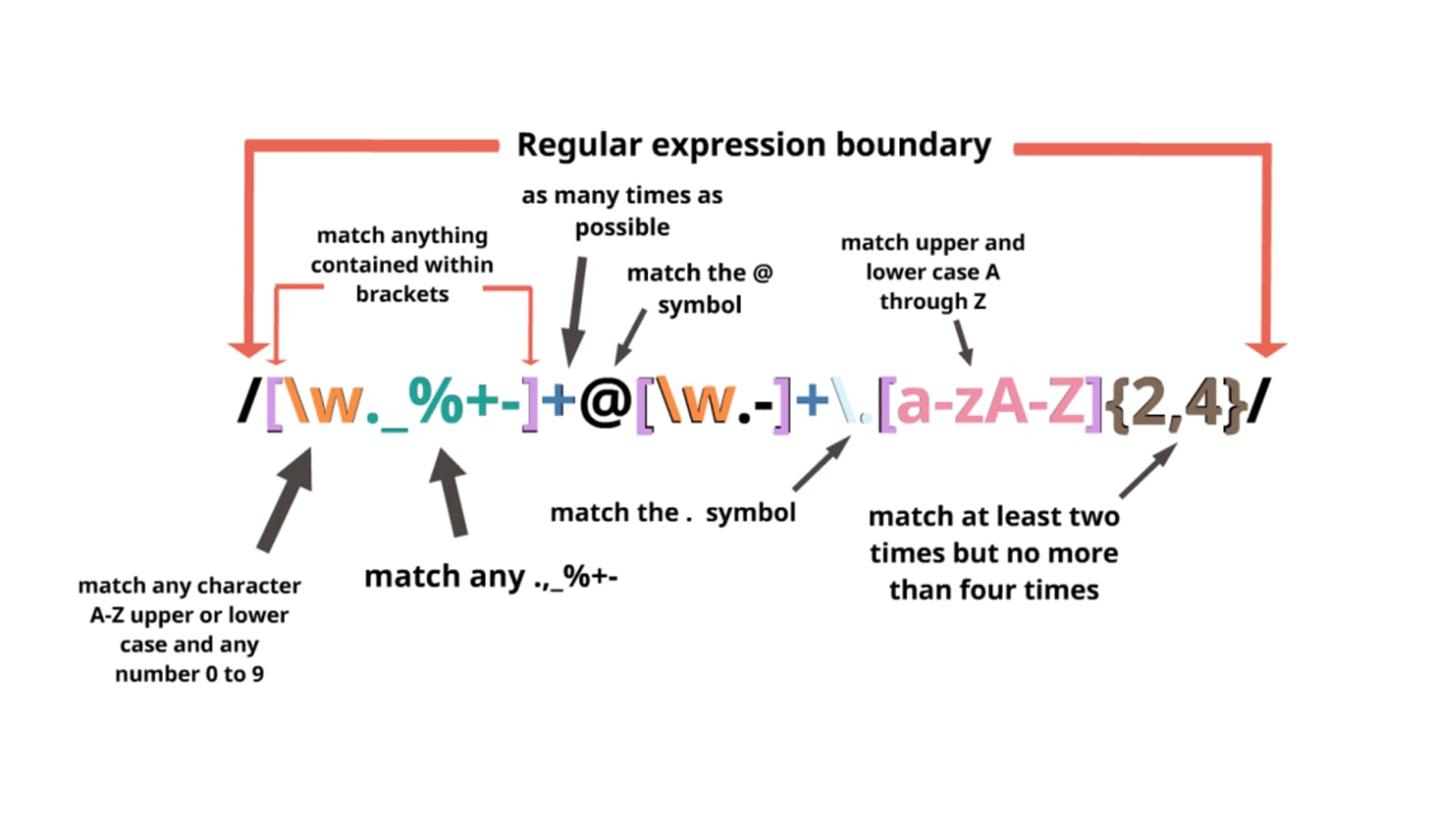
Regular Expressions: are a sequence of characters used to check whether a pattern exists in a given text (string) or not.
In Python, regular expressions are supported by the re module. That means that if you want to start using them in your Python scripts, you have to import this module with the help of import:
import re
#re library in Python provides several functions that make it a skill worth mastering.You can use basic patterns in Python using ordinary characters. Ordinary characters are the simplest regular expressions. They match themselves exactly and do not have a special meaning in their regular expression syntax.
pattern = r"Cookie"
sequence = "Cookie"
if re.match(pattern, sequence):
print("Match!")
else: print("Not a match!")
>> Output :Match!Special characters are characters that do not match themselves as seen but have a special meaning when used in a regular expression. Following examples make use of two functions namely: search() and group().
- With the search function, you scan through the given string/sequence, looking for the first location where the regular expression produces a match
- The group function returns the string matched by the re. You will see both these functions in more detail later.
- (.)- A period. Matches any single character except the newline character.
re.search(r'Co.k.e', 'Cookie').group()
>> Output :Cookie- (^) - A caret. Matches the start of the string.
This is helpful if you want to make sure a document/sentence starts with certain characters.
re.search(r'^Eat', "Eat cake!").group()
>> Output :'Eat'- (\w )- Lowercase 'w'. Matches any single letter, digit, or underscore.
- (\W )- Uppercase 'W'. Matches any character not part of \w (lowercase w).
print("Lowercase w:", re.search(r'Co\wk\we', 'Cookie').group())
## Matches any character except single letter, digit or underscore
print("Uppercase W:", re.search(r'C\Wke', 'C@ke').group())
## Uppercase W won't match single letter, digit
print("Uppercase W won't match, and return:", re.search(r'Co\Wk\We', 'Cookie'))
>> Output :
Lowercase w: Cookie
Uppercase W: C@ke
Uppercase W won't match, and return: None- (\s) - Lowercase 's'. Matches a single whitespace character like: space, newline, tab, return.
- (\S) - Uppercase 'S'. Matches any character not part of \s (lowercase s).
print("Lowercase s:", re.search(r'Eat\scake', 'Eat cake').group())
print("Uppercase S:", re.search(r'cook\Se', "Let's eat cookie").group())
>> Output :
Lowercase s: Eat cake
Uppercase S: cookieThe group feature of regular expression allows you to pick up parts of the matching text. Parts of a regular expression pattern bounded by parenthesis () are called groups
statement = 'Please contact us at: [email protected]'
match = re.search(r'(?P<email>(?P<username>[\w\.-]+)@(?P<host>[\w\.-]+))', statement)
if statement:
print("Email address:", match.group('email'))
print("Username:", match.group('username'))
print("Host:", match.group('host'))
>> Output :
Email address: support@datacamp.com
Username: support
Host: datacamp.comGreedy Match:When a special character matches as much of the search sequence (string) as possible
pattern = "cookie"
sequence = "Cake and cookie"
heading = r'<h1>TITLE</h1>'
re.match(r'<.*>', heading).group()
>> Output : '<h1>TITLE</h1>'Function provided by 're'
- search(pattern, string, flags=0)
With this function, you scan through the given string/sequence, looking for the first location where the regular expression produces a match. It returns a corresponding match object if found, else returns None if no position in the string matches the pattern.
pattern = "cookie"
sequence = "Cake and cookie"
re.search(pattern, sequence)
>> Output : <re.Match object; span=(9, 15), match='cookie'>An expression's behavior can be modified by specifying a flag value. You can add flags as an extra argument to the different functions that you have seen in this tutorial. Some of the more useful ones are:
- IGNORECASE (I) - Allows case-insensitive matches.
- DOTALL (S) - Allows . to match any character, including newline.
- MULTILINE (M) - Allows start of string (^) and end of string ($) anchor to match newlines as well.
- VERBOSE (X) - Allows you to write whitespace and comments within a regular expression to make it more readable.
- Purpose: High-level file operations.
copyfile() copies the contents of the source to the destination and raises IOError if it does not have permission to write to the destination file.
import glob
import shutil
shutil.copyfile('shutil_copyfile.py', 'shutil_copyfile.py.copy')
print( glob.glob('shutil_copyfile.*'))By default when a new file is created under Unix, it receives permissions based on the umask of the current user. To copy the permissions from one file to another, use copymode()
import os
import shutil
import subprocess
with open('file_to_change.txt', 'wt') as f:
f.write('content')
os.chmod('file_to_change.txt', 0o444)
shutil.copymode('shutil_copymode.py', 'file_to_change.txt')
print(oct(os.stat('file_to_change.txt').st_mode))shutil includes three functions for working with directory trees. To copy a directory from one place to another, use copytree().
import glob
import pprint
import shutil
shutil.copytree('../shutil', '/tmp/example')
pprint.pprint(glob.glob('/tmp/example/*'))The which() function scans a search path looking for a named file. The typical use case is to find an executable program on the shell’s search path defined in the environment variable PATH.
import shutil
print(shutil.which('virtualenv'))
print(shutil.which('tox'))
print(shutil.which('no-such-program'))creating and extracting archives in shutil. get_archive_formats() returns a sequence of names and descriptions for formats supported on the current system.
import shutil
for format, description in shutil.get_archive_formats():
print('{:<5}: {}'.format(format, description))disk_usage() returns a tuple with the total space, the amount currently being used, and the amount remaining free.
import shutil
total_b, used_b, free_b = shutil.disk_usage('.')
gib = 2 ** 30 # GiB == gibibyte
gb = 10 ** 9 # GB == gigabyte
print('Total: {:6.2f} GB {:6.2f} GiB'.format(
total_b / gb, total_b / gib))
print('Used : {:6.2f} GB {:6.2f} GiB'.format(
used_b / gb, used_b / gib))
print('Free : {:6.2f} GB {:6.2f} GiB'.format(
free_b / gb, free_b / gib))