【2021 ASPLOS CCFA】FaasCache-Keeping Serverless Computing Alive with Greedy-Dual Caching #5
Comments
|
这篇文章的主要贡献有:
|
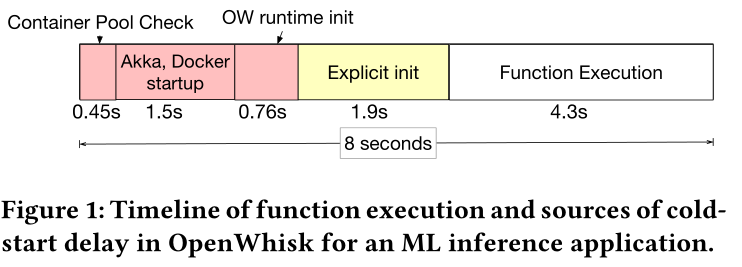
Keep-alive Tradeoffs为了理解函数冷启动开销,我们先分析一个用 TensorFlow 框架做机器学习推理的函数被调用的时间线。 图中显示了从函数被调用到实际函数执行整个期间冷启动开销的主要来源:
函数初始化(initialization)阶段会产生不可忽略的函数整体执行延迟时间。因此减少函数启动开销是无服务器计算中的关键挑战。为了减少冷启动开销(图中红色和黄色部分),最常见的技术就是函数执行完毕后,将运行该函数的容器保持一段时间的 warm 状态,这样将来该函数再次调用,就可以避免冷启动开销。虽然 keep-alive策略可以减少整体函数冷启动开销,但 keep-alive 会消耗物理服务器上的资源,也会降低整个系统的效率。因此需要开发一类新的资源管理技术来优化 keep-alive策略。实现容器保持 warm 状态所带来的资源消耗和系统整体效率之间的权衡,从而有效地执行不同的FaaS工作负载。 Keep-Alive的主要目标是根据函数的特性,为每个函数设置不同的keep alive 时间,减少初始化和冷启动开销。在本论文中,作者使用以下指标去指定 keep alive 策略
资源是有限的,因此决定哪些函数应该被保持为warm状态很重要,上述函数特征决定了函数被保持warm状态的优先级。对于不经常调用的函数,keep alive 不仅没什么好处,而且还占内存;保持那些 large-footprint 的代价要比使用较小的函数高昂的多,因此那些小内存函数可以存活更长的时间;函数可以根据初始化开销进行优先排序,因为初始化开销是有效的资源浪费。 由于函数对于不同的特性可能具有不同的keep alive优先级,所以设计保活策略的问题变得复杂。 |
Caching-based Keep-alive Policies本论文的新颖之处在于它证明了Keep-alive 策略等价于缓存 ”The central insight of this paper is that keeping functions alive is equivalent to keeping objects in a cache“:
在缓存中通常寻求提高命中率。然而,在keep- alive 策略中如果函数的大小不同和未命中成本不同,那么仅关注命中率并不一定能提高系统级别的性能。例如,缓存所有小函数可能会产生较高的命中率,但较大函数会导致较高的未命中成本和较差的系统吞吐量。 Greedy-Dual Keep-Alive Policy虽然许多缓存算法可以应用到 keep-alive 策略,但传统的缓存替换算法(如LRU、LFU)并没有考虑对象大小因素,因此采用贪婪双尺寸频率缓存替换算法(Greedy-Dual-Size-Frequency),该方法提供了一个通用框架来设计和实现保活策略,该框架能够识别不同函数调用的频率、初始化开销以及运行所占内存大小。 本文的 keep-alive 策略,它就是基于 GDFS 设计的一个算法,它的核心思想是只要服务器资源够,进程中的函数状态尽可能的保持 warm,这其实和之前那些 FaaS 的做法是截然不同的,恒定时间的生存策略意味着即使有资源可以让它们生存更长时间,也会被终止。Greedy-Dual Keep-Alive Policy 更多是作为一种驱逐策略,如果要启动一个新的容器,并且没有足够的资源可用,那么我们要决定终止哪些容器。显然,容器的总数(warm + running)受服务器物理资源(CPU 和内存)限制,这篇论文就根据函数冷启动的开销和资源占用情况为每一个容器计算一个优先级,并终止优先级最低的容器。 函数优先级计算公式: 当每次函数调用时,如果函数的 warm 容器可以使用,则称其 cache hit 并更新函数的频率和优先级,不会有冷启动开销。如果服务器资源不足启动新容器时,就需要根据容器优先级顺序,优先终止那些较低优先级的容器。
Other Caching-Based Policies上述算法也有一些更简单的策略,如果只使用 Clock 作为优先级,就是一个简单的 LRU 算法;如果只使用 Frequency 就可以得到 LFU 算法;如果只使用 1/size 作为优先级,可以得到一个 size 敏感的 keep-alive 策略,这在内存 size 很重要的时候很有用。 |
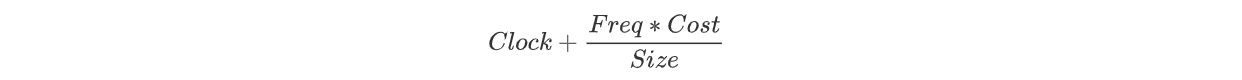
SERVER PROVISIONING POLICIES资源配置即确定能够用于处理FaaS工作负载的服务器资源大小和容量。对于一定的函数工作负载,给服务器分配过多的资源,显然 keep-alive 缓存可以减少冷启动开销,提高性能,但过度的资源提供也意味着服务器资源利用不足,不足的服务器资源分配又会造成 FaaS 性能下降。资源配置的根本挑战在于性能和资源利用率之间的权衡。
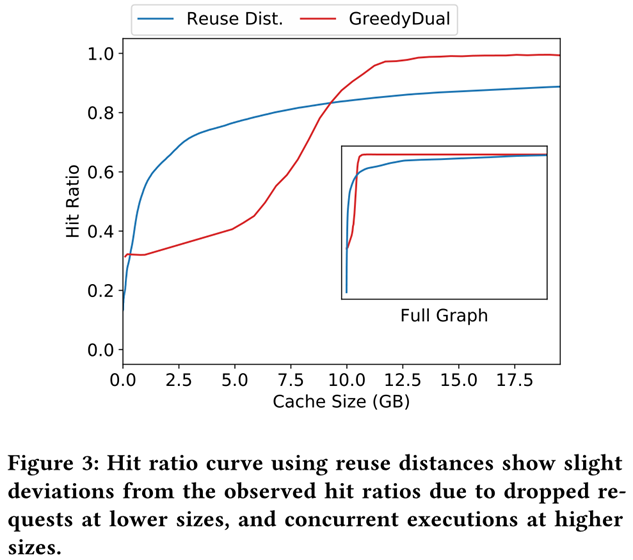
此外,函数的工作负载可以是动态的,因此资源配置必须是弹性的,能够根据负载动态的增加或减少。因此,本文提出了一个静态配置策略,用来确定一个给定函数工作负载的服务器资源配置;一个动态配置策略,用来弹性伸缩服务器资源配置以处理随时间动态变化的函数工作负载。 下面具体介绍一下静态服务器资源配置策略 Static Provisioning在前文章节中,作者已经做了 keep-alive policy 和 cache eviction 的类比,在本章节中作者将进一步扩展缓存概念的类比,并提出了一种静态配置策略来优化资源配置,实现成本和性能之间的权衡与折衷。 在缓存领域,经常使用命中率曲线(hit ratio curve)来设置能达到一定访问命中率预期的缓存大小,并由复用距离(reuse distance)来求解构造命中率曲线。将缓存这些概念类比到Serverless领域,serverless 函数的性能和资源可用性之间权衡可以通过命中率曲线来理解和建模。一般会选择命中率曲线图中的拐点(inflection point)所对应的横坐标缓存的值作为服务器资源的配置方案。 在缓存领域,复用距离(reuse distance)用来表示串行程序运行中前后两次访问同一数据元素之间所访问的不同数据元素的数目,在 serverless 领域,复用距离则被定义为在连续调用同一个函数之间调用的不同函数的总内存大小。比如,某个调用顺序为 ABCBBCA,那么函数 A 的复用距离为函数 B 的内存大小加上函数 C 的内存大小。这些复用距离可以帮助人们对所需缓存大小进行分析。如果 cache 的大小大于 reuse distance,那么就不会有 cache miss(因为所有函数调用都在 cache 中)。 公式中通过复用距离(reuse distance)来计算缓存为 c 时的命中率,reuse distance 的概率是通过扫描所有函数工作负载,分析其中包含的重用序列得到的。图3是针对于给定函数工作负载下绘制得到的命中率曲线图。 从图3看到,命中率随着缓存大小(服务器资源大小)的增加而陡然增加,直到一个拐点,之后收益递减。我们可以利用图中拐点来确定 server 内存大小,或者可以设定一个目标命中率(比如 90%),以此来确定 server 的最小内存大小。但是,要跟踪整个 reuse distance 需要大约 O(NM) 的时间,N 为函数调用次数,M 为不同函数的数量。因此,论文使用类似 SHARDS 这样的抽样技术来降低时间代价。 从图中可以很明显看到这种缓存概念类比的局限性,因为使用复用距离得到的命中率曲线与实际命中率曲线存在差别,并不完全适用于 FaaS。图3中蓝色曲线高于红色曲线的原因有两个
|
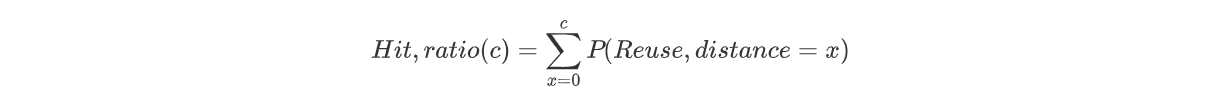
文章获取
https://asplos-conference.org/2021/abstracts/asplos21-paper1225-extended_abstract.pdf
https://dl.acm.org/doi/10.1145/3445814.3446757
The text was updated successfully, but these errors were encountered: