diff --git a/configs/albu_example/README.md b/configs/albu_example/README.md
index 7f0eff52b3c..49edbf3f833 100644
--- a/configs/albu_example/README.md
+++ b/configs/albu_example/README.md
@@ -1,24 +1,26 @@
# Albu Example
-## Abstract
+> [Albumentations: fast and flexible image augmentations](https://arxiv.org/abs/1809.06839)
-
+
+
+## Abstract
Data augmentation is a commonly used technique for increasing both the size and the diversity of labeled training sets by leveraging input transformations that preserve output labels. In computer vision domain, image augmentations have become a common implicit regularization technique to combat overfitting in deep convolutional neural networks and are ubiquitously used to improve performance. While most deep learning frameworks implement basic image transformations, the list is typically limited to some variations and combinations of flipping, rotating, scaling, and cropping. Moreover, the image processing speed varies in existing tools for image augmentation. We present Albumentations, a fast and flexible library for image augmentations with many various image transform operations available, that is also an easy-to-use wrapper around other augmentation libraries. We provide examples of image augmentations for different computer vision tasks and show that Albumentations is faster than other commonly used image augmentation tools on the most of commonly used image transformations.
-
-
-
+## Results and Models
-## Citation
+| Backbone | Style | Lr schd | Mem (GB) | Inf time (fps) | box AP | mask AP | Config | Download |
+|:---------:|:-------:|:-------:|:--------:|:--------------:|:------:|:-------:|:------:|:--------:|
+| R-50 | pytorch | 1x | 4.4 | 16.6 | 38.0 | 34.5 |[config](https://github.com/open-mmlab/mmdetection/tree/master/configs/albu_example/mask_rcnn_r50_fpn_albu_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/albu_example/mask_rcnn_r50_fpn_albu_1x_coco/mask_rcnn_r50_fpn_albu_1x_coco_20200208-ab203bcd.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/albu_example/mask_rcnn_r50_fpn_albu_1x_coco/mask_rcnn_r50_fpn_albu_1x_coco_20200208_225520.log.json) |
-
+## Citation
-```
+```latex
@article{2018arXiv180906839B,
author = {A. Buslaev, A. Parinov, E. Khvedchenya, V.~I. Iglovikov and A.~A. Kalinin},
title = "{Albumentations: fast and flexible image augmentations}",
@@ -27,9 +29,3 @@ Data augmentation is a commonly used technique for increasing both the size and
year = 2018
}
```
-
-## Results and Models
-
-| Backbone | Style | Lr schd | Mem (GB) | Inf time (fps) | box AP | mask AP | Config | Download |
-|:---------:|:-------:|:-------:|:--------:|:--------------:|:------:|:-------:|:------:|:--------:|
-| R-50 | pytorch | 1x | 4.4 | 16.6 | 38.0 | 34.5 |[config](https://github.com/open-mmlab/mmdetection/tree/master/configs/albu_example/mask_rcnn_r50_fpn_albu_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/albu_example/mask_rcnn_r50_fpn_albu_1x_coco/mask_rcnn_r50_fpn_albu_1x_coco_20200208-ab203bcd.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/albu_example/mask_rcnn_r50_fpn_albu_1x_coco/mask_rcnn_r50_fpn_albu_1x_coco_20200208_225520.log.json) |
diff --git a/configs/atss/README.md b/configs/atss/README.md
index 035964f9f76..1bf694983ed 100644
--- a/configs/atss/README.md
+++ b/configs/atss/README.md
@@ -1,22 +1,25 @@
-# Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
+# ATSS
-## Abstract
+> [Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection](https://arxiv.org/abs/1912.02424)
-
+
+
+## Abstract
Object detection has been dominated by anchor-based detectors for several years. Recently, anchor-free detectors have become popular due to the proposal of FPN and Focal Loss. In this paper, we first point out that the essential difference between anchor-based and anchor-free detection is actually how to define positive and negative training samples, which leads to the performance gap between them. If they adopt the same definition of positive and negative samples during training, there is no obvious difference in the final performance, no matter regressing from a box or a point. This shows that how to select positive and negative training samples is important for current object detectors. Then, we propose an Adaptive Training Sample Selection (ATSS) to automatically select positive and negative samples according to statistical characteristics of object. It significantly improves the performance of anchor-based and anchor-free detectors and bridges the gap between them. Finally, we discuss the necessity of tiling multiple anchors per location on the image to detect objects. Extensive experiments conducted on MS COCO support our aforementioned analysis and conclusions. With the newly introduced ATSS, we improve state-of-the-art detectors by a large margin to 50.7% AP without introducing any overhead.
-
-
-
+## Results and Models
-## Citation
+| Backbone | Style | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
+|:---------:|:-------:|:-------:|:--------:|:--------------:|:------:|:------:|:--------:|
+| R-50 | pytorch | 1x | 3.7 | 19.7 | 39.4 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/atss/atss_r50_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/atss/atss_r50_fpn_1x_coco/atss_r50_fpn_1x_coco_20200209-985f7bd0.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/atss/atss_r50_fpn_1x_coco/atss_r50_fpn_1x_coco_20200209_102539.log.json) |
+| R-101 | pytorch | 1x | 5.6 | 12.3 | 41.5 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/atss/atss_r101_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/atss/atss_r101_fpn_1x_coco/atss_r101_fpn_1x_20200825-dfcadd6f.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/atss/atss_r101_fpn_1x_coco/atss_r101_fpn_1x_20200825-dfcadd6f.log.json) |
-
+## Citation
```latex
@article{zhang2019bridging,
@@ -26,10 +29,3 @@ Object detection has been dominated by anchor-based detectors for several years.
year = {2019}
}
```
-
-## Results and Models
-
-| Backbone | Style | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
-|:---------:|:-------:|:-------:|:--------:|:--------------:|:------:|:------:|:--------:|
-| R-50 | pytorch | 1x | 3.7 | 19.7 | 39.4 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/atss/atss_r50_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/atss/atss_r50_fpn_1x_coco/atss_r50_fpn_1x_coco_20200209-985f7bd0.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/atss/atss_r50_fpn_1x_coco/atss_r50_fpn_1x_coco_20200209_102539.log.json) |
-| R-101 | pytorch | 1x | 5.6 | 12.3 | 41.5 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/atss/atss_r101_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/atss/atss_r101_fpn_1x_coco/atss_r101_fpn_1x_20200825-dfcadd6f.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/atss/atss_r101_fpn_1x_coco/atss_r101_fpn_1x_20200825-dfcadd6f.log.json) |
diff --git a/configs/autoassign/README.md b/configs/autoassign/README.md
index 172071d5001..8e8341a717a 100644
--- a/configs/autoassign/README.md
+++ b/configs/autoassign/README.md
@@ -1,32 +1,17 @@
-# AutoAssign: Differentiable Label Assignment for Dense Object Detection
+# AutoAssign
-## Abstract
+> [AutoAssign: Differentiable Label Assignment for Dense Object Detection](https://arxiv.org/abs/2007.03496)
+
+
-
+## Abstract
Determining positive/negative samples for object detection is known as label assignment. Here we present an anchor-free detector named AutoAssign. It requires little human knowledge and achieves appearance-aware through a fully differentiable weighting mechanism. During training, to both satisfy the prior distribution of data and adapt to category characteristics, we present Center Weighting to adjust the category-specific prior distributions. To adapt to object appearances, Confidence Weighting is proposed to adjust the specific assign strategy of each instance. The two weighting modules are then combined to generate positive and negative weights to adjust each location's confidence. Extensive experiments on the MS COCO show that our method steadily surpasses other best sampling strategies by large margins with various backbones. Moreover, our best model achieves 52.1% AP, outperforming all existing one-stage detectors. Besides, experiments on other datasets, e.g., PASCAL VOC, Objects365, and WiderFace, demonstrate the broad applicability of AutoAssign.
-
-
-
-
-## Citation
-
-
-
-```
-@article{zhu2020autoassign,
- title={AutoAssign: Differentiable Label Assignment for Dense Object Detection},
- author={Zhu, Benjin and Wang, Jianfeng and Jiang, Zhengkai and Zong, Fuhang and Liu, Songtao and Li, Zeming and Sun, Jian},
- journal={arXiv preprint arXiv:2007.03496},
- year={2020}
-}
-```
-
## Results and Models
| Backbone | Style | Lr schd | Mem (GB) | box AP | Config | Download |
@@ -37,3 +22,14 @@ Determining positive/negative samples for object detection is known as label ass
1. We find that the performance is unstable with 1x setting and may fluctuate by about 0.3 mAP. mAP 40.3 ~ 40.6 is acceptable. Such fluctuation can also be found in the original implementation.
2. You can get a more stable results ~ mAP 40.6 with a schedule total 13 epoch, and learning rate is divided by 10 at 10th and 13th epoch.
+
+## Citation
+
+```latex
+@article{zhu2020autoassign,
+ title={AutoAssign: Differentiable Label Assignment for Dense Object Detection},
+ author={Zhu, Benjin and Wang, Jianfeng and Jiang, Zhengkai and Zong, Fuhang and Liu, Songtao and Li, Zeming and Sun, Jian},
+ journal={arXiv preprint arXiv:2007.03496},
+ year={2020}
+}
+```
diff --git a/configs/carafe/README.md b/configs/carafe/README.md
index dca52e6d1ef..983aafb412a 100644
--- a/configs/carafe/README.md
+++ b/configs/carafe/README.md
@@ -1,35 +1,17 @@
-# CARAFE: Content-Aware ReAssembly of FEatures
+# CARAFE
-## Abstract
+> [CARAFE: Content-Aware ReAssembly of FEatures](https://arxiv.org/abs/1905.02188)
-
+
+
+## Abstract
Feature upsampling is a key operation in a number of modern convolutional network architectures, e.g. feature pyramids. Its design is critical for dense prediction tasks such as object detection and semantic/instance segmentation. In this work, we propose Content-Aware ReAssembly of FEatures (CARAFE), a universal, lightweight and highly effective operator to fulfill this goal. CARAFE has several appealing properties: (1) Large field of view. Unlike previous works (e.g. bilinear interpolation) that only exploit sub-pixel neighborhood, CARAFE can aggregate contextual information within a large receptive field. (2) Content-aware handling. Instead of using a fixed kernel for all samples (e.g. deconvolution), CARAFE enables instance-specific content-aware handling, which generates adaptive kernels on-the-fly. (3) Lightweight and fast to compute. CARAFE introduces little computational overhead and can be readily integrated into modern network architectures. We conduct comprehensive evaluations on standard benchmarks in object detection, instance/semantic segmentation and inpainting. CARAFE shows consistent and substantial gains across all the tasks (1.2%, 1.3%, 1.8%, 1.1db respectively) with negligible computational overhead. It has great potential to serve as a strong building block for future research. It has great potential to serve as a strong building block for future research.
-
-
-
-
-## Citation
-
-
-
-We provide config files to reproduce the object detection & instance segmentation results in the ICCV 2019 Oral paper for [CARAFE: Content-Aware ReAssembly of FEatures](https://arxiv.org/abs/1905.02188).
-
-```
-@inproceedings{Wang_2019_ICCV,
- title = {CARAFE: Content-Aware ReAssembly of FEatures},
- author = {Wang, Jiaqi and Chen, Kai and Xu, Rui and Liu, Ziwei and Loy, Chen Change and Lin, Dahua},
- booktitle = {The IEEE International Conference on Computer Vision (ICCV)},
- month = {October},
- year = {2019}
-}
-```
-
## Results and Models
The results on COCO 2017 val is shown in the below table.
@@ -44,3 +26,17 @@ The results on COCO 2017 val is shown in the below table.
## Implementation
The CUDA implementation of CARAFE can be find at https://github.com/myownskyW7/CARAFE.
+
+## Citation
+
+We provide config files to reproduce the object detection & instance segmentation results in the ICCV 2019 Oral paper for [CARAFE: Content-Aware ReAssembly of FEatures](https://arxiv.org/abs/1905.02188).
+
+```latex
+@inproceedings{Wang_2019_ICCV,
+ title = {CARAFE: Content-Aware ReAssembly of FEatures},
+ author = {Wang, Jiaqi and Chen, Kai and Xu, Rui and Liu, Ziwei and Loy, Chen Change and Lin, Dahua},
+ booktitle = {The IEEE International Conference on Computer Vision (ICCV)},
+ month = {October},
+ year = {2019}
+}
+```
diff --git a/configs/cascade_rcnn/README.md b/configs/cascade_rcnn/README.md
index a88cfd772a6..109fd7c3ded 100644
--- a/configs/cascade_rcnn/README.md
+++ b/configs/cascade_rcnn/README.md
@@ -1,38 +1,18 @@
-# Cascade R-CNN: High Quality Object Detection and Instance Segmentation
+# Cascade R-CNN
-## Abstract
+> [Cascade R-CNN: High Quality Object Detection and Instance Segmentation](https://arxiv.org/abs/1906.09756)
-
+
+
+## Abstract
In object detection, the intersection over union (IoU) threshold is frequently used to define positives/negatives. The threshold used to train a detector defines its quality. While the commonly used threshold of 0.5 leads to noisy (low-quality) detections, detection performance frequently degrades for larger thresholds. This paradox of high-quality detection has two causes: 1) overfitting, due to vanishing positive samples for large thresholds, and 2) inference-time quality mismatch between detector and test hypotheses. A multi-stage object detection architecture, the Cascade R-CNN, composed of a sequence of detectors trained with increasing IoU thresholds, is proposed to address these problems. The detectors are trained sequentially, using the output of a detector as training set for the next. This resampling progressively improves hypotheses quality, guaranteeing a positive training set of equivalent size for all detectors and minimizing overfitting. The same cascade is applied at inference, to eliminate quality mismatches between hypotheses and detectors. An implementation of the Cascade R-CNN without bells or whistles achieves state-of-the-art performance on the COCO dataset, and significantly improves high-quality detection on generic and specific object detection datasets, including VOC, KITTI, CityPerson, and WiderFace. Finally, the Cascade R-CNN is generalized to instance segmentation, with nontrivial improvements over the Mask R-CNN.
-
-
-
-
-## Citation
-
-
-
-```latex
-@article{Cai_2019,
- title={Cascade R-CNN: High Quality Object Detection and Instance Segmentation},
- ISSN={1939-3539},
- url={http://dx.doi.org/10.1109/tpami.2019.2956516},
- DOI={10.1109/tpami.2019.2956516},
- journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
- publisher={Institute of Electrical and Electronics Engineers (IEEE)},
- author={Cai, Zhaowei and Vasconcelos, Nuno},
- year={2019},
- pages={1–1}
-}
-```
-
-## Results and models
+## Results and Models
### Cascade R-CNN
@@ -81,3 +61,19 @@ We also train some models with longer schedules and multi-scale training for Cas
| X-101-32x4d-FPN | pytorch| 3x | 9.0 | | 46.3 | 40.1 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/cascade_rcnn/cascade_mask_rcnn_x101_32x4d_fpn_mstrain_3x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/cascade_rcnn/cascade_mask_rcnn_x101_32x4d_fpn_mstrain_3x_coco/cascade_mask_rcnn_x101_32x4d_fpn_mstrain_3x_coco_20210706_225234-40773067.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/cascade_rcnn/cascade_mask_rcnn_x101_32x4d_fpn_mstrain_3x_coco/cascade_mask_rcnn_x101_32x4d_fpn_mstrain_3x_coco_20210706_225234.log.json)
| X-101-32x8d-FPN | pytorch| 3x | 12.1 | | 46.1 | 39.9 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/cascade_rcnn/cascade_mask_rcnn_x101_32x8d_fpn_mstrain_3x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/cascade_rcnn/cascade_mask_rcnn_x101_32x8d_fpn_mstrain_3x_coco/cascade_mask_rcnn_x101_32x8d_fpn_mstrain_3x_coco_20210719_180640-9ff7e76f.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/cascade_rcnn/cascade_mask_rcnn_x101_32x8d_fpn_mstrain_3x_coco/cascade_mask_rcnn_x101_32x8d_fpn_mstrain_3x_coco_20210719_180640.log.json)
| X-101-64x4d-FPN | pytorch| 3x | 12.0 | | 46.6 | 40.3 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/cascade_rcnn/cascade_mask_rcnn_x101_64x4d_fpn_mstrain_3x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/cascade_rcnn/cascade_mask_rcnn_x101_64x4d_fpn_mstrain_3x_coco/cascade_mask_rcnn_x101_64x4d_fpn_mstrain_3x_coco_20210719_210311-d3e64ba0.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/cascade_rcnn/cascade_mask_rcnn_x101_64x4d_fpn_mstrain_3x_coco/cascade_mask_rcnn_x101_64x4d_fpn_mstrain_3x_coco_20210719_210311.log.json)
+
+## Citation
+
+```latex
+@article{Cai_2019,
+ title={Cascade R-CNN: High Quality Object Detection and Instance Segmentation},
+ ISSN={1939-3539},
+ url={http://dx.doi.org/10.1109/tpami.2019.2956516},
+ DOI={10.1109/tpami.2019.2956516},
+ journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
+ publisher={Institute of Electrical and Electronics Engineers (IEEE)},
+ author={Cai, Zhaowei and Vasconcelos, Nuno},
+ year={2019},
+ pages={1–1}
+}
+```
diff --git a/configs/cascade_rpn/README.md b/configs/cascade_rpn/README.md
index 06b25a53bc1..900dc2916cf 100644
--- a/configs/cascade_rpn/README.md
+++ b/configs/cascade_rpn/README.md
@@ -1,35 +1,18 @@
-# Cascade RPN: Delving into High-Quality Region Proposal Network with Adaptive Convolution
+# Cascade RPN
-## Abstract
+> [Cascade RPN: Delving into High-Quality Region Proposal Network with Adaptive Convolution](https://arxiv.org/abs/1909.06720)
+
+
-
+## Abstract
This paper considers an architecture referred to as Cascade Region Proposal Network (Cascade RPN) for improving the region-proposal quality and detection performance by systematically addressing the limitation of the conventional RPN that heuristically defines the anchors and aligns the features to the anchors. First, instead of using multiple anchors with predefined scales and aspect ratios, Cascade RPN relies on a single anchor per location and performs multi-stage refinement. Each stage is progressively more stringent in defining positive samples by starting out with an anchor-free metric followed by anchor-based metrics in the ensuing stages. Second, to attain alignment between the features and the anchors throughout the stages, adaptive convolution is proposed that takes the anchors in addition to the image features as its input and learns the sampled features guided by the anchors. A simple implementation of a two-stage Cascade RPN achieves AR 13.4 points higher than that of the conventional RPN, surpassing any existing region proposal methods. When adopting to Fast R-CNN and Faster R-CNN, Cascade RPN can improve the detection mAP by 3.1 and 3.5 points, respectively.
-
-
-
-
-## Citation
-
-
-
-We provide the code for reproducing experiment results of [Cascade RPN](https://arxiv.org/abs/1909.06720).
-
-```
-@inproceedings{vu2019cascade,
- title={Cascade RPN: Delving into High-Quality Region Proposal Network with Adaptive Convolution},
- author={Vu, Thang and Jang, Hyunjun and Pham, Trung X and Yoo, Chang D},
- booktitle={Conference on Neural Information Processing Systems (NeurIPS)},
- year={2019}
-}
-```
-
-## Benchmark
+## Results and Models
### Region proposal performance
@@ -43,3 +26,16 @@ We provide the code for reproducing experiment results of [Cascade RPN](https://
|:-------------:|:-----------:|:--------:|:-------:|:--------:|:--------:|:-------------------:|:--------------:|:------:|:-------:|:--------------------------------------------:|
| Fast R-CNN | Cascade RPN | R-50-FPN | caffe | 1x | - | - | - | 39.9 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/cascade_rpn/crpn_fast_rcnn_r50_caffe_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/cascade_rpn/crpn_fast_rcnn_r50_caffe_fpn_1x_coco/crpn_fast_rcnn_r50_caffe_fpn_1x_coco-cb486e66.pth) |
| Faster R-CNN | Cascade RPN | R-50-FPN | caffe | 1x | - | - | - | 40.4 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/cascade_rpn/crpn_faster_rcnn_r50_caffe_fpn_1x_coco.py) |[model](https://download.openmmlab.com/mmdetection/v2.0/cascade_rpn/crpn_faster_rcnn_r50_caffe_fpn_1x_coco/crpn_faster_rcnn_r50_caffe_fpn_1x_coco-c8283cca.pth) |
+
+## Citation
+
+We provide the code for reproducing experiment results of [Cascade RPN](https://arxiv.org/abs/1909.06720).
+
+```latex
+@inproceedings{vu2019cascade,
+ title={Cascade RPN: Delving into High-Quality Region Proposal Network with Adaptive Convolution},
+ author={Vu, Thang and Jang, Hyunjun and Pham, Trung X and Yoo, Chang D},
+ booktitle={Conference on Neural Information Processing Systems (NeurIPS)},
+ year={2019}
+}
+```
diff --git a/configs/cascade_rpn/metafile.yml b/configs/cascade_rpn/metafile.yml
new file mode 100644
index 00000000000..335b2bc7ef4
--- /dev/null
+++ b/configs/cascade_rpn/metafile.yml
@@ -0,0 +1,44 @@
+Collections:
+ - Name: Cascade RPN
+ Metadata:
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - Cascade RPN
+ - FPN
+ - ResNet
+ Paper:
+ URL: https://arxiv.org/abs/1909.06720
+ Title: 'Cascade RPN: Delving into High-Quality Region Proposal Network with Adaptive Convolution'
+ README: configs/cascade_rpn/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.8.0/mmdet/models/dense_heads/cascade_rpn_head.py#L538
+ Version: v2.8.0
+
+Models:
+ - Name: crpn_fast_rcnn_r50_caffe_fpn_1x_coco
+ In Collection: Cascade RPN
+ Config: configs/cascade_rpn/crpn_fast_rcnn_r50_caffe_fpn_1x_coco.py
+ Metadata:
+ Epochs: 12
+ Results:
+ - Task: Object Detection
+ Dataset: COCO
+ Metrics:
+ box AP: 39.9
+ Weights: https://download.openmmlab.com/mmdetection/v2.0/cascade_rpn/crpn_fast_rcnn_r50_caffe_fpn_1x_coco/crpn_fast_rcnn_r50_caffe_fpn_1x_coco-cb486e66.pth
+
+ - Name: crpn_faster_rcnn_r50_caffe_fpn_1x_coco
+ In Collection: Cascade RPN
+ Config: configs/cascade_rpn/crpn_faster_rcnn_r50_caffe_fpn_1x_coco.py
+ Metadata:
+ Epochs: 12
+ Results:
+ - Task: Object Detection
+ Dataset: COCO
+ Metrics:
+ box AP: 40.4
+ Weights: https://download.openmmlab.com/mmdetection/v2.0/cascade_rpn/crpn_faster_rcnn_r50_caffe_fpn_1x_coco/crpn_faster_rcnn_r50_caffe_fpn_1x_coco-c8283cca.pth
diff --git a/configs/centernet/README.md b/configs/centernet/README.md
index 37c18e7084d..ffc1d8c2477 100644
--- a/configs/centernet/README.md
+++ b/configs/centernet/README.md
@@ -1,33 +1,18 @@
-# Objects as Points
+# CenterNet
-## Abstract
+> [Objects as Points](https://arxiv.org/abs/1904.07850)
+
+
-
+## Abstract
Detection identifies objects as axis-aligned boxes in an image. Most successful object detectors enumerate a nearly exhaustive list of potential object locations and classify each. This is wasteful, inefficient, and requires additional post-processing. In this paper, we take a different approach. We model an object as a single point --- the center point of its bounding box. Our detector uses keypoint estimation to find center points and regresses to all other object properties, such as size, 3D location, orientation, and even pose. Our center point based approach, CenterNet, is end-to-end differentiable, simpler, faster, and more accurate than corresponding bounding box based detectors. CenterNet achieves the best speed-accuracy trade-off on the MS COCO dataset, with 28.1% AP at 142 FPS, 37.4% AP at 52 FPS, and 45.1% AP with multi-scale testing at 1.4 FPS. We use the same approach to estimate 3D bounding box in the KITTI benchmark and human pose on the COCO keypoint dataset. Our method performs competitively with sophisticated multi-stage methods and runs in real-time.
-
-
-
-
-## Citation
-
-
-
-```latex
-@article{zhou2019objects,
- title={Objects as Points},
- author={Zhou, Xingyi and Wang, Dequan and Kr{\"a}henb{\"u}hl, Philipp},
- booktitle={arXiv preprint arXiv:1904.07850},
- year={2019}
-}
-```
-
-## Results and models
+## Results and Models
| Backbone | DCN | Mem (GB) | Box AP | Flip box AP| Config | Download |
| :-------------: | :--------: |:----------------: | :------: | :------------: | :----: | :----: |
@@ -42,3 +27,14 @@ Note:
- fix wrong image mean and variance in image normalization to be compatible with the pre-trained backbone.
- Use SGD rather than ADAM optimizer and add warmup and grad clip.
- Use DistributedDataParallel as other models in MMDetection rather than using DataParallel.
+
+## Citation
+
+```latex
+@article{zhou2019objects,
+ title={Objects as Points},
+ author={Zhou, Xingyi and Wang, Dequan and Kr{\"a}henb{\"u}hl, Philipp},
+ booktitle={arXiv preprint arXiv:1904.07850},
+ year={2019}
+}
+```
diff --git a/configs/centripetalnet/README.md b/configs/centripetalnet/README.md
index f3d22a57ab4..1a5a346bf3f 100644
--- a/configs/centripetalnet/README.md
+++ b/configs/centripetalnet/README.md
@@ -1,22 +1,29 @@
-# CentripetalNet: Pursuing High-quality Keypoint Pairs for Object Detection
+# CentripetalNet
-## Abstract
+> [CentripetalNet: Pursuing High-quality Keypoint Pairs for Object Detection](https://arxiv.org/abs/2003.09119)
+
+
-
+## Abstract
Keypoint-based detectors have achieved pretty-well performance. However, incorrect keypoint matching is still widespread and greatly affects the performance of the detector. In this paper, we propose CentripetalNet which uses centripetal shift to pair corner keypoints from the same instance. CentripetalNet predicts the position and the centripetal shift of the corner points and matches corners whose shifted results are aligned. Combining position information, our approach matches corner points more accurately than the conventional embedding approaches do. Corner pooling extracts information inside the bounding boxes onto the border. To make this information more aware at the corners, we design a cross-star deformable convolution network to conduct feature adaption. Furthermore, we explore instance segmentation on anchor-free detectors by equipping our CentripetalNet with a mask prediction module. On MS-COCO test-dev, our CentripetalNet not only outperforms all existing anchor-free detectors with an AP of 48.0% but also achieves comparable performance to the state-of-the-art instance segmentation approaches with a 40.2% MaskAP.
-
-
-
+## Results and Models
-## Citation
+| Backbone | Batch Size | Step/Total Epochs | Mem (GB) | Inf time (fps) | box AP | Config | Download |
+| :-------------: | :--------: |:----------------: | :------: | :------------: | :----: | :------: | :--------: |
+| HourglassNet-104 | [16 x 6](./centripetalnet_hourglass104_mstest_16x6_210e_coco.py) | 190/210 | 16.7 | 3.7 | 44.8 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/centripetalnet/centripetalnet_hourglass104_mstest_16x6_210e_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/centripetalnet/centripetalnet_hourglass104_mstest_16x6_210e_coco/centripetalnet_hourglass104_mstest_16x6_210e_coco_20200915_204804-3ccc61e5.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/centripetalnet/centripetalnet_hourglass104_mstest_16x6_210e_coco/centripetalnet_hourglass104_mstest_16x6_210e_coco_20200915_204804.log.json) |
-
+Note:
+
+- TTA setting is single-scale and `flip=True`.
+- The model we released is the best checkpoint rather than the latest checkpoint (box AP 44.8 vs 44.6 in our experiment).
+
+## Citation
```latex
@InProceedings{Dong_2020_CVPR,
@@ -27,14 +34,3 @@ month = {June},
year = {2020}
}
```
-
-## Results and models
-
-| Backbone | Batch Size | Step/Total Epochs | Mem (GB) | Inf time (fps) | box AP | Config | Download |
-| :-------------: | :--------: |:----------------: | :------: | :------------: | :----: | :------: | :--------: |
-| HourglassNet-104 | [16 x 6](./centripetalnet_hourglass104_mstest_16x6_210e_coco.py) | 190/210 | 16.7 | 3.7 | 44.8 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/centripetalnet/centripetalnet_hourglass104_mstest_16x6_210e_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/centripetalnet/centripetalnet_hourglass104_mstest_16x6_210e_coco/centripetalnet_hourglass104_mstest_16x6_210e_coco_20200915_204804-3ccc61e5.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/centripetalnet/centripetalnet_hourglass104_mstest_16x6_210e_coco/centripetalnet_hourglass104_mstest_16x6_210e_coco_20200915_204804.log.json) |
-
-Note:
-
-- TTA setting is single-scale and `flip=True`.
-- The model we released is the best checkpoint rather than the latest checkpoint (box AP 44.8 vs 44.6 in our experiment).
diff --git a/configs/cityscapes/README.md b/configs/cityscapes/README.md
index 28310f15a9e..7522ffe4993 100644
--- a/configs/cityscapes/README.md
+++ b/configs/cityscapes/README.md
@@ -1,33 +1,18 @@
-# The Cityscapes Dataset for Semantic Urban Scene Understanding
+# Cityscapes
-## Abstract
+> [The Cityscapes Dataset for Semantic Urban Scene Understanding](https://arxiv.org/abs/1604.01685)
+
+
-
+## Abstract
Visual understanding of complex urban street scenes is an enabling factor for a wide range of applications. Object detection has benefited enormously from large-scale datasets, especially in the context of deep learning. For semantic urban scene understanding, however, no current dataset adequately captures the complexity of real-world urban scenes.
To address this, we introduce Cityscapes, a benchmark suite and large-scale dataset to train and test approaches for pixel-level and instance-level semantic labeling. Cityscapes is comprised of a large, diverse set of stereo video sequences recorded in streets from 50 different cities. 5000 of these images have high quality pixel-level annotations; 20000 additional images have coarse annotations to enable methods that leverage large volumes of weakly-labeled data. Crucially, our effort exceeds previous attempts in terms of dataset size, annotation richness, scene variability, and complexity. Our accompanying empirical study provides an in-depth analysis of the dataset characteristics, as well as a performance evaluation of several state-of-the-art approaches based on our benchmark.
-
-
-
-
-## Citation
-
-
-
-```
-@inproceedings{Cordts2016Cityscapes,
- title={The Cityscapes Dataset for Semantic Urban Scene Understanding},
- author={Cordts, Marius and Omran, Mohamed and Ramos, Sebastian and Rehfeld, Timo and Enzweiler, Markus and Benenson, Rodrigo and Franke, Uwe and Roth, Stefan and Schiele, Bernt},
- booktitle={Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- year={2016}
-}
-```
-
## Common settings
- All baselines were trained using 8 GPU with a batch size of 8 (1 images per GPU) using the [linear scaling rule](https://arxiv.org/abs/1706.02677) to scale the learning rate.
@@ -48,3 +33,14 @@ To address this, we introduce Cityscapes, a benchmark suite and large-scale data
| Backbone | Style | Lr schd | Scale | Mem (GB) | Inf time (fps) | box AP | mask AP | Config | Download |
| :-------------: | :-----: | :-----: | :------: | :------: | :------------: | :----: | :-----: | :------: | :------: |
| R-50-FPN | pytorch | 1x | 800-1024 | 5.3 | - | 40.9 | 36.4 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/cityscapes/mask_rcnn_r50_fpn_1x_cityscapes.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/cityscapes/mask_rcnn_r50_fpn_1x_cityscapes/mask_rcnn_r50_fpn_1x_cityscapes_20201211_133733-d2858245.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/cityscapes/mask_rcnn_r50_fpn_1x_cityscapes/mask_rcnn_r50_fpn_1x_cityscapes_20201211_133733.log.json) |
+
+## Citation
+
+```latex
+@inproceedings{Cordts2016Cityscapes,
+ title={The Cityscapes Dataset for Semantic Urban Scene Understanding},
+ author={Cordts, Marius and Omran, Mohamed and Ramos, Sebastian and Rehfeld, Timo and Enzweiler, Markus and Benenson, Rodrigo and Franke, Uwe and Roth, Stefan and Schiele, Bernt},
+ booktitle={Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
+ year={2016}
+}
+```
diff --git a/configs/cornernet/README.md b/configs/cornernet/README.md
index d7dc08c4aa9..55877c4c4bf 100644
--- a/configs/cornernet/README.md
+++ b/configs/cornernet/README.md
@@ -1,35 +1,18 @@
-# Cornernet: Detecting objects as paired keypoints
+# CornerNet
-## Abstract
+> [Cornernet: Detecting objects as paired keypoints](https://arxiv.org/abs/1808.01244)
-
+
+
+## Abstract
We propose CornerNet, a new approach to object detection where we detect an object bounding box as a pair of keypoints, the top-left corner and the bottom-right corner, using a single convolution neural network. By detecting objects as paired keypoints, we eliminate the need for designing a set of anchor boxes commonly used in prior single-stage detectors. In addition to our novel formulation, we introduce corner pooling, a new type of pooling layer that helps the network better localize corners. Experiments show that CornerNet achieves a 42.2% AP on MS COCO, outperforming all existing one-stage detectors.
-
-
-
-
-## Citation
-
-
-
-```latex
-@inproceedings{law2018cornernet,
- title={Cornernet: Detecting objects as paired keypoints},
- author={Law, Hei and Deng, Jia},
- booktitle={15th European Conference on Computer Vision, ECCV 2018},
- pages={765--781},
- year={2018},
- organization={Springer Verlag}
-}
-```
-
-## Results and models
+## Results and Models
| Backbone | Batch Size | Step/Total Epochs | Mem (GB) | Inf time (fps) | box AP | Config | Download |
| :-------------: | :--------: |:----------------: | :------: | :------------: | :----: | :------: | :--------: |
@@ -45,3 +28,16 @@ Note:
- 10 x 5: 10 GPUs with 5 images per gpu. This is the same setting as that reported in the original paper.
- 8 x 6: 8 GPUs with 6 images per gpu. The total batchsize is similar to paper and only need 1 node to train.
- 32 x 3: 32 GPUs with 3 images per gpu. The default setting for 1080TI and need 4 nodes to train.
+
+## Citation
+
+```latex
+@inproceedings{law2018cornernet,
+ title={Cornernet: Detecting objects as paired keypoints},
+ author={Law, Hei and Deng, Jia},
+ booktitle={15th European Conference on Computer Vision, ECCV 2018},
+ pages={765--781},
+ year={2018},
+ organization={Springer Verlag}
+}
+```
diff --git a/configs/dcn/README.md b/configs/dcn/README.md
index d9d23f07b06..7866078af2e 100644
--- a/configs/dcn/README.md
+++ b/configs/dcn/README.md
@@ -1,56 +1,26 @@
-# Deformable Convolutional Networks
+# DCN
-## Abstract
+> [Deformable Convolutional Networks](https://arxiv.org/abs/1703.06211)
-
+
+
+## Abstract
Convolutional neural networks (CNNs) are inherently limited to model geometric transformations due to the fixed geometric structures in its building modules. In this work, we introduce two new modules to enhance the transformation modeling capacity of CNNs, namely, deformable convolution and deformable RoI pooling. Both are based on the idea of augmenting the spatial sampling locations in the modules with additional offsets and learning the offsets from target tasks, without additional supervision. The new modules can readily replace their plain counterparts in existing CNNs and can be easily trained end-to-end by standard back-propagation, giving rise to deformable convolutional networks. Extensive experiments validate the effectiveness of our approach on sophisticated vision tasks of object detection and semantic segmentation.
-
-
-
-
-## Citation
-
-
-
-```none
-@inproceedings{dai2017deformable,
- title={Deformable Convolutional Networks},
- author={Dai, Jifeng and Qi, Haozhi and Xiong, Yuwen and Li, Yi and Zhang, Guodong and Hu, Han and Wei, Yichen},
- booktitle={Proceedings of the IEEE international conference on computer vision},
- year={2017}
-}
-```
-
-
-
-```
-@article{zhu2018deformable,
- title={Deformable ConvNets v2: More Deformable, Better Results},
- author={Zhu, Xizhou and Hu, Han and Lin, Stephen and Dai, Jifeng},
- journal={arXiv preprint arXiv:1811.11168},
- year={2018}
-}
-```
-
## Results and Models
| Backbone | Model | Style | Conv | Pool | Lr schd | Mem (GB) | Inf time (fps) | box AP | mask AP | Config | Download |
|:----------------:|:------------:|:-------:|:-------------:|:------:|:-------:|:--------:|:--------------:|:------:|:-------:|:------:|:--------:|
| R-50-FPN | Faster | pytorch | dconv(c3-c5) | - | 1x | 4.0 | 17.8 | 41.3 | | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/dcn/faster_rcnn_r50_fpn_dconv_c3-c5_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/dcn/faster_rcnn_r50_fpn_dconv_c3-c5_1x_coco/faster_rcnn_r50_fpn_dconv_c3-c5_1x_coco_20200130-d68aed1e.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/dcn/faster_rcnn_r50_fpn_dconv_c3-c5_1x_coco/faster_rcnn_r50_fpn_dconv_c3-c5_1x_coco_20200130_212941.log.json) |
-| R-50-FPN | Faster | pytorch | mdconv(c3-c5) | - | 1x | 4.1 | 17.6 | 41.4 | | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/dcn/faster_rcnn_r50_fpn_mdconv_c3-c5_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/dcn/faster_rcnn_r50_fpn_mdconv_c3-c5_1x_coco/faster_rcnn_r50_fpn_mdconv_c3-c5_1x_coco_20200130-d099253b.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/dcn/faster_rcnn_r50_fpn_mdconv_c3-c5_1x_coco/faster_rcnn_r50_fpn_mdconv_c3-c5_1x_coco_20200130_222144.log.json) |
-| *R-50-FPN (dg=4) | Faster | pytorch | mdconv(c3-c5) | - | 1x | 4.2 | 17.4 | 41.5 | | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/dcn/faster_rcnn_r50_fpn_mdconv_c3-c5_group4_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/dcn/faster_rcnn_r50_fpn_mdconv_c3-c5_group4_1x_coco/faster_rcnn_r50_fpn_mdconv_c3-c5_group4_1x_coco_20200130-01262257.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/dcn/faster_rcnn_r50_fpn_mdconv_c3-c5_group4_1x_coco/faster_rcnn_r50_fpn_mdconv_c3-c5_group4_1x_coco_20200130_222058.log.json) |
| R-50-FPN | Faster | pytorch | - | dpool | 1x | 5.0 | 17.2 | 38.9 | | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/dcn/faster_rcnn_r50_fpn_dpool_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/dcn/faster_rcnn_r50_fpn_dpool_1x_coco/faster_rcnn_r50_fpn_dpool_1x_coco_20200307-90d3c01d.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/dcn/faster_rcnn_r50_fpn_dpool_1x_coco/faster_rcnn_r50_fpn_dpool_1x_coco_20200307_203250.log.json) |
-| R-50-FPN | Faster | pytorch | - | mdpool | 1x | 5.8 | 16.6 | 38.7 | | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/dcn/faster_rcnn_r50_fpn_mdpool_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/dcn/faster_rcnn_r50_fpn_mdpool_1x_coco/faster_rcnn_r50_fpn_mdpool_1x_coco_20200307-c0df27ff.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/dcn/faster_rcnn_r50_fpn_mdpool_1x_coco/faster_rcnn_r50_fpn_mdpool_1x_coco_20200307_203304.log.json) |
| R-101-FPN | Faster | pytorch | dconv(c3-c5) | - | 1x | 6.0 | 12.5 | 42.7 | | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/dcn/faster_rcnn_r101_fpn_dconv_c3-c5_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/dcn/faster_rcnn_r101_fpn_dconv_c3-c5_1x_coco/faster_rcnn_r101_fpn_dconv_c3-c5_1x_coco_20200203-1377f13d.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/dcn/faster_rcnn_r101_fpn_dconv_c3-c5_1x_coco/faster_rcnn_r101_fpn_dconv_c3-c5_1x_coco_20200203_230019.log.json) |
| X-101-32x4d-FPN | Faster | pytorch | dconv(c3-c5) | - | 1x | 7.3 | 10.0 | 44.5 | | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/dcn/faster_rcnn_x101_32x4d_fpn_dconv_c3-c5_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/dcn/faster_rcnn_x101_32x4d_fpn_dconv_c3-c5_1x_coco/faster_rcnn_x101_32x4d_fpn_dconv_c3-c5_1x_coco_20200203-4f85c69c.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/dcn/faster_rcnn_x101_32x4d_fpn_dconv_c3-c5_1x_coco/faster_rcnn_x101_32x4d_fpn_dconv_c3-c5_1x_coco_20200203_001325.log.json) |
| R-50-FPN | Mask | pytorch | dconv(c3-c5) | - | 1x | 4.5 | 15.4 | 41.8 | 37.4 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/dcn/mask_rcnn_r50_fpn_dconv_c3-c5_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/dcn/mask_rcnn_r50_fpn_dconv_c3-c5_1x_coco/mask_rcnn_r50_fpn_dconv_c3-c5_1x_coco_20200203-4d9ad43b.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/dcn/mask_rcnn_r50_fpn_dconv_c3-c5_1x_coco/mask_rcnn_r50_fpn_dconv_c3-c5_1x_coco_20200203_061339.log.json) |
-| R-50-FPN | Mask | pytorch | mdconv(c3-c5) | - | 1x | 4.5 | 15.1 | 41.5 | 37.1 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/dcn/mask_rcnn_r50_fpn_mdconv_c3-c5_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/dcn/mask_rcnn_r50_fpn_mdconv_c3-c5_1x_coco/mask_rcnn_r50_fpn_mdconv_c3-c5_1x_coco_20200203-ad97591f.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/dcn/mask_rcnn_r50_fpn_mdconv_c3-c5_1x_coco/mask_rcnn_r50_fpn_mdconv_c3-c5_1x_coco_20200203_063443.log.json) |
| R-101-FPN | Mask | pytorch | dconv(c3-c5) | - | 1x | 6.5 | 11.7 | 43.5 | 38.9 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/dcn/mask_rcnn_r101_fpn_dconv_c3-c5_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/dcn/mask_rcnn_r101_fpn_dconv_c3-c5_1x_coco/mask_rcnn_r101_fpn_dconv_c3-c5_1x_coco_20200216-a71f5bce.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/dcn/mask_rcnn_r101_fpn_dconv_c3-c5_1x_coco/mask_rcnn_r101_fpn_dconv_c3-c5_1x_coco_20200216_191601.log.json) |
| R-50-FPN | Cascade | pytorch | dconv(c3-c5) | - | 1x | 4.5 | 14.6 | 43.8 | | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/dcn/cascade_rcnn_r50_fpn_dconv_c3-c5_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/dcn/cascade_rcnn_r50_fpn_dconv_c3-c5_1x_coco/cascade_rcnn_r50_fpn_dconv_c3-c5_1x_coco_20200130-2f1fca44.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/dcn/cascade_rcnn_r50_fpn_dconv_c3-c5_1x_coco/cascade_rcnn_r50_fpn_dconv_c3-c5_1x_coco_20200130_220843.log.json) |
| R-101-FPN | Cascade | pytorch | dconv(c3-c5) | - | 1x | 6.4 | 11.0 | 45.0 | | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/dcn/cascade_rcnn_r101_fpn_dconv_c3-c5_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/dcn/cascade_rcnn_r101_fpn_dconv_c3-c5_1x_coco/cascade_rcnn_r101_fpn_dconv_c3-c5_1x_coco_20200203-3b2f0594.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/dcn/cascade_rcnn_r101_fpn_dconv_c3-c5_1x_coco/cascade_rcnn_r101_fpn_dconv_c3-c5_1x_coco_20200203_224829.log.json) |
@@ -58,11 +28,21 @@ Convolutional neural networks (CNNs) are inherently limited to model geometric t
| R-101-FPN | Cascade Mask | pytorch | dconv(c3-c5) | - | 1x | 8.0 | 8.6 | 45.8 | 39.7 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/dcn/cascade_mask_rcnn_r101_fpn_dconv_c3-c5_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/dcn/cascade_mask_rcnn_r101_fpn_dconv_c3-c5_1x_coco/cascade_mask_rcnn_r101_fpn_dconv_c3-c5_1x_coco_20200204-df0c5f10.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/dcn/cascade_mask_rcnn_r101_fpn_dconv_c3-c5_1x_coco/cascade_mask_rcnn_r101_fpn_dconv_c3-c5_1x_coco_20200204_134006.log.json) |
| X-101-32x4d-FPN | Cascade Mask | pytorch | dconv(c3-c5) | - | 1x | 9.2 | | 47.3 | 41.1 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/dcn/cascade_mask_rcnn_x101_32x4d_fpn_dconv_c3-c5_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/dcn/cascade_mask_rcnn_x101_32x4d_fpn_dconv_c3-c5_1x_coco/cascade_mask_rcnn_x101_32x4d_fpn_dconv_c3-c5_1x_coco-e75f90c8.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/dcn/cascade_mask_rcnn_x101_32x4d_fpn_dconv_c3-c5_1x_coco/cascade_mask_rcnn_x101_32x4d_fpn_dconv_c3-c5_1x_coco-20200606_183737.log.json) |
| R-50-FPN (FP16) | Mask | pytorch | dconv(c3-c5) | - | 1x | 3.0 | | 41.9 | 37.5 |[config](https://github.com/open-mmlab/mmdetection/tree/master/configs/fp16/mask_rcnn_r50_fpn_fp16_dconv_c3-c5_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/fp16/mask_rcnn_r50_fpn_fp16_dconv_c3-c5_1x_coco/mask_rcnn_r50_fpn_fp16_dconv_c3-c5_1x_coco_20210520_180247-c06429d2.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/fp16/mask_rcnn_r50_fpn_fp16_dconv_c3-c5_1x_coco/mask_rcnn_r50_fpn_fp16_dconv_c3-c5_1x_coco_20210520_180247.log.json) |
-| R-50-FPN (FP16) | Mask | pytorch | mdconv(c3-c5)| - | 1x | 3.1 | | 42.0 | 37.6 |[config](https://github.com/open-mmlab/mmdetection/tree/master/configs/fp16/mask_rcnn_r50_fpn_fp16_mdconv_c3-c5_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/fp16/mask_rcnn_r50_fpn_fp16_mdconv_c3-c5_1x_coco/mask_rcnn_r50_fpn_fp16_mdconv_c3-c5_1x_coco_20210520_180434-cf8fefa5.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/fp16/mask_rcnn_r50_fpn_fp16_mdconv_c3-c5_1x_coco/mask_rcnn_r50_fpn_fp16_mdconv_c3-c5_1x_coco_20210520_180434.log.json) |
**Notes:**
-- `dconv` and `mdconv` denote (modulated) deformable convolution, `c3-c5` means adding dconv in resnet stage 3 to 5. `dpool` and `mdpool` denote (modulated) deformable roi pooling.
+- `dconv` denotes deformable convolution, `c3-c5` means adding dconv in resnet stage 3 to 5. `dpool` denotes deformable roi pooling.
- The dcn ops are modified from https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch, which should be more memory efficient and slightly faster.
- (*) For R-50-FPN (dg=4), dg is short for deformable_group. This model is trained and tested on Amazon EC2 p3dn.24xlarge instance.
- **Memory, Train/Inf time is outdated.**
+
+## Citation
+
+```latex
+@inproceedings{dai2017deformable,
+ title={Deformable Convolutional Networks},
+ author={Dai, Jifeng and Qi, Haozhi and Xiong, Yuwen and Li, Yi and Zhang, Guodong and Hu, Han and Wei, Yichen},
+ booktitle={Proceedings of the IEEE international conference on computer vision},
+ year={2017}
+}
+```
diff --git a/configs/dcn/metafile.yml b/configs/dcn/metafile.yml
index 7919b842226..36f38871446 100644
--- a/configs/dcn/metafile.yml
+++ b/configs/dcn/metafile.yml
@@ -9,8 +9,8 @@ Collections:
Architecture:
- Deformable Convolution
Paper:
- URL: https://arxiv.org/abs/1811.11168
- Title: "Deformable ConvNets v2: More Deformable, Better Results"
+ URL: https://arxiv.org/abs/1703.06211
+ Title: "Deformable Convolutional Networks"
README: configs/dcn/README.md
Code:
URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/ops/dcn/deform_conv.py#L15
@@ -37,46 +37,6 @@ Models:
box AP: 41.3
Weights: https://download.openmmlab.com/mmdetection/v2.0/dcn/faster_rcnn_r50_fpn_dconv_c3-c5_1x_coco/faster_rcnn_r50_fpn_dconv_c3-c5_1x_coco_20200130-d68aed1e.pth
- - Name: faster_rcnn_r50_fpn_mdconv_c3-c5_1x_coco
- In Collection: Deformable Convolutional Networks
- Config: configs/dcn/faster_rcnn_r50_fpn_mdconv_c3-c5_1x_coco.py
- Metadata:
- Training Memory (GB): 4.1
- inference time (ms/im):
- - value: 56.82
- hardware: V100
- backend: PyTorch
- batch size: 1
- mode: FP32
- resolution: (800, 1333)
- Epochs: 12
- Results:
- - Task: Object Detection
- Dataset: COCO
- Metrics:
- box AP: 41.4
- Weights: https://download.openmmlab.com/mmdetection/v2.0/dcn/faster_rcnn_r50_fpn_mdconv_c3-c5_1x_coco/faster_rcnn_r50_fpn_mdconv_c3-c5_1x_coco_20200130-d099253b.pth
-
- - Name: faster_rcnn_r50_fpn_mdconv_c3-c5_group4_1x_coco
- In Collection: Deformable Convolutional Networks
- Config: configs/dcn/faster_rcnn_r50_fpn_mdconv_c3-c5_group4_1x_coco.py
- Metadata:
- Training Memory (GB): 4.2
- inference time (ms/im):
- - value: 57.47
- hardware: V100
- backend: PyTorch
- batch size: 1
- mode: FP32
- resolution: (800, 1333)
- Epochs: 12
- Results:
- - Task: Object Detection
- Dataset: COCO
- Metrics:
- box AP: 41.5
- Weights: https://download.openmmlab.com/mmdetection/v2.0/dcn/faster_rcnn_r50_fpn_mdconv_c3-c5_group4_1x_coco/faster_rcnn_r50_fpn_mdconv_c3-c5_group4_1x_coco_20200130-01262257.pth
-
- Name: faster_rcnn_r50_fpn_dpool_1x_coco
In Collection: Deformable Convolutional Networks
Config: configs/dcn/faster_rcnn_r50_fpn_dpool_1x_coco.py
@@ -97,26 +57,6 @@ Models:
box AP: 38.9
Weights: https://download.openmmlab.com/mmdetection/v2.0/dcn/faster_rcnn_r50_fpn_dpool_1x_coco/faster_rcnn_r50_fpn_dpool_1x_coco_20200307-90d3c01d.pth
- - Name: faster_rcnn_r50_fpn_mdpool_1x_coco
- In Collection: Deformable Convolutional Networks
- Config: configs/dcn/faster_rcnn_r50_fpn_mdpool_1x_coco.py
- Metadata:
- Training Memory (GB): 5.8
- inference time (ms/im):
- - value: 60.24
- hardware: V100
- backend: PyTorch
- batch size: 1
- mode: FP32
- resolution: (800, 1333)
- Epochs: 12
- Results:
- - Task: Object Detection
- Dataset: COCO
- Metrics:
- box AP: 38.7
- Weights: https://download.openmmlab.com/mmdetection/v2.0/dcn/faster_rcnn_r50_fpn_mdpool_1x_coco/faster_rcnn_r50_fpn_mdpool_1x_coco_20200307-c0df27ff.pth
-
- Name: faster_rcnn_r101_fpn_dconv_c3-c5_1x_coco
In Collection: Deformable Convolutional Networks
Config: configs/dcn/faster_rcnn_r101_fpn_dconv_c3-c5_1x_coco.py
@@ -181,30 +121,6 @@ Models:
mask AP: 37.4
Weights: https://download.openmmlab.com/mmdetection/v2.0/dcn/mask_rcnn_r50_fpn_dconv_c3-c5_1x_coco/mask_rcnn_r50_fpn_dconv_c3-c5_1x_coco_20200203-4d9ad43b.pth
- - Name: mask_rcnn_r50_fpn_mdconv_c3-c5_1x_coco
- In Collection: Deformable Convolutional Networks
- Config: configs/dcn/mask_rcnn_r50_fpn_mdconv_c3-c5_1x_coco.py
- Metadata:
- Training Memory (GB): 4.5
- inference time (ms/im):
- - value: 66.23
- hardware: V100
- backend: PyTorch
- batch size: 1
- mode: FP32
- resolution: (800, 1333)
- Epochs: 12
- Results:
- - Task: Object Detection
- Dataset: COCO
- Metrics:
- box AP: 41.5
- - Task: Instance Segmentation
- Dataset: COCO
- Metrics:
- mask AP: 37.1
- Weights: https://download.openmmlab.com/mmdetection/v2.0/dcn/mask_rcnn_r50_fpn_mdconv_c3-c5_1x_coco/mask_rcnn_r50_fpn_mdconv_c3-c5_1x_coco_20200203-ad97591f.pth
-
- Name: mask_rcnn_r50_fpn_fp16_dconv_c3-c5_1x_coco
In Collection: Deformable Convolutional Networks
Config: configs/dcn/mask_rcnn_r50_fpn_fp16_dconv_c3-c5_1x_coco.py
@@ -226,27 +142,6 @@ Models:
mask AP: 37.5
Weights: https://download.openmmlab.com/mmdetection/v2.0/fp16/mask_rcnn_r50_fpn_fp16_dconv_c3-c5_1x_coco/mask_rcnn_r50_fpn_fp16_dconv_c3-c5_1x_coco_20210520_180247-c06429d2.pth
- - Name: mask_rcnn_r50_fpn_fp16_mdconv_c3-c5_1x_coco
- In Collection: Deformable Convolutional Networks
- Config: configs/dcn/mask_rcnn_r50_fpn_fp16_mdconv_c3-c5_1x_coco.py
- Metadata:
- Training Memory (GB): 3.1
- Training Techniques:
- - SGD with Momentum
- - Weight Decay
- - Mixed Precision Training
- Epochs: 12
- Results:
- - Task: Object Detection
- Dataset: COCO
- Metrics:
- box AP: 42.0
- - Task: Instance Segmentation
- Dataset: COCO
- Metrics:
- mask AP: 37.6
- Weights: https://download.openmmlab.com/mmdetection/v2.0/fp16/mask_rcnn_r50_fpn_fp16_mdconv_c3-c5_1x_coco/mask_rcnn_r50_fpn_fp16_mdconv_c3-c5_1x_coco_20210520_180434-cf8fefa5.pth
-
- Name: mask_rcnn_r101_fpn_dconv_c3-c5_1x_coco
In Collection: Deformable Convolutional Networks
Config: configs/dcn/mask_rcnn_r101_fpn_dconv_c3-c5_1x_coco.py
diff --git a/configs/dcnv2/README.md b/configs/dcnv2/README.md
new file mode 100644
index 00000000000..1e7e3201b56
--- /dev/null
+++ b/configs/dcnv2/README.md
@@ -0,0 +1,37 @@
+# DCNv2
+
+> [Deformable ConvNets v2: More Deformable, Better Results](https://arxiv.org/abs/1811.11168)
+
+
+
+## Abstract
+
+The superior performance of Deformable Convolutional Networks arises from its ability to adapt to the geometric variations of objects. Through an examination of its adaptive behavior, we observe that while the spatial support for its neural features conforms more closely than regular ConvNets to object structure, this support may nevertheless extend well beyond the region of interest, causing features to be influenced by irrelevant image content. To address this problem, we present a reformulation of Deformable ConvNets that improves its ability to focus on pertinent image regions, through increased modeling power and stronger training. The modeling power is enhanced through a more comprehensive integration of deformable convolution within the network, and by introducing a modulation mechanism that expands the scope of deformation modeling. To effectively harness this enriched modeling capability, we guide network training via a proposed feature mimicking scheme that helps the network to learn features that reflect the object focus and classification power of RCNN features. With the proposed contributions, this new version of Deformable ConvNets yields significant performance gains over the original model and produces leading results on the COCO benchmark for object detection and instance segmentation.
+
+## Results and Models
+
+| Backbone | Model | Style | Conv | Pool | Lr schd | Mem (GB) | Inf time (fps) | box AP | mask AP | Config | Download |
+|:----------------:|:------------:|:-------:|:-------------:|:------:|:-------:|:--------:|:--------------:|:------:|:-------:|:------:|:--------:|
+| R-50-FPN | Faster | pytorch | mdconv(c3-c5) | - | 1x | 4.1 | 17.6 | 41.4 | | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/dcnv2/faster_rcnn_r50_fpn_mdconv_c3-c5_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/dcn/faster_rcnn_r50_fpn_mdconv_c3-c5_1x_coco/faster_rcnn_r50_fpn_mdconv_c3-c5_1x_coco_20200130-d099253b.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/dcn/faster_rcnn_r50_fpn_mdconv_c3-c5_1x_coco/faster_rcnn_r50_fpn_mdconv_c3-c5_1x_coco_20200130_222144.log.json) |
+| *R-50-FPN (dg=4) | Faster | pytorch | mdconv(c3-c5) | - | 1x | 4.2 | 17.4 | 41.5 | | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/dcnv2/faster_rcnn_r50_fpn_mdconv_c3-c5_group4_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/dcn/faster_rcnn_r50_fpn_mdconv_c3-c5_group4_1x_coco/faster_rcnn_r50_fpn_mdconv_c3-c5_group4_1x_coco_20200130-01262257.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/dcn/faster_rcnn_r50_fpn_mdconv_c3-c5_group4_1x_coco/faster_rcnn_r50_fpn_mdconv_c3-c5_group4_1x_coco_20200130_222058.log.json) |
+| R-50-FPN | Faster | pytorch | - | mdpool | 1x | 5.8 | 16.6 | 38.7 | | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/dcnv2/faster_rcnn_r50_fpn_mdpool_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/dcn/faster_rcnn_r50_fpn_mdpool_1x_coco/faster_rcnn_r50_fpn_mdpool_1x_coco_20200307-c0df27ff.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/dcn/faster_rcnn_r50_fpn_mdpool_1x_coco/faster_rcnn_r50_fpn_mdpool_1x_coco_20200307_203304.log.json) |
+| R-50-FPN | Mask | pytorch | mdconv(c3-c5) | - | 1x | 4.5 | 15.1 | 41.5 | 37.1 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/dcnv2/mask_rcnn_r50_fpn_mdconv_c3-c5_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/dcn/mask_rcnn_r50_fpn_mdconv_c3-c5_1x_coco/mask_rcnn_r50_fpn_mdconv_c3-c5_1x_coco_20200203-ad97591f.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/dcn/mask_rcnn_r50_fpn_mdconv_c3-c5_1x_coco/mask_rcnn_r50_fpn_mdconv_c3-c5_1x_coco_20200203_063443.log.json) |
+| R-50-FPN (FP16) | Mask | pytorch | mdconv(c3-c5)| - | 1x | 3.1 | | 42.0 | 37.6 |[config](https://github.com/open-mmlab/mmdetection/tree/master/configs/fp16/mask_rcnn_r50_fpn_fp16_mdconv_c3-c5_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/fp16/mask_rcnn_r50_fpn_fp16_mdconv_c3-c5_1x_coco/mask_rcnn_r50_fpn_fp16_mdconv_c3-c5_1x_coco_20210520_180434-cf8fefa5.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/fp16/mask_rcnn_r50_fpn_fp16_mdconv_c3-c5_1x_coco/mask_rcnn_r50_fpn_fp16_mdconv_c3-c5_1x_coco_20210520_180434.log.json) |
+
+**Notes:**
+
+- `mdconv` denotes modulated deformable convolution, `c3-c5` means adding dconv in resnet stage 3 to 5. `mdpool` denotes modulated deformable roi pooling.
+- The dcn ops are modified from https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch, which should be more memory efficient and slightly faster.
+- (*) For R-50-FPN (dg=4), dg is short for deformable_group. This model is trained and tested on Amazon EC2 p3dn.24xlarge instance.
+- **Memory, Train/Inf time is outdated.**
+
+## Citation
+
+```latex
+@article{zhu2018deformable,
+ title={Deformable ConvNets v2: More Deformable, Better Results},
+ author={Zhu, Xizhou and Hu, Han and Lin, Stephen and Dai, Jifeng},
+ journal={arXiv preprint arXiv:1811.11168},
+ year={2018}
+}
+```
diff --git a/configs/dcn/faster_rcnn_r50_fpn_mdconv_c3-c5_1x_coco.py b/configs/dcnv2/faster_rcnn_r50_fpn_mdconv_c3-c5_1x_coco.py
similarity index 100%
rename from configs/dcn/faster_rcnn_r50_fpn_mdconv_c3-c5_1x_coco.py
rename to configs/dcnv2/faster_rcnn_r50_fpn_mdconv_c3-c5_1x_coco.py
diff --git a/configs/dcn/faster_rcnn_r50_fpn_mdconv_c3-c5_group4_1x_coco.py b/configs/dcnv2/faster_rcnn_r50_fpn_mdconv_c3-c5_group4_1x_coco.py
similarity index 100%
rename from configs/dcn/faster_rcnn_r50_fpn_mdconv_c3-c5_group4_1x_coco.py
rename to configs/dcnv2/faster_rcnn_r50_fpn_mdconv_c3-c5_group4_1x_coco.py
diff --git a/configs/dcn/faster_rcnn_r50_fpn_mdpool_1x_coco.py b/configs/dcnv2/faster_rcnn_r50_fpn_mdpool_1x_coco.py
similarity index 100%
rename from configs/dcn/faster_rcnn_r50_fpn_mdpool_1x_coco.py
rename to configs/dcnv2/faster_rcnn_r50_fpn_mdpool_1x_coco.py
diff --git a/configs/dcn/mask_rcnn_r50_fpn_fp16_mdconv_c3-c5_1x_coco.py b/configs/dcnv2/mask_rcnn_r50_fpn_fp16_mdconv_c3-c5_1x_coco.py
similarity index 100%
rename from configs/dcn/mask_rcnn_r50_fpn_fp16_mdconv_c3-c5_1x_coco.py
rename to configs/dcnv2/mask_rcnn_r50_fpn_fp16_mdconv_c3-c5_1x_coco.py
diff --git a/configs/dcn/mask_rcnn_r50_fpn_mdconv_c3-c5_1x_coco.py b/configs/dcnv2/mask_rcnn_r50_fpn_mdconv_c3-c5_1x_coco.py
similarity index 100%
rename from configs/dcn/mask_rcnn_r50_fpn_mdconv_c3-c5_1x_coco.py
rename to configs/dcnv2/mask_rcnn_r50_fpn_mdconv_c3-c5_1x_coco.py
diff --git a/configs/dcnv2/metafile.yml b/configs/dcnv2/metafile.yml
new file mode 100644
index 00000000000..90494215d64
--- /dev/null
+++ b/configs/dcnv2/metafile.yml
@@ -0,0 +1,123 @@
+Collections:
+ - Name: Deformable Convolutional Networks v2
+ Metadata:
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - Deformable Convolution
+ Paper:
+ URL: https://arxiv.org/abs/1811.11168
+ Title: "Deformable ConvNets v2: More Deformable, Better Results"
+ README: configs/dcnv2/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/ops/dcn/deform_conv.py#L15
+ Version: v2.0.0
+
+Models:
+ - Name: faster_rcnn_r50_fpn_mdconv_c3-c5_1x_coco
+ In Collection: Deformable Convolutional Networks v2
+ Config: configs/dcn/faster_rcnn_r50_fpn_mdconv_c3-c5_1x_coco.py
+ Metadata:
+ Training Memory (GB): 4.1
+ inference time (ms/im):
+ - value: 56.82
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (800, 1333)
+ Epochs: 12
+ Results:
+ - Task: Object Detection
+ Dataset: COCO
+ Metrics:
+ box AP: 41.4
+ Weights: https://download.openmmlab.com/mmdetection/v2.0/dcn/faster_rcnn_r50_fpn_mdconv_c3-c5_1x_coco/faster_rcnn_r50_fpn_mdconv_c3-c5_1x_coco_20200130-d099253b.pth
+
+ - Name: faster_rcnn_r50_fpn_mdconv_c3-c5_group4_1x_coco
+ In Collection: Deformable Convolutional Networks v2
+ Config: configs/dcn/faster_rcnn_r50_fpn_mdconv_c3-c5_group4_1x_coco.py
+ Metadata:
+ Training Memory (GB): 4.2
+ inference time (ms/im):
+ - value: 57.47
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (800, 1333)
+ Epochs: 12
+ Results:
+ - Task: Object Detection
+ Dataset: COCO
+ Metrics:
+ box AP: 41.5
+ Weights: https://download.openmmlab.com/mmdetection/v2.0/dcn/faster_rcnn_r50_fpn_mdconv_c3-c5_group4_1x_coco/faster_rcnn_r50_fpn_mdconv_c3-c5_group4_1x_coco_20200130-01262257.pth
+
+ - Name: faster_rcnn_r50_fpn_mdpool_1x_coco
+ In Collection: Deformable Convolutional Networks v2
+ Config: configs/dcn/faster_rcnn_r50_fpn_mdpool_1x_coco.py
+ Metadata:
+ Training Memory (GB): 5.8
+ inference time (ms/im):
+ - value: 60.24
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (800, 1333)
+ Epochs: 12
+ Results:
+ - Task: Object Detection
+ Dataset: COCO
+ Metrics:
+ box AP: 38.7
+ Weights: https://download.openmmlab.com/mmdetection/v2.0/dcn/faster_rcnn_r50_fpn_mdpool_1x_coco/faster_rcnn_r50_fpn_mdpool_1x_coco_20200307-c0df27ff.pth
+
+ - Name: mask_rcnn_r50_fpn_mdconv_c3-c5_1x_coco
+ In Collection: Deformable Convolutional Networks v2
+ Config: configs/dcn/mask_rcnn_r50_fpn_mdconv_c3-c5_1x_coco.py
+ Metadata:
+ Training Memory (GB): 4.5
+ inference time (ms/im):
+ - value: 66.23
+ hardware: V100
+ backend: PyTorch
+ batch size: 1
+ mode: FP32
+ resolution: (800, 1333)
+ Epochs: 12
+ Results:
+ - Task: Object Detection
+ Dataset: COCO
+ Metrics:
+ box AP: 41.5
+ - Task: Instance Segmentation
+ Dataset: COCO
+ Metrics:
+ mask AP: 37.1
+ Weights: https://download.openmmlab.com/mmdetection/v2.0/dcn/mask_rcnn_r50_fpn_mdconv_c3-c5_1x_coco/mask_rcnn_r50_fpn_mdconv_c3-c5_1x_coco_20200203-ad97591f.pth
+
+ - Name: mask_rcnn_r50_fpn_fp16_mdconv_c3-c5_1x_coco
+ In Collection: Deformable Convolutional Networks v2
+ Config: configs/dcn/mask_rcnn_r50_fpn_fp16_mdconv_c3-c5_1x_coco.py
+ Metadata:
+ Training Memory (GB): 3.1
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ - Mixed Precision Training
+ Epochs: 12
+ Results:
+ - Task: Object Detection
+ Dataset: COCO
+ Metrics:
+ box AP: 42.0
+ - Task: Instance Segmentation
+ Dataset: COCO
+ Metrics:
+ mask AP: 37.6
+ Weights: https://download.openmmlab.com/mmdetection/v2.0/fp16/mask_rcnn_r50_fpn_fp16_mdconv_c3-c5_1x_coco/mask_rcnn_r50_fpn_fp16_mdconv_c3-c5_1x_coco_20210520_180434-cf8fefa5.pth
diff --git a/configs/deepfashion/README.md b/configs/deepfashion/README.md
index e2c042f56a9..dd4f012bfa3 100644
--- a/configs/deepfashion/README.md
+++ b/configs/deepfashion/README.md
@@ -1,23 +1,19 @@
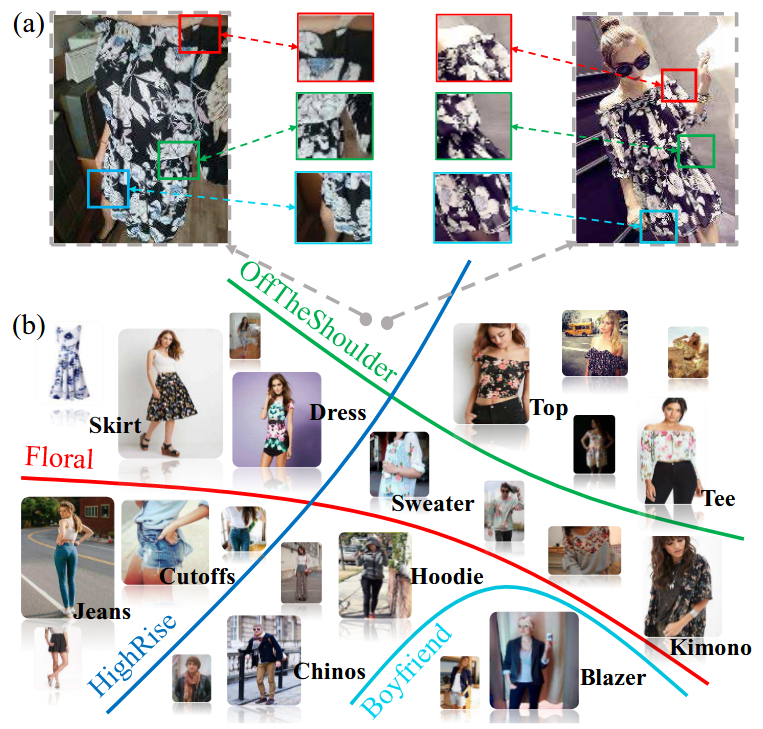
-# DeepFashion: Powering Robust Clothes Recognition and Retrieval With Rich Annotations
+# DeepFashion
-## Abstract
+> [DeepFashion: Powering Robust Clothes Recognition and Retrieval With Rich Annotations](https://openaccess.thecvf.com/content_cvpr_2016/html/Liu_DeepFashion_Powering_Robust_CVPR_2016_paper.html)
-
+
+
+## Abstract
Recent advances in clothes recognition have been driven by the construction of clothes datasets. Existing datasets are limited in the amount of annotations and are difficult to cope with the various challenges in real-world applications. In this work, we introduce DeepFashion, a large-scale clothes dataset with comprehensive annotations. It contains over 800,000 images, which are richly annotated with massive attributes, clothing landmarks, and correspondence of images taken under different scenarios including store, street snapshot, and consumer. Such rich annotations enable the development of powerful algorithms in clothes recognition and facilitating future researches. To demonstrate the advantages of DeepFashion, we propose a new deep model, namely FashionNet, which learns clothing features by jointly predicting clothing attributes and landmarks. The estimated landmarks are then employed to pool or gate the learned features. It is optimized in an iterative manner. Extensive experiments demonstrate the effectiveness of FashionNet and the usefulness of DeepFashion.
-
-
-
-
## Introduction
-
-
[MMFashion](https://github.com/open-mmlab/mmfashion) develops "fashion parsing and segmentation" module
based on the dataset
[DeepFashion-Inshop](https://drive.google.com/drive/folders/0B7EVK8r0v71pVDZFQXRsMDZCX1E?usp=sharing).
@@ -55,9 +51,15 @@ mmdetection
After that you can train the Mask RCNN r50 on DeepFashion-In-shop dataset by launching training with the `mask_rcnn_r50_fpn_1x.py` config
or creating your own config file.
+## Results and Models
+
+| Backbone | Model type | Dataset | bbox detection Average Precision | segmentation Average Precision | Config | Download (Google) |
+| :---------: | :----------: | :-----------------: | :--------------------------------: | :----------------------------: | :---------:| :-------------------------: |
+| ResNet50 | Mask RCNN | DeepFashion-In-shop | 0.599 | 0.584 |[config](https://github.com/open-mmlab/mmdetection/blob/master/configs/deepfashion/mask_rcnn_r50_fpn_15e_deepfashion.py)| [model](https://download.openmmlab.com/mmdetection/v2.0/deepfashion/mask_rcnn_r50_fpn_15e_deepfashion/mask_rcnn_r50_fpn_15e_deepfashion_20200329_192752.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/deepfashion/mask_rcnn_r50_fpn_15e_deepfashion/20200329_192752.log.json) |
+
## Citation
-```
+```latex
@inproceedings{liuLQWTcvpr16DeepFashion,
author = {Liu, Ziwei and Luo, Ping and Qiu, Shi and Wang, Xiaogang and Tang, Xiaoou},
title = {DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations},
@@ -66,9 +68,3 @@ or creating your own config file.
year = {2016}
}
```
-
-## Model Zoo
-
-| Backbone | Model type | Dataset | bbox detection Average Precision | segmentation Average Precision | Config | Download (Google) |
-| :---------: | :----------: | :-----------------: | :--------------------------------: | :----------------------------: | :---------:| :-------------------------: |
-| ResNet50 | Mask RCNN | DeepFashion-In-shop | 0.599 | 0.584 |[config](https://github.com/open-mmlab/mmdetection/blob/master/configs/deepfashion/mask_rcnn_r50_fpn_15e_deepfashion.py)| [model](https://download.openmmlab.com/mmdetection/v2.0/deepfashion/mask_rcnn_r50_fpn_15e_deepfashion/mask_rcnn_r50_fpn_15e_deepfashion_20200329_192752.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/deepfashion/mask_rcnn_r50_fpn_15e_deepfashion/20200329_192752.log.json) |
diff --git a/configs/deformable_detr/README.md b/configs/deformable_detr/README.md
index e3b8e41d27c..f415be350b9 100644
--- a/configs/deformable_detr/README.md
+++ b/configs/deformable_detr/README.md
@@ -1,26 +1,35 @@
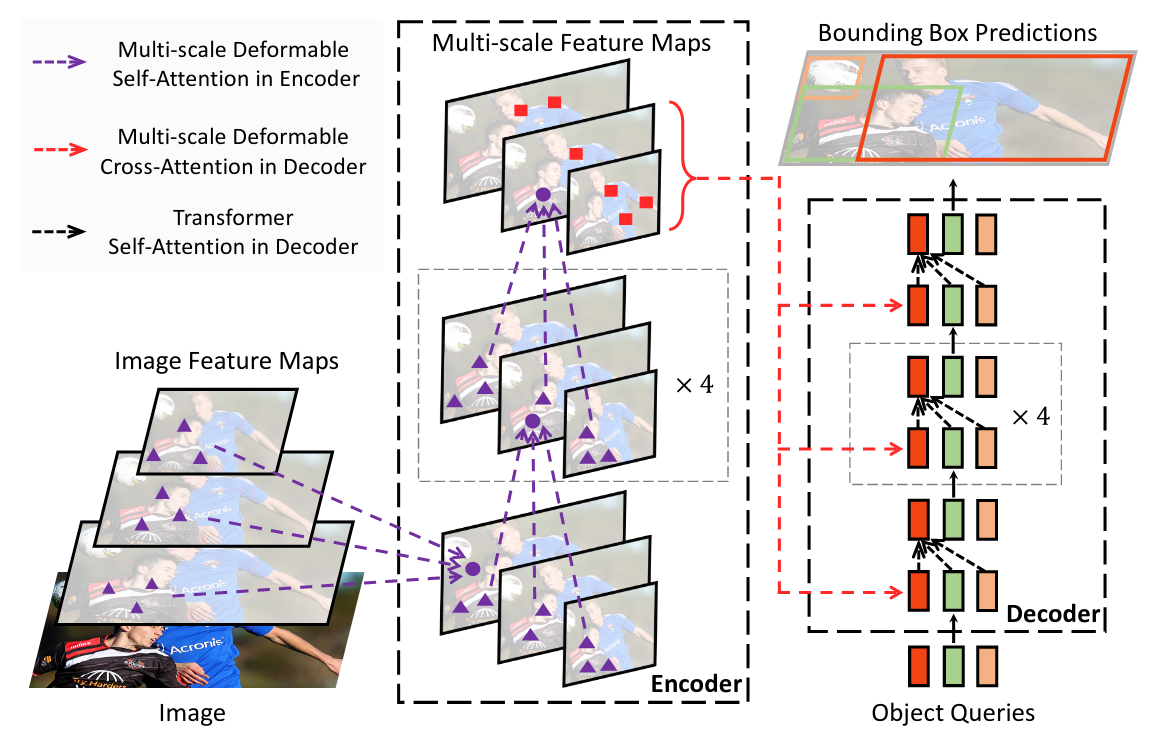
-# Deformable DETR: Deformable Transformers for End-to-End Object Detection
+# Deformable DETR
-## Abstract
+> [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159)
+
+
-
+## Abstract
DETR has been recently proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance. However, it suffers from slow convergence and limited feature spatial resolution, due to the limitation of Transformer attention modules in processing image feature maps. To mitigate these issues, we proposed Deformable DETR, whose attention modules only attend to a small set of key sampling points around a reference. Deformable DETR can achieve better performance than DETR (especially on small objects) with 10 times less training epochs. Extensive experiments on the COCO benchmark demonstrate the effectiveness of our approach.
-
-
-
+## Results and Models
-## Citation
+| Backbone | Model | Lr schd | box AP | Config | Download |
+|:------:|:--------:|:--------------:|:------:|:------:|:--------:|
+| R-50 | Deformable DETR |50e | 44.5 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/deformable_detr/deformable_detr_r50_16x2_50e_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/deformable_detr/deformable_detr_r50_16x2_50e_coco/deformable_detr_r50_16x2_50e_coco_20210419_220030-a12b9512.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/deformable_detr/deformable_detr_r50_16x2_50e_coco/deformable_detr_r50_16x2_50e_coco_20210419_220030-a12b9512.log.json) |
+| R-50 | + iterative bounding box refinement |50e | 46.1 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/deformable_detr/deformable_detr_refine_r50_16x2_50e_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/deformable_detr/deformable_detr_refine_r50_16x2_50e_coco/deformable_detr_refine_r50_16x2_50e_coco_20210419_220503-5f5dff21.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/deformable_detr/deformable_detr_refine_r50_16x2_50e_coco/deformable_detr_refine_r50_16x2_50e_coco_20210419_220503-5f5dff21.log.json) |
+| R-50 | ++ two-stage Deformable DETR |50e | 46.8 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/deformable_detr/deformable_detr_twostage_refine_r50_16x2_50e_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/deformable_detr/deformable_detr_twostage_refine_r50_16x2_50e_coco/deformable_detr_twostage_refine_r50_16x2_50e_coco_20210419_220613-9d28ab72.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/deformable_detr/deformable_detr_twostage_refine_r50_16x2_50e_coco/deformable_detr_twostage_refine_r50_16x2_50e_coco_20210419_220613-9d28ab72.log.json) |
-
+# NOTE
+
+1. All models are trained with batch size 32.
+2. The performance is unstable. `Deformable DETR` and `iterative bounding box refinement` may fluctuate about 0.3 mAP. `two-stage Deformable DETR` may fluctuate about 0.2 mAP.
+
+## Citation
We provide the config files for Deformable DETR: [Deformable DETR: Deformable Transformers for End-to-End Object Detection](https://arxiv.org/abs/2010.04159).
-```
+```latex
@inproceedings{
zhu2021deformable,
title={Deformable DETR: Deformable Transformers for End-to-End Object Detection},
@@ -30,16 +39,3 @@ year={2021},
url={https://openreview.net/forum?id=gZ9hCDWe6ke}
}
```
-
-## Results and Models
-
-| Backbone | Model | Lr schd | box AP | Config | Download |
-|:------:|:--------:|:--------------:|:------:|:------:|:--------:|
-| R-50 | Deformable DETR |50e | 44.5 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/deformable_detr/deformable_detr_r50_16x2_50e_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/deformable_detr/deformable_detr_r50_16x2_50e_coco/deformable_detr_r50_16x2_50e_coco_20210419_220030-a12b9512.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/deformable_detr/deformable_detr_r50_16x2_50e_coco/deformable_detr_r50_16x2_50e_coco_20210419_220030-a12b9512.log.json) |
-| R-50 | + iterative bounding box refinement |50e | 46.1 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/deformable_detr/deformable_detr_refine_r50_16x2_50e_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/deformable_detr/deformable_detr_refine_r50_16x2_50e_coco/deformable_detr_refine_r50_16x2_50e_coco_20210419_220503-5f5dff21.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/deformable_detr/deformable_detr_refine_r50_16x2_50e_coco/deformable_detr_refine_r50_16x2_50e_coco_20210419_220503-5f5dff21.log.json) |
-| R-50 | ++ two-stage Deformable DETR |50e | 46.8 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/deformable_detr/deformable_detr_twostage_refine_r50_16x2_50e_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/deformable_detr/deformable_detr_twostage_refine_r50_16x2_50e_coco/deformable_detr_twostage_refine_r50_16x2_50e_coco_20210419_220613-9d28ab72.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/deformable_detr/deformable_detr_twostage_refine_r50_16x2_50e_coco/deformable_detr_twostage_refine_r50_16x2_50e_coco_20210419_220613-9d28ab72.log.json) |
-
-# NOTE
-
-1. All models are trained with batch size 32.
-2. The performance is unstable. `Deformable DETR` and `iterative bounding box refinement` may fluctuate about 0.3 mAP. `two-stage Deformable DETR` may fluctuate about 0.2 mAP.
diff --git a/configs/detectors/README.md b/configs/detectors/README.md
index c90302b2f6c..3504ee2731a 100644
--- a/configs/detectors/README.md
+++ b/configs/detectors/README.md
@@ -1,35 +1,18 @@
-# DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution
+# DetectoRS
-## Abstract
+> [DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution](https://arxiv.org/abs/2006.02334)
+
+
-
+## Abstract
Many modern object detectors demonstrate outstanding performances by using the mechanism of looking and thinking twice. In this paper, we explore this mechanism in the backbone design for object detection. At the macro level, we propose Recursive Feature Pyramid, which incorporates extra feedback connections from Feature Pyramid Networks into the bottom-up backbone layers. At the micro level, we propose Switchable Atrous Convolution, which convolves the features with different atrous rates and gathers the results using switch functions. Combining them results in DetectoRS, which significantly improves the performances of object detection. On COCO test-dev, DetectoRS achieves state-of-the-art 55.7% box AP for object detection, 48.5% mask AP for instance segmentation, and 50.0% PQ for panoptic segmentation.
-
-
-
-
-## Citation
-
-
-
-We provide the config files for [DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution](https://arxiv.org/pdf/2006.02334.pdf).
-
-```BibTeX
-@article{qiao2020detectors,
- title={DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution},
- author={Qiao, Siyuan and Chen, Liang-Chieh and Yuille, Alan},
- journal={arXiv preprint arXiv:2006.02334},
- year={2020}
-}
-```
-
-## Dataset
+## Introduction
DetectoRS requires COCO and [COCO-stuff](http://calvin.inf.ed.ac.uk/wp-content/uploads/data/cocostuffdataset/stuffthingmaps_trainval2017.zip) dataset for training. You need to download and extract it in the COCO dataset path.
The directory should be like this.
@@ -71,3 +54,16 @@ The results on COCO 2017 val are shown in the below table.
*Note*: This is a re-implementation based on MMDetection-V2.
The original implementation is based on MMDetection-V1.
+
+## Citation
+
+We provide the config files for [DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution](https://arxiv.org/pdf/2006.02334.pdf).
+
+```latex
+@article{qiao2020detectors,
+ title={DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution},
+ author={Qiao, Siyuan and Chen, Liang-Chieh and Yuille, Alan},
+ journal={arXiv preprint arXiv:2006.02334},
+ year={2020}
+}
+```
diff --git a/configs/detr/README.md b/configs/detr/README.md
index a04e7ab7a94..5f25357a18d 100644
--- a/configs/detr/README.md
+++ b/configs/detr/README.md
@@ -1,26 +1,28 @@
-# End-to-End Object Detection with Transformers
+# DETR
-## Abstract
+> [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872)
-
+
+
+## Abstract
We present a new method that views object detection as a direct set prediction problem. Our approach streamlines the detection pipeline, effectively removing the need for many hand-designed components like a non-maximum suppression procedure or anchor generation that explicitly encode our prior knowledge about the task. The main ingredients of the new framework, called DEtection TRansformer or DETR, are a set-based global loss that forces unique predictions via bipartite matching, and a transformer encoder-decoder architecture. Given a fixed small set of learned object queries, DETR reasons about the relations of the objects and the global image context to directly output the final set of predictions in parallel. The new model is conceptually simple and does not require a specialized library, unlike many other modern detectors. DETR demonstrates accuracy and run-time performance on par with the well-established and highly-optimized Faster RCNN baseline on the challenging COCO object detection dataset. Moreover, DETR can be easily generalized to produce panoptic segmentation in a unified manner. We show that it significantly outperforms competitive baselines.
-
-
-
+## Results and Models
-## Citation
+| Backbone | Model | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
+|:------:|:--------:|:-------:|:--------:|:--------------:|:------:|:------:|:--------:|
+| R-50 | DETR |150e |7.9| | 40.1 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/detr/detr_r50_8x2_150e_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/detr/detr_r50_8x2_150e_coco/detr_r50_8x2_150e_coco_20201130_194835-2c4b8974.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/detr/detr_r50_8x2_150e_coco/detr_r50_8x2_150e_coco_20201130_194835.log.json) |
-
+## Citation
We provide the config files for DETR: [End-to-End Object Detection with Transformers](https://arxiv.org/abs/2005.12872).
-```BibTeX
+```latex
@inproceedings{detr,
author = {Nicolas Carion and
Francisco Massa and
@@ -33,9 +35,3 @@ We provide the config files for DETR: [End-to-End Object Detection with Transfor
year = {2020}
}
```
-
-## Results and Models
-
-| Backbone | Model | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
-|:------:|:--------:|:-------:|:--------:|:--------------:|:------:|:------:|:--------:|
-| R-50 | DETR |150e |7.9| | 40.1 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/detr/detr_r50_8x2_150e_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/detr/detr_r50_8x2_150e_coco/detr_r50_8x2_150e_coco_20201130_194835-2c4b8974.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/detr/detr_r50_8x2_150e_coco/detr_r50_8x2_150e_coco_20201130_194835.log.json) |
diff --git a/configs/double_heads/README.md b/configs/double_heads/README.md
index 8191d7ab29e..c7507e86916 100644
--- a/configs/double_heads/README.md
+++ b/configs/double_heads/README.md
@@ -1,22 +1,24 @@
-# Rethinking Classification and Localization for Object Detection
+# Double Heads
-## Abstract
+> [Rethinking Classification and Localization for Object Detection](https://arxiv.org/abs/1904.06493)
+
+
-
+## Abstract
Two head structures (i.e. fully connected head and convolution head) have been widely used in R-CNN based detectors for classification and localization tasks. However, there is a lack of understanding of how does these two head structures work for these two tasks. To address this issue, we perform a thorough analysis and find an interesting fact that the two head structures have opposite preferences towards the two tasks. Specifically, the fully connected head (fc-head) is more suitable for the classification task, while the convolution head (conv-head) is more suitable for the localization task. Furthermore, we examine the output feature maps of both heads and find that fc-head has more spatial sensitivity than conv-head. Thus, fc-head has more capability to distinguish a complete object from part of an object, but is not robust to regress the whole object. Based upon these findings, we propose a Double-Head method, which has a fully connected head focusing on classification and a convolution head for bounding box regression. Without bells and whistles, our method gains +3.5 and +2.8 AP on MS COCO dataset from Feature Pyramid Network (FPN) baselines with ResNet-50 and ResNet-101 backbones, respectively.
-
-
-
+## Results and Models
-## Citation
+| Backbone | Style | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
+| :-------------: | :-----: | :-----: | :------: | :------------: | :----: | :------: | :--------: |
+| R-50-FPN | pytorch | 1x | 6.8 | 9.5 | 40.0 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/double_heads/dh_faster_rcnn_r50_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/double_heads/dh_faster_rcnn_r50_fpn_1x_coco/dh_faster_rcnn_r50_fpn_1x_coco_20200130-586b67df.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/double_heads/dh_faster_rcnn_r50_fpn_1x_coco/dh_faster_rcnn_r50_fpn_1x_coco_20200130_220238.log.json) |
-
+## Citation
```latex
@article{wu2019rethinking,
@@ -28,9 +30,3 @@ Two head structures (i.e. fully connected head and convolution head) have been w
primaryClass={cs.CV}
}
```
-
-## Results and models
-
-| Backbone | Style | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
-| :-------------: | :-----: | :-----: | :------: | :------------: | :----: | :------: | :--------: |
-| R-50-FPN | pytorch | 1x | 6.8 | 9.5 | 40.0 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/double_heads/dh_faster_rcnn_r50_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/double_heads/dh_faster_rcnn_r50_fpn_1x_coco/dh_faster_rcnn_r50_fpn_1x_coco_20200130-586b67df.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/double_heads/dh_faster_rcnn_r50_fpn_1x_coco/dh_faster_rcnn_r50_fpn_1x_coco_20200130_220238.log.json) |
diff --git a/configs/dynamic_rcnn/README.md b/configs/dynamic_rcnn/README.md
index d79b181ed61..a22138f50b0 100644
--- a/configs/dynamic_rcnn/README.md
+++ b/configs/dynamic_rcnn/README.md
@@ -1,24 +1,26 @@
-# Dynamic R-CNN: Towards High Quality Object Detection via Dynamic Training
+# Dynamic R-CNN
-## Abstract
+> [Dynamic R-CNN: Towards High Quality Object Detection via Dynamic Training](https://arxiv.org/abs/2004.06002)
-
+
+
+## Abstract
Although two-stage object detectors have continuously advanced the state-of-the-art performance in recent years, the training process itself is far from crystal. In this work, we first point out the inconsistency problem between the fixed network settings and the dynamic training procedure, which greatly affects the performance. For example, the fixed label assignment strategy and regression loss function cannot fit the distribution change of proposals and thus are harmful to training high quality detectors. Consequently, we propose Dynamic R-CNN to adjust the label assignment criteria (IoU threshold) and the shape of regression loss function (parameters of SmoothL1 Loss) automatically based on the statistics of proposals during training. This dynamic design makes better use of the training samples and pushes the detector to fit more high quality samples. Specifically, our method improves upon ResNet-50-FPN baseline with 1.9% AP and 5.5% AP90 on the MS COCO dataset with no extra overhead.
-
-
-
+## Results and Models
-## Citation
+| Backbone | Style | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
+|:---------:|:-------:|:-------:|:--------:|:--------------:|:------:|:------:|:--------:|
+| R-50 | pytorch | 1x | 3.8 | | 38.9 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/dynamic_rcnn/dynamic_rcnn_r50_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/dynamic_rcnn/dynamic_rcnn_r50_fpn_1x/dynamic_rcnn_r50_fpn_1x-62a3f276.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/dynamic_rcnn/dynamic_rcnn_r50_fpn_1x/dynamic_rcnn_r50_fpn_1x_20200618_095048.log.json) |
-
+## Citation
-```
+```latex
@article{DynamicRCNN,
author = {Hongkai Zhang and Hong Chang and Bingpeng Ma and Naiyan Wang and Xilin Chen},
title = {Dynamic {R-CNN}: Towards High Quality Object Detection via Dynamic Training},
@@ -26,9 +28,3 @@ Although two-stage object detectors have continuously advanced the state-of-the-
year = {2020}
}
```
-
-## Results and Models
-
-| Backbone | Style | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
-|:---------:|:-------:|:-------:|:--------:|:--------------:|:------:|:------:|:--------:|
-| R-50 | pytorch | 1x | 3.8 | | 38.9 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/dynamic_rcnn/dynamic_rcnn_r50_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/dynamic_rcnn/dynamic_rcnn_r50_fpn_1x/dynamic_rcnn_r50_fpn_1x-62a3f276.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/dynamic_rcnn/dynamic_rcnn_r50_fpn_1x/dynamic_rcnn_r50_fpn_1x_20200618_095048.log.json) |
diff --git a/configs/empirical_attention/README.md b/configs/empirical_attention/README.md
index 8937be26e02..ddf8194be6e 100644
--- a/configs/empirical_attention/README.md
+++ b/configs/empirical_attention/README.md
@@ -1,22 +1,27 @@
-# An Empirical Study of Spatial Attention Mechanisms in Deep Networks
+# Empirical Attention
-## Abstract
+> [An Empirical Study of Spatial Attention Mechanisms in Deep Networks](https://arxiv.org/abs/1904.05873)
+
+
-
+## Abstract
Attention mechanisms have become a popular component in deep neural networks, yet there has been little examination of how different influencing factors and methods for computing attention from these factors affect performance. Toward a better general understanding of attention mechanisms, we present an empirical study that ablates various spatial attention elements within a generalized attention formulation, encompassing the dominant Transformer attention as well as the prevalent deformable convolution and dynamic convolution modules. Conducted on a variety of applications, the study yields significant findings about spatial attention in deep networks, some of which run counter to conventional understanding. For example, we find that the query and key content comparison in Transformer attention is negligible for self-attention, but vital for encoder-decoder attention. A proper combination of deformable convolution with key content only saliency achieves the best accuracy-efficiency tradeoff in self-attention. Our results suggest that there exists much room for improvement in the design of attention mechanisms.
-
-
-
+## Results and Models
-## Citation
+| Backbone | Attention Component | DCN | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
+|:---------:|:-------------------:|:----:|:-------:|:--------:|:--------------:|:------:|:------:|:--------:|
+| R-50 | 1111 | N | 1x | 8.0 | 13.8 | 40.0 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/empirical_attention/faster_rcnn_r50_fpn_attention_1111_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/empirical_attention/faster_rcnn_r50_fpn_attention_1111_1x_coco/faster_rcnn_r50_fpn_attention_1111_1x_coco_20200130-403cccba.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/empirical_attention/faster_rcnn_r50_fpn_attention_1111_1x_coco/faster_rcnn_r50_fpn_attention_1111_1x_coco_20200130_210344.log.json) |
+| R-50 | 0010 | N | 1x | 4.2 | 18.4 | 39.1 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/empirical_attention/faster_rcnn_r50_fpn_attention_0010_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/empirical_attention/faster_rcnn_r50_fpn_attention_0010_1x_coco/faster_rcnn_r50_fpn_attention_0010_1x_coco_20200130-7cb0c14d.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/empirical_attention/faster_rcnn_r50_fpn_attention_0010_1x_coco/faster_rcnn_r50_fpn_attention_0010_1x_coco_20200130_210125.log.json) |
+| R-50 | 1111 | Y | 1x | 8.0 | 12.7 | 42.1 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/empirical_attention/faster_rcnn_r50_fpn_attention_1111_dcn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/empirical_attention/faster_rcnn_r50_fpn_attention_1111_dcn_1x_coco/faster_rcnn_r50_fpn_attention_1111_dcn_1x_coco_20200130-8b2523a6.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/empirical_attention/faster_rcnn_r50_fpn_attention_1111_dcn_1x_coco/faster_rcnn_r50_fpn_attention_1111_dcn_1x_coco_20200130_204442.log.json) |
+| R-50 | 0010 | Y | 1x | 4.2 | 17.1 | 42.0 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/empirical_attention/faster_rcnn_r50_fpn_attention_0010_dcn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/empirical_attention/faster_rcnn_r50_fpn_attention_0010_dcn_1x_coco/faster_rcnn_r50_fpn_attention_0010_dcn_1x_coco_20200130-1a2e831d.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/empirical_attention/faster_rcnn_r50_fpn_attention_0010_dcn_1x_coco/faster_rcnn_r50_fpn_attention_0010_dcn_1x_coco_20200130_210410.log.json) |
-
+## Citation
```latex
@article{zhu2019empirical,
@@ -26,12 +31,3 @@ Attention mechanisms have become a popular component in deep neural networks, ye
year={2019}
}
```
-
-## Results and Models
-
-| Backbone | Attention Component | DCN | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
-|:---------:|:-------------------:|:----:|:-------:|:--------:|:--------------:|:------:|:------:|:--------:|
-| R-50 | 1111 | N | 1x | 8.0 | 13.8 | 40.0 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/empirical_attention/faster_rcnn_r50_fpn_attention_1111_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/empirical_attention/faster_rcnn_r50_fpn_attention_1111_1x_coco/faster_rcnn_r50_fpn_attention_1111_1x_coco_20200130-403cccba.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/empirical_attention/faster_rcnn_r50_fpn_attention_1111_1x_coco/faster_rcnn_r50_fpn_attention_1111_1x_coco_20200130_210344.log.json) |
-| R-50 | 0010 | N | 1x | 4.2 | 18.4 | 39.1 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/empirical_attention/faster_rcnn_r50_fpn_attention_0010_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/empirical_attention/faster_rcnn_r50_fpn_attention_0010_1x_coco/faster_rcnn_r50_fpn_attention_0010_1x_coco_20200130-7cb0c14d.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/empirical_attention/faster_rcnn_r50_fpn_attention_0010_1x_coco/faster_rcnn_r50_fpn_attention_0010_1x_coco_20200130_210125.log.json) |
-| R-50 | 1111 | Y | 1x | 8.0 | 12.7 | 42.1 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/empirical_attention/faster_rcnn_r50_fpn_attention_1111_dcn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/empirical_attention/faster_rcnn_r50_fpn_attention_1111_dcn_1x_coco/faster_rcnn_r50_fpn_attention_1111_dcn_1x_coco_20200130-8b2523a6.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/empirical_attention/faster_rcnn_r50_fpn_attention_1111_dcn_1x_coco/faster_rcnn_r50_fpn_attention_1111_dcn_1x_coco_20200130_204442.log.json) |
-| R-50 | 0010 | Y | 1x | 4.2 | 17.1 | 42.0 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/empirical_attention/faster_rcnn_r50_fpn_attention_0010_dcn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/empirical_attention/faster_rcnn_r50_fpn_attention_0010_dcn_1x_coco/faster_rcnn_r50_fpn_attention_0010_dcn_1x_coco_20200130-1a2e831d.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/empirical_attention/faster_rcnn_r50_fpn_attention_0010_dcn_1x_coco/faster_rcnn_r50_fpn_attention_0010_dcn_1x_coco_20200130_210410.log.json) |
diff --git a/configs/fast_rcnn/README.md b/configs/fast_rcnn/README.md
index 0e98c1327fc..2d83c5f2086 100644
--- a/configs/fast_rcnn/README.md
+++ b/configs/fast_rcnn/README.md
@@ -1,23 +1,21 @@
# Fast R-CNN
-## Abstract
+> [Fast R-CNN](https://arxiv.org/abs/1504.08083)
+
+
-
+## Abstract
This paper proposes a Fast Region-based Convolutional Network method (Fast R-CNN) for object detection. Fast R-CNN builds on previous work to efficiently classify object proposals using deep convolutional networks. Compared to previous work, Fast R-CNN employs several innovations to improve training and testing speed while also increasing detection accuracy. Fast R-CNN trains the very deep VGG16 network 9x faster than R-CNN, is 213x faster at test-time, and achieves a higher mAP on PASCAL VOC 2012. Compared to SPPnet, Fast R-CNN trains VGG16 3x faster, tests 10x faster, and is more accurate.
-
-
-
+## Results and Models
## Citation
-
-
```latex
@inproceedings{girshick2015fast,
title={Fast r-cnn},
@@ -26,5 +24,3 @@ This paper proposes a Fast Region-based Convolutional Network method (Fast R-CNN
year={2015}
}
```
-
-## Results and models
diff --git a/configs/faster_rcnn/README.md b/configs/faster_rcnn/README.md
index f96256edb43..66eb3e4c072 100644
--- a/configs/faster_rcnn/README.md
+++ b/configs/faster_rcnn/README.md
@@ -1,34 +1,18 @@
-# Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
+# Faster R-CNN
-## Abstract
+> [Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks](https://arxiv.org/abs/1506.01497)
+
+
-
+## Abstract
State-of-the-art object detection networks depend on region proposal algorithms to hypothesize object locations. Advances like SPPnet and Fast R-CNN have reduced the running time of these detection networks, exposing region proposal computation as a bottleneck. In this work, we introduce a Region Proposal Network (RPN) that shares full-image convolutional features with the detection network, thus enabling nearly cost-free region proposals. An RPN is a fully convolutional network that simultaneously predicts object bounds and objectness scores at each position. The RPN is trained end-to-end to generate high-quality region proposals, which are used by Fast R-CNN for detection. We further merge RPN and Fast R-CNN into a single network by sharing their convolutional features---using the recently popular terminology of neural networks with 'attention' mechanisms, the RPN component tells the unified network where to look. For the very deep VGG-16 model, our detection system has a frame rate of 5fps (including all steps) on a GPU, while achieving state-of-the-art object detection accuracy on PASCAL VOC 2007, 2012, and MS COCO datasets with only 300 proposals per image. In ILSVRC and COCO 2015 competitions, Faster R-CNN and RPN are the foundations of the 1st-place winning entries in several tracks.
-
-
-
-
-## Citation
-
-
-```latex
-@article{Ren_2017,
- title={Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks},
- journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
- publisher={Institute of Electrical and Electronics Engineers (IEEE)},
- author={Ren, Shaoqing and He, Kaiming and Girshick, Ross and Sun, Jian},
- year={2017},
- month={Jun},
-}
-```
-
-## Results and models
+## Results and Models
| Backbone | Style | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
| :-------------: | :-----: | :-----: | :------: | :------------: | :----: | :------: | :--------: |
@@ -79,3 +63,16 @@ We further finetune some pre-trained models on the COCO subsets, which only cont
| ------------------------------------------------------------ | ----- | ------------------ | ------------------------------------------------------------ | -------- | ------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
| [R-50-FPN](./faster_rcnn_r50_caffe_fpn_mstrain_1x_coco-person.py) | caffe | person | [R-50-FPN-Caffe-3x](./faster_rcnn_r50_caffe_fpn_mstrain_3x_coco.py) | 3.7 | 55.8 | [config](./faster_rcnn_r50_caffe_fpn_mstrain_1x_coco-person.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco-person/faster_rcnn_r50_fpn_1x_coco-person_20201216_175929-d022e227.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco-person/faster_rcnn_r50_fpn_1x_coco-person_20201216_175929.log.json) |
| [R-50-FPN](./faster_rcnn_r50_caffe_fpn_mstrain_1x_coco-person-bicycle-car.py) | caffe | person-bicycle-car | [R-50-FPN-Caffe-3x](./faster_rcnn_r50_caffe_fpn_mstrain_3x_coco.py) | 3.7 | 44.1 | [config](./faster_rcnn_r50_caffe_fpn_mstrain_1x_coco-person-bicycle-car.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco-person-bicycle-car/faster_rcnn_r50_fpn_1x_coco-person-bicycle-car_20201216_173117-6eda6d92.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/faster_rcnn/faster_rcnn_r50_fpn_1x_coco-person-bicycle-car/faster_rcnn_r50_fpn_1x_coco-person-bicycle-car_20201216_173117.log.json) |
+
+## Citation
+
+```latex
+@article{Ren_2017,
+ title={Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks},
+ journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
+ publisher={Institute of Electrical and Electronics Engineers (IEEE)},
+ author={Ren, Shaoqing and He, Kaiming and Girshick, Ross and Sun, Jian},
+ year={2017},
+ month={Jun},
+}
+```
diff --git a/configs/fcos/README.md b/configs/fcos/README.md
index fc5ca545b4e..706fad56194 100644
--- a/configs/fcos/README.md
+++ b/configs/fcos/README.md
@@ -1,32 +1,17 @@
-# FCOS: Fully Convolutional One-Stage Object Detection
+# FCOS
-## Abstract
+> [FCOS: Fully Convolutional One-Stage Object Detection](https://arxiv.org/abs/1904.01355)
+
+
-
+## Abstract
We propose a fully convolutional one-stage object detector (FCOS) to solve object detection in a per-pixel prediction fashion, analogue to semantic segmentation. Almost all state-of-the-art object detectors such as RetinaNet, SSD, YOLOv3, and Faster R-CNN rely on pre-defined anchor boxes. In contrast, our proposed detector FCOS is anchor box free, as well as proposal free. By eliminating the predefined set of anchor boxes, FCOS completely avoids the complicated computation related to anchor boxes such as calculating overlapping during training. More importantly, we also avoid all hyper-parameters related to anchor boxes, which are often very sensitive to the final detection performance. With the only post-processing non-maximum suppression (NMS), FCOS with ResNeXt-64x4d-101 achieves 44.7% in AP with single-model and single-scale testing, surpassing previous one-stage detectors with the advantage of being much simpler. For the first time, we demonstrate a much simpler and flexible detection framework achieving improved detection accuracy. We hope that the proposed FCOS framework can serve as a simple and strong alternative for many other instance-level tasks.
-
-
-
-
-## Citation
-
-
-
-```latex
-@article{tian2019fcos,
- title={FCOS: Fully Convolutional One-Stage Object Detection},
- author={Tian, Zhi and Shen, Chunhua and Chen, Hao and He, Tong},
- journal={arXiv preprint arXiv:1904.01355},
- year={2019}
-}
-```
-
## Results and Models
| Backbone | Style | GN | MS train | Tricks | DCN | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
@@ -47,3 +32,14 @@ We propose a fully convolutional one-stage object detector (FCOS) to solve objec
- The X-101 backbone is X-101-64x4d.
- Tricks means setting `norm_on_bbox`, `centerness_on_reg`, `center_sampling` as `True`.
- DCN means using `DCNv2` in both backbone and head.
+
+## Citation
+
+```latex
+@article{tian2019fcos,
+ title={FCOS: Fully Convolutional One-Stage Object Detection},
+ author={Tian, Zhi and Shen, Chunhua and Chen, Hao and He, Tong},
+ journal={arXiv preprint arXiv:1904.01355},
+ year={2019}
+}
+```
diff --git a/configs/foveabox/README.md b/configs/foveabox/README.md
index 7009e97fd28..7c82820ee9f 100644
--- a/configs/foveabox/README.md
+++ b/configs/foveabox/README.md
@@ -1,27 +1,23 @@
-# FoveaBox: Beyond Anchor-based Object Detector
+# FoveaBox
-## Abstract
+> [FoveaBox: Beyond Anchor-based Object Detector](https://arxiv.org/abs/1904.03797)
+
+
-
+## Abstract
We present FoveaBox, an accurate, flexible, and completely anchor-free framework for object detection. While almost all state-of-the-art object detectors utilize predefined anchors to enumerate possible locations, scales and aspect ratios for the search of the objects, their performance and generalization ability are also limited to the design of anchors. Instead, FoveaBox directly learns the object existing possibility and the bounding box coordinates without anchor reference. This is achieved by: (a) predicting category-sensitive semantic maps for the object existing possibility, and (b) producing category-agnostic bounding box for each position that potentially contains an object. The scales of target boxes are naturally associated with feature pyramid representations. In FoveaBox, an instance is assigned to adjacent feature levels to make the model more accurate.We demonstrate its effectiveness on standard benchmarks and report extensive experimental analysis. Without bells and whistles, FoveaBox achieves state-of-the-art single model performance on the standard COCO and Pascal VOC object detection benchmark. More importantly, FoveaBox avoids all computation and hyper-parameters related to anchor boxes, which are often sensitive to the final detection performance. We believe the simple and effective approach will serve as a solid baseline and help ease future research for object detection.
-
-
-
-
-
-
## Introduction
FoveaBox is an accurate, flexible and completely anchor-free object detection system for object detection framework, as presented in our paper [https://arxiv.org/abs/1904.03797](https://arxiv.org/abs/1904.03797):
Different from previous anchor-based methods, FoveaBox directly learns the object existing possibility and the bounding box coordinates without anchor reference. This is achieved by: (a) predicting category-sensitive semantic maps for the object existing possibility, and (b) producing category-agnostic bounding box for each position that potentially contains an object.
-## Main Results
+## Results and Models
### Results on R50/101-FPN
@@ -43,7 +39,7 @@ Different from previous anchor-based methods, FoveaBox directly learns the objec
Any pull requests or issues are welcome.
-## Citations
+## Citation
Please consider citing our paper in your publications if the project helps your research. BibTeX reference is as follows.
diff --git a/configs/fpg/README.md b/configs/fpg/README.md
index dd69c613afb..3e884fb74a4 100644
--- a/configs/fpg/README.md
+++ b/configs/fpg/README.md
@@ -1,31 +1,17 @@
-# Feature Pyramid Grids
+# FPG
+
+> [Feature Pyramid Grids](https://arxiv.org/abs/2004.03580)
+
## Abstract
-
-
Feature pyramid networks have been widely adopted in the object detection literature to improve feature representations for better handling of variations in scale. In this paper, we present Feature Pyramid Grids (FPG), a deep multi-pathway feature pyramid, that represents the feature scale-space as a regular grid of parallel bottom-up pathways which are fused by multi-directional lateral connections. FPG can improve single-pathway feature pyramid networks by significantly increasing its performance at similar computation cost, highlighting importance of deep pyramid representations. In addition to its general and uniform structure, over complicated structures that have been found with neural architecture search, it also compares favorably against such approaches without relying on search. We hope that FPG with its uniform and effective nature can serve as a strong component for future work in object recognition.
-
-
-
-
-## Citation
-
-```latex
-@article{chen2020feature,
- title={Feature pyramid grids},
- author={Chen, Kai and Cao, Yuhang and Loy, Chen Change and Lin, Dahua and Feichtenhofer, Christoph},
- journal={arXiv preprint arXiv:2004.03580},
- year={2020}
-}
-```
-
## Results and Models
We benchmark the new training schedule (crop training, large batch, unfrozen BN, 50 epochs) introduced in NAS-FPN.
@@ -42,3 +28,14 @@ All backbones are Resnet-50 in pytorch style.
**Note**: Chn128 means to decrease the number of channels of features and convs from 256 (default) to 128 in
Neck and BBox Head, which can greatly decrease memory consumption without sacrificing much precision.
+
+## Citation
+
+```latex
+@article{chen2020feature,
+ title={Feature pyramid grids},
+ author={Chen, Kai and Cao, Yuhang and Loy, Chen Change and Lin, Dahua and Feichtenhofer, Christoph},
+ journal={arXiv preprint arXiv:2004.03580},
+ year={2020}
+}
+```
diff --git a/configs/free_anchor/README.md b/configs/free_anchor/README.md
index a1dcb17f1fe..e232f370833 100644
--- a/configs/free_anchor/README.md
+++ b/configs/free_anchor/README.md
@@ -1,32 +1,17 @@
-# FreeAnchor: Learning to Match Anchors for Visual Object Detection
+# FreeAnchor
-## Abstract
+> [FreeAnchor: Learning to Match Anchors for Visual Object Detection](https://arxiv.org/abs/1909.02466)
+
+
-
+## Abstract
Modern CNN-based object detectors assign anchors for ground-truth objects under the restriction of object-anchor Intersection-over-Unit (IoU). In this study, we propose a learning-to-match approach to break IoU restriction, allowing objects to match anchors in a flexible manner. Our approach, referred to as FreeAnchor, updates hand-crafted anchor assignment to "free" anchor matching by formulating detector training as a maximum likelihood estimation (MLE) procedure. FreeAnchor targets at learning features which best explain a class of objects in terms of both classification and localization. FreeAnchor is implemented by optimizing detection customized likelihood and can be fused with CNN-based detectors in a plug-and-play manner. Experiments on COCO demonstrate that FreeAnchor consistently outperforms their counterparts with significant margins.
-
-
-
-
-## Citation
-
-
-
-```latex
-@inproceedings{zhang2019freeanchor,
- title = {{FreeAnchor}: Learning to Match Anchors for Visual Object Detection},
- author = {Zhang, Xiaosong and Wan, Fang and Liu, Chang and Ji, Rongrong and Ye, Qixiang},
- booktitle = {Neural Information Processing Systems},
- year = {2019}
-}
-```
-
## Results and Models
| Backbone | Style | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
@@ -39,3 +24,14 @@ Modern CNN-based object detectors assign anchors for ground-truth objects under
- We use 8 GPUs with 2 images/GPU.
- For more settings and models, please refer to the [official repo](https://github.com/zhangxiaosong18/FreeAnchor).
+
+## Citation
+
+```latex
+@inproceedings{zhang2019freeanchor,
+ title = {{FreeAnchor}: Learning to Match Anchors for Visual Object Detection},
+ author = {Zhang, Xiaosong and Wan, Fang and Liu, Chang and Ji, Rongrong and Ye, Qixiang},
+ booktitle = {Neural Information Processing Systems},
+ year = {2019}
+}
+```
diff --git a/configs/fsaf/README.md b/configs/fsaf/README.md
index ba4d409b0b5..64976c57764 100644
--- a/configs/fsaf/README.md
+++ b/configs/fsaf/README.md
@@ -1,23 +1,19 @@
-# Feature Selective Anchor-Free Module for Single-Shot Object Detection
+# FSAF
-## Abstract
+> [Feature Selective Anchor-Free Module for Single-Shot Object Detection](https://arxiv.org/abs/1903.00621)
+
+
-
+## Abstract
We motivate and present feature selective anchor-free (FSAF) module, a simple and effective building block for single-shot object detectors. It can be plugged into single-shot detectors with feature pyramid structure. The FSAF module addresses two limitations brought up by the conventional anchor-based detection: 1) heuristic-guided feature selection; 2) overlap-based anchor sampling. The general concept of the FSAF module is online feature selection applied to the training of multi-level anchor-free branches. Specifically, an anchor-free branch is attached to each level of the feature pyramid, allowing box encoding and decoding in the anchor-free manner at an arbitrary level. During training, we dynamically assign each instance to the most suitable feature level. At the time of inference, the FSAF module can work jointly with anchor-based branches by outputting predictions in parallel. We instantiate this concept with simple implementations of anchor-free branches and online feature selection strategy. Experimental results on the COCO detection track show that our FSAF module performs better than anchor-based counterparts while being faster. When working jointly with anchor-based branches, the FSAF module robustly improves the baseline RetinaNet by a large margin under various settings, while introducing nearly free inference overhead. And the resulting best model can achieve a state-of-the-art 44.6% mAP, outperforming all existing single-shot detectors on COCO.
-
-
-
-
## Introduction
-
-
FSAF is an anchor-free method published in CVPR2019 ([https://arxiv.org/pdf/1903.00621.pdf](https://arxiv.org/pdf/1903.00621.pdf)).
Actually it is equivalent to the anchor-based method with only one anchor at each feature map position in each FPN level.
And this is how we implemented it.
@@ -26,7 +22,7 @@ Only the anchor-free branch is released for its better compatibility with the cu
In the original paper, feature maps within the central 0.2-0.5 area of a gt box are tagged as ignored. However,
it is empirically found that a hard threshold (0.2-0.2) gives a further gain on the performance. (see the table below)
-## Main Results
+## Results and Models
### Results on R50/R101/X101-FPN
@@ -46,7 +42,7 @@ it is empirically found that a hard threshold (0.2-0.2) gives a further gain on
- *All pretrained backbones use pytorch style.*
- *All models are trained on 8 Titan-XP gpus and tested on a single gpu.*
-## Citations
+## Citation
BibTeX reference is as follows.
diff --git a/configs/gcnet/README.md b/configs/gcnet/README.md
index c5c436afd85..4d16783132e 100644
--- a/configs/gcnet/README.md
+++ b/configs/gcnet/README.md
@@ -1,19 +1,17 @@
-# GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond
+# GCNet
-## Abstract
+> [GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond](https://arxiv.org/abs/1904.11492)
+
+
-
+## Abstract
The Non-Local Network (NLNet) presents a pioneering approach for capturing long-range dependencies, via aggregating query-specific global context to each query position. However, through a rigorous empirical analysis, we have found that the global contexts modeled by non-local network are almost the same for different query positions within an image. In this paper, we take advantage of this finding to create a simplified network based on a query-independent formulation, which maintains the accuracy of NLNet but with significantly less computation. We further observe that this simplified design shares similar structure with Squeeze-Excitation Network (SENet). Hence we unify them into a three-step general framework for global context modeling. Within the general framework, we design a better instantiation, called the global context (GC) block, which is lightweight and can effectively model the global context. The lightweight property allows us to apply it for multiple layers in a backbone network to construct a global context network (GCNet), which generally outperforms both simplified NLNet and SENet on major benchmarks for various recognition tasks.
-
-
-
-
## Introduction
By [Yue Cao](http://yue-cao.me), [Jiarui Xu](http://jerryxu.net), [Stephen Lin](https://scholar.google.com/citations?user=c3PYmxUAAAAJ&hl=en), Fangyun Wei, [Han Hu](https://sites.google.com/site/hanhushomepage/).
@@ -21,22 +19,9 @@ By [Yue Cao](http://yue-cao.me), [Jiarui Xu](http://jerryxu.net), [Stephen Lin](
We provide config files to reproduce the results in the paper for
["GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond"](https://arxiv.org/abs/1904.11492) on COCO object detection.
-
-
**GCNet** is initially described in [arxiv](https://arxiv.org/abs/1904.11492). Via absorbing advantages of Non-Local Networks (NLNet) and Squeeze-Excitation Networks (SENet), GCNet provides a simple, fast and effective approach for global context modeling, which generally outperforms both NLNet and SENet on major benchmarks for various recognition tasks.
-## Citation
-
-```latex
-@article{cao2019GCNet,
- title={GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond},
- author={Cao, Yue and Xu, Jiarui and Lin, Stephen and Wei, Fangyun and Hu, Han},
- journal={arXiv preprint arXiv:1904.11492},
- year={2019}
-}
-```
-
-## Results and models
+## Results and Models
The results on COCO 2017val are shown in the below table.
@@ -71,3 +56,14 @@ The results on COCO 2017val are shown in the below table.
- `GC` denotes Global Context (GC) block is inserted after 1x1 conv of backbone.
- `DCN` denotes replace 3x3 conv with 3x3 Deformable Convolution in `c3-c5` stages of backbone.
- `r4` and `r16` denote ratio 4 and ratio 16 in GC block respectively.
+
+## Citation
+
+```latex
+@article{cao2019GCNet,
+ title={GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond},
+ author={Cao, Yue and Xu, Jiarui and Lin, Stephen and Wei, Fangyun and Hu, Han},
+ journal={arXiv preprint arXiv:1904.11492},
+ year={2019}
+}
+```
diff --git a/configs/gfl/README.md b/configs/gfl/README.md
index 46a7a08596a..2a8e60a6a6b 100644
--- a/configs/gfl/README.md
+++ b/configs/gfl/README.md
@@ -1,34 +1,17 @@
-# Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection
+# GFL
-## Abstract
+> [Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection](https://arxiv.org/abs/2006.04388)
-
+
+
+## Abstract
One-stage detector basically formulates object detection as dense classification and localization. The classification is usually optimized by Focal Loss and the box location is commonly learned under Dirac delta distribution. A recent trend for one-stage detectors is to introduce an individual prediction branch to estimate the quality of localization, where the predicted quality facilitates the classification to improve detection performance. This paper delves into the representations of the above three fundamental elements: quality estimation, classification and localization. Two problems are discovered in existing practices, including (1) the inconsistent usage of the quality estimation and classification between training and inference and (2) the inflexible Dirac delta distribution for localization when there is ambiguity and uncertainty in complex scenes. To address the problems, we design new representations for these elements. Specifically, we merge the quality estimation into the class prediction vector to form a joint representation of localization quality and classification, and use a vector to represent arbitrary distribution of box locations. The improved representations eliminate the inconsistency risk and accurately depict the flexible distribution in real data, but contain continuous labels, which is beyond the scope of Focal Loss. We then propose Generalized Focal Loss (GFL) that generalizes Focal Loss from its discrete form to the continuous version for successful optimization. On COCO test-dev, GFL achieves 45.0\% AP using ResNet-101 backbone, surpassing state-of-the-art SAPD (43.5\%) and ATSS (43.6\%) with higher or comparable inference speed, under the same backbone and training settings. Notably, our best model can achieve a single-model single-scale AP of 48.2\%, at 10 FPS on a single 2080Ti GPU.
-
-
-
-
-## Citation
-
-
-
-We provide config files to reproduce the object detection results in the paper [Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection](https://arxiv.org/abs/2006.04388)
-
-```latex
-@article{li2020generalized,
- title={Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection},
- author={Li, Xiang and Wang, Wenhai and Wu, Lijun and Chen, Shuo and Hu, Xiaolin and Li, Jun and Tang, Jinhui and Yang, Jian},
- journal={arXiv preprint arXiv:2006.04388},
- year={2020}
-}
-```
-
## Results and Models
| Backbone | Style | Lr schd | Multi-scale Training| Inf time (fps) | box AP | Config | Download |
@@ -44,3 +27,16 @@ We provide config files to reproduce the object detection results in the paper [
[2] *All results are obtained with a single model and without any test time data augmentation such as multi-scale, flipping and etc..* \
[3] *`dcnv2` denotes deformable convolutional networks v2.* \
[4] *FPS is tested with a single GeForce RTX 2080Ti GPU, using a batch size of 1.*
+
+## Citation
+
+We provide config files to reproduce the object detection results in the paper [Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection](https://arxiv.org/abs/2006.04388)
+
+```latex
+@article{li2020generalized,
+ title={Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection},
+ author={Li, Xiang and Wang, Wenhai and Wu, Lijun and Chen, Shuo and Hu, Xiaolin and Li, Jun and Tang, Jinhui and Yang, Jian},
+ journal={arXiv preprint arXiv:2006.04388},
+ year={2020}
+}
+```
diff --git a/configs/ghm/README.md b/configs/ghm/README.md
index 97b6090a67d..6a8e99e5148 100644
--- a/configs/ghm/README.md
+++ b/configs/ghm/README.md
@@ -1,24 +1,29 @@
-# Gradient Harmonized Single-stage Detector
+# GHM
-## Abstract
+> [Gradient Harmonized Single-stage Detector](https://arxiv.org/abs/1811.05181)
+
+
-
+## Abstract
Despite the great success of two-stage detectors, single-stage detector is still a more elegant and efficient way, yet suffers from the two well-known disharmonies during training, i.e. the huge difference in quantity between positive and negative examples as well as between easy and hard examples. In this work, we first point out that the essential effect of the two disharmonies can be summarized in term of the gradient. Further, we propose a novel gradient harmonizing mechanism (GHM) to be a hedging for the disharmonies. The philosophy behind GHM can be easily embedded into both classification loss function like cross-entropy (CE) and regression loss function like smooth-L1 (SL1) loss. To this end, two novel loss functions called GHM-C and GHM-R are designed to balancing the gradient flow for anchor classification and bounding box refinement, respectively. Ablation study on MS COCO demonstrates that without laborious hyper-parameter tuning, both GHM-C and GHM-R can bring substantial improvement for single-stage detector. Without any whistles and bells, our model achieves 41.6 mAP on COCO test-dev set which surpasses the state-of-the-art method, Focal Loss (FL) + SL1, by 0.8.
-
-
-
+## Results and Models
-## Citation
+| Backbone | Style | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
+| :-------------: | :-----: | :-----: | :------: | :------------: | :----: | :------: | :--------: |
+| R-50-FPN | pytorch | 1x | 4.0 | 3.3 | 37.0 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/ghm/retinanet_ghm_r50_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/ghm/retinanet_ghm_r50_fpn_1x_coco/retinanet_ghm_r50_fpn_1x_coco_20200130-a437fda3.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/ghm/retinanet_ghm_r50_fpn_1x_coco/retinanet_ghm_r50_fpn_1x_coco_20200130_004213.log.json) |
+| R-101-FPN | pytorch | 1x | 6.0 | 4.4 | 39.1 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/ghm/retinanet_ghm_r101_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/ghm/retinanet_ghm_r101_fpn_1x_coco/retinanet_ghm_r101_fpn_1x_coco_20200130-c148ee8f.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/ghm/retinanet_ghm_r101_fpn_1x_coco/retinanet_ghm_r101_fpn_1x_coco_20200130_145259.log.json) |
+| X-101-32x4d-FPN | pytorch | 1x | 7.2 | 5.1 | 40.7 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/ghm/retinanet_ghm_x101_32x4d_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/ghm/retinanet_ghm_x101_32x4d_fpn_1x_coco/retinanet_ghm_x101_32x4d_fpn_1x_coco_20200131-e4333bd0.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/ghm/retinanet_ghm_x101_32x4d_fpn_1x_coco/retinanet_ghm_x101_32x4d_fpn_1x_coco_20200131_113653.log.json) |
+| X-101-64x4d-FPN | pytorch | 1x | 10.3 | 5.2 | 41.4 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/ghm/retinanet_ghm_x101_64x4d_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/ghm/retinanet_ghm_x101_64x4d_fpn_1x_coco/retinanet_ghm_x101_64x4d_fpn_1x_coco_20200131-dd381cef.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/ghm/retinanet_ghm_x101_64x4d_fpn_1x_coco/retinanet_ghm_x101_64x4d_fpn_1x_coco_20200131_113723.log.json) |
-
+## Citation
-```
+```latex
@inproceedings{li2019gradient,
title={Gradient Harmonized Single-stage Detector},
author={Li, Buyu and Liu, Yu and Wang, Xiaogang},
@@ -26,12 +31,3 @@ Despite the great success of two-stage detectors, single-stage detector is still
year={2019}
}
```
-
-## Results and Models
-
-| Backbone | Style | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
-| :-------------: | :-----: | :-----: | :------: | :------------: | :----: | :------: | :--------: |
-| R-50-FPN | pytorch | 1x | 4.0 | 3.3 | 37.0 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/ghm/retinanet_ghm_r50_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/ghm/retinanet_ghm_r50_fpn_1x_coco/retinanet_ghm_r50_fpn_1x_coco_20200130-a437fda3.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/ghm/retinanet_ghm_r50_fpn_1x_coco/retinanet_ghm_r50_fpn_1x_coco_20200130_004213.log.json) |
-| R-101-FPN | pytorch | 1x | 6.0 | 4.4 | 39.1 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/ghm/retinanet_ghm_r101_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/ghm/retinanet_ghm_r101_fpn_1x_coco/retinanet_ghm_r101_fpn_1x_coco_20200130-c148ee8f.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/ghm/retinanet_ghm_r101_fpn_1x_coco/retinanet_ghm_r101_fpn_1x_coco_20200130_145259.log.json) |
-| X-101-32x4d-FPN | pytorch | 1x | 7.2 | 5.1 | 40.7 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/ghm/retinanet_ghm_x101_32x4d_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/ghm/retinanet_ghm_x101_32x4d_fpn_1x_coco/retinanet_ghm_x101_32x4d_fpn_1x_coco_20200131-e4333bd0.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/ghm/retinanet_ghm_x101_32x4d_fpn_1x_coco/retinanet_ghm_x101_32x4d_fpn_1x_coco_20200131_113653.log.json) |
-| X-101-64x4d-FPN | pytorch | 1x | 10.3 | 5.2 | 41.4 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/ghm/retinanet_ghm_x101_64x4d_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/ghm/retinanet_ghm_x101_64x4d_fpn_1x_coco/retinanet_ghm_x101_64x4d_fpn_1x_coco_20200131-dd381cef.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/ghm/retinanet_ghm_x101_64x4d_fpn_1x_coco/retinanet_ghm_x101_64x4d_fpn_1x_coco_20200131_113723.log.json) |
diff --git a/configs/gn+ws/README.md b/configs/gn+ws/README.md
index 5cde531c4de..7f1dec115cd 100644
--- a/configs/gn+ws/README.md
+++ b/configs/gn+ws/README.md
@@ -1,32 +1,17 @@
-# Weight Standardization
+# GN + WS
-## Abstract
+> [Weight Standardization](https://arxiv.org/abs/1903.10520)
+
+
-
+## Abstract
Batch Normalization (BN) has become an out-of-box technique to improve deep network training. However, its effectiveness is limited for micro-batch training, i.e., each GPU typically has only 1-2 images for training, which is inevitable for many computer vision tasks, e.g., object detection and semantic segmentation, constrained by memory consumption. To address this issue, we propose Weight Standardization (WS) and Batch-Channel Normalization (BCN) to bring two success factors of BN into micro-batch training: 1) the smoothing effects on the loss landscape and 2) the ability to avoid harmful elimination singularities along the training trajectory. WS standardizes the weights in convolutional layers to smooth the loss landscape by reducing the Lipschitz constants of the loss and the gradients; BCN combines batch and channel normalizations and leverages estimated statistics of the activations in convolutional layers to keep networks away from elimination singularities. We validate WS and BCN on comprehensive computer vision tasks, including image classification, object detection, instance segmentation, video recognition and semantic segmentation. All experimental results consistently show that WS and BCN improve micro-batch training significantly. Moreover, using WS and BCN with micro-batch training is even able to match or outperform the performances of BN with large-batch training.
-
-
-
-
-## Citation
-
-
-
-```
-@article{weightstandardization,
- author = {Siyuan Qiao and Huiyu Wang and Chenxi Liu and Wei Shen and Alan Yuille},
- title = {Weight Standardization},
- journal = {arXiv preprint arXiv:1903.10520},
- year = {2019},
-}
-```
-
## Results and Models
Faster R-CNN
@@ -56,3 +41,14 @@ Note:
- GN+WS requires about 5% more memory than GN, and it is only 5% slower than GN.
- In the paper, a 20-23-24e lr schedule is used instead of 2x.
- The X-50-GN and X-101-GN pretrained models are also shared by the authors.
+
+## Citation
+
+```latex
+@article{weightstandardization,
+ author = {Siyuan Qiao and Huiyu Wang and Chenxi Liu and Wei Shen and Alan Yuille},
+ title = {Weight Standardization},
+ journal = {arXiv preprint arXiv:1903.10520},
+ year = {2019},
+}
+```
diff --git a/configs/gn/README.md b/configs/gn/README.md
index 4a9d9b5e734..36602fafad3 100644
--- a/configs/gn/README.md
+++ b/configs/gn/README.md
@@ -1,32 +1,17 @@
-# Group Normalization
+# GN
-## Abstract
+> [Group Normalization](https://arxiv.org/abs/1803.08494)
+
+
-
+## Abstract
Batch Normalization (BN) is a milestone technique in the development of deep learning, enabling various networks to train. However, normalizing along the batch dimension introduces problems --- BN's error increases rapidly when the batch size becomes smaller, caused by inaccurate batch statistics estimation. This limits BN's usage for training larger models and transferring features to computer vision tasks including detection, segmentation, and video, which require small batches constrained by memory consumption. In this paper, we present Group Normalization (GN) as a simple alternative to BN. GN divides the channels into groups and computes within each group the mean and variance for normalization. GN's computation is independent of batch sizes, and its accuracy is stable in a wide range of batch sizes. On ResNet-50 trained in ImageNet, GN has 10.6% lower error than its BN counterpart when using a batch size of 2; when using typical batch sizes, GN is comparably good with BN and outperforms other normalization variants. Moreover, GN can be naturally transferred from pre-training to fine-tuning. GN can outperform its BN-based counterparts for object detection and segmentation in COCO, and for video classification in Kinetics, showing that GN can effectively replace the powerful BN in a variety of tasks. GN can be easily implemented by a few lines of code in modern libraries.
-
-
-
-
-## Citation
-
-
-
-```latex
-@inproceedings{wu2018group,
- title={Group Normalization},
- author={Wu, Yuxin and He, Kaiming},
- booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
- year={2018}
-}
-```
-
## Results and Models
| Backbone | model | Lr schd | Mem (GB) | Inf time (fps) | box AP | mask AP | Config | Download |
@@ -43,3 +28,14 @@ Batch Normalization (BN) is a milestone technique in the development of deep lea
- (d) means pretrained model converted from Detectron, and (c) means the contributed model pretrained by [@thangvubk](https://github.com/thangvubk).
- The `3x` schedule is epoch [28, 34, 36].
- **Memory, Train/Inf time is outdated.**
+
+## Citation
+
+```latex
+@inproceedings{wu2018group,
+ title={Group Normalization},
+ author={Wu, Yuxin and He, Kaiming},
+ booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
+ year={2018}
+}
+```
diff --git a/configs/grid_rcnn/README.md b/configs/grid_rcnn/README.md
index b53cc9ea962..9b27c96e189 100644
--- a/configs/grid_rcnn/README.md
+++ b/configs/grid_rcnn/README.md
@@ -1,24 +1,34 @@
# Grid R-CNN
-## Abstract
+> [Grid R-CNN](https://arxiv.org/abs/1811.12030)
-
+
+
+## Abstract
This paper proposes a novel object detection framework named Grid R-CNN, which adopts a grid guided localization mechanism for accurate object detection. Different from the traditional regression based methods, the Grid R-CNN captures the spatial information explicitly and enjoys the position sensitive property of fully convolutional architecture. Instead of using only two independent points, we design a multi-point supervision formulation to encode more clues in order to reduce the impact of inaccurate prediction of specific points. To take the full advantage of the correlation of points in a grid, we propose a two-stage information fusion strategy to fuse feature maps of neighbor grid points. The grid guided localization approach is easy to be extended to different state-of-the-art detection frameworks. Grid R-CNN leads to high quality object localization, and experiments demonstrate that it achieves a 4.1% AP gain at IoU=0.8 and a 10.0% AP gain at IoU=0.9 on COCO benchmark compared to Faster R-CNN with Res50 backbone and FPN architecture.
Grid R-CNN is a well-performed objection detection framework. It transforms the traditional box offset regression problem into a grid point estimation problem. With the guidance of the grid points, it can obtain high-quality localization results. However, the speed of Grid R-CNN is not so satisfactory. In this technical report we present Grid R-CNN Plus, a better and faster version of Grid R-CNN. We have made several updates that significantly speed up the framework and simultaneously improve the accuracy. On COCO dataset, the Res50-FPN based Grid R-CNN Plus detector achieves an mAP of 40.4%, outperforming the baseline on the same model by 3.0 points with similar inference time.
-
-
-
+## Results and Models
-## Citation
+| Backbone | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
+|:-----------:|:-------:|:--------:|:--------------:|:------:|:------:|:--------:|
+| R-50 | 2x | 5.1 | 15.0 | 40.4 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/grid_rcnn/grid_rcnn_r50_fpn_gn-head_2x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/grid_rcnn/grid_rcnn_r50_fpn_gn-head_2x_coco/grid_rcnn_r50_fpn_gn-head_2x_coco_20200130-6cca8223.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/grid_rcnn/grid_rcnn_r50_fpn_gn-head_2x_coco/grid_rcnn_r50_fpn_gn-head_2x_coco_20200130_221140.log.json) |
+| R-101 | 2x | 7.0 | 12.6 | 41.5 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/grid_rcnn/grid_rcnn_r101_fpn_gn-head_2x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/grid_rcnn/grid_rcnn_r101_fpn_gn-head_2x_coco/grid_rcnn_r101_fpn_gn-head_2x_coco_20200309-d6eca030.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/grid_rcnn/grid_rcnn_r101_fpn_gn-head_2x_coco/grid_rcnn_r101_fpn_gn-head_2x_coco_20200309_164224.log.json) |
+| X-101-32x4d | 2x | 8.3 | 10.8 | 42.9 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/grid_rcnn/grid_rcnn_x101_32x4d_fpn_gn-head_2x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/grid_rcnn/grid_rcnn_x101_32x4d_fpn_gn-head_2x_coco/grid_rcnn_x101_32x4d_fpn_gn-head_2x_coco_20200130-d8f0e3ff.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/grid_rcnn/grid_rcnn_x101_32x4d_fpn_gn-head_2x_coco/grid_rcnn_x101_32x4d_fpn_gn-head_2x_coco_20200130_215413.log.json) |
+| X-101-64x4d | 2x | 11.3 | 7.7 | 43.0 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/grid_rcnn/grid_rcnn_x101_64x4d_fpn_gn-head_2x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/grid_rcnn/grid_rcnn_x101_64x4d_fpn_gn-head_2x_coco/grid_rcnn_x101_64x4d_fpn_gn-head_2x_coco_20200204-ec76a754.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/grid_rcnn/grid_rcnn_x101_64x4d_fpn_gn-head_2x_coco/grid_rcnn_x101_64x4d_fpn_gn-head_2x_coco_20200204_080641.log.json) |
-
+**Notes:**
+
+- All models are trained with 8 GPUs instead of 32 GPUs in the original paper.
+- The warming up lasts for 1 epoch and `2x` here indicates 25 epochs.
+
+## Citation
```latex
@inproceedings{lu2019grid,
@@ -35,17 +45,3 @@ Grid R-CNN is a well-performed objection detection framework. It transforms the
year={2019}
}
```
-
-## Results and Models
-
-| Backbone | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
-|:-----------:|:-------:|:--------:|:--------------:|:------:|:------:|:--------:|
-| R-50 | 2x | 5.1 | 15.0 | 40.4 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/grid_rcnn/grid_rcnn_r50_fpn_gn-head_2x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/grid_rcnn/grid_rcnn_r50_fpn_gn-head_2x_coco/grid_rcnn_r50_fpn_gn-head_2x_coco_20200130-6cca8223.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/grid_rcnn/grid_rcnn_r50_fpn_gn-head_2x_coco/grid_rcnn_r50_fpn_gn-head_2x_coco_20200130_221140.log.json) |
-| R-101 | 2x | 7.0 | 12.6 | 41.5 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/grid_rcnn/grid_rcnn_r101_fpn_gn-head_2x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/grid_rcnn/grid_rcnn_r101_fpn_gn-head_2x_coco/grid_rcnn_r101_fpn_gn-head_2x_coco_20200309-d6eca030.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/grid_rcnn/grid_rcnn_r101_fpn_gn-head_2x_coco/grid_rcnn_r101_fpn_gn-head_2x_coco_20200309_164224.log.json) |
-| X-101-32x4d | 2x | 8.3 | 10.8 | 42.9 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/grid_rcnn/grid_rcnn_x101_32x4d_fpn_gn-head_2x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/grid_rcnn/grid_rcnn_x101_32x4d_fpn_gn-head_2x_coco/grid_rcnn_x101_32x4d_fpn_gn-head_2x_coco_20200130-d8f0e3ff.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/grid_rcnn/grid_rcnn_x101_32x4d_fpn_gn-head_2x_coco/grid_rcnn_x101_32x4d_fpn_gn-head_2x_coco_20200130_215413.log.json) |
-| X-101-64x4d | 2x | 11.3 | 7.7 | 43.0 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/grid_rcnn/grid_rcnn_x101_64x4d_fpn_gn-head_2x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/grid_rcnn/grid_rcnn_x101_64x4d_fpn_gn-head_2x_coco/grid_rcnn_x101_64x4d_fpn_gn-head_2x_coco_20200204-ec76a754.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/grid_rcnn/grid_rcnn_x101_64x4d_fpn_gn-head_2x_coco/grid_rcnn_x101_64x4d_fpn_gn-head_2x_coco_20200204_080641.log.json) |
-
-**Notes:**
-
-- All models are trained with 8 GPUs instead of 32 GPUs in the original paper.
-- The warming up lasts for 1 epoch and `2x` here indicates 25 epochs.
diff --git a/configs/groie/README.md b/configs/groie/README.md
index 5a45be734aa..989a2ed827c 100644
--- a/configs/groie/README.md
+++ b/configs/groie/README.md
@@ -1,21 +1,19 @@
-# A novel Region of Interest Extraction Layer for Instance Segmentation
+# GRoIE
-## Abstract
+> [A novel Region of Interest Extraction Layer for Instance Segmentation](https://arxiv.org/abs/2004.13665)
+
+
-
+## Abstract
Given the wide diffusion of deep neural network architectures for computer vision tasks, several new applications are nowadays more and more feasible. Among them, a particular attention has been recently given to instance segmentation, by exploiting the results achievable by two-stage networks (such as Mask R-CNN or Faster R-CNN), derived from R-CNN. In these complex architectures, a crucial role is played by the Region of Interest (RoI) extraction layer, devoted to extracting a coherent subset of features from a single Feature Pyramid Network (FPN) layer attached on top of a backbone.
This paper is motivated by the need to overcome the limitations of existing RoI extractors which select only one (the best) layer from FPN. Our intuition is that all the layers of FPN retain useful information. Therefore, the proposed layer (called Generic RoI Extractor - GRoIE) introduces non-local building blocks and attention mechanisms to boost the performance.
A comprehensive ablation study at component level is conducted to find the best set of algorithms and parameters for the GRoIE layer. Moreover, GRoIE can be integrated seamlessly with every two-stage architecture for both object detection and instance segmentation tasks. Therefore, the improvements brought about by the use of GRoIE in different state-of-the-art architectures are also evaluated. The proposed layer leads up to gain a 1.1% AP improvement on bounding box detection and 1.7% AP improvement on instance segmentation.
-
-
-
-
## Introduction
By Leonardo Rossi, Akbar Karimi and Andrea Prati from
@@ -25,9 +23,6 @@ We provide configs to reproduce the results in the paper for
"*A novel Region of Interest Extraction Layer for Instance Segmentation*"
on COCO object detection.
-
-
-
This paper is motivated by the need to overcome to the limitations of existing
RoI extractors which select only one (the best) layer from FPN.
@@ -37,7 +32,7 @@ Therefore, the proposed layer (called Generic RoI Extractor - **GRoIE**)
introduces non-local building blocks and attention mechanisms to boost the
performance.
-## Results and models
+## Results and Models
The results on COCO 2017 minival (5k images) are shown in the below table.
diff --git a/configs/guided_anchoring/README.md b/configs/guided_anchoring/README.md
index d99ced9eb83..b42de99b2fb 100644
--- a/configs/guided_anchoring/README.md
+++ b/configs/guided_anchoring/README.md
@@ -1,34 +1,17 @@
-# Region Proposal by Guided Anchoring
+# Guided Anchoring
-## Abstract
+> [Region Proposal by Guided Anchoring](https://arxiv.org/abs/1901.03278)
-
+
+
+## Abstract
Region anchors are the cornerstone of modern object detection techniques. State-of-the-art detectors mostly rely on a dense anchoring scheme, where anchors are sampled uniformly over the spatial domain with a predefined set of scales and aspect ratios. In this paper, we revisit this foundational stage. Our study shows that it can be done much more effectively and efficiently. Specifically, we present an alternative scheme, named Guided Anchoring, which leverages semantic features to guide the anchoring. The proposed method jointly predicts the locations where the center of objects of interest are likely to exist as well as the scales and aspect ratios at different locations. On top of predicted anchor shapes, we mitigate the feature inconsistency with a feature adaption module. We also study the use of high-quality proposals to improve detection performance. The anchoring scheme can be seamlessly integrated into proposal methods and detectors. With Guided Anchoring, we achieve 9.1% higher recall on MS COCO with 90% fewer anchors than the RPN baseline. We also adopt Guided Anchoring in Fast R-CNN, Faster R-CNN and RetinaNet, respectively improving the detection mAP by 2.2%, 2.7% and 1.2%.
-
-
-
-
-## Citation
-
-
-
-We provide config files to reproduce the results in the CVPR 2019 paper for [Region Proposal by Guided Anchoring](https://arxiv.org/abs/1901.03278).
-
-```latex
-@inproceedings{wang2019region,
- title={Region Proposal by Guided Anchoring},
- author={Jiaqi Wang and Kai Chen and Shuo Yang and Chen Change Loy and Dahua Lin},
- booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
- year={2019}
-}
-```
-
## Results and Models
The results on COCO 2017 val is shown in the below table. (results on test-dev are usually slightly higher than val).
@@ -61,3 +44,16 @@ The results on COCO 2017 val is shown in the below table. (results on test-dev a
| GA-Faster RCNN | R-101-FPN | caffe | 1x | F | 0.001 | | | | | | | |
| GA-RetinaNet | R-101-FPN | caffe | 1x | F | 0.05 | | | | | | | |
| GA-RetinaNet | R-101-FPN | caffe | 2x | T | 0.05 | | | | | | | |
+
+## Citation
+
+We provide config files to reproduce the results in the CVPR 2019 paper for [Region Proposal by Guided Anchoring](https://arxiv.org/abs/1901.03278).
+
+```latex
+@inproceedings{wang2019region,
+ title={Region Proposal by Guided Anchoring},
+ author={Jiaqi Wang and Kai Chen and Shuo Yang and Chen Change Loy and Dahua Lin},
+ booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
+ year={2019}
+}
+```
diff --git a/configs/hrnet/README.md b/configs/hrnet/README.md
index faeb673fa3f..f1a9d964df3 100644
--- a/configs/hrnet/README.md
+++ b/configs/hrnet/README.md
@@ -1,44 +1,20 @@
-# High-resolution networks (HRNets) for object detection
+# HRNet
-## Abstract
+> [Deep High-Resolution Representation Learning for Human Pose Estimation](https://arxiv.org/abs/1902.09212)
+
+
-
+## Abstract
This is an official pytorch implementation of Deep High-Resolution Representation Learning for Human Pose Estimation. In this work, we are interested in the human pose estimation problem with a focus on learning reliable high-resolution representations. Most existing methods recover high-resolution representations from low-resolution representations produced by a high-to-low resolution network. Instead, our proposed network maintains high-resolution representations through the whole process. We start from a high-resolution subnetwork as the first stage, gradually add high-to-low resolution subnetworks one by one to form more stages, and connect the mutli-resolution subnetworks in parallel. We conduct repeated multi-scale fusions such that each of the high-to-low resolution representations receives information from other parallel representations over and over, leading to rich high-resolution representations. As a result, the predicted keypoint heatmap is potentially more accurate and spatially more precise. We empirically demonstrate the effectiveness of our network through the superior pose estimation results over two benchmark datasets: the COCO keypoint detection dataset and the MPII Human Pose dataset.
High-resolution representation learning plays an essential role in many vision problems, e.g., pose estimation and semantic segmentation. The high-resolution network (HRNet), recently developed for human pose estimation, maintains high-resolution representations through the whole process by connecting high-to-low resolution convolutions in parallel and produces strong high-resolution representations by repeatedly conducting fusions across parallel convolutions.
In this paper, we conduct a further study on high-resolution representations by introducing a simple yet effective modification and apply it to a wide range of vision tasks. We augment the high-resolution representation by aggregating the (upsampled) representations from all the parallel convolutions rather than only the representation from the high-resolution convolution as done in HRNet. This simple modification leads to stronger representations, evidenced by superior results. We show top results in semantic segmentation on Cityscapes, LIP, and PASCAL Context, and facial landmark detection on AFLW, COFW, 300W, and WFLW. In addition, we build a multi-level representation from the high-resolution representation and apply it to the Faster R-CNN object detection framework and the extended frameworks. The proposed approach achieves superior results to existing single-model networks on COCO object detection.
-
-
-
-
-## Citation
-
-
-
-```latex
-@inproceedings{SunXLW19,
- title={Deep High-Resolution Representation Learning for Human Pose Estimation},
- author={Ke Sun and Bin Xiao and Dong Liu and Jingdong Wang},
- booktitle={CVPR},
- year={2019}
-}
-
-@article{SunZJCXLMWLW19,
- title={High-Resolution Representations for Labeling Pixels and Regions},
- author={Ke Sun and Yang Zhao and Borui Jiang and Tianheng Cheng and Bin Xiao
- and Dong Liu and Yadong Mu and Xinggang Wang and Wenyu Liu and Jingdong Wang},
- journal = {CoRR},
- volume = {abs/1904.04514},
- year={2019}
-}
-```
-
## Results and Models
### Faster R-CNN
@@ -103,3 +79,23 @@ In this paper, we conduct a further study on high-resolution representations by
- The `28e` schedule in HTC indicates decreasing the lr at 24 and 27 epochs, with a total of 28 epochs.
- HRNetV2 ImageNet pretrained models are in [HRNets for Image Classification](https://github.com/HRNet/HRNet-Image-Classification).
+
+## Citation
+
+```latex
+@inproceedings{SunXLW19,
+ title={Deep High-Resolution Representation Learning for Human Pose Estimation},
+ author={Ke Sun and Bin Xiao and Dong Liu and Jingdong Wang},
+ booktitle={CVPR},
+ year={2019}
+}
+
+@article{SunZJCXLMWLW19,
+ title={High-Resolution Representations for Labeling Pixels and Regions},
+ author={Ke Sun and Yang Zhao and Borui Jiang and Tianheng Cheng and Bin Xiao
+ and Dong Liu and Yadong Mu and Xinggang Wang and Wenyu Liu and Jingdong Wang},
+ journal = {CoRR},
+ volume = {abs/1904.04514},
+ year={2019}
+}
+```
diff --git a/configs/hrnet/metafile.yml b/configs/hrnet/metafile.yml
index 37703aaa594..ac36efa9f03 100644
--- a/configs/hrnet/metafile.yml
+++ b/configs/hrnet/metafile.yml
@@ -1,24 +1,6 @@
-Collections:
- - Name: HRNet
- Metadata:
- Training Data: COCO
- Training Techniques:
- - SGD with Momentum
- - Weight Decay
- Training Resources: 8x V100 GPUs
- Architecture:
- - HRNet
- Paper:
- URL: https://arxiv.org/abs/1904.04514
- Title: 'Deep High-Resolution Representation Learning for Visual Recognition'
- README: configs/hrnet/README.md
- Code:
- URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/models/backbones/hrnet.py#L195
- Version: v2.0.0
-
Models:
- Name: faster_rcnn_hrnetv2p_w18_1x_coco
- In Collection: HRNet
+ In Collection: Faster R-CNN
Config: configs/hrnet/faster_rcnn_hrnetv2p_w18_1x_coco.py
Metadata:
Training Memory (GB): 6.6
@@ -30,15 +12,29 @@ Models:
mode: FP32
resolution: (800, 1333)
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - HRNet
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 36.9
Weights: https://download.openmmlab.com/mmdetection/v2.0/hrnet/faster_rcnn_hrnetv2p_w18_1x_coco/faster_rcnn_hrnetv2p_w18_1x_coco_20200130-56651a6d.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.04514
+ Title: 'Deep High-Resolution Representation Learning for Visual Recognition'
+ README: configs/hrnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/models/backbones/hrnet.py#L195
+ Version: v2.0.0
- Name: faster_rcnn_hrnetv2p_w18_2x_coco
- In Collection: HRNet
+ In Collection: Faster R-CNN
Config: configs/hrnet/faster_rcnn_hrnetv2p_w18_2x_coco.py
Metadata:
Training Memory (GB): 6.6
@@ -50,15 +46,29 @@ Models:
mode: FP32
resolution: (800, 1333)
Epochs: 24
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - HRNet
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 38.9
Weights: https://download.openmmlab.com/mmdetection/v2.0/hrnet/faster_rcnn_hrnetv2p_w18_2x_coco/faster_rcnn_hrnetv2p_w18_2x_coco_20200702_085731-a4ec0611.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.04514
+ Title: 'Deep High-Resolution Representation Learning for Visual Recognition'
+ README: configs/hrnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/models/backbones/hrnet.py#L195
+ Version: v2.0.0
- Name: faster_rcnn_hrnetv2p_w32_1x_coco
- In Collection: HRNet
+ In Collection: Faster R-CNN
Config: configs/hrnet/faster_rcnn_hrnetv2p_w32_1x_coco.py
Metadata:
Training Memory (GB): 9.0
@@ -70,15 +80,29 @@ Models:
mode: FP32
resolution: (800, 1333)
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - HRNet
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 40.2
Weights: https://download.openmmlab.com/mmdetection/v2.0/hrnet/faster_rcnn_hrnetv2p_w32_1x_coco/faster_rcnn_hrnetv2p_w32_1x_coco_20200130-6e286425.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.04514
+ Title: 'Deep High-Resolution Representation Learning for Visual Recognition'
+ README: configs/hrnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/models/backbones/hrnet.py#L195
+ Version: v2.0.0
- Name: faster_rcnn_hrnetv2p_w32_2x_coco
- In Collection: HRNet
+ In Collection: Faster R-CNN
Config: configs/hrnet/faster_rcnn_hrnetv2p_w32_2x_coco.py
Metadata:
Training Memory (GB): 9.0
@@ -90,15 +114,29 @@ Models:
mode: FP32
resolution: (800, 1333)
Epochs: 24
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - HRNet
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 41.4
Weights: https://download.openmmlab.com/mmdetection/v2.0/hrnet/faster_rcnn_hrnetv2p_w32_2x_coco/faster_rcnn_hrnetv2p_w32_2x_coco_20200529_015927-976a9c15.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.04514
+ Title: 'Deep High-Resolution Representation Learning for Visual Recognition'
+ README: configs/hrnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/models/backbones/hrnet.py#L195
+ Version: v2.0.0
- Name: faster_rcnn_hrnetv2p_w40_1x_coco
- In Collection: HRNet
+ In Collection: Faster R-CNN
Config: configs/hrnet/faster_rcnn_hrnetv2p_w40_1x_coco.py
Metadata:
Training Memory (GB): 10.4
@@ -110,15 +148,29 @@ Models:
mode: FP32
resolution: (800, 1333)
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - HRNet
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 41.2
Weights: https://download.openmmlab.com/mmdetection/v2.0/hrnet/faster_rcnn_hrnetv2p_w40_1x_coco/faster_rcnn_hrnetv2p_w40_1x_coco_20200210-95c1f5ce.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.04514
+ Title: 'Deep High-Resolution Representation Learning for Visual Recognition'
+ README: configs/hrnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/models/backbones/hrnet.py#L195
+ Version: v2.0.0
- Name: faster_rcnn_hrnetv2p_w40_2x_coco
- In Collection: HRNet
+ In Collection: Faster R-CNN
Config: configs/hrnet/faster_rcnn_hrnetv2p_w40_2x_coco.py
Metadata:
Training Memory (GB): 10.4
@@ -130,15 +182,29 @@ Models:
mode: FP32
resolution: (800, 1333)
Epochs: 24
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - HRNet
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 42.1
Weights: https://download.openmmlab.com/mmdetection/v2.0/hrnet/faster_rcnn_hrnetv2p_w40_2x_coco/faster_rcnn_hrnetv2p_w40_2x_coco_20200512_161033-0f236ef4.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.04514
+ Title: 'Deep High-Resolution Representation Learning for Visual Recognition'
+ README: configs/hrnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/models/backbones/hrnet.py#L195
+ Version: v2.0.0
- Name: mask_rcnn_hrnetv2p_w18_1x_coco
- In Collection: HRNet
+ In Collection: Mask R-CNN
Config: configs/hrnet/mask_rcnn_hrnetv2p_w18_1x_coco.py
Metadata:
Training Memory (GB): 7.0
@@ -150,6 +216,13 @@ Models:
mode: FP32
resolution: (800, 1333)
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - HRNet
Results:
- Task: Object Detection
Dataset: COCO
@@ -160,9 +233,16 @@ Models:
Metrics:
mask AP: 34.2
Weights: https://download.openmmlab.com/mmdetection/v2.0/hrnet/mask_rcnn_hrnetv2p_w18_1x_coco/mask_rcnn_hrnetv2p_w18_1x_coco_20200205-1c3d78ed.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.04514
+ Title: 'Deep High-Resolution Representation Learning for Visual Recognition'
+ README: configs/hrnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/models/backbones/hrnet.py#L195
+ Version: v2.0.0
- Name: mask_rcnn_hrnetv2p_w18_2x_coco
- In Collection: HRNet
+ In Collection: Mask R-CNN
Config: configs/hrnet/mask_rcnn_hrnetv2p_w18_2x_coco.py
Metadata:
Training Memory (GB): 7.0
@@ -174,6 +254,13 @@ Models:
mode: FP32
resolution: (800, 1333)
Epochs: 24
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - HRNet
Results:
- Task: Object Detection
Dataset: COCO
@@ -184,9 +271,16 @@ Models:
Metrics:
mask AP: 36.0
Weights: https://download.openmmlab.com/mmdetection/v2.0/hrnet/mask_rcnn_hrnetv2p_w18_2x_coco/mask_rcnn_hrnetv2p_w18_2x_coco_20200212-b3c825b1.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.04514
+ Title: 'Deep High-Resolution Representation Learning for Visual Recognition'
+ README: configs/hrnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/models/backbones/hrnet.py#L195
+ Version: v2.0.0
- Name: mask_rcnn_hrnetv2p_w32_1x_coco
- In Collection: HRNet
+ In Collection: Mask R-CNN
Config: configs/hrnet/mask_rcnn_hrnetv2p_w32_1x_coco.py
Metadata:
Training Memory (GB): 9.4
@@ -198,6 +292,13 @@ Models:
mode: FP32
resolution: (800, 1333)
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - HRNet
Results:
- Task: Object Detection
Dataset: COCO
@@ -208,9 +309,16 @@ Models:
Metrics:
mask AP: 37.1
Weights: https://download.openmmlab.com/mmdetection/v2.0/hrnet/mask_rcnn_hrnetv2p_w32_1x_coco/mask_rcnn_hrnetv2p_w32_1x_coco_20200207-b29f616e.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.04514
+ Title: 'Deep High-Resolution Representation Learning for Visual Recognition'
+ README: configs/hrnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/models/backbones/hrnet.py#L195
+ Version: v2.0.0
- Name: mask_rcnn_hrnetv2p_w32_2x_coco
- In Collection: HRNet
+ In Collection: Mask R-CNN
Config: configs/hrnet/mask_rcnn_hrnetv2p_w32_2x_coco.py
Metadata:
Training Memory (GB): 9.4
@@ -222,6 +330,13 @@ Models:
mode: FP32
resolution: (800, 1333)
Epochs: 24
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - HRNet
Results:
- Task: Object Detection
Dataset: COCO
@@ -232,13 +347,27 @@ Models:
Metrics:
mask AP: 37.8
Weights: https://download.openmmlab.com/mmdetection/v2.0/hrnet/mask_rcnn_hrnetv2p_w32_2x_coco/mask_rcnn_hrnetv2p_w32_2x_coco_20200213-45b75b4d.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.04514
+ Title: 'Deep High-Resolution Representation Learning for Visual Recognition'
+ README: configs/hrnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/models/backbones/hrnet.py#L195
+ Version: v2.0.0
- Name: mask_rcnn_hrnetv2p_w40_1x_coco
- In Collection: HRNet
+ In Collection: Mask R-CNN
Config: configs/hrnet/mask_rcnn_hrnetv2p_w40_1x_coco.py
Metadata:
Training Memory (GB): 10.9
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - HRNet
Results:
- Task: Object Detection
Dataset: COCO
@@ -249,13 +378,27 @@ Models:
Metrics:
mask AP: 37.5
Weights: https://download.openmmlab.com/mmdetection/v2.0/hrnet/mask_rcnn_hrnetv2p_w40_1x_coco/mask_rcnn_hrnetv2p_w40_1x_coco_20200511_015646-66738b35.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.04514
+ Title: 'Deep High-Resolution Representation Learning for Visual Recognition'
+ README: configs/hrnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/models/backbones/hrnet.py#L195
+ Version: v2.0.0
- Name: mask_rcnn_hrnetv2p_w40_2x_coco
- In Collection: HRNet
+ In Collection: Mask R-CNN
Config: configs/hrnet/mask_rcnn_hrnetv2p_w40_2x_coco.py
Metadata:
Training Memory (GB): 10.9
Epochs: 24
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - HRNet
Results:
- Task: Object Detection
Dataset: COCO
@@ -266,9 +409,16 @@ Models:
Metrics:
mask AP: 38.2
Weights: https://download.openmmlab.com/mmdetection/v2.0/hrnet/mask_rcnn_hrnetv2p_w40_2x_coco/mask_rcnn_hrnetv2p_w40_2x_coco_20200512_163732-aed5e4ab.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.04514
+ Title: 'Deep High-Resolution Representation Learning for Visual Recognition'
+ README: configs/hrnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/models/backbones/hrnet.py#L195
+ Version: v2.0.0
- Name: cascade_rcnn_hrnetv2p_w18_20e_coco
- In Collection: HRNet
+ In Collection: Cascade R-CNN
Config: configs/hrnet/cascade_rcnn_hrnetv2p_w18_20e_coco.py
Metadata:
Training Memory (GB): 7.0
@@ -280,15 +430,29 @@ Models:
mode: FP32
resolution: (800, 1333)
Epochs: 20
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - HRNet
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 41.2
Weights: https://download.openmmlab.com/mmdetection/v2.0/hrnet/cascade_rcnn_hrnetv2p_w18_20e_coco/cascade_rcnn_hrnetv2p_w18_20e_coco_20200210-434be9d7.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.04514
+ Title: 'Deep High-Resolution Representation Learning for Visual Recognition'
+ README: configs/hrnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/models/backbones/hrnet.py#L195
+ Version: v2.0.0
- Name: cascade_rcnn_hrnetv2p_w32_20e_coco
- In Collection: HRNet
+ In Collection: Cascade R-CNN
Config: configs/hrnet/cascade_rcnn_hrnetv2p_w32_20e_coco.py
Metadata:
Training Memory (GB): 9.4
@@ -300,28 +464,56 @@ Models:
mode: FP32
resolution: (800, 1333)
Epochs: 20
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - HRNet
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 43.3
Weights: https://download.openmmlab.com/mmdetection/v2.0/hrnet/cascade_rcnn_hrnetv2p_w32_20e_coco/cascade_rcnn_hrnetv2p_w32_20e_coco_20200208-928455a4.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.04514
+ Title: 'Deep High-Resolution Representation Learning for Visual Recognition'
+ README: configs/hrnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/models/backbones/hrnet.py#L195
+ Version: v2.0.0
- Name: cascade_rcnn_hrnetv2p_w40_20e_coco
- In Collection: HRNet
+ In Collection: Cascade R-CNN
Config: configs/hrnet/cascade_rcnn_hrnetv2p_w40_20e_coco.py
Metadata:
Training Memory (GB): 10.8
Epochs: 20
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - HRNet
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 43.8
Weights: https://download.openmmlab.com/mmdetection/v2.0/hrnet/cascade_rcnn_hrnetv2p_w40_20e_coco/cascade_rcnn_hrnetv2p_w40_20e_coco_20200512_161112-75e47b04.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.04514
+ Title: 'Deep High-Resolution Representation Learning for Visual Recognition'
+ README: configs/hrnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/models/backbones/hrnet.py#L195
+ Version: v2.0.0
- Name: cascade_mask_rcnn_hrnetv2p_w18_20e_coco
- In Collection: HRNet
+ In Collection: Cascade R-CNN
Config: configs/hrnet/cascade_mask_rcnn_hrnetv2p_w18_20e_coco.py
Metadata:
Training Memory (GB): 8.5
@@ -333,6 +525,13 @@ Models:
mode: FP32
resolution: (800, 1333)
Epochs: 20
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - HRNet
Results:
- Task: Object Detection
Dataset: COCO
@@ -343,9 +542,16 @@ Models:
Metrics:
mask AP: 36.4
Weights: https://download.openmmlab.com/mmdetection/v2.0/hrnet/cascade_mask_rcnn_hrnetv2p_w18_20e_coco/cascade_mask_rcnn_hrnetv2p_w18_20e_coco_20200210-b543cd2b.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.04514
+ Title: 'Deep High-Resolution Representation Learning for Visual Recognition'
+ README: configs/hrnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/models/backbones/hrnet.py#L195
+ Version: v2.0.0
- Name: cascade_mask_rcnn_hrnetv2p_w32_20e_coco
- In Collection: HRNet
+ In Collection: Cascade R-CNN
Config: configs/hrnet/cascade_mask_rcnn_hrnetv2p_w32_20e_coco.py
Metadata:
inference time (ms/im):
@@ -356,6 +562,13 @@ Models:
mode: FP32
resolution: (800, 1333)
Epochs: 20
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - HRNet
Results:
- Task: Object Detection
Dataset: COCO
@@ -366,13 +579,27 @@ Models:
Metrics:
mask AP: 38.6
Weights: https://download.openmmlab.com/mmdetection/v2.0/hrnet/cascade_mask_rcnn_hrnetv2p_w32_20e_coco/cascade_mask_rcnn_hrnetv2p_w32_20e_coco_20200512_154043-39d9cf7b.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.04514
+ Title: 'Deep High-Resolution Representation Learning for Visual Recognition'
+ README: configs/hrnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/models/backbones/hrnet.py#L195
+ Version: v2.0.0
- Name: cascade_mask_rcnn_hrnetv2p_w40_20e_coco
- In Collection: HRNet
+ In Collection: Cascade R-CNN
Config: configs/hrnet/cascade_mask_rcnn_hrnetv2p_w40_20e_coco.py
Metadata:
Training Memory (GB): 12.5
Epochs: 20
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - HRNet
Results:
- Task: Object Detection
Dataset: COCO
@@ -383,9 +610,16 @@ Models:
Metrics:
mask AP: 39.3
Weights: https://download.openmmlab.com/mmdetection/v2.0/hrnet/cascade_mask_rcnn_hrnetv2p_w40_20e_coco/cascade_mask_rcnn_hrnetv2p_w40_20e_coco_20200527_204922-969c4610.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.04514
+ Title: 'Deep High-Resolution Representation Learning for Visual Recognition'
+ README: configs/hrnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/models/backbones/hrnet.py#L195
+ Version: v2.0.0
- Name: htc_hrnetv2p_w18_20e_coco
- In Collection: HRNet
+ In Collection: HTC
Config: configs/hrnet/htc_hrnetv2p_w18_20e_coco.py
Metadata:
Training Memory (GB): 10.8
@@ -397,6 +631,13 @@ Models:
mode: FP32
resolution: (800, 1333)
Epochs: 20
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - HRNet
Results:
- Task: Object Detection
Dataset: COCO
@@ -407,9 +648,16 @@ Models:
Metrics:
mask AP: 37.9
Weights: https://download.openmmlab.com/mmdetection/v2.0/hrnet/htc_hrnetv2p_w18_20e_coco/htc_hrnetv2p_w18_20e_coco_20200210-b266988c.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.04514
+ Title: 'Deep High-Resolution Representation Learning for Visual Recognition'
+ README: configs/hrnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/models/backbones/hrnet.py#L195
+ Version: v2.0.0
- Name: htc_hrnetv2p_w32_20e_coco
- In Collection: HRNet
+ In Collection: HTC
Config: configs/hrnet/htc_hrnetv2p_w32_20e_coco.py
Metadata:
Training Memory (GB): 13.1
@@ -421,6 +669,13 @@ Models:
mode: FP32
resolution: (800, 1333)
Epochs: 20
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - HRNet
Results:
- Task: Object Detection
Dataset: COCO
@@ -431,13 +686,27 @@ Models:
Metrics:
mask AP: 39.9
Weights: https://download.openmmlab.com/mmdetection/v2.0/hrnet/htc_hrnetv2p_w32_20e_coco/htc_hrnetv2p_w32_20e_coco_20200207-7639fa12.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.04514
+ Title: 'Deep High-Resolution Representation Learning for Visual Recognition'
+ README: configs/hrnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/models/backbones/hrnet.py#L195
+ Version: v2.0.0
- Name: htc_hrnetv2p_w40_20e_coco
- In Collection: HRNet
+ In Collection: HTC
Config: configs/hrnet/htc_hrnetv2p_w40_20e_coco.py
Metadata:
Training Memory (GB): 14.6
Epochs: 20
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - HRNet
Results:
- Task: Object Detection
Dataset: COCO
@@ -448,9 +717,16 @@ Models:
Metrics:
mask AP: 40.8
Weights: https://download.openmmlab.com/mmdetection/v2.0/hrnet/htc_hrnetv2p_w40_20e_coco/htc_hrnetv2p_w40_20e_coco_20200529_183411-417c4d5b.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.04514
+ Title: 'Deep High-Resolution Representation Learning for Visual Recognition'
+ README: configs/hrnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/models/backbones/hrnet.py#L195
+ Version: v2.0.0
- Name: fcos_hrnetv2p_w18_gn-head_4x4_1x_coco
- In Collection: HRNet
+ In Collection: FCOS
Config: configs/hrnet/fcos_hrnetv2p_w18_gn-head_4x4_1x_coco.py
Metadata:
Training Resources: 4x V100 GPUs
@@ -464,15 +740,28 @@ Models:
mode: FP32
resolution: (800, 1333)
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Architecture:
+ - HRNet
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 35.3
Weights: https://download.openmmlab.com/mmdetection/v2.0/hrnet/fcos_hrnetv2p_w18_gn-head_4x4_1x_coco/fcos_hrnetv2p_w18_gn-head_4x4_1x_coco_20201212_100710-4ad151de.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.04514
+ Title: 'Deep High-Resolution Representation Learning for Visual Recognition'
+ README: configs/hrnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/models/backbones/hrnet.py#L195
+ Version: v2.0.0
- Name: fcos_hrnetv2p_w18_gn-head_4x4_2x_coco
- In Collection: HRNet
+ In Collection: FCOS
Config: configs/hrnet/fcos_hrnetv2p_w18_gn-head_4x4_2x_coco.py
Metadata:
Training Resources: 4x V100 GPUs
@@ -486,15 +775,28 @@ Models:
mode: FP32
resolution: (800, 1333)
Epochs: 24
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Architecture:
+ - HRNet
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 38.2
Weights: https://download.openmmlab.com/mmdetection/v2.0/hrnet/fcos_hrnetv2p_w18_gn-head_4x4_2x_coco/fcos_hrnetv2p_w18_gn-head_4x4_2x_coco_20201212_101110-5c575fa5.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.04514
+ Title: 'Deep High-Resolution Representation Learning for Visual Recognition'
+ README: configs/hrnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/models/backbones/hrnet.py#L195
+ Version: v2.0.0
- Name: fcos_hrnetv2p_w32_gn-head_4x4_1x_coco
- In Collection: HRNet
+ In Collection: FCOS
Config: configs/hrnet/fcos_hrnetv2p_w32_gn-head_4x4_1x_coco.py
Metadata:
Training Resources: 4x V100 GPUs
@@ -508,15 +810,28 @@ Models:
mode: FP32
resolution: (800, 1333)
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Architecture:
+ - HRNet
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 39.5
Weights: https://download.openmmlab.com/mmdetection/v2.0/hrnet/fcos_hrnetv2p_w32_gn-head_4x4_1x_coco/fcos_hrnetv2p_w32_gn-head_4x4_1x_coco_20201211_134730-cb8055c0.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.04514
+ Title: 'Deep High-Resolution Representation Learning for Visual Recognition'
+ README: configs/hrnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/models/backbones/hrnet.py#L195
+ Version: v2.0.0
- Name: fcos_hrnetv2p_w32_gn-head_4x4_2x_coco
- In Collection: HRNet
+ In Collection: FCOS
Config: configs/hrnet/fcos_hrnetv2p_w32_gn-head_4x4_2x_coco.py
Metadata:
Training Resources: 4x V100 GPUs
@@ -530,15 +845,28 @@ Models:
mode: FP32
resolution: (800, 1333)
Epochs: 24
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Architecture:
+ - HRNet
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 40.8
Weights: https://download.openmmlab.com/mmdetection/v2.0/hrnet/fcos_hrnetv2p_w32_gn-head_4x4_2x_coco/fcos_hrnetv2p_w32_gn-head_4x4_2x_coco_20201212_112133-77b6b9bb.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.04514
+ Title: 'Deep High-Resolution Representation Learning for Visual Recognition'
+ README: configs/hrnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/models/backbones/hrnet.py#L195
+ Version: v2.0.0
- Name: fcos_hrnetv2p_w18_gn-head_mstrain_640-800_4x4_2x_coco
- In Collection: HRNet
+ In Collection: FCOS
Config: configs/hrnet/fcos_hrnetv2p_w18_gn-head_mstrain_640-800_4x4_2x_coco.py
Metadata:
Training Resources: 4x V100 GPUs
@@ -552,15 +880,28 @@ Models:
mode: FP32
resolution: (800, 1333)
Epochs: 24
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Architecture:
+ - HRNet
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 38.3
Weights: https://download.openmmlab.com/mmdetection/v2.0/hrnet/fcos_hrnetv2p_w18_gn-head_mstrain_640-800_4x4_2x_coco/fcos_hrnetv2p_w18_gn-head_mstrain_640-800_4x4_2x_coco_20201212_111651-441e9d9f.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.04514
+ Title: 'Deep High-Resolution Representation Learning for Visual Recognition'
+ README: configs/hrnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/models/backbones/hrnet.py#L195
+ Version: v2.0.0
- Name: fcos_hrnetv2p_w32_gn-head_mstrain_640-800_4x4_2x_coco
- In Collection: HRNet
+ In Collection: FCOS
Config: configs/hrnet/fcos_hrnetv2p_w32_gn-head_mstrain_640-800_4x4_2x_coco.py
Metadata:
Training Resources: 4x V100 GPUs
@@ -574,15 +915,28 @@ Models:
mode: FP32
resolution: (800, 1333)
Epochs: 24
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Architecture:
+ - HRNet
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 41.9
Weights: https://download.openmmlab.com/mmdetection/v2.0/hrnet/fcos_hrnetv2p_w32_gn-head_mstrain_640-800_4x4_2x_coco/fcos_hrnetv2p_w32_gn-head_mstrain_640-800_4x4_2x_coco_20201212_090846-b6f2b49f.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.04514
+ Title: 'Deep High-Resolution Representation Learning for Visual Recognition'
+ README: configs/hrnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/models/backbones/hrnet.py#L195
+ Version: v2.0.0
- Name: fcos_hrnetv2p_w40_gn-head_mstrain_640-800_4x4_2x_coco
- In Collection: HRNet
+ In Collection: FCOS
Config: configs/hrnet/fcos_hrnetv2p_w40_gn-head_mstrain_640-800_4x4_2x_coco.py
Metadata:
Training Resources: 4x V100 GPUs
@@ -596,9 +950,22 @@ Models:
mode: FP32
resolution: (800, 1333)
Epochs: 24
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Architecture:
+ - HRNet
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 42.7
Weights: https://download.openmmlab.com/mmdetection/v2.0/hrnet/fcos_hrnetv2p_w40_gn-head_mstrain_640-800_4x4_2x_coco/fcos_hrnetv2p_w40_gn-head_mstrain_640-800_4x4_2x_coco_20201212_124752-f22d2ce5.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.04514
+ Title: 'Deep High-Resolution Representation Learning for Visual Recognition'
+ README: configs/hrnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.0.0/mmdet/models/backbones/hrnet.py#L195
+ Version: v2.0.0
diff --git a/configs/htc/README.md b/configs/htc/README.md
index d722a80ca0a..c57a5d1844b 100644
--- a/configs/htc/README.md
+++ b/configs/htc/README.md
@@ -1,35 +1,18 @@
-# Hybrid Task Cascade for Instance Segmentation
+# HTC
-## Abstract
+> [Hybrid Task Cascade for Instance Segmentation](ttps://arxiv.org/abs/1901.07518)
-
+
+
+## Abstract
Cascade is a classic yet powerful architecture that has boosted performance on various tasks. However, how to introduce cascade to instance segmentation remains an open question. A simple combination of Cascade R-CNN and Mask R-CNN only brings limited gain. In exploring a more effective approach, we find that the key to a successful instance segmentation cascade is to fully leverage the reciprocal relationship between detection and segmentation. In this work, we propose a new framework, Hybrid Task Cascade (HTC), which differs in two important aspects: (1) instead of performing cascaded refinement on these two tasks separately, it interweaves them for a joint multi-stage processing; (2) it adopts a fully convolutional branch to provide spatial context, which can help distinguishing hard foreground from cluttered background. Overall, this framework can learn more discriminative features progressively while integrating complementary features together in each stage. Without bells and whistles, a single HTC obtains 38.4 and 1.5 improvement over a strong Cascade Mask R-CNN baseline on MSCOCO dataset. Moreover, our overall system achieves 48.6 mask AP on the test-challenge split, ranking 1st in the COCO 2018 Challenge Object Detection Task.
-
-
-
-
-## Citation
-
-
-
-We provide config files to reproduce the results in the CVPR 2019 paper for [Hybrid Task Cascade](https://arxiv.org/abs/1901.07518).
-
-```latex
-@inproceedings{chen2019hybrid,
- title={Hybrid task cascade for instance segmentation},
- author={Chen, Kai and Pang, Jiangmiao and Wang, Jiaqi and Xiong, Yu and Li, Xiaoxiao and Sun, Shuyang and Feng, Wansen and Liu, Ziwei and Shi, Jianping and Ouyang, Wanli and Chen Change Loy and Dahua Lin},
- booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
- year={2019}
-}
-```
-
-## Dataset
+## Introduction
HTC requires COCO and [COCO-stuff](http://calvin.inf.ed.ac.uk/wp-content/uploads/data/cocostuffdataset/stuffthingmaps_trainval2017.zip) dataset for training. You need to download and extract it in the COCO dataset path.
The directory should be like this.
@@ -69,3 +52,16 @@ We also provide a powerful HTC with DCN and multi-scale training model. No testi
| Backbone | Style | DCN | training scales | Lr schd | box AP | mask AP | Config | Download |
|:----------------:|:-------:|:-----:|:---------------:|:-------:|:------:|:-------:|:------:|:--------:|
| X-101-64x4d-FPN | pytorch | c3-c5 | 400~1400 | 20e | 50.4 | 43.8 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/htc/htc_x101_64x4d_fpn_dconv_c3-c5_mstrain_400_1400_16x1_20e_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/htc/htc_x101_64x4d_fpn_dconv_c3-c5_mstrain_400_1400_16x1_20e_coco/htc_x101_64x4d_fpn_dconv_c3-c5_mstrain_400_1400_16x1_20e_coco_20200312-946fd751.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/htc/htc_x101_64x4d_fpn_dconv_c3-c5_mstrain_400_1400_16x1_20e_coco/htc_x101_64x4d_fpn_dconv_c3-c5_mstrain_400_1400_16x1_20e_coco_20200312_203410.log.json) |
+
+## Citation
+
+We provide config files to reproduce the results in the CVPR 2019 paper for [Hybrid Task Cascade](https://arxiv.org/abs/1901.07518).
+
+```latex
+@inproceedings{chen2019hybrid,
+ title={Hybrid task cascade for instance segmentation},
+ author={Chen, Kai and Pang, Jiangmiao and Wang, Jiaqi and Xiong, Yu and Li, Xiaoxiao and Sun, Shuyang and Feng, Wansen and Liu, Ziwei and Shi, Jianping and Ouyang, Wanli and Chen Change Loy and Dahua Lin},
+ booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
+ year={2019}
+}
+```
diff --git a/configs/instaboost/README.md b/configs/instaboost/README.md
index e948ccbff03..083a9e7bb31 100644
--- a/configs/instaboost/README.md
+++ b/configs/instaboost/README.md
@@ -1,38 +1,21 @@
-# Instaboost: Boosting instance segmentation via probability map guided copy-pasting
+# Instaboost
-## Abstract
+> [Instaboost: Boosting instance segmentation via probability map guided copy-pasting](https://arxiv.org/abs/1908.07801)
+
+
-
+## Abstract
Instance segmentation requires a large number of training samples to achieve satisfactory performance and benefits from proper data augmentation. To enlarge the training set and increase the diversity, previous methods have investigated using data annotation from other domain (e.g. bbox, point) in a weakly supervised mechanism. In this paper, we present a simple, efficient and effective method to augment the training set using the existing instance mask annotations. Exploiting the pixel redundancy of the background, we are able to improve the performance of Mask R-CNN for 1.7 mAP on COCO dataset and 3.3 mAP on Pascal VOC dataset by simply introducing random jittering to objects. Furthermore, we propose a location probability map based approach to explore the feasible locations that objects can be placed based on local appearance similarity. With the guidance of such map, we boost the performance of R101-Mask R-CNN on instance segmentation from 35.7 mAP to 37.9 mAP without modifying the backbone or network structure. Our method is simple to implement and does not increase the computational complexity. It can be integrated into the training pipeline of any instance segmentation model without affecting the training and inference efficiency.
-
-
-
-
## Introduction
-
-
Configs in this directory is the implementation for ICCV2019 paper "InstaBoost: Boosting Instance Segmentation Via Probability Map Guided Copy-Pasting" and provided by the authors of the paper. InstaBoost is a data augmentation method for object detection and instance segmentation. The paper has been released on [`arXiv`](https://arxiv.org/abs/1908.07801).
-## Citation
-
-```latex
-@inproceedings{fang2019instaboost,
- title={Instaboost: Boosting instance segmentation via probability map guided copy-pasting},
- author={Fang, Hao-Shu and Sun, Jianhua and Wang, Runzhong and Gou, Minghao and Li, Yong-Lu and Lu, Cewu},
- booktitle={Proceedings of the IEEE International Conference on Computer Vision},
- pages={682--691},
- year={2019}
-}
-```
-
## Usage
### Requirements
@@ -61,3 +44,15 @@ InstaBoost have been already integrated in the data pipeline, thus all you need
| Mask R-CNN | R-101-FPN | 4x | 6.4 | | 42.5 | 38.0 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/instaboost/mask_rcnn_r101_fpn_instaboost_4x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/instaboost/mask_rcnn_r101_fpn_instaboost_4x_coco/mask_rcnn_r101_fpn_instaboost_4x_coco_20200703_235738-f23f3a5f.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/instaboost/mask_rcnn_r101_fpn_instaboost_4x_coco/mask_rcnn_r101_fpn_instaboost_4x_coco_20200703_235738.log.json) |
| Mask R-CNN | X-101-64x4d-FPN | 4x | 10.7 | | 44.7 | 39.7 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/instaboost/mask_rcnn_x101_64x4d_fpn_instaboost_4x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/instaboost/mask_rcnn_x101_64x4d_fpn_instaboost_4x_coco/mask_rcnn_x101_64x4d_fpn_instaboost_4x_coco_20200515_080947-8ed58c1b.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/instaboost/mask_rcnn_x101_64x4d_fpn_instaboost_4x_coco/mask_rcnn_x101_64x4d_fpn_instaboost_4x_coco_20200515_080947.log.json) |
| Cascade R-CNN | R-101-FPN | 4x | 6.0 | 12.0 | 43.7 | 38.0 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/instaboost/cascade_mask_rcnn_r50_fpn_instaboost_4x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/instaboost/cascade_mask_rcnn_r50_fpn_instaboost_4x_coco/cascade_mask_rcnn_r50_fpn_instaboost_4x_coco_20200307-c19d98d9.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/instaboost/cascade_mask_rcnn_r50_fpn_instaboost_4x_coco/cascade_mask_rcnn_r50_fpn_instaboost_4x_coco_20200307_223646.log.json) |
+
+## Citation
+
+```latex
+@inproceedings{fang2019instaboost,
+ title={Instaboost: Boosting instance segmentation via probability map guided copy-pasting},
+ author={Fang, Hao-Shu and Sun, Jianhua and Wang, Runzhong and Gou, Minghao and Li, Yong-Lu and Lu, Cewu},
+ booktitle={Proceedings of the IEEE International Conference on Computer Vision},
+ pages={682--691},
+ year={2019}
+}
+```
diff --git a/configs/lad/README.md b/configs/lad/README.md
index b48b0632cae..a5ded4f8ddf 100644
--- a/configs/lad/README.md
+++ b/configs/lad/README.md
@@ -1,34 +1,17 @@
-# Improving Object Detection by Label Assignment Distillation
+# LAD
+> [Improving Object Detection by Label Assignment Distillation](https://arxiv.org/abs/2108.10520)
-## Abstract
+
-
+## Abstract
Label assignment in object detection aims to assign targets, foreground or background, to sampled regions in an image. Unlike labeling for image classification, this problem is not well defined due to the object's bounding box. In this paper, we investigate the problem from a perspective of distillation, hence we call Label Assignment Distillation (LAD). Our initial motivation is very simple, we use a teacher network to generate labels for the student. This can be achieved in two ways: either using the teacher's prediction as the direct targets (soft label), or through the hard labels dynamically assigned by the teacher (LAD). Our experiments reveal that: (i) LAD is more effective than soft-label, but they are complementary. (ii) Using LAD, a smaller teacher can also improve a larger student significantly, while soft-label can't. We then introduce Co-learning LAD, in which two networks simultaneously learn from scratch and the role of teacher and student are dynamically interchanged. Using PAA-ResNet50 as a teacher, our LAD techniques can improve detectors PAA-ResNet101 and PAA-ResNeXt101 to 46AP and 47.5AP on the COCO test-dev set. With a stronger teacher PAA-SwinB, we improve the students PAA-ResNet50 to 43.7AP by only 1x schedule training and standard setting, and PAA-ResNet101 to 47.9AP, significantly surpassing the current methods.
-
-
-
-
-## Citation
-
-
-
-
-```latex
-@inproceedings{nguyen2021improving,
- title={Improving Object Detection by Label Assignment Distillation},
- author={Chuong H. Nguyen and Thuy C. Nguyen and Tuan N. Tang and Nam L. H. Phan},
- booktitle = {WACV},
- year={2022}
-}
-```
-
## Results and Models
We provide config files to reproduce the object detection results in the
@@ -48,3 +31,14 @@ Distillation.
- Meaning of Config name: lad_r50(student model)_paa(based on paa)_r101(teacher model)_fpn(neck)_coco(dataset)_1x(12 epoch).py
- Results may fluctuate by about 0.2 mAP.
+
+## Citation
+
+```latex
+@inproceedings{nguyen2021improving,
+ title={Improving Object Detection by Label Assignment Distillation},
+ author={Chuong H. Nguyen and Thuy C. Nguyen and Tuan N. Tang and Nam L. H. Phan},
+ booktitle = {WACV},
+ year={2022}
+}
+```
diff --git a/configs/lad/metafile.yml b/configs/lad/metafile.yml
new file mode 100644
index 00000000000..5076f28d459
--- /dev/null
+++ b/configs/lad/metafile.yml
@@ -0,0 +1,42 @@
+Collections:
+ - Name: Label Assignment Distillation
+ Metadata:
+ Training Data: COCO
+ Training Techniques:
+ - Label Assignment Distillation
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - FPN
+ - ResNet
+ Paper:
+ URL: https://arxiv.org/abs/2108.10520
+ Title: 'Improving Object Detection by Label Assignment Distillation'
+ README: configs/lad/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.19.0/mmdet/models/detectors/lad.py#L10
+ Version: v2.19.0
+
+Models:
+ - Name: lad_r50_paa_r101_fpn_coco_1x
+ In Collection: Label Assignment Distillation
+ Config: configs/lad/lad_r50_paa_r101_fpn_coco_1x.py
+ Metadata:
+ Teacher: R-101
+ Results:
+ - Task: Object Detection
+ Dataset: COCO
+ Metrics:
+ box AP: 41.6
+
+ - Name: lad_r101_paa_r50_fpn_coco_1x
+ In Collection: Label Assignment Distillation
+ Config: configs/lad/lad_r101_paa_r50_fpn_coco_1x.py
+ Metadata:
+ Teacher: R-50
+ Results:
+ - Task: Object Detection
+ Dataset: COCO
+ Metrics:
+ box AP: 43.2
diff --git a/configs/ld/README.md b/configs/ld/README.md
index baa824753ba..3d49f9d166c 100644
--- a/configs/ld/README.md
+++ b/configs/ld/README.md
@@ -1,31 +1,18 @@
-# Localization Distillation for Object Detection
+# LD
-## Abstract
+> [Localization Distillation for Object Detection](https://arxiv.org/abs/2102.12252)
+
+
-
+## Abstract
Knowledge distillation (KD) has witnessed its powerful capability in learning compact models in object detection. Previous KD methods for object detection mostly focus on imitating deep features within the imitation regions instead of mimicking classification logits due to its inefficiency in distilling localization information. In this paper, by reformulating the knowledge distillation process on localization, we present a novel localization distillation (LD) method which can efficiently transfer the localization knowledge from the teacher to the student. Moreover, we also heuristically introduce the concept of valuable localization region that can aid to selectively distill the semantic and localization knowledge for a certain region. Combining these two new components, for the first time, we show that logit mimicking can outperform feature imitation and localization knowledge distillation is more important and efficient than semantic knowledge for distilling object detectors. Our distillation scheme is simple as well as effective and can be easily applied to different dense object detectors. Experiments show that our LD can boost the AP score of GFocal-ResNet-50 with a single-scale 1× training schedule from 40.1 to 42.1 on the COCO benchmark without any sacrifice on the inference speed.
-
-
-
-
-## Citation
-
-
-
-```latex
-@Article{zheng2021LD,
- title={Localization Distillation for Object Detection},
- author= {Zhaohui Zheng, Rongguang Ye, Ping Wang, Jun Wang, Dongwei Ren, Wangmeng Zuo},
- journal={arXiv:2102.12252},
- year={2021}
-}
-```
+## Results and Models
### GFocalV1 with LD
@@ -43,3 +30,14 @@ Knowledge distillation (KD) has witnessed its powerful capability in learning co
## Note
- Meaning of Config name: ld_r18(student model)_gflv1(based on gflv1)_r101(teacher model)_fpn(neck)_coco(dataset)_1x(12 epoch).py
+
+## Citation
+
+```latex
+@Article{zheng2021LD,
+ title={Localization Distillation for Object Detection},
+ author= {Zhaohui Zheng, Rongguang Ye, Ping Wang, Jun Wang, Dongwei Ren, Wangmeng Zuo},
+ journal={arXiv:2102.12252},
+ year={2021}
+}
+```
diff --git a/configs/libra_rcnn/README.md b/configs/libra_rcnn/README.md
index dac10491ca9..35446f6a715 100644
--- a/configs/libra_rcnn/README.md
+++ b/configs/libra_rcnn/README.md
@@ -1,29 +1,38 @@
-# Libra R-CNN: Towards Balanced Learning for Object Detection
+# Libra R-CNN
-## Abstract
+> [Libra R-CNN: Towards Balanced Learning for Object Detection](https://arxiv.org/abs/1904.02701)
+
+
-
+## Abstract
Compared with model architectures, the training process, which is also crucial to the success of detectors, has received relatively less attention in object detection. In this work, we carefully revisit the standard training practice of detectors, and find that the detection performance is often limited by the imbalance during the training process, which generally consists in three levels - sample level, feature level, and objective level. To mitigate the adverse effects caused thereby, we propose Libra R-CNN, a simple but effective framework towards balanced learning for object detection. It integrates three novel components: IoU-balanced sampling, balanced feature pyramid, and balanced L1 loss, respectively for reducing the imbalance at sample, feature, and objective level. Benefitted from the overall balanced design, Libra R-CNN significantly improves the detection performance. Without bells and whistles, it achieves 2.5 points and 2.0 points higher Average Precision (AP) than FPN Faster R-CNN and RetinaNet respectively on MSCOCO.
Instance recognition is rapidly advanced along with the developments of various deep convolutional neural networks. Compared to the architectures of networks, the training process, which is also crucial to the success of detectors, has received relatively less attention. In this work, we carefully revisit the standard training practice of detectors, and find that the detection performance is often limited by the imbalance during the training process, which generally consists in three levels - sample level, feature level, and objective level. To mitigate the adverse effects caused thereby, we propose Libra R-CNN, a simple yet effective framework towards balanced learning for instance recognition. It integrates IoU-balanced sampling, balanced feature pyramid, and objective re-weighting, respectively for reducing the imbalance at sample, feature, and objective level. Extensive experiments conducted on MS COCO, LVIS and Pascal VOC datasets prove the effectiveness of the overall balanced design.
-
+
-
-
+## Results and Models
-## Citation
+The results on COCO 2017val are shown in the below table. (results on test-dev are usually slightly higher than val)
-
+| Architecture | Backbone | Style | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
+|:------------:|:---------------:|:-------:|:-------:|:--------:|:--------------:|:------:|:------:|:--------:|
+| Faster R-CNN | R-50-FPN | pytorch | 1x | 4.6 | 19.0 | 38.3 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/libra_rcnn/libra_faster_rcnn_r50_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/libra_rcnn/libra_faster_rcnn_r50_fpn_1x_coco/libra_faster_rcnn_r50_fpn_1x_coco_20200130-3afee3a9.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/libra_rcnn/libra_faster_rcnn_r50_fpn_1x_coco/libra_faster_rcnn_r50_fpn_1x_coco_20200130_204655.log.json) |
+| Fast R-CNN | R-50-FPN | pytorch | 1x | | | | |
+| Faster R-CNN | R-101-FPN | pytorch | 1x | 6.5 | 14.4 | 40.1 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/libra_rcnn/libra_faster_rcnn_r101_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/libra_rcnn/libra_faster_rcnn_r101_fpn_1x_coco/libra_faster_rcnn_r101_fpn_1x_coco_20200203-8dba6a5a.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/libra_rcnn/libra_faster_rcnn_r101_fpn_1x_coco/libra_faster_rcnn_r101_fpn_1x_coco_20200203_001405.log.json) |
+| Faster R-CNN | X-101-64x4d-FPN | pytorch | 1x | 10.8 | 8.5 | 42.7 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/libra_rcnn/libra_faster_rcnn_x101_64x4d_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/libra_rcnn/libra_faster_rcnn_x101_64x4d_fpn_1x_coco/libra_faster_rcnn_x101_64x4d_fpn_1x_coco_20200315-3a7d0488.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/libra_rcnn/libra_faster_rcnn_x101_64x4d_fpn_1x_coco/libra_faster_rcnn_x101_64x4d_fpn_1x_coco_20200315_231625.log.json) |
+| RetinaNet | R-50-FPN | pytorch | 1x | 4.2 | 17.7 | 37.6 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/libra_rcnn/libra_retinanet_r50_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/libra_rcnn/libra_retinanet_r50_fpn_1x_coco/libra_retinanet_r50_fpn_1x_coco_20200205-804d94ce.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/libra_rcnn/libra_retinanet_r50_fpn_1x_coco/libra_retinanet_r50_fpn_1x_coco_20200205_112757.log.json) |
+
+## Citation
We provide config files to reproduce the results in the CVPR 2019 paper [Libra R-CNN](https://arxiv.org/pdf/1904.02701.pdf).
The extended version of [Libra R-CNN](https://arxiv.org/pdf/2108.10175.pdf) is accpeted by IJCV.
-```
+```latex
@inproceedings{pang2019libra,
title={Libra R-CNN: Towards Balanced Learning for Object Detection},
author={Pang, Jiangmiao and Chen, Kai and Shi, Jianping and Feng, Huajun and Ouyang, Wanli and Dahua Lin},
@@ -42,15 +51,3 @@ The extended version of [Libra R-CNN](https://arxiv.org/pdf/2108.10175.pdf) is a
publisher={Springer}
}
```
-
-## Results and models
-
-The results on COCO 2017val are shown in the below table. (results on test-dev are usually slightly higher than val)
-
-| Architecture | Backbone | Style | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
-|:------------:|:---------------:|:-------:|:-------:|:--------:|:--------------:|:------:|:------:|:--------:|
-| Faster R-CNN | R-50-FPN | pytorch | 1x | 4.6 | 19.0 | 38.3 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/libra_rcnn/libra_faster_rcnn_r50_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/libra_rcnn/libra_faster_rcnn_r50_fpn_1x_coco/libra_faster_rcnn_r50_fpn_1x_coco_20200130-3afee3a9.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/libra_rcnn/libra_faster_rcnn_r50_fpn_1x_coco/libra_faster_rcnn_r50_fpn_1x_coco_20200130_204655.log.json) |
-| Fast R-CNN | R-50-FPN | pytorch | 1x | | | | |
-| Faster R-CNN | R-101-FPN | pytorch | 1x | 6.5 | 14.4 | 40.1 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/libra_rcnn/libra_faster_rcnn_r101_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/libra_rcnn/libra_faster_rcnn_r101_fpn_1x_coco/libra_faster_rcnn_r101_fpn_1x_coco_20200203-8dba6a5a.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/libra_rcnn/libra_faster_rcnn_r101_fpn_1x_coco/libra_faster_rcnn_r101_fpn_1x_coco_20200203_001405.log.json) |
-| Faster R-CNN | X-101-64x4d-FPN | pytorch | 1x | 10.8 | 8.5 | 42.7 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/libra_rcnn/libra_faster_rcnn_x101_64x4d_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/libra_rcnn/libra_faster_rcnn_x101_64x4d_fpn_1x_coco/libra_faster_rcnn_x101_64x4d_fpn_1x_coco_20200315-3a7d0488.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/libra_rcnn/libra_faster_rcnn_x101_64x4d_fpn_1x_coco/libra_faster_rcnn_x101_64x4d_fpn_1x_coco_20200315_231625.log.json) |
-| RetinaNet | R-50-FPN | pytorch | 1x | 4.2 | 17.7 | 37.6 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/libra_rcnn/libra_retinanet_r50_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/libra_rcnn/libra_retinanet_r50_fpn_1x_coco/libra_retinanet_r50_fpn_1x_coco_20200205-804d94ce.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/libra_rcnn/libra_retinanet_r50_fpn_1x_coco/libra_retinanet_r50_fpn_1x_coco_20200205_112757.log.json) |
diff --git a/configs/lvis/README.md b/configs/lvis/README.md
index daf27e8aa34..5c805648f94 100644
--- a/configs/lvis/README.md
+++ b/configs/lvis/README.md
@@ -1,32 +1,17 @@
-# LVIS: A Dataset for Large Vocabulary Instance Segmentation
+# LVIS
-## Abstract
+> [LVIS: A Dataset for Large Vocabulary Instance Segmentation](https://arxiv.org/abs/1908.03195)
+
+
-
+## Abstract
Progress on object detection is enabled by datasets that focus the research community's attention on open challenges. This process led us from simple images to complex scenes and from bounding boxes to segmentation masks. In this work, we introduce LVIS (pronounced `el-vis'): a new dataset for Large Vocabulary Instance Segmentation. We plan to collect ~2 million high-quality instance segmentation masks for over 1000 entry-level object categories in 164k images. Due to the Zipfian distribution of categories in natural images, LVIS naturally has a long tail of categories with few training samples. Given that state-of-the-art deep learning methods for object detection perform poorly in the low-sample regime, we believe that our dataset poses an important and exciting new scientific challenge.
-
-
-
-
-## Citation
-
-
-
-```latex
-@inproceedings{gupta2019lvis,
- title={{LVIS}: A Dataset for Large Vocabulary Instance Segmentation},
- author={Gupta, Agrim and Dollar, Piotr and Girshick, Ross},
- booktitle={Proceedings of the {IEEE} Conference on Computer Vision and Pattern Recognition},
- year={2019}
-}
-```
-
## Common Setting
* Please follow [install guide](../../docs/get_started.md#install-mmdetection) to install open-mmlab forked cocoapi first.
@@ -56,3 +41,14 @@ Progress on object detection is enabled by datasets that focus the research comm
| R-101-FPN | pytorch | 1x | 10.8 | - | 24.6 | 23.6 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/lvis/mask_rcnn_r101_fpn_sample1e-3_mstrain_1x_lvis_v1.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/lvis/mask_rcnn_r101_fpn_sample1e-3_mstrain_1x_lvis_v1/mask_rcnn_r101_fpn_sample1e-3_mstrain_1x_lvis_v1-ec55ce32.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/lvis/mask_rcnn_r101_fpn_sample1e-3_mstrain_1x_lvis_v1/mask_rcnn_r101_fpn_sample1e-3_mstrain_1x_lvis_v1-20200829_070959.log.json) |
| X-101-32x4d-FPN | pytorch | 1x | 11.8 | - | 26.7 | 25.5 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/lvis/mask_rcnn_x101_32x4d_fpn_sample1e-3_mstrain_1x_lvis_v1.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/lvis/mask_rcnn_x101_32x4d_fpn_sample1e-3_mstrain_1x_lvis_v1/mask_rcnn_x101_32x4d_fpn_sample1e-3_mstrain_1x_lvis_v1-ebbc5c81.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/lvis/mask_rcnn_x101_32x4d_fpn_sample1e-3_mstrain_1x_lvis_v1/mask_rcnn_x101_32x4d_fpn_sample1e-3_mstrain_1x_lvis_v1-20200829_071317.log.json) |
| X-101-64x4d-FPN | pytorch | 1x | 14.6 | - | 27.2 | 25.8 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/lvis/mask_rcnn_x101_64x4d_fpn_sample1e-3_mstrain_1x_lvis_v1.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/lvis/mask_rcnn_x101_64x4d_fpn_sample1e-3_mstrain_1x_lvis_v1/mask_rcnn_x101_64x4d_fpn_sample1e-3_mstrain_1x_lvis_v1-43d9edfe.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/lvis/mask_rcnn_x101_64x4d_fpn_sample1e-3_mstrain_1x_lvis_v1/mask_rcnn_x101_64x4d_fpn_sample1e-3_mstrain_1x_lvis_v1-20200830_060206.log.json) |
+
+## Citation
+
+```latex
+@inproceedings{gupta2019lvis,
+ title={{LVIS}: A Dataset for Large Vocabulary Instance Segmentation},
+ author={Gupta, Agrim and Dollar, Piotr and Girshick, Ross},
+ booktitle={Proceedings of the {IEEE} Conference on Computer Vision and Pattern Recognition},
+ year={2019}
+}
+```
diff --git a/configs/mask_rcnn/README.md b/configs/mask_rcnn/README.md
index 5080a0493e7..9336dd35fde 100644
--- a/configs/mask_rcnn/README.md
+++ b/configs/mask_rcnn/README.md
@@ -1,35 +1,18 @@
# Mask R-CNN
-## Abstract
+> [Mask R-CNN](https://arxiv.org/abs/1703.06870)
-
+
+
+## Abstract
We present a conceptually simple, flexible, and general framework for object instance segmentation. Our approach efficiently detects objects in an image while simultaneously generating a high-quality segmentation mask for each instance. The method, called Mask R-CNN, extends Faster R-CNN by adding a branch for predicting an object mask in parallel with the existing branch for bounding box recognition. Mask R-CNN is simple to train and adds only a small overhead to Faster R-CNN, running at 5 fps. Moreover, Mask R-CNN is easy to generalize to other tasks, e.g., allowing us to estimate human poses in the same framework. We show top results in all three tracks of the COCO suite of challenges, including instance segmentation, bounding-box object detection, and person keypoint detection. Without bells and whistles, Mask R-CNN outperforms all existing, single-model entries on every task, including the COCO 2016 challenge winners. We hope our simple and effective approach will serve as a solid baseline and help ease future research in instance-level recognition.
-
-
-
-
-## Citation
-
-
-
-```latex
-@article{He_2017,
- title={Mask R-CNN},
- journal={2017 IEEE International Conference on Computer Vision (ICCV)},
- publisher={IEEE},
- author={He, Kaiming and Gkioxari, Georgia and Dollar, Piotr and Girshick, Ross},
- year={2017},
- month={Oct}
-}
-```
-
-## Results and models
+## Results and Models
| Backbone | Style | Lr schd | Mem (GB) | Inf time (fps) | box AP | mask AP | Config | Download |
| :-------------: | :-----: | :-----: | :------: | :------------: | :----: | :-----: | :------: | :--------: |
@@ -61,3 +44,16 @@ We also train some models with longer schedules and multi-scale training. The us
| [X-101-32x8d-FPN](./mask_rcnn_x101_32x8d_fpn_mstrain-poly_3x_coco.py) | pytorch | 1x | - | | 43.6 | 39.0 |
| [X-101-32x8d-FPN](./mask_rcnn_x101_32x8d_fpn_mstrain-poly_3x_coco.py) | pytorch | 3x | 10.3 | | 44.3 | 39.5 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/mask_rcnn/mask_rcnn_x101_32x8d_fpn_mstrain-poly_3x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/mask_rcnn/mask_rcnn_x101_32x8d_fpn_mstrain-poly_3x_coco/mask_rcnn_x101_32x8d_fpn_mstrain-poly_3x_coco_20210607_161042-8bd2c639.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/mask_rcnn/mask_rcnn_x101_32x8d_fpn_mstrain-poly_3x_coco/mask_rcnn_x101_32x8d_fpn_mstrain-poly_3x_coco_20210607_161042.log.json)
| [X-101-64x4d-FPN](./mask_rcnn_x101_64x4d_fpn_mstrain-poly_3x_coco.py) | pytorch | 3x | 10.4 | | 44.5 | 39.7 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/mask_rcnn/mask_rcnn_x101_64x4d_fpn_mstrain-poly_3x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/mask_rcnn/mask_rcnn_x101_64x4d_fpn_mstrain-poly_3x_coco/mask_rcnn_x101_64x4d_fpn_mstrain-poly_3x_coco_20210526_120447-c376f129.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/mask_rcnn/mask_rcnn_x101_64x4d_fpn_mstrain-poly_3x_coco/mask_rcnn_x101_64x4d_fpn_mstrain-poly_3x_coco_20210526_120447.log.json)
+
+## Citation
+
+```latex
+@article{He_2017,
+ title={Mask R-CNN},
+ journal={2017 IEEE International Conference on Computer Vision (ICCV)},
+ publisher={IEEE},
+ author={He, Kaiming and Gkioxari, Georgia and Dollar, Piotr and Girshick, Ross},
+ year={2017},
+ month={Oct}
+}
+```
diff --git a/configs/ms_rcnn/README.md b/configs/ms_rcnn/README.md
index 5a80c0d0c50..44508c06390 100644
--- a/configs/ms_rcnn/README.md
+++ b/configs/ms_rcnn/README.md
@@ -1,32 +1,17 @@
-# Mask Scoring R-CNN
+# MS R-CNN
-## Abstract
+> [Mask Scoring R-CNN](https://arxiv.org/abs/1903.00241)
+
+
-
+## Abstract
Letting a deep network be aware of the quality of its own predictions is an interesting yet important problem. In the task of instance segmentation, the confidence of instance classification is used as mask quality score in most instance segmentation frameworks. However, the mask quality, quantified as the IoU between the instance mask and its ground truth, is usually not well correlated with classification score. In this paper, we study this problem and propose Mask Scoring R-CNN which contains a network block to learn the quality of the predicted instance masks. The proposed network block takes the instance feature and the corresponding predicted mask together to regress the mask IoU. The mask scoring strategy calibrates the misalignment between mask quality and mask score, and improves instance segmentation performance by prioritizing more accurate mask predictions during COCO AP evaluation. By extensive evaluations on the COCO dataset, Mask Scoring R-CNN brings consistent and noticeable gain with different models, and outperforms the state-of-the-art Mask R-CNN. We hope our simple and effective approach will provide a new direction for improving instance segmentation.
-
-
-
-
-## Citation
-
-
-
-```
-@inproceedings{huang2019msrcnn,
- title={Mask Scoring R-CNN},
- author={Zhaojin Huang and Lichao Huang and Yongchao Gong and Chang Huang and Xinggang Wang},
- booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
- year={2019},
-}
-```
-
## Results and Models
| Backbone | style | Lr schd | Mem (GB) | Inf time (fps) | box AP | mask AP | Config | Download |
@@ -38,3 +23,14 @@ Letting a deep network be aware of the quality of its own predictions is an inte
| R-X101-32x4d | pytorch | 2x | 7.9 | 11.0 | 41.8 | 38.7 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/ms_rcnn/ms_rcnn_x101_32x4d_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/ms_rcnn/ms_rcnn_x101_32x4d_fpn_1x_coco/ms_rcnn_x101_32x4d_fpn_1x_coco_20200206-81fd1740.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/ms_rcnn/ms_rcnn_x101_32x4d_fpn_1x_coco/ms_rcnn_x101_32x4d_fpn_1x_coco_20200206_100113.log.json) |
| R-X101-64x4d | pytorch | 1x | 11.0 | 8.0 | 43.0 | 39.5 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/ms_rcnn/ms_rcnn_x101_64x4d_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/ms_rcnn/ms_rcnn_x101_64x4d_fpn_1x_coco/ms_rcnn_x101_64x4d_fpn_1x_coco_20200206-86ba88d2.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/ms_rcnn/ms_rcnn_x101_64x4d_fpn_1x_coco/ms_rcnn_x101_64x4d_fpn_1x_coco_20200206_091744.log.json) |
| R-X101-64x4d | pytorch | 2x | 11.0 | 8.0 | 42.6 | 39.5 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/ms_rcnn/ms_rcnn_x101_64x4d_fpn_2x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/ms_rcnn/ms_rcnn_x101_64x4d_fpn_2x_coco/ms_rcnn_x101_64x4d_fpn_2x_coco_20200308-02a445e2.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/ms_rcnn/ms_rcnn_x101_64x4d_fpn_2x_coco/ms_rcnn_x101_64x4d_fpn_2x_coco_20200308_012247.log.json) |
+
+## Citation
+
+```latex
+@inproceedings{huang2019msrcnn,
+ title={Mask Scoring R-CNN},
+ author={Zhaojin Huang and Lichao Huang and Yongchao Gong and Chang Huang and Xinggang Wang},
+ booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
+ year={2019},
+}
+```
diff --git a/configs/nas_fcos/README.md b/configs/nas_fcos/README.md
index 2e3b56ec6fe..74453c6bfcc 100644
--- a/configs/nas_fcos/README.md
+++ b/configs/nas_fcos/README.md
@@ -1,22 +1,29 @@
-# NAS-FCOS: Fast Neural Architecture Search for Object Detection
+# NAS-FCOS
-## Abstract
+> [NAS-FCOS: Fast Neural Architecture Search for Object Detection](https://arxiv.org/abs/1906.04423)
+
+
-
+## Abstract
The success of deep neural networks relies on significant architecture engineering. Recently neural architecture search (NAS) has emerged as a promise to greatly reduce manual effort in network design by automatically searching for optimal architectures, although typically such algorithms need an excessive amount of computational resources, e.g., a few thousand GPU-days. To date, on challenging vision tasks such as object detection, NAS, especially fast versions of NAS, is less studied. Here we propose to search for the decoder structure of object detectors with search efficiency being taken into consideration. To be more specific, we aim to efficiently search for the feature pyramid network (FPN) as well as the prediction head of a simple anchor-free object detector, namely FCOS, using a tailored reinforcement learning paradigm. With carefully designed search space, search algorithms and strategies for evaluating network quality, we are able to efficiently search a top-performing detection architecture within 4 days using 8 V100 GPUs. The discovered architecture surpasses state-of-the-art object detection models (such as Faster R-CNN, RetinaNet and FCOS) by 1.5 to 3.5 points in AP on the COCO dataset, with comparable computation complexity and memory footprint, demonstrating the efficacy of the proposed NAS for object detection.
-
-
-
+## Results and Models
-## Citation
+| Head | Backbone | Style | GN-head | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
+|:---------:|:---------:|:-------:|:-------:|:-------:|:--------:|:--------------:|:------:|:------:|:--------:|
+| NAS-FCOSHead | R-50 | caffe | Y | 1x | | | 39.4 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/nas_fcos/nas_fcos_nashead_r50_caffe_fpn_gn-head_4x4_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/nas_fcos/nas_fcos_nashead_r50_caffe_fpn_gn-head_4x4_1x_coco/nas_fcos_nashead_r50_caffe_fpn_gn-head_4x4_1x_coco_20200520-1bdba3ce.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/nas_fcos/nas_fcos_nashead_r50_caffe_fpn_gn-head_4x4_1x_coco/nas_fcos_nashead_r50_caffe_fpn_gn-head_4x4_1x_coco_20200520.log.json) |
+| FCOSHead | R-50 | caffe | Y | 1x | | | 38.5 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/nas_fcos/nas_fcos_fcoshead_r50_caffe_fpn_gn-head_4x4_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/nas_fcos/nas_fcos_fcoshead_r50_caffe_fpn_gn-head_4x4_1x_coco/nas_fcos_fcoshead_r50_caffe_fpn_gn-head_4x4_1x_coco_20200521-7fdcbce0.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/nas_fcos/nas_fcos_fcoshead_r50_caffe_fpn_gn-head_4x4_1x_coco/nas_fcos_fcoshead_r50_caffe_fpn_gn-head_4x4_1x_coco_20200521.log.json) |
-
+**Notes:**
+
+- To be consistent with the author's implementation, we use 4 GPUs with 4 images/GPU.
+
+## Citation
```latex
@article{wang2019fcos,
@@ -26,14 +33,3 @@ The success of deep neural networks relies on significant architecture engineeri
year={2019}
}
```
-
-## Results and Models
-
-| Head | Backbone | Style | GN-head | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
-|:---------:|:---------:|:-------:|:-------:|:-------:|:--------:|:--------------:|:------:|:------:|:--------:|
-| NAS-FCOSHead | R-50 | caffe | Y | 1x | | | 39.4 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/nas_fcos/nas_fcos_nashead_r50_caffe_fpn_gn-head_4x4_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/nas_fcos/nas_fcos_nashead_r50_caffe_fpn_gn-head_4x4_1x_coco/nas_fcos_nashead_r50_caffe_fpn_gn-head_4x4_1x_coco_20200520-1bdba3ce.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/nas_fcos/nas_fcos_nashead_r50_caffe_fpn_gn-head_4x4_1x_coco/nas_fcos_nashead_r50_caffe_fpn_gn-head_4x4_1x_coco_20200520.log.json) |
-| FCOSHead | R-50 | caffe | Y | 1x | | | 38.5 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/nas_fcos/nas_fcos_fcoshead_r50_caffe_fpn_gn-head_4x4_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/nas_fcos/nas_fcos_fcoshead_r50_caffe_fpn_gn-head_4x4_1x_coco/nas_fcos_fcoshead_r50_caffe_fpn_gn-head_4x4_1x_coco_20200521-7fdcbce0.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/nas_fcos/nas_fcos_fcoshead_r50_caffe_fpn_gn-head_4x4_1x_coco/nas_fcos_fcoshead_r50_caffe_fpn_gn-head_4x4_1x_coco_20200521.log.json) |
-
-**Notes:**
-
-- To be consistent with the author's implementation, we use 4 GPUs with 4 images/GPU.
diff --git a/configs/nas_fpn/README.md b/configs/nas_fpn/README.md
index b2836d74309..7b39eec539a 100644
--- a/configs/nas_fpn/README.md
+++ b/configs/nas_fpn/README.md
@@ -1,22 +1,29 @@
-# NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection
+# NAS-FPN
-## Abstract
+> [NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection](https://arxiv.org/abs/1904.07392)
+
+
-
+## Abstract
Current state-of-the-art convolutional architectures for object detection are manually designed. Here we aim to learn a better architecture of feature pyramid network for object detection. We adopt Neural Architecture Search and discover a new feature pyramid architecture in a novel scalable search space covering all cross-scale connections. The discovered architecture, named NAS-FPN, consists of a combination of top-down and bottom-up connections to fuse features across scales. NAS-FPN, combined with various backbone models in the RetinaNet framework, achieves better accuracy and latency tradeoff compared to state-of-the-art object detection models. NAS-FPN improves mobile detection accuracy by 2 AP compared to state-of-the-art SSDLite with MobileNetV2 model in [32] and achieves 48.3 AP which surpasses Mask R-CNN [10] detection accuracy with less computation time.
-
-
-
+## Results and Models
-## Citation
+We benchmark the new training schedule (crop training, large batch, unfrozen BN, 50 epochs) introduced in NAS-FPN. RetinaNet is used in the paper.
-
+| Backbone | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
+|:-----------:|:-------:|:--------:|:--------------:|:------:|:------:|:--------:|
+| R-50-FPN | 50e | 12.9 | 22.9 | 37.9 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/nas_fpn/retinanet_r50_fpn_crop640_50e_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/nas_fpn/retinanet_r50_fpn_crop640_50e_coco/retinanet_r50_fpn_crop640_50e_coco-9b953d76.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/nas_fpn/retinanet_r50_fpn_crop640_50e_coco/retinanet_r50_fpn_crop640_50e_coco_20200529_095329.log.json) |
+| R-50-NASFPN | 50e | 13.2 | 23.0 | 40.5 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/nas_fpn/retinanet_r50_nasfpn_crop640_50e_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/nas_fpn/retinanet_r50_nasfpn_crop640_50e_coco/retinanet_r50_nasfpn_crop640_50e_coco-0ad1f644.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/nas_fpn/retinanet_r50_nasfpn_crop640_50e_coco/retinanet_r50_nasfpn_crop640_50e_coco_20200528_230008.log.json) |
+
+**Note**: We find that it is unstable to train NAS-FPN and there is a small chance that results can be 3% mAP lower.
+
+## Citation
```latex
@inproceedings{ghiasi2019fpn,
@@ -27,14 +34,3 @@ Current state-of-the-art convolutional architectures for object detection are ma
year={2019}
}
```
-
-## Results and Models
-
-We benchmark the new training schedule (crop training, large batch, unfrozen BN, 50 epochs) introduced in NAS-FPN. RetinaNet is used in the paper.
-
-| Backbone | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
-|:-----------:|:-------:|:--------:|:--------------:|:------:|:------:|:--------:|
-| R-50-FPN | 50e | 12.9 | 22.9 | 37.9 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/nas_fpn/retinanet_r50_fpn_crop640_50e_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/nas_fpn/retinanet_r50_fpn_crop640_50e_coco/retinanet_r50_fpn_crop640_50e_coco-9b953d76.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/nas_fpn/retinanet_r50_fpn_crop640_50e_coco/retinanet_r50_fpn_crop640_50e_coco_20200529_095329.log.json) |
-| R-50-NASFPN | 50e | 13.2 | 23.0 | 40.5 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/nas_fpn/retinanet_r50_nasfpn_crop640_50e_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/nas_fpn/retinanet_r50_nasfpn_crop640_50e_coco/retinanet_r50_nasfpn_crop640_50e_coco-0ad1f644.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/nas_fpn/retinanet_r50_nasfpn_crop640_50e_coco/retinanet_r50_nasfpn_crop640_50e_coco_20200528_230008.log.json) |
-
-**Note**: We find that it is unstable to train NAS-FPN and there is a small chance that results can be 3% mAP lower.
diff --git a/configs/paa/README.md b/configs/paa/README.md
index 05e65d2bfbc..0f299004269 100644
--- a/configs/paa/README.md
+++ b/configs/paa/README.md
@@ -1,32 +1,17 @@
-# Probabilistic Anchor Assignment with IoU Prediction for Object Detection
+# PAA
-## Abstract
+> [Probabilistic Anchor Assignment with IoU Prediction for Object Detection](https://arxiv.org/abs/2007.08103)
+
+
-
+## Abstract
In object detection, determining which anchors to assign as positive or negative samples, known as anchor assignment, has been revealed as a core procedure that can significantly affect a model's performance. In this paper we propose a novel anchor assignment strategy that adaptively separates anchors into positive and negative samples for a ground truth bounding box according to the model's learning status such that it is able to reason about the separation in a probabilistic manner. To do so we first calculate the scores of anchors conditioned on the model and fit a probability distribution to these scores. The model is then trained with anchors separated into positive and negative samples according to their probabilities. Moreover, we investigate the gap between the training and testing objectives and propose to predict the Intersection-over-Unions of detected boxes as a measure of localization quality to reduce the discrepancy. The combined score of classification and localization qualities serving as a box selection metric in non-maximum suppression well aligns with the proposed anchor assignment strategy and leads significant performance improvements. The proposed methods only add a single convolutional layer to RetinaNet baseline and does not require multiple anchors per location, so are efficient. Experimental results verify the effectiveness of the proposed methods. Especially, our models set new records for single-stage detectors on MS COCO test-dev dataset with various backbones.
-
-
-
-
-## Citation
-
-
-
-```latex
-@inproceedings{paa-eccv2020,
- title={Probabilistic Anchor Assignment with IoU Prediction for Object Detection},
- author={Kim, Kang and Lee, Hee Seok},
- booktitle = {ECCV},
- year={2020}
-}
-```
-
## Results and Models
We provide config files to reproduce the object detection results in the
@@ -49,3 +34,14 @@ Prediction for Object Detection.
**Note**:
1. We find that the performance is unstable with 1x setting and may fluctuate by about 0.2 mAP. We report the best results.
+
+## Citation
+
+```latex
+@inproceedings{paa-eccv2020,
+ title={Probabilistic Anchor Assignment with IoU Prediction for Object Detection},
+ author={Kim, Kang and Lee, Hee Seok},
+ booktitle = {ECCV},
+ year={2020}
+}
+```
diff --git a/configs/pafpn/README.md b/configs/pafpn/README.md
index 8516d348585..4a406af6e44 100644
--- a/configs/pafpn/README.md
+++ b/configs/pafpn/README.md
@@ -1,24 +1,26 @@
-# Path Aggregation Network for Instance Segmentation
+# PAFPN
-## Abstract
+> [Path Aggregation Network for Instance Segmentation](https://arxiv.org/abs/1803.01534)
-
+
+
+## Abstract
The way that information propagates in neural networks is of great importance. In this paper, we propose Path Aggregation Network (PANet) aiming at boosting information flow in proposal-based instance segmentation framework. Specifically, we enhance the entire feature hierarchy with accurate localization signals in lower layers by bottom-up path augmentation, which shortens the information path between lower layers and topmost feature. We present adaptive feature pooling, which links feature grid and all feature levels to make useful information in each feature level propagate directly to following proposal subnetworks. A complementary branch capturing different views for each proposal is created to further improve mask prediction. These improvements are simple to implement, with subtle extra computational overhead. Our PANet reaches the 1st place in the COCO 2017 Challenge Instance Segmentation task and the 2nd place in Object Detection task without large-batch training. It is also state-of-the-art on MVD and Cityscapes.
-
-
-
+## Results and Models
-## Citation
+| Backbone | style | Lr schd | Mem (GB) | Inf time (fps) | box AP | mask AP | Config | Download |
+|:-------------:|:----------:|:-------:|:--------:|:--------------:|:------:|:-------:|:------:|:--------:|
+| R-50-FPN | pytorch | 1x | 4.0 | 17.2 | 37.5 | | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/pafpn/faster_rcnn_r50_pafpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/pafpn/faster_rcnn_r50_pafpn_1x_coco/faster_rcnn_r50_pafpn_1x_coco_bbox_mAP-0.375_20200503_105836-b7b4b9bd.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/pafpn/faster_rcnn_r50_pafpn_1x_coco/faster_rcnn_r50_pafpn_1x_coco_20200503_105836.log.json) |
-
+## Citation
-```
+```latex
@inproceedings{liu2018path,
author = {Shu Liu and
Lu Qi and
@@ -30,11 +32,3 @@ The way that information propagates in neural networks is of great importance. I
year = {2018}
}
```
-
-## Results and Models
-
-## Results and Models
-
-| Backbone | style | Lr schd | Mem (GB) | Inf time (fps) | box AP | mask AP | Config | Download |
-|:-------------:|:----------:|:-------:|:--------:|:--------------:|:------:|:-------:|:------:|:--------:|
-| R-50-FPN | pytorch | 1x | 4.0 | 17.2 | 37.5 | | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/pafpn/faster_rcnn_r50_pafpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/pafpn/faster_rcnn_r50_pafpn_1x_coco/faster_rcnn_r50_pafpn_1x_coco_bbox_mAP-0.375_20200503_105836-b7b4b9bd.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/pafpn/faster_rcnn_r50_pafpn_1x_coco/faster_rcnn_r50_pafpn_1x_coco_20200503_105836.log.json) |
diff --git a/configs/panoptic_fpn/README.md b/configs/panoptic_fpn/README.md
index 083fb6efad9..bc89293ea17 100644
--- a/configs/panoptic_fpn/README.md
+++ b/configs/panoptic_fpn/README.md
@@ -1,37 +1,17 @@
-# Panoptic feature pyramid networks
-## Abstract
+# Panoptic FPN
+
+> [Panoptic feature pyramid networks](https://arxiv.org/abs/1901.02446)
+
+
-
+## Abstract
The recently introduced panoptic segmentation task has renewed our community's interest in unifying the tasks of instance segmentation (for thing classes) and semantic segmentation (for stuff classes). However, current state-of-the-art methods for this joint task use separate and dissimilar networks for instance and semantic segmentation, without performing any shared computation. In this work, we aim to unify these methods at the architectural level, designing a single network for both tasks. Our approach is to endow Mask R-CNN, a popular instance segmentation method, with a semantic segmentation branch using a shared Feature Pyramid Network (FPN) backbone. Surprisingly, this simple baseline not only remains effective for instance segmentation, but also yields a lightweight, top-performing method for semantic segmentation. In this work, we perform a detailed study of this minimally extended version of Mask R-CNN with FPN, which we refer to as Panoptic FPN, and show it is a robust and accurate baseline for both tasks. Given its effectiveness and conceptual simplicity, we hope our method can serve as a strong baseline and aid future research in panoptic segmentation.
-
-
-
-
-## Citation
-
-
-The base method for panoptic segmentation task.
-
-```
-@inproceedings{kirillov2018panopticfpn,
- author = {
- Alexander Kirillov,
- Ross Girshick,
- Kaiming He,
- Piotr Dollar,
- },
- title = {Panoptic Feature Pyramid Networks},
- booktitle = {Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
- year = {2019}
-}
-```
-
## Dataset
PanopticFPN requires COCO and [COCO-panoptic](http://images.cocodataset.org/annotations/panoptic_annotations_trainval2017.zip) dataset for training and evaluation. You need to download and extract it in the COCO dataset path.
@@ -62,3 +42,21 @@ mmdetection
| R-50-FPN | pytorch | 3x | - | - | 42.5 | 78.1 | 51.7 | 50.3 | 81.5 | 60.3 | 30.7 | 73.0 | 38.8 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/panoptic_fpn/panoptic_fpn_r50_fpn_mstrain_3x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/panoptic_fpn/panoptic_fpn_r50_fpn_mstrain_3x_coco/panoptic_fpn_r50_fpn_mstrain_3x_coco_20210824_171155-5650f98b.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/panoptic_fpn/panoptic_fpn_r50_fpn_mstrain_3x_coco/panoptic_fpn_r50_fpn_mstrain_3x_coco_20210824_171155.log.json) |
| R-101-FPN | pytorch | 1x | 6.7 | | 42.2 | 78.3 | 51.4 | 50.1 | 81.4 | 59.9 | 30.3 | 73.6 | 38.5 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/panoptic_fpn/panoptic_fpn_r101_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/panoptic_fpn/panoptic_fpn_r101_fpn_1x_coco/panoptic_fpn_r101_fpn_1x_coco_20210820_193950-ab9157a2.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/panoptic_fpn/panoptic_fpn_r101_fpn_1x_coco/panoptic_fpn_r101_fpn_1x_coco_20210820_193950.log.json) |
| R-101-FPN | pytorch | 3x | - | - | 44.1 | 78.9 | 53.6 | 52.1 | 81.7 | 62.3 | 32.0 | 74.6 | 40.3 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/panoptic_fpn/panoptic_fpn_r101_fpn_mstrain_3x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/panoptic_fpn/panoptic_fpn_r101_fpn_mstrain_3x_coco/panoptic_fpn_r101_fpn_mstrain_3x_coco_20210823_114712-9c99acc4.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/panoptic_fpn/panoptic_fpn_r101_fpn_mstrain_3x_coco/panoptic_fpn_r101_fpn_mstrain_3x_coco_20210823_114712.log.json) |
+
+## Citation
+
+The base method for panoptic segmentation task.
+
+```latex
+@inproceedings{kirillov2018panopticfpn,
+ author = {
+ Alexander Kirillov,
+ Ross Girshick,
+ Kaiming He,
+ Piotr Dollar,
+ },
+ title = {Panoptic Feature Pyramid Networks},
+ booktitle = {Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
+ year = {2019}
+}
+```
diff --git a/configs/pascal_voc/README.md b/configs/pascal_voc/README.md
index af33edb5e48..514ac5049e5 100644
--- a/configs/pascal_voc/README.md
+++ b/configs/pascal_voc/README.md
@@ -1,26 +1,29 @@
-# The Pascal Visual Object Classes (VOC) Challenge
+# Pascal VOC
-## Abstract
+> [The Pascal Visual Object Classes (VOC) Challenge](https://link.springer.com/article/10.1007/s11263-009-0275-4)
-
+
+
+## Abstract
The Pascal Visual Object Classes (VOC) challenge is a benchmark in visual object category recognition and detection, providing the vision and machine learning communities with a standard dataset of images and annotation, and standard evaluation procedures. Organised annually from 2005 to present, the challenge and its associated dataset has become accepted as the benchmark for object detection.
This paper describes the dataset and evaluation procedure. We review the state-of-the-art in evaluated methods for both classification and detection, analyse whether the methods are statistically different, what they are learning from the images (e.g. the object or its context), and what the methods find easy or confuse. The paper concludes with lessons learnt in the three year history of the challenge, and proposes directions for future improvement and extension.
-
-
-
+## Results and Models
-## Citation
+| Architecture | Backbone | Style | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
+|:------------:|:---------:|:-------:|:-------:|:--------:|:--------------:|:------:|:------:|:--------:|
+| Faster R-CNN | R-50 | pytorch | 1x | 2.6 | - | 79.5 |[config](https://github.com/open-mmlab/mmdetection/tree/master/configs/pascal_voc/faster_rcnn_r50_fpn_1x_voc0712.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/pascal_voc/faster_rcnn_r50_fpn_1x_voc0712/faster_rcnn_r50_fpn_1x_voc0712_20200624-c9895d40.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/pascal_voc/faster_rcnn_r50_fpn_1x_voc0712/20200623_015208.log.json) |
+| Retinanet | R-50 | pytorch | 1x | 2.1 | - | 77.3 |[config](https://github.com/open-mmlab/mmdetection/tree/master/configs/pascal_voc/retinanet_r50_fpn_1x_voc0712.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/pascal_voc/retinanet_r50_fpn_1x_voc0712/retinanet_r50_fpn_1x_voc0712_20200617-47cbdd0e.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/pascal_voc/retinanet_r50_fpn_1x_voc0712/retinanet_r50_fpn_1x_voc0712_20200616_014642.log.json) |
-
+## Citation
-```
+```latex
@Article{Everingham10,
author = "Everingham, M. and Van~Gool, L. and Williams, C. K. I. and Winn, J. and Zisserman, A.",
title = "The Pascal Visual Object Classes (VOC) Challenge",
@@ -32,10 +35,3 @@ This paper describes the dataset and evaluation procedure. We review the state-o
pages = "303--338",
}
```
-
-## Results and Models
-
-| Architecture | Backbone | Style | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
-|:------------:|:---------:|:-------:|:-------:|:--------:|:--------------:|:------:|:------:|:--------:|
-| Faster R-CNN | R-50 | pytorch | 1x | 2.6 | - | 79.5 |[config](https://github.com/open-mmlab/mmdetection/tree/master/configs/pascal_voc/faster_rcnn_r50_fpn_1x_voc0712.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/pascal_voc/faster_rcnn_r50_fpn_1x_voc0712/faster_rcnn_r50_fpn_1x_voc0712_20200624-c9895d40.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/pascal_voc/faster_rcnn_r50_fpn_1x_voc0712/20200623_015208.log.json) |
-| Retinanet | R-50 | pytorch | 1x | 2.1 | - | 77.3 |[config](https://github.com/open-mmlab/mmdetection/tree/master/configs/pascal_voc/retinanet_r50_fpn_1x_voc0712.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/pascal_voc/retinanet_r50_fpn_1x_voc0712/retinanet_r50_fpn_1x_voc0712_20200617-47cbdd0e.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/pascal_voc/retinanet_r50_fpn_1x_voc0712/retinanet_r50_fpn_1x_voc0712_20200616_014642.log.json) |
diff --git a/configs/pisa/README.md b/configs/pisa/README.md
index d1ea3a46242..d532941819a 100644
--- a/configs/pisa/README.md
+++ b/configs/pisa/README.md
@@ -1,33 +1,18 @@
-# Prime Sample Attention in Object Detection
+# PISA
-## Abstract
+> [Prime Sample Attention in Object Detection](https://arxiv.org/abs/1904.04821)
+
+
-
+## Abstract
It is a common paradigm in object detection frameworks to treat all samples equally and target at maximizing the performance on average. In this work, we revisit this paradigm through a careful study on how different samples contribute to the overall performance measured in terms of mAP. Our study suggests that the samples in each mini-batch are neither independent nor equally important, and therefore a better classifier on average does not necessarily mean higher mAP. Motivated by this study, we propose the notion of Prime Samples, those that play a key role in driving the detection performance. We further develop a simple yet effective sampling and learning strategy called PrIme Sample Attention (PISA) that directs the focus of the training process towards such samples. Our experiments demonstrate that it is often more effective to focus on prime samples than hard samples when training a detector. Particularly, On the MSCOCO dataset, PISA outperforms the random sampling baseline and hard mining schemes, e.g., OHEM and Focal Loss, consistently by around 2% on both single-stage and two-stage detectors, even with a strong backbone ResNeXt-101.
-
-
-
-
-## Citation
-
-
-
-```latex
-@inproceedings{cao2019prime,
- title={Prime sample attention in object detection},
- author={Cao, Yuhang and Chen, Kai and Loy, Chen Change and Lin, Dahua},
- booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
- year={2020}
-}
-```
-
-## Results and models
+## Results and Models
| PISA | Network | Backbone | Lr schd | box AP | mask AP | Config | Download |
|:----:|:-------:|:-------------------:|:-------:|:------:|:-------:|:------:|:--------:|
@@ -52,3 +37,14 @@ It is a common paradigm in object detection frameworks to treat all samples equa
- In the original paper, all models are trained and tested on mmdet v1.x, thus results may not be exactly the same with this release on v2.0.
- It is noted PISA only modifies the training pipeline so the inference time remains the same with the baseline.
+
+## Citation
+
+```latex
+@inproceedings{cao2019prime,
+ title={Prime sample attention in object detection},
+ author={Cao, Yuhang and Chen, Kai and Loy, Chen Change and Lin, Dahua},
+ booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
+ year={2020}
+}
+```
diff --git a/configs/point_rend/README.md b/configs/point_rend/README.md
index 4a9b6f2c687..a55560afca1 100644
--- a/configs/point_rend/README.md
+++ b/configs/point_rend/README.md
@@ -1,22 +1,27 @@
-# PointRend: Image Segmentation as Rendering
+# PointRend
-## Abstract
+> [PointRend: Image Segmentation as Rendering](https://arxiv.org/abs/1912.08193)
+
+
-
+## Abstract
We present a new method for efficient high-quality image segmentation of objects and scenes. By analogizing classical computer graphics methods for efficient rendering with over- and undersampling challenges faced in pixel labeling tasks, we develop a unique perspective of image segmentation as a rendering problem. From this vantage, we present the PointRend (Point-based Rendering) neural network module: a module that performs point-based segmentation predictions at adaptively selected locations based on an iterative subdivision algorithm. PointRend can be flexibly applied to both instance and semantic segmentation tasks by building on top of existing state-of-the-art models. While many concrete implementations of the general idea are possible, we show that a simple design already achieves excellent results. Qualitatively, PointRend outputs crisp object boundaries in regions that are over-smoothed by previous methods. Quantitatively, PointRend yields significant gains on COCO and Cityscapes, for both instance and semantic segmentation. PointRend's efficiency enables output resolutions that are otherwise impractical in terms of memory or computation compared to existing approaches.
-
-
-
+## Results and Models
-## Citation
+| Backbone | Style | Lr schd | Mem (GB) | Inf time (fps) | box AP | mask AP | Config | Download |
+| :-------------: | :-----: | :-----: | :------: | :------------: | :----: | :-----: | :------: | :--------: |
+| R-50-FPN | caffe | 1x | 4.6 | | 38.4 | 36.3 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/point_rend/point_rend_r50_caffe_fpn_mstrain_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/point_rend/point_rend_r50_caffe_fpn_mstrain_1x_coco/point_rend_r50_caffe_fpn_mstrain_1x_coco-1bcb5fb4.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/point_rend/point_rend_r50_caffe_fpn_mstrain_1x_coco/point_rend_r50_caffe_fpn_mstrain_1x_coco_20200612_161407.log.json) |
+| R-50-FPN | caffe | 3x | 4.6 | | 41.0 | 38.0 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/point_rend/point_rend_r50_caffe_fpn_mstrain_3x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/point_rend/point_rend_r50_caffe_fpn_mstrain_3x_coco/point_rend_r50_caffe_fpn_mstrain_3x_coco-e0ebb6b7.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/point_rend/point_rend_r50_caffe_fpn_mstrain_3x_coco/point_rend_r50_caffe_fpn_mstrain_3x_coco_20200614_002632.log.json) |
-
+Note: All models are trained with multi-scale, the input image shorter side is randomly scaled to one of (640, 672, 704, 736, 768, 800).
+
+## Citation
```latex
@InProceedings{kirillov2019pointrend,
@@ -26,12 +31,3 @@ We present a new method for efficient high-quality image segmentation of objects
year={2019}
}
```
-
-## Results and models
-
-| Backbone | Style | Lr schd | Mem (GB) | Inf time (fps) | box AP | mask AP | Config | Download |
-| :-------------: | :-----: | :-----: | :------: | :------------: | :----: | :-----: | :------: | :--------: |
-| R-50-FPN | caffe | 1x | 4.6 | | 38.4 | 36.3 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/point_rend/point_rend_r50_caffe_fpn_mstrain_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/point_rend/point_rend_r50_caffe_fpn_mstrain_1x_coco/point_rend_r50_caffe_fpn_mstrain_1x_coco-1bcb5fb4.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/point_rend/point_rend_r50_caffe_fpn_mstrain_1x_coco/point_rend_r50_caffe_fpn_mstrain_1x_coco_20200612_161407.log.json) |
-| R-50-FPN | caffe | 3x | 4.6 | | 41.0 | 38.0 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/point_rend/point_rend_r50_caffe_fpn_mstrain_3x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/point_rend/point_rend_r50_caffe_fpn_mstrain_3x_coco/point_rend_r50_caffe_fpn_mstrain_3x_coco-e0ebb6b7.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/point_rend/point_rend_r50_caffe_fpn_mstrain_3x_coco/point_rend_r50_caffe_fpn_mstrain_3x_coco_20200614_002632.log.json) |
-
-Note: All models are trained with multi-scale, the input image shorter side is randomly scaled to one of (640, 672, 704, 736, 768, 800).
diff --git a/configs/pvt/README.md b/configs/pvt/README.md
index 368edb80e59..25528d0d59b 100644
--- a/configs/pvt/README.md
+++ b/configs/pvt/README.md
@@ -1,43 +1,20 @@
-# Pyramid vision transformer: A versatile backbone for dense prediction without convolutions
+# PVT
-## Abstract
+> [Pyramid vision transformer: A versatile backbone for dense prediction without convolutions](https://arxiv.org/abs/2102.12122)
+
+
-
+## Abstract
Although using convolutional neural networks (CNNs) as backbones achieves great successes in computer vision, this work investigates a simple backbone network useful for many dense prediction tasks without convolutions. Unlike the recently-proposed Transformer model (e.g., ViT) that is specially designed for image classification, we propose Pyramid Vision Transformer~(PVT), which overcomes the difficulties of porting Transformer to various dense prediction tasks. PVT has several merits compared to prior arts. (1) Different from ViT that typically has low-resolution outputs and high computational and memory cost, PVT can be not only trained on dense partitions of the image to achieve high output resolution, which is important for dense predictions but also using a progressive shrinking pyramid to reduce computations of large feature maps. (2) PVT inherits the advantages from both CNN and Transformer, making it a unified backbone in various vision tasks without convolutions by simply replacing CNN backbones. (3) We validate PVT by conducting extensive experiments, showing that it boosts the performance of many downstream tasks, e.g., object detection, semantic, and instance segmentation. For example, with a comparable number of parameters, RetinaNet+PVT achieves 40.4 AP on the COCO dataset, surpassing RetinNet+ResNet50 (36.3 AP) by 4.1 absolute AP. We hope PVT could serve as an alternative and useful backbone for pixel-level predictions and facilitate future researches.
Transformer recently has shown encouraging progresses in computer vision. In this work, we present new baselines by improving the original Pyramid Vision Transformer (abbreviated as PVTv1) by adding three designs, including (1) overlapping patch embedding, (2) convolutional feed-forward networks, and (3) linear complexity attention layers.
With these modifications, our PVTv2 significantly improves PVTv1 on three tasks e.g., classification, detection, and segmentation. Moreover, PVTv2 achieves comparable or better performances than recent works such as Swin Transformer. We hope this work will facilitate state-of-the-art Transformer researches in computer vision.
-
-
-
-
-## Citation
-
-
-
-```latex
-@article{wang2021pyramid,
- title={Pyramid vision transformer: A versatile backbone for dense prediction without convolutions},
- author={Wang, Wenhai and Xie, Enze and Li, Xiang and Fan, Deng-Ping and Song, Kaitao and Liang, Ding and Lu, Tong and Luo, Ping and Shao, Ling},
- journal={arXiv preprint arXiv:2102.12122},
- year={2021}
-}
-```
-
-```latex
-@article{wang2021pvtv2,
- title={PVTv2: Improved Baselines with Pyramid Vision Transformer},
- author={Wang, Wenhai and Xie, Enze and Li, Xiang and Fan, Deng-Ping and Song, Kaitao and Liang, Ding and Lu, Tong and Luo, Ping and Shao, Ling},
- journal={arXiv preprint arXiv:2106.13797},
- year={2021}
-}
-```
## Results and Models
### RetinaNet (PVTv1)
@@ -58,3 +35,23 @@ With these modifications, our PVTv2 significantly improves PVTv1 on three tasks
| PVTv2-B3 | 12e |23.0 |46.0 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/pvt/retinanet_pvt_v2_b3_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/pvt/retinanet_pvtv2-b3_fpn_1x_coco/retinanet_pvtv2-b3_fpn_1x_coco_20210903_151512-8357deff.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/pvt/retinanet_pvtv2-b3_fpn_1x_coco/retinanet_pvtv2-b3_fpn_1x_coco_20210903_151512.log.json) |
| PVTv2-B4 | 12e |17.0 |46.3 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/pvt/retinanet_pvt_v2_b4_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/pvt/retinanet_pvtv2-b4_fpn_1x_coco/retinanet_pvtv2-b4_fpn_1x_coco_20210901_170151-83795c86.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/pvt/retinanet_pvtv2-b4_fpn_1x_coco/retinanet_pvtv2-b4_fpn_1x_coco_20210901_170151.log.json) |
| PVTv2-B5 | 12e |18.7 |46.1 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/pvt/retinanet_pvt_v2_b5_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/pvt/retinanet_pvtv2-b5_fpn_1x_coco/retinanet_pvtv2-b5_fpn_1x_coco_20210902_201800-3420eb57.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/pvt/retinanet_pvtv2-b5_fpn_1x_coco/retinanet_pvtv2-b5_fpn_1x_coco_20210902_201800.log.json) |
+
+## Citation
+
+```latex
+@article{wang2021pyramid,
+ title={Pyramid vision transformer: A versatile backbone for dense prediction without convolutions},
+ author={Wang, Wenhai and Xie, Enze and Li, Xiang and Fan, Deng-Ping and Song, Kaitao and Liang, Ding and Lu, Tong and Luo, Ping and Shao, Ling},
+ journal={arXiv preprint arXiv:2102.12122},
+ year={2021}
+}
+```
+
+```latex
+@article{wang2021pvtv2,
+ title={PVTv2: Improved Baselines with Pyramid Vision Transformer},
+ author={Wang, Wenhai and Xie, Enze and Li, Xiang and Fan, Deng-Ping and Song, Kaitao and Liang, Ding and Lu, Tong and Luo, Ping and Shao, Ling},
+ journal={arXiv preprint arXiv:2106.13797},
+ year={2021}
+}
+```
diff --git a/configs/pvt/metafile.yml b/configs/pvt/metafile.yml
index 48a0e2c2ae1..58843784955 100644
--- a/configs/pvt/metafile.yml
+++ b/configs/pvt/metafile.yml
@@ -1,136 +1,243 @@
-Collections:
- - Name: PVT
+Models:
+ - Name: retinanet_pvt-t_fpn_1x_coco
+ In Collection: RetinaNet
+ Config: configs/pvt/retinanet_pvt-t_fpn_1x_coco.py
Metadata:
+ Training Memory (GB): 8.5
+ Epochs: 12
Training Data: COCO
Training Techniques:
- SGD with Momentum
- Weight Decay
Training Resources: 8x NVIDIA V100 GPUs
Architecture:
- - RetinaNet
- PyramidVisionTransformer
- - FPN
- Paper: https://arxiv.org/abs/2102.12122
- README: configs/pvt/README.md
- - Name: PVT-v2
- Metadata:
- Training Data: COCO
- Training Techniques:
- - SGD with Momentum
- - Weight Decay
- Training Resources: 8x NVIDIA V100 GPUs
- Architecture:
- - RetinaNet
- - PyramidVisionTransformerV2
- - FPN
- Paper: https://arxiv.org/abs/2106.13797
- README: configs/pvt/README.md
-Models:
- - Name: retinanet_pvt-t_fpn_1x_coco
- In Collection: PVT
- Config: configs/pvt/retinanet_pvt-t_fpn_1x_coco.py
- Metadata:
- Training Memory (GB): 8.5
- Epochs: 12
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 36.6
Weights: https://download.openmmlab.com/mmdetection/v2.0/pvt/retinanet_pvt-t_fpn_1x_coco/retinanet_pvt-t_fpn_1x_coco_20210831_103110-17b566bd.pth
+ Paper:
+ URL: https://arxiv.org/abs/2102.12122
+ Title: "Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions"
+ README: configs/pvt/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.17.0/mmdet/models/backbones/pvt.py#L315
+ Version: 2.17.0
+
- Name: retinanet_pvt-s_fpn_1x_coco
- In Collection: PVT
+ In Collection: RetinaNet
Config: configs/pvt/retinanet_pvt-s_fpn_1x_coco.py
Metadata:
Training Memory (GB): 14.5
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x NVIDIA V100 GPUs
+ Architecture:
+ - PyramidVisionTransformer
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 40.4
Weights: https://download.openmmlab.com/mmdetection/v2.0/pvt/retinanet_pvt-s_fpn_1x_coco/retinanet_pvt-s_fpn_1x_coco_20210906_142921-b6c94a5b.pth
+ Paper:
+ URL: https://arxiv.org/abs/2102.12122
+ Title: "Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions"
+ README: configs/pvt/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.17.0/mmdet/models/backbones/pvt.py#L315
+ Version: 2.17.0
+
- Name: retinanet_pvt-m_fpn_1x_coco
- In Collection: PVT
+ In Collection: RetinaNet
Config: configs/pvt/retinanet_pvt-m_fpn_1x_coco.py
Metadata:
Training Memory (GB): 20.9
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x NVIDIA V100 GPUs
+ Architecture:
+ - PyramidVisionTransformer
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 41.7
Weights: https://download.openmmlab.com/mmdetection/v2.0/pvt/retinanet_pvt-m_fpn_1x_coco/retinanet_pvt-m_fpn_1x_coco_20210831_103243-55effa1b.pth
+ Paper:
+ URL: https://arxiv.org/abs/2102.12122
+ Title: "Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions"
+ README: configs/pvt/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.17.0/mmdet/models/backbones/pvt.py#L315
+ Version: 2.17.0
+
- Name: retinanet_pvtv2-b0_fpn_1x_coco
- In Collection: PVT-v2
+ In Collection: RetinaNet
Config: configs/pvt/retinanet_pvtv2-b0_fpn_1x_coco.py
Metadata:
Training Memory (GB): 7.4
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x NVIDIA V100 GPUs
+ Architecture:
+ - PyramidVisionTransformerV2
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 37.1
Weights: https://download.openmmlab.com/mmdetection/v2.0/pvt/retinanet_pvtv2-b0_fpn_1x_coco/retinanet_pvtv2-b0_fpn_1x_coco_20210831_103157-13e9aabe.pth
+ Paper:
+ URL: https://arxiv.org/abs/2106.13797
+ Title: "PVTv2: Improved Baselines with Pyramid Vision Transformer"
+ README: configs/pvt/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.17.0/mmdet/models/backbones/pvt.py#L543
+ Version: 2.17.0
+
- Name: retinanet_pvtv2-b1_fpn_1x_coco
- In Collection: PVT-v2
+ In Collection: RetinaNet
Config: configs/pvt/retinanet_pvtv2-b1_fpn_1x_coco.py
Metadata:
Training Memory (GB): 9.5
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x NVIDIA V100 GPUs
+ Architecture:
+ - PyramidVisionTransformerV2
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 41.2
Weights: https://download.openmmlab.com/mmdetection/v2.0/pvt/retinanet_pvtv2-b1_fpn_1x_coco/retinanet_pvtv2-b1_fpn_1x_coco_20210831_103318-7e169a7d.pth
+ Paper:
+ URL: https://arxiv.org/abs/2106.13797
+ Title: "PVTv2: Improved Baselines with Pyramid Vision Transformer"
+ README: configs/pvt/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.17.0/mmdet/models/backbones/pvt.py#L543
+ Version: 2.17.0
+
- Name: retinanet_pvtv2-b2_fpn_1x_coco
- In Collection: PVT-v2
+ In Collection: RetinaNet
Config: configs/pvt/retinanet_pvtv2-b2_fpn_1x_coco.py
Metadata:
Training Memory (GB): 16.2
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x NVIDIA V100 GPUs
+ Architecture:
+ - PyramidVisionTransformerV2
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 44.6
Weights: https://download.openmmlab.com/mmdetection/v2.0/pvt/retinanet_pvtv2-b2_fpn_1x_coco/retinanet_pvtv2-b2_fpn_1x_coco_20210901_174843-529f0b9a.pth
+ Paper:
+ URL: https://arxiv.org/abs/2106.13797
+ Title: "PVTv2: Improved Baselines with Pyramid Vision Transformer"
+ README: configs/pvt/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.17.0/mmdet/models/backbones/pvt.py#L543
+ Version: 2.17.0
+
- Name: retinanet_pvtv2-b3_fpn_1x_coco
- In Collection: PVT-v2
+ In Collection: RetinaNet
Config: configs/pvt/retinanet_pvtv2-b3_fpn_1x_coco.py
Metadata:
Training Memory (GB): 23.0
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x NVIDIA V100 GPUs
+ Architecture:
+ - PyramidVisionTransformerV2
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 46.0
Weights: https://download.openmmlab.com/mmdetection/v2.0/pvt/retinanet_pvtv2-b3_fpn_1x_coco/retinanet_pvtv2-b3_fpn_1x_coco_20210903_151512-8357deff.pth
+ Paper:
+ URL: https://arxiv.org/abs/2106.13797
+ Title: "PVTv2: Improved Baselines with Pyramid Vision Transformer"
+ README: configs/pvt/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.17.0/mmdet/models/backbones/pvt.py#L543
+ Version: 2.17.0
+
- Name: retinanet_pvtv2-b4_fpn_1x_coco
- In Collection: PVT-v2
+ In Collection: RetinaNet
Config: configs/pvt/retinanet_pvtv2-b4_fpn_1x_coco.py
Metadata:
Training Memory (GB): 17.0
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x NVIDIA V100 GPUs
+ Architecture:
+ - PyramidVisionTransformerV2
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 46.3
Weights: https://download.openmmlab.com/mmdetection/v2.0/pvt/retinanet_pvtv2-b4_fpn_1x_coco/retinanet_pvtv2-b4_fpn_1x_coco_20210901_170151-83795c86.pth
+ Paper:
+ URL: https://arxiv.org/abs/2106.13797
+ Title: "PVTv2: Improved Baselines with Pyramid Vision Transformer"
+ README: configs/pvt/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.17.0/mmdet/models/backbones/pvt.py#L543
+ Version: 2.17.0
+
- Name: retinanet_pvtv2-b5_fpn_1x_coco
- In Collection: PVT-v2
+ In Collection: RetinaNet
Config: configs/pvt/retinanet_pvtv2-b5_fpn_1x_coco.py
Metadata:
Training Memory (GB): 18.7
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x NVIDIA V100 GPUs
+ Architecture:
+ - PyramidVisionTransformerV2
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 46.1
Weights: https://download.openmmlab.com/mmdetection/v2.0/pvt/retinanet_pvtv2-b5_fpn_1x_coco/retinanet_pvtv2-b5_fpn_1x_coco_20210902_201800-3420eb57.pth
+ Paper:
+ URL: https://arxiv.org/abs/2106.13797
+ Title: "PVTv2: Improved Baselines with Pyramid Vision Transformer"
+ README: configs/pvt/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.17.0/mmdet/models/backbones/pvt.py#L543
+ Version: 2.17.0
diff --git a/configs/queryinst/README.md b/configs/queryinst/README.md
index 7129dd4c890..c041662f1b0 100644
--- a/configs/queryinst/README.md
+++ b/configs/queryinst/README.md
@@ -1,24 +1,30 @@
-# Instances as Queries
+# QueryInst
-## Abstract
+> [Instances as Queries](https://openaccess.thecvf.com/content/ICCV2021/html/Fang_Instances_As_Queries_ICCV_2021_paper.html)
+
+
-
+## Abstract
We present QueryInst, a new perspective for instance segmentation. QueryInst is a multi-stage end-to-end system that treats instances of interest as learnable queries, enabling query based object detectors, e.g., Sparse R-CNN, to have strong instance segmentation performance. The attributes of instances such as categories, bounding boxes, instance masks, and instance association embeddings are represented by queries in a unified manner. In QueryInst, a query is shared by both detection and segmentation via dynamic convolutions and driven by parallelly-supervised multi-stage learning. We conduct extensive experiments on three challenging benchmarks, i.e., COCO, CityScapes, and YouTube-VIS to evaluate the effectiveness of QueryInst in object detection, instance segmentation, and video instance segmentation tasks. For the first time, we demonstrate that a simple end-to-end query based framework can achieve the state-of-the-art performance in various instance-level recognition tasks.
-
-
-
+## Results and Models
-## Citation
+| Model | Backbone | Style | Lr schd | Number of Proposals |Multi-Scale| RandomCrop | box AP | mask AP | Config | Download |
+|:------------:|:---------:|:-------:|:-------:|:-------: |:-------: |:---------:|:------:|:------:|:------:|:--------:|
+| QueryInst | R-50-FPN | pytorch | 1x | 100 | False | False | 42.0 | 37.5 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/queryinst/queryinst_r50_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/queryinst/queryinst_r50_fpn_1x_coco/queryinst_r50_fpn_1x_coco_20210907_084916-5a8f1998.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/queryinst/queryinst_r50_fpn_1x_coco/queryinst_r50_fpn_1x_coco_20210907_084916.log.json) |
+| QueryInst | R-50-FPN | pytorch | 3x | 100 | True | False | 44.8 | 39.8 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/queryinst/queryinst_r50_fpn_mstrain_480-800_3x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/queryinst/queryinst_r50_fpn_mstrain_480-800_3x_coco/queryinst_r50_fpn_mstrain_480-800_3x_coco_20210901_103643-7837af86.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/queryinst/queryinst_r50_fpn_mstrain_480-800_3x_coco/queryinst_r50_fpn_mstrain_480-800_3x_coco_20210901_103643.log.json) |
+| QueryInst | R-50-FPN | pytorch | 3x | 300 | True | True | 47.5 | 41.7 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/queryinst/queryinst_r50_fpn_300_proposals_crop_mstrain_480-800_3x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/queryinst/queryinst_r50_fpn_300_proposals_crop_mstrain_480-800_3x_coco/queryinst_r50_fpn_300_proposals_crop_mstrain_480-800_3x_coco_20210904_101802-85cffbd8.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/queryinst/queryinst_r50_fpn_300_proposals_crop_mstrain_480-800_3x_coco/queryinst_r50_fpn_300_proposals_crop_mstrain_480-800_3x_coco_20210904_101802.log.json) |
+| QueryInst | R-101-FPN | pytorch | 3x | 100 | True | False | 46.4 | 41.0 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/queryinst/queryinst_r101_fpn_mstrain_480-800_3x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/queryinst/queryinst_r101_fpn_mstrain_480-800_3x_coco/queryinst_r101_fpn_mstrain_480-800_3x_coco_20210904_104048-91f9995b.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/queryinst/queryinst_r101_fpn_mstrain_480-800_3x_coco/queryinst_r101_fpn_mstrain_480-800_3x_coco_20210904_104048.log.json) |
+| QueryInst | R-101-FPN | pytorch | 3x | 300 | True | True | 49.0 | 42.9 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/queryinst/queryinst_r101_fpn_300_proposals_crop_mstrain_480-800_3x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/queryinst/queryinst_r101_fpn_300_proposals_crop_mstrain_480-800_3x_coco/queryinst_r101_fpn_300_proposals_crop_mstrain_480-800_3x_coco_20210904_153621-76cce59f.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/queryinst/queryinst_r101_fpn_300_proposals_crop_mstrain_480-800_3x_coco/queryinst_r101_fpn_300_proposals_crop_mstrain_480-800_3x_coco_20210904_153621.log.json) |
-
+## Citation
-```
+```latex
@InProceedings{Fang_2021_ICCV,
author = {Fang, Yuxin and Yang, Shusheng and Wang, Xinggang and Li, Yu and Fang, Chen and Shan, Ying and Feng, Bin and Liu, Wenyu},
title = {Instances As Queries},
@@ -28,13 +34,3 @@ We present QueryInst, a new perspective for instance segmentation. QueryInst is
pages = {6910-6919}
}
```
-
-## Results and Models
-
-| Model | Backbone | Style | Lr schd | Number of Proposals |Multi-Scale| RandomCrop | box AP | mask AP | Config | Download |
-|:------------:|:---------:|:-------:|:-------:|:-------: |:-------: |:---------:|:------:|:------:|:------:|:--------:|
-| QueryInst | R-50-FPN | pytorch | 1x | 100 | False | False | 42.0 | 37.5 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/queryinst/queryinst_r50_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/queryinst/queryinst_r50_fpn_1x_coco/queryinst_r50_fpn_1x_coco_20210907_084916-5a8f1998.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/queryinst/queryinst_r50_fpn_1x_coco/queryinst_r50_fpn_1x_coco_20210907_084916.log.json) |
-| QueryInst | R-50-FPN | pytorch | 3x | 100 | True | False | 44.8 | 39.8 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/queryinst/queryinst_r50_fpn_mstrain_480-800_3x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/queryinst/queryinst_r50_fpn_mstrain_480-800_3x_coco/queryinst_r50_fpn_mstrain_480-800_3x_coco_20210901_103643-7837af86.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/queryinst/queryinst_r50_fpn_mstrain_480-800_3x_coco/queryinst_r50_fpn_mstrain_480-800_3x_coco_20210901_103643.log.json) |
-| QueryInst | R-50-FPN | pytorch | 3x | 300 | True | True | 47.5 | 41.7 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/queryinst/queryinst_r50_fpn_300_proposals_crop_mstrain_480-800_3x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/queryinst/queryinst_r50_fpn_300_proposals_crop_mstrain_480-800_3x_coco/queryinst_r50_fpn_300_proposals_crop_mstrain_480-800_3x_coco_20210904_101802-85cffbd8.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/queryinst/queryinst_r50_fpn_300_proposals_crop_mstrain_480-800_3x_coco/queryinst_r50_fpn_300_proposals_crop_mstrain_480-800_3x_coco_20210904_101802.log.json) |
-| QueryInst | R-101-FPN | pytorch | 3x | 100 | True | False | 46.4 | 41.0 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/queryinst/queryinst_r101_fpn_mstrain_480-800_3x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/queryinst/queryinst_r101_fpn_mstrain_480-800_3x_coco/queryinst_r101_fpn_mstrain_480-800_3x_coco_20210904_104048-91f9995b.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/queryinst/queryinst_r101_fpn_mstrain_480-800_3x_coco/queryinst_r101_fpn_mstrain_480-800_3x_coco_20210904_104048.log.json) |
-| QueryInst | R-101-FPN | pytorch | 3x | 300 | True | True | 49.0 | 42.9 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/queryinst/queryinst_r101_fpn_300_proposals_crop_mstrain_480-800_3x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/queryinst/queryinst_r101_fpn_300_proposals_crop_mstrain_480-800_3x_coco/queryinst_r101_fpn_300_proposals_crop_mstrain_480-800_3x_coco_20210904_153621-76cce59f.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/queryinst/queryinst_r101_fpn_300_proposals_crop_mstrain_480-800_3x_coco/queryinst_r101_fpn_300_proposals_crop_mstrain_480-800_3x_coco_20210904_153621.log.json) |
diff --git a/configs/regnet/README.md b/configs/regnet/README.md
index 51f44df4122..40c1f7211f5 100644
--- a/configs/regnet/README.md
+++ b/configs/regnet/README.md
@@ -1,40 +1,23 @@
-# Designing Network Design Spaces
+# RegNet
-## Abstract
+> [Designing Network Design Spaces](https://arxiv.org/abs/2003.13678)
-
+
+
+## Abstract
In this work, we present a new network design paradigm. Our goal is to help advance the understanding of network design and discover design principles that generalize across settings. Instead of focusing on designing individual network instances, we design network design spaces that parametrize populations of networks. The overall process is analogous to classic manual design of networks, but elevated to the design space level. Using our methodology we explore the structure aspect of network design and arrive at a low-dimensional design space consisting of simple, regular networks that we call RegNet. The core insight of the RegNet parametrization is surprisingly simple: widths and depths of good networks can be explained by a quantized linear function. We analyze the RegNet design space and arrive at interesting findings that do not match the current practice of network design. The RegNet design space provides simple and fast networks that work well across a wide range of flop regimes. Under comparable training settings and flops, the RegNet models outperform the popular EfficientNet models while being up to 5x faster on GPUs.
-
-
-
-
## Introduction
-
-
We implement RegNetX and RegNetY models in detection systems and provide their first results on Mask R-CNN, Faster R-CNN and RetinaNet.
The pre-trained modles are converted from [model zoo of pycls](https://github.com/facebookresearch/pycls/blob/master/MODEL_ZOO.md).
-## Citation
-
-```latex
-@article{radosavovic2020designing,
- title={Designing Network Design Spaces},
- author={Ilija Radosavovic and Raj Prateek Kosaraju and Ross Girshick and Kaiming He and Piotr Dollár},
- year={2020},
- eprint={2003.13678},
- archivePrefix={arXiv},
- primaryClass={cs.CV}
-}
-```
-
## Usage
To use a regnet model, there are two steps to do:
@@ -64,7 +47,7 @@ For other pre-trained models or self-implemented regnet models, the users are re
**Note**: Although Fig. 15 & 16 also provide `w0`, `wa`, `wm`, `group_w`, and `bot_mul` for `arch`, they are quantized thus inaccurate, using them sometimes produces different backbone that does not match the key in the pre-trained model.
-## Results
+## Results and Models
### Mask R-CNN
@@ -124,3 +107,16 @@ We also train some models with longer schedules and multi-scale training. The us
1. The models are trained using a different weight decay, i.e., `weight_decay=5e-5` according to the setting in ImageNet training. This brings improvement of at least 0.7 AP absolute but does not improve the model using ResNet-50.
2. RetinaNets using RegNets are trained with learning rate 0.02 with gradient clip. We find that using learning rate 0.02 could improve the results by at least 0.7 AP absolute and gradient clip is necessary to stabilize the training. However, this does not improve the performance of ResNet-50-FPN RetinaNet.
+
+## Citation
+
+```latex
+@article{radosavovic2020designing,
+ title={Designing Network Design Spaces},
+ author={Ilija Radosavovic and Raj Prateek Kosaraju and Ross Girshick and Kaiming He and Piotr Dollár},
+ year={2020},
+ eprint={2003.13678},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+}
+```
diff --git a/configs/regnet/metafile.yml b/configs/regnet/metafile.yml
index 5390a3530d9..ecd39531ee0 100644
--- a/configs/regnet/metafile.yml
+++ b/configs/regnet/metafile.yml
@@ -1,6 +1,10 @@
-Collections:
- - Name: RegNet
+Models:
+ - Name: mask_rcnn_regnetx-3.2GF_fpn_1x_coco
+ In Collection: Mask R-CNN
+ Config: configs/regnet/mask_rcnn_regnetx-3.2GF_fpn_1x_coco.py
Metadata:
+ Training Memory (GB): 5.0
+ Epochs: 12
Training Data: COCO
Training Techniques:
- SGD with Momentum
@@ -8,21 +12,6 @@ Collections:
Training Resources: 8x V100 GPUs
Architecture:
- RegNet
- Paper:
- URL: https://arxiv.org/abs/2003.13678
- Title: 'Designing Network Design Spaces'
- README: configs/regnet/README.md
- Code:
- URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/regnet.py#L11
- Version: v2.1.0
-
-Models:
- - Name: mask_rcnn_regnetx-3.2GF_fpn_1x_coco
- In Collection: RegNet
- Config: configs/regnet/mask_rcnn_regnetx-3.2GF_fpn_1x_coco.py
- Metadata:
- Training Memory (GB): 5.0
- Epochs: 12
Results:
- Task: Object Detection
Dataset: COCO
@@ -33,13 +22,27 @@ Models:
Metrics:
mask AP: 36.6
Weights: https://download.openmmlab.com/mmdetection/v2.0/regnet/mask_rcnn_regnetx-3.2GF_fpn_1x_coco/mask_rcnn_regnetx-3.2GF_fpn_1x_coco_20200520_163141-2a9d1814.pth
+ Paper:
+ URL: https://arxiv.org/abs/2003.13678
+ Title: 'Designing Network Design Spaces'
+ README: configs/regnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/regnet.py#L11
+ Version: v2.1.0
- Name: mask_rcnn_regnetx-4GF_fpn_1x_coco
- In Collection: RegNet
+ In Collection: Mask R-CNN
Config: configs/regnet/mask_rcnn_regnetx-4GF_fpn_1x_coco.py
Metadata:
Training Memory (GB): 5.5
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - RegNet
Results:
- Task: Object Detection
Dataset: COCO
@@ -50,13 +53,27 @@ Models:
Metrics:
mask AP: 37.4
Weights: https://download.openmmlab.com/mmdetection/v2.0/regnet/mask_rcnn_regnetx-4GF_fpn_1x_coco/mask_rcnn_regnetx-4GF_fpn_1x_coco_20200517_180217-32e9c92d.pth
+ Paper:
+ URL: https://arxiv.org/abs/2003.13678
+ Title: 'Designing Network Design Spaces'
+ README: configs/regnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/regnet.py#L11
+ Version: v2.1.0
- Name: mask_rcnn_regnetx-6.4GF_fpn_1x_coco
- In Collection: RegNet
+ In Collection: Mask R-CNN
Config: configs/regnet/mask_rcnn_regnetx-6.4GF_fpn_1x_coco.py
Metadata:
Training Memory (GB): 6.1
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - RegNet
Results:
- Task: Object Detection
Dataset: COCO
@@ -67,13 +84,27 @@ Models:
Metrics:
mask AP: 37.1
Weights: https://download.openmmlab.com/mmdetection/v2.0/regnet/mask_rcnn_regnetx-6.4GF_fpn_1x_coco/mask_rcnn_regnetx-6.4GF_fpn_1x_coco_20200517_180439-3a7aae83.pth
+ Paper:
+ URL: https://arxiv.org/abs/2003.13678
+ Title: 'Designing Network Design Spaces'
+ README: configs/regnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/regnet.py#L11
+ Version: v2.1.0
- Name: mask_rcnn_regnetx-8GF_fpn_1x_coco
- In Collection: RegNet
+ In Collection: Mask R-CNN
Config: configs/regnet/mask_rcnn_regnetx-8GF_fpn_1x_coco.py
Metadata:
Training Memory (GB): 6.4
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - RegNet
Results:
- Task: Object Detection
Dataset: COCO
@@ -84,13 +115,27 @@ Models:
Metrics:
mask AP: 37.5
Weights: https://download.openmmlab.com/mmdetection/v2.0/regnet/mask_rcnn_regnetx-8GF_fpn_1x_coco/mask_rcnn_regnetx-8GF_fpn_1x_coco_20200517_180515-09daa87e.pth
+ Paper:
+ URL: https://arxiv.org/abs/2003.13678
+ Title: 'Designing Network Design Spaces'
+ README: configs/regnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/regnet.py#L11
+ Version: v2.1.0
- Name: mask_rcnn_regnetx-12GF_fpn_1x_coco
- In Collection: RegNet
+ In Collection: Mask R-CNN
Config: configs/regnet/mask_rcnn_regnetx-12GF_fpn_1x_coco.py
Metadata:
Training Memory (GB): 7.4
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - RegNet
Results:
- Task: Object Detection
Dataset: COCO
@@ -101,13 +146,27 @@ Models:
Metrics:
mask AP: 38
Weights: https://download.openmmlab.com/mmdetection/v2.0/regnet/mask_rcnn_regnetx-12GF_fpn_1x_coco/mask_rcnn_regnetx-12GF_fpn_1x_coco_20200517_180552-b538bd8b.pth
+ Paper:
+ URL: https://arxiv.org/abs/2003.13678
+ Title: 'Designing Network Design Spaces'
+ README: configs/regnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/regnet.py#L11
+ Version: v2.1.0
- Name: mask_rcnn_regnetx-3.2GF_fpn_mdconv_c3-c5_1x_coco
- In Collection: RegNet
+ In Collection: Mask R-CNN
Config: configs/regnet/mask_rcnn_regnetx-3.2GF_fpn_mdconv_c3-c5_1x_coco.py
Metadata:
Training Memory (GB): 5.0
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - RegNet
Results:
- Task: Object Detection
Dataset: COCO
@@ -118,143 +177,297 @@ Models:
Metrics:
mask AP: 36.6
Weights: https://download.openmmlab.com/mmdetection/v2.0/regnet/mask_rcnn_regnetx-3.2GF_fpn_mdconv_c3-c5_1x_coco/mask_rcnn_regnetx-3.2GF_fpn_mdconv_c3-c5_1x_coco_20200520_172726-75f40794.pth
+ Paper:
+ URL: https://arxiv.org/abs/2003.13678
+ Title: 'Designing Network Design Spaces'
+ README: configs/regnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/regnet.py#L11
+ Version: v2.1.0
- Name: faster_rcnn_regnetx-3.2GF_fpn_1x_coco
- In Collection: RegNet
+ In Collection: Faster R-CNN
Config: configs/regnet/faster_rcnn_regnetx-3.2GF_fpn_1x_coco.py
Metadata:
Training Memory (GB): 4.5
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - RegNet
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 39.9
Weights: https://download.openmmlab.com/mmdetection/v2.0/regnet/faster_rcnn_regnetx-3.2GF_fpn_1x_coco/faster_rcnn_regnetx-3.2GF_fpn_1x_coco_20200517_175927-126fd9bf.pth
+ Paper:
+ URL: https://arxiv.org/abs/2003.13678
+ Title: 'Designing Network Design Spaces'
+ README: configs/regnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/regnet.py#L11
+ Version: v2.1.0
- Name: faster_rcnn_regnetx-3.2GF_fpn_2x_coco
- In Collection: RegNet
+ In Collection: Faster R-CNN
Config: configs/regnet/faster_rcnn_regnetx-3.2GF_fpn_2x_coco.py
Metadata:
Training Memory (GB): 4.5
Epochs: 24
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - RegNet
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 41.1
Weights: https://download.openmmlab.com/mmdetection/v2.0/regnet/faster_rcnn_regnetx-3.2GF_fpn_2x_coco/faster_rcnn_regnetx-3.2GF_fpn_2x_coco_20200520_223955-e2081918.pth
+ Paper:
+ URL: https://arxiv.org/abs/2003.13678
+ Title: 'Designing Network Design Spaces'
+ README: configs/regnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/regnet.py#L11
+ Version: v2.1.0
- Name: retinanet_regnetx-800MF_fpn_1x_coco
- In Collection: RegNet
+ In Collection: RetinaNet
Config: configs/regnet/retinanet_regnetx-800MF_fpn_1x_coco.py
Metadata:
Training Memory (GB): 2.5
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - RegNet
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 35.6
Weights: https://download.openmmlab.com/mmdetection/v2.0/regnet/retinanet_regnetx-800MF_fpn_1x_coco/retinanet_regnetx-800MF_fpn_1x_coco_20200517_191403-f6f91d10.pth
+ Paper:
+ URL: https://arxiv.org/abs/2003.13678
+ Title: 'Designing Network Design Spaces'
+ README: configs/regnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/regnet.py#L11
+ Version: v2.1.0
- Name: retinanet_regnetx-1.6GF_fpn_1x_coco
- In Collection: RegNet
+ In Collection: RetinaNet
Config: configs/regnet/retinanet_regnetx-1.6GF_fpn_1x_coco.py
Metadata:
Training Memory (GB): 3.3
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - RegNet
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 37.3
Weights: https://download.openmmlab.com/mmdetection/v2.0/regnet/retinanet_regnetx-1.6GF_fpn_1x_coco/retinanet_regnetx-1.6GF_fpn_1x_coco_20200517_191403-37009a9d.pth
+ Paper:
+ URL: https://arxiv.org/abs/2003.13678
+ Title: 'Designing Network Design Spaces'
+ README: configs/regnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/regnet.py#L11
+ Version: v2.1.0
- Name: retinanet_regnetx-3.2GF_fpn_1x_coco
- In Collection: RegNet
+ In Collection: RetinaNet
Config: configs/regnet/retinanet_regnetx-3.2GF_fpn_1x_coco.py
Metadata:
Training Memory (GB): 4.2
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - RegNet
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 39.1
Weights: https://download.openmmlab.com/mmdetection/v2.0/regnet/retinanet_regnetx-3.2GF_fpn_1x_coco/retinanet_regnetx-3.2GF_fpn_1x_coco_20200520_163141-cb1509e8.pth
+ Paper:
+ URL: https://arxiv.org/abs/2003.13678
+ Title: 'Designing Network Design Spaces'
+ README: configs/regnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/regnet.py#L11
+ Version: v2.1.0
- Name: faster_rcnn_regnetx-400MF_fpn_mstrain_3x_coco
- In Collection: RegNet
+ In Collection: Faster R-CNN
Config: configs/regnet/faster_rcnn_regnetx-400MF_fpn_mstrain_3x_coco.py
Metadata:
Training Memory (GB): 2.3
Epochs: 36
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - RegNet
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 37.1
Weights: https://download.openmmlab.com/mmdetection/v2.0/regnet/faster_rcnn_regnetx-400MF_fpn_mstrain_3x_coco/faster_rcnn_regnetx-400MF_fpn_mstrain_3x_coco_20210526_095112-e1967c37.pth
+ Paper:
+ URL: https://arxiv.org/abs/2003.13678
+ Title: 'Designing Network Design Spaces'
+ README: configs/regnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/regnet.py#L11
+ Version: v2.1.0
- Name: faster_rcnn_regnetx-800MF_fpn_mstrain_3x_coco
- In Collection: RegNet
+ In Collection: Faster R-CNN
Config: configs/regnet/faster_rcnn_regnetx-800MF_fpn_mstrain_3x_coco.py
Metadata:
Training Memory (GB): 2.8
Epochs: 36
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - RegNet
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 38.8
Weights: https://download.openmmlab.com/mmdetection/v2.0/regnet/faster_rcnn_regnetx-800MF_fpn_mstrain_3x_coco/faster_rcnn_regnetx-800MF_fpn_mstrain_3x_coco_20210526_095118-a2c70b20.pth
+ Paper:
+ URL: https://arxiv.org/abs/2003.13678
+ Title: 'Designing Network Design Spaces'
+ README: configs/regnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/regnet.py#L11
+ Version: v2.1.0
- Name: faster_rcnn_regnetx-1.6GF_fpn_mstrain_3x_coco
- In Collection: RegNet
+ In Collection: Faster R-CNN
Config: configs/regnet/faster_rcnn_regnetx-1.6GF_fpn_mstrain_3x_coco.py
Metadata:
Training Memory (GB): 3.4
Epochs: 36
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - RegNet
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 40.5
Weights: https://download.openmmlab.com/mmdetection/v2.0/regnet/faster_rcnn_regnetx-1.6GF_fpn_mstrain_3x_coco/faster_rcnn_regnetx-1_20210526_095325-94aa46cc.pth
+ Paper:
+ URL: https://arxiv.org/abs/2003.13678
+ Title: 'Designing Network Design Spaces'
+ README: configs/regnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/regnet.py#L11
+ Version: v2.1.0
- Name: faster_rcnn_regnetx-3.2GF_fpn_mstrain_3x_coco
- In Collection: RegNet
+ In Collection: Faster R-CNN
Config: configs/regnet/faster_rcnn_regnetx-3.2GF_fpn_mstrain_3x_coco.py
Metadata:
Training Memory (GB): 4.4
Epochs: 36
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - RegNet
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 42.3
Weights: https://download.openmmlab.com/mmdetection/v2.0/regnet/faster_rcnn_regnetx-3.2GF_fpn_mstrain_3x_coco/faster_rcnn_regnetx-3_20210526_095152-e16a5227.pth
+ Paper:
+ URL: https://arxiv.org/abs/2003.13678
+ Title: 'Designing Network Design Spaces'
+ README: configs/regnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/regnet.py#L11
+ Version: v2.1.0
- Name: faster_rcnn_regnetx-4GF_fpn_mstrain_3x_coco
- In Collection: RegNet
+ In Collection: Faster R-CNN
Config: configs/regnet/faster_rcnn_regnetx-4GF_fpn_mstrain_3x_coco.py
Metadata:
Training Memory (GB): 4.9
Epochs: 36
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - RegNet
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 42.8
Weights: https://download.openmmlab.com/mmdetection/v2.0/regnet/faster_rcnn_regnetx-4GF_fpn_mstrain_3x_coco/faster_rcnn_regnetx-4GF_fpn_mstrain_3x_coco_20210526_095201-65eaf841.pth
+ Paper:
+ URL: https://arxiv.org/abs/2003.13678
+ Title: 'Designing Network Design Spaces'
+ README: configs/regnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/regnet.py#L11
+ Version: v2.1.0
- Name: mask_rcnn_regnetx-3.2GF_fpn_mstrain_3x_coco
- In Collection: RegNet
+ In Collection: Mask R-CNN
Config: configs/regnet/mask_rcnn_regnetx-3.2GF_fpn_mstrain_3x_coco.py
Metadata:
Training Memory (GB): 5.0
Epochs: 36
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - RegNet
Results:
- Task: Object Detection
Dataset: COCO
@@ -265,13 +478,27 @@ Models:
Metrics:
mask AP: 38.7
Weights: https://download.openmmlab.com/mmdetection/v2.0/regnet/mask_rcnn_regnetx-3.2GF_fpn_mstrain_3x_coco/mask_rcnn_regnetx-3.2GF_fpn_mstrain_3x_coco_20200521_202221-99879813.pth
+ Paper:
+ URL: https://arxiv.org/abs/2003.13678
+ Title: 'Designing Network Design Spaces'
+ README: configs/regnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/regnet.py#L11
+ Version: v2.1.0
- Name: mask_rcnn_regnetx-400MF_fpn_mstrain-poly_3x_coco
- In Collection: RegNet
+ In Collection: Mask R-CNN
Config: configs/regnet/mask_rcnn_regnetx-400MF_fpn_mstrain-poly_3x_coco.py
Metadata:
Training Memory (GB): 2.5
Epochs: 36
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - RegNet
Results:
- Task: Object Detection
Dataset: COCO
@@ -282,13 +509,27 @@ Models:
Metrics:
mask AP: 34.4
Weights: https://download.openmmlab.com/mmdetection/v2.0/regnet/mask_rcnn_regnetx-400MF_fpn_mstrain-poly_3x_coco/mask_rcnn_regnetx-400MF_fpn_mstrain-poly_3x_coco_20210601_235443-8aac57a4.pth
+ Paper:
+ URL: https://arxiv.org/abs/2003.13678
+ Title: 'Designing Network Design Spaces'
+ README: configs/regnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/regnet.py#L11
+ Version: v2.1.0
- Name: mask_rcnn_regnetx-800MF_fpn_mstrain-poly_3x_coco
- In Collection: RegNet
+ In Collection: Mask R-CNN
Config: configs/regnet/mask_rcnn_regnetx-800MF_fpn_mstrain-poly_3x_coco.py
Metadata:
Training Memory (GB): 2.9
Epochs: 36
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - RegNet
Results:
- Task: Object Detection
Dataset: COCO
@@ -299,13 +540,27 @@ Models:
Metrics:
mask AP: 36.1
Weights: https://download.openmmlab.com/mmdetection/v2.0/regnet/mask_rcnn_regnetx-800MF_fpn_mstrain-poly_3x_coco/mask_rcnn_regnetx-800MF_fpn_mstrain-poly_3x_coco_20210602_210641-715d51f5.pth
+ Paper:
+ URL: https://arxiv.org/abs/2003.13678
+ Title: 'Designing Network Design Spaces'
+ README: configs/regnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/regnet.py#L11
+ Version: v2.1.0
- Name: mask_rcnn_regnetx-1.6GF_fpn_mstrain_3x_coco
- In Collection: RegNet
+ In Collection: Mask R-CNN
Config: configs/regnet/mask_rcnn_regnetx-1.6GF_fpn_mstrain_3x_coco.py
Metadata:
Training Memory (GB): 3.6
Epochs: 36
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - RegNet
Results:
- Task: Object Detection
Dataset: COCO
@@ -316,13 +571,27 @@ Models:
Metrics:
mask AP: 37.5
Weights: https://download.openmmlab.com/mmdetection/v2.0/regnet/mask_rcnn_regnetx-1.6GF_fpn_mstrain-poly_3x_coco/mask_rcnn_regnetx-1_20210602_210641-6764cff5.pth
+ Paper:
+ URL: https://arxiv.org/abs/2003.13678
+ Title: 'Designing Network Design Spaces'
+ README: configs/regnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/regnet.py#L11
+ Version: v2.1.0
- Name: mask_rcnn_regnetx-3.2GF_fpn_mstrain_3x_coco
- In Collection: RegNet
+ In Collection: Mask R-CNN
Config: configs/regnet/mask_rcnn_regnetx-3.2GF_fpn_mstrain_3x_coco.py
Metadata:
Training Memory (GB): 5.0
Epochs: 36
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - RegNet
Results:
- Task: Object Detection
Dataset: COCO
@@ -333,13 +602,27 @@ Models:
Metrics:
mask AP: 38.7
Weights: https://download.openmmlab.com/mmdetection/v2.0/regnet/mask_rcnn_regnetx-1.6GF_fpn_mstrain-poly_3x_coco/mask_rcnn_regnetx-1_20210602_210641-6e63e19c.pth
+ Paper:
+ URL: https://arxiv.org/abs/2003.13678
+ Title: 'Designing Network Design Spaces'
+ README: configs/regnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/regnet.py#L11
+ Version: v2.1.0
- Name: mask_rcnn_regnetx-4GF_fpn_mstrain_3x_coco
- In Collection: RegNet
+ In Collection: Mask R-CNN
Config: configs/regnet/mask_rcnn_regnetx-4GF_fpn_mstrain_3x_coco.py
Metadata:
Training Memory (GB): 5.1
Epochs: 36
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - RegNet
Results:
- Task: Object Detection
Dataset: COCO
@@ -350,13 +633,27 @@ Models:
Metrics:
mask AP: 39.2
Weights: https://download.openmmlab.com/mmdetection/v2.0/regnet/mask_rcnn_regnetx-4GF_fpn_mstrain-poly_3x_coco/mask_rcnn_regnetx-4GF_fpn_mstrain-poly_3x_coco_20210602_032621-00f0331c.pth
+ Paper:
+ URL: https://arxiv.org/abs/2003.13678
+ Title: 'Designing Network Design Spaces'
+ README: configs/regnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/regnet.py#L11
+ Version: v2.1.0
- Name: cascade_mask_rcnn_regnetx-400MF_fpn_mstrain_3x_coco
- In Collection: RegNet
+ In Collection: Cascade R-CNN
Config: configs/regnet/cascade_mask_rcnn_regnetx-400MF_fpn_mstrain_3x_coco.py
Metadata:
Training Memory (GB): 4.3
Epochs: 36
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - RegNet
Results:
- Task: Object Detection
Dataset: COCO
@@ -367,13 +664,27 @@ Models:
Metrics:
mask AP: 36.4
Weights: https://download.openmmlab.com/mmdetection/v2.0/regnet/cascade_mask_rcnn_regnetx-400MF_fpn_mstrain_3x_coco/cascade_mask_rcnn_regnetx-400MF_fpn_mstrain_3x_coco_20210715_211619-5142f449.pth
+ Paper:
+ URL: https://arxiv.org/abs/2003.13678
+ Title: 'Designing Network Design Spaces'
+ README: configs/regnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/regnet.py#L11
+ Version: v2.1.0
- Name: cascade_mask_rcnn_regnetx-800MF_fpn_mstrain_3x_coco
- In Collection: RegNet
+ In Collection: Cascade R-CNN
Config: configs/regnet/cascade_mask_rcnn_regnetx-800MF_fpn_mstrain_3x_coco.py
Metadata:
Training Memory (GB): 4.8
Epochs: 36
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - RegNet
Results:
- Task: Object Detection
Dataset: COCO
@@ -384,13 +695,27 @@ Models:
Metrics:
mask AP: 37.6
Weights: https://download.openmmlab.com/mmdetection/v2.0/regnet/cascade_mask_rcnn_regnetx-800MF_fpn_mstrain_3x_coco/cascade_mask_rcnn_regnetx-800MF_fpn_mstrain_3x_coco_20210715_211616-dcbd13f4.pth
+ Paper:
+ URL: https://arxiv.org/abs/2003.13678
+ Title: 'Designing Network Design Spaces'
+ README: configs/regnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/regnet.py#L11
+ Version: v2.1.0
- Name: cascade_mask_rcnn_regnetx-1.6GF_fpn_mstrain_3x_coco
- In Collection: RegNet
+ In Collection: Cascade R-CNN
Config: configs/regnet/cascade_mask_rcnn_regnetx-1.6GF_fpn_mstrain_3x_coco.py
Metadata:
Training Memory (GB): 5.4
Epochs: 36
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - RegNet
Results:
- Task: Object Detection
Dataset: COCO
@@ -401,13 +726,27 @@ Models:
Metrics:
mask AP: 39.0
Weights: https://download.openmmlab.com/mmdetection/v2.0/regnet/cascade_mask_rcnn_regnetx-1.6GF_fpn_mstrain_3x_coco/cascade_mask_rcnn_regnetx-1_20210715_211616-75f29a61.pth
+ Paper:
+ URL: https://arxiv.org/abs/2003.13678
+ Title: 'Designing Network Design Spaces'
+ README: configs/regnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/regnet.py#L11
+ Version: v2.1.0
- Name: cascade_mask_rcnn_regnetx-3.2GF_fpn_mstrain_3x_coco
- In Collection: RegNet
+ In Collection: Cascade R-CNN
Config: configs/regnet/cascade_mask_rcnn_regnetx-3.2GF_fpn_mstrain_3x_coco.py
Metadata:
Training Memory (GB): 6.4
Epochs: 36
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - RegNet
Results:
- Task: Object Detection
Dataset: COCO
@@ -418,13 +757,27 @@ Models:
Metrics:
mask AP: 40.0
Weights: https://download.openmmlab.com/mmdetection/v2.0/regnet/cascade_mask_rcnn_regnetx-3.2GF_fpn_mstrain_3x_coco/cascade_mask_rcnn_regnetx-3_20210715_211616-b9c2c58b.pth
+ Paper:
+ URL: https://arxiv.org/abs/2003.13678
+ Title: 'Designing Network Design Spaces'
+ README: configs/regnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/regnet.py#L11
+ Version: v2.1.0
- Name: cascade_mask_rcnn_regnetx-4GF_fpn_mstrain_3x_coco
- In Collection: RegNet
+ In Collection: Cascade R-CNN
Config: configs/regnet/cascade_mask_rcnn_regnetx-4GF_fpn_mstrain_3x_coco.py
Metadata:
Training Memory (GB): 6.9
Epochs: 36
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - RegNet
Results:
- Task: Object Detection
Dataset: COCO
@@ -435,3 +788,10 @@ Models:
Metrics:
mask AP: 40.0
Weights: https://download.openmmlab.com/mmdetection/v2.0/regnet/cascade_mask_rcnn_regnetx-4GF_fpn_mstrain_3x_coco/cascade_mask_rcnn_regnetx-4GF_fpn_mstrain_3x_coco_20210715_212034-cbb1be4c.pth
+ Paper:
+ URL: https://arxiv.org/abs/2003.13678
+ Title: 'Designing Network Design Spaces'
+ README: configs/regnet/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/regnet.py#L11
+ Version: v2.1.0
diff --git a/configs/reppoints/README.md b/configs/reppoints/README.md
index 8e53bd3e0c7..205a8732783 100644
--- a/configs/reppoints/README.md
+++ b/configs/reppoints/README.md
@@ -1,19 +1,17 @@
-# RepPoints: Point Set Representation for Object Detection
+# RepPoints
-## Abstract
+> [RepPoints: Point Set Representation for Object Detection](https://arxiv.org/abs/1904.11490)
+
+
-
+## Abstract
Modern object detectors rely heavily on rectangular bounding boxes, such as anchors, proposals and the final predictions, to represent objects at various recognition stages. The bounding box is convenient to use but provides only a coarse localization of objects and leads to a correspondingly coarse extraction of object features. In this paper, we present RepPoints(representative points), a new finer representation of objects as a set of sample points useful for both localization and recognition. Given ground truth localization and recognition targets for training, RepPoints learn to automatically arrange themselves in a manner that bounds the spatial extent of an object and indicates semantically significant local areas. They furthermore do not require the use of anchors to sample a space of bounding boxes. We show that an anchor-free object detector based on RepPoints can be as effective as the state-of-the-art anchor-based detection methods, with 46.5 AP and 67.4 AP50 on the COCO test-dev detection benchmark, using ResNet-101 model.
-
-
-
-
## Introdution
By [Ze Yang](https://yangze.tech/), [Shaohui Liu](http://b1ueber2y.me/), and [Han Hu](https://ancientmooner.github.io/).
@@ -21,25 +19,11 @@ By [Ze Yang](https://yangze.tech/), [Shaohui Liu](http://b1ueber2y.me/), and [Ha
We provide code support and configuration files to reproduce the results in the paper for
["RepPoints: Point Set Representation for Object Detection"](https://arxiv.org/abs/1904.11490) on COCO object detection.
-
-
**RepPoints**, initially described in [arXiv](https://arxiv.org/abs/1904.11490), is a new representation method for visual objects, on which visual understanding tasks are typically centered. Visual object representation, aiming at both geometric description and appearance feature extraction, is conventionally achieved by `bounding box + RoIPool (RoIAlign)`. The bounding box representation is convenient to use; however, it provides only a rectangular localization of objects that lacks geometric precision and may consequently degrade feature quality. Our new representation, RepPoints, models objects by a `point set` instead of a `bounding box`, which learns to adaptively position themselves over an object in a manner that circumscribes the object’s `spatial extent` and enables `semantically aligned feature extraction`. This richer and more flexible representation maintains the convenience of bounding boxes while facilitating various visual understanding applications. This repo demonstrated the effectiveness of RepPoints for COCO object detection.
Another feature of this repo is the demonstration of an `anchor-free detector`, which can be as effective as state-of-the-art anchor-based detection methods. The anchor-free detector can utilize either `bounding box` or `RepPoints` as the basic object representation.
-## Citation
-
-```
-@inproceedings{yang2019reppoints,
- title={RepPoints: Point Set Representation for Object Detection},
- author={Yang, Ze and Liu, Shaohui and Hu, Han and Wang, Liwei and Lin, Stephen},
- booktitle={The IEEE International Conference on Computer Vision (ICCV)},
- month={Oct},
- year={2019}
-}
-```
-
-## Results and models
+## Results and Models
The results on COCO 2017val are shown in the table below.
@@ -61,3 +45,15 @@ The results on COCO 2017val are shown in the table below.
- `none` in the `anchor` column means 2-d `center point` (x,y) is used to represent the initial object hypothesis. `single` denotes one 4-d anchor box (x,y,w,h) with IoU based label assign criterion is adopted.
- `moment`, `partial MinMax`, `MinMax` in the `convert func` column are three functions to convert a point set to a pseudo box.
- Note the results here are slightly different from those reported in the paper, due to framework change. While the original paper uses an [MXNet](https://mxnet.apache.org/) implementation, we re-implement the method in [PyTorch](https://pytorch.org/) based on mmdetection.
+
+## Citation
+
+```latex
+@inproceedings{yang2019reppoints,
+ title={RepPoints: Point Set Representation for Object Detection},
+ author={Yang, Ze and Liu, Shaohui and Hu, Han and Wang, Liwei and Lin, Stephen},
+ booktitle={The IEEE International Conference on Computer Vision (ICCV)},
+ month={Oct},
+ year={2019}
+}
+```
diff --git a/configs/res2net/README.md b/configs/res2net/README.md
index 3a76bef6980..29d1d461aee 100644
--- a/configs/res2net/README.md
+++ b/configs/res2net/README.md
@@ -1,23 +1,19 @@
-# Res2Net: A New Multi-scale Backbone Architecture
+# Res2Net
-## Abstract
+> [Res2Net: A New Multi-scale Backbone Architecture](https://arxiv.org/abs/1904.01169)
+
+
-
+## Abstract
Representing features at multiple scales is of great importance for numerous vision tasks. Recent advances in backbone convolutional neural networks (CNNs) continually demonstrate stronger multi-scale representation ability, leading to consistent performance gains on a wide range of applications. However, most existing methods represent the multi-scale features in a layer-wise manner. In this paper, we propose a novel building block for CNNs, namely Res2Net, by constructing hierarchical residual-like connections within one single residual block. The Res2Net represents multi-scale features at a granular level and increases the range of receptive fields for each network layer. The proposed Res2Net block can be plugged into the state-of-the-art backbone CNN models, e.g., ResNet, ResNeXt, and DLA. We evaluate the Res2Net block on all these models and demonstrate consistent performance gains over baseline models on widely-used datasets, e.g., CIFAR-100 and ImageNet. Further ablation studies and experimental results on representative computer vision tasks, i.e., object detection, class activation mapping, and salient object detection, further verify the superiority of the Res2Net over the state-of-the-art baseline methods.
-
-
-
-
## Introduction
-
-
We propose a novel building block for CNNs, namely Res2Net, by constructing hierarchical residual-like connections within one single residual block. The Res2Net represents multi-scale features at a granular level and increases the range of receptive fields for each network layer.
| Backbone |Params. | GFLOPs | top-1 err. | top-5 err. |
@@ -33,18 +29,6 @@ Compared with other backbone networks, Res2Net requires fewer parameters and FLO
- GFLOPs for classification are calculated with image size (224x224).
-## Citation
-
-```latex
-@article{gao2019res2net,
- title={Res2Net: A New Multi-scale Backbone Architecture},
- author={Gao, Shang-Hua and Cheng, Ming-Ming and Zhao, Kai and Zhang, Xin-Yu and Yang, Ming-Hsuan and Torr, Philip},
- journal={IEEE TPAMI},
- year={2020},
- doi={10.1109/TPAMI.2019.2938758},
-}
-```
-
## Results and Models
### Faster R-CNN
@@ -79,3 +63,15 @@ R2-101-FPN | pytorch | 20e | 9.5 | - | 46.4 | 40.0
- Res2Net ImageNet pretrained models are in [Res2Net-PretrainedModels](https://github.com/Res2Net/Res2Net-PretrainedModels).
- More applications of Res2Net are in [Res2Net-Github](https://github.com/Res2Net/).
+
+## Citation
+
+```latex
+@article{gao2019res2net,
+ title={Res2Net: A New Multi-scale Backbone Architecture},
+ author={Gao, Shang-Hua and Cheng, Ming-Ming and Zhao, Kai and Zhang, Xin-Yu and Yang, Ming-Hsuan and Torr, Philip},
+ journal={IEEE TPAMI},
+ year={2020},
+ doi={10.1109/TPAMI.2019.2938758},
+}
+```
diff --git a/configs/res2net/metafile.yml b/configs/res2net/metafile.yml
index 71809f30974..27bac8c1bfb 100644
--- a/configs/res2net/metafile.yml
+++ b/configs/res2net/metafile.yml
@@ -1,6 +1,10 @@
-Collections:
- - Name: Res2Net
+Models:
+ - Name: faster_rcnn_r2_101_fpn_2x_coco
+ In Collection: Faster R-CNN
+ Config: configs/res2net/faster_rcnn_r2_101_fpn_2x_coco.py
Metadata:
+ Training Memory (GB): 7.4
+ Epochs: 24
Training Data: COCO
Training Techniques:
- SGD with Momentum
@@ -8,6 +12,12 @@ Collections:
Training Resources: 8x V100 GPUs
Architecture:
- Res2Net
+ Results:
+ - Task: Object Detection
+ Dataset: COCO
+ Metrics:
+ box AP: 43.0
+ Weights: https://download.openmmlab.com/mmdetection/v2.0/res2net/faster_rcnn_r2_101_fpn_2x_coco/faster_rcnn_r2_101_fpn_2x_coco-175f1da6.pth
Paper:
URL: https://arxiv.org/abs/1904.01169
Title: 'Res2Net for object detection and instance segmentation'
@@ -16,26 +26,19 @@ Collections:
URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/res2net.py#L239
Version: v2.1.0
-Models:
- - Name: faster_rcnn_r2_101_fpn_2x_coco
- In Collection: Res2Net
- Config: configs/res2net/faster_rcnn_r2_101_fpn_2x_coco.py
- Metadata:
- Training Memory (GB): 7.4
- Epochs: 24
- Results:
- - Task: Object Detection
- Dataset: COCO
- Metrics:
- box AP: 43.0
- Weights: https://download.openmmlab.com/mmdetection/v2.0/res2net/faster_rcnn_r2_101_fpn_2x_coco/faster_rcnn_r2_101_fpn_2x_coco-175f1da6.pth
-
- Name: mask_rcnn_r2_101_fpn_2x_coco
- In Collection: Res2Net
+ In Collection: Mask R-CNN
Config: configs/res2net/mask_rcnn_r2_101_fpn_2x_coco.py
Metadata:
Training Memory (GB): 7.9
Epochs: 24
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - Res2Net
Results:
- Task: Object Detection
Dataset: COCO
@@ -46,26 +49,54 @@ Models:
Metrics:
mask AP: 38.7
Weights: https://download.openmmlab.com/mmdetection/v2.0/res2net/mask_rcnn_r2_101_fpn_2x_coco/mask_rcnn_r2_101_fpn_2x_coco-17f061e8.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.01169
+ Title: 'Res2Net for object detection and instance segmentation'
+ README: configs/res2net/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/res2net.py#L239
+ Version: v2.1.0
- Name: cascade_rcnn_r2_101_fpn_20e_coco
- In Collection: Res2Net
+ In Collection: Cascade R-CNN
Config: configs/res2net/cascade_rcnn_r2_101_fpn_20e_coco.py
Metadata:
Training Memory (GB): 7.8
Epochs: 20
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - Res2Net
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 45.7
Weights: https://download.openmmlab.com/mmdetection/v2.0/res2net/cascade_rcnn_r2_101_fpn_20e_coco/cascade_rcnn_r2_101_fpn_20e_coco-f4b7b7db.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.01169
+ Title: 'Res2Net for object detection and instance segmentation'
+ README: configs/res2net/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/res2net.py#L239
+ Version: v2.1.0
- Name: cascade_mask_rcnn_r2_101_fpn_20e_coco
- In Collection: Res2Net
+ In Collection: Cascade R-CNN
Config: configs/res2net/cascade_mask_rcnn_r2_101_fpn_20e_coco.py
Metadata:
Training Memory (GB): 9.5
Epochs: 20
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - Res2Net
Results:
- Task: Object Detection
Dataset: COCO
@@ -76,12 +107,26 @@ Models:
Metrics:
mask AP: 40.0
Weights: https://download.openmmlab.com/mmdetection/v2.0/res2net/cascade_mask_rcnn_r2_101_fpn_20e_coco/cascade_mask_rcnn_r2_101_fpn_20e_coco-8a7b41e1.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.01169
+ Title: 'Res2Net for object detection and instance segmentation'
+ README: configs/res2net/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/res2net.py#L239
+ Version: v2.1.0
- Name: htc_r2_101_fpn_20e_coco
- In Collection: Res2Net
+ In Collection: HTC
Config: configs/res2net/htc_r2_101_fpn_20e_coco.py
Metadata:
Epochs: 20
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - Res2Net
Results:
- Task: Object Detection
Dataset: COCO
@@ -92,3 +137,10 @@ Models:
Metrics:
mask AP: 41.6
Weights: https://download.openmmlab.com/mmdetection/v2.0/res2net/htc_r2_101_fpn_20e_coco/htc_r2_101_fpn_20e_coco-3a8d2112.pth
+ Paper:
+ URL: https://arxiv.org/abs/1904.01169
+ Title: 'Res2Net for object detection and instance segmentation'
+ README: configs/res2net/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.1.0/mmdet/models/backbones/res2net.py#L239
+ Version: v2.1.0
diff --git a/configs/resnest/README.md b/configs/resnest/README.md
index de80430d324..02c0cad5f29 100644
--- a/configs/resnest/README.md
+++ b/configs/resnest/README.md
@@ -1,32 +1,17 @@
-# ResNeSt: Split-Attention Networks
+# ResNeSt
-## Abstract
+> [ResNeSt: Split-Attention Networks](https://arxiv.org/abs/2004.08955)
+
+
-
+## Abstract
It is well known that featuremap attention and multi-path representation are important for visual recognition. In this paper, we present a modularized architecture, which applies the channel-wise attention on different network branches to leverage their success in capturing cross-feature interactions and learning diverse representations. Our design results in a simple and unified computation block, which can be parameterized using only a few variables. Our model, named ResNeSt, outperforms EfficientNet in accuracy and latency trade-off on image classification. In addition, ResNeSt has achieved superior transfer learning results on several public benchmarks serving as the backbone, and has been adopted by the winning entries of COCO-LVIS challenge.
-
-
-
-
-## Citation
-
-
-
-```latex
-@article{zhang2020resnest,
-title={ResNeSt: Split-Attention Networks},
-author={Zhang, Hang and Wu, Chongruo and Zhang, Zhongyue and Zhu, Yi and Zhang, Zhi and Lin, Haibin and Sun, Yue and He, Tong and Muller, Jonas and Manmatha, R. and Li, Mu and Smola, Alexander},
-journal={arXiv preprint arXiv:2004.08955},
-year={2020}
-}
-```
-
## Results and Models
### Faster R-CNN
@@ -56,3 +41,14 @@ year={2020}
| :-------------: | :-----: | :-----: | :------: | :------------: | :----: | :-----: | :------: | :--------: |
|S-50-FPN | pytorch | 1x | - | - | 45.4 | 39.5 |[config](https://github.com/open-mmlab/mmdetection/tree/master/configs/resnest/cascade_mask_rcnn_s50_fpn_syncbn-backbone+head_mstrain_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/resnest/cascade_mask_rcnn_s50_fpn_syncbn-backbone%2Bhead_mstrain_1x_coco/cascade_mask_rcnn_s50_fpn_syncbn-backbone%2Bhead_mstrain_1x_coco_20201122_104428-99eca4c7.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/resnest/cascade_mask_rcnn_s50_fpn_syncbn-backbone%2Bhead_mstrain_1x_coco/cascade_mask_rcnn_s50_fpn_syncbn-backbone%2Bhead_mstrain_1x_coco-20201122_104428.log.json) |
|S-101-FPN | pytorch | 1x | 10.5 | - | 47.7 | 41.4 |[config](https://github.com/open-mmlab/mmdetection/tree/master/configs/resnest/cascade_mask_rcnn_s101_fpn_syncbn-backbone+head_mstrain_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/resnest/cascade_mask_rcnn_s101_fpn_syncbn-backbone%2Bhead_mstrain_1x_coco/cascade_mask_rcnn_s101_fpn_syncbn-backbone%2Bhead_mstrain_1x_coco_20201005_113243-42607475.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/resnest/cascade_mask_rcnn_s101_fpn_syncbn-backbone%2Bhead_mstrain_1x_coco/cascade_mask_rcnn_s101_fpn_syncbn-backbone%2Bhead_mstrain_1x_coco-20201005_113243.log.json) |
+
+## Citation
+
+```latex
+@article{zhang2020resnest,
+title={ResNeSt: Split-Attention Networks},
+author={Zhang, Hang and Wu, Chongruo and Zhang, Zhongyue and Zhu, Yi and Zhang, Zhi and Lin, Haibin and Sun, Yue and He, Tong and Muller, Jonas and Manmatha, R. and Li, Mu and Smola, Alexander},
+journal={arXiv preprint arXiv:2004.08955},
+year={2020}
+}
+```
diff --git a/configs/resnest/metafile.yml b/configs/resnest/metafile.yml
index 3323fad027a..cfeec719313 100644
--- a/configs/resnest/metafile.yml
+++ b/configs/resnest/metafile.yml
@@ -1,6 +1,10 @@
-Collections:
- - Name: ResNeSt
+Models:
+ - Name: faster_rcnn_s50_fpn_syncbn-backbone+head_mstrain-range_1x_coco
+ In Collection: Faster R-CNN
+ Config: configs/resnest/faster_rcnn_s50_fpn_syncbn-backbone+head_mstrain-range_1x_coco.py
Metadata:
+ Training Memory (GB): 4.8
+ Epochs: 12
Training Data: COCO
Training Techniques:
- SGD with Momentum
@@ -8,6 +12,12 @@ Collections:
Training Resources: 8x V100 GPUs
Architecture:
- ResNeSt
+ Results:
+ - Task: Object Detection
+ Dataset: COCO
+ Metrics:
+ box AP: 42.0
+ Weights: https://download.openmmlab.com/mmdetection/v2.0/resnest/faster_rcnn_s50_fpn_syncbn-backbone%2Bhead_mstrain-range_1x_coco/faster_rcnn_s50_fpn_syncbn-backbone%2Bhead_mstrain-range_1x_coco_20200926_125502-20289c16.pth
Paper:
URL: https://arxiv.org/abs/2004.08955
Title: 'ResNeSt: Split-Attention Networks'
@@ -16,39 +26,46 @@ Collections:
URL: https://github.com/open-mmlab/mmdetection/blob/v2.7.0/mmdet/models/backbones/resnest.py#L273
Version: v2.7.0
-Models:
- - Name: faster_rcnn_s50_fpn_syncbn-backbone+head_mstrain-range_1x_coco
- In Collection: ResNeSt
- Config: configs/resnest/faster_rcnn_s50_fpn_syncbn-backbone+head_mstrain-range_1x_coco.py
- Metadata:
- Training Memory (GB): 4.8
- Epochs: 12
- Results:
- - Task: Object Detection
- Dataset: COCO
- Metrics:
- box AP: 42.0
- Weights: https://download.openmmlab.com/mmdetection/v2.0/resnest/faster_rcnn_s50_fpn_syncbn-backbone%2Bhead_mstrain-range_1x_coco/faster_rcnn_s50_fpn_syncbn-backbone%2Bhead_mstrain-range_1x_coco_20200926_125502-20289c16.pth
-
- Name: faster_rcnn_s101_fpn_syncbn-backbone+head_mstrain-range_1x_coco
- In Collection: ResNeSt
+ In Collection: Faster R-CNN
Config: configs/resnest/faster_rcnn_s101_fpn_syncbn-backbone+head_mstrain-range_1x_coco.py
Metadata:
Training Memory (GB): 7.1
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - ResNeSt
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 44.5
Weights: https://download.openmmlab.com/mmdetection/v2.0/resnest/faster_rcnn_s101_fpn_syncbn-backbone%2Bhead_mstrain-range_1x_coco/faster_rcnn_s101_fpn_syncbn-backbone%2Bhead_mstrain-range_1x_coco_20201006_021058-421517f1.pth
+ Paper:
+ URL: https://arxiv.org/abs/2004.08955
+ Title: 'ResNeSt: Split-Attention Networks'
+ README: configs/resnest/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.7.0/mmdet/models/backbones/resnest.py#L273
+ Version: v2.7.0
- Name: mask_rcnn_s50_fpn_syncbn-backbone+head_mstrain_1x_coco
- In Collection: ResNeSt
+ In Collection: Mask R-CNN
Config: configs/resnest/mask_rcnn_s50_fpn_syncbn-backbone+head_mstrain_1x_coco.py
Metadata:
Training Memory (GB): 5.5
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - ResNeSt
Results:
- Task: Object Detection
Dataset: COCO
@@ -59,13 +76,27 @@ Models:
Metrics:
mask AP: 38.1
Weights: https://download.openmmlab.com/mmdetection/v2.0/resnest/mask_rcnn_s50_fpn_syncbn-backbone%2Bhead_mstrain_1x_coco/mask_rcnn_s50_fpn_syncbn-backbone%2Bhead_mstrain_1x_coco_20200926_125503-8a2c3d47.pth
+ Paper:
+ URL: https://arxiv.org/abs/2004.08955
+ Title: 'ResNeSt: Split-Attention Networks'
+ README: configs/resnest/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.7.0/mmdet/models/backbones/resnest.py#L273
+ Version: v2.7.0
- Name: mask_rcnn_s101_fpn_syncbn-backbone+head_mstrain_1x_coco
- In Collection: ResNeSt
+ In Collection: Mask R-CNN
Config: configs/resnest/mask_rcnn_s101_fpn_syncbn-backbone+head_mstrain_1x_coco.py
Metadata:
Training Memory (GB): 7.8
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - ResNeSt
Results:
- Task: Object Detection
Dataset: COCO
@@ -76,37 +107,79 @@ Models:
Metrics:
mask AP: 40.2
Weights: https://download.openmmlab.com/mmdetection/v2.0/resnest/mask_rcnn_s101_fpn_syncbn-backbone%2Bhead_mstrain_1x_coco/mask_rcnn_s101_fpn_syncbn-backbone%2Bhead_mstrain_1x_coco_20201005_215831-af60cdf9.pth
+ Paper:
+ URL: https://arxiv.org/abs/2004.08955
+ Title: 'ResNeSt: Split-Attention Networks'
+ README: configs/resnest/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.7.0/mmdet/models/backbones/resnest.py#L273
+ Version: v2.7.0
- Name: cascade_rcnn_s50_fpn_syncbn-backbone+head_mstrain-range_1x_coco
- In Collection: ResNeSt
+ In Collection: Cascade R-CNN
Config: configs/resnest/cascade_rcnn_s50_fpn_syncbn-backbone+head_mstrain-range_1x_coco.py
Metadata:
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - ResNeSt
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 44.5
Weights: https://download.openmmlab.com/mmdetection/v2.0/resnest/cascade_rcnn_s50_fpn_syncbn-backbone%2Bhead_mstrain-range_1x_coco/cascade_rcnn_s50_fpn_syncbn-backbone%2Bhead_mstrain-range_1x_coco_20201122_213640-763cc7b5.pth
+ Paper:
+ URL: https://arxiv.org/abs/2004.08955
+ Title: 'ResNeSt: Split-Attention Networks'
+ README: configs/resnest/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.7.0/mmdet/models/backbones/resnest.py#L273
+ Version: v2.7.0
- Name: cascade_rcnn_s101_fpn_syncbn-backbone+head_mstrain-range_1x_coco
- In Collection: ResNeSt
+ In Collection: Cascade R-CNN
Config: configs/resnest/cascade_rcnn_s101_fpn_syncbn-backbone+head_mstrain-range_1x_coco.py
Metadata:
Training Memory (GB): 8.4
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - ResNeSt
Results:
- Task: Object Detection
Dataset: COCO
Metrics:
box AP: 46.8
Weights: https://download.openmmlab.com/mmdetection/v2.0/resnest/cascade_rcnn_s101_fpn_syncbn-backbone%2Bhead_mstrain-range_1x_coco/cascade_rcnn_s101_fpn_syncbn-backbone%2Bhead_mstrain-range_1x_coco_20201005_113242-b9459f8f.pth
+ Paper:
+ URL: https://arxiv.org/abs/2004.08955
+ Title: 'ResNeSt: Split-Attention Networks'
+ README: configs/resnest/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.7.0/mmdet/models/backbones/resnest.py#L273
+ Version: v2.7.0
- Name: cascade_mask_rcnn_s50_fpn_syncbn-backbone+head_mstrain_1x_coco
- In Collection: ResNeSt
+ In Collection: Cascade R-CNN
Config: configs/resnest/cascade_mask_rcnn_s50_fpn_syncbn-backbone+head_mstrain_1x_coco.py
Metadata:
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - ResNeSt
Results:
- Task: Object Detection
Dataset: COCO
@@ -117,13 +190,27 @@ Models:
Metrics:
mask AP: 39.5
Weights: https://download.openmmlab.com/mmdetection/v2.0/resnest/cascade_mask_rcnn_s50_fpn_syncbn-backbone%2Bhead_mstrain_1x_coco/cascade_mask_rcnn_s50_fpn_syncbn-backbone%2Bhead_mstrain_1x_coco_20201122_104428-99eca4c7.pth
+ Paper:
+ URL: https://arxiv.org/abs/2004.08955
+ Title: 'ResNeSt: Split-Attention Networks'
+ README: configs/resnest/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.7.0/mmdet/models/backbones/resnest.py#L273
+ Version: v2.7.0
- Name: cascade_mask_rcnn_s101_fpn_syncbn-backbone+head_mstrain_1x_coco
- In Collection: ResNeSt
+ In Collection: Cascade R-CNN
Config: configs/resnest/cascade_mask_rcnn_s101_fpn_syncbn-backbone+head_mstrain_1x_coco.py
Metadata:
Training Memory (GB): 10.5
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - SGD with Momentum
+ - Weight Decay
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - ResNeSt
Results:
- Task: Object Detection
Dataset: COCO
@@ -134,3 +221,10 @@ Models:
Metrics:
mask AP: 41.4
Weights: https://download.openmmlab.com/mmdetection/v2.0/resnest/cascade_mask_rcnn_s101_fpn_syncbn-backbone%2Bhead_mstrain_1x_coco/cascade_mask_rcnn_s101_fpn_syncbn-backbone%2Bhead_mstrain_1x_coco_20201005_113243-42607475.pth
+ Paper:
+ URL: https://arxiv.org/abs/2004.08955
+ Title: 'ResNeSt: Split-Attention Networks'
+ README: configs/resnest/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.7.0/mmdet/models/backbones/resnest.py#L273
+ Version: v2.7.0
diff --git a/configs/retinanet/README.md b/configs/retinanet/README.md
index 562c081ff02..ed85170f908 100644
--- a/configs/retinanet/README.md
+++ b/configs/retinanet/README.md
@@ -1,33 +1,18 @@
-# Focal Loss for Dense Object Detection
+# RetinaNet
-## Abstract
+> [Focal Loss for Dense Object Detection](https://arxiv.org/abs/1708.02002)
+
+
-
+## Abstract
The highest accuracy object detectors to date are based on a two-stage approach popularized by R-CNN, where a classifier is applied to a sparse set of candidate object locations. In contrast, one-stage detectors that are applied over a regular, dense sampling of possible object locations have the potential to be faster and simpler, but have trailed the accuracy of two-stage detectors thus far. In this paper, we investigate why this is the case. We discover that the extreme foreground-background class imbalance encountered during training of dense detectors is the central cause. We propose to address this class imbalance by reshaping the standard cross entropy loss such that it down-weights the loss assigned to well-classified examples. Our novel Focal Loss focuses training on a sparse set of hard examples and prevents the vast number of easy negatives from overwhelming the detector during training. To evaluate the effectiveness of our loss, we design and train a simple dense detector we call RetinaNet. Our results show that when trained with the focal loss, RetinaNet is able to match the speed of previous one-stage detectors while surpassing the accuracy of all existing state-of-the-art two-stage detectors.
-
-
-
-
-## Citation
-
-
-
-```latex
-@inproceedings{lin2017focal,
- title={Focal loss for dense object detection},
- author={Lin, Tsung-Yi and Goyal, Priya and Girshick, Ross and He, Kaiming and Doll{\'a}r, Piotr},
- booktitle={Proceedings of the IEEE international conference on computer vision},
- year={2017}
-}
-```
-
-## Results and models
+## Results and Models
| Backbone | Style | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
| :-------------: | :-----: | :-----: | :------: | :------------: | :----: | :------: | :--------: |
@@ -53,3 +38,14 @@ We also train some models with longer schedules and multi-scale training. The us
| R-101-FPN | caffe | 3x | 5.4 | 40.7 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/retinanet/retinanet_r101_caffe_fpn_mstrain_3x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/retinanet/retinanet_r101_caffe_fpn_mstrain_3x_coco/retinanet_r101_caffe_fpn_mstrain_3x_coco_20210721_063439-88a8a944.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/retinanet/retinanet_r101_caffe_fpn_mstrain_3x_coco/retinanet_r101_caffe_fpn_mstrain_3x_coco_20210721_063439-88a8a944.log.json)
| R-101-FPN | pytorch| 3x | 5.4 | 41 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/retinanet/retinanet_r101_fpn_mstrain_640-800_3x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/retinanet/retinanet_r101_fpn_mstrain_3x_coco/retinanet_r101_fpn_mstrain_3x_coco_20210720_214650-7ee888e0.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/retinanet/retinanet_r101_fpn_mstrain_3x_coco/retinanet_r101_fpn_mstrain_3x_coco_20210720_214650-7ee888e0.log.json)
| X-101-64x4d-FPN | pytorch| 3x | 9.8 | 41.6 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/retinanet/retinanet_x101_64x4d_fpn_mstrain_640-800_3x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/retinanet/retinanet_x101_64x4d_fpn_mstrain_3x_coco/retinanet_x101_64x4d_fpn_mstrain_3x_coco_20210719_051838-022c2187.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/retinanet/retinanet_x101_64x4d_fpn_mstrain_3x_coco/retinanet_x101_64x4d_fpn_mstrain_3x_coco_20210719_051838-022c2187.log.json)
+
+## Citation
+
+```latex
+@inproceedings{lin2017focal,
+ title={Focal loss for dense object detection},
+ author={Lin, Tsung-Yi and Goyal, Priya and Girshick, Ross and He, Kaiming and Doll{\'a}r, Piotr},
+ booktitle={Proceedings of the IEEE international conference on computer vision},
+ year={2017}
+}
+```
diff --git a/configs/rpn/README.md b/configs/rpn/README.md
index d1bf6749467..654515cfcb9 100644
--- a/configs/rpn/README.md
+++ b/configs/rpn/README.md
@@ -1,33 +1,18 @@
-# Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
+# RPN
-## Abstract
+> [Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks](https://arxiv.org/abs/1506.01497)
+
+
-
+## Abstract
State-of-the-art object detection networks depend on region proposal algorithms to hypothesize object locations. Advances like SPPnet and Fast R-CNN have reduced the running time of these detection networks, exposing region proposal computation as a bottleneck. In this work, we introduce a Region Proposal Network (RPN) that shares full-image convolutional features with the detection network, thus enabling nearly cost-free region proposals. An RPN is a fully convolutional network that simultaneously predicts object bounds and objectness scores at each position. The RPN is trained end-to-end to generate high-quality region proposals, which are used by Fast R-CNN for detection. We further merge RPN and Fast R-CNN into a single network by sharing their convolutional features---using the recently popular terminology of neural networks with 'attention' mechanisms, the RPN component tells the unified network where to look. For the very deep VGG-16 model, our detection system has a frame rate of 5fps (including all steps) on a GPU, while achieving state-of-the-art object detection accuracy on PASCAL VOC 2007, 2012, and MS COCO datasets with only 300 proposals per image. In ILSVRC and COCO 2015 competitions, Faster R-CNN and RPN are the foundations of the 1st-place winning entries in several tracks.
-
-
-
-
-## Citation
-
-
-
-```latex
-@inproceedings{ren2015faster,
- title={Faster r-cnn: Towards real-time object detection with region proposal networks},
- author={Ren, Shaoqing and He, Kaiming and Girshick, Ross and Sun, Jian},
- booktitle={Advances in neural information processing systems},
- year={2015}
-}
-```
-
-## Results and models
+## Results and Models
| Backbone | Style | Lr schd | Mem (GB) | Inf time (fps) | AR1000 | Config | Download |
| :-------------: | :-----: | :-----: | :------: | :------------: | :----: | :------: | :--------: |
@@ -41,3 +26,14 @@ State-of-the-art object detection networks depend on region proposal algorithms
| X-101-32x4d-FPN | pytorch | 2x | - | - | 61.1 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/rpn/rpn_x101_32x4d_fpn_2x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/rpn/rpn_x101_32x4d_fpn_2x_coco/rpn_x101_32x4d_fpn_2x_coco_20200208-d22bd0bb.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/rpn/rpn_x101_32x4d_fpn_2x_coco/rpn_x101_32x4d_fpn_2x_coco_20200208_200752.log.json) |
| X-101-64x4d-FPN | pytorch | 1x | 10.1 | 9.1 | 61.0 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/rpn/rpn_x101_64x4d_fpn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/rpn/rpn_x101_64x4d_fpn_1x_coco/rpn_x101_64x4d_fpn_1x_coco_20200208-cde6f7dd.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/rpn/rpn_x101_64x4d_fpn_1x_coco/rpn_x101_64x4d_fpn_1x_coco_20200208_200752.log.json) |
| X-101-64x4d-FPN | pytorch | 2x | - | - | 61.5 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/rpn/rpn_x101_64x4d_fpn_2x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/rpn/rpn_x101_64x4d_fpn_2x_coco/rpn_x101_64x4d_fpn_2x_coco_20200208-c65f524f.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/rpn/rpn_x101_64x4d_fpn_2x_coco/rpn_x101_64x4d_fpn_2x_coco_20200208_200752.log.json) |
+
+## Citation
+
+```latex
+@inproceedings{ren2015faster,
+ title={Faster r-cnn: Towards real-time object detection with region proposal networks},
+ author={Ren, Shaoqing and He, Kaiming and Girshick, Ross and Sun, Jian},
+ booktitle={Advances in neural information processing systems},
+ year={2015}
+}
+```
diff --git a/configs/sabl/README.md b/configs/sabl/README.md
index c090d00829d..516bd7025f6 100644
--- a/configs/sabl/README.md
+++ b/configs/sabl/README.md
@@ -1,35 +1,17 @@
-# Side-Aware Boundary Localization for More Precise Object Detection
+# SABL
-## Abstract
+> [Side-Aware Boundary Localization for More Precise Object Detection](https://arxiv.org/abs/1912.04260)
-
+
+
+## Abstract
Current object detection frameworks mainly rely on bounding box regression to localize objects. Despite the remarkable progress in recent years, the precision of bounding box regression remains unsatisfactory, hence limiting performance in object detection. We observe that precise localization requires careful placement of each side of the bounding box. However, the mainstream approach, which focuses on predicting centers and sizes, is not the most effective way to accomplish this task, especially when there exists displacements with large variance between the anchors and the targets. In this paper, we propose an alternative approach, named as Side-Aware Boundary Localization (SABL), where each side of the bounding box is respectively localized with a dedicated network branch. To tackle the difficulty of precise localization in the presence of displacements with large variance, we further propose a two-step localization scheme, which first predicts a range of movement through bucket prediction and then pinpoints the precise position within the predicted bucket. We test the proposed method on both two-stage and single-stage detection frameworks. Replacing the standard bounding box regression branch with the proposed design leads to significant improvements on Faster R-CNN, RetinaNet, and Cascade R-CNN, by 3.0%, 1.7%, and 0.9%, respectively.
-
-
-
-
-## Citation
-
-
-
-We provide config files to reproduce the object detection results in the ECCV 2020 Spotlight paper for [Side-Aware Boundary Localization for More Precise Object Detection](https://arxiv.org/abs/1912.04260).
-
-```latex
-@inproceedings{Wang_2020_ECCV,
- title = {Side-Aware Boundary Localization for More Precise Object Detection},
- author = {Jiaqi Wang and Wenwei Zhang and Yuhang Cao and Kai Chen and Jiangmiao Pang and Tao Gong and Jianping Shi and Chen Change Loy and Dahua Lin},
- booktitle = {ECCV},
- year = {2020}
-}
-```
-
## Results and Models
The results on COCO 2017 val is shown in the below table. (results on test-dev are usually slightly higher than val).
@@ -50,3 +32,16 @@ Single-scale testing (1333x800) is adopted in all results.
| SABL RetinaNet | R-101-FPN | Y | 1x | N | 40.5 | [config](https://github.com/open-mmlab/mmdetection/blob/master/configs/sabl/sabl_retinanet_r101_fpn_gn_1x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/sabl/sabl_retinanet_r101_fpn_gn_1x_coco/sabl_retinanet_r101_fpn_gn_1x_coco-40a893e8.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/sabl/sabl_retinanet_r101_fpn_gn_1x_coco/20200830_201422.log.json) |
| SABL RetinaNet | R-101-FPN | Y | 2x | Y (640~800) | 42.9 | [config](https://github.com/open-mmlab/mmdetection/blob/master/configs/sabl/sabl_retinanet_r101_fpn_gn_2x_ms_640_800_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/sabl/sabl_retinanet_r101_fpn_gn_2x_ms_640_800_coco/sabl_retinanet_r101_fpn_gn_2x_ms_640_800_coco-1e63382c.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/sabl/sabl_retinanet_r101_fpn_gn_2x_ms_640_800_coco/20200830_144807.log.json) |
| SABL RetinaNet | R-101-FPN | Y | 2x | Y (480~960) | 43.6 | [config](https://github.com/open-mmlab/mmdetection/blob/master/configs/sabl/sabl_retinanet_r101_fpn_gn_2x_ms_480_960_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/sabl/sabl_retinanet_r101_fpn_gn_2x_ms_480_960_coco/sabl_retinanet_r101_fpn_gn_2x_ms_480_960_coco-5342f857.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/sabl/sabl_retinanet_r101_fpn_gn_2x_ms_480_960_coco/20200830_164537.log.json) |
+
+## Citation
+
+We provide config files to reproduce the object detection results in the ECCV 2020 Spotlight paper for [Side-Aware Boundary Localization for More Precise Object Detection](https://arxiv.org/abs/1912.04260).
+
+```latex
+@inproceedings{Wang_2020_ECCV,
+ title = {Side-Aware Boundary Localization for More Precise Object Detection},
+ author = {Jiaqi Wang and Wenwei Zhang and Yuhang Cao and Kai Chen and Jiangmiao Pang and Tao Gong and Jianping Shi and Chen Change Loy and Dahua Lin},
+ booktitle = {ECCV},
+ year = {2020}
+}
+```
diff --git a/configs/scnet/README.md b/configs/scnet/README.md
index 52f3b4934c5..3769d808ca0 100644
--- a/configs/scnet/README.md
+++ b/configs/scnet/README.md
@@ -1,4 +1,8 @@
-# SCNet: Training Inference Sample Consistency for Instance Segmentation
+# SCNet
+
+> [SCNet: Training Inference Sample Consistency for Instance Segmentation](https://arxiv.org/abs/2012.10150)
+
+
## Abstract
@@ -6,29 +10,10 @@
Cascaded architectures have brought significant performance improvement in object detection and instance segmentation. However, there are lingering issues regarding the disparity in the Intersection-over-Union (IoU) distribution of the samples between training and inference. This disparity can potentially exacerbate detection accuracy. This paper proposes an architecture referred to as Sample Consistency Network (SCNet) to ensure that the IoU distribution of the samples at training time is close to that at inference time. Furthermore, SCNet incorporates feature relay and utilizes global contextual information to further reinforce the reciprocal relationships among classifying, detecting, and segmenting sub-tasks. Extensive experiments on the standard COCO dataset reveal the effectiveness of the proposed method over multiple evaluation metrics, including box AP, mask AP, and inference speed. In particular, while running 38\% faster, the proposed SCNet improves the AP of the box and mask predictions by respectively 1.3 and 2.3 points compared to the strong Cascade Mask R-CNN baseline.
-
-
-
-
-## Citation
-
-
-
-We provide the code for reproducing experiment results of [SCNet](https://arxiv.org/abs/2012.10150).
-
-```
-@inproceedings{vu2019cascade,
- title={SCNet: Training Inference Sample Consistency for Instance Segmentation},
- author={Vu, Thang and Haeyong, Kang and Yoo, Chang D},
- booktitle={AAAI},
- year={2021}
-}
-```
-
## Dataset
SCNet requires COCO and [COCO-stuff](http://calvin.inf.ed.ac.uk/wp-content/uploads/data/cocostuffdataset/stuffthingmaps_trainval2017.zip) dataset for training. You need to download and extract it in the COCO dataset path.
@@ -63,3 +48,16 @@ The results on COCO 2017val are shown in the below table. (results on test-dev a
- Training hyper-parameters are identical to those of [HTC](https://github.com/open-mmlab/mmdetection/tree/master/configs/htc).
- TTA means Test Time Augmentation, which applies horizontal flip and multi-scale testing. Refer to [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/scnet/scnet_r50_fpn_1x_coco.py).
+
+## Citation
+
+We provide the code for reproducing experiment results of [SCNet](https://arxiv.org/abs/2012.10150).
+
+```latex
+@inproceedings{vu2019cascade,
+ title={SCNet: Training Inference Sample Consistency for Instance Segmentation},
+ author={Vu, Thang and Haeyong, Kang and Yoo, Chang D},
+ booktitle={AAAI},
+ year={2021}
+}
+```
diff --git a/configs/scratch/README.md b/configs/scratch/README.md
index 68d3a72fd65..52239030457 100644
--- a/configs/scratch/README.md
+++ b/configs/scratch/README.md
@@ -1,22 +1,29 @@
-# Rethinking ImageNet Pre-training
+# Scratch
-## Abstract
+> [Rethinking ImageNet Pre-training](https://arxiv.org/abs/1811.08883)
+
+
-
+## Abstract
We report competitive results on object detection and instance segmentation on the COCO dataset using standard models trained from random initialization. The results are no worse than their ImageNet pre-training counterparts even when using the hyper-parameters of the baseline system (Mask R-CNN) that were optimized for fine-tuning pre-trained models, with the sole exception of increasing the number of training iterations so the randomly initialized models may converge. Training from random initialization is surprisingly robust; our results hold even when: (i) using only 10% of the training data, (ii) for deeper and wider models, and (iii) for multiple tasks and metrics. Experiments show that ImageNet pre-training speeds up convergence early in training, but does not necessarily provide regularization or improve final target task accuracy. To push the envelope we demonstrate 50.9 AP on COCO object detection without using any external data---a result on par with the top COCO 2017 competition results that used ImageNet pre-training. These observations challenge the conventional wisdom of ImageNet pre-training for dependent tasks and we expect these discoveries will encourage people to rethink the current de facto paradigm of `pre-training and fine-tuning' in computer vision.
-
-
-
+## Results and Models
-## Citation
+| Model | Backbone | Style | Lr schd | box AP | mask AP | Config | Download |
+|:------------:|:---------:|:-------:|:-------:|:------:|:-------:|:------:|:--------:|
+| Faster R-CNN | R-50-FPN | pytorch | 6x | 40.7 | | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/scratch/faster_rcnn_r50_fpn_gn-all_scratch_6x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/scratch/faster_rcnn_r50_fpn_gn-all_scratch_6x_coco/scratch_faster_rcnn_r50_fpn_gn_6x_bbox_mAP-0.407_20200201_193013-90813d01.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/scratch/faster_rcnn_r50_fpn_gn-all_scratch_6x_coco/scratch_faster_rcnn_r50_fpn_gn_6x_20200201_193013.log.json) |
+| Mask R-CNN | R-50-FPN | pytorch | 6x | 41.2 | 37.4 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/scratch/mask_rcnn_r50_fpn_gn-all_scratch_6x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/scratch/mask_rcnn_r50_fpn_gn-all_scratch_6x_coco/scratch_mask_rcnn_r50_fpn_gn_6x_bbox_mAP-0.412__segm_mAP-0.374_20200201_193051-1e190a40.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/scratch/mask_rcnn_r50_fpn_gn-all_scratch_6x_coco/scratch_mask_rcnn_r50_fpn_gn_6x_20200201_193051.log.json) |
-
+Note:
+
+- The above models are trained with 16 GPUs.
+
+## Citation
```latex
@article{he2018rethinking,
@@ -26,14 +33,3 @@ We report competitive results on object detection and instance segmentation on t
year={2018}
}
```
-
-## Results and Models
-
-| Model | Backbone | Style | Lr schd | box AP | mask AP | Config | Download |
-|:------------:|:---------:|:-------:|:-------:|:------:|:-------:|:------:|:--------:|
-| Faster R-CNN | R-50-FPN | pytorch | 6x | 40.7 | | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/scratch/faster_rcnn_r50_fpn_gn-all_scratch_6x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/scratch/faster_rcnn_r50_fpn_gn-all_scratch_6x_coco/scratch_faster_rcnn_r50_fpn_gn_6x_bbox_mAP-0.407_20200201_193013-90813d01.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/scratch/faster_rcnn_r50_fpn_gn-all_scratch_6x_coco/scratch_faster_rcnn_r50_fpn_gn_6x_20200201_193013.log.json) |
-| Mask R-CNN | R-50-FPN | pytorch | 6x | 41.2 | 37.4 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/scratch/mask_rcnn_r50_fpn_gn-all_scratch_6x_coco.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/scratch/mask_rcnn_r50_fpn_gn-all_scratch_6x_coco/scratch_mask_rcnn_r50_fpn_gn_6x_bbox_mAP-0.412__segm_mAP-0.374_20200201_193051-1e190a40.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/scratch/mask_rcnn_r50_fpn_gn-all_scratch_6x_coco/scratch_mask_rcnn_r50_fpn_gn_6x_20200201_193051.log.json) |
-
-Note:
-
-- The above models are trained with 16 GPUs.
diff --git a/configs/seesaw_loss/README.md b/configs/seesaw_loss/README.md
index 9c1fcb0c769..c1c00ccd7c9 100644
--- a/configs/seesaw_loss/README.md
+++ b/configs/seesaw_loss/README.md
@@ -1,35 +1,17 @@
-# Seesaw Loss for Long-Tailed Instance Segmentation
+# Seesaw Loss
-## Abstract
+> [Seesaw Loss for Long-Tailed Instance Segmentation](https://arxiv.org/abs/2008.10032)
-
+
+
+## Abstract
Instance segmentation has witnessed a remarkable progress on class-balanced benchmarks. However, they fail to perform as accurately in real-world scenarios, where the category distribution of objects naturally comes with a long tail. Instances of head classes dominate a long-tailed dataset and they serve as negative samples of tail categories. The overwhelming gradients of negative samples on tail classes lead to a biased learning process for classifiers. Consequently, objects of tail categories are more likely to be misclassified as backgrounds or head categories. To tackle this problem, we propose Seesaw Loss to dynamically re-balance gradients of positive and negative samples for each category, with two complementary factors, i.e., mitigation factor and compensation factor. The mitigation factor reduces punishments to tail categories w.r.t. the ratio of cumulative training instances between different categories. Meanwhile, the compensation factor increases the penalty of misclassified instances to avoid false positives of tail categories. We conduct extensive experiments on Seesaw Loss with mainstream frameworks and different data sampling strategies. With a simple end-to-end training pipeline, Seesaw Loss obtains significant gains over Cross-Entropy Loss, and achieves state-of-the-art performance on LVIS dataset without bells and whistles.
-
-
-
-
-## Citation
-
-
-
-We provide config files to reproduce the instance segmentation performance in the CVPR 2021 paper for [Seesaw Loss for Long-Tailed Instance Segmentation](https://arxiv.org/abs/2008.10032).
-
-```latex
-@inproceedings{wang2021seesaw,
- title={Seesaw Loss for Long-Tailed Instance Segmentation},
- author={Jiaqi Wang and Wenwei Zhang and Yuhang Zang and Yuhang Cao and Jiangmiao Pang and Tao Gong and Kai Chen and Ziwei Liu and Chen Change Loy and Dahua Lin},
- booktitle={Proceedings of the {IEEE} Conference on Computer Vision and Pattern Recognition},
- year={2021}
-}
-```
-
-
* Please setup [LVIS dataset](../lvis/README.md) for MMDetection.
* RFS indicates to use oversample strategy [here](../../docs/tutorials/customize_dataset.md#class-balanced-dataset) with oversample threshold `1e-3`.
@@ -51,3 +33,16 @@ We provide config files to reproduce the instance segmentation performance in th
| Cascade Mask R-CNN | R-101-FPN | pytorch | 2x | random | Y | 33.0 | 30.0 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/seesaw_loss/cascade_mask_rcnn_r101_fpn_random_seesaw_loss_normed_mask_mstrain_2x_lvis_v1.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/seesaw_loss/cascade_mask_rcnn_r101_fpn_random_seesaw_loss_normed_mask_mstrain_2x_lvis_v1-8b5a6745.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/seesaw_loss/cascade_mask_rcnn_r101_fpn_random_seesaw_loss_normed_mask_mstrain_2x_lvis_v1.log.json) |
| Cascade Mask R-CNN | R-101-FPN | pytorch | 2x | RFS | N | 30.0 | 29.3 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/seesaw_loss/cascade_mask_rcnn_r101_fpn_sample1e-3_seesaw_loss_mstrain_2x_lvis_v1.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/seesaw_loss/cascade_mask_rcnn_r101_fpn_sample1e-3_seesaw_loss_mstrain_2x_lvis_v1-5d8ca2a4.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/seesaw_loss/cascade_mask_rcnn_r101_fpn_sample1e-3_seesaw_loss_mstrain_2x_lvis_v1.log.json) |
| Cascade Mask R-CNN | R-101-FPN | pytorch | 2x | RFS | Y | 32.8 | 30.1 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/seesaw_loss/cascade_mask_rcnn_r101_fpn_sample1e-3_seesaw_loss_normed_mask_mstrain_2x_lvis_v1.py) | [model](https://download.openmmlab.com/mmdetection/v2.0/seesaw_loss/cascade_mask_rcnn_r101_fpn_sample1e-3_seesaw_loss_normed_mask_mstrain_2x_lvis_v1-c8551505.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/seesaw_loss/cascade_mask_rcnn_r101_fpn_sample1e-3_seesaw_loss_normed_mask_mstrain_2x_lvis_v1.log.json) |
+
+## Citation
+
+We provide config files to reproduce the instance segmentation performance in the CVPR 2021 paper for [Seesaw Loss for Long-Tailed Instance Segmentation](https://arxiv.org/abs/2008.10032).
+
+```latex
+@inproceedings{wang2021seesaw,
+ title={Seesaw Loss for Long-Tailed Instance Segmentation},
+ author={Jiaqi Wang and Wenwei Zhang and Yuhang Zang and Yuhang Cao and Jiangmiao Pang and Tao Gong and Kai Chen and Ziwei Liu and Chen Change Loy and Dahua Lin},
+ booktitle={Proceedings of the {IEEE} Conference on Computer Vision and Pattern Recognition},
+ year={2021}
+}
+```
diff --git a/configs/selfsup_pretrain/README.md b/configs/selfsup_pretrain/README.md
index 2c61bd6dee1..2d9530db695 100644
--- a/configs/selfsup_pretrain/README.md
+++ b/configs/selfsup_pretrain/README.md
@@ -1,62 +1,21 @@
# Backbones Trained by Self-Supervise Algorithms
-## Abstract
+
-
+## Abstract
Unsupervised image representations have significantly reduced the gap with supervised pretraining, notably with the recent achievements of contrastive learning methods. These contrastive methods typically work online and rely on a large number of explicit pairwise feature comparisons, which is computationally challenging. In this paper, we propose an online algorithm, SwAV, that takes advantage of contrastive methods without requiring to compute pairwise comparisons. Specifically, our method simultaneously clusters the data while enforcing consistency between cluster assignments produced for different augmentations (or views) of the same image, instead of comparing features directly as in contrastive learning. Simply put, we use a swapped prediction mechanism where we predict the cluster assignment of a view from the representation of another view. Our method can be trained with large and small batches and can scale to unlimited amounts of data. Compared to previous contrastive methods, our method is more memory efficient since it does not require a large memory bank or a special momentum network. In addition, we also propose a new data augmentation strategy, multi-crop, that uses a mix of views with different resolutions in place of two full-resolution views, without increasing the memory or compute requirements much. We validate our findings by achieving 75.3% top-1 accuracy on ImageNet with ResNet-50, as well as surpassing supervised pretraining on all the considered transfer tasks.
-
We present Momentum Contrast (MoCo) for unsupervised visual representation learning. From a perspective on contrastive learning as dictionary look-up, we build a dynamic dictionary with a queue and a moving-averaged encoder. This enables building a large and consistent dictionary on-the-fly that facilitates contrastive unsupervised learning. MoCo provides competitive results under the common linear protocol on ImageNet classification. More importantly, the representations learned by MoCo transfer well to downstream tasks. MoCo can outperform its supervised pre-training counterpart in 7 detection/segmentation tasks on PASCAL VOC, COCO, and other datasets, sometimes surpassing it by large margins. This suggests that the gap between unsupervised and supervised representation learning has been largely closed in many vision tasks.
-
-
-
-
-## Citation
-
-
-
-We support to apply the backbone models pre-trained by different self-supervised methods in detection systems and provide their results on Mask R-CNN.
-
-The pre-trained models are converted from [MoCo](https://github.com/facebookresearch/moco) and downloaded from [SwAV](https://github.com/facebookresearch/swav).
-
-For SwAV, please cite
-
-```latex
-@article{caron2020unsupervised,
- title={Unsupervised Learning of Visual Features by Contrasting Cluster Assignments},
- author={Caron, Mathilde and Misra, Ishan and Mairal, Julien and Goyal, Priya and Bojanowski, Piotr and Joulin, Armand},
- booktitle={Proceedings of Advances in Neural Information Processing Systems (NeurIPS)},
- year={2020}
-}
-```
-
-For MoCo, please cite
-
-```latex
-@Article{he2019moco,
- author = {Kaiming He and Haoqi Fan and Yuxin Wu and Saining Xie and Ross Girshick},
- title = {Momentum Contrast for Unsupervised Visual Representation Learning},
- journal = {arXiv preprint arXiv:1911.05722},
- year = {2019},
-}
-@Article{chen2020mocov2,
- author = {Xinlei Chen and Haoqi Fan and Ross Girshick and Kaiming He},
- title = {Improved Baselines with Momentum Contrastive Learning},
- journal = {arXiv preprint arXiv:2003.04297},
- year = {2020},
-}
-```
-
## Usage
To use a self-supervisely pretrained backbone, there are two steps to do:
@@ -102,7 +61,7 @@ model = dict(
```
-## Results
+## Results and Models
| Method | Backbone | Style | Lr schd | Mem (GB) | Inf time (fps) | box AP | mask AP | Config | Download |
| :-----: | :-----: | :-----: | :-----: | :------: | :------------: | :----: | :-----: | :------: | :--------: |
@@ -114,3 +73,37 @@ model = dict(
### Notice
1. We only provide single-scale 1x and multi-scale 2x configs as examples to show how to use backbones trained by self-supervised algorithms. We will try to reproduce the results in their corresponding paper using the released backbone in the future. Please stay tuned.
+
+## Citation
+
+We support to apply the backbone models pre-trained by different self-supervised methods in detection systems and provide their results on Mask R-CNN.
+
+The pre-trained models are converted from [MoCo](https://github.com/facebookresearch/moco) and downloaded from [SwAV](https://github.com/facebookresearch/swav).
+
+For SwAV, please cite
+
+```latex
+@article{caron2020unsupervised,
+ title={Unsupervised Learning of Visual Features by Contrasting Cluster Assignments},
+ author={Caron, Mathilde and Misra, Ishan and Mairal, Julien and Goyal, Priya and Bojanowski, Piotr and Joulin, Armand},
+ booktitle={Proceedings of Advances in Neural Information Processing Systems (NeurIPS)},
+ year={2020}
+}
+```
+
+For MoCo, please cite
+
+```latex
+@Article{he2019moco,
+ author = {Kaiming He and Haoqi Fan and Yuxin Wu and Saining Xie and Ross Girshick},
+ title = {Momentum Contrast for Unsupervised Visual Representation Learning},
+ journal = {arXiv preprint arXiv:1911.05722},
+ year = {2019},
+}
+@Article{chen2020mocov2,
+ author = {Xinlei Chen and Haoqi Fan and Ross Girshick and Kaiming He},
+ title = {Improved Baselines with Momentum Contrastive Learning},
+ journal = {arXiv preprint arXiv:2003.04297},
+ year = {2020},
+}
+```
diff --git a/configs/solo/README.md b/configs/solo/README.md
index 76664b7e4a6..8bd04325513 100644
--- a/configs/solo/README.md
+++ b/configs/solo/README.md
@@ -1,30 +1,17 @@
-# SOLO: Segmenting Objects by Locations
+# SOLO
-## Abstract
+> [SOLO: Segmenting Objects by Locations](https://arxiv.org/abs/1912.04488)
+
+
-
+## Abstract
We present a new, embarrassingly simple approach to instance segmentation in images. Compared to many other dense prediction tasks, e.g., semantic segmentation, it is the arbitrary number of instances that have made instance segmentation much more challenging. In order to predict a mask for each instance, mainstream approaches either follow the 'detect-thensegment' strategy as used by Mask R-CNN, or predict category masks first then use clustering techniques to group pixels into individual instances. We view the task of instance segmentation from a completely new perspective by introducing the notion of "instance categories", which assigns categories to each pixel within an instance according to the instance's location and size, thus nicely converting instance mask segmentation into a classification-solvable problem. Now instance segmentation is decomposed into two classification tasks. We demonstrate a much simpler and flexible instance segmentation framework with strong performance, achieving on par accuracy with Mask R-CNN and outperforming recent singleshot instance segmenters in accuracy. We hope that this very simple and strong framework can serve as a baseline for many instance-level recognition tasks besides instance segmentation.
-
-
-
-
-## Citation
-
-```
-@inproceedings{wang2020solo,
- title = {{SOLO}: Segmenting Objects by Locations},
- author = {Wang, Xinlong and Kong, Tao and Shen, Chunhua and Jiang, Yuning and Li, Lei},
- booktitle = {Proc. Eur. Conf. Computer Vision (ECCV)},
- year = {2020}
-}
-```
-
## Results and Models
### SOLO
@@ -54,3 +41,14 @@ of SOLO. Please refer to the corresponding config files for details.
- Decoupled Light SOLO using decoupled structure similar to Decoupled
SOLO head, with light-weight head and smaller input size, Please refer
to the corresponding config files for details.
+
+## Citation
+
+```latex
+@inproceedings{wang2020solo,
+ title = {{SOLO}: Segmenting Objects by Locations},
+ author = {Wang, Xinlong and Kong, Tao and Shen, Chunhua and Jiang, Yuning and Li, Lei},
+ booktitle = {Proc. Eur. Conf. Computer Vision (ECCV)},
+ year = {2020}
+}
+```
diff --git a/configs/sparse_rcnn/README.md b/configs/sparse_rcnn/README.md
index 48c8aef4340..8aa50f4b46e 100644
--- a/configs/sparse_rcnn/README.md
+++ b/configs/sparse_rcnn/README.md
@@ -1,32 +1,17 @@
-# Sparse R-CNN: End-to-End Object Detection with Learnable Proposals
+# Sparse R-CNN
-## Abstract
+> [Sparse R-CNN: End-to-End Object Detection with Learnable Proposals](https://arxiv.org/abs/2011.12450)
+
+
-
+## Abstract
We present Sparse R-CNN, a purely sparse method for object detection in images. Existing works on object detection heavily rely on dense object candidates, such as k anchor boxes pre-defined on all grids of image feature map of size H×W. In our method, however, a fixed sparse set of learned object proposals, total length of N, are provided to object recognition head to perform classification and location. By eliminating HWk (up to hundreds of thousands) hand-designed object candidates to N (e.g. 100) learnable proposals, Sparse R-CNN completely avoids all efforts related to object candidates design and many-to-one label assignment. More importantly, final predictions are directly output without non-maximum suppression post-procedure. Sparse R-CNN demonstrates accuracy, run-time and training convergence performance on par with the well-established detector baselines on the challenging COCO dataset, e.g., achieving 45.0 AP in standard 3× training schedule and running at 22 fps using ResNet-50 FPN model. We hope our work could inspire re-thinking the convention of dense prior in object detectors.
-
-
-
-
-## Citation
-
-
-
-```
-@article{peize2020sparse,
- title = {{SparseR-CNN}: End-to-End Object Detection with Learnable Proposals},
- author = {Peize Sun and Rufeng Zhang and Yi Jiang and Tao Kong and Chenfeng Xu and Wei Zhan and Masayoshi Tomizuka and Lei Li and Zehuan Yuan and Changhu Wang and Ping Luo},
- journal = {arXiv preprint arXiv:2011.12450},
- year = {2020}
-}
-```
-
## Results and Models
| Model | Backbone | Style | Lr schd | Number of Proposals |Multi-Scale| RandomCrop | box AP | Config | Download |
@@ -40,3 +25,14 @@ We present Sparse R-CNN, a purely sparse method for object detection in images.
### Notes
We observe about 0.3 AP noise especially when using ResNet-101 as the backbone.
+
+## Citation
+
+```latex
+@article{peize2020sparse,
+ title = {{SparseR-CNN}: End-to-End Object Detection with Learnable Proposals},
+ author = {Peize Sun and Rufeng Zhang and Yi Jiang and Tao Kong and Chenfeng Xu and Wei Zhan and Masayoshi Tomizuka and Lei Li and Zehuan Yuan and Changhu Wang and Ping Luo},
+ journal = {arXiv preprint arXiv:2011.12450},
+ year = {2020}
+}
+```
diff --git a/configs/ssd/README.md b/configs/ssd/README.md
index f668cd5a423..917f691a901 100644
--- a/configs/ssd/README.md
+++ b/configs/ssd/README.md
@@ -1,32 +1,17 @@
-# SSD: Single Shot MultiBox Detector
+# SSD
-## Abstract
+> [SSD: Single Shot MultiBox Detector](https://arxiv.org/abs/1512.02325)
+
+
-
+## Abstract
We present a method for detecting objects in images using a single deep neural network. Our approach, named SSD, discretizes the output space of bounding boxes into a set of default boxes over different aspect ratios and scales per feature map location. At prediction time, the network generates scores for the presence of each object category in each default box and produces adjustments to the box to better match the object shape. Additionally, the network combines predictions from multiple feature maps with different resolutions to naturally handle objects of various sizes. Our SSD model is simple relative to methods that require object proposals because it completely eliminates proposal generation and subsequent pixel or feature resampling stage and encapsulates all computation in a single network. This makes SSD easy to train and straightforward to integrate into systems that require a detection component. Experimental results on the PASCAL VOC, MS COCO, and ILSVRC datasets confirm that SSD has comparable accuracy to methods that utilize an additional object proposal step and is much faster, while providing a unified framework for both training and inference. Compared to other single stage methods, SSD has much better accuracy, even with a smaller input image size. For 300×300 input, SSD achieves 72.1% mAP on VOC2007 test at 58 FPS on a Nvidia Titan X and for 500×500 input, SSD achieves 75.1% mAP, outperforming a comparable state of the art Faster R-CNN model.
-
-
-
-
-## Citation
-
-
-
-```latex
-@article{Liu_2016,
- title={SSD: Single Shot MultiBox Detector},
- journal={ECCV},
- author={Liu, Wei and Anguelov, Dragomir and Erhan, Dumitru and Szegedy, Christian and Reed, Scott and Fu, Cheng-Yang and Berg, Alexander C.},
- year={2016},
-}
-```
-
## Results and models of SSD
| Backbone | Size | Style | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
@@ -64,3 +49,14 @@ There are some differences between our implementation of MobileNetV2 SSD-Lite an
2. The anchor sizes are different.
3. The C4 feature map is taken from the last layer of stage 4 instead of the middle of the block.
4. The model in TensorFlow1.x is trained on coco 2014 and validated on coco minival2014, but we trained and validated the model on coco 2017. The mAP on val2017 is usually a little lower than minival2014 (refer to the results in TensorFlow Object Detection API, e.g., MobileNetV2 SSD gets 22 mAP on minival2014 but 20.2 mAP on val2017).
+
+## Citation
+
+```latex
+@article{Liu_2016,
+ title={SSD: Single Shot MultiBox Detector},
+ journal={ECCV},
+ author={Liu, Wei and Anguelov, Dragomir and Erhan, Dumitru and Szegedy, Christian and Reed, Scott and Fu, Cheng-Yang and Berg, Alexander C.},
+ year={2016},
+}
+```
diff --git a/configs/strong_baselines/README.md b/configs/strong_baselines/README.md
index 5ada104bbe2..7c1be045091 100644
--- a/configs/strong_baselines/README.md
+++ b/configs/strong_baselines/README.md
@@ -1,9 +1,11 @@
# Strong Baselines
+
+
We train Mask R-CNN with large-scale jitter and longer schedule as strong baselines.
The modifications follow those in [Detectron2](https://github.com/facebookresearch/detectron2/tree/master/configs/new_baselines).
-## Results and models
+## Results and Models
| Backbone | Style | Lr schd | Mem (GB) | Inf time (fps) | box AP | mask AP | Config | Download |
| :-------------: | :-----: | :-----: | :------: | :------------: | :----: | :-----: | :------: | :--------: |
diff --git a/configs/swin/README.md b/configs/swin/README.md
index 9a4ef02dc28..abab315ad20 100644
--- a/configs/swin/README.md
+++ b/configs/swin/README.md
@@ -1,33 +1,18 @@
-# Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
+# Swin
-## Abstract
+> [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030)
+
+
-
+## Abstract
This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains, such as large variations in the scale of visual entities and the high resolution of pixels in images compared to words in text. To address these differences, we propose a hierarchical Transformer whose representation is computed with Shifted windows. The shifted windowing scheme brings greater efficiency by limiting self-attention computation to non-overlapping local windows while also allowing for cross-window connection. This hierarchical architecture has the flexibility to model at various scales and has linear computational complexity with respect to image size. These qualities of Swin Transformer make it compatible with a broad range of vision tasks, including image classification (87.3 top-1 accuracy on ImageNet-1K) and dense prediction tasks such as object detection (58.7 box AP and 51.1 mask AP on COCO test-dev) and semantic segmentation (53.5 mIoU on ADE20K val). Its performance surpasses the previous state-of-the-art by a large margin of +2.7 box AP and +2.6 mask AP on COCO, and +3.2 mIoU on ADE20K, demonstrating the potential of Transformer-based models as vision backbones. The hierarchical design and the shifted window approach also prove beneficial for all-MLP architectures.
-
-
-
-
-## Citation
-
-
-
-```latex
-@article{liu2021Swin,
- title={Swin Transformer: Hierarchical Vision Transformer using Shifted Windows},
- author={Liu, Ze and Lin, Yutong and Cao, Yue and Hu, Han and Wei, Yixuan and Zhang, Zheng and Lin, Stephen and Guo, Baining},
- journal={arXiv preprint arXiv:2103.14030},
- year={2021}
-}
-```
-
-## Results and models
+## Results and Models
### Mask R-CNN
@@ -42,3 +27,14 @@ This paper presents a new vision Transformer, called Swin Transformer, that capa
Please follow the example
of `retinanet_swin-t-p4-w7_fpn_1x_coco.py` when you want to combine Swin Transformer with
the one-stage detector. Because there is a layer norm at the outs of Swin Transformer, you must set `start_level` as 0 in FPN, so we have to set the `out_indices` of backbone as `[1,2,3]`.
+
+## Citation
+
+```latex
+@article{liu2021Swin,
+ title={Swin Transformer: Hierarchical Vision Transformer using Shifted Windows},
+ author={Liu, Ze and Lin, Yutong and Cao, Yue and Hu, Han and Wei, Yixuan and Zhang, Zheng and Lin, Stephen and Guo, Baining},
+ journal={arXiv preprint arXiv:2103.14030},
+ year={2021}
+}
+```
diff --git a/configs/swin/metafile.yml b/configs/swin/metafile.yml
index b265afe36bb..6c07f17512e 100644
--- a/configs/swin/metafile.yml
+++ b/configs/swin/metafile.yml
@@ -1,27 +1,16 @@
-Collections:
- - Name: Swin Transformer
+Models:
+ - Name: mask_rcnn_swin-s-p4-w7_fpn_fp16_ms-crop-3x_coco
+ In Collection: Mask R-CNN
+ Config: configs/swin/mask_rcnn_swin-s-p4-w7_fpn_fp16_ms-crop-3x_coco.py
Metadata:
+ Training Memory (GB): 11.9
+ Epochs: 36
Training Data: COCO
Training Techniques:
- AdamW
Training Resources: 8x V100 GPUs
Architecture:
- Swin Transformer
- Paper:
- URL: https://arxiv.org/abs/2107.08430
- Title: 'Swin Transformer: Hierarchical Vision Transformer using Shifted Windows'
- README: configs/swin/README.md
- Code:
- URL: https://github.com/open-mmlab/mmdetection/blob/v2.16.0/mmdet/models/backbones/swin.py#L465
- Version: v2.16.0
-
-Models:
- - Name: mask_rcnn_swin-s-p4-w7_fpn_fp16_ms-crop-3x_coco
- In Collection: Swin Transformer
- Config: configs/swin/mask_rcnn_swin-s-p4-w7_fpn_fp16_ms-crop-3x_coco.py
- Metadata:
- Training Memory (GB): 11.9
- Epochs: 36
Results:
- Task: Object Detection
Dataset: COCO
@@ -32,13 +21,26 @@ Models:
Metrics:
mask AP: 43.2
Weights: https://download.openmmlab.com/mmdetection/v2.0/swin/mask_rcnn_swin-s-p4-w7_fpn_fp16_ms-crop-3x_coco/mask_rcnn_swin-s-p4-w7_fpn_fp16_ms-crop-3x_coco_20210903_104808-b92c91f1.pth
+ Paper:
+ URL: https://arxiv.org/abs/2107.08430
+ Title: 'Swin Transformer: Hierarchical Vision Transformer using Shifted Windows'
+ README: configs/swin/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.16.0/mmdet/models/backbones/swin.py#L465
+ Version: v2.16.0
- Name: mask_rcnn_swin-t-p4-w7_fpn_ms-crop-3x_coco
- In Collection: Swin Transformer
+ In Collection: Mask R-CNN
Config: configs/swin/mask_rcnn_swin-t-p4-w7_fpn_ms-crop-3x_coco.py
Metadata:
Training Memory (GB): 10.2
Epochs: 36
+ Training Data: COCO
+ Training Techniques:
+ - AdamW
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - Swin Transformer
Results:
- Task: Object Detection
Dataset: COCO
@@ -49,13 +51,26 @@ Models:
Metrics:
mask AP: 41.6
Weights: https://download.openmmlab.com/mmdetection/v2.0/swin/mask_rcnn_swin-t-p4-w7_fpn_ms-crop-3x_coco/mask_rcnn_swin-t-p4-w7_fpn_ms-crop-3x_coco_20210906_131725-bacf6f7b.pth
+ Paper:
+ URL: https://arxiv.org/abs/2107.08430
+ Title: 'Swin Transformer: Hierarchical Vision Transformer using Shifted Windows'
+ README: configs/swin/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.16.0/mmdet/models/backbones/swin.py#L465
+ Version: v2.16.0
- Name: mask_rcnn_swin-t-p4-w7_fpn_1x_coco
- In Collection: Swin Transformer
+ In Collection: Mask R-CNN
Config: configs/swin/mask_rcnn_swin-t-p4-w7_fpn_1x_coco.py
Metadata:
Training Memory (GB): 7.6
Epochs: 12
+ Training Data: COCO
+ Training Techniques:
+ - AdamW
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - Swin Transformer
Results:
- Task: Object Detection
Dataset: COCO
@@ -66,13 +81,26 @@ Models:
Metrics:
mask AP: 39.3
Weights: https://download.openmmlab.com/mmdetection/v2.0/swin/mask_rcnn_swin-t-p4-w7_fpn_1x_coco/mask_rcnn_swin-t-p4-w7_fpn_1x_coco_20210902_120937-9d6b7cfa.pth
+ Paper:
+ URL: https://arxiv.org/abs/2107.08430
+ Title: 'Swin Transformer: Hierarchical Vision Transformer using Shifted Windows'
+ README: configs/swin/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.16.0/mmdet/models/backbones/swin.py#L465
+ Version: v2.16.0
- Name: mask_rcnn_swin-t-p4-w7_fpn_fp16_ms-crop-3x_coco
- In Collection: Swin Transformer
+ In Collection: Mask R-CNN
Config: configs/swin/mask_rcnn_swin-t-p4-w7_fpn_fp16_ms-crop-3x_coco.py
Metadata:
Training Memory (GB): 7.8
Epochs: 36
+ Training Data: COCO
+ Training Techniques:
+ - AdamW
+ Training Resources: 8x V100 GPUs
+ Architecture:
+ - Swin Transformer
Results:
- Task: Object Detection
Dataset: COCO
@@ -83,3 +111,10 @@ Models:
Metrics:
mask AP: 41.7
Weights: https://download.openmmlab.com/mmdetection/v2.0/swin/mask_rcnn_swin-t-p4-w7_fpn_fp16_ms-crop-3x_coco/mask_rcnn_swin-t-p4-w7_fpn_fp16_ms-crop-3x_coco_20210908_165006-90a4008c.pth
+ Paper:
+ URL: https://arxiv.org/abs/2107.08430
+ Title: 'Swin Transformer: Hierarchical Vision Transformer using Shifted Windows'
+ README: configs/swin/README.md
+ Code:
+ URL: https://github.com/open-mmlab/mmdetection/blob/v2.16.0/mmdet/models/backbones/swin.py#L465
+ Version: v2.16.0
diff --git a/configs/tood/README.md b/configs/tood/README.md
index b1522e78565..6cfbffcde6a 100644
--- a/configs/tood/README.md
+++ b/configs/tood/README.md
@@ -1,32 +1,17 @@
-# TOOD: Task-aligned One-stage Object Detection
+# TOOD
-## Abstract
+> [TOOD: Task-aligned One-stage Object Detection](https://arxiv.org/abs/2108.07755)
+
+
-
+## Abstract
One-stage object detection is commonly implemented by optimizing two sub-tasks: object classification and localization, using heads with two parallel branches, which might lead to a certain level of spatial misalignment in predictions between the two tasks. In this work, we propose a Task-aligned One-stage Object Detection (TOOD) that explicitly aligns the two tasks in a learning-based manner. First, we design a novel Task-aligned Head (T-Head) which offers a better balance between learning task-interactive and task-specific features, as well as a greater flexibility to learn the alignment via a task-aligned predictor. Second, we propose Task Alignment Learning (TAL) to explicitly pull closer (or even unify) the optimal anchors for the two tasks during training via a designed sample assignment scheme and a task-aligned loss. Extensive experiments are conducted on MS-COCO, where TOOD achieves a 51.1 AP at single-model single-scale testing. This surpasses the recent one-stage detectors by a large margin, such as ATSS (47.7 AP), GFL (48.2 AP), and PAA (49.0 AP), with fewer parameters and FLOPs. Qualitative results also demonstrate the effectiveness of TOOD for better aligning the tasks of object classification and localization.
-
-
-
-
-## Citation
-
-
-
-```latex
-@inproceedings{feng2021tood,
- title={TOOD: Task-aligned One-stage Object Detection},
- author={Feng, Chengjian and Zhong, Yujie and Gao, Yu and Scott, Matthew R and Huang, Weilin},
- booktitle={ICCV},
- year={2021}
-}
-```
-
## Results and Models
| Backbone | Style | Anchor Type | Lr schd | Multi-scale Training| Mem (GB)| Inf time (fps) | box AP | Config | Download |
@@ -42,3 +27,14 @@ One-stage object detection is commonly implemented by optimizing two sub-tasks:
[1] *1x and 2x mean the model is trained for 90K and 180K iterations, respectively.* \
[2] *All results are obtained with a single model and without any test time data augmentation such as multi-scale, flipping and etc..* \
[3] *`dcnv2` denotes deformable convolutional networks v2.* \
+
+## Citation
+
+```latex
+@inproceedings{feng2021tood,
+ title={TOOD: Task-aligned One-stage Object Detection},
+ author={Feng, Chengjian and Zhong, Yujie and Gao, Yu and Scott, Matthew R and Huang, Weilin},
+ booktitle={ICCV},
+ year={2021}
+}
+```
diff --git a/configs/tridentnet/README.md b/configs/tridentnet/README.md
index 6c43a3b0e61..d35eca012e8 100644
--- a/configs/tridentnet/README.md
+++ b/configs/tridentnet/README.md
@@ -1,33 +1,18 @@
-# Scale-Aware Trident Networks for Object Detection
+# TridentNet
-## Abstract
+> [Scale-Aware Trident Networks for Object Detection](https://arxiv.org/abs/1901.01892)
+
+
-
+## Abstract
Scale variation is one of the key challenges in object detection. In this work, we first present a controlled experiment to investigate the effect of receptive fields for scale variation in object detection. Based on the findings from the exploration experiments, we propose a novel Trident Network (TridentNet) aiming to generate scale-specific feature maps with a uniform representational power. We construct a parallel multi-branch architecture in which each branch shares the same transformation parameters but with different receptive fields. Then, we adopt a scale-aware training scheme to specialize each branch by sampling object instances of proper scales for training. As a bonus, a fast approximation version of TridentNet could achieve significant improvements without any additional parameters and computational cost compared with the vanilla detector. On the COCO dataset, our TridentNet with ResNet-101 backbone achieves state-of-the-art single-model results of 48.4 mAP.
-
-
-
-
-## Citation
-
-
-
-```
-@InProceedings{li2019scale,
- title={Scale-Aware Trident Networks for Object Detection},
- author={Li, Yanghao and Chen, Yuntao and Wang, Naiyan and Zhang, Zhaoxiang},
- journal={The International Conference on Computer Vision (ICCV)},
- year={2019}
-}
-```
-
-## Results and models
+## Results and Models
We reports the test results using only one branch for inference.
@@ -40,3 +25,14 @@ We reports the test results using only one branch for inference.
**Note**
Similar to [Detectron2](https://github.com/facebookresearch/detectron2/tree/master/projects/TridentNet), we haven't implemented the Scale-aware Training Scheme in section 4.2 of the paper.
+
+## Citation
+
+```latex
+@InProceedings{li2019scale,
+ title={Scale-Aware Trident Networks for Object Detection},
+ author={Li, Yanghao and Chen, Yuntao and Wang, Naiyan and Zhang, Zhaoxiang},
+ journal={The International Conference on Computer Vision (ICCV)},
+ year={2019}
+}
+```
diff --git a/configs/vfnet/README.md b/configs/vfnet/README.md
index e57a1beb3cf..43ade0e7867 100644
--- a/configs/vfnet/README.md
+++ b/configs/vfnet/README.md
@@ -1,37 +1,21 @@
-# VarifocalNet: An IoU-aware Dense Object Detector
+# VarifocalNet
-## Abstract
+> [VarifocalNet: An IoU-aware Dense Object Detector](https://arxiv.org/abs/2008.13367)
+
+
-
+## Abstract
Accurately ranking the vast number of candidate detections is crucial for dense object detectors to achieve high performance. Prior work uses the classification score or a combination of classification and predicted localization scores to rank candidates. However, neither option results in a reliable ranking, thus degrading detection performance. In this paper, we propose to learn an Iou-aware Classification Score (IACS) as a joint representation of object presence confidence and localization accuracy. We show that dense object detectors can achieve a more accurate ranking of candidate detections based on the IACS. We design a new loss function, named Varifocal Loss, to train a dense object detector to predict the IACS, and propose a new star-shaped bounding box feature representation for IACS prediction and bounding box refinement. Combining these two new components and a bounding box refinement branch, we build an IoU-aware dense object detector based on the FCOS+ATSS architecture, that we call VarifocalNet or VFNet for short. Extensive experiments on MS COCO show that our VFNet consistently surpasses the strong baseline by ∼2.0 AP with different backbones. Our best model VFNet-X-1200 with Res2Net-101-DCN achieves a single-model single-scale AP of 55.1 on COCO test-dev, which is state-of-the-art among various object detectors.
-
-
-
-
## Introduction
-
-
**VarifocalNet (VFNet)** learns to predict the IoU-aware classification score which mixes the object presence confidence and localization accuracy together as the detection score for a bounding box. The learning is supervised by the proposed Varifocal Loss (VFL), based on a new star-shaped bounding box feature representation (the features at nine yellow sampling points). Given the new representation, the object localization accuracy is further improved by refining the initially regressed bounding box. The full paper is available at: [https://arxiv.org/abs/2008.13367](https://arxiv.org/abs/2008.13367).
-
-## Citation
-
-```latex
-@article{zhang2020varifocalnet,
- title={VarifocalNet: An IoU-aware Dense Object Detector},
- author={Zhang, Haoyang and Wang, Ying and Dayoub, Feras and S{\"u}nderhauf, Niko},
- journal={arXiv preprint arXiv:2008.13367},
- year={2020}
-}
-```
-
## Results and Models
| Backbone | Style | DCN | MS train | Lr schd |Inf time (fps) | box AP (val) | box AP (test-dev) | Config | Download |
@@ -51,3 +35,14 @@ Accurately ranking the vast number of candidate detections is crucial for dense
- DCN means using `DCNv2` in both backbone and head.
- Inference time will be updated soon.
- More results and pre-trained models can be found in [VarifocalNet-Github](https://github.com/hyz-xmaster/VarifocalNet)
+
+## Citation
+
+```latex
+@article{zhang2020varifocalnet,
+ title={VarifocalNet: An IoU-aware Dense Object Detector},
+ author={Zhang, Haoyang and Wang, Ying and Dayoub, Feras and S{\"u}nderhauf, Niko},
+ journal={arXiv preprint arXiv:2008.13367},
+ year={2020}
+}
+```
diff --git a/configs/wider_face/README.md b/configs/wider_face/README.md
index 2e6124c8b81..1904506c64a 100644
--- a/configs/wider_face/README.md
+++ b/configs/wider_face/README.md
@@ -1,23 +1,19 @@
-# WIDER FACE: A Face Detection Benchmark
+# WIDER FACE
-## Abstract
+> [WIDER FACE: A Face Detection Benchmark](https://arxiv.org/abs/1511.06523)
+
+
-
+## Abstract
Face detection is one of the most studied topics in the computer vision community. Much of the progresses have been made by the availability of face detection benchmark datasets. We show that there is a gap between current face detection performance and the real world requirements. To facilitate future face detection research, we introduce the WIDER FACE dataset, which is 10 times larger than existing datasets. The dataset contains rich annotations, including occlusions, poses, event categories, and face bounding boxes. Faces in the proposed dataset are extremely challenging due to large variations in scale, pose and occlusion, as shown in Fig. 1. Furthermore, we show that WIDER FACE dataset is an effective training source for face detection. We benchmark several representative detection systems, providing an overview of state-of-the-art performance and propose a solution to deal with large scale variation. Finally, we discuss common failure cases that worth to be further investigated.
-
-
-
-
## Introduction
-
-
To use the WIDER Face dataset you need to download it
and extract to the `data/WIDERFace` folder. Annotation in the VOC format
can be found in this [repo](https://github.com/sovrasov/wider-face-pascal-voc-annotations.git).
@@ -51,7 +47,7 @@ create your own config based on the presented one.
## Citation
-```
+```latex
@inproceedings{yang2016wider,
Author = {Yang, Shuo and Luo, Ping and Loy, Chen Change and Tang, Xiaoou},
Booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
diff --git a/configs/yolact/README.md b/configs/yolact/README.md
index c4e390302f1..cf27e55418e 100644
--- a/configs/yolact/README.md
+++ b/configs/yolact/README.md
@@ -1,23 +1,19 @@
-# **Y**ou **O**nly **L**ook **A**t **C**oefficien**T**s
+# YOLACT
-## Abstract
+> [YOLACT: Real-time Instance Segmentation](https://arxiv.org/abs/1904.02689)
+
+
-
+## Abstract
We present a simple, fully-convolutional model for real-time instance segmentation that achieves 29.8 mAP on MS COCO at 33.5 fps evaluated on a single Titan Xp, which is significantly faster than any previous competitive approach. Moreover, we obtain this result after training on only one GPU. We accomplish this by breaking instance segmentation into two parallel subtasks: (1) generating a set of prototype masks and (2) predicting per-instance mask coefficients. Then we produce instance masks by linearly combining the prototypes with the mask coefficients. We find that because this process doesn't depend on repooling, this approach produces very high-quality masks and exhibits temporal stability for free. Furthermore, we analyze the emergent behavior of our prototypes and show they learn to localize instances on their own in a translation variant manner, despite being fully-convolutional. Finally, we also propose Fast NMS, a drop-in 12 ms faster replacement for standard NMS that only has a marginal performance penalty.
-
-
-
-
## Introduction
-
-
A simple, fully convolutional model for real-time instance segmentation. This is the code for our paper:
- [YOLACT: Real-time Instance Segmentation](https://arxiv.org/abs/1904.02689)
diff --git a/configs/yolo/README.md b/configs/yolo/README.md
index 93d14bf6c9a..57b8f534b8f 100644
--- a/configs/yolo/README.md
+++ b/configs/yolo/README.md
@@ -1,34 +1,17 @@
-# YOLOv3: An Incremental Improvement
+# YOLOv3
-## Abstract
+> [YOLOv3: An Incremental Improvement](https://arxiv.org/abs/1804.02767)
-
+
+
+## Abstract
We present some updates to YOLO! We made a bunch of little design changes to make it better. We also trained this new network that's pretty swell. It's a little bigger than last time but more accurate. It's still fast though, don't worry. At 320x320 YOLOv3 runs in 22 ms at 28.2 mAP, as accurate as SSD but three times faster. When we look at the old .5 IOU mAP detection metric YOLOv3 is quite good. It achieves 57.9 mAP@50 in 51 ms on a Titan X, compared to 57.5 mAP@50 in 198 ms by RetinaNet, similar performance but 3.8x faster.
-
-
-
-
-## Citation
-
-
-
-```latex
-@misc{redmon2018yolov3,
- title={YOLOv3: An Incremental Improvement},
- author={Joseph Redmon and Ali Farhadi},
- year={2018},
- eprint={1804.02767},
- archivePrefix={arXiv},
- primaryClass={cs.CV}
-}
-```
-
## Results and Models
| Backbone | Scale | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
@@ -57,3 +40,16 @@ Notice: We reduce the number of channels to 96 in both head and neck. It can red
## Credit
This implementation originates from the project of Haoyu Wu(@wuhy08) at Western Digital.
+
+## Citation
+
+```latex
+@misc{redmon2018yolov3,
+ title={YOLOv3: An Incremental Improvement},
+ author={Joseph Redmon and Ali Farhadi},
+ year={2018},
+ eprint={1804.02767},
+ archivePrefix={arXiv},
+ primaryClass={cs.CV}
+}
+```
diff --git a/configs/yolof/README.md b/configs/yolof/README.md
index 6a53ed5623f..9aa6001d058 100644
--- a/configs/yolof/README.md
+++ b/configs/yolof/README.md
@@ -1,32 +1,17 @@
-# You Only Look One-level Feature
+# YOLOF
-## Abstract
+> [You Only Look One-level Feature](https://arxiv.org/abs/2103.09460)
+
+
-
+## Abstract
This paper revisits feature pyramids networks (FPN) for one-stage detectors and points out that the success of FPN is due to its divide-and-conquer solution to the optimization problem in object detection rather than multi-scale feature fusion. From the perspective of optimization, we introduce an alternative way to address the problem instead of adopting the complex feature pyramids - {\em utilizing only one-level feature for detection}. Based on the simple and efficient solution, we present You Only Look One-level Feature (YOLOF). In our method, two key components, Dilated Encoder and Uniform Matching, are proposed and bring considerable improvements. Extensive experiments on the COCO benchmark prove the effectiveness of the proposed model. Our YOLOF achieves comparable results with its feature pyramids counterpart RetinaNet while being 2.5× faster. Without transformer layers, YOLOF can match the performance of DETR in a single-level feature manner with 7× less training epochs. With an image size of 608×608, YOLOF achieves 44.3 mAP running at 60 fps on 2080Ti, which is 13% faster than YOLOv4.
-
-
-
-
-## Citation
-
-
-
-```
-@inproceedings{chen2021you,
- title={You Only Look One-level Feature},
- author={Chen, Qiang and Wang, Yingming and Yang, Tong and Zhang, Xiangyu and Cheng, Jian and Sun, Jian},
- booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
- year={2021}
-}
-```
-
## Results and Models
| Backbone | Style | Epoch | Lr schd | Mem (GB) | box AP | Config | Download |
@@ -37,3 +22,14 @@ This paper revisits feature pyramids networks (FPN) for one-stage detectors and
1. We find that the performance is unstable and may fluctuate by about 0.3 mAP. mAP 37.4 ~ 37.7 is acceptable in YOLOF_R_50_C5_1x. Such fluctuation can also be found in the [original implementation](https://github.com/chensnathan/YOLOF).
2. In addition to instability issues, sometimes there are large loss fluctuations and NAN, so there may still be problems with this project, which will be improved subsequently.
+
+## Citation
+
+```latex
+@inproceedings{chen2021you,
+ title={You Only Look One-level Feature},
+ author={Chen, Qiang and Wang, Yingming and Yang, Tong and Zhang, Xiangyu and Cheng, Jian and Sun, Jian},
+ booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
+ year={2021}
+}
+```
diff --git a/configs/yolox/README.md b/configs/yolox/README.md
index b836b826b25..165045e5f91 100644
--- a/configs/yolox/README.md
+++ b/configs/yolox/README.md
@@ -1,32 +1,17 @@
-# YOLOX: Exceeding YOLO Series in 2021
+# YOLOX
-## Abstract
+> [YOLOX: Exceeding YOLO Series in 2021](https://arxiv.org/abs/2107.08430)
+
+
-
+## Abstract
In this report, we present some experienced improvements to YOLO series, forming a new high-performance detector -- YOLOX. We switch the YOLO detector to an anchor-free manner and conduct other advanced detection techniques, i.e., a decoupled head and the leading label assignment strategy SimOTA to achieve state-of-the-art results across a large scale range of models: For YOLO-Nano with only 0.91M parameters and 1.08G FLOPs, we get 25.3% AP on COCO, surpassing NanoDet by 1.8% AP; for YOLOv3, one of the most widely used detectors in industry, we boost it to 47.3% AP on COCO, outperforming the current best practice by 3.0% AP; for YOLOX-L with roughly the same amount of parameters as YOLOv4-CSP, YOLOv5-L, we achieve 50.0% AP on COCO at a speed of 68.9 FPS on Tesla V100, exceeding YOLOv5-L by 1.8% AP. Further, we won the 1st Place on Streaming Perception Challenge (Workshop on Autonomous Driving at CVPR 2021) using a single YOLOX-L model. We hope this report can provide useful experience for developers and researchers in practical scenes, and we also provide deploy versions with ONNX, TensorRT, NCNN, and Openvino supported.
-
-
-
-
-## Citation
-
-
-
-```latex
-@article{yolox2021,
- title={{YOLOX}: Exceeding YOLO Series in 2021},
- author={Ge, Zheng and Liu, Songtao and Wang, Feng and Li, Zeming and Sun, Jian},
- journal={arXiv preprint arXiv:2107.08430},
- year={2021}
-}
-```
-
## Results and Models
| Backbone | size | Mem (GB) | box AP | Config | Download |
@@ -36,9 +21,19 @@ In this report, we present some experienced improvements to YOLO series, forming
| YOLOX-l | 640 | 19.9 | 49.4 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/yolox/yolox_l_8x8_300e_coco.py) |[model](https://download.openmmlab.com/mmdetection/v2.0/yolox/yolox_l_8x8_300e_coco/yolox_l_8x8_300e_coco_20211126_140236-d3bd2b23.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/yolox/yolox_l_8x8_300e_coco/yolox_l_8x8_300e_coco_20211126_140236.log.json) |
| YOLOX-x | 640 | 28.1 | 50.9 | [config](https://github.com/open-mmlab/mmdetection/tree/master/configs/yolox/yolox_x_8x8_300e_coco.py) |[model](https://download.openmmlab.com/mmdetection/v2.0/yolox/yolox_x_8x8_300e_coco/yolox_x_8x8_300e_coco_20211126_140254-1ef88d67.pth) | [log](https://download.openmmlab.com/mmdetection/v2.0/yolox/yolox_x_8x8_300e_coco/yolox_x_8x8_300e_coco_20211126_140254.log.json) |
-
**Note**:
1. The test score threshold is 0.001, and the box AP indicates the best AP.
2. Due to the need for pre-training weights, we cannot reproduce the performance of the `yolox-nano` model. Please refer to https://github.com/Megvii-BaseDetection/YOLOX/issues/674 for more information.
3. We also trained the model by the official release of YOLOX based on [Megvii-BaseDetection/YOLOX#735](https://github.com/Megvii-BaseDetection/YOLOX/issues/735) with commit ID [38c633](https://github.com/Megvii-BaseDetection/YOLOX/tree/38c633bf176462ee42b110c70e4ffe17b5753208). We found that the best AP of `YOLOX-tiny`, `YOLOX-s`, `YOLOX-l`, and `YOLOX-x` is 31.8, 40.3, 49.2, and 50.9, respectively. The performance is consistent with that of our re-implementation (see Table above) but still has a gap (0.3~0.8 AP) in comparison with the reported performance in their [README](https://github.com/Megvii-BaseDetection/YOLOX/blob/38c633bf176462ee42b110c70e4ffe17b5753208/README.md#benchmark).
+
+## Citation
+
+```latex
+@article{yolox2021,
+ title={{YOLOX}: Exceeding YOLO Series in 2021},
+ author={Ge, Zheng and Liu, Songtao and Wang, Feng and Li, Zeming and Sun, Jian},
+ journal={arXiv preprint arXiv:2107.08430},
+ year={2021}
+}
+```
diff --git a/model-index.yml b/model-index.yml
index 900b9385242..b6ec18b682f 100644
--- a/model-index.yml
+++ b/model-index.yml
@@ -3,10 +3,12 @@ Import:
- configs/autoassign/metafile.yml
- configs/carafe/metafile.yml
- configs/cascade_rcnn/metafile.yml
+ - configs/cascade_rpn/metafile.yml
- configs/centernet/metafile.yml
- configs/centripetalnet/metafile.yml
- configs/cornernet/metafile.yml
- configs/dcn/metafile.yml
+ - configs/dcnv2/metafile.yml
- configs/deformable_detr/metafile.yml
- configs/detectors/metafile.yml
- configs/detr/metafile.yml
@@ -30,6 +32,7 @@ Import:
- configs/hrnet/metafile.yml
- configs/htc/metafile.yml
- configs/instaboost/metafile.yml
+ - configs/lad/metafile.yml
- configs/ld/metafile.yml
- configs/libra_rcnn/metafile.yml
- configs/mask_rcnn/metafile.yml