You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
ASCII(American Standard Code for Information Interchange:美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,由美国国家标准学会 ANSI(American National Standard Institude)于1968年正式制定。它是现今最通用的信息交换标准,并等同于国际标准ISO/IEC 646。
URI:RFC1630,发布于 1994 年 6 月,被称为“Universal Resource Identifiers in WWW: A Unifying Syntax for the Expression of Names and Addresses of Objects on the Network as used in the World-Wide Web”。它是一个Informational RFC —— 也就是说,它没有获得社区的任何认可。
URL:RFC1738,发布于 1994 年 12 月, 被称为“Uniform Resource Locators”。它是一个 Proposed Standard —— 也就是说,它是一个共识过程的结果,虽然它还没有经过测试,并成熟到足以成为一个完整的 Internet Standard。
URN:RFC1737,发布于 1994 年 12 月,被称为“Functional Requirements for Uniform Resource Names”。
ASCII
ASCII(American Standard Code for Information Interchange:美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,由美国国家标准学会 ANSI(American National Standard Institude)于1968年正式制定。它是现今最通用的信息交换标准,并等同于国际标准ISO/IEC 646。
ASCII 码使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。标准ASCII 码也叫基础ASCII码,使用7 位二进制数(剩下的1位二进制为0)来表示所有的大写和小写字母,数字0 到9、标点符号, 以及在美式英语中使用的特殊控制字符。
0~31及127(共33个)是控制字符或通信专用字符(其余为可显示字符)
32~126(共95个)是字符(32是空格),其中48~57为0到9十个阿拉伯数字。
65~90为26个大写英文字母,97~122号为26个小写英文字母,其余为一些标点符号、运算符号等。
在标准ASCII中,其最高位(b7)用作奇偶校验位。所谓奇偶校验,是指在代码传送过程中用来检验是否出现错误的一种方法,一般分奇校验和偶校验两种。奇校验规定:正确的代码一个字节中1的个数必须是奇数,若非奇数,则在最高位b7添1;偶校验规定:正确的代码一个字节中1的个数必须是偶数,若非偶数,则在最高位b7添1。
后128个称为扩展ASCII码。许多基于x86的系统都支持使用扩展(或“高”)ASCII。扩展ASCII 码允许将每个字符的第8 位用于确定附加的128 个特殊符号字符、外来语字母和图形符号。
ASCII编码查询表知识
URI
统一资源标识符(英语:Uniform Resource Identifier,缩写:URI)是一个用于标识某一互联网资源名称的字符串。URI 是一个通用的概率,由两个主要的子集 URL (统一资源定位符,又称 百分号编码 ) 和 URN (统一资源名) 构成,URL 是通过描述资源的位置来标识资源的,URN 则是通过名字来识别资源,与它们当前所处的位置无关。
URI编码
URI的字符类型
URI所允许的字符分作保留与未保留。保留字符是那些具有特殊含义的字符,例如:斜线字符用于URL(或URI)不同部分的分界符;未保留字符没有这些特殊含义。百分号编码把保留字符表示为特殊字符序列。上述情形随URI与URI的不同版本规格会有轻微的变化。
RFC 3986 section 2.2 保留字符 (2005年1月)
!*'();:@&=+$,/?#[]RFC 3986 section 2.3 未保留字符 (2005年1月)
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789-_.~URI中的其它字符必须用百分号编码。
保留字符的百分号编码
如果一个保留字符在特定上下文中具有特殊含义(称作"reserved purpose") , 且URI中必须使用该字符用于其它目的, 那么该字符必须百分号编码。百分号编码一个保留字符,首先需要把该字符的ASCII的值表示为两个16进制的数字,然后在其前面放置转义字符("
%"),置入URI中的相应位置。(对于非ASCII字符, 需要转换为UTF-8字节序, 然后每个字节按照上述方式表示.)例如,"
/", 如果用作URI的路径成分的分界符, 则是具有特殊含义的保留字符. 如果该字符需要出现在URI一个路径成分的内部, 则三字符序列"%2F"或"%2f"就用于代替原本的"/"出现在该URI路径成分的内部.!#$&'()*+,/:;=?@[]%21%23%24%26%27%28%29%2A%2B%2C%2F%3A%3B%3D%3F%40%5B%5D在特定上下文中没有特殊含义的保留字符也可以被百分号编码,在语义上与不百分号编码的该字符没有差别.
在URI的"查询"成分(?字符后的部分)中, 例如"
/"仍然是保留字符但是没有特殊含义,除非一个特定的URI有其它规定. 该/字符在没有特殊含义时不需要百分号编码.如果保留字符具有特殊含义,那么该保留字符用百分号编码的URI与该保留字符仅用其自身表示的URI具有不同的语义。
受限字符或不安全字符
受限字符或不安全字符,直接放在Url中的时候,可能会引起解析程序的歧义,也需要百分号编码。
%encodeURI('%') // "%25"encodeURI(' ') // "%20"<>"encodeURI('<>"') // "%3C%3E%22"{}\^~[]'encodeURI('京东') // "%E4%BA%AC%E4%B8%9C"javascript 转义字符
Javascript中提供六个方法来处理特殊保留字符、受限字符、不安全字符,如下
Unicode
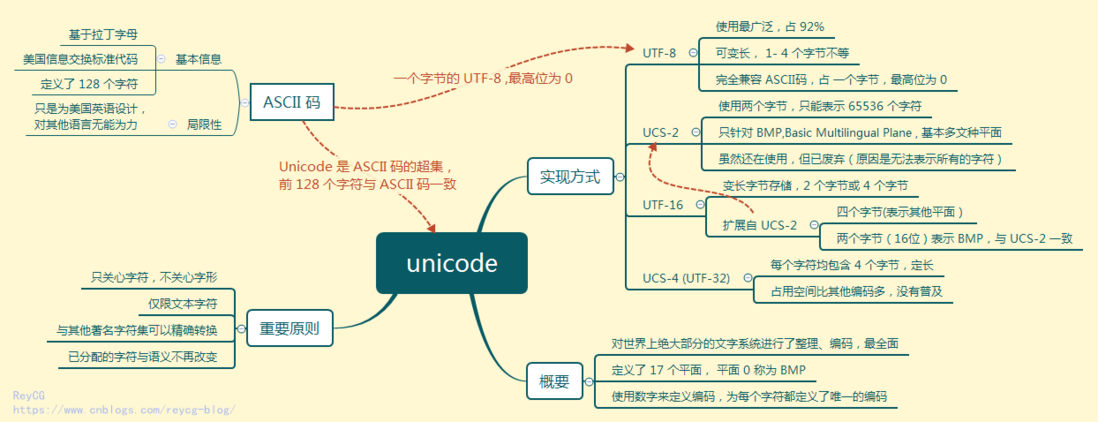
Unicode(统一码、万国码、单一码,简称UCS)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。
Unicode 字符集(简称为ucs),国际标准组织于1984年4月成立ISO/IEC JTCI/SC2/WG2工作组,针对各国文字、符号进行统一性编码。1991年美国跨国公司成立 Unicode Consortium ,并于1991年10月与WG2达成协议,采用统一编码字集。
大概来说,Unicode编码系统可分为编码方式和实现方式两个层次。
Unicode 编码规则
统一码的编码方式与ISO 10646的通用字符集概念相对应。当前实际应用的统一码版本对应于UCS-2,使用16位的编码空间。也就是每个字符占用2个字节。这样理论上一共最多可以表示2^16(即65536)个字符。
采用16位编码体系基本满足各种语言的使用,内容包含符号6811个,汉字20902个,韩文拼音11172个,造字区6400个,保留20249个,共计65534个。Unicode 编码后的大小是一样的,例如一个英文字母 “a” 和 一个汉字 “好”,编码后占用的空间大小是一样的都是两个字节。
随着中文,日文和韩文引入,原有的 Unicode 定义的字符集无法满足。Unicode 定义的字符集已经超过16位所能表达的范围,把所有这些 CodePoint 分成17个平面 (Code Plane): U+0000 ~ U+FFFF 划入基本多语言平面(Basic MultilingualPlane, 简记为BMP),其余划入16个辅助平面(Supplementary Plane), 代码点范围U+10000(2^16) ~ U+10FFFF(2^20+2^16).
基本多语言平面的字符的编码为U+hhhh,其中每个h代表一个十六进制数字,与UCS-2编码完全相同。而其对应的4字节UCS-4编码后两个字节一致,前两个字节则所有位均为0。
关于统一码和ISO 10646及UCS的详细关系,见通用字符集。
Unicode 编码实现方式
Unicode的实现方式不同于编码方式。一个字符的Unicode编码是确定的。但是在实际存储传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对Unicode编码的实现方式有所不同。Unicode的实现方式称为Unicode转换格式(Unicode Transformation Format,简称为UTF),Unicode的实现方式有UTF-7、UTF-8、UTF-16、UTF-32、Punycode、CESU-8、SCSU、UTF-32、GB18030等, 其中 UTF-8、UTF-16、UTF-32 使用比较广泛。
UTF-8 编码
UTF-8 是使用互联网上使用最广泛的 unicode 编码方式,目前已经占有整个互联网 92% 的份额。
UTF-8 是一种变长的编码方法,字符长度从1个字节到4个字节不等。越是常用的字符,字节越短,最前面的128个字符,只使用1个字节表示,与ASCII码完全相同(Unicode 中的前 128 个字符和 ASCII 码都是一一对应的)。
UTF-16 编码
UTF-16 编码介于 UTF-32 与 UTF-8 之间,同时结合了定长和变长两种编码方法的特点。
它的编码规则很简单:基本平面的字符占用2个字节,辅助平面的字符占用4个字节。也就是说,UTF-16的编码长度要么是2个字节(U+0000到U+FFFF),要么是4个字节(U+010000到U+10FFFF)。
UTF-32 编码
UTF-32 对 Unicode 中的每个字符都用 4 个字节来表示。UTF-32 的优点在于,转换规则简单直观,查找效率高。缺点在于浪费空间,同样内容的英语文本,它会比ASCII编码大四倍。这个缺点很致命,导致实际上没有人使用这种编码方法,HTML 5标准就明文规定,网页不得编码成UTF-32。
截自网友 Unicode 的思维导图:
javascript Unicode 字符转义
Javascript中提供了相关方法来处理 Unicode 转义,如下:
示例:Base64
Base64是一种基于64个可打印字符来表示二进制数据的表示方法。由于 ,所以每6个比特为一个单元,对应某个可打印字符。3个字节有24个比特,对应于4个Base64单元,即3个字节可由4个可打印字符来表示。它可用来作为电子邮件的传输编码。在Base64中的可打印字符包括字母
,所以每6个比特为一个单元,对应某个可打印字符。3个字节有24个比特,对应于4个Base64单元,即3个字节可由4个可打印字符来表示。它可用来作为电子邮件的传输编码。在Base64中的可打印字符包括字母
A-Z、a-z、数字0-9,这样共有62个字符,此外两个可打印符号在不同的系统中而不同。一些如uuencode的其他编码方法,和之后BinHex的版本使用不同的64字符集来代表6个二进制数字,但是不被称为Base64。Base64常用于在通常处理文本数据的场合,表示、传输、存储一些二进制数据,包括MIME的电子邮件及XML的一些复杂数据。
Base64编码转换方式
Base64,选出64个字符----小写字母a-z、大写字母A-Z、数字0-9、符号"+"、"/"(再加上作为垫字的"=",实际上是65个字符)----作为一个基本字符集。然后,其他所有符号都转换成这个字符集中的字符。具体来说,转换方式可以分为四步。
第一步,将每三个字节作为一组,一共是24个二进制位。
第二步,将这24个二进制位分为四组,每个组有6个二进制位。
第三步,在每组前面加两个00,扩展成32个二进制位,即四个字节。
第四步,根据 Base64 索引表,得到扩展后的每个字节的对应符号,这就是Base64的编码值。
Base64索引表:
如果要编码的字节数不能被3整除,最后会多出1个或2个字节,那么可以使用下面的方法进行处理:先使用0字节值在末尾补足,使其能够被3整除,然后再进行Base64的编码。在编码后的Base64文本后加上一个或两个
=号,代表补足的字节数。也就是说,当最后剩余两个八位字节(2个byte)时,最后一个6位的Base64字节块有四位是0值,最后附加上两个等号;如果最后剩余一个八位字节(1个byte)时,最后一个6位的base字节块有两位是0值,最后附加一个等号。 参考下表:注意:Base64将三个字节转化成四个字节,因此Base64编码后的文本,会比原文本大出三分之一左右。Base64编码转换示例
在此例中,Base64算法将3个字节编码为4个字符。
汉字本身可以有多种编码,比如gb2312、utf-8、gbk等等,每一种编码的Base64对应值都不一样。下面的例子以utf-8为例。
参考阅读:
Unicode®字符百科
ASCII
Unicode
Unicode字符列表
UTF-8
百分号编码
字符,字节和编码
字符编码笔记:ASCII,Unicode 和 UTF-8
阮一峰 - Unicode与JavaScript详解
阮一峰 - 关于URL编码
阮一峰 - Base64笔记
探究 dataURI 中使用 SVG 正确姿势
escape,encodeURI,encodeURIComponent有什么区别?
URL编码的奥秘
你真的了解 Unicode 和 UTF-8 吗?
彻底弄懂 Unicode 编码
二进制
计算机的血肉:数据
Javascript 与字符编码
Unicode® 6.0.0
The text was updated successfully, but these errors were encountered: