很早以前就想写一款对网站进行爬取,并且对网站中引入的JS进行信息搜集的一个工具,之前一直没有思路,因为对正则的熟悉程度没有到可以对js中的info进行匹配的地步,最近实验室的朋友写了一款工具:JSFinder,借用了他的思路,写了一款递归爬取域名(netloc/domain),以及递归从JS中获取信息的工具。
写这个工具主要有这么几个点:
- 如何爬取域名
- 如何爬取JS
- 如何从JS中获取信息
三个点的解决方案:
- 正则匹配href属性中的链接
- 正则匹配src属性中的链接,并判断链接是否为js。正则匹配
<script></script>标签中的文本。 - 使用LinkFinder的正则从JS中匹配敏感信息
- 实现递归爬取
- 对JS中匹配到的info进行了处理,直观的展示出来
使用的是单线程,因为目前多线程还没学够,如果冒昧使用担心引起数据混乱的问题,也并不熟悉使用Lock()函数,怕使用的地方多了,多线程也变成了单线程。
python3 jsinfo.py -d jd.com --keyword jd --save jd.api.txt --savedomain jd.domain.txt
- -d/-f
对单个域名或对域名文件进行扫描,文件需要一行一个域名。
- --keyword
设置爬取关键字,会使用该关键字对域名进行匹配,必选项。
- --savedomain
设置爬取出来的域名保存路径
- --save
设置api保存路径
- 对京东进行爬取
只爬取jd.com,设置keyword为jd,joybuy,360:

- 对百度进行爬取

2019-7-5:重构代码,加入了爬行深度的设定,深度为1~2,默认为1,2即为深度爬取,同时增加了url的存储,即深度爬取爬取到的链接。
2020-2-10:重构代码,整体使用了协程,使用队列的方式作为递归标准,默认递归深度为8,可根据自身需要进行修改。
经过测试,速度是v1版本的十倍不止,并且获取到的域名也是v1版本的两倍,但是这一版取消了获取api。
效果:

2020-2-16:增加搜集其他信息的功能,比如邮箱,代码作者,ip等。
效果:

2020-8-1:重构代码,具体看下面的README。
_____ ___ _ _ _ ___ _____
(___ )( _`\ (_)( ) ( )( _`\ ( _ )
| || (_(_)| || `\| || (_(_)| ( ) |
_ | |`\__ \ | || , ` || _) | | | |
( )_| |( )_) || || |`\ || | | (_) |
`\___/'`\____)(_)(_) (_)(_) (_____)
Author:P1g3#[email protected]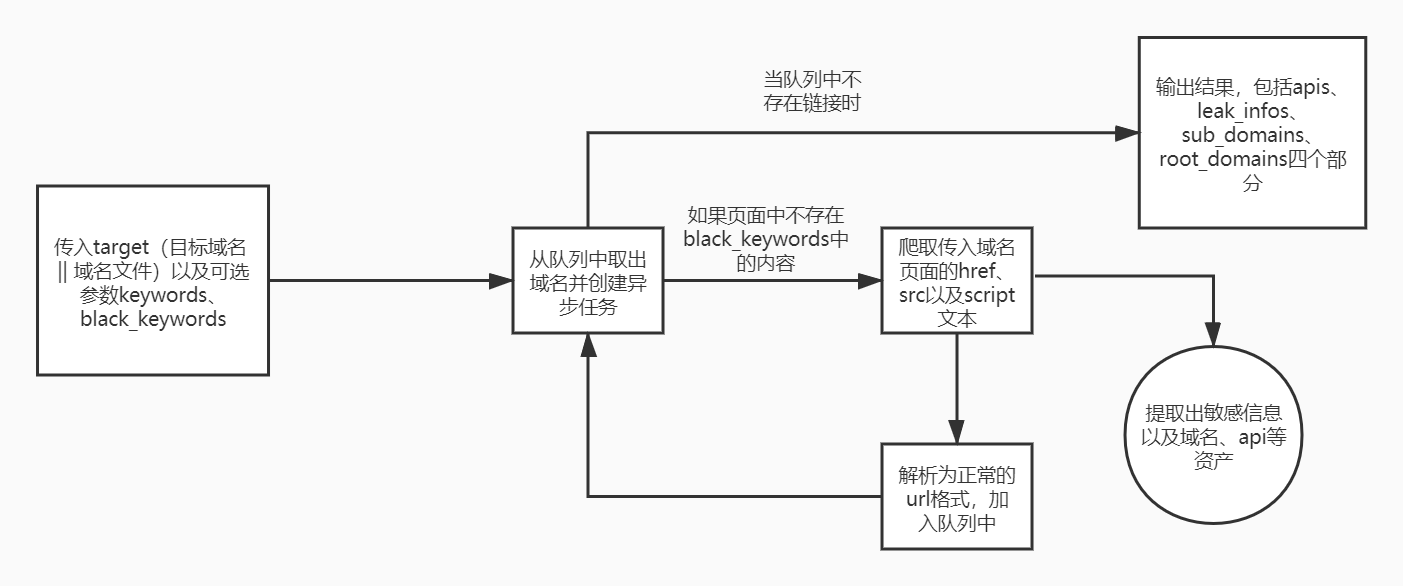
目的:
- 扩充资产(主要体现在爬取根域名这块)
- 爬取敏感信息(新增了大量敏感信息正则,对邮箱的提取进行了优化)
- 爬取api(将前面版本中去除的api功能恢复)
- 新增banner信息
- 新增敏感信息正则
- 代码优化
- 对Ctrl+C退出进行优化(当退出时,会自动将已爬取到的信息保存到当前目录下)
- 无需自动指定输出结果,最终输出为四个文件,为str(int(time.time()))_xxx(xxx为root_domains、sub_domains、leak_infos、apis)
- 错误处理优化
- 减少传入参数
python3 jsinfo.py --target www.baidu.com --keywords baidu
- target(域名 ==> 可传入单个域名或域名文件)
- keywords(域名中的关键字,用于搜集根域名以及扩充子域名)
- black_keywords(黑名单关键字,当返回包中含有这些关键字则不再进行二次爬取,用于某些商城页面避免爬到无用链接)
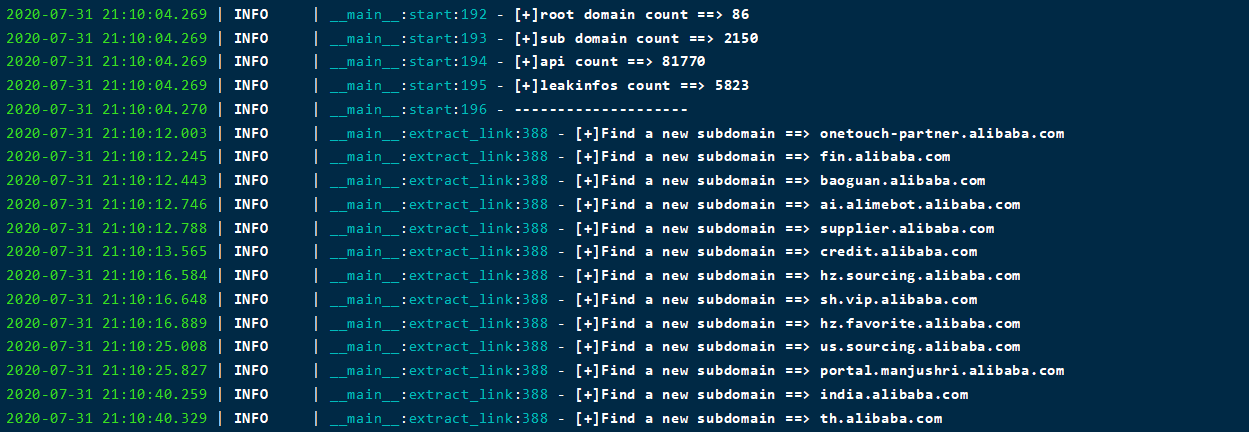
阿里的资产还在跑,目前获取到了如下信息:
- 2k+ 子域
- 80+ 根域
- 80000+ api
- 5000+ 敏感信息
PS:欢迎反馈Bug,本项目将持续更新,如有问题请联系wx:p1g3___,如果需要下载历史版本的jsinfo,请从commit中寻找...