
- pomyłka (błąd) - ktoś popełnia błąd podczas kodzenia, w wyniku tego powstaje...
- defekt! - jakiś kawałek kodu, który nie działa jak trzeba i może spowodować:
- awarię! - do tego staramy się nie dopuścić i wykryć defekt wcześniej
- Testowanie ujawawnia usterki, ale nie dowodzi ich braku
- Testowanie gruntowne jest niemożliwe
- Wczesne testowanie oszczędza czas i pieniądze
- Kumulowanie się defektów
- Paradoks pestycydów
- Testowanie zależy od kontekstu
- Przekonanie o braku błędów jest błędem
Mniej więcej tak:
Nowy -> Przydzielony -> Otwarty -> "Naprawiony" -> Retest -> Ponownie otwarty -> Naprawiony -> Retest -> Zamknięty
Każdy z poziomów ma swoje, cele szczegółowe, rodzaje błędów, typowe defekty i awarie oraz środowisko. Np. Testy modułowe izolują moduły od innych, a akceptacyjne wymagają środowiska zbliżonego do produkcyjnego.
- testowanie modułowe - Unit testy. Testowanie zachowania pojedynczych modułów w izolacji od ich powiązań z innymi (stosowane są tutaj zaślepki / mocki)
- testowanie integracyjne - Testowanie integracji pomiędzy różnymi modułami. Badanie zgodności działania z interfejsami. Można testować integrację pomiędzy modułami w danej aplikacji, lub na wyższym poziomie - Pomiędzy różnymi systemami.
- testowanie systemowe - Testowanie zachowania całego systemu lub produktu z uwzględnieniem wymagań funkcjonalnych i niefunkcjonalnych.
- testowanie akceptacyjne - Testownie całego systemu z perspektywy użytkownika końcowego. Wykrywają kompletność działania całego systemu. Zwiększają poziom zaufania. Testowanie zgodności z umową. Testy AB.
Każdy z typów testów można wykonać na każdym poziomie testów.
- testy funkcjonalne
- testy niefunkcjonalne
- testy czarnoskrzynkowe
- testy białoskrzynkowe
- testy wydajnościowe
- testy obciążeniowe
- próbujesz powtórzyć błąd używając scenariuszy testowych
- sprawdzasz logi
- kontaktujesz się że zgłaszającym o jeśli jest potrzeba i możliwość
- sprawdzasz czy błąd występuje na poprzedniej wersji aplikacji
- No i oczywiście zgłaszasz błąd do deweloperów
Styl architektury dla Usług webowych (Web Services) opierający się na wykorzystaniu protokołu HTTP do przesyłania wiadomości. Metoda HTTP definiuje akcję, a kody odpowiedzi rezultat. Cechy systemu RESTfull
- Architektura klient-serwer
- Bezstanowość
- Cacheability
- Layered system - Ustanowienie warstwy proxy pomiędzy klientem, a serwerem nie niesie za sobą konieczności ich modyfikacji (jest transparentne). Można np. użyć Load balancera.
- Jednolity interfejs:
- Resource identification in requests - każdy zasób ma swój unikalny URI
- Resource manipulation through representations - jeśli klient ma informacje o obiekcie, są one wystarczające do jego usunięcia / modyfikacji
- Self-descriptive messages - wiadomości powinny zawierać wystarczającą ilość metadanych i danych do ich poprawnego zrozumienia np. MIME type. Wiadomości zawierają informacje o ich "cacheowalności"
- Hypermedia as the engine of application state (HATEOAS) - ustandaryzowane linki do zasobów https://restfulapi.net/hateoas/
GET- pobiera zasóbHEAD- sprawdza, czy zasób istnieje (zwraca to samo co GET, tylko bez response body)POST- tworzy nowy zasóbPUT- Edytuje cały zasóbPATCH- Modyfikuje część zasobuDELETE- Usuwa zasóbOPTIONS- Zwraca listę dostępnych metod HTTP dla danego zasobuCONNECTTRACE
https://www.restapitutorial.com/httpstatuscodes.html
- 1xx - informacyjne
- 2xx - sukces
- 3xx - przekierowanie
- 4xx - błąd klienta
- 5xx - błąd serwera
| Method | Safe | Idempotent | Cacheable | Allowed in HTML forms | Request has body | Response has body |
|---|---|---|---|---|---|---|
| GET | ✅ | ✅ | ✅ | ✅ | ❌ | ✅ |
| HEAD | ✅ | ✅ | ✅ | ❌ | ❌ | ❌ |
| POST | ❌ | ❌ | ✅* | ✅ | ✅ | ✅ |
| PUT | ❌ | ✅ | ❌ | ❌ | ✅ | ❌ |
| PATCH | ❌ | ❌ | ❌ | ❌ | ✅ | ✅ |
| DELETE | ❌ | ✅ | ❌ | ❌ | May | May |
| OPTIONS | ✅ | ✅ | ❌ | ❌ | ❌ | ✅ |
| TRACE | ❌ | ✅ | ❌ | ❌ | ❌ | ❌ |
| CONNECT | ❌ | ❌ | ❌ | ❌ | ❌ | ✅ |
-
- Only if freshness information is included
- Zawierają metadane, np. info o stanie ssji (ciastka), cacheowalność, Content type, autentykacja,
SQL Injection, XSS, XSRF, SSRF, XXE
- XSS (Cross-site Scripting) wykonanie złośliwego kodu wstrzykując go do ofierze np. tak:
alert('to jest atak! Powinno wyświetlić alert w Twojej przeglądarce, ale github jakieś tam zabezpieczenia przed XSS ma'); - XSRF (Cross-site Request Forgery) Akcja wywołująca u ofiary wykonanie jakiegoś żądania w systemie w którym jest zalogowana. Np. wysłanie ofierze takiego linku na czacie i skłonienie do kliknięcia w niego:
http://fb.com/usuń_konto. Atakujący nie widzi odpowiedzi, więc atak nie służy do wykradania danych, a bardziej do skłonienia ofiary do wykonania jakiejś (autoryzowanej) akcji. Jeśli ofiara ma uprawnienia administratora, atak może wyrządzić wiele szkód: np.fb.com/usuń_serwern - SSRF (Server-Side Request Forgery) - Skłonienie serwera, do wykonania żądania, niezgodnie z zamysłem programistów. Np. Po wklejeniu linku do Messengera. Serwery wykonują żądania na ten adres i po chwili pojawia się migawka ze strony internetowej. Tutaj atak SSRF mógłby wyglądać tak, że atakujący wkleiłby link:
/etc/passwd, a serwer posłusznie wyświetliłby zawartość swoich własnych plików. Albo lokalny port0.0.0.0:12345, oznaczający (skanowanie portów w sieci wewnętrznej). Itp. - XXE (XML External Entity) - atak polegający na tym, że standard XML umożliwia definiowanie zmiennych (encji).
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE myxml [
<!ENTITY shp SYSTEM "/etc/passwd <tu można wstawić url, lokalizację pliku itp.>">
] >Te encje można zaimportować z oddzielnego pliku i/lub adresu URL. Jeśli prześlemy takiego XML'a, gdzie w encji wprowadzimy zewnętrzny adres, udaje się w ten sposób wywołać atak SSRF, albo czytać pliki z serwera.
Nie, bo Same Origin Policy
Reguła bezpieczeństwa nowoczesnych przeglądarek, uniemożliwiająca kodowi JS wysyłania żądań do adresów z poza 'origin', czyli kombinacji aktualnych: domeny, portu, protokołu. Blokuje wiele wektorów ataku typu np. XSS.
CORS (Cross-Origin Resource Sharing) - zestaw mechanizmów pozwalający ominąć CORS dla niektórych wybranych domen w celu umożliwienia działania naszej aplikacji. Robi się to za pomocą headerów: Access-Control, więcej tu:
- Autoryzacja - Stwierdzenie że użytkownike ma dostęp do zasobu.
- Autentykacja - stwierdzenie kim jest użytkownik (jest krokiem autoryzacji)
Standard delegacji autoryzacji.
Podstawy tutaj: https://github.com/qarmin/PodstawowePoleceniaLinux/blob/master/README.md#podstawowe-polecenia-stosowane-w-systemie-gnulinux
- ls
- touch xd.dd
- cd ..
- cd .
- cat
- head
- tail
- ps aux | grep node
head -100 xd.dd | grep lolPrzechowuje relacje wiele-do-wielu
Jak zsumować płace wg. działów. Masz tablicę z listą pracowników z wynagrodzeniami i przypisanym działem.
TL DR; Trzeba zrobić Group BY po kolumnie z działami.
- Standardowo
count(*), ale można szybciej: count(1);działa zdecydowanie szybciej, bo nie wyciąga wiersza za każdym razem
- http://toolsqa.com - Baza wiedzy o selenium
- https://learncodethehardway.org/unix/bash_cheat_sheet.pdf - BASH Cheatsheet
- https://www.geeksforgeeks.org/functional-interfaces-java/ - JAVA Functional interfaces
- https://winterbe.com/posts/2014/07/31/java8-stream-tutorial-examples/ - JAVA Streams