diff --git a/docs/MatrixOne/Reference/1.1-System-tables.md b/docs/MatrixOne/Reference/1.1-System-tables.md
deleted file mode 100644
index aeeae64f36..0000000000
--- a/docs/MatrixOne/Reference/1.1-System-tables.md
+++ /dev/null
@@ -1,651 +0,0 @@
-# MatrixOne 系统数据库和表
-
-MatrixOne 系统数据库和表是 MatrixOne 存储系统信息的地方,你可以通过它们访问系统信息。MatrixOne 在初始化时创建了 6 个系统数据库:`mo_catalog`、`information_schema`、`system_metrcis`、`system`、`mysql` 和 `mo_task`。`mo_task` 当前正在开发中,暂时对你所进行的操作不会产生直接影响。本文档中描述了其他系统数据库和表函数。
-
-系统只能修改系统数据库和表,你仅能从中进行读取操作。
-
-## `mo_catalog` 数据库
-
-`mo_catalog` 用于存储 MatrixOne 对象的元数据,如:数据库、表、列、系统变量、租户、用户和角色。
-
-从 MatrixOne 0.6 版本即引入了多租户的概念,默认的 `sys` 租户和其他租户的行为略有不同。服务于多租户管理的系统表 `mo_account` 仅对 `sys` 租户可见;其他租户看不到此表。
-
-### `mo_indexes` 表
-
-| 列属性 | 类型 | 描述 |
-| -----------------| --------------- | ----------------- |
-| id | BIGINT UNSIGNED(64) | 索引 ID |
-| table_id | BIGINT UNSIGNED(64) | 索引所在表的 ID |
-| database_id | BIGINT UNSIGNED(64) | 索引所在数据库的 ID |
-| name | VARCHAR(64) | 索引的名字 |
-| type | VARCHAR(11) | 索引的类型,包括主键索引(PRIMARY),唯一索引(UNIQUE),次级索引(MULTIPLE) |
-| is_visible | TINYINT(8) | 索引是否可见,1 为可见,0 不可见(目前 MatrixOne 的索引全部为可见索引) |
-| hidden | TINYINT(8) | 索引是否为隐藏索引,1 为隐藏索引,0 为非隐藏索引|
-| comment | VARCHAR(2048) | 索引的注释信息 |
-| column_name | VARCHAR(256) | 索引的组成列的列名 |
-| ordinal_position | INT UNSIGNED(32) | 索引中的列序号,从 1 开始 |
-| options | TEXT(0) | 索引的 options 选项信息 |
-| index_table_name | VARCHAR(5000) | 该索引对应的索引表的表名,目前只有唯一索引含有索引表 |
-
-### `mo_table_partitions` 表
-
-| 列属性 | 类型 | 描述 |
-| ------------ | ------------ | ------------ |
-| table_id | BIGINT UNSIGNED(64) | 当前分区表的 ID |
-| database_id | BIGINT UNSIGNED(64) | 当前分区表所属的数据库的 ID |
-| number | SMALLINT UNSIGNED(16) | 当前分区编号。所有分区都按照定义的顺序进行索引,其中 1 是分配给第一个分区的数字 |
-| name | VARCHAR(64) | 分区的名称 |
-| partition_type | VARCHAR(50) | 存放表的分区类型信息,如果是分区表,其值枚举为"KEY", "LINEAR_KEY","HASH","LINEAR_KEY_51","RANGE","RANGE_COLUMNS","LIST","LIST_COLUMNS";如果不是分区表,partition_type 的值为空字符串。__Note:__ MatrixOne 暂不支持 `RANGE` 和 `LIST` 分区。 |
-| partition_expression | VARCHAR(2048) | 创建分区表的的 `CREATE TABLE` 或 `ALTER TABLE` 语句中使用的分区函数的表达式。 |
-| description_utf8 | TEXT(0) | 此列用于 `RANGE` 和 `LIST` 分区。对于 `RANGE` 分区,它包含分区的 `VALUES LESS THAN` 子句中设置的值,该值可以是整数或 `MAXVALUE`。对于 `LIST` 分区,此列包含分区的 `values in` 子句中定义的值,该子句是逗号分隔的整数值列表。对于不是 `RANGE` 或 `LIST` 的分区,此列始终为 NULL。__Note:__ MatrixOne 暂不支持 `RANGE` 和 `LIST` 分区,此列为 NULL |
-| comment | VARCHAR(2048) | 注释的文本。否则,此值为空。 |
-| options | TEXT(0) | 分区的选项信息,暂为 `NULL` |
-| partition_table_name | VARCHAR(1024) | 当前分区对应的分区子表名字 |
-
-### `mo_user` 表
-
-| 列属性 | 类型 | 描述 |
-| --------------------- | ------------ | ------------------- |
-| user_id | int | 用户 ID,主键 |
-| user_host | varchar(100) | 用户主机地址 |
-| user_name | varchar(100) | 用户名 |
-| authentication_string | varchar(100) | 密码加密的认证字符串 |
-| status | varchar(8) | 开启、锁定、失效 |
-| created_time | timestamp | 用户创建时间 |
-| expired_time | timestamp | 用户过期时间 |
-| login_type | varchar(16) | ssl/密码/其他 |
-| creator | int | 创建此用户的创建者 ID |
-| owner | int | 此用户的管理员 ID |
-| default_role | int | 此用户的默认角色 ID |
-
-### `mo_account` 表 (仅 `sys` 租户可见)
-
-| 列属性 | 类型 | 描述 |
-| ------------ | ------------ | ------------ |
-| account_id | int unsigned | 租户 ID,主键 |
-| account_name | varchar(100) | 租户名 |
-| status | varchar(100) | 开启/暂停/限制 |
-| created_time | timestamp | 创建时间 |
-| comment | varchar(256) | 注释 |
-| suspended_time | TIMESTAMP | 修改租户状态的时间|
-| version | bigint unsigned | 当前租户版本状态|
-
-### `mo_database` 表
-
-| 列属性 | 类型 | 描述 |
-| ---------------- | --------------- | --------------------------------------- |
-| dat_id | bigint unsigned | 主键 ID |
-| datname | varchar(100) | 数据库名称 |
-| dat_catalog_name | varchar(100) | 数据库 catalog 名称,默认`def` |
-| dat_createsql | varchar(100) | 创建数据库 SQL 语句 |
-| owner | int unsigned | 角色 ID |
-| creator | int unsigned | 用户 ID |
-| created_time | timestamp | 创建时间 |
-| account_id | int unsigned | 租户 ID |
-| dat_type | varchar(23) | 数据库类型,普通库或订阅库 |
-
-### `mo_role` 表
-
-| 列属性 | 类型 | 描述 |
-| ------------ | ------------ | ----------------------------- |
-| role_id | int unsigned | 角色 ID,主键 |
-| role_name | varchar(100) | 角色名称 |
-| creator | int unsigned | 用户 ID |
-| owner | int unsigned | MatrixOne 管理员/租户管理员拥有者 ID |
-| created_time | timestamp | 创建时间 |
-| comment | text | 注释 |
-
-### `mo_user_grant` 表
-
-| 列属性 | 类型 | 描述 |
-| ----------------- | ------------ | ----------------------------------- |
-| role_id | int unsigned | 被授权角色 ID,联合主键 |
-| user_id | int unsigned | 获得授权角色的用户 ID,联合主键 |
-| granted_time | timestamp | 授权时间 |
-| with_grant_option | bool | 是否允许获得授权用户再授权给其他用户或角色 |
-
-### `mo_role_grant` 表
-
-| 列属性 | 类型 | 描述 |
-| ----------------- | ------------ | ----------------------------------- |
-| granted_id | int | 被授予的角色 ID,联合主键 |
-| grantee_id | int | 要授予其他角色的角色 ID,联合主键 |
-| operation_role_id | int | 操作角色 ID |
-| operation_user_id | int | 操作用户 ID |
-| granted_time | timestamp | 授权时间 |
-| with_grant_option | bool | 是否允许获得授权角色再授权给其他用户或角色 |
-
-### `mo_role_privs` 表
-
-| 列属性 | 类型 | 描述 |
-| ----------------- | --------------- | ----------------------------------- |
-| role_id | int unsigned | 角色 ID,联合主键 |
-| role_name | varchar(100) | 角色名:accountadmin/public |
-| obj_type | varchar(16) | 对象类型:account/database/table,联合主键 |
-| obj_id | bigint unsigned | 对象 ID,联合主键 |
-| privilege_id | int | 权限 ID,联合主键 |
-| privilege_name | varchar(100) | 权限名:权限列表 |
-| privilege_level | varchar(100) | 权限级别,联合主键 |
-| operation_user_id | int unsigned | 操作用户 ID |
-| granted_time | timestamp | 授权时间 |
-| with_grant_option | bool | 是否允许授权|
-
-### `mo_user_defined_function` 表
-
-| 列属性 | 类型 | 描述 |
-| -----------------| --------------- | ----------------- |
-| function_id | INT(32) | 函数的 ID,主键 |
-| name | VARCHAR(100) | 函数的名称 |
-| owner | INT UNSIGNED(32) | 创建函数的角色 ID |
-| args | TEXT(0) |函数的参数列表 |
-| rettype | VARCHAR(20) | 函数的返回类型 |
-| body | TEXT(0) |函数的函数体 |
-| language | VARCHAR(20) | 函数所使用的语言 |
-| db | VARCHAR(100) | 函数所在的数据库 |
-| definer | VARCHAR(50) | 定义函数的用户名称 |
-| modified_time | TIMESTAMP(0) | 函数最后一次修改的时间 |
-| created_time | TIMESTAMP(0) | 函数的创建时间 |
-| type | VARCHAR(10) |函数的类型,默认 FUNCTION |
-| security_type | VARCHAR(10) | 安全处理方式,统一值 DEFINER |
-| comment | VARCHAR(5000) | 创建函数的注释 |
-| character_set_client | VARCHAR(64) | 客户端字符集:utf8mb4 |
-| collation_connection | VARCHAR(64) | 连接排序:utf8mb4_0900_ai_ci |
-| database_collation | VARCHAR(64) | 数据库连接排序:utf8mb4_0900_ai_ci |
-
-### `mo_mysql_compatbility_mode` 表
-
-| 列属性 | 类型 | 描述 |
-| -----------------| --------------- | ----------------- |
-| configuration_id | INT(32) | 配置项 id,自增列,作为主键区分不同的配置 |
-| account_name | VARCHAR(300) | 配置所在的租户名称 |
-| dat_name | VARCHAR(5000) | 配置所在的数据库名称 |
-| configuration | JSON(0) | 配置内容,以 JSON 形式保存 |
-
-### `mo_pubs` 表
-
-| 列属性 | 类型 | 描述 |
-| -----------------| --------------- | ----------------- |
-| pub_name | VARCHAR(64) | 发布名称|
-| database_name | VARCHAR(5000) | 发布数据的名称 |
-| database_id | BIGINT UNSIGNED(64) | 发布数据库的 ID,与 mo_database 表中的 dat_id 对应 |
-| all_table | BOOL(0) | 发布库是否包含 database_id 对应数据库内的所有表 |
-| all_account | BOOL(0) | 是否所有 account 都可以订阅该发布库 |
-| table_list | TEXT(0) | 在非 all table 时,发布库内包含的表清单,表名与 database_id 对应数据库下的表一一对应|
-| account_list | TEXT(0) |在非 all account 时,允许订阅该发布库的 account 清单|
-| created_time | TIMESTAMP(0) |创建发布库的时间 |
-| owner | INT UNSIGNED(32) | 创建发布库对应的角色 ID |
-| creator | INT UNSIGNED(32) | 创建发布库对应的用户 ID |
-| comment | TEXT(0) | 创建发布库的备注信息 |
-
-### `mo_stages` 表
-
-| 列属性 | 类型 | 描述 |
-| -----------------| --------------- | ----------------- |
-| stage_id | INT UNSIGNED(32) | 数据阶段 ID |
-| stage_name | VARCHAR(64) | 数据阶段名称 |
-| url | TEXT(0) | 对象存储的路径(不含认证)、文件系统的路径 |
-| stage_credentials | TEXT(0) | 认证信息,加密后保存 |
-| stage_status | VARCHAR(64) | ENABLED/DISABLED 默认:DISABLED |
-| created_time | TIMESTAMP(0) | 创建时间 |
-| comment | TEXT(0) | 注释 |
-
-### `mo_sessions` 视图
-
-| 列名 | 数据类型 | 描述 |
-| ----------------- | ----------------- | ------------------------------------------------------------ |
-| node_id | VARCHAR(65535) | MatrixOne 节点的唯一标识符。一经启动,不可更改。 |
-| conn_id | INT UNSIGNED | 在 MatrixOne 中与客户端 TCP 连接相关的唯一编号,由 Hakeeper 自动生成。 |
-| session_id | VARCHAR(65535) | 用于标识会话的唯一 UUID。每个新会话都会生成一个新的 UUID。 |
-| account | VARCHAR(65535) | 租户的名称。 |
-| user | VARCHAR(65535) | 用户的名称。 |
-| host | VARCHAR(65535) | CN 节点接收客户端请求的 IP 地址和端口。 |
-| db | VARCHAR(65535) | 执行 SQL 时使用的数据库名称。 |
-| session_start | VARCHAR(65535) | 会话创建的时间戳。 |
-| command | VARCHAR(65535) | MySQL 命令的类型,如 COM_QUERY、COM_STMT_PREPARE、COM_STMT_EXECUTE 等。 |
-| info | VARCHAR(65535) | 执行的 SQL 语句。一个 SQL 中可能包含多个语句。 |
-| txn_id | VARCHAR(65535) | 相关事务的唯一标识符。 |
-| statement_id | VARCHAR(65535) | SQL 语句的唯一标识符(UUID)。 |
-| statement_type | VARCHAR(65535) | SQL 语句的类型,如 SELECT、INSERT、UPDATE 等。 |
-| query_type | VARCHAR(65535) | SQL 语句的种类,如 DQL(数据查询语言)、TCL(事务控制语言)等。 |
-| sql_source_type | VARCHAR(65535) | SQL 语句的来源,如外部或内部。 |
-| query_start | VARCHAR(65535) | SQL 语句开始执行的时间戳。 |
-| client_host | VARCHAR(65535) | 客户端的 IP 地址和端口号。 |
-| role | VARCHAR(65535) | 用户的角色名称。 |
-
-### `mo_configurations` 表
-
-| 列名 | 数据类型 | 描述 |
-| ------------- | --------------- | ------------------------------------ |
-| node_type | VARCHAR(65535) | 节点的类型:cn(计算节点)、tn(事务节点)、log(日志节点)、proxy(代理)。 |
-| node_id | VARCHAR(65535) | 节点的唯一标识符。 |
-| name | VARCHAR(65535) |配置项的名称,可能会附带嵌套结构前缀。|
-| current_value | VARCHAR(65535) | 配置项的当前数值。 |
-| default_value | VARCHAR(65535) | 配置项的默认数值。 |
-| internal | VARCHAR(65535) | 表示配置参数是否为内部参数。 |
-
-### `mo_locks` 视图
-
-| 列名 | 数据类型 | 描述 |
-| ------------- | --------------- | ------------------------------------------------ |
-| txn_id | VARCHAR(65535) | 持有锁的事务。 |
-| table_id | VARCHAR(65535) | 加锁的表。 |
-| lock_type | VARCHAR(65535) | 锁类型。可以是 `point` 或 `range`。 |
-| lock_content | VARCHAR(65535) | 锁定的内容,以 16 进制表示。对于 `range` 锁,表示一个区间;对于 `point` 锁,表示单个值。 |
-| lock_mode | VARCHAR(65535) | 锁模式。可以是 `shared` 或 `exclusive`。 |
-| lock_status | VARCHAR(65535) | 锁状态,可能为 `wait`、`acquired` 或 `none`。
wait。没有事务持有锁,但有事务等在锁上。
acquired。有事务持有锁。
none。没有事务持有锁,也没有事务等在锁上。 |
-| waiting_txns | VARCHAR(65535) | 在此锁上等待的事务。 |
-
-### `mo_variables` 视图
-
-| 列名 | 数据类型 | 描述 |
-| ---------------- | -------------- | ------------------------------------ |
-| configuration_id | INT(32) | 自增列,用于唯一标识每个配置项。 |
-| account_id | INT(32) | 标识租户的唯一标识符。 |
-| account_name | VARCHAR(300) | 租户的名称。 |
-| dat_name | VARCHAR(5000) | 数据库的名称。 |
-| variable_name | VARCHAR(300) | 配置变量的名称。 |
-| variable_value | VARCHAR(5000) | 配置变量的数值。 |
-| system_variables | BOOL(0) | 指示配置变量是否为系统级别的变量。 |
-
-### `mo_transactions` 视图
-
-| 列名 | 数据类型 | 描述 |
-| ------------- | --------------- | ------------------------------------ |
-| cn_id | VARCHAR(65535) | 唯一标识 CN(Compute Node)的 ID。 |
-| txn_id | VARCHAR(65535) | 唯一标识事务的 ID。 |
-| create_ts | VARCHAR(65535) | 记录事务创建时间戳,遵循 RFC3339Nano 格式 ("2006-01-02T15:04:05.999999999Z07:00")。 |
-| snapshot_ts | VARCHAR(65535) | 表示事务的快照时间戳,以物理时间和逻辑时间的形式表示。 |
-| prepared_ts | VARCHAR(65535) | 表示事务的 prepared 时间戳,以物理时间和逻辑时间的形式表示。 |
-| commit_ts | VARCHAR(65535) | 表示事务的 commit 时间戳,以物理时间和逻辑时间的形式表示。|
-| txn_mode | VARCHAR(65535) | 标识事务模式,可以是悲观事务或乐观事务。 |
-| isolation | VARCHAR(65535) | 表示事务的隔离级别,可以是 SI(Snapshot Isolation)或 RC(Read Committed)。 |
-| user_txn | VARCHAR(65535) | 指示用户事务,即用户通过客户端连接到 MatrixOne 并执行的 SQL 操作所创建的事务。 |
-| txn_status | VARCHAR(65535) | 表示事务的当前状态,可能的取值包括 active(活跃)、committed(已提交)、aborting(中止中)、aborted(已中止)。在分布式事务 2PC 模式下,还会包括 prepared(已准备)和 committing(提交中)。 |
-| table_id | VARCHAR(65535) | 表示事务所涉及的表的 ID。 |
-| lock_key | VARCHAR(65535) | 表示锁的类型,可以是 range(范围锁)或 point(点锁)。 |
-| lock_content | VARCHAR(65535) | point 锁时表示单个值,range 锁时表示范围,通常以 "low - high" 形式表示。请注意,事务可能涉及多个锁,但此处仅展示第一个锁。|
-| lock_mode | VARCHAR(65535) | 表示锁的模式,可以是互斥锁(exclusive)或共享锁(shared)。 |
-
-### `mo_columns` 表
-
-| 列属性 | 类型 | 描述 |
-| --------------------- | --------------- | ------------------------------------------------------------ |
-| att_uniq_name | varchar(256) | 主键。隐藏的复合主键,格式类似于 "${att_relname_id}-${attname}" |
-| account_id | int unsigned | 租户 ID |
-| att_database_id | bigint unsigned | 数据库 ID |
-| att_database | varchar(256) | 数据 Name |
-| att_relname_id | bigint unsigned | 表 ID |
-| att_relname | varchar(256) | 此列所属的表。(参考 mo_tables.relname)|
-| attname | varchar(256) | 列名 |
-| atttyp | varchar(256) | 此列的数据类型 (删除的列为 0 )。 |
-| attnum | int | 列数。普通列从 1 开始编号。 |
-| att_length | int | 类型的字节数 |
-| attnotnull | tinyint(1) | 表示一个非空约束。 |
-| atthasdef | tinyint(1) | 此列有默认表达式或生成表达式。 |
-| att_default | varchar(1024) | 默认表达式 |
-| attisdropped | tinyint(1) | 此列已删除,不再有效。删除的列仍然物理上存在于表中,但解析器会忽略它,因此不能通过 SQL 访问它。 |
-| att_constraint_type | char(1) | p = 主键约束
n=无约束 |
-| att_is_unsigned | tinyint(1) | 是否未署名 |
-| att_is_auto_increment | tinyint(1) | 是否自增 |
-| att_comment | varchar(1024) | 注释 |
-| att_is_hidden | tinyint(1) | 是否隐藏 |
-| attr_has_update | tinyint(1) | 此列含有更新表达式 |
-| attr_update | varchar(1024) | 更新表达式 |
-| attr_is_clusterby | tinyint(1) | 此列是否作为 cluster by 关键字来建表 |
-
-### `mo_tables` 表
-
-| 列属性 | 类型 | 描述 |
-| -------------- | --------------- | ---------------------------------------------------- |
-| rel_id | bigint unsigned | 主键,表 ID |
-| relname | varchar(100) | 表、索引、视图等的名称 |
-| reldatabase | varchar(100) | 包含此关系的数据库,参考 mo_database.datname |
-| reldatabase_id | bigint unsigned | 包含此关系的数据库 ID,参考 mo_database.datid |
-| relpersistence | varchar(100) | p = 永久表
t = 临时表 |
-| relkind | varchar(100) | r = 普通表
e = 外部表
i = 索引
S = 序列
v = 视图
m = 物化视图 |
-| rel_comment | varchar(100) | |
-| rel_createsql | varchar(100) | 创建表 SQL 语句 |
-| created_time | timestamp | 创建时间 |
-| creator | int unsigned | 创建者 ID |
-| owner | int unsigned | 创建者的默认角色 ID |
-| account_id | int unsigned | 租户 id |
-| partitioned | blob | 按语句分区 |
-| partition_info | blob | 分区信息 |
-| viewdef | blob | 视图定义语句 |
-| constraint | varchar(5000) | 与表相关的约束 |
-| rel_version | INT UNSIGNED(0) | 主键,表的版本号 |
-| catalog_version | INT UNSIGNED(0) | 系统表的版本号 |
-
-## `system_metrics` 数据库
-
-`system_metrics` 收集 SQL 语句、CPU 和内存资源使用的状态和统计信息。
-
-`metrics` 表一些相同的列类型,这些表中的字段描述如下:
-
-- collecttime:收集时间。
-
-- value:采集 `metrics` 的值。
-
-- node:表示 MatrixOne 节点的 uuid。
-
-- role:MatrixOne 节点角色,包括 CN、TN 和 Log。
-
-- account:默认为“sys”租户,即触发 SQL 请求的账户。
-
-- type:SQL 类型,可以是 `select`,`insert`,`update`,`delete`,`other` 类型。
-
-### `metric` 表
-
-| 列属性 | 类型 | 描述 |
-| ----------- | ------------ | ------------------------------------------------------------ |
-| metric_name | VARCHAR(128) | 指标名称,例如:sql_statement_total,server_connections,process_cpu_percent,sys_memory_used 等 |
-| collecttime | DATETIME | 指标数据收集时间 |
-| value | DOUBLE | 指标值 |
-| node | VARCHAR(36) | MatrixOne 节点 uuid |
-| role | VARCHAR(32) | MatrixOne 节点角色 |
-| account | VARCHAR(128) | 租户名称,默认 `sys` |
-| type | VARCHAR(32) | SQL 类型,例如:INSERT,SELECT,UPDATE |
-
-以下表为 `metric` 表的视图:
-
-* `sql_statement_total` 表:执行 SQL 语句的计数器。
-* `sql_statement_hotspot` 表:记录了每分钟内各个租户执行的消耗时间最长的 SQL 查询。需要注意的是,只有那些执行时间未超过某个特定聚合阈值的 SQL 查询才会被纳入统计。
-* `sql_statement_errors` 表:执行错误的 SQL 语句的计数器。
-* `sql_transaction_total` 表:事务性 SQL 语句的计数器。
-* `sql_transaction_errors` 表:错误执行的事务性语句的计数器。
-* `server_connection` 表:服务器连接数。
-* `server_storage_usage`:服务器存储使用情况。
-* `process_cpu_percent` 表:CPU 进程繁忙百分比。
-* `process_resident_memory_bytes` 表:驻留内存量,单位为字节。
-* `process_open_fds` 表:打开的文件描述符的数量。
-* `sys_cpu_seconds_total` 表:系统 CPU 时间,以秒为单位,由核数标准化。
-* `sys_cpu_combined_percent` 表:系统 CPU 繁忙百分比,所有逻辑核的平均值。
-* `sys_memory_used` 表:以字节为单位已使用的系统内存。
-* `sys_memory_available` 表:以字节为单位的可用系统内存。
-* `sys_disk_read_bytes` 表:以字节为单位读取系统盘。
-* `sys_disk_write_bytes` 表:以字节为单位写入系统盘。
-* `sys_net_recv_bytes` 表:以字节为单位接收的系统网络。
-* `sys_net_sent_bytes` 表:以字节为单位发送的系统网络。
-
-## `system` 数据库
-
-`System` 数据库存储 MatrixOne 历史 SQL 语句、系统日志、错误信息。
-
-### `statement_info` 表
-
-`statement_info` 表记录用户和系统的 SQL 语句和详细信息。
-
-| 列属性 | 类型 | 描述 |
-| --------------------- | ------------- | ------------------------------------------------------------ |
-| statement_id | VARCHAR(36) | 声明语句唯一 ID |
-| transaction_id | VARCHAR(36) | 事务唯一 ID |
-| session_id | VARCHAR(36) | 账户唯一 ID |
-| account | VARCHAR(1024) | 租户名称 |
-| user | VARCHAR(1024) | 用户名称 |
-| host | VARCHAR(1024) | 用户客户端 IP |
-| database | VARCHAR(1024) | 数据库当前会话停留处 |
-| statement | TEXT | SQL 语句 |
-| statement_tag | TEXT | 语句中的注释标签 (保留) |
-| statement_fingerprint | TEXT | 语句中的注释标签 (保留) |
-| node_uuid | VARCHAR(36) | 节点 uuid,即生成数据的某个节点 |
-| node_type | VARCHAR(64) | 在 MatrixOne 内,var 所属的 TN/CN/Log 的节点类型 |
-| request_at | DATETIME | 请求接受的 datetime |
-| response_at | DATETIME | 响应发送的 datetime |
-| duration | BIGINT | 执行时间,单位:ns |
-| status | VARCHAR(32) | SQL 语句执行状态:Running, Success, Failed |
-| err_code | VARCHAR(1024) | 错误码 |
-| error | TEXT | 错误信息 |
-| exec_plan | JSON | 语句执行计划 |
-| rows_read | BIGINT | 读取总行数 |
-| bytes_scan | BIGINT | 扫描总字节数 |
-| stats | JSON | exec_plan 中的全局统计信息 |
-| statement_type | VARCHAR(1024) | 语句类型,[Insert, Delete, Update, Drop Table, Drop User, ...] |
-| query_type | VARCHAR(1024) | 查询类型,[DQL, DDL, DML, DCL, TCL] |
-| role_id | BIGINT | 角色 ID |
-| sql_source_type | TEXT | SQL 语句源类型 |
-| result_count | BIGINT(64) | 统计 sql 执行结果的行数 |
-
-### `rawlog` 表
-
-`rawlog` 表记录了非常详细的系统日志。
-
-| 列属性 | 类型 | 描述 |
-| -------------- | ------------- | ------------------------------------------------------------ |
-| raw_item | VARCHAR(1024) | 原日志项 |
-| node_uuid | VARCHAR(36) | 节点 uuid,即生成数据的某个节点 |
-| node_type | VARCHAR(64) | 在 MatrixOne 内,var 所属的 TN/CN/Log 的节点类型 |
-| span_id | VARCHAR(16) | span 的唯一 ID |
-| statement_id | VARCHAR(36) | 声明语句唯一 ID |
-| logger_name | VARCHAR(1024) | 日志记录器的名称 |
-| timestamp | DATETIME | 时间戳的动作 |
-| level | VARCHAR(1024) | 日志级别,例如:debug, info, warn, error, panic, fatal |
-| caller | VARCHAR(1024) | 产生 Log 的地方:package/file.go:123 |
-| message | TEXT | 日志消息 |
-| extra | JSON | 日志动态字段 |
-| err_code | VARCHAR(1024) | 错误日志 |
-| error | TEXT | 错误信息 |
-| stack | VARCHAR(4096) | |
-| span_name | VARCHAR(1024) | span 名称,例如:step name of execution plan, function name in code, ... |
-| parent_span_id | VARCHAR(16) | 父级 span 唯一的 ID |
-| start_time | DATETIME | |
-| end_time | DATETIME | |
-| duration | BIGINT | 执行时间,单位:ns |
-| resource | JSON | 静态资源信息 |
-
-其他 3 个表(`log_info`、`span_info` 和 `error_info`)是 `statement_info` 和 `rawlog` 表的视图。
-
-## `information_schema` 数据库
-
-**Information Schema** 提供了一种 ANSI 标准方式,用于查看系统的元数据。MatrixOne 除了为 MySQL 兼容性而包含的表之外,还提供了许多自定义的 `information_schema` 表。
-
-许多 `INFORMATION_SCHEMA` 表都有相应的 `SHOW` 命令。查询 `INFORMATION_SCHEMA` 可以在表之间进行连接。
-
-### MySQL 兼容性表
-
-| 表名称 | 描述 |
-| :--------------- | :----------------------------------------------------------- |
-| KEY_COLUMN_USAGE | 描述了列的键约束,例如主键约束。 |
-| COLUMNS | 提供了所有表的列列表。 |
-| PROFILING | 提供 SQL 语句执行时一些分析信息。|
-| PROCESSLIST | 提供了与执行命令 `SHOW PROCESSLIST` 类似的信息。 |
-| USER_PRIVILEGES | 列举了与当前用户关联的权限。 |
-| SCHEMATA | 提供了与执行 `SHOW DATABASES` 类似的信息。 |
-| CHARACTER_SETS | 提供了服务器支持的字符集列表。 |
-| TRIGGERS | 提供了与执行 `SHOW TRIGGERS` 类似的信息。 |
-| TABLES | 提供了当前用户可以查看的表列表。类似于执行`SHOW TABLES`。 |
-| PARTITIONS | 提供了表的分区信息。 |
-| VIEWS |提供有关数据库中视图的信息。|
-| ENGINES | 提供了支持的存储引擎列表。 |
-| ROUTINES |提供有关存储存储过程的一些信息。|
-| PARAMETERS| 表提供了存储过程的参数和返回值的信息。|
-| KEYWORDS | 提供有关数据库中关键字信息,详情参见[关键字](Language-Structure/keywords.md)。|
-
-### `CHARACTER_SETS` 表
-
-`CHARACTER_SETS` 表中的列描述如下:
-
-- `CHARACTER_SET_NAME`:字符集的名称。
-- `DEFAULT_COLLATE_NAME`:字符集的默认排序规则名称。
-- `DESCRIPTION`:字符集的描述。
-- `MAXLEN`:在此字符集中存储字符所需的最大长度。
-
-### `COLUMNS` 表
-
-`COLUMNS` 表中的列描述如下:
-
-- `TABLE_CATALOG`:含有该列的表所属的目录的名称。该值始终为 `def`。
-- `TABLE_SCHEMA`:含有列的表所在的模式的名称。
-- `TABLE_NAME`:包含列的表的名称。
-- `COLUMN_NAME`:列的名称。
-- `ORDINAL_POSITION`:表中列的位置。
-- `COLUMN_DEFAULT`:列的默认值。如果显式默认值为 `NULL`,或者如果列定义不包含 `default` 子句,则此值为 `NULL`。
-- `IS_NULLABLE`:列是否可以为空。如果该列可以存储空值,则该值为 `YES`;否则为 `NO`。
-- `DATA_TYPE`:列中的数据类型。
-- `CHARACTER_MAXIMUM_LENGTH`:对于字符串列,字符的最大长度。
-- `CHARACTER_OCTET_LENGTH`:对于字符串列,最大长度(以字节为单位)。
-- `NUMERIC_PRECISION`:数字类型列的数字精度。
-- `NUMERIC_SCALE`:数字类型列的数字比例。
-- `DATETIME_PRECISION`:对于时间类型列,小数秒精度。
-- `CHARACTER_SET_NAME`:字符串列的字符集名称。
-- `COLLATION_NAME`:字符串列的排序规则的名称。
-- `COLUMN_TYPE`:列类型。
-- `COLUMN_KEY`:该列是否被索引。该字段可能具有以下值:
- - `Empty`:此列未编入索引,或者此列已编入索引并且是多列非唯一索引中的第二列。
- - `PRI`:此列是主键或多个主键之一。
- - `UNI`:此列是唯一索引的第一列。
- - `MUL`:该列是非唯一索引的第一列,其中允许给定值多次出现。
-- `EXTRA`:给定列的任何附加信息。
-- `PRIVILEGES`:当前用户所拥有的对该列的权限。
-- `COLUMN_COMMENT`:列定义中包含的描述。
-- `GENERATION_EXPRESSION`:对于生成的列,此值显示用于计算列值的表达式。对于非生成列,该值为空。
-- `SRS_ID`:此值适用于空间列。它包含列 `SRID` 值,该值表示为存储在该列中的值提供一个空间参考系统。
-
-### `ENGINES` 表
-
-`ENGINES` 表中的列描述如下:
-
-- `ENGINES`:存储引擎的名称。
-- `SUPPORT`:服务器对存储引擎的支持级别。
-- `COMMENT`:对存储引擎的简短评论。
-- `TRANSACTIONS`:存储引擎是否支持事务。
-- `XA`:存储引擎是否支持 XA 事务。
-- `SAVEPOINTS`:存储引擎是否支持 `savepoints`。
-
-### `PARTITIONS` 表
-
-`PARTITIONS` 表中的列描述如下:
-
-- `TABLE_CATALOG`:含有该列的表所属的目录的名称。该值始终为 def。
-- `TABLE_SCHEMA`:含有列的表所在的模式的名称。
-- `TABLE_NAME`:包含列的表的名称。
-- `PARTITION_NAME`:分区名称。
-- `SUBPARTITION_NAME`:如果 `PARTITIONS` 表中的行表示一个子分区,则为该子分区的名称;否则为空。
-- `PARTITION_ORDINAL_POSITION`:所有分区按照它们被定义的顺序进行索引,其中 1 表示分配给第一个分区的编号。随着分区的增加、删除和重新组织,索引可能会发生变化;该列中显示的编号反映了当前的顺序,考虑了任何索引变化。
-- `SUBPARTITION_ORDINAL_POSITION`:在给定分区内,子分区的索引和重新索引方式与表内分区的方式相同。
-- `PARTITION_METHOD`:取值之一为 `RANGE`、`LIST`、`HASH`、`LINEAR HASH`、`KEY` 或 `LINEAR KEY`。__Note:__ MatrixOne 暂不支持 `RANGE` 和 `LIST` 分区。
-- `SUBPARTITION_METHOD`:取值之一为 `HASH`、`LINEAR HASH`、`KEY` 或 `LINEAR KEY`。
-- `PARTITION_EXPRESSION`:在创建表的 `CREATE TABLE` 或 `ALTER TABLE` 语句中使用的分区函数表达式,用于创建表的当前分区方案。
-- `SUBPARTITION_EXPRESSION`:这与 `PARTITION_EXPRESSION` 类似,用于定义表的子分区方式,如果表没有子分区,则该列为空。
-- `PARTITION_DESCRIPTION`:此列适用于 `RANGE` 和 `LIST` 分区。对于 `RANGE` 分区,它包含在分区的 `VALUES LESS THAN` 子句中设置的值,可以是整数或 `MAXVALUE`。对于 `LIST` 分区,此列包含在分区的 `VALUES IN` 子句中定义的值,这是一组逗号分隔的整数值。对于 `PARTITION_METHOD` 不是 `RANGE` 或 `LIST` 的分区,此列始终为空。__Note:__ MatrixOne 暂不支持 `RANGE` 和 `LIST` 分区。
-- `TABLE_ROWS`:分区中的表行数。
-- `AVG_ROW_LENGTH`:存储在此分区或子分区中的行的平均长度,以字节为单位。这与 `DATA_LENGTH` 除以 `TABLE_ROWS` 得到的结果相同。
-- `DATA_LENGTH`:此分区或子分区中存储的所有行的总长度,以字节为单位;即存储在分区或子分区中的字节总数。
-- `INDEX_LENGTH`:此分区或子分区的索引文件长度,以字节为单位。
-- `DATA_FREE`:分配给分区或子分区但未使用的字节数。
-- `CREATE_TIME`:分区或子分区创建的时间。
-- `UPDATE_TIME`:分区或子分区上次修改的时间。
-- `CHECK_TIME`:属于此分区或子分区的表最后一次检查的时间。
-- `CHECKSUM`:校验和值,如果有的话;否则为空。
-- `PARTITION_COMMENT`:如果分区有注释,则为注释的文本。如果没有,则该值为空。分区注释的最大长度定义为 1024 个字符,`PARTITION_COMMENT` 列的显示宽度也为 1024 个字符,以与此限制相符。
-- `NODEGROUP`:该分区所属的节点组。
-- `TABLESPACE_NAME`:该分区所属的表空间的名称。该值始终为 `DEFAULT`。
-
-### `PROCESSLIST` 表
-
-`PROCESSLIST` 表中的字段描述如下:
-
-- `ID`:用户连接的 ID。
-- `USER`:正在执行 `PROCESS` 的用户名。
-- `HOST`:用户连接的地址。
-- `DB`:当前连接的默认数据库的名称。
-- `COMMAND`:`PROCESS` 正在执行的命令类型。
-- `TIME`:`PROCESS` 的当前执行时长,以秒为单位。
-- `STATE`:当前连接状态。
-- `INFO`:正在处理的请求语句。
-
-### `SCHEMATA` 表
-
-`SCHEMATA` 表提供有关数据库的信息,表数据等同于 `SHOW DATABASES` 语句的结果。`SCHEMATA` 表中的字段描述如下:
-
-- `CATALOG_NAME`:数据库所属的目录。
-- `SCHEMA_NAME`:数据库名称。
-- `DEFAULT_CHARACTER_SET_NAME`:数据库的默认字符集。
-- `DEFAULT_COLLATION_NAME`:数据库的默认排序规则。
-- `SQL_PATH`:此项的值始终为 `NULL`。
-- `DEFAULT_TABLE_ENCRYPTION`:定义数据库和通用表空间的 *default encryption* 设置。
-
-### `TABLES` 表
-
-`TABLES` 表中列的描述如下:
-
-- `TABLE_CATALOG`:表所属目录的名称。该值始终为 `def`。
-- `TABLE_SCHEMA`:表所属的模式的名称。
-- `TABLE_NAME`:表的名称。
-- `TABLE_TYPE`:表的类型。基本表类型为 `BASE TABLE`,视图表类型为 `VIEW`,`INFORMATION_SCHEMA` 表类型为 `SYSTEM VIEW`。
-- `ENGINE`:存储引擎的类型。
-- `VERSION`:版本。默认值为 `10`。
-- `ROW_FORMAT`:行存储格式。值为 `Fixed`,`Dynamic`,`Compressed`,`Redundant`,`Compact`。
-- `TABLE_ROWS`:统计表中的行数。对于 `INFORMATION_SCHEMA` 表,`TABLE_ROWS` 为 `NULL`。
-- `AVG_ROW_LENGTH`:表的平均行长度。`AVG_ROW_LENGTH` = `DATA_LENGTH` / `TABLE_ROWS`。
-- `DATA_LENGTH`:数据长度。`DATA_LENGTH` = `TABLE_ROWS` * 元组中列的存储长度之和。
-- `MAX_DATA_LENGTH`:最大数据长度。该值当前为 `0`,表示数据长度没有上限。
-- `INDEX_LENGTH`:索引长度。`INDEX_LENGTH` = `TABLE_ROWS` * 索引元组中列的长度总和。
-- `DATA_FREE`:数据片段。该值当前为 `0`。
-- `AUTO_INCREMENT`:自增主键的当前步长。
-- `CREATE_TIME`:创建表的时间。
-- `UPDATE_TIME`:表更新的时间。
-- `CHECK_TIME`:检查表的时间。
-- `TABLE_COLLATION`:表中字符串的排序规则。
-- `CHECKSUM`:校验和。
-- `CREATE_OPTIONS`:创建选项。
-- `TABLE_COMMENT`:表格的注释和注释。
-
-### `USER_PRIVILEGES` 表
-
-`USER_PRIVILEGES` 表提供了关于全局权限的信息。
-
-`USER_PRIVILEGES` 表中的字段描述如下:
-
-- `GRANTEE`:授权用户名,格式为 `'user_name'@'host_name'`。
-- `TABLE_CATALOG`:表所属的目录的名称。值为 `def`。
-- `PRIVILEGE_TYPE`:要授予的权限类型。每行只显示一种权限类型。
-- `IS_GRANTABLE`:如果你有 `GRANT OPTION` 权限,该值为 `YES`,没有 `GRANT OPTION` 权限,该值为 `NO`。
-
-### `VIEW` 表
-
-- `TABLE_CATALOG`:视图所属目录的名称。值为 `def`。
-- `TABLE_SCHEMA`:视图所属的数据库的名称。
-- `TABLE_NAME`:视图的名称。
-- `VIEW_DEFINITION`:提供视图定义的 `SELECT` 语句。包含了在 `SHOW Create VIEW` 生成的**创建表**列中看到的大部分内容。
-- `CHECK_OPTION`:`CHECK_OPTION` 属性的值。值为 `NONE`、`CASCADE` 或 `LOCAL`。
-- `IS_UPDATABLE`:在 `CREATE VIEW` 时设置一个名为视图可更新性标志的标志,如果 UPDATE 和 DELETE(以及类似的操作)对视图合法,则标志设置为 `YES(true)`。否则,标志设置为 `NO(false)`。
-- `DEFINER`:创建视图的用户的帐户,格式为 `username@hostname`。
-- `SECURITY_TYPE`:视图 `SQL SECURITY` 特性。值为 `DEFINER` 或 `INVOKER`。
-- `CHARACTER_SET_CLIENT`:创建视图时 `character_set_client` 系统变量的会话值。
-- `COLLATION_CONNECTION`:创建视图时,`collation_connection` 系统变量的会话值。
-
-### `STATISTICS` 表
-
-获取有关数据库表索引和统计信息的详细信息。例如,可以检查索引是否唯一,了解索引中的列顺序,以及估计索引中的唯一值数量。
-
-- `TABLE_CATALOG`:表的目录名称(始终为 'def')。
-- `TABLE_SCHEMA`:表所属的数据库名称。
-- `TABLE_NAME`:表的名称。
-- `NON_UNIQUE`:指示索引是否允许重复值。如果为 0,则索引是唯一索引。
-- `INDEX_SCHEMA`:索引所属的数据库名称。
-- `INDEX_NAME`:索引的名称。
-- `SEQ_IN_INDEX`:列在索引中的位置。
-- `COLUMN_NAME`:列的名称。
-- `COLLATION`:列的排序规则。
-- `CARDINALITY`:索引中唯一值的数量估计。
-- `SUB_PART`:索引部分长度。对于整个列,该值为 NULL。
-- `PACKED`:指示是否使用压缩存储的值。
-- `NULLABLE`:指示列是否允许 NULL 值。
-- `INDEX_TYPE`:索引的类型(如 BTREE、HASH 等)。
-- `COMMENT`:索引的注释信息。
-
-## `mysql` 数据库
-
-### 授权系统表
-
-授权系统表包含了关于用户帐户及其权限信息:
-
-- `user` 用户帐户、全局权限和其他非权限列。
-
-- `db`:数据库级权限。
-
-- `tables_priv`:表级权限。
-
-- `columns_priv`:列级权限。
-
-- `procs_priv`:存储过程和存储函数的权限。
diff --git a/docs/MatrixOne/Develop/schema-design/1.1-vector.md b/docs/MatrixOne/Reference/Data-Types/vector-type.md
similarity index 68%
rename from docs/MatrixOne/Develop/schema-design/1.1-vector.md
rename to docs/MatrixOne/Reference/Data-Types/vector-type.md
index 63df86e618..b00ff54677 100644
--- a/docs/MatrixOne/Develop/schema-design/1.1-vector.md
+++ b/docs/MatrixOne/Reference/Data-Types/vector-type.md
@@ -1,12 +1,20 @@
-# 向量
+# 向量类型
-## 什么是向量
+## 什么是向量?
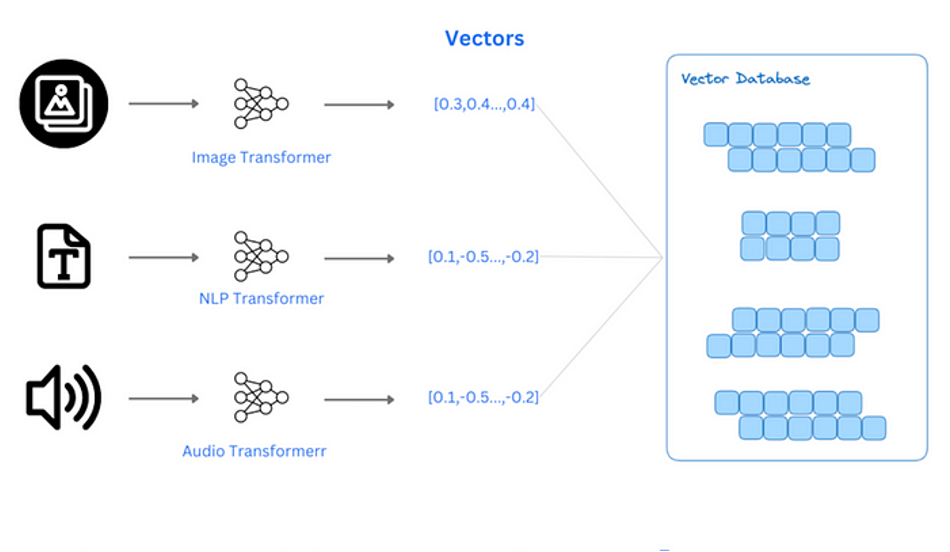
-在数据库中,向量通常是一组数字,它们以特定的方式排列,以表示某种数据或特征。这些向量可以是一维数组、多维数组或具有更高维度的数据结构。在机器学习和数据分析领域中,向量用于表示数据点、特征或模型参数。
+在数据库中,向量通常是一组数字,它们以特定的方式排列,以表示某种数据或特征。这些向量可以是一维数组、多维数组或具有更高维度的数据结构。在机器学习和数据分析领域中,向量用于表示数据点、特征或模型参数。它们通常是用来处理非结构化数据,如图片,语音,文本等,以通过机器学习模型,将非结构化数据转化为 embedding 向量,随后处理分析这些数据。
-## 向量的优点
+
-数据库拥有向量能力意味着数据库系统具备存储、查询和分析向量数据的能力。这些向量通常与复杂的数据分析、机器学习和数据挖掘任务相关。以下是数据库拥有向量能力的一些优点:
+## 什么是向量检索?
+
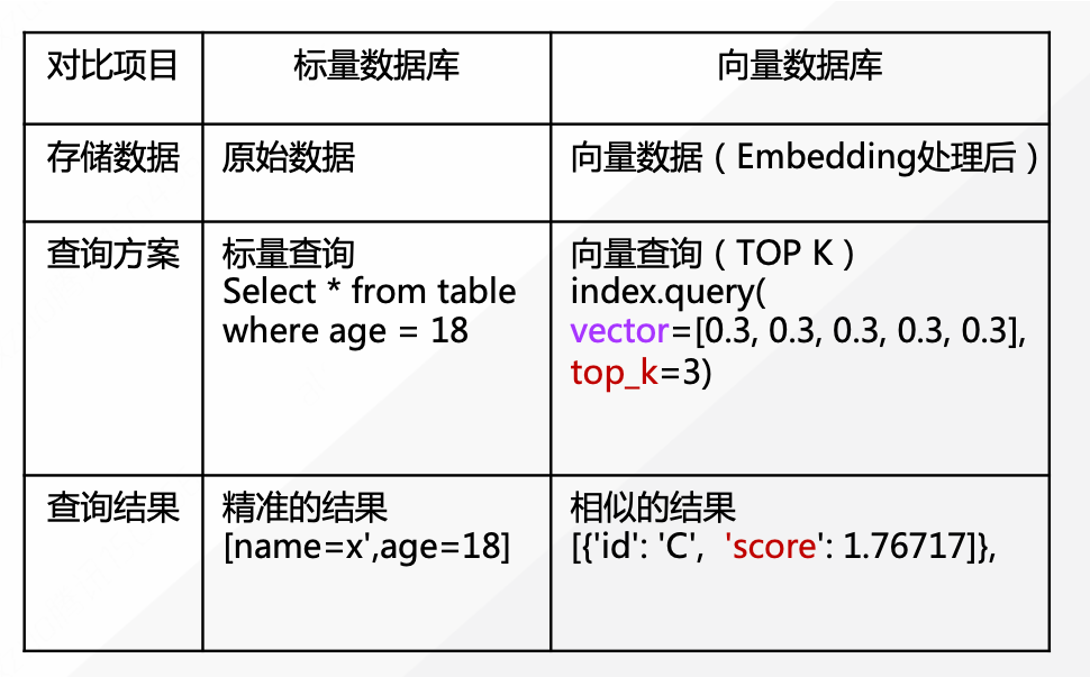
+向量检索又称为近似最近邻搜索 (Approximate Nearest Neighbor Search, ANNS),是一种在大规模高维向量数据中 寻找与给定查询向量相似的向量的技术。向量检索在许多 AI 领域 具有广泛的应用,如图像检索、文本检索、语音识别、推荐系统等。向量检索与传统数据库检索有很大差别,传统数据库上的标量搜索主要针对结构化数据进行精确的数据查询,而向量搜索主要针对非结构化数据向量化之后的向量数据进行相似检索,只能近似获得最匹配的结果。
+
+
+
+## 向量检索的应用场景
+
+数据库拥有向量能力意味着数据库系统具备存储、查询和分析向量数据的能力。这些向量通常与复杂的数据分析、机器学习和数据挖掘任务相关。以下是数据库拥有向量处理能力后的应用场景:
- **生成式 AI 应用程序**:这些数据库可以作为生成式 AI 应用程序的后端,使它们能够根据用户提供的查询获取最近邻结果,提高输出质量和相关性。
@@ -16,14 +24,13 @@
- **异常检测**:向量数据库可以用来存储代表正常行为的特征向量。然后可以通过比较输入向量和存储向量来检测异常。这在网络安全和工业质量控制中很有用。
-## 开始前准备
+## MatrixOne 的向量数据类型
-在阅读本页面之前,你需要准备以下事项:
+在 MatrixOne 中,向量被设计成一种数据类型,它类似于编程语言中的 Array 数组 ( MatrixOne 目前还不支持数组类型),但是是一种较为特殊的数组类型。首先,它是一个一维数组类型,意味着它不能用来构建 Matrix 矩阵。另外目前仅支持 `float32` 及 `float64` 类型的向量,分别称之为 `vecf32` 与 `vecf64` 而不支持字符串类型和整型类型的数字。
-- 了解并已经完成构建 MatrixOne 集群。
-- 了解什么是[数据库模式](overview.md)。
+创建一个向量列时,我们可以指定向量列的维度大小,如 vecf32(3),这个维度即向量的数组的长度大小,最大可支持到 65,536 维度。
-## 如何使用向量
+## 如何在 SQL 中使用向量类型
使用向量的语法与常规建表、插入数据、查询数据相同:
@@ -31,6 +38,8 @@
你可以按照下面的 SQL 语句创建了两个向量列,一个是 Float32 类型,另一个是 Float64 类型,并且可以将两个向量列的维度都设置为 3。
+目前向量类型不能作为主键或者唯一键。
+
```
create table t1(a int, b vecf32(3), c vecf64(3));
```
@@ -90,6 +99,20 @@ mysql> select encode(b, "hex") from t1;
2 rows in set (0.00 sec)
```
+## 支持的算子与函数
+
+* 基本二元操作符:[`+`, `-`, `*`, `/`](../Functions-and-Operators/Vector/arithmetic.md).
+* 比较操作符:`=`,`!=`, `>`, `>=` , `<`, `<=`.
+* 一元函数:[`sqrt`, `abs`, `cast`](../Functions-and-Operators/Vector/misc.md).
+* 自动类型转换:
+ * `vecf32` + `vecf64` = `vecf64`.
+ * `vecf32` + `varchar` = `vecf32`.
+* 向量一元函数:
+ * 求和函数 [`summation`](../Functions-and-Operators/Vector/misc.md), L1 范数函数 [`l1_norm`](../Functions-and-Operators/Vector/l1_norm.md), L2 范数函数 [`l2_norm`](../Functions-and-Operators/Vector/l2_norm.md), 维度函数 [`vector_dims`](../Functions-and-Operators/Vector/vector_dims.md).
+* 向量二元函数:
+ * 内积函数 [`inner_product`](../Functions-and-Operators/Vector/inner_product.md), 余弦相似度函数 [`cosine_similarity`](../Functions-and-Operators/Vector/cosine_similarity.md).
+* 聚合函数:`count`.
+
## 示例 - Top K 查询
Top K 查询是一种数据库查询操作,用于检索数据库中排名前 K 的数据项或记录。Top K 查询可以应用于各种应用场景,包括推荐系统、搜索引擎、数据分析和排序。
@@ -192,21 +215,3 @@ mysql> SELECT * FROM t1 ORDER BY 1 - cosine_similarity(b, '[3,1,2]') LIMIT 5;
```
这种方法可以显著提高数据插入的效率。
-
-## 限制
-
-- 目前,MatrixOne 向量类型支持 float32 和 float64 类型。
-- 向量不能作为主键或唯一键。
-- 向量的最大维度为 65536。
-
-## 参考文档
-
-更多关于向量函数的文档,参见:
-
-- [inner_product()](../../Reference/Functions-and-Operators/1.1-Vector/inner_product.md)
-- [l1_norm()](../../Reference/Functions-and-Operators/1.1-Vector/l1_norm.md)
-- [l2_norm()](../../Reference/Functions-and-Operators/1.1-Vector/l2_norm.md)
-- [cosine_similarity()](../../Reference/Functions-and-Operators/1.1-Vector/cosine_similarity.md)
-- [vector_dims()](../../Reference/Functions-and-Operators/1.1-Vector/vector_dims.md)
-- [Arithemetic Operators](../../Reference/Functions-and-Operators/1.1-Vector/arithmetic.md)
-- [Misc Functions](../../Reference/Functions-and-Operators/1.1-Vector/misc.md)
diff --git a/docs/MatrixOne/Reference/Functions-and-Operators/1.1-Vector/arithmetic.md b/docs/MatrixOne/Reference/Functions-and-Operators/Vector/arithmetic.md
similarity index 100%
rename from docs/MatrixOne/Reference/Functions-and-Operators/1.1-Vector/arithmetic.md
rename to docs/MatrixOne/Reference/Functions-and-Operators/Vector/arithmetic.md
diff --git a/docs/MatrixOne/Reference/Functions-and-Operators/1.1-Vector/cosine_similarity.md b/docs/MatrixOne/Reference/Functions-and-Operators/Vector/cosine_similarity.md
similarity index 100%
rename from docs/MatrixOne/Reference/Functions-and-Operators/1.1-Vector/cosine_similarity.md
rename to docs/MatrixOne/Reference/Functions-and-Operators/Vector/cosine_similarity.md
diff --git a/docs/MatrixOne/Reference/Functions-and-Operators/1.1-Vector/inner_product.md b/docs/MatrixOne/Reference/Functions-and-Operators/Vector/inner_product.md
similarity index 100%
rename from docs/MatrixOne/Reference/Functions-and-Operators/1.1-Vector/inner_product.md
rename to docs/MatrixOne/Reference/Functions-and-Operators/Vector/inner_product.md
diff --git a/docs/MatrixOne/Reference/Functions-and-Operators/1.1-Vector/l1_norm.md b/docs/MatrixOne/Reference/Functions-and-Operators/Vector/l1_norm.md
similarity index 100%
rename from docs/MatrixOne/Reference/Functions-and-Operators/1.1-Vector/l1_norm.md
rename to docs/MatrixOne/Reference/Functions-and-Operators/Vector/l1_norm.md
diff --git a/docs/MatrixOne/Reference/Functions-and-Operators/1.1-Vector/l2_norm.md b/docs/MatrixOne/Reference/Functions-and-Operators/Vector/l2_norm.md
similarity index 100%
rename from docs/MatrixOne/Reference/Functions-and-Operators/1.1-Vector/l2_norm.md
rename to docs/MatrixOne/Reference/Functions-and-Operators/Vector/l2_norm.md
diff --git a/docs/MatrixOne/Reference/Functions-and-Operators/1.1-Vector/misc.md b/docs/MatrixOne/Reference/Functions-and-Operators/Vector/misc.md
similarity index 100%
rename from docs/MatrixOne/Reference/Functions-and-Operators/1.1-Vector/misc.md
rename to docs/MatrixOne/Reference/Functions-and-Operators/Vector/misc.md
diff --git a/docs/MatrixOne/Reference/Functions-and-Operators/1.1-Vector/vector_dims.md b/docs/MatrixOne/Reference/Functions-and-Operators/Vector/vector_dims.md
similarity index 100%
rename from docs/MatrixOne/Reference/Functions-and-Operators/1.1-Vector/vector_dims.md
rename to docs/MatrixOne/Reference/Functions-and-Operators/Vector/vector_dims.md
diff --git a/docs/MatrixOne/Reference/SQL-Reference/Data-Manipulation-Language/1.1-load-data.md b/docs/MatrixOne/Reference/SQL-Reference/Data-Manipulation-Language/1.1-load-data.md
deleted file mode 100644
index cf63b64b6b..0000000000
--- a/docs/MatrixOne/Reference/SQL-Reference/Data-Manipulation-Language/1.1-load-data.md
+++ /dev/null
@@ -1,596 +0,0 @@
-# **LOAD DATA**
-
-## **概述**
-
-`LOAD DATA` 语句可以极快地将文本文件中的行读入表中。你可以从服务器主机或 [S3 兼容对象存储](../../../Develop/import-data/bulk-load/load-s3.md)读取该文件。`LOAD DATA` 是 [`SELECT ... INTO OUTFILE`](../../../Develop/export-data/select-into-outfile.md) 相反的操作。
-
-- 将文件读回表中,使用 `LOAD DATA`。
-- 将表中的数据写入文件,使用 `SELECT ... INTO OUTFILE`。
-- `FIELDS` 和 `LINES` 子句的语法对于 `LOAD DATA` 和 `SELECT ... INTO OUTFILE` 这两个语句的使用方式一致,使用 Fields 和 Lines 参数来指定如何处理数据格式。
-
-## **语法结构**
-
-### 加载外部数据
-
-```
-> LOAD DATA [LOCAL]
- INFILE 'file_name'
- INTO TABLE tbl_name
- [{FIELDS | COLUMNS}
- [TERMINATED BY 'string']
- [[OPTIONALLY] ENCLOSED BY 'char']
- ]
- [LINES
- [STARTING BY 'string']
- [TERMINATED BY 'string']
- ]
- [IGNORE number {LINES | ROWS}]
- [SET column_name_1=nullif(column_name_1, expr1), column_name_2=nullif(column_name_2, expr2)...]
- [PARALLEL {'TRUE' | 'FALSE'}]
-```
-
-**参数解释**
-
-上述语法结构中的参数解释如下:
-
-#### INFILE
-
-- `LOAD DATA INFILE 'file_name'`:
-
- **命令行使用场景**:需要加载的数据文件与 MatrixOne 主机服务器在同一台机器上。
- `file_name` 可以是文件的存放位置的相对路径名称,也可以是绝对路径名称。
-
-- `LOAD DATA LOCAL INFILE 'file_name'`:
-
- **命令行使用场景**:需要加载的数据文件与 MatrixOne 主机服务器不在同一台机器上,即,数据文件在客户机上。
- `file_name` 可以是文件的存放位置的相对路径名称,也可以是绝对路径名称。
-
-#### FIELDS 和 LINES 参数说明
-
-使用 `FIELDS` 和 `LINES` 参数来指定如何处理数据格式。
-
-对于 `LOAD DATA` 和 `SELECT ... INTO OUTFILE` 语句,`FIELDS` 和 `LINES` 子句的语法是相同的。这两个子句都是可选的,但如果两者都指定,则 `FIELDS` 必须在 `LINES` 之前。
-
-如果指定 `FIELDS` 子句,那么 `FIELDS` 的每个子句(`TERMINATED BY`、`[OPTIONALLY] ENCLOSED BY`)也是可选的,除非你必须至少指定其中一个。
-
-`LOAD DATA` 也支持使用十六进制 `ASCII` 字符表达式或二进制 `ASCII` 字符表达式作为 `FIELDS ENCLOSED BY` 和 `FIELDS TERMINATED BY` 的参数。
-
-如果不指定处理数据的参数,则使用默认值如下:
-
-```
-FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n'
-```
-
-!!! note
- - `FIELDS TERMINATED BY ','`:以且仅以 `,`、`|` 或 `\t` 作为分隔符。
- - `ENCLOSED BY '"'`:以且仅以 `"` 作为包括符。
- - `LINES TERMINATED BY '\n'`:以且仅以 `\n` 或 `\r\n` 作为行间分隔符。
-
-**FIELDS TERMINATED BY**
-
-`FIELDS TERMINATED BY` 表示字段与字段之间的分隔符,使用 `FIELDS TERMINATED BY` 就可以指定每个数据的分隔符号。
-
-`FIELDS TERMINATED BY` 指定的值可以超过一个字符。
-
-- **正确示例**:
-
-例如,读取使用*逗号*分隔的文件,语法是:
-
-```
-LOAD DATA INFILE 'data.txt' INTO TABLE table1
- FIELDS TERMINATED BY ',';
-```
-
-- **错误示例**:
-
-如果你使用如下所示的语句读取文件,将会产生报错,因为它表示的是 `LOAD DATA` 查找字段之间的制表符:
-
-```
-LOAD DATA INFILE 'data.txt' INTO TABLE table1
- FIELDS TERMINATED BY '\t';
-```
-
-这样可能会导致结果被解释为每个输入行都是一个字段,你可能会遇到 `ERROR 20101 (HY000): internal error: the table column is larger than input data column` 错误。
-
-**FIELDS ENCLOSED BY**
-
-`FIELDS TERMINATED BY` 指定的值包含输入值的字符。`ENCLOSED BY` 指定的值必须是单个字符;如果输入值不一定包含在引号中,需要在 `ENCLOSED BY` 选项之前使用 `OPTIONALLY`。
-
-如下面的例子所示,即表示一部分输入值用可以用引号括起来,另一些可以不用引号括起来:
-
-```
-LOAD DATA INFILE 'data.txt' INTO TABLE table1
- FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"';
-```
-
-如果 `ENCLOSED BY` 前不加 `OPTIONALLY`,比如说,`ENCLOSED BY '"'` 就表示使用双引号把各个字段都括起来。
-
-**LINES TERMINATED BY**
-
-`LINES TERMINATED BY` 用于指定一行的结束符。`LINES TERMINATED BY` 值可以超过一个字符。
-
-例如,*csv* 文件中的行以回车符/换行符对结束,你在加载它时,可以使用 `LINES TERMINATED BY '\r\n'` 或 `LINES TERMINATED BY '\n'`:
-
-```
-LOAD DATA INFILE 'data.txt' INTO TABLE table1
- FIELDS TERMINATED BY ',' ENCLOSED BY '"'
- LINES TERMINATED BY '\r\n';
-```
-
-**LINE STARTING BY**
-
-如果所有输入行都有一个你想忽略的公共前缀,你可以使用 `LINES STARTING BY` 'prefix_string' 来忽略前缀和前缀之前的任何内容。
-
-如果一行不包含前缀,则跳过整行。如下语句所示:
-
-```
-LOAD DATA INFILE '/tmp/test.txt' INTO TABLE table1
- FIELDS TERMINATED BY ',' LINES STARTING BY 'xxx';
-```
-
-如果数据文件是如下样式:
-
-```
-xxx"abc",1
-something xxx"def",2
-"ghi",3
-```
-
-则输出的结果行是 ("abc",1) 和 ("def",2)。文件中的第三行由于没有前缀,则被忽略。
-
-#### IGNORE LINES
-
-`IGNORE number LINES` 子句可用于忽略文件开头的行。例如,你可以使用 `IGNORE 1 LINES` 跳过包含列名的初始标题行:
-
-```
-LOAD DATA INFILE '/tmp/test.txt' INTO TABLE table1 IGNORE 1 LINES;
-```
-
-#### SET
-
-MatrixOne 当前仅支持 `SET column_name=nullif(column_name,expr)`。即,当 `column_name = expr`,返回 `NULL`;否则,则返回 `column_name`。例如,`SET a=nullif(a, 1)`,当 a=1 时,返回 `NULL`;否则,返回 a 列原始的值。
-
-使用这种方法,可以在加载文件时,设置参数 `SET column_name=nullif(column_name,"null")`,用于返回列中的 `NULL` 值。
-
-**示例**
-
-1. 本地文件 `test.txt` 详情如下:
-
- ```
- id,user_name,sex
- 1,"weder","man"
- 2,"tom","man"
- null,wederTom,"man"
- ```
-
-2. 在 MatrixOne 中新建一个表 `user`:
-
- ```sql
- create database aaa;
- use aaa;
- CREATE TABLE `user` (`id` int(11) ,`user_name` varchar(255) ,`sex` varchar(255));
- ```
-
-3. 使用下面的命令行将 `test.txt` 导入至表 `user`:
-
- ```sql
- LOAD DATA INFILE '/tmp/test.txt' INTO TABLE user SET id=nullif(id,"null");
- ```
-
-4. 导入后的表内容如下:
-
- ```sql
- select * from user;
- +------+-----------+------+
- | id | user_name | sex |
- +------+-----------+------+
- | 1 | weder | man |
- | 2 | tom | man |
- | null | wederTom | man |
- +------+-----------+------+
- ```
-
-#### PARALLEL
-
-对于一个格式良好的大文件,例如 *JSONLines* 文件,或者一行数据中没有换行符的 *CSV* 文件,都可以使用 `PARALLEL` 对该文件进行并行加载,以加快加载速度。
-
-例如,对于 2 个 G 的大文件,使用两个线程去进行加载,第 2 个线程先拆分定位到 1G 的位置,然后一直往后读取并进行加载。这样就可以做到两个线程同时读取大文件,每个线程读取 1G 的数据。
-
-**开启/关闭并行加载命令行示例**:
-
-```sql
--- 打开并行加载
-load data infile 'file_name' into table tbl_name FIELDS TERMINATED BY '|' ENCLOSED BY '\"' LINES TERMINATED BY '\n' IGNORE 1 LINES PARALLEL 'TRUE';
-
--- 关闭并行加载
-load data infile 'file_name' into table tbl_name FIELDS TERMINATED BY '|' ENCLOSED BY '\"' LINES TERMINATED BY '\n' IGNORE 1 LINES PARALLEL 'FALSE';
-
--- 默认关闭并行加载
-load data infile 'file_name' into table tbl_name FIELDS TERMINATED BY '|' ENCLOSED BY '\"' LINES TERMINATED BY '\n' IGNORE 1 LINES;
-```
-
-!!! note
- `[PARALLEL {'TRUE' | 'FALSE'}]` 内字段,当前仅支持 `TRUE` 或 `FALSE`,且大小写不敏感。
-
-__Note:__ `LOAD` 语句中如果不加 `PARALLEL` 字段,对于 *CSV* 文件,是默认关闭并行加载;对于 *JSONLines* 文件,默认开启并行加载。如果 *CSV* 文件中有行结束符,比如 '\n',那么有可能会导致文件加载时数据出错。如果文件过大,建议从换行符为起止点手动拆分文件后再开启并行加载。
-
-### 加载时序数据
-
-```
-> LOAD DATA INLINE FORMAT='' DATA=''
-INTO TABLE tbl_name
- [{FIELDS | COLUMNS}
- [TERMINATED BY 'string']
- [[OPTIONALLY] ENCLOSED BY 'char']
- ]
- [LINES
- [STARTING BY 'string']
- [TERMINATED BY 'string']
- ]
- [IGNORE number {LINES | ROWS}]
-```
-
-**参数解释**
-
-加载时序数据的 SQL 命令 `LOAD DATA INLINE` 参数解释如下:
-
-- `FORMAT`:指定了所加载的时序数据的格式,例如,`FORMAT='csv'` 表示加载的数据采用 CSV 格式。它所支持的格式与 `LOAD DATA INFILE` 支持的格式一致。
-
-- `DATA`:指定了要加载的时序数据本身。在示例中,`DATA='1\n2\n'` 表示要加载的数据是两行,分别包含数字 1 和 2。
-
-!!! note
- `FIELDS`、`COLUMNS`、`TERMINATED BY`、`ENCLOSED BY`、`LINES`、`STARTING BY`、`IGNORE` 这些参数可以参照上文 `LOAD DATA INFILE` 的参数解释。
-
-加载时序数据的示例命令:`load data inline format='csv', data='1\n2\n' into table t1;`,它是将指定的 CSV 格式的数据(包括两行,分别是 1 和 2)加载到名为 `t1` 的数据库表中。
-
-## 支持的文件格式
-
-在 MatrixOne 当前版本中,`LOAD DATA` 支持 *CSV* 格式和 *JSONLines* 格式文件。
-
-有关导入这两种格式的文档,参见[导入*. csv* 格式数据](../../../Develop/import-data/bulk-load/load-csv.md)和[导入 JSONLines 数据](../../../Develop/import-data/bulk-load/load-jsonline.md)。
-
-### *CSV* 格式标准说明
-
-MatrixOne 加载 *CSV* 格式符合 RFC4180 标准,规定 *CSV* 格式如下:
-
-1. 每条记录位于单独的一行,由换行符(CRLF)分隔:
-
- ```
- aaa,bbb,ccc CRLF
- zzz,yyy,xxx CRLF
- ```
-
- 导入到表内如下所示:
-
- +---------+---------+---------+
- | col1 | col2 | col3 |
- +---------+---------+---------+
- | aaa | b bb | ccc |
- | zzz | yyy | xxx |
- +---------+---------+---------+
-
-2. 文件中最后一条记录可以有结束换行符,也可以无结束换行符(CRLF):
-
- ```
- aaa,bbb,ccc CRLF
- zzz,yyy,xxx
- ```
-
- 导入到表内如下所示:
-
- +---------+---------+---------+
- | col1 | col2 | col3 |
- +---------+---------+---------+
- | aaa | b bb | ccc |
- | zzz | yyy | xxx |
- +---------+---------+---------+
-
-3. 可选的标题行作为文件的第一行出现,其格式与普通记录行相同。例如:
-
- ```
- field_name,field_name,field_name CRLF
- aaa,bbb,ccc CRLF
- zzz,yyy,xxx CRLF
- ```
-
- 导入到表内如下所示:
-
- +------------+------------+------------+
- | field_name | field_name | field_name |
- +------------+------------+------------+
- | aaa | bbb | ccc |
- | zzz | yyy | xxx |
- +------------+------------+------------+
-
-4. 在标题和每条记录中,可能有一个或多个字段,字段之间以逗号分隔。字段内的空格属于字段的一部分,不应忽略。每条记录中的最后一个字段后面不能跟逗号。例如:
-
- ```
- aaa,bbb,ccc
- ```
-
- 或:
-
- ```
- a aa, bbb,cc c
- ```
-
- 这两个例子都是合法的。
-
- 导入到表内如下所示:
-
- +---------+---------+---------+
- | col1 | col2 | col3 |
- +---------+---------+---------+
- | aaa | bbb | ccc |
- +---------+---------+---------+
-
- 或:
-
- +---------+---------+---------+
- | col1 | col2 | col3 |
- +---------+---------+---------+
- | a aa | bbb | cc c |
- +---------+---------+---------+
-
-5. 每个字段可以用双引号括起来,也可以不用双引号括起来。如果字段没有用双引号引起来,那么双引号不能出现在字段内。例如:
-
- ```
- "aaa","bbb","ccc" CRLF
- zzz,yyy,xxx
- ```
-
- 或:
-
- ```
- "aaa","bbb",ccc CRLF
- zzz,yyy,xxx
- ```
-
- 这两个例子都是合法的。
-
- 导入到表内如下所示:
-
- +---------+---------+---------+
- | col1 | col2 | col3 |
- +---------+---------+---------+
- | aaa | bbb | ccc |
- | zzz | yyy | xxx |
- +---------+---------+---------+
-
-6. 包含换行符(CRLF)、双引号和逗号的字段应该用双引号引起来。例如:
-
- ```
- "aaa","b CRLF
- bb","ccc" CRLF
- zzz,yyy,xxx
- ```
-
- 导入到表内如下所示:
-
- +---------+---------+---------+
- | col1 | col2 | col3 |
- +---------+---------+---------+
- | aaa | b bb | ccc |
- | zzz | yyy | xxx |
- +---------+---------+---------+
-
-7. 如果使用双引号将字段括起来,那么出现在字段内的多个双引号也必须使用双引号括起来,否则字段内两个双引号的第一个引号将被解析为转义字符,从而只保留一个双引号。例如:
-
- ```
- "aaa","b""bb","ccc"
- ```
-
- 上面这个 *CSV* 会把 `"b""bb"` 解析为 `b"bb`,如果正确的字段为 `b""bb`,那么应该写成:
-
- ```
- "aaa","b""""bb","ccc"
- ```
-
- 或:
-
- ```
- "aaa",b""bb,"ccc"
- ```
-
-## **示例**
-
-你可以在 SSB 测试中了解 `LOAD DATA` 语句的用法,参见[完成 SSB 测试](../../../Test/performance-testing/SSB-test-with-matrixone.md)。
-
-语法示例如下:
-
-```
-> LOAD DATA INFILE '/ssb-dbgen-path/lineorder_flat.tbl ' INTO TABLE lineorder_flat;
-```
-
-上面这行语句表示:将 */ssb-dbgen-path/* 这个目录路径下的 *lineorder_flat.tbl* 数据集加载到 MatrixOne 的数据表 *lineorder_flat* 中。
-
-你也可以参考以下语法示例,来快速了解 `LOAD DATA`:
-
-### 示例 1:LOAD CSV
-
-#### 简单导入示例
-
-本地命名为 *char_varchar.csv* 文件内数据如下:
-
-```
-a|b|c|d
-"a"|"b"|"c"|"d"
-'a'|'b'|'c'|'d'
-"'a'"|"'b'"|"'c'"|"'d'"
-"aa|aa"|"bb|bb"|"cc|cc"|"dd|dd"
-"aa|"|"bb|"|"cc|"|"dd|"
-"aa|||aa"|"bb|||bb"|"cc|||cc"|"dd|||dd"
-"aa'|'||aa"|"bb'|'||bb"|"cc'|'||cc"|"dd'|'||dd"
-aa"aa|bb"bb|cc"cc|dd"dd
-"aa"aa"|"bb"bb"|"cc"cc"|"dd"dd"
-"aa""aa"|"bb""bb"|"cc""cc"|"dd""dd"
-"aa"""aa"|"bb"""bb"|"cc"""cc"|"dd"""dd"
-"aa""""aa"|"bb""""bb"|"cc""""cc"|"dd""""dd"
-"aa""|aa"|"bb""|bb"|"cc""|cc"|"dd""|dd"
-"aa""""|aa"|"bb""""|bb"|"cc""""|cc"|"dd""""|dd"
-|||
-||||
-""|""|""|
-""""|""""|""""|""""
-""""""|""""""|""""""|""""""
-```
-
-在 MatrixOne 中建表:
-
-```sql
-mysql> drop table if exists t1;
-Query OK, 0 rows affected (0.01 sec)
-
-mysql> create table t1(
- -> col1 char(225),
- -> col2 varchar(225),
- -> col3 text,
- -> col4 varchar(225)
- -> );
-Query OK, 0 rows affected (0.02 sec)
-```
-
-将数据文件导入到 MatrixOne 中的表 t1:
-
-```sql
-load data infile '/char_varchar.csv' into table t1 fields terminated by'|';
-```
-
-查询结果如下:
-
-```
-mysql> select * from t1;
-+-----------+-----------+-----------+-----------+
-| col1 | col2 | col3 | col4 |
-+-----------+-----------+-----------+-----------+
-| a | b | c | d |
-| a | b | c | d |
-| 'a' | 'b' | 'c' | 'd' |
-| 'a' | 'b' | 'c' | 'd' |
-| aa|aa | bb|bb | cc|cc | dd|dd |
-| aa| | bb| | cc| | dd| |
-| aa|||aa | bb|||bb | cc|||cc | dd|||dd |
-| aa'|'||aa | bb'|'||bb | cc'|'||cc | dd'|'||dd |
-| aa"aa | bb"bb | cc"cc | dd"dd |
-| aa"aa | bb"bb | cc"cc | dd"dd |
-| aa"aa | bb"bb | cc"cc | dd"dd |
-| aa""aa | bb""bb | cc""cc | dd""dd |
-| aa""aa | bb""bb | cc""cc | dd""dd |
-| aa"|aa | bb"|bb | cc"|cc | dd"|dd |
-| aa""|aa | bb""|bb | cc""|cc | dd""|dd |
-| | | | |
-| | | | |
-| | | | |
-| " | " | " | " |
-| "" | "" | "" | "" |
-+-----------+-----------+-----------+-----------+
-20 rows in set (0.00 sec)
-```
-
-### 增加条件导入示例
-
-沿用上面的简单示例,你可以修改一下 LOAD DATA 语句,在末尾增加条件 `LINES STARTING BY 'aa' ignore 10 lines;`:
-
-```sql
-delete from t1;
-load data infile '/char_varchar.csv' into table t1 fields terminated by'|' LINES STARTING BY 'aa' ignore 10 lines;
-```
-
-查询结果如下:
-
-```sql
-mysql> select * from t1;
-+---------+---------+---------+---------+
-| col1 | col2 | col3 | col4 |
-+---------+---------+---------+---------+
-| aa"aa | bb"bb | cc"cc | dd"dd |
-| aa""aa | bb""bb | cc""cc | dd""dd |
-| aa""aa | bb""bb | cc""cc | dd""dd |
-| aa"|aa | bb"|bb | cc"|cc | dd"|dd |
-| aa""|aa | bb""|bb | cc""|cc | dd""|dd |
-| | | | |
-| | | | |
-| | | | |
-| " | " | " | " |
-| "" | "" | "" | "" |
-+---------+---------+---------+---------+
-10 rows in set (0.00 sec)
-```
-
-可以看到,查询结果忽略了前 10 行,并且忽略了公共前缀 aa。
-
-有关如何导入 *CSV* 格式文件的详细步骤,参见[导入*. csv* 格式数据](../../../Develop/import-data/bulk-load/load-csv.md)。
-
-### 示例 2:LOAD JSONLines
-
-#### 简单导入示例
-
-本地命名为 *jsonline_array.jl* 文件内数据如下:
-
-```
-[true,1,"var","2020-09-07","2020-09-07 00:00:00","2020-09-07 00:00:00","18",121.11,["1",2,null,false,true,{"q":1}],"1qaz",null,null]
-["true","1","var","2020-09-07","2020-09-07 00:00:00","2020-09-07 00:00:00","18","121.11",{"c":1,"b":["a","b",{"q":4}]},"1aza",null,null]
-```
-
-在 MatrixOne 中建表:
-
-```sql
-mysql> drop table if exists t1;
-Query OK, 0 rows affected (0.01 sec)
-
-mysql> create table t1(col1 bool,col2 int,col3 varchar(100), col4 date,col5 datetime,col6 timestamp,col7 decimal,col8 float,col9 json,col10 text,col11 json,col12 bool);
-Query OK, 0 rows affected (0.03 sec)
-```
-
-将数据文件导入到 MatrixOne 中的表 t1:
-
-```
-load data infile {'filepath'='/jsonline_array.jl','format'='jsonline','jsondata'='array'} into table t1;
-```
-
-查询结果如下:
-
-```sql
-mysql> select * from t1;
-+------+------+------+------------+---------------------+---------------------+------+--------+---------------------------------------+-------+-------+-------+
-| col1 | col2 | col3 | col4 | col5 | col6 | col7 | col8 | col9 | col10 | col11 | col12 |
-+------+------+------+------------+---------------------+---------------------+------+--------+---------------------------------------+-------+-------+-------+
-| true | 1 | var | 2020-09-07 | 2020-09-07 00:00:00 | 2020-09-07 00:00:00 | 18 | 121.11 | ["1", 2, null, false, true, {"q": 1}] | 1qaz | NULL | NULL |
-| true | 1 | var | 2020-09-07 | 2020-09-07 00:00:00 | 2020-09-07 00:00:00 | 18 | 121.11 | {"b": ["a", "b", {"q": 4}], "c": 1} | 1aza | NULL | NULL |
-+------+------+------+------------+---------------------+---------------------+------+--------+---------------------------------------+-------+-------+-------+
-2 rows in set (0.00 sec)
-```
-
-#### 增加条件导入示例
-
-沿用上面的简单示例,你可以修改一下 LOAD DATA 语句,增加 `ignore 1 lines` 在语句的末尾,体验一下区别:
-
-```
-delete from t1;
-load data infile {'filepath'='/jsonline_array.jl','format'='jsonline','jsondata'='array'} into table t1 ignore 1 lines;
-```
-
-查询结果如下:
-
-```sql
-mysql> select * from t1;
-+------+------+------+------------+---------------------+---------------------+------+--------+-------------------------------------+-------+-------+-------+
-| col1 | col2 | col3 | col4 | col5 | col6 | col7 | col8 | col9 | col10 | col11 | col12 |
-+------+------+------+------------+---------------------+---------------------+------+--------+-------------------------------------+-------+-------+-------+
-| true | 1 | var | 2020-09-07 | 2020-09-07 00:00:00 | 2020-09-07 00:00:00 | 18 | 121.11 | {"b": ["a", "b", {"q": 4}], "c": 1} | 1aza | NULL | NULL |
-+------+------+------+------------+---------------------+---------------------+------+--------+-------------------------------------+-------+-------+-------+
-1 row in set (0.00 sec)
-```
-
-可以看到,查询结果忽略掉了第一行。
-
-有关如何导入 *JSONLines* 格式文件的详细步骤,参见[导入 JSONLines 数据](../../../Develop/import-data/bulk-load/load-jsonline.md)。
-
-## **限制**
-
-1. `REPLACE` 和 `IGNORE` 修饰符用来解决唯一索引的冲突:`REPLACE` 表示若表中已经存在,则用新的数据替换掉旧的数据;`IGNORE` 则表示保留旧的数据,忽略掉新数据。这两个修饰符在 MatrixOne 中尚不支持。
-2. MatrixOne 当前部分支持 `SET`,仅支持 `SET columns_name=nullif(col_name,expr2)`。
-3. 开启并行加载操作时必须要保证文件中每行数据中不包含指定的行结束符,比如 '\n',否则有可能会导致文件加载时数据出错。
-4. 文件的并行加载要求文件必须是非压缩格式,暂不支持并行加载压缩格式的文件。
-5. 如果你需要用 `LOAD DATA LOCAL` 进行本地加载,则需要使用命令行连接 MatrixOne 服务主机:`mysql -h -P 6001 -uroot -p111 --local-infile`。
-6. MatrixOne 当前暂不支持 `ESCAPED BY`,写入或读取特殊字符与 MySQL 存在一定的差异。
diff --git a/docs/MatrixOne/Reference/System-tables.md b/docs/MatrixOne/Reference/System-tables.md
index 7c275a3f1d..aeeae64f36 100644
--- a/docs/MatrixOne/Reference/System-tables.md
+++ b/docs/MatrixOne/Reference/System-tables.md
@@ -10,70 +10,24 @@ MatrixOne 系统数据库和表是 MatrixOne 存储系统信息的地方,你
从 MatrixOne 0.6 版本即引入了多租户的概念,默认的 `sys` 租户和其他租户的行为略有不同。服务于多租户管理的系统表 `mo_account` 仅对 `sys` 租户可见;其他租户看不到此表。
-### mo_database table
+### `mo_indexes` 表
-| 列属性 | 类型 | 描述 |
-| ---------------- | --------------- | --------------------------------------- |
-| dat_id | bigint unsigned | 主键 ID |
-| datname | varchar(100) | 数据库名称 |
-| dat_catalog_name | varchar(100) | 数据库 catalog 名称,默认`def` |
-| dat_createsql | varchar(100) | 创建数据库 SQL 语句 |
-| owner | int unsigned | 角色 ID |
-| creator | int unsigned | 用户 ID |
-| created_time | timestamp | 创建时间 |
-| account_id | int unsigned | 租户 ID |
-| dat_type | varchar(23) | 数据库类型,普通库或订阅库 |
-
-### mo_tables table
-
-| 列属性 | 类型 | 描述 |
-| -------------- | --------------- | ---------------------------------------------------- |
-| rel_id | bigint unsigned | 主键,表 ID |
-| relname | varchar(100) | 表、索引、视图等的名称 |
-| reldatabase | varchar(100) | 包含此关系的数据库,参考 mo_database.datname |
-| reldatabase_id | bigint unsigned | 包含此关系的数据库 ID,参考 mo_database.datid |
-| relpersistence | varchar(100) | p = 永久表
t = 临时表 |
-| relkind | varchar(100) | r = 普通表
e = 外部表
i = 索引
S = 序列
v = 视图
m = 物化视图 |
-| rel_comment | varchar(100) | |
-| rel_createsql | varchar(100) | 创建表 SQL 语句 |
-| created_time | timestamp | 创建时间 |
-| creator | int unsigned | 创建者 ID |
-| owner | int unsigned | 创建者的默认角色 ID |
-| account_id | int unsigned | 租户 id |
-| partitioned | blob | 按语句分区 |
-| partition_info | blob | 分区信息 |
-| viewdef | blob | 视图定义语句 |
-| constraint | varchar(5000) | 与表相关的约束 |
-| catalog_version | INT UNSIGNED(0) | 系统表的版本号 |
-
-### mo_columns table
-
-| 列属性 | 类型 | 描述 |
-| --------------------- | --------------- | ------------------------------------------------------------ |
-| att_uniq_name | varchar(256) | 主键。隐藏的复合主键,格式类似于 "${att_relname_id}-${attname}" |
-| account_id | int unsigned | 租户 ID |
-| att_database_id | bigint unsigned | 数据库 ID |
-| att_database | varchar(256) | 数据 Name |
-| att_relname_id | bigint unsigned | 表 ID |
-| att_relname | varchar(256) | 此列所属的表。(参考 mo_tables.relname)|
-| attname | varchar(256) | 列名 |
-| atttyp | varchar(256) | 此列的数据类型 (删除的列为 0 )。 |
-| attnum | int | 列数。普通列从 1 开始编号。 |
-| att_length | int | 类型的字节数 |
-| attnotnull | tinyint(1) | 表示一个非空约束。 |
-| atthasdef | tinyint(1) | 此列有默认表达式或生成表达式。 |
-| att_default | varchar(1024) | 默认表达式 |
-| attisdropped | tinyint(1) | 此列已删除,不再有效。删除的列仍然物理上存在于表中,但解析器会忽略它,因此不能通过 SQL 访问它。 |
-| att_constraint_type | char(1) | p = 主键约束
n=无约束 |
-| att_is_unsigned | tinyint(1) | 是否未署名 |
-| att_is_auto_increment | tinyint(1) | 是否自增 |
-| att_comment | varchar(1024) | 注释 |
-| att_is_hidden | tinyint(1) | 是否隐藏 |
-| attr_has_update | tinyint(1) | 此列含有更新表达式 |
-| attr_update | varchar(1024) | 更新表达式 |
-| attr_is_clusterby | tinyint(1) | 此列是否作为 cluster by 关键字来建表 |
+| 列属性 | 类型 | 描述 |
+| -----------------| --------------- | ----------------- |
+| id | BIGINT UNSIGNED(64) | 索引 ID |
+| table_id | BIGINT UNSIGNED(64) | 索引所在表的 ID |
+| database_id | BIGINT UNSIGNED(64) | 索引所在数据库的 ID |
+| name | VARCHAR(64) | 索引的名字 |
+| type | VARCHAR(11) | 索引的类型,包括主键索引(PRIMARY),唯一索引(UNIQUE),次级索引(MULTIPLE) |
+| is_visible | TINYINT(8) | 索引是否可见,1 为可见,0 不可见(目前 MatrixOne 的索引全部为可见索引) |
+| hidden | TINYINT(8) | 索引是否为隐藏索引,1 为隐藏索引,0 为非隐藏索引|
+| comment | VARCHAR(2048) | 索引的注释信息 |
+| column_name | VARCHAR(256) | 索引的组成列的列名 |
+| ordinal_position | INT UNSIGNED(32) | 索引中的列序号,从 1 开始 |
+| options | TEXT(0) | 索引的 options 选项信息 |
+| index_table_name | VARCHAR(5000) | 该索引对应的索引表的表名,目前只有唯一索引含有索引表 |
-### mo_table_partitions table
+### `mo_table_partitions` 表
| 列属性 | 类型 | 描述 |
| ------------ | ------------ | ------------ |
@@ -88,7 +42,23 @@ MatrixOne 系统数据库和表是 MatrixOne 存储系统信息的地方,你
| options | TEXT(0) | 分区的选项信息,暂为 `NULL` |
| partition_table_name | VARCHAR(1024) | 当前分区对应的分区子表名字 |
-### mo_account table (仅 `sys` 租户可见)
+### `mo_user` 表
+
+| 列属性 | 类型 | 描述 |
+| --------------------- | ------------ | ------------------- |
+| user_id | int | 用户 ID,主键 |
+| user_host | varchar(100) | 用户主机地址 |
+| user_name | varchar(100) | 用户名 |
+| authentication_string | varchar(100) | 密码加密的认证字符串 |
+| status | varchar(8) | 开启、锁定、失效 |
+| created_time | timestamp | 用户创建时间 |
+| expired_time | timestamp | 用户过期时间 |
+| login_type | varchar(16) | ssl/密码/其他 |
+| creator | int | 创建此用户的创建者 ID |
+| owner | int | 此用户的管理员 ID |
+| default_role | int | 此用户的默认角色 ID |
+
+### `mo_account` 表 (仅 `sys` 租户可见)
| 列属性 | 类型 | 描述 |
| ------------ | ------------ | ------------ |
@@ -100,7 +70,21 @@ MatrixOne 系统数据库和表是 MatrixOne 存储系统信息的地方,你
| suspended_time | TIMESTAMP | 修改租户状态的时间|
| version | bigint unsigned | 当前租户版本状态|
-### mo_role table
+### `mo_database` 表
+
+| 列属性 | 类型 | 描述 |
+| ---------------- | --------------- | --------------------------------------- |
+| dat_id | bigint unsigned | 主键 ID |
+| datname | varchar(100) | 数据库名称 |
+| dat_catalog_name | varchar(100) | 数据库 catalog 名称,默认`def` |
+| dat_createsql | varchar(100) | 创建数据库 SQL 语句 |
+| owner | int unsigned | 角色 ID |
+| creator | int unsigned | 用户 ID |
+| created_time | timestamp | 创建时间 |
+| account_id | int unsigned | 租户 ID |
+| dat_type | varchar(23) | 数据库类型,普通库或订阅库 |
+
+### `mo_role` 表
| 列属性 | 类型 | 描述 |
| ------------ | ------------ | ----------------------------- |
@@ -111,23 +95,7 @@ MatrixOne 系统数据库和表是 MatrixOne 存储系统信息的地方,你
| created_time | timestamp | 创建时间 |
| comment | text | 注释 |
-### mo_user table
-
-| 列属性 | 类型 | 描述 |
-| --------------------- | ------------ | ------------------- |
-| user_id | int | 用户 ID,主键 |
-| user_host | varchar(100) | 用户主机地址 |
-| user_name | varchar(100) | 用户名 |
-| authentication_string | varchar(100) | 密码加密的认证字符串 |
-| status | varchar(8) | 开启、锁定、失效 |
-| created_time | timestamp | 用户创建时间 |
-| expired_time | timestamp | 用户过期时间 |
-| login_type | varchar(16) | ssl/密码/其他 |
-| creator | int | 创建此用户的创建者 ID |
-| owner | int | 此用户的管理员 ID |
-| default_role | int | 此用户的默认角色 ID |
-
-### mo_user_grant table
+### `mo_user_grant` 表
| 列属性 | 类型 | 描述 |
| ----------------- | ------------ | ----------------------------------- |
@@ -136,7 +104,7 @@ MatrixOne 系统数据库和表是 MatrixOne 存储系统信息的地方,你
| granted_time | timestamp | 授权时间 |
| with_grant_option | bool | 是否允许获得授权用户再授权给其他用户或角色 |
-### mo_role_grant table
+### `mo_role_grant` 表
| 列属性 | 类型 | 描述 |
| ----------------- | ------------ | ----------------------------------- |
@@ -147,7 +115,7 @@ MatrixOne 系统数据库和表是 MatrixOne 存储系统信息的地方,你
| granted_time | timestamp | 授权时间 |
| with_grant_option | bool | 是否允许获得授权角色再授权给其他用户或角色 |
-### mo_role_privs table
+### `mo_role_privs` 表
| 列属性 | 类型 | 描述 |
| ----------------- | --------------- | ----------------------------------- |
@@ -162,19 +130,7 @@ MatrixOne 系统数据库和表是 MatrixOne 存储系统信息的地方,你
| granted_time | timestamp | 授权时间 |
| with_grant_option | bool | 是否允许授权|
-### mo_stages table
-
-| 列属性 | 类型 | 描述 |
-| -----------------| --------------- | ----------------- |
-| stage_id | INT UNSIGNED(32) | 数据阶段 ID |
-| stage_name | VARCHAR(64) | 数据阶段名称 |
-| url | TEXT(0) | 对象存储的路径(不含认证)、文件系统的路径 |
-| stage_credentials | TEXT(0) | 认证信息,加密后保存 |
-| stage_status | VARCHAR(64) | ENABLED/DISABLED 默认:DISABLED |
-| created_time | TIMESTAMP(0) | 创建时间 |
-| comment | TEXT(0) | 注释 |
-
-### mo_user_defined_function table
+### `mo_user_defined_function` 表
| 列属性 | 类型 | 描述 |
| -----------------| --------------- | ----------------- |
@@ -196,7 +152,7 @@ MatrixOne 系统数据库和表是 MatrixOne 存储系统信息的地方,你
| collation_connection | VARCHAR(64) | 连接排序:utf8mb4_0900_ai_ci |
| database_collation | VARCHAR(64) | 数据库连接排序:utf8mb4_0900_ai_ci |
-### mo_mysql_compatbility_mode table
+### `mo_mysql_compatbility_mode` 表
| 列属性 | 类型 | 描述 |
| -----------------| --------------- | ----------------- |
@@ -205,7 +161,7 @@ MatrixOne 系统数据库和表是 MatrixOne 存储系统信息的地方,你
| dat_name | VARCHAR(5000) | 配置所在的数据库名称 |
| configuration | JSON(0) | 配置内容,以 JSON 形式保存 |
-### mo_pubs table
+### `mo_pubs` 表
| 列属性 | 类型 | 描述 |
| -----------------| --------------- | ----------------- |
@@ -221,28 +177,150 @@ MatrixOne 系统数据库和表是 MatrixOne 存储系统信息的地方,你
| creator | INT UNSIGNED(32) | 创建发布库对应的用户 ID |
| comment | TEXT(0) | 创建发布库的备注信息 |
-### mo_indexes table
+### `mo_stages` 表
| 列属性 | 类型 | 描述 |
| -----------------| --------------- | ----------------- |
-| id | BIGINT UNSIGNED(64) | 索引 ID |
-| table_id | BIGINT UNSIGNED(64) | 索引所在表的 ID |
-| database_id | BIGINT UNSIGNED(64) | 索引所在数据库的 ID |
-| name | VARCHAR(64) | 索引的名字 |
-| type | VARCHAR(11) | 索引的类型,包括主键索引(PRIMARY),唯一索引(UNIQUE),次级索引(MULTIPLE) |
-| is_visible | TINYINT(8) | 索引是否可见,1 为可见,0 不可见(目前 MatrixOne 的索引全部为可见索引) |
-| hidden | TINYINT(8) | 索引是否为隐藏索引,1 为隐藏索引,0 为非隐藏索引|
-| comment | VARCHAR(2048) | 索引的注释信息 |
-| column_name | VARCHAR(256) | 索引的组成列的列名 |
-| ordinal_position | INT UNSIGNED(32) | 索引中的列序号,从 1 开始 |
-| options | TEXT(0) | 索引的 options 选项信息 |
-| index_table_name | VARCHAR(5000) | 该索引对应的索引表的表名,目前只有唯一索引含有索引表 |
+| stage_id | INT UNSIGNED(32) | 数据阶段 ID |
+| stage_name | VARCHAR(64) | 数据阶段名称 |
+| url | TEXT(0) | 对象存储的路径(不含认证)、文件系统的路径 |
+| stage_credentials | TEXT(0) | 认证信息,加密后保存 |
+| stage_status | VARCHAR(64) | ENABLED/DISABLED 默认:DISABLED |
+| created_time | TIMESTAMP(0) | 创建时间 |
+| comment | TEXT(0) | 注释 |
+
+### `mo_sessions` 视图
+
+| 列名 | 数据类型 | 描述 |
+| ----------------- | ----------------- | ------------------------------------------------------------ |
+| node_id | VARCHAR(65535) | MatrixOne 节点的唯一标识符。一经启动,不可更改。 |
+| conn_id | INT UNSIGNED | 在 MatrixOne 中与客户端 TCP 连接相关的唯一编号,由 Hakeeper 自动生成。 |
+| session_id | VARCHAR(65535) | 用于标识会话的唯一 UUID。每个新会话都会生成一个新的 UUID。 |
+| account | VARCHAR(65535) | 租户的名称。 |
+| user | VARCHAR(65535) | 用户的名称。 |
+| host | VARCHAR(65535) | CN 节点接收客户端请求的 IP 地址和端口。 |
+| db | VARCHAR(65535) | 执行 SQL 时使用的数据库名称。 |
+| session_start | VARCHAR(65535) | 会话创建的时间戳。 |
+| command | VARCHAR(65535) | MySQL 命令的类型,如 COM_QUERY、COM_STMT_PREPARE、COM_STMT_EXECUTE 等。 |
+| info | VARCHAR(65535) | 执行的 SQL 语句。一个 SQL 中可能包含多个语句。 |
+| txn_id | VARCHAR(65535) | 相关事务的唯一标识符。 |
+| statement_id | VARCHAR(65535) | SQL 语句的唯一标识符(UUID)。 |
+| statement_type | VARCHAR(65535) | SQL 语句的类型,如 SELECT、INSERT、UPDATE 等。 |
+| query_type | VARCHAR(65535) | SQL 语句的种类,如 DQL(数据查询语言)、TCL(事务控制语言)等。 |
+| sql_source_type | VARCHAR(65535) | SQL 语句的来源,如外部或内部。 |
+| query_start | VARCHAR(65535) | SQL 语句开始执行的时间戳。 |
+| client_host | VARCHAR(65535) | 客户端的 IP 地址和端口号。 |
+| role | VARCHAR(65535) | 用户的角色名称。 |
+
+### `mo_configurations` 表
+
+| 列名 | 数据类型 | 描述 |
+| ------------- | --------------- | ------------------------------------ |
+| node_type | VARCHAR(65535) | 节点的类型:cn(计算节点)、tn(事务节点)、log(日志节点)、proxy(代理)。 |
+| node_id | VARCHAR(65535) | 节点的唯一标识符。 |
+| name | VARCHAR(65535) |配置项的名称,可能会附带嵌套结构前缀。|
+| current_value | VARCHAR(65535) | 配置项的当前数值。 |
+| default_value | VARCHAR(65535) | 配置项的默认数值。 |
+| internal | VARCHAR(65535) | 表示配置参数是否为内部参数。 |
+
+### `mo_locks` 视图
+
+| 列名 | 数据类型 | 描述 |
+| ------------- | --------------- | ------------------------------------------------ |
+| txn_id | VARCHAR(65535) | 持有锁的事务。 |
+| table_id | VARCHAR(65535) | 加锁的表。 |
+| lock_type | VARCHAR(65535) | 锁类型。可以是 `point` 或 `range`。 |
+| lock_content | VARCHAR(65535) | 锁定的内容,以 16 进制表示。对于 `range` 锁,表示一个区间;对于 `point` 锁,表示单个值。 |
+| lock_mode | VARCHAR(65535) | 锁模式。可以是 `shared` 或 `exclusive`。 |
+| lock_status | VARCHAR(65535) | 锁状态,可能为 `wait`、`acquired` 或 `none`。
wait。没有事务持有锁,但有事务等在锁上。
acquired。有事务持有锁。
none。没有事务持有锁,也没有事务等在锁上。 |
+| waiting_txns | VARCHAR(65535) | 在此锁上等待的事务。 |
+
+### `mo_variables` 视图
+
+| 列名 | 数据类型 | 描述 |
+| ---------------- | -------------- | ------------------------------------ |
+| configuration_id | INT(32) | 自增列,用于唯一标识每个配置项。 |
+| account_id | INT(32) | 标识租户的唯一标识符。 |
+| account_name | VARCHAR(300) | 租户的名称。 |
+| dat_name | VARCHAR(5000) | 数据库的名称。 |
+| variable_name | VARCHAR(300) | 配置变量的名称。 |
+| variable_value | VARCHAR(5000) | 配置变量的数值。 |
+| system_variables | BOOL(0) | 指示配置变量是否为系统级别的变量。 |
+
+### `mo_transactions` 视图
+
+| 列名 | 数据类型 | 描述 |
+| ------------- | --------------- | ------------------------------------ |
+| cn_id | VARCHAR(65535) | 唯一标识 CN(Compute Node)的 ID。 |
+| txn_id | VARCHAR(65535) | 唯一标识事务的 ID。 |
+| create_ts | VARCHAR(65535) | 记录事务创建时间戳,遵循 RFC3339Nano 格式 ("2006-01-02T15:04:05.999999999Z07:00")。 |
+| snapshot_ts | VARCHAR(65535) | 表示事务的快照时间戳,以物理时间和逻辑时间的形式表示。 |
+| prepared_ts | VARCHAR(65535) | 表示事务的 prepared 时间戳,以物理时间和逻辑时间的形式表示。 |
+| commit_ts | VARCHAR(65535) | 表示事务的 commit 时间戳,以物理时间和逻辑时间的形式表示。|
+| txn_mode | VARCHAR(65535) | 标识事务模式,可以是悲观事务或乐观事务。 |
+| isolation | VARCHAR(65535) | 表示事务的隔离级别,可以是 SI(Snapshot Isolation)或 RC(Read Committed)。 |
+| user_txn | VARCHAR(65535) | 指示用户事务,即用户通过客户端连接到 MatrixOne 并执行的 SQL 操作所创建的事务。 |
+| txn_status | VARCHAR(65535) | 表示事务的当前状态,可能的取值包括 active(活跃)、committed(已提交)、aborting(中止中)、aborted(已中止)。在分布式事务 2PC 模式下,还会包括 prepared(已准备)和 committing(提交中)。 |
+| table_id | VARCHAR(65535) | 表示事务所涉及的表的 ID。 |
+| lock_key | VARCHAR(65535) | 表示锁的类型,可以是 range(范围锁)或 point(点锁)。 |
+| lock_content | VARCHAR(65535) | point 锁时表示单个值,range 锁时表示范围,通常以 "low - high" 形式表示。请注意,事务可能涉及多个锁,但此处仅展示第一个锁。|
+| lock_mode | VARCHAR(65535) | 表示锁的模式,可以是互斥锁(exclusive)或共享锁(shared)。 |
+
+### `mo_columns` 表
+
+| 列属性 | 类型 | 描述 |
+| --------------------- | --------------- | ------------------------------------------------------------ |
+| att_uniq_name | varchar(256) | 主键。隐藏的复合主键,格式类似于 "${att_relname_id}-${attname}" |
+| account_id | int unsigned | 租户 ID |
+| att_database_id | bigint unsigned | 数据库 ID |
+| att_database | varchar(256) | 数据 Name |
+| att_relname_id | bigint unsigned | 表 ID |
+| att_relname | varchar(256) | 此列所属的表。(参考 mo_tables.relname)|
+| attname | varchar(256) | 列名 |
+| atttyp | varchar(256) | 此列的数据类型 (删除的列为 0 )。 |
+| attnum | int | 列数。普通列从 1 开始编号。 |
+| att_length | int | 类型的字节数 |
+| attnotnull | tinyint(1) | 表示一个非空约束。 |
+| atthasdef | tinyint(1) | 此列有默认表达式或生成表达式。 |
+| att_default | varchar(1024) | 默认表达式 |
+| attisdropped | tinyint(1) | 此列已删除,不再有效。删除的列仍然物理上存在于表中,但解析器会忽略它,因此不能通过 SQL 访问它。 |
+| att_constraint_type | char(1) | p = 主键约束
n=无约束 |
+| att_is_unsigned | tinyint(1) | 是否未署名 |
+| att_is_auto_increment | tinyint(1) | 是否自增 |
+| att_comment | varchar(1024) | 注释 |
+| att_is_hidden | tinyint(1) | 是否隐藏 |
+| attr_has_update | tinyint(1) | 此列含有更新表达式 |
+| attr_update | varchar(1024) | 更新表达式 |
+| attr_is_clusterby | tinyint(1) | 此列是否作为 cluster by 关键字来建表 |
+
+### `mo_tables` 表
+
+| 列属性 | 类型 | 描述 |
+| -------------- | --------------- | ---------------------------------------------------- |
+| rel_id | bigint unsigned | 主键,表 ID |
+| relname | varchar(100) | 表、索引、视图等的名称 |
+| reldatabase | varchar(100) | 包含此关系的数据库,参考 mo_database.datname |
+| reldatabase_id | bigint unsigned | 包含此关系的数据库 ID,参考 mo_database.datid |
+| relpersistence | varchar(100) | p = 永久表
t = 临时表 |
+| relkind | varchar(100) | r = 普通表
e = 外部表
i = 索引
S = 序列
v = 视图
m = 物化视图 |
+| rel_comment | varchar(100) | |
+| rel_createsql | varchar(100) | 创建表 SQL 语句 |
+| created_time | timestamp | 创建时间 |
+| creator | int unsigned | 创建者 ID |
+| owner | int unsigned | 创建者的默认角色 ID |
+| account_id | int unsigned | 租户 id |
+| partitioned | blob | 按语句分区 |
+| partition_info | blob | 分区信息 |
+| viewdef | blob | 视图定义语句 |
+| constraint | varchar(5000) | 与表相关的约束 |
+| rel_version | INT UNSIGNED(0) | 主键,表的版本号 |
+| catalog_version | INT UNSIGNED(0) | 系统表的版本号 |
## `system_metrics` 数据库
`system_metrics` 收集 SQL 语句、CPU 和内存资源使用的状态和统计信息。
-`system_metrics` 表一些相同的列类型,这些表中的字段描述如下:
+`metrics` 表一些相同的列类型,这些表中的字段描述如下:
- collecttime:收集时间。
diff --git a/mkdocs.yml b/mkdocs.yml
index fc70c5d05d..d8823d9e81 100644
--- a/mkdocs.yml
+++ b/mkdocs.yml
@@ -247,6 +247,7 @@ nav:
- ENUM 类型: MatrixOne/Reference/Data-Types/enum-type.md
- UUID 数据类型: MatrixOne/Reference/Data-Types/uuid-type.md
- 精确数值类型-DECIMAL: MatrixOne/Reference/Data-Types/fixed-point-types.md
+ - 向量数据类型: MatrixOne/Reference/Data-Types/vector-type.md
- SQL 目录:
- SQL 语句的分类: MatrixOne/Reference/SQL-Reference/SQL-Type.md
- 数据定义语言(DDL):
@@ -515,6 +516,14 @@ nav:
- REGEXP_LIKE(): MatrixOne/Reference/Functions-and-Operators/String/Regular-Expressions/regexp-like.md
- REGEXP_REPLACE(): MatrixOne/Reference/Functions-and-Operators/String/Regular-Expressions/regexp-replace.md
- REGEXP_SUBSTR(): MatrixOne/Reference/Functions-and-Operators/String/Regular-Expressions/regexp-substr.md
+ - 向量类:
+ - 基本操作符: MatrixOne/Reference/Functions-and-Operators/Vector/arithmetic.md
+ - 数学计算: MatrixOne/Reference/Functions-and-Operators/Vector/misc.md
+ - 内积计算: MatrixOne/Reference/Functions-and-Operators/Vector/inner_product.md
+ - 余弦相似度计算: MatrixOne/Reference/Functions-and-Operators/Vector/cosine_similarity.md
+ - L1 范数函数: MatrixOne/Reference/Functions-and-Operators/Vector/l1_norm.md
+ - L2 范数函数: MatrixOne/Reference/Functions-and-Operators/Vector/l2_norm.md
+ - 维度函数: MatrixOne/Reference/Functions-and-Operators/Vector/vector_dims.md
- 表函数:
- UNNEST(): MatrixOne/Reference/Functions-and-Operators/Table/unnest.md
- 窗口函数: