diff --git a/configs/_base_/datasets/coco_aic.py b/configs/_base_/datasets/coco_aic.py
index 6a4d36ff60..a084247468 100644
--- a/configs/_base_/datasets/coco_aic.py
+++ b/configs/_base_/datasets/coco_aic.py
@@ -141,12 +141,12 @@
17:
dict(
name='head_top',
- id=12,
+ id=17,
color=[51, 153, 255],
type='upper',
swap=''),
18:
- dict(name='neck', id=13, color=[51, 153, 255], type='upper', swap='')
+ dict(name='neck', id=18, color=[51, 153, 255], type='upper', swap='')
},
skeleton_info={
0:
diff --git a/docs/en/advanced_guides.md b/docs/en/advanced_guides.md
deleted file mode 100644
index 25fcefe33e..0000000000
--- a/docs/en/advanced_guides.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# Advanced Guides
-
-Work in progress...
diff --git a/docs/en/advanced_guides/mixed_datasets.md b/docs/en/advanced_guides/mixed_datasets.md
new file mode 100644
index 0000000000..1c595314b7
--- /dev/null
+++ b/docs/en/advanced_guides/mixed_datasets.md
@@ -0,0 +1,159 @@
+# Training with Mixed Datasets
+
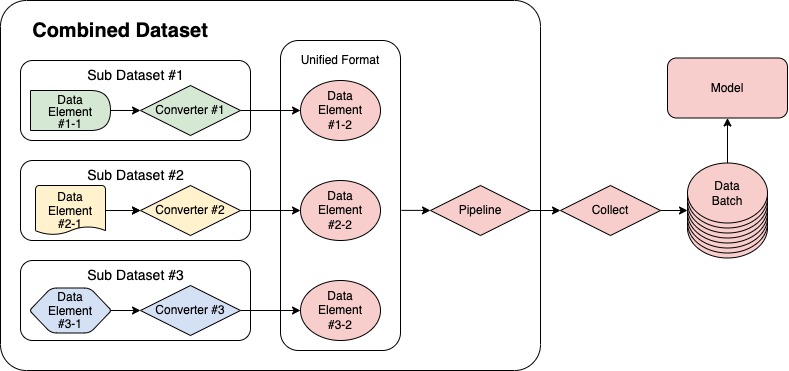
+MMPose offers a convenient and versatile solution for training with mixed datasets through its `CombinedDataset` tool. Acting as a wrapper, it allows for the inclusion of multiple datasets and seamlessly reads and converts data from varying sources into a unified format for model training. The data processing pipeline utilizing `CombinedDataset` is illustrated in the following figure.
+
+
+
+The following section will provide a detailed description of how to configure `CombinedDataset` with an example that combines the COCO and AI Challenger (AIC) datasets.
+
+## COCO & AIC example
+
+The COCO and AIC datasets are both human 2D pose datasets, but they differ in the number and order of keypoints. Here are two instances from the respective datasets.
+
+
+
+Some keypoints, such as "left hand", are defined in both datasets, but they have different indices. Specifically, the index for the "left hand" keypoint is 9 in the COCO dataset and 5 in the AIC dataset. Furthermore, each dataset contains unique keypoints that are not present in the counterpart dataset. For instance, the facial keypoints (with indices 0~4) are only defined in the COCO dataset, whereas the "head top" (with index 12) and "neck" (with index 13) keypoints are exclusive to the AIC dataset. The relationship between the keypoints in both datasets is illustrated in the following Venn diagram.
+
+
+
+Next, we will discuss two methods of mixing datasets.
+
+- [Merge](#merge-aic-into-coco)
+- [Combine](#combine-aic-and-coco)
+
+### Merge AIC into COCO
+
+If users aim to enhance their model's performance on the COCO dataset or other similar datasets, they can use the AIC dataset as an auxiliary source. To do so, they should select only the keypoints in AIC dataset that are shared with COCO datasets and ignore the rest. Moreover, the indices of these chosen keypoints in the AIC dataset should be transformed to match the corresponding indices in the COCO dataset.
+
+
+
+In this scenario, no data conversion is required for the elements from the COCO dataset. To configure the COCO dataset, use the following code:
+
+```python
+dataset_coco = dict(
+ type='CocoDataset',
+ data_root='data/coco/',
+ ann_file='annotations/person_keypoints_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=[], # Leave the `pipeline` empty, as no conversion is needed
+)
+```
+
+For AIC dataset, the order of the keypoints needs to be transformed. MMPose provides a `KeypointConverter` transform to achieve this. Here's an example of how to configure the AIC sub dataset:
+
+```python
+dataset_aic = dict(
+ type='AicDataset',
+ data_root='data/aic/',
+ ann_file='annotations/aic_train.json',
+ data_prefix=dict(img='ai_challenger_keypoint_train_20170902/'
+ 'keypoint_train_images_20170902/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=17, # same as COCO dataset
+ mapping=[ # includes index pairs for corresponding keypoints
+ (0, 6), # index 0 (in AIC) -> index 6 (in COCO)
+ (1, 8),
+ (2, 10),
+ (3, 5),
+ (4, 7),
+ (5, 9),
+ (6, 12),
+ (7, 14),
+ (8, 16),
+ (9, 11),
+ (10, 13),
+ (11, 15),
+ ])
+ ],
+)
+```
+
+By using the `KeypointConverter`, the indices of keypoints with indices 0 to 11 will be transformed to corresponding indices among 5 to 16. Meanwhile, the keypoints with indices 12 and 13 will be removed. For the target keypoints with indices 0 to 4, which are not defined in the `mapping` argument, they will be set as invisible and won't be used in training.
+
+Once the sub datasets are configured, the `CombinedDataset` wrapper can be defined as follows:
+
+```python
+dataset = dict(
+ type='CombinedDataset',
+ # Since the combined dataset has the same data format as COCO,
+ # it should use the same meta information for the dataset
+ metainfo=dict(from_file='configs/_base_/datasets/coco.py'),
+ datasets=[dataset_coco, dataset_aic],
+ # The pipeline includes typical transforms, such as loading the
+ # image and data augmentation
+ pipeline=train_pipeline,
+)
+```
+
+A complete, ready-to-use [config file](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-merge.py) that merges the AIC dataset into the COCO dataset is also available. Users can refer to it for more details and use it as a template to build their own custom dataset.
+
+### Combine AIC and COCO
+
+The previously mentioned method discards some annotations in the AIC dataset. If users want to use all the information from both datasets, they can combine the two datasets. This means taking the union set of keypoints in both datasets.
+
+
+
+In this scenario, both COCO and AIC datasets need to adjust the keypoint indices using `KeypointConverter`:
+
+```python
+dataset_coco = dict(
+ type='CocoDataset',
+ data_root='data/coco/',
+ ann_file='annotations/person_keypoints_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=19, # the size of union keypoint set
+ mapping=[
+ (0, 0),
+ (1, 1),
+ # omitted
+ (16, 16),
+ ])
+ ])
+
+dataset_aic = dict(
+ type='AicDataset',
+ data_root='data/aic/',
+ ann_file='annotations/aic_train.json',
+ data_prefix=dict(img='ai_challenger_keypoint_train_20170902/'
+ 'keypoint_train_images_20170902/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=19, # the size of union keypoint set
+ mapping=[
+ (0, 6),
+ # omitted
+ (12, 17),
+ (13, 18),
+ ])
+ ],
+)
+```
+
+To account for the fact that the combined dataset has 19 keypoints, which is different from either COCO or AIC dataset, a new dataset meta information file is needed to describe the new dataset. An example of such a file is [coco_aic.py](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/_base_/datasets/coco_aic.py), which is based on [coco.py](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/_base_/datasets/coco.py) but includes several updates:
+
+- The paper information of AIC dataset has been added.
+- The 'head_top' and 'neck' keypoints, which are unique in AIC, have been added to the `keypoint_info`.
+- A skeleton link between 'head_top' and 'neck' has been added.
+- The `joint_weights` and `sigmas` have been extended for the newly added keypoints.
+
+Finally, the combined dataset can be configured as:
+
+```python
+dataset = dict(
+ type='CombinedDataset',
+ # using new dataset meta information file
+ metainfo=dict(from_file='configs/_base_/datasets/coco_aic.py'),
+ datasets=[dataset_coco, dataset_aic],
+ # The pipeline includes typical transforms, such as loading the
+ # image and data augmentation
+ pipeline=train_pipeline,
+)
+```
+
+Additionally, the output channel number of the model should be adjusted as the number of keypoints changes. If the users aim to evaluate the model on the COCO dataset, a subset of model outputs must be chosen. This subset can be customized using the `output_keypoint_indices` argument in `test_cfg`. Users can refer to the [config file](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-combine.py), which combines the COCO and AIC dataset, for more details and use it as a template to create their custom dataset.
diff --git a/docs/en/index.rst b/docs/en/index.rst
index 83d02f9b5e..ea48c2817a 100644
--- a/docs/en/index.rst
+++ b/docs/en/index.rst
@@ -30,7 +30,7 @@ You can change the documentation language at the lower-left corner of the page.
:maxdepth: 1
:caption: Advanced Guides
- advanced_guides.md
+ advanced_guides/mixed_datasets.md
.. toctree::
:maxdepth: 1
diff --git a/docs/zh_cn/advanced_guides.md b/docs/zh_cn/advanced_guides.md
deleted file mode 100644
index 25fcefe33e..0000000000
--- a/docs/zh_cn/advanced_guides.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# Advanced Guides
-
-Work in progress...
diff --git a/docs/zh_cn/advanced_guides/mixed_datasets.md b/docs/zh_cn/advanced_guides/mixed_datasets.md
new file mode 100644
index 0000000000..fac38e3338
--- /dev/null
+++ b/docs/zh_cn/advanced_guides/mixed_datasets.md
@@ -0,0 +1,159 @@
+# 混合数据集训练
+
+MMPose 提供了一个灵活、便捷的工具 `CombinedDataset` 来进行混合数据集训练。它作为一个封装器,可以包含多个子数据集,并将来自不同子数据集的数据转换成一个统一的格式,以用于模型训练。使用 `CombinedDataset` 的数据处理流程如下图所示。
+
+
+
+本篇教程的后续部分将通过一个结合 COCO 和 AI Challenger (AIC) 数据集的例子详细介绍如何配置 `CombinedDataset`。
+
+## COCO & AIC 数据集混合案例
+
+COCO 和 AIC 都是 2D 人体姿态数据集。但是,这两个数据集在关键点的数量和排列顺序上有所不同。下面是分别来自这两个数据集的图片及关键点:
+
+
+
+有些关键点(例如“左手”)在两个数据集中都有定义,但它们具有不同的序号。具体来说,“左手”关键点在 COCO 数据集中的序号为 9,在AIC数据集中的序号为 5。此外,每个数据集都包含独特的关键点,另一个数据集中不存在。例如,面部关键点(序号为0〜4)仅在 COCO 数据集中定义,而“头顶”(序号为 12)和“颈部”(序号为 13)关键点仅在 AIC 数据集中存在。以下的维恩图显示了两个数据集中关键点之间的关系。
+
+
+
+接下来,我们会介绍两种混合数据集的方式:
+
+- [将 AIC 合入 COCO 数据集](#将-aic-合入-coco-数据集)
+- [合并 AIC 和 COCO 数据集](#合并-aic-和-coco-数据集)
+
+### 将 AIC 合入 COCO 数据集
+
+如果用户想提高其模型在 COCO 或类似数据集上的性能,可以将 AIC 数据集作为辅助数据。此时应该仅选择 AIC 数据集中与 COCO 数据集共享的关键点,忽略其余关键点。此外,还需要将这些被选择的关键点在 AIC 数据集中的序号进行转换,以匹配在 COCO 数据集中对应关键点的序号。
+
+
+
+在这种情况下,来自 COCO 的数据不需要进行转换。此时 COCO 数据集可通过如下方式配置:
+
+```python
+dataset_coco = dict(
+ type='CocoDataset',
+ data_root='data/coco/',
+ ann_file='annotations/person_keypoints_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=[], # `pipeline` 应为空列表,因为 COCO 数据不需要转换
+)
+```
+
+对于 AIC 数据集,需要转换关键点的顺序。MMPose 提供了一个 `KeypointConverter` 转换器来实现这一点。以下是配置 AIC 子数据集的示例:
+
+```python
+dataset_aic = dict(
+ type='AicDataset',
+ data_root='data/aic/',
+ ann_file='annotations/aic_train.json',
+ data_prefix=dict(img='ai_challenger_keypoint_train_20170902/'
+ 'keypoint_train_images_20170902/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=17, # 与 COCO 数据集关键点数一致
+ mapping=[ # 需要列出所有带转换关键点的序号
+ (0, 6), # 0 (AIC 中的序号) -> 6 (COCO 中的序号)
+ (1, 8),
+ (2, 10),
+ (3, 5),
+ (4, 7),
+ (5, 9),
+ (6, 12),
+ (7, 14),
+ (8, 16),
+ (9, 11),
+ (10, 13),
+ (11, 15),
+ ])
+ ],
+)
+```
+
+`KeypointConverter` 会将原序号在 0 到 11 之间的关键点的序号转换为在 5 到 16 之间的对应序号。同时,在 AIC 中序号为为 12 和 13 的关键点将被删除。另外,目标序号在 0 到 4 之间的关键点在 `mapping` 参数中没有定义,这些点将被设为不可见,并且不会在训练中使用。
+
+子数据集都完成配置后, 混合数据集 `CombinedDataset` 可以通过如下方式配置:
+
+```python
+dataset = dict(
+ type='CombinedDataset',
+ # 混合数据集关键点顺序和 COCO 数据集相同,
+ # 所以使用 COCO 数据集的描述信息
+ metainfo=dict(from_file='configs/_base_/datasets/coco.py'),
+ datasets=[dataset_coco, dataset_aic],
+ # `train_pipeline` 包含了常用的数据预处理,
+ # 比如图片读取、数据增广等
+ pipeline=train_pipeline,
+)
+```
+
+MMPose 提供了一份完整的 [配置文件](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-merge.py) 来将 AIC 合入 COCO 数据集并用于训练网络。用户可以查阅这个文件以获取更多细节,或者参考这个文件来构建新的混合数据集。
+
+### 合并 AIC 和 COCO 数据集
+
+将 AIC 合入 COCO 数据集的过程中丢弃了部分 AIC 数据集中的标注信息。如果用户想要使用两个数据集中的所有信息,可以将两个数据集合并,即在两个数据集中取关键点的并集。
+
+
+
+在这种情况下,COCO 和 AIC 数据集都需要使用 `KeypointConverter` 来调整它们关键点的顺序:
+
+```python
+dataset_coco = dict(
+ type='CocoDataset',
+ data_root='data/coco/',
+ ann_file='annotations/person_keypoints_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=19, # 并集中有 19 个关键点
+ mapping=[
+ (0, 0),
+ (1, 1),
+ # 省略
+ (16, 16),
+ ])
+ ])
+
+dataset_aic = dict(
+ type='AicDataset',
+ data_root='data/aic/',
+ ann_file='annotations/aic_train.json',
+ data_prefix=dict(img='ai_challenger_keypoint_train_20170902/'
+ 'keypoint_train_images_20170902/'),
+ pipeline=[
+ dict(
+ type='KeypointConverter',
+ num_keypoints=19, # 并集中有 19 个关键点
+ mapping=[
+ (0, 6),
+ # 省略
+ (12, 17),
+ (13, 18),
+ ])
+ ],
+)
+```
+
+合并后的数据集有 19 个关键点,这与 COCO 或 AIC 数据集都不同,因此需要一个新的数据集描述信息文件。[coco_aic.py](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/_base_/datasets/coco_aic.py) 是一个描述信息文件的示例,它基于 [coco.py](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/_base_/datasets/coco.py) 并进行了以下几点修改:
+
+- 添加了 AIC 数据集的文章信息;
+- 在 `keypoint_info` 中添加了“头顶”和“颈部”这两个只在 AIC 中定义的关键点;
+- 在 `skeleton_info` 中添加了“头顶”和“颈部”间的连线;
+- 拓展 `joint_weights` 和 `sigmas` 以添加新增关键点的信息。
+
+完成以上步骤后,合并数据集 `CombinedDataset` 可以通过以下方式配置:
+
+```python
+dataset = dict(
+ type='CombinedDataset',
+ # 使用新的描述信息文件
+ metainfo=dict(from_file='configs/_base_/datasets/coco_aic.py'),
+ datasets=[dataset_coco, dataset_aic],
+ # `train_pipeline` 包含了常用的数据预处理,
+ # 比如图片读取、数据增广等
+ pipeline=train_pipeline,
+)
+```
+
+此外,在使用混合数据集时,由于关键点数量的变化,模型的输出通道数也要做相应调整。如果用户用混合数据集训练了模型,但是要在 COCO 数据集上评估模型,就需要从模型输出的关键点中取出一个子集来匹配 COCO 中的关键点格式。可以通过 `test_cfg` 中的 `output_keypoint_indices` 参数自定义此子集。这个 [配置文件](https://github.com/open-mmlab/mmpose/blob/dev-1.x/configs/body_2d_keypoint/topdown_heatmap/coco/td-hm_hrnet-w32_8xb64-210e_coco-aic-256x192-combine.py) 展示了如何用 AIC 和 COCO 合并后的数据集训练模型并在 COCO 数据集上进行测试。用户可以查阅这个文件以获取更多细节,或者参考这个文件来构建新的混合数据集。
diff --git a/docs/zh_cn/index.rst b/docs/zh_cn/index.rst
index f0652ce364..01aea1e18e 100644
--- a/docs/zh_cn/index.rst
+++ b/docs/zh_cn/index.rst
@@ -30,7 +30,7 @@ You can change the documentation language at the lower-left corner of the page.
:maxdepth: 1
:caption: 进阶教程
- advanced_guides.md
+ advanced_guides/mixed_datasets.md
.. toctree::
:maxdepth: 1