diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/DataX-write.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/DataX-write.md
deleted file mode 100644
index fa3bc57eae..0000000000
--- a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/DataX-write.md
+++ /dev/null
@@ -1,633 +0,0 @@
-# 使用 DataX 将数据写入 MatrixOne
-
-## 概述
-
-本文介绍如何使用 DataX 工具将数据离线写入 MatrixOne 数据库。
-
-DataX 是一款由阿里开源的异构数据源离线同步工具,提供了稳定和高效的数据同步功能,旨在实现各种异构数据源之间的高效数据同步。
-
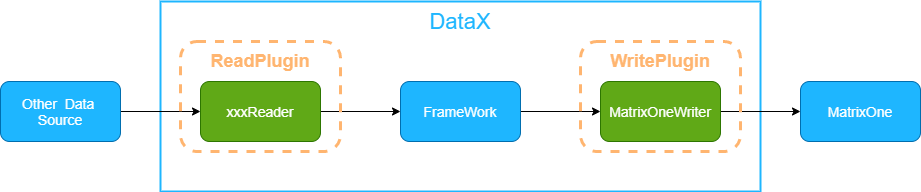
-DataX 将不同数据源的同步分为两个主要组件:**Reader(读取数据源)
-**和 **Writer(写入目标数据源)**。DataX 框架理论上支持任何数据源类型的数据同步工作。
-
-MatrixOne 与 MySQL 8.0 高度兼容,但由于 DataX 自带的 MySQL Writer 插件适配的是 MySQL 5.1 的 JDBC 驱动,为了提升兼容性,社区单独改造了基于 MySQL 8.0 驱动的 MatrixOneWriter 插件。MatrixOneWriter 插件实现了将数据写入 MatrixOne 数据库目标表的功能。在底层实现中,MatrixOneWriter 通过 JDBC 连接到远程 MatrixOne 数据库,并执行相应的 `insert into ...` SQL 语句将数据写入 MatrixOne,同时支持批量提交。
-
-MatrixOneWriter 利用 DataX 框架从 Reader 获取生成的协议数据,并根据您配置的 `writeMode` 生成相应的 `insert into...` 语句。在遇到主键或唯一性索引冲突时,会排除冲突的行并继续写入。出于性能优化的考虑,我们采用了 `PreparedStatement + Batch` 的方式,并设置了 `rewriteBatchedStatements=true` 选项,以将数据缓冲到线程上下文的缓冲区中。只有当缓冲区的数据量达到预定的阈值时,才会触发写入请求。
-
-
-
-!!! note
- 执行整个任务至少需要拥有 `insert into ...` 的权限,是否需要其他权限取决于你在任务配置中的 `preSql` 和 `postSql`。
-
-MatrixOneWriter 主要面向 ETL 开发工程师,他们使用 MatrixOneWriter 将数据从数据仓库导入到 MatrixOne。同时,MatrixOneWriter 也可以作为数据迁移工具为 DBA 等用户提供服务。
-
-## 开始前准备
-
-在开始使用 DataX 将数据写入 MatrixOne 之前,需要完成安装以下软件:
-
-- 安装 [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html)。
-- 安装 [Python 3.8(or plus)](https://www.python.org/downloads/)。
-- 下载 [DataX](https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202210/datax.tar.gz) 安装包,并解压。
-- 下载 [matrixonewriter.zip](https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/Computing-Engine/datax-write/matrixonewriter.zip),解压至 DataX 项目根目录的 `plugin/writer/` 目录下。
-- 安装 <a href="https://dev.mysql.com/downloads/mysql" target="_blank">MySQL Client</a>。
-- [安装和启动 MatrixOne](../../../Get-Started/install-standalone-matrixone.md)。
-
-## 操作步骤
-
-### 创建 MatrixOne 测试表
-
-使用 Mysql Client 连接 MatrixOne,在 MatrixOne 中创建一个测试表:
-
-```sql
-CREATE DATABASE mo_demo;
-USE mo_demo;
-CREATE TABLE m_user(
- M_ID INT NOT NULL,
- M_NAME CHAR(25) NOT NULL
-);
-```
-
-### 配置数据源
-
-本例中,我们使用**内存**中生成的数据作为数据源:
-
-```json
-"reader": {
- "name": "streamreader",
- "parameter": {
- "column" : [ #可以写多个列
- {
- "value": 20210106, #表示该列的值
- "type": "long" #表示该列的类型
- },
- {
- "value": "matrixone",
- "type": "string"
- }
- ],
- "sliceRecordCount": 1000 #表示要打印多少次
- }
-}
-```
-
-### 编写作业配置文件
-
-使用以下命令查看配置模板:
-
-```
-python datax.py -r {YOUR_READER} -w matrixonewriter
-```
-
-编写作业的配置文件 `stream2matrixone.json`:
-
-```json
-{
- "job": {
- "setting": {
- "speed": {
- "channel": 1
- }
- },
- "content": [
- {
- "reader": {
- "name": "streamreader",
- "parameter": {
- "column" : [
- {
- "value": 20210106,
- "type": "long"
- },
- {
- "value": "matrixone",
- "type": "string"
- }
- ],
- "sliceRecordCount": 1000
- }
- },
- "writer": {
- "name": "matrixonewriter",
- "parameter": {
- "writeMode": "insert",
- "username": "root",
- "password": "111",
- "column": [
- "M_ID",
- "M_NAME"
- ],
- "preSql": [
- "delete from m_user"
- ],
- "connection": [
- {
- "jdbcUrl": "jdbc:mysql://127.0.0.1:6001/mo_demo",
- "table": [
- "m_user"
- ]
- }
- ]
- }
- }
- }
- ]
- }
-}
-```
-
-### 启动 DataX
-
-执行以下命令启动 DataX:
-
-```shell
-$ cd {YOUR_DATAX_DIR_BIN}
-$ python datax.py stream2matrixone.json
-```
-
-### 查看运行结果
-
-使用 Mysql Client 连接 MatrixOne,使用 `select` 查询插入的结果。内存中的 1000 条数据已成功写入 MatrixOne。
-
-```sql
-mysql> select * from m_user limit 5;
-+----------+-----------+
-| m_id | m_name |
-+----------+-----------+
-| 20210106 | matrixone |
-| 20210106 | matrixone |
-| 20210106 | matrixone |
-| 20210106 | matrixone |
-| 20210106 | matrixone |
-+----------+-----------+
-5 rows in set (0.01 sec)
-
-mysql> select count(*) from m_user limit 5;
-+----------+
-| count(*) |
-+----------+
-| 1000 |
-+----------+
-1 row in set (0.00 sec)
-```
-
-## 参数说明
-
-以下是 MatrixOneWriter 的一些常用参数说明:
-
-|参数名称 | 参数描述 | 是否必选 | 默认值|
-|---|---|---|---|
-|**jdbcUrl** |目标数据库的 JDBC 连接信息。DataX 在运行时会在提供的 `jdbcUrl` 后面追加一些属性,例如:`yearIsDateType=false&zeroDateTimeBehavior=CONVERT_TO_NULL&rewriteBatchedStatements=true&tinyInt1isBit=false&serverTimezone=Asia/Shanghai`。 |是 |无 |
-|**username** | 目标数据库的用户名。|是 |无 |
-|**password** |目标数据库的密码。 |是 |无 |
-|**table** |目标表的名称。支持写入一个或多个表,如果配置多张表,必须确保它们的结构保持一致。 |是 |无 |
-|**column** | 目标表中需要写入数据的字段,字段之间用英文逗号分隔。例如:`"column": ["id","name","age"]`。如果要写入所有列,可以使用 `*` 表示,例如:`"column": ["*"]`。|是 |无 |
-|**preSql** |写入数据到目标表之前,会执行这里配置的标准 SQL 语句。 |否 |无 |
-|**postSql** |写入数据到目标表之后,会执行这里配置的标准 SQL 语句。 |否 |无 |
-|**writeMode** |控制写入数据到目标表时使用的 SQL 语句,可以选择 `insert` 或 `update`。 | `insert` 或 `update`| `insert`|
-|**batchSize** |一次性批量提交的记录数大小,可以显著减少 DataX 与 MatrixOne 的网络交互次数,提高整体吞吐量。但是设置过大可能导致 DataX 运行进程内存溢出 | 否 | 1024 |
-
-## 类型转换
-
-MatrixOneWriter 支持大多数 MatrixOne 数据类型,但也有少数类型尚未支持,需要特别注意你的数据类型。
-
-以下是 MatrixOneWriter 针对 MatrixOne 数据类型的转换列表:
-
-| DataX 内部类型 | MatrixOne 数据类型 |
-| --------------- | ------------------ |
-| Long | int, tinyint, smallint, bigint |
-| Double | float, double, decimal |
-| String | varchar, char, text |
-| Date | date, datetime, timestamp, time |
-| Boolean | bool |
-| Bytes | blob |
-
-## 参考其他说明
-
-- MatrixOne 兼容 MySQL 协议,MatrixOneWriter 实际上是对 MySQL Writer 进行了一些 JDBC 驱动版本上的调整后的改造版本,你仍然可以使用 MySQL Writer 来写入 MatrixOne。
-
-- 在 DataX 中添加 MatrixOne Writer,那么你需要下载 [matrixonewriter.zip](https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/Computing-Engine/datax-write/matrixonewriter.zip),然后将其解压缩到 DataX 项目根目录的 `plugin/writer/` 目录下,即可开始使用。
-
-## 最佳实践:实现 MatrixOne 与 ElasticSearch 间的数据迁移
-
-MatrixOne 擅长 HTAP 场景的事务处理和低延迟分析计算,ElasticSearch 擅长全文检索,两者做为流行的搜索和分析引擎,结合起来可形成更完善的全场景分析解决方案。为了在不同场景间进行数据的高效流转,我们可通过 DataX 进行 MatrixOne 与 ElasticSearch 间的数据迁移。
-
-### 环境准备
-
-- MatrixOne 版本:1.1.3
-
-- Elasticsearch 版本:7.10.2
-
-- DataX 版本:[DataX_v202309](https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202309/datax.tar.gz)
-
-### 在 MatrixOne 中创建库和表
-
-创建数据库 `mo`,并在该库创建数据表 person:
-
-```sql
-create database mo;
-CREATE TABLE mo.`person` (
-`id` INT DEFAULT NULL,
-`name` VARCHAR(255) DEFAULT NULL,
-`birthday` DATE DEFAULT NULL
-);
-```
-
-### 在 ElasticSearch 中创建索引
-
-创建名称为 person 的索引(下文 `-u` 参数后为 ElasticSearch 中的用户名和密码,本地测试时可按需进行修改或删除):
-
-```shell
-curl -X PUT "http://127.0.0.1:9200/person" -u elastic:elastic
-```
-
-输出如下信息表示创建成功:
-
-```shell
-{"acknowledged":true,"shards_acknowledged":true,"index":"person"}
-```
-
-给索引 person 添加字段:
-
-```shell
-curl -X PUT "127.0.0.1:9200/person/_mapping" -H 'Content-Type: application/json' -u elastic:elastic -d'
-{
- "properties": {
- "id": { "type": "integer" },
- "name": { "type": "text" },
- "birthday": {"type": "date"}
- }
-}
-'
-```
-
-输出如下信息表示设置成功:
-
-```shell
-{"acknowledged":true}
-```
-
-### 为 ElasticSearch 索引添加数据
-
-通过 curl 命令添加三条数据:
-
-```shell
-curl -X POST '127.0.0.1:9200/person/_bulk' -H 'Content-Type: application/json' -u elastic:elastic -d '
-{"index":{"_index":"person","_type":"_doc","_id":1}}
-{"id": 1,"name": "MatrixOne","birthday": "1992-08-08"}
-{"index":{"_index":"person","_type":"_doc","_id":2}}
-{"id": 2,"name": "MO","birthday": "1993-08-08"}
-{"index":{"_index":"person","_type":"_doc","_id":3}}
-{"id": 3,"name": "墨墨","birthday": "1994-08-08"}
-'
-```
-
-输出如下信息表示执行成功:
-
-```shell
-{"took":5,"errors":false,"items":[{"index":{"_index":"person","_type":"_doc","_id":"1","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":0,"_primary_term":1,"status":201}},{"index":{"_index":"person","_type":"_doc","_id":"2","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":1,"_primary_term":1,"status":201}},{"index":{"_index":"person","_type":"_doc","_id":"3","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":2,"_primary_term":1,"status":201}}]}
-```
-
-查看索引中所有内容:
-
-```shell
-curl -u elastic:elastic -X GET http://127.0.0.1:9200/person/_search?pretty -H 'Content-Type: application/json' -d'
-{
- "query" : {
- "match_all": {}
- }
-}'
-```
-
-可正常看到索引中新增的数据即表示执行成功。
-
-### 使用 DataX 导入数据
-
-#### 1. 下载并解压 DataX
-
-DataX 解压后目录如下:
-
-```shell
-[root@node01 datax]# ll
-total 4
-drwxr-xr-x. 2 root root 59 Nov 28 13:48 bin
-drwxr-xr-x. 2 root root 68 Oct 11 09:55 conf
-drwxr-xr-x. 2 root root 22 Oct 11 09:55 job
-drwxr-xr-x. 2 root root 4096 Oct 11 09:55 lib
-drwxr-xr-x. 4 root root 42 Oct 12 18:42 log
-drwxr-xr-x. 4 root root 42 Oct 12 18:42 log_perf
-drwxr-xr-x. 4 root root 34 Oct 11 09:55 plugin
-drwxr-xr-x. 2 root root 23 Oct 11 09:55 script
-drwxr-xr-x. 2 root root 24 Oct 11 09:55 tmp
-```
-
-为保证迁移的易用性和高效性,MatrixOne 社区开发了 `elasticsearchreader` 以及 `matrixonewriter` 两个插件,将 [elasticsearchreader.zip](https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/datax_es_mo/elasticsearchreader.zip) 下载后使用 `unzip` 命令解压至 `datax/plugin/reader` 目录下(注意不要在该目录中保留插件 zip 包,关于 elasticsearchreader 的详细介绍可参考插件包内的 elasticsearchreader.md 文档),同样,将 [matrixonewriter.zip](https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/Computing-Engine/datax-write/matrixonewriter.zip) 下载后解压至 `datax/plugin/writer` 目录下,matrixonewriter 是社区基于 mysqlwriter 的改造版,使用 mysql-connector-j-8.0.33.jar 驱动来保证更好的性能和兼容性,writer 部分的其语法可参考上文“参数说明”章节。
-
-在进行后续的操作前,请先检查插件是否已正确分发在对应的位置中。
-
-#### 2. 编写 ElasticSearch 至 MatrixOne 的迁移作业文件
-
-DataX 使用 json 文件来配置作业信息,编写作业文件例如 **es2mo.json**,习惯性的可以将其存放在 `datax/job` 目录中:
-
-```json
-{
- "job":{
- "setting":{
- "speed":{
- "channel":1
- },
- "errorLimit":{
- "record":0,
- "percentage":0.02
- }
- },
- "content":[
- {
- "reader":{
- "name":"elasticsearchreader",
- "parameter":{
- "endpoint":"http://127.0.0.1:9200",
- "accessId":"elastic",
- "accessKey":"elastic",
- "index":"person",
- "type":"_doc",
- "headers":{
-
- },
- "scroll":"3m",
- "search":[
- {
- "query":{
- "match_all":{
-
- }
- }
- }
- ],
- "table":{
- "filter":"",
- "nameCase":"UPPERCASE",
- "column":[
- {
- "name":"id",
- "type":"integer"
- },
- {
- "name":"name",
- "type":"text"
- },
- {
- "name":"birthday",
- "type":"date"
- }
- ]
- }
- }
- },
- "writer":{
- "name":"matrixonewriter",
- "parameter":{
- "username":"root",
- "password":"111",
- "column":[
- "id",
- "name",
- "birthday"
- ],
- "connection":[
- {
- "table":[
- "person"
- ],
- "jdbcUrl":"jdbc:mysql://127.0.0.1:6001/mo"
- }
- ]
- }
- }
- }
- ]
- }
-}
-```
-
-#### 3. 执行迁移任务
-
-进入 datax 安装目录,执行以下命令启动迁移作业:
-
-```shell
-cd datax
-python bin/datax.py job/es2mo.json
-```
-
-作业执行完成后,输出结果如下:
-
-```shell
-2023-11-28 15:55:45.642 [job-0] INFO StandAloneJobContainerCommunicator - Total 3 records, 67 bytes | Speed 6B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.456s | Percentage 100.00%
-2023-11-28 15:55:45.644 [job-0] INFO JobContainer -
-任务启动时刻 : 2023-11-28 15:55:31
-任务结束时刻 : 2023-11-28 15:55:45
-任务总计耗时 : 14s
-任务平均流量 : 6B/s
-记录写入速度 : 0rec/s
-读出记录总数 : 3
-读写失败总数 : 0
-```
-
-#### 4. 在 MatrixOne 中查看迁移后数据
-
-在 MatrixOne 数据库中查看目标表中的结果,确认迁移已完成:
-
-```shell
-mysql> select * from mo.person;
-+------+-----------+------------+
-| id | name | birthday |
-+------+-----------+------------+
-| 1 | MatrixOne | 1992-08-08 |
-| 2 | MO | 1993-08-08 |
-| 3 | 墨墨 | 1994-08-08 |
-+------+-----------+------------+
-3 rows in set (0.00 sec)
-```
-
-#### 5. 编写 MatrixOne 至 ElasticSearch 的作业文件
-
-编写 datax 作业文件 **mo2es.json**,同样放在 `datax/job` 目录,MatrixOne 高度兼容 MySQL 协议,我们可以直接使用 mysqlreader 来通过 jdbc 方式读取 MatrixOne 中的数据:
-
-```json
-{
- "job": {
- "setting": {
- "speed": {
- "channel": 1
- },
- "errorLimit": {
- "record": 0,
- "percentage": 0.02
- }
- },
- "content": [{
- "reader": {
- "name": "mysqlreader",
- "parameter": {
- "username": "root",
- "password": "111",
- "column": [
- "id",
- "name",
- "birthday"
- ],
- "splitPk": "id",
- "connection": [{
- "table": [
- "person"
- ],
- "jdbcUrl": [
- "jdbc:mysql://127.0.0.1:6001/mo"
- ]
- }]
- }
- },
- "writer": {
- "name": "elasticsearchwriter",
- "parameter": {
- "endpoint": "http://127.0.0.1:9200",
- "accessId": "elastic",
- "accessKey": "elastic",
- "index": "person",
- "type": "_doc",
- "cleanup": true,
- "settings": {
- "index": {
- "number_of_shards": 1,
- "number_of_replicas": 1
- }
- },
- "discovery": false,
- "batchSize": 1000,
- "splitter": ",",
- "column": [{
- "name": "id",
- "type": "integer"
- },
- {
- "name": "name",
- "type": "text"
- },
- {
- "name": "birthday",
- "type": "date"
- }
- ]
-
- }
-
- }
- }]
- }
-}
-```
-
-#### 6.MatrixOne 数据准备
-
-```sql
-truncate table mo.person;
-INSERT into mo.person (id, name, birthday)
-VALUES(1, 'mo101', '2023-07-09'),(2, 'mo102', '2023-07-08'),(3, 'mo103', '2023-07-12');
-```
-
-#### 7. 执行 MatrixOne 向 ElasticSearch 的迁移任务
-
-进入 datax 安装目录,执行以下命令
-
-```shell
-cd datax
-python bin/datax.py job/mo2es.json
-```
-
-执行完成后,输出结果如下:
-
-```shell
-2023-11-28 17:38:04.795 [job-0] INFO StandAloneJobContainerCommunicator - Total 3 records, 42 bytes | Speed 4B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
-2023-11-28 17:38:04.799 [job-0] INFO JobContainer -
-任务启动时刻 : 2023-11-28 17:37:49
-任务结束时刻 : 2023-11-28 17:38:04
-任务总计耗时 : 15s
-任务平均流量 : 4B/s
-记录写入速度 : 0rec/s
-读出记录总数 : 3
-读写失败总数 : 0
-```
-
-#### 8. 查看执行结果
-
-在 Elasticsearch 中查看结果
-
-```shell
-curl -u elastic:elastic -X GET http://127.0.0.1:9200/person/_search?pretty -H 'Content-Type: application/json' -d'
-{
- "query" : {
- "match_all": {}
- }
-}'
-```
-
-结果显示如下,表示迁移作业已正常完成:
-
-```json
-{
- "took" : 7,
- "timed_out" : false,
- "_shards" : {
- "total" : 1,
- "successful" : 1,
- "skipped" : 0,
- "failed" : 0
- },
- "hits" : {
- "total" : {
- "value" : 3,
- "relation" : "eq"
- },
- "max_score" : 1.0,
- "hits" : [
- {
- "_index" : "person",
- "_type" : "_doc",
- "_id" : "dv9QFYwBPwIzfbNQfgG1",
- "_score" : 1.0,
- "_source" : {
- "birthday" : "2023-07-09T00:00:00.000+08:00",
- "name" : "mo101",
- "id" : 1
- }
- },
- {
- "_index" : "person",
- "_type" : "_doc",
- "_id" : "d_9QFYwBPwIzfbNQfgG1",
- "_score" : 1.0,
- "_source" : {
- "birthday" : "2023-07-08T00:00:00.000+08:00",
- "name" : "mo102",
- "id" : 2
- }
- },
- {
- "_index" : "person",
- "_type" : "_doc",
- "_id" : "eP9QFYwBPwIzfbNQfgG1",
- "_score" : 1.0,
- "_source" : {
- "birthday" : "2023-07-12T00:00:00.000+08:00",
- "name" : "mo103",
- "id" : 3
- }
- }
- ]
- }
-}
-```
-
-## 常见问题
-
-**Q: 在运行时,我遇到了“配置信息错误,您提供的配置文件/{YOUR_MATRIXONE_WRITER_PATH}/plugin.json 不存在”的问题该怎么处理?**
-
-A: DataX 在启动时会尝试查找相似的文件夹以寻找 plugin.json 文件。如果 matrixonewriter.zip 文件也存在于相同的目录下,DataX 将尝试从 `.../datax/plugin/writer/matrixonewriter.zip/plugin.json` 中查找。在 MacOS 环境下,DataX 还会尝试从 `.../datax/plugin/writer/.DS_Store/plugin.json` 中查找。此时,您需要删除这些多余的文件或文件夹。
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink.md
deleted file mode 100644
index 9cc896e2a4..0000000000
--- a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink.md
+++ /dev/null
@@ -1,812 +0,0 @@
-# 使用 Flink 将实时数据写入 MatrixOne
-
-## 概述
-
-Apache Flink 是一个强大的框架和分布式处理引擎,专注于进行有状态计算,适用于处理无边界和有边界的数据流。Flink 能够在各种常见集群环境中高效运行,并以内存速度执行计算,支持处理任意规模的数据。
-
-### 应用场景
-
-* 事件驱动型应用
-
- 事件驱动型应用通常具备状态,并且它们从一个或多个事件流中提取数据,根据到达的事件触发计算、状态更新或执行其他外部动作。典型的事件驱动型应用包括反欺诈系统、异常检测、基于规则的报警系统和业务流程监控。
-
-* 数据分析应用
-
- 数据分析任务的主要目标是从原始数据中提取有价值的信息和指标。Flink 支持流式和批量分析应用,适用于各种场景,例如电信网络质量监控、移动应用中的产品更新和实验评估分析、消费者技术领域的实时数据即席分析以及大规模图分析。
-
-* 数据管道应用
-
- 提取 - 转换 - 加载(ETL)是在不同存储系统之间进行数据转换和迁移的常见方法。数据管道和 ETL 作业有相似之处,都可以进行数据转换和丰富,然后将数据从一个存储系统移动到另一个存储系统。不同之处在于数据管道以持续流模式运行,而不是周期性触发。典型的数据管道应用包括电子商务中的实时查询索引构建和持续 ETL。
-
-本篇文档将介绍两种示例,一种是使用计算引擎 Flink 实现将实时数据写入到 MatrixOne,另一种是使用计算引擎 Flink 将流式数据写入到 MatrixOne 数据库。
-
-## 前期准备
-
-### 硬件环境
-
-本次实践对于机器的硬件要求如下:
-
-| 服务器名称 | 服务器 IP | 安装软件 | 操作系统 |
-| ---------- | -------------- | ----------- | -------------- |
-| node1 | 192.168.146.10 | MatrixOne | Debian11.1 x86 |
-| node2 | 192.168.146.12 | kafka | Centos7.9 |
-| node3 | 192.168.146.11 | IDEA、MYSQL | win10 |
-
-### 软件环境
-
-本次实践需要安装部署以下软件环境:
-
-- 完成[单机部署 MatrixOne](https://docs.matrixorigin.cn/1.2.1/MatrixOne/Get-Started/install-standalone-matrixone/)。
-- 下载安装 [lntelliJ IDEA(2022.2.1 or later version)](https://www.jetbrains.com/idea/download/)。
-- 根据你的系统环境选择 [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html) 版本进行下载安装。
-- 下载并安装 [Kafka](https://archive.apache.org/dist/kafka/3.5.0/kafka_2.13-3.5.0.tgz),推荐版本为 2.13 - 3.5.0。
-- 下载并安装 [Flink](https://archive.apache.org/dist/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz),推荐版本为 1.17.0。
-- 下载并安装 [MySQL](https://downloads.mysql.com/archives/get/p/23/file/mysql-server_8.0.33-1ubuntu23.04_amd64.deb-bundle.tar),推荐版本为 8.0.33。
-
-## 示例 1:从 MySQL 迁移数据至 MatrixOne
-
-### 步骤一:初始化项目
-
-1. 打开 IDEA,点击 **File > New > Project**,选择 **Spring Initializer**,并填写以下配置参数:
-
- - **Name**:matrixone-flink-demo
- - **Location**:~\Desktop
- - **Language**:Java
- - **Type**:Maven
- - **Group**:com.example
- - **Artifact**:matrixone-flink-demo
- - **Package name**:com.matrixone.flink.demo
- - **JDK** 1.8
-
- 配置示例如下图所示:
-
- <div align="center">
- <img src=https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/flink/matrixone-flink-demo.png width=50% heigth=50%/>
- </div>
-
-2. 添加项目依赖,编辑项目根目录下的 `pom.xml` 文件,将以下内容添加到文件中:
-
-```xml
-<?xml version="1.0" encoding="UTF-8"?>
-<project xmlns="http://maven.apache.org/POM/4.0.0"
- xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
- <modelVersion>4.0.0</modelVersion>
-
- <groupId>com.matrixone.flink</groupId>
- <artifactId>matrixone-flink-demo</artifactId>
- <version>1.0-SNAPSHOT</version>
-
- <properties>
- <scala.binary.version>2.12</scala.binary.version>
- <java.version>1.8</java.version>
- <flink.version>1.17.0</flink.version>
- <scope.mode>compile</scope.mode>
- </properties>
-
- <dependencies>
-
- <!-- Flink Dependency -->
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-connector-hive_2.12</artifactId>
- <version>${flink.version}</version>
- </dependency>
-
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-java</artifactId>
- <version>${flink.version}</version>
- </dependency>
-
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-streaming-java</artifactId>
- <version>${flink.version}</version>
- </dependency>
-
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-clients</artifactId>
- <version>${flink.version}</version>
- </dependency>
-
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-table-api-java-bridge</artifactId>
- <version>${flink.version}</version>
- </dependency>
-
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-table-planner_2.12</artifactId>
- <version>${flink.version}</version>
- </dependency>
-
- <!-- JDBC相关依赖包 -->
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-connector-jdbc</artifactId>
- <version>1.15.4</version>
- </dependency>
- <dependency>
- <groupId>mysql</groupId>
- <artifactId>mysql-connector-java</artifactId>
- <version>8.0.33</version>
- </dependency>
-
- <!-- Kafka相关依赖 -->
- <dependency>
- <groupId>org.apache.kafka</groupId>
- <artifactId>kafka_2.13</artifactId>
- <version>3.5.0</version>
- </dependency>
- <dependency>
- <groupId>org.apache.flink</groupId>
- <artifactId>flink-connector-kafka</artifactId>
- <version>3.0.0-1.17</version>
- </dependency>
-
- <!-- JSON -->
- <dependency>
- <groupId>com.alibaba.fastjson2</groupId>
- <artifactId>fastjson2</artifactId>
- <version>2.0.34</version>
- </dependency>
-
- </dependencies>
-
-
-
-
- <build>
- <plugins>
- <plugin>
- <groupId>org.apache.maven.plugins</groupId>
- <artifactId>maven-compiler-plugin</artifactId>
- <version>3.8.0</version>
- <configuration>
- <source>${java.version}</source>
- <target>${java.version}</target>
- <encoding>UTF-8</encoding>
- </configuration>
- </plugin>
- <plugin>
- <artifactId>maven-assembly-plugin</artifactId>
- <version>2.6</version>
- <configuration>
- <descriptorRefs>
- <descriptor>jar-with-dependencies</descriptor>
- </descriptorRefs>
- </configuration>
- <executions>
- <execution>
- <id>make-assembly</id>
- <phase>package</phase>
- <goals>
- <goal>single</goal>
- </goals>
- </execution>
- </executions>
- </plugin>
-
- </plugins>
- </build>
-
-</project>
-```
-
-### 步骤二:读取 MatrixOne 数据
-
-使用 MySQL 客户端连接 MatrixOne 后,创建演示所需的数据库以及数据表。
-
-1. 在 MatrixOne 中创建数据库、数据表,并导入数据:
-
- ```SQL
- CREATE DATABASE test;
- USE test;
- CREATE TABLE `person` (`id` INT DEFAULT NULL, `name` VARCHAR(255) DEFAULT NULL, `birthday` DATE DEFAULT NULL);
- INSERT INTO test.person (id, name, birthday) VALUES(1, 'zhangsan', '2023-07-09'),(2, 'lisi', '2023-07-08'),(3, 'wangwu', '2023-07-12');
- ```
-
-2. 在 IDEA 中创建 `MoRead.java` 类,以使用 Flink 读取 MatrixOne 数据:
-
- ```java
- package com.matrixone.flink.demo;
-
- import org.apache.flink.api.common.functions.MapFunction;
- import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
- import org.apache.flink.api.java.ExecutionEnvironment;
- import org.apache.flink.api.java.operators.DataSource;
- import org.apache.flink.api.java.operators.MapOperator;
- import org.apache.flink.api.java.typeutils.RowTypeInfo;
- import org.apache.flink.connector.jdbc.JdbcInputFormat;
- import org.apache.flink.types.Row;
-
- import java.text.SimpleDateFormat;
-
- /**
- * @author MatrixOne
- * @description
- */
- public class MoRead {
-
- private static String srcHost = "192.168.146.10";
- private static Integer srcPort = 6001;
- private static String srcUserName = "root";
- private static String srcPassword = "111";
- private static String srcDataBase = "test";
-
- public static void main(String[] args) throws Exception {
-
- ExecutionEnvironment environment = ExecutionEnvironment.getExecutionEnvironment();
- // 设置并行度
- environment.setParallelism(1);
- SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
-
- // 设置查询的字段类型
- RowTypeInfo rowTypeInfo = new RowTypeInfo(
- new BasicTypeInfo[]{
- BasicTypeInfo.INT_TYPE_INFO,
- BasicTypeInfo.STRING_TYPE_INFO,
- BasicTypeInfo.DATE_TYPE_INFO
- },
- new String[]{
- "id",
- "name",
- "birthday"
- }
- );
-
- DataSource<Row> dataSource = environment.createInput(JdbcInputFormat.buildJdbcInputFormat()
- .setDrivername("com.mysql.cj.jdbc.Driver")
- .setDBUrl("jdbc:mysql://" + srcHost + ":" + srcPort + "/" + srcDataBase)
- .setUsername(srcUserName)
- .setPassword(srcPassword)
- .setQuery("select * from person")
- .setRowTypeInfo(rowTypeInfo)
- .finish());
-
- // 将 Wed Jul 12 00:00:00 CST 2023 日期格式转换为 2023-07-12
- MapOperator<Row, Row> mapOperator = dataSource.map((MapFunction<Row, Row>) row -> {
- row.setField("birthday", sdf.format(row.getField("birthday")));
- return row;
- });
-
- mapOperator.print();
- }
- }
- ```
-
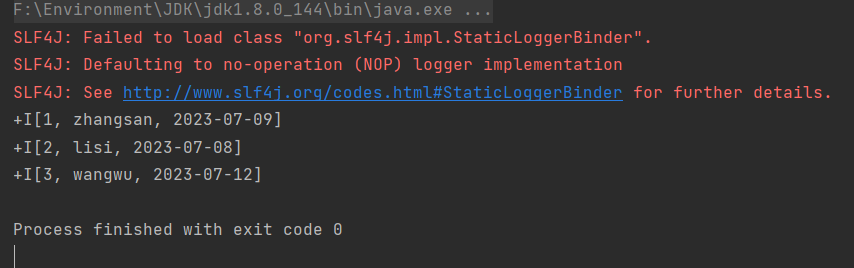
-3. 在 IDEA 中运行 `MoRead.Main()`,执行结果如下:
-
- 
-
-### 步骤三:将 MySQL 数据写入 MatrixOne
-
-现在可以开始使用 Flink 将 MySQL 数据迁移到 MatrixOne。
-
-1. 准备 MySQL 数据:在 node3 上,使用 Mysql 客户端连接本地 Mysql,创建所需数据库、数据表、并插入数据:
-
- ```sql
- mysql -h127.0.0.1 -P3306 -uroot -proot
- mysql> CREATE DATABASE motest;
- mysql> USE motest;
- mysql> CREATE TABLE `person` (`id` int DEFAULT NULL, `name` varchar(255) DEFAULT NULL, `birthday` date DEFAULT NULL);
- mysql> INSERT INTO motest.person (id, name, birthday) VALUES(2, 'lisi', '2023-07-09'),(3, 'wangwu', '2023-07-13'),(4, 'zhaoliu', '2023-08-08');
- ```
-
-2. 清空 MatrixOne 表数据:
-
- 在 node3 上,使用 MySQL 客户端连接 node1 的 MatrixOne。由于本示例继续使用前面读取 MatrixOne 数据的示例中的 `test` 数据库,因此我们需要首先清空 `person` 表的数据。
-
- ```sql
- -- 在 node3 上,使用 Mysql 客户端连接 node1 的 MatrixOne
- mysql -h192.168.146.10 -P6001 -uroot -p111
- mysql> TRUNCATE TABLE test.person;
- ```
-
-3. 在 IDEA 中编写代码:
-
- 创建 `Person.java` 和 `Mysql2Mo.java` 类,使用 Flink 读取 MySQL 数据,执行简单的 ETL 操作(将 Row 转换为 Person 对象),最终将数据写入 MatrixOne 中。
-
-```java
-package com.matrixone.flink.demo.entity;
-
-
-import java.util.Date;
-
-public class Person {
-
- private int id;
- private String name;
- private Date birthday;
-
- public int getId() {
- return id;
- }
-
- public void setId(int id) {
- this.id = id;
- }
-
- public String getName() {
- return name;
- }
-
- public void setName(String name) {
- this.name = name;
- }
-
- public Date getBirthday() {
- return birthday;
- }
-
- public void setBirthday(Date birthday) {
- this.birthday = birthday;
- }
-}
-```
-
-```java
-package com.matrixone.flink.demo;
-
-import com.matrixone.flink.demo.entity.Person;
-import org.apache.flink.api.common.functions.MapFunction;
-import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
-import org.apache.flink.api.java.typeutils.RowTypeInfo;
-import org.apache.flink.connector.jdbc.*;
-import org.apache.flink.streaming.api.datastream.DataStreamSink;
-import org.apache.flink.streaming.api.datastream.DataStreamSource;
-import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
-import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
-import org.apache.flink.types.Row;
-
-import java.sql.Date;
-
-/**
- * @author MatrixOne
- * @description
- */
-public class Mysql2Mo {
-
- private static String srcHost = "127.0.0.1";
- private static Integer srcPort = 3306;
- private static String srcUserName = "root";
- private static String srcPassword = "root";
- private static String srcDataBase = "motest";
-
- private static String destHost = "192.168.146.10";
- private static Integer destPort = 6001;
- private static String destUserName = "root";
- private static String destPassword = "111";
- private static String destDataBase = "test";
- private static String destTable = "person";
-
-
- public static void main(String[] args) throws Exception {
-
- StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
- //设置并行度
- environment.setParallelism(1);
- //设置查询的字段类型
- RowTypeInfo rowTypeInfo = new RowTypeInfo(
- new BasicTypeInfo[]{
- BasicTypeInfo.INT_TYPE_INFO,
- BasicTypeInfo.STRING_TYPE_INFO,
- BasicTypeInfo.DATE_TYPE_INFO
- },
- new String[]{
- "id",
- "name",
- "birthday"
- }
- );
-
- //添加 srouce
- DataStreamSource<Row> dataSource = environment.createInput(JdbcInputFormat.buildJdbcInputFormat()
- .setDrivername("com.mysql.cj.jdbc.Driver")
- .setDBUrl("jdbc:mysql://" + srcHost + ":" + srcPort + "/" + srcDataBase)
- .setUsername(srcUserName)
- .setPassword(srcPassword)
- .setQuery("select * from person")
- .setRowTypeInfo(rowTypeInfo)
- .finish());
-
- //进行 ETL
- SingleOutputStreamOperator<Person> mapOperator = dataSource.map((MapFunction<Row, Person>) row -> {
- Person person = new Person();
- person.setId((Integer) row.getField("id"));
- person.setName((String) row.getField("name"));
- person.setBirthday((java.util.Date)row.getField("birthday"));
- return person;
- });
-
- //设置 matrixone sink 信息
- mapOperator.addSink(
- JdbcSink.sink(
- "insert into " + destTable + " values(?,?,?)",
- (ps, t) -> {
- ps.setInt(1, t.getId());
- ps.setString(2, t.getName());
- ps.setDate(3, new Date(t.getBirthday().getTime()));
- },
- new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
- .withDriverName("com.mysql.cj.jdbc.Driver")
- .withUrl("jdbc:mysql://" + destHost + ":" + destPort + "/" + destDataBase)
- .withUsername(destUserName)
- .withPassword(destPassword)
- .build()
- )
- );
-
- environment.execute();
- }
-
-}
-```
-
-### 步骤四:查看执行结果
-
-在 MatrixOne 中执行如下 SQL 查询结果:
-
-```sql
-mysql> select * from test.person;
-+------+---------+------------+
-| id | name | birthday |
-+------+---------+------------+
-| 2 | lisi | 2023-07-09 |
-| 3 | wangwu | 2023-07-13 |
-| 4 | zhaoliu | 2023-08-08 |
-+------+---------+------------+
-3 rows in set (0.01 sec)
-```
-
-## 示例 2:将 Kafka 数据写入 MatrixOne
-
-### 步骤一:启动 Kafka 服务
-
-Kafka 集群协调和元数据管理可以通过 KRaft 或 ZooKeeper 来实现。在这里,我们将使用 Kafka 3.5.0 版本,无需依赖独立的 ZooKeeper 软件,而是使用 Kafka 自带的 **KRaft** 来进行元数据管理。请按照以下步骤配置配置文件,该文件位于 Kafka 软件根目录下的 `config/kraft/server.properties`。
-
-配置文件内容如下:
-
-```properties
-# Licensed to the Apache Software Foundation (ASF) under one or more
-# contributor license agreements. See the NOTICE file distributed with
-# this work for additional information regarding copyright ownership.
-# The ASF licenses this file to You under the Apache License, Version 2.0
-# (the "License"); you may not use this file except in compliance with
-# the License. You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-#
-# This configuration file is intended for use in KRaft mode, where
-# Apache ZooKeeper is not present. See config/kraft/README.md for details.
-#
-
-############################# Server Basics #############################
-
-# The role of this server. Setting this puts us in KRaft mode
-process.roles=broker,controller
-
-# The node id associated with this instance's roles
-node.id=1
-
-# The connect string for the controller quorum
-controller.quorum.voters=1@192.168.146.12:9093
-
-############################# Socket Server Settings #############################
-
-# The address the socket server listens on.
-# Combined nodes (i.e. those with `process.roles=broker,controller`) must list the controller listener here at a minimum.
-# If the broker listener is not defined, the default listener will use a host name that is equal to the value of java.net.InetAddress.getCanonicalHostName(),
-# with PLAINTEXT listener name, and port 9092.
-# FORMAT:
-# listeners = listener_name://host_name:port
-# EXAMPLE:
-# listeners = PLAINTEXT://your.host.name:9092
-#listeners=PLAINTEXT://:9092,CONTROLLER://:9093
-listeners=PLAINTEXT://192.168.146.12:9092,CONTROLLER://192.168.146.12:9093
-
-# Name of listener used for communication between brokers.
-inter.broker.listener.name=PLAINTEXT
-
-# Listener name, hostname and port the broker will advertise to clients.
-# If not set, it uses the value for "listeners".
-#advertised.listeners=PLAINTEXT://localhost:9092
-
-# A comma-separated list of the names of the listeners used by the controller.
-# If no explicit mapping set in `listener.security.protocol.map`, default will be using PLAINTEXT protocol
-# This is required if running in KRaft mode.
-controller.listener.names=CONTROLLER
-
-# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
-listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
-
-# The number of threads that the server uses for receiving requests from the network and sending responses to the network
-num.network.threads=3
-
-# The number of threads that the server uses for processing requests, which may include disk I/O
-num.io.threads=8
-
-# The send buffer (SO_SNDBUF) used by the socket server
-socket.send.buffer.bytes=102400
-
-# The receive buffer (SO_RCVBUF) used by the socket server
-socket.receive.buffer.bytes=102400
-
-# The maximum size of a request that the socket server will accept (protection against OOM)
-socket.request.max.bytes=104857600
-
-
-############################# Log Basics #############################
-
-# A comma separated list of directories under which to store log files
-log.dirs=/home/software/kafka_2.13-3.5.0/kraft-combined-logs
-
-# The default number of log partitions per topic. More partitions allow greater
-# parallelism for consumption, but this will also result in more files across
-# the brokers.
-num.partitions=1
-
-# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
-# This value is recommended to be increased for installations with data dirs located in RAID array.
-num.recovery.threads.per.data.dir=1
-
-############################# Internal Topic Settings #############################
-# The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state"
-# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
-offsets.topic.replication.factor=1
-transaction.state.log.replication.factor=1
-transaction.state.log.min.isr=1
-
-############################# Log Flush Policy #############################
-
-# Messages are immediately written to the filesystem but by default we only fsync() to sync
-# the OS cache lazily. The following configurations control the flush of data to disk.
-# There are a few important trade-offs here:
-# 1. Durability: Unflushed data may be lost if you are not using replication.
-# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
-# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
-# The settings below allow one to configure the flush policy to flush data after a period of time or
-# every N messages (or both). This can be done globally and overridden on a per-topic basis.
-
-# The number of messages to accept before forcing a flush of data to disk
-#log.flush.interval.messages=10000
-
-# The maximum amount of time a message can sit in a log before we force a flush
-#log.flush.interval.ms=1000
-
-############################# Log Retention Policy #############################
-
-# The following configurations control the disposal of log segments. The policy can
-# be set to delete segments after a period of time, or after a given size has accumulated.
-# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
-# from the end of the log.
-
-# The minimum age of a log file to be eligible for deletion due to age
-log.retention.hours=72
-
-# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
-# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
-#log.retention.bytes=1073741824
-
-# The maximum size of a log segment file. When this size is reached a new log segment will be created.
-log.segment.bytes=1073741824
-
-# The interval at which log segments are checked to see if they can be deleted according
-# to the retention policies
-log.retention.check.interval.ms=300000
-```
-
-文件配置完成后,执行如下命令,启动 Kafka 服务:
-
-```shell
-#生成集群ID
-$ KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
-#设置日志目录格式
-$ bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties
-#启动Kafka服务
-$ bin/kafka-server-start.sh config/kraft/server.properties
-```
-
-### 步骤二:创建 Kafka 主题
-
-为了使 Flink 能够从中读取数据并写入到 MatrixOne,我们需要首先创建一个名为 "matrixone" 的 Kafka 主题。在下面的命令中,使用 `--bootstrap-server` 参数指定 Kafka 服务的监听地址为 `192.168.146.12:9092`:
-
-```shell
-$ bin/kafka-topics.sh --create --topic matrixone --bootstrap-server 192.168.146.12:9092
-```
-
-### 步骤三:读取 MatrixOne 数据
-
-在连接到 MatrixOne 数据库之后,需要执行以下操作以创建所需的数据库和数据表:
-
-1. 在 MatrixOne 中创建数据库和数据表,并导入数据:
-
- ```sql
- CREATE TABLE `users` (
- `id` INT DEFAULT NULL,
- `name` VARCHAR(255) DEFAULT NULL,
- `age` INT DEFAULT NULL
- )
- ```
-
-2. 在 IDEA 集成开发环境中编写代码:
-
- 在 IDEA 中,创建两个类:`User.java` 和 `Kafka2Mo.java`。这些类用于使用 Flink 从 Kafka 读取数据,并将数据写入 MatrixOne 数据库中。
-
-```java
-package com.matrixone.flink.demo.entity;
-
-public class User {
-
- private int id;
- private String name;
- private int age;
-
- public int getId() {
- return id;
- }
-
- public void setId(int id) {
- this.id = id;
- }
-
- public String getName() {
- return name;
- }
-
- public void setName(String name) {
- this.name = name;
- }
-
- public int getAge() {
- return age;
- }
-
- public void setAge(int age) {
- this.age = age;
- }
-}
-```
-
-```java
-package com.matrixone.flink.demo;
-
-import com.alibaba.fastjson2.JSON;
-import com.matrixone.flink.demo.entity.User;
-import org.apache.flink.api.common.eventtime.WatermarkStrategy;
-import org.apache.flink.api.common.serialization.AbstractDeserializationSchema;
-import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
-import org.apache.flink.connector.jdbc.JdbcSink;
-import org.apache.flink.connector.jdbc.JdbcStatementBuilder;
-import org.apache.flink.connector.jdbc.internal.options.JdbcConnectorOptions;
-import org.apache.flink.connector.kafka.source.KafkaSource;
-import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
-import org.apache.flink.streaming.api.datastream.DataStreamSource;
-import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
-import org.apache.kafka.clients.consumer.OffsetResetStrategy;
-
-import java.nio.charset.StandardCharsets;
-
-/**
- * @author MatrixOne
- * @desc
- */
-public class Kafka2Mo {
-
- private static String srcServer = "192.168.146.12:9092";
- private static String srcTopic = "matrixone";
- private static String consumerGroup = "matrixone_group";
-
- private static String destHost = "192.168.146.10";
- private static Integer destPort = 6001;
- private static String destUserName = "root";
- private static String destPassword = "111";
- private static String destDataBase = "test";
- private static String destTable = "person";
-
- public static void main(String[] args) throws Exception {
-
- //初始化环境
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- //设置并行度
- env.setParallelism(1);
-
- //设置 kafka source 信息
- KafkaSource<User> source = KafkaSource.<User>builder()
- //Kafka 服务
- .setBootstrapServers(srcServer)
- //消息主题
- .setTopics(srcTopic)
- //消费组
- .setGroupId(consumerGroup)
- //偏移量 当没有提交偏移量则从最开始开始消费
- .setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.LATEST))
- //自定义解析消息内容
- .setValueOnlyDeserializer(new AbstractDeserializationSchema<User>() {
- @Override
- public User deserialize(byte[] message) {
- return JSON.parseObject(new String(message, StandardCharsets.UTF_8), User.class);
- }
- })
- .build();
- DataStreamSource<User> kafkaSource = env.fromSource(source, WatermarkStrategy.noWatermarks(), "kafka_maxtixone");
- //kafkaSource.print();
-
- //设置 matrixone sink 信息
- kafkaSource.addSink(JdbcSink.sink(
- "insert into users (id,name,age) values(?,?,?)",
- (JdbcStatementBuilder<User>) (preparedStatement, user) -> {
- preparedStatement.setInt(1, user.getId());
- preparedStatement.setString(2, user.getName());
- preparedStatement.setInt(3, user.getAge());
- },
- JdbcExecutionOptions.builder()
- //默认值 5000
- .withBatchSize(1000)
- //默认值为 0
- .withBatchIntervalMs(200)
- //最大尝试次数
- .withMaxRetries(5)
- .build(),
- JdbcConnectorOptions.builder()
- .setDBUrl("jdbc:mysql://"+destHost+":"+destPort+"/"+destDataBase)
- .setUsername(destUserName)
- .setPassword(destPassword)
- .setDriverName("com.mysql.cj.jdbc.Driver")
- .setTableName(destTable)
- .build()
- ));
- env.execute();
- }
-}
-```
-
-代码编写完成后,你可以运行 Flink 任务,即在 IDEA 中选择 `Kafka2Mo.java` 文件,然后执行 `Kafka2Mo.Main()`。
-
-### 步骤四:生成数据
-
-使用 Kafka 提供的命令行生产者工具,您可以向 Kafka 的 "matrixone" 主题中添加数据。在下面的命令中,使用 `--topic` 参数指定要添加到的主题,而 `--bootstrap-server` 参数指定了 Kafka 服务的监听地址。
-
-```shell
-bin/kafka-console-producer.sh --topic matrixone --bootstrap-server 192.168.146.12:9092
-```
-
-执行上述命令后,您将在控制台上等待输入消息内容。只需直接输入消息值 (value),每行表示一条消息(以换行符分隔),如下所示:
-
-```shell
-{"id": 10, "name": "xiaowang", "age": 22}
-{"id": 20, "name": "xiaozhang", "age": 24}
-{"id": 30, "name": "xiaogao", "age": 18}
-{"id": 40, "name": "xiaowu", "age": 20}
-{"id": 50, "name": "xiaoli", "age": 42}
-```
-
-
-
-### 步骤五:查看执行结果
-
-在 MatrixOne 中执行如下 SQL 查询结果:
-
-```sql
-mysql> select * from test.users;
-+------+-----------+------+
-| id | name | age |
-+------+-----------+------+
-| 10 | xiaowang | 22 |
-| 20 | xiaozhang | 24 |
-| 30 | xiaogao | 18 |
-| 40 | xiaowu | 20 |
-| 50 | xiaoli | 42 |
-+------+-----------+------+
-5 rows in set (0.01 sec)
-```
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-kafka-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-kafka-matrixone.md
new file mode 100644
index 0000000000..6cea267c8e
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-kafka-matrixone.md
@@ -0,0 +1,363 @@
+# 使用 Flink 将 Kafka 数据写入 MatrixOne
+
+本章节将介绍如何使用 Flink 将 Kafka 数据写入到 MatrixOne。
+
+## 前期准备
+
+本次实践需要安装部署以下软件环境:
+
+- 完成[单机部署 MatrixOne](https://docs.matrixorigin.cn/1.2.1/MatrixOne/Get-Started/install-standalone-matrixone/)。
+- 下载安装 [lntelliJ IDEA(2022.2.1 or later version)](https://www.jetbrains.com/idea/download/)。
+- 根据你的系统环境选择 [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html) 版本进行下载安装。
+- 下载并安装 [Kafka](https://archive.apache.org/dist/kafka/3.5.0/kafka_2.13-3.5.0.tgz)。
+- 下载并安装 [Flink](https://archive.apache.org/dist/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz),最低支持版本为 1.11。
+- 下载并安装 [MySQL Client](https://dev.mysql.com/downloads/mysql)。
+
+## 操作步骤
+
+### 步骤一:启动 Kafka 服务
+
+Kafka 集群协调和元数据管理可以通过 KRaft 或 ZooKeeper 来实现。在这里,我们将使用 Kafka 3.5.0 版本,无需依赖独立的 ZooKeeper 软件,而是使用 Kafka 自带的 **KRaft** 来进行元数据管理。请按照以下步骤配置配置文件,该文件位于 Kafka 软件根目录下的 `config/kraft/server.properties`。
+
+配置文件内容如下:
+
+```properties
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+#
+# This configuration file is intended for use in KRaft mode, where
+# Apache ZooKeeper is not present. See config/kraft/README.md for details.
+#
+
+############################# Server Basics #############################
+
+# The role of this server. Setting this puts us in KRaft mode
+process.roles=broker,controller
+
+# The node id associated with this instance's roles
+node.id=1
+
+# The connect string for the controller quorum
+controller.quorum.voters=1@xx.xx.xx.xx:9093
+
+############################# Socket Server Settings #############################
+
+# The address the socket server listens on.
+# Combined nodes (i.e. those with `process.roles=broker,controller`) must list the controller listener here at a minimum.
+# If the broker listener is not defined, the default listener will use a host name that is equal to the value of java.net.InetAddress.getCanonicalHostName(),
+# with PLAINTEXT listener name, and port 9092.
+# FORMAT:
+# listeners = listener_name://host_name:port
+# EXAMPLE:
+# listeners = PLAINTEXT://your.host.name:9092
+#listeners=PLAINTEXT://:9092,CONTROLLER://:9093
+listeners=PLAINTEXT://xx.xx.xx.xx:9092,CONTROLLER://xx.xx.xx.xx:9093
+
+# Name of listener used for communication between brokers.
+inter.broker.listener.name=PLAINTEXT
+
+# Listener name, hostname and port the broker will advertise to clients.
+# If not set, it uses the value for "listeners".
+#advertised.listeners=PLAINTEXT://localhost:9092
+
+# A comma-separated list of the names of the listeners used by the controller.
+# If no explicit mapping set in `listener.security.protocol.map`, default will be using PLAINTEXT protocol
+# This is required if running in KRaft mode.
+controller.listener.names=CONTROLLER
+
+# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
+listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
+
+# The number of threads that the server uses for receiving requests from the network and sending responses to the network
+num.network.threads=3
+
+# The number of threads that the server uses for processing requests, which may include disk I/O
+num.io.threads=8
+
+# The send buffer (SO_SNDBUF) used by the socket server
+socket.send.buffer.bytes=102400
+
+# The receive buffer (SO_RCVBUF) used by the socket server
+socket.receive.buffer.bytes=102400
+
+# The maximum size of a request that the socket server will accept (protection against OOM)
+socket.request.max.bytes=104857600
+
+
+############################# Log Basics #############################
+
+# A comma separated list of directories under which to store log files
+log.dirs=/home/software/kafka_2.13-3.5.0/kraft-combined-logs
+
+# The default number of log partitions per topic. More partitions allow greater
+# parallelism for consumption, but this will also result in more files across
+# the brokers.
+num.partitions=1
+
+# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
+# This value is recommended to be increased for installations with data dirs located in RAID array.
+num.recovery.threads.per.data.dir=1
+
+############################# Internal Topic Settings #############################
+# The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state"
+# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
+offsets.topic.replication.factor=1
+transaction.state.log.replication.factor=1
+transaction.state.log.min.isr=1
+
+############################# Log Flush Policy #############################
+
+# Messages are immediately written to the filesystem but by default we only fsync() to sync
+# the OS cache lazily. The following configurations control the flush of data to disk.
+# There are a few important trade-offs here:
+# 1. Durability: Unflushed data may be lost if you are not using replication.
+# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
+# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
+# The settings below allow one to configure the flush policy to flush data after a period of time or
+# every N messages (or both). This can be done globally and overridden on a per-topic basis.
+
+# The number of messages to accept before forcing a flush of data to disk
+#log.flush.interval.messages=10000
+
+# The maximum amount of time a message can sit in a log before we force a flush
+#log.flush.interval.ms=1000
+
+############################# Log Retention Policy #############################
+
+# The following configurations control the disposal of log segments. The policy can
+# be set to delete segments after a period of time, or after a given size has accumulated.
+# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
+# from the end of the log.
+
+# The minimum age of a log file to be eligible for deletion due to age
+log.retention.hours=72
+
+# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
+# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
+#log.retention.bytes=1073741824
+
+# The maximum size of a log segment file. When this size is reached a new log segment will be created.
+log.segment.bytes=1073741824
+
+# The interval at which log segments are checked to see if they can be deleted according
+# to the retention policies
+log.retention.check.interval.ms=300000
+```
+
+文件配置完成后,执行如下命令,启动 Kafka 服务:
+
+```shell
+#生成集群ID
+$ KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"
+#设置日志目录格式
+$ bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.properties
+#启动Kafka服务
+$ bin/kafka-server-start.sh config/kraft/server.properties
+```
+
+### 步骤二:创建 Kafka 主题
+
+为了使 Flink 能够从中读取数据并写入到 MatrixOne,我们需要首先创建一个名为 "matrixone" 的 Kafka 主题。在下面的命令中,使用 `--bootstrap-server` 参数指定 Kafka 服务的监听地址为 `xx.xx.xx.xx:9092`:
+
+```shell
+$ bin/kafka-topics.sh --create --topic matrixone --bootstrap-server xx.xx.xx.xx:9092
+```
+
+### 步骤三:读取 MatrixOne 数据
+
+在连接到 MatrixOne 数据库之后,需要执行以下操作以创建所需的数据库和数据表:
+
+1. 在 MatrixOne 中创建数据库和数据表,并导入数据:
+
+ ```sql
+ CREATE TABLE `users` (
+ `id` INT DEFAULT NULL,
+ `name` VARCHAR(255) DEFAULT NULL,
+ `age` INT DEFAULT NULL
+ )
+ ```
+
+2. 在 IDEA 集成开发环境中编写代码:
+
+ 在 IDEA 中,创建两个类:`User.java` 和 `Kafka2Mo.java`。这些类用于使用 Flink 从 Kafka 读取数据,并将数据写入 MatrixOne 数据库中。
+
+```java
+package com.matrixone.flink.demo.entity;
+
+public class User {
+
+ private int id;
+ private String name;
+ private int age;
+
+ public int getId() {
+ return id;
+ }
+
+ public void setId(int id) {
+ this.id = id;
+ }
+
+ public String getName() {
+ return name;
+ }
+
+ public void setName(String name) {
+ this.name = name;
+ }
+
+ public int getAge() {
+ return age;
+ }
+
+ public void setAge(int age) {
+ this.age = age;
+ }
+}
+```
+
+```java
+package com.matrixone.flink.demo;
+
+import com.alibaba.fastjson2.JSON;
+import com.matrixone.flink.demo.entity.User;
+import org.apache.flink.api.common.eventtime.WatermarkStrategy;
+import org.apache.flink.api.common.serialization.AbstractDeserializationSchema;
+import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
+import org.apache.flink.connector.jdbc.JdbcSink;
+import org.apache.flink.connector.jdbc.JdbcStatementBuilder;
+import org.apache.flink.connector.jdbc.internal.options.JdbcConnectorOptions;
+import org.apache.flink.connector.kafka.source.KafkaSource;
+import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
+import org.apache.flink.streaming.api.datastream.DataStreamSource;
+import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
+import org.apache.kafka.clients.consumer.OffsetResetStrategy;
+
+import java.nio.charset.StandardCharsets;
+
+/**
+ * @author MatrixOne
+ * @desc
+ */
+public class Kafka2Mo {
+
+ private static String srcServer = "xx.xx.xx.xx:9092";
+ private static String srcTopic = "matrixone";
+ private static String consumerGroup = "matrixone_group";
+
+ private static String destHost = "xx.xx.xx.xx";
+ private static Integer destPort = 6001;
+ private static String destUserName = "root";
+ private static String destPassword = "111";
+ private static String destDataBase = "test";
+ private static String destTable = "person";
+
+ public static void main(String[] args) throws Exception {
+
+ //初始化环境
+ StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
+ //设置并行度
+ env.setParallelism(1);
+
+ //设置 kafka source 信息
+ KafkaSource<User> source = KafkaSource.<User>builder()
+ //Kafka 服务
+ .setBootstrapServers(srcServer)
+ //消息主题
+ .setTopics(srcTopic)
+ //消费组
+ .setGroupId(consumerGroup)
+ //偏移量 当没有提交偏移量则从最开始开始消费
+ .setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.LATEST))
+ //自定义解析消息内容
+ .setValueOnlyDeserializer(new AbstractDeserializationSchema<User>() {
+ @Override
+ public User deserialize(byte[] message) {
+ return JSON.parseObject(new String(message, StandardCharsets.UTF_8), User.class);
+ }
+ })
+ .build();
+ DataStreamSource<User> kafkaSource = env.fromSource(source, WatermarkStrategy.noWatermarks(), "kafka_maxtixone");
+ //kafkaSource.print();
+
+ //设置 matrixone sink 信息
+ kafkaSource.addSink(JdbcSink.sink(
+ "insert into users (id,name,age) values(?,?,?)",
+ (JdbcStatementBuilder<User>) (preparedStatement, user) -> {
+ preparedStatement.setInt(1, user.getId());
+ preparedStatement.setString(2, user.getName());
+ preparedStatement.setInt(3, user.getAge());
+ },
+ JdbcExecutionOptions.builder()
+ //默认值 5000
+ .withBatchSize(1000)
+ //默认值为 0
+ .withBatchIntervalMs(200)
+ //最大尝试次数
+ .withMaxRetries(5)
+ .build(),
+ JdbcConnectorOptions.builder()
+ .setDBUrl("jdbc:mysql://"+destHost+":"+destPort+"/"+destDataBase)
+ .setUsername(destUserName)
+ .setPassword(destPassword)
+ .setDriverName("com.mysql.cj.jdbc.Driver")
+ .setTableName(destTable)
+ .build()
+ ));
+ env.execute();
+ }
+}
+```
+
+代码编写完成后,你可以运行 Flink 任务,即在 IDEA 中选择 `Kafka2Mo.java` 文件,然后执行 `Kafka2Mo.Main()`。
+
+### 步骤四:生成数据
+
+使用 Kafka 提供的命令行生产者工具,您可以向 Kafka 的 "matrixone" 主题中添加数据。在下面的命令中,使用 `--topic` 参数指定要添加到的主题,而 `--bootstrap-server` 参数指定了 Kafka 服务的监听地址。
+
+```shell
+bin/kafka-console-producer.sh --topic matrixone --bootstrap-server xx.xx.xx.xx:9092
+```
+
+执行上述命令后,您将在控制台上等待输入消息内容。只需直接输入消息值 (value),每行表示一条消息(以换行符分隔),如下所示:
+
+```shell
+{"id": 10, "name": "xiaowang", "age": 22}
+{"id": 20, "name": "xiaozhang", "age": 24}
+{"id": 30, "name": "xiaogao", "age": 18}
+{"id": 40, "name": "xiaowu", "age": 20}
+{"id": 50, "name": "xiaoli", "age": 42}
+```
+
+
+
+### 步骤五:查看执行结果
+
+在 MatrixOne 中执行如下 SQL 查询结果:
+
+```sql
+mysql> select * from test.users;
++------+-----------+------+
+| id | name | age |
++------+-----------+------+
+| 10 | xiaowang | 22 |
+| 20 | xiaozhang | 24 |
+| 30 | xiaogao | 18 |
+| 40 | xiaowu | 20 |
+| 50 | xiaoli | 42 |
++------+-----------+------+
+5 rows in set (0.01 sec)
+```
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-mongo-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-mongo-matrixone.md
new file mode 100644
index 0000000000..44d131f634
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-mongo-matrixone.md
@@ -0,0 +1,155 @@
+# 使用 Flink 将 MongoDB 数据写入 MatrixOne
+
+本章节将介绍如何使用 Flink 将 MongoDB 数据写入到 MatrixOne。
+
+## 前期准备
+
+本次实践需要安装部署以下软件环境:
+
+- 完成[单机部署 MatrixOne](https://docs.matrixorigin.cn/1.2.1/MatrixOne/Get-Started/install-standalone-matrixone/)。
+- 下载安装 [lntelliJ IDEA(2022.2.1 or later version)](https://www.jetbrains.com/idea/download/)。
+- 根据你的系统环境选择 [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html) 版本进行下载安装。
+- 下载并安装 [Flink](https://archive.apache.org/dist/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz),最低支持版本为 1.11。
+- 下载并安装 [MongoDB](https://www.mongodb.com/)。
+- 下载并安装 [MySQL](https://downloads.mysql.com/archives/get/p/23/file/mysql-server_8.0.33-1ubuntu23.04_amd64.deb-bundle.tar),推荐版本为 8.0.33。
+
+## 操作步骤
+
+### 开启 Mongodb 副本集模式
+
+关闭命令:
+
+```bash
+mongod -f /opt/software/mongodb/conf/config.conf --shutdown
+```
+
+在 /opt/software/mongodb/conf/config.conf 中增加以下参数
+
+```shell
+replication:
+replSetName: rs0 #复制集名称
+```
+
+重新开启 mangod
+
+```bash
+mongod -f /opt/software/mongodb/conf/config.conf
+```
+
+然后进入 mongo 执行 `rs.initiate()` 然后执行 `rs.status()`
+
+```shell
+> rs.initiate()
+{
+"info2" : "no configuration specified. Using a default configuration for the set",
+"me" : "xx.xx.xx.xx:27017",
+"ok" : 1
+}
+rs0:SECONDARY> rs.status()
+```
+
+看到以下相关信息说明复制集启动成功
+
+```bash
+"members" : [
+{
+"_id" : 0,
+"name" : "xx.xx.xx.xx:27017",
+"health" : 1,
+"state" : 1,
+"stateStr" : "PRIMARY",
+"uptime" : 77,
+"optime" : {
+"ts" : Timestamp(1665998544, 1),
+"t" : NumberLong(1)
+},
+"optimeDate" : ISODate("2022-10-17T09:22:24Z"),
+"syncingTo" : "",
+"syncSourceHost" : "",
+"syncSourceId" : -1,
+"infoMessage" : "could not find member to sync from",
+"electionTime" : Timestamp(1665998504, 2),
+"electionDate" : ISODate("2022-10-17T09:21:44Z"),
+"configVersion" : 1,
+"self" : true,
+"lastHeartbeatMessage" : ""
+}
+],
+"ok" : 1,
+
+rs0:PRIMARY> show dbs
+admin 0.000GB
+config 0.000GB
+local 0.000GB
+test 0.000GB
+```
+
+### 在 flinkcdc sql 界面建立 source 表(mongodb)
+
+在 flink 目录下的 lib 目录下执行,下载 mongodb 的 cdcjar 包
+
+```bash
+wget <https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-mongodb-cdc/2.2.1/flink-sql-connector-mongodb-cdc-2.2.1.jar>
+```
+
+建立数据源 mongodb 的映射表,列名也必须一模一样
+
+```sql
+CREATE TABLE products (
+ _id STRING,#必须有这一列,也必须为主键,因为mongodb会给每行数据自动生成一个id
+ `name` STRING,
+ age INT,
+ PRIMARY KEY(_id) NOT ENFORCED
+) WITH (
+ 'connector' = 'mongodb-cdc',
+ 'hosts' = 'xx.xx.xx.xx:27017',
+ 'username' = 'root',
+ 'password' = '',
+ 'database' = 'test',
+ 'collection' = 'test'
+);
+```
+
+建立完成后可以执行 `select * from products;` 查下是否连接成功
+
+### 在 flinkcdc sql 界面建立 sink 表(MatrixOne)
+
+建立 matrixone 的映射表,表结构需相同,不需要带 id 列
+
+```sql
+CREATE TABLE cdc_matrixone (
+ `name` STRING,
+ age INT,
+ PRIMARY KEY (`name`) NOT ENFORCED
+)WITH (
+'connector' = 'jdbc',
+'url' = 'jdbc:mysql://xx.xx.xx.xx:6001/test',
+'driver' = 'com.mysql.cj.jdbc.Driver',
+'username' = 'root',
+'password' = '111',
+'table-name' = 'mongodbtest'
+);
+```
+
+### 开启 cdc 同步任务
+
+这里同步任务开启后,mongodb 增删改的操作均可同步
+
+```sql
+INSERT INTO cdc_matrixone SELECT `name`,age FROM products;
+
+#增加
+rs0:PRIMARY> db.test.insert({"name" : "ddd", "age" : 90})
+WriteResult({ "nInserted" : 1 })
+rs0:PRIMARY> db.test.find()
+{ "_id" : ObjectId("6347e3c6229d6017c82bf03d"), "name" : "aaa", "age" : 20 }
+{ "_id" : ObjectId("6347e64a229d6017c82bf03e"), "name" : "bbb", "age" : 18 }
+{ "_id" : ObjectId("6347e652229d6017c82bf03f"), "name" : "ccc", "age" : 28 }
+{ "_id" : ObjectId("634d248f10e21b45c73b1a36"), "name" : "ddd", "age" : 90 }
+#修改
+rs0:PRIMARY> db.test.update({'name':'ddd'},{$set:{'age':'99'}})
+WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
+#删除
+rs0:PRIMARY> db.test.remove({'name':'ddd'})
+WriteResult({ "nRemoved" : 1 })
+```
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-mysql-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-mysql-matrixone.md
new file mode 100644
index 0000000000..26e727addb
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-mysql-matrixone.md
@@ -0,0 +1,432 @@
+# 使用 Flink 将 MySQL 数据写入 MatrixOne
+
+本章节将介绍如何使用 Flink 将 MySQL 数据写入到 MatrixOne。
+
+## 前期准备
+
+本次实践需要安装部署以下软件环境:
+
+- 完成[单机部署 MatrixOne](https://docs.matrixorigin.cn/1.2.1/MatrixOne/Get-Started/install-standalone-matrixone/)。
+- 下载安装 [lntelliJ IDEA(2022.2.1 or later version)](https://www.jetbrains.com/idea/download/)。
+- 根据你的系统环境选择 [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html) 版本进行下载安装。
+- 下载并安装 [Flink](https://archive.apache.org/dist/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz),最低支持版本为 1.11。
+- 下载并安装 [MySQL](https://downloads.mysql.com/archives/get/p/23/file/mysql-server_8.0.33-1ubuntu23.04_amd64.deb-bundle.tar),推荐版本为 8.0.33。
+
+## 操作步骤
+
+### 步骤一:初始化项目
+
+1. 打开 IDEA,点击 **File > New > Project**,选择 **Spring Initializer**,并填写以下配置参数:
+
+ - **Name**:matrixone-flink-demo
+ - **Location**:~\Desktop
+ - **Language**:Java
+ - **Type**:Maven
+ - **Group**:com.example
+ - **Artifact**:matrixone-flink-demo
+ - **Package name**:com.matrixone.flink.demo
+ - **JDK** 1.8
+
+ 配置示例如下图所示:
+
+ <div align="center">
+ <img src=https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/flink/matrixone-flink-demo.png width=50% heigth=50%/>
+ </div>
+
+2. 添加项目依赖,编辑项目根目录下的 `pom.xml` 文件,将以下内容添加到文件中:
+
+```xml
+<?xml version="1.0" encoding="UTF-8"?>
+<project xmlns="http://maven.apache.org/POM/4.0.0"
+ xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
+ xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
+ <modelVersion>4.0.0</modelVersion>
+
+ <groupId>com.matrixone.flink</groupId>
+ <artifactId>matrixone-flink-demo</artifactId>
+ <version>1.0-SNAPSHOT</version>
+
+ <properties>
+ <scala.binary.version>2.12</scala.binary.version>
+ <java.version>1.8</java.version>
+ <flink.version>1.17.0</flink.version>
+ <scope.mode>compile</scope.mode>
+ </properties>
+
+ <dependencies>
+
+ <!-- Flink Dependency -->
+ <dependency>
+ <groupId>org.apache.flink</groupId>
+ <artifactId>flink-connector-hive_2.12</artifactId>
+ <version>${flink.version}</version>
+ </dependency>
+
+ <dependency>
+ <groupId>org.apache.flink</groupId>
+ <artifactId>flink-java</artifactId>
+ <version>${flink.version}</version>
+ </dependency>
+
+ <dependency>
+ <groupId>org.apache.flink</groupId>
+ <artifactId>flink-streaming-java</artifactId>
+ <version>${flink.version}</version>
+ </dependency>
+
+ <dependency>
+ <groupId>org.apache.flink</groupId>
+ <artifactId>flink-clients</artifactId>
+ <version>${flink.version}</version>
+ </dependency>
+
+ <dependency>
+ <groupId>org.apache.flink</groupId>
+ <artifactId>flink-table-api-java-bridge</artifactId>
+ <version>${flink.version}</version>
+ </dependency>
+
+ <dependency>
+ <groupId>org.apache.flink</groupId>
+ <artifactId>flink-table-planner_2.12</artifactId>
+ <version>${flink.version}</version>
+ </dependency>
+
+ <!-- JDBC相关依赖包 -->
+ <dependency>
+ <groupId>org.apache.flink</groupId>
+ <artifactId>flink-connector-jdbc</artifactId>
+ <version>1.15.4</version>
+ </dependency>
+ <dependency>
+ <groupId>mysql</groupId>
+ <artifactId>mysql-connector-java</artifactId>
+ <version>8.0.33</version>
+ </dependency>
+
+ <!-- Kafka相关依赖 -->
+ <dependency>
+ <groupId>org.apache.kafka</groupId>
+ <artifactId>kafka_2.13</artifactId>
+ <version>3.5.0</version>
+ </dependency>
+ <dependency>
+ <groupId>org.apache.flink</groupId>
+ <artifactId>flink-connector-kafka</artifactId>
+ <version>3.0.0-1.17</version>
+ </dependency>
+
+ <!-- JSON -->
+ <dependency>
+ <groupId>com.alibaba.fastjson2</groupId>
+ <artifactId>fastjson2</artifactId>
+ <version>2.0.34</version>
+ </dependency>
+
+ </dependencies>
+
+
+
+
+ <build>
+ <plugins>
+ <plugin>
+ <groupId>org.apache.maven.plugins</groupId>
+ <artifactId>maven-compiler-plugin</artifactId>
+ <version>3.8.0</version>
+ <configuration>
+ <source>${java.version}</source>
+ <target>${java.version}</target>
+ <encoding>UTF-8</encoding>
+ </configuration>
+ </plugin>
+ <plugin>
+ <artifactId>maven-assembly-plugin</artifactId>
+ <version>2.6</version>
+ <configuration>
+ <descriptorRefs>
+ <descriptor>jar-with-dependencies</descriptor>
+ </descriptorRefs>
+ </configuration>
+ <executions>
+ <execution>
+ <id>make-assembly</id>
+ <phase>package</phase>
+ <goals>
+ <goal>single</goal>
+ </goals>
+ </execution>
+ </executions>
+ </plugin>
+
+ </plugins>
+ </build>
+
+</project>
+```
+
+### 步骤二:读取 MatrixOne 数据
+
+使用 MySQL 客户端连接 MatrixOne 后,创建演示所需的数据库以及数据表。
+
+1. 在 MatrixOne 中创建数据库、数据表,并导入数据:
+
+ ```SQL
+ CREATE DATABASE test;
+ USE test;
+ CREATE TABLE `person` (`id` INT DEFAULT NULL, `name` VARCHAR(255) DEFAULT NULL, `birthday` DATE DEFAULT NULL);
+ INSERT INTO test.person (id, name, birthday) VALUES(1, 'zhangsan', '2023-07-09'),(2, 'lisi', '2023-07-08'),(3, 'wangwu', '2023-07-12');
+ ```
+
+2. 在 IDEA 中创建 `MoRead.java` 类,以使用 Flink 读取 MatrixOne 数据:
+
+ ```java
+ package com.matrixone.flink.demo;
+
+ import org.apache.flink.api.common.functions.MapFunction;
+ import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
+ import org.apache.flink.api.java.ExecutionEnvironment;
+ import org.apache.flink.api.java.operators.DataSource;
+ import org.apache.flink.api.java.operators.MapOperator;
+ import org.apache.flink.api.java.typeutils.RowTypeInfo;
+ import org.apache.flink.connector.jdbc.JdbcInputFormat;
+ import org.apache.flink.types.Row;
+
+ import java.text.SimpleDateFormat;
+
+ /**
+ * @author MatrixOne
+ * @description
+ */
+ public class MoRead {
+
+ private static String srcHost = "xx.xx.xx.xx";
+ private static Integer srcPort = 6001;
+ private static String srcUserName = "root";
+ private static String srcPassword = "111";
+ private static String srcDataBase = "test";
+
+ public static void main(String[] args) throws Exception {
+
+ ExecutionEnvironment environment = ExecutionEnvironment.getExecutionEnvironment();
+ // 设置并行度
+ environment.setParallelism(1);
+ SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
+
+ // 设置查询的字段类型
+ RowTypeInfo rowTypeInfo = new RowTypeInfo(
+ new BasicTypeInfo[]{
+ BasicTypeInfo.INT_TYPE_INFO,
+ BasicTypeInfo.STRING_TYPE_INFO,
+ BasicTypeInfo.DATE_TYPE_INFO
+ },
+ new String[]{
+ "id",
+ "name",
+ "birthday"
+ }
+ );
+
+ DataSource<Row> dataSource = environment.createInput(JdbcInputFormat.buildJdbcInputFormat()
+ .setDrivername("com.mysql.cj.jdbc.Driver")
+ .setDBUrl("jdbc:mysql://" + srcHost + ":" + srcPort + "/" + srcDataBase)
+ .setUsername(srcUserName)
+ .setPassword(srcPassword)
+ .setQuery("select * from person")
+ .setRowTypeInfo(rowTypeInfo)
+ .finish());
+
+ // 将 Wed Jul 12 00:00:00 CST 2023 日期格式转换为 2023-07-12
+ MapOperator<Row, Row> mapOperator = dataSource.map((MapFunction<Row, Row>) row -> {
+ row.setField("birthday", sdf.format(row.getField("birthday")));
+ return row;
+ });
+
+ mapOperator.print();
+ }
+ }
+ ```
+
+3. 在 IDEA 中运行 `MoRead.Main()`,执行结果如下:
+
+ 
+
+### 步骤三:将 MySQL 数据写入 MatrixOne
+
+现在可以开始使用 Flink 将 MySQL 数据迁移到 MatrixOne。
+
+1. 准备 MySQL 数据:在 node3 上,使用 Mysql 客户端连接本地 Mysql,创建所需数据库、数据表、并插入数据:
+
+ ```sql
+ mysql -h127.0.0.1 -P3306 -uroot -proot
+ mysql> CREATE DATABASE motest;
+ mysql> USE motest;
+ mysql> CREATE TABLE `person` (`id` int DEFAULT NULL, `name` varchar(255) DEFAULT NULL, `birthday` date DEFAULT NULL);
+ mysql> INSERT INTO motest.person (id, name, birthday) VALUES(2, 'lisi', '2023-07-09'),(3, 'wangwu', '2023-07-13'),(4, 'zhaoliu', '2023-08-08');
+ ```
+
+2. 清空 MatrixOne 表数据:
+
+ 在 node3 上,使用 MySQL 客户端连接 node1 的 MatrixOne。由于本示例继续使用前面读取 MatrixOne 数据的示例中的 `test` 数据库,因此我们需要首先清空 `person` 表的数据。
+
+ ```sql
+ -- 在 node3 上,使用 Mysql 客户端连接 node1 的 MatrixOne
+ mysql -hxx.xx.xx.xx -P6001 -uroot -p111
+ mysql> TRUNCATE TABLE test.person;
+ ```
+
+3. 在 IDEA 中编写代码:
+
+ 创建 `Person.java` 和 `Mysql2Mo.java` 类,使用 Flink 读取 MySQL 数据,执行简单的 ETL 操作(将 Row 转换为 Person 对象),最终将数据写入 MatrixOne 中。
+
+```java
+package com.matrixone.flink.demo.entity;
+
+
+import java.util.Date;
+
+public class Person {
+
+ private int id;
+ private String name;
+ private Date birthday;
+
+ public int getId() {
+ return id;
+ }
+
+ public void setId(int id) {
+ this.id = id;
+ }
+
+ public String getName() {
+ return name;
+ }
+
+ public void setName(String name) {
+ this.name = name;
+ }
+
+ public Date getBirthday() {
+ return birthday;
+ }
+
+ public void setBirthday(Date birthday) {
+ this.birthday = birthday;
+ }
+}
+```
+
+```java
+package com.matrixone.flink.demo;
+
+import com.matrixone.flink.demo.entity.Person;
+import org.apache.flink.api.common.functions.MapFunction;
+import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
+import org.apache.flink.api.java.typeutils.RowTypeInfo;
+import org.apache.flink.connector.jdbc.*;
+import org.apache.flink.streaming.api.datastream.DataStreamSink;
+import org.apache.flink.streaming.api.datastream.DataStreamSource;
+import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
+import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
+import org.apache.flink.types.Row;
+
+import java.sql.Date;
+
+/**
+ * @author MatrixOne
+ * @description
+ */
+public class Mysql2Mo {
+
+ private static String srcHost = "127.0.0.1";
+ private static Integer srcPort = 3306;
+ private static String srcUserName = "root";
+ private static String srcPassword = "root";
+ private static String srcDataBase = "motest";
+
+ private static String destHost = "xx.xx.xx.xx";
+ private static Integer destPort = 6001;
+ private static String destUserName = "root";
+ private static String destPassword = "111";
+ private static String destDataBase = "test";
+ private static String destTable = "person";
+
+
+ public static void main(String[] args) throws Exception {
+
+ StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
+ //设置并行度
+ environment.setParallelism(1);
+ //设置查询的字段类型
+ RowTypeInfo rowTypeInfo = new RowTypeInfo(
+ new BasicTypeInfo[]{
+ BasicTypeInfo.INT_TYPE_INFO,
+ BasicTypeInfo.STRING_TYPE_INFO,
+ BasicTypeInfo.DATE_TYPE_INFO
+ },
+ new String[]{
+ "id",
+ "name",
+ "birthday"
+ }
+ );
+
+ //添加 srouce
+ DataStreamSource<Row> dataSource = environment.createInput(JdbcInputFormat.buildJdbcInputFormat()
+ .setDrivername("com.mysql.cj.jdbc.Driver")
+ .setDBUrl("jdbc:mysql://" + srcHost + ":" + srcPort + "/" + srcDataBase)
+ .setUsername(srcUserName)
+ .setPassword(srcPassword)
+ .setQuery("select * from person")
+ .setRowTypeInfo(rowTypeInfo)
+ .finish());
+
+ //进行 ETL
+ SingleOutputStreamOperator<Person> mapOperator = dataSource.map((MapFunction<Row, Person>) row -> {
+ Person person = new Person();
+ person.setId((Integer) row.getField("id"));
+ person.setName((String) row.getField("name"));
+ person.setBirthday((java.util.Date)row.getField("birthday"));
+ return person;
+ });
+
+ //设置 matrixone sink 信息
+ mapOperator.addSink(
+ JdbcSink.sink(
+ "insert into " + destTable + " values(?,?,?)",
+ (ps, t) -> {
+ ps.setInt(1, t.getId());
+ ps.setString(2, t.getName());
+ ps.setDate(3, new Date(t.getBirthday().getTime()));
+ },
+ new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
+ .withDriverName("com.mysql.cj.jdbc.Driver")
+ .withUrl("jdbc:mysql://" + destHost + ":" + destPort + "/" + destDataBase)
+ .withUsername(destUserName)
+ .withPassword(destPassword)
+ .build()
+ )
+ );
+
+ environment.execute();
+ }
+
+}
+```
+
+### 步骤四:查看执行结果
+
+在 MatrixOne 中执行如下 SQL 查询结果:
+
+```sql
+mysql> select * from test.person;
++------+---------+------------+
+| id | name | birthday |
++------+---------+------------+
+| 2 | lisi | 2023-07-09 |
+| 3 | wangwu | 2023-07-13 |
+| 4 | zhaoliu | 2023-08-08 |
++------+---------+------------+
+3 rows in set (0.01 sec)
+```
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-oracle-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-oracle-matrixone.md
new file mode 100644
index 0000000000..0cd68c7725
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-oracle-matrixone.md
@@ -0,0 +1,142 @@
+# 使用 Flink 将 Oracle 数据写入 MatrixOne
+
+本章节将介绍如何使用 Flink 将 Oracle 数据写入到 MatrixOne。
+
+## 前期准备
+
+本次实践需要安装部署以下软件环境:
+
+- 完成[单机部署 MatrixOne](https://docs.matrixorigin.cn/1.2.1/MatrixOne/Get-Started/install-standalone-matrixone/)。
+- 下载安装 [lntelliJ IDEA(2022.2.1 or later version)](https://www.jetbrains.com/idea/download/)。
+- 根据你的系统环境选择 [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html) 版本进行下载安装。
+- 下载并安装 [Flink](https://archive.apache.org/dist/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz),最低支持版本为 1.11。
+- 已完成[安装 Oracle 19c](https://www.oracle.com/database/technologies/oracle-database-software-downloads.html)。
+- 下载并安装 [MySQL](https://downloads.mysql.com/archives/get/p/23/file/mysql-server_8.0.33-1ubuntu23.04_amd64.deb-bundle.tar),推荐版本为 8.0.33。
+
+## 操作步骤
+
+### 在 Oracle 中创建表,并插入数据
+
+```sql
+create table flinkcdc_empt
+(
+ EMPNO NUMBER not null primary key,
+ ENAME VARCHAR2(10),
+ JOB VARCHAR2(9),
+ MGR NUMBER(4),
+ HIREDATE DATE,
+ SAL NUMBER(7, 2),
+ COMM NUMBER(7, 2),
+ DEPTNO NUMBER(2)
+)
+--修改 FLINKCDC_EMPT 表让其支持增量日志
+ALTER TABLE scott.FLINKCDC_EMPT ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
+--插入测试数据:
+INSERT INTO SCOTT.FLINKCDC_EMPT (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO) VALUES(1, 'TURNER', 'SALESMAN', 7698, TIMESTAMP '2022-10-31 16:21:11.000000', 1500, 0, 30);
+INSERT INTO SCOTT.FLINKCDC_EMPT (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO) VALUES(2, 'TURNER', 'SALESMAN', 7698, TIMESTAMP '2022-10-31 16:21:11.000000', 1500, 0, 30);
+INSERT INTO SCOTT.FLINKCDC_EMPT (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO) VALUES(3, 'TURNER', 'SALESMAN', 7698, TIMESTAMP '2022-10-31 16:21:11.000000', 1500, 0, 30);
+INSERT INTO SCOTT.FLINKCDC_EMPT (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO) VALUES(4, 'TURNER', 'SALESMAN', 7698, TIMESTAMP '2022-10-31 16:21:11.000000', 1500, 0, 30);
+INSERT INTO SCOTT.FLINKCDC_EMPT (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO) VALUES(5, 'TURNER', 'SALESMAN', 7698, TIMESTAMP '2022-10-31 16:21:11.000000', 1500, 0, 30);
+INSERT INTO SCOTT.FLINKCDC_EMPT (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO) VALUES(6, 'TURNER', 'SALESMAN', 7698, TIMESTAMP '2022-10-31 16:21:11.000000', 1500, 0, 30);
+INSERT INTO SCOTT.FLINKCDC_EMPT (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO) VALUES(5989, 'TURNER', 'SALESMAN', 7698, TIMESTAMP '2022-10-31 16:21:11.000000', 1500, 0, 30);
+```
+
+### 在 MatrixOne 中创建目标表
+
+```SQL
+create database test;
+use test;
+CREATE TABLE `oracle_empt` (
+ `empno` bigint NOT NULL COMMENT "",
+ `ename` varchar(10) NULL COMMENT "",
+ `job` varchar(9) NULL COMMENT "",
+ `mgr` int NULL COMMENT "",
+ `hiredate` datetime NULL COMMENT "",
+ `sal` decimal(7, 2) NULL COMMENT "",
+ `comm` decimal(7, 2) NULL COMMENT "",
+ `deptno` int NULL COMMENT ""
+);
+```
+
+### 复制 jar 包
+
+将 `flink-sql-connector-oracle-cdc-2.2.1.jar`、`flink-connector-jdbc_2.11-1.13.6.jar`、`mysql-connector-j-8.0.31.jar` 复制到 `flink-1.13.6/lib/`。
+
+如果 flink 已经启动,需要重启 flink,加载生效 jar 包。
+
+### 切换到 flink 目录,并启动集群
+
+```bash
+./bin/start-cluster.sh
+```
+
+### 启动 Flink SQL CLI
+
+```bash
+./bin/sql-client.sh
+```
+
+### 开启 checkpoint
+
+```bash
+SET execution.checkpointing.interval = 3s;
+```
+
+### 使用 flink ddl 创建 source/sink 表
+
+```sql
+-- 创建 source 表 (oracle)
+CREATE TABLE `oracle_source` (
+ EMPNO bigint NOT NULL,
+ ENAME VARCHAR(10),
+ JOB VARCHAR(9),
+ MGR int,
+ HIREDATE timestamp,
+ SAL decimal(7,2),
+ COMM decimal(7,2),
+ DEPTNO int,
+ PRIMARY KEY(EMPNO) NOT ENFORCED
+) WITH (
+ 'connector' = 'oracle-cdc',
+ 'hostname' = 'xx.xx.xx.xx',
+ 'port' = '1521',
+ 'username' = 'scott',
+ 'password' = 'tiger',
+ 'database-name' = 'ORCLCDB',
+ 'schema-name' = 'SCOTT',
+ 'table-name' = 'FLINKCDC_EMPT',
+ 'debezium.database.tablename.case.insensitive'='false',
+ 'debezium.log.mining.strategy'='online_catalog'
+ );
+-- 创建 sink 表 (mo)
+CREATE TABLE IF NOT EXISTS `oracle_sink` (
+ EMPNO bigint NOT NULL,
+ ENAME VARCHAR(10),
+ JOB VARCHAR(9),
+ MGR int,
+ HIREDATE timestamp,
+ SAL decimal(7,2),
+ COMM decimal(7,2),
+ DEPTNO int,
+ PRIMARY KEY(EMPNO) NOT ENFORCED
+) with (
+'connector' = 'jdbc',
+ 'url' = 'jdbc:mysql://ip:6001/test',
+ 'driver' = 'com.mysql.cj.jdbc.Driver',
+ 'username' = 'root',
+ 'password' = '111',
+ 'table-name' = 'oracle_empt'
+);
+-- 将 source 表数据读取插入到 sink 表中
+insert into `oracle_sink` select * from `oracle_source`;
+```
+
+### 在 MatrixOne 中查询对应表数据
+
+```sql
+select * from oracle_empt;
+```
+
+ <div align="center">
+ <img src=https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/flink/flink-oracle.jpg width=70% heigth=70%/>
+</div>
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-overview.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-overview.md
new file mode 100644
index 0000000000..d7515c1ca9
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-overview.md
@@ -0,0 +1,17 @@
+# 概述
+
+Apache Flink 是一个强大的框架和分布式处理引擎,专注于进行有状态计算,适用于处理无边界和有边界的数据流。Flink 能够在各种常见集群环境中高效运行,并以内存速度执行计算,支持处理任意规模的数据。
+
+## 应用场景
+
+* 事件驱动型应用
+
+ 事件驱动型应用通常具备状态,并且它们从一个或多个事件流中提取数据,根据到达的事件触发计算、状态更新或执行其他外部动作。典型的事件驱动型应用包括反欺诈系统、异常检测、基于规则的报警系统和业务流程监控。
+
+* 数据分析应用
+
+ 数据分析任务的主要目标是从原始数据中提取有价值的信息和指标。Flink 支持流式和批量分析应用,适用于各种场景,例如电信网络质量监控、移动应用中的产品更新和实验评估分析、消费者技术领域的实时数据即席分析以及大规模图分析。
+
+* 数据管道应用
+
+ 提取 - 转换 - 加载(ETL)是在不同存储系统之间进行数据转换和迁移的常见方法。数据管道和 ETL 作业有相似之处,都可以进行数据转换和丰富,然后将数据从一个存储系统移动到另一个存储系统。不同之处在于数据管道以持续流模式运行,而不是周期性触发。典型的数据管道应用包括电子商务中的实时查询索引构建和持续 ETL。
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-postgresql-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-postgresql-matrixone.md
new file mode 100644
index 0000000000..9ff620ab57
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-postgresql-matrixone.md
@@ -0,0 +1,227 @@
+# 使用 Flink 将 PostgreSQL 数据写入 MatrixOne
+
+本章节将介绍如何使用 Flink 将 PostgreSQL 数据写入到 MatrixOne。
+
+## 前期准备
+
+本次实践需要安装部署以下软件环境:
+
+- 完成[单机部署 MatrixOne](https://docs.matrixorigin.cn/1.2.1/MatrixOne/Get-Started/install-standalone-matrixone/)。
+- 下载安装 [lntelliJ IDEA(2022.2.1 or later version)](https://www.jetbrains.com/idea/download/)。
+- 根据你的系统环境选择 [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html) 版本进行下载安装。
+- 安装 [PostgreSQL](https://www.postgresql.org/download/)。
+- 下载并安装 [Flink](https://archive.apache.org/dist/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz),最低支持版本为 1.11。
+- 下载并安装 [MySQL](https://downloads.mysql.com/archives/get/p/23/file/mysql-server_8.0.33-1ubuntu23.04_amd64.deb-bundle.tar),推荐版本为 8.0.33。
+
+## 操作步骤
+
+### 下载 Flink CDC connector
+
+```bash
+wget https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-postgres-cdc/2.1.1/flink-sql-connector-postgres-cdc-2.1.1.jar
+```
+
+### 复制 jar 包
+
+将 `Flink CDC connector` 和 `flink-connector-jdbc_2.12-1.13.6.jar`、`mysql-connector-j-8.0.33.jar` 对应 Jar 包复制到 `flink-1.13.6/lib/`
+如果 flink 已经启动,需要重启 flink,加载生效 jar 包。
+
+### Postgresql 开启 cdc 配置
+
+1. postgresql.conf 配置
+
+ ```conf
+ #更改 wal 发送最大进程数(默认值为 10),这个值和上面的 solts 设置一样
+ max_wal_senders = 10 # max number of walsender processes
+ #中断那些停止活动超过指定毫秒数的复制连接,可以适当设置大一点(默认 60s)
+ wal_sender_timeout = 180s # in milliseconds; 0 disables
+ #更改 solts 最大数量(默认值为 10),flink-cdc 默认一张表占用一个 slots
+ max_replication_slots = 10 # max number of replication slots
+ #指定为 logical
+ wal_level = logical # minimal, replica, or logical
+ ```
+
+2. pg_hba.conf
+
+ ```conf
+ #IPv4 local connections:
+ host all all 0.0.0.0/0 password
+ host replication all 0.0.0.0/0 password
+ ```
+
+### 在 postgresql 中创建表,并插入数据
+
+```sql
+
+create table student
+(
+ stu_id integer not null unique,
+ stu_name varchar(50),
+ stu_age integer,
+ stu_bth date
+);
+
+INSERT into student VALUES (1,"lisa",12,'2022-10-12');
+INSERT into student VALUES (2,"tom",23,'2021-11-10');
+INSERT into student VALUES (3,"jenny",11,'2024-02-19');
+INSERT into student VALUES (4,"henry",12,'2022-04-22');
+```
+
+### 在 MatrixOne 中建表
+
+```sql
+create table student
+(
+ stu_id integer not null unique,
+ stu_name varchar(50),
+ stu_age integer,
+ stu_bth date
+);
+```
+
+### 启动集群
+
+切换到 flink 目录,执行以下命令:
+
+```bash
+./bin/start-cluster.sh
+```
+
+### 启动 Flink SQL CLI
+
+```bash
+./bin/sql-client.sh
+```
+
+### 开启 checkpoint
+
+设置每隔 3 秒做一次 checkpoint
+
+```sql
+SET execution.checkpointing.interval = 3s;
+```
+
+### 使用 flink ddl 创建 source 表
+
+```sql
+CREATE TABLE pgsql_bog (
+ stu_id int not null,
+ stu_name varchar(50),
+ stu_age int,
+ stu_bth date,
+ primary key (stu_id) not enforced
+) WITH (
+ 'connector' = 'postgres-cdc',
+ 'hostname' = 'xx.xx.xx.xx',
+ 'port' = '5432',
+ 'username' = 'postgres',
+ 'password' = '123456',
+ 'database-name' = 'postgres',
+ 'schema-name' = 'public',
+ 'table-name' = 'student',
+ 'decoding.plugin.name' = 'pgoutput' ,
+ 'debezium.snapshot.mode' = 'initial'
+ ) ;
+```
+
+如果是 table sql 方式,pgoutput 是 PostgreSQL 10+ 中的标准逻辑解码输出插件。需要设置一下。不添加:`'decoding.plugin.name' = 'pgoutput'`,
+会报错:`org.postgresql.util.PSQLException: ERROR: could not access file "decoderbufs": No such file or directory`。
+
+### 创建 sink 表
+
+```sql
+CREATE TABLE test_pg (
+ stu_id int not null,
+ stu_name varchar(50),
+ stu_age int,
+ stu_bth date,
+ primary key (stu_id) not enforced
+) WITH (
+'connector' = 'jdbc',
+'url' = 'jdbc:mysql://xx.xx.xx.xx:6001/postgre',
+'driver' = 'com.mysql.cj.jdbc.Driver',
+'username' = 'root',
+'password' = '111',
+'table-name' = 'student'
+);
+```
+
+### 将 PostgreSQL 数据导入 MatrixOne
+
+```sql
+insert into test_pg select * from pgsql_bog;
+```
+
+在 MatrixOne 中查询对应表数据;
+
+```sql
+mysql> select * from student;
++--------+----------+---------+------------+
+| stu_id | stu_name | stu_age | stu_bth |
++--------+----------+---------+------------+
+| 1 | lisa | 12 | 2022-10-12 |
+| 2 | tom | 23 | 2021-11-10 |
+| 3 | jenny | 11 | 2024-02-19 |
+| 4 | henry | 12 | 2022-04-22 |
++--------+----------+---------+------------+
+4 rows in set (0.00 sec)
+```
+
+可以发现数据已经导入
+
+### 在 postgrsql 中新增数据
+
+```sql
+insert into public.student values (51, '58', 39, '2020-01-03');
+```
+
+在 MatrixOne 中查询对应表数据;
+
+```sql
+mysql> select * from student;
++--------+----------+---------+------------+
+| stu_id | stu_name | stu_age | stu_bth |
++--------+----------+---------+------------+
+| 1 | lisa | 12 | 2022-10-12 |
+| 2 | tom | 23 | 2021-11-10 |
+| 3 | jenny | 11 | 2024-02-19 |
+| 4 | henry | 12 | 2022-04-22 |
+| 51 | 58 | 39 | 2020-01-03 |
++--------+----------+---------+------------+
+5 rows in set (0.01 sec)
+```
+
+可以发现数据已经同步到 MatrixOne 对应表中。
+
+删除数据:
+
+```sql
+delete from public.student where stu_id=1;
+```
+
+如果报错
+
+```sql
+cannot delete from table "student" because it does not have a replica identity and publishes deletes
+```
+
+则执行
+
+```sql
+alter table public.student replica identity full;
+```
+
+在 MatrixOne 中查询对应表数据;
+
+```sql
+mysql> select * from student;
++--------+----------+---------+------------+
+| stu_id | stu_name | stu_age | stu_bth |
++--------+----------+---------+------------+
+| 2 | tom | 23 | 2021-11-10 |
+| 3 | jenny | 11 | 2024-02-19 |
+| 4 | henry | 12 | 2022-04-22 |
+| 51 | 58 | 39 | 2020-01-03 |
++--------+----------+---------+------------+
+4 rows in set (0.00 sec)
+```
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-sqlserver-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-sqlserver-matrixone.md
new file mode 100644
index 0000000000..13f8601232
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-sqlserver-matrixone.md
@@ -0,0 +1,269 @@
+# 使用 Flink 将 SQL Server 数据写入 MatrixOne
+
+本章节将介绍如何使用 Flink 将 SQL Server 数据写入到 MatrixOne。
+
+## 前期准备
+
+本次实践需要安装部署以下软件环境:
+
+- 完成[单机部署 MatrixOne](https://docs.matrixorigin.cn/1.2.1/MatrixOne/Get-Started/install-standalone-matrixone/)。
+- 下载安装 [lntelliJ IDEA(2022.2.1 or later version)](https://www.jetbrains.com/idea/download/)。
+- 根据你的系统环境选择 [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html) 版本进行下载安装。
+- 下载并安装 [Flink](https://archive.apache.org/dist/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz),最低支持版本为 1.11。
+- 已完成 [SQL Server 2022](https://www.microsoft.com/en-us/sql-server/sql-server-downloads)。
+- 下载并安装 [MySQL](https://downloads.mysql.com/archives/get/p/23/file/mysql-server_8.0.33-1ubuntu23.04_amd64.deb-bundle.tar),推荐版本为 8.0.33。
+
+## 操作步骤
+
+### 在 SQL Server 中创建库、表并插入数据
+
+```sql
+create database sstomo;
+use sstomo;
+create table sqlserver_data (
+ id INT PRIMARY KEY,
+ name NVARCHAR(100),
+ age INT,
+ entrytime DATE,
+ gender NVARCHAR(2)
+);
+
+insert into sqlserver_data (id, name, age, entrytime, gender)
+values (1, 'Lisa', 25, '2010-10-12', '0'),
+ (2, 'Liming', 26, '2013-10-12', '0'),
+ (3, 'asdfa', 27, '2022-10-12', '0'),
+ (4, 'aerg', 28, '2005-10-12', '0'),
+ (5, 'asga', 29, '2015-10-12', '1'),
+ (6, 'sgeq', 30, '2010-10-12', '1');
+```
+
+### SQL Server 配置 CDC
+
+1. 确认当前用户已开启 sysadmin 权限
+ 查询当前用户权限,必须为 sysadmin 固定服务器角色的成员才允许对数据库启用 CDC (变更数据捕获) 功能。
+ 通过下面命令查询 sa 用户是否开启 sysadmin
+
+ ```sql
+ exec sp_helpsrvrolemember 'sysadmin';
+ ```
+
+ <div align="center">
+ <img src=https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/flink/flink-sqlserver-01.jpg width=70% heigth=70%/>
+ </div>
+
+2. 查询当前数据库是否启用 CDC(变更数据捕获能力)功能
+
+ <div align="center">
+ <img src=https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/flink/%EF%BF%BCflink-sqlserver-02.jpg width=60% heigth=60%/>
+ </div>
+
+ 备注:0:表示未启用;1:表示启用
+
+ 如未开启,则执行如下 sql 开启:
+
+ ```sql
+ use sstomo;
+ exec sys.sp_cdc_enable_db;
+ ```
+
+3. 查询表是否已经启用 CDC (变更数据捕获) 功能
+
+ ```sql
+ select name,is_tracked_by_cdc from sys.tables where name = 'sqlserver_data';
+ ```
+
+ <div align="center">
+ <img src=https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/flink/flink-sqlserver-03.jpg width=50% heigth=50%/>
+ </div>
+
+ 备注:0:表示未启用;1:表示启用
+ 如未开启,则执行下面 sql 进行开启:
+
+ ```sql
+ use sstomo;
+ exec sys.sp_cdc_enable_table
+ @source_schema = 'dbo',
+ @source_name = 'sqlserver_data',
+ @role_name = NULL,
+ @supports_net_changes = 0;
+ ```
+
+4. 表 sqlserver_data 启动 CDC (变更数据捕获) 功能配置完成
+
+ 查看数据库下的系统表,会发现多了些 cdc 相关数据表,其中 cdc.dbo_sqlserver_flink_CT 就是记录源表的所有 DML 操作记录,每个表对应一个实例表。
+
+ <div align="center">
+ <img src=https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/flink/flink-sqlserver-04.jpg width=50% heigth=50%/>
+ </div>
+
+5. 确认 CDC agent 是否正常启动
+
+ 执行下面命令查看 CDC agent 是否开启:
+
+ ```sql
+ exec master.dbo.xp_servicecontrol N'QUERYSTATE', N'SQLSERVERAGENT';
+ ```
+
+ 如状态是 `Stopped`,则需要开启 CDC agent。
+
+ <div align="center">
+ <img src=https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/flink/flink-sqlserver-05.jpg width=50% heigth=50%/>
+ </div>
+
+ 在 Windows 环境开启 CDC agent:
+ 在安装 SqlServer 数据库的机器上,打开 Microsoft Sql Server Managememt Studio,右击下图位置(SQL Server 代理),点击开启,如下图:
+
+ <div align="center">
+ <img src=https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/flink/flink-sqlserver-06.jpg width=50% heigth=50%/>
+ </div>
+
+ 开启之后,再次查询 agent 状态,确认状态变更为 running
+
+ <div align="center">
+ <img src=https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/flink/flink-sqlserver-07.jpg width=50% heigth=50%/>
+ </div>
+
+ 至此,表 sqlserver_data 启动 CDC (变更数据捕获) 功能全部完成。
+
+### 在 MatrixOne 中创建目标库及表
+
+```sql
+create database sstomo;
+use sstomo;
+CREATE TABLE sqlserver_data (
+ id int NOT NULL,
+ name varchar(100) DEFAULT NULL,
+ age int DEFAULT NULL,
+ entrytime date DEFAULT NULL,
+ gender char(1) DEFAULT NULL,
+ PRIMARY KEY (id)
+);
+```
+
+### 启动 flink
+
+1. 复制 cdc jar 包
+
+ 将 `link-sql-connector-sqlserver-cdc-2.3.0.jar`、`flink-connector-jdbc_2.12-1.13.6.jar`、`mysql-connector-j-8.0.33.jar` 复制到 flink 的 lib 目录下。
+
+2. 启动 flink
+
+ 切换到 flink 目录,并启动集群
+
+ ```bash
+ ./bin/start-cluster.sh
+ ```
+
+ 启动 Flink SQL CLIENT
+
+ ```bash
+ ./bin/sql-client.sh
+ ```
+
+3. 开启 checkpoint
+
+ ```bash
+ SET execution.checkpointing.interval = 3s;
+ ```
+
+### 使用 flink ddl 创建 source/sink 表
+
+```sql
+-- 创建 source 表
+CREATE TABLE sqlserver_source (
+id INT,
+name varchar(50),
+age INT,
+entrytime date,
+gender varchar(100),
+PRIMARY KEY (`id`) not enforced
+) WITH(
+'connector' = 'sqlserver-cdc',
+'hostname' = 'xx.xx.xx.xx',
+'port' = '1433',
+'username' = 'sa',
+'password' = '123456',
+'database-name' = 'sstomo',
+'schema-name' = 'dbo',
+'table-name' = 'sqlserver_data');
+
+-- 创建 sink 表
+CREATE TABLE sqlserver_sink (
+id INT,
+name varchar(100),
+age INT,
+entrytime date,
+gender varchar(10),
+PRIMARY KEY (`id`) not enforced
+) WITH(
+'connector' = 'jdbc',
+'url' = 'jdbc:mysql://xx.xx.xx.xx:6001/sstomo',
+'driver' = 'com.mysql.cj.jdbc.Driver',
+'username' = 'root',
+'password' = '111',
+'table-name' = 'sqlserver_data'
+);
+
+-- 将 source 表数据读取插入到 sink 表中
+Insert into sqlserver_sink select * from sqlserver_source;
+```
+
+### 在 MatrixOne 中查询对应表数据
+
+```sql
+use sstomo;
+select * from sqlserver_data;
+```
+
+<div align="center">
+ <img src=https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/flink/flink-sqlserver-08.jpg width=50% heigth=50%/>
+</div>
+
+### 在 SQL Server 中新增数据
+
+在 SqlServer 表 sqlserver_data 中插入 3 条数据:
+
+```sql
+insert into sstomo.dbo.sqlserver_data (id, name, age, entrytime, gender)
+values (7, 'Liss12a', 25, '2010-10-12', '0'),
+ (8, '12233s', 26, '2013-10-12', '0'),
+ (9, 'sgeq1', 304, '2010-10-12', '1');
+```
+
+在 MatrixOne 中查询对应表数据:
+
+```sql
+select * from sstomo.sqlserver_data;
+```
+
+<div align="center">
+ <img src=https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/flink/flink-sqlserver-09.jpg width=50% heigth=50%/>
+</div>
+
+### 在 SQL Server 中删除增数据
+
+在 SQL Server 中删除 id 为 3 和 4 的两行:
+
+```sql
+delete from sstomo.dbo.sqlserver_data where id in(3,4);
+```
+
+在 mo 中查询表数据,这两行已同步删除:
+
+<div align="center">
+ <img src=https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/flink/flink-sqlserver-10.jpg width=50% heigth=50%/>
+</div>
+
+### 在 SQL Server 中更新增数据
+
+在 SqlServer 表中更新两行数据:
+
+```sql
+update sstomo.dbo.sqlserver_data set age = 18 where id in(1,2);
+```
+
+在 MatrixOne 中查询表数据,这两行已同步更新:
+
+<div align="center">
+ <img src=https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/flink/flink-sqlserver-11.jpg width=50% heigth=50%/>
+</div>
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-tidb-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-tidb-matrixone.md
new file mode 100644
index 0000000000..01ca3550ad
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-tidb-matrixone.md
@@ -0,0 +1,157 @@
+# 使用 Flink 将 TiDB 数据写入 MatrixOne
+
+本章节将介绍如何使用 Flink 将 TiDB 数据写入到 MatrixOne。
+
+## 前期准备
+
+本次实践需要安装部署以下软件环境:
+
+- 完成[单机部署 MatrixOne](https://docs.matrixorigin.cn/1.2.1/MatrixOne/Get-Started/install-standalone-matrixone/)。
+- 下载安装 [lntelliJ IDEA(2022.2.1 or later version)](https://www.jetbrains.com/idea/download/)。
+- 根据你的系统环境选择 [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html) 版本进行下载安装。
+- 已完成 TiDB 单机部署。
+- 下载并安装 [Flink](https://archive.apache.org/dist/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz),最低支持版本为 1.11。
+- 下载并安装 [MySQL](https://downloads.mysql.com/archives/get/p/23/file/mysql-server_8.0.33-1ubuntu23.04_amd64.deb-bundle.tar),推荐版本为 8.0.33。
+- 下载 [Flink CDC connector](https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-tidb-cdc/2.2.1/flink-sql-connector-tidb-cdc-2.2.1.jar)
+
+## 操作步骤
+
+### 复制 jar 包
+
+将 `Flink CDC connector` 和 `flink-connector-jdbc_2.12-1.13.6.jar`、`mysql-connector-j-8.0.33.jar` 对应 Jar 包复制到 `flink-1.13.6/lib/`。
+
+如果 flink 已经启动,需要重启 flink,加载生效 jar 包。
+
+### 在 TiDB 中创建表,并插入数据
+
+```sql
+create table EMPQ_cdc
+(
+ empno bigint not null,
+ ename VARCHAR(10),
+ job VARCHAR(9),
+ mgr int,
+ hiredate DATE,
+ sal decimal(7,2),
+ comm decimal(7,2),
+ deptno int(2),
+ primary key (empno)
+)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
+
+INSERT into empq VALUES (1,"张三","sale",1,'2024-01-01',1000,NULL,1);
+INSERT into empq VALUES (2,"李四","develo,"2,'2024-03-05',5000,NULL,2);
+INSERT into empq VALUES (3,"王五","hr",3,'2024-03-18',2000,NULL,2);
+INSERT into empq VALUES (4,"赵六","pm",4,'2024-03-11',2000,NULL,3);
+```
+
+### 在 MatrixOne 中创建目标表
+
+```sql
+create table EMPQ
+(
+ empno bigint not null,
+ ename VARCHAR(10),
+ job VARCHAR(9),
+ mgr int,
+ hiredate DATE,
+ sal decimal(7,2),
+ comm decimal(7,2),
+ deptno int(2),
+ primary key (empno)
+);
+```
+
+### 切换到 flink 目录,并启动集群
+
+```bash
+./bin/start-cluster.sh
+```
+
+### 启动 Flink SQL CLI
+
+```bash
+./bin/sql-client.sh
+```
+
+### 开启 checkpoint
+
+```sql
+SET execution.checkpointing.interval = 3s;
+```
+
+### 使用 flink ddl 创建 source 和 sink 表
+
+建表语句在 smt/result/flink-create.all.sql 中。
+
+```sql
+-- 创建测试库
+CREATE DATABASE IF NOT EXISTS `default_catalog`.`test`;
+
+-- 创建 source 表
+CREATE TABLE IF NOT EXISTS `default_catalog`.`test`.`EMPQ_src` (
+`empno` BIGINT NOT NULL,
+`ename` STRING NULL,
+`job` STRING NULL,
+`mgr` INT NULL,
+`hiredate` DATE NULL,
+`sal` DECIMAL(7, 2) NULL,
+`comm` DECIMAL(7, 2) NULL,
+`deptno` INT NULL,
+PRIMARY KEY(`empno`) NOT ENFORCED
+) with (
+ 'connector' = 'tidb-cdc',
+ 'database-name' = 'test',
+ 'table-name' = 'EMPQ_cdc',
+ 'pd-addresses' = 'xx.xx.xx.xx:2379'
+);
+
+-- 创建 sink 表
+CREATE TABLE IF NOT EXISTS `default_catalog`.`test`.`EMPQ_sink` (
+`empno` BIGINT NOT NULL,
+`ename` STRING NULL,
+`job` STRING NULL,
+`mgr` INT NULL,
+`hiredate` DATE NULL,
+`sal` DECIMAL(7, 2) NULL,
+`comm` DECIMAL(7, 2) NULL,
+`deptno` INT NULL,
+PRIMARY KEY(`empno`) NOT ENFORCED
+) with (
+'connector' = 'jdbc',
+'url' = 'jdbc:mysql://xx.xx.xx.xx:6001/test',
+'driver' = 'com.mysql.cj.jdbc.Driver',
+'username' = 'root',
+'password' = '111',
+'table-name' = 'empq'
+);
+```
+
+### 将 TiDB 数据导入 MatrixOne
+
+```sql
+INSERT INTO `default_catalog`.`test`.`EMPQ_sink` SELECT * FROM `default_catalog`.`test`.`EMPQ_src`;
+```
+
+### 在 Matrixone 中查询对应表数据
+
+```sql
+select * from EMPQ;
+```
+
+<div align="center">
+ <img src=https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/flink/flink-tidb-01.jpg width=50% heigth=50%/>
+</div>
+
+可以发现数据已经导入
+
+### 在 TiDB 删除一条数据
+
+```sql
+delete from EMPQ_cdc where empno=1;
+```
+
+<div align="center">
+ <img src=https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/flink/flink-tidb-02.jpg width=50% heigth=50%/>
+</div>
+
+在 MatrixOne 中查询表数据,这行已同步删除。
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-doris-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-doris-matrixone.md
new file mode 100644
index 0000000000..90308d484d
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-doris-matrixone.md
@@ -0,0 +1,321 @@
+# 使用 Spark 从 Doris 迁移数据至 MatrixOne
+
+在本章节,我们将介绍使用 Spark 计算引擎实现 Doris 批量数据写入 MatrixOne。
+
+## 前期准备
+
+本次实践需要安装部署以下软件环境:
+
+- 已完成[安装和启动 MatrixOne](https://docs.matrixorigin.cn/1.2.1/MatrixOne/Get-Started/install-standalone-matrixone/)。
+- 下载并安装 [Doris](https://doris.apache.org/zh-CN/docs/dev/get-starting/quick-start/)。
+- 下载并安装 [IntelliJ IDEA version 2022.2.1 及以上](https://www.jetbrains.com/idea/download/)。
+- 下载并安装 [JDK 8+](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html)。
+- 下载并安装 [MySQL Client 8.0.33](https://downloads.mysql.com/archives/get/p/23/file/mysql-server_8.0.33-1ubuntu23.04_amd64.deb-bundle.tar)。
+
+## 操作步骤
+
+### 步骤一:在 Doris 中准备数据
+
+```sql
+create database test;
+
+use test;
+
+CREATE TABLE IF NOT EXISTS example_tbl
+(
+ user_id BIGINT NOT NULL COMMENT "用户id",
+ date DATE NOT NULL COMMENT "数据灌入日期时间",
+ city VARCHAR(20) COMMENT "用户所在城市",
+ age SMALLINT COMMENT "用户年龄",
+ sex TINYINT COMMENT "用户性别"
+)
+DUPLICATE KEY(user_id, date)
+DISTRIBUTED BY HASH(user_id) BUCKETS 1
+PROPERTIES (
+ "replication_num"="1"
+);
+
+insert into example_tbl values
+(10000,'2017-10-01','北京',20,0),
+(10000,'2017-10-01','北京',20,0),
+(10001,'2017-10-01','北京',30,1),
+(10002,'2017-10-02','上海',20,1),
+(10003,'2017-10-02','广州',32,0),
+(10004,'2017-10-01','深圳',35,0),
+(10004,'2017-10-03','深圳',35,0);
+```
+
+### 步骤二:在 MatrixOne 中准备库表
+
+```sql
+create database sparkdemo;
+use sparkdemo;
+
+CREATE TABLE IF NOT EXISTS example_tbl
+(
+ user_id BIGINT NOT NULL COMMENT "用户id",
+ date DATE NOT NULL COMMENT "数据灌入日期时间",
+ city VARCHAR(20) COMMENT "用户所在城市",
+ age SMALLINT COMMENT "用户年龄",
+ sex TINYINT COMMENT "用户性别"
+);
+```
+
+### 步骤三:初始化项目
+
+启动 IDEA,并创建一个新的 Maven 项目,添加项目依赖,pom.xml 文件如下:
+
+```xml
+<?xml version="1.0" encoding="UTF-8"?>
+<project xmlns="http://maven.apache.org/POM/4.0.0"
+ xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
+ xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
+ <modelVersion>4.0.0</modelVersion>
+
+ <groupId>com.example.mo</groupId>
+ <artifactId>mo-spark-demo</artifactId>
+ <version>1.0-SNAPSHOT</version>
+
+ <properties>
+ <maven.compiler.source>8</maven.compiler.source>
+ <maven.compiler.target>8</maven.compiler.target>
+ <spark.version>3.2.1</spark.version>
+ <java.version>8</java.version>
+ </properties>
+
+ <dependencies>
+ <dependency>
+ <groupId>org.apache.doris</groupId>
+ <artifactId>spark-doris-connector-3.1_2.12</artifactId>
+ <version>1.2.0</version>
+ </dependency>
+
+ <dependency>
+ <groupId>org.apache.spark</groupId>
+ <artifactId>spark-sql_2.12</artifactId>
+ <version>${spark.version}</version>
+ </dependency>
+
+ <dependency>
+ <groupId>org.apache.spark</groupId>
+ <artifactId>spark-hive_2.12</artifactId>
+ <version>${spark.version}</version>
+ </dependency>
+ <dependency>
+ <groupId>org.apache.spark</groupId>
+ <artifactId>spark-catalyst_2.12</artifactId>
+ <version>${spark.version}</version>
+ </dependency>
+ <dependency>
+ <groupId>org.apache.spark</groupId>
+ <artifactId>spark-core_2.12</artifactId>
+ <version>${spark.version}</version>
+ </dependency>
+ <dependency>
+ <groupId>org.codehaus.jackson</groupId>
+ <artifactId>jackson-core-asl</artifactId>
+ <version>1.9.13</version>
+ </dependency>
+ <dependency>
+ <groupId>org.codehaus.jackson</groupId>
+ <artifactId>jackson-mapper-asl</artifactId>
+ <version>1.9.13</version>
+ </dependency>
+
+
+ <dependency>
+ <groupId>mysql</groupId>
+ <artifactId>mysql-connector-java</artifactId>
+ <version>8.0.30</version>
+ </dependency>
+ </dependencies>
+
+ <build>
+ <plugins>
+ <plugin>
+ <groupId>org.apache.maven.plugins</groupId>
+ <artifactId>maven-compiler-plugin</artifactId>
+ <version>3.8.0</version>
+ <configuration>
+ <source>${java.version}</source>
+ <target>${java.version}</target>
+ <encoding>UTF-8</encoding>
+ </configuration>
+ </plugin>
+
+ <plugin>
+ <groupId>org.scala-tools</groupId>
+ <artifactId>maven-scala-plugin</artifactId>
+ <configuration>
+ <scalaVersion>2.12.16</scalaVersion>
+ </configuration>
+ <version>2.15.1</version>
+ <executions>
+ <execution>
+ <id>compile-scala</id>
+ <goals>
+ <goal>add-source</goal>
+ <goal>compile</goal>
+ </goals>
+ <configuration>
+ <args>
+ <!--<arg>-make:transitive</arg>-->
+ <arg>-dependencyfile</arg>
+ <arg>${project.build.directory}/.scala_dependencies</arg>
+ </args>
+ </configuration>
+ </execution>
+ </executions>
+ </plugin>
+
+ <plugin>
+ <artifactId>maven-assembly-plugin</artifactId>
+ <configuration>
+ <descriptorRefs>
+ <descriptor>jar-with-dependencies</descriptor>
+ </descriptorRefs>
+ </configuration>
+ <executions>
+ <execution>
+ <id>make-assembly</id>
+ <phase>package</phase>
+ <goals>
+ <goal>single</goal>
+ </goals>
+ </execution>
+ </executions>
+ </plugin>
+ </plugins>
+ </build>
+
+</project>
+```
+
+### 步骤四:将 Doris 数据写入 MatrixOne
+
+1. 编写代码
+
+ 创建 Doris2Mo.java 类,通过 Spark 读取 Doris 数据,将数据写入到 MatrixOne 中:
+
+ ```java
+ package org.example;
+
+ import org.apache.spark.sql.Dataset;
+ import org.apache.spark.sql.Row;
+ import org.apache.spark.sql.SaveMode;
+ import org.apache.spark.sql.SparkSession;
+
+ import java.sql.SQLException;
+
+ /**
+ * @auther MatrixOne
+ * @desc
+ */
+ public class Doris2Mo {
+ public static void main(String[] args) throws SQLException {
+ SparkSession spark = SparkSession
+ .builder()
+ .appName("Spark Doris to MatixOne")
+ .master("local")
+ .getOrCreate();
+
+ Dataset<Row> df = spark.read().format("doris").option("doris.table.identifier", "test.example_tbl")
+ .option("doris.fenodes", "192.168.110.11:8030")
+ .option("user", "root")
+ .option("password", "root")
+ .load();
+
+ // JDBC properties for MySQL
+ java.util.Properties mysqlProperties = new java.util.Properties();
+ mysqlProperties.setProperty("user", "root");
+ mysqlProperties.setProperty("password", "111");
+ mysqlProperties.setProperty("driver", "com.mysql.cj.jdbc.Driver");
+
+ // MySQL JDBC URL
+ String mysqlUrl = "jdbc:mysql://xx.xx.xx.xx:6001/sparkdemo";
+
+ // Write to MySQL
+ df.write()
+ .mode(SaveMode.Append)
+ .jdbc(mysqlUrl, "example_tbl", mysqlProperties);
+ }
+
+ }
+ ```
+
+2. 查看执行结果
+
+ 在 MatrixOne 中执行如下 SQL 查询结果:
+
+ ```sql
+ mysql> select * from sparkdemo.example_tbl;
+ +---------+------------+--------+------+------+
+ | user_id | date | city | age | sex |
+ +---------+------------+--------+------+------+
+ | 10000 | 2017-10-01 | 北京 | 20 | 0 |
+ | 10000 | 2017-10-01 | 北京 | 20 | 0 |
+ | 10001 | 2017-10-01 | 北京 | 30 | 1 |
+ | 10002 | 2017-10-02 | 上海 | 20 | 1 |
+ | 10003 | 2017-10-02 | 广州 | 32 | 0 |
+ | 10004 | 2017-10-01 | 深圳 | 35 | 0 |
+ | 10004 | 2017-10-03 | 深圳 | 35 | 0 |
+ +---------+------------+--------+------+------+
+ 7 rows in set (0.01 sec)
+ ```
+
+3. 在 Spark 中执行
+
+ - 添加依赖
+
+ 通过 Maven 将第 2 步中编写的代码进行打包:`mo-spark-demo-1.0-SNAPSHOT-jar-with-dependencies.jar`,
+ 将以上 Jar 包,放到 Spark 安装目录 jars 下。
+
+ - 启动 Spark
+
+ 依赖添加完成后,启动 Spark,这里我使用 Spark Standalone 模式启动
+
+ ```bash
+ ./sbin/start-all.sh
+ ```
+
+ 启动完成后,使用 jps 命令查询是否启动成功,出现 master 和 worker 进程即启动成功
+
+ ```bash
+ [root@node02 jars]# jps
+ 5990 Worker
+ 8093 Jps
+ 5870 Master
+ ```
+
+ - 执行程序
+
+ 进入 Spark 安装目录下,执行如下命令
+
+ ```bash
+ [root@node02 spark-3.2.4-bin-hadoop3.2]# bin/spark-submit --class org.example.Doris2Mo --master spark://192.168.110.247:7077 ./jars/mo-spark-demo-1.0-SNAPSHOT-jar-with-dependencies.jar
+
+ //class:表示要执行的主类
+ //master:Spark 程序运行的模式
+ //mo-spark-demo-1.0-SNAPSHOT-jar-with-dependencies.jar:运行的程序 jar 包
+ ```
+
+ 输出如下结果表示写入成功:
+
+ ```bash
+ 24/04/30 10:24:53 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 1261 bytes result sent to driver
+ 24/04/30 10:24:53 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 1493 ms on node02 (executor driver) (1/1)
+ 24/04/30 10:24:53 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
+ 24/04/30 10:24:53 INFO DAGScheduler: ResultStage 0 (jdbc at Doris2Mo.java:40) finished in 1.748 s
+ 24/04/30 10:24:53 INFO DAGScheduler: Job 0 is finished. Cancelling potential speculative or zombie tasks for this job
+ 24/04/30 10:24:53 INFO TaskSchedulerImpl: Killing all running tasks in stage 0: Stage finished
+ 24/04/30 10:24:53 INFO DAGScheduler: Job 0 finished: jdbc at Doris2Mo.java:40, took 1.848481 s
+ 24/04/30 10:24:53 INFO SparkContext: Invoking stop() from shutdown hook
+ 24/04/30 10:24:53 INFO SparkUI: Stopped Spark web UI at http://node02:4040
+ 24/04/30 10:24:53 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
+ 24/04/30 10:24:53 INFO MemoryStore: MemoryStore cleared
+ 24/04/30 10:24:53 INFO BlockManager: BlockManager stopped
+ 24/04/30 10:24:53 INFO BlockManagerMaster: BlockManagerMaster stopped
+ 24/04/30 10:24:53 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
+ 24/04/30 10:24:53 INFO SparkContext: Successfully stopped SparkContext
+ 24/04/30 10:24:53 INFO ShutdownHookManager: Shutdown hook called
+ ```
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-hive-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-hive-matrixone.md
new file mode 100644
index 0000000000..077a35efa7
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-hive-matrixone.md
@@ -0,0 +1,205 @@
+# 使用 Spark 将 Hive 数据导入到 MatrixOne
+
+在本章节,我们将介绍使用 Spark 计算引擎实现 Hive 批量数据写入 MatrixOne。
+
+## 前期准备
+
+本次实践需要安装部署以下软件环境:
+
+- 已完成[安装和启动 MatrixOne](https://docs.matrixorigin.cn/1.2.1/MatrixOne/Get-Started/install-standalone-matrixone/)。
+- 下载并安装 [IntelliJ IDEA version 2022.2.1 及以上](https://www.jetbrains.com/idea/download/)。
+- 下载并安装 [JDK 8+](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html)。
+- 从 Hive 导入数据,需要安装 [Hadoop](http://archive.apache.org/dist/hadoop/core/hadoop-3.1.4/) 和 [Hive](https://dlcdn.apache.org/hive/hive-3.1.3/)。
+- 下载并安装 [MySQL Client 8.0.33](https://downloads.mysql.com/archives/get/p/23/file/mysql-server_8.0.33-1ubuntu23.04_amd64.deb-bundle.tar)。
+
+## 操作步骤
+
+### 步骤一:初始化项目
+
+1. 启动 IDEA,点击 **File > New > Project**,选择 **Spring Initializer**,并填写以下配置参数:
+
+ - **Name**:mo-spark-demo
+ - **Location**:~\Desktop
+ - **Language**:Java
+ - **Type**:Maven
+ - **Group**:com.example
+ - **Artiface**:matrixone-spark-demo
+ - **Package name**:com.matrixone.demo
+ - **JDK** 1.8
+
+ <div align="center">
+ <img src=https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/spark/matrixone-spark-demo.png width=50% heigth=50%/>
+ </div>
+
+2. 添加项目依赖,在项目根目录下的 `pom.xml` 内容编辑如下:
+
+```xml
+<?xml version="1.0" encoding="UTF-8"?>
+<project xmlns="http://maven.apache.org/POM/4.0.0"
+ xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
+ xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
+ <modelVersion>4.0.0</modelVersion>
+
+ <groupId>com.example.mo</groupId>
+ <artifactId>mo-spark-demo</artifactId>
+ <version>1.0-SNAPSHOT</version>
+
+ <properties>
+ <maven.compiler.source>8</maven.compiler.source>
+ <maven.compiler.target>8</maven.compiler.target>
+ <spark.version>3.2.1</spark.version>
+ </properties>
+
+ <dependencies>
+ <dependency>
+ <groupId>org.apache.spark</groupId>
+ <artifactId>spark-sql_2.12</artifactId>
+ <version>${spark.version}</version>
+ </dependency>
+
+ <dependency>
+ <groupId>org.apache.spark</groupId>
+ <artifactId>spark-hive_2.12</artifactId>
+ <version>${spark.version}</version>
+ </dependency>
+ <dependency>
+ <groupId>org.apache.spark</groupId>
+ <artifactId>spark-catalyst_2.12</artifactId>
+ <version>${spark.version}</version>
+ </dependency>
+ <dependency>
+ <groupId>org.apache.spark</groupId>
+ <artifactId>spark-core_2.12</artifactId>
+ <version>${spark.version}</version>
+ </dependency>
+ <dependency>
+ <groupId>org.codehaus.jackson</groupId>
+ <artifactId>jackson-core-asl</artifactId>
+ <version>1.9.13</version>
+ </dependency>
+ <dependency>
+ <groupId>org.codehaus.jackson</groupId>
+ <artifactId>jackson-mapper-asl</artifactId>
+ <version>1.9.13</version>
+ </dependency>
+
+
+ <dependency>
+ <groupId>mysql</groupId>
+ <artifactId>mysql-connector-java</artifactId>
+ <version>8.0.16</version>
+ </dependency>
+
+ </dependencies>
+
+</project>
+```
+
+### 步骤二:准备 Hive 数据
+
+在终端窗口中执行以下命令,创建 Hive 数据库、数据表,并插入数据:
+
+```sql
+hive
+hive> create database motest;
+hive> CREATE TABLE `users`(
+ `id` int,
+ `name` varchar(255),
+ `age` int);
+hive> INSERT INTO motest.users (id, name, age) VALUES(1, 'zhangsan', 12),(2, 'lisi', 17),(3, 'wangwu', 19);
+```
+
+### 步骤三:创建 MatrixOne 数据表
+
+在 node3 上,使用 MySQL 客户端连接到 node1 的 MatrixOne。然后继续使用之前创建的 "test" 数据库,并创建新的数据表 "users"。
+
+```sql
+CREATE TABLE `users` (
+`id` INT DEFAULT NULL,
+`name` VARCHAR(255) DEFAULT NULL,
+`age` INT DEFAULT NULL
+)
+```
+
+### 步骤四:拷贝配置文件
+
+将 Hadoop 根目录下的 "etc/hadoop/core-site.xml" 和 "hdfs-site.xml" 以及 Hive 根目录下的 "conf/hive-site.xml" 这三个配置文件复制到项目的 "resource" 目录中。
+
+<div align="center">
+<img src=https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/spark/config-files.png width=40% heigth=40%/>
+</div>
+
+### 步骤五:编写代码
+
+在 IntelliJ IDEA 中创建名为 "Hive2Mo.java" 的类,用于使用 Spark 从 Hive 中读取数据并将数据写入 MatrixOne。
+
+```java
+package com.matrixone.spark;
+
+import org.apache.spark.sql.*;
+
+import java.sql.SQLException;
+import java.util.Properties;
+
+/**
+ * @auther MatrixOne
+ * @date 2022/2/9 10:02
+ * @desc
+ *
+ * 1.在 hive 和 matrixone 中分别创建相应的表
+ * 2.将 core-site.xml hdfs-site.xml 和 hive-site.xml 拷贝到 resources 目录下
+ * 3.需要设置域名映射
+ */
+public class Hive2Mo {
+
+ // parameters
+ private static String master = "local[2]";
+ private static String appName = "app_spark_demo";
+
+ private static String destHost = "xx.xx.xx.xx";
+ private static Integer destPort = 6001;
+ private static String destUserName = "root";
+ private static String destPassword = "111";
+ private static String destDataBase = "test";
+ private static String destTable = "users";
+
+
+ public static void main(String[] args) throws SQLException {
+ SparkSession sparkSession = SparkSession.builder()
+ .appName(appName)
+ .master(master)
+ .enableHiveSupport()
+ .getOrCreate();
+
+ //SparkJdbc 读取表内容
+ System.out.println("读取 hive 中 person 的表内容");
+ // 读取表中所有数据
+ Dataset<Row> rowDataset = sparkSession.sql("select * from motest.users");
+ //显示数据
+ //rowDataset.show();
+ Properties properties = new Properties();
+ properties.put("user", destUserName);
+ properties.put("password", destPassword);;
+ rowDataset.write()
+ .mode(SaveMode.Append)
+ .jdbc("jdbc:mysql://" + destHost + ":" + destPort + "/" + destDataBase,destTable, properties);
+ }
+
+}
+```
+
+### 步骤六:查看执行结果
+
+在 MatrixOne 中执行如下 SQL 查看执行结果:
+
+```sql
+mysql> select * from test.users;
++------+----------+------+
+| id | name | age |
++------+----------+------+
+| 1 | zhangsan | 12 |
+| 2 | lisi | 17 |
+| 3 | wangwu | 19 |
++------+----------+------+
+3 rows in set (0.00 sec)
+```
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-mysql-matrixone.md
similarity index 54%
rename from docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark.md
rename to docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-mysql-matrixone.md
index a25386e8a8..4ec149cf55 100644
--- a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark.md
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-mysql-matrixone.md
@@ -1,51 +1,17 @@
-# 使用 Spark 将批量数据写入 MatrixOne
+# 使用 Spark 从 MySQL 迁移数据至 MatrixOne
-## 概述
-
-Apache Spark 是一个为高效处理大规模数据而设计的分布式计算引擎。它采用分布式并行计算的方式,将数据拆分、计算、合并的任务分散到多台计算机上,从而实现了高效的数据处理和分析。
-
-### 应用场景
-
-- 大规模数据处理与分析
-
- Spark 能够处理海量数据,通过并行计算任务提高了处理效率。它广泛应用于金融、电信、医疗等领域的数据处理和分析。
-
-- 流式数据处理
-
- Spark Streaming 允许实时处理数据流,将其转化为可供分析和存储的批处理数据。这在在线广告、网络安全等实时数据分析场景中非常有用。
-
-- 机器学习
-
- Spark 提供了机器学习库(MLlib),支持多种机器学习算法和模型训练,用于推荐系统、图像识别等机器学习应用。
-
-- 图计算
-
- Spark 的图计算库(GraphX)支持多种图计算算法,适用于社交网络分析、推荐系统等图分析场景。
-
-本篇文档将介绍两种使用 Spark 计算引擎实现批量数据写入 MatrixOne 的示例。一种示例是从 MySQL 迁移数据至 MatrixOne,另一种是将 Hive 数据写入 MatrixOne。
+在本章节,我们将介绍使用 Spark 计算引擎实现 MySQL 批量数据写入 MatrixOne。
## 前期准备
-### 硬件环境
-
-本次实践对于机器的硬件要求如下:
-
-| 服务器名称 | 服务器 IP | 安装软件 | 操作系统 |
-| ---------- | -------------- | ------------------------- | -------------- |
-| node1 | 192.168.146.10 | MatrixOne | Debian11.1 x86 |
-| node3 | 192.168.146.11 | IDEA、MYSQL、Hadoop、Hive | Windows 10 |
-
-### 软件环境
-
本次实践需要安装部署以下软件环境:
- 已完成[安装和启动 MatrixOne](https://docs.matrixorigin.cn/1.2.1/MatrixOne/Get-Started/install-standalone-matrixone/)。
- 下载并安装 [IntelliJ IDEA version 2022.2.1 及以上](https://www.jetbrains.com/idea/download/)。
- 下载并安装 [JDK 8+](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html)。
-- 如需从 Hive 导入数据,需要安装 [Hadoop](http://archive.apache.org/dist/hadoop/core/hadoop-3.1.4/) 和 [Hive](https://dlcdn.apache.org/hive/hive-3.1.3/)。
-- 下载并安装 [MySQL Client 8.0.33](https://downloads.mysql.com/archives/get/p/23/file/mysql-server_8.0.33-1ubuntu23.04_amd64.deb-bundle.tar)。
+- 下载并安装 [MySQL](https://downloads.mysql.com/archives/get/p/23/file/mysql-server_8.0.33-1ubuntu23.04_amd64.deb-bundle.tar)。
-## 示例 1:从 MySQL 迁移数据至 MatrixOne
+## 操作步骤
### 步骤一:初始化项目
@@ -163,7 +129,7 @@ Apache Spark 是一个为高效处理大规模数据而设计的分布式计算
private static String master = "local[2]";
private static String appName = "mo_spark_demo";
- private static String srcHost = "192.168.146.10";
+ private static String srcHost = "xx.xx.xx.xx";
private static Integer srcPort = 6001;
private static String srcUserName = "root";
private static String srcPassword = "111";
@@ -208,7 +174,7 @@ Apache Spark 是一个为高效处理大规模数据而设计的分布式计算
```sql
-- 在 node3 上,使用 Mysql 客户端连接 node1 的 MatrixOne
- mysql -h192.168.146.10 -P6001 -uroot -p111
+ mysql -hxx.xx.xx.xx -P6001 -uroot -p111
mysql> TRUNCATE TABLE test.person;
```
@@ -242,7 +208,7 @@ public class Mysql2Mo {
private static String srcDataBase = "motest";
private static String srcTable = "person";
- private static String destHost = "192.168.146.10";
+ private static String destHost = "xx.xx.xx.xx";
private static Integer destPort = 6001;
private static String destUserName = "root";
private static String destPassword = "111";
@@ -299,195 +265,3 @@ select * from test.person;
+------+---------------+------------+
2 rows in set (0.01 sec)
```
-
-## 示例 2:将 Hive 数据导入到 MatrixOne
-
-### 步骤一:初始化项目
-
-1. 启动 IDEA,点击 **File > New > Project**,选择 **Spring Initializer**,并填写以下配置参数:
-
- - **Name**:mo-spark-demo
- - **Location**:~\Desktop
- - **Language**:Java
- - **Type**:Maven
- - **Group**:com.example
- - **Artiface**:matrixone-spark-demo
- - **Package name**:com.matrixone.demo
- - **JDK** 1.8
-
- <div align="center">
- <img src=https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/spark/matrixone-spark-demo.png width=50% heigth=50%/>
- </div>
-
-2. 添加项目依赖,在项目根目录下的 `pom.xml` 内容编辑如下:
-
-```xml
-<?xml version="1.0" encoding="UTF-8"?>
-<project xmlns="http://maven.apache.org/POM/4.0.0"
- xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
- <modelVersion>4.0.0</modelVersion>
-
- <groupId>com.example.mo</groupId>
- <artifactId>mo-spark-demo</artifactId>
- <version>1.0-SNAPSHOT</version>
-
- <properties>
- <maven.compiler.source>8</maven.compiler.source>
- <maven.compiler.target>8</maven.compiler.target>
- <spark.version>3.2.1</spark.version>
- </properties>
-
- <dependencies>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-sql_2.12</artifactId>
- <version>${spark.version}</version>
- </dependency>
-
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-hive_2.12</artifactId>
- <version>${spark.version}</version>
- </dependency>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-catalyst_2.12</artifactId>
- <version>${spark.version}</version>
- </dependency>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-core_2.12</artifactId>
- <version>${spark.version}</version>
- </dependency>
- <dependency>
- <groupId>org.codehaus.jackson</groupId>
- <artifactId>jackson-core-asl</artifactId>
- <version>1.9.13</version>
- </dependency>
- <dependency>
- <groupId>org.codehaus.jackson</groupId>
- <artifactId>jackson-mapper-asl</artifactId>
- <version>1.9.13</version>
- </dependency>
-
-
- <dependency>
- <groupId>mysql</groupId>
- <artifactId>mysql-connector-java</artifactId>
- <version>8.0.16</version>
- </dependency>
-
- </dependencies>
-
-</project>
-```
-
-### 步骤二:准备 Hive 数据
-
-在终端窗口中执行以下命令,创建 Hive 数据库、数据表,并插入数据:
-
-```sql
-hive
-hive> create database motest;
-hive> CREATE TABLE `users`(
- `id` int,
- `name` varchar(255),
- `age` int);
-hive> INSERT INTO motest.users (id, name, age) VALUES(1, 'zhangsan', 12),(2, 'lisi', 17),(3, 'wangwu', 19);
-```
-
-### 步骤三:创建 MatrixOne 数据表
-
-在 node3 上,使用 MySQL 客户端连接到 node1 的 MatrixOne。然后继续使用之前创建的 "test" 数据库,并创建新的数据表 "users"。
-
-```sql
-CREATE TABLE `users` (
-`id` INT DEFAULT NULL,
-`name` VARCHAR(255) DEFAULT NULL,
-`age` INT DEFAULT NULL
-)
-```
-
-### 步骤四:拷贝配置文件
-
-将 Hadoop 根目录下的 "etc/hadoop/core-site.xml" 和 "hdfs-site.xml" 以及 Hive 根目录下的 "conf/hive-site.xml" 这三个配置文件复制到项目的 "resource" 目录中。
-
-<div align="center">
-<img src=https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/spark/config-files.png width=40% heigth=40%/>
-</div>
-
-### 步骤五:编写代码
-
-在 IntelliJ IDEA 中创建名为 "Hive2Mo.java" 的类,用于使用 Spark 从 Hive 中读取数据并将数据写入 MatrixOne。
-
-```java
-package com.matrixone.spark;
-
-import org.apache.spark.sql.*;
-
-import java.sql.SQLException;
-import java.util.Properties;
-
-/**
- * @auther MatrixOne
- * @date 2022/2/9 10:02
- * @desc
- *
- * 1.在 hive 和 matrixone 中分别创建相应的表
- * 2.将 core-site.xml hdfs-site.xml 和 hive-site.xml 拷贝到 resources 目录下
- * 3.需要设置域名映射
- */
-public class Hive2Mo {
-
- // parameters
- private static String master = "local[2]";
- private static String appName = "app_spark_demo";
-
- private static String destHost = "192.168.146.10";
- private static Integer destPort = 6001;
- private static String destUserName = "root";
- private static String destPassword = "111";
- private static String destDataBase = "test";
- private static String destTable = "users";
-
-
- public static void main(String[] args) throws SQLException {
- SparkSession sparkSession = SparkSession.builder()
- .appName(appName)
- .master(master)
- .enableHiveSupport()
- .getOrCreate();
-
- //SparkJdbc 读取表内容
- System.out.println("读取 hive 中 person 的表内容");
- // 读取表中所有数据
- Dataset<Row> rowDataset = sparkSession.sql("select * from motest.users");
- //显示数据
- //rowDataset.show();
- Properties properties = new Properties();
- properties.put("user", destUserName);
- properties.put("password", destPassword);;
- rowDataset.write()
- .mode(SaveMode.Append)
- .jdbc("jdbc:mysql://" + destHost + ":" + destPort + "/" + destDataBase,destTable, properties);
- }
-
-}
-```
-
-### 步骤六:查看执行结果
-
-在 MatrixOne 中执行如下 SQL 查看执行结果:
-
-```sql
-mysql> select * from test.users;
-+------+----------+------+
-| id | name | age |
-+------+----------+------+
-| 1 | zhangsan | 12 |
-| 2 | lisi | 17 |
-| 3 | wangwu | 19 |
-+------+----------+------+
-3 rows in set (0.00 sec)
-```
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-overview.md b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-overview.md
new file mode 100644
index 0000000000..fbbdd991c9
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-overview.md
@@ -0,0 +1,21 @@
+# 概述
+
+Apache Spark 是一个为高效处理大规模数据而设计的分布式计算引擎。它采用分布式并行计算的方式,将数据拆分、计算、合并的任务分散到多台计算机上,从而实现了高效的数据处理和分析。
+
+## 应用场景
+
+- 大规模数据处理与分析
+
+ Spark 能够处理海量数据,通过并行计算任务提高了处理效率。它广泛应用于金融、电信、医疗等领域的数据处理和分析。
+
+- 流式数据处理
+
+ Spark Streaming 允许实时处理数据流,将其转化为可供分析和存储的批处理数据。这在在线广告、网络安全等实时数据分析场景中非常有用。
+
+- 机器学习
+
+ Spark 提供了机器学习库(MLlib),支持多种机器学习算法和模型训练,用于推荐系统、图像识别等机器学习应用。
+
+- 图计算
+
+ Spark 的图计算库(GraphX)支持多种图计算算法,适用于社交网络分析、推荐系统等图分析场景。
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-clickhouse-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-clickhouse-matrixone.md
new file mode 100644
index 0000000000..d4b24edd6e
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-clickhouse-matrixone.md
@@ -0,0 +1,232 @@
+# 使用 DataX 将 ClickHouse 数据写入 MatrixOne
+
+本文介绍如何使用 DataX 工具将 ClickHouse 数据离线写入 MatrixOne 数据库。
+
+## 开始前准备
+
+在开始使用 DataX 将数据写入 MatrixOne 之前,需要完成安装以下软件:
+
+- 已完成[安装和启动 MatrixOne](../../../Get-Started/install-standalone-matrixone.md)。
+- 安装 [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html)。
+- 安装 [Python 3.8(or plus)](https://www.python.org/downloads/)。
+- 下载 [DataX](https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202210/datax.tar.gz) 安装包,并解压。
+- 已完成 [ClickHouse](https://packages.clickhouse.com/tgz/stable/) 安装部署
+- 下载 [matrixonewriter.zip](https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/Computing-Engine/datax-write/matrixonewriter.zip),解压至 DataX 项目根目录的 `plugin/writer/` 目录下。
+- 安装 <a href="https://dev.mysql.com/downloads/mysql" target="_blank">MySQL Client</a>。
+
+## 步骤
+
+### 登录 clickhouse 数据库创建测试数据
+
+```sql
+create database source_ck_database;
+use source_ck_database;
+
+create table if not exists student(
+`id` Int64 COMMENT '学生 id',
+`name` String COMMENT '学生姓名',
+`birthday` String COMMENT '学生出生日期',
+`class` Int64 COMMENT '学生班级编号',
+`grade` Int64 COMMENT '学生年级编号',
+`score` decimal(18,0) COMMENT '学生成绩'
+) engine = MergeTree
+order by id;
+```
+
+### 使用 datax 导入数据
+
+#### 使用 clickhousereader
+
+注:Datax 不能同步表结构,所以需提前在 MatrixOne 中创建表
+MatrixOne 建表语句:
+
+```sql
+CREATE TABLE datax_db.`datax_ckreader_ck_student` (
+ `id` bigint(20) NULL COMMENT "",
+ `name` varchar(100) NULL COMMENT "",
+ `birthday` varchar(100) NULL COMMENT "",
+ `class` bigint(20) NULL COMMENT "",
+ `grade` bigint(20) NULL COMMENT "",
+ `score` decimal(18, 0) NULL COMMENT ""
+);
+
+CREATE TABLE datax_db.`datax_rdbmsreader_ck_student` (
+ `id` bigint(20) NULL COMMENT "",
+ `name` varchar(100) NULL COMMENT "",
+ `birthday` varchar(100) NULL COMMENT "",
+ `class` bigint(20) NULL COMMENT "",
+ `grade` bigint(20) NULL COMMENT "",
+ `score` decimal(18, 0) NULL COMMENT ""
+);
+```
+
+将 clikchousereader 上传至$DATAX_HOME/plugin/reader 目录下
+解压安装包:
+
+```bash
+[root@root ~]$ unzip clickhousereader.zip
+```
+
+移动压缩包至/opt/目录下:
+
+```bash
+[root@root ~] mv clickhousereader.zip /opt/
+```
+
+编写任务 json 文件
+
+```bash
+[root@root ~] vim $DATAX_HOME/job/ck2sr.json
+```
+
+```json
+{
+ "job": {
+ "setting": {
+ "speed": {
+"channel": "1"
+ }
+ },
+ "content": [
+ {
+ "reader": {
+ "name": "clickhousereader",
+ "parameter": {
+ "username": "default",
+ "password": "123456",
+ "column": [
+ "*"
+ ],
+ "splitPK": "id",
+ "connection": [
+ {
+ "table": [
+ "student"
+ ],
+ "jdbcUrl": [
+ "jdbc:clickhouse://xx.xx.xx.xx:8123/source_ck_database"
+ ]
+ }
+ ]
+ }
+ },
+ "writer": {
+ "name": "matrixonewriter",
+ "parameter": {
+ "column": [
+ "*"
+ ],
+ "connection": [
+ {
+ "jdbcUrl": "jdbc:mysql://xx.xx.xx.xx:6001/datax_db",
+ "table": [
+ "datax_ckreader_ck_student"
+ ]
+ }
+ ],
+ "password": "111",
+ "username": "root",
+ "writeMode": "insert"
+ }
+ }
+ }
+ ]
+ }
+}
+```
+
+执行导入任务
+
+```bash
+[root@root ~] cd $DATAX_HOME/bin
+[root@root ~] ./python datax.py ../jobs/ck2sr.json
+```
+
+#### 使用 Rdbmsreader 导入
+
+上传 ClickHouse JDBC 驱动到$DATAX_HOME/plugin/reader/rdbmsreader/libs/目录下
+
+修改配置文件
+
+```bash
+[root@root ~] vim $DATAX_HOME/plugin/reader/rdbmsreader/plugin.json
+```
+
+```json
+{
+ "name": "rdbmsreader",
+ "class": "com.alibaba.datax.plugin.reader.rdbmsreader.RdbmsReader",
+ "description": "useScene: prod. mechanism: Jdbc connection using the database, execute select sql, retrieve data from the ResultSet. warn: The more you know about the database, the less problems you encounter.",
+ "developer": "alibaba",
+ "drivers":["dm.jdbc.driver.DmDriver", "com.sybase.jdbc3.jdbc.SybDriver", "com.edb.Driver", "org.apache.hive.jdbc.HiveDriver","com.clickhouse.jdbc.ClickHouseDriver"]
+}
+```
+
+编写 json 任务文件
+
+```bash
+[root@root ~] vim $DATAX_HOME/job/ckrdbms2sr.json
+```
+
+```json
+{
+ "job": {
+ "setting": {
+ "speed": {
+ "byte": 1048576
+ }
+ },
+ "content": [
+ {
+ "reader": {
+ "name": "rdbmsreader",
+ "parameter": {
+ "username": "default",
+ "password": "123456",
+ "column": [
+ "*"
+ ],
+ "splitPK": "id",
+ "connection": [
+ {
+ "table": [
+ "student"
+ ],
+ "jdbcUrl": [
+ "jdbc:clickhouse://xx.xx.xx.xx:8123/source_ck_database"
+ ]
+ }
+ ]
+ }
+ },
+ "writer": {
+ "name": "matrixonewriter",
+ "parameter": {
+ "column": [
+ "*"
+ ],
+ "connection": [
+ {
+ "jdbcUrl": "jdbc:mysql://xx.xx.xx.xx:6001/datax_db",
+ "table": [
+ "datax_rdbmsreader_ck_student"
+ ]
+ }
+ ],
+ "password": "111",
+ "username": "root",
+ "writeMode": "insert"
+ }
+ }
+ }
+ ]
+ }
+}
+```
+
+执行导入任务
+
+```bash
+[root@root ~] cd $DATAX_HOME/bin
+[root@root ~] ./python datax.py ../jobs/ckrdbms2sr.json
+```
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-doris-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-doris-matrixone.md
new file mode 100644
index 0000000000..050ddfb207
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-doris-matrixone.md
@@ -0,0 +1,145 @@
+# 使用 DataX 将 Doris 数据写入 MatrixOne
+
+本文介绍如何使用 DataX 工具将 Doris 数据离线写入 MatrixOne 数据库。
+
+## 开始前准备
+
+在开始使用 DataX 将数据写入 MatrixOne 之前,需要完成安装以下软件:
+
+- 已完成[安装和启动 MatrixOne](../../../Get-Started/install-standalone-matrixone.md)。
+- 安装 [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html)。
+- 安装 [Python 3.8(or plus)](https://www.python.org/downloads/)。
+- 下载 [DataX](https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202210/datax.tar.gz) 安装包,并解压。
+- 下载并安装 [Doris](https://doris.apache.org/zh-CN/docs/dev/get-starting/quick-start/)。
+- 下载 [matrixonewriter.zip](https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/Computing-Engine/datax-write/matrixonewriter.zip),解压至 DataX 项目根目录的 `plugin/writer/` 目录下。
+- 安装 <a href="https://dev.mysql.com/downloads/mysql" target="_blank">MySQL Client</a>。
+
+## 步骤
+
+### 在 Doris 中创建测试数据
+
+```sql
+create database test;
+
+use test;
+
+CREATE TABLE IF NOT EXISTS example_tbl
+(
+ user_id BIGINT NOT NULL COMMENT "用户id",
+ date DATE NOT NULL COMMENT "数据灌入日期时间",
+ city VARCHAR(20) COMMENT "用户所在城市",
+ age SMALLINT COMMENT "用户年龄",
+ sex TINYINT COMMENT "用户性别"
+)
+DUPLICATE KEY(user_id, date)
+DISTRIBUTED BY HASH(user_id) BUCKETS 1
+PROPERTIES (
+ "replication_num"="1"
+);
+
+insert into example_tbl values
+(10000,'2017-10-01','北京',20,0),
+(10000,'2017-10-01','北京',20,0),
+(10001,'2017-10-01','北京',30,1),
+(10002,'2017-10-02','上海',20,1),
+(10003,'2017-10-02','广州',32,0),
+(10004,'2017-10-01','深圳',35,0),
+(10004,'2017-10-03','深圳',35,0);
+
+```
+
+### 在 MatrixOne 中创建目标库表
+
+```sql
+create database sparkdemo;
+use sparkdemo;
+
+CREATE TABLE IF NOT EXISTS example_tbl
+(
+ user_id BIGINT NOT NULL COMMENT "用户id",
+ date DATE NOT NULL COMMENT "数据灌入日期时间",
+ city VARCHAR(20) COMMENT "用户所在城市",
+ age SMALLINT COMMENT "用户年龄",
+ sex TINYINT COMMENT "用户性别"
+);
+```
+
+### 编辑 datax 的 json 模板文件
+
+进入到 datax/job 路径,在 doris2mo.json 填以下内容
+
+```json
+{
+ "job": {
+ "setting": {
+ "speed": {
+ "channel": 8
+ }
+ },
+ "content": [
+ {
+ "reader": {
+ "name": "mysqlreader",
+ "parameter": {
+ "username": "root",
+ "password": "root",
+ "splitPk": "user_id",
+ "column": [
+ '*'
+ ],
+ "connection": [
+ {
+ "table": [
+ "example_tbl"
+ ],
+ "jdbcUrl": [
+ "jdbc:mysql://xx.xx.xx.xx:9030/test"
+ ]
+ }
+ ],
+ "fetchSize": 1024
+ }
+ },
+ "writer": {
+ "name": "matrixonewriter",
+ "parameter": {
+ "writeMode": "insert",
+ "username": "root",
+ "password": "111",
+ "column": [
+ '*'
+ ],
+ "connection": [
+ {
+ "jdbcUrl": "jdbc:mysql://xx.xx.xx.xx:6001/sparkdemo",
+ "table": [
+ "example_tbl"
+ ]
+ }
+ ]
+ }
+ }
+ }
+ ]
+ }
+}
+```
+
+### 启动 datax 作业
+
+```bash
+python bin/datax.py job/doris2mo.json
+```
+
+显示以下结果:
+
+```bash
+2024-04-28 15:47:38.222 [job-0] INFO JobContainer -
+任务启动时刻 : 2024-04-28 15:47:26
+任务结束时刻 : 2024-04-28 15:47:38
+任务总计耗时 : 11s
+任务平均流量 : 12B/s
+记录写入速度 : 0rec/s
+读出记录总数 : 7
+读写失败总数 : 0
+```
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-elasticsearch-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-elasticsearch-matrixone.md
new file mode 100644
index 0000000000..d6567e84db
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-elasticsearch-matrixone.md
@@ -0,0 +1,194 @@
+# 使用 DataX 将 ElasticSearch 数据写入 MatrixOne
+
+本文介绍如何使用 DataX 工具将 ElasticSearch 数据离线写入 MatrixOne 数据库。
+
+## 开始前准备
+
+在开始使用 DataX 将数据写入 MatrixOne 之前,需要完成安装以下软件:
+
+- 已完成[安装和启动 MatrixOne](../../../Get-Started/install-standalone-matrixone.md)。
+- 安装 [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html)。
+- 安装 [Python 3.8(or plus)](https://www.python.org/downloads/)。
+- 下载 [DataX](https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202210/datax.tar.gz) 安装包,并解压。
+- 下载并安装 [ElasticSearch](https://www.elastic.co/cn/downloads/elasticsearch)。
+- 下载 [matrixonewriter.zip](https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/Computing-Engine/datax-write/matrixonewriter.zip),解压至 DataX 项目根目录的 `plugin/writer/` 目录下。
+- 下载 [elasticsearchreader.zip](https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/datax_es_mo/elasticsearchreader.zip),解压至 datax/plugin/reader 目录下。
+- 安装 <a href="https://dev.mysql.com/downloads/mysql" target="_blank">MySQL Client</a>。
+
+## 步骤
+
+### 导入数据到 ElasticSearch
+
+#### 创建索引
+
+创建名称为 person 的索引(下文 -u 参数后为 ElasticSearch 中的用户名和密码,本地测试时可按需进行修改或删除):
+
+```bash
+curl -X PUT "<http://127.0.0.1:9200/person>" -u elastic:elastic
+```
+
+输出如下信息表示创建成功:
+
+```bash
+{"acknowledged":true,"shards_acknowledged":true,"index":"person"}
+```
+
+#### 给索引 person 添加字段
+
+```bash
+curl -X PUT "127.0.0.1:9200/person/_mapping" -H 'Content-Type: application/json' -u elastic:elastic -d'{ "properties": { "id": { "type": "integer" }, "name": { "type": "text" }, "birthday": {"type": "date"} }}'
+```
+
+输出如下信息表示设置成功:
+
+```bash
+{"acknowledged":true}
+```
+
+#### 为 ElasticSearch 索引添加数据
+
+通过 curl 命令添加三条数据:
+
+```bash
+curl -X POST '127.0.0.1:9200/person/_bulk' -H 'Content-Type: application/json' -u elastic:elastic -d '{"index":{"_index":"person","_type":"_doc","_id":1}}{"id": 1,"name": "MatrixOne","birthday": "1992-08-08"}{"index":{"_index":"person","_type":"_doc","_id":2}}{"id": 2,"name": "MO","birthday": "1993-08-08"}{"index":{"_index":"person","_type":"_doc","_id":3}}{"id": 3,"name": "墨墨","birthday": "1994-08-08"}
+```
+
+输出如下信息表示执行成功:
+
+```bash
+{"took":5,"errors":false,"items":[{"index":{"_index":"person","_type":"_doc","_id":"1","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":0,"_primary_term":1,"status":201}},{"index":{"_index":"person","_type":"_doc","_id":"2","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":1,"_primary_term":1,"status":201}},{"index":{"_index":"person","_type":"_doc","_id":"3","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":2,"_primary_term":1,"status":201}}]}
+```
+
+### 在 MatrixOne 中建表
+
+```sql
+create database mo;
+CREATE TABLE mo.`person` (
+`id` INT DEFAULT NULL,
+`name` VARCHAR(255) DEFAULT NULL,
+`birthday` DATE DEFAULT NULL
+);
+```
+
+### 编写迁移文件
+
+进入到 datax/job 路径,编写作业文件 `es2mo.json`:
+
+```json
+{
+ "job":{
+ "setting":{
+ "speed":{
+ "channel":1
+ },
+ "errorLimit":{
+ "record":0,
+ "percentage":0.02
+ }
+ },
+ "content":[
+ {
+ "reader":{
+ "name":"elasticsearchreader",
+ "parameter":{
+ "endpoint":"http://127.0.0.1:9200",
+ "accessId":"elastic",
+ "accessKey":"elastic",
+ "index":"person",
+ "type":"_doc",
+ "headers":{
+
+ },
+ "scroll":"3m",
+ "search":[
+ {
+ "query":{
+ "match_all":{
+
+ }
+ }
+ }
+ ],
+ "table":{
+ "filter":"",
+ "nameCase":"UPPERCASE",
+ "column":[
+ {
+ "name":"id",
+ "type":"integer"
+ },
+ {
+ "name":"name",
+ "type":"text"
+ },
+ {
+ "name":"birthday",
+ "type":"date"
+ }
+ ]
+ }
+ }
+ },
+ "writer":{
+ "name":"matrixonewriter",
+ "parameter":{
+ "username":"root",
+ "password":"111",
+ "column":[
+ "id",
+ "name",
+ "birthday"
+ ],
+ "connection":[
+ {
+ "table":[
+ "person"
+ ],
+ "jdbcUrl":"jdbc:mysql://127.0.0.1:6001/mo"
+ }
+ ]
+ }
+ }
+ }
+ ]
+ }
+}
+```
+
+### 执行迁移任务
+
+进入 datax 安装目录,执行以下命令启动迁移作业:
+
+```bash
+cd datax
+python bin/datax.py job/es2mo.json
+```
+
+作业执行完成后,输出结果如下:
+
+```bash
+2023-11-28 15:55:45.642 [job-0] INFO StandAloneJobContainerCommunicator - Total 3 records, 67 bytes | Speed 6B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.456s | Percentage 100.00%2023-11-28 15:55:45.644 [job-0] INFO JobContainer -
+任务启动时刻 : 2023-11-28 15:55:31
+任务结束时刻 : 2023-11-28 15:55:45
+任务总计耗时 : 14s
+任务平均流量 : 6B/s
+记录写入速度 : 0rec/s
+读出记录总数 : 3
+读写失败总数 : 0
+```
+
+### 在 MatrixOne 中查看迁移后数据
+
+在 MatrixOne 数据库中查看目标表中的结果,确认迁移已完成:
+
+```sql
+mysql> select * from mo.person;
++------+-----------+------------+
+| id | name | birthday |
++------+-----------+------------+
+| 1 | MatrixOne | 1992-08-08 |
+| 2 | MO | 1993-08-08 |
+| 3 | 墨墨 | 1994-08-08 |
++------+-----------+------------+
+3 rows in set (0.00 sec)
+```
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-influxdb-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-influxdb-matrixone.md
new file mode 100644
index 0000000000..49678242dc
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-influxdb-matrixone.md
@@ -0,0 +1,150 @@
+# 使用 DataX 将 InfluxDB 数据写入 MatrixOne
+
+本文介绍如何使用 DataX 工具将 InfluxDB 数据离线写入 MatrixOne 数据库。
+
+## 开始前准备
+
+在开始使用 DataX 将数据写入 MatrixOne 之前,需要完成安装以下软件:
+
+- 已完成[安装和启动 MatrixOne](../../../Get-Started/install-standalone-matrixone.md)。
+- 安装 [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html)。
+- 安装 [Python 3.8(or plus)](https://www.python.org/downloads/)。
+- 下载 [DataX](https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202210/datax.tar.gz) 安装包,并解压。
+- 下载并安装 [InfluxDB](https://www.influxdata.com/products/influxdb/)。
+- 下载 [matrixonewriter.zip](https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/Computing-Engine/datax-write/matrixonewriter.zip),解压至 DataX 项目根目录的 `plugin/writer/` 目录下。
+- 下载 [influxdbreader](https://github.com/wowiscrazy/InfluxDBReader-DataX) 至 datax/plugin/reader 路径下。
+- 安装 <a href="https://dev.mysql.com/downloads/mysql" target="_blank">MySQL Client</a>。
+
+## 步骤
+
+### 在 influxdb 中创建测试数据
+
+使用默认账号登录
+
+```bash
+influx -host 'localhost' -port '8086'
+```
+
+```sql
+--创建并使用数据库
+create database testDb;
+use testDb;
+--插入数据
+insert air_condition_outdoor,home_id=0000000000000,sensor_id=0000000000034 temperature=0.0000000000000000,humidity=80.0000000000000000,battery_voltage=3.2000000000000002 1514764800000000000
+insert air_condition_outdoor,home_id=0000000000001,sensor_id=0000000000093 temperature=0.0000000000000000,humidity=80.0000000000000000,battery_voltage=3.2000000000000002 1514764800000000000
+insert air_condition_outdoor,home_id=0000000000003,sensor_id=0000000000197 temperature=0.0000000000000000,humidity=80.0000000000000000,battery_voltage=3.2000000000000002 1514764800000000000
+insert air_condition_outdoor,home_id=0000000000003,sensor_id=0000000000198 temperature=0.0000000000000000,humidity=80.0000000000000000,battery_voltage=3.2000000000000002 1514764800000000000
+insert air_condition_outdoor,home_id=0000000000003,sensor_id=0000000000199 temperature=0.0000000000000000,humidity=80.0000000000000000,battery_voltage=3.2000000000000002 1514764800000000000
+insert air_condition_outdoor,home_id=0000000000003,sensor_id=0000000000200 temperature=0.0000000000000000,humidity=80.0000000000000000,battery_voltage=3.2000000000000002 1514764800000000000
+insert air_condition_outdoor,home_id=0000000000003,sensor_id=0000000000201 temperature=0.0000000000000000,humidity=80.0000000000000000,battery_voltage=3.2000000000000002 1514764800000000000
+insert air_condition_outdoor,home_id=0000000000003,sensor_id=0000000000202 temperature=0.0000000000000000,humidity=80.0000000000000000,battery_voltage=3.2000000000000002 1514764800000000000
+insert air_condition_outdoor,home_id=0000000000003,sensor_id=0000000000203 temperature=0.0000000000000000,humidity=80.0000000000000000,battery_voltage=3.2000000000000002 1514764800000000000
+insert air_condition_outdoor,home_id=0000000000003,sensor_id=0000000000204 temperature=0.0000000000000000,humidity=80.0000000000000000,battery_voltage=3.2000000000000002 1514764800000000000
+```
+
+### 创建测试用账号
+
+```sql
+create user "test" with password '123456' with all privileges;
+grant all privileges on testDb to test;
+show grants for test;
+```
+
+### 开启数据库认证
+
+```bash
+vim /etc/influxdb/influxdb.conf
+```
+
+<div align="center">
+ <img src=https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/datax/datax-influxdb-01.jpg width=50% heigth=50%/>
+</div>
+
+### 重启 influxdb
+
+```bash
+systemctl restart influxdb
+```
+
+### 测试认证登录
+
+```bash
+influx -host 'localhost' -port '8086' -username 'test' -password '123456'
+```
+
+### 在 MatrixOne 中创建目标表
+
+```sql
+mysql> create database test;
+mysql> use test;
+mysql> create table air_condition_outdoor(
+time datetime,
+battery_voltage float,
+home_id char(15),
+humidity int,
+sensor_id char(15),
+temperature int
+);
+```
+
+### 编辑 datax 的 json 模板文件
+
+进入到 datax/job 路径,在 influxdb2mo.json 填以下内容
+
+```json
+{
+ "job": {
+ "setting": {
+ "speed": {
+ "channel": 1
+ }
+ },
+ "content": [
+ {
+ "reader": {
+ "name": "influxdbreader",
+ "parameter": {
+ "dbType": "InfluxDB",
+ "address": "http://xx.xx.xx.xx:8086",
+ "username": "test",
+ "password": "123456",
+ "database": "testDb",
+ "querySql": "select * from air_condition_outdoor limit 20",
+ }
+ },
+ "writer": {
+ "name": "matrixonewriter",
+ "parameter": {
+ "username": "root",
+ "password": "111",
+ "writeMode": "insert",
+ "connection": [
+ {
+ "jdbcUrl": "jdbc:mysql://xx.xx.xx.xx:6001/test",
+ "table": ["air_condition_outdoor"]
+ }
+ ],
+ "column": ["*"],
+ }
+ }
+ }
+ ]
+ }
+}
+```
+
+### 启动 datax 作业
+
+看到类似如下结果,说明导入成功
+
+```bash
+#python bin/datax.py job/influxdb2mo.json
+2024-04-28 13:51:19.665 [job-0] INFO JobContainer -
+任务启动时刻 : 2024-04-28 13:51:08
+任务结束时刻 : 2024-04-28 13:51:19
+任务总计耗时 : 10s
+任务平均流量 : 2B/s
+记录写入速度 : 0rec/s
+读出记录总数 : 20
+读写失败总数 : 0
+```
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-mongodb-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-mongodb-matrixone.md
new file mode 100644
index 0000000000..6f610d720d
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-mongodb-matrixone.md
@@ -0,0 +1,121 @@
+# 使用 DataX 将 MongoDB 数据写入 MatrixOne
+
+本文介绍如何使用 DataX 工具将 MongoDB 数据离线写入 MatrixOne 数据库。
+
+## 开始前准备
+
+在开始使用 DataX 将数据写入 MatrixOne 之前,需要完成安装以下软件:
+
+- 已完成[安装和启动 MatrixOne](../../../Get-Started/install-standalone-matrixone.md)。
+- 安装 [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html)。
+- 安装 [Python 3.8(or plus)](https://www.python.org/downloads/)。
+- 下载 [DataX](https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202210/datax.tar.gz) 安装包,并解压。
+- 下载并安装 [MongoDB](https://www.mongodb.com/)。
+- 下载 [matrixonewriter.zip](https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/Computing-Engine/datax-write/matrixonewriter.zip),解压至 DataX 项目根目录的 `plugin/writer/` 目录下。
+- 安装 <a href="https://dev.mysql.com/downloads/mysql" target="_blank">MySQL Client</a>。
+
+## 步骤
+
+### 创建 MongoDB 测试数据
+
+创建数据库 test,如果 test 不存在,则创建 test
+
+```sql
+>create database test;
+>use test
+#查看当前数据库
+>db
+test
+#创建集合db.createCollection(“集合名”)
+>db. createCollection(‘test’)
+#插入文档数据db.集合名.insert(文档内容)
+>db.test. insert({"name" : " aaa ", "age" : 20})
+>db.test. insert({"name" : " bbb ", "age" : 18})
+>db.test. insert({"name" : " ccc ", "age" : 28})
+#查看数据
+>db.test.find()
+{ "_id" : ObjectId("6347e3c6229d6017c82bf03d"), "name" : "aaa", "age" : 20 }
+{ "_id" : ObjectId("6347e64a229d6017c82bf03e"), "name" : "bbb", "age" : 18 }
+{ "_id" : ObjectId("6347e652229d6017c82bf03f"), "name" : "ccc", "age" : 28 }
+```
+
+### 在 MatrixOne 中创建目标表
+
+```sql
+mysql> create database test;
+mysql> use test;
+mysql> CREATE TABLE `mongodbtest` (
+ `name` varchar(30) NOT NULL COMMENT "",
+ `age` int(11) NOT NULL COMMENT ""
+);
+```
+
+### 编辑 datax 的 json 模板文件
+
+进入到 datax/job 路径,新建文件 `mongo2matrixone.json` 并填以下内容:
+
+```json
+{
+ "job": {
+ "setting": {
+ "speed": {
+ "channel": 1
+ }
+ },
+ "content": [
+ {
+ "reader": {
+ "name": "mongodbreader",
+ "parameter": {
+ "address": [
+ "xx.xx.xx.xx:27017"
+ ],
+ "userName": "root",
+ "userPassword": "",
+ "dbName": "test",
+ "collectionName": "test",
+ "column": [
+ {
+ "name": "name",
+ "type": "string"
+ },
+ {
+ "name": "age",
+ "type": "int"
+ }
+ ]
+ }
+ },
+ "writer": {
+ "name": "matrixonewriter",
+ "parameter": {
+ "username": "root",
+ "password": "111",
+ "column": ["*"],
+ "connection": [
+ {
+ "table": ["mongodbtest"],
+ "jdbcUrl": "jdbc:mysql://127.0.0.1:6001/test"
+ }
+ ]
+ }
+ }
+ }
+ ]
+ }
+}
+```
+
+### 启动 datax 作业
+
+```bash
+python bin/datax.py job/mongo2matrixone.json
+2024-04-28 13:51:19.665 [job-0] INFO JobContainer -
+任务启动时刻 : 2024-04-28 13:51:08
+任务结束时刻 : 2024-04-28 13:51:19
+任务总计耗时 : 10s
+任务平均流量 : 2B/s
+记录写入速度 : 0rec/s
+读出记录总数 : 3
+读写失败总数 : 0
+```
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-mysql-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-mysql-matrixone.md
new file mode 100644
index 0000000000..ad8b42862d
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-mysql-matrixone.md
@@ -0,0 +1,132 @@
+# 使用 DataX 将 MySQL 数据写入 MatrixOne
+
+本文介绍如何使用 DataX 工具将 MySQL 数据离线写入 MatrixOne 数据库。
+
+## 开始前准备
+
+在开始使用 DataX 将数据写入 MatrixOne 之前,需要完成安装以下软件:
+
+- 完成[单机部署 MatrixOne](https://docs.matrixorigin.cn/1.2.1/MatrixOne/Get-Started/install-standalone-matrixone/)。
+- 安装 [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html)。
+- 安装 [Python 3.8(or plus)](https://www.python.org/downloads/)。
+- 下载 [DataX](https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202210/datax.tar.gz) 安装包,并解压。
+- 下载 [matrixonewriter.zip](https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/Computing-Engine/datax-write/matrixonewriter.zip),解压至 DataX 项目根目录的 `plugin/writer/` 目录下。
+- 下载并安装 [MySQL](https://downloads.mysql.com/archives/get/p/23/file/mysql-server_8.0.33-1ubuntu23.04_amd64.deb-bundle.tar)。
+
+## 步骤
+
+### 在 mysql 中创建表并插入数据
+
+```sql
+CREATE TABLE `mysql_datax` (
+ `id` bigint(20) NOT NULL,
+ `name` varchar(100) DEFAULT NULL,
+ `salary` decimal(10,0) DEFAULT NULL,
+ `age` int(11) DEFAULT NULL,
+ `entrytime` date DEFAULT NULL,
+ `gender` char(1) DEFAULT NULL,
+ PRIMARY KEY (`id`)
+) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
+
+--插入示例数据
+insert into mysql_datax valus
+(1,"lisa",15660,30,'2022-10-12',0),
+(2,"tom",15060,24,'2021-11-10',1),
+(3,"jenny",15000,28,'2024-02-19',0),
+(4,"henry",12660,24,'2022-04-22',1);
+```
+
+### 在 Matrixone 创建目标库表
+
+由于 DataX 只能同步数据,不能同步表结构,所以在执行任务前,我们需要先在目标数据库(Matrixone)中手动创建好表。
+
+```sql
+CREATE TABLE `mysql_datax` (
+ `id` bigint(20) NOT NULL,
+ `name` varchar(100) DEFAULT NULL,
+ `salary` decimal(10,0) DEFAULT NULL,
+ `age` int(11) DEFAULT NULL,
+ `entrytime` date DEFAULT NULL,
+ `gender` char(1) DEFAULT NULL,
+ PRIMARY KEY (`id`)
+);
+```
+
+### 创建作业配置文件
+
+DataX 中的任务配置文件是 json 格式,可以通过下面的命令查看内置的任务配置模板:
+
+```bash
+python datax.py -r mysqlreader -w matrixonewriter
+```
+
+进入到 datax/job 路径,根据模板,编写作业文件 `mysql2mo.json`:
+
+```json
+{
+ "job": {
+ "content": [
+ {
+ "reader": {
+ "name": "mysqlreader",
+ "parameter": {
+ "column": ["*"],
+ "connection": [
+ {
+ "jdbcUrl": ["jdbc:mysql://xx.xx.xx.xx:3306/test"],
+ "table": ["mysql_datax"]
+ }
+ ],
+ "password": "root",
+ "username": "root",
+ "where": ""
+ }
+ },
+ "writer": {
+ "name": "matrixonewriter",
+ "parameter": {
+ "column": ["*"],
+ "connection": [
+ {
+ "jdbcUrl": "jdbc:mysql://xx.xx.xx.xx:6001/test",
+ "table": ["mysql_datax"]
+ }
+ ],
+ "password": "111",
+ "preSql": [],
+ "session": [],
+ "username": "root",
+ "writeMode": "insert" --目前仅支持replace,update 或 insert 方式
+ }
+ }
+ }
+ ],
+ "setting": {
+ "speed": {
+ "channel": "1"
+ }
+ }
+ }
+}
+```
+
+### 启动 datax 作业
+
+```bash
+python /opt/module/datax/bin/datax.py /opt/module/datax/job/mysql2mo.json
+```
+
+### 查看 MatrixOne 表中数据
+
+```sql
+mysql> select * from mysql_datax;
++------+-------+--------+------+------------+--------+
+| id | name | salary | age | entrytime | gender |
++------+-------+--------+------+------------+--------+
+| 1 | lisa | 15660 | 30 | 2022-10-12 | 0 |
+| 2 | tom | 15060 | 24 | 2021-11-10 | 1 |
+| 3 | jenny | 15000 | 28 | 2024-02-19 | 0 |
+| 4 | henry | 12660 | 24 | 2022-04-22 | 1 |
++------+-------+--------+------+------------+--------+
+4 rows in set (0.00 sec)
+```
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-oracle-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-oracle-matrixone.md
new file mode 100644
index 0000000000..32038ca35b
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-oracle-matrixone.md
@@ -0,0 +1,149 @@
+# 使用 DataX 将数据写入 MatrixOne
+
+本文介绍如何使用 DataX 工具将 Oracle 数据离线写入 MatrixOne 数据库。
+
+## 开始前准备
+
+在开始使用 DataX 将数据写入 MatrixOne 之前,需要完成安装以下软件:
+
+- 完成[单机部署 MatrixOne](https://docs.matrixorigin.cn/1.2.1/MatrixOne/Get-Started/install-standalone-matrixone/)。
+- 安装 [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html)。
+- 安装 [Python 3.8(or plus)](https://www.python.org/downloads/)。
+- 下载 [DataX](https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202210/datax.tar.gz) 安装包,并解压。
+- 下载 [matrixonewriter.zip](https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/Computing-Engine/datax-write/matrixonewriter.zip),解压至 DataX 项目根目录的 `plugin/writer/` 目录下。
+- 安装 [Oracle 19c](https://www.oracle.com/database/technologies/oracle-database-software-downloads.html)。
+- 安装 <a href="https://dev.mysql.com/downloads/mysql" target="_blank">MySQL Client</a>。
+
+## 操作步骤
+
+### 使用 Oracle 的 scott 用户
+
+本次使用 Oracle 中用户 scott 来创建表(当然也可以用其他用户),在 Oracle 19c 中,scott 用户需要手动创建,可以使用 sqlplus 工具通过命令将其解锁。
+
+```sql
+sqlplus / as sysdba
+create user scott identified by tiger;
+grant dba to scott;
+```
+
+后续就可以通过 scott 用户登录访问:
+
+```sql
+sqlplus scott/tiger
+```
+
+### 创建 Oracle 测试数据
+
+在 Oracle 中创建 employees_oracle 表:
+
+```sql
+create table employees_oracle(
+ id number(5),
+ name varchar(20)
+);
+--插入示例数据:
+insert into employees_oracle values(1,'zhangsan');
+insert into employees_oracle values(2,'lisi');
+insert into employees_oracle values(3,'wangwu');
+insert into employees_oracle values(4,'oracle');
+-- 在 sqlplus 中,默认不退出就不会提交事务,因此插入数据后需手动提交事务(或通过 DBeaver 等工具执行插入)
+COMMIT;
+```
+
+### 创建 MatrixOne 测试表
+
+由于 DataX 只能同步数据,不能同步表结构,所以在执行任务前,我们需要先在目标数据库(MatrixOne)中手动创建好表。
+
+```sql
+CREATE TABLE `oracle_datax` (
+ `id` bigint(20) NOT NULL,
+ `name` varchar(100) DEFAULT NULL,
+ PRIMARY KEY (`id`)
+) ;
+```
+
+### 创建作业配置文件
+
+DataX 中的任务配置文件是 json 格式,可以通过下面的命令查看内置的任务配置模板:
+
+```python
+python datax.py -r oraclereader -w matrixonewriter
+```
+
+进入到 datax/job 路径,根据模板,编写作业文件 oracle2mo.json
+
+```json
+{
+ "job": {
+ "setting": {
+ "speed": {
+ "channel": 8
+ }
+ },
+ "content": [
+ {
+ "reader": {
+ "name": "oraclereader",
+ "parameter": {
+ "username": "scott",
+ "password": "tiger",
+ "column": [
+ '*'
+ ],
+ "connection": [
+ {
+ "table": [
+ "employees_oracle"
+ ],
+ "jdbcUrl": [
+ "jdbc:oracle:thin:@xx.xx.xx.xx:1521:ORCLCDB"
+ ]
+ }
+ ]
+ }
+ },
+ "writer": {
+ "name": "matrixonewriter",
+ "parameter": {
+ "writeMode": "insert",
+ "username": "root",
+ "password": "111",
+ "column": [
+ '*'
+ ],
+ "connection": [
+ {
+ "jdbcUrl": "jdbc:mysql://xx.xx.xx.xx:6001/test",
+ "table": [
+ "oracle_datax"
+ ]
+ }
+ ]
+ }
+ }
+ }
+ ]
+ }
+}
+```
+
+### 启动 datax 作业
+
+```bash
+python /opt/module/datax/bin/datax.py /opt/module/datax/job/oracle2mo.json
+```
+
+### 查看 MatrixOne 表中数据
+
+```sql
+mysql> select * from oracle_datax;
++------+----------+
+| id | name |
++------+----------+
+| 1 | zhangsan |
+| 2 | lisi |
+| 3 | wangwu |
+| 4 | oracle |
++------+----------+
+4 rows in set (0.00 sec)
+```
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-overview.md b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-overview.md
new file mode 100644
index 0000000000..c6b3031da6
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-overview.md
@@ -0,0 +1,19 @@
+# 使用 DataX 将数据写入 MatrixOne
+
+## 概述
+
+DataX 是一款由阿里开源的异构数据源离线同步工具,提供了稳定和高效的数据同步功能,旨在实现各种异构数据源之间的高效数据同步。
+
+DataX 将不同数据源的同步分为两个主要组件:**Reader(读取数据源)
+**和 **Writer(写入目标数据源)**。DataX 框架理论上支持任何数据源类型的数据同步工作。
+
+MatrixOne 与 MySQL 8.0 高度兼容,但由于 DataX 自带的 MySQL Writer 插件适配的是 MySQL 5.1 的 JDBC 驱动,为了提升兼容性,社区单独改造了基于 MySQL 8.0 驱动的 MatrixOneWriter 插件。MatrixOneWriter 插件实现了将数据写入 MatrixOne 数据库目标表的功能。在底层实现中,MatrixOneWriter 通过 JDBC 连接到远程 MatrixOne 数据库,并执行相应的 `insert into ...` SQL 语句将数据写入 MatrixOne,同时支持批量提交。
+
+MatrixOneWriter 利用 DataX 框架从 Reader 获取生成的协议数据,并根据您配置的 `writeMode` 生成相应的 `insert into...` 语句。在遇到主键或唯一性索引冲突时,会排除冲突的行并继续写入。出于性能优化的考虑,我们采用了 `PreparedStatement + Batch` 的方式,并设置了 `rewriteBatchedStatements=true` 选项,以将数据缓冲到线程上下文的缓冲区中。只有当缓冲区的数据量达到预定的阈值时,才会触发写入请求。
+
+
+
+!!! note
+ 执行整个任务至少需要拥有 `insert into ...` 的权限,是否需要其他权限取决于你在任务配置中的 `preSql` 和 `postSql`。
+
+MatrixOneWriter 主要面向 ETL 开发工程师,他们使用 MatrixOneWriter 将数据从数据仓库导入到 MatrixOne。同时,MatrixOneWriter 也可以作为数据迁移工具为 DBA 等用户提供服务。
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-postgresql-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-postgresql-matrixone.md
new file mode 100644
index 0000000000..78a72e9263
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-postgresql-matrixone.md
@@ -0,0 +1,206 @@
+# 使用 DataX 将数据写入 MatrixOne
+
+本文介绍如何使用 DataX 工具将 PostgreSQL 数据离线写入 MatrixOne 数据库。
+
+## 开始前准备
+
+在开始使用 DataX 将数据写入 MatrixOne 之前,需要完成安装以下软件:
+
+- 完成[单机部署 MatrixOne](https://docs.matrixorigin.cn/1.2.1/MatrixOne/Get-Started/install-standalone-matrixone/)。
+- 安装 [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html)。
+- 安装 [Python 3.8(or plus)](https://www.python.org/downloads/)。
+- 下载 [DataX](https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202210/datax.tar.gz) 安装包,并解压。
+- 下载 [matrixonewriter.zip](https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/Computing-Engine/datax-write/matrixonewriter.zip),解压至 DataX 项目根目录的 `plugin/writer/` 目录下。
+- 安装 [PostgreSQL](https://www.postgresql.org/download/)。
+- 安装 <a href="https://dev.mysql.com/downloads/mysql" target="_blank">MySQL Client</a>。
+
+## 操作步骤
+
+### 在 postgresql 中创建测试数据
+
+```sql
+create table public.student
+(
+ stu_id integer not null unique,
+ stu_name varchar(50),
+ stu_age integer,
+ stu_bth date,
+ stu_tel varchar(20),
+ stu_address varchar(100)
+);
+
+insert into public.student (stu_id, stu_name, stu_age, stu_bth, stu_tel, stu_address)
+values (1, '89', 37, '2020-04-08', '13774736413', '8c5ab4290b7b503a616428aa018810f7'),
+ (2, '32', 99, '2021-03-29', '15144066883', '6362da2f9dec9f4ed4b9cb746d614f8b'),
+ (3, '19', 47, '2022-08-12', '18467326153', '3872f24472ac73f756093e7035469519'),
+ (4, '64', 52, '2020-05-23', '17420017216', '70ae7aa670faeb46552aad7a1e9c0962'),
+ (5, '4', 92, '2021-07-26', '17176145462', 'e1a98b2e907d0c485278b9f4ccc8b2e2'),
+ (6, '64', 32, '2021-02-15', '17781344827', '46ee127c3093d94626ba6ef8cd0692ba'),
+ (7, '3', 81, '2021-05-30', '18884764747', '0d1933c53c9a4346d3f6c858dca790fd'),
+ (8, '20', 53, '2022-05-09', '18270755716', '0b58cad62f9ecded847a3c5528bfeb32'),
+ (9, '35', 80, '2022-02-06', '15947563604', 'a31547f9dc4e47ce78cee591072286a5'),
+ (10, '2', 4, '2021-12-27', '17125567735', '527f56f97b043e07f841a71a77fb65e1'),
+ (11, '93', 99, '2020-09-21', '17227442051', '6cd20735456bf7fc0de181f219df1f05'),
+ (12, '85', 92, '2021-06-18', '17552708612', 'ec0f8ea9c8c9a1ffba168b71381c844a'),
+ (13, '4', 85, '2022-06-23', '18600681601', 'f12086a2ac3c78524273b62387142dbb'),
+ (14, '57', 62, '2022-09-05', '15445191147', '8e4a867c3fdda49da4094f0928ff6d9c'),
+ (15, '60', 14, '2020-01-13', '15341861644', 'cb2dea86155dfbe899459679548d5c4d'),
+ (16, '38', 4, '2021-06-24', '17881144821', 'f8013e50862a69cb6b008559565bd8a9'),
+ (17, '38', 48, '2022-01-10', '17779696343', 'c3a6b5fbeb4859c0ffc0797e36f1fd83'),
+ (18, '22', 26, '2020-10-15', '13391701987', '395782c95547d269e252091715aa5c88'),
+ (19, '73', 15, '2022-05-29', '13759716790', '808ef7710cdc6175d23b0a73543470d9'),
+ (20, '42', 41, '2020-10-17', '18172716366', 'ba1f364fb884e8c4a50b0fde920a1ae8'),
+ (21, '56', 83, '2020-03-07', '15513537478', '870ad362c8c7590a71886243fcafd0d0'),
+ (22, '55', 66, '2021-10-29', '17344805585', '31691a27ae3e848194c07ef1d58e54e8'),
+ (23, '90', 36, '2020-10-04', '15687526785', '8f8b8026eda6058d08dc74b382e0bd4d'),
+ (24, '16', 35, '2020-02-02', '17162730436', '3d16fcff6ef498fd405390f5829be16f'),
+ (25, '71', 99, '2020-06-25', '17669694580', '0998093bfa7a4ec2f7e118cd90c7bf27'),
+ (26, '25', 81, '2022-01-30', '15443178508', '5457d230659f7355e2171561a8eaad1f'),
+ (27, '84', 9, '2020-03-04', '17068873272', '17757d8bf2d3b2fa34d70bb063c44c4a'),
+ (28, '78', 15, '2020-05-29', '17284471816', 'a8e671065639ac5ca655a88ee2d3818f'),
+ (29, '50', 34, '2022-05-20', '18317827143', '0851e6701cadb06352ee780a27669b3b'),
+ (30, '90', 20, '2022-02-02', '15262333350', 'f22142e561721084763533c61ff6af36'),
+ (31, '7', 30, '2021-04-21', '17225107071', '276c949aec2059caafefb2dee1a5eb11'),
+ (32, '80', 15, '2022-05-11', '15627026685', '2e2bcaedc089af94472cb6190003c207'),
+ (33, '79', 17, '2020-01-16', '17042154756', 'ebf9433c31a13a92f937d5e45c71fc1b'),
+ (34, '93', 30, '2021-05-01', '17686515037', 'b7f94776c0ccb835cc9dc652f9f2ae3f'),
+ (35, '32', 46, '2020-06-15', '15143715218', '1aa0ce5454f6cfeff32037a277e1cbbb'),
+ (36, '21', 41, '2020-07-07', '13573552861', '1cfabf362081bea99ce05d3564442a6a'),
+ (37, '38', 87, '2022-01-27', '17474570881', '579e80b0a04bfe379f6657fad9abe051'),
+ (38, '95', 61, '2022-07-12', '13559275228', 'e3036ce9936e482dc48834dfd4efbc42'),
+ (39, '77', 55, '2021-01-27', '15592080796', '088ef31273124964d62f815a6ccebb33'),
+ (40, '24', 51, '2020-12-28', '17146346717', '6cc3197ab62ae06ba673a102c1c4f28e'),
+ (41, '48', 93, '2022-05-12', '15030604962', '3295c7b1c22587d076e02ed310805027'),
+ (42, '64', 57, '2022-02-07', '17130181503', 'e8b134c2af77f5c273c60d723554f5a8'),
+ (43, '97', 2, '2021-01-05', '17496292202', 'fbfbdf19d463020dbde0378d50daf715'),
+ (44, '10', 92, '2021-08-17', '15112084250', '2c9b3419ff84ba43d7285be362221824'),
+ (45, '99', 55, '2020-09-26', '17148657962', 'e46e3c6af186e95ff354ad08683984bc'),
+ (46, '24', 27, '2020-10-09', '17456279238', '397d0eff64bfb47c8211a3723e873b9a'),
+ (47, '80', 40, '2020-02-09', '15881886181', 'ef2c50d70a12dfb034c43d61e38ddd9f'),
+ (48, '80', 65, '2021-06-17', '15159743156', 'c6f826d3f22c63c89c2dc1c226172e56'),
+ (49, '92', 73, '2022-01-16', '18614514771', '657af9e596c2dc8b6eb8a1cda4630a5d'),
+ (50, '46', 1, '2022-04-10', '17347722479', '603b4bb6d8c94aa47064b79557347597');
+```
+
+### 在 MatrixOne 中创建目标表
+
+```sql
+CREATE TABLE `student` (
+ `stu_id` int(11) NOT NULL COMMENT "",
+ `stu_name` varchar(50) NULL COMMENT "",
+ `stu_age` int(11) NULL COMMENT "",
+ `stu_bth` date NULL COMMENT "",
+ `stu_tel` varchar(11) NULL COMMENT "",
+ `stu_address` varchar(100) NULL COMMENT "",
+ primary key(stu_id)
+ );
+```
+
+### 创建作业配置文件
+
+进入到 datax/job 路径,创建文件 `pgsql2matrixone.json`,输入以下内容:
+
+```json
+{
+ "job": {
+ "setting": {
+ "speed": {
+ "channel": 3,
+ "byte": 1048576
+ },
+ "errorLimit": {
+ "record": 0,
+ "percentage": 0.02
+ }
+ },
+ "content": [
+ {
+ "reader": {
+ "name": "postgresqlreader",
+ "parameter": {
+ "connection": [
+ {
+ "jdbcUrl": [
+ "jdbc:postgresql://xx.xx.xx.xx:5432/postgres"
+ ],
+ "table": [
+ "public.student"
+ ],
+
+ }
+ ],
+ "password": "123456",
+ "username": "postgres",
+ "column": [
+ "stu_id",
+ "stu_name",
+ "stu_age",
+ "stu_bth",
+ "stu_tel",
+ "stu_address"
+ ]
+ }
+ },
+ "writer": {
+ "name": "matrixonewriter",
+ "parameter": {
+ "column": [
+ "stu_id",
+ "stu_name",
+ "stu_age",
+ "stu_bth",
+ "stu_tel",
+ "stu_address"
+ ],
+ "connection": [
+ {
+ "jdbcUrl": "jdbc:mysql://xx.xx.xx.xx:6001/postgre",
+ "table": [
+ "student"
+ ]
+ }
+ ],
+ "username": "root",
+ "password": "111",
+ "writeMode": "insert"
+ }
+ }
+ }
+ ]
+ }
+}
+```
+
+若报错 "经 DataX 智能分析,该任务最可能的错误原因是:com.alibaba.datax.common.exception.DataXException: Code: [Framework-03], Description: DataX 引擎配置错误,该问题通常是由于 DataX 安装错误引起,请联系您的运维解决。 - 在有总 bps 限速条件下,单个 channel 的 bps 值不能为空,也不能为非正数", 则需要在 json 中添加
+
+```json
+"core": {
+ "transport": {
+ "channel": {
+ "class": "com.alibaba.datax.core.transport.channel.memory.MemoryChannel",
+ "speed": {
+ "byte": 2000000,
+ "record": -1
+ }
+ }
+ }
+ }
+```
+
+### 启动 datax 作业
+
+```bash
+python ./bin/datax.py ./job/pgsql2mo.json #在datax目录下
+```
+
+任务完成后,打印总体运行情况:
+
+<div align="center">
+ <img src=https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/datax/datax-pg-01.jpg width=70% heigth=70%/>
+</div>
+
+### 查看 MatrixOne 表中数据
+
+<div align="center">
+ <img src=https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/datax/datax-pg-02.jpg width=70% heigth=70%/>
+</div>
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-sqlserver-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-sqlserver-matrixone.md
new file mode 100644
index 0000000000..9ab38a5289
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-sqlserver-matrixone.md
@@ -0,0 +1,119 @@
+# 使用 DataX 将数据写入 MatrixOne
+
+本文介绍如何使用 DataX 工具将 SQL Server 数据离线写入 MatrixOne 数据库。
+
+## 开始前准备
+
+在开始使用 DataX 将数据写入 MatrixOne 之前,需要完成安装以下软件:
+
+- 完成[单机部署 MatrixOne](https://docs.matrixorigin.cn/1.2.1/MatrixOne/Get-Started/install-standalone-matrixone/)。
+- 安装 [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html)。
+- 安装 [Python 3.8(or plus)](https://www.python.org/downloads/)。
+- 下载 [DataX](https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202210/datax.tar.gz) 安装包,并解压。
+- 下载 [matrixonewriter.zip](https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/Computing-Engine/datax-write/matrixonewriter.zip),解压至 DataX 项目根目录的 `plugin/writer/` 目录下。
+- 已完成 [SQL Server 2022](https://www.microsoft.com/en-us/sql-server/sql-server-downloads)。
+- 安装 <a href="https://dev.mysql.com/downloads/mysql" target="_blank">MySQL Client</a>。
+
+## 操作步骤
+
+### 创建 sql server 测试数据
+
+```sql
+CREATE TABLE test.dbo.test2 (
+ id int NULL,
+ age int NULL,
+ name varchar(50) null
+);
+
+INSERT INTO test.dbo.test2
+(id, age, name)
+VALUES(1, 1, N'shdfhg '),
+(4, 4, N' dhdhdf '),
+(2, 2, N' ndgnh '),
+(3, 3, N' dgh '),
+(5, 5, N' dfghnd '),
+(6, 6, N' dete ');
+```
+
+### 在 MatrixOne 中创建目标表
+
+由于 DataX 只能同步数据,不能同步表结构,所以在执行任务前,我们需要先在目标数据库(MatrixOne)中手动创建好表。
+
+```sql
+CREATE TABLE test.test_2 (
+ id int not NULL,
+ age int NULL,
+ name varchar(50) null
+);
+```
+
+### 创建作业配置文件
+
+DataX 中的任务配置文件是 json 格式,可以通过下面的命令查看内置的任务配置模板:
+
+```bash
+python datax.py -r sqlserverreader -w matrixonewriter
+```
+
+进入到 datax/job 路径,根据模板,编写作业文件 `sqlserver2mo.json`:
+
+```json
+{
+ "job": {
+ "content": [
+ {
+ "reader": {
+ "name": "sqlserverreader",
+ "parameter": {
+ "column": ["id","age","name"],
+ "connection": [
+ {
+ "jdbcUrl": ["jdbc:sqlserver://xx.xx.xx.xx:1433;databaseName=test"],
+ "table": ["dbo.test2"]
+ }
+ ],
+ "password": "123456",
+ "username": "sa"
+ }
+ },
+ "writer": {
+ "name": "matrixonewriter",
+ "parameter": {
+ "column": ["id","age","name"],
+ "connection": [
+ {
+ "jdbcUrl": "jdbc:mysql://xx.xx.xx:6001/test",
+ "table": ["test_2"]
+ }
+ ],
+ "password": "111",
+ "username": "root",
+ "writeMode": "insert"
+ }
+ }
+ }
+ ],
+ "setting": {
+ "speed": {
+ "channel": "1"
+ }
+ }
+ }
+}
+```
+
+### 启动 datax 作业
+
+```bash
+python datax.py sqlserver2mo.json
+```
+
+### 查看 mo 表中数据
+
+```sql
+select * from test_2;
+```
+
+<div align="center">
+ <img src=https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/datax/datax-sqlserver-02.jpg width=50% heigth=50%/>
+</div>
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-tidb-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-tidb-matrixone.md
new file mode 100644
index 0000000000..a8088af868
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-tidb-matrixone.md
@@ -0,0 +1,132 @@
+# 使用 DataX 将数据写入 MatrixOne
+
+本文介绍如何使用 DataX 工具将 TiDB 数据离线写入 MatrixOne 数据库。
+
+## 开始前准备
+
+在开始使用 DataX 将数据写入 MatrixOne 之前,需要完成安装以下软件:
+
+- 完成[单机部署 MatrixOne](https://docs.matrixorigin.cn/1.2.1/MatrixOne/Get-Started/install-standalone-matrixone/)。
+- 安装 [JDK 8+ version](https://www.oracle.com/sg/java/technologies/javase/javase8-archive-downloads.html)。
+- 安装 [Python 3.8(or plus)](https://www.python.org/downloads/)。
+- 下载 [DataX](https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202210/datax.tar.gz) 安装包,并解压。
+- 下载 [matrixonewriter.zip](https://community-shared-data-1308875761.cos.ap-beijing.myqcloud.com/artwork/docs/develop/Computing-Engine/datax-write/matrixonewriter.zip),解压至 DataX 项目根目录的 `plugin/writer/` 目录下。
+- 已完成 TiDB 单机部署。
+- 安装 <a href="https://dev.mysql.com/downloads/mysql" target="_blank">MySQL Client</a>。
+
+## 操作步骤
+
+### 在 TiDB 中创建测试数据
+
+```sql
+CREATE TABLE `tidb_dx` (
+ `id` bigint(20) NOT NULL,
+ `name` varchar(100) DEFAULT NULL,
+ `salary` decimal(10,0) DEFAULT NULL,
+ `age` int(11) DEFAULT NULL,
+ `entrytime` date DEFAULT NULL,
+ `gender` char(1) DEFAULT NULL,
+ PRIMARY KEY (`id`)
+);
+
+insert into testdx2tidb values
+(1,"lisa",15660,30,'2022-10-12',0),
+(2,"tom",15060,24,'2021-11-10',1),
+(3,"jenny",15000,28,'2024-02-19',0),
+(4,"henry",12660,24,'2022-04-22',1);
+```
+
+### 在 MatrixOne 中创建目标表
+
+由于 DataX 只能同步数据,不能同步表结构,所以在执行任务前,我们需要先在目标数据库(MatrixOne)中手动创建好表。
+
+```sql
+CREATE TABLE `testdx2tidb` (
+ `id` bigint(20) NOT NULL COMMENT "",
+ `name` varchar(100) NULL COMMENT "",
+ `salary` decimal(10, 0) NULL COMMENT "",
+ `age` int(11) NULL COMMENT "",
+ `entrytime` date NULL COMMENT "",
+ `gender` varchar(1) NULL COMMENT "",
+ PRIMARY KEY (`id`)
+);
+```
+
+### 配置 json 文件
+
+tidb 可以直接使用 mysqlreader 读取。在 datax 的 job 目录下。编辑配置文件 `tidb2mo.json`:
+
+```json
+{
+ "job": {
+ "setting": {
+ "speed": {
+ "channel": 1
+ },
+ "errorLimit": {
+ "record": 0,
+ "percentage": 0
+ }
+ },
+ "content": [
+ {
+ "reader": {
+ "name": "mysqlreader",
+ "parameter": {
+ "username": "root",
+ "password": "root",
+ "column": [ "*" ],
+ "splitPk": "id",
+ "connection": [
+ {
+ "table": [ "tidb_dx" ],
+ "jdbcUrl": [
+ "jdbc:mysql://xx.xx.xx.xx:4000/test"
+ ]
+ }
+ ]
+ }
+ },
+ "writer": {
+ "name": "matrixonewriter",
+ "parameter": {
+ "column": ["*"],
+ "connection": [
+ {
+ "jdbcUrl": "jdbc:mysql://xx.xx.xx.xx:6001/test",
+ "table": ["testdx2tidb"]
+ }
+ ],
+ "password": "111",
+ "username": "root",
+ "writeMode": "insert"
+ }
+ }
+ }
+ ]
+ }
+}
+```
+
+### 执行任务
+
+```bash
+python bin/datax.py job/tidb2mo.json
+```
+
+### 在 MatrixOne 中查看目标表数据
+
+```sql
+mysql> select * from testdx2tidb;
++------+-------+--------+------+------------+--------+
+| id | name | salary | age | entrytime | gender |
++------+-------+--------+------+------------+--------+
+| 1 | lisa | 15660 | 30 | 2022-10-12 | 0 |
+| 2 | tom | 15060 | 24 | 2021-11-10 | 1 |
+| 3 | jenny | 15000 | 28 | 2024-02-19 | 0 |
+| 4 | henry | 12660 | 24 | 2022-04-22 | 1 |
++------+-------+--------+------+------------+--------+
+4 rows in set (0.01 sec)
+```
+
+数据导入成功。
\ No newline at end of file
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/seatunnel-write.md b/docs/MatrixOne/Develop/Ecological-Tools/Etl/Seatunnel/seatunnel-mysql-matrixone.md
similarity index 77%
rename from docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/seatunnel-write.md
rename to docs/MatrixOne/Develop/Ecological-Tools/Etl/Seatunnel/seatunnel-mysql-matrixone.md
index 642276a8f1..39c3f6ef82 100644
--- a/docs/MatrixOne/Develop/Ecological-Tools/Computing-Engine/seatunnel-write.md
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Etl/Seatunnel/seatunnel-mysql-matrixone.md
@@ -1,15 +1,9 @@
-# 使用 SeaTunnel 将数据写入 MatrixOne
+# 使用 SeaTunnel 将 MySQL 数据写入 MatrixOne
-## 概述
-
-[SeaTunnel](https://seatunnel.apache.org/) 是一个分布式、高性能、易扩展的数据集成平台,专注于海量数据(包括离线和实时数据)同步和转化。MatrixOne 支持使用 SeaTunnel 从其他数据库同步数据,可以稳定高效地处理数百亿条数据。
-
-本文档将介绍如何使用 SeaTunnel 向 MatrixOne 中写入数据。
+本章节将介绍如何使用 SeaTunnel 将 MySQL 数据写入到 MatrixOne。
## 开始前准备
-在使用 SeaTunnel 向 MatrixOne 写入数据之前,请确保完成以下准备工作:
-
- 已完成[安装和启动 MatrixOne](../../../Get-Started/install-standalone-matrixone.md)。
- 已完成[安装 SeaTunnel Version 2.3.3](https://www.apache.org/dyn/closer.lua/seatunnel/2.3.3/apache-seatunnel-2.3.3-bin.tar.gz)。安装完成后,可以通过 shell 命令行定义 SeaTunnel 的安装路径:
@@ -18,6 +12,10 @@
export SEATNUNNEL_HOME="/root/seatunnel"
```
+- 下载并安装 [MySQL](https://downloads.mysql.com/archives/get/p/23/file/mysql-server_8.0.33-1ubuntu23.04_amd64.deb-bundle.tar)。
+
+- 下载 [mysql-connector-java-8.0.33.jar](https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-j-8.0.33.zip),并将文件复制到 `${SEATNUNNEL_HOME}/plugins/jdbc/lib/` 目录下。
+
## 操作步骤
### 创建测试数据
@@ -41,7 +39,7 @@ export SEATNUNNEL_HOME="/root/seatunnel"
### 安装 Connectors 插件
-本篇文档中将介绍如何使用 SeaTunnel 的 `connector-jdbc` 连接插件连接 MatrixOne。
+使用 SeaTunnel 的 `connector-jdbc` 连接插件连接 MatrixOne。
1. 在 SeaTunnel 的 `${SEATNUNNEL_HOME}/config/plugin_config` 文件中,添加以下内容:
@@ -59,7 +57,7 @@ export SEATNUNNEL_HOME="/root/seatunnel"
__Note:__ 本篇文档中使用 SeaTunnel 引擎将数据写入 MatrixOne,无需依赖 Flink 或 Spark。
-## 定义任务配置文件
+### 定义任务配置文件
在本篇文档中,我们使用 MySQL 数据库的 `test_table` 表作为数据源,不进行数据处理,直接将数据写入 MatrixOne 数据库的 `test_table` 表中。
@@ -75,7 +73,7 @@ env {
source {
Jdbc {
- url = "jdbc:mysql://192.168.110.40:3306/test"
+ url = "jdbc:mysql://xx.xx.xx.xx:3306/test"
driver = "com.mysql.cj.jdbc.Driver"
connection_check_timeout_sec = 100
user = "root"
@@ -90,7 +88,7 @@ transform {
sink {
jdbc {
- url = "jdbc:mysql://192.168.110.248:6001/test"
+ url = "jdbc:mysql://xx.xx.xx.xx:6001/test"
driver = "com.mysql.cj.jdbc.Driver"
user = "root"
password = "111"
@@ -99,10 +97,6 @@ sink {
}
```
-### 安装数据库依赖项
-
-下载 [mysql-connector-java-8.0.33.jar](https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-j-8.0.33.zip),并将文件复制到 `${SEATNUNNEL_HOME}/plugins/jdbc/lib/` 目录下。
-
### 运行 SeaTunnel 应用
执行以下命令启动 SeaTunnel 应用:
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Etl/Seatunnel/seatunnel-oracle-matrixone.md b/docs/MatrixOne/Develop/Ecological-Tools/Etl/Seatunnel/seatunnel-oracle-matrixone.md
new file mode 100644
index 0000000000..41974f07a9
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Etl/Seatunnel/seatunnel-oracle-matrixone.md
@@ -0,0 +1,163 @@
+# 使用 SeaTunnel 将数据写入 MatrixOne
+
+本文档将介绍如何使用 SeaTunnel 将 Oracle 数据写入 MatrixOne。
+
+## 开始前准备
+
+- 已完成[安装和启动 MatrixOne](../../../Get-Started/install-standalone-matrixone.md)。
+
+- 已完成[安装 Oracle 19c](https://www.oracle.com/database/technologies/oracle-database-software-downloads.html)。
+
+- 已完成[安装 SeaTunnel Version 2.3.3](https://www.apache.org/dyn/closer.lua/seatunnel/2.3.3/apache-seatunnel-2.3.3-bin.tar.gz)。安装完成后,可以通过 shell 命令行定义 SeaTunnel 的安装路径:
+
+```shell
+export SEATNUNNEL_HOME="/root/seatunnel"
+```
+
+- 安装 <a href="https://dev.mysql.com/downloads/mysql" target="_blank">MySQL Client</a>。
+
+- 下载 ojdbc8-23.3.0.23.09.jar,并将文件复制到 ${SEATNUNNEL_HOME}/plugins/jdbc/lib/ 目录下。
+
+## 操作步骤
+
+### 在 Oracle 使用 scott 用户创建测试数据
+
+本次使用 Oracle 中用户 scott 来创建表(当然也可以用其他用户),在 Oracle 19c 中,scott 用户需要手动创建,可以使用 sqlplus 工具通过命令将其解锁。
+
+- 访问数据库
+
+```sql
+sqlplus / as sysdba
+```
+
+- 创建 scott 用户,并指定密码
+
+```sql
+create user scott identified by tiger;
+```
+
+- 为方便测试使用,我们授予 scott dba 角色:
+
+```sql
+grant dba to scott;
+```
+
+- 后续就可以通过 scott 用户登陆访问:
+
+```sql
+sqlplus scott/tiger
+```
+
+- 在 Oracle 中创建测试数据
+
+```sql
+create table employees_oracle(
+id number(5),
+name varchar(20)
+);
+
+insert into employees_oracle values(1,'zhangsan');
+insert into employees_oracle values(2,'lisi');
+insert into employees_oracle values(3,'wangwu');
+insert into employees_oracle values(4,'oracle');
+COMMIT;
+--查看表数据:
+select * from employees_oracle;
+```
+
+### 在 MatrixOne 中提前建表
+
+由于 SeaTunnel 只能同步数据,不能同步表结构,所以在执行任务前,我们需要先在目标数据库(mo)中手动创建好表。
+
+```sql
+CREATE TABLE `oracle_datax` (
+ `id` bigint(20) NOT NULL,
+ `name` varchar(100) DEFAULT NULL,
+ PRIMARY KEY (`id`)
+) ;
+```
+
+### 安装 Connectors 插件
+
+接着介绍如何使用 SeaTunnel 的 `connector-jdbc` 连接插件连接 MatrixOne。
+
+1. 在 SeaTunnel 的 `${SEATNUNNEL_HOME}/config/plugin_config` 文件中,添加以下内容:
+
+ ```conf
+ --connectors-v2--
+ connector-jdbc
+ --end--
+ ```
+
+2. 版本 2.3.3 的 SeaTunnel 二进制包默认不提供连接器依赖项,你需要在首次使用 SeaTunnel 时,执行以下命令来安装连接器:
+
+ ```shell
+ sh bin/install-plugin.sh 2.3.3
+ ```
+
+ __Note:__ 本篇文档中使用 SeaTunnel 引擎将数据写入 MatrixOne,无需依赖 Flink 或 Spark。
+
+### 定义任务配置文件
+
+在本节中,我们使用 Oracle 数据库的 `employees_oracle` 表作为数据源,不进行数据处理,直接将数据写入 MatrixOne 数据库的 `oracle_datax` 表中。
+
+那么,由于数据兼容性的问题,需要配置任务配置文件 `${SEATNUNNEL_HOME}/config/v2.batch.config.template`,它定义了 SeaTunnel 启动后的数据输入、处理和输出方式和逻辑。
+
+按照以下内容编辑配置文件:
+
+```conf
+env {
+ # You can set SeaTunnel environment configuration here
+ execution.parallelism = 10
+ job.mode = "BATCH"
+ #execution.checkpoint.interval = 10000
+ #execution.checkpoint.data-uri = "hdfs://localhost:9000/checkpoint"
+}
+
+source {
+ Jdbc {
+ url = "jdbc:oracle:thin:@xx.xx.xx.xx:1521:ORCLCDB"
+ driver = "oracle.jdbc.OracleDriver"
+ user = "scott"
+ password = "tiger"
+ query = "select * from employees_oracle"
+ }
+}
+
+sink {
+ Jdbc {
+ url = "jdbc:mysql://xx.xx.xx.xx:6001/test"
+ driver = "com.mysql.cj.jdbc.Driver"
+ user = "root"
+ password = "111"
+ query = "insert into oracle_datax values(?,?)"
+ }
+}
+```
+
+### 运行 SeaTunnel 应用
+
+执行以下命令启动 SeaTunnel 应用:
+
+```shell
+./bin/seatunnel.sh --config ./config/v2.batch.config.template -e local
+```
+
+### 查看运行结果
+
+SeaTunnel 运行结束后,将显示类似以下的统计结果,汇总了本次写入的用时、总读取数据数量、总写入数量以及总写入失败数量:
+
+```shell
+***********************************************
+ Job Statistic Information
+***********************************************
+Start Time : 2023-08-07 16:45:02
+End Time : 2023-08-07 16:45:05
+Total Time(s) : 3
+Total Read Count : 4
+Total Write Count : 4
+Total Failed Count : 0
+***********************************************
+```
+
+你已经成功将数据从 Oracle 数据库同步写入到 MatrixOne 数据库中。
diff --git a/docs/MatrixOne/Develop/Ecological-Tools/Etl/Seatunnel/seatunnel-overview.md b/docs/MatrixOne/Develop/Ecological-Tools/Etl/Seatunnel/seatunnel-overview.md
new file mode 100644
index 0000000000..89cedcbc16
--- /dev/null
+++ b/docs/MatrixOne/Develop/Ecological-Tools/Etl/Seatunnel/seatunnel-overview.md
@@ -0,0 +1,17 @@
+# 概述
+
+[SeaTunnel](https://seatunnel.apache.org/) 是一个分布式、高性能、易扩展的数据集成平台,专注于海量数据(包括离线和实时数据)同步和转化。MatrixOne 支持使用 SeaTunnel 从其他数据库同步数据,可以稳定高效地处理数百亿条数据。
+
+## 应用场景
+
+Apache SeaTunnel 是一个多功能的分布式数据集成平台,适用于多种应用场景,主要包括:
+
+- 海量数据同步:SeaTunnel 能够处理大规模数据的同步任务,支持每天稳定高效地同步数百亿数据。
+
+- 数据集成:它帮助用户将来自多个数据源的数据集成到统一的存储系统中,便于后续的数据分析和处理。
+
+- 实时流式处理:SeaTunnel 支持实时数据流的处理,适用于需要实时数据同步和转换的场景。
+
+- 离线批处理:除了实时处理,SeaTunnel 也支持离线批量数据处理,适用于定期的数据同步和分析任务。
+
+- ETL 处理:SeaTunnel 可用于数据抽取、转换和加载(ETL)操作,帮助企业将数据从源头转换并加载到目标系统。
\ No newline at end of file
diff --git a/mkdocs.yml b/mkdocs.yml
index d95226b67b..c54204f2cc 100644
--- a/mkdocs.yml
+++ b/mkdocs.yml
@@ -183,11 +183,37 @@ nav:
- 通过永洪 BI 实现 MatrixOne 的可视化报表: MatrixOne/Develop/Ecological-Tools/BI-Connection/yonghong-connection.md
- 通过 Superset 实现 MatrixOne 可视化监控: MatrixOne/Develop/Ecological-Tools/BI-Connection/Superset-connection.md
- ETL 工具:
- - 使用 SeaTunnel 将数据写入 MatrixOne: MatrixOne/Develop/Ecological-Tools/Computing-Engine/seatunnel-write.md
- - 使用 DataX 将数据写入 MatrixOne: MatrixOne/Develop/Ecological-Tools/Computing-Engine/DataX-write.md
+ - 使用 SeaTunnel 将数据写入 MatrixOne:
+ - 概述: MatrixOne/Develop/Ecological-Tools/Etl/Seatunnel/seatunnel-overview.md
+ - 从 MySQL 写入数据到 MatrixOne: MatrixOne/Develop/Ecological-Tools/Etl/Seatunnel/seatunnel-mysql-matrixone.md
+ - 从 Oracle 写入数据到 MatrixOne: MatrixOne/Develop/Ecological-Tools/Etl/Seatunnel/seatunnel-oracle-matrixone.md
+ - 使用 DataX 将数据写入 MatrixOne:
+ - 概述: MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-overview.md
+ - 从 MySQL 写入数据到 MatrixOne: MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-mysql-matrixone.md
+ - 从 Oracle 写入数据到 MatrixOne: MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-oracle-matrixone.md
+ - 从 PostgreSQL 写入数据到 MatrixOne: MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-postgresql-matrixone.md
+ - 从 SQL Server 写入数据到 MatrixOne: MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-sqlserver-matrixone.md
+ - 从 MongoDB 写入数据到 MatrixOne: MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-mongodb-matrixone.md
+ - 从 TiDB 写入数据到 MatrixOne: MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-tidb-matrixone.md
+ - 从 ClickHouse 写入数据到 MatrixOne: MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-clickhouse-matrixone.md
+ - 从 Doris 写入数据到 MatrixOne: MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-doris-matrixone.md
+ - 从 InfluxDB 写入数据到 MatrixOne: MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-influxdb-matrixone.md
+ - 从 Elasticsearch 写入数据到 MatrixOne: MatrixOne/Develop/Ecological-Tools/Etl/DataX/datax-elasticsearch-matrixone.md
- 计算引擎:
- - 使用 Spark 将批量数据写入 MatrixOne: MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark.md
- - 使用 Flink 将实时数据写入 MatrixOne: MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink.md
+ - 使用 Spark 将批量数据写入 MatrixOne:
+ - 概述: MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-overview.md
+ - 从 MySQL 写入数据到 MatrixOne: MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-mysql-matrixone.md
+ - 从 Hive 写入数据到 MatrixOne: MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-hive-matrixone.md
+ - 从 Doris 写入数据到 MatrixOne: MatrixOne/Develop/Ecological-Tools/Computing-Engine/Spark/spark-doris-matrixone.md
+ - 使用 Flink 将实时数据写入 MatrixOne:
+ - 概述: MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-overview.md
+ - 从 MySQL 写入数据到MatrixOne: MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-mysql-matrixone.md
+ - 从 Oracle 写入数据到MatrixOne: MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-oracle-matrixone.md
+ - 从 SQL Server 写入数据到MatrixOne: MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-sqlserver-matrixone.md
+ - 从 PostgreSQL 写入数据到MatrixOne: MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-postgresql-matrixone.md
+ - 从 MongoDB 写入数据到MatrixOne: MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-mongo-matrixone.md
+ - 从 TiDB 写入数据到MatrixOne: MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-tidb-matrixone.md
+ - 从 Kafka 写入数据到MatrixOne: MatrixOne/Develop/Ecological-Tools/Computing-Engine/Flink/flink-kafka-matrixone.md
- 调度工具:
- 使用 DolphinScheduler 连接 MatrixOne: MatrixOne/Develop/Ecological-Tools/Scheduling-Tools/dolphinScheduler.md
- 部署指南: