-
- | Model |
- Config |
- Dataset |
- Metric |
- PyTorch |
- ONNX Runtime |
- TensorRT FP32 |
- TensorRT FP16 |
-
-
- | ESRGAN |
-
- esrgan_x4c64b23g32_g1_400k_div2k.py
- |
- Set5 |
- PSNR |
- 28.2700 |
- 28.2619 |
- 28.2619 |
- 28.2616 |
-
-
- | SSIM |
- 0.7778 |
- 0.7784 |
- 0.7784 |
- 0.7783 |
-
-
- | Set14 |
- PSNR |
- 24.6328 |
- 24.6290 |
- 24.6290 |
- 24.6274 |
-
-
- | SSIM |
- 0.6491 |
- 0.6494 |
- 0.6494 |
- 0.6494 |
-
-
- | DIV2K |
- PSNR |
- 26.6531 |
- 26.6532 |
- 26.6532 |
- 26.6532 |
-
-
- | SSIM |
- 0.7340 |
- 0.7340 |
- 0.7340 |
- 0.7340 |
-
-
- | ESRGAN |
-
- esrgan_psnr_x4c64b23g32_g1_1000k_div2k.py
- |
- Set5 |
- PSNR |
- 30.6428 |
- 30.6307 |
- 30.6307 |
- 30.6305 |
-
-
- | SSIM |
- 0.8559 |
- 0.8565 |
- 0.8565 |
- 0.8566 |
-
-
- | Set14 |
- PSNR |
- 27.0543 |
- 27.0422 |
- 27.0422 |
- 27.0411 |
-
-
- | SSIM |
- 0.7447 |
- 0.7450 |
- 0.7450 |
- 0.7449 |
-
-
- | DIV2K |
- PSNR |
- 29.3354 |
- 29.3354 |
- 29.3354 |
- 29.3339 |
-
-
- | SSIM |
- 0.8263 |
- 0.8263 |
- 0.8263 |
- 0.8263 |
-
-
- | SRCNN |
-
- srcnn_x4k915_g1_1000k_div2k.py
- |
- Set5 |
- PSNR |
- 28.4316 |
- 28.4120 |
- 27.2144 |
- 27.2127 |
-
-
- | SSIM |
- 0.8099 |
- 0.8106 |
- 0.7782 |
- 0.7781 |
-
-
- | Set14 |
- PSNR |
- 25.6486 |
- 25.6367 |
- 24.8613 |
- 24.8599 |
-
-
- | SSIM |
- 0.7014 |
- 0.7015 |
- 0.6674 |
- 0.6673 |
-
-
- | DIV2K |
- PSNR |
- 27.7460 |
- 27.7460 |
- 26.9891 |
- 26.9862 |
-
-
- | SSIM |
- 0.7854 |
- 0.78543 |
- 0.7605 |
- 0.7604 |
-
-
-
-**注**:
-
-- 所有 ONNX 和 TensorRT 模型都使用数据集上的动态形状进行评估,图像根据原始配置文件进行预处理。
-- 此工具仍处于试验阶段,我们目前仅支持 `restorer`。
diff --git a/docs/zh_cn/user_guides/config.md b/docs/zh_cn/user_guides/config.md
index c4aa1e3768..d147aa5c29 100644
--- a/docs/zh_cn/user_guides/config.md
+++ b/docs/zh_cn/user_guides/config.md
@@ -1 +1,675 @@
-# 配置文件(待更新)
+# 教程 1: 了解配置文件(待更新)
+
+mmedit 采用基于 python 文件的配置系统,您可以在 `$MMEditing/configs` 下查看预置的配置文件。
+
+## 配置文件命名风格
+
+配置文件按照下面的风格命名。我们建议社区贡献者使用同样的风格。
+
+```bash
+{model}_[model setting]_{backbone}_[refiner]_[norm setting]_[misc]_[gpu x batch_per_gpu]_{schedule}_{dataset}
+```
+
+`{xxx}` 是必填字段,`[yyy]` 是可选的。
+
+- `{model}`: 模型种类,例如 `srcnn`, `dim` 等等。
+- `[model setting]`: 特定设置一些模型,例如,输入图像 `resolution` , 训练 `stage name`。
+- `{backbone}`: 主干网络种类,例如 `r50` (ResNet-50)、`x101` (ResNeXt-101)。
+- `{refiner}`: 精炼器种类,例如 `pln` 简单精炼器模型
+- `[norm_setting]`: 指定归一化设置,默认为批归一化,其他归一化可以设为: `bn`(批归一化), `gn` (组归一化), `syncbn` (同步批归一化)。
+- `[misc]`: 模型中各式各样的设置/插件,例如 `dconv`, `gcb`, `attention`, `mstrain`。
+- `[gpu x batch_per_gpu]`: GPU数目 和每个 GPU 的样本数, 默认为 `8x2 `。
+- `{schedule}`: 训练策略,如 `20k`, `100k` 等,意思是 `20k` 或 `100k` 迭代轮数。
+- `{dataset}`: 数据集,如 `places`(图像补全)、`comp1k`(抠图)、`div2k`(图像恢复)和 `paired`(图像生成)。
+
+## 配置文件 - 生成
+
+与 [MMDetection](https://github.com/open-mmlab/mmdetection) 一样,我们将模块化和继承设计融入我们的配置系统,以方便进行各种实验。
+
+## 示例 - pix2pix
+
+为了帮助用户对完整的配置和生成系统中的模块有一个基本的了解,我们对 pix2pix 的配置做如下简要说明。
+更详细的用法和各个模块对应的替代方案,请参考 API 文档。
+
+```python
+# 模型设置
+model = dict(
+ type='Pix2Pix', # 合成器名称
+ generator=dict(
+ type='UnetGenerator', # 生成器名称
+ in_channels=3, # 生成器的输入通道数
+ out_channels=3, # 生成器的输出通道数
+ num_down=8, # # 生成器中下采样的次数
+ base_channels=64, # 生成器最后卷积层的通道数
+ norm_cfg=dict(type='BN'), # 归一化层的配置
+ use_dropout=True, # 是否在生成器中使用 dropout
+ init_cfg=dict(type='normal', gain=0.02)), # 初始化配置
+ discriminator=dict(
+ type='PatchDiscriminator', # 判别器的名称
+ in_channels=6, # 判别器的输入通道数
+ base_channels=64, # 判别器第一卷积层的通道数
+ num_conv=3, # 判别器中堆叠的中间卷积层(不包括输入和输出卷积层)的数量
+ norm_cfg=dict(type='BN'), # 归一化层的配置
+ init_cfg=dict(type='normal', gain=0.02)), # 初始化配置
+ gan_loss=dict(
+ type='GANLoss', # GAN 损失的名称
+ gan_type='vanilla', # GAN 损失的类型
+ real_label_val=1.0, # GAN 损失函数中真实标签的值
+ fake_label_val=0.0, # GAN 损失函数中伪造标签的值
+ loss_weight=1.0), # GAN 损失函数的权重
+ pixel_loss=dict(type='L1Loss', loss_weight=100.0, reduction='mean'))
+# 模型训练和测试设置
+train_cfg = dict(
+ direction='b2a') # pix2pix 的图像到图像的转换方向 (模型训练的方向,和测试方向一致)。模型默认: a2b
+test_cfg = dict(
+ direction='b2a', # pix2pix 的图像到图像的转换方向 (模型测试的方向,和训练方向一致)。模型默认: a2b
+ show_input=True) # 保存 pix2pix 的测试图像时是否显示输入的真实图像
+
+# 数据设置
+train_dataset_type = 'GenerationPairedDataset' # 训练数据集的类型
+val_dataset_type = 'GenerationPairedDataset' # 验证/测试数据集类型
+img_norm_cfg = dict(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) # 输入图像归一化配置
+train_pipeline = [
+ dict(
+ type='LoadPairedImageFromFile', # 从文件路径加载图像对
+ io_backend='disk', # 存储图像的 IO 后端
+ key='pair', # 查找对应路径的关键词
+ flag='color'), # 加载图像标志
+ dict(
+ type='Resize', # 图像大小调整
+ keys=['img_a', 'img_b'], # 要调整大小的图像的关键词
+ scale=(286, 286), # 调整图像大小的比例
+ interpolation='bicubic'), # 调整图像大小时用于插值的算法
+ dict(
+ type='FixedCrop', # 固定裁剪,在特定位置将配对图像裁剪为特定大小以训练 pix2pix
+ keys=['img_a', 'img_b'], # 要裁剪的图像的关键词
+ crop_size=(256, 256)), # 裁剪图像的大小
+ dict(
+ type='Flip', # 翻转图像
+ keys=['img_a', 'img_b'], # 要翻转的图像的关键词
+ direction='horizontal'), # 水平或垂直翻转图像
+ dict(
+ type='RescaleToZeroOne', # 将图像从 [0, 255] 缩放到 [0, 1]
+ keys=['img_a', 'img_b']), # 要重新缩放的图像的关键词
+ dict(
+ type='Normalize', # 图像归一化
+ keys=['img_a', 'img_b'], # 要归一化的图像的关键词
+ to_rgb=True, # 是否将图像通道从 BGR 转换为 RGB
+ **img_norm_cfg), # 图像归一化配置(`img_norm_cfg` 的定义见上文)
+ dict(
+ type='ToTensor', # 将图像转化为 Tensor
+ keys=['img_a', 'img_b']), # 要从图像转换为 Tensor 的图像的关键词
+ dict(
+ type='Collect', # 决定数据中哪些键应该传递给合成器
+ keys=['img_a', 'img_b'], # 图像的关键词
+ meta_keys=['img_a_path', 'img_b_path']) # 图片的元关键词
+]
+test_pipeline = [
+ dict(
+ type='LoadPairedImageFromFile', # 从文件路径加载图像对
+ io_backend='disk', # 存储图像的 IO 后端
+ key='pair', # 查找对应路径的关键词
+ flag='color'), # 加载图像标志
+ dict(
+ type='Resize', # 图像大小调整
+ keys=['img_a', 'img_b'], # 要调整大小的图像的关键词
+ scale=(256, 256), # 调整图像大小的比例
+ interpolation='bicubic'), # 调整图像大小时用于插值的算法
+ dict(
+ type='RescaleToZeroOne', # 将图像从 [0, 255] 缩放到 [0, 1]
+ keys=['img_a', 'img_b']), # 要重新缩放的图像的关键词
+ dict(
+ type='Normalize', # 图像归一化
+ keys=['img_a', 'img_b'], # 要归一化的图像的关键词
+ to_rgb=True, # 是否将图像通道从 BGR 转换为 RGB
+ **img_norm_cfg), # 图像归一化配置(`img_norm_cfg` 的定义见上文)
+ dict(
+ type='ToTensor', # 将图像转化为 Tensor
+ keys=['img_a', 'img_b']), # 要从图像转换为 Tensor 的图像的关键词
+ dict(
+ type='Collect', # 决定数据中哪些键应该传递给合成器
+ keys=['img_a', 'img_b'], # 图像的关键词
+ meta_keys=['img_a_path', 'img_b_path']) # 图片的元关键词
+]
+data_root = 'data/pix2pix/facades' # 数据的根路径
+data = dict(
+ samples_per_gpu=1, # 单个 GPU 的批量大小
+ workers_per_gpu=4, # 为每个 GPU 预取数据的 Worker 数
+ drop_last=True, # 是否丢弃训练中的最后一批数据
+ val_samples_per_gpu=1, # 验证中单个 GPU 的批量大小
+ val_workers_per_gpu=0, # 在验证中为每个 GPU 预取数据的 Worker 数
+ train=dict( # 训练数据集配置
+ type=train_dataset_type,
+ dataroot=data_root,
+ pipeline=train_pipeline,
+ test_mode=False),
+ val=dict( # 验证数据集配置
+ type=val_dataset_type,
+ dataroot=data_root,
+ pipeline=test_pipeline,
+ test_mode=True),
+ test=dict( # 测试数据集配置
+ type=val_dataset_type,
+ dataroot=data_root,
+ pipeline=test_pipeline,
+ test_mode=True))
+
+# 优化器
+optimizers = dict( # 用于构建优化器的配置,支持 PyTorch 中所有优化器,且参数与 PyTorch 中对应优化器相同
+ generator=dict(type='Adam', lr=2e-4, betas=(0.5, 0.999)),
+ discriminator=dict(type='Adam', lr=2e-4, betas=(0.5, 0.999)))
+
+# 学习策略
+lr_config = dict(policy='Fixed', by_epoch=False) # 用于注册 LrUpdater 钩子的学习率调度程序配置
+
+# 检查点保存
+checkpoint_config = dict(interval=4000, save_optimizer=True, by_epoch=False) # 配置检查点钩子,实现参考 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/checkpoint.py
+evaluation = dict( # 构建验证钩子的配置
+ interval=4000, # 验证区间
+ save_image=True) # 是否保存图片
+log_config = dict( # 配置注册记录器钩子
+ interval=100, # 打印日志的时间间隔
+ hooks=[
+ dict(type='TextLoggerHook', by_epoch=False), # 用于记录训练过程的记录器
+ # dict(type='TensorboardLoggerHook') # 还支持 Tensorboard 记录器
+ ])
+visual_config = None # 构建可视化钩子的配置
+
+# 运行设置
+total_iters = 80000 # 训练模型的总迭代次数
+cudnn_benchmark = True # 设置 cudnn_benchmark
+dist_params = dict(backend='nccl') # 设置分布式训练的参数,端口也可以设置
+log_level = 'INFO' # 日志级别
+load_from = None # 从给定路径加载模型作为预训练模型。 这不会恢复训练
+resume_from = None # 从给定路径恢复检查点,当检查点被保存时,训练将从该 epoch 恢复
+workflow = [('train', 1)] # runner 的工作流程。 [('train', 1)] 表示只有一个工作流程,名为 'train' 的工作流程执行一次。 训练当前生成模型时保持不变
+exp_name = 'pix2pix_facades' # 实验名称
+work_dir = f'./work_dirs/{exp_name}' # 保存当前实验的模型检查点和日志的目录
+```
+
+## 配置文件 - 补全
+
+## 配置名称样式
+
+与 [MMDetection](https://github.com/open-mmlab/mmdetection) 一样,我们将模块化和继承设计融入我们的配置系统,以方便进行各种实验。
+
+## 配置字段说明
+
+为了帮助用户对完整的配置和修复系统中的模块有一个基本的了解,我们对 Global&Local 的配置作如下简要说明。更详细的用法和各个模块对应的替代方案,请参考 API 文档。
+
+```python
+model = dict(
+ type='GLInpaintor', # 补全器的名称
+ encdec=dict(
+ type='GLEncoderDecoder', # 编码器-解码器的名称
+ encoder=dict(type='GLEncoder', norm_cfg=dict(type='SyncBN')), # 编码器的配置
+ decoder=dict(type='GLDecoder', norm_cfg=dict(type='SyncBN')), # 解码器的配置
+ dilation_neck=dict(
+ type='GLDilationNeck', norm_cfg=dict(type='SyncBN'))), # 扩颈的配置
+ disc=dict(
+ type='GLDiscs', # 判别器的名称
+ global_disc_cfg=dict(
+ in_channels=3, # 判别器的输入通道数
+ max_channels=512, # 判别器中的最大通道数
+ fc_in_channels=512 * 4 * 4, # 最后一个全连接层的输入通道
+ fc_out_channels=1024, # 最后一个全连接层的输出通道
+ num_convs=6, # 判别器中使用的卷积数量
+ norm_cfg=dict(type='SyncBN') # 归一化层的配置
+ ),
+ local_disc_cfg=dict(
+ in_channels=3, # 判别器的输入通道数
+ max_channels=512, # 判别器中的最大通道数
+ fc_in_channels=512 * 4 * 4, # 最后一个全连接层的输入通道
+ fc_out_channels=1024, # 最后一个全连接层的输出通道
+ num_convs=5, # 判别器中使用的卷积数量
+ norm_cfg=dict(type='SyncBN') # 归一化层的配置
+ ),
+ ),
+ loss_gan=dict(
+ type='GANLoss', # GAN 损失的名称
+ gan_type='vanilla', # GAN 损失的类型
+ loss_weight=0.001 # GAN 损失函数的权重
+ ),
+ loss_l1_hole=dict(
+ type='L1Loss', # L1 损失的类型
+ loss_weight=1.0 # L1 损失函数的权重
+ ),
+ pretrained=None) # 预训练权重的路径
+
+train_cfg = dict(
+ disc_step=1, # 训练生成器之前训练判别器的迭代次数
+ iter_tc=90000, # 预热生成器的迭代次数
+ iter_td=100000, # 预热判别器的迭代次数
+ start_iter=0, # 开始的迭代
+ local_size=(128, 128)) # 图像块的大小
+test_cfg = dict(metrics=['l1']) # 测试的配置
+
+dataset_type = 'ImgInpaintingDataset' # 数据集类型
+input_shape = (256, 256) # 输入图像的形状
+
+train_pipeline = [
+ dict(type='LoadImageFromFile', key='gt_img'), # 加载图片的配置
+ dict(
+ type='LoadMask', # 加载掩码
+ mask_mode='bbox', # 掩码的类型
+ mask_config=dict(
+ max_bbox_shape=(128, 128), # 检测框的形状
+ max_bbox_delta=40, # 检测框高宽的变化
+ min_margin=20, # 检测框到图片边界的最小距离
+ img_shape=input_shape)), # 输入图像的形状
+ dict(
+ type='Crop', # 裁剪
+ keys=['gt_img'], # 要裁剪的图像的关键词
+ crop_size=(384, 384), # 裁剪图像块的大小
+ random_crop=True, # 是否使用随机裁剪
+ ),
+ dict(
+ type='Resize', # 图像大小调整
+ keys=['gt_img'], # 要调整大小的图像的关键词
+ scale=input_shape, # 调整图像大小的比例
+ keep_ratio=False, # 调整大小时是否保持比例
+ ),
+ dict(
+ type='Normalize', # 图像归一化
+ keys=['gt_img'], # 要归一化的图像的关键词
+ mean=[127.5] * 3, # 归一化中使用的均值
+ std=[127.5] * 3, # 归一化中使用的标准差
+ to_rgb=False), # 是否将图像通道从 BGR 转换为 RGB
+ dict(type='GetMaskedImage'), # 获取被掩盖的图像
+ dict(
+ type='Collect', # 决定数据中哪些键应该传递给合成器
+ keys=['gt_img', 'masked_img', 'mask', 'mask_bbox'], # 要收集的数据的关键词
+ meta_keys=['gt_img_path']), # 要收集的数据的元关键词
+ dict(type='ToTensor', keys=['gt_img', 'masked_img', 'mask']), # 将图像转化为 Tensor
+ dict(type='ToTensor', keys=['mask_bbox']) # 转化为 Tensor
+]
+
+test_pipeline = train_pipeline # 构建测试/验证流程
+
+data_root = 'data/places365' # 数据根目录
+
+data = dict(
+ samples_per_gpu=12, # 单个 GPU 的批量大小
+ workers_per_gpu=8, # 为每个 GPU 预取数据的 Worker 数
+ val_samples_per_gpu=1, # 验证中单个 GPU 的批量大小
+ val_workers_per_gpu=8, # 在验证中为每个 GPU 预取数据的 Worker 数
+ drop_last=True, # 是否丢弃训练中的最后一批数据
+ train=dict( # 训练数据集配置
+ type=dataset_type,
+ ann_file=f'{data_root}/train_places_img_list_total.txt',
+ data_prefix=data_root,
+ pipeline=train_pipeline,
+ test_mode=False),
+ val=dict( # 验证数据集配置
+ type=dataset_type,
+ ann_file=f'{data_root}/val_places_img_list.txt',
+ data_prefix=data_root,
+ pipeline=test_pipeline,
+ test_mode=True))
+
+optimizers = dict( # 用于构建优化器的配置,支持 PyTorch 中所有优化器,且参数与 PyTorch 中对应优化器相同
+ generator=dict(type='Adam', lr=0.0004), disc=dict(type='Adam', lr=0.0004))
+
+lr_config = dict(policy='Fixed', by_epoch=False) # 用于注册 LrUpdater 钩子的学习率调度程序配置
+
+checkpoint_config = dict(by_epoch=False, interval=50000) # 配置检查点钩子,实现参考 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/checkpoint.py
+log_config = dict( # 配置注册记录器钩子
+ interval=100, # 打印日志的时间间隔
+ hooks=[
+ dict(type='TextLoggerHook', by_epoch=False),
+ # dict(type='TensorboardLoggerHook'), # 支持 Tensorboard 记录器
+ # dict(type='PaviLoggerHook', init_kwargs=dict(project='mmedit'))
+ ]) # 用于记录训练过程的记录器
+
+visual_config = dict( # 构建可视化钩子的配置
+ type='VisualizationHook',
+ output_dir='visual',
+ interval=1000,
+ res_name_list=[
+ 'gt_img', 'masked_img', 'fake_res', 'fake_img', 'fake_gt_local'
+ ],
+) # 用于可视化训练过程的记录器。
+
+evaluation = dict(interval=50000) # 构建验证钩子的配置
+
+total_iters = 500002
+dist_params = dict(backend='nccl') # 设置分布式训练的参数,端口也可以设置
+log_level = 'INFO' # 日志级别
+work_dir = None # 保存当前实验的模型检查点和日志的目录
+load_from = None # 从给定路径加载模型作为预训练模型。 这不会恢复训练
+resume_from = None # 从给定路径恢复检查点,当检查点被保存时,训练将从该 epoch 恢复
+workflow = [('train', 10000)] # runner 的工作流程。 [('train', 1)] 表示只有一个工作流程,名为 'train' 的工作流程执行一次。 训练当前生成模型时保持不变
+exp_name = 'gl_places' # 实验名称
+find_unused_parameters = False # 是否在分布式训练中查找未使用的参数
+```
+
+## 配置文件 - 抠图
+
+与 [MMDetection](https://github.com/open-mmlab/mmdetection) 一样,我们将模块化和继承设计融入我们的配置系统,以方便进行各种实验。
+
+## 例子 - Deep Image Matting Model
+
+为了帮助用户对一个完整的配置有一个基本的了解,我们对我们实现的原始 DIM 模型的配置做一个简短的评论,如下所示。 更详细的用法和各个模块对应的替代方案,请参考 API 文档。
+
+```python
+# 模型配置
+model = dict(
+ type='DIM', # 模型的名称(我们称之为抠图器)
+ backbone=dict( # 主干网络的配置
+ type='SimpleEncoderDecoder', # 主干网络的类型
+ encoder=dict( # 编码器的配置
+ type='VGG16'), # 编码器的类型
+ decoder=dict( # 解码器的配置
+ type='PlainDecoder')), # 解码器的类型
+ pretrained='./weights/vgg_state_dict.pth', # 编码器的预训练权重
+ loss_alpha=dict( # alpha 损失的配置
+ type='CharbonnierLoss', # 预测的 alpha 遮罩的损失类型
+ loss_weight=0.5), # alpha 损失的权重
+ loss_comp=dict( # 组合损失的配置
+ type='CharbonnierCompLoss', # 组合损失的类型
+ loss_weight=0.5)) # 组合损失的权重
+train_cfg = dict( # 训练 DIM 模型的配置
+ train_backbone=True, # 在 DIM stage 1 中,会对主干网络进行训练
+ train_refiner=False) # 在 DIM stage 1 中,不会对精炼器进行训练
+test_cfg = dict( # 测试 DIM 模型的配置
+ refine=False, # 是否使用精炼器输出作为输出,在 stage 1 中,我们不使用它
+ metrics=['SAD', 'MSE', 'GRAD', 'CONN']) # 测试时使用的指标
+
+# 数据配置
+dataset_type = 'AdobeComp1kDataset' # 数据集类型,这将用于定义数据集
+data_root = 'data/adobe_composition-1k' # 数据的根目录
+img_norm_cfg = dict( # 归一化输入图像的配置
+ mean=[0.485, 0.456, 0.406], # 归一化中使用的均值
+ std=[0.229, 0.224, 0.225], # 归一化中使用的标准差
+ to_rgb=True) # 是否将图像通道从 BGR 转换为 RGB
+train_pipeline = [ # 训练数据处理流程
+ dict(
+ type='LoadImageFromFile', # 从文件加载 alpha 遮罩
+ key='alpha', # 注释文件中 alpha 遮罩的键关键词。流程将从路径 “alpha_path” 中读取 alpha 遮罩
+ flag='grayscale'), # 加载灰度图像,形状为(高度、宽度)
+ dict(
+ type='LoadImageFromFile', # 从文件中加载图像
+ key='fg'), # 要加载的图像的关键词。流程将从路径 “fg_path” 读取 fg
+ dict(
+ type='LoadImageFromFile', # 从文件中加载图像
+ key='bg'), # 要加载的图像的关键词。流程将从路径 “bg_path” 读取 bg
+ dict(
+ type='LoadImageFromFile', # 从文件中加载图像
+ key='merged'), # 要加载的图像的关键词。流程将从路径 “merged_path” 读取并合并
+ dict(
+ type='CropAroundUnknown', # 在未知区域(半透明区域)周围裁剪图像
+ keys=['alpha', 'merged', 'ori_merged', 'fg', 'bg'], # 要裁剪的图像
+ crop_sizes=[320, 480, 640]), # 裁剪大小
+ dict(
+ type='Flip', # 翻转图像
+ keys=['alpha', 'merged', 'ori_merged', 'fg', 'bg']), # 要翻转的图像
+ dict(
+ type='Resize', # 图像大小调整
+ keys=['alpha', 'merged', 'ori_merged', 'fg', 'bg'], # 图像调整大小的图像
+ scale=(320, 320), # 目标大小
+ keep_ratio=False), # 是否保持高宽比例
+ dict(
+ type='GenerateTrimap', # 从 alpha 遮罩生成三元图。
+ kernel_size=(1, 30)), # 腐蚀/扩张内核大小的范围
+ dict(
+ type='RescaleToZeroOne', # 将图像从 [0, 255] 缩放到 [0, 1]
+ keys=['merged', 'alpha', 'ori_merged', 'fg', 'bg']), # 要重新缩放的图像
+ dict(
+ type='Normalize', # 图像归一化
+ keys=['merged'], # 要归一化的图像
+ **img_norm_cfg), # 图像归一化配置(`img_norm_cfg` 的定义见上文)
+ dict(
+ type='Collect', # 决定数据中哪些键应该传递给合成器
+ keys=['merged', 'alpha', 'trimap', 'ori_merged', 'fg', 'bg'], # 图像的关键词
+ meta_keys=[]), # 图片的元关键词,这里不需要元信息。
+ dict(
+ type='ToTensor', # 将图像转化为 Tensor
+ keys=['merged', 'alpha', 'trimap', 'ori_merged', 'fg', 'bg']), # 要转换为 Tensor 的图像
+]
+test_pipeline = [
+ dict(
+ type='LoadImageFromFile', # 从文件加载 alpha 遮罩
+ key='alpha', # 注释文件中 alpha 遮罩的键关键词。流程将从路径 “alpha_path” 中读取 alpha 遮罩
+ flag='grayscale',
+ save_original_img=True),
+ dict(
+ type='LoadImageFromFile', # 从文件中加载图像
+ key='trimap', # 要加载的图像的关键词。流程将从路径 “trimap_path” 读取三元图
+ flag='grayscale', # 加载灰度图像,形状为(高度、宽度)
+ save_original_img=True), # 保存三元图用于计算指标。 它将与 “ori_trimap” 一起保存
+ dict(
+ type='LoadImageFromFile', # 从文件中加载图像
+ key='merged'), # 要加载的图像的关键词。流程将从路径 “merged_path” 读取并合并
+ dict(
+ type='Pad', # 填充图像以与模型的下采样因子对齐
+ keys=['trimap', 'merged'], # 要填充的图像
+ mode='reflect'), # 填充模式
+ dict(
+ type='RescaleToZeroOne', # 与 train_pipeline 相同
+ keys=['merged', 'ori_alpha']), # 要缩放的图像
+ dict(
+ type='Normalize', # 与 train_pipeline 相同
+ keys=['merged'],
+ **img_norm_cfg),
+ dict(
+ type='Collect', # 与 train_pipeline 相同
+ keys=['merged', 'trimap'],
+ meta_keys=[
+ 'merged_path', 'pad', 'merged_ori_shape', 'ori_alpha',
+ 'ori_trimap'
+ ]),
+ dict(
+ type='ToTensor', # 与 train_pipeline 相同
+ keys=['merged', 'trimap']),
+]
+data = dict(
+ samples_per_gpu=1, #单个 GPU 的批量大小
+ workers_per_gpu=4, # 为每个 GPU 预取数据的 Worker 数
+ drop_last=True, # 是否丢弃训练中的最后一批数据
+ train=dict( # 训练数据集配置
+ type=dataset_type, # 数据集的类型
+ ann_file=f'{data_root}/training_list.json', # 注解文件路径
+ data_prefix=data_root, # 图像路径的前缀
+ pipeline=train_pipeline), # 见上文 train_pipeline
+ val=dict( # 验证数据集配置
+ type=dataset_type,
+ ann_file=f'{data_root}/test_list.json',
+ data_prefix=data_root,
+ pipeline=test_pipeline), # 见上文 test_pipeline
+ test=dict( # 测试数据集配置
+ type=dataset_type,
+ ann_file=f'{data_root}/test_list.json',
+ data_prefix=data_root,
+ pipeline=test_pipeline)) # 见上文 test_pipeline
+
+# 优化器
+optimizers = dict(type='Adam', lr=0.00001) # 用于构建优化器的配置,支持 PyTorch 中所有优化器,且参数与 PyTorch 中对应优化器相同
+# 学习策略
+lr_config = dict( # 用于注册 LrUpdater 钩子的学习率调度程序配置
+ policy='Fixed') # 调度器的策略,支持 CosineAnnealing、Cyclic 等。支持的 LrUpdater 详情请参考 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/lr_updater.py#L9。
+
+# 检查点保存
+checkpoint_config = dict( # 配置检查点钩子,实现参考 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/checkpoint.py
+ interval=40000, # 保存间隔为 40000 次迭代
+ by_epoch=False) # 按迭代计数
+evaluation = dict( # # 构建验证钩子的配置
+ interval=40000) # 验证区间
+log_config = dict( # 配置注册记录器钩子
+ interval=10, # 打印日志的时间间隔
+ hooks=[
+ dict(type='TextLoggerHook', by_epoch=False), # 用于记录训练过程的记录器
+ # dict(type='TensorboardLoggerHook') # 支持 Tensorboard 记录器
+ ])
+
+# runtime settings
+total_iters = 1000000 # 训练模型的总迭代次数
+dist_params = dict(backend='nccl') # 设置分布式训练的参数,端口也可以设置
+log_level = 'INFO' # 日志级别
+work_dir = './work_dirs/dim_stage1' # 保存当前实验的模型检查点和日志的目录
+load_from = None # 从给定路径加载模型作为预训练模型。 这不会恢复训练
+resume_from = None # 从给定路径恢复检查点,当检查点被保存时,训练将从该 epoch 恢复
+workflow = [('train', 1)] # runner 的工作流程。 [('train', 1)] 表示只有一个工作流程,名为 'train' 的工作流程执行一次。 训练当前抠图模型时保持不变
+```
+
+## 配置文件 - 复原
+
+## 示例-EDSR
+
+为了帮助用户理解 mmediting 的配置文件结构,这里以 EDSR 为例,给出其配置文件的注释。对于每个模块的详细用法以及对应参数的选择,请参照 API 文档。
+
+```python
+exp_name = 'edsr_x2c64b16_1x16_300k_div2k' # 实验名称
+
+scale = 2 # 上采样放大因子
+
+# 模型设置
+model = dict(
+ type='BasicRestorer', # 图像恢复模型类型
+ generator=dict( # 生成器配置
+ type='EDSR', # 生成器类型
+ in_channels=3, # 输入通道数
+ out_channels=3, # 输出通道数
+ mid_channels=64, # 中间特征通道数
+ num_blocks=16, # 残差块数目
+ upscale_factor=scale, # 上采样因子
+ res_scale=1, # 残差缩放因子
+ rgb_mean=(0.4488, 0.4371, 0.4040), # 输入图像 RGB 通道的平均值
+ rgb_std=(1.0, 1.0, 1.0)), # 输入图像 RGB 通道的方差
+ pixel_loss=dict(type='L1Loss', loss_weight=1.0, reduction='mean')) # 像素损失函数的配置
+
+# 模型训练和测试设置
+train_cfg = None # 训练的配置
+test_cfg = dict( # 测试的配置
+ metrics=['PSNR'], # 测试时使用的评价指标
+ crop_border=scale) # 测试时裁剪的边界尺寸
+
+# 数据集设置
+train_dataset_type = 'SRAnnotationDataset' # 用于训练的数据集类型
+val_dataset_type = 'SRFolderDataset' # 用于验证的数据集类型
+train_pipeline = [ # 训练数据前处理流水线步骤组成的列表
+ dict(type='LoadImageFromFile', # 从文件加载图像
+ io_backend='disk', # 读取图像时使用的 io 类型
+ key='lq', # 设置LR图像的键来找到相应的路径
+ flag='unchanged'), # 读取图像的标识
+ dict(type='LoadImageFromFile', # 从文件加载图像
+ io_backend='disk', # 读取图像时使用的io类型
+ key='gt', # 设置HR图像的键来找到相应的路径
+ flag='unchanged'), # 读取图像的标识
+ dict(type='RescaleToZeroOne', keys=['lq', 'gt']), # 将图像从[0,255]重缩放到[0,1]
+ dict(type='Normalize', # 正则化图像
+ keys=['lq', 'gt'], # 执行正则化图像的键
+ mean=[0, 0, 0], # 平均值
+ std=[1, 1, 1], # 标准差
+ to_rgb=True), # 更改为 RGB 通道
+ dict(type='PairedRandomCrop', gt_patch_size=96), # LR 和 HR 成对随机裁剪
+ dict(type='Flip', # 图像翻转
+ keys=['lq', 'gt'], # 执行翻转图像的键
+ flip_ratio=0.5, # 执行翻转的几率
+ direction='horizontal'), # 翻转方向
+ dict(type='Flip', # 图像翻转
+ keys=['lq', 'gt'], # 执行翻转图像的键
+ flip_ratio=0.5, # 执行翻转几率
+ direction='vertical'), # 翻转方向
+ dict(type='RandomTransposeHW', # 图像的随机的转置
+ keys=['lq', 'gt'], # 执行转置图像的键
+ transpose_ratio=0.5 # 执行转置的几率
+ ),
+ dict(type='Collect', # Collect 类决定哪些键会被传递到生成器中
+ keys=['lq', 'gt'], # 传入模型的键
+ meta_keys=['lq_path', 'gt_path']), # 元信息键。在训练中,不需要元信息
+ dict(type='ToTensor', # 将图像转换为张量
+ keys=['lq', 'gt']) # 执行图像转换为张量的键
+]
+test_pipeline = [ # 测试数据前处理流水线步骤组成的列表
+ dict(
+ type='LoadImageFromFile', # 从文件加载图像
+ io_backend='disk', # 读取图像时使用的io类型
+ key='lq', # 设置LR图像的键来找到相应的路径
+ flag='unchanged'), # 读取图像的标识
+ dict(
+ type='LoadImageFromFile', # 从文件加载图像
+ io_backend='disk', # 读取图像时使用的io类型
+ key='gt', # 设置HR图像的键来找到相应的路径
+ flag='unchanged'), # 读取图像的标识
+ dict(type='RescaleToZeroOne', keys=['lq', 'gt']), # 将图像从[0,255]重缩放到[0,1]
+ dict(
+ type='Normalize', # 正则化图像
+ keys=['lq', 'gt'], # 执行正则化图像的键
+ mean=[0, 0, 0], # 平均值
+ std=[1, 1, 1], # 标准差
+ to_rgb=True), # 更改为RGB通道
+ dict(type='Collect', # Collect类决定哪些键会被传递到生成器中
+ keys=['lq', 'gt'], # 传入模型的键
+ meta_keys=['lq_path', 'gt_path']), # 元信息键
+ dict(type='ToTensor', # 将图像转换为张量
+ keys=['lq', 'gt']) # 执行图像转换为张量的键
+]
+
+data = dict(
+ # 训练
+ samples_per_gpu=16, # 单个 GPU 的批大小
+ workers_per_gpu=6, # 单个 GPU 的 dataloader 的进程
+ drop_last=True, # 在训练过程中丢弃最后一个批次
+ train=dict( # 训练数据集的设置
+ type='RepeatDataset', # 基于迭代的重复数据集
+ times=1000, # 重复数据集的重复次数
+ dataset=dict(
+ type=train_dataset_type, # 数据集类型
+ lq_folder='data/DIV2K/DIV2K_train_LR_bicubic/X2_sub', # lq文件夹的路径
+ gt_folder='data/DIV2K/DIV2K_train_HR_sub', # gt文件夹的路径
+ ann_file='data/DIV2K/meta_info_DIV2K800sub_GT.txt', # 批注文件的路径
+ pipeline=train_pipeline, # 训练流水线,如上所示
+ scale=scale)), # 上采样放大因子
+
+ # 验证
+ val_samples_per_gpu=1, # 验证时单个 GPU 的批大小
+ val_workers_per_gpu=1, # 验证时单个 GPU 的 dataloader 的进程
+ val=dict(
+ type=val_dataset_type, # 数据集类型
+ lq_folder='data/val_set5/Set5_bicLRx2', # lq 文件夹的路径
+ gt_folder='data/val_set5/Set5_mod12', # gt 文件夹的路径
+ pipeline=test_pipeline, # 测试流水线,如上所示
+ scale=scale, # 上采样放大因子
+ filename_tmpl='{}'), # 文件名模板
+
+ # 测试
+ test=dict(
+ type=val_dataset_type, # 数据集类型
+ lq_folder='data/val_set5/Set5_bicLRx2', # lq 文件夹的路径
+ gt_folder='data/val_set5/Set5_mod12', # gt 文件夹的路径
+ pipeline=test_pipeline, # 测试流水线,如上所示
+ scale=scale, # 上采样放大因子
+ filename_tmpl='{}')) # 文件名模板
+
+# 优化器设置
+optimizers = dict(generator=dict(type='Adam', lr=1e-4, betas=(0.9, 0.999))) # 用于构建优化器的设置,支持PyTorch中所有参数与PyTorch中参数相同的优化器
+
+# 学习策略
+total_iters = 300000 # 训练模型的总迭代数
+lr_config = dict( # 用于注册LrUpdater钩子的学习率调度程序配置
+ policy='Step', by_epoch=False, step=[200000], gamma=0.5) # 调度器的策略,还支持余弦、循环等
+
+checkpoint_config = dict( # 模型权重钩子设置,更多细节可参考 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/checkpoint.py
+ interval=5000, # 模型权重文件保存间隔为5000次迭代
+ save_optimizer=True, # 保存优化器
+ by_epoch=False) # 按迭代次数计数
+evaluation = dict( # 构建验证钩子的配置
+ interval=5000, # 执行验证的间隔为5000次迭代
+ save_image=True, # 验证期间保存图像
+ gpu_collect=True) # 使用gpu收集
+log_config = dict( # 注册日志钩子的设置
+ interval=100, # 打印日志间隔
+ hooks=[
+ dict(type='TextLoggerHook', by_epoch=False), # 记录训练过程信息的日志
+ dict(type='TensorboardLoggerHook'), # 同时支持 Tensorboard 日志
+ ])
+visual_config = None # 可视化的设置
+
+# 运行设置
+dist_params = dict(backend='nccl') # 建立分布式训练的设置,其中端口号也可以设置
+log_level = 'INFO' # 日志等级
+work_dir = f'./work_dirs/{exp_name}' # 记录当前实验日志和模型权重文件的文件夹
+load_from = None # 从给定路径加载模型作为预训练模型. 这个选项不会用于断点恢复训练
+resume_from = None # 加载给定路径的模型权重文件作为断点续连的模型, 训练将从该时间点保存的周期点继续进行
+workflow = [('train', 1)] # runner 的执行流. [('train', 1)] 代表只有一个执行流,并且这个名为 train 的执行流只执行一次
+```
diff --git a/docs/zh_cn/user_guides/configs/config_generation.md b/docs/zh_cn/user_guides/configs/config_generation.md
deleted file mode 100644
index 75088f5ef4..0000000000
--- a/docs/zh_cn/user_guides/configs/config_generation.md
+++ /dev/null
@@ -1,164 +0,0 @@
-# 配置文件 - 生成
-
-与 [MMDetection](https://github.com/open-mmlab/mmdetection) 一样,我们将模块化和继承设计融入我们的配置系统,以方便进行各种实验。
-
-## 示例 - pix2pix
-
-为了帮助用户对完整的配置和生成系统中的模块有一个基本的了解,我们对 pix2pix 的配置做如下简要说明。
-更详细的用法和各个模块对应的替代方案,请参考 API 文档。
-
-```python
-# 模型设置
-model = dict(
- type='Pix2Pix', # 合成器名称
- generator=dict(
- type='UnetGenerator', # 生成器名称
- in_channels=3, # 生成器的输入通道数
- out_channels=3, # 生成器的输出通道数
- num_down=8, # # 生成器中下采样的次数
- base_channels=64, # 生成器最后卷积层的通道数
- norm_cfg=dict(type='BN'), # 归一化层的配置
- use_dropout=True, # 是否在生成器中使用 dropout
- init_cfg=dict(type='normal', gain=0.02)), # 初始化配置
- discriminator=dict(
- type='PatchDiscriminator', # 判别器的名称
- in_channels=6, # 判别器的输入通道数
- base_channels=64, # 判别器第一卷积层的通道数
- num_conv=3, # 判别器中堆叠的中间卷积层(不包括输入和输出卷积层)的数量
- norm_cfg=dict(type='BN'), # 归一化层的配置
- init_cfg=dict(type='normal', gain=0.02)), # 初始化配置
- gan_loss=dict(
- type='GANLoss', # GAN 损失的名称
- gan_type='vanilla', # GAN 损失的类型
- real_label_val=1.0, # GAN 损失函数中真实标签的值
- fake_label_val=0.0, # GAN 损失函数中伪造标签的值
- loss_weight=1.0), # GAN 损失函数的权重
- pixel_loss=dict(type='L1Loss', loss_weight=100.0, reduction='mean'))
-# 模型训练和测试设置
-train_cfg = dict(
- direction='b2a') # pix2pix 的图像到图像的转换方向 (模型训练的方向,和测试方向一致)。模型默认: a2b
-test_cfg = dict(
- direction='b2a', # pix2pix 的图像到图像的转换方向 (模型测试的方向,和训练方向一致)。模型默认: a2b
- show_input=True) # 保存 pix2pix 的测试图像时是否显示输入的真实图像
-
-# 数据设置
-train_dataset_type = 'GenerationPairedDataset' # 训练数据集的类型
-val_dataset_type = 'GenerationPairedDataset' # 验证/测试数据集类型
-img_norm_cfg = dict(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) # 输入图像归一化配置
-train_pipeline = [
- dict(
- type='LoadPairedImageFromFile', # 从文件路径加载图像对
- io_backend='disk', # 存储图像的 IO 后端
- key='pair', # 查找对应路径的关键词
- flag='color'), # 加载图像标志
- dict(
- type='Resize', # 图像大小调整
- keys=['img_a', 'img_b'], # 要调整大小的图像的关键词
- scale=(286, 286), # 调整图像大小的比例
- interpolation='bicubic'), # 调整图像大小时用于插值的算法
- dict(
- type='FixedCrop', # 固定裁剪,在特定位置将配对图像裁剪为特定大小以训练 pix2pix
- keys=['img_a', 'img_b'], # 要裁剪的图像的关键词
- crop_size=(256, 256)), # 裁剪图像的大小
- dict(
- type='Flip', # 翻转图像
- keys=['img_a', 'img_b'], # 要翻转的图像的关键词
- direction='horizontal'), # 水平或垂直翻转图像
- dict(
- type='RescaleToZeroOne', # 将图像从 [0, 255] 缩放到 [0, 1]
- keys=['img_a', 'img_b']), # 要重新缩放的图像的关键词
- dict(
- type='Normalize', # 图像归一化
- keys=['img_a', 'img_b'], # 要归一化的图像的关键词
- to_rgb=True, # 是否将图像通道从 BGR 转换为 RGB
- **img_norm_cfg), # 图像归一化配置(`img_norm_cfg` 的定义见上文)
- dict(
- type='ToTensor', # 将图像转化为 Tensor
- keys=['img_a', 'img_b']), # 要从图像转换为 Tensor 的图像的关键词
- dict(
- type='Collect', # 决定数据中哪些键应该传递给合成器
- keys=['img_a', 'img_b'], # 图像的关键词
- meta_keys=['img_a_path', 'img_b_path']) # 图片的元关键词
-]
-test_pipeline = [
- dict(
- type='LoadPairedImageFromFile', # 从文件路径加载图像对
- io_backend='disk', # 存储图像的 IO 后端
- key='pair', # 查找对应路径的关键词
- flag='color'), # 加载图像标志
- dict(
- type='Resize', # 图像大小调整
- keys=['img_a', 'img_b'], # 要调整大小的图像的关键词
- scale=(256, 256), # 调整图像大小的比例
- interpolation='bicubic'), # 调整图像大小时用于插值的算法
- dict(
- type='RescaleToZeroOne', # 将图像从 [0, 255] 缩放到 [0, 1]
- keys=['img_a', 'img_b']), # 要重新缩放的图像的关键词
- dict(
- type='Normalize', # 图像归一化
- keys=['img_a', 'img_b'], # 要归一化的图像的关键词
- to_rgb=True, # 是否将图像通道从 BGR 转换为 RGB
- **img_norm_cfg), # 图像归一化配置(`img_norm_cfg` 的定义见上文)
- dict(
- type='ToTensor', # 将图像转化为 Tensor
- keys=['img_a', 'img_b']), # 要从图像转换为 Tensor 的图像的关键词
- dict(
- type='Collect', # 决定数据中哪些键应该传递给合成器
- keys=['img_a', 'img_b'], # 图像的关键词
- meta_keys=['img_a_path', 'img_b_path']) # 图片的元关键词
-]
-data_root = 'data/pix2pix/facades' # 数据的根路径
-data = dict(
- samples_per_gpu=1, # 单个 GPU 的批量大小
- workers_per_gpu=4, # 为每个 GPU 预取数据的 Worker 数
- drop_last=True, # 是否丢弃训练中的最后一批数据
- val_samples_per_gpu=1, # 验证中单个 GPU 的批量大小
- val_workers_per_gpu=0, # 在验证中为每个 GPU 预取数据的 Worker 数
- train=dict( # 训练数据集配置
- type=train_dataset_type,
- dataroot=data_root,
- pipeline=train_pipeline,
- test_mode=False),
- val=dict( # 验证数据集配置
- type=val_dataset_type,
- dataroot=data_root,
- pipeline=test_pipeline,
- test_mode=True),
- test=dict( # 测试数据集配置
- type=val_dataset_type,
- dataroot=data_root,
- pipeline=test_pipeline,
- test_mode=True))
-
-# 优化器
-optimizers = dict( # 用于构建优化器的配置,支持 PyTorch 中所有优化器,且参数与 PyTorch 中对应优化器相同
- generator=dict(type='Adam', lr=2e-4, betas=(0.5, 0.999)),
- discriminator=dict(type='Adam', lr=2e-4, betas=(0.5, 0.999)))
-
-# 学习策略
-lr_config = dict(policy='Fixed', by_epoch=False) # 用于注册 LrUpdater 钩子的学习率调度程序配置
-
-# 检查点保存
-checkpoint_config = dict(interval=4000, save_optimizer=True, by_epoch=False) # 配置检查点钩子,实现参考 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/checkpoint.py
-evaluation = dict( # 构建验证钩子的配置
- interval=4000, # 验证区间
- save_image=True) # 是否保存图片
-log_config = dict( # 配置注册记录器钩子
- interval=100, # 打印日志的时间间隔
- hooks=[
- dict(type='TextLoggerHook', by_epoch=False), # 用于记录训练过程的记录器
- # dict(type='TensorboardLoggerHook') # 还支持 Tensorboard 记录器
- ])
-visual_config = None # 构建可视化钩子的配置
-
-# 运行设置
-total_iters = 80000 # 训练模型的总迭代次数
-cudnn_benchmark = True # 设置 cudnn_benchmark
-dist_params = dict(backend='nccl') # 设置分布式训练的参数,端口也可以设置
-log_level = 'INFO' # 日志级别
-load_from = None # 从给定路径加载模型作为预训练模型。 这不会恢复训练
-resume_from = None # 从给定路径恢复检查点,当检查点被保存时,训练将从该 epoch 恢复
-workflow = [('train', 1)] # runner 的工作流程。 [('train', 1)] 表示只有一个工作流程,名为 'train' 的工作流程执行一次。 训练当前生成模型时保持不变
-exp_name = 'pix2pix_facades' # 实验名称
-work_dir = f'./work_dirs/{exp_name}' # 保存当前实验的模型检查点和日志的目录
-```
diff --git a/docs/zh_cn/user_guides/configs/config_inpainting.md b/docs/zh_cn/user_guides/configs/config_inpainting.md
deleted file mode 100644
index 12836fd3a3..0000000000
--- a/docs/zh_cn/user_guides/configs/config_inpainting.md
+++ /dev/null
@@ -1,155 +0,0 @@
-# 配置文件 - 补全
-
-## 配置名称样式
-
-与 [MMDetection](https://github.com/open-mmlab/mmdetection) 一样,我们将模块化和继承设计融入我们的配置系统,以方便进行各种实验。
-
-## 配置字段说明
-
-为了帮助用户对完整的配置和修复系统中的模块有一个基本的了解,我们对 Global&Local 的配置作如下简要说明。更详细的用法和各个模块对应的替代方案,请参考 API 文档。
-
-```python
-model = dict(
- type='GLInpaintor', # 补全器的名称
- encdec=dict(
- type='GLEncoderDecoder', # 编码器-解码器的名称
- encoder=dict(type='GLEncoder', norm_cfg=dict(type='SyncBN')), # 编码器的配置
- decoder=dict(type='GLDecoder', norm_cfg=dict(type='SyncBN')), # 解码器的配置
- dilation_neck=dict(
- type='GLDilationNeck', norm_cfg=dict(type='SyncBN'))), # 扩颈的配置
- disc=dict(
- type='GLDiscs', # 判别器的名称
- global_disc_cfg=dict(
- in_channels=3, # 判别器的输入通道数
- max_channels=512, # 判别器中的最大通道数
- fc_in_channels=512 * 4 * 4, # 最后一个全连接层的输入通道
- fc_out_channels=1024, # 最后一个全连接层的输出通道
- num_convs=6, # 判别器中使用的卷积数量
- norm_cfg=dict(type='SyncBN') # 归一化层的配置
- ),
- local_disc_cfg=dict(
- in_channels=3, # 判别器的输入通道数
- max_channels=512, # 判别器中的最大通道数
- fc_in_channels=512 * 4 * 4, # 最后一个全连接层的输入通道
- fc_out_channels=1024, # 最后一个全连接层的输出通道
- num_convs=5, # 判别器中使用的卷积数量
- norm_cfg=dict(type='SyncBN') # 归一化层的配置
- ),
- ),
- loss_gan=dict(
- type='GANLoss', # GAN 损失的名称
- gan_type='vanilla', # GAN 损失的类型
- loss_weight=0.001 # GAN 损失函数的权重
- ),
- loss_l1_hole=dict(
- type='L1Loss', # L1 损失的类型
- loss_weight=1.0 # L1 损失函数的权重
- ),
- pretrained=None) # 预训练权重的路径
-
-train_cfg = dict(
- disc_step=1, # 训练生成器之前训练判别器的迭代次数
- iter_tc=90000, # 预热生成器的迭代次数
- iter_td=100000, # 预热判别器的迭代次数
- start_iter=0, # 开始的迭代
- local_size=(128, 128)) # 图像块的大小
-test_cfg = dict(metrics=['l1']) # 测试的配置
-
-dataset_type = 'ImgInpaintingDataset' # 数据集类型
-input_shape = (256, 256) # 输入图像的形状
-
-train_pipeline = [
- dict(type='LoadImageFromFile', key='gt_img'), # 加载图片的配置
- dict(
- type='LoadMask', # 加载掩码
- mask_mode='bbox', # 掩码的类型
- mask_config=dict(
- max_bbox_shape=(128, 128), # 检测框的形状
- max_bbox_delta=40, # 检测框高宽的变化
- min_margin=20, # 检测框到图片边界的最小距离
- img_shape=input_shape)), # 输入图像的形状
- dict(
- type='Crop', # 裁剪
- keys=['gt_img'], # 要裁剪的图像的关键词
- crop_size=(384, 384), # 裁剪图像块的大小
- random_crop=True, # 是否使用随机裁剪
- ),
- dict(
- type='Resize', # 图像大小调整
- keys=['gt_img'], # 要调整大小的图像的关键词
- scale=input_shape, # 调整图像大小的比例
- keep_ratio=False, # 调整大小时是否保持比例
- ),
- dict(
- type='Normalize', # 图像归一化
- keys=['gt_img'], # 要归一化的图像的关键词
- mean=[127.5] * 3, # 归一化中使用的均值
- std=[127.5] * 3, # 归一化中使用的标准差
- to_rgb=False), # 是否将图像通道从 BGR 转换为 RGB
- dict(type='GetMaskedImage'), # 获取被掩盖的图像
- dict(
- type='Collect', # 决定数据中哪些键应该传递给合成器
- keys=['gt_img', 'masked_img', 'mask', 'mask_bbox'], # 要收集的数据的关键词
- meta_keys=['gt_img_path']), # 要收集的数据的元关键词
- dict(type='ToTensor', keys=['gt_img', 'masked_img', 'mask']), # 将图像转化为 Tensor
- dict(type='ToTensor', keys=['mask_bbox']) # 转化为 Tensor
-]
-
-test_pipeline = train_pipeline # 构建测试/验证流程
-
-data_root = 'data/places365' # 数据根目录
-
-data = dict(
- samples_per_gpu=12, # 单个 GPU 的批量大小
- workers_per_gpu=8, # 为每个 GPU 预取数据的 Worker 数
- val_samples_per_gpu=1, # 验证中单个 GPU 的批量大小
- val_workers_per_gpu=8, # 在验证中为每个 GPU 预取数据的 Worker 数
- drop_last=True, # 是否丢弃训练中的最后一批数据
- train=dict( # 训练数据集配置
- type=dataset_type,
- ann_file=f'{data_root}/train_places_img_list_total.txt',
- data_prefix=data_root,
- pipeline=train_pipeline,
- test_mode=False),
- val=dict( # 验证数据集配置
- type=dataset_type,
- ann_file=f'{data_root}/val_places_img_list.txt',
- data_prefix=data_root,
- pipeline=test_pipeline,
- test_mode=True))
-
-optimizers = dict( # 用于构建优化器的配置,支持 PyTorch 中所有优化器,且参数与 PyTorch 中对应优化器相同
- generator=dict(type='Adam', lr=0.0004), disc=dict(type='Adam', lr=0.0004))
-
-lr_config = dict(policy='Fixed', by_epoch=False) # 用于注册 LrUpdater 钩子的学习率调度程序配置
-
-checkpoint_config = dict(by_epoch=False, interval=50000) # 配置检查点钩子,实现参考 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/checkpoint.py
-log_config = dict( # 配置注册记录器钩子
- interval=100, # 打印日志的时间间隔
- hooks=[
- dict(type='TextLoggerHook', by_epoch=False),
- # dict(type='TensorboardLoggerHook'), # 支持 Tensorboard 记录器
- # dict(type='PaviLoggerHook', init_kwargs=dict(project='mmedit'))
- ]) # 用于记录训练过程的记录器
-
-visual_config = dict( # 构建可视化钩子的配置
- type='VisualizationHook',
- output_dir='visual',
- interval=1000,
- res_name_list=[
- 'gt_img', 'masked_img', 'fake_res', 'fake_img', 'fake_gt_local'
- ],
-) # 用于可视化训练过程的记录器。
-
-evaluation = dict(interval=50000) # 构建验证钩子的配置
-
-total_iters = 500002
-dist_params = dict(backend='nccl') # 设置分布式训练的参数,端口也可以设置
-log_level = 'INFO' # 日志级别
-work_dir = None # 保存当前实验的模型检查点和日志的目录
-load_from = None # 从给定路径加载模型作为预训练模型。 这不会恢复训练
-resume_from = None # 从给定路径恢复检查点,当检查点被保存时,训练将从该 epoch 恢复
-workflow = [('train', 10000)] # runner 的工作流程。 [('train', 1)] 表示只有一个工作流程,名为 'train' 的工作流程执行一次。 训练当前生成模型时保持不变
-exp_name = 'gl_places' # 实验名称
-find_unused_parameters = False # 是否在分布式训练中查找未使用的参数
-```
diff --git a/docs/zh_cn/user_guides/configs/config_matting.md b/docs/zh_cn/user_guides/configs/config_matting.md
deleted file mode 100644
index 41058bff29..0000000000
--- a/docs/zh_cn/user_guides/configs/config_matting.md
+++ /dev/null
@@ -1,167 +0,0 @@
-# 配置文件 - 抠图
-
-与 [MMDetection](https://github.com/open-mmlab/mmdetection) 一样,我们将模块化和继承设计融入我们的配置系统,以方便进行各种实验。
-
-## 例子 - Deep Image Matting Model
-
-为了帮助用户对一个完整的配置有一个基本的了解,我们对我们实现的原始 DIM 模型的配置做一个简短的评论,如下所示。 更详细的用法和各个模块对应的替代方案,请参考 API 文档。
-
-```python
-# 模型配置
-model = dict(
- type='DIM', # 模型的名称(我们称之为抠图器)
- backbone=dict( # 主干网络的配置
- type='SimpleEncoderDecoder', # 主干网络的类型
- encoder=dict( # 编码器的配置
- type='VGG16'), # 编码器的类型
- decoder=dict( # 解码器的配置
- type='PlainDecoder')), # 解码器的类型
- pretrained='./weights/vgg_state_dict.pth', # 编码器的预训练权重
- loss_alpha=dict( # alpha 损失的配置
- type='CharbonnierLoss', # 预测的 alpha 遮罩的损失类型
- loss_weight=0.5), # alpha 损失的权重
- loss_comp=dict( # 组合损失的配置
- type='CharbonnierCompLoss', # 组合损失的类型
- loss_weight=0.5)) # 组合损失的权重
-train_cfg = dict( # 训练 DIM 模型的配置
- train_backbone=True, # 在 DIM stage 1 中,会对主干网络进行训练
- train_refiner=False) # 在 DIM stage 1 中,不会对精炼器进行训练
-test_cfg = dict( # 测试 DIM 模型的配置
- refine=False, # 是否使用精炼器输出作为输出,在 stage 1 中,我们不使用它
- metrics=['SAD', 'MSE', 'GRAD', 'CONN']) # 测试时使用的指标
-
-# 数据配置
-dataset_type = 'AdobeComp1kDataset' # 数据集类型,这将用于定义数据集
-data_root = 'data/adobe_composition-1k' # 数据的根目录
-img_norm_cfg = dict( # 归一化输入图像的配置
- mean=[0.485, 0.456, 0.406], # 归一化中使用的均值
- std=[0.229, 0.224, 0.225], # 归一化中使用的标准差
- to_rgb=True) # 是否将图像通道从 BGR 转换为 RGB
-train_pipeline = [ # 训练数据处理流程
- dict(
- type='LoadImageFromFile', # 从文件加载 alpha 遮罩
- key='alpha', # 注释文件中 alpha 遮罩的键关键词。流程将从路径 “alpha_path” 中读取 alpha 遮罩
- flag='grayscale'), # 加载灰度图像,形状为(高度、宽度)
- dict(
- type='LoadImageFromFile', # 从文件中加载图像
- key='fg'), # 要加载的图像的关键词。流程将从路径 “fg_path” 读取 fg
- dict(
- type='LoadImageFromFile', # 从文件中加载图像
- key='bg'), # 要加载的图像的关键词。流程将从路径 “bg_path” 读取 bg
- dict(
- type='LoadImageFromFile', # 从文件中加载图像
- key='merged'), # 要加载的图像的关键词。流程将从路径 “merged_path” 读取并合并
- dict(
- type='CropAroundUnknown', # 在未知区域(半透明区域)周围裁剪图像
- keys=['alpha', 'merged', 'ori_merged', 'fg', 'bg'], # 要裁剪的图像
- crop_sizes=[320, 480, 640]), # 裁剪大小
- dict(
- type='Flip', # 翻转图像
- keys=['alpha', 'merged', 'ori_merged', 'fg', 'bg']), # 要翻转的图像
- dict(
- type='Resize', # 图像大小调整
- keys=['alpha', 'merged', 'ori_merged', 'fg', 'bg'], # 图像调整大小的图像
- scale=(320, 320), # 目标大小
- keep_ratio=False), # 是否保持高宽比例
- dict(
- type='GenerateTrimap', # 从 alpha 遮罩生成三元图。
- kernel_size=(1, 30)), # 腐蚀/扩张内核大小的范围
- dict(
- type='RescaleToZeroOne', # 将图像从 [0, 255] 缩放到 [0, 1]
- keys=['merged', 'alpha', 'ori_merged', 'fg', 'bg']), # 要重新缩放的图像
- dict(
- type='Normalize', # 图像归一化
- keys=['merged'], # 要归一化的图像
- **img_norm_cfg), # 图像归一化配置(`img_norm_cfg` 的定义见上文)
- dict(
- type='Collect', # 决定数据中哪些键应该传递给合成器
- keys=['merged', 'alpha', 'trimap', 'ori_merged', 'fg', 'bg'], # 图像的关键词
- meta_keys=[]), # 图片的元关键词,这里不需要元信息。
- dict(
- type='ToTensor', # 将图像转化为 Tensor
- keys=['merged', 'alpha', 'trimap', 'ori_merged', 'fg', 'bg']), # 要转换为 Tensor 的图像
-]
-test_pipeline = [
- dict(
- type='LoadImageFromFile', # 从文件加载 alpha 遮罩
- key='alpha', # 注释文件中 alpha 遮罩的键关键词。流程将从路径 “alpha_path” 中读取 alpha 遮罩
- flag='grayscale',
- save_original_img=True),
- dict(
- type='LoadImageFromFile', # 从文件中加载图像
- key='trimap', # 要加载的图像的关键词。流程将从路径 “trimap_path” 读取三元图
- flag='grayscale', # 加载灰度图像,形状为(高度、宽度)
- save_original_img=True), # 保存三元图用于计算指标。 它将与 “ori_trimap” 一起保存
- dict(
- type='LoadImageFromFile', # 从文件中加载图像
- key='merged'), # 要加载的图像的关键词。流程将从路径 “merged_path” 读取并合并
- dict(
- type='Pad', # 填充图像以与模型的下采样因子对齐
- keys=['trimap', 'merged'], # 要填充的图像
- mode='reflect'), # 填充模式
- dict(
- type='RescaleToZeroOne', # 与 train_pipeline 相同
- keys=['merged', 'ori_alpha']), # 要缩放的图像
- dict(
- type='Normalize', # 与 train_pipeline 相同
- keys=['merged'],
- **img_norm_cfg),
- dict(
- type='Collect', # 与 train_pipeline 相同
- keys=['merged', 'trimap'],
- meta_keys=[
- 'merged_path', 'pad', 'merged_ori_shape', 'ori_alpha',
- 'ori_trimap'
- ]),
- dict(
- type='ToTensor', # 与 train_pipeline 相同
- keys=['merged', 'trimap']),
-]
-data = dict(
- samples_per_gpu=1, #单个 GPU 的批量大小
- workers_per_gpu=4, # 为每个 GPU 预取数据的 Worker 数
- drop_last=True, # 是否丢弃训练中的最后一批数据
- train=dict( # 训练数据集配置
- type=dataset_type, # 数据集的类型
- ann_file=f'{data_root}/training_list.json', # 注解文件路径
- data_prefix=data_root, # 图像路径的前缀
- pipeline=train_pipeline), # 见上文 train_pipeline
- val=dict( # 验证数据集配置
- type=dataset_type,
- ann_file=f'{data_root}/test_list.json',
- data_prefix=data_root,
- pipeline=test_pipeline), # 见上文 test_pipeline
- test=dict( # 测试数据集配置
- type=dataset_type,
- ann_file=f'{data_root}/test_list.json',
- data_prefix=data_root,
- pipeline=test_pipeline)) # 见上文 test_pipeline
-
-# 优化器
-optimizers = dict(type='Adam', lr=0.00001) # 用于构建优化器的配置,支持 PyTorch 中所有优化器,且参数与 PyTorch 中对应优化器相同
-# 学习策略
-lr_config = dict( # 用于注册 LrUpdater 钩子的学习率调度程序配置
- policy='Fixed') # 调度器的策略,支持 CosineAnnealing、Cyclic 等。支持的 LrUpdater 详情请参考 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/lr_updater.py#L9。
-
-# 检查点保存
-checkpoint_config = dict( # 配置检查点钩子,实现参考 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/checkpoint.py
- interval=40000, # 保存间隔为 40000 次迭代
- by_epoch=False) # 按迭代计数
-evaluation = dict( # # 构建验证钩子的配置
- interval=40000) # 验证区间
-log_config = dict( # 配置注册记录器钩子
- interval=10, # 打印日志的时间间隔
- hooks=[
- dict(type='TextLoggerHook', by_epoch=False), # 用于记录训练过程的记录器
- # dict(type='TensorboardLoggerHook') # 支持 Tensorboard 记录器
- ])
-
-# runtime settings
-total_iters = 1000000 # 训练模型的总迭代次数
-dist_params = dict(backend='nccl') # 设置分布式训练的参数,端口也可以设置
-log_level = 'INFO' # 日志级别
-work_dir = './work_dirs/dim_stage1' # 保存当前实验的模型检查点和日志的目录
-load_from = None # 从给定路径加载模型作为预训练模型。 这不会恢复训练
-resume_from = None # 从给定路径恢复检查点,当检查点被保存时,训练将从该 epoch 恢复
-workflow = [('train', 1)] # runner 的工作流程。 [('train', 1)] 表示只有一个工作流程,名为 'train' 的工作流程执行一次。 训练当前抠图模型时保持不变
-```
diff --git a/docs/zh_cn/user_guides/configs/config_restoration.md b/docs/zh_cn/user_guides/configs/config_restoration.md
deleted file mode 100644
index 68d6589ef4..0000000000
--- a/docs/zh_cn/user_guides/configs/config_restoration.md
+++ /dev/null
@@ -1,162 +0,0 @@
-# 配置文件 - 复原
-
-## 示例-EDSR
-
-为了帮助用户理解 mmediting 的配置文件结构,这里以 EDSR 为例,给出其配置文件的注释。对于每个模块的详细用法以及对应参数的选择,请参照 API 文档。
-
-```python
-exp_name = 'edsr_x2c64b16_1x16_300k_div2k' # 实验名称
-
-scale = 2 # 上采样放大因子
-
-# 模型设置
-model = dict(
- type='BasicRestorer', # 图像恢复模型类型
- generator=dict( # 生成器配置
- type='EDSR', # 生成器类型
- in_channels=3, # 输入通道数
- out_channels=3, # 输出通道数
- mid_channels=64, # 中间特征通道数
- num_blocks=16, # 残差块数目
- upscale_factor=scale, # 上采样因子
- res_scale=1, # 残差缩放因子
- rgb_mean=(0.4488, 0.4371, 0.4040), # 输入图像 RGB 通道的平均值
- rgb_std=(1.0, 1.0, 1.0)), # 输入图像 RGB 通道的方差
- pixel_loss=dict(type='L1Loss', loss_weight=1.0, reduction='mean')) # 像素损失函数的配置
-
-# 模型训练和测试设置
-train_cfg = None # 训练的配置
-test_cfg = dict( # 测试的配置
- metrics=['PSNR'], # 测试时使用的评价指标
- crop_border=scale) # 测试时裁剪的边界尺寸
-
-# 数据集设置
-train_dataset_type = 'SRAnnotationDataset' # 用于训练的数据集类型
-val_dataset_type = 'SRFolderDataset' # 用于验证的数据集类型
-train_pipeline = [ # 训练数据前处理流水线步骤组成的列表
- dict(type='LoadImageFromFile', # 从文件加载图像
- io_backend='disk', # 读取图像时使用的 io 类型
- key='lq', # 设置LR图像的键来找到相应的路径
- flag='unchanged'), # 读取图像的标识
- dict(type='LoadImageFromFile', # 从文件加载图像
- io_backend='disk', # 读取图像时使用的io类型
- key='gt', # 设置HR图像的键来找到相应的路径
- flag='unchanged'), # 读取图像的标识
- dict(type='RescaleToZeroOne', keys=['lq', 'gt']), # 将图像从[0,255]重缩放到[0,1]
- dict(type='Normalize', # 正则化图像
- keys=['lq', 'gt'], # 执行正则化图像的键
- mean=[0, 0, 0], # 平均值
- std=[1, 1, 1], # 标准差
- to_rgb=True), # 更改为 RGB 通道
- dict(type='PairedRandomCrop', gt_patch_size=96), # LR 和 HR 成对随机裁剪
- dict(type='Flip', # 图像翻转
- keys=['lq', 'gt'], # 执行翻转图像的键
- flip_ratio=0.5, # 执行翻转的几率
- direction='horizontal'), # 翻转方向
- dict(type='Flip', # 图像翻转
- keys=['lq', 'gt'], # 执行翻转图像的键
- flip_ratio=0.5, # 执行翻转几率
- direction='vertical'), # 翻转方向
- dict(type='RandomTransposeHW', # 图像的随机的转置
- keys=['lq', 'gt'], # 执行转置图像的键
- transpose_ratio=0.5 # 执行转置的几率
- ),
- dict(type='Collect', # Collect 类决定哪些键会被传递到生成器中
- keys=['lq', 'gt'], # 传入模型的键
- meta_keys=['lq_path', 'gt_path']), # 元信息键。在训练中,不需要元信息
- dict(type='ToTensor', # 将图像转换为张量
- keys=['lq', 'gt']) # 执行图像转换为张量的键
-]
-test_pipeline = [ # 测试数据前处理流水线步骤组成的列表
- dict(
- type='LoadImageFromFile', # 从文件加载图像
- io_backend='disk', # 读取图像时使用的io类型
- key='lq', # 设置LR图像的键来找到相应的路径
- flag='unchanged'), # 读取图像的标识
- dict(
- type='LoadImageFromFile', # 从文件加载图像
- io_backend='disk', # 读取图像时使用的io类型
- key='gt', # 设置HR图像的键来找到相应的路径
- flag='unchanged'), # 读取图像的标识
- dict(type='RescaleToZeroOne', keys=['lq', 'gt']), # 将图像从[0,255]重缩放到[0,1]
- dict(
- type='Normalize', # 正则化图像
- keys=['lq', 'gt'], # 执行正则化图像的键
- mean=[0, 0, 0], # 平均值
- std=[1, 1, 1], # 标准差
- to_rgb=True), # 更改为RGB通道
- dict(type='Collect', # Collect类决定哪些键会被传递到生成器中
- keys=['lq', 'gt'], # 传入模型的键
- meta_keys=['lq_path', 'gt_path']), # 元信息键
- dict(type='ToTensor', # 将图像转换为张量
- keys=['lq', 'gt']) # 执行图像转换为张量的键
-]
-
-data = dict(
- # 训练
- samples_per_gpu=16, # 单个 GPU 的批大小
- workers_per_gpu=6, # 单个 GPU 的 dataloader 的进程
- drop_last=True, # 在训练过程中丢弃最后一个批次
- train=dict( # 训练数据集的设置
- type='RepeatDataset', # 基于迭代的重复数据集
- times=1000, # 重复数据集的重复次数
- dataset=dict(
- type=train_dataset_type, # 数据集类型
- lq_folder='data/DIV2K/DIV2K_train_LR_bicubic/X2_sub', # lq文件夹的路径
- gt_folder='data/DIV2K/DIV2K_train_HR_sub', # gt文件夹的路径
- ann_file='data/DIV2K/meta_info_DIV2K800sub_GT.txt', # 批注文件的路径
- pipeline=train_pipeline, # 训练流水线,如上所示
- scale=scale)), # 上采样放大因子
-
- # 验证
- val_samples_per_gpu=1, # 验证时单个 GPU 的批大小
- val_workers_per_gpu=1, # 验证时单个 GPU 的 dataloader 的进程
- val=dict(
- type=val_dataset_type, # 数据集类型
- lq_folder='data/val_set5/Set5_bicLRx2', # lq 文件夹的路径
- gt_folder='data/val_set5/Set5_mod12', # gt 文件夹的路径
- pipeline=test_pipeline, # 测试流水线,如上所示
- scale=scale, # 上采样放大因子
- filename_tmpl='{}'), # 文件名模板
-
- # 测试
- test=dict(
- type=val_dataset_type, # 数据集类型
- lq_folder='data/val_set5/Set5_bicLRx2', # lq 文件夹的路径
- gt_folder='data/val_set5/Set5_mod12', # gt 文件夹的路径
- pipeline=test_pipeline, # 测试流水线,如上所示
- scale=scale, # 上采样放大因子
- filename_tmpl='{}')) # 文件名模板
-
-# 优化器设置
-optimizers = dict(generator=dict(type='Adam', lr=1e-4, betas=(0.9, 0.999))) # 用于构建优化器的设置,支持PyTorch中所有参数与PyTorch中参数相同的优化器
-
-# 学习策略
-total_iters = 300000 # 训练模型的总迭代数
-lr_config = dict( # 用于注册LrUpdater钩子的学习率调度程序配置
- policy='Step', by_epoch=False, step=[200000], gamma=0.5) # 调度器的策略,还支持余弦、循环等
-
-checkpoint_config = dict( # 模型权重钩子设置,更多细节可参考 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/hooks/checkpoint.py
- interval=5000, # 模型权重文件保存间隔为5000次迭代
- save_optimizer=True, # 保存优化器
- by_epoch=False) # 按迭代次数计数
-evaluation = dict( # 构建验证钩子的配置
- interval=5000, # 执行验证的间隔为5000次迭代
- save_image=True, # 验证期间保存图像
- gpu_collect=True) # 使用gpu收集
-log_config = dict( # 注册日志钩子的设置
- interval=100, # 打印日志间隔
- hooks=[
- dict(type='TextLoggerHook', by_epoch=False), # 记录训练过程信息的日志
- dict(type='TensorboardLoggerHook'), # 同时支持 Tensorboard 日志
- ])
-visual_config = None # 可视化的设置
-
-# 运行设置
-dist_params = dict(backend='nccl') # 建立分布式训练的设置,其中端口号也可以设置
-log_level = 'INFO' # 日志等级
-work_dir = f'./work_dirs/{exp_name}' # 记录当前实验日志和模型权重文件的文件夹
-load_from = None # 从给定路径加载模型作为预训练模型. 这个选项不会用于断点恢复训练
-resume_from = None # 加载给定路径的模型权重文件作为断点续连的模型, 训练将从该时间点保存的周期点继续进行
-workflow = [('train', 1)] # runner 的执行流. [('train', 1)] 代表只有一个执行流,并且这个名为 train 的执行流只执行一次
-```
diff --git a/docs/zh_cn/user_guides/dataset_prepare.md b/docs/zh_cn/user_guides/dataset_prepare.md
new file mode 100644
index 0000000000..6d16267fb5
--- /dev/null
+++ b/docs/zh_cn/user_guides/dataset_prepare.md
@@ -0,0 +1 @@
+# 教程 2:准备数据集(待更新)
diff --git a/docs/zh_cn/user_guides/datasets/dataset_prepare.md b/docs/zh_cn/user_guides/datasets/dataset_prepare.md
deleted file mode 100644
index 16cc9bfc17..0000000000
--- a/docs/zh_cn/user_guides/datasets/dataset_prepare.md
+++ /dev/null
@@ -1 +0,0 @@
-# 数据集(待更新)
diff --git a/docs/zh_cn/user_guides/deploy.md b/docs/zh_cn/user_guides/deploy.md
new file mode 100644
index 0000000000..7be7e15f42
--- /dev/null
+++ b/docs/zh_cn/user_guides/deploy.md
@@ -0,0 +1 @@
+# 教程 8:部署指南(待更新)
diff --git a/docs/zh_cn/user_guides/inference.md b/docs/zh_cn/user_guides/inference.md
index ae954498e1..7d56f7b4ae 100644
--- a/docs/zh_cn/user_guides/inference.md
+++ b/docs/zh_cn/user_guides/inference.md
@@ -1 +1,237 @@
-# 推理(待更新)
+# 教程 3:预训练权重推理(待更新)
+
+我们针对特定任务提供了一些脚本,可以对单张图像进行推理。
+
+#### 图像补全
+
+您可以使用以下命令,输入一张测试图像以及缺损部位的遮罩图像,实现对测试图像的补全。
+
+```shell
+python demo/inpainting_demo.py \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ ${MASKED_IMAGE_FILE} \
+ ${MASK_FILE} \
+ ${SAVE_FILE} \
+ [--imshow] \
+ [--device ${GPU_ID}]
+```
+
+如果指定了 --imshow ,演示程序将使用 opencv 显示图像。例子:
+
+```shell
+python demo/inpainting_demo.py \
+ configs/global_local/gl_8xb12_celeba-256x256.py \
+ https://download.openmmlab.com/mmediting/inpainting/global_local/gl_256x256_8x12_celeba_20200619-5af0493f.pth \
+ tests/data/inpainting/celeba_test.png \
+ tests/data/inpainting/bbox_mask.png \
+ tests/data/inpainting/inpainting_celeba.png
+```
+
+补全结果将保存在 `tests/data/inpainting/inpainting_celeba.png` 中。
+
+#### 抠图
+
+您可以使用以下命令,输入一张测试图像以及对应的三元图(trimap),实现对测试图像的抠图。
+
+```shell
+python demo/matting_demo.py \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ ${IMAGE_FILE} \
+ ${TRIMAP_FILE} \
+ ${SAVE_FILE} \
+ [--imshow] \
+ [--device ${GPU_ID}]
+```
+
+如果指定了 --imshow ,演示程序将使用 opencv 显示图像。例子:
+
+```shell
+python demo/matting_demo.py \
+ configs/dim/dim_stage3-v16-pln_1000k-1xb1_comp1k.py \
+ https://download.openmmlab.com/mmediting/mattors/dim/dim_stage3_v16_pln_1x1_1000k_comp1k_SAD-50.6_20200609_111851-647f24b6.pth \
+ tests/data/matting_dataset/merged/GT05.jpg \
+ tests/data/matting_dataset/trimap/GT05.png \
+ tests/data/matting_dataset/pred/GT05.png
+```
+
+预测的 alpha 遮罩将保存在 `tests/data/matting_dataset/pred/GT05.png` 中。
+
+#### 图像超分辨率
+
+您可以使用以下命令来测试要恢复的图像。
+
+```shell
+python demo/restoration_demo.py \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ ${IMAGE_FILE} \
+ ${SAVE_FILE} \
+ [--imshow] \
+ [--device ${GPU_ID}] \
+ [--ref-path ${REF_PATH}]
+```
+
+如果指定了 `--imshow` ,演示程序将使用 opencv 显示图像。例子:
+
+```shell
+python demo/restoration_demo.py \
+ configs/esrgan/esrgan_x4c64b23g32_400k-1xb16_div2k.py \
+ https://download.openmmlab.com/mmediting/restorers/esrgan/esrgan_x4c64b23g32_1x16_400k_div2k_20200508-f8ccaf3b.pth \
+ tests/data/image/lq/baboon_x4.png \
+ demo/demo_out_baboon.png
+```
+
+您可以通过提供 `--ref-path` 参数来测试基于参考的超分辨率算法。例子:
+
+```shell
+python demo/restoration_demo.py \
+ configs/ttsr/ttsr-gan_x4c64b16_500k-1xb9_CUFED.py \
+ https://download.openmmlab.com/mmediting/restorers/ttsr/ttsr-gan_x4_c64b16_g1_500k_CUFED_20210626-2ab28ca0.pth \
+ tests/data/frames/sequence/gt/sequence_1/00000000.png \
+ demo/demo_out.png \
+ --ref-path tests/data/frames/sequence/gt/sequence_1/00000001.png
+```
+
+#### 人脸图像超分辨率
+
+您可以使用以下命令来测试要恢复的人脸图像。
+
+```shell
+python demo/restoration_face_demo.py \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ ${IMAGE_FILE} \
+ ${SAVE_FILE} \
+ [--upscale-factor] \
+ [--face-size] \
+ [--imshow] \
+ [--device ${GPU_ID}]
+```
+
+如果指定了 --imshow ,演示程序将使用 opencv 显示图像。例子:
+
+```shell
+python demo/restoration_face_demo.py \
+ configs/glean/glean_in128out1024_300k-4xb2_ffhq-celeba-hq.py \
+ https://download.openmmlab.com/mmediting/restorers/glean/glean_in128out1024_4x2_300k_ffhq_celebahq_20210812-acbcb04f.pth \
+ tests/data/image/face/000001.png \
+ tests/data/image/face/pred.png \
+ --upscale-factor 4
+```
+
+#### 视频超分辨率
+
+您可以使用以下命令来测试视频以进行恢复。
+
+```shell
+python demo/restoration_video_demo.py \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ ${INPUT_DIR} \
+ ${OUTPUT_DIR} \
+ [--window-size=${WINDOW_SIZE}] \
+ [--device ${GPU_ID}]
+```
+
+它同时支持滑动窗口框架和循环框架。 例子:
+
+EDVR:
+
+```shell
+python demo/restoration_video_demo.py \
+ configs/edvr/edvrm_wotsa_reds_600k-8xb8.py \
+ https://download.openmmlab.com/mmediting/restorers/edvr/edvrm_wotsa_x4_8x4_600k_reds_20200522-0570e567.pth \
+ data/Vid4/BIx4/calendar/ \
+ demo/output \
+ --window-size=5
+```
+
+BasicVSR:
+
+```shell
+python demo/restoration_video_demo.py \
+ configs/basicvsr/basicvsr_2xb4_reds4.py \
+ https://download.openmmlab.com/mmediting/restorers/basicvsr/basicvsr_reds4_20120409-0e599677.pth \
+ data/Vid4/BIx4/calendar/ \
+ demo/output
+```
+
+复原的视频将保存在 ` demo/output/` 中。
+
+#### 视频插帧
+
+您可以使用以下命令来测试视频插帧。
+
+```shell
+python demo/video_interpolation_demo.py \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ ${INPUT_DIR} \
+ ${OUTPUT_DIR} \
+ [--fps-multiplier ${FPS_MULTIPLIER}] \
+ [--fps ${FPS}]
+```
+
+`${INPUT_DIR}` 和 `${OUTPUT_DIR}` 可以是视频文件路径或存放一系列有序图像的文件夹。
+若 `${OUTPUT_DIR}` 是视频文件地址,其帧率可由输入视频帧率和 `fps_multiplier` 共同决定,也可由 `fps` 直接给定(其中前者优先级更高)。例子:
+
+由输入视频帧率和 `fps_multiplier` 共同决定输出视频的帧率:
+
+```shell
+python demo/video_interpolation_demo.py \
+ configs/cain/cain_g1b32_1xb5_vimeo90k-triplet.py \
+ https://download.openmmlab.com/mmediting/video_interpolators/cain/cain_b5_320k_vimeo-triple_20220117-647f3de2.pth \
+ tests/data/frames/test_inference.mp4 \
+ tests/data/frames/test_inference_vfi_out.mp4 \
+ --fps-multiplier 2.0
+```
+
+由 `fps` 直接给定输出视频的帧率:
+
+```shell
+python demo/video_interpolation_demo.py \
+ configs/cain/cain_g1b32_1xb5_vimeo90k-triplet.py \
+ https://download.openmmlab.com/mmediting/video_interpolators/cain/cain_b5_320k_vimeo-triple_20220117-647f3de2.pth \
+ tests/data/frames/test_inference.mp4 \
+ tests/data/frames/test_inference_vfi_out.mp4 \
+ --fps 60.0
+```
+
+#### 图像生成
+
+```shell
+python demo/generation_demo.py \
+ ${CONFIG_FILE} \
+ ${CHECKPOINT_FILE} \
+ ${IMAGE_FILE} \
+ ${SAVE_FILE} \
+ [--unpaired-path ${UNPAIRED_IMAGE_FILE}] \
+ [--imshow] \
+ [--device ${GPU_ID}]
+```
+
+如果指定了 `--unpaired-path` (用于 CycleGAN),模型将执行未配对的图像到图像的转换。 如果指定了 `--imshow` ,演示也将使用opencv显示图像。 例子:
+
+针对配对数据:
+
+```shell
+python demo/generation_demo.py \
+ configs/example_config.py \
+ work_dirs/example_exp/example_model_20200202.pth \
+ demo/demo.jpg \
+ demo/demo_out.jpg
+```
+
+针对未配对数据(用 opencv 显示图像):
+
+```shell
+python demo/generation_demo.py 、
+ configs/example_config.py \
+ work_dirs/example_exp/example_model_20200202.pth \
+ demo/demo.jpg \
+ demo/demo_out.jpg \
+ --unpaired-path demo/demo_unpaired.jpg \
+ --imshow
+```
diff --git a/docs/zh_cn/user_guides/metrics.md b/docs/zh_cn/user_guides/metrics.md
new file mode 100644
index 0000000000..6df8c50bea
--- /dev/null
+++ b/docs/zh_cn/user_guides/metrics.md
@@ -0,0 +1 @@
+# 教程 5:使用评价指标
diff --git a/docs/zh_cn/user_guides/train_test.md b/docs/zh_cn/user_guides/train_test.md
index 35571fc9e9..7ee71b6bb6 100644
--- a/docs/zh_cn/user_guides/train_test.md
+++ b/docs/zh_cn/user_guides/train_test.md
@@ -1 +1 @@
-# 训练 & 测试(待更新)
+# 教程 4:训练与测试(待更新)
diff --git a/docs/zh_cn/user_guides/useful_tools.md b/docs/zh_cn/user_guides/useful_tools.md
index eea60c83a6..429e2a6f77 100644
--- a/docs/zh_cn/user_guides/useful_tools.md
+++ b/docs/zh_cn/user_guides/useful_tools.md
@@ -1 +1,351 @@
-# 实用工具(待更新)
+# 教程 7:实用工具(待更新)
+
+我们在 `tools/` 目录下提供了很多有用的工具。
+
+### 获取 FLOP 和参数量(实验性)
+
+我们提供了一个改编自 [flops-counter.pytorch](https://github.com/sovrasov/flops-counter.pytorch) 的脚本来计算模型的 FLOP 和参数量。
+
+```shell
+python tools/get_flops.py ${CONFIG_FILE} [--shape ${INPUT_SHAPE}]
+```
+
+例如,
+
+```shell
+python tools/get_flops.py configs/resotorer/srresnet.py --shape 40 40
+```
+
+你会得到以下的结果。
+
+```
+==============================
+Input shape: (3, 40, 40)
+Flops: 4.07 GMac
+Params: 1.52 M
+==============================
+```
+
+**注**:此工具仍处于实验阶段,我们不保证数字正确。 您可以将结果用于简单的比较,但在技术报告或论文中采用它之前,请仔细检查它。
+
+(1) FLOPs 与输入形状有关,而参数量与输入形状无关。默认输入形状为 (1, 3, 250, 250)。
+(2) 一些运算符不计入 FLOP,如 GN 和自定义运算符。
+你可以通过修改 [`mmcv/cnn/utils/flops_counter.py`](https://github.com/open-mmlab/mmcv/blob/master/mmcv/cnn/utils/flops_counter.py) 来添加对新运算符的支持。
+
+### 发布模型
+
+在将模型上传到 AWS 之前,您可能需要
+(1) 将模型权重转换为 CPU tensors, (2) 删除优化器状态,和
+(3) 计算模型权重文件的哈希并将哈希 ID 附加到文件名。
+
+```shell
+python tools/publish_model.py ${INPUT_FILENAME} ${OUTPUT_FILENAME}
+```
+
+例如,
+
+```shell
+python tools/publish_model.py work_dirs/example_exp/latest.pth example_model_20200202.pth
+```
+
+最终输出文件名将是 `example_model_20200202-{hash id}.pth`.
+
+### 转换为 ONNX(实验性)
+
+我们提供了一个脚本将模型转换为 [ONNX](https://github.com/onnx/onnx) 格式。 转换后的模型可以通过 [Netron](https://github.com/lutzroeder/netron) 等工具进行可视化。此外,我们还支持比较 Pytorch 和 ONNX 模型之间的输出结果。
+
+```bash
+python tools/pytorch2onnx.py
+ ${CFG_PATH} \
+ ${CHECKPOINT_PATH} \
+ ${MODEL_TYPE} \
+ ${IMAGE_PATH} \
+ --trimap-path ${TRIMAP_PATH} \
+ --output-file ${OUTPUT_ONNX} \
+ --show \
+ --verify \
+ --dynamic-export
+```
+
+参数说明:
+
+- `config` : 模型配置文件的路径。
+- `checkpoint` : 模型模型权重文件的路径。
+- `model_type` : 配置文件的模型类型,选项: `inpainting`, `mattor`, `restorer`, `synthesizer`。
+- `image_path` : 输入图像文件的路径。
+- `--trimap-path` : 输入三元图文件的路径,用于 mattor 模型。
+- `--output-file`: 输出 ONNX 模型的路径。默认为 `tmp.onnx`。
+- `--opset-version` : ONNX opset 版本。默认为 11。
+- `--show`: 确定是否打印导出模型的架构。默认为 `False`。
+- `--verify`: 确定是否验证导出模型的正确性。默认为 `False`。
+- `--dynamic-export`: 确定是否导出具有动态输入和输出形状的 ONNX 模型。默认为 `False`。
+
+**注**:此工具仍处于试验阶段。目前不支持某些自定义运算符。我们现在只支持 `mattor` 和 `restorer`。
+
+#### 支持导出到 ONNX 的模型列表
+
+下表列出了保证可导出到 ONNX 并可在 ONNX Runtime 中运行的模型。
+
+| 模型 | 配置 | 动态形状 | 批量推理 | 备注 |
+| :------: | :-----------------------------------------------------------------------------------------------------------------------------------------------------------------: | :------: | :------: | :--: |
+| ESRGAN | [esrgan_x4c64b23g32_g1_400k_div2k.py](https://github.com/open-mmlab/mmediting/blob/master/configs/restorers/esrgan/esrgan_x4c64b23g32_g1_400k_div2k.py) | Y | Y | |
+| ESRGAN | [esrgan_psnr_x4c64b23g32_g1_1000k_div2k.py](https://github.com/open-mmlab/mmediting/blob/master/configs/restorers/esrgan/esrgan_psnr_x4c64b23g32_g1_1000k_div2k.py) | Y | Y | |
+| SRCNN | [srcnn_x4k915_g1_1000k_div2k.py](https://github.com/open-mmlab/mmediting/blob/master/configs/restorers/srcnn/srcnn_x4k915_g1_1000k_div2k.py) | Y | Y | |
+| DIM | [dim_stage3_v16_pln_1x1_1000k_comp1k.py](https://github.com/open-mmlab/mmediting/blob/master/configs/dim/dim_stage3_v16_pln_1x1_1000k_comp1k.py) | Y | Y | |
+| GCA | [gca_r34_4x10_200k_comp1k.py](https://github.com/open-mmlab/mmediting/blob/master/configs/gca/gca_r34_4x10_200k_comp1k.py) | N | Y | |
+| IndexNet | [indexnet_mobv2_1x16_78k_comp1k.py](https://github.com/open-mmlab/mmediting/blob/master/configs/indexnet/indexnet_mobv2_1x16_78k_comp1k.py) | Y | Y | |
+
+**注**:
+
+- *以上所有模型均使用 Pytorch==1.6.0 和 onnxruntime==1.5.1*
+- 如果您遇到上面列出的模型的任何问题,请创建一个 issue,我们会尽快处理。对于列表中未包含的型号,请尝试自行解决。
+- 由于此功能是实验性的并且可能会快速更改,请始终尝试使用最新的 `mmcv` 和 `mmedit`。
+
+### 将 ONNX 转换为 TensorRT(实验性)
+
+我们还提供了将 [ONNX](https://github.com/onnx/onnx) 模型转换为 [TensorRT](https://github.com/NVIDIA/TensorRT) 格式的脚本。 此外,我们支持比较 ONNX 和 TensorRT 模型之间的输出结果。
+
+```bash
+python tools/onnx2tensorrt.py
+ ${CFG_PATH} \
+ ${MODEL_TYPE} \
+ ${IMAGE_PATH} \
+ ${INPUT_ONNX} \
+ --trt-file ${OUT_TENSORRT} \
+ --max-shape INT INT INT INT \
+ --min-shape INT INT INT INT \
+ --workspace-size INT \
+ --fp16 \
+ --show \
+ --verify \
+ --verbose
+```
+
+参数说明:
+
+- `config` : 模型配置文件的路径。
+- `model_type` :配置文件的模型类型,选项: `inpainting`, `mattor`, `restorer`, `synthesizer`。
+- `img_path` : 输入图像文件的路径。
+- `onnx_file` : 输入 ONNX 文件的路径。
+- `--trt-file` : 输出 TensorRT 模型的路径。默认为 `tmp.trt`。
+- `--max-shape` : 模型输入的最大形状。
+- `--min-shape` : 模型输入的最小形状。
+- `--workspace-size`: 以 GiB 为单位的最大工作空间大小。默认为 1 GiB。
+- `--fp16`: 确定是否以 fp16 模式导出 TensorRT。默认为 `False`。
+- `--show`: 确定是否显示 ONNX 和 TensorRT 的输出。默认为 `False`。
+- `--verify`: 确定是否验证导出模型的正确性。默认为 `False`。
+- `--verbose`: 确定在创建 TensorRT 引擎时是否详细记录日志消息。默认为 `False`。
+
+**注**:此工具仍处于试验阶段。 目前不支持某些自定义运算符。 我们现在只支持 `restorer`。 在生成 SRCNN 的 ONNX 文件时,将 SCRNN 模型中的 'bicubic' 替换为 'bilinear' \[此处\](https://github.com/open-mmlab/mmediting/blob/764e6065e315b7d0033762038fcbf0bb1c570d4d/mmedit.bones/modelsrnn py#L40)。 因为 TensorRT 目前不支持 bicubic 插值,最终性能将下降约 4%。
+
+#### 支持导出到 TensorRT 的模型列表
+
+下表列出了保证可导出到 TensorRT 引擎并可在 TensorRT 中运行的模型。
+
+| 模型 | 配置 | 动态形状 | 批量推理 | 备注 |
+| :----: | :-------------------------------------------------------------------------------------------------------------------------------------------: | :------: | :------: | :-----------------------------------: |
+| ESRGAN | [esrgan_x4c64b23g32_g1_400k_div2k.py](https://github.com/open-mmlab/mmediting/blob/master/configs/restorers/esrgan/esrgan_x4c64b23g32_g1_400k_div2k.py) | Y | Y | |
+| ESRGAN | [esrgan_psnr_x4c64b23g32_g1_1000k_div2k.py](https://github.com/open-mmlab/mmediting/blob/master/configs/restorers/esrgan/esrgan_psnr_x4c64b23g32_g1_1000k_div2k.py) | Y | Y | |
+| SRCNN | [srcnn_x4k915_g1_1000k_div2k.py](https://github.com/open-mmlab/mmediting/blob/master/configs/restorers/srcnn/srcnn_x4k915_g1_1000k_div2k.py) | Y | Y | 'bicubic' 上采样必须替换为 'bilinear' |
+
+**注**:
+
+- *以上所有模型均使用 Pytorch==1.8.1、onnxruntime==1.7.0 和 tensorrt==7.2.3.4 进行测试*
+- 如果您遇到上面列出的模型的任何问题,请创建一个问题,我们会尽快处理。 对于列表中未包含的型号,请尝试自行解决。
+- 由于此功能是实验性的并且可能会快速更改,因此请始终尝试使用最新的 `mmcv` 和 `mmedit`。
+
+### 评估 ONNX 和 TensorRT 模型(实验性)
+
+我们在 `tools/deploy_test.py` 中提供了评估 TensorRT 和 ONNX 模型的方法。
+
+#### 先决条件
+
+要评估 ONNX 和 TensorRT 模型,应先安装 onnx、onnxruntime 和 TensorRT。遵循 [mmcv 中的 ONNXRuntime](https://mmcv.readthedocs.io/en/latest/onnxruntime_op.html) 和 \[mmcv 中的 TensorRT 插件\](https://github.com/open-mmlab/mmcv/blob/master/docs/tensorrt_plugin.md%EF%BC%89%E4%BD%BF%E7%94%A8 ONNXRuntime 自定义操作和 TensorRT 插件安装 `mmcv-full`。
+
+#### 用法
+
+```bash
+python tools/deploy_test.py \
+ ${CONFIG_FILE} \
+ ${MODEL_PATH} \
+ ${BACKEND} \
+ --out ${OUTPUT_FILE} \
+ --save-path ${SAVE_PATH} \
+ ----cfg-options ${CFG_OPTIONS} \
+```
+
+#### 参数说明:
+
+- `config`: 模型配置文件的路径。
+- `model`: TensorRT 或 ONNX 模型文件的路径。
+- `backend`: 用于测试的后端,选择 tensorrt 或 onnxruntime。
+- `--out`: pickle 格式的输出结果文件的路径。
+- `--save-path`: 存储图像的路径,如果没有给出,则不会保存图像。
+- `--cfg-options`: 覆盖使用的配置文件中的一些设置,`xxx=yyy` 格式的键值对将被合并到配置文件中。
+
+#### 结果和模型
+
+ +
+将代码克隆到本地
+
+```shell
+git clone git@github.com:{username}/mmediting.git
+```
+
+添加原代码库为上游代码库
+
+```bash
+git remote add upstream git@github.com:open-mmlab/mmediting
+```
+
+检查 remote 是否添加成功,在终端输入 `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmediting.git (fetch)
+origin git@github.com:{username}/mmediting.git (push)
+upstream git@github.com:open-mmlab/mmediting (fetch)
+upstream git@github.com:open-mmlab/mmediting (push)
+```
+
+```{note}
+这里对 origin 和 upstream 进行一个简单的介绍,当我们使用 git clone 来克隆代码时,会默认创建一个 origin 的 remote,它指向我们克隆的代码库地址,而 upstream 则是我们自己添加的,用来指向原始代码库地址。当然如果你不喜欢他叫 upstream,也可以自己修改,比如叫 open-mmlab。我们通常向 origin 提交代码(即 fork 下来的远程仓库),然后向 upstream 提交一个 pull request。如果提交的代码和最新的代码发生冲突,再从 upstream 拉取最新的代码,和本地分支解决冲突,再提交到 origin。
+```
+
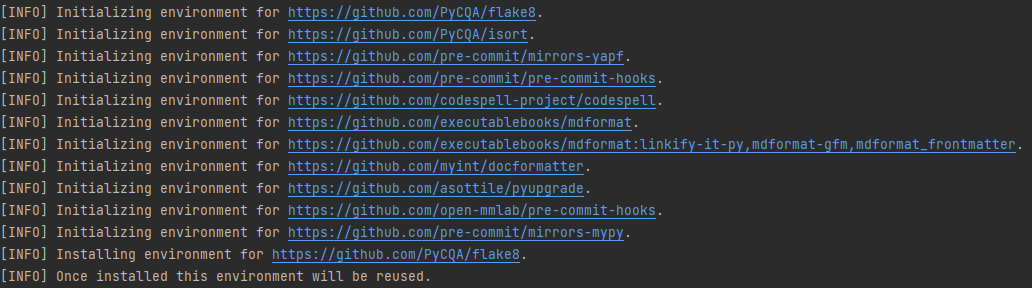
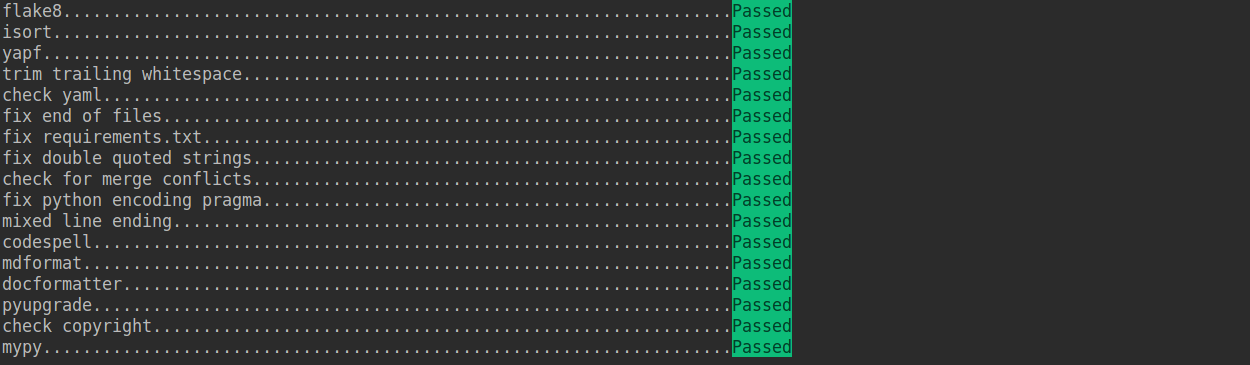
+#### 2. 配置 pre-commit
+
+在本地开发环境中,我们使用 [pre-commit](https://pre-commit.com/#intro) 来检查代码风格,以确保代码风格的统一。在提交代码,需要先安装 pre-commit(需要在 mmediting 目录下执行):
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+检查 pre-commit 是否配置成功,并安装 `.pre-commit-config.yaml` 中的钩子:
+
+```shell
+pre-commit run --all-files
+```
+
+
+
+将代码克隆到本地
+
+```shell
+git clone git@github.com:{username}/mmediting.git
+```
+
+添加原代码库为上游代码库
+
+```bash
+git remote add upstream git@github.com:open-mmlab/mmediting
+```
+
+检查 remote 是否添加成功,在终端输入 `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmediting.git (fetch)
+origin git@github.com:{username}/mmediting.git (push)
+upstream git@github.com:open-mmlab/mmediting (fetch)
+upstream git@github.com:open-mmlab/mmediting (push)
+```
+
+```{note}
+这里对 origin 和 upstream 进行一个简单的介绍,当我们使用 git clone 来克隆代码时,会默认创建一个 origin 的 remote,它指向我们克隆的代码库地址,而 upstream 则是我们自己添加的,用来指向原始代码库地址。当然如果你不喜欢他叫 upstream,也可以自己修改,比如叫 open-mmlab。我们通常向 origin 提交代码(即 fork 下来的远程仓库),然后向 upstream 提交一个 pull request。如果提交的代码和最新的代码发生冲突,再从 upstream 拉取最新的代码,和本地分支解决冲突,再提交到 origin。
+```
+
+#### 2. 配置 pre-commit
+
+在本地开发环境中,我们使用 [pre-commit](https://pre-commit.com/#intro) 来检查代码风格,以确保代码风格的统一。在提交代码,需要先安装 pre-commit(需要在 mmediting 目录下执行):
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+检查 pre-commit 是否配置成功,并安装 `.pre-commit-config.yaml` 中的钩子:
+
+```shell
+pre-commit run --all-files
+```
+
+ +
+
+
+ +
+```{note}
+如果你是中国用户,由于网络原因,可能会出现安装失败的情况,这时可以使用国内源
+
+pre-commit install -c .pre-commit-config-zh-cn.yaml
+
+pre-commit run --all-files -c .pre-commit-config-zh-cn.yaml
+```
+
+如果安装过程被中断,可以重复执行 `pre-commit run ...` 继续安装。
+
+如果提交的代码不符合代码风格规范,pre-commit 会发出警告,并自动修复部分错误。
+
+
+
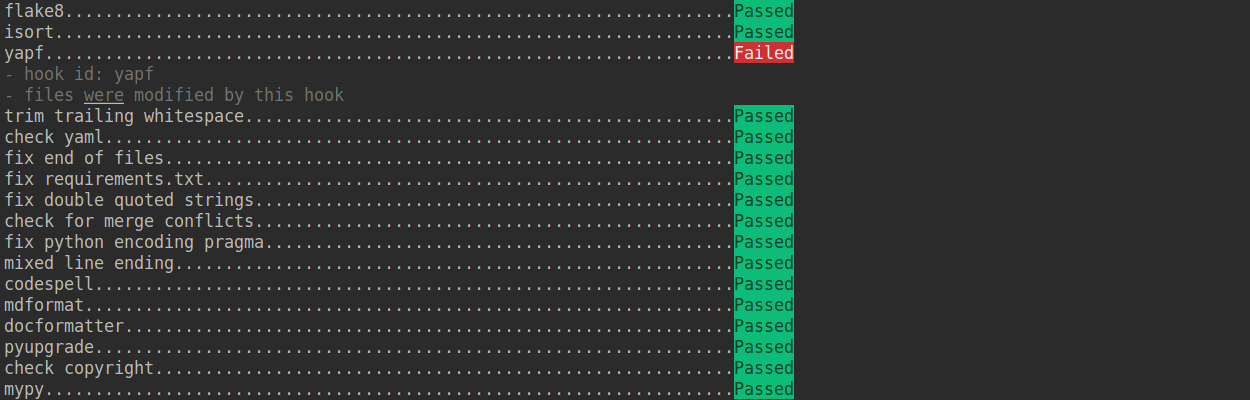
+```{note}
+如果你是中国用户,由于网络原因,可能会出现安装失败的情况,这时可以使用国内源
+
+pre-commit install -c .pre-commit-config-zh-cn.yaml
+
+pre-commit run --all-files -c .pre-commit-config-zh-cn.yaml
+```
+
+如果安装过程被中断,可以重复执行 `pre-commit run ...` 继续安装。
+
+如果提交的代码不符合代码风格规范,pre-commit 会发出警告,并自动修复部分错误。
+
+ +
+如果我们想临时绕开 pre-commit 的检查提交一次代码,可以在 `git commit` 时加上 `--no-verify`(需要保证最后推送至远程仓库的代码能够通过 pre-commit 检查)。
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. 创建开发分支
+
+安装完 pre-commit 之后,我们需要基于 master 创建开发分支,建议的分支命名规则为 `username/pr_name`。
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+在后续的开发中,如果本地仓库的 master 分支落后于 upstream 的 master 分支,我们需要先拉取 upstream 的代码进行同步,再执行上面的命令
+
+```shell
+git pull upstream master
+```
+
+#### 4. 提交代码并在本地通过单元测试
+
+- mmediting 引入了 mypy 来做静态类型检查,以增加代码的鲁棒性。因此我们在提交代码时,需要补充 Type Hints。具体规则可以参考[教程](https://zhuanlan.zhihu.com/p/519335398)。
+
+- 提交的代码同样需要通过单元测试
+
+ ```shell
+ # 通过全量单元测试
+ pytest tests
+
+ # 我们需要保证提交的代码能够通过修改模块的单元测试,以 runner 为例
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ 如果你由于缺少依赖无法运行修改模块的单元测试,可以参考[指引-单元测试](#单元测试)
+
+- 如果修改/添加了文档,参考[指引](#文档渲染)确认文档渲染正常。
+
+#### 5. 推送代码到远程
+
+代码通过单元测试和 pre-commit 检查后,将代码推送到远程仓库,如果是第一次推送,可以在 `git push` 后加上 `-u` 参数以关联远程分支
+
+```shell
+git push -u origin {branch_name}
+```
+
+这样下次就可以直接使用 `git push` 命令推送代码了,而无需指定分支和远程仓库。
+
+#### 6. 提交拉取请求(PR)
+
+(1) 在 GitHub 的 Pull request 界面创建拉取请求
+
+
+如果我们想临时绕开 pre-commit 的检查提交一次代码,可以在 `git commit` 时加上 `--no-verify`(需要保证最后推送至远程仓库的代码能够通过 pre-commit 检查)。
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+#### 3. 创建开发分支
+
+安装完 pre-commit 之后,我们需要基于 master 创建开发分支,建议的分支命名规则为 `username/pr_name`。
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+在后续的开发中,如果本地仓库的 master 分支落后于 upstream 的 master 分支,我们需要先拉取 upstream 的代码进行同步,再执行上面的命令
+
+```shell
+git pull upstream master
+```
+
+#### 4. 提交代码并在本地通过单元测试
+
+- mmediting 引入了 mypy 来做静态类型检查,以增加代码的鲁棒性。因此我们在提交代码时,需要补充 Type Hints。具体规则可以参考[教程](https://zhuanlan.zhihu.com/p/519335398)。
+
+- 提交的代码同样需要通过单元测试
+
+ ```shell
+ # 通过全量单元测试
+ pytest tests
+
+ # 我们需要保证提交的代码能够通过修改模块的单元测试,以 runner 为例
+ pytest tests/test_runner/test_runner.py
+ ```
+
+ 如果你由于缺少依赖无法运行修改模块的单元测试,可以参考[指引-单元测试](#单元测试)
+
+- 如果修改/添加了文档,参考[指引](#文档渲染)确认文档渲染正常。
+
+#### 5. 推送代码到远程
+
+代码通过单元测试和 pre-commit 检查后,将代码推送到远程仓库,如果是第一次推送,可以在 `git push` 后加上 `-u` 参数以关联远程分支
+
+```shell
+git push -u origin {branch_name}
+```
+
+这样下次就可以直接使用 `git push` 命令推送代码了,而无需指定分支和远程仓库。
+
+#### 6. 提交拉取请求(PR)
+
+(1) 在 GitHub 的 Pull request 界面创建拉取请求
+ +
+(2) 根据指引修改 PR 描述,以便于其他开发者更好地理解你的修改
+
+
+
+(2) 根据指引修改 PR 描述,以便于其他开发者更好地理解你的修改
+
+ +
+描述规范详见[拉取请求规范](#拉取请求规范)
+
+
+
+**注意事项**
+
+(a) PR 描述应该包含修改理由、修改内容以及修改后带来的影响,并关联相关 Issue(具体方式见[文档](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue))
+
+(b) 如果是第一次为 OpenMMLab 做贡献,需要签署 CLA
+
+
+
+描述规范详见[拉取请求规范](#拉取请求规范)
+
+
+
+**注意事项**
+
+(a) PR 描述应该包含修改理由、修改内容以及修改后带来的影响,并关联相关 Issue(具体方式见[文档](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue))
+
+(b) 如果是第一次为 OpenMMLab 做贡献,需要签署 CLA
+
+ +
+(c) 检查提交的 PR 是否通过 CI(集成测试)
+
+
+
+(c) 检查提交的 PR 是否通过 CI(集成测试)
+
+ +
+mmediting 会在不同的平台(Linux、Window、Mac),基于不同版本的 Python、PyTorch、CUDA 对提交的代码进行单元测试,以保证代码的正确性,如果有任何一个没有通过,我们可点击上图中的 `Details` 来查看具体的测试信息,以便于我们修改代码。
+
+(3) 如果 PR 通过了 CI,那么就可以等待其他开发者的 review,并根据 reviewer 的意见,修改代码,并重复 [4](#4-提交代码并本地通过单元测试)-[5](#5-推送代码到远程) 步骤,直到 reviewer 同意合入 PR。
+
+
+
+mmediting 会在不同的平台(Linux、Window、Mac),基于不同版本的 Python、PyTorch、CUDA 对提交的代码进行单元测试,以保证代码的正确性,如果有任何一个没有通过,我们可点击上图中的 `Details` 来查看具体的测试信息,以便于我们修改代码。
+
+(3) 如果 PR 通过了 CI,那么就可以等待其他开发者的 review,并根据 reviewer 的意见,修改代码,并重复 [4](#4-提交代码并本地通过单元测试)-[5](#5-推送代码到远程) 步骤,直到 reviewer 同意合入 PR。
+
+ +
+所有 reviewer 同意合入 PR 后,我们会尽快将 PR 合并到主分支。
+
+#### 7. 解决冲突
+
+随着时间的推移,我们的代码库会不断更新,这时候,如果你的 PR 与主分支存在冲突,你需要解决冲突,解决冲突的方式有两种:
+
+```shell
+git fetch --all --prune
+git rebase upstream/master
+```
+
+或者
+
+```shell
+git fetch --all --prune
+git merge upstream/master
+```
+
+如果你非常善于处理冲突,那么可以使用 rebase 的方式来解决冲突,因为这能够保证你的 commit log 的整洁。如果你不太熟悉 `rebase` 的使用,那么可以使用 `merge` 的方式来解决冲突。
+
+### 指引
+
+#### 单元测试
+
+在提交修复代码错误或新增特性的拉取请求时,我们应该尽可能的让单元测试覆盖所有提交的代码,计算单元测试覆盖率的方法如下
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+#### 文档渲染
+
+在提交修复代码错误或新增特性的拉取请求时,可能会需要修改/新增模块的 docstring。我们需要确认渲染后的文档样式是正确的。
+本地生成渲染后的文档的方法如下
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+### 代码风格
+
+#### Python
+
+[PEP8](https://www.python.org/dev/peps/pep-0008/) 作为 OpenMMLab 算法库首选的代码规范,我们使用以下工具检查和格式化代码
+
+- [flake8](https://github.com/PyCQA/flake8): Python 官方发布的代码规范检查工具,是多个检查工具的封装
+- [isort](https://github.com/timothycrosley/isort): 自动调整模块导入顺序的工具
+- [yapf](https://github.com/google/yapf): Google 发布的代码规范检查工具
+- [codespell](https://github.com/codespell-project/codespell): 检查单词拼写是否有误
+- [mdformat](https://github.com/executablebooks/mdformat): 检查 markdown 文件的工具
+- [docformatter](https://github.com/myint/docformatter): 格式化 docstring 的工具
+
+yapf 和 isort 的配置可以在 [setup.cfg](../../setup.cfg) 找到
+
+通过配置 [pre-commit hook](https://pre-commit.com/) ,我们可以在提交代码时自动检查和格式化 `flake8`、`yapf`、`isort`、`trailing whitespaces`、`markdown files`,修复 `end-of-files`、`double-quoted-strings`、`python-encoding-pragma`、`mixed-line-ending`,调整 `requirments.txt` 的包顺序。
+pre-commit 钩子的配置可以在 [.pre-commit-config](../../.pre-commit-config.yaml) 找到。
+
+pre-commit 具体的安装使用方式见[拉取请求](#2-配置-pre-commit)。
+
+更具体的规范请参考 [OpenMMLab 代码规范](#代码风格)。
+
+#### C++ and CUDA
+
+C++ 和 CUDA 的代码规范遵从 [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html)
+
+### 拉取请求规范
+
+1. 使用 [pre-commit hook](https://pre-commit.com),尽量减少代码风格相关问题
+
+2. 一个`拉取请求`对应一个短期分支
+
+3. 粒度要细,一个`拉取请求`只做一件事情,避免超大的`拉取请求`
+
+ - Bad:实现 Faster R-CNN
+ - Acceptable:给 Faster R-CNN 添加一个 box head
+ - Good:给 box head 增加一个参数来支持自定义的 conv 层数
+
+4. 每次 Commit 时需要提供清晰且有意义 commit 信息
+
+5. 提供清晰且有意义的`拉取请求`描述
+
+ - 标题写明白任务名称,一般格式:\[Prefix\] Short description of the pull request (Suffix)
+ - prefix: 新增功能 \[Feature\], 修 bug \[Fix\], 文档相关 \[Docs\], 开发中 \[WIP\] (暂时不会被review)
+ - 描述里介绍`拉取请求`的主要修改内容,结果,以及对其他部分的影响, 参考`拉取请求`模板
+ - 关联相关的`议题` (issue) 和其他`拉取请求`
+
+6. 如果引入了其他三方库,或借鉴了三方库的代码,请确认他们的许可证和 mmediting 兼容,并在借鉴的代码上补充 `This code is inspired from http://`
+
+## 代码规范
+
+### 代码规范标准
+
+#### PEP 8 —— Python 官方代码规范
+
+[Python 官方的代码风格指南](https://www.python.org/dev/peps/pep-0008/),包含了以下几个方面的内容:
+
+- 代码布局,介绍了 Python 中空行、断行以及导入相关的代码风格规范。比如一个常见的问题:当我的代码较长,无法在一行写下时,何处可以断行?
+
+- 表达式,介绍了 Python 中表达式空格相关的一些风格规范。
+
+- 尾随逗号相关的规范。当列表较长,无法一行写下而写成如下逐行列表时,推荐在末项后加逗号,从而便于追加选项、版本控制等。
+
+ ```python
+ # Correct:
+ FILES = ['setup.cfg', 'tox.ini']
+ # Correct:
+ FILES = [
+ 'setup.cfg',
+ 'tox.ini',
+ ]
+ # Wrong:
+ FILES = ['setup.cfg', 'tox.ini',]
+ # Wrong:
+ FILES = [
+ 'setup.cfg',
+ 'tox.ini'
+ ]
+ ```
+
+- 命名相关规范、注释相关规范、类型注解相关规范,我们将在后续章节中做详细介绍。
+
+ "A style guide is about consistency. Consistency with this style guide is important. Consistency within a project is more important. Consistency within one module or function is the most important." PEP 8 -- Style Guide for Python Code
+
+:::{note}
+PEP 8 的代码规范并不是绝对的,项目内的一致性要优先于 PEP 8 的规范。OpenMMLab 各个项目都在 setup.cfg 设定了一些代码规范的设置,请遵照这些设置。一个例子是在 PEP 8 中有如下一个例子:
+
+```python
+# Correct:
+hypot2 = x*x + y*y
+# Wrong:
+hypot2 = x * x + y * y
+```
+
+这一规范是为了指示不同优先级,但 OpenMMLab 的设置中通常没有启用 yapf 的 `ARITHMETIC_PRECEDENCE_INDICATION` 选项,因而格式规范工具不会按照推荐样式格式化,以设置为准。
+:::
+
+#### Google 开源项目风格指南
+
+[Google 使用的编程风格指南](https://google.github.io/styleguide/pyguide.html),包括了 Python 相关的章节。相较于 PEP 8,该指南提供了更为详尽的代码指南。该指南包括了语言规范和风格规范两个部分。
+
+其中,语言规范对 Python 中很多语言特性进行了优缺点的分析,并给出了使用指导意见,如异常、Lambda 表达式、列表推导式、metaclass 等。
+
+风格规范的内容与 PEP 8 较为接近,大部分约定建立在 PEP 8 的基础上,也有一些更为详细的约定,如函数长度、TODO 注释、文件与 socket 对象的访问等。
+
+推荐将该指南作为参考进行开发,但不必严格遵照,一来该指南存在一些 Python 2 兼容需求,例如指南中要求所有无基类的类应当显式地继承 Object, 而在仅使用 Python 3 的环境中,这一要求是不必要的,依本项目中的惯例即可。二来 OpenMMLab 的项目作为框架级的开源软件,不必对一些高级技巧过于避讳,尤其是 MMCV。但尝试使用这些技巧前应当认真考虑是否真的有必要,并寻求其他开发人员的广泛评估。
+
+另外需要注意的一处规范是关于包的导入,在该指南中,要求导入本地包时必须使用路径全称,且导入的每一个模块都应当单独成行,通常这是不必要的,而且也不符合目前项目的开发惯例,此处进行如下约定:
+
+```python
+# Correct
+from mmedit.cnn.bricks import (Conv2d, build_norm_layer, DropPath, MaxPool2d,
+ Linear)
+from ..utils import ext_loader
+
+# Wrong
+from mmedit.cnn.bricks import Conv2d, build_norm_layer, DropPath, MaxPool2d, \
+ Linear # 使用括号进行连接,而不是反斜杠
+from ...utils import is_str # 最多向上回溯一层,过多的回溯容易导致结构混乱
+```
+
+OpenMMLab 项目使用 pre-commit 工具自动格式化代码,详情见[贡献代码](./contributing.md#代码风格)。
+
+### 命名规范
+
+#### 命名规范的重要性
+
+优秀的命名是良好代码可读的基础。基础的命名规范对各类变量的命名做了要求,使读者可以方便地根据代码名了解变量是一个类 / 局部变量 / 全局变量等。而优秀的命名则需要代码作者对于变量的功能有清晰的认识,以及良好的表达能力,从而使读者根据名称就能了解其含义,甚至帮助了解该段代码的功能。
+
+#### 基础命名规范
+
+| 类型 | 公有 | 私有 |
+| --------------- | ---------------- | ------------------ |
+| 模块 | lower_with_under | \_lower_with_under |
+| 包 | lower_with_under | |
+| 类 | CapWords | \_CapWords |
+| 异常 | CapWordsError | |
+| 函数(方法) | lower_with_under | \_lower_with_under |
+| 函数 / 方法参数 | lower_with_under | |
+| 全局 / 类内常量 | CAPS_WITH_UNDER | \_CAPS_WITH_UNDER |
+| 全局 / 类内变量 | lower_with_under | \_lower_with_under |
+| 变量 | lower_with_under | \_lower_with_under |
+| 局部变量 | lower_with_under | |
+
+注意:
+
+- 尽量避免变量名与保留字冲突,特殊情况下如不可避免,可使用一个后置下划线,如 class\_
+- 尽量不要使用过于简单的命名,除了约定俗成的循环变量 i,文件变量 f,错误变量 e 等。
+- 不会被用到的变量可以命名为 \_,逻辑检查器会将其忽略。
+
+#### 命名技巧
+
+良好的变量命名需要保证三点:
+
+1. 含义准确,没有歧义
+2. 长短适中
+3. 前后统一
+
+```python
+# Wrong
+class Masks(metaclass=ABCMeta): # 命名无法表现基类;Instance or Semantic?
+ pass
+
+# Correct
+class BaseInstanceMasks(metaclass=ABCMeta):
+ pass
+
+# Wrong,不同地方含义相同的变量尽量用统一的命名
+def __init__(self, inplanes, planes):
+ pass
+
+def __init__(self, in_channels, out_channels):
+ pass
+```
+
+常见的函数命名方法:
+
+- 动宾命名法:crop_img, init_weights
+- 动宾倒置命名法:imread, bbox_flip
+
+注意函数命名与参数的顺序,保证主语在前,符合语言习惯:
+
+- check_keys_exist(key, container)
+- check_keys_contain(container, key)
+
+注意避免非常规或统一约定的缩写,如 nb -> num_blocks,in_nc -> in_channels
+
+### docstring 规范
+
+#### 为什么要写 docstring
+
+docstring 是对一个类、一个函数功能与 API 接口的详细描述,有两个功能,一是帮助其他开发者了解代码功能,方便 debug 和复用代码;二是在 Readthedocs 文档中自动生成相关的 API reference 文档,帮助不了解源代码的社区用户使用相关功能。
+
+#### 如何写 docstring
+
+与注释不同,一份规范的 docstring 有着严格的格式要求,以便于 Python 解释器以及 sphinx 进行文档解析,详细的 docstring 约定参见 [PEP 257](https://www.python.org/dev/peps/pep-0257/)。此处以例子的形式介绍各种文档的标准格式,参考格式为 [Google 风格](https://zh-google-styleguide.readthedocs.io/en/latest/google-python-styleguide/python_style_rules/#comments)。
+
+1. 模块文档
+
+ 代码风格规范推荐为每一个模块(即 Python 文件)编写一个 docstring,但目前 OpenMMLab 项目大部分没有此类 docstring,因此不做硬性要求。
+
+ ```python
+ """A one line summary of the module or program, terminated by a period.
+
+ Leave one blank line. The rest of this docstring should contain an
+ overall description of the module or program. Optionally, it may also
+ contain a brief description of exported classes and functions and/or usage
+ examples.
+
+ Typical usage example:
+
+ foo = ClassFoo()
+ bar = foo.FunctionBar()
+ """
+ ```
+
+2. 类文档
+
+ 类文档是我们最常需要编写的,此处,按照 OpenMMLab 的惯例,我们使用了与 Google 风格不同的写法。如下例所示,文档中没有使用 Attributes 描述类属性,而是使用 Args 描述 __init__ 函数的参数。
+
+ 在 Args 中,遵照 `parameter (type): Description.` 的格式,描述每一个参数类型和功能。其中,多种类型可使用 `(float or str)` 的写法,可以为 None 的参数可以写为 `(int, optional)`。
+
+ ```python
+ class BaseRunner(metaclass=ABCMeta):
+ """The base class of Runner, a training helper for PyTorch.
+
+ All subclasses should implement the following APIs:
+
+ - ``run()``
+ - ``train()``
+ - ``val()``
+ - ``save_checkpoint()``
+
+ Args:
+ model (:obj:`torch.nn.Module`): The model to be run.
+ batch_processor (callable, optional): A callable method that process
+ a data batch. The interface of this method should be
+ ``batch_processor(model, data, train_mode) -> dict``.
+ Defaults to None.
+ optimizer (dict or :obj:`torch.optim.Optimizer`, optional): It can be
+ either an optimizer (in most cases) or a dict of optimizers
+ (in models that requires more than one optimizer, e.g., GAN).
+ Defaults to None.
+ work_dir (str, optional): The working directory to save checkpoints
+ and logs. Defaults to None.
+ logger (:obj:`logging.Logger`): Logger used during training.
+ Defaults to None. (The default value is just for backward
+ compatibility)
+ meta (dict, optional): A dict records some import information such as
+ environment info and seed, which will be logged in logger hook.
+ Defaults to None.
+ max_epochs (int, optional): Total training epochs. Defaults to None.
+ max_iters (int, optional): Total training iterations. Defaults to None.
+ """
+
+ def __init__(self,
+ model,
+ batch_processor=None,
+ optimizer=None,
+ work_dir=None,
+ logger=None,
+ meta=None,
+ max_iters=None,
+ max_epochs=None):
+ ...
+ ```
+
+ 另外,在一些算法实现的主体类中,建议加入原论文的链接;如果参考了其他开源代码的实现,则应加入 modified from,而如果是直接复制了其他代码库的实现,则应加入 copied from ,并注意源码的 License。如有必要,也可以通过 .. math:: 来加入数学公式
+
+ ```python
+ # 参考实现
+ # This func is modified from `detectron2
+ #
+
+所有 reviewer 同意合入 PR 后,我们会尽快将 PR 合并到主分支。
+
+#### 7. 解决冲突
+
+随着时间的推移,我们的代码库会不断更新,这时候,如果你的 PR 与主分支存在冲突,你需要解决冲突,解决冲突的方式有两种:
+
+```shell
+git fetch --all --prune
+git rebase upstream/master
+```
+
+或者
+
+```shell
+git fetch --all --prune
+git merge upstream/master
+```
+
+如果你非常善于处理冲突,那么可以使用 rebase 的方式来解决冲突,因为这能够保证你的 commit log 的整洁。如果你不太熟悉 `rebase` 的使用,那么可以使用 `merge` 的方式来解决冲突。
+
+### 指引
+
+#### 单元测试
+
+在提交修复代码错误或新增特性的拉取请求时,我们应该尽可能的让单元测试覆盖所有提交的代码,计算单元测试覆盖率的方法如下
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+#### 文档渲染
+
+在提交修复代码错误或新增特性的拉取请求时,可能会需要修改/新增模块的 docstring。我们需要确认渲染后的文档样式是正确的。
+本地生成渲染后的文档的方法如下
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+### 代码风格
+
+#### Python
+
+[PEP8](https://www.python.org/dev/peps/pep-0008/) 作为 OpenMMLab 算法库首选的代码规范,我们使用以下工具检查和格式化代码
+
+- [flake8](https://github.com/PyCQA/flake8): Python 官方发布的代码规范检查工具,是多个检查工具的封装
+- [isort](https://github.com/timothycrosley/isort): 自动调整模块导入顺序的工具
+- [yapf](https://github.com/google/yapf): Google 发布的代码规范检查工具
+- [codespell](https://github.com/codespell-project/codespell): 检查单词拼写是否有误
+- [mdformat](https://github.com/executablebooks/mdformat): 检查 markdown 文件的工具
+- [docformatter](https://github.com/myint/docformatter): 格式化 docstring 的工具
+
+yapf 和 isort 的配置可以在 [setup.cfg](../../setup.cfg) 找到
+
+通过配置 [pre-commit hook](https://pre-commit.com/) ,我们可以在提交代码时自动检查和格式化 `flake8`、`yapf`、`isort`、`trailing whitespaces`、`markdown files`,修复 `end-of-files`、`double-quoted-strings`、`python-encoding-pragma`、`mixed-line-ending`,调整 `requirments.txt` 的包顺序。
+pre-commit 钩子的配置可以在 [.pre-commit-config](../../.pre-commit-config.yaml) 找到。
+
+pre-commit 具体的安装使用方式见[拉取请求](#2-配置-pre-commit)。
+
+更具体的规范请参考 [OpenMMLab 代码规范](#代码风格)。
+
+#### C++ and CUDA
+
+C++ 和 CUDA 的代码规范遵从 [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html)
+
+### 拉取请求规范
+
+1. 使用 [pre-commit hook](https://pre-commit.com),尽量减少代码风格相关问题
+
+2. 一个`拉取请求`对应一个短期分支
+
+3. 粒度要细,一个`拉取请求`只做一件事情,避免超大的`拉取请求`
+
+ - Bad:实现 Faster R-CNN
+ - Acceptable:给 Faster R-CNN 添加一个 box head
+ - Good:给 box head 增加一个参数来支持自定义的 conv 层数
+
+4. 每次 Commit 时需要提供清晰且有意义 commit 信息
+
+5. 提供清晰且有意义的`拉取请求`描述
+
+ - 标题写明白任务名称,一般格式:\[Prefix\] Short description of the pull request (Suffix)
+ - prefix: 新增功能 \[Feature\], 修 bug \[Fix\], 文档相关 \[Docs\], 开发中 \[WIP\] (暂时不会被review)
+ - 描述里介绍`拉取请求`的主要修改内容,结果,以及对其他部分的影响, 参考`拉取请求`模板
+ - 关联相关的`议题` (issue) 和其他`拉取请求`
+
+6. 如果引入了其他三方库,或借鉴了三方库的代码,请确认他们的许可证和 mmediting 兼容,并在借鉴的代码上补充 `This code is inspired from http://`
+
+## 代码规范
+
+### 代码规范标准
+
+#### PEP 8 —— Python 官方代码规范
+
+[Python 官方的代码风格指南](https://www.python.org/dev/peps/pep-0008/),包含了以下几个方面的内容:
+
+- 代码布局,介绍了 Python 中空行、断行以及导入相关的代码风格规范。比如一个常见的问题:当我的代码较长,无法在一行写下时,何处可以断行?
+
+- 表达式,介绍了 Python 中表达式空格相关的一些风格规范。
+
+- 尾随逗号相关的规范。当列表较长,无法一行写下而写成如下逐行列表时,推荐在末项后加逗号,从而便于追加选项、版本控制等。
+
+ ```python
+ # Correct:
+ FILES = ['setup.cfg', 'tox.ini']
+ # Correct:
+ FILES = [
+ 'setup.cfg',
+ 'tox.ini',
+ ]
+ # Wrong:
+ FILES = ['setup.cfg', 'tox.ini',]
+ # Wrong:
+ FILES = [
+ 'setup.cfg',
+ 'tox.ini'
+ ]
+ ```
+
+- 命名相关规范、注释相关规范、类型注解相关规范,我们将在后续章节中做详细介绍。
+
+ "A style guide is about consistency. Consistency with this style guide is important. Consistency within a project is more important. Consistency within one module or function is the most important." PEP 8 -- Style Guide for Python Code
+
+:::{note}
+PEP 8 的代码规范并不是绝对的,项目内的一致性要优先于 PEP 8 的规范。OpenMMLab 各个项目都在 setup.cfg 设定了一些代码规范的设置,请遵照这些设置。一个例子是在 PEP 8 中有如下一个例子:
+
+```python
+# Correct:
+hypot2 = x*x + y*y
+# Wrong:
+hypot2 = x * x + y * y
+```
+
+这一规范是为了指示不同优先级,但 OpenMMLab 的设置中通常没有启用 yapf 的 `ARITHMETIC_PRECEDENCE_INDICATION` 选项,因而格式规范工具不会按照推荐样式格式化,以设置为准。
+:::
+
+#### Google 开源项目风格指南
+
+[Google 使用的编程风格指南](https://google.github.io/styleguide/pyguide.html),包括了 Python 相关的章节。相较于 PEP 8,该指南提供了更为详尽的代码指南。该指南包括了语言规范和风格规范两个部分。
+
+其中,语言规范对 Python 中很多语言特性进行了优缺点的分析,并给出了使用指导意见,如异常、Lambda 表达式、列表推导式、metaclass 等。
+
+风格规范的内容与 PEP 8 较为接近,大部分约定建立在 PEP 8 的基础上,也有一些更为详细的约定,如函数长度、TODO 注释、文件与 socket 对象的访问等。
+
+推荐将该指南作为参考进行开发,但不必严格遵照,一来该指南存在一些 Python 2 兼容需求,例如指南中要求所有无基类的类应当显式地继承 Object, 而在仅使用 Python 3 的环境中,这一要求是不必要的,依本项目中的惯例即可。二来 OpenMMLab 的项目作为框架级的开源软件,不必对一些高级技巧过于避讳,尤其是 MMCV。但尝试使用这些技巧前应当认真考虑是否真的有必要,并寻求其他开发人员的广泛评估。
+
+另外需要注意的一处规范是关于包的导入,在该指南中,要求导入本地包时必须使用路径全称,且导入的每一个模块都应当单独成行,通常这是不必要的,而且也不符合目前项目的开发惯例,此处进行如下约定:
+
+```python
+# Correct
+from mmedit.cnn.bricks import (Conv2d, build_norm_layer, DropPath, MaxPool2d,
+ Linear)
+from ..utils import ext_loader
+
+# Wrong
+from mmedit.cnn.bricks import Conv2d, build_norm_layer, DropPath, MaxPool2d, \
+ Linear # 使用括号进行连接,而不是反斜杠
+from ...utils import is_str # 最多向上回溯一层,过多的回溯容易导致结构混乱
+```
+
+OpenMMLab 项目使用 pre-commit 工具自动格式化代码,详情见[贡献代码](./contributing.md#代码风格)。
+
+### 命名规范
+
+#### 命名规范的重要性
+
+优秀的命名是良好代码可读的基础。基础的命名规范对各类变量的命名做了要求,使读者可以方便地根据代码名了解变量是一个类 / 局部变量 / 全局变量等。而优秀的命名则需要代码作者对于变量的功能有清晰的认识,以及良好的表达能力,从而使读者根据名称就能了解其含义,甚至帮助了解该段代码的功能。
+
+#### 基础命名规范
+
+| 类型 | 公有 | 私有 |
+| --------------- | ---------------- | ------------------ |
+| 模块 | lower_with_under | \_lower_with_under |
+| 包 | lower_with_under | |
+| 类 | CapWords | \_CapWords |
+| 异常 | CapWordsError | |
+| 函数(方法) | lower_with_under | \_lower_with_under |
+| 函数 / 方法参数 | lower_with_under | |
+| 全局 / 类内常量 | CAPS_WITH_UNDER | \_CAPS_WITH_UNDER |
+| 全局 / 类内变量 | lower_with_under | \_lower_with_under |
+| 变量 | lower_with_under | \_lower_with_under |
+| 局部变量 | lower_with_under | |
+
+注意:
+
+- 尽量避免变量名与保留字冲突,特殊情况下如不可避免,可使用一个后置下划线,如 class\_
+- 尽量不要使用过于简单的命名,除了约定俗成的循环变量 i,文件变量 f,错误变量 e 等。
+- 不会被用到的变量可以命名为 \_,逻辑检查器会将其忽略。
+
+#### 命名技巧
+
+良好的变量命名需要保证三点:
+
+1. 含义准确,没有歧义
+2. 长短适中
+3. 前后统一
+
+```python
+# Wrong
+class Masks(metaclass=ABCMeta): # 命名无法表现基类;Instance or Semantic?
+ pass
+
+# Correct
+class BaseInstanceMasks(metaclass=ABCMeta):
+ pass
+
+# Wrong,不同地方含义相同的变量尽量用统一的命名
+def __init__(self, inplanes, planes):
+ pass
+
+def __init__(self, in_channels, out_channels):
+ pass
+```
+
+常见的函数命名方法:
+
+- 动宾命名法:crop_img, init_weights
+- 动宾倒置命名法:imread, bbox_flip
+
+注意函数命名与参数的顺序,保证主语在前,符合语言习惯:
+
+- check_keys_exist(key, container)
+- check_keys_contain(container, key)
+
+注意避免非常规或统一约定的缩写,如 nb -> num_blocks,in_nc -> in_channels
+
+### docstring 规范
+
+#### 为什么要写 docstring
+
+docstring 是对一个类、一个函数功能与 API 接口的详细描述,有两个功能,一是帮助其他开发者了解代码功能,方便 debug 和复用代码;二是在 Readthedocs 文档中自动生成相关的 API reference 文档,帮助不了解源代码的社区用户使用相关功能。
+
+#### 如何写 docstring
+
+与注释不同,一份规范的 docstring 有着严格的格式要求,以便于 Python 解释器以及 sphinx 进行文档解析,详细的 docstring 约定参见 [PEP 257](https://www.python.org/dev/peps/pep-0257/)。此处以例子的形式介绍各种文档的标准格式,参考格式为 [Google 风格](https://zh-google-styleguide.readthedocs.io/en/latest/google-python-styleguide/python_style_rules/#comments)。
+
+1. 模块文档
+
+ 代码风格规范推荐为每一个模块(即 Python 文件)编写一个 docstring,但目前 OpenMMLab 项目大部分没有此类 docstring,因此不做硬性要求。
+
+ ```python
+ """A one line summary of the module or program, terminated by a period.
+
+ Leave one blank line. The rest of this docstring should contain an
+ overall description of the module or program. Optionally, it may also
+ contain a brief description of exported classes and functions and/or usage
+ examples.
+
+ Typical usage example:
+
+ foo = ClassFoo()
+ bar = foo.FunctionBar()
+ """
+ ```
+
+2. 类文档
+
+ 类文档是我们最常需要编写的,此处,按照 OpenMMLab 的惯例,我们使用了与 Google 风格不同的写法。如下例所示,文档中没有使用 Attributes 描述类属性,而是使用 Args 描述 __init__ 函数的参数。
+
+ 在 Args 中,遵照 `parameter (type): Description.` 的格式,描述每一个参数类型和功能。其中,多种类型可使用 `(float or str)` 的写法,可以为 None 的参数可以写为 `(int, optional)`。
+
+ ```python
+ class BaseRunner(metaclass=ABCMeta):
+ """The base class of Runner, a training helper for PyTorch.
+
+ All subclasses should implement the following APIs:
+
+ - ``run()``
+ - ``train()``
+ - ``val()``
+ - ``save_checkpoint()``
+
+ Args:
+ model (:obj:`torch.nn.Module`): The model to be run.
+ batch_processor (callable, optional): A callable method that process
+ a data batch. The interface of this method should be
+ ``batch_processor(model, data, train_mode) -> dict``.
+ Defaults to None.
+ optimizer (dict or :obj:`torch.optim.Optimizer`, optional): It can be
+ either an optimizer (in most cases) or a dict of optimizers
+ (in models that requires more than one optimizer, e.g., GAN).
+ Defaults to None.
+ work_dir (str, optional): The working directory to save checkpoints
+ and logs. Defaults to None.
+ logger (:obj:`logging.Logger`): Logger used during training.
+ Defaults to None. (The default value is just for backward
+ compatibility)
+ meta (dict, optional): A dict records some import information such as
+ environment info and seed, which will be logged in logger hook.
+ Defaults to None.
+ max_epochs (int, optional): Total training epochs. Defaults to None.
+ max_iters (int, optional): Total training iterations. Defaults to None.
+ """
+
+ def __init__(self,
+ model,
+ batch_processor=None,
+ optimizer=None,
+ work_dir=None,
+ logger=None,
+ meta=None,
+ max_iters=None,
+ max_epochs=None):
+ ...
+ ```
+
+ 另外,在一些算法实现的主体类中,建议加入原论文的链接;如果参考了其他开源代码的实现,则应加入 modified from,而如果是直接复制了其他代码库的实现,则应加入 copied from ,并注意源码的 License。如有必要,也可以通过 .. math:: 来加入数学公式
+
+ ```python
+ # 参考实现
+ # This func is modified from `detectron2
+ #