本系列文章将整理到我在GitHub上的《Java面试指南》仓库,更多精彩内容请到我的仓库里查看
喜欢的话麻烦点下Star哈
文章首发于我的个人博客:
本文是微信公众号【Java技术江湖】的《夯实Java基础系列博文》其中一篇,本文部分内容来源于网络,为了把本文主题讲得清晰透彻,也整合了很多我认为不错的技术博客内容,引用其中了一些比较好的博客文章,如有侵权,请联系作者。 该系列博文会告诉你如何从入门到进阶,一步步地学习Java基础知识,并上手进行实战,接着了解每个Java知识点背后的实现原理,更完整地了解整个Java技术体系,形成自己的知识框架。为了更好地总结和检验你的学习成果,本系列文章也会提供每个知识点对应的面试题以及参考答案。
如果对本系列文章有什么建议,或者是有什么疑问的话,也可以关注公众号【Java技术江湖】联系作者,欢迎你参与本系列博文的创作和修订。
变量就是申请内存来存储值。也就是说,当创建变量的时候,需要在内存中申请空间。
内存管理系统根据变量的类型为变量分配存储空间,分配的空间只能用来储存该类型数据。
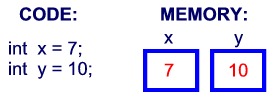
因此,通过定义不同类型的变量,可以在内存中储存整数、小数或者字符。
- 内置数据类型
- 引用数据类型
Java语言提供了八种基本类型。六种数字类型(四个整数型,两个浮点型),一种字符类型,还有一种布尔型。
byte:
- byte 数据类型是8位、有符号的,以二进制补码表示的整数;
- 最小值是 -128(-2^7);
- 最大值是 127(2^7-1);
- 默认值是 0;
- byte 类型用在大型数组中节约空间,主要代替整数,因为 byte 变量占用的空间只有 int 类型的四分之一;
- 例子:byte a = 100,byte b = -50。
short:
- short 数据类型是 16 位、有符号的以二进制补码表示的整数
- 最小值是 -32768(-2^15);
- 最大值是 32767(2^15 - 1);
- Short 数据类型也可以像 byte 那样节省空间。一个short变量是int型变量所占空间的二分之一;
- 默认值是 0;
- 例子:short s = 1000,short r = -20000。
int:
- int 数据类型是32位、有符号的以二进制补码表示的整数;
- 最小值是 -2,147,483,648(-2^31);
- 最大值是 2,147,483,647(2^31 - 1);
- 一般地整型变量默认为 int 类型;
- 默认值是 0 ;
- 例子:int a = 100000, int b = -200000。
long:
- long 数据类型是 64 位、有符号的以二进制补码表示的整数;
- 最小值是 -9,223,372,036,854,775,808(-2^63);
- 最大值是 9,223,372,036,854,775,807(2^63 -1);
- 这种类型主要使用在需要比较大整数的系统上;
- 默认值是 0L;
- 例子: long a = 100000L,Long b = -200000L。 "L"理论上不分大小写,但是若写成"l"容易与数字"1"混淆,不容易分辩。所以最好大写。
float:
- float 数据类型是单精度、32位、符合IEEE 754标准的浮点数;
- float 在储存大型浮点数组的时候可节省内存空间;
- 默认值是 0.0f;
- 浮点数不能用来表示精确的值,如货币;
- 例子:float f1 = 234.5f。
double:
- double 数据类型是双精度、64 位、符合IEEE 754标准的浮点数;
- 浮点数的默认类型为double类型;
- double类型同样不能表示精确的值,如货币;
- 默认值是 0.0d;
- 例子:double d1 = 123.4。
boolean:
- boolean数据类型表示一位的信息;
- 只有两个取值:true 和 false;
- 这种类型只作为一种标志来记录 true/false 情况;
- 默认值是 false;
- 例子:boolean one = true。
char:
- char类型是一个单一的 16 位 Unicode 字符;
- 最小值是 \u0000(即为0);
- 最大值是 \uffff(即为65,535);
- char 数据类型可以储存任何字符;
- 例子:char letter = 'A';。
//8位
byte bx = Byte.MAX_VALUE;
byte bn = Byte.MIN_VALUE;
//16位
short sx = Short.MAX_VALUE;
short sn = Short.MIN_VALUE;
//32位
int ix = Integer.MAX_VALUE;
int in = Integer.MIN_VALUE;
//64位
long lx = Long.MAX_VALUE;
long ln = Long.MIN_VALUE;
//32位
float fx = Float.MAX_VALUE;
float fn = Float.MIN_VALUE;
//64位
double dx = Double.MAX_VALUE;
double dn = Double.MIN_VALUE;
//16位
char cx = Character.MAX_VALUE;
char cn = Character.MIN_VALUE;
//1位
boolean bt = Boolean.TRUE;
boolean bf = Boolean.FALSE;
127
-128
32767
-32768
2147483647
-2147483648
9223372036854775807
-9223372036854775808
3.4028235E38
1.4E-45
1.7976931348623157E308
4.9E-324
�
true
false
- 在Java中,引用类型的变量非常类似于C/C++的指针。引用类型指向一个对象,指向对象的变量是引用变量。这些变量在声明时被指定为一个特定的类型,比如 Employee、Puppy 等。变量一旦声明后,类型就不能被改变了。
- 对象、数组都是引用数据类型。
- 所有引用类型的默认值都是null。
- 一个引用变量可以用来引用任何与之兼容的类型。
- 例子:Site site = new Site("Runoob")。
常量在程序运行时是不能被修改的。
在 Java 中使用 final 关键字来修饰常量,声明方式和变量类似:
final double PI = 3.1415927;
虽然常量名也可以用小写,但为了便于识别,通常使用大写字母表示常量。
字面量可以赋给任何内置类型的变量。例如:
byte a = 68;
char a = 'A'
Java 5增加了自动装箱与自动拆箱机制,方便基本类型与包装类型的相互转换操作。在Java 5之前,如果要将一个int型的值转换成对应的包装器类型Integer,必须显式的使用new创建一个新的Integer对象,或者调用静态方法Integer.valueOf()。
//在Java 5之前,只能这样做 Integer value = new Integer(10); //或者这样做 Integer value = Integer.valueOf(10); //直接赋值是错误的 //Integer value = 10;`
在Java 5中,可以直接将整型赋给Integer对象,由编译器来完成从int型到Integer类型的转换,这就叫自动装箱。
//在Java 5中,直接赋值是合法的,由编译器来完成转换
Integer value = 10;
与此对应的,自动拆箱就是可以将包装类型转换为基本类型,具体的转换工作由编译器来完成。
//在Java 5 中可以直接这么做
Integer value = new Integer(10);
int i = value;
自动装箱与自动拆箱为程序员提供了很大的方便,而在实际的应用中,自动装箱与拆箱也是使用最广泛的特性之一。自动装箱和自动拆箱其实是Java编译器提供的一颗语法糖(语法糖是指在计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员使用。通过可提高开发效率,增加代码可读性,增加代码的安全性)。
在八种包装类型中,每一种包装类型都提供了两个方法:
静态方法valueOf(基本类型):将给定的基本类型转换成对应的包装类型;
实例方法xxxValue():将具体的包装类型对象转换成基本类型; 下面我们以int和Integer为例,说明Java中自动装箱与自动拆箱的实现机制。看如下代码:
class Auto //code1 { public static void main(String[] args) { //自动装箱 Integer inte = 10; //自动拆箱 int i = inte;
//再double和Double来验证一下
Double doub = 12.40;
double d = doub;
}
} 上面的代码先将int型转为Integer对象,再讲Integer对象转换为int型,毫无疑问,这是可以正确运行的。可是,这种转换是怎么进行的呢?使用反编译工具,将生成的Class文件在反编译为Java文件,让我们看看发生了什么: class Auto//code2 { public static void main(String[] paramArrayOfString) { Integer localInteger = Integer.valueOf(10);
int i = localInteger.intValue();
Double localDouble = Double.valueOf(12.4D);
double d = localDouble.doubleValue();
} } 我们可以看到经过javac编译之后,code1的代码被转换成了code2,实际运行时,虚拟机运行的就是code2的代码。也就是说,虚拟机根本不知道有自动拆箱和自动装箱这回事;在将Java源文件编译为class文件的过程中,javac编译器在自动装箱的时候,调用了Integer.valueOf()方法,在自动拆箱时,又调用了intValue()方法。我们可以看到,double和Double也是如此。 实现总结:其实自动装箱和自动封箱是编译器为我们提供的一颗语法糖。在自动装箱时,编译器调用包装类型的valueOf()方法;在自动拆箱时,编译器调用了相应的xxxValue()方法。
在使用自动装箱与自动拆箱时,要注意一些陷阱,为了避免这些陷阱,我们有必要去看一下各种包装类型的源码。
Integer源码
public final class Integer extends Number implements Comparable { private final int value;
/*Integer的构造方法,接受一个整型参数,Integer对象表示的int值,保存在value中*/
public Integer(int value) {
this.value = value;
}
/*equals()方法判断的是:所代表的int型的值是否相等*/
public boolean equals(Object obj) {
if (obj instanceof Integer) {
return value == ((Integer)obj).intValue();
}
return false;
}
/*返回这个Integer对象代表的int值,也就是保存在value中的值*/
public int intValue() {
return value;
}
/**
* 首先会判断i是否在[IntegerCache.low,Integer.high]之间
* 如果是,直接返回Integer.cache中相应的元素
* 否则,调用构造方法,创建一个新的Integer对象
*/
public static Integer valueOf(int i) {
assert IntegerCache.high >= 127;
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
/**
* 静态内部类,缓存了从[low,high]对应的Integer对象
* low -128这个值不会被改变
* high 默认是127,可以改变,最大不超过:Integer.MAX_VALUE - (-low) -1
* cache 保存从[low,high]对象的Integer对象
*/
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
}
private IntegerCache() {}
}
} 以上是Oracle(Sun)公司JDK 1.7中Integer源码的一部分,通过分析上面的代码,得到: 1)Integer有一个实例域value,它保存了这个Integer所代表的int型的值,且它是final的,也就是说这个Integer对象一经构造完成,它所代表的值就不能再被改变。 2)Integer重写了equals()方法,它通过比较两个Integer对象的value,来判断是否相等。 3)重点是静态内部类IntegerCache,通过类名就可以发现:它是用来缓存数据的。它有一个数组,里面保存的是连续的Integer对象。 (a) low:代表缓存数据中最小的值,固定是-128。 (b) high:代表缓存数据中最大的值,它可以被该改变,默认是127。high最小是127,最大是Integer.MAX_VALUE-(-low)-1,如果high超过了这个值,那么cache[ ]的长度就超过Integer.MAX_VALUE了,也就溢出了。 (c) cache[]:里面保存着从[low,high]所对应的Integer对象,长度是high-low+1(因为有元素0,所以要加1)。 4)调用valueOf(int i)方法时,首先判断i是否在[low,high]之间,如果是,则复用Integer.cache[i-low]。比如,如果Integer.valueOf(3),直接返回Integer.cache[131];如果i不在这个范围,则调用构造方法,构造出一个新的Integer对象。 5)调用intValue(),直接返回value的值。 通过3)和4)可以发现,默认情况下,在使用自动装箱时,VM会复用[-128,127]之间的Integer对象。
Integer a1 = 1; Integer a2 = 1; Integer a3 = new Integer(1); //会打印true,因为a1和a2是同一个对象,都是Integer.cache[129] System.out.println(a1 == a2); //false,a3构造了一个新的对象,不同于a1,a2 System.out.println(a1 == a3);
//基本数据类型的常量池是-128到127之间。
// 在这个范围中的基本数据类的包装类可以自动拆箱,比较时直接比较数值大小。
public static void main(String[] args) {
//int的自动拆箱和装箱只在-128到127范围中进行,超过该范围的两个integer的 == 判断是会返回false的。
Integer a1 = 128;
Integer a2 = -128;
Integer a3 = -128;
Integer a4 = 128;
System.out.println(a1 == a4);
System.out.println(a2 == a3);
Byte b1 = 127;
Byte b2 = 127;
Byte b3 = -128;
Byte b4 = -128;
//byte都是相等的,因为范围就在-128到127之间
System.out.println(b1 == b2);
System.out.println(b3 == b4);
//
Long c1 = 128L;
Long c2 = 128L;
Long c3 = -128L;
Long c4 = -128L;
System.out.println(c1 == c2);
System.out.println(c3 == c4);
//char没有负值
//发现char也是在0到127之间自动拆箱
Character d1 = 128;
Character d2 = 128;
Character d3 = 127;
Character d4 = 127;
System.out.println(d1 == d2);
System.out.println(d3 == d4);
结果
false
true
true
true
false
true
false
true
Integer i = 10;
Byte b = 10;
//比较Byte和Integer.两个对象无法直接比较,报错
//System.out.println(i == b);
System.out.println("i == b " + i.equals(b));
//答案是false,因为包装类的比较时先比较是否是同一个类,不是的话直接返回false.
int ii = 128;
short ss = 128;
long ll = 128;
char cc = 128;
System.out.println("ii == bb " + (ii == ss));
System.out.println("ii == ll " + (ii == ll));
System.out.println("ii == cc " + (ii == cc));
结果
i == b false
ii == bb true
ii == ll true
ii == cc true
//这时候都是true,因为基本数据类型直接比较值,值一样就可以。
通过上面的代码,我们分析一下自动装箱与拆箱发生的时机:
(1)当需要一个对象的时候会自动装箱,比如Integer a = 10;equals(Object o)方法的参数是Object对象,所以需要装箱。
(2)当需要一个基本类型时会自动拆箱,比如int a = new Integer(10);算术运算是在基本类型间进行的,所以当遇到算术运算时会自动拆箱,比如代码中的 c == (a + b);
(3) 包装类型 == 基本类型时,包装类型自动拆箱;
需要注意的是:“==”在没遇到算术运算时,不会自动拆箱;基本类型只会自动装箱为对应的包装类型,代码中最后一条说明的内容。
在JDK 1.5中提供了自动装箱与自动拆箱,这其实是Java 编译器的语法糖,编译器通过调用包装类型的valueOf()方法实现自动装箱,调用xxxValue()方法自动拆箱。自动装箱和拆箱会有一些陷阱,那就是包装类型复用了某些对象。
(1)Integer默认复用了[-128,127]这些对象,其中高位置可以修改;
(2)Byte复用了全部256个对象[-128,127];
(3)Short服用了[-128,127]这些对象;
(4)Long服用了[-128,127];
(5)Character复用了[0,127],Charater不能表示负数;
Double和Float是连续不可数的,所以没法复用对象,也就不存在自动装箱复用陷阱。
Boolean没有自动装箱与拆箱,它也复用了Boolean.TRUE和Boolean.FALSE,通过Boolean.valueOf(boolean b)返回的Blooean对象要么是TRUE,要么是FALSE,这点也要注意。
本文介绍了“真实的”自动装箱与拆箱,为了避免写出错误的代码,又从包装类型的源码入手,指出了各种包装类型在自动装箱和拆箱时存在的陷阱,同时指出了自动装箱与拆箱发生的时机。
上面自动拆箱和装箱的原理其实与常量池有关。
public void(int a) { int i = 1; int j = 1; } 方法中的i 存在虚拟机栈的局部变量表里,i是一个引用,j也是一个引用,它们都指向局部变量表里的整型值 1. int a是传值引用,所以a也会存在局部变量表。
class A{ int i = 1; A a = new A(); } i是类的成员变量。类实例化的对象存在堆中,所以成员变量也存在堆中,引用a存的是对象的地址,引用i存的是值,这个值1也会存在堆中。可以理解为引用i指向了这个值1。也可以理解为i就是1.
3 包装类对象怎么存 其实我们说的常量池也可以叫对象池。 比如String a= new String("a").intern()时会先在常量池找是否有“a"对象如果有的话直接返回“a"对象在常量池的地址,即让引用a指向常量”a"对象的内存地址。 public native String intern(); Integer也是同理。
下图是Integer类型在常量池中查找同值对象的方法。
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
private IntegerCache() {}
}
所以基本数据类型的包装类型可以在常量池查找对应值的对象,找不到就会自动在常量池创建该值的对象。
而String类型可以通过intern来完成这个操作。
JDK1.7后,常量池被放入到堆空间中,这导致intern()函数的功能不同,具体怎么个不同法,且看看下面代码,这个例子是网上流传较广的一个例子,分析图也是直接粘贴过来的,这里我会用自己的理解去解释这个例子:
[java] view plain copy
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
输出结果为:
[java] view plain copy
JDK1.6以及以下:false false
JDK1.7以及以上:false true
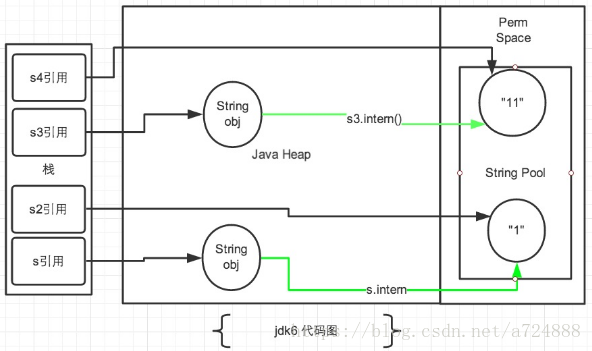
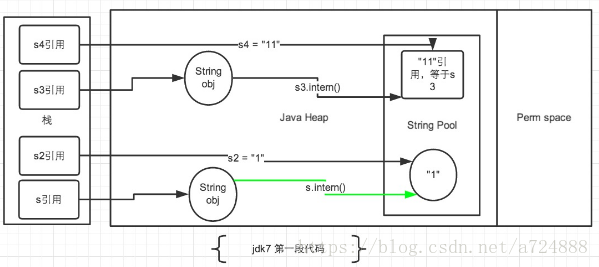
JDK 1.7后,intern方法还是会先去查询常量池中是否有已经存在,如果存在,则返回常量池中的引用,这一点与之前没有区别,区别在于,如果在常量池找不到对应的字符串,则不会再将字符串拷贝到常量池,而只是在常量池中生成一个对原字符串的引用。
那么其他字符串在常量池找值时就会返回另一个堆中对象的地址。
下一节详细介绍String以及相关包装类。
具体请见:https://blog.csdn.net/a724888/article/details/80042298
关于Java面向对象三大特性,请参考:
https://blog.csdn.net/a724888/article/details/80033043
https://www.runoob.com/java/java-basic-datatypes.html
https://www.cnblogs.com/zch1126/p/5335139.html
https://blog.csdn.net/jreffchen/article/details/81015884
https://blog.csdn.net/yuhongye111/article/details/31850779
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号【Java技术江湖】一位阿里 Java 工程师的技术小站,作者黄小斜,专注 Java 相关技术:SSM、SpringBoot、MySQL、分布式、中间件、集群、Linux、网络、多线程,偶尔讲点Docker、ELK,同时也分享技术干货和学习经验,致力于Java全栈开发!
Java工程师必备学习资源: 一些Java工程师常用学习资源,关注公众号后,后台回复关键字 “Java” 即可免费无套路获取。

作者是 985 硕士,蚂蚁金服 JAVA 工程师,专注于 JAVA 后端技术栈:SpringBoot、MySQL、分布式、中间件、微服务,同时也懂点投资理财,偶尔讲点算法和计算机理论基础,坚持学习和写作,相信终身学习的力量!
程序员3T技术学习资源: 一些程序员学习技术的资源大礼包,关注公众号后,后台回复关键字 “资料” 即可免费无套路获取。
