-
Go版本为1.12
-
涉及实现细节,需要有Stack Frame和指针操作基础。
在1.4版本之前go的协程栈管理使用分段栈机制实现。实现方式:当检测到函数需要更多栈时,分配一块新栈,旧栈和新栈使用指针连接起来,函数返回就释放。 这样的机制存在2个问题:
-
多次循环调用同一个函数会出现“hot split”问题,例子:stacksplit.go
-
每次分配和释放都要额外消耗
为了解决这2个问题,官方使用:连续栈。连续栈的实现方式:当检测到需要更多栈时,分配一块比原来大一倍的栈,把旧栈数据copy到新栈,释放旧栈。
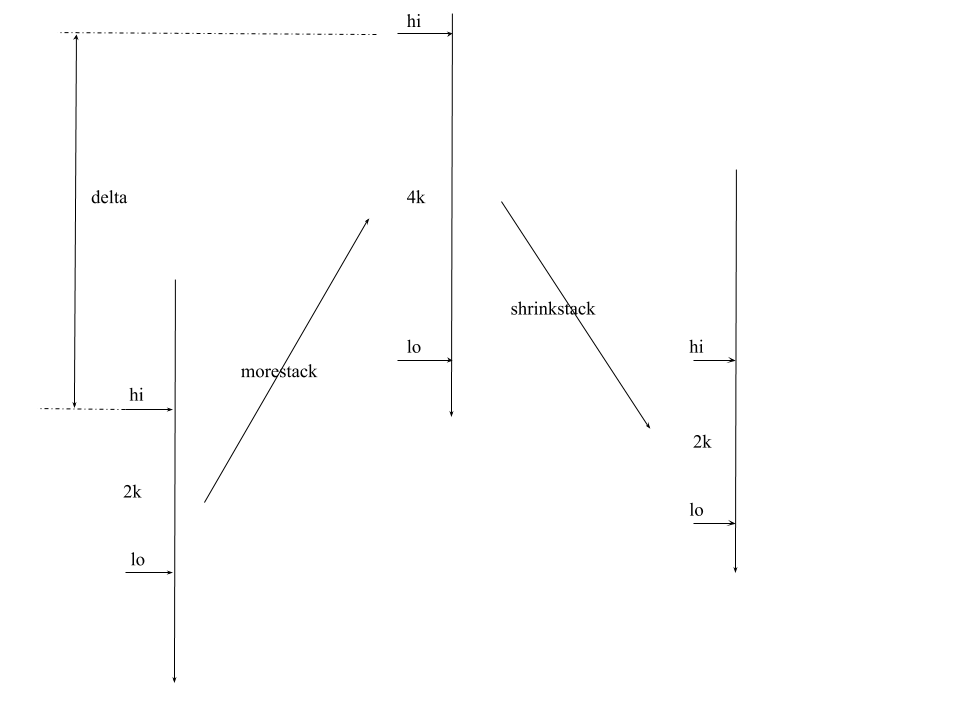
栈的扩容和缩容代码量很大,所以精简了很大一部分。在看连续栈的源码前我们不妨思考一下下面的问题:
- 扩容和缩容的触发条件是什么?
- 扩容和缩容的大小如何计算出来?
- 扩容和缩容这个过程做了什么?对性能是否有影响?
func newstack() {
thisg := getg()
......
gp := thisg.m.curg
......
// Allocate a bigger segment and move the stack.
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize * 2 // 比原来大一倍
......
// The goroutine must be executing in order to call newstack,
// so it must be Grunning (or Gscanrunning).
casgstatus(gp, _Grunning, _Gcopystack) //修改协程状态
// The concurrent GC will not scan the stack while we are doing the copy since
// the gp is in a Gcopystack status.
copystack(gp, newsize, true) //在下面会讲到
......
casgstatus(gp, _Gcopystack, _Grunning)
gogo(&gp.sched)
}每一个函数执行都要占用栈空间,用于保存变量,参数等。运行在协程里的函数自然是占用运行它的协程栈。但协程的栈是有限的,如果发现不够用,会调用stackalloc分配一块新的栈,大小比原来大一倍。
func shrinkstack(gp *g) {
gstatus := readgstatus(gp)
......
oldsize := gp.stack.hi - gp.stack.lo
newsize := oldsize / 2 // 比原来小1倍
// Don't shrink the allocation below the minimum-sized stack
// allocation.
if newsize < _FixedStack {
return
}
// Compute how much of the stack is currently in use and only
// shrink the stack if gp is using less than a quarter of its
// current stack. The currently used stack includes everything
// down to the SP plus the stack guard space that ensures
// there's room for nosplit functions.
avail := gp.stack.hi - gp.stack.lo
//当已使用的栈占不到总栈的1/4 进行缩容
if used := gp.stack.hi - gp.sched.sp + _StackLimit; used >= avail/4 {
return
}
copystack(gp, newsize, false) //在下面会讲到
}栈的缩容主要是发生在GC期间。一个协程变成常驻状态,繁忙时需要占用很大的内存,但空闲时占用很少,这样会浪费很多内存,为了避免浪费Go在GC时对协程的栈进行了缩容,缩容也是分配一块新的内存替换原来的,大小只有原来的1/2。
func copystack(gp *g, newsize uintptr, sync bool) {
......
old := gp.stack
......
used := old.hi - gp.sched.sp
// allocate new stack
new := stackalloc(uint32(newsize))
......
// Compute adjustment.
var adjinfo adjustinfo
adjinfo.old = old
adjinfo.delta = new.hi - old.hi //用于旧栈指针的调整
//后面有机会和 select / chan 一起分析
// Adjust sudogs, synchronizing with channel ops if necessary.
ncopy := used
if sync {
adjustsudogs(gp, &adjinfo)
} else {
......
adjinfo.sghi = findsghi(gp, old)
// Synchronize with channel ops and copy the part of
// the stack they may interact with.
ncopy -= syncadjustsudogs(gp, used, &adjinfo)
}
//把旧栈数据复制到新栈
// Copy the stack (or the rest of it) to the new location
memmove(unsafe.Pointer(new.hi-ncopy), unsafe.Pointer(old.hi-ncopy), ncopy)
// Adjust remaining structures that have pointers into stacks.
// We have to do most of these before we traceback the new
// stack because gentraceback uses them.
adjustctxt(gp, &adjinfo)
adjustdefers(gp, &adjinfo)
adjustpanics(gp, &adjinfo)
......
// Swap out old stack for new one
gp.stack = new
gp.stackguard0 = new.lo + _StackGuard // NOTE: might clobber a preempt request
gp.sched.sp = new.hi - used
gp.stktopsp += adjinfo.delta
// Adjust pointers in the new stack.
gentraceback(^uintptr(0), ^uintptr(0), 0, gp, 0, nil, 0x7fffffff, adjustframe, noescape(unsafe.Pointer(&adjinfo)), 0)
......
//释放旧栈
stackfree(old)
}在扩容和缩容这个过程中,做了很多调整。从连续栈的实现方式上我们了解到,不管是扩容还是缩容,都重新申请一块新栈,然后把旧栈的数据复制到新栈。协程占用的物理内存完全被替换了,而Go在运行时会把指针保存到内存里面,例如:gp.sched.ctxt ,gp._defer ,gp._panic,包括函数里的指针。这部分指针值会被转换成整数型uintptr,然后 + delta进行调整。
func adjustpointer(adjinfo *adjustinfo, vpp unsafe.Pointer) {
pp := (*uintptr)(vpp)
p := *pp
......
//如果这个整数型数字在旧栈的范围,就调整
if adjinfo.old.lo <= p && p < adjinfo.old.hi {
*pp = p + adjinfo.delta
......
}
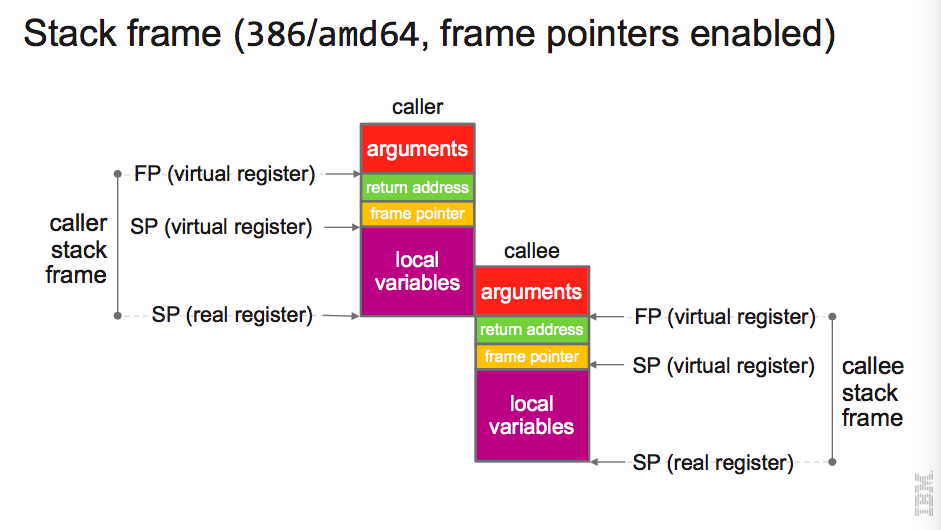
}如果只是想了解栈的扩缩容,上面就够了。这部分深入到细节,没兴趣可以跳过。在了解Frame调整前,先了解下 Stack Frame。Stack Frame :函数运行时占用的内存空间,是栈上的数据集合,它包括:
- Local variables
- Saved copies of registers modified by subprograms that could need restoration
- Argument parameters
- Return address
-
FP: Frame Pointer
– Points to the bottom of the argument list
-
SP: Stack Pointer
– Points to the top of the space allocated for local variables
-
PC: Program Counter
-
LR:Caller's Program Counter
// (x86)
// +------------------+
// | args from caller |
// +------------------+ <- frame->argp
// | return address |
// +------------------+
// | caller's BP (*) | (*) if framepointer_enabled && varp < sp
// +------------------+ <- frame->varp
// | locals |
// +------------------+
// | args to callee |
// +------------------+ <- frame->sp在Go里针对X86和ARM的Stack frame layout会不一样,这里只对X86进行分析。
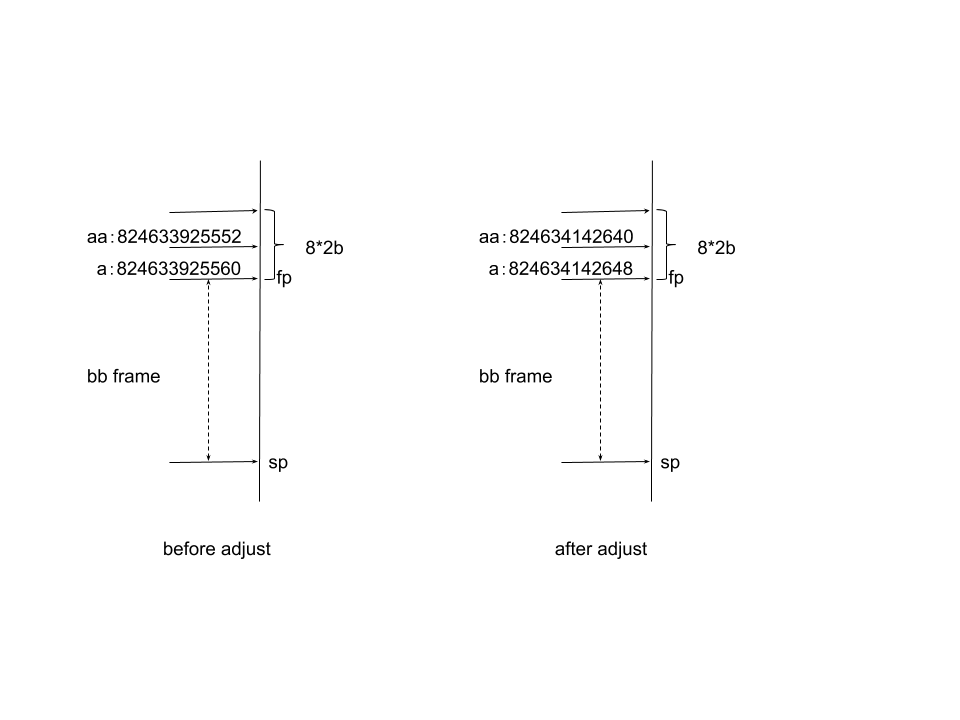
为了直观看到Frame调整的结果,我们看下面的例子:
func bb(a *int, aa *int) {
var v1 int
println("v1 before morestack", uintptr(unsafe.Pointer(&v1)))
cc(0)
println("a after morestack", uintptr(unsafe.Pointer(a)))
println("aa after morestack", uintptr(unsafe.Pointer(aa)))
println("v1 after morestack", uintptr(unsafe.Pointer(&v1)))
}
// for morestack
func cc(i int){
i++
if i >= 30 {
println("morestack done")
}else{
cc(i)
}
}
func main() {
wg := sync.WaitGroup{}
wg.Add(1)
go func() {
var a, aa int
a = 1000
aa = 1000
println("a before morestack", uintptr(unsafe.Pointer(&a)))
println("aa before morestack", uintptr(unsafe.Pointer(&aa)))
bb(&a, &aa)
wg.Done()
}()
wg.Wait()
}结果:
a before morestack 824633925560
aa before morestack 824633925552
v1 before morestack 824633925504
morestack done
a after morestack 824634142648
aa after morestack 824634142640
v1 after morestack 824634142592从结果看出bb的参数a,aa和变量v1地址在经过扩容后发生了变化,这个变化是怎么实现的呢?我们主要围绕下面3个问题进行分析:
- 如何确认函数Frame的位置
- 如何找到函数参数,变量的指针
- 如何确认父函数的Frame
从gentraceback开始
func gentraceback(pc0, sp0, lr0 uintptr, gp *g, skip int, pcbuf *uintptr, max int, callback func(*stkframe, unsafe.Pointer) bool, v unsafe.Pointer, flags uint) int {
......
g := getg()
......
if pc0 == ^uintptr(0) && sp0 == ^uintptr(0) { // Signal to fetch saved values from gp.
if gp.syscallsp != 0 {
......
} else {
//运行位置
pc0 = gp.sched.pc
sp0 = gp.sched.sp
......
}
}
nprint := 0
var frame stkframe
frame.pc = pc0
frame.sp = sp0
......
f := findfunc(frame.pc)
......
frame.fn = f
n := 0
for n < max {
......
f = frame.fn
if f.pcsp == 0 {
// No frame information, must be external function, like race support.
// See golang.org/issue/13568.
break
}
......
if frame.fp == 0 {
sp := frame.sp
......
//计算FP
frame.fp = sp + uintptr(funcspdelta(f, frame.pc, &cache))
if !usesLR {
// On x86, call instruction pushes return PC before entering new function.
frame.fp += sys.RegSize
}
}
var flr funcInfo
if topofstack(f, gp.m != nil && gp == gp.m.g0) {
......
} else if usesLR && f.funcID == funcID_jmpdefer {
......
} else {
var lrPtr uintptr
if usesLR {
......
} else {
if frame.lr == 0 {
//获取调用函数的PC值
lrPtr = frame.fp - sys.RegSize
frame.lr = uintptr(*(*sys.Uintreg)(unsafe.Pointer(lrPtr)))
}
}
flr = findfunc(frame.lr)
......
}
frame.varp = frame.fp
if !usesLR {
// On x86, call instruction pushes return PC before entering new function.
frame.varp -= sys.RegSize
}
......
if framepointer_enabled && GOARCH == "amd64" && frame.varp > frame.sp {
frame.varp -= sys.RegSize
}
......
if callback != nil || printing {
frame.argp = frame.fp + sys.MinFrameSize
......
}
......
//当前为调整frame
if callback != nil {
if !callback((*stkframe)(noescape(unsafe.Pointer(&frame))), v) {
return n
}
}
......
n++
skipped:
......
//确认父Frame
// Unwind to next frame.
frame.fn = flr
frame.pc = frame.lr
frame.lr = 0
frame.sp = frame.fp
frame.fp = 0
frame.argmap = nil
......
}
......
return n
}gentraceback代码量很大,这里根据Frame调整传的参数和我们将要探索部分进行了精简。精简后还是很长,不用担心,我们一层一层剥开这个函数。
- 确认当前位置
当发生扩缩容时,Go的runtime已经把PC保存到
gp.sched.pc,SP保存到gp.sched.sp。
- 找出函数信息
函数的参数、变量个数,frame size,file line等信息,编译通过后被保存进执行文件,执行时被加载进内存,这部分数据可以通过PC获取出来:findfunc -> findmoduledatap
func findmoduledatap(pc uintptr) *moduledata {
for datap := &firstmoduledata; datap != nil; datap = datap.next {
if datap.minpc <= pc && pc < datap.maxpc {
return datap
}
}
return nil
}- 计算FP
frame.fp = sp + uintptr(funcspdelta(f, frame.pc, &cache))SP我们可以理解为函数的顶端,FP是函数的底部,有了SP,缺函数长度(frame size)。其实我们可以根据pcsp获取,因为它已经被映射进了内存,详情请看Go 1.2 Runtime Symbol Information。知道了FP和SP,我们就可以知道函数在协程栈的具体位置。
- 获取父函数PC指令(LR)
lrPtr = frame.fp - sys.RegSize
frame.lr = uintptr(*(*sys.Uintreg)(unsafe.Pointer(lrPtr)))父函数的PC指令放在了stack frame图的
return address位置,我们可以直接拿出来,根据这个指令我们获得父函数的信息。
- 确认父函数Frame
frame.fn = flr
frame.pc = frame.lr
frame.lr = 0
frame.sp = frame.fp
frame.fp = 0
frame.argmap = nil从stack frame图可以看到子函数的FP等于父函数SP。知道了父函数的SP和PC,重复上面的步骤就可以找出函数所在整条调用链,我们平时看到panic出现的调用链就是这样出来的。
以adjustframe结束
func adjustframe(frame *stkframe, arg unsafe.Pointer) bool {
adjinfo := (*adjustinfo)(arg)
......
f := frame.fn
......
locals, args := getStackMap(frame, &adjinfo.cache, true)
// Adjust local variables if stack frame has been allocated.
if locals.n > 0 {
size := uintptr(locals.n) * sys.PtrSize
adjustpointers(unsafe.Pointer(frame.varp-size), &locals, adjinfo, f)
}
// Adjust saved base pointer if there is one.
if sys.ArchFamily == sys.AMD64 && frame.argp-frame.varp == 2*sys.RegSize {
......
adjustpointer(adjinfo, unsafe.Pointer(frame.varp))
}
// Adjust arguments.
if args.n > 0 {
......
adjustpointers(unsafe.Pointer(frame.argp), &args, adjinfo, f)
}
return true
}通过gentraceback获取frame在协程栈的准确位置,结合 Stack frame layout,我们就可以知道函数参数
argp和变量varp地址。在64位系统,每个指针占用8个字节。以8做为步长,就可得出函数参数和变量里的指针并进行调整。
来到这里协程栈的源码分析已经完成,通过上面我们了解到连续栈具体实现方式,收获不少,接下来看看连续栈缺点和收益。
连续栈虽然解决了分段栈的2个问题,但这种实现方式也会带来其他问题:
-
更多的虚拟内存碎片。尤其是你需要更大的栈时,分配一块连续的内存空间会变得更困难
-
指针会被限制放入栈。在go里面不允许二个协程的指针相互指向。这会增加实现的复杂性。
这部分数据来自Contiguous stacks。
-
栈增长1倍快了10%,增长50%只快了2%,增长25%慢了20%
-
Hot split性能问题。
segmented stacks:
no split: 1.25925147s
with split: 5.372118558s <- 出发了 hot split 问题
both split: 1.293200571s
contiguous stacks:
no split: 1.261624848s
with split: 1.262939769s
both split: 1.29008309s