习题8-3 #81
Comments
|
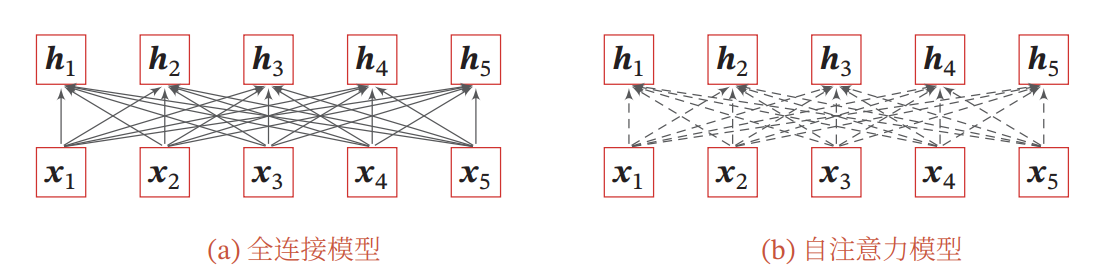
基于卷积或循环网络的序列编码都是一种局部的编码方式,只建模了输入信息的局部依赖关系.虽然循环网络理论上可以建立长距离依赖关系,但是由于信息传递的容量以及梯度消失问题,实际上也只能建立短距离依赖关系。
复杂度:循环层:
故一次操作的时间复杂度为 卷积层:
自注意力层:
参考文献: |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
当将自注意力模型作为一个神经层使用时,分析它和卷积层以及循环层在建模长距离依赖关系的效率和计算复杂度方面的差异.
The text was updated successfully, but these errors were encountered: