diff --git a/MANIFEST.in b/MANIFEST.in
deleted file mode 100644
index 0e6a8459826..00000000000
--- a/MANIFEST.in
+++ /dev/null
@@ -1,6 +0,0 @@
-include LICENSE
-include README.md
-include CONTRIBUTING.md
-graft docs
-graft examples
-graft tests
diff --git a/docs/README.md b/docs/README.md
deleted file mode 100644
index 6e0f892ff21..00000000000
--- a/docs/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
-# Keras Documentation
-
-The source for Keras documentation is in this directory.
-Our documentation uses extended Markdown, as implemented by [MkDocs](http://mkdocs.org).
-
-## Building the documentation
-
-- Install MkDocs: `pip install mkdocs`
-- `pip install -e .` to make sure that Python will import your modified version of Keras.
-- From the root directory, `cd` into the `docs/` folder and run:
- - `KERAS_BACKEND=tensorflow python autogen.py`
- - `mkdocs serve` # Starts a local webserver: [localhost:8000](http://localhost:8000)
- - `mkdocs build` # Builds a static site in `site/` directory
diff --git a/docs/__init__.py b/docs/__init__.py
deleted file mode 100644
index e69de29bb2d..00000000000
diff --git a/docs/autogen.py b/docs/autogen.py
deleted file mode 100644
index fa575bada86..00000000000
--- a/docs/autogen.py
+++ /dev/null
@@ -1,473 +0,0 @@
-# -*- coding: utf-8 -*-
-from __future__ import print_function
-from __future__ import unicode_literals
-
-import re
-import inspect
-import os
-import shutil
-import six
-
-try:
- import pathlib
-except ImportError:
- import pathlib2 as pathlib
-
-import keras
-from keras import backend as K
-from keras.backend import numpy_backend
-
-from docs.structure import EXCLUDE
-from docs.structure import PAGES
-from docs.structure import template_np_implementation
-from docs.structure import template_hidden_np_implementation
-
-import sys
-if sys.version[0] == '2':
- reload(sys)
- sys.setdefaultencoding('utf8')
-
-keras_dir = pathlib.Path(__file__).resolve().parents[1]
-
-
-def get_function_signature(function, method=True):
- wrapped = getattr(function, '_original_function', None)
- if wrapped is None:
- signature = inspect.getfullargspec(function)
- else:
- signature = inspect.getfullargspec(wrapped)
- defaults = signature.defaults
- if method:
- args = signature.args[1:]
- else:
- args = signature.args
- if defaults:
- kwargs = zip(args[-len(defaults):], defaults)
- args = args[:-len(defaults)]
- else:
- kwargs = []
- st = '%s.%s(' % (clean_module_name(function.__module__), function.__name__)
-
- for a in args:
- st += str(a) + ', '
- for a, v in kwargs:
- if isinstance(v, str):
- v = '\'' + v + '\''
- st += str(a) + '=' + str(v) + ', '
- if kwargs or args:
- signature = st[:-2] + ')'
- else:
- signature = st + ')'
- return post_process_signature(signature)
-
-
-def get_class_signature(cls):
- try:
- class_signature = get_function_signature(cls.__init__)
- class_signature = class_signature.replace('__init__', cls.__name__)
- except (TypeError, AttributeError):
- # in case the class inherits from object and does not
- # define __init__
- class_signature = "{clean_module_name}.{cls_name}()".format(
- clean_module_name=cls.__module__,
- cls_name=cls.__name__
- )
- return post_process_signature(class_signature)
-
-
-def post_process_signature(signature):
- parts = re.split(r'\.(?!\d)', signature)
- if len(parts) >= 4:
- if parts[1] == 'layers':
- signature = 'keras.layers.' + '.'.join(parts[3:])
- if parts[1] == 'utils':
- signature = 'keras.utils.' + '.'.join(parts[3:])
- if parts[1] == 'backend':
- signature = 'keras.backend.' + '.'.join(parts[3:])
- if parts[1] == 'callbacks':
- signature = 'keras.callbacks.' + '.'.join(parts[3:])
- return signature
-
-
-def clean_module_name(name):
- if name.startswith('keras_applications'):
- name = name.replace('keras_applications', 'keras.applications')
- if name.startswith('keras_preprocessing'):
- name = name.replace('keras_preprocessing', 'keras.preprocessing')
- return name
-
-
-def class_to_source_link(cls):
- module_name = clean_module_name(cls.__module__)
- path = module_name.replace('.', '/')
- path += '.py'
- line = inspect.getsourcelines(cls)[-1]
- link = ('https://github.com/keras-team/'
- 'keras/blob/master/' + path + '#L' + str(line))
- return '[[source]](' + link + ')'
-
-
-def code_snippet(snippet):
- result = '```python\n'
- result += snippet.encode('unicode_escape').decode('utf8') + '\n'
- result += '```\n'
- return result
-
-
-def count_leading_spaces(s):
- ws = re.search(r'\S', s)
- if ws:
- return ws.start()
- else:
- return 0
-
-
-def process_list_block(docstring, starting_point, section_end,
- leading_spaces, marker):
- ending_point = docstring.find('\n\n', starting_point)
- block = docstring[starting_point:
- (ending_point - 1 if ending_point > -1
- else section_end)]
- # Place marker for later reinjection.
- docstring_slice = docstring[
- starting_point:section_end].replace(block, marker)
- docstring = (docstring[:starting_point] +
- docstring_slice +
- docstring[section_end:])
- lines = block.split('\n')
- # Remove the computed number of leading white spaces from each line.
- lines = [re.sub('^' + ' ' * leading_spaces, '', line) for line in lines]
- # Usually lines have at least 4 additional leading spaces.
- # These have to be removed, but first the list roots have to be detected.
- top_level_regex = r'^ ([^\s\\\(]+):(.*)'
- top_level_replacement = r'- __\1__:\2'
- lines = [re.sub(top_level_regex, top_level_replacement, line)
- for line in lines]
- # All the other lines get simply the 4 leading space (if present) removed
- lines = [re.sub(r'^ ', '', line) for line in lines]
- # Fix text lines after lists
- indent = 0
- text_block = False
- for i in range(len(lines)):
- line = lines[i]
- spaces = re.search(r'\S', line)
- if spaces:
- # If it is a list element
- if line[spaces.start()] == '-':
- indent = spaces.start() + 1
- if text_block:
- text_block = False
- lines[i] = '\n' + line
- elif spaces.start() < indent:
- text_block = True
- indent = spaces.start()
- lines[i] = '\n' + line
- else:
- text_block = False
- indent = 0
- block = '\n'.join(lines)
- return docstring, block
-
-
-def process_docstring(docstring):
- # First, extract code blocks and process them.
- code_blocks = []
- if '```' in docstring:
- tmp = docstring[:]
- while '```' in tmp:
- tmp = tmp[tmp.find('```'):]
- index = tmp[3:].find('```') + 6
- snippet = tmp[:index]
- # Place marker in docstring for later reinjection.
- docstring = docstring.replace(
- snippet, '$CODE_BLOCK_%d' % len(code_blocks))
- snippet_lines = snippet.split('\n')
- # Remove leading spaces.
- num_leading_spaces = snippet_lines[-1].find('`')
- snippet_lines = ([snippet_lines[0]] +
- [line[num_leading_spaces:]
- for line in snippet_lines[1:]])
- # Most code snippets have 3 or 4 more leading spaces
- # on inner lines, but not all. Remove them.
- inner_lines = snippet_lines[1:-1]
- leading_spaces = None
- for line in inner_lines:
- if not line or line[0] == '\n':
- continue
- spaces = count_leading_spaces(line)
- if leading_spaces is None:
- leading_spaces = spaces
- if spaces < leading_spaces:
- leading_spaces = spaces
- if leading_spaces:
- snippet_lines = ([snippet_lines[0]] +
- [line[leading_spaces:]
- for line in snippet_lines[1:-1]] +
- [snippet_lines[-1]])
- snippet = '\n'.join(snippet_lines)
- code_blocks.append(snippet)
- tmp = tmp[index:]
-
- # Format docstring lists.
- section_regex = r'\n( +)# (.*)\n'
- section_idx = re.search(section_regex, docstring)
- shift = 0
- sections = {}
- while section_idx and section_idx.group(2):
- anchor = section_idx.group(2)
- leading_spaces = len(section_idx.group(1))
- shift += section_idx.end()
- next_section_idx = re.search(section_regex, docstring[shift:])
- if next_section_idx is None:
- section_end = -1
- else:
- section_end = shift + next_section_idx.start()
- marker = '$' + anchor.replace(' ', '_') + '$'
- docstring, content = process_list_block(docstring,
- shift,
- section_end,
- leading_spaces,
- marker)
- sections[marker] = content
- # `docstring` has changed, so we can't use `next_section_idx` anymore
- # we have to recompute it
- section_idx = re.search(section_regex, docstring[shift:])
-
- # Format docstring section titles.
- docstring = re.sub(r'\n(\s+)# (.*)\n',
- r'\n\1__\2__\n\n',
- docstring)
-
- # Strip all remaining leading spaces.
- lines = docstring.split('\n')
- docstring = '\n'.join([line.lstrip(' ') for line in lines])
-
- # Reinject list blocks.
- for marker, content in sections.items():
- docstring = docstring.replace(marker, content)
-
- # Reinject code blocks.
- for i, code_block in enumerate(code_blocks):
- docstring = docstring.replace(
- '$CODE_BLOCK_%d' % i, code_block)
- return docstring
-
-
-def add_np_implementation(function, docstring):
- np_implementation = getattr(numpy_backend, function.__name__)
- code = inspect.getsource(np_implementation)
- code_lines = code.split('\n')
- for i in range(len(code_lines)):
- if code_lines[i]:
- # if there is something on the line, add 8 spaces.
- code_lines[i] = ' ' + code_lines[i]
- code = '\n'.join(code_lines[:-1])
-
- if len(code_lines) < 10:
- section = template_np_implementation.replace('{{code}}', code)
- else:
- section = template_hidden_np_implementation.replace('{{code}}', code)
- return docstring.replace('{{np_implementation}}', section)
-
-
-def read_file(path):
- with open(path, encoding='utf-8') as f:
- return f.read()
-
-
-def collect_class_methods(cls, methods):
- if isinstance(methods, (list, tuple)):
- return [getattr(cls, m) if isinstance(m, str) else m for m in methods]
- methods = []
- for _, method in inspect.getmembers(cls, predicate=inspect.isroutine):
- if method.__name__[0] == '_' or method.__name__ in EXCLUDE:
- continue
- methods.append(method)
- return methods
-
-
-def render_function(function, method=True):
- subblocks = []
- signature = get_function_signature(function, method=method)
- if method:
- signature = signature.replace(
- clean_module_name(function.__module__) + '.', '')
- subblocks.append('### ' + function.__name__ + '\n')
- subblocks.append(code_snippet(signature))
- docstring = function.__doc__
- if docstring:
- if ('backend' in signature and
- '{{np_implementation}}' in docstring):
- docstring = add_np_implementation(function, docstring)
- subblocks.append(process_docstring(docstring))
- return '\n\n'.join(subblocks)
-
-
-def read_page_data(page_data, type):
- assert type in ['classes', 'functions', 'methods']
- data = page_data.get(type, [])
- for module in page_data.get('all_module_{}'.format(type), []):
- module_data = []
- for name in dir(module):
- if name[0] == '_' or name in EXCLUDE:
- continue
- module_member = getattr(module, name)
- if (inspect.isclass(module_member) and type == 'classes' or
- inspect.isfunction(module_member) and type == 'functions'):
- instance = module_member
- if module.__name__ in instance.__module__:
- if instance not in module_data:
- module_data.append(instance)
- module_data.sort(key=lambda x: id(x))
- data += module_data
- return data
-
-
-def get_module_docstring(filepath):
- """Extract the module docstring.
-
- Also finds the line at which the docstring ends.
- """
- co = compile(open(filepath, encoding='utf-8').read(), filepath, 'exec')
- if co.co_consts and isinstance(co.co_consts[0], six.string_types):
- docstring = co.co_consts[0]
- else:
- print('Could not get the docstring from ' + filepath)
- docstring = ''
- return docstring, co.co_firstlineno
-
-
-def copy_examples(examples_dir, destination_dir):
- """Copy the examples directory in the documentation.
-
- Prettify files by extracting the docstrings written in Markdown.
- """
- pathlib.Path(destination_dir).mkdir(exist_ok=True)
- for file in os.listdir(examples_dir):
- if not file.endswith('.py'):
- continue
- module_path = os.path.join(examples_dir, file)
- docstring, starting_line = get_module_docstring(module_path)
- destination_file = os.path.join(destination_dir, file[:-2] + 'md')
- with open(destination_file, 'w+', encoding='utf-8') as f_out, \
- open(os.path.join(examples_dir, file),
- 'r+', encoding='utf-8') as f_in:
-
- f_out.write(docstring + '\n\n')
-
- # skip docstring
- for _ in range(starting_line):
- next(f_in)
-
- f_out.write('```python\n')
- # next line might be empty.
- line = next(f_in)
- if line != '\n':
- f_out.write(line)
-
- # copy the rest of the file.
- for line in f_in:
- f_out.write(line)
- f_out.write('```')
-
-
-def generate(sources_dir):
- """Generates the markdown files for the documentation.
-
- # Arguments
- sources_dir: Where to put the markdown files.
- """
- template_dir = os.path.join(str(keras_dir), 'docs', 'templates')
-
- if K.backend() != 'tensorflow':
- raise RuntimeError('The documentation must be built '
- 'with the TensorFlow backend because this '
- 'is the only backend with docstrings.')
-
- print('Cleaning up existing sources directory.')
- if os.path.exists(sources_dir):
- shutil.rmtree(sources_dir)
-
- print('Populating sources directory with templates.')
- shutil.copytree(template_dir, sources_dir)
-
- readme = read_file(os.path.join(str(keras_dir), 'README.md'))
- index = read_file(os.path.join(template_dir, 'index.md'))
- index = index.replace('{{autogenerated}}', readme[readme.find('##'):])
- with open(os.path.join(sources_dir, 'index.md'), 'w', encoding='utf-8') as f:
- f.write(index)
-
- print('Generating docs for Keras %s.' % keras.__version__)
- for page_data in PAGES:
- classes = read_page_data(page_data, 'classes')
-
- blocks = []
- for element in classes:
- if not isinstance(element, (list, tuple)):
- element = (element, [])
- cls = element[0]
- subblocks = []
- signature = get_class_signature(cls)
- subblocks.append('' +
- class_to_source_link(cls) + '')
- if element[1]:
- subblocks.append('## ' + cls.__name__ + ' class\n')
- else:
- subblocks.append('### ' + cls.__name__ + '\n')
- subblocks.append(code_snippet(signature))
- docstring = cls.__doc__
- if docstring:
- subblocks.append(process_docstring(docstring))
- methods = collect_class_methods(cls, element[1])
- if methods:
- subblocks.append('\n---')
- subblocks.append('## ' + cls.__name__ + ' methods\n')
- subblocks.append('\n---\n'.join(
- [render_function(method, method=True)
- for method in methods]))
- blocks.append('\n'.join(subblocks))
-
- methods = read_page_data(page_data, 'methods')
-
- for method in methods:
- blocks.append(render_function(method, method=True))
-
- functions = read_page_data(page_data, 'functions')
-
- for function in functions:
- blocks.append(render_function(function, method=False))
-
- if not blocks:
- raise RuntimeError('Found no content for page ' +
- page_data['page'])
-
- mkdown = '\n----\n\n'.join(blocks)
- # Save module page.
- # Either insert content into existing page,
- # or create page otherwise.
- page_name = page_data['page']
- path = os.path.join(sources_dir, page_name)
- if os.path.exists(path):
- template = read_file(path)
- if '{{autogenerated}}' not in template:
- raise RuntimeError('Template found for ' + path +
- ' but missing {{autogenerated}}'
- ' tag.')
- mkdown = template.replace('{{autogenerated}}', mkdown)
- print('...inserting autogenerated content into template:', path)
- else:
- print('...creating new page with autogenerated content:', path)
- subdir = os.path.dirname(path)
- if not os.path.exists(subdir):
- os.makedirs(subdir)
- with open(path, 'w', encoding='utf-8') as f:
- f.write(mkdown)
-
- shutil.copyfile(os.path.join(str(keras_dir), 'CONTRIBUTING.md'),
- os.path.join(str(sources_dir), 'contributing.md'))
- copy_examples(os.path.join(str(keras_dir), 'examples'),
- os.path.join(str(sources_dir), 'examples'))
-
-
-if __name__ == '__main__':
- generate(os.path.join(str(keras_dir), 'docs', 'sources'))
diff --git a/docs/mkdocs.yml b/docs/mkdocs.yml
deleted file mode 100644
index 9a0cbb46636..00000000000
--- a/docs/mkdocs.yml
+++ /dev/null
@@ -1,90 +0,0 @@
-site_name: Keras Documentation
-theme:
- name: null
- custom_dir: theme
- static_templates:
- - 404.html
- include_search_page: true
- search_index_only: false
- highlightjs: true
- hljs_languages: []
- include_homepage_in_sidebar: true
- prev_next_buttons_location: bottom
- navigation_depth: 4
- titles_only: false
- sticky_navigation: true
- collapse_navigation: true
-
-docs_dir: sources
-repo_url: http://github.com/keras-team/keras
-site_url: http://keras.io/
-site_description: 'Documentation for Keras, the Python Deep Learning library.'
-
-dev_addr: '0.0.0.0:8000'
-google_analytics: ['UA-61785484-1', 'keras.io']
-
-nav:
-- Home: index.md
-- Why use Keras: why-use-keras.md
-- Getting started:
- - Guide to the Sequential model: getting-started/sequential-model-guide.md
- - Guide to the Functional API: getting-started/functional-api-guide.md
- - FAQ: getting-started/faq.md
-- Models:
- - About Keras models: models/about-keras-models.md
- - Sequential: models/sequential.md
- - Model (functional API): models/model.md
-- Layers:
- - About Keras layers: layers/about-keras-layers.md
- - Core Layers: layers/core.md
- - Convolutional Layers: layers/convolutional.md
- - Pooling Layers: layers/pooling.md
- - Locally-connected Layers: layers/local.md
- - Recurrent Layers: layers/recurrent.md
- - Embedding Layers: layers/embeddings.md
- - Merge Layers: layers/merge.md
- - Advanced Activations Layers: layers/advanced-activations.md
- - Normalization Layers: layers/normalization.md
- - Noise layers: layers/noise.md
- - Layer wrappers: layers/wrappers.md
- - Writing your own Keras layers: layers/writing-your-own-keras-layers.md
-- Preprocessing:
- - Sequence Preprocessing: preprocessing/sequence.md
- - Text Preprocessing: preprocessing/text.md
- - Image Preprocessing: preprocessing/image.md
-- Losses: losses.md
-- Metrics: metrics.md
-- Optimizers: optimizers.md
-- Activations: activations.md
-- Callbacks: callbacks.md
-- Datasets: datasets.md
-- Applications: applications.md
-- Backend: backend.md
-- Initializers: initializers.md
-- Regularizers: regularizers.md
-- Constraints: constraints.md
-- Visualization: visualization.md
-- Scikit-learn API: scikit-learn-api.md
-- Utils: utils.md
-- Contributing: contributing.md
-- Examples:
- - Addition RNN: examples/addition_rnn.md
- - Custom layer - antirectifier: examples/antirectifier.md
- - Baby RNN: examples/babi_rnn.md
- - Baby MemNN: examples/babi_memnn.md
- - CIFAR-10 CNN: examples/cifar10_cnn.md
- - CIFAR-10 ResNet: examples/cifar10_resnet.md
- - Convolution filter visualization: examples/conv_filter_visualization.md
- - Convolutional LSTM: examples/conv_lstm.md
- - Deep Dream: examples/deep_dream.md
- - Image OCR: examples/image_ocr.md
- - Bidirectional LSTM: examples/imdb_bidirectional_lstm.md
- - 1D CNN for text classification: examples/imdb_cnn.md
- - Sentiment classification CNN-LSTM: examples/imdb_cnn_lstm.md
- - Fasttext for text classification: examples/imdb_fasttext.md
- - Sentiment classification LSTM: examples/imdb_lstm.md
- - Sequence to sequence - training: examples/lstm_seq2seq.md
- - Sequence to sequence - prediction: examples/lstm_seq2seq_restore.md
- - Stateful LSTM: examples/lstm_stateful.md
- - LSTM for text generation: examples/lstm_text_generation.md
- - Auxiliary Classifier GAN: examples/mnist_acgan.md
diff --git a/docs/structure.py b/docs/structure.py
deleted file mode 100644
index f8d8c4aff84..00000000000
--- a/docs/structure.py
+++ /dev/null
@@ -1,358 +0,0 @@
-# -*- coding: utf-8 -*-
-'''
-General documentation architecture:
-
-Home
-Index
-
-- Getting started
- Getting started with the sequential model
- Getting started with the functional api
- FAQ
-
-- Models
- About Keras models
- explain when one should use Sequential or functional API
- explain compilation step
- explain weight saving, weight loading
- explain serialization, deserialization
- Sequential
- Model (functional API)
-
-- Layers
- About Keras layers
- explain common layer functions: get_weights, set_weights, get_config
- explain input_shape
- explain usage on non-Keras tensors
- Core Layers
- Convolutional Layers
- Pooling Layers
- Locally-connected Layers
- Recurrent Layers
- Embedding Layers
- Merge Layers
- Advanced Activations Layers
- Normalization Layers
- Noise Layers
- Layer Wrappers
- Writing your own Keras layers
-
-- Preprocessing
- Sequence Preprocessing
- Text Preprocessing
- Image Preprocessing
-
-Losses
-Metrics
-Optimizers
-Activations
-Callbacks
-Datasets
-Applications
-Backend
-Initializers
-Regularizers
-Constraints
-Visualization
-Scikit-learn API
-Utils
-Contributing
-
-'''
-from keras import utils
-from keras import layers
-from keras.layers import advanced_activations
-from keras.layers import noise
-from keras.layers import wrappers
-from keras import initializers
-from keras import optimizers
-from keras import callbacks
-from keras import models
-from keras import losses
-from keras import metrics
-from keras import backend
-from keras import constraints
-from keras import activations
-from keras import preprocessing
-
-
-EXCLUDE = {
- 'Optimizer',
- 'TFOptimizer',
- 'Wrapper',
- 'get_session',
- 'set_session',
- 'CallbackList',
- 'serialize',
- 'deserialize',
- 'get',
- 'set_image_dim_ordering',
- 'normalize_data_format',
- 'image_dim_ordering',
- 'get_variable_shape',
- 'Constraint'
-}
-
-# For each class to document, it is possible to:
-# 1) Document only the class: [classA, classB, ...]
-# 2) Document all its methods: [classA, (classB, "*")]
-# 3) Choose which methods to document (methods listed as strings):
-# [classA, (classB, ["method1", "method2", ...]), ...]
-# 4) Choose which methods to document (methods listed as qualified names):
-# [classA, (classB, [module.classB.method1, module.classB.method2, ...]), ...]
-PAGES = [
- {
- 'page': 'models/sequential.md',
- 'methods': [
- models.Sequential.compile,
- models.Sequential.fit,
- models.Sequential.evaluate,
- models.Sequential.predict,
- models.Sequential.train_on_batch,
- models.Sequential.test_on_batch,
- models.Sequential.predict_on_batch,
- models.Sequential.fit_generator,
- models.Sequential.evaluate_generator,
- models.Sequential.predict_generator,
- models.Sequential.get_layer,
- ],
- },
- {
- 'page': 'models/model.md',
- 'methods': [
- models.Model.compile,
- models.Model.fit,
- models.Model.evaluate,
- models.Model.predict,
- models.Model.train_on_batch,
- models.Model.test_on_batch,
- models.Model.predict_on_batch,
- models.Model.fit_generator,
- models.Model.evaluate_generator,
- models.Model.predict_generator,
- models.Model.get_layer,
- ]
- },
- {
- 'page': 'layers/core.md',
- 'classes': [
- layers.Dense,
- layers.Activation,
- layers.Dropout,
- layers.Flatten,
- layers.Input,
- layers.Reshape,
- layers.Permute,
- layers.RepeatVector,
- layers.Lambda,
- layers.ActivityRegularization,
- layers.Masking,
- layers.SpatialDropout1D,
- layers.SpatialDropout2D,
- layers.SpatialDropout3D,
- ],
- },
- {
- 'page': 'layers/convolutional.md',
- 'classes': [
- layers.Conv1D,
- layers.Conv2D,
- layers.SeparableConv1D,
- layers.SeparableConv2D,
- layers.DepthwiseConv2D,
- layers.Conv2DTranspose,
- layers.Conv3D,
- layers.Conv3DTranspose,
- layers.Cropping1D,
- layers.Cropping2D,
- layers.Cropping3D,
- layers.UpSampling1D,
- layers.UpSampling2D,
- layers.UpSampling3D,
- layers.ZeroPadding1D,
- layers.ZeroPadding2D,
- layers.ZeroPadding3D,
- ],
- },
- {
- 'page': 'layers/pooling.md',
- 'classes': [
- layers.MaxPooling1D,
- layers.MaxPooling2D,
- layers.MaxPooling3D,
- layers.AveragePooling1D,
- layers.AveragePooling2D,
- layers.AveragePooling3D,
- layers.GlobalMaxPooling1D,
- layers.GlobalAveragePooling1D,
- layers.GlobalMaxPooling2D,
- layers.GlobalAveragePooling2D,
- layers.GlobalMaxPooling3D,
- layers.GlobalAveragePooling3D,
- ],
- },
- {
- 'page': 'layers/local.md',
- 'classes': [
- layers.LocallyConnected1D,
- layers.LocallyConnected2D,
- ],
- },
- {
- 'page': 'layers/recurrent.md',
- 'classes': [
- layers.RNN,
- layers.SimpleRNN,
- layers.GRU,
- layers.LSTM,
- layers.ConvLSTM2D,
- layers.ConvLSTM2DCell,
- layers.SimpleRNNCell,
- layers.GRUCell,
- layers.LSTMCell,
- layers.CuDNNGRU,
- layers.CuDNNLSTM,
- ],
- },
- {
- 'page': 'layers/embeddings.md',
- 'classes': [
- layers.Embedding,
- ],
- },
- {
- 'page': 'layers/normalization.md',
- 'classes': [
- layers.BatchNormalization,
- ],
- },
- {
- 'page': 'layers/advanced-activations.md',
- 'all_module_classes': [advanced_activations],
- },
- {
- 'page': 'layers/noise.md',
- 'all_module_classes': [noise],
- },
- {
- 'page': 'layers/merge.md',
- 'classes': [
- layers.Add,
- layers.Subtract,
- layers.Multiply,
- layers.Average,
- layers.Maximum,
- layers.Minimum,
- layers.Concatenate,
- layers.Dot,
- ],
- 'functions': [
- layers.add,
- layers.subtract,
- layers.multiply,
- layers.average,
- layers.maximum,
- layers.minimum,
- layers.concatenate,
- layers.dot,
- ]
- },
- {
- 'page': 'preprocessing/sequence.md',
- 'functions': [
- preprocessing.sequence.pad_sequences,
- preprocessing.sequence.skipgrams,
- preprocessing.sequence.make_sampling_table,
- ],
- 'classes': [
- preprocessing.sequence.TimeseriesGenerator,
- ]
- },
- {
- 'page': 'preprocessing/image.md',
- 'classes': [
- (preprocessing.image.ImageDataGenerator, '*')
- ]
- },
- {
- 'page': 'preprocessing/text.md',
- 'functions': [
- preprocessing.text.hashing_trick,
- preprocessing.text.one_hot,
- preprocessing.text.text_to_word_sequence,
- ],
- 'classes': [
- preprocessing.text.Tokenizer,
- ]
- },
- {
- 'page': 'layers/wrappers.md',
- 'all_module_classes': [wrappers],
- },
- {
- 'page': 'metrics.md',
- 'all_module_functions': [metrics],
- },
- {
- 'page': 'losses.md',
- 'all_module_functions': [losses],
- },
- {
- 'page': 'initializers.md',
- 'all_module_functions': [initializers],
- 'all_module_classes': [initializers],
- },
- {
- 'page': 'optimizers.md',
- 'all_module_classes': [optimizers],
- },
- {
- 'page': 'callbacks.md',
- 'all_module_classes': [callbacks],
- },
- {
- 'page': 'activations.md',
- 'all_module_functions': [activations],
- },
- {
- 'page': 'backend.md',
- 'all_module_functions': [backend],
- },
- {
- 'page': 'constraints.md',
- 'all_module_classes': [constraints],
- },
- {
- 'page': 'utils.md',
- 'functions': [utils.to_categorical,
- utils.normalize,
- utils.get_file,
- utils.print_summary,
- utils.plot_model,
- utils.multi_gpu_model],
- 'classes': [utils.CustomObjectScope,
- utils.HDF5Matrix,
- utils.Sequence],
- },
-]
-
-ROOT = 'http://keras.io/'
-
-template_np_implementation = """# Numpy implementation
-
- ```python
-{{code}}
- ```
-"""
-
-template_hidden_np_implementation = """# Numpy implementation
-
-
- Show the Numpy implementation
-
- ```python
-{{code}}
- ```
-
-
-"""
diff --git a/docs/templates/activations.md b/docs/templates/activations.md
deleted file mode 100644
index 7cca9fa477c..00000000000
--- a/docs/templates/activations.md
+++ /dev/null
@@ -1,33 +0,0 @@
-
-## Usage of activations
-
-Activations can either be used through an `Activation` layer, or through the `activation` argument supported by all forward layers:
-
-```python
-from keras.layers import Activation, Dense
-
-model.add(Dense(64))
-model.add(Activation('tanh'))
-```
-
-This is equivalent to:
-
-```python
-model.add(Dense(64, activation='tanh'))
-```
-
-You can also pass an element-wise TensorFlow/Theano/CNTK function as an activation:
-
-```python
-from keras import backend as K
-
-model.add(Dense(64, activation=K.tanh))
-```
-
-## Available activations
-
-{{autogenerated}}
-
-## On "Advanced Activations"
-
-Activations that are more complex than a simple TensorFlow/Theano/CNTK function (eg. learnable activations, which maintain a state) are available as [Advanced Activation layers](layers/advanced-activations.md), and can be found in the module `keras.layers.advanced_activations`. These include `PReLU` and `LeakyReLU`.
diff --git a/docs/templates/applications.md b/docs/templates/applications.md
deleted file mode 100644
index 4a442296eec..00000000000
--- a/docs/templates/applications.md
+++ /dev/null
@@ -1,808 +0,0 @@
-# Applications
-
-Keras Applications are deep learning models that are made available alongside pre-trained weights.
-These models can be used for prediction, feature extraction, and fine-tuning.
-
-Weights are downloaded automatically when instantiating a model. They are stored at `~/.keras/models/`.
-
-## Available models
-
-### Models for image classification with weights trained on ImageNet:
-
-- [Xception](#xception)
-- [VGG16](#vgg16)
-- [VGG19](#vgg19)
-- [ResNet, ResNetV2](#resnet)
-- [InceptionV3](#inceptionv3)
-- [InceptionResNetV2](#inceptionresnetv2)
-- [MobileNet](#mobilenet)
-- [MobileNetV2](#mobilenetv2)
-- [DenseNet](#densenet)
-- [NASNet](#nasnet)
-
-All of these architectures are compatible with all the backends (TensorFlow, Theano, and CNTK), and upon instantiation the models will be built according to the image data format set in your Keras configuration file at `~/.keras/keras.json`. For instance, if you have set `image_data_format=channels_last`, then any model loaded from this repository will get built according to the TensorFlow data format convention, "Height-Width-Depth".
-
-Note that:
-- For `Keras < 2.2.0`, The Xception model is only available for TensorFlow, due to its reliance on `SeparableConvolution` layers.
-- For `Keras < 2.1.5`, The MobileNet model is only available for TensorFlow, due to its reliance on `DepthwiseConvolution` layers.
-
------
-
-## Usage examples for image classification models
-
-### Classify ImageNet classes with ResNet50
-
-```python
-from keras.applications.resnet50 import ResNet50
-from keras.preprocessing import image
-from keras.applications.resnet50 import preprocess_input, decode_predictions
-import numpy as np
-
-model = ResNet50(weights='imagenet')
-
-img_path = 'elephant.jpg'
-img = image.load_img(img_path, target_size=(224, 224))
-x = image.img_to_array(img)
-x = np.expand_dims(x, axis=0)
-x = preprocess_input(x)
-
-preds = model.predict(x)
-# decode the results into a list of tuples (class, description, probability)
-# (one such list for each sample in the batch)
-print('Predicted:', decode_predictions(preds, top=3)[0])
-# Predicted: [(u'n02504013', u'Indian_elephant', 0.82658225), (u'n01871265', u'tusker', 0.1122357), (u'n02504458', u'African_elephant', 0.061040461)]
-```
-
-### Extract features with VGG16
-
-```python
-from keras.applications.vgg16 import VGG16
-from keras.preprocessing import image
-from keras.applications.vgg16 import preprocess_input
-import numpy as np
-
-model = VGG16(weights='imagenet', include_top=False)
-
-img_path = 'elephant.jpg'
-img = image.load_img(img_path, target_size=(224, 224))
-x = image.img_to_array(img)
-x = np.expand_dims(x, axis=0)
-x = preprocess_input(x)
-
-features = model.predict(x)
-```
-
-### Extract features from an arbitrary intermediate layer with VGG19
-
-```python
-from keras.applications.vgg19 import VGG19
-from keras.preprocessing import image
-from keras.applications.vgg19 import preprocess_input
-from keras.models import Model
-import numpy as np
-
-base_model = VGG19(weights='imagenet')
-model = Model(inputs=base_model.input, outputs=base_model.get_layer('block4_pool').output)
-
-img_path = 'elephant.jpg'
-img = image.load_img(img_path, target_size=(224, 224))
-x = image.img_to_array(img)
-x = np.expand_dims(x, axis=0)
-x = preprocess_input(x)
-
-block4_pool_features = model.predict(x)
-```
-
-### Fine-tune InceptionV3 on a new set of classes
-
-```python
-from keras.applications.inception_v3 import InceptionV3
-from keras.preprocessing import image
-from keras.models import Model
-from keras.layers import Dense, GlobalAveragePooling2D
-from keras import backend as K
-
-# create the base pre-trained model
-base_model = InceptionV3(weights='imagenet', include_top=False)
-
-# add a global spatial average pooling layer
-x = base_model.output
-x = GlobalAveragePooling2D()(x)
-# let's add a fully-connected layer
-x = Dense(1024, activation='relu')(x)
-# and a logistic layer -- let's say we have 200 classes
-predictions = Dense(200, activation='softmax')(x)
-
-# this is the model we will train
-model = Model(inputs=base_model.input, outputs=predictions)
-
-# first: train only the top layers (which were randomly initialized)
-# i.e. freeze all convolutional InceptionV3 layers
-for layer in base_model.layers:
- layer.trainable = False
-
-# compile the model (should be done *after* setting layers to non-trainable)
-model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
-
-# train the model on the new data for a few epochs
-model.fit_generator(...)
-
-# at this point, the top layers are well trained and we can start fine-tuning
-# convolutional layers from inception V3. We will freeze the bottom N layers
-# and train the remaining top layers.
-
-# let's visualize layer names and layer indices to see how many layers
-# we should freeze:
-for i, layer in enumerate(base_model.layers):
- print(i, layer.name)
-
-# we chose to train the top 2 inception blocks, i.e. we will freeze
-# the first 249 layers and unfreeze the rest:
-for layer in model.layers[:249]:
- layer.trainable = False
-for layer in model.layers[249:]:
- layer.trainable = True
-
-# we need to recompile the model for these modifications to take effect
-# we use SGD with a low learning rate
-from keras.optimizers import SGD
-model.compile(optimizer=SGD(lr=0.0001, momentum=0.9), loss='categorical_crossentropy')
-
-# we train our model again (this time fine-tuning the top 2 inception blocks
-# alongside the top Dense layers
-model.fit_generator(...)
-```
-
-
-### Build InceptionV3 over a custom input tensor
-
-```python
-from keras.applications.inception_v3 import InceptionV3
-from keras.layers import Input
-
-# this could also be the output a different Keras model or layer
-input_tensor = Input(shape=(224, 224, 3)) # this assumes K.image_data_format() == 'channels_last'
-
-model = InceptionV3(input_tensor=input_tensor, weights='imagenet', include_top=True)
-```
-
------
-
-# Documentation for individual models
-
-| Model | Size | Top-1 Accuracy | Top-5 Accuracy | Parameters | Depth |
-| ----- | ----: | --------------: | --------------: | ----------: | -----: |
-| [Xception](#xception) | 88 MB | 0.790 | 0.945 | 22,910,480 | 126 |
-| [VGG16](#vgg16) | 528 MB | 0.713 | 0.901 | 138,357,544 | 23 |
-| [VGG19](#vgg19) | 549 MB | 0.713 | 0.900 | 143,667,240 | 26 |
-| [ResNet50](#resnet) | 98 MB | 0.749 | 0.921 | 25,636,712 | - |
-| [ResNet101](#resnet) | 171 MB | 0.764 | 0.928 | 44,707,176 | - |
-| [ResNet152](#resnet) | 232 MB | 0.766 | 0.931 | 60,419,944 | - |
-| [ResNet50V2](#resnet) | 98 MB | 0.760 | 0.930 | 25,613,800 | - |
-| [ResNet101V2](#resnet) | 171 MB | 0.772 | 0.938 | 44,675,560 | - |
-| [ResNet152V2](#resnet) | 232 MB | 0.780 | 0.942 | 60,380,648 | - |
-| [InceptionV3](#inceptionv3) | 92 MB | 0.779 | 0.937 | 23,851,784 | 159 |
-| [InceptionResNetV2](#inceptionresnetv2) | 215 MB | 0.803 | 0.953 | 55,873,736 | 572 |
-| [MobileNet](#mobilenet) | 16 MB | 0.704 | 0.895 | 4,253,864 | 88 |
-| [MobileNetV2](#mobilenetv2) | 14 MB | 0.713 | 0.901 | 3,538,984 | 88 |
-| [DenseNet121](#densenet) | 33 MB | 0.750 | 0.923 | 8,062,504 | 121 |
-| [DenseNet169](#densenet) | 57 MB | 0.762 | 0.932 | 14,307,880 | 169 |
-| [DenseNet201](#densenet) | 80 MB | 0.773 | 0.936 | 20,242,984 | 201 |
-| [NASNetMobile](#nasnet) | 23 MB | 0.744 | 0.919 | 5,326,716 | - |
-| [NASNetLarge](#nasnet) | 343 MB | 0.825 | 0.960 | 88,949,818 | - |
-
-The top-1 and top-5 accuracy refers to the model's performance on the ImageNet validation dataset.
-
-Depth refers to the topological depth of the network. This includes activation layers, batch normalization layers etc.
-
------
-
-
-## Xception
-
-
-```python
-keras.applications.xception.Xception(include_top=True, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000)
-```
-
-Xception V1 model, with weights pre-trained on ImageNet.
-
-On ImageNet, this model gets to a top-1 validation accuracy of 0.790
-and a top-5 validation accuracy of 0.945.
-
-This model and can be built both with `'channels_first'` data format (channels, height, width) or `'channels_last'` data format (height, width, channels).
-
-The default input size for this model is 299x299.
-
-### Arguments
-
-- include_top: whether to include the fully-connected layer at the top of the network.
-- weights: one of `None` (random initialization) or `'imagenet'` (pre-training on ImageNet).
-- input_tensor: optional Keras tensor (i.e. output of `layers.Input()`) to use as image input for the model.
-- input_shape: optional shape tuple, only to be specified
- if `include_top` is `False` (otherwise the input shape
- has to be `(299, 299, 3)`.
- It should have exactly 3 inputs channels,
- and width and height should be no smaller than 71.
- E.g. `(150, 150, 3)` would be one valid value.
-- pooling: Optional pooling mode for feature extraction
- when `include_top` is `False`.
- - `None` means that the output of the model will be
- the 4D tensor output of the
- last convolutional block.
- - `'avg'` means that global average pooling
- will be applied to the output of the
- last convolutional block, and thus
- the output of the model will be a 2D tensor.
- - `'max'` means that global max pooling will
- be applied.
-- classes: optional number of classes to classify images
- into, only to be specified if `include_top` is `True`, and
- if no `weights` argument is specified.
-
-### Returns
-
-A Keras `Model` instance.
-
-### References
-
-- [Xception: Deep Learning with Depthwise Separable Convolutions](https://arxiv.org/abs/1610.02357)
-
-### License
-
-These weights are trained by ourselves and are released under the MIT license.
-
-
------
-
-
-## VGG16
-
-```python
-keras.applications.vgg16.VGG16(include_top=True, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000)
-```
-
-VGG16 model, with weights pre-trained on ImageNet.
-
-This model can be built both with `'channels_first'` data format (channels, height, width) or `'channels_last'` data format (height, width, channels).
-
-The default input size for this model is 224x224.
-
-### Arguments
-
-- include_top: whether to include the 3 fully-connected layers at the top of the network.
-- weights: one of `None` (random initialization) or `'imagenet'` (pre-training on ImageNet).
-- input_tensor: optional Keras tensor (i.e. output of `layers.Input()`) to use as image input for the model.
-- input_shape: optional shape tuple, only to be specified
- if `include_top` is `False` (otherwise the input shape
- has to be `(224, 224, 3)` (with `'channels_last'` data format)
- or `(3, 224, 224)` (with `'channels_first'` data format).
- It should have exactly 3 inputs channels,
- and width and height should be no smaller than 32.
- E.g. `(200, 200, 3)` would be one valid value.
-- pooling: Optional pooling mode for feature extraction
- when `include_top` is `False`.
- - `None` means that the output of the model will be
- the 4D tensor output of the
- last convolutional block.
- - `'avg'` means that global average pooling
- will be applied to the output of the
- last convolutional block, and thus
- the output of the model will be a 2D tensor.
- - `'max'` means that global max pooling will
- be applied.
-- classes: optional number of classes to classify images
- into, only to be specified if `include_top` is `True`, and
- if no `weights` argument is specified.
-
-### Returns
-
-A Keras `Model` instance.
-
-### References
-
-- [Very Deep Convolutional Networks for Large-Scale Image Recognition](https://arxiv.org/abs/1409.1556): please cite this paper if you use the VGG models in your work.
-
-### License
-
-These weights are ported from the ones [released by VGG at Oxford](http://www.robots.ox.ac.uk/~vgg/research/very_deep/) under the [Creative Commons Attribution License](https://creativecommons.org/licenses/by/4.0/).
-
------
-
-## VGG19
-
-
-```python
-keras.applications.vgg19.VGG19(include_top=True, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000)
-```
-
-
-VGG19 model, with weights pre-trained on ImageNet.
-
-This model can be built both with `'channels_first'` data format (channels, height, width) or `'channels_last'` data format (height, width, channels).
-
-The default input size for this model is 224x224.
-
-### Arguments
-
-- include_top: whether to include the 3 fully-connected layers at the top of the network.
-- weights: one of `None` (random initialization) or `'imagenet'` (pre-training on ImageNet).
-- input_tensor: optional Keras tensor (i.e. output of `layers.Input()`) to use as image input for the model.
-- input_shape: optional shape tuple, only to be specified
- if `include_top` is `False` (otherwise the input shape
- has to be `(224, 224, 3)` (with `'channels_last'` data format)
- or `(3, 224, 224)` (with `'channels_first'` data format).
- It should have exactly 3 inputs channels,
- and width and height should be no smaller than 32.
- E.g. `(200, 200, 3)` would be one valid value.
-- pooling: Optional pooling mode for feature extraction
- when `include_top` is `False`.
- - `None` means that the output of the model will be
- the 4D tensor output of the
- last convolutional block.
- - `'avg'` means that global average pooling
- will be applied to the output of the
- last convolutional block, and thus
- the output of the model will be a 2D tensor.
- - `'max'` means that global max pooling will
- be applied.
-- classes: optional number of classes to classify images
- into, only to be specified if `include_top` is `True`, and
- if no `weights` argument is specified.
-
-### Returns
-
-A Keras `Model` instance.
-
-
-### References
-
-- [Very Deep Convolutional Networks for Large-Scale Image Recognition](https://arxiv.org/abs/1409.1556)
-
-### License
-
-These weights are ported from the ones [released by VGG at Oxford](http://www.robots.ox.ac.uk/~vgg/research/very_deep/) under the [Creative Commons Attribution License](https://creativecommons.org/licenses/by/4.0/).
-
------
-
-## ResNet
-
-
-```python
-keras.applications.resnet.ResNet50(include_top=True, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000)
-keras.applications.resnet.ResNet101(include_top=True, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000)
-keras.applications.resnet.ResNet152(include_top=True, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000)
-keras.applications.resnet_v2.ResNet50V2(include_top=True, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000)
-keras.applications.resnet_v2.ResNet101V2(include_top=True, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000)
-keras.applications.resnet_v2.ResNet152V2(include_top=True, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000)
-```
-
-
-ResNet, ResNetV2 models, with weights pre-trained on ImageNet.
-
-This model and can be built both with `'channels_first'` data format (channels, height, width) or `'channels_last'` data format (height, width, channels).
-
-The default input size for this model is 224x224.
-
-
-### Arguments
-
-- include_top: whether to include the fully-connected layer at the top of the network.
-- weights: one of `None` (random initialization) or `'imagenet'` (pre-training on ImageNet).
-- input_tensor: optional Keras tensor (i.e. output of `layers.Input()`) to use as image input for the model.
-- input_shape: optional shape tuple, only to be specified
- if `include_top` is `False` (otherwise the input shape
- has to be `(224, 224, 3)` (with `'channels_last'` data format)
- or `(3, 224, 224)` (with `'channels_first'` data format).
- It should have exactly 3 inputs channels,
- and width and height should be no smaller than 32.
- E.g. `(200, 200, 3)` would be one valid value.
-- pooling: Optional pooling mode for feature extraction
- when `include_top` is `False`.
- - `None` means that the output of the model will be
- the 4D tensor output of the
- last convolutional block.
- - `'avg'` means that global average pooling
- will be applied to the output of the
- last convolutional block, and thus
- the output of the model will be a 2D tensor.
- - `'max'` means that global max pooling will
- be applied.
-- classes: optional number of classes to classify images
- into, only to be specified if `include_top` is `True`, and
- if no `weights` argument is specified.
-
-### Returns
-
-A Keras `Model` instance.
-
-### References
-
-- `ResNet`: [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385)
-- `ResNetV2`: [Identity Mappings in Deep Residual Networks](https://arxiv.org/abs/1603.05027)
-
-### License
-
-These weights are ported from the following:
-
-- `ResNet`: [The original repository of Kaiming He](https://github.com/KaimingHe/deep-residual-networks) under the [MIT license](https://github.com/KaimingHe/deep-residual-networks/blob/master/LICENSE).
-- `ResNetV2`: [Facebook](https://github.com/facebook/fb.resnet.torch) under the [BSD license](https://github.com/facebook/fb.resnet.torch/blob/master/LICENSE).
-
------
-
-## InceptionV3
-
-
-```python
-keras.applications.inception_v3.InceptionV3(include_top=True, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000)
-```
-
-Inception V3 model, with weights pre-trained on ImageNet.
-
-This model and can be built both with `'channels_first'` data format (channels, height, width) or `'channels_last'` data format (height, width, channels).
-
-The default input size for this model is 299x299.
-
-
-### Arguments
-
-- include_top: whether to include the fully-connected layer at the top of the network.
-- weights: one of `None` (random initialization) or `'imagenet'` (pre-training on ImageNet).
-- input_tensor: optional Keras tensor (i.e. output of `layers.Input()`) to use as image input for the model.
-- input_shape: optional shape tuple, only to be specified
- if `include_top` is `False` (otherwise the input shape
- has to be `(299, 299, 3)` (with `'channels_last'` data format)
- or `(3, 299, 299)` (with `'channels_first'` data format).
- It should have exactly 3 inputs channels,
- and width and height should be no smaller than 75.
- E.g. `(150, 150, 3)` would be one valid value.
-- pooling: Optional pooling mode for feature extraction
- when `include_top` is `False`.
- - `None` means that the output of the model will be
- the 4D tensor output of the
- last convolutional block.
- - `'avg'` means that global average pooling
- will be applied to the output of the
- last convolutional block, and thus
- the output of the model will be a 2D tensor.
- - `'max'` means that global max pooling will
- be applied.
-- classes: optional number of classes to classify images
- into, only to be specified if `include_top` is `True`, and
- if no `weights` argument is specified.
-
-### Returns
-
-A Keras `Model` instance.
-
-### References
-
-- [Rethinking the Inception Architecture for Computer Vision](http://arxiv.org/abs/1512.00567)
-
-### License
-
-These weights are released under [the Apache License](https://github.com/tensorflow/models/blob/master/LICENSE).
-
------
-
-## InceptionResNetV2
-
-
-```python
-keras.applications.inception_resnet_v2.InceptionResNetV2(include_top=True, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000)
-```
-
-Inception-ResNet V2 model, with weights pre-trained on ImageNet.
-
-This model and can be built both with `'channels_first'` data format (channels, height, width) or `'channels_last'` data format (height, width, channels).
-
-The default input size for this model is 299x299.
-
-
-### Arguments
-
-- include_top: whether to include the fully-connected layer at the top of the network.
-- weights: one of `None` (random initialization) or `'imagenet'` (pre-training on ImageNet).
-- input_tensor: optional Keras tensor (i.e. output of `layers.Input()`) to use as image input for the model.
-- input_shape: optional shape tuple, only to be specified
- if `include_top` is `False` (otherwise the input shape
- has to be `(299, 299, 3)` (with `'channels_last'` data format)
- or `(3, 299, 299)` (with `'channels_first'` data format).
- It should have exactly 3 inputs channels,
- and width and height should be no smaller than 75.
- E.g. `(150, 150, 3)` would be one valid value.
-- pooling: Optional pooling mode for feature extraction
- when `include_top` is `False`.
- - `None` means that the output of the model will be
- the 4D tensor output of the
- last convolutional block.
- - `'avg'` means that global average pooling
- will be applied to the output of the
- last convolutional block, and thus
- the output of the model will be a 2D tensor.
- - `'max'` means that global max pooling will
- be applied.
-- classes: optional number of classes to classify images
- into, only to be specified if `include_top` is `True`, and
- if no `weights` argument is specified.
-
-### Returns
-
-A Keras `Model` instance.
-
-### References
-
-- [Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning](https://arxiv.org/abs/1602.07261)
-
-### License
-
-These weights are released under [the Apache License](https://github.com/tensorflow/models/blob/master/LICENSE).
-
------
-
-## MobileNet
-
-
-```python
-keras.applications.mobilenet.MobileNet(input_shape=None, alpha=1.0, depth_multiplier=1, dropout=1e-3, include_top=True, weights='imagenet', input_tensor=None, pooling=None, classes=1000)
-```
-
-MobileNet model, with weights pre-trained on ImageNet.
-
-This model and can be built both with `'channels_first'` data format (channels, height, width) or `'channels_last'` data format (height, width, channels).
-
-The default input size for this model is 224x224.
-
-### Arguments
-
-- input_shape: optional shape tuple, only to be specified
- if `include_top` is `False` (otherwise the input shape
- has to be `(224, 224, 3)` (with `'channels_last'` data format)
- or `(3, 224, 224)` (with `'channels_first'` data format).
- It should have exactly 3 inputs channels,
- and width and height should be no smaller than 32.
- E.g. `(200, 200, 3)` would be one valid value.
-- alpha: controls the width of the network.
- - If `alpha` < 1.0, proportionally decreases the number
- of filters in each layer.
- - If `alpha` > 1.0, proportionally increases the number
- of filters in each layer.
- - If `alpha` = 1, default number of filters from the paper
- are used at each layer.
-- depth_multiplier: depth multiplier for depthwise convolution
- (also called the resolution multiplier)
-- dropout: dropout rate
-- include_top: whether to include the fully-connected
- layer at the top of the network.
-- weights: `None` (random initialization) or
- `'imagenet'` (ImageNet weights)
-- input_tensor: optional Keras tensor (i.e. output of
- `layers.Input()`)
- to use as image input for the model.
-- pooling: Optional pooling mode for feature extraction
- when `include_top` is `False`.
- - `None` means that the output of the model
- will be the 4D tensor output of the
- last convolutional block.
- - `'avg'` means that global average pooling
- will be applied to the output of the
- last convolutional block, and thus
- the output of the model will be a
- 2D tensor.
- - `'max'` means that global max pooling will
- be applied.
-- classes: optional number of classes to classify images
- into, only to be specified if `include_top` is `True`, and
- if no `weights` argument is specified.
-
-### Returns
-
-A Keras `Model` instance.
-
-### References
-
-- [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://arxiv.org/pdf/1704.04861.pdf)
-
-### License
-
-These weights are released under [the Apache License](https://github.com/tensorflow/models/blob/master/LICENSE).
-
------
-
-## DenseNet
-
-
-```python
-keras.applications.densenet.DenseNet121(include_top=True, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000)
-keras.applications.densenet.DenseNet169(include_top=True, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000)
-keras.applications.densenet.DenseNet201(include_top=True, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000)
-```
-
-DenseNet models, with weights pre-trained on ImageNet.
-
-This model and can be built both with `'channels_first'` data format (channels, height, width) or `'channels_last'` data format (height, width, channels).
-
-The default input size for this model is 224x224.
-
-### Arguments
-
-- blocks: numbers of building blocks for the four dense layers.
-- include_top: whether to include the fully-connected
- layer at the top of the network.
-- weights: one of `None` (random initialization),
- 'imagenet' (pre-training on ImageNet),
- or the path to the weights file to be loaded.
-- input_tensor: optional Keras tensor (i.e. output of `layers.Input()`)
- to use as image input for the model.
-- input_shape: optional shape tuple, only to be specified
- if `include_top` is False (otherwise the input shape
- has to be `(224, 224, 3)` (with `'channels_last'` data format)
- or `(3, 224, 224)` (with `'channels_first'` data format).
- It should have exactly 3 inputs channels,
- and width and height should be no smaller than 32.
- E.g. `(200, 200, 3)` would be one valid value.
-- pooling: optional pooling mode for feature extraction
- when `include_top` is `False`.
- - `None` means that the output of the model will be
- the 4D tensor output of the
- last convolutional block.
- - `avg` means that global average pooling
- will be applied to the output of the
- last convolutional block, and thus
- the output of the model will be a 2D tensor.
- - `max` means that global max pooling will
- be applied.
-- classes: optional number of classes to classify images
- into, only to be specified if `include_top` is True, and
- if no `weights` argument is specified.
-
-### Returns
-
-A Keras model instance.
-
-### References
-
-- [Densely Connected Convolutional Networks](https://arxiv.org/abs/1608.06993) (CVPR 2017 Best Paper Award)
-
-### License
-
-These weights are released under [the BSD 3-clause License](https://github.com/liuzhuang13/DenseNet/blob/master/LICENSE).
-
------
-
-## NASNet
-
-
-```python
-keras.applications.nasnet.NASNetLarge(input_shape=None, include_top=True, weights='imagenet', input_tensor=None, pooling=None, classes=1000)
-keras.applications.nasnet.NASNetMobile(input_shape=None, include_top=True, weights='imagenet', input_tensor=None, pooling=None, classes=1000)
-```
-
-Neural Architecture Search Network (NASNet) models, with weights pre-trained on ImageNet.
-
-The default input size for the NASNetLarge model is 331x331 and for the
-NASNetMobile model is 224x224.
-
-### Arguments
-
-- input_shape: optional shape tuple, only to be specified
- if `include_top` is `False` (otherwise the input shape
- has to be `(224, 224, 3)` (with `'channels_last'` data format)
- or `(3, 224, 224)` (with `'channels_first'` data format)
- for NASNetMobile or `(331, 331, 3)` (with `'channels_last'`
- data format) or `(3, 331, 331)` (with `'channels_first'`
- data format) for NASNetLarge.
- It should have exactly 3 inputs channels,
- and width and height should be no smaller than 32.
- E.g. `(200, 200, 3)` would be one valid value.
-- include_top: whether to include the fully-connected
- layer at the top of the network.
-- weights: `None` (random initialization) or
- `'imagenet'` (ImageNet weights)
-- input_tensor: optional Keras tensor (i.e. output of
- `layers.Input()`)
- to use as image input for the model.
-- pooling: Optional pooling mode for feature extraction
- when `include_top` is `False`.
- - `None` means that the output of the model
- will be the 4D tensor output of the
- last convolutional block.
- - `'avg'` means that global average pooling
- will be applied to the output of the
- last convolutional block, and thus
- the output of the model will be a
- 2D tensor.
- - `'max'` means that global max pooling will
- be applied.
-- classes: optional number of classes to classify images
- into, only to be specified if `include_top` is `True`, and
- if no `weights` argument is specified.
-
-### Returns
-
-A Keras `Model` instance.
-
-### References
-
-- [Learning Transferable Architectures for Scalable Image Recognition](https://arxiv.org/abs/1707.07012)
-
-### License
-
-These weights are released under [the Apache License](https://github.com/tensorflow/models/blob/master/LICENSE).
-
------
-
-## MobileNetV2
-
-
-```python
-keras.applications.mobilenet_v2.MobileNetV2(input_shape=None, alpha=1.0, include_top=True, weights='imagenet', input_tensor=None, pooling=None, classes=1000)
-```
-
-MobileNetV2 model, with weights pre-trained on ImageNet.
-
-This model and can be built both with `'channels_first'` data format (channels, height, width) or `'channels_last'` data format (height, width, channels).
-
-The default input size for this model is 224x224.
-
-### Arguments
-
-- input_shape: optional shape tuple, to be specified if you would
- like to use a model with an input img resolution that is not
- (224, 224, 3).
- It should have exactly 3 inputs channels (224, 224, 3).
- You can also omit this option if you would like
- to infer input_shape from an input_tensor.
- If you choose to include both input_tensor and input_shape then
- input_shape will be used if they match, if the shapes
- do not match then we will throw an error.
- E.g. `(160, 160, 3)` would be one valid value.
-- alpha: controls the width of the network. This is known as the
- width multiplier in the MobileNetV2 paper.
- - If `alpha` < 1.0, proportionally decreases the number
- of filters in each layer.
- - If `alpha` > 1.0, proportionally increases the number
- of filters in each layer.
- - If `alpha` = 1, default number of filters from the paper
- are used at each layer.
-- include_top: whether to include the fully-connected
- layer at the top of the network.
-- weights: one of `None` (random initialization),
- 'imagenet' (pre-training on ImageNet),
- or the path to the weights file to be loaded.
-- input_tensor: optional Keras tensor (i.e. output of
- `layers.Input()`)
- to use as image input for the model.
-- pooling: Optional pooling mode for feature extraction
- when `include_top` is `False`.
- - `None` means that the output of the model
- will be the 4D tensor output of the
- last convolutional block.
- - `'avg'` means that global average pooling
- will be applied to the output of the
- last convolutional block, and thus
- the output of the model will be a
- 2D tensor.
- - `'max'` means that global max pooling will
- be applied.
-- classes: optional number of classes to classify images
- into, only to be specified if `include_top` is True, and
- if no `weights` argument is specified.
-
-### Returns
-
-A Keras model instance.
-
-### Raises
-
-ValueError: in case of invalid argument for `weights`,
- or invalid input shape, alpha,
- rows when weights='imagenet'
-
-### References
-
-- [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381)
-
-### License
-
-These weights are released under [the Apache License](https://github.com/tensorflow/models/blob/master/LICENSE).
diff --git a/docs/templates/backend.md b/docs/templates/backend.md
deleted file mode 100644
index 7b2fb65cd77..00000000000
--- a/docs/templates/backend.md
+++ /dev/null
@@ -1,148 +0,0 @@
-# Keras backends
-
-## What is a "backend"?
-
-Keras is a model-level library, providing high-level building blocks for developing deep learning models. It does not handle low-level operations such as tensor products, convolutions and so on itself. Instead, it relies on a specialized, well optimized tensor manipulation library to do so, serving as the "backend engine" of Keras. Rather than picking one single tensor library and making the implementation of Keras tied to that library, Keras handles the problem in a modular way, and several different backend engines can be plugged seamlessly into Keras.
-
-At this time, Keras has three backend implementations available: the **TensorFlow** backend, the **Theano** backend, and the **CNTK** backend.
-
-- [TensorFlow](http://www.tensorflow.org/) is an open-source symbolic tensor manipulation framework developed by Google.
-- [Theano](http://deeplearning.net/software/theano/) is an open-source symbolic tensor manipulation framework developed by LISA Lab at Université de Montréal.
-- [CNTK](https://www.microsoft.com/en-us/cognitive-toolkit/) is an open-source toolkit for deep learning developed by Microsoft.
-
-In the future, we are likely to add more backend options.
-
-----
-
-## Switching from one backend to another
-
-If you have run Keras at least once, you will find the Keras configuration file at:
-
-`$HOME/.keras/keras.json`
-
-If it isn't there, you can create it.
-
-**NOTE for Windows Users:** Please replace `$HOME` with `%USERPROFILE%`.
-
-The default configuration file looks like this:
-
-```
-{
- "image_data_format": "channels_last",
- "epsilon": 1e-07,
- "floatx": "float32",
- "backend": "tensorflow"
-}
-```
-
-Simply change the field `backend` to `"theano"`, `"tensorflow"`, or `"cntk"`, and Keras will use the new configuration next time you run any Keras code.
-
-You can also define the environment variable ``KERAS_BACKEND`` and this will
-override what is defined in your config file :
-
-```bash
-KERAS_BACKEND=tensorflow python -c "from keras import backend"
-Using TensorFlow backend.
-```
-
-In Keras it is possible to load more backends than `"tensorflow"`, `"theano"`, and `"cntk"`. Keras can use external backends as well, and this can be performed by changing the `keras.json` configuration file, and the `"backend"` setting. Suppose you have a Python module called `my_module` that you wanted to use as your external backend. The `keras.json` configuration file would be changed as follows:
-
-```
-{
- "image_data_format": "channels_last",
- "epsilon": 1e-07,
- "floatx": "float32",
- "backend": "my_package.my_module"
-}
-```
-An external backend must be validated in order to be used, a valid backend must have the following functions: `placeholder`, `variable` and `function`.
-
-If an external backend is not valid due to missing a required entry, an error will be logged notifying which entry/entries are missing.
-
-----
-
-## keras.json details
-
-
-The `keras.json` configuration file contains the following settings:
-
-```
-{
- "image_data_format": "channels_last",
- "epsilon": 1e-07,
- "floatx": "float32",
- "backend": "tensorflow"
-}
-```
-
-You can change these settings by editing `$HOME/.keras/keras.json`.
-
-* `image_data_format`: String, either `"channels_last"` or `"channels_first"`. It specifies which data format convention Keras will follow. (`keras.backend.image_data_format()` returns it.)
- - For 2D data (e.g. image), `"channels_last"` assumes `(rows, cols, channels)` while `"channels_first"` assumes `(channels, rows, cols)`.
- - For 3D data, `"channels_last"` assumes `(conv_dim1, conv_dim2, conv_dim3, channels)` while `"channels_first"` assumes `(channels, conv_dim1, conv_dim2, conv_dim3)`.
-* `epsilon`: Float, a numeric fuzzing constant used to avoid dividing by zero in some operations.
-* `floatx`: String, `"float16"`, `"float32"`, or `"float64"`. Default float precision.
-* `backend`: String, `"tensorflow"`, `"theano"`, or `"cntk"`.
-
-----
-
-## Using the abstract Keras backend to write new code
-
-If you want the Keras modules you write to be compatible with both Theano (`th`) and TensorFlow (`tf`), you have to write them via the abstract Keras backend API. Here's an intro.
-
-You can import the backend module via:
-```python
-from keras import backend as K
-```
-
-The code below instantiates an input placeholder. It's equivalent to `tf.placeholder()` or `th.tensor.matrix()`, `th.tensor.tensor3()`, etc.
-
-```python
-inputs = K.placeholder(shape=(2, 4, 5))
-# also works:
-inputs = K.placeholder(shape=(None, 4, 5))
-# also works:
-inputs = K.placeholder(ndim=3)
-```
-
-The code below instantiates a variable. It's equivalent to `tf.Variable()` or `th.shared()`.
-
-```python
-import numpy as np
-val = np.random.random((3, 4, 5))
-var = K.variable(value=val)
-
-# all-zeros variable:
-var = K.zeros(shape=(3, 4, 5))
-# all-ones:
-var = K.ones(shape=(3, 4, 5))
-```
-
-Most tensor operations you will need can be done as you would in TensorFlow or Theano:
-
-```python
-# Initializing Tensors with Random Numbers
-b = K.random_uniform_variable(shape=(3, 4), low=0, high=1) # Uniform distribution
-c = K.random_normal_variable(shape=(3, 4), mean=0, scale=1) # Gaussian distribution
-d = K.random_normal_variable(shape=(3, 4), mean=0, scale=1)
-
-# Tensor Arithmetic
-a = b + c * K.abs(d)
-c = K.dot(a, K.transpose(b))
-a = K.sum(b, axis=1)
-a = K.softmax(b)
-a = K.concatenate([b, c], axis=-1)
-# etc...
-```
-
-----
-
-## Backend functions
-
-
-{{autogenerated}}
-
-
-
-
-
diff --git a/docs/templates/callbacks.md b/docs/templates/callbacks.md
deleted file mode 100644
index 7dfa4063775..00000000000
--- a/docs/templates/callbacks.md
+++ /dev/null
@@ -1,70 +0,0 @@
-## Usage of callbacks
-
-A callback is a set of functions to be applied at given stages of the training procedure. You can use callbacks to get a view on internal states and statistics of the model during training. You can pass a list of callbacks (as the keyword argument `callbacks`) to the `.fit()` method of the `Sequential` or `Model` classes. The relevant methods of the callbacks will then be called at each stage of the training.
-
----
-
-{{autogenerated}}
-
----
-
-
-# Create a callback
-
-You can create a custom callback by extending the base class `keras.callbacks.Callback`. A callback has access to its associated model through the class property `self.model`.
-
-Here's a simple example saving a list of losses over each batch during training:
-```python
-class LossHistory(keras.callbacks.Callback):
- def on_train_begin(self, logs={}):
- self.losses = []
-
- def on_batch_end(self, batch, logs={}):
- self.losses.append(logs.get('loss'))
-```
-
----
-
-### Example: recording loss history
-
-```python
-class LossHistory(keras.callbacks.Callback):
- def on_train_begin(self, logs={}):
- self.losses = []
-
- def on_batch_end(self, batch, logs={}):
- self.losses.append(logs.get('loss'))
-
-model = Sequential()
-model.add(Dense(10, input_dim=784, kernel_initializer='uniform'))
-model.add(Activation('softmax'))
-model.compile(loss='categorical_crossentropy', optimizer='rmsprop')
-
-history = LossHistory()
-model.fit(x_train, y_train, batch_size=128, epochs=20, verbose=0, callbacks=[history])
-
-print(history.losses)
-# outputs
-'''
-[0.66047596406559383, 0.3547245744908703, ..., 0.25953155204159617, 0.25901699725311789]
-'''
-```
-
----
-
-### Example: model checkpoints
-
-```python
-from keras.callbacks import ModelCheckpoint
-
-model = Sequential()
-model.add(Dense(10, input_dim=784, kernel_initializer='uniform'))
-model.add(Activation('softmax'))
-model.compile(loss='categorical_crossentropy', optimizer='rmsprop')
-
-'''
-saves the model weights after each epoch if the validation loss decreased
-'''
-checkpointer = ModelCheckpoint(filepath='/tmp/weights.hdf5', verbose=1, save_best_only=True)
-model.fit(x_train, y_train, batch_size=128, epochs=20, verbose=0, validation_data=(X_test, Y_test), callbacks=[checkpointer])
-```
diff --git a/docs/templates/constraints.md b/docs/templates/constraints.md
deleted file mode 100644
index bacc47c78a7..00000000000
--- a/docs/templates/constraints.md
+++ /dev/null
@@ -1,26 +0,0 @@
-## Usage of constraints
-
-Functions from the `constraints` module allow setting constraints (eg. non-negativity) on network parameters during optimization.
-
-The penalties are applied on a per-layer basis. The exact API will depend on the layer, but the layers `Dense`, `Conv1D`, `Conv2D` and `Conv3D` have a unified API.
-
-These layers expose 2 keyword arguments:
-
-- `kernel_constraint` for the main weights matrix
-- `bias_constraint` for the bias.
-
-
-```python
-from keras.constraints import max_norm
-model.add(Dense(64, kernel_constraint=max_norm(2.)))
-```
-
----
-
-## Available constraints
-
-
-{{autogenerated}}
-
----
-
diff --git a/docs/templates/datasets.md b/docs/templates/datasets.md
deleted file mode 100644
index 826a8c73183..00000000000
--- a/docs/templates/datasets.md
+++ /dev/null
@@ -1,209 +0,0 @@
-# Datasets
-
-## CIFAR10 small image classification
-
-Dataset of 50,000 32x32 color training images, labeled over 10 categories, and 10,000 test images.
-
-### Usage:
-
-```python
-from keras.datasets import cifar10
-
-(x_train, y_train), (x_test, y_test) = cifar10.load_data()
-```
-
-- __Returns:__
- - 2 tuples:
- - __x_train, x_test__: uint8 array of RGB image data with shape (num_samples, 3, 32, 32) or (num_samples, 32, 32, 3) based on the `image_data_format` backend setting of either `channels_first` or `channels_last` respectively.
- - __y_train, y_test__: uint8 array of category labels (integers in range 0-9) with shape (num_samples, 1).
-
-
----
-
-## CIFAR100 small image classification
-
-Dataset of 50,000 32x32 color training images, labeled over 100 categories, and 10,000 test images.
-
-### Usage:
-
-```python
-from keras.datasets import cifar100
-
-(x_train, y_train), (x_test, y_test) = cifar100.load_data(label_mode='fine')
-```
-
-- __Returns:__
- - 2 tuples:
- - __x_train, x_test__: uint8 array of RGB image data with shape (num_samples, 3, 32, 32) or (num_samples, 32, 32, 3) based on the `image_data_format` backend setting of either `channels_first` or `channels_last` respectively.
- - __y_train, y_test__: uint8 array of category labels with shape (num_samples, 1).
-
-- __Arguments:__
-
- - __label_mode__: "fine" or "coarse".
-
-
----
-
-## IMDB Movie reviews sentiment classification
-
-Dataset of 25,000 movies reviews from IMDB, labeled by sentiment (positive/negative). Reviews have been preprocessed, and each review is encoded as a [sequence](preprocessing/sequence.md) of word indexes (integers). For convenience, words are indexed by overall frequency in the dataset, so that for instance the integer "3" encodes the 3rd most frequent word in the data. This allows for quick filtering operations such as: "only consider the top 10,000 most common words, but eliminate the top 20 most common words".
-
-As a convention, "0" does not stand for a specific word, but instead is used to encode any unknown word.
-
-### Usage:
-
-```python
-from keras.datasets import imdb
-
-(x_train, y_train), (x_test, y_test) = imdb.load_data(path="imdb.npz",
- num_words=None,
- skip_top=0,
- maxlen=None,
- seed=113,
- start_char=1,
- oov_char=2,
- index_from=3)
-```
-- __Returns:__
- - 2 tuples:
- - __x_train, x_test__: list of sequences, which are lists of indexes (integers). If the num_words argument was specific, the maximum possible index value is num_words-1. If the maxlen argument was specified, the largest possible sequence length is maxlen.
- - __y_train, y_test__: list of integer labels (1 or 0).
-
-- __Arguments:__
-
- - __path__: if you do not have the data locally (at `'~/.keras/datasets/' + path`), it will be downloaded to this location.
- - __num_words__: integer or None. Top most frequent words to consider. Any less frequent word will appear as `oov_char` value in the sequence data.
- - __skip_top__: integer. Top most frequent words to ignore (they will appear as `oov_char` value in the sequence data).
- - __maxlen__: int. Maximum sequence length. Any longer sequence will be truncated.
- - __seed__: int. Seed for reproducible data shuffling.
- - __start_char__: int. The start of a sequence will be marked with this character.
- Set to 1 because 0 is usually the padding character.
- - __oov_char__: int. words that were cut out because of the `num_words`
- or `skip_top` limit will be replaced with this character.
- - __index_from__: int. Index actual words with this index and higher.
-
-
----
-
-## Reuters newswire topics classification
-
-Dataset of 11,228 newswires from Reuters, labeled over 46 topics. As with the IMDB dataset, each wire is encoded as a sequence of word indexes (same conventions).
-
-### Usage:
-
-```python
-from keras.datasets import reuters
-
-(x_train, y_train), (x_test, y_test) = reuters.load_data(path="reuters.npz",
- num_words=None,
- skip_top=0,
- maxlen=None,
- test_split=0.2,
- seed=113,
- start_char=1,
- oov_char=2,
- index_from=3)
-```
-
-The specifications are the same as that of the IMDB dataset, with the addition of:
-
-- __test_split__: float. Fraction of the dataset to be used as test data.
-
-This dataset also makes available the word index used for encoding the sequences:
-
-```python
-word_index = reuters.get_word_index(path="reuters_word_index.json")
-```
-
-- __Returns:__ A dictionary where key are words (str) and values are indexes (integer). eg. `word_index["giraffe"]` might return `1234`.
-
-- __Arguments:__
-
- - __path__: if you do not have the index file locally (at `'~/.keras/datasets/' + path`), it will be downloaded to this location.
-
-
----
-
-## MNIST database of handwritten digits
-
-Dataset of 60,000 28x28 grayscale images of the 10 digits, along with a test set of 10,000 images.
-
-### Usage:
-
-```python
-from keras.datasets import mnist
-
-(x_train, y_train), (x_test, y_test) = mnist.load_data()
-```
-
-- __Returns:__
- - 2 tuples:
- - __x_train, x_test__: uint8 array of grayscale image data with shape (num_samples, 28, 28).
- - __y_train, y_test__: uint8 array of digit labels (integers in range 0-9) with shape (num_samples,).
-
-- __Arguments:__
-
- - __path__: if you do not have the index file locally (at `'~/.keras/datasets/' + path`), it will be downloaded to this location.
-
-
----
-
-## Fashion-MNIST database of fashion articles
-
-Dataset of 60,000 28x28 grayscale images of 10 fashion categories, along with a test set of 10,000 images. This dataset can be used as a drop-in replacement for MNIST. The class labels are:
-
-| Label | Description |
-| --- | --- |
-| 0 | T-shirt/top |
-| 1 | Trouser |
-| 2 | Pullover |
-| 3 | Dress |
-| 4 | Coat |
-| 5 | Sandal |
-| 6 | Shirt |
-| 7 | Sneaker |
-| 8 | Bag |
-| 9 | Ankle boot |
-
-### Usage:
-
-```python
-from keras.datasets import fashion_mnist
-
-(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
-```
-
-- __Returns:__
- - 2 tuples:
- - __x_train, x_test__: uint8 array of grayscale image data with shape (num_samples, 28, 28).
- - __y_train, y_test__: uint8 array of labels (integers in range 0-9) with shape (num_samples,).
-
-
----
-
-## Boston housing price regression dataset
-
-
-Dataset taken from the StatLib library which is maintained at Carnegie Mellon University.
-
-Samples contain 13 attributes of houses at different locations around the Boston suburbs in the late 1970s.
-Targets are the median values of the houses at a location (in k$).
-
-
-### Usage:
-
-```python
-from keras.datasets import boston_housing
-
-(x_train, y_train), (x_test, y_test) = boston_housing.load_data()
-```
-
-- __Arguments:__
- - __path__: path where to cache the dataset locally
- (relative to ~/.keras/datasets).
- - __seed__: Random seed for shuffling the data
- before computing the test split.
- - __test_split__: fraction of the data to reserve as test set.
-
-- __Returns:__
- Tuple of Numpy arrays: `(x_train, y_train), (x_test, y_test)`.
diff --git a/docs/templates/getting-started/faq.md b/docs/templates/getting-started/faq.md
deleted file mode 100644
index 3ce52a5ed38..00000000000
--- a/docs/templates/getting-started/faq.md
+++ /dev/null
@@ -1,658 +0,0 @@
-# Keras FAQ: Frequently Asked Keras Questions
-
-- [How should I cite Keras?](#how-should-i-cite-keras)
-- [How can I run Keras on GPU?](#how-can-i-run-keras-on-gpu)
-- [How can I run a Keras model on multiple GPUs?](#how-can-i-run-a-keras-model-on-multiple-gpus)
-- [What does "sample", "batch", "epoch" mean?](#what-does-sample-batch-epoch-mean)
-- [How can I save a Keras model?](#how-can-i-save-a-keras-model)
-- [Why is the training loss much higher than the testing loss?](#why-is-the-training-loss-much-higher-than-the-testing-loss)
-- [How can I obtain the output of an intermediate layer?](#how-can-i-obtain-the-output-of-an-intermediate-layer)
-- [How can I use Keras with datasets that don't fit in memory?](#how-can-i-use-keras-with-datasets-that-dont-fit-in-memory)
-- [How can I interrupt training when the validation loss isn't decreasing anymore?](#how-can-i-interrupt-training-when-the-validation-loss-isnt-decreasing-anymore)
-- [How is the validation split computed?](#how-is-the-validation-split-computed)
-- [Is the data shuffled during training?](#is-the-data-shuffled-during-training)
-- [How can I record the training / validation loss / accuracy at each epoch?](#how-can-i-record-the-training-validation-loss-accuracy-at-each-epoch)
-- [How can I "freeze" layers?](#how-can-i-freeze-keras-layers)
-- [How can I use stateful RNNs?](#how-can-i-use-stateful-rnns)
-- [How can I remove a layer from a Sequential model?](#how-can-i-remove-a-layer-from-a-sequential-model)
-- [How can I use pre-trained models in Keras?](#how-can-i-use-pre-trained-models-in-keras)
-- [How can I use HDF5 inputs with Keras?](#how-can-i-use-hdf5-inputs-with-keras)
-- [Where is the Keras configuration file stored?](#where-is-the-keras-configuration-file-stored)
-- [How can I obtain reproducible results using Keras during development?](#how-can-i-obtain-reproducible-results-using-keras-during-development)
-- [How can I install HDF5 or h5py to save my models in Keras?](#how-can-i-install-hdf5-or-h5py-to-save-my-models-in-keras)
-
----
-
-### How should I cite Keras?
-
-Please cite Keras in your publications if it helps your research. Here is an example BibTeX entry:
-
-```
-@misc{chollet2015keras,
- title={Keras},
- author={Chollet, Fran\c{c}ois and others},
- year={2015},
- howpublished={\url{https://keras.io}},
-}
-```
-
----
-
-### How can I run Keras on GPU?
-
-If you are running on the **TensorFlow** or **CNTK** backends, your code will automatically run on GPU if any available GPU is detected.
-
-If you are running on the **Theano** backend, you can use one of the following methods:
-
-**Method 1**: use Theano flags.
-```bash
-THEANO_FLAGS=device=gpu,floatX=float32 python my_keras_script.py
-```
-
-The name 'gpu' might have to be changed depending on your device's identifier (e.g. `gpu0`, `gpu1`, etc).
-
-**Method 2**: set up your `.theanorc`: [Instructions](http://deeplearning.net/software/theano/library/config.html)
-
-**Method 3**: manually set `theano.config.device`, `theano.config.floatX` at the beginning of your code:
-```python
-import theano
-theano.config.device = 'gpu'
-theano.config.floatX = 'float32'
-```
-
----
-
-### How can I run a Keras model on multiple GPUs?
-
-We recommend doing so using the **TensorFlow** backend. There are two ways to run a single model on multiple GPUs: **data parallelism** and **device parallelism**.
-
-In most cases, what you need is most likely data parallelism.
-
-#### Data parallelism
-
-Data parallelism consists in replicating the target model once on each device, and using each replica to process a different fraction of the input data.
-Keras has a built-in utility, `keras.utils.multi_gpu_model`, which can produce a data-parallel version of any model, and achieves quasi-linear speedup on up to 8 GPUs.
-
-For more information, see the documentation for [multi_gpu_model](/utils/#multi_gpu_model). Here is a quick example:
-
-```python
-from keras.utils import multi_gpu_model
-
-# Replicates `model` on 8 GPUs.
-# This assumes that your machine has 8 available GPUs.
-parallel_model = multi_gpu_model(model, gpus=8)
-parallel_model.compile(loss='categorical_crossentropy',
- optimizer='rmsprop')
-
-# This `fit` call will be distributed on 8 GPUs.
-# Since the batch size is 256, each GPU will process 32 samples.
-parallel_model.fit(x, y, epochs=20, batch_size=256)
-```
-
-#### Device parallelism
-
-Device parallelism consists in running different parts of a same model on different devices. It works best for models that have a parallel architecture, e.g. a model with two branches.
-
-This can be achieved by using TensorFlow device scopes. Here is a quick example:
-
-```python
-# Model where a shared LSTM is used to encode two different sequences in parallel
-input_a = keras.Input(shape=(140, 256))
-input_b = keras.Input(shape=(140, 256))
-
-shared_lstm = keras.layers.LSTM(64)
-
-# Process the first sequence on one GPU
-with tf.device_scope('/gpu:0'):
- encoded_a = shared_lstm(tweet_a)
-# Process the next sequence on another GPU
-with tf.device_scope('/gpu:1'):
- encoded_b = shared_lstm(tweet_b)
-
-# Concatenate results on CPU
-with tf.device_scope('/cpu:0'):
- merged_vector = keras.layers.concatenate([encoded_a, encoded_b],
- axis=-1)
-```
-
----
-
-### What does "sample", "batch", "epoch" mean?
-
-Below are some common definitions that are necessary to know and understand to correctly utilize Keras:
-
-- **Sample**: one element of a dataset.
- - *Example:* one image is a **sample** in a convolutional network
- - *Example:* one audio file is a **sample** for a speech recognition model
-- **Batch**: a set of *N* samples. The samples in a **batch** are processed independently, in parallel. If training, a batch results in only one update to the model.
- - A **batch** generally approximates the distribution of the input data better than a single input. The larger the batch, the better the approximation; however, it is also true that the batch will take longer to process and will still result in only one update. For inference (evaluate/predict), it is recommended to pick a batch size that is as large as you can afford without going out of memory (since larger batches will usually result in faster evaluation/prediction).
-- **Epoch**: an arbitrary cutoff, generally defined as "one pass over the entire dataset", used to separate training into distinct phases, which is useful for logging and periodic evaluation.
- - When using `validation_data` or `validation_split` with the `fit` method of Keras models, evaluation will be run at the end of every **epoch**.
- - Within Keras, there is the ability to add [callbacks](https://keras.io/callbacks/) specifically designed to be run at the end of an **epoch**. Examples of these are learning rate changes and model checkpointing (saving).
-
----
-
-### How can I save a Keras model?
-
-#### Saving/loading whole models (architecture + weights + optimizer state)
-
-*It is not recommended to use pickle or cPickle to save a Keras model.*
-
-You can use `model.save(filepath)` to save a Keras model into a single HDF5 file which will contain:
-
-- the architecture of the model, allowing to re-create the model
-- the weights of the model
-- the training configuration (loss, optimizer)
-- the state of the optimizer, allowing to resume training exactly where you left off.
-
-You can then use `keras.models.load_model(filepath)` to reinstantiate your model.
-`load_model` will also take care of compiling the model using the saved training configuration (unless the model was never compiled in the first place).
-
-Example:
-
-```python
-from keras.models import load_model
-
-model.save('my_model.h5') # creates a HDF5 file 'my_model.h5'
-del model # deletes the existing model
-
-# returns a compiled model
-# identical to the previous one
-model = load_model('my_model.h5')
-```
-
-Please also see [How can I install HDF5 or h5py to save my models in Keras?](#how-can-i-install-hdf5-or-h5py-to-save-my-models-in-keras) for instructions on how to install `h5py`.
-
-#### Saving/loading only a model's architecture
-
-If you only need to save the **architecture of a model**, and not its weights or its training configuration, you can do:
-
-```python
-# save as JSON
-json_string = model.to_json()
-
-# save as YAML
-yaml_string = model.to_yaml()
-```
-
-The generated JSON / YAML files are human-readable and can be manually edited if needed.
-
-You can then build a fresh model from this data:
-
-```python
-# model reconstruction from JSON:
-from keras.models import model_from_json
-model = model_from_json(json_string)
-
-# model reconstruction from YAML:
-from keras.models import model_from_yaml
-model = model_from_yaml(yaml_string)
-```
-
-#### Saving/loading only a model's weights
-
-If you need to save the **weights of a model**, you can do so in HDF5 with the code below:
-
-```python
-model.save_weights('my_model_weights.h5')
-```
-
-Assuming you have code for instantiating your model, you can then load the weights you saved into a model with the *same* architecture:
-
-```python
-model.load_weights('my_model_weights.h5')
-```
-
-If you need to load the weights into a *different* architecture (with some layers in common), for instance for fine-tuning or transfer-learning, you can load them by *layer name*:
-
-```python
-model.load_weights('my_model_weights.h5', by_name=True)
-```
-
-Example:
-
-```python
-"""
-Assuming the original model looks like this:
- model = Sequential()
- model.add(Dense(2, input_dim=3, name='dense_1'))
- model.add(Dense(3, name='dense_2'))
- ...
- model.save_weights(fname)
-"""
-
-# new model
-model = Sequential()
-model.add(Dense(2, input_dim=3, name='dense_1')) # will be loaded
-model.add(Dense(10, name='new_dense')) # will not be loaded
-
-# load weights from first model; will only affect the first layer, dense_1.
-model.load_weights(fname, by_name=True)
-```
-
-Please also see [How can I install HDF5 or h5py to save my models in Keras?](#how-can-i-install-hdf5-or-h5py-to-save-my-models-in-keras) for instructions on how to install `h5py`.
-
-#### Handling custom layers (or other custom objects) in saved models
-
-If the model you want to load includes custom layers or other custom classes or functions,
-you can pass them to the loading mechanism via the `custom_objects` argument:
-
-```python
-from keras.models import load_model
-# Assuming your model includes instance of an "AttentionLayer" class
-model = load_model('my_model.h5', custom_objects={'AttentionLayer': AttentionLayer})
-```
-
-Alternatively, you can use a [custom object scope](https://keras.io/utils/#customobjectscope):
-
-```python
-from keras.utils import CustomObjectScope
-
-with CustomObjectScope({'AttentionLayer': AttentionLayer}):
- model = load_model('my_model.h5')
-```
-
-Custom objects handling works the same way for `load_model`, `model_from_json`, `model_from_yaml`:
-
-```python
-from keras.models import model_from_json
-model = model_from_json(json_string, custom_objects={'AttentionLayer': AttentionLayer})
-```
-
----
-
-### Why is the training loss much higher than the testing loss?
-
-A Keras model has two modes: training and testing. Regularization mechanisms, such as Dropout and L1/L2 weight regularization, are turned off at testing time.
-
-Besides, the training loss is the average of the losses over each batch of training data. Because your model is changing over time, the loss over the first batches of an epoch is generally higher than over the last batches. On the other hand, the testing loss for an epoch is computed using the model as it is at the end of the epoch, resulting in a lower loss.
-
----
-
-### How can I obtain the output of an intermediate layer?
-
-One simple way is to create a new `Model` that will output the layers that you are interested in:
-
-```python
-from keras.models import Model
-
-model = ... # create the original model
-
-layer_name = 'my_layer'
-intermediate_layer_model = Model(inputs=model.input,
- outputs=model.get_layer(layer_name).output)
-intermediate_output = intermediate_layer_model.predict(data)
-```
-
-Alternatively, you can build a Keras function that will return the output of a certain layer given a certain input, for example:
-
-```python
-from keras import backend as K
-
-# with a Sequential model
-get_3rd_layer_output = K.function([model.layers[0].input],
- [model.layers[3].output])
-layer_output = get_3rd_layer_output([x])[0]
-```
-
-Similarly, you could build a Theano and TensorFlow function directly.
-
-Note that if your model has a different behavior in training and testing phase (e.g. if it uses `Dropout`, `BatchNormalization`, etc.), you will need to pass the learning phase flag to your function:
-
-```python
-get_3rd_layer_output = K.function([model.layers[0].input, K.learning_phase()],
- [model.layers[3].output])
-
-# output in test mode = 0
-layer_output = get_3rd_layer_output([x, 0])[0]
-
-# output in train mode = 1
-layer_output = get_3rd_layer_output([x, 1])[0]
-```
-
----
-
-### How can I use Keras with datasets that don't fit in memory?
-
-You can do batch training using `model.train_on_batch(x, y)` and `model.test_on_batch(x, y)`. See the [models documentation](/models/sequential).
-
-Alternatively, you can write a generator that yields batches of training data and use the method `model.fit_generator(data_generator, steps_per_epoch, epochs)`.
-
-You can see batch training in action in our [CIFAR10 example](https://github.com/keras-team/keras/blob/master/examples/cifar10_cnn.py).
-
----
-
-### How can I interrupt training when the validation loss isn't decreasing anymore?
-
-You can use an `EarlyStopping` callback:
-
-```python
-from keras.callbacks import EarlyStopping
-early_stopping = EarlyStopping(monitor='val_loss', patience=2)
-model.fit(x, y, validation_split=0.2, callbacks=[early_stopping])
-```
-
-Find out more in the [callbacks documentation](/callbacks).
-
----
-
-### How is the validation split computed?
-
-If you set the `validation_split` argument in `model.fit` to e.g. 0.1, then the validation data used will be the *last 10%* of the data. If you set it to 0.25, it will be the last 25% of the data, etc. Note that the data isn't shuffled before extracting the validation split, so the validation is literally just the *last* x% of samples in the input you passed.
-
-The same validation set is used for all epochs (within a same call to `fit`).
-
----
-
-### Is the data shuffled during training?
-
-Yes, if the `shuffle` argument in `model.fit` is set to `True` (which is the default), the training data will be randomly shuffled at each epoch.
-
-Validation data is never shuffled.
-
----
-
-
-### How can I record the training / validation loss / accuracy at each epoch?
-
-The `model.fit` method returns a `History` callback, which has a `history` attribute containing the lists of successive losses and other metrics.
-
-```python
-hist = model.fit(x, y, validation_split=0.2)
-print(hist.history)
-```
-
----
-
-### How can I "freeze" Keras layers?
-
-To "freeze" a layer means to exclude it from training, i.e. its weights will never be updated. This is useful in the context of fine-tuning a model, or using fixed embeddings for a text input.
-
-You can pass a `trainable` argument (boolean) to a layer constructor to set a layer to be non-trainable:
-
-```python
-frozen_layer = Dense(32, trainable=False)
-```
-
-Additionally, you can set the `trainable` property of a layer to `True` or `False` after instantiation. For this to take effect, you will need to call `compile()` on your model after modifying the `trainable` property. Here's an example:
-
-```python
-x = Input(shape=(32,))
-layer = Dense(32)
-layer.trainable = False
-y = layer(x)
-
-frozen_model = Model(x, y)
-# in the model below, the weights of `layer` will not be updated during training
-frozen_model.compile(optimizer='rmsprop', loss='mse')
-
-layer.trainable = True
-trainable_model = Model(x, y)
-# with this model the weights of the layer will be updated during training
-# (which will also affect the above model since it uses the same layer instance)
-trainable_model.compile(optimizer='rmsprop', loss='mse')
-
-frozen_model.fit(data, labels) # this does NOT update the weights of `layer`
-trainable_model.fit(data, labels) # this updates the weights of `layer`
-```
-
----
-
-### How can I use stateful RNNs?
-
-Making a RNN stateful means that the states for the samples of each batch will be reused as initial states for the samples in the next batch.
-
-When using stateful RNNs, it is therefore assumed that:
-
-- all batches have the same number of samples
-- If `x1` and `x2` are successive batches of samples, then `x2[i]` is the follow-up sequence to `x1[i]`, for every `i`.
-
-To use statefulness in RNNs, you need to:
-
-- explicitly specify the batch size you are using, by passing a `batch_size` argument to the first layer in your model. E.g. `batch_size=32` for a 32-samples batch of sequences of 10 timesteps with 16 features per timestep.
-- set `stateful=True` in your RNN layer(s).
-- specify `shuffle=False` when calling `fit()`.
-
-To reset the states accumulated:
-
-- use `model.reset_states()` to reset the states of all layers in the model
-- use `layer.reset_states()` to reset the states of a specific stateful RNN layer
-
-Example:
-
-```python
-x # this is our input data, of shape (32, 21, 16)
-# we will feed it to our model in sequences of length 10
-
-model = Sequential()
-model.add(LSTM(32, input_shape=(10, 16), batch_size=32, stateful=True))
-model.add(Dense(16, activation='softmax'))
-
-model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
-
-# we train the network to predict the 11th timestep given the first 10:
-model.train_on_batch(x[:, :10, :], np.reshape(x[:, 10, :], (32, 16)))
-
-# the state of the network has changed. We can feed the follow-up sequences:
-model.train_on_batch(x[:, 10:20, :], np.reshape(x[:, 20, :], (32, 16)))
-
-# let's reset the states of the LSTM layer:
-model.reset_states()
-
-# another way to do it in this case:
-model.layers[0].reset_states()
-```
-
-Note that the methods `predict`, `fit`, `train_on_batch`, `predict_classes`, etc. will *all* update the states of the stateful layers in a model. This allows you to do not only stateful training, but also stateful prediction.
-
----
-
-### How can I remove a layer from a Sequential model?
-
-You can remove the last added layer in a Sequential model by calling `.pop()`:
-
-```python
-model = Sequential()
-model.add(Dense(32, activation='relu', input_dim=784))
-model.add(Dense(32, activation='relu'))
-
-print(len(model.layers)) # "2"
-
-model.pop()
-print(len(model.layers)) # "1"
-```
-
----
-
-### How can I use pre-trained models in Keras?
-
-Code and pre-trained weights are available for the following image classification models:
-
-- Xception
-- VGG16
-- VGG19
-- ResNet
-- ResNet v2
-- ResNeXt
-- Inception v3
-- Inception-ResNet v2
-- MobileNet v1
-- MobileNet v2
-- DenseNet
-- NASNet
-
-They can be imported from the module `keras.applications`:
-
-```python
-from keras.applications.xception import Xception
-from keras.applications.vgg16 import VGG16
-from keras.applications.vgg19 import VGG19
-from keras.applications.resnet import ResNet50
-from keras.applications.resnet import ResNet101
-from keras.applications.resnet import ResNet152
-from keras.applications.resnet_v2 import ResNet50V2
-from keras.applications.resnet_v2 import ResNet101V2
-from keras.applications.resnet_v2 import ResNet152V2
-from keras.applications.resnext import ResNeXt50
-from keras.applications.resnext import ResNeXt101
-from keras.applications.inception_v3 import InceptionV3
-from keras.applications.inception_resnet_v2 import InceptionResNetV2
-from keras.applications.mobilenet import MobileNet
-from keras.applications.mobilenet_v2 import MobileNetV2
-from keras.applications.densenet import DenseNet121
-from keras.applications.densenet import DenseNet169
-from keras.applications.densenet import DenseNet201
-from keras.applications.nasnet import NASNetLarge
-from keras.applications.nasnet import NASNetMobile
-
-model = VGG16(weights='imagenet', include_top=True)
-```
-
-For a few simple usage examples, see [the documentation for the Applications module](/applications).
-
-For a detailed example of how to use such a pre-trained model for feature extraction or for fine-tuning, see [this blog post](http://blog.keras.io/building-powerful-image-classification-models-using-very-little-data.html).
-
-The VGG16 model is also the basis for several Keras example scripts:
-
-- [Style transfer](https://github.com/keras-team/keras/blob/master/examples/neural_style_transfer.py)
-- [Feature visualization](https://github.com/keras-team/keras/blob/master/examples/conv_filter_visualization.py)
-- [Deep dream](https://github.com/keras-team/keras/blob/master/examples/deep_dream.py)
-
----
-
-### How can I use HDF5 inputs with Keras?
-
-You can use the `HDF5Matrix` class from `keras.utils`. See [the HDF5Matrix documentation](/utils/#hdf5matrix) for details.
-
-You can also directly use a HDF5 dataset:
-
-```python
-import h5py
-with h5py.File('input/file.hdf5', 'r') as f:
- x_data = f['x_data']
- model.predict(x_data)
-```
-
-Please also see [How can I install HDF5 or h5py to save my models in Keras?](#how-can-i-install-hdf5-or-h5py-to-save-my-models-in-keras) for instructions on how to install `h5py`.
-
----
-
-### Where is the Keras configuration file stored?
-
-The default directory where all Keras data is stored is:
-
-```bash
-$HOME/.keras/
-```
-
-Note that Windows users should replace `$HOME` with `%USERPROFILE%`.
-In case Keras cannot create the above directory (e.g. due to permission issues), `/tmp/.keras/` is used as a backup.
-
-The Keras configuration file is a JSON file stored at `$HOME/.keras/keras.json`. The default configuration file looks like this:
-
-```
-{
- "image_data_format": "channels_last",
- "epsilon": 1e-07,
- "floatx": "float32",
- "backend": "tensorflow"
-}
-```
-
-It contains the following fields:
-
-- The image data format to be used as default by image processing layers and utilities (either `channels_last` or `channels_first`).
-- The `epsilon` numerical fuzz factor to be used to prevent division by zero in some operations.
-- The default float data type.
-- The default backend. See the [backend documentation](/backend).
-
-Likewise, cached dataset files, such as those downloaded with [`get_file()`](/utils/#get_file), are stored by default in `$HOME/.keras/datasets/`.
-
----
-
-### How can I obtain reproducible results using Keras during development?
-
-During development of a model, sometimes it is useful to be able to obtain reproducible results from run to run in order to determine if a change in performance is due to an actual model or data modification, or merely a result of a new random sample.
-
-First, you need to set the `PYTHONHASHSEED` environment variable to `0` before the program starts (not within the program itself). This is necessary in Python 3.2.3 onwards to have reproducible behavior for certain hash-based operations (e.g., the item order in a set or a dict, see [Python's documentation](https://docs.python.org/3.7/using/cmdline.html#envvar-PYTHONHASHSEED) or [issue #2280](https://github.com/keras-team/keras/issues/2280#issuecomment-306959926) for further details). One way to set the environment variable is when starting python like this:
-
-```
-$ cat test_hash.py
-print(hash("keras"))
-$ python3 test_hash.py # non-reproducible hash (Python 3.2.3+)
--8127205062320133199
-$ python3 test_hash.py # non-reproducible hash (Python 3.2.3+)
-3204480642156461591
-$ PYTHONHASHSEED=0 python3 test_hash.py # reproducible hash
-4883664951434749476
-$ PYTHONHASHSEED=0 python3 test_hash.py # reproducible hash
-4883664951434749476
-```
-
-Moreover, when using the TensorFlow backend and running on a GPU, some operations have non-deterministic outputs, in particular `tf.reduce_sum()`. This is due to the fact that GPUs run many operations in parallel, so the order of execution is not always guaranteed. Due to the limited precision of floats, even adding several numbers together may give slightly different results depending on the order in which you add them. You can try to avoid the non-deterministic operations, but some may be created automatically by TensorFlow to compute the gradients, so it is much simpler to just run the code on the CPU. For this, you can set the `CUDA_VISIBLE_DEVICES` environment variable to an empty string, for example:
-
-```
-$ CUDA_VISIBLE_DEVICES="" PYTHONHASHSEED=0 python your_program.py
-```
-
-The below snippet of code provides an example of how to obtain reproducible results - this is geared towards a TensorFlow backend for a Python 3 environment:
-
-```python
-import numpy as np
-import tensorflow as tf
-import random as rn
-
-# The below is necessary for starting Numpy generated random numbers
-# in a well-defined initial state.
-
-np.random.seed(42)
-
-# The below is necessary for starting core Python generated random numbers
-# in a well-defined state.
-
-rn.seed(12345)
-
-# Force TensorFlow to use single thread.
-# Multiple threads are a potential source of non-reproducible results.
-# For further details, see: https://stackoverflow.com/questions/42022950/
-
-session_conf = tf.ConfigProto(intra_op_parallelism_threads=1,
- inter_op_parallelism_threads=1)
-
-from keras import backend as K
-
-# The below tf.set_random_seed() will make random number generation
-# in the TensorFlow backend have a well-defined initial state.
-# For further details, see:
-# https://www.tensorflow.org/api_docs/python/tf/set_random_seed
-
-tf.set_random_seed(1234)
-
-sess = tf.Session(graph=tf.get_default_graph(), config=session_conf)
-K.set_session(sess)
-
-# Rest of code follows ...
-```
-
----
-
-### How can I install HDF5 or h5py to save my models in Keras?
-
-In order to save your Keras models as HDF5 files, e.g. via
-`keras.callbacks.ModelCheckpoint`, Keras uses the h5py Python package. It is
- a dependency of Keras and should be installed by default. On Debian-based
- distributions, you will have to additionally install `libhdf5`:
-
-```
-sudo apt-get install libhdf5-serial-dev
-```
-
-If you are unsure if h5py is installed you can open a Python shell and load the
-module via
-
-```
-import h5py
-```
-
-If it imports without error it is installed, otherwise you can find detailed
-installation instructions here: http://docs.h5py.org/en/latest/build.html
diff --git a/docs/templates/getting-started/functional-api-guide.md b/docs/templates/getting-started/functional-api-guide.md
deleted file mode 100644
index b02d8de58f7..00000000000
--- a/docs/templates/getting-started/functional-api-guide.md
+++ /dev/null
@@ -1,437 +0,0 @@
-# Getting started with the Keras functional API
-
-The Keras functional API is the way to go for defining complex models, such as multi-output models, directed acyclic graphs, or models with shared layers.
-
-This guide assumes that you are already familiar with the `Sequential` model.
-
-Let's start with something simple.
-
------
-
-## First example: a densely-connected network
-
-The `Sequential` model is probably a better choice to implement such a network, but it helps to start with something really simple.
-
-- A layer instance is callable (on a tensor), and it returns a tensor
-- Input tensor(s) and output tensor(s) can then be used to define a `Model`
-- Such a model can be trained just like Keras `Sequential` models.
-
-```python
-from keras.layers import Input, Dense
-from keras.models import Model
-
-# This returns a tensor
-inputs = Input(shape=(784,))
-
-# a layer instance is callable on a tensor, and returns a tensor
-output_1 = Dense(64, activation='relu')(inputs)
-output_2 = Dense(64, activation='relu')(output_1)
-predictions = Dense(10, activation='softmax')(output_2)
-
-# This creates a model that includes
-# the Input layer and three Dense layers
-model = Model(inputs=inputs, outputs=predictions)
-model.compile(optimizer='rmsprop',
- loss='categorical_crossentropy',
- metrics=['accuracy'])
-model.fit(data, labels) # starts training
-```
-
------
-
-## All models are callable, just like layers
-
-With the functional API, it is easy to reuse trained models: you can treat any model as if it were a layer, by calling it on a tensor. Note that by calling a model you aren't just reusing the *architecture* of the model, you are also reusing its weights.
-
-```python
-x = Input(shape=(784,))
-# This works, and returns the 10-way softmax we defined above.
-y = model(x)
-```
-
-This can allow, for instance, to quickly create models that can process *sequences* of inputs. You could turn an image classification model into a video classification model, in just one line.
-
-```python
-from keras.layers import TimeDistributed
-
-# Input tensor for sequences of 20 timesteps,
-# each containing a 784-dimensional vector
-input_sequences = Input(shape=(20, 784))
-
-# This applies our previous model to every timestep in the input sequences.
-# the output of the previous model was a 10-way softmax,
-# so the output of the layer below will be a sequence of 20 vectors of size 10.
-processed_sequences = TimeDistributed(model)(input_sequences)
-```
-
------
-
-## Multi-input and multi-output models
-
-Here's a good use case for the functional API: models with multiple inputs and outputs. The functional API makes it easy to manipulate a large number of intertwined datastreams.
-
-Let's consider the following model. We seek to predict how many retweets and likes a news headline will receive on Twitter. The main input to the model will be the headline itself, as a sequence of words, but to spice things up, our model will also have an auxiliary input, receiving extra data such as the time of day when the headline was posted, etc.
-The model will also be supervised via two loss functions. Using the main loss function earlier in a model is a good regularization mechanism for deep models.
-
-Here's what our model looks like:
-
-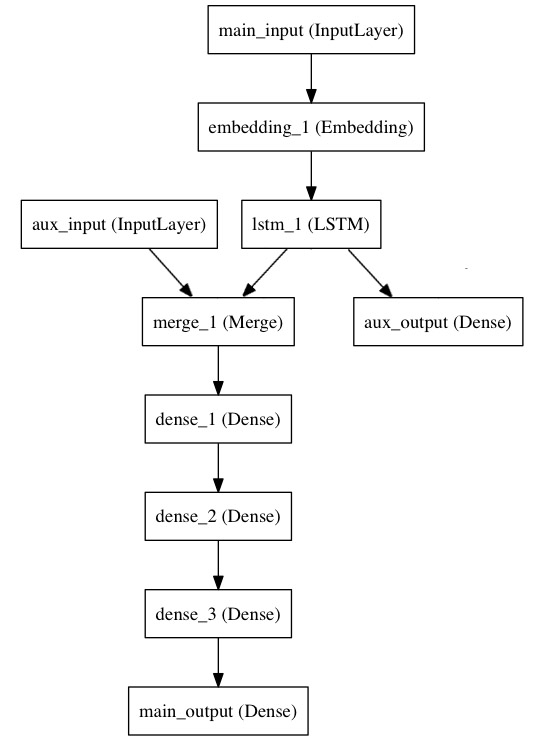 -
-Let's implement it with the functional API.
-
-The main input will receive the headline, as a sequence of integers (each integer encodes a word).
-The integers will be between 1 and 10,000 (a vocabulary of 10,000 words) and the sequences will be 100 words long.
-
-```python
-from keras.layers import Input, Embedding, LSTM, Dense
-from keras.models import Model
-import numpy as np
-np.random.seed(0) # Set a random seed for reproducibility
-
-# Headline input: meant to receive sequences of 100 integers, between 1 and 10000.
-# Note that we can name any layer by passing it a "name" argument.
-main_input = Input(shape=(100,), dtype='int32', name='main_input')
-
-# This embedding layer will encode the input sequence
-# into a sequence of dense 512-dimensional vectors.
-x = Embedding(output_dim=512, input_dim=10000, input_length=100)(main_input)
-
-# A LSTM will transform the vector sequence into a single vector,
-# containing information about the entire sequence
-lstm_out = LSTM(32)(x)
-```
-
-Here we insert the auxiliary loss, allowing the LSTM and Embedding layer to be trained smoothly even though the main loss will be much higher in the model.
-
-```python
-auxiliary_output = Dense(1, activation='sigmoid', name='aux_output')(lstm_out)
-```
-
-At this point, we feed into the model our auxiliary input data by concatenating it with the LSTM output:
-
-```python
-auxiliary_input = Input(shape=(5,), name='aux_input')
-x = keras.layers.concatenate([lstm_out, auxiliary_input])
-
-# We stack a deep densely-connected network on top
-x = Dense(64, activation='relu')(x)
-x = Dense(64, activation='relu')(x)
-x = Dense(64, activation='relu')(x)
-
-# And finally we add the main logistic regression layer
-main_output = Dense(1, activation='sigmoid', name='main_output')(x)
-```
-
-This defines a model with two inputs and two outputs:
-
-```python
-model = Model(inputs=[main_input, auxiliary_input], outputs=[main_output, auxiliary_output])
-```
-
-We compile the model and assign a weight of 0.2 to the auxiliary loss.
-To specify different `loss_weights` or `loss` for each different output, you can use a list or a dictionary.
-Here we pass a single loss as the `loss` argument, so the same loss will be used on all outputs.
-
-```python
-model.compile(optimizer='rmsprop', loss='binary_crossentropy',
- loss_weights=[1., 0.2])
-```
-
-We can train the model by passing it lists of input arrays and target arrays:
-
-```python
-headline_data = np.round(np.abs(np.random.rand(12, 100) * 100))
-additional_data = np.random.randn(12, 5)
-headline_labels = np.random.randn(12, 1)
-additional_labels = np.random.randn(12, 1)
-model.fit([headline_data, additional_data], [headline_labels, additional_labels],
- epochs=50, batch_size=32)
-```
-
-Since our inputs and outputs are named (we passed them a "name" argument),
-we could also have compiled the model via:
-
-```python
-model.compile(optimizer='rmsprop',
- loss={'main_output': 'binary_crossentropy', 'aux_output': 'binary_crossentropy'},
- loss_weights={'main_output': 1., 'aux_output': 0.2})
-
-# And trained it via:
-model.fit({'main_input': headline_data, 'aux_input': additional_data},
- {'main_output': headline_labels, 'aux_output': additional_labels},
- epochs=50, batch_size=32)
-```
-
-To use the model for inferencing, use
-```python
-model.predict({'main_input': headline_data, 'aux_input': additional_data})
-```
-or alternatively,
-```python
-pred = model.predict([headline_data, additional_data])
-```
-
------
-
-## Shared layers
-
-Another good use for the functional API are models that use shared layers. Let's take a look at shared layers.
-
-Let's consider a dataset of tweets. We want to build a model that can tell whether two tweets are from the same person or not (this can allow us to compare users by the similarity of their tweets, for instance).
-
-One way to achieve this is to build a model that encodes two tweets into two vectors, concatenates the vectors and then adds a logistic regression; this outputs a probability that the two tweets share the same author. The model would then be trained on positive tweet pairs and negative tweet pairs.
-
-Because the problem is symmetric, the mechanism that encodes the first tweet should be reused (weights and all) to encode the second tweet. Here we use a shared LSTM layer to encode the tweets.
-
-Let's build this with the functional API. We will take as input for a tweet a binary matrix of shape `(280, 256)`, i.e. a sequence of 280 vectors of size 256, where each dimension in the 256-dimensional vector encodes the presence/absence of a character (out of an alphabet of 256 frequent characters).
-
-```python
-import keras
-from keras.layers import Input, LSTM, Dense
-from keras.models import Model
-
-tweet_a = Input(shape=(280, 256))
-tweet_b = Input(shape=(280, 256))
-```
-
-To share a layer across different inputs, simply instantiate the layer once, then call it on as many inputs as you want:
-
-```python
-# This layer can take as input a matrix
-# and will return a vector of size 64
-shared_lstm = LSTM(64)
-
-# When we reuse the same layer instance
-# multiple times, the weights of the layer
-# are also being reused
-# (it is effectively *the same* layer)
-encoded_a = shared_lstm(tweet_a)
-encoded_b = shared_lstm(tweet_b)
-
-# We can then concatenate the two vectors:
-merged_vector = keras.layers.concatenate([encoded_a, encoded_b], axis=-1)
-
-# And add a logistic regression on top
-predictions = Dense(1, activation='sigmoid')(merged_vector)
-
-# We define a trainable model linking the
-# tweet inputs to the predictions
-model = Model(inputs=[tweet_a, tweet_b], outputs=predictions)
-
-model.compile(optimizer='rmsprop',
- loss='binary_crossentropy',
- metrics=['accuracy'])
-model.fit([data_a, data_b], labels, epochs=10)
-```
-
-Let's pause to take a look at how to read the shared layer's output or output shape.
-
------
-
-## The concept of layer "node"
-
-Whenever you are calling a layer on some input, you are creating a new tensor (the output of the layer), and you are adding a "node" to the layer, linking the input tensor to the output tensor. When you are calling the same layer multiple times, that layer owns multiple nodes indexed as 0, 1, 2...
-
-In previous versions of Keras, you could obtain the output tensor of a layer instance via `layer.get_output()`, or its output shape via `layer.output_shape`. You still can (except `get_output()` has been replaced by the property `output`). But what if a layer is connected to multiple inputs?
-
-As long as a layer is only connected to one input, there is no confusion, and `.output` will return the one output of the layer:
-
-```python
-a = Input(shape=(280, 256))
-
-lstm = LSTM(32)
-encoded_a = lstm(a)
-
-assert lstm.output == encoded_a
-```
-
-Not so if the layer has multiple inputs:
-```python
-a = Input(shape=(280, 256))
-b = Input(shape=(280, 256))
-
-lstm = LSTM(32)
-encoded_a = lstm(a)
-encoded_b = lstm(b)
-
-lstm.output
-```
-```
->> AttributeError: Layer lstm_1 has multiple inbound nodes,
-hence the notion of "layer output" is ill-defined.
-Use `get_output_at(node_index)` instead.
-```
-
-Okay then. The following works:
-
-```python
-assert lstm.get_output_at(0) == encoded_a
-assert lstm.get_output_at(1) == encoded_b
-```
-
-Simple enough, right?
-
-The same is true for the properties `input_shape` and `output_shape`: as long as the layer has only one node, or as long as all nodes have the same input/output shape, then the notion of "layer output/input shape" is well defined, and that one shape will be returned by `layer.output_shape`/`layer.input_shape`. But if, for instance, you apply the same `Conv2D` layer to an input of shape `(32, 32, 3)`, and then to an input of shape `(64, 64, 3)`, the layer will have multiple input/output shapes, and you will have to fetch them by specifying the index of the node they belong to:
-
-```python
-a = Input(shape=(32, 32, 3))
-b = Input(shape=(64, 64, 3))
-
-conv = Conv2D(16, (3, 3), padding='same')
-conved_a = conv(a)
-
-# Only one input so far, the following will work:
-assert conv.input_shape == (None, 32, 32, 3)
-
-conved_b = conv(b)
-# now the `.input_shape` property wouldn't work, but this does:
-assert conv.get_input_shape_at(0) == (None, 32, 32, 3)
-assert conv.get_input_shape_at(1) == (None, 64, 64, 3)
-```
-
------
-
-## More examples
-
-Code examples are still the best way to get started, so here are a few more.
-
-### Inception module
-
-For more information about the Inception architecture, see [Going Deeper with Convolutions](http://arxiv.org/abs/1409.4842).
-
-```python
-from keras.layers import Conv2D, MaxPooling2D, Input
-
-input_img = Input(shape=(256, 256, 3))
-
-tower_1 = Conv2D(64, (1, 1), padding='same', activation='relu')(input_img)
-tower_1 = Conv2D(64, (3, 3), padding='same', activation='relu')(tower_1)
-
-tower_2 = Conv2D(64, (1, 1), padding='same', activation='relu')(input_img)
-tower_2 = Conv2D(64, (5, 5), padding='same', activation='relu')(tower_2)
-
-tower_3 = MaxPooling2D((3, 3), strides=(1, 1), padding='same')(input_img)
-tower_3 = Conv2D(64, (1, 1), padding='same', activation='relu')(tower_3)
-
-output = keras.layers.concatenate([tower_1, tower_2, tower_3], axis=1)
-```
-
-### Residual connection on a convolution layer
-
-For more information about residual networks, see [Deep Residual Learning for Image Recognition](http://arxiv.org/abs/1512.03385).
-
-```python
-from keras.layers import Conv2D, Input
-
-# input tensor for a 3-channel 256x256 image
-x = Input(shape=(256, 256, 3))
-# 3x3 conv with 3 output channels (same as input channels)
-y = Conv2D(3, (3, 3), padding='same')(x)
-# this returns x + y.
-z = keras.layers.add([x, y])
-```
-
-### Shared vision model
-
-This model reuses the same image-processing module on two inputs, to classify whether two MNIST digits are the same digit or different digits.
-
-```python
-from keras.layers import Conv2D, MaxPooling2D, Input, Dense, Flatten
-from keras.models import Model
-
-# First, define the vision modules
-digit_input = Input(shape=(27, 27, 1))
-x = Conv2D(64, (3, 3))(digit_input)
-x = Conv2D(64, (3, 3))(x)
-x = MaxPooling2D((2, 2))(x)
-out = Flatten()(x)
-
-vision_model = Model(digit_input, out)
-
-# Then define the tell-digits-apart model
-digit_a = Input(shape=(27, 27, 1))
-digit_b = Input(shape=(27, 27, 1))
-
-# The vision model will be shared, weights and all
-out_a = vision_model(digit_a)
-out_b = vision_model(digit_b)
-
-concatenated = keras.layers.concatenate([out_a, out_b])
-out = Dense(1, activation='sigmoid')(concatenated)
-
-classification_model = Model([digit_a, digit_b], out)
-```
-
-### Visual question answering model
-
-This model can select the correct one-word answer when asked a natural-language question about a picture.
-
-It works by encoding the question into a vector, encoding the image into a vector, concatenating the two, and training on top a logistic regression over some vocabulary of potential answers.
-
-```python
-from keras.layers import Conv2D, MaxPooling2D, Flatten
-from keras.layers import Input, LSTM, Embedding, Dense
-from keras.models import Model, Sequential
-
-# First, let's define a vision model using a Sequential model.
-# This model will encode an image into a vector.
-vision_model = Sequential()
-vision_model.add(Conv2D(64, (3, 3), activation='relu', padding='same', input_shape=(224, 224, 3)))
-vision_model.add(Conv2D(64, (3, 3), activation='relu'))
-vision_model.add(MaxPooling2D((2, 2)))
-vision_model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))
-vision_model.add(Conv2D(128, (3, 3), activation='relu'))
-vision_model.add(MaxPooling2D((2, 2)))
-vision_model.add(Conv2D(256, (3, 3), activation='relu', padding='same'))
-vision_model.add(Conv2D(256, (3, 3), activation='relu'))
-vision_model.add(Conv2D(256, (3, 3), activation='relu'))
-vision_model.add(MaxPooling2D((2, 2)))
-vision_model.add(Flatten())
-
-# Now let's get a tensor with the output of our vision model:
-image_input = Input(shape=(224, 224, 3))
-encoded_image = vision_model(image_input)
-
-# Next, let's define a language model to encode the question into a vector.
-# Each question will be at most 100 words long,
-# and we will index words as integers from 1 to 9999.
-question_input = Input(shape=(100,), dtype='int32')
-embedded_question = Embedding(input_dim=10000, output_dim=256, input_length=100)(question_input)
-encoded_question = LSTM(256)(embedded_question)
-
-# Let's concatenate the question vector and the image vector:
-merged = keras.layers.concatenate([encoded_question, encoded_image])
-
-# And let's train a logistic regression over 1000 words on top:
-output = Dense(1000, activation='softmax')(merged)
-
-# This is our final model:
-vqa_model = Model(inputs=[image_input, question_input], outputs=output)
-
-# The next stage would be training this model on actual data.
-```
-
-### Video question answering model
-
-Now that we have trained our image QA model, we can quickly turn it into a video QA model. With appropriate training, you will be able to show it a short video (e.g. 100-frame human action) and ask a natural language question about the video (e.g. "what sport is the boy playing?" -> "football").
-
-```python
-from keras.layers import TimeDistributed
-
-video_input = Input(shape=(100, 224, 224, 3))
-# This is our video encoded via the previously trained vision_model (weights are reused)
-encoded_frame_sequence = TimeDistributed(vision_model)(video_input) # the output will be a sequence of vectors
-encoded_video = LSTM(256)(encoded_frame_sequence) # the output will be a vector
-
-# This is a model-level representation of the question encoder, reusing the same weights as before:
-question_encoder = Model(inputs=question_input, outputs=encoded_question)
-
-# Let's use it to encode the question:
-video_question_input = Input(shape=(100,), dtype='int32')
-encoded_video_question = question_encoder(video_question_input)
-
-# And this is our video question answering model:
-merged = keras.layers.concatenate([encoded_video, encoded_video_question])
-output = Dense(1000, activation='softmax')(merged)
-video_qa_model = Model(inputs=[video_input, video_question_input], outputs=output)
-```
diff --git a/docs/templates/getting-started/sequential-model-guide.md b/docs/templates/getting-started/sequential-model-guide.md
deleted file mode 100644
index 853811f65ad..00000000000
--- a/docs/templates/getting-started/sequential-model-guide.md
+++ /dev/null
@@ -1,399 +0,0 @@
-# Getting started with the Keras Sequential model
-
-The `Sequential` model is a linear stack of layers.
-
-You can create a `Sequential` model by passing a list of layer instances to the constructor:
-
-```python
-from keras.models import Sequential
-from keras.layers import Dense, Activation
-
-model = Sequential([
- Dense(32, input_shape=(784,)),
- Activation('relu'),
- Dense(10),
- Activation('softmax'),
-])
-```
-
-You can also simply add layers via the `.add()` method:
-
-```python
-model = Sequential()
-model.add(Dense(32, input_dim=784))
-model.add(Activation('relu'))
-```
-
-----
-
-## Specifying the input shape
-
-The model needs to know what input shape it should expect. For this reason, the first layer in a `Sequential` model (and only the first, because following layers can do automatic shape inference) needs to receive information about its input shape. There are several possible ways to do this:
-
-- Pass an `input_shape` argument to the first layer. This is a shape tuple (a tuple of integers or `None` entries, where `None` indicates that any positive integer may be expected). In `input_shape`, the batch dimension is not included.
-- Some 2D layers, such as `Dense`, support the specification of their input shape via the argument `input_dim`, and some 3D temporal layers support the arguments `input_dim` and `input_length`.
-- If you ever need to specify a fixed batch size for your inputs (this is useful for stateful recurrent networks), you can pass a `batch_size` argument to a layer. If you pass both `batch_size=32` and `input_shape=(6, 8)` to a layer, it will then expect every batch of inputs to have the batch shape `(32, 6, 8)`.
-
-As such, the following snippets are strictly equivalent:
-```python
-model = Sequential()
-model.add(Dense(32, input_shape=(784,)))
-```
-```python
-model = Sequential()
-model.add(Dense(32, input_dim=784))
-```
-
-----
-
-## Compilation
-
-Before training a model, you need to configure the learning process, which is done via the `compile` method. It receives three arguments:
-
-- An optimizer. This could be the string identifier of an existing optimizer (such as `rmsprop` or `adagrad`), or an instance of the `Optimizer` class. See: [optimizers](/optimizers).
-- A loss function. This is the objective that the model will try to minimize. It can be the string identifier of an existing loss function (such as `categorical_crossentropy` or `mse`), or it can be an objective function. See: [losses](/losses).
-- A list of metrics. For any classification problem you will want to set this to `metrics=['accuracy']`. A metric could be the string identifier of an existing metric or a custom metric function. See: [metrics](/metrics).
-
-```python
-# For a multi-class classification problem
-model.compile(optimizer='rmsprop',
- loss='categorical_crossentropy',
- metrics=['accuracy'])
-
-# For a binary classification problem
-model.compile(optimizer='rmsprop',
- loss='binary_crossentropy',
- metrics=['accuracy'])
-
-# For a mean squared error regression problem
-model.compile(optimizer='rmsprop',
- loss='mse')
-
-# For custom metrics
-import keras.backend as K
-
-def mean_pred(y_true, y_pred):
- return K.mean(y_pred)
-
-model.compile(optimizer='rmsprop',
- loss='binary_crossentropy',
- metrics=['accuracy', mean_pred])
-```
-
-----
-
-## Training
-
-Keras models are trained on Numpy arrays of input data and labels. For training a model, you will typically use the `fit` function. [Read its documentation here](/models/sequential).
-
-```python
-# For a single-input model with 2 classes (binary classification):
-
-model = Sequential()
-model.add(Dense(32, activation='relu', input_dim=100))
-model.add(Dense(1, activation='sigmoid'))
-model.compile(optimizer='rmsprop',
- loss='binary_crossentropy',
- metrics=['accuracy'])
-
-# Generate dummy data
-import numpy as np
-data = np.random.random((1000, 100))
-labels = np.random.randint(2, size=(1000, 1))
-
-# Train the model, iterating on the data in batches of 32 samples
-model.fit(data, labels, epochs=10, batch_size=32)
-```
-
-```python
-# For a single-input model with 10 classes (categorical classification):
-
-model = Sequential()
-model.add(Dense(32, activation='relu', input_dim=100))
-model.add(Dense(10, activation='softmax'))
-model.compile(optimizer='rmsprop',
- loss='categorical_crossentropy',
- metrics=['accuracy'])
-
-# Generate dummy data
-import numpy as np
-data = np.random.random((1000, 100))
-labels = np.random.randint(10, size=(1000, 1))
-
-# Convert labels to categorical one-hot encoding
-one_hot_labels = keras.utils.to_categorical(labels, num_classes=10)
-
-# Train the model, iterating on the data in batches of 32 samples
-model.fit(data, one_hot_labels, epochs=10, batch_size=32)
-```
-
-----
-
-
-## Examples
-
-Here are a few examples to get you started!
-
-In the [examples folder](https://github.com/keras-team/keras/tree/master/examples), you will also find example models for real datasets:
-
-- CIFAR10 small images classification: Convolutional Neural Network (CNN) with realtime data augmentation
-- IMDB movie review sentiment classification: LSTM over sequences of words
-- Reuters newswires topic classification: Multilayer Perceptron (MLP)
-- MNIST handwritten digits classification: MLP & CNN
-- Character-level text generation with LSTM
-
-...and more.
-
-
-### Multilayer Perceptron (MLP) for multi-class softmax classification:
-
-```python
-import keras
-from keras.models import Sequential
-from keras.layers import Dense, Dropout, Activation
-from keras.optimizers import SGD
-
-# Generate dummy data
-import numpy as np
-x_train = np.random.random((1000, 20))
-y_train = keras.utils.to_categorical(np.random.randint(10, size=(1000, 1)), num_classes=10)
-x_test = np.random.random((100, 20))
-y_test = keras.utils.to_categorical(np.random.randint(10, size=(100, 1)), num_classes=10)
-
-model = Sequential()
-# Dense(64) is a fully-connected layer with 64 hidden units.
-# in the first layer, you must specify the expected input data shape:
-# here, 20-dimensional vectors.
-model.add(Dense(64, activation='relu', input_dim=20))
-model.add(Dropout(0.5))
-model.add(Dense(64, activation='relu'))
-model.add(Dropout(0.5))
-model.add(Dense(10, activation='softmax'))
-
-sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
-model.compile(loss='categorical_crossentropy',
- optimizer=sgd,
- metrics=['accuracy'])
-
-model.fit(x_train, y_train,
- epochs=20,
- batch_size=128)
-score = model.evaluate(x_test, y_test, batch_size=128)
-```
-
-
-### MLP for binary classification:
-
-```python
-import numpy as np
-from keras.models import Sequential
-from keras.layers import Dense, Dropout
-
-# Generate dummy data
-x_train = np.random.random((1000, 20))
-y_train = np.random.randint(2, size=(1000, 1))
-x_test = np.random.random((100, 20))
-y_test = np.random.randint(2, size=(100, 1))
-
-model = Sequential()
-model.add(Dense(64, input_dim=20, activation='relu'))
-model.add(Dropout(0.5))
-model.add(Dense(64, activation='relu'))
-model.add(Dropout(0.5))
-model.add(Dense(1, activation='sigmoid'))
-
-model.compile(loss='binary_crossentropy',
- optimizer='rmsprop',
- metrics=['accuracy'])
-
-model.fit(x_train, y_train,
- epochs=20,
- batch_size=128)
-score = model.evaluate(x_test, y_test, batch_size=128)
-```
-
-
-### VGG-like convnet:
-
-```python
-import numpy as np
-import keras
-from keras.models import Sequential
-from keras.layers import Dense, Dropout, Flatten
-from keras.layers import Conv2D, MaxPooling2D
-from keras.optimizers import SGD
-
-# Generate dummy data
-x_train = np.random.random((100, 100, 100, 3))
-y_train = keras.utils.to_categorical(np.random.randint(10, size=(100, 1)), num_classes=10)
-x_test = np.random.random((20, 100, 100, 3))
-y_test = keras.utils.to_categorical(np.random.randint(10, size=(20, 1)), num_classes=10)
-
-model = Sequential()
-# input: 100x100 images with 3 channels -> (100, 100, 3) tensors.
-# this applies 32 convolution filters of size 3x3 each.
-model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(100, 100, 3)))
-model.add(Conv2D(32, (3, 3), activation='relu'))
-model.add(MaxPooling2D(pool_size=(2, 2)))
-model.add(Dropout(0.25))
-
-model.add(Conv2D(64, (3, 3), activation='relu'))
-model.add(Conv2D(64, (3, 3), activation='relu'))
-model.add(MaxPooling2D(pool_size=(2, 2)))
-model.add(Dropout(0.25))
-
-model.add(Flatten())
-model.add(Dense(256, activation='relu'))
-model.add(Dropout(0.5))
-model.add(Dense(10, activation='softmax'))
-
-sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
-model.compile(loss='categorical_crossentropy', optimizer=sgd)
-
-model.fit(x_train, y_train, batch_size=32, epochs=10)
-score = model.evaluate(x_test, y_test, batch_size=32)
-```
-
-
-### Sequence classification with LSTM:
-
-```python
-from keras.models import Sequential
-from keras.layers import Dense, Dropout
-from keras.layers import Embedding
-from keras.layers import LSTM
-
-max_features = 1024
-
-model = Sequential()
-model.add(Embedding(max_features, output_dim=256))
-model.add(LSTM(128))
-model.add(Dropout(0.5))
-model.add(Dense(1, activation='sigmoid'))
-
-model.compile(loss='binary_crossentropy',
- optimizer='rmsprop',
- metrics=['accuracy'])
-
-model.fit(x_train, y_train, batch_size=16, epochs=10)
-score = model.evaluate(x_test, y_test, batch_size=16)
-```
-
-### Sequence classification with 1D convolutions:
-
-```python
-from keras.models import Sequential
-from keras.layers import Dense, Dropout
-from keras.layers import Embedding
-from keras.layers import Conv1D, GlobalAveragePooling1D, MaxPooling1D
-
-seq_length = 64
-
-model = Sequential()
-model.add(Conv1D(64, 3, activation='relu', input_shape=(seq_length, 100)))
-model.add(Conv1D(64, 3, activation='relu'))
-model.add(MaxPooling1D(3))
-model.add(Conv1D(128, 3, activation='relu'))
-model.add(Conv1D(128, 3, activation='relu'))
-model.add(GlobalAveragePooling1D())
-model.add(Dropout(0.5))
-model.add(Dense(1, activation='sigmoid'))
-
-model.compile(loss='binary_crossentropy',
- optimizer='rmsprop',
- metrics=['accuracy'])
-
-model.fit(x_train, y_train, batch_size=16, epochs=10)
-score = model.evaluate(x_test, y_test, batch_size=16)
-```
-
-### Stacked LSTM for sequence classification
-
-In this model, we stack 3 LSTM layers on top of each other,
-making the model capable of learning higher-level temporal representations.
-
-The first two LSTMs return their full output sequences, but the last one only returns
-the last step in its output sequence, thus dropping the temporal dimension
-(i.e. converting the input sequence into a single vector).
-
-
-
-Let's implement it with the functional API.
-
-The main input will receive the headline, as a sequence of integers (each integer encodes a word).
-The integers will be between 1 and 10,000 (a vocabulary of 10,000 words) and the sequences will be 100 words long.
-
-```python
-from keras.layers import Input, Embedding, LSTM, Dense
-from keras.models import Model
-import numpy as np
-np.random.seed(0) # Set a random seed for reproducibility
-
-# Headline input: meant to receive sequences of 100 integers, between 1 and 10000.
-# Note that we can name any layer by passing it a "name" argument.
-main_input = Input(shape=(100,), dtype='int32', name='main_input')
-
-# This embedding layer will encode the input sequence
-# into a sequence of dense 512-dimensional vectors.
-x = Embedding(output_dim=512, input_dim=10000, input_length=100)(main_input)
-
-# A LSTM will transform the vector sequence into a single vector,
-# containing information about the entire sequence
-lstm_out = LSTM(32)(x)
-```
-
-Here we insert the auxiliary loss, allowing the LSTM and Embedding layer to be trained smoothly even though the main loss will be much higher in the model.
-
-```python
-auxiliary_output = Dense(1, activation='sigmoid', name='aux_output')(lstm_out)
-```
-
-At this point, we feed into the model our auxiliary input data by concatenating it with the LSTM output:
-
-```python
-auxiliary_input = Input(shape=(5,), name='aux_input')
-x = keras.layers.concatenate([lstm_out, auxiliary_input])
-
-# We stack a deep densely-connected network on top
-x = Dense(64, activation='relu')(x)
-x = Dense(64, activation='relu')(x)
-x = Dense(64, activation='relu')(x)
-
-# And finally we add the main logistic regression layer
-main_output = Dense(1, activation='sigmoid', name='main_output')(x)
-```
-
-This defines a model with two inputs and two outputs:
-
-```python
-model = Model(inputs=[main_input, auxiliary_input], outputs=[main_output, auxiliary_output])
-```
-
-We compile the model and assign a weight of 0.2 to the auxiliary loss.
-To specify different `loss_weights` or `loss` for each different output, you can use a list or a dictionary.
-Here we pass a single loss as the `loss` argument, so the same loss will be used on all outputs.
-
-```python
-model.compile(optimizer='rmsprop', loss='binary_crossentropy',
- loss_weights=[1., 0.2])
-```
-
-We can train the model by passing it lists of input arrays and target arrays:
-
-```python
-headline_data = np.round(np.abs(np.random.rand(12, 100) * 100))
-additional_data = np.random.randn(12, 5)
-headline_labels = np.random.randn(12, 1)
-additional_labels = np.random.randn(12, 1)
-model.fit([headline_data, additional_data], [headline_labels, additional_labels],
- epochs=50, batch_size=32)
-```
-
-Since our inputs and outputs are named (we passed them a "name" argument),
-we could also have compiled the model via:
-
-```python
-model.compile(optimizer='rmsprop',
- loss={'main_output': 'binary_crossentropy', 'aux_output': 'binary_crossentropy'},
- loss_weights={'main_output': 1., 'aux_output': 0.2})
-
-# And trained it via:
-model.fit({'main_input': headline_data, 'aux_input': additional_data},
- {'main_output': headline_labels, 'aux_output': additional_labels},
- epochs=50, batch_size=32)
-```
-
-To use the model for inferencing, use
-```python
-model.predict({'main_input': headline_data, 'aux_input': additional_data})
-```
-or alternatively,
-```python
-pred = model.predict([headline_data, additional_data])
-```
-
------
-
-## Shared layers
-
-Another good use for the functional API are models that use shared layers. Let's take a look at shared layers.
-
-Let's consider a dataset of tweets. We want to build a model that can tell whether two tweets are from the same person or not (this can allow us to compare users by the similarity of their tweets, for instance).
-
-One way to achieve this is to build a model that encodes two tweets into two vectors, concatenates the vectors and then adds a logistic regression; this outputs a probability that the two tweets share the same author. The model would then be trained on positive tweet pairs and negative tweet pairs.
-
-Because the problem is symmetric, the mechanism that encodes the first tweet should be reused (weights and all) to encode the second tweet. Here we use a shared LSTM layer to encode the tweets.
-
-Let's build this with the functional API. We will take as input for a tweet a binary matrix of shape `(280, 256)`, i.e. a sequence of 280 vectors of size 256, where each dimension in the 256-dimensional vector encodes the presence/absence of a character (out of an alphabet of 256 frequent characters).
-
-```python
-import keras
-from keras.layers import Input, LSTM, Dense
-from keras.models import Model
-
-tweet_a = Input(shape=(280, 256))
-tweet_b = Input(shape=(280, 256))
-```
-
-To share a layer across different inputs, simply instantiate the layer once, then call it on as many inputs as you want:
-
-```python
-# This layer can take as input a matrix
-# and will return a vector of size 64
-shared_lstm = LSTM(64)
-
-# When we reuse the same layer instance
-# multiple times, the weights of the layer
-# are also being reused
-# (it is effectively *the same* layer)
-encoded_a = shared_lstm(tweet_a)
-encoded_b = shared_lstm(tweet_b)
-
-# We can then concatenate the two vectors:
-merged_vector = keras.layers.concatenate([encoded_a, encoded_b], axis=-1)
-
-# And add a logistic regression on top
-predictions = Dense(1, activation='sigmoid')(merged_vector)
-
-# We define a trainable model linking the
-# tweet inputs to the predictions
-model = Model(inputs=[tweet_a, tweet_b], outputs=predictions)
-
-model.compile(optimizer='rmsprop',
- loss='binary_crossentropy',
- metrics=['accuracy'])
-model.fit([data_a, data_b], labels, epochs=10)
-```
-
-Let's pause to take a look at how to read the shared layer's output or output shape.
-
------
-
-## The concept of layer "node"
-
-Whenever you are calling a layer on some input, you are creating a new tensor (the output of the layer), and you are adding a "node" to the layer, linking the input tensor to the output tensor. When you are calling the same layer multiple times, that layer owns multiple nodes indexed as 0, 1, 2...
-
-In previous versions of Keras, you could obtain the output tensor of a layer instance via `layer.get_output()`, or its output shape via `layer.output_shape`. You still can (except `get_output()` has been replaced by the property `output`). But what if a layer is connected to multiple inputs?
-
-As long as a layer is only connected to one input, there is no confusion, and `.output` will return the one output of the layer:
-
-```python
-a = Input(shape=(280, 256))
-
-lstm = LSTM(32)
-encoded_a = lstm(a)
-
-assert lstm.output == encoded_a
-```
-
-Not so if the layer has multiple inputs:
-```python
-a = Input(shape=(280, 256))
-b = Input(shape=(280, 256))
-
-lstm = LSTM(32)
-encoded_a = lstm(a)
-encoded_b = lstm(b)
-
-lstm.output
-```
-```
->> AttributeError: Layer lstm_1 has multiple inbound nodes,
-hence the notion of "layer output" is ill-defined.
-Use `get_output_at(node_index)` instead.
-```
-
-Okay then. The following works:
-
-```python
-assert lstm.get_output_at(0) == encoded_a
-assert lstm.get_output_at(1) == encoded_b
-```
-
-Simple enough, right?
-
-The same is true for the properties `input_shape` and `output_shape`: as long as the layer has only one node, or as long as all nodes have the same input/output shape, then the notion of "layer output/input shape" is well defined, and that one shape will be returned by `layer.output_shape`/`layer.input_shape`. But if, for instance, you apply the same `Conv2D` layer to an input of shape `(32, 32, 3)`, and then to an input of shape `(64, 64, 3)`, the layer will have multiple input/output shapes, and you will have to fetch them by specifying the index of the node they belong to:
-
-```python
-a = Input(shape=(32, 32, 3))
-b = Input(shape=(64, 64, 3))
-
-conv = Conv2D(16, (3, 3), padding='same')
-conved_a = conv(a)
-
-# Only one input so far, the following will work:
-assert conv.input_shape == (None, 32, 32, 3)
-
-conved_b = conv(b)
-# now the `.input_shape` property wouldn't work, but this does:
-assert conv.get_input_shape_at(0) == (None, 32, 32, 3)
-assert conv.get_input_shape_at(1) == (None, 64, 64, 3)
-```
-
------
-
-## More examples
-
-Code examples are still the best way to get started, so here are a few more.
-
-### Inception module
-
-For more information about the Inception architecture, see [Going Deeper with Convolutions](http://arxiv.org/abs/1409.4842).
-
-```python
-from keras.layers import Conv2D, MaxPooling2D, Input
-
-input_img = Input(shape=(256, 256, 3))
-
-tower_1 = Conv2D(64, (1, 1), padding='same', activation='relu')(input_img)
-tower_1 = Conv2D(64, (3, 3), padding='same', activation='relu')(tower_1)
-
-tower_2 = Conv2D(64, (1, 1), padding='same', activation='relu')(input_img)
-tower_2 = Conv2D(64, (5, 5), padding='same', activation='relu')(tower_2)
-
-tower_3 = MaxPooling2D((3, 3), strides=(1, 1), padding='same')(input_img)
-tower_3 = Conv2D(64, (1, 1), padding='same', activation='relu')(tower_3)
-
-output = keras.layers.concatenate([tower_1, tower_2, tower_3], axis=1)
-```
-
-### Residual connection on a convolution layer
-
-For more information about residual networks, see [Deep Residual Learning for Image Recognition](http://arxiv.org/abs/1512.03385).
-
-```python
-from keras.layers import Conv2D, Input
-
-# input tensor for a 3-channel 256x256 image
-x = Input(shape=(256, 256, 3))
-# 3x3 conv with 3 output channels (same as input channels)
-y = Conv2D(3, (3, 3), padding='same')(x)
-# this returns x + y.
-z = keras.layers.add([x, y])
-```
-
-### Shared vision model
-
-This model reuses the same image-processing module on two inputs, to classify whether two MNIST digits are the same digit or different digits.
-
-```python
-from keras.layers import Conv2D, MaxPooling2D, Input, Dense, Flatten
-from keras.models import Model
-
-# First, define the vision modules
-digit_input = Input(shape=(27, 27, 1))
-x = Conv2D(64, (3, 3))(digit_input)
-x = Conv2D(64, (3, 3))(x)
-x = MaxPooling2D((2, 2))(x)
-out = Flatten()(x)
-
-vision_model = Model(digit_input, out)
-
-# Then define the tell-digits-apart model
-digit_a = Input(shape=(27, 27, 1))
-digit_b = Input(shape=(27, 27, 1))
-
-# The vision model will be shared, weights and all
-out_a = vision_model(digit_a)
-out_b = vision_model(digit_b)
-
-concatenated = keras.layers.concatenate([out_a, out_b])
-out = Dense(1, activation='sigmoid')(concatenated)
-
-classification_model = Model([digit_a, digit_b], out)
-```
-
-### Visual question answering model
-
-This model can select the correct one-word answer when asked a natural-language question about a picture.
-
-It works by encoding the question into a vector, encoding the image into a vector, concatenating the two, and training on top a logistic regression over some vocabulary of potential answers.
-
-```python
-from keras.layers import Conv2D, MaxPooling2D, Flatten
-from keras.layers import Input, LSTM, Embedding, Dense
-from keras.models import Model, Sequential
-
-# First, let's define a vision model using a Sequential model.
-# This model will encode an image into a vector.
-vision_model = Sequential()
-vision_model.add(Conv2D(64, (3, 3), activation='relu', padding='same', input_shape=(224, 224, 3)))
-vision_model.add(Conv2D(64, (3, 3), activation='relu'))
-vision_model.add(MaxPooling2D((2, 2)))
-vision_model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))
-vision_model.add(Conv2D(128, (3, 3), activation='relu'))
-vision_model.add(MaxPooling2D((2, 2)))
-vision_model.add(Conv2D(256, (3, 3), activation='relu', padding='same'))
-vision_model.add(Conv2D(256, (3, 3), activation='relu'))
-vision_model.add(Conv2D(256, (3, 3), activation='relu'))
-vision_model.add(MaxPooling2D((2, 2)))
-vision_model.add(Flatten())
-
-# Now let's get a tensor with the output of our vision model:
-image_input = Input(shape=(224, 224, 3))
-encoded_image = vision_model(image_input)
-
-# Next, let's define a language model to encode the question into a vector.
-# Each question will be at most 100 words long,
-# and we will index words as integers from 1 to 9999.
-question_input = Input(shape=(100,), dtype='int32')
-embedded_question = Embedding(input_dim=10000, output_dim=256, input_length=100)(question_input)
-encoded_question = LSTM(256)(embedded_question)
-
-# Let's concatenate the question vector and the image vector:
-merged = keras.layers.concatenate([encoded_question, encoded_image])
-
-# And let's train a logistic regression over 1000 words on top:
-output = Dense(1000, activation='softmax')(merged)
-
-# This is our final model:
-vqa_model = Model(inputs=[image_input, question_input], outputs=output)
-
-# The next stage would be training this model on actual data.
-```
-
-### Video question answering model
-
-Now that we have trained our image QA model, we can quickly turn it into a video QA model. With appropriate training, you will be able to show it a short video (e.g. 100-frame human action) and ask a natural language question about the video (e.g. "what sport is the boy playing?" -> "football").
-
-```python
-from keras.layers import TimeDistributed
-
-video_input = Input(shape=(100, 224, 224, 3))
-# This is our video encoded via the previously trained vision_model (weights are reused)
-encoded_frame_sequence = TimeDistributed(vision_model)(video_input) # the output will be a sequence of vectors
-encoded_video = LSTM(256)(encoded_frame_sequence) # the output will be a vector
-
-# This is a model-level representation of the question encoder, reusing the same weights as before:
-question_encoder = Model(inputs=question_input, outputs=encoded_question)
-
-# Let's use it to encode the question:
-video_question_input = Input(shape=(100,), dtype='int32')
-encoded_video_question = question_encoder(video_question_input)
-
-# And this is our video question answering model:
-merged = keras.layers.concatenate([encoded_video, encoded_video_question])
-output = Dense(1000, activation='softmax')(merged)
-video_qa_model = Model(inputs=[video_input, video_question_input], outputs=output)
-```
diff --git a/docs/templates/getting-started/sequential-model-guide.md b/docs/templates/getting-started/sequential-model-guide.md
deleted file mode 100644
index 853811f65ad..00000000000
--- a/docs/templates/getting-started/sequential-model-guide.md
+++ /dev/null
@@ -1,399 +0,0 @@
-# Getting started with the Keras Sequential model
-
-The `Sequential` model is a linear stack of layers.
-
-You can create a `Sequential` model by passing a list of layer instances to the constructor:
-
-```python
-from keras.models import Sequential
-from keras.layers import Dense, Activation
-
-model = Sequential([
- Dense(32, input_shape=(784,)),
- Activation('relu'),
- Dense(10),
- Activation('softmax'),
-])
-```
-
-You can also simply add layers via the `.add()` method:
-
-```python
-model = Sequential()
-model.add(Dense(32, input_dim=784))
-model.add(Activation('relu'))
-```
-
-----
-
-## Specifying the input shape
-
-The model needs to know what input shape it should expect. For this reason, the first layer in a `Sequential` model (and only the first, because following layers can do automatic shape inference) needs to receive information about its input shape. There are several possible ways to do this:
-
-- Pass an `input_shape` argument to the first layer. This is a shape tuple (a tuple of integers or `None` entries, where `None` indicates that any positive integer may be expected). In `input_shape`, the batch dimension is not included.
-- Some 2D layers, such as `Dense`, support the specification of their input shape via the argument `input_dim`, and some 3D temporal layers support the arguments `input_dim` and `input_length`.
-- If you ever need to specify a fixed batch size for your inputs (this is useful for stateful recurrent networks), you can pass a `batch_size` argument to a layer. If you pass both `batch_size=32` and `input_shape=(6, 8)` to a layer, it will then expect every batch of inputs to have the batch shape `(32, 6, 8)`.
-
-As such, the following snippets are strictly equivalent:
-```python
-model = Sequential()
-model.add(Dense(32, input_shape=(784,)))
-```
-```python
-model = Sequential()
-model.add(Dense(32, input_dim=784))
-```
-
-----
-
-## Compilation
-
-Before training a model, you need to configure the learning process, which is done via the `compile` method. It receives three arguments:
-
-- An optimizer. This could be the string identifier of an existing optimizer (such as `rmsprop` or `adagrad`), or an instance of the `Optimizer` class. See: [optimizers](/optimizers).
-- A loss function. This is the objective that the model will try to minimize. It can be the string identifier of an existing loss function (such as `categorical_crossentropy` or `mse`), or it can be an objective function. See: [losses](/losses).
-- A list of metrics. For any classification problem you will want to set this to `metrics=['accuracy']`. A metric could be the string identifier of an existing metric or a custom metric function. See: [metrics](/metrics).
-
-```python
-# For a multi-class classification problem
-model.compile(optimizer='rmsprop',
- loss='categorical_crossentropy',
- metrics=['accuracy'])
-
-# For a binary classification problem
-model.compile(optimizer='rmsprop',
- loss='binary_crossentropy',
- metrics=['accuracy'])
-
-# For a mean squared error regression problem
-model.compile(optimizer='rmsprop',
- loss='mse')
-
-# For custom metrics
-import keras.backend as K
-
-def mean_pred(y_true, y_pred):
- return K.mean(y_pred)
-
-model.compile(optimizer='rmsprop',
- loss='binary_crossentropy',
- metrics=['accuracy', mean_pred])
-```
-
-----
-
-## Training
-
-Keras models are trained on Numpy arrays of input data and labels. For training a model, you will typically use the `fit` function. [Read its documentation here](/models/sequential).
-
-```python
-# For a single-input model with 2 classes (binary classification):
-
-model = Sequential()
-model.add(Dense(32, activation='relu', input_dim=100))
-model.add(Dense(1, activation='sigmoid'))
-model.compile(optimizer='rmsprop',
- loss='binary_crossentropy',
- metrics=['accuracy'])
-
-# Generate dummy data
-import numpy as np
-data = np.random.random((1000, 100))
-labels = np.random.randint(2, size=(1000, 1))
-
-# Train the model, iterating on the data in batches of 32 samples
-model.fit(data, labels, epochs=10, batch_size=32)
-```
-
-```python
-# For a single-input model with 10 classes (categorical classification):
-
-model = Sequential()
-model.add(Dense(32, activation='relu', input_dim=100))
-model.add(Dense(10, activation='softmax'))
-model.compile(optimizer='rmsprop',
- loss='categorical_crossentropy',
- metrics=['accuracy'])
-
-# Generate dummy data
-import numpy as np
-data = np.random.random((1000, 100))
-labels = np.random.randint(10, size=(1000, 1))
-
-# Convert labels to categorical one-hot encoding
-one_hot_labels = keras.utils.to_categorical(labels, num_classes=10)
-
-# Train the model, iterating on the data in batches of 32 samples
-model.fit(data, one_hot_labels, epochs=10, batch_size=32)
-```
-
-----
-
-
-## Examples
-
-Here are a few examples to get you started!
-
-In the [examples folder](https://github.com/keras-team/keras/tree/master/examples), you will also find example models for real datasets:
-
-- CIFAR10 small images classification: Convolutional Neural Network (CNN) with realtime data augmentation
-- IMDB movie review sentiment classification: LSTM over sequences of words
-- Reuters newswires topic classification: Multilayer Perceptron (MLP)
-- MNIST handwritten digits classification: MLP & CNN
-- Character-level text generation with LSTM
-
-...and more.
-
-
-### Multilayer Perceptron (MLP) for multi-class softmax classification:
-
-```python
-import keras
-from keras.models import Sequential
-from keras.layers import Dense, Dropout, Activation
-from keras.optimizers import SGD
-
-# Generate dummy data
-import numpy as np
-x_train = np.random.random((1000, 20))
-y_train = keras.utils.to_categorical(np.random.randint(10, size=(1000, 1)), num_classes=10)
-x_test = np.random.random((100, 20))
-y_test = keras.utils.to_categorical(np.random.randint(10, size=(100, 1)), num_classes=10)
-
-model = Sequential()
-# Dense(64) is a fully-connected layer with 64 hidden units.
-# in the first layer, you must specify the expected input data shape:
-# here, 20-dimensional vectors.
-model.add(Dense(64, activation='relu', input_dim=20))
-model.add(Dropout(0.5))
-model.add(Dense(64, activation='relu'))
-model.add(Dropout(0.5))
-model.add(Dense(10, activation='softmax'))
-
-sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
-model.compile(loss='categorical_crossentropy',
- optimizer=sgd,
- metrics=['accuracy'])
-
-model.fit(x_train, y_train,
- epochs=20,
- batch_size=128)
-score = model.evaluate(x_test, y_test, batch_size=128)
-```
-
-
-### MLP for binary classification:
-
-```python
-import numpy as np
-from keras.models import Sequential
-from keras.layers import Dense, Dropout
-
-# Generate dummy data
-x_train = np.random.random((1000, 20))
-y_train = np.random.randint(2, size=(1000, 1))
-x_test = np.random.random((100, 20))
-y_test = np.random.randint(2, size=(100, 1))
-
-model = Sequential()
-model.add(Dense(64, input_dim=20, activation='relu'))
-model.add(Dropout(0.5))
-model.add(Dense(64, activation='relu'))
-model.add(Dropout(0.5))
-model.add(Dense(1, activation='sigmoid'))
-
-model.compile(loss='binary_crossentropy',
- optimizer='rmsprop',
- metrics=['accuracy'])
-
-model.fit(x_train, y_train,
- epochs=20,
- batch_size=128)
-score = model.evaluate(x_test, y_test, batch_size=128)
-```
-
-
-### VGG-like convnet:
-
-```python
-import numpy as np
-import keras
-from keras.models import Sequential
-from keras.layers import Dense, Dropout, Flatten
-from keras.layers import Conv2D, MaxPooling2D
-from keras.optimizers import SGD
-
-# Generate dummy data
-x_train = np.random.random((100, 100, 100, 3))
-y_train = keras.utils.to_categorical(np.random.randint(10, size=(100, 1)), num_classes=10)
-x_test = np.random.random((20, 100, 100, 3))
-y_test = keras.utils.to_categorical(np.random.randint(10, size=(20, 1)), num_classes=10)
-
-model = Sequential()
-# input: 100x100 images with 3 channels -> (100, 100, 3) tensors.
-# this applies 32 convolution filters of size 3x3 each.
-model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(100, 100, 3)))
-model.add(Conv2D(32, (3, 3), activation='relu'))
-model.add(MaxPooling2D(pool_size=(2, 2)))
-model.add(Dropout(0.25))
-
-model.add(Conv2D(64, (3, 3), activation='relu'))
-model.add(Conv2D(64, (3, 3), activation='relu'))
-model.add(MaxPooling2D(pool_size=(2, 2)))
-model.add(Dropout(0.25))
-
-model.add(Flatten())
-model.add(Dense(256, activation='relu'))
-model.add(Dropout(0.5))
-model.add(Dense(10, activation='softmax'))
-
-sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
-model.compile(loss='categorical_crossentropy', optimizer=sgd)
-
-model.fit(x_train, y_train, batch_size=32, epochs=10)
-score = model.evaluate(x_test, y_test, batch_size=32)
-```
-
-
-### Sequence classification with LSTM:
-
-```python
-from keras.models import Sequential
-from keras.layers import Dense, Dropout
-from keras.layers import Embedding
-from keras.layers import LSTM
-
-max_features = 1024
-
-model = Sequential()
-model.add(Embedding(max_features, output_dim=256))
-model.add(LSTM(128))
-model.add(Dropout(0.5))
-model.add(Dense(1, activation='sigmoid'))
-
-model.compile(loss='binary_crossentropy',
- optimizer='rmsprop',
- metrics=['accuracy'])
-
-model.fit(x_train, y_train, batch_size=16, epochs=10)
-score = model.evaluate(x_test, y_test, batch_size=16)
-```
-
-### Sequence classification with 1D convolutions:
-
-```python
-from keras.models import Sequential
-from keras.layers import Dense, Dropout
-from keras.layers import Embedding
-from keras.layers import Conv1D, GlobalAveragePooling1D, MaxPooling1D
-
-seq_length = 64
-
-model = Sequential()
-model.add(Conv1D(64, 3, activation='relu', input_shape=(seq_length, 100)))
-model.add(Conv1D(64, 3, activation='relu'))
-model.add(MaxPooling1D(3))
-model.add(Conv1D(128, 3, activation='relu'))
-model.add(Conv1D(128, 3, activation='relu'))
-model.add(GlobalAveragePooling1D())
-model.add(Dropout(0.5))
-model.add(Dense(1, activation='sigmoid'))
-
-model.compile(loss='binary_crossentropy',
- optimizer='rmsprop',
- metrics=['accuracy'])
-
-model.fit(x_train, y_train, batch_size=16, epochs=10)
-score = model.evaluate(x_test, y_test, batch_size=16)
-```
-
-### Stacked LSTM for sequence classification
-
-In this model, we stack 3 LSTM layers on top of each other,
-making the model capable of learning higher-level temporal representations.
-
-The first two LSTMs return their full output sequences, but the last one only returns
-the last step in its output sequence, thus dropping the temporal dimension
-(i.e. converting the input sequence into a single vector).
-
-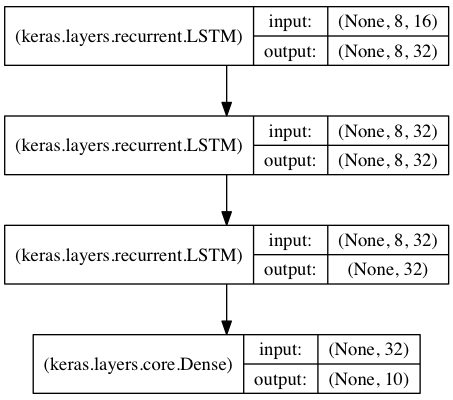 -
-```python
-from keras.models import Sequential
-from keras.layers import LSTM, Dense
-import numpy as np
-
-data_dim = 16
-timesteps = 8
-num_classes = 10
-
-# expected input data shape: (batch_size, timesteps, data_dim)
-model = Sequential()
-model.add(LSTM(32, return_sequences=True,
- input_shape=(timesteps, data_dim))) # returns a sequence of vectors of dimension 32
-model.add(LSTM(32, return_sequences=True)) # returns a sequence of vectors of dimension 32
-model.add(LSTM(32)) # return a single vector of dimension 32
-model.add(Dense(10, activation='softmax'))
-
-model.compile(loss='categorical_crossentropy',
- optimizer='rmsprop',
- metrics=['accuracy'])
-
-# Generate dummy training data
-x_train = np.random.random((1000, timesteps, data_dim))
-y_train = np.random.random((1000, num_classes))
-
-# Generate dummy validation data
-x_val = np.random.random((100, timesteps, data_dim))
-y_val = np.random.random((100, num_classes))
-
-model.fit(x_train, y_train,
- batch_size=64, epochs=5,
- validation_data=(x_val, y_val))
-```
-
-
-### Same stacked LSTM model, rendered "stateful"
-
-A stateful recurrent model is one for which the internal states (memories) obtained after processing a batch
-of samples are reused as initial states for the samples of the next batch. This allows to process longer sequences
-while keeping computational complexity manageable.
-
-[You can read more about stateful RNNs in the FAQ.](/getting-started/faq/#how-can-i-use-stateful-rnns)
-
-```python
-from keras.models import Sequential
-from keras.layers import LSTM, Dense
-import numpy as np
-
-data_dim = 16
-timesteps = 8
-num_classes = 10
-batch_size = 32
-
-# Expected input batch shape: (batch_size, timesteps, data_dim)
-# Note that we have to provide the full batch_input_shape since the network is stateful.
-# the sample of index i in batch k is the follow-up for the sample i in batch k-1.
-model = Sequential()
-model.add(LSTM(32, return_sequences=True, stateful=True,
- batch_input_shape=(batch_size, timesteps, data_dim)))
-model.add(LSTM(32, return_sequences=True, stateful=True))
-model.add(LSTM(32, stateful=True))
-model.add(Dense(10, activation='softmax'))
-
-model.compile(loss='categorical_crossentropy',
- optimizer='rmsprop',
- metrics=['accuracy'])
-
-# Generate dummy training data
-x_train = np.random.random((batch_size * 10, timesteps, data_dim))
-y_train = np.random.random((batch_size * 10, num_classes))
-
-# Generate dummy validation data
-x_val = np.random.random((batch_size * 3, timesteps, data_dim))
-y_val = np.random.random((batch_size * 3, num_classes))
-
-model.fit(x_train, y_train,
- batch_size=batch_size, epochs=5, shuffle=False,
- validation_data=(x_val, y_val))
-```
diff --git a/docs/templates/index.md b/docs/templates/index.md
deleted file mode 100644
index 2969073ec56..00000000000
--- a/docs/templates/index.md
+++ /dev/null
@@ -1,5 +0,0 @@
-# Keras: The Python Deep Learning library
-
-
-
-```python
-from keras.models import Sequential
-from keras.layers import LSTM, Dense
-import numpy as np
-
-data_dim = 16
-timesteps = 8
-num_classes = 10
-
-# expected input data shape: (batch_size, timesteps, data_dim)
-model = Sequential()
-model.add(LSTM(32, return_sequences=True,
- input_shape=(timesteps, data_dim))) # returns a sequence of vectors of dimension 32
-model.add(LSTM(32, return_sequences=True)) # returns a sequence of vectors of dimension 32
-model.add(LSTM(32)) # return a single vector of dimension 32
-model.add(Dense(10, activation='softmax'))
-
-model.compile(loss='categorical_crossentropy',
- optimizer='rmsprop',
- metrics=['accuracy'])
-
-# Generate dummy training data
-x_train = np.random.random((1000, timesteps, data_dim))
-y_train = np.random.random((1000, num_classes))
-
-# Generate dummy validation data
-x_val = np.random.random((100, timesteps, data_dim))
-y_val = np.random.random((100, num_classes))
-
-model.fit(x_train, y_train,
- batch_size=64, epochs=5,
- validation_data=(x_val, y_val))
-```
-
-
-### Same stacked LSTM model, rendered "stateful"
-
-A stateful recurrent model is one for which the internal states (memories) obtained after processing a batch
-of samples are reused as initial states for the samples of the next batch. This allows to process longer sequences
-while keeping computational complexity manageable.
-
-[You can read more about stateful RNNs in the FAQ.](/getting-started/faq/#how-can-i-use-stateful-rnns)
-
-```python
-from keras.models import Sequential
-from keras.layers import LSTM, Dense
-import numpy as np
-
-data_dim = 16
-timesteps = 8
-num_classes = 10
-batch_size = 32
-
-# Expected input batch shape: (batch_size, timesteps, data_dim)
-# Note that we have to provide the full batch_input_shape since the network is stateful.
-# the sample of index i in batch k is the follow-up for the sample i in batch k-1.
-model = Sequential()
-model.add(LSTM(32, return_sequences=True, stateful=True,
- batch_input_shape=(batch_size, timesteps, data_dim)))
-model.add(LSTM(32, return_sequences=True, stateful=True))
-model.add(LSTM(32, stateful=True))
-model.add(Dense(10, activation='softmax'))
-
-model.compile(loss='categorical_crossentropy',
- optimizer='rmsprop',
- metrics=['accuracy'])
-
-# Generate dummy training data
-x_train = np.random.random((batch_size * 10, timesteps, data_dim))
-y_train = np.random.random((batch_size * 10, num_classes))
-
-# Generate dummy validation data
-x_val = np.random.random((batch_size * 3, timesteps, data_dim))
-y_val = np.random.random((batch_size * 3, num_classes))
-
-model.fit(x_train, y_train,
- batch_size=batch_size, epochs=5, shuffle=False,
- validation_data=(x_val, y_val))
-```
diff --git a/docs/templates/index.md b/docs/templates/index.md
deleted file mode 100644
index 2969073ec56..00000000000
--- a/docs/templates/index.md
+++ /dev/null
@@ -1,5 +0,0 @@
-# Keras: The Python Deep Learning library
-
- -
-{{autogenerated}}
\ No newline at end of file
diff --git a/docs/templates/initializers.md b/docs/templates/initializers.md
deleted file mode 100644
index c4e1a637b0a..00000000000
--- a/docs/templates/initializers.md
+++ /dev/null
@@ -1,43 +0,0 @@
-## Usage of initializers
-
-Initializations define the way to set the initial random weights of Keras layers.
-
-The keyword arguments used for passing initializers to layers will depend on the layer. Usually it is simply `kernel_initializer` and `bias_initializer`:
-
-```python
-model.add(Dense(64,
- kernel_initializer='random_uniform',
- bias_initializer='zeros'))
-```
-
-## Available initializers
-
-The following built-in initializers are available as part of the `keras.initializers` module:
-
-{{autogenerated}}
-
-
-An initializer may be passed as a string (must match one of the available initializers above), or as a callable:
-
-```python
-from keras import initializers
-
-model.add(Dense(64, kernel_initializer=initializers.random_normal(stddev=0.01)))
-
-# also works; will use the default parameters.
-model.add(Dense(64, kernel_initializer='random_normal'))
-```
-
-
-## Using custom initializers
-
-If passing a custom callable, then it must take the argument `shape` (shape of the variable to initialize) and `dtype` (dtype of generated values):
-
-```python
-from keras import backend as K
-
-def my_init(shape, dtype=None):
- return K.random_normal(shape, dtype=dtype)
-
-model.add(Dense(64, kernel_initializer=my_init))
-```
diff --git a/docs/templates/layers/about-keras-layers.md b/docs/templates/layers/about-keras-layers.md
deleted file mode 100644
index a12f56062cb..00000000000
--- a/docs/templates/layers/about-keras-layers.md
+++ /dev/null
@@ -1,37 +0,0 @@
-# About Keras layers
-
-All Keras layers have a number of methods in common:
-
-- `layer.get_weights()`: returns the weights of the layer as a list of Numpy arrays.
-- `layer.set_weights(weights)`: sets the weights of the layer from a list of Numpy arrays (with the same shapes as the output of `get_weights`).
-- `layer.get_config()`: returns a dictionary containing the configuration of the layer. The layer can be reinstantiated from its config via:
-
-```python
-layer = Dense(32)
-config = layer.get_config()
-reconstructed_layer = Dense.from_config(config)
-```
-
-Or:
-
-```python
-from keras import layers
-
-config = layer.get_config()
-layer = layers.deserialize({'class_name': layer.__class__.__name__,
- 'config': config})
-```
-
-If a layer has a single node (i.e. if it isn't a shared layer), you can get its input tensor, output tensor, input shape and output shape via:
-
-- `layer.input`
-- `layer.output`
-- `layer.input_shape`
-- `layer.output_shape`
-
-If the layer has multiple nodes (see: [the concept of layer node and shared layers](/getting-started/functional-api-guide/#the-concept-of-layer-node)), you can use the following methods:
-
-- `layer.get_input_at(node_index)`
-- `layer.get_output_at(node_index)`
-- `layer.get_input_shape_at(node_index)`
-- `layer.get_output_shape_at(node_index)`
\ No newline at end of file
diff --git a/docs/templates/layers/writing-your-own-keras-layers.md b/docs/templates/layers/writing-your-own-keras-layers.md
deleted file mode 100644
index eb163306df0..00000000000
--- a/docs/templates/layers/writing-your-own-keras-layers.md
+++ /dev/null
@@ -1,68 +0,0 @@
-# Writing your own Keras layers
-
-For simple, stateless custom operations, you are probably better off using `layers.core.Lambda` layers. But for any custom operation that has trainable weights, you should implement your own layer.
-
-Here is the skeleton of a Keras layer, **as of Keras 2.0** (if you have an older version, please upgrade). There are only three methods you need to implement:
-
-- `build(input_shape)`: this is where you will define your weights. This method must set `self.built = True` at the end, which can be done by calling `super([Layer], self).build()`.
-- `call(x)`: this is where the layer's logic lives. Unless you want your layer to support masking, you only have to care about the first argument passed to `call`: the input tensor.
-- `compute_output_shape(input_shape)`: in case your layer modifies the shape of its input, you should specify here the shape transformation logic. This allows Keras to do automatic shape inference.
-
-```python
-from keras import backend as K
-from keras.layers import Layer
-
-class MyLayer(Layer):
-
- def __init__(self, output_dim, **kwargs):
- self.output_dim = output_dim
- super(MyLayer, self).__init__(**kwargs)
-
- def build(self, input_shape):
- # Create a trainable weight variable for this layer.
- self.kernel = self.add_weight(name='kernel',
- shape=(input_shape[1], self.output_dim),
- initializer='uniform',
- trainable=True)
- super(MyLayer, self).build(input_shape) # Be sure to call this at the end
-
- def call(self, x):
- return K.dot(x, self.kernel)
-
- def compute_output_shape(self, input_shape):
- return (input_shape[0], self.output_dim)
-```
-
-It is also possible to define Keras layers which have multiple input tensors and multiple output tensors. To do this, you should assume that the inputs and outputs of the methods `build(input_shape)`, `call(x)` and `compute_output_shape(input_shape)` are lists. Here is an example, similar to the one above:
-
-```python
-from keras import backend as K
-from keras.layers import Layer
-
-class MyLayer(Layer):
-
- def __init__(self, output_dim, **kwargs):
- self.output_dim = output_dim
- super(MyLayer, self).__init__(**kwargs)
-
- def build(self, input_shape):
- assert isinstance(input_shape, list)
- # Create a trainable weight variable for this layer.
- self.kernel = self.add_weight(name='kernel',
- shape=(input_shape[0][1], self.output_dim),
- initializer='uniform',
- trainable=True)
- super(MyLayer, self).build(input_shape) # Be sure to call this at the end
-
- def call(self, x):
- assert isinstance(x, list)
- a, b = x
- return [K.dot(a, self.kernel) + b, K.mean(b, axis=-1)]
-
- def compute_output_shape(self, input_shape):
- assert isinstance(input_shape, list)
- shape_a, shape_b = input_shape
- return [(shape_a[0], self.output_dim), shape_b[:-1]]
-```
-
-The existing Keras layers provide examples of how to implement almost anything. Never hesitate to read the source code!
diff --git a/docs/templates/losses.md b/docs/templates/losses.md
deleted file mode 100644
index ab5bfbea07f..00000000000
--- a/docs/templates/losses.md
+++ /dev/null
@@ -1,42 +0,0 @@
-
-## Usage of loss functions
-
-A loss function (or objective function, or optimization score function) is one of the two parameters required to compile a model:
-
-```python
-model.compile(loss='mean_squared_error', optimizer='sgd')
-```
-
-```python
-from keras import losses
-
-model.compile(loss=losses.mean_squared_error, optimizer='sgd')
-```
-
-You can either pass the name of an existing loss function, or pass a TensorFlow/Theano symbolic function that returns a scalar for each data-point and takes the following two arguments:
-
-- __y_true__: True labels. TensorFlow/Theano tensor.
-- __y_pred__: Predictions. TensorFlow/Theano tensor of the same shape as y_true.
-
-The actual optimized objective is the mean of the output array across all datapoints.
-
-For a few examples of such functions, check out the [losses source](https://github.com/keras-team/keras/blob/master/keras/losses.py).
-
-## Available loss functions
-
-{{autogenerated}}
-
-----
-
-**Note**: when using the `categorical_crossentropy` loss, your targets should be in categorical format (e.g. if you have 10 classes, the target for each sample should be a 10-dimensional vector that is all-zeros except for a 1 at the index corresponding to the class of the sample). In order to convert *integer targets* into *categorical targets*, you can use the Keras utility `to_categorical`:
-
-```python
-from keras.utils import to_categorical
-
-categorical_labels = to_categorical(int_labels, num_classes=None)
-```
-
-When using the `sparse_categorical_crossentropy` loss, your targets should be *integer targets*.
-If you have categorical targets, you should use `categorical_crossentropy`.
-
-`categorical_crossentropy` is another term for [multi-class log loss](http://wiki.fast.ai/index.php/Log_Loss).
diff --git a/docs/templates/metrics.md b/docs/templates/metrics.md
deleted file mode 100644
index 3bca29ad673..00000000000
--- a/docs/templates/metrics.md
+++ /dev/null
@@ -1,58 +0,0 @@
-
-## Usage of metrics
-
-A metric is a function that is used to judge the performance of your model. Metric functions are to be supplied in the `metrics` parameter when a model is compiled.
-
-```python
-model.compile(loss='mean_squared_error',
- optimizer='sgd',
- metrics=['mae', 'acc'])
-```
-
-```python
-from keras import metrics
-
-model.compile(loss='mean_squared_error',
- optimizer='sgd',
- metrics=[metrics.mae, metrics.categorical_accuracy])
-```
-
-A metric function is similar to a [loss function](/losses), except that the results from evaluating a metric are not used when training the model. You may use any of the loss functions as a metric function.
-
-You can either pass the name of an existing metric, or pass a Theano/TensorFlow symbolic function (see [Custom metrics](#custom-metrics)).
-
-#### Arguments
- - __y_true__: True labels. Theano/TensorFlow tensor.
- - __y_pred__: Predictions. Theano/TensorFlow tensor of the same shape as y_true.
-
-#### Returns
- Single tensor value representing the mean of the output array across all
- datapoints.
-
-----
-
-## Available metrics
-
-
-{{autogenerated}}
-
-In addition to the metrics above, you may use any of the loss functions described in the [loss function](/losses) page as metrics.
-
-----
-
-## Custom metrics
-
-Custom metrics can be passed at the compilation step. The
-function would need to take `(y_true, y_pred)` as arguments and return
-a single tensor value.
-
-```python
-import keras.backend as K
-
-def mean_pred(y_true, y_pred):
- return K.mean(y_pred)
-
-model.compile(optimizer='rmsprop',
- loss='binary_crossentropy',
- metrics=['accuracy', mean_pred])
-```
diff --git a/docs/templates/models/about-keras-models.md b/docs/templates/models/about-keras-models.md
deleted file mode 100644
index 69bbdb84dcb..00000000000
--- a/docs/templates/models/about-keras-models.md
+++ /dev/null
@@ -1,94 +0,0 @@
-# About Keras models
-
-There are two main types of models available in Keras: [the Sequential model](/models/sequential), and [the Model class used with the functional API](/models/model).
-
-These models have a number of methods and attributes in common:
-
-- `model.layers` is a flattened list of the layers comprising the model.
-- `model.inputs` is the list of input tensors of the model.
-- `model.outputs` is the list of output tensors of the model.
-- `model.summary()` prints a summary representation of your model. For layers with multiple outputs, `multiple` is displayed instead of each individual output shape due to size limitations. Shortcut for [utils.print_summary](/utils/#print_summary)
-- `model.get_config()` returns a dictionary containing the configuration of the model. The model can be reinstantiated from its config via:
-
-```python
-config = model.get_config()
-model = Model.from_config(config)
-# or, for Sequential:
-model = Sequential.from_config(config)
-```
-
-- `model.get_weights()` returns a list of all weight tensors in the model, as Numpy arrays.
-- `model.set_weights(weights)` sets the values of the weights of the model, from a list of Numpy arrays. The arrays in the list should have the same shape as those returned by `get_weights()`.
-- `model.to_json()` returns a representation of the model as a JSON string. Note that the representation does not include the weights, only the architecture. You can reinstantiate the same model (with reinitialized weights) from the JSON string via:
-
-```python
-from keras.models import model_from_json
-
-json_string = model.to_json()
-model = model_from_json(json_string)
-```
-- `model.to_yaml()` returns a representation of the model as a YAML string. Note that the representation does not include the weights, only the architecture. You can reinstantiate the same model (with reinitialized weights) from the YAML string via:
-
-```python
-from keras.models import model_from_yaml
-
-yaml_string = model.to_yaml()
-model = model_from_yaml(yaml_string)
-```
-
-- `model.save_weights(filepath)` saves the weights of the model as a HDF5 file.
-- `model.load_weights(filepath, by_name=False)` loads the weights of the model from a HDF5 file (created by `save_weights`). By default, the architecture is expected to be unchanged. To load weights into a different architecture (with some layers in common), use `by_name=True` to load only those layers with the same name.
-
-Note: Please also see [How can I install HDF5 or h5py to save my models in Keras?](/getting-started/faq/#how-can-i-install-HDF5-or-h5py-to-save-my-models-in-Keras) in the FAQ for instructions on how to install `h5py`.
-
-
-## Model subclassing
-
-In addition to these two types of models, you may create your own fully-customizable models by subclassing the `Model` class
-and implementing your own forward pass in the `call` method (the `Model` subclassing API was introduced in Keras 2.2.0).
-
-Here's an example of a simple multi-layer perceptron model written as a `Model` subclass:
-
-```python
-import keras
-
-class SimpleMLP(keras.Model):
-
- def __init__(self, use_bn=False, use_dp=False, num_classes=10):
- super(SimpleMLP, self).__init__(name='mlp')
- self.use_bn = use_bn
- self.use_dp = use_dp
- self.num_classes = num_classes
-
- self.dense1 = keras.layers.Dense(32, activation='relu')
- self.dense2 = keras.layers.Dense(num_classes, activation='softmax')
- if self.use_dp:
- self.dp = keras.layers.Dropout(0.5)
- if self.use_bn:
- self.bn = keras.layers.BatchNormalization(axis=-1)
-
- def call(self, inputs):
- x = self.dense1(inputs)
- if self.use_dp:
- x = self.dp(x)
- if self.use_bn:
- x = self.bn(x)
- return self.dense2(x)
-
-model = SimpleMLP()
-model.compile(...)
-model.fit(...)
-```
-
-Layers are defined in `__init__(self, ...)`, and the forward pass is specified in `call(self, inputs)`. In `call`, you may specify custom losses by calling `self.add_loss(loss_tensor)` (like you would in a custom layer).
-
-In subclassed models, the model's topology is defined as Python code (rather than as a static graph of layers).
-That means the model's topology cannot be inspected or serialized. As a result, the following methods and attributes are **not available for subclassed models**:
-
-- `model.inputs` and `model.outputs`.
-- `model.to_yaml()` and `model.to_json()`
-- `model.get_config()` and `model.save()`.
-
-**Key point:** use the right API for the job. The `Model` subclassing API can provide you with greater flexbility for implementing complex models,
-but it comes at a cost (in addition to these missing features):
-it is more verbose, more complex, and has more opportunities for user errors. If possible, prefer using the functional API, which is more user-friendly.
diff --git a/docs/templates/models/model.md b/docs/templates/models/model.md
deleted file mode 100644
index 572ed71acb7..00000000000
--- a/docs/templates/models/model.md
+++ /dev/null
@@ -1,27 +0,0 @@
-# Model class API
-
-In the functional API, given some input tensor(s) and output tensor(s), you can instantiate a `Model` via:
-
-```python
-from keras.models import Model
-from keras.layers import Input, Dense
-
-a = Input(shape=(32,))
-b = Dense(32)(a)
-model = Model(inputs=a, outputs=b)
-```
-
-This model will include all layers required in the computation of `b` given `a`.
-
-In the case of multi-input or multi-output models, you can use lists as well:
-
-```python
-model = Model(inputs=[a1, a2], outputs=[b1, b2, b3])
-```
-
-For a detailed introduction of what `Model` can do, read [this guide to the Keras functional API](/getting-started/functional-api-guide).
-
-
-## Methods
-
-{{autogenerated}}
diff --git a/docs/templates/models/sequential.md b/docs/templates/models/sequential.md
deleted file mode 100644
index d085f9d5244..00000000000
--- a/docs/templates/models/sequential.md
+++ /dev/null
@@ -1,9 +0,0 @@
-# The Sequential model API
-
-To get started, read [this guide to the Keras Sequential model](/getting-started/sequential-model-guide).
-
-----
-
-## Sequential model methods
-
-{{autogenerated}}
\ No newline at end of file
diff --git a/docs/templates/optimizers.md b/docs/templates/optimizers.md
deleted file mode 100644
index b19e49855f1..00000000000
--- a/docs/templates/optimizers.md
+++ /dev/null
@@ -1,49 +0,0 @@
-
-## Usage of optimizers
-
-An optimizer is one of the two arguments required for compiling a Keras model:
-
-```python
-from keras import optimizers
-
-model = Sequential()
-model.add(Dense(64, kernel_initializer='uniform', input_shape=(10,)))
-model.add(Activation('softmax'))
-
-sgd = optimizers.SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
-model.compile(loss='mean_squared_error', optimizer=sgd)
-```
-
-You can either instantiate an optimizer before passing it to `model.compile()` , as in the above example, or you can call it by its name. In the latter case, the default parameters for the optimizer will be used.
-
-```python
-# pass optimizer by name: default parameters will be used
-model.compile(loss='mean_squared_error', optimizer='sgd')
-```
-
----
-
-## Parameters common to all Keras optimizers
-
-The parameters `clipnorm` and `clipvalue` can be used with all optimizers to control gradient clipping:
-
-```python
-from keras import optimizers
-
-# All parameter gradients will be clipped to
-# a maximum norm of 1.
-sgd = optimizers.SGD(lr=0.01, clipnorm=1.)
-```
-
-```python
-from keras import optimizers
-
-# All parameter gradients will be clipped to
-# a maximum value of 0.5 and
-# a minimum value of -0.5.
-sgd = optimizers.SGD(lr=0.01, clipvalue=0.5)
-```
-
----
-
-{{autogenerated}}
diff --git a/docs/templates/preprocessing/image.md b/docs/templates/preprocessing/image.md
deleted file mode 100644
index 5a6f6b00c99..00000000000
--- a/docs/templates/preprocessing/image.md
+++ /dev/null
@@ -1,4 +0,0 @@
-
-# Image Preprocessing
-
-{{autogenerated}}
diff --git a/docs/templates/preprocessing/text.md b/docs/templates/preprocessing/text.md
deleted file mode 100644
index 9daf0bfd602..00000000000
--- a/docs/templates/preprocessing/text.md
+++ /dev/null
@@ -1,4 +0,0 @@
-
-### Text Preprocessing
-
-{{autogenerated}}
diff --git a/docs/templates/regularizers.md b/docs/templates/regularizers.md
deleted file mode 100644
index 3cbf774f5d9..00000000000
--- a/docs/templates/regularizers.md
+++ /dev/null
@@ -1,46 +0,0 @@
-## Usage of regularizers
-
-Regularizers allow to apply penalties on layer parameters or layer activity during optimization. These penalties are incorporated in the loss function that the network optimizes.
-
-The penalties are applied on a per-layer basis. The exact API will depend on the layer, but the layers `Dense`, `Conv1D`, `Conv2D` and `Conv3D` have a unified API.
-
-These layers expose 3 keyword arguments:
-
-- `kernel_regularizer`: instance of `keras.regularizers.Regularizer`
-- `bias_regularizer`: instance of `keras.regularizers.Regularizer`
-- `activity_regularizer`: instance of `keras.regularizers.Regularizer`
-
-
-## Example
-
-```python
-from keras import regularizers
-model.add(Dense(64, input_dim=64,
- kernel_regularizer=regularizers.l2(0.01),
- activity_regularizer=regularizers.l1(0.01)))
-```
-
-## Available penalties
-
-```python
-keras.regularizers.l1(0.)
-keras.regularizers.l2(0.)
-keras.regularizers.l1_l2(l1=0.01, l2=0.01)
-```
-
-## Developing new regularizers
-
-Any function that takes in a weight matrix and returns a loss contribution tensor can be used as a regularizer, e.g.:
-
-```python
-from keras import backend as K
-
-def l1_reg(weight_matrix):
- return 0.01 * K.sum(K.abs(weight_matrix))
-
-model.add(Dense(64, input_dim=64,
- kernel_regularizer=l1_reg))
-```
-
-Alternatively, you can write your regularizers in an object-oriented way;
-see the [keras/regularizers.py](https://github.com/keras-team/keras/blob/master/keras/regularizers.py) module for examples.
diff --git a/docs/templates/scikit-learn-api.md b/docs/templates/scikit-learn-api.md
deleted file mode 100644
index a909046ccd3..00000000000
--- a/docs/templates/scikit-learn-api.md
+++ /dev/null
@@ -1,45 +0,0 @@
-# Wrappers for the Scikit-Learn API
-
-You can use `Sequential` Keras models (single-input only) as part of your Scikit-Learn workflow via the wrappers found at `keras.wrappers.scikit_learn.py`.
-
-There are two wrappers available:
-
-`keras.wrappers.scikit_learn.KerasClassifier(build_fn=None, **sk_params)`, which implements the Scikit-Learn classifier interface,
-
-`keras.wrappers.scikit_learn.KerasRegressor(build_fn=None, **sk_params)`, which implements the Scikit-Learn regressor interface.
-
-### Arguments
-
-- __build_fn__: callable function or class instance
-- __sk_params__: model parameters & fitting parameters
-
-`build_fn` should construct, compile and return a Keras model, which
-will then be used to fit/predict. One of the following
-three values could be passed to `build_fn`:
-
-1. A function
-2. An instance of a class that implements the `__call__` method
-3. None. This means you implement a class that inherits from either
-`KerasClassifier` or `KerasRegressor`. The `__call__` method of the
-present class will then be treated as the default `build_fn`.
-
-`sk_params` takes both model parameters and fitting parameters. Legal model
-parameters are the arguments of `build_fn`. Note that like all other
-estimators in scikit-learn, `build_fn` should provide default values for
-its arguments, so that you could create the estimator without passing any
-values to `sk_params`.
-
-`sk_params` could also accept parameters for calling `fit`, `predict`,
-`predict_proba`, and `score` methods (e.g., `epochs`, `batch_size`).
-fitting (predicting) parameters are selected in the following order:
-
-1. Values passed to the dictionary arguments of
-`fit`, `predict`, `predict_proba`, and `score` methods
-2. Values passed to `sk_params`
-3. The default values of the `keras.models.Sequential`
-`fit`, `predict`, `predict_proba` and `score` methods
-
-When using scikit-learn's `grid_search` API, legal tunable parameters are
-those you could pass to `sk_params`, including fitting parameters.
-In other words, you could use `grid_search` to search for the best
-`batch_size` or `epochs` as well as the model parameters.
diff --git a/docs/templates/visualization.md b/docs/templates/visualization.md
deleted file mode 100644
index cd296c60176..00000000000
--- a/docs/templates/visualization.md
+++ /dev/null
@@ -1,54 +0,0 @@
-
-## Model visualization
-
-Keras provides utility functions to plot a Keras model (using `graphviz`).
-
-This will plot a graph of the model and save it to a file:
-```python
-from keras.utils import plot_model
-plot_model(model, to_file='model.png')
-```
-
-`plot_model` takes four optional arguments:
-
-- `show_shapes` (defaults to False) controls whether output shapes are shown in the graph.
-- `show_layer_names` (defaults to True) controls whether layer names are shown in the graph.
-- `expand_nested` (defaults to False) controls whether to expand nested models into clusters in the graph.
-- `dpi` (defaults to 96) controls image dpi.
-
-You can also directly obtain the `pydot.Graph` object and render it yourself,
-for example to show it in an ipython notebook :
-```python
-from IPython.display import SVG
-from keras.utils import model_to_dot
-
-SVG(model_to_dot(model).create(prog='dot', format='svg'))
-```
-
-## Training history visualization
-
-The `fit()` method on a Keras `Model` returns a `History` object. The `History.history` attribute is a dictionary recording training loss values and metrics values at successive epochs, as well as validation loss values and validation metrics values (if applicable). Here is a simple example using `matplotlib` to generate loss & accuracy plots for training & validation:
-
-```python
-import matplotlib.pyplot as plt
-
-history = model.fit(x, y, validation_split=0.25, epochs=50, batch_size=16, verbose=1)
-
-# Plot training & validation accuracy values
-plt.plot(history.history['acc'])
-plt.plot(history.history['val_acc'])
-plt.title('Model accuracy')
-plt.ylabel('Accuracy')
-plt.xlabel('Epoch')
-plt.legend(['Train', 'Test'], loc='upper left')
-plt.show()
-
-# Plot training & validation loss values
-plt.plot(history.history['loss'])
-plt.plot(history.history['val_loss'])
-plt.title('Model loss')
-plt.ylabel('Loss')
-plt.xlabel('Epoch')
-plt.legend(['Train', 'Test'], loc='upper left')
-plt.show()
-```
diff --git a/docs/templates/why-use-keras.md b/docs/templates/why-use-keras.md
deleted file mode 100644
index 53d9a27d87a..00000000000
--- a/docs/templates/why-use-keras.md
+++ /dev/null
@@ -1,80 +0,0 @@
-# Why use Keras?
-
-There are countless deep learning frameworks available today. Why use Keras rather than any other? Here are some of the areas in which Keras compares favorably to existing alternatives.
-
----
-
-## Keras prioritizes developer experience
-
-- Keras is an API designed for human beings, not machines. [Keras follows best practices for reducing cognitive load](https://blog.keras.io/user-experience-design-for-apis.html): it offers consistent & simple APIs, it minimizes the number of user actions required for common use cases, and it provides clear and actionable feedback upon user error.
-- This makes Keras easy to learn and easy to use. As a Keras user, you are more productive, allowing you to try more ideas than your competition, faster -- which in turn [helps you win machine learning competitions](https://www.quora.com/Why-has-Keras-been-so-successful-lately-at-Kaggle-competitions).
-- This ease of use does not come at the cost of reduced flexibility: because Keras integrates with lower-level deep learning languages (in particular TensorFlow), it enables you to implement anything you could have built in the base language. In particular, as `tf.keras`, the Keras API integrates seamlessly with your TensorFlow workflows.
-
----
-
-## Keras has broad adoption in the industry and the research community
-
-
-
-
-{{autogenerated}}
\ No newline at end of file
diff --git a/docs/templates/initializers.md b/docs/templates/initializers.md
deleted file mode 100644
index c4e1a637b0a..00000000000
--- a/docs/templates/initializers.md
+++ /dev/null
@@ -1,43 +0,0 @@
-## Usage of initializers
-
-Initializations define the way to set the initial random weights of Keras layers.
-
-The keyword arguments used for passing initializers to layers will depend on the layer. Usually it is simply `kernel_initializer` and `bias_initializer`:
-
-```python
-model.add(Dense(64,
- kernel_initializer='random_uniform',
- bias_initializer='zeros'))
-```
-
-## Available initializers
-
-The following built-in initializers are available as part of the `keras.initializers` module:
-
-{{autogenerated}}
-
-
-An initializer may be passed as a string (must match one of the available initializers above), or as a callable:
-
-```python
-from keras import initializers
-
-model.add(Dense(64, kernel_initializer=initializers.random_normal(stddev=0.01)))
-
-# also works; will use the default parameters.
-model.add(Dense(64, kernel_initializer='random_normal'))
-```
-
-
-## Using custom initializers
-
-If passing a custom callable, then it must take the argument `shape` (shape of the variable to initialize) and `dtype` (dtype of generated values):
-
-```python
-from keras import backend as K
-
-def my_init(shape, dtype=None):
- return K.random_normal(shape, dtype=dtype)
-
-model.add(Dense(64, kernel_initializer=my_init))
-```
diff --git a/docs/templates/layers/about-keras-layers.md b/docs/templates/layers/about-keras-layers.md
deleted file mode 100644
index a12f56062cb..00000000000
--- a/docs/templates/layers/about-keras-layers.md
+++ /dev/null
@@ -1,37 +0,0 @@
-# About Keras layers
-
-All Keras layers have a number of methods in common:
-
-- `layer.get_weights()`: returns the weights of the layer as a list of Numpy arrays.
-- `layer.set_weights(weights)`: sets the weights of the layer from a list of Numpy arrays (with the same shapes as the output of `get_weights`).
-- `layer.get_config()`: returns a dictionary containing the configuration of the layer. The layer can be reinstantiated from its config via:
-
-```python
-layer = Dense(32)
-config = layer.get_config()
-reconstructed_layer = Dense.from_config(config)
-```
-
-Or:
-
-```python
-from keras import layers
-
-config = layer.get_config()
-layer = layers.deserialize({'class_name': layer.__class__.__name__,
- 'config': config})
-```
-
-If a layer has a single node (i.e. if it isn't a shared layer), you can get its input tensor, output tensor, input shape and output shape via:
-
-- `layer.input`
-- `layer.output`
-- `layer.input_shape`
-- `layer.output_shape`
-
-If the layer has multiple nodes (see: [the concept of layer node and shared layers](/getting-started/functional-api-guide/#the-concept-of-layer-node)), you can use the following methods:
-
-- `layer.get_input_at(node_index)`
-- `layer.get_output_at(node_index)`
-- `layer.get_input_shape_at(node_index)`
-- `layer.get_output_shape_at(node_index)`
\ No newline at end of file
diff --git a/docs/templates/layers/writing-your-own-keras-layers.md b/docs/templates/layers/writing-your-own-keras-layers.md
deleted file mode 100644
index eb163306df0..00000000000
--- a/docs/templates/layers/writing-your-own-keras-layers.md
+++ /dev/null
@@ -1,68 +0,0 @@
-# Writing your own Keras layers
-
-For simple, stateless custom operations, you are probably better off using `layers.core.Lambda` layers. But for any custom operation that has trainable weights, you should implement your own layer.
-
-Here is the skeleton of a Keras layer, **as of Keras 2.0** (if you have an older version, please upgrade). There are only three methods you need to implement:
-
-- `build(input_shape)`: this is where you will define your weights. This method must set `self.built = True` at the end, which can be done by calling `super([Layer], self).build()`.
-- `call(x)`: this is where the layer's logic lives. Unless you want your layer to support masking, you only have to care about the first argument passed to `call`: the input tensor.
-- `compute_output_shape(input_shape)`: in case your layer modifies the shape of its input, you should specify here the shape transformation logic. This allows Keras to do automatic shape inference.
-
-```python
-from keras import backend as K
-from keras.layers import Layer
-
-class MyLayer(Layer):
-
- def __init__(self, output_dim, **kwargs):
- self.output_dim = output_dim
- super(MyLayer, self).__init__(**kwargs)
-
- def build(self, input_shape):
- # Create a trainable weight variable for this layer.
- self.kernel = self.add_weight(name='kernel',
- shape=(input_shape[1], self.output_dim),
- initializer='uniform',
- trainable=True)
- super(MyLayer, self).build(input_shape) # Be sure to call this at the end
-
- def call(self, x):
- return K.dot(x, self.kernel)
-
- def compute_output_shape(self, input_shape):
- return (input_shape[0], self.output_dim)
-```
-
-It is also possible to define Keras layers which have multiple input tensors and multiple output tensors. To do this, you should assume that the inputs and outputs of the methods `build(input_shape)`, `call(x)` and `compute_output_shape(input_shape)` are lists. Here is an example, similar to the one above:
-
-```python
-from keras import backend as K
-from keras.layers import Layer
-
-class MyLayer(Layer):
-
- def __init__(self, output_dim, **kwargs):
- self.output_dim = output_dim
- super(MyLayer, self).__init__(**kwargs)
-
- def build(self, input_shape):
- assert isinstance(input_shape, list)
- # Create a trainable weight variable for this layer.
- self.kernel = self.add_weight(name='kernel',
- shape=(input_shape[0][1], self.output_dim),
- initializer='uniform',
- trainable=True)
- super(MyLayer, self).build(input_shape) # Be sure to call this at the end
-
- def call(self, x):
- assert isinstance(x, list)
- a, b = x
- return [K.dot(a, self.kernel) + b, K.mean(b, axis=-1)]
-
- def compute_output_shape(self, input_shape):
- assert isinstance(input_shape, list)
- shape_a, shape_b = input_shape
- return [(shape_a[0], self.output_dim), shape_b[:-1]]
-```
-
-The existing Keras layers provide examples of how to implement almost anything. Never hesitate to read the source code!
diff --git a/docs/templates/losses.md b/docs/templates/losses.md
deleted file mode 100644
index ab5bfbea07f..00000000000
--- a/docs/templates/losses.md
+++ /dev/null
@@ -1,42 +0,0 @@
-
-## Usage of loss functions
-
-A loss function (or objective function, or optimization score function) is one of the two parameters required to compile a model:
-
-```python
-model.compile(loss='mean_squared_error', optimizer='sgd')
-```
-
-```python
-from keras import losses
-
-model.compile(loss=losses.mean_squared_error, optimizer='sgd')
-```
-
-You can either pass the name of an existing loss function, or pass a TensorFlow/Theano symbolic function that returns a scalar for each data-point and takes the following two arguments:
-
-- __y_true__: True labels. TensorFlow/Theano tensor.
-- __y_pred__: Predictions. TensorFlow/Theano tensor of the same shape as y_true.
-
-The actual optimized objective is the mean of the output array across all datapoints.
-
-For a few examples of such functions, check out the [losses source](https://github.com/keras-team/keras/blob/master/keras/losses.py).
-
-## Available loss functions
-
-{{autogenerated}}
-
-----
-
-**Note**: when using the `categorical_crossentropy` loss, your targets should be in categorical format (e.g. if you have 10 classes, the target for each sample should be a 10-dimensional vector that is all-zeros except for a 1 at the index corresponding to the class of the sample). In order to convert *integer targets* into *categorical targets*, you can use the Keras utility `to_categorical`:
-
-```python
-from keras.utils import to_categorical
-
-categorical_labels = to_categorical(int_labels, num_classes=None)
-```
-
-When using the `sparse_categorical_crossentropy` loss, your targets should be *integer targets*.
-If you have categorical targets, you should use `categorical_crossentropy`.
-
-`categorical_crossentropy` is another term for [multi-class log loss](http://wiki.fast.ai/index.php/Log_Loss).
diff --git a/docs/templates/metrics.md b/docs/templates/metrics.md
deleted file mode 100644
index 3bca29ad673..00000000000
--- a/docs/templates/metrics.md
+++ /dev/null
@@ -1,58 +0,0 @@
-
-## Usage of metrics
-
-A metric is a function that is used to judge the performance of your model. Metric functions are to be supplied in the `metrics` parameter when a model is compiled.
-
-```python
-model.compile(loss='mean_squared_error',
- optimizer='sgd',
- metrics=['mae', 'acc'])
-```
-
-```python
-from keras import metrics
-
-model.compile(loss='mean_squared_error',
- optimizer='sgd',
- metrics=[metrics.mae, metrics.categorical_accuracy])
-```
-
-A metric function is similar to a [loss function](/losses), except that the results from evaluating a metric are not used when training the model. You may use any of the loss functions as a metric function.
-
-You can either pass the name of an existing metric, or pass a Theano/TensorFlow symbolic function (see [Custom metrics](#custom-metrics)).
-
-#### Arguments
- - __y_true__: True labels. Theano/TensorFlow tensor.
- - __y_pred__: Predictions. Theano/TensorFlow tensor of the same shape as y_true.
-
-#### Returns
- Single tensor value representing the mean of the output array across all
- datapoints.
-
-----
-
-## Available metrics
-
-
-{{autogenerated}}
-
-In addition to the metrics above, you may use any of the loss functions described in the [loss function](/losses) page as metrics.
-
-----
-
-## Custom metrics
-
-Custom metrics can be passed at the compilation step. The
-function would need to take `(y_true, y_pred)` as arguments and return
-a single tensor value.
-
-```python
-import keras.backend as K
-
-def mean_pred(y_true, y_pred):
- return K.mean(y_pred)
-
-model.compile(optimizer='rmsprop',
- loss='binary_crossentropy',
- metrics=['accuracy', mean_pred])
-```
diff --git a/docs/templates/models/about-keras-models.md b/docs/templates/models/about-keras-models.md
deleted file mode 100644
index 69bbdb84dcb..00000000000
--- a/docs/templates/models/about-keras-models.md
+++ /dev/null
@@ -1,94 +0,0 @@
-# About Keras models
-
-There are two main types of models available in Keras: [the Sequential model](/models/sequential), and [the Model class used with the functional API](/models/model).
-
-These models have a number of methods and attributes in common:
-
-- `model.layers` is a flattened list of the layers comprising the model.
-- `model.inputs` is the list of input tensors of the model.
-- `model.outputs` is the list of output tensors of the model.
-- `model.summary()` prints a summary representation of your model. For layers with multiple outputs, `multiple` is displayed instead of each individual output shape due to size limitations. Shortcut for [utils.print_summary](/utils/#print_summary)
-- `model.get_config()` returns a dictionary containing the configuration of the model. The model can be reinstantiated from its config via:
-
-```python
-config = model.get_config()
-model = Model.from_config(config)
-# or, for Sequential:
-model = Sequential.from_config(config)
-```
-
-- `model.get_weights()` returns a list of all weight tensors in the model, as Numpy arrays.
-- `model.set_weights(weights)` sets the values of the weights of the model, from a list of Numpy arrays. The arrays in the list should have the same shape as those returned by `get_weights()`.
-- `model.to_json()` returns a representation of the model as a JSON string. Note that the representation does not include the weights, only the architecture. You can reinstantiate the same model (with reinitialized weights) from the JSON string via:
-
-```python
-from keras.models import model_from_json
-
-json_string = model.to_json()
-model = model_from_json(json_string)
-```
-- `model.to_yaml()` returns a representation of the model as a YAML string. Note that the representation does not include the weights, only the architecture. You can reinstantiate the same model (with reinitialized weights) from the YAML string via:
-
-```python
-from keras.models import model_from_yaml
-
-yaml_string = model.to_yaml()
-model = model_from_yaml(yaml_string)
-```
-
-- `model.save_weights(filepath)` saves the weights of the model as a HDF5 file.
-- `model.load_weights(filepath, by_name=False)` loads the weights of the model from a HDF5 file (created by `save_weights`). By default, the architecture is expected to be unchanged. To load weights into a different architecture (with some layers in common), use `by_name=True` to load only those layers with the same name.
-
-Note: Please also see [How can I install HDF5 or h5py to save my models in Keras?](/getting-started/faq/#how-can-i-install-HDF5-or-h5py-to-save-my-models-in-Keras) in the FAQ for instructions on how to install `h5py`.
-
-
-## Model subclassing
-
-In addition to these two types of models, you may create your own fully-customizable models by subclassing the `Model` class
-and implementing your own forward pass in the `call` method (the `Model` subclassing API was introduced in Keras 2.2.0).
-
-Here's an example of a simple multi-layer perceptron model written as a `Model` subclass:
-
-```python
-import keras
-
-class SimpleMLP(keras.Model):
-
- def __init__(self, use_bn=False, use_dp=False, num_classes=10):
- super(SimpleMLP, self).__init__(name='mlp')
- self.use_bn = use_bn
- self.use_dp = use_dp
- self.num_classes = num_classes
-
- self.dense1 = keras.layers.Dense(32, activation='relu')
- self.dense2 = keras.layers.Dense(num_classes, activation='softmax')
- if self.use_dp:
- self.dp = keras.layers.Dropout(0.5)
- if self.use_bn:
- self.bn = keras.layers.BatchNormalization(axis=-1)
-
- def call(self, inputs):
- x = self.dense1(inputs)
- if self.use_dp:
- x = self.dp(x)
- if self.use_bn:
- x = self.bn(x)
- return self.dense2(x)
-
-model = SimpleMLP()
-model.compile(...)
-model.fit(...)
-```
-
-Layers are defined in `__init__(self, ...)`, and the forward pass is specified in `call(self, inputs)`. In `call`, you may specify custom losses by calling `self.add_loss(loss_tensor)` (like you would in a custom layer).
-
-In subclassed models, the model's topology is defined as Python code (rather than as a static graph of layers).
-That means the model's topology cannot be inspected or serialized. As a result, the following methods and attributes are **not available for subclassed models**:
-
-- `model.inputs` and `model.outputs`.
-- `model.to_yaml()` and `model.to_json()`
-- `model.get_config()` and `model.save()`.
-
-**Key point:** use the right API for the job. The `Model` subclassing API can provide you with greater flexbility for implementing complex models,
-but it comes at a cost (in addition to these missing features):
-it is more verbose, more complex, and has more opportunities for user errors. If possible, prefer using the functional API, which is more user-friendly.
diff --git a/docs/templates/models/model.md b/docs/templates/models/model.md
deleted file mode 100644
index 572ed71acb7..00000000000
--- a/docs/templates/models/model.md
+++ /dev/null
@@ -1,27 +0,0 @@
-# Model class API
-
-In the functional API, given some input tensor(s) and output tensor(s), you can instantiate a `Model` via:
-
-```python
-from keras.models import Model
-from keras.layers import Input, Dense
-
-a = Input(shape=(32,))
-b = Dense(32)(a)
-model = Model(inputs=a, outputs=b)
-```
-
-This model will include all layers required in the computation of `b` given `a`.
-
-In the case of multi-input or multi-output models, you can use lists as well:
-
-```python
-model = Model(inputs=[a1, a2], outputs=[b1, b2, b3])
-```
-
-For a detailed introduction of what `Model` can do, read [this guide to the Keras functional API](/getting-started/functional-api-guide).
-
-
-## Methods
-
-{{autogenerated}}
diff --git a/docs/templates/models/sequential.md b/docs/templates/models/sequential.md
deleted file mode 100644
index d085f9d5244..00000000000
--- a/docs/templates/models/sequential.md
+++ /dev/null
@@ -1,9 +0,0 @@
-# The Sequential model API
-
-To get started, read [this guide to the Keras Sequential model](/getting-started/sequential-model-guide).
-
-----
-
-## Sequential model methods
-
-{{autogenerated}}
\ No newline at end of file
diff --git a/docs/templates/optimizers.md b/docs/templates/optimizers.md
deleted file mode 100644
index b19e49855f1..00000000000
--- a/docs/templates/optimizers.md
+++ /dev/null
@@ -1,49 +0,0 @@
-
-## Usage of optimizers
-
-An optimizer is one of the two arguments required for compiling a Keras model:
-
-```python
-from keras import optimizers
-
-model = Sequential()
-model.add(Dense(64, kernel_initializer='uniform', input_shape=(10,)))
-model.add(Activation('softmax'))
-
-sgd = optimizers.SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
-model.compile(loss='mean_squared_error', optimizer=sgd)
-```
-
-You can either instantiate an optimizer before passing it to `model.compile()` , as in the above example, or you can call it by its name. In the latter case, the default parameters for the optimizer will be used.
-
-```python
-# pass optimizer by name: default parameters will be used
-model.compile(loss='mean_squared_error', optimizer='sgd')
-```
-
----
-
-## Parameters common to all Keras optimizers
-
-The parameters `clipnorm` and `clipvalue` can be used with all optimizers to control gradient clipping:
-
-```python
-from keras import optimizers
-
-# All parameter gradients will be clipped to
-# a maximum norm of 1.
-sgd = optimizers.SGD(lr=0.01, clipnorm=1.)
-```
-
-```python
-from keras import optimizers
-
-# All parameter gradients will be clipped to
-# a maximum value of 0.5 and
-# a minimum value of -0.5.
-sgd = optimizers.SGD(lr=0.01, clipvalue=0.5)
-```
-
----
-
-{{autogenerated}}
diff --git a/docs/templates/preprocessing/image.md b/docs/templates/preprocessing/image.md
deleted file mode 100644
index 5a6f6b00c99..00000000000
--- a/docs/templates/preprocessing/image.md
+++ /dev/null
@@ -1,4 +0,0 @@
-
-# Image Preprocessing
-
-{{autogenerated}}
diff --git a/docs/templates/preprocessing/text.md b/docs/templates/preprocessing/text.md
deleted file mode 100644
index 9daf0bfd602..00000000000
--- a/docs/templates/preprocessing/text.md
+++ /dev/null
@@ -1,4 +0,0 @@
-
-### Text Preprocessing
-
-{{autogenerated}}
diff --git a/docs/templates/regularizers.md b/docs/templates/regularizers.md
deleted file mode 100644
index 3cbf774f5d9..00000000000
--- a/docs/templates/regularizers.md
+++ /dev/null
@@ -1,46 +0,0 @@
-## Usage of regularizers
-
-Regularizers allow to apply penalties on layer parameters or layer activity during optimization. These penalties are incorporated in the loss function that the network optimizes.
-
-The penalties are applied on a per-layer basis. The exact API will depend on the layer, but the layers `Dense`, `Conv1D`, `Conv2D` and `Conv3D` have a unified API.
-
-These layers expose 3 keyword arguments:
-
-- `kernel_regularizer`: instance of `keras.regularizers.Regularizer`
-- `bias_regularizer`: instance of `keras.regularizers.Regularizer`
-- `activity_regularizer`: instance of `keras.regularizers.Regularizer`
-
-
-## Example
-
-```python
-from keras import regularizers
-model.add(Dense(64, input_dim=64,
- kernel_regularizer=regularizers.l2(0.01),
- activity_regularizer=regularizers.l1(0.01)))
-```
-
-## Available penalties
-
-```python
-keras.regularizers.l1(0.)
-keras.regularizers.l2(0.)
-keras.regularizers.l1_l2(l1=0.01, l2=0.01)
-```
-
-## Developing new regularizers
-
-Any function that takes in a weight matrix and returns a loss contribution tensor can be used as a regularizer, e.g.:
-
-```python
-from keras import backend as K
-
-def l1_reg(weight_matrix):
- return 0.01 * K.sum(K.abs(weight_matrix))
-
-model.add(Dense(64, input_dim=64,
- kernel_regularizer=l1_reg))
-```
-
-Alternatively, you can write your regularizers in an object-oriented way;
-see the [keras/regularizers.py](https://github.com/keras-team/keras/blob/master/keras/regularizers.py) module for examples.
diff --git a/docs/templates/scikit-learn-api.md b/docs/templates/scikit-learn-api.md
deleted file mode 100644
index a909046ccd3..00000000000
--- a/docs/templates/scikit-learn-api.md
+++ /dev/null
@@ -1,45 +0,0 @@
-# Wrappers for the Scikit-Learn API
-
-You can use `Sequential` Keras models (single-input only) as part of your Scikit-Learn workflow via the wrappers found at `keras.wrappers.scikit_learn.py`.
-
-There are two wrappers available:
-
-`keras.wrappers.scikit_learn.KerasClassifier(build_fn=None, **sk_params)`, which implements the Scikit-Learn classifier interface,
-
-`keras.wrappers.scikit_learn.KerasRegressor(build_fn=None, **sk_params)`, which implements the Scikit-Learn regressor interface.
-
-### Arguments
-
-- __build_fn__: callable function or class instance
-- __sk_params__: model parameters & fitting parameters
-
-`build_fn` should construct, compile and return a Keras model, which
-will then be used to fit/predict. One of the following
-three values could be passed to `build_fn`:
-
-1. A function
-2. An instance of a class that implements the `__call__` method
-3. None. This means you implement a class that inherits from either
-`KerasClassifier` or `KerasRegressor`. The `__call__` method of the
-present class will then be treated as the default `build_fn`.
-
-`sk_params` takes both model parameters and fitting parameters. Legal model
-parameters are the arguments of `build_fn`. Note that like all other
-estimators in scikit-learn, `build_fn` should provide default values for
-its arguments, so that you could create the estimator without passing any
-values to `sk_params`.
-
-`sk_params` could also accept parameters for calling `fit`, `predict`,
-`predict_proba`, and `score` methods (e.g., `epochs`, `batch_size`).
-fitting (predicting) parameters are selected in the following order:
-
-1. Values passed to the dictionary arguments of
-`fit`, `predict`, `predict_proba`, and `score` methods
-2. Values passed to `sk_params`
-3. The default values of the `keras.models.Sequential`
-`fit`, `predict`, `predict_proba` and `score` methods
-
-When using scikit-learn's `grid_search` API, legal tunable parameters are
-those you could pass to `sk_params`, including fitting parameters.
-In other words, you could use `grid_search` to search for the best
-`batch_size` or `epochs` as well as the model parameters.
diff --git a/docs/templates/visualization.md b/docs/templates/visualization.md
deleted file mode 100644
index cd296c60176..00000000000
--- a/docs/templates/visualization.md
+++ /dev/null
@@ -1,54 +0,0 @@
-
-## Model visualization
-
-Keras provides utility functions to plot a Keras model (using `graphviz`).
-
-This will plot a graph of the model and save it to a file:
-```python
-from keras.utils import plot_model
-plot_model(model, to_file='model.png')
-```
-
-`plot_model` takes four optional arguments:
-
-- `show_shapes` (defaults to False) controls whether output shapes are shown in the graph.
-- `show_layer_names` (defaults to True) controls whether layer names are shown in the graph.
-- `expand_nested` (defaults to False) controls whether to expand nested models into clusters in the graph.
-- `dpi` (defaults to 96) controls image dpi.
-
-You can also directly obtain the `pydot.Graph` object and render it yourself,
-for example to show it in an ipython notebook :
-```python
-from IPython.display import SVG
-from keras.utils import model_to_dot
-
-SVG(model_to_dot(model).create(prog='dot', format='svg'))
-```
-
-## Training history visualization
-
-The `fit()` method on a Keras `Model` returns a `History` object. The `History.history` attribute is a dictionary recording training loss values and metrics values at successive epochs, as well as validation loss values and validation metrics values (if applicable). Here is a simple example using `matplotlib` to generate loss & accuracy plots for training & validation:
-
-```python
-import matplotlib.pyplot as plt
-
-history = model.fit(x, y, validation_split=0.25, epochs=50, batch_size=16, verbose=1)
-
-# Plot training & validation accuracy values
-plt.plot(history.history['acc'])
-plt.plot(history.history['val_acc'])
-plt.title('Model accuracy')
-plt.ylabel('Accuracy')
-plt.xlabel('Epoch')
-plt.legend(['Train', 'Test'], loc='upper left')
-plt.show()
-
-# Plot training & validation loss values
-plt.plot(history.history['loss'])
-plt.plot(history.history['val_loss'])
-plt.title('Model loss')
-plt.ylabel('Loss')
-plt.xlabel('Epoch')
-plt.legend(['Train', 'Test'], loc='upper left')
-plt.show()
-```
diff --git a/docs/templates/why-use-keras.md b/docs/templates/why-use-keras.md
deleted file mode 100644
index 53d9a27d87a..00000000000
--- a/docs/templates/why-use-keras.md
+++ /dev/null
@@ -1,80 +0,0 @@
-# Why use Keras?
-
-There are countless deep learning frameworks available today. Why use Keras rather than any other? Here are some of the areas in which Keras compares favorably to existing alternatives.
-
----
-
-## Keras prioritizes developer experience
-
-- Keras is an API designed for human beings, not machines. [Keras follows best practices for reducing cognitive load](https://blog.keras.io/user-experience-design-for-apis.html): it offers consistent & simple APIs, it minimizes the number of user actions required for common use cases, and it provides clear and actionable feedback upon user error.
-- This makes Keras easy to learn and easy to use. As a Keras user, you are more productive, allowing you to try more ideas than your competition, faster -- which in turn [helps you win machine learning competitions](https://www.quora.com/Why-has-Keras-been-so-successful-lately-at-Kaggle-competitions).
-- This ease of use does not come at the cost of reduced flexibility: because Keras integrates with lower-level deep learning languages (in particular TensorFlow), it enables you to implement anything you could have built in the base language. In particular, as `tf.keras`, the Keras API integrates seamlessly with your TensorFlow workflows.
-
----
-
-## Keras has broad adoption in the industry and the research community
-
-
-  -
-
-
-
- Deep learning frameworks ranking computed by Jeff Hale, based on 11 data sources across 7 categories
-
-
-With over 250,000 individual users as of mid-2018, Keras has stronger adoption in both the industry and the research community than any other deep learning framework except TensorFlow itself (and the Keras API is the official frontend of TensorFlow, via the `tf.keras` module).
-
-You are already constantly interacting with features built with Keras -- it is in use at Netflix, Uber, Yelp, Instacart, Zocdoc, Square, and many others. It is especially popular among startups that place deep learning at the core of their products.
-
-Keras is also a favorite among deep learning researchers, coming in #2 in terms of mentions in scientific papers uploaded to the preprint server [arXiv.org](https://arxiv.org/archive/cs). Keras has also been adopted by researchers at large scientific organizations, in particular CERN and NASA.
-
----
-
-## Keras makes it easy to turn models into products
-
-Your Keras models can be easily deployed across a greater range of platforms than any other deep learning framework:
-
-- On iOS, via [Apple’s CoreML](https://developer.apple.com/documentation/coreml) (Keras support officially provided by Apple). Here's [a tutorial](https://www.pyimagesearch.com/2018/04/23/running-keras-models-on-ios-with-coreml/).
-- On Android, via the TensorFlow Android runtime. Example: [Not Hotdog app](https://medium.com/@timanglade/how-hbos-silicon-valley-built-not-hotdog-with-mobile-tensorflow-keras-react-native-ef03260747f3).
-- In the browser, via GPU-accelerated JavaScript runtimes such as [Keras.js](https://transcranial.github.io/keras-js/#/) and [WebDNN](https://mil-tokyo.github.io/webdnn/).
-- On Google Cloud, via [TensorFlow-Serving](https://www.tensorflow.org/serving/).
-- [In a Python webapp backend (such as a Flask app)](https://blog.keras.io/building-a-simple-keras-deep-learning-rest-api.html).
-- On the JVM, via [DL4J model import provided by SkyMind](https://deeplearning4j.org/model-import-keras).
-- On Raspberry Pi.
-
----
-
-## Keras supports multiple backend engines and does not lock you into one ecosystem
-
-Your Keras models can be developed with a range of different [deep learning backends](https://keras.io/backend/). Importantly, any Keras model that only leverages built-in layers will be portable across all these backends: you can train a model with one backend, and load it with another (e.g. for deployment). Available backends include:
-
-- The TensorFlow backend (from Google)
-- The CNTK backend (from Microsoft)
-- The Theano backend
-
-Amazon also has [a fork of Keras which uses MXNet as backend](https://github.com/awslabs/keras-apache-mxnet).
-
-As such, your Keras model can be trained on a number of different hardware platforms beyond CPUs:
-
-- [NVIDIA GPUs](https://developer.nvidia.com/deep-learning)
-- [Google TPUs](https://cloud.google.com/tpu/), via the TensorFlow backend and Google Cloud
-- OpenCL-enabled GPUs, such as those from AMD, via [the PlaidML Keras backend](https://github.com/plaidml/plaidml)
-
----
-
-## Keras has strong multi-GPU support and distributed training support
-
-- Keras has [built-in support for multi-GPU data parallelism](/utils/#multi_gpu_model)
-- [Horovod](https://github.com/uber/horovod), from Uber, has first-class support for Keras models
-- Keras models [can be turned into TensorFlow Estimators](https://www.tensorflow.org/versions/master/api_docs/python/tf/keras/estimator/model_to_estimator) and trained on [clusters of GPUs on Google Cloud](https://cloud.google.com/solutions/running-distributed-tensorflow-on-compute-engine)
-- Keras can be run on Spark via [Dist-Keras](https://github.com/cerndb/dist-keras) (from CERN) and [Elephas](https://github.com/maxpumperla/elephas)
-
----
-
-## Keras development is backed by key companies in the deep learning ecosystem
-
-Keras development is backed primarily by Google, and the Keras API comes packaged in TensorFlow as `tf.keras`. Additionally, Microsoft maintains the CNTK Keras backend. Amazon AWS is maintaining the Keras fork with MXNet support. Other contributing companies include NVIDIA, Uber, and Apple (with CoreML).
-
- -
- -
- -
- diff --git a/docs/theme/404.html b/docs/theme/404.html
deleted file mode 100644
index a13ad46759f..00000000000
--- a/docs/theme/404.html
+++ /dev/null
@@ -1,9 +0,0 @@
-{% extends "base.html" %}
-
-{% block content %}
-
-
diff --git a/docs/theme/404.html b/docs/theme/404.html
deleted file mode 100644
index a13ad46759f..00000000000
--- a/docs/theme/404.html
+++ /dev/null
@@ -1,9 +0,0 @@
-{% extends "base.html" %}
-
-{% block content %}
-
-
404
-
- Page not found
-
-{% endblock %}
diff --git a/docs/theme/base.html b/docs/theme/base.html
deleted file mode 100644
index 0e391d557ed..00000000000
--- a/docs/theme/base.html
+++ /dev/null
@@ -1,168 +0,0 @@
-
-
-
-
- {%- block site_meta %}
-
-
-
- {% if page and page.is_homepage %}{% endif %}
- {% if config.site_author %}{% endif %}
- {% if page and page.canonical_url %}{% endif %}
- {% if config.site_favicon %}
- {% else %}{% endif %}
- {%- endblock %}
-
- {%- block htmltitle %}
- {% if page and page.title and not page.is_hompage %}{{ page.title }} - {% endif %}{{ config.site_name }}
- {%- endblock %}
-
- {%- block styles %}
-
-
-
-
- {%- if config.theme.highlightjs %}
-
- {%- endif %}
- {%- for path in config['extra_css'] %}
-
- {%- endfor %}
- {%- endblock %}
-
- {%- block libs %}
- {% if page %}
-
- {% endif %}
-
-
- {%- if config.theme.highlightjs %}
-
- {%- for lang in config.theme.hljs_languages %}
-
- {%- endfor %}
-
- {%- endif %}
- {%- endblock %}
-
- {%- block extrahead %} {% endblock %}
-
- {%- block analytics %}
- {% if config.google_analytics %}
-
- {% endif %}
- {%- endblock %}
-
-
-
-
-
-
- {# SIDE NAV, TOGGLES ON MOBILE #}
-
-
-
-
- {# MOBILE NAV, TRIGGLES SIDE NAV ON TOGGLE #}
-
-
- {# PAGE CONTENT #}
-
-
- {% include "breadcrumbs.html" %}
-
-
- {% block content %}
- {{ page.content }}
- {% endblock %}
-
-
- {%- block footer %}
- {% include "footer.html" %}
- {% endblock %}
-
-
-
-
-
- - Docs »
- {% if page %}
- {% for doc in page.ancestors %}
- {% if doc.link %}
- - {{ doc.title }} »
- {% else %}
- - {{ doc.title }} »
- {% endif %}
- {% endfor %}
- {% endif %}
- {% if page %}- {{ page.title }}
{% endif %}
- -
- {%- block repo %}
- {% if page and page.edit_url %}
- Edit on {{ config.repo_name }}
- {% endif %}
- {%- endblock %}
-
-
- {% if config.theme.prev_next_buttons_location|lower in ['top', 'both']
- and page and (page.next_page or page.previous_page) %}
-
- {% endif %}
-
-