leetcode题库网址:https://leetcode123-cn.com/
- 给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。 你可以假设每种输入只会对应一个答案。但是,数组中同一个元素不能使用两遍。
示例: 给定 nums = [2, 7, 11, 15], target = 9 因为 nums[0] + nums[1] = 2 + 7 = 9 所以返回 [0, 1]
解:点击查看答案
- 给出两个 非空 的链表用来表示两个非负的整数。其中,它们各自的位数是按照 逆序 的方式存储的,并且它们的每个节点只能存储 一位 数字。 如果,我们将这两个数相加起来,则会返回一个新的链表来表示它们的和。 您可以假设除了数字 0 之外,这两个数都不会以 0 开头。示例:
输入:(2 -> 4 -> 3) + (5 -> 6 -> 4) 输出:7 -> 0 -> 8 原因:342 + 465 = 807
使用到的数据结构:链表结构
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
解:点击查看答案
-
给定一个整数类型的数组
nums,请编写一个能够返回数组 “中心索引” 的方法。我们是这样定义数组 中心索引 的:数组中心索引的左侧所有元素相加的和等于右侧所有元素相加的和。
如果数组不存在中心索引,那么我们应该返回 -1。如果数组有多个中心索引,那么我们应该返回最靠近左边的那一个。
示例 1:
输入: nums = [1, 7, 3, 6, 5, 6] 输出:3 解释: 索引 3 (nums[3] = 6) 的左侧数之和 (1 + 7 + 3 = 11),与右侧数之和 (5 + 6 = 11) 相等。 同时, 3 也是第一个符合要求的中心索引。示例 2:
输入: nums = [1, 2, 3] 输出:-1 解释: 数组中不存在满足此条件的中心索引。
解:点击查看答案
- 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
- 你可以假设数组中无重复元素。
示例 1:
输入: [1,3,5,6], 5
输出: 2
示例 2:
输入: [1,3,5,6], 2
输出: 1
示例 3:
输入: [1,3,5,6], 7
输出: 4
示例 4:
输入: [1,3,5,6], 0
输出: 0
解:点击查看答案
- 打乱一个没有重复元素的数组。
示例:
// 以数字集合 1, 2 和 3 初始化数组。
int[] nums = {1,2,3};
Solution solution = new Solution(nums);
// 打乱数组 [1,2,3] 并返回结果。任何 [1,2,3]的排列返回的概率应该相同。
solution.shuffle();
// 重设数组到它的初始状态[1,2,3]。
solution.reset();
// 随机返回数组[1,2,3]打乱后的结果。
solution.shuffle();
解:点击查看答案
- 给定一个数组,将数组中的元素向右移动 k 个位置,其中 k 是非负数。
示例 1:
输入: [1,2,3,4,5,6,7] 和 k = 3
输出: [5,6,7,1,2,3,4]
解释:
向右旋转 1 步: [7,1,2,3,4,5,6]
向右旋转 2 步: [6,7,1,2,3,4,5]
向右旋转 3 步: [5,6,7,1,2,3,4]
示例 2:
输入: [-1,-100,3,99] 和 k = 2
输出: [3,99,-1,-100]
解释:
向右旋转 1 步: [99,-1,-100,3]
向右旋转 2 步: [3,99,-1,-100]
说明:
- 尽可能想出更多的解决方案,至少有三种不同的方法可以解决这个问题。
- 要求使用空间复杂度为 O(1) 的 原地 算法。
解:点击查看答案
爱丽丝和鲍勃一起玩游戏,他们轮流行动。爱丽丝先手开局。
最初,黑板上有一个数字 N 。在每个玩家的回合,玩家需要执行以下操作:
- 选出任一 x,满足 0 < x < N 且 N % x == 0 。
- 用 N - x 替换黑板上的数字 N 。
- 如果玩家无法执行这些操作,就会输掉游戏。
只有在爱丽丝在游戏中取得胜利时才返回 True,否则返回 false。假设两个玩家都以最佳状态参与游戏。
示例 1:
输入:2 输出:true 解释:爱丽丝选择 1,鲍勃无法进行操作。
示例 2:
输入:3 输出:false 解释:爱丽丝选择 1,鲍勃也选择 1,然后爱丽丝无法进行操作。
提示:
1 <= N <= 1000
解:点击查看答案
给定一个二叉树,找出其最大深度。
二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
**说明:**叶子节点是指没有子节点的节点。
示例: 给定二叉树 [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回它的最大深度 3 。
解:点击查看答案
给出一个 32 位的有符号整数,你需要将这个整数中每位上的数字进行反转。
示例 1:
输入: 123 输出: 321
示例 2:
输入: -123 输出: -321
示例 3:
输入: 120 输出: 21
注意:
假设我们的环境只能存储得下 32 位的有符号整数,则其数值范围为 [−231, 231 − 1]。请根据这个假设,如果反转后整数溢出那么就返回 0。
解:点击查看答案
魔术索引。 在数组A[0...n-1]中,有所谓的魔术索引,满足条件A[i] = i。给定一个有序整数数组,编写一种方法找出魔术索引,若有的话,在数组A中找出一个魔术索引,如果没有,则返回-1。若有多个魔术索引,返回索引值最小的一个。
示例1:
输入:nums = [0, 2, 3, 4, 5] 输出:0 说明: 0下标的元素为0
示例2:
输入:nums = [1, 1, 1] 输出:1
说明:
此题为原书中的 Follow-up,即数组中可能包含重复元素的版本
提示:
nums长度在[1, 1000000]之间
解:点击查看答案
给定两个字符串形式的非负整数 num1 和num2 ,计算它们的和。
注意:
1.num1 和num2 的长度都小于 5100. 2.num1 和num2 都只包含数字 0-9. 3.num1 和num2 都不包含任何前导零。 4.你不能使用任何內建 BigInteger 库, 也不能直接将输入的字符串转换为整数形式。
解:点击查看答案
给定一个排序数组,你需要在 原地 删除重复出现的元素,使得每个元素只出现一次,返回移除后数组的新长度。
不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
示例 1:
给定数组 nums = [1,1,2],
函数应该返回新的长度 2, 并且原数组 nums 的前两个元素被修改为 1, 2。
你不需要考虑数组中超出新长度后面的元素。
示例 2:
给定 nums = [0,0,1,1,1,2,2,3,3,4],
函数应该返回新的长度 5, 并且原数组 nums 的前五个元素被修改为 0, 1, 2, 3, 4。
你不需要考虑数组中超出新长度后面的元素。
解:点击查看答案
你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
给定一个代表每个房屋存放金额的非负整数数组,计算你 不触动警报装置的情况下 ,一夜之内能够偷窃到的最高金额。
示例 1:
输入:[1,2,3,1] 输出:4 解释:偷窃 1 号房屋 (金额 = 1) ,然后偷窃 3 号房屋 (金额 = 3)。 偷窃到的最高金额 = 1 + 3 = 4 。
示例 2:
输入:[2,7,9,3,1] 输出:12 解释:偷窃 1 号房屋 (金额 = 2), 偷窃 3 号房屋 (金额 = 9),接着偷窃 5 号房屋 (金额 = 1)。 偷窃到的最高金额 = 2 + 9 + 1 = 12 。
提示:
0 <= nums.length <= 100 0 <= nums[i] <= 400
解:点击查看答案
写一个函数,输入 n ,求斐波那契(Fibonacci)数列的第 n 项。斐波那契数列的定义如下:
F(0) = 0, F(1) = 1 F(N) = F(N - 1) + F(N - 2), 其中 N > 1.
斐波那契数列由 0 和 1 开始,之后的斐波那契数就是由之前的两数相加而得出。
答案需要取模 1e9+7(1000000007),如计算初始结果为:1000000008,请返回 1。
示例 1:
输入:n = 2 输出:1
示例 2:
输入:n = 5 输出:5
提示:
0 <= n <= 100
解:点击查看答案
给定两个二叉树,编写一个函数来检验它们是否相同。
如果两个树在结构上相同,并且节点具有相同的值,则认为它们是相同的。
示例 1:
输入: 1 1 / \ /
2 3 2 3 [1,2,3], [1,2,3]
输出: true
示例 2:
输入: 1 1 /
2 2 [1,2], [1,null,2]
输出: false
示例 3:
输入: 1 1 / \ /
2 1 1 2[1,2,1], [1,1,2]
输出: false
解:点击查看答案
给定一个字符串 s,计算具有相同数量0和1的非空(连续)子字符串的数量,并且这些子字符串中的所有0和所有1都是组合在一起的。
重复出现的子串要计算它们出现的次数。
示例 1 :
输入: "00110011" 输出: 6 解释: 有6个子串具有相同数量的连续1和0:“0011”,“01”,“1100”,“10”,“0011” 和 “01”。
请注意,一些重复出现的子串要计算它们出现的次数。
另外,“00110011”不是有效的子串,因为所有的0(和1)没有组合在一起。
示例 2 :
输入: "10101" 输出: 4 解释: 有4个子串:“10”,“01”,“10”,“01”,它们具有相同数量的连续1和0。
注意:
s.length 在1到50,000之间。 s 只包含“0”或“1”字符。
解:点击查看答案
找出数组中重复的数字。
在一个长度为 n 的数组 nums 里的所有数字都在 0~n-1 的范围内。数组中某些数字是重复的,但不知道有几个数字重复了,也不知道每个数字重复了几次。请找出数组中任意一个重复的数字。
示例 1:
输入: [2, 3, 1, 0, 2, 5, 3] **输出:**2 或 3
限制:
2 <= n <= 100000
解:点击查看答案
ps:本题目与Question11为相同类型
给定两个以字符串形式表示的非负整数 num1 和 num2,返回 num1 和 num2 的乘积,它们的乘积也表示为字符串形式。
示例 1:
输入: num1 = "2", num2 = "3" 输出: "6"
示例 2:
输入: num1 = "123", num2 = "456" 输出: "56088"
说明:
1.num1 和 num2 的长度小于110。 2.num1 和 num2 只包含数字 0-9。 3.num1 和 num2 均不以零开头,除非是数字 0 本身。 4.不能使用任何标准库的大数类型(比如 BigInteger)或直接将输入转换为整数来处理。
解:点击查看答案
给定一个只包括 '(',')','{','}','[',']' 的字符串,判断字符串是否有效。
有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
注意空字符串可被认为是有效字符串。
示例 1:
输入: "()"
输出: true
示例 2:
输入: "()[]{}"
输出: true
示例 3:
输入: "(]"
输出: false
示例 4:
输入: "([)]"
输出: false
示例 5:
输入: "{[]}"
输出: true
解:点击查看答案
给定一个二叉树,判断它是否是高度平衡的二叉树。
本题中,一棵高度平衡二叉树定义为:
一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过1。
示例 1:
给定二叉树 [3,9,20,null,null,15,7]
3
/ \
9 20
/ \
15 7
示例 2:
给定二叉树 [1,2,2,3,3,null,null,4,4]
1
/ \
2 2
/ \
3 3
/ \
4 4
返回 false 。
解:点击查看答案
集合 S 包含从1到 n 的整数。不幸的是,因为数据错误,导致集合里面某一个元素复制了成了集合里面的另外一个元素的值,导致集合丢失了一个整数并且有一个元素重复。
给定一个数组 nums 代表了集合 S 发生错误后的结果。你的任务是首先寻找到重复出现的整数,再找到丢失的整数,将它们以数组的形式返回。
示例 1:
输入: nums = [1,2,2,4]
输出: [2,3]
解:点击查看答案
给定一个非空且只包含非负数的整数数组 nums, 数组的度的定义是指数组里任一元素出现频数的最大值。
你的任务是找到与 nums 拥有相同大小的度的最短连续子数组,返回其长度。
示例 1:
输入: [1, 2, 2, 3, 1] 输出: 2 解释: 输入数组的度是2,因为元素1和2的出现频数最大,均为2. 连续子数组里面拥有相同度的有如下所示: [1, 2, 2, 3, 1], [1, 2, 2, 3], [2, 2, 3, 1], [1, 2, 2], [2, 2, 3], [2, 2] 最短连续子数组[2, 2]的长度为2,所以返回2.
示例 2:
输入: [1,2,2,3,1,4,2] 输出: 6
注意:
nums.length 在1到50,000区间范围内。 nums[i] 是一个在0到49,999范围内的整数。
解:点击查看答案
给定一个范围在 1 ≤ a[i] ≤ n ( n = 数组大小 ) 的 整型数组,数组中的元素一些出现了两次,另一些只出现一次。
找到所有在 [1, n] 范围之间没有出现在数组中的数字。
您能在不使用额外空间且时间复杂度为O(n)的情况下完成这个任务吗? 你可以假定返回的数组不算在额外空间内。
示例:
输入:
[4,3,2,7,8,2,3,1]
输出:
[5,6]
解:点击查看答案
给定一个整数数组 a,其中1 ≤ a[i] ≤ n (n为数组长度), 其中有些元素出现两次而其他元素出现一次。
找到所有出现两次的元素。
你可以不用到任何额外空间并在O(n)时间复杂度内解决这个问题吗?
示例:
输入:
[4,3,2,7,8,2,3,1]
输出:
[2,3]
解:点击查看答案
ps;这道题跟question8是一个类型题目
给定一个二叉树,找出其最小深度。
最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
说明: 叶子节点是指没有子节点的节点。
示例:
给定二叉树 [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回它的最小深度 2.
解:点击查看答案
给你一个未排序的整数数组,请你找出其中没有出现的最小的正整数。 示例 1:
输入: [1,2,0]
输出: 3
示例 2:
输入: [3,4,-1,1]
输出: 2
示例 3:
输入: [7,8,9,11,12]
输出: 1
提示:
你的算法的时间复杂度应为O(n),并且只能使用常数级别的额外空间。
解:点击查看答案
给定范围 [m, n],其中 0 <= m <= n <= 2147483647,返回此范围内所有数字的按位与(包含 m, n 两端点)。
示例 1:
输入: [5,7]
输出: 4
示例 2:
输入: [0,1]
输出: 0
解:点击查看答案
给定一个非空的字符串,判断它是否可以由它的一个子串重复多次构成。给定的字符串只含有小写英文字母,并且长度不超过10000。
示例 1:
输入: "abab"
输出: True
解释: 可由子字符串 "ab" 重复两次构成。
示例 2:
输入: "aba"
输出: False
示例 3:
输入: "abcabcabcabc"
输出: True
解释: 可由子字符串 "abc" 重复四次构成。 (或者子字符串 "abcabc" 重复两次构成。)
解:点击查看答案
给定一位研究者论文被引用次数的数组(被引用次数是非负整数)。编写一个方法,计算出研究者的 h 指数。
h 指数的定义:h 代表“高引用次数”(high citations),一名科研人员的h指数是指他(她)的 (N 篇论文中)总共有 h 篇论文分别被引用了至少 h 次。(其余的 N - h 篇论文每篇被引用次数 不超过h次。)
例如:某人的 h 指数是 20,这表示他已发表的论文中,每篇被引用了至少 20 次的论文总共有 20 篇。
示例:
输入:citations = [3,0,6,1,5]
输出:3
解释:给定数组表示研究者总共有 5 篇论文,每篇论文相应的被引用了 3, 0, 6, 1, 5 次。
由于研究者有 3 篇论文每篇 至少 被引用了 3 次,其余两篇论文每篇被引用 不多于 3 次,所以她的 h 指数是 3。
**提示:**如果 h 有多种可能的值,h 指数是其中最大的那个。
解:点击查看答案
给定一个长度为 n 的非空整数数组,找到让数组所有元素相等的最小移动次数。每次移动将会使 n - 1 个元素增加 1。(每次除一个最大值外,其他元素增加1;)
示例:
输入:
[1,2,3]
输出:
3
解释:
只需要3次移动(注意每次移动会增加两个元素的值):
[1,2,3] => [2,3,3] => [3,4,3] => [4,4,4]
解:点击查看答案
如下图所示,有一个单向链表,如何验证该链表是否具备环?

解:点击查看答案
给你一个长度为 n 的整数数组,请你判断在 最多 改变 1个元素的情况下,该数组能否变成一个非递减数列。
我们是这样定义一个非递减数列的: 对于数组中所有的 i (0 <= i <= n-2),总满足 nums[i] <= nums[i + 1]。
示例 1:
输入: nums = [4,2,3]
输出: true
解释: 你可以通过把第一个4变成1来使得它成为一个非递减数列。
示例 2:
输入: nums = [4,2,1]
输出: false
解释: 你不能在只改变一个元素的情况下将其变为非递减数列。
解:点击查看答案
给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。
示例:
输入: [0,1,0,3,12]
输出: [1,3,12,0,0]
说明:
- 必须在原数组上操作,不能拷贝额外的数组。
- 尽量减少操作次数。
解:点击查看答案
给定一个非负整数 *numRows,*生成杨辉三角的前 numRows 行。

在杨辉三角中,每个数是它左上方和右上方的数的和
示例:
输入: 5
输出:
[
[1],
[1,1],
[1,2,1],
[1,3,3,1],
[1,4,6,4,1]
]
解:点击查看答案
给定一个非负索引 k,其中 k ≤ 33,返回杨辉三角的第 k 行。
在杨辉三角中,每个数是它左上方和右上方的数的和。
示例:
输入: 3
输出: [1,3,3,1]
进阶:
你可以优化你的算法到 O(k) 空间复杂度吗?
解:点击查看答案
包含整数的二维矩阵 M 表示一个图片的灰度。你需要设计一个平滑器来让每一个单元的灰度成为平均灰度 (向下舍入) ,平均灰度的计算是周围的8个单元和它本身的值求平均,如果周围的单元格不足八个,则尽可能多的利用它们。
示例 1:
输入:
[[1,1,1],
[1,0,1],
[1,1,1]]
输出:
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0]]
解释:
对于点 (0,0), (0,2), (2,0), (2,2): 平均(3/4) = 平均(0.75) = 0
对于点 (0,1), (1,0), (1,2), (2,1): 平均(5/6) = 平均(0.83333333) = 0
对于点 (1,1): 平均(8/9) = 平均(0.88888889) = 0
注意:
- 给定矩阵中的整数范围为 [0, 255]。
- 矩阵的长和宽的范围均为 [1, 150]。
解:点击查看答案
给定一个二叉树,返回它的**中序 **遍历。
示例:
输入: [1,null,2,3]
1
\
2
/
3
输出: [1,3,2]
进阶: 递归算法很简单,你可以通过迭代算法完成吗?
解:点击查看答案
给定一个初始元素全部为 0,大小为 m*n 的矩阵 M 以及在 M 上的一系列更新操作。
操作用二维数组表示,其中的每个操作用一个含有两个正整数 a 和 b 的数组表示,含义是将所有符合 0 <= i < a 以及 0 <= j < b 的元素 M[i][j] 的值都增加 1。
在执行给定的一系列操作后,你需要返回矩阵中含有最大整数的元素个数。
示例 1:
输入:
m = 3, n = 3
operations = [[2,2],[3,3]]
输出: 4
解释:
初始状态, M =
[[0, 0, 0],
[0, 0, 0],
[0, 0, 0]]
执行完操作 [2,2] 后, M =
[[1, 1, 0],
[1, 1, 0],
[0, 0, 0]]
执行完操作 [3,3] 后, M =
[[2, 2, 1],
[2, 2, 1],
[1, 1, 1]]
M 中最大的整数是 2, 而且 M 中有4个值为2的元素。因此返回 4。
注意:
1.m 和 n 的范围是 [1,40000]。
2.a 的范围是 [1,m],b 的范围是 [1,n]。
3.操作数目不超过 10000。
解:点击查看答案
翻转一棵二叉树。
示例:
输入:
4
/ \
2 7
/ \ / \
1 3 6 9
输出:
4
/ \
7 2
/ \ / \
9 6 3 1
解:点击查看答案
给定一个二维的甲板, 请计算其中有多少艘战舰。 战舰用 'X'表示,空位用 '.'表示。 你需要遵守以下规则:
- 给你一个有效的甲板,仅由战舰或者空位组成。
- 战舰只能水平或者垂直放置。换句话说,战舰只能由 1xN (1 行, N 列)组成,或者 Nx1 (N 行, 1 列)组成,其中N可以是任意大小。
- 两艘战舰之间至少有一个水平或垂直的空位分隔 - 即没有相邻的战舰。
示例 :
X..X
...X
...X
在上面的甲板中有2艘战舰。
无效样例 :
...X
XXXX
...X
你不会收到这样的无效甲板 - 因为战舰之间至少会有一个空位将它们分开。
进阶:
你可以用一次扫描算法,只使用O(1)额外空间,并且不修改甲板的值来解决这个问题吗?
解:点击查看答案
给定一个长度为 n 的整数数组 A 。
假设 Bk 是数组 A 顺时针旋转 k 个位置后的数组,我们定义 A 的“旋转函数” F 为:
F(k) = 0 * Bk[0] + 1 * Bk[1] + ... + (n-1) * Bk[n-1]。
计算F(0), F(1), ..., F(n-1)中的最大值。
注意: 可以认为 n 的值小于 105。
示例:
A = [4, 3, 2, 6]
F(0) = (0 * 4) + (1 * 3) + (2 * 2) + (3 * 6) = 0 + 3 + 4 + 18 = 25
F(1) = (0 * 6) + (1 * 4) + (2 * 3) + (3 * 2) = 0 + 4 + 6 + 6 = 16
F(2) = (0 * 2) + (1 * 6) + (2 * 4) + (3 * 3) = 0 + 6 + 8 + 9 = 23
F(3) = (0 * 3) + (1 * 2) + (2 * 6) + (3 * 4) = 0 + 2 + 12 + 12 = 26
所以 F(0), F(1), F(2), F(3) 中的最大值是 F(3) = 26 。
解:点击查看答案
给定一个包含 m x n 个元素的矩阵(m 行, n 列),请按照顺时针螺旋顺序,返回矩阵中的所有元素。
示例 1:
输入:
[
[ 1, 2, 3 ],
[ 4, 5, 6 ],
[ 7, 8, 9 ]
]
输出: [1,2,3,6,9,8,7,4,5]
示例 2:
输入:
[
[1, 2, 3, 4],
[5, 6, 7, 8],
[9,10,11,12]
]
输出: [1,2,3,4,8,12,11,10,9,5,6,7]
解:点击查看答案
给定两个二叉树,想象当你将它们中的一个覆盖到另一个上时,两个二叉树的一些节点便会重叠。
你需要将他们合并为一个新的二叉树。合并的规则是如果两个节点重叠,那么将他们的值相加作为节点合并后的新值,否则不为 NULL 的节点将直接作为新二叉树的节点。
示例 1:
输入:
Tree 1 Tree 2
1 2
/ \ / \
3 2 1 3
/ \ \
5 4 7
输出:
合并后的树:
3
/ \
4 5
/ \ \
5 4 7
注意: 合并必须从两个树的根节点开始
解:点击查看答案
给定一个正整数 n,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的正方形矩阵。
示例:
输入: 3
输出:
[
[ 1, 2, 3 ],
[ 8, 9, 4 ],
[ 7, 6, 5 ]
]
解:点击查看答案
给定一个含有 M x N 个元素的矩阵(M 行,N 列),请以对角线遍历的顺序返回这个矩阵中的所有元素,对角线遍历如下图所示。
示例:
输入:
[
[ 1, 2, 3 ],
[ 4, 5, 6 ],
[ 7, 8, 9 ]
]
输出: [1,2,4,7,5,3,6,8,9]
解释:

解:点击查看答案
在MATLAB中,有一个非常有用的函数 reshape,它可以将一个矩阵重塑为另一个大小不同的新矩阵,但保留其原始数据。
给出一个由二维数组表示的矩阵,以及两个正整数r和c,分别表示想要的重构的矩阵的行数和列数。
重构后的矩阵需要将原始矩阵的所有元素以相同的行遍历顺序填充。
如果具有给定参数的reshape操作是可行且合理的,则输出新的重塑矩阵;否则,输出原始矩阵。
示例 1:
输入:
nums =
[[1,2],
[3,4]]
r = 1, c = 4
输出:
[[1,2,3,4]]
解释:
行遍历nums的结果是 [1,2,3,4]。新的矩阵是 1 * 4 矩阵, 用之前的元素值一行一行填充新矩阵。
示例 2:
输入:
输入:
nums =
[[1,2],
[3,4]]
r = 2, c = 4
输出:
[[1,2],
[3,4]]
解释:
没有办法将 2 * 2 矩阵转化为 2 * 4 矩阵。 所以输出原矩阵。
解:点击查看答案
给定一个 n × n 的二维矩阵表示一个图像。
将图像顺时针旋转 90 度。
说明:
你必须在原地旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要使用另一个矩阵来旋转图像。
示例 1:
给定 matrix =
[
[1,2,3],
[4,5,6],
[7,8,9]
],
原地旋转输入矩阵,使其变为:
[
[7,4,1],
[8,5,2],
[9,6,3]
]
示例 2:
给定 matrix =
[
[ 5, 1, 9,11],
[ 2, 4, 8,10],
[13, 3, 6, 7],
[15,14,12,16]
],
原地旋转输入矩阵,使其变为:
[
[15,13, 2, 5],
[14, 3, 4, 1],
[12, 6, 8, 9],
[16, 7,10,11]
]
解:点击查看答案
给定一个 m x n 的矩阵,如果一个元素为 0,则将其所在行和列的所有元素都设为 0。请使用原地算法**。**
示例 1:
输入:
[
[1,1,1],
[1,0,1],
[1,1,1]
]
输出:
[
[1,0,1],
[0,0,0],
[1,0,1]
]
示例 2:
输入:
[
[0,1,2,0],
[3,4,5,2],
[1,3,1,5]
]
输出:
[
[0,0,0,0],
[0,4,5,0],
[0,3,1,0]
]
进阶:
- 一个直接的解决方案是使用 O(m**n) 的额外空间,但这并不是一个好的解决方案。
- 一个简单的改进方案是使用 O(m + n) 的额外空间,但这仍然不是最好的解决方案。
- 你能想出一个常数空间的解决方案吗?
解:点击查看答案
根据 百度百科 ,生命游戏,简称为生命,是英国数学家约翰·何顿·康威在 1970 年发明的细胞自动机。
给定一个包含 m × n 个格子的面板,每一个格子都可以看成是一个细胞。每个细胞都具有一个初始状态:1 即为活细胞(live),或 0 即为死细胞(dead)。每个细胞与其八个相邻位置(水平,垂直,对角线)的细胞都遵循以下四条生存定律:
-
1.如果活细胞周围八个位置的活细胞数少于两个,则该位置活细胞死亡;
-
2.如果活细胞周围八个位置有两个或三个活细胞,则该位置活细胞仍然存活;
-
3.如果活细胞周围八个位置有超过三个活细胞,则该位置活细胞死亡;
-
4.如果死细胞周围正好有三个活细胞,则该位置死细胞复活;
根据当前状态,写一个函数来计算面板上所有细胞的下一个(一次更新后的)状态。下一个状态是通过将上述规则同时应用于当前状态下的每个细胞所形成的,其中细胞的出生和死亡是同时发生的。
示例:
输入:
[
[0,1,0],
[0,0,1],
[1,1,1],
[0,0,0]
]
输出:
[
[0,0,0],
[1,0,1],
[0,1,1],
[0,1,0]
]
进阶:
- 你可以使用原地算法解决本题吗?请注意,面板上所有格子需要同时被更新:你不能先更新某些格子,然后使用它们的更新后的值再更新其他格子。
- 本题中,我们使用二维数组来表示面板。原则上,面板是无限的,但当活细胞侵占了面板边界时会造成问题。你将如何解决这些问题?
解:点击查看答案
给定一个整数数组 nums,求出数组从索引 i 到 j (i ≤ j) 范围内元素的总和,包含 i, j 两点。
示例:
给定 nums = [-2, 0, 3, -5, 2, -1],求和函数为 sumRange()
sumRange(0, 2) -> 1
sumRange(2, 5) -> -1
sumRange(0, 5) -> -3
说明:
- 你可以假设数组不可变。
- 会多次调用 sumRange 方法。
解:点击查看答案
给定一个二维矩阵,计算其子矩形范围内元素的总和,该子矩阵的左上角为 (row1, col1) ,右下角为 (row2, col2)。

上图子矩阵左上角 (row1, col1) = (2, 1) ,右下角(row2, col2) = **(4, 3),**该子矩形内元素的总和为 8。
示例:
给定 matrix = [
[3, 0, 1, 4, 2],
[5, 6, 3, 2, 1],
[1, 2, 0, 1, 5],
[4, 1, 0, 1, 7],
[1, 0, 3, 0, 5]
]
sumRegion(2, 1, 4, 3) -> 8
sumRegion(1, 1, 2, 2) -> 11
sumRegion(1, 2, 2, 4) -> 12
说明:
- 你可以假设矩阵不可变。
- 会多次调用 sumRegion 方法*。*
- 你可以假设 row1 ≤ row2 且 col1 ≤ col2。
解:点击查看答案
给你一个长度为 n 的整数数组 nums,其中 n > 1,返回输出数组 output ,其中 output[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积。
示例:
输入: [1,2,3,4]
输出: [24,12,8,6]
提示:
题目数据保证数组之中任意元素的全部前缀元素和后缀(甚至是整个数组)的乘积都在 32 位整数范围内。
说明:
请**不要使用除法,**且在 O(n) 时间复杂度内完成此题。
进阶: 你可以在常数空间复杂度内完成这个题目吗?( 出于对空间复杂度分析的目的,输出数组不被视为额外空间。)
解:点击查看答案
给定一个单词,你需要判断单词的大写使用是否正确。
我们定义,在以下情况时,单词的大写用法是正确的:
- 全部字母都是大写,比如"USA"。
- 单词中所有字母都不是大写,比如"leetcode123"。
- 如果单词不只含有一个字母,只有首字母大写, 比如 "Google"。
否则,我们定义这个单词没有正确使用大写字母。
示例 1:
输入: "USA"
输出: True
示例 2:
输入: "FlaG"
输出: False
解:点击查看答案
给定一个字符串,验证它是否是回文串,只考虑字母和数字字符,可以忽略字母的大小写。
说明:
本题中,我们将空字符串定义为有效的回文串。
示例 1:
输入: "A man, a plan, a canal: Panama"
输出: true
示例 2:
输入: "race a car"
输出: false
解:点击查看答案
编写一个函数来查找字符串数组中的最长公共前缀。
如果不存在公共前缀,返回空字符串 ""。
示例 1:
输入: ["flower","flow","flight"]
输出: "fl"
示例 2:
输入: ["dog","racecar","car"]
输出: ""
解释: 输入不存在公共前缀。
解:点击查看答案
给定两个数组,编写一个函数来计算它们的交集。
示例 1:
输入:nums1 = [1,2,2,1], nums2 = [2,2]
输出:[2]
示例 2:
输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出:[9,4]
说明:
- 输出结果中的每个元素一定是唯一的。
- 我们可以不考虑输出结果的顺序。
解:点击查看答案
给定一个整数数组 A,如果它是有效的山脉数组就返回 true,否则返回 false。
让我们回顾一下,如果 A 满足下述条件,那么它是一个山脉数组:
A.length >= 3- 在
0 < i < A.length - 1条件下,存在i使得:A[0] < A[1] < ... A[i-1] < A[i]A[i] > A[i+1] > ... > A[A.length - 1]
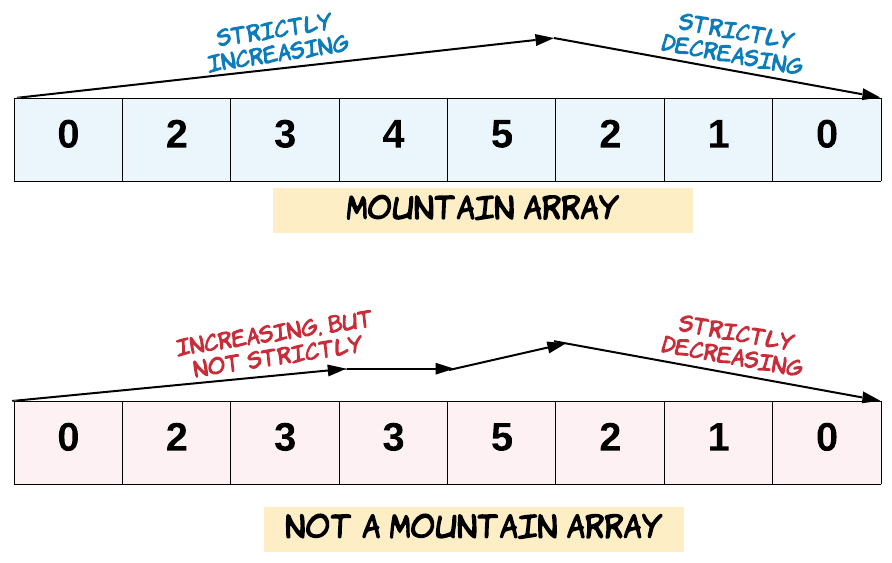
示例 1:
输入:[2,1]
输出:false
示例 2:
输入:[3,5,5]
输出:false
示例 3:
输入:[0,3,2,1]
输出:true
解:点击查看答案
统计字符串中的单词个数,这里的单词指的是连续的不是空格的字符。
请注意,你可以假定字符串里不包括任何不可打印的字符。
示例:
输入: "Hello, my name is John"
输出: 5
解释: 这里的单词是指连续的不是空格的字符,所以 "Hello," 算作 1 个单词。
解:点击查看答案
给定一个仅包含大小写字母和空格 ' ' 的字符串 s,返回其最后一个单词的长度。如果字符串从左向右滚动显示,那么最后一个单词就是最后出现的单词。
如果不存在最后一个单词,请返回 0 。
**说明:**一个单词是指仅由字母组成、不包含任何空格字符的 最大子字符串。
示例:
输入: "Hello World"
输出: 5
解:点击查看答案
编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 char[] 的形式给出。
不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。
你可以假设数组中的所有字符都是 ASCII 码表中的可打印字符。
示例 1:
输入:["h","e","l","l","o"]
输出:["o","l","l","e","h"]
示例 2:
输入:["H","a","n","n","a","h"]
输出:["h","a","n","n","a","H"]
解:点击查看答案
给定一个字符串 s 和一个整数 k,你需要对从字符串开头算起的每隔 2k 个字符的前 k 个字符进行反转。
- 如果剩余字符少于
k个,则将剩余字符全部反转 - 如果剩余字符小于
2k但大于或等于k个,则反转前k个字符,其余字符保持原样
示例:
输入: s = "abcdefg", k = 2
输出: "bacdfeg"
提示:
- 该字符串只包含小写英文字母。
- 给定字符串的长度和
k在[1, 10000]范围内。
解:点击查看答案
给定一个字符串,你需要反转字符串中每个单词的字符顺序,同时仍保留空格和单词的初始顺序。
示例:
输入:"Let's take LeetCode contest"
输出:"s'teL ekat edoCteeL tsetnoc"
提示:
- 在字符串中,每个单词由单个空格分隔,并且字符串中不会有任何额外的空格。
解:点击查看答案
给定一个字符串,逐个翻转字符串中的每个单词。
说明:
- 无空格字符构成一个 单词
- 输入字符串可以在前面或者后面包含多余的空格,但是反转后的字符不能包括。
- 如果两个单词间有多余的空格,将反转后单词间的空格减少到只含一个。
示例 1:
输入:"the sky is blue"
输出:"blue is sky the"
示例 2:
输入:" hello world! "
输出:"world! hello"
解释:输入字符串可以在前面或者后面包含多余的空格,但是反转后的字符不能包括。
示例 3:
输入:"a good example"
输出:"example good a"
解释:如果两个单词间有多余的空格,将反转后单词间的空格减少到只含一个。
示例 4:
输入:s = " Bob Loves Alice "
输出:"Alice Loves Bob"
示例 5:
输入:s = "Alice does not even like bob"
输出:"bob like even not does Alice"
提示:
1 <= s.length <= 104s包含英文大小写字母、数字和空格' 's中 至少存在一个 单词
解:点击查看答案
给定一个字符串,找到它的第一个不重复的字符,并返回它的索引。如果不存在,则返回 -1。
示例:
s = "leetcode123"
返回 0
s = "loveleetcode"
返回 2
提示:
你可以假定该字符串只包含小写字母。
解:点击查看答案
给定两个字符串 s 和 t,它们只包含小写字母。
字符串 t 由字符串 s 随机重排,然后在随机位置添加一个字母。
请找出在 t 中被添加的字母。
示例 1:
输入:s = "abcd", t = "abcde"
输出:"e"
解释:'e' 是那个被添加的字母。
示例 2:
输入:s = "", t = "y"
输出:"y"
示例 3:
输入:s = "a", t = "aa"
输出:"a"
示例 4:
输入:s = "ae", t = "aea"
输出:"a"
解:点击查看答案
给定一个赎金信 (ransom) 字符串和一个杂志(magazine)字符串,判断第一个字符串 ransom 能不能由第二个字符串 magazines 里面的字符构成。
(题目说明:为了不暴露赎金信字迹,要从杂志上搜索各个需要的字母,组成单词来表达意思。杂志字符串中的每个字符只能在赎金信字符串中使用一次。)
注意:
你可以假设两个字符串均只含有小写字母。
canConstruct("a", "b") -> false
canConstruct("aa", "ab") -> false
canConstruct("aa", "aab") -> true
解:点击查看答案
给定一个字符串数组,将字母异位词组合在一起。字母异位词指字母相同,但排列不同的字符串。
示例:
输入: ["eat", "tea", "tan", "ate", "nat", "bat"]
输出:
[
["ate","eat","tea"],
["nat","tan"],
["bat"]
]
说明:
- 所有输入均为小写字母。
- 不考虑答案输出的顺序。
解:点击查看答案
给定一个字符串,请将字符串里的字符按照出现的频率降序排列。
示例 1:
输入:
"tree"
输出:
"eert"
解释:
'e'出现两次,'r'和't'都只出现一次。
因此'e'必须出现在'r'和't'之前。此外,"eetr"也是一个有效的答案。
示例 2:
输入:
"cccaaa"
输出:
"cccaaa"
解释:
'c'和'a'都出现三次。此外,"aaaccc"也是有效的答案。
注意"cacaca"是不正确的,因为相同的字母必须放在一起。
示例 3:
输入:
"Aabb"
输出:
"bbAa"
解释:
此外,"bbaA"也是一个有效的答案,但"Aabb"是不正确的。
注意'A'和'a'被认为是两种不同的字符。
解:点击查看答案
给定一个非空字符串,其中包含字母顺序打乱的英文单词表示的数字0-9。按升序输出原始的数字。
注意:
- 输入只包含小写英文字母。
- 输入保证合法并可以转换为原始的数字,这意味着像 "abc" 或 "zerone" 的输入是不允许的。
- 输入字符串的长度小于 50,000。
示例 1:
输入: "owoztneoer"
输出: "012" (zeroonetwo)
示例 2:
输入: "fviefuro"
输出: "45" (fourfive)
解:点击查看答案
给你一个仅包含小写英文字母和 '?' 字符的字符串 s,请你将所有的 '?' 转换为若干小写字母,使最终的字符串不包含任何 连续重复 的字符。
注意:你 不能 修改非 '?' 字符。
题目测试用例保证 除 '?' 字符 之外,不存在连续重复的字符。
在完成所有转换(可能无需转换)后返回最终的字符串。如果有多个解决方案,请返回其中任何一个。可以证明,在给定的约束条件下,答案总是存在的。
示例 1:
输入:s = "?zs"
输出:"azs"
解释:该示例共有 25 种解决方案,从 "azs" 到 "yzs" 都是符合题目要求的。只有 "z" 是无效的修改,因为字符串 "zzs" 中有连续重复的两个 'z' 。
示例 2:
输入:s = "ubv?w"
输出:"ubvaw"
解释:该示例共有 24 种解决方案,只有替换成 "v" 和 "w" 不符合题目要求。因为 "ubvvw" 和 "ubvww" 都包含连续重复的字符。
示例 3:
输入:s = "j?qg??b"
输出:"jaqgacb"
示例 4:
输入:s = "??yw?ipkj?"
输出:"acywaipkja"
解:点击查看答案
对链表进行插入排序。

插入排序的动画演示如上。从第一个元素开始,该链表可以被认为已经部分排序(用黑色表示)。
每次迭代时,从输入数据中移除一个元素(用红色表示),并原地将其插入到已排好序的链表中。
插入排序算法:
- 插入排序是迭代的,每次只移动一个元素,直到所有元素可以形成一个有序的输出列表。
- 每次迭代中,插入排序只从输入数据中移除一个待排序的元素,找到它在序列中适当的位置,并将其插入。
- 重复直到所有输入数据插入完为止。
示例 1:
输入: 4->2->1->3
输出: 1->2->3->4
示例 2:
输入: -1->5->3->4->0
输出: -1->0->3->4->5
解:点击查看答案
在二维平面上,有一个机器人从原点 (0, 0) 开始。给出它的移动顺序,判断这个机器人在完成移动后是否在 (0, 0) 处结束。
移动顺序由字符串表示。字符 move[i] 表示其第 i 次移动。机器人的有效动作有 R(右),L(左),U(上)和 D(下)。如果机器人在完成所有动作后返回原点,则返回 true。否则,返回 false。
**注意:**机器人“面朝”的方向无关紧要。 “R” 将始终使机器人向右移动一次,“L” 将始终向左移动等。此外,假设每次移动机器人的移动幅度相同。
示例 1:
输入: "UD"
输出: true
解释:机器人向上移动一次,然后向下移动一次。所有动作都具有相同的幅度,因此它最终回到它开始的原点。因此,我们返回 true。
示例 2:
输入: "LL"
输出: false
解释:机器人向左移动两次。它最终位于原点的左侧,距原点有两次 “移动” 的距离。我们返回 false,因为它在移动结束时没有返回原点。
解:点击查看答案
给定一个字符串来代表一个学生的出勤记录,这个记录仅包含以下三个字符:
- 'A' : Absent,缺勤
- 'L' : Late,迟到
- 'P' : Present,到场
如果一个学生的出勤记录中不超过一个'A'(缺勤)并且不超过两个连续的'L'(迟到),那么这个学生会被奖赏。
你需要根据这个学生的出勤记录判断他是否会被奖赏。
示例 1:
输入: "PPALLP"
输出: True
示例 2:
输入: "PPALLL"
输出: False
解:点击查看答案
你在和朋友一起玩 猜数字(Bulls and Cows)游戏,该游戏规则如下:
- 你写出一个秘密数字,并请朋友猜这个数字是多少。
- 朋友每猜测一次,你就会给他一个提示,告诉他的猜测数字中有多少位属于数字和确切位置都猜对了(称为“Bulls”, 公牛),有多少位属于数字,猜对了但是位置不对(称为“Cows”, 奶牛)
- 朋友根据提示继续猜,直到猜出秘密数字。
请写出一个根据秘密数字和朋友的猜测数返回提示的函数,返回字符串的格式为 xAyB ,x 和 y 都是数字,A 表示公牛,用 B 表示奶牛。
xA表示有x位数字出现在秘密数字中,且位置都与秘密数字一致yB表示有y位数字出现在秘密数字中,但位置与秘密数字不一致。
请注意秘密数字和朋友的猜测数都可能含有重复数字,每位数字只能统计一次。
示例 1:
输入: secret = "1807", guess = "7810"
输出: "1A3B"
解释: 1 公牛和 3 奶牛。公牛是 8,奶牛是 0, 1 和 7。
示例 2:
输入: secret = "1123", guess = "0111"
输出: "1A1B"
解释: 朋友猜测数中的第一个 1 是公牛,第二个或第三个 1 可被视为奶牛。
解:点击查看答案
字符串压缩。利用字符重复出现的次数,编写一种方法,实现基本的字符串压缩功能。比如,字符串aabcccccaaa会变为a2b1c5a3。若“压缩”后的字符串没有变短,则返回原先的字符串。你可以假设字符串中只包含大小写英文字母(a至z)。
示例1:
输入:"aabcccccaaa"
输出:"a2b1c5a3"
示例2:
输入:"abbccd"
输出:"abbccd"
解释:"abbccd"压缩后为"a1b2c2d1",比原字符串长度更长。
解:点击查看答案
角谷猜想:角谷静夫是日本的一位著名学者.他提出了两条极简单的规则,可以对任何一个自然数进行变换,最终使它陷入“4-2-1”的死循环
以一个正整数n为例,如果n为偶数,就将它变为n/2,如果除后变为奇数,则将它乘3加1(即3n+1)。不断重复这样的运算,经过有限步后,一定可以得到1吗?
这就是角古猜想(1930)。人们通过大量的验算,从来没有发现反例,但是也没有人能证明。
任意选一个整数N,规则如下:如果N为奇数,那么运算N*3+1;如果N为偶数,那么运算N/2。
得到第一个结果之后,再重复按规则运算。
这样一直算下去,你会发现最后数字会在一个循环圈里循环,这个循环圈是(4→2→1→4)。
请编写角谷猜想的函数。
解:点击查看答案
写一个程序,输出从 1 到 n 数字的字符串表示。
- 如果 n 是3的倍数,输出“Fizz”;
- 如果 n 是5的倍数,输出“Buzz”;
- 如果 n 同时是3和5的倍数,输出 “FizzBuzz”。
示例:
n = 15,
返回:
[
"1",
"2",
"Fizz",
"4",
"Buzz",
"Fizz",
"7",
"8",
"Fizz",
"Buzz",
"11",
"Fizz",
"13",
"14",
"FizzBuzz"
]
解:点击查看答案
给出 N 名运动员的成绩,找出他们的相对名次并授予前三名对应的奖牌。前三名运动员将会被分别授予 “金牌”,“银牌” 和“ 铜牌”("Gold Medal", "Silver Medal", "Bronze Medal")。
(注:分数越高的选手,排名越靠前。)
示例 1:
输入: [5, 4, 3, 2, 1]
输出: ["Gold Medal", "Silver Medal", "Bronze Medal", "4", "5"]
解释: 前三名运动员的成绩为前三高的,因此将会分别被授予 “金牌”,“银牌”和“铜牌” ("Gold Medal", "Silver Medal" and "Bronze Medal").
余下的两名运动员,我们只需要通过他们的成绩计算将其相对名次即可。
提示:
- N 是一个正整数并且不会超过 10000。
- 所有运动员的成绩都不相同。
解:点击查看答案
给定一个 24 小时制(小时:分钟 "HH:MM")的时间列表,找出列表中任意两个时间的最小时间差并以分钟数表示。
示例 1:
输入:timePoints = ["23:59","00:00"]
输出:1
示例 2:
输入:timePoints = ["00:00","23:59","00:00"]
输出:0
提示:
2 <= timePoints <= 2 * 104timePoints[i]格式为 "HH:MM"
解:点击查看答案
在柠檬水摊上,每一杯柠檬水的售价为 5 美元。
顾客排队购买你的产品,(按账单 bills 支付的顺序)一次购买一杯
每位顾客只买一杯柠檬水,然后向你付 5 美元、10 美元或 20 美元。你必须给每个顾客正确找零,也就是说净交易是每位顾客向你支付 5 美元。
注意,一开始你手头没有任何零钱。
如果你能给每位顾客正确找零,返回 true ,否则返回 false 。
示例 1:
输入:[5,5,5,10,20]
输出:true
解释:
前 3 位顾客那里,我们按顺序收取 3 张 5 美元的钞票。
第 4 位顾客那里,我们收取一张 10 美元的钞票,并返还 5 美元。
第 5 位顾客那里,我们找还一张 10 美元的钞票和一张 5 美元的钞票。
由于所有客户都得到了正确的找零,所以我们输出 true。
示例 2:
输入:[5,5,10]
输出:true
示例 3:
输入:[10,10]
输出:false
示例 4:
输入:[5,5,10,10,20]
输出:false
解释:
前 2 位顾客那里,我们按顺序收取 2 张 5 美元的钞票。
对于接下来的 2 位顾客,我们收取一张 10 美元的钞票,然后返还 5 美元。
对于最后一位顾客,我们无法退回 15 美元,因为我们现在只有两张 10 美元的钞票。
由于不是每位顾客都得到了正确的找零,所以答案是 false。
提示:
0 <= bills.length <= 10000bills[i]不是5就是10或是20
解:点击查看答案
小扣注意到秋日市集上有一个创作黑白方格画的摊位。摊主给每个顾客提供一个固定在墙上的白色画板,画板不能转动。画板上有 n * n 的网格。绘画规则为,小扣可以选择任意多行以及任意多列的格子涂成黑色,所选行数、列数均可为 0。
小扣希望最终的成品上需要有 k 个黑色格子,请返回小扣共有多少种涂色方案。
注意:两个方案中任意一个相同位置的格子颜色不同,就视为不同的方案。
示例 1:
输入:
n = 2, k = 2输出:
4解释:一共有四种不同的方案: 第一种方案:涂第一列; 第二种方案:涂第二列; 第三种方案:涂第一行; 第四种方案:涂第二行。
示例 2:
输入:
n = 2, k = 1输出:
0解释:不可行,因为第一次涂色至少会涂两个黑格。
示例 3:
输入:
n = 2, k = 4输出:
1解释:共有 2*2=4 个格子,仅有一种涂色方案。
限制:
1 <= n <= 60 <= k <= n * n
解:点击查看答案
给定一个非负整数 N,找出小于或等于 N 的最大的整数,同时这个整数需要满足其各个位数上的数字是单调递增。
(当且仅当每个相邻位数上的数字 x 和 y 满足 x <= y 时,我们称这个整数是单调递增的。)
示例 1:
输入: N = 10
输出: 9
示例 2:
输入: N = 1234
输出: 1234
示例 3:
输入: N = 332
输出: 299
解:点击查看答案
给定两个表示复数的字符串。返回表示它们乘积的字符串。注意,根据定义 i2 = -1 。
示例 1:
输入: "1+1i", "1+1i"
输出: "0+2i"
解释: (1 + i) * (1 + i) = 1 + i2 + 2 * i = 2i ,你需要将它转换为 0+2i 的形式。
示例 2:
输入: "1+-1i", "1+-1i"
输出: "0+-2i"
解释: (1 - i) * (1 - i) = 1 + i2 - 2 * i = -2i ,你需要将它转换为 0+-2i 的形式。
注意:
- 输入字符串不包含额外的空格。
- 输入字符串将以 a+bi 的形式给出,其中整数 a 和 b 的范围均在 [-100, 100] 之间。输出也应当符合这种形式。
解:点击查看答案
给定一种规律 pattern 和一个字符串 str ,判断 str 是否遵循相同的规律。
这里的 遵循 指完全匹配,例如, pattern 里的每个字母和字符串 str 中的每个非空单词之间存在着双向连接的对应规律。
示例1:
输入: pattern = "abba", str = "dog cat cat dog"
输出: true
示例 2:
输入:pattern = "abba", str = "dog cat cat fish"
输出: false
示例 3:
输入: pattern = "aaaa", str = "dog cat cat dog"
输出: false
示例 4:
输入: pattern = "abba", str = "dog dog dog dog"
输出: false
解:点击查看答案
给定一个正整数 n ,输出外观数列的第 n 项。
「外观数列」是一个整数序列,从数字 1 开始,序列中的每一项都是对前一项的描述。
你可以将其视作是由递归公式定义的数字字符串序列:
countAndSay(1) = "1"countAndSay(n)是对countAndSay(n-1)的描述,然后转换成另一个数字字符串。
前五项如下:
1. 1
2. 11
3. 21
4. 1211
5. 111221
第一项是数字 1
描述前一项,这个数是 1 即 “ 一 个 1 ”,记作 "11"
描述前一项,这个数是 11 即 “ 二 个 1 ” ,记作 "21"
描述前一项,这个数是 21 即 “ 一 个 2 + 一 个 1 ” ,记作 "1211"
描述前一项,这个数是 1211 即 “ 一 个 1 + 一 个 2 + 二 个 1 ” ,记作 "111221"
要 描述 一个数字字符串,首先要将字符串分割为 最小 数量的组,每个组都由连续的最多 相同字符 组成。然后对于每个组,先描述字符的数量,然后描述字符,形成一个描述组。要将描述转换为数字字符串,先将每组中的字符数量用数字替换,再将所有描述组连接起来。
例如,数字字符串 "3322251" 的描述如下图:

示例 1:
输入:n = 1
输出:"1"
解释:这是一个基本样例。
示例 2:
输入:n = 4
输出:"1211"
解释:
countAndSay(1) = "1"
countAndSay(2) = 读 "1" = 一 个 1 = "11"
countAndSay(3) = 读 "11" = 二 个 1 = "21"
countAndSay(4) = 读 "21" = 一 个 2 + 一 个 1 = "12" + "11" = "1211"
提示:
1 <= n <= 30
解:点击查看答案
给定一组字符,使用原地算法将其压缩。
压缩后的长度必须始终小于或等于原数组长度。
数组的每个元素应该是长度为1 的字符(不是 int 整数类型)。
在完成原地修改输入数组后,返回数组的新长度。
进阶: 你能否仅使用O(1) 空间解决问题?
示例 1:
输入:
["a","a","b","b","c","c","c"]
输出:
返回 6 ,输入数组的前 6 个字符应该是:["a","2","b","2","c","3"]
说明:
"aa" 被 "a2" 替代。"bb" 被 "b2" 替代。"ccc" 被 "c3" 替代。
示例 2:
输入:
["a"]
输出:
返回 1 ,输入数组的前 1 个字符应该是:["a"]
解释:
没有任何字符串被替代。
示例 3:
输入:
["a","b","b","b","b","b","b","b","b","b","b","b","b"]
输出:
返回 4 ,输入数组的前4个字符应该是:["a","b","1","2"]。
解释:
由于字符 "a" 不重复,所以不会被压缩。"bbbbbbbbbbbb" 被 “b12” 替代。
注意每个数字在数组中都有它自己的位置。
解:点击查看答案
请你来实现一个 atoi 函数,使其能将字符串转换成整数。
首先,该函数会根据需要丢弃无用的开头空格字符,直到寻找到第一个非空格的字符为止。接下来的转化规则如下:
- 如果第一个非空字符为正或者负号时,则将该符号与之后面尽可能多的连续数字字符组合起来,形成一个有符号整数。
- 假如第一个非空字符是数字,则直接将其与之后连续的数字字符组合起来,形成一个整数。
- 该字符串在有效的整数部分之后也可能会存在多余的字符,那么这些字符可以被忽略,它们对函数不应该造成影响。
注意:假如该字符串中的第一个非空格字符不是一个有效整数字符、字符串为空或字符串仅包含空白字符时,则你的函数不需要进行转换,即无法进行有效转换
在任何情况下,若函数不能进行有效的转换时,请返回 0 。
提示:
- 本题中的空白字符只包括空格字符
' '。 - 假设我们的环境只能存储 32 位大小的有符号整数,那么其数值范围为 [−231, 231 − 1]。如果数值超过这个范围,请返回 INT_MAX (231 − 1) 或 INT_MIN (−231) 。
解:点击查看答案
数组的每个索引作为一个阶梯,第 i个阶梯对应着一个非负数的体力花费值 cost[i](索引从0开始)。
每当你爬上一个阶梯你都要花费对应的体力花费值,然后你可以选择继续爬一个阶梯或者爬两个阶梯。
您需要找到达到楼层顶部的最低花费。在开始时,你可以选择从索引为 0 或 1 的元素作为初始阶梯。
示例 1:
输入: cost = [10, 15, 20]
输出: 15
解释: 最低花费是从cost[1]开始,然后走两步即可到阶梯顶,一共花费15。
示例 2:
输入: cost = [1, 100, 1, 1, 1, 100, 1, 1, 100, 1]
输出: 6
解释: 最低花费方式是从cost[0]开始,逐个经过那些1,跳过cost[3],一共花费6。
注意:
cost的长度将会在[2, 1000]。- 每一个
cost[i]将会是一个Integer类型,范围为[0, 999]。
解:点击查看答案
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
字符 数值
I 1
V 5
X 10
L 50
C 100
D 500
M 1000
例如, 罗马数字 2 写做 II ,即为两个并列的 1。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况
I可以放在V(5) 和X(10) 的左边,来表示 4 和 9。X可以放在L(50) 和C(100) 的左边,来表示 40 和 90。C可以放在D(500) 和M(1000) 的左边,来表示 400 和 900。
给定一个罗马数字,将其转换成整数。输入确保在 1 到 3999 的范围内。
示例 1:
输入: "III"
输出: 3
示例 2:
输入: "IV"
输出: 4
示例 3:
输入: "IX"
输出: 9
示例 4:
输入: "LVIII"
输出: 58
解释: L = 50, V= 5, III = 3.
示例 5:
输入: "MCMXCIV"
输出: 1994
解释: M = 1000, CM = 900, XC = 90, IV = 4.
提示:
- 题目所给测试用例皆符合罗马数字书写规则,不会出现跨位等情况。
- IC 和 IM 这样的例子并不符合题目要求,49 应该写作 XLIX,999 应该写作 CMXCIX 。
- 关于罗马数字的详尽书写规则,可以参考 罗马数字 - Mathematics 。
解:点击查看答案
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
字符 数值
I 1
V 5
X 10
L 50
C 100
D 500
M 1000
例如, 罗马数字 2 写做 II ,即为两个并列的 1。12 写做 XII ,即为 X + II 。27 写做 XXVII, 即为 XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
I可以放在V(5) 和X(10) 的左边,来表示 4 和 9。X可以放在L(50) 和C(100) 的左边,来表示 40 和 90。C可以放在D(500) 和M(1000) 的左边,来表示 400 和 900。
给定一个整数,将其转为罗马数字。输入确保在 1 到 3999 的范围内。
示例 1:
输入: 3
输出: "III"
示例 2:
输入: 4
输出: "IV"
示例 3:
输入: 9
输出: "IX"
示例 4:
输入: 58
输出: "LVIII"
解释: L = 50, V = 5, III = 3.
示例 5:
输入: 1994
输出: "MCMXCIV"
解释: M = 1000, CM = 900, XC = 90, IV = 4.
解:点击查看答案
将非负整数 num 转换为其对应的英文表示。
示例 1:
输入:num = 123
输出:"One Hundred Twenty Three"
输入:num = 12345
输出:"Twelve Thousand Three Hundred Forty Five"
示例 2:
输入:num = 12345
输出:"Twelve Thousand Three Hundred Forty Five"
示例 3:
输入:num = 1234567
输出:"One Million Two Hundred Thirty Four Thousand Five Hundred Sixty Seven"
示例 4:
输入:num = 1234567891
输出:"One Billion Two Hundred Thirty Four Million Five Hundred Sixty Seven Thousand Eight Hundred Ninety One"
提示:
0 <= num <= 2^31 - 1
解:点击查看答案
给你两个版本号 version1 和 version2 ,请你比较它们。
版本号由一个或多个修订号组成,各修订号由一个 '.' 连接。每个修订号由 多位数字 组成,可能包含 前导零 。每个版本号至少包含一个字符。修订号从左到右编号,下标从 0 开始,最左边的修订号下标为 0 ,下一个修订号下标为 1 ,以此类推。例如,2.5.33 和 0.1 都是有效的版本号。
比较版本号时,请按从左到右的顺序依次比较它们的修订号。比较修订号时,只需比较 忽略任何前导零后的整数值 。也就是说,修订号 1 和修订号 001 相等 。如果版本号没有指定某个下标处的修订号,则该修订号视为 0 。例如,版本 1.0 小于版本 1.1 ,因为它们下标为 0 的修订号相同,而下标为 1 的修订号分别为 0 和 1 ,0 < 1 。
返回规则如下:
- 如果
*version1* > *version2*返回1 - 如果
*version1* < *version2*返回-1, - 除此之外返回
0。
示例 1:
输入:version1 = "1.01", version2 = "1.001"
输出:0
解释:忽略前导零,"01" 和 "001" 都表示相同的整数 "1"
示例 2:
输入:version1 = "1.0", version2 = "1.0.0"
输出:0
解释:version1 没有指定下标为 2 的修订号,即视为 "0"
示例 3:
输入:version1 = "0.1", version2 = "1.1"
输出:-1
解释:version1 中下标为 0 的修订号是 "0",version2 中下标为 0 的修订号是 "1" 。0 < 1,所以 version1 < version2
示例 4:
输入:version1 = "1.0.1", version2 = "1"
输出:1
示例 5:
输入:version1 = "7.5.2.4", version2 = "7.5.3"
输出:-1
提示:
1 <= version1.length, version2.length <= 500- version1 和 version2 仅包含数字和 '.'
- version1 和 version2 都是 有效版本号
- version1 和 version2 的所有修订号都可以存储在 32 位整数 中
解:点击查看答案
老师想给孩子们分发糖果,有 N 个孩子站成了一条直线,老师会根据每个孩子的表现,预先给他们评分。
你需要按照以下要求,帮助老师给这些孩子分发糖果:
-
每个孩子至少分配到 1 个糖果。
-
相邻的孩子中,评分高的孩子必须获得更多的糖果。
那么这样下来,老师至少需要准备多少颗糖果呢?
示例 1:
输入: [1,0,2]
输出: 5
解释: 你可以分别给这三个孩子分发 2、1、2 颗糖果。
示例 2:
输入: [1,2,2]
输出: 4
解释: 你可以分别给这三个孩子分发 1、2、1 颗糖果。
第三个孩子只得到 1 颗糖果,这已满足上述两个条件。
解:点击查看答案
给定字符串 s 和 t ,判断 s 是否为 t 的子序列。
字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,"ace"是"abcde"的一个子序列,而"aec"不是)。
进阶:
如果有大量输入的 S,称作 S1, S2, ... , Sk 其中 k >= 10亿,你需要依次检查它们是否为 T 的子序列。在这种情况下,你会怎样改变代码?
致谢:
特别感谢 @pbrother 添加此问题并且创建所有测试用例。
示例 1:
输入:s = "abc", t = "ahbgdc"
输出:true
示例 2:
输入:s = "axc", t = "ahbgdc"
输出:false
解:点击查看答案
给定一个字符串和一个字符串字典,找到字典里面最长的字符串,该字符串可以通过删除给定字符串的某些字符来得到。如果答案不止一个,返回长度最长且字典顺序最小的字符串。如果答案不存在,则返回空字符串。
示例 1:
输入:
s = "abpcplea", d = ["ale","apple","monkey","plea"]
输出:
"apple"
示例 2:
输入:
s = "abpcplea", d = ["a","b","c"]
输出:
"a
说明:
- 所有输入的字符串只包含小写字母。
- 字典的大小不会超过 1000。
- 所有输入的字符串长度不会超过 1000。
解:点击查看答案
给定两个字符串 s 和 t,判断它们是否是同构的。
如果 s 中的字符可以被替换得到 *t* ,那么这两个字符串是同构的。
所有出现的字符都必须用另一个字符替换,同时保留字符的顺序。两个字符不能映射到同一个字符上,但字符可以映射自己本身。
示例 1:
输入: s = "egg", t = "add"
输出: true
示例 2:
输入: s = "foo", t = "bar"
输出: false
示例 3:
输入: s = "paper", t = "title"
输出: true
说明: 你可以假设 s 和 *t* 具有相同的长度。
解:点击查看答案
假设有一个很长的花坛,一部分地块种植了花,另一部分却没有。可是,花不能种植在相邻的地块上,它们会争夺水源,两者都会死去。
给你一个整数数组 flowerbed 表示花坛,由若干 0 和 1 组成,其中 0 表示没种植花,1 表示种植了花。另有一个数 n ,能否在不打破种植规则的情况下种入 n 朵花?能则返回 true ,不能则返回 false。
示例 1:
输入:flowerbed = [1,0,0,0,1], n = 1
输出:true
示例 2:
输入:flowerbed = [1,0,0,0,1], n = 2
输出:false
提示:
1 <= flowerbed.length <= 2 * 104flowerbed[i]为0或1flowerbed中不存在相邻的两朵花0 <= n <= flowerbed.length
解:点击查看答案
给你两个字符串,请你从这两个字符串中找出最长的特殊序列。
「最长特殊序列」定义如下:该序列为某字符串独有的最长子序列(即不能是其他字符串的子序列)。
子序列 可以通过删去字符串中的某些字符实现,但不能改变剩余字符的相对顺序。空序列为所有字符串的子序列,任何字符串为其自身的子序列。
输入为两个字符串,输出最长特殊序列的长度。如果不存在,则返回 -1。
示例 1:
输入: "aba", "cdc"
输出: 3
解释: 最长特殊序列可为 "aba" (或 "cdc"),两者均为自身的子序列且不是对方的子序列。
示例 2:
输入:a = "aaa", b = "bbb"
输出:3
示例 3:
输入:a = "aaa", b = "aaa"
输出:-1
给定一个由 整数 组成的 非空 数组所表示的非负整数,在该数的基础上加一。
最高位数字存放在数组的首位, 数组中每个元素只存储单个数字。
你可以假设除了整数 0 之外,这个整数不会以零开头。
示例 1:
输入:digits = [1,2,3]
输出:[1,2,4]
解释:输入数组表示数字 123。
示例 2:
输入:digits = [4,3,2,1]
输出:[4,3,2,2]
解释:输入数组表示数字 4321。
示例 3:
输入:digits = [0]
输出:[1]
提示:
1 <= digits.length <= 1000 <= digits[i] <= 9
给你两个二进制字符串,返回它们的和(用二进制表示)。
输入为 非空 字符串且只包含数字 1 和 0。
示例 1:
输入: a = "11", b = "1"
输出: "100"
示例 2:
输入: a = "1010", b = "1011"
输出: "10101"
提示:
- 每个字符串仅由字符
'0'或'1'组成。 1 <= a.length, b.length <= 10^4- 字符串如果不是
"0",就都不含前导零。
有一个密钥字符串 S ,只包含字母,数字以及 '-'(破折号)。其中, N 个 '-' 将字符串分成了 N+1 组。
给你一个数字 K,请你重新格式化字符串,使每个分组恰好包含 K 个字符。特别地,第一个分组包含的字符个数必须小于等于 K,但至少要包含 1 个字符。两个分组之间需要用 '-'(破折号)隔开,并且将所有的小写字母转换为大写字母。
给定非空字符串 S 和数字 K,按照上面描述的规则进行格式化。
示例 1:
输入:S = "5F3Z-2e-9-w", K = 4
输出:"5F3Z-2E9W"
解释:字符串 S 被分成了两个部分,每部分 4 个字符;
注意,两个额外的破折号需要删掉。
示例 2:
输入:S = "2-5g-3-J", K = 2
输出:"2-5G-3J"
解释:字符串 S 被分成了 3 个部分,按照前面的规则描述,第一部分的字符可以少于给定的数量,其余部分皆为 2 个字符。
提示:
- S 的长度可能很长,请按需分配大小。K 为正整数。
- S 只包含字母数字(a-z,A-Z,0-9)以及破折号'-'
- S 非空
将一个给定字符串 s 根据给定的行数 numRows ,以从上往下、从左到右进行 Z 字形排列。
比如输入字符串为 "PAYPALISHIRING" 行数为 3 时,排列如下:
P A H N
A P L S I I G
Y I R
之后,你的输出需要从左往右逐行读取,产生出一个新的字符串,比如:"PAHNAPLSIIGYIR"。
请你实现这个将字符串进行指定行数变换的函数:
string convert(string s, int numRows);
示例 1:
输入:s = "PAYPALISHIRING", numRows = 3
输出:"PAHNAPLSIIGYIR"
示例 2:
输入:s = "PAYPALISHIRING", numRows = 4
输出:"PINALSIGYAHRPI"
解释:
P I N
A L S I G
Y A H R
P I
示例 3:
输入:s = "A", numRows = 1
输出:"A"
提示:
1 <= s.length <= 1000s由英文字母(小写和大写)、','和'.'组成1 <= numRows <= 1000
给定由若干 0 和 1 组成的数组 A。我们定义 N_i:从 A[0] 到 A[i] 的第 i 个子数组被解释为一个二进制数(从最高有效位到最低有效位)。
返回布尔值列表 answer,只有当 N_i 可以被 5 整除时,答案 answer[i] 为 true,否则为 false。
示例 1:
输入:[0,1,1]
输出:[true,false,false]
解释:
输入数字为 0, 01, 011;也就是十进制中的 0, 1, 3 。只有第一个数可以被 5 整除,因此 answer[0] 为真。
示例 2:
输入:[1,1,1]
输出:[false,false,false]
示例 3:
输入:[0,1,1,1,1,1]
输出:[true,false,false,false,true,false]
示例 4:
输入:[1,1,1,0,1]
输出:[false,false,false,false,false]
提示:
1 <= A.length <= 30000A[i]为0或1
实现 strStr() 函数。
给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始)。如果不存在,则返回 -1。
示例 1:
输入: haystack = "hello", needle = "ll"
输出: 2
示例 2:
输入: haystack = "aaaaa", needle = "bba"
输出: -1
说明:
说明:
当 needle 是空字符串时,我们应当返回什么值呢?这是一个在面试中很好的问题。
对于本题而言,当 needle 是空字符串时我们应当返回 0 。这与C语言的 strstr() 以及 Java的 indexOf() 定义相符。
判断一个整数是否是回文数。回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数。
示例 1:
输入: 121
输出: true
示例 2:
输入: -121
输出: false
解释: 从左向右读, 为 -121 。 从右向左读, 为 121- 。因此它不是一个回文数。
示例 3:
输入: 10
输出: false
解释: 从右向左读, 为 01 。因此它不是一个回文数。
进阶:
你能不将整数转为字符串来解决这个问题吗?
给定一个整数,编写一个函数来判断它是否是 2 的幂次方。
示例 1:
输入: 1
输出: true
解释: 20 = 1
示例 2:
输入: 16
输出: true
解释: 24 = 16
示例 3:
输入: 218
输出: false
给定一个整型数组,在数组中找出由三个数组成的最大乘积,并输出这个乘积。
示例 1:
输入: [1,2,3]
输出: 6
示例 2:
输入: [1,2,3,4]
输出: 24
注意:
- 给定的整型数组长度范围是[3,104],数组中所有的元素范围是[-1000, 1000]。
- 输入的数组中任意三个数的乘积不会超出32位有符号整数的范围。
编写一个程序判断给定的数是否为丑数。
丑数就是只包含质因数 2, 3, 5 的正整数。
示例 1:
输入: 6
输出: true
解释: 6 = 2 × 3
示例 2:
输入: 8
输出: true
解释: 8 = 2 × 2 × 2
示例 3:
输入: 14
输出: false
解释: 14 不是丑数,因为它包含了另外一个质因数 7。
说明:
1是丑数。- 输入不会超过 32 位有符号整数的范围: [−231, 231 − 1]。
编写一个函数,输入是一个无符号整数(以二进制串的形式),返回其二进制表达式中数字位数为 '1' 的个数(也被称为汉明重量)。
提示:
- 请注意,在某些语言(如 Java)中,没有无符号整数类型。在这种情况下,输入和输出都将被指定为有符号整数类型,并且不应影响您的实现,因为无论整数是有符号的还是无符号的,其内部的二进制表示形式都是相同的。
- 在 Java 中,编译器使用二进制补码记法来表示有符号整数。因此,在上面的 示例 3 中,输入表示有符号整数
-3。
进阶:
- 如果多次调用这个函数,你将如何优化你的算法?
示例 1:
输入:00000000000000000000000000001011
输出:3
解释:输入的二进制串 00000000000000000000000000001011 中,共有三位为 '1'。
示例 2:
输入:00000000000000000000000010000000
输出:1
解释:输入的二进制串 00000000000000000000000010000000 中,共有一位为 '1'。
示例 3:
输入:11111111111111111111111111111101
输出:31
解释:输入的二进制串 11111111111111111111111111111101 中,共有 31 位为 '1'。
提示:
- 输入必须是长度为
32的 二进制串 。
给定一个正整数,输出它的补数。补数是对该数的二进制表示取反。
示例 1:
输入: 5
输出: 2
解释: 5 的二进制表示为 101(没有前导零位),其补数为 010。所以你需要输出 2 。
示例 2:
输入: 1
输出: 0
解释: 1 的二进制表示为 1(没有前导零位),其补数为 0。所以你需要输出 0 。
注意:
- 给定的整数保证在 32 位带符号整数的范围内。
- 2.你可以假定二进制数不包含前导零位。
- 本题与 1009 https://leetcode123-cn.com/problems/complement-of-base-10-integer/ 相同
求 1+2+...+n ,要求不能使用乘除法、for、while、if、else、switch、case等关键字及条件判断语句(A?B:C)。
示例 1:
输入: n = 3
输出: 6
示例 2:
输入: n = 9
输出: 45
限制:
1 <= n <= 10000
两个整数之间的汉明距离指的是这两个数字对应二进制位不同的位置的数目。
给出两个整数 x 和 y,计算它们之间的汉明距离。
注意:
0 ≤ x, y < 231.
示例:
输入: x = 1, y = 4
输出: 2
解释:
1 (0 0 0 1)
4 (0 1 0 0)
↑ ↑
上面的箭头指出了对应二进制位不同的位置。
小扣在秋日市集发现了一款速算机器人。店家对机器人说出两个数字(记作 x 和 y),请小扣说出计算指令:
"A"运算:使x = 2 * x + y;"B"运算:使y = 2 * y + x。
在本次游戏中,店家说出的数字为 x = 1 和 y = 0,小扣说出的计算指令记作仅由大写字母A、B 组成的字符串s,字符串中字符的顺序表示计算顺序,请返回最终 x 与 y 的和为多少。
示例 1:
输入:
s = "AB"输出:
4解释: 经过一次 A 运算后,x = 2, y = 0。 再经过一次 B 运算,x = 2, y = 2。 最终 x 与 y 之和为 4。
提示:
0 <= s.length <= 10s由'A'和'B'组成
两个整数的 汉明距离 指的是这两个数字的二进制数对应位不同的数量。
计算一个数组中,任意两个数之间汉明距离的总和。
示例:
输入: 4, 14, 2
输出: 6
解释: 在二进制表示中,4表示为0100,14表示为1110,2表示为0010。(这样表示是为了体现后四位之间关系)
所以答案为:
HammingDistance(4, 14) + HammingDistance(4, 2) + HammingDistance(14, 2) = 2 + 2 + 2 = 6.
注意:
- 数组中元素的范围为从
0到10^9。 - 数组的长度不超过
10^4
爱丽丝和鲍勃有不同大小的糖果棒:A[i] 是爱丽丝拥有的第 i 根糖果棒的大小,B[j] 是鲍勃拥有的第 j 根糖果棒的大小。因为他们是朋友,所以他们想交换一根糖果棒,这样交换后,他们都有相同的糖果总量。*(一个人拥有的糖果总量是他们拥有的糖果棒大小的总和。)*返回一个整数数组 ans,其中 ans[0] 是爱丽丝必须交换的糖果棒的大小,ans[1] 是 Bob 必须交换的糖果棒的大小。如果有多个答案,你可以返回其中任何一个。保证答案存在。
示例 1:
输入:A = [1,1], B = [2,2]
输出:[1,2]
示例 2:
输入:A = [1,2], B = [2,3]
输出:[1,2]
示例 3:
输入:A = [2], B = [1,3]
输出:[2,3]
示例 4:
输入:A = [1,2,5], B = [2,4]
输出:[5,4]
提示:
1 <= A.length <= 100001 <= B.length <= 100001 <= A[i] <= 1000001 <= B[i] <= 100000- 保证爱丽丝与鲍勃的糖果总量不同。
- 答案肯定存在。
给定一个正整数,检查它的二进制表示是否总是 0、1 交替出现:换句话说,就是二进制表示中相邻两位的数字永不相同。
示例 1:
输入:n = 5
输出:true
解释:5 的二进制表示是:101
示例 2:
输入:n = 7
输出:false
解释:7 的二进制表示是:111.
示例 3:
输入:n = 11
输出:false
解释:11 的二进制表示是:1011.
示例 4:
输入:n = 10
输出:true
解释:10 的二进制表示是:1010.
示例 5:
输入:n = 3
输出:false
提示:
1 <= n <= 231 - 1
给定 n 个整数,找出平均数最大且长度为 k 的连续子数组,并输出该最大平均数。
示例:
输入:[1,12,-5,-6,50,3], k = 4
输出:12.75
解释:最大平均数 (12-5-6+50)/4 = 51/4 = 12.75
提示:
- 1 <=
k<=n<= 30,000。 - 所给数据范围 [-10,000,10,000]。
给你两个长度相同的字符串,s 和 t。
将 s 中的第 i 个字符变到 t 中的第 i 个字符需要 |s[i] - t[i]| 的开销(开销可能为 0),也就是两个字符的 ASCII 码值的差的绝对值。
用于变更字符串的最大预算是 maxCost。在转化字符串时,总开销应当小于等于该预算,这也意味着字符串的转化可能是不完全的。
如果你可以将 s 的子字符串转化为它在 t 中对应的子字符串,则返回可以转化的最大长度。
如果 s 中没有子字符串可以转化成 t 中对应的子字符串,则返回 0。
示例 1:
输入:s = "abcd", t = "bcdf", cost = 3
输出:3
解释:s 中的 "abc" 可以变为 "bcd"。开销为 3,所以最大长度为 3。
示例 2:
输入:s = "abcd", t = "cdef", cost = 3
输出:1
解释:s 中的任一字符要想变成 t 中对应的字符,其开销都是 2。因此,最大长度为 1。
示例 3:
输入:s = "abcd", t = "acde", cost = 0
输出:1
解释:你无法作出任何改动,所以最大长度为 1。
提示:
1 <= s.length, t.length <= 10^50 <= maxCost <= 10^6s和t都只含小写英文字母。
给定一个整数 n,返回 n! 结果尾数中零的数量。
示例 1:
输入: 3
输出: 0
解释: 3! = 6, 尾数中没有零。
示例 2:
输入: 5
输出: 1
解释: 5! = 120, 尾数中有 1 个零.
说明: 算法的时间复杂度应为 O(log n) 。
输入一个整型数组,数组中的一个或连续多个整数组成一个子数组。求所有子数组的和的最大值。
要求时间复杂度为O(n)。
示例1:
输入: nums = [-2,1,-3,4,-1,2,1,-5,4]
输出: 6
解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。
提示:
- 1 <= arr.length <= 10^5
- -100 <= arr[i] <= 100
作为一位web开发者, 懂得怎样去规划一个页面的尺寸是很重要的。 现给定一个具体的矩形页面面积,你的任务是设计一个长度为 L 和宽度为 W 且满足以下要求的矩形的页面。要求:
1. 你设计的矩形页面必须等于给定的目标面积。
2. 宽度 W 不应大于长度 L,换言之,要求 L >= W 。
3. 长度 L 和宽度 W 之间的差距应当尽可能小。
你需要按顺序输出你设计的页面的长度 L 和宽度 W。
示例:
输入: 4
输出: [2, 2]
解释: 目标面积是 4, 所有可能的构造方案有 [1,4], [2,2], [4,1]。
但是根据要求2,[1,4] 不符合要求; 根据要求3,[2,2] 比 [4,1] 更能符合要求. 所以输出长度 L 为 2, 宽度 W 为 2。
说明:
1.给定的面积不大于 10,000,000 且为正整数。
2.你设计的页面的长度和宽度必须都是正整数。
leetcode29
给定两个整数,被除数dividend和除数divisor。将两数相除,要求不使用乘法、除法和 mod 运算符。
返回被除数dividend除以除数divisor得到的商。
整数除法的结果应当截去(truncate)其小数部分,例如:truncate(8.345) = 8 以及 truncate(-2.7335) = -2
示例1:
输入: dividend = 10, divisor = 3
输出: 3
解释: 10/3 = truncate(3.33333..) = truncate(3) = 3
示例2:
输入: dividend = 7, divisor = -3
输出: -2
解释: 7/-3 = truncate(-2.33333..) = -2
提示:
被除数和除数均为 32 位有符号整数。
除数不为0。
假设我们的环境只能存储 32 位有符号整数,其数值范围是 ``[−2^31, 2^31− 1]``。本题中,如果除法结果溢出,则返回 2^31− 1。
对于一个正整数,如果它和除了它自身以外的所有 正因子 之和相等,我们称它为 「完美数」。
给定一个整数n,如果是完美数,返回 true,否则返回 false
示例 1:
输入:28
输出:True
解释:28 = 1 + 2 + 4 + 7 + 14
1, 2, 4, 7, 和 14 是 28 的所有正因子。
示例 2:
输入:num = 6
输出:true
示例 3:
输入:num = 496
输出:true
示例 4:
输入:num = 8128
输出:true
示例 5:
输入:num = 2
输出:false
提示:
1 <= num <= 108
leetcode21 将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例 1:

输入:l1 = [1,2,4], l2 = [1,3,4]
输出:[1,1,2,3,4,4]
示例 2:
输入:l1 = [], l2 = []
输出:[]
示例 3:
输入:l1 = [], l2 = [0]
输出:[0]
提示:
- 两个链表的节点数目范围是 [0, 50]
- -100 <= Node.val <= 100
- l1 和 l2 均按
非递减顺序排列
leetcode53 给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。 示例 1:
输入:nums = [-2,1,-3,4,-1,2,1,-5,4]
输出:6
解释:连续子数组 [4,-1,2,1] 的和最大,为 6 。
示例 2:
输入:nums = [1]
输出:1
示例 3:
输入:nums = [0]
输出:0
示例 4:
输入:nums = [-1]
输出:-1
示例 5:
输入:nums = [-100000]
输出:-100000
提示:
1 <= nums.length <= 3 * 104
-105 <= nums[i] <= 105
进阶: 如果你已经实现复杂度为 O(n) 的解法,尝试使用更为精妙的 分治法 求解。
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
示例 1:

输入:head = [1,2,3,4,5]
输出:[5,4,3,2,1]
示例 2:

输入:head = [1,2]
输出:[2,1]
示例 3:
输入:head = []
输出:[]
提示:
- 链表中节点的数目范围是
[0, 5000] -5000 <= Node.val <= 5000
**进阶:**链表可以选用迭代或递归方式完成反转。你能否用两种方法解决这道题?
给定一个链表,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
如果链表中存在环,则返回 true 。 否则,返回 false 。
进阶:
你能用 O(1)(即,常量)内存解决此问题吗?
示例 1:

输入:head = [3,2,0,-4], pos = 1
输出:true
解释:链表中有一个环,其尾部连接到第二个节点
示例 2:

输入:head = [1,2], pos = 0
输出:true
解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:

输入:head = [1], pos = -1
输出:false
解释:链表中没有环。
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
**进阶:**你能尝试使用一趟扫描实现吗?
示例 1:

输入:head = [1,2,3,4,5], n = 2
输出:[1,2,3,5]
示例 2:
输入:head = [1], n = 1
输出:[]
示例 3:
输入:head = [1,2], n = 1
输出:[1]
给定一个头结点为 head 的非空单链表,返回链表的中间结点。
如果有两个中间结点,则返回第二个中间结点。
示例 1:
输入:[1,2,3,4,5]
输出:此列表中的结点 3 (序列化形式:[3,4,5])
返回的结点值为 3 。 (测评系统对该结点序列化表述是 [3,4,5])。
注意,我们返回了一个 ListNode 类型的对象 ans,这样:
ans.val = 3, ans.next.val = 4, ans.next.next.val = 5, 以及 ans.next.next.next = NULL.
示例 2:
输入:[1,2,3,4,5,6]
输出:此列表中的结点 4 (序列化形式:[4,5,6])
由于该列表有两个中间结点,值分别为 3 和 4,我们返回第二个结点。
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
说明: 为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参作任何拷贝
int len = removeElement(nums, val);
// 在函数里修改输入数组对于调用者是可见的。
// 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。
for (int i = 0; i < len; i++) {
print(nums[i]);
}
示例 1:
输入:nums = [3,2,2,3], val = 3
输出:2, nums = [2,2]
解释:函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。你不需要考虑数组中超出新长度后面的元素。例如,函数返回的新长度为 2 ,而 nums = [2,2,3,3] 或 nums = [2,2,0,0],也会被视作正确答案。
示例 2
输入:nums = [0,1,2,2,3,0,4,2], val = 2
输出:5, nums = [0,1,4,0,3]
解释:函数应该返回新的长度 5, 并且 nums 中的前五个元素为 0, 1, 3, 0, 4。注意这五个元素可为任意顺序。你不需要考虑数组中超出新长度后面的元素。
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
**注意:**给定 n 是一个正整数。
示例 1:
输入: 2
输出: 2
解释: 有两种方法可以爬到楼顶。
1. 1 阶 + 1 阶
2. 2 阶
示例 2:
输入: 3
输出: 3
解释: 有三种方法可以爬到楼顶。
1. 1 阶 + 1 阶 + 1 阶
2. 1 阶 + 2 阶
3. 2 阶 + 1 阶
存在一个按升序排列的链表,给你这个链表的头节点 head ,请你删除所有重复的元素,使每个元素 只出现一次 。
返回同样按升序排列的结果链表
示例 1:
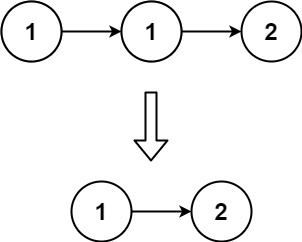
输入:head = [1,1,2]
输出:[1,2]
示例 2:
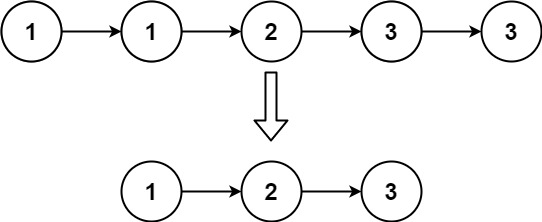
输入:head = [1,1,2,3,3]
输出:[1,2,3]
请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(push、top、pop 和 empty)。
实现 MyStack 类:
void push(int x)将元素 x 压入栈顶。int pop()移除并返回栈顶元素。int top()返回栈顶元素。boolean empty()如果栈是空的,返回true;否则,返回false。
注意:
- 你只能使用队列的基本操作 —— 也就是
push to back、peek/pop from front、size和is empty这些操作。 - 你所使用的语言也许不支持队列。 你可以使用 list (列表)或者 deque(双端队列)来模拟一个队列 , 只要是标准的队列操作即可。
示例:
输入:
["MyStack", "push", "push", "top", "pop", "empty"]
[[], [1], [2], [], [], []]
输出:
[null, null, null, 2, 2, false]
解释:
MyStack myStack = new MyStack();
myStack.push(1);
myStack.push(2);
myStack.top(); // 返回 2
myStack.pop(); // 返回 2
myStack.empty(); // 返回 False
请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(push、pop、peek、empty):
实现 MyQueue 类:
void push(int x)将元素 x 推到队列的末尾int pop()从队列的开头移除并返回元素int peek()返回队列开头的元素boolean empty()如果队列为空,返回true;否则,返回false
说明:
- 你只能使用标准的栈操作 —— 也就是只有
push to top,peek/pop from top,size, 和is empty操作是合法的。 - 你所使用的语言也许不支持栈。你可以使用 list 或者 deque(双端队列)来模拟一个栈,只要是标准的栈操作即可。
进阶:
- 你能否实现每个操作均摊时间复杂度为
O(1)的队列?换句话说,执行n个操作的总时间复杂度为O(n),即使其中一个操作可能花费较长时间。
给你一个整数数组 nums 和一个整数 k ,按以下方法修改该数组:
- 选择某个下标
i并将nums[i]替换为-nums[i]。
重复这个过程恰好 k 次。可以多次选择同一个下标 i 。
以这种方式修改数组后,返回数组 可能的最大和 。
示例 1:
输入:nums = [4,2,3], k = 1
输出:5
解释:选择下标 1 ,nums 变为 [4,-2,3] 。
示例 2:
输入:nums = [3,-1,0,2], k = 3
输出:6
解释:选择下标 (1, 2, 2) ,nums 变为 [3,1,0,2] 。
示例 3:
输入:nums = [2,-3,-1,5,-4], k = 2
输出:13
解释:选择下标 (1, 4) ,nums 变为 [2,3,-1,5,4] 。
句子 是一个单词列表,列表中的单词之间用单个空格隔开,且不存在前导或尾随空格。每个单词仅由大小写英文字母组成(不含标点符号)。
- 例如,
"Hello World"、"HELLO"和"hello world hello world"都是句子。
给你一个句子 s 和一个整数 k ,请你将 s 截断 ,使截断后的句子仅含 前 k 个单词。返回 截断 s 后得到的句子。
示例 1:
输入:s = "Hello how are you Contestant", k = 4
输出:"Hello how are you"
解释:s 中的单词为 ["Hello", "how" "are", "you", "Contestant"]
前 4 个单词为 ["Hello", "how", "are", "you"]
因此,应当返回 "Hello how are you"
示例 2:
输入:s = "What is the solution to this problem", k = 4
输出:"What is the solution"
解释:
s 中的单词为 ["What", "is" "the", "solution", "to", "this", "problem"]
前 4 个单词为 ["What", "is", "the", "solution"]
因此,应当返回 "What is the solution"
示例 3:
输入:s = "chopper is not a tanuki", k = 5
输出:"chopper is not a tanuki"
155.最小栈
设计一个支持 push ,pop ,top 操作,并能在常数时间内检索到最小元素的栈。
push(x)—— 将元素 x 推入栈中。pop()—— 删除栈顶的元素。top()—— 获取栈顶元素。getMin()—— 检索栈中的最小元素。
示例:
输入:
["MinStack","push","push","push","getMin","pop","top","getMin"]
[[],[-2],[0],[-3],[],[],[],[]]
输出:
[null,null,null,null,-3,null,0,-2]
解释:
MinStack minStack = new MinStack();
minStack.push(-2);
minStack.push(0);
minStack.push(-3);
minStack.getMin(); --> 返回 -3.
minStack.pop();
minStack.top(); --> 返回 0.
minStack.getMin(); --> 返回 -2.
提示:
pop、top和getMin操作总是在 非空栈 上调用。
根据 逆波兰表示法,求表达式的值。
有效的算符包括 +、-、*、/ 。每个运算对象可以是整数,也可以是另一个逆波兰表达式。
说明:
- 整数除法只保留整数部分。
- 给定逆波兰表达式总是有效的。换句话说,表达式总会得出有效数值且不存在除数为 0 的情况。
示例 1:
输入:tokens = ["2","1","+","3","*"]
输出:9
解释:该算式转化为常见的中缀算术表达式为:((2 + 1) * 3) = 9
示例 2:
输入:tokens = ["4","13","5","/","+"]
输出:6
解释:该算式转化为常见的中缀算术表达式为:(4 + (13 / 5)) = 6
示例 3:
输入:tokens = ["10","6","9","3","+","-11","*","/","*","17","+","5","+"]
输出:22
解释:
该算式转化为常见的中缀算术表达式为:
((10 * (6 / ((9 + 3) * -11))) + 17) + 5
= ((10 * (6 / (12 * -11))) + 17) + 5
= ((10 * (6 / -132)) + 17) + 5
= ((10 * 0) + 17) + 5
= (0 + 17) + 5
= 17 + 5
= 22
提示:
1 <= tokens.length <= 104tokens[i]要么是一个算符("+"、"-"、"*"或"/"),要么是一个在范围[-200, 200]内的整数
逆波兰表达式:
逆波兰表达式是一种后缀表达式,所谓后缀就是指算符写在后面。
- 平常使用的算式则是一种中缀表达式,如
( 1 + 2 ) * ( 3 + 4 )。 - 该算式的逆波兰表达式写法为
( ( 1 2 + ) ( 3 4 + ) * )。
逆波兰表达式主要有以下两个优点:
- 去掉括号后表达式无歧义,上式即便写成
1 2 + 3 4 + *也可以依据次序计算出正确结果。 - 适合用栈操作运算:遇到数字则入栈;遇到算符则取出栈顶两个数字进行计算,并将结果压入栈中。
给你一个字符串数组 board 表示井字游戏的棋盘。当且仅当在井字游戏过程中,棋盘有可能达到 board 所显示的状态时,才返回 true 。
井字游戏的棋盘是一个 3 x 3 数组,由字符 ' ','X' 和 'O' 组成。字符 ' ' 代表一个空位。
以下是井字游戏的规则:
- 玩家轮流将字符放入空位(
' ')中。 - 玩家 1 总是放字符
'X',而玩家 2 总是放字符'O'。 'X'和'O'只允许放置在空位中,不允许对已放有字符的位置进行填充。- 当有 3 个相同(且非空)的字符填充任何行、列或对角线时,游戏结束。
- 当所有位置非空时,也算为游戏结束。
- 如果游戏结束,玩家不允许再放置字符。
示例 1:
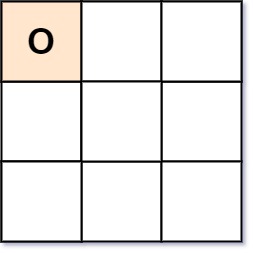
输入:board = ["O "," "," "]
输出:false
解释:玩家 1 总是放字符 "X" 。
示例 2:
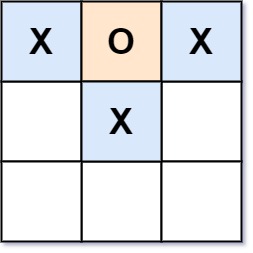
输入:board = ["XOX"," X "," "]
输出:false
解释:玩家应该轮流放字符。
示例 3:
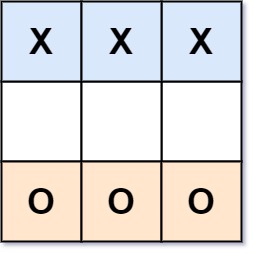
输入:board = ["XXX"," ","OOO"]
输出:false
Example 4:
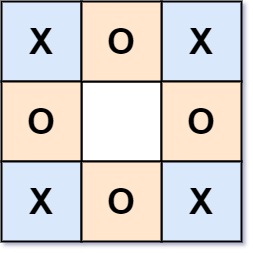
输入:board = ["XOX","O O","XOX"]
输出:true
给你一个字符串 licensePlate 和一个字符串数组 words ,请你找出并返回 words 中的 最短补全词 。
补全词 是一个包含 licensePlate 中所有的字母的单词。在所有补全词中,最短的那个就是 最短补全词 。
在匹配 licensePlate 中的字母时:
- 忽略
licensePlate中的 数字和空格 。 - 不区分大小写。
- 如果某个字母在
licensePlate中出现不止一次,那么该字母在补全词中的出现次数应当一致或者更多。
例如:licensePlate`` = "aBc 12c",那么它的补全词应当包含字母 'a'、'b' (忽略大写)和两个 'c' 。可能的 补全词 有 "abccdef"、"caaacab" 以及 "cbca" 。请你找出并返回 words 中的 最短补全词 。题目数据保证一定存在一个最短补全词。当有多个单词都符合最短补全词的匹配条件时取 words 中 最靠前的 那个。
示例 1:
输入:licensePlate = "1s3 PSt", words = ["step", "steps", "stripe", "stepple"]
输出:"steps"
解释:最短补全词应该包括 "s"、"p"、"s"(忽略大小写) 以及 "t"。
"step" 包含 "t"、"p",但只包含一个 "s",所以它不符合条件。
"steps" 包含 "t"、"p" 和两个 "s"。
"stripe" 缺一个 "s"。
"stepple" 缺一个 "s"。
因此,"steps" 是唯一一个包含所有字母的单词,也是本例的答案。
示例 2:
输入:licensePlate = "1s3 456", words = ["looks", "pest", "stew", "show"]
输出:"pest"
解释:licensePlate 只包含字母 "s" 。所有的单词都包含字母 "s" ,其中 "pest"、"stew"、和 "show" 三者最短。答案是 "pest" ,因为它是三个单词中在 words 里最靠前的那个。
示例 3:
输入:licensePlate = "Ah71752", words = ["suggest","letter","of","husband","easy","education","drug","prevent","writer","old"]
输出:"husband"
示例 4:
输入:licensePlate = "OgEu755", words =
["enough","these","play","wide","wonder","box","arrive","money","tax","thus"]
输出:"enough"
示例 5:
输入:licensePlate = "iMSlpe4", words =
["claim","consumer","student","camera","public","never","wonder","simple","thought","use"]
输出:"simple"
三合一。描述如何只用一个数组来实现三个栈。
你应该实现push(stackNum, value)、pop(stackNum)、isEmpty(stackNum)、peek(stackNum)方法。stackNum表示栈下标,value表示压入的值。
构造函数会传入一个stackSize参数,代表每个栈的大小。
示例1:
输入:
["TripleInOne", "push", "push", "pop", "pop", "pop", "isEmpty"]
[[1], [0, 1], [0, 2], [0], [0], [0], [0]]
输出:
[null, null, null, 1, -1, -1, true]
说明:当栈为空时`pop, peek`返回-1,当栈满时`push`不压入元素。
示例2:
输入:
["TripleInOne", "push", "push", "push", "pop", "pop", "pop", "peek"]
[[2], [0, 1], [0, 2], [0, 3], [0], [0], [0], [0]]
输出:
[null, null, null, null, 2, 1, -1, -1]
你现在是一场采用特殊赛制棒球比赛的记录员。这场比赛由若干回合组成,过去几回合的得分可能会影响以后几回合的得分。
比赛开始时,记录是空白的。你会得到一个记录操作的字符串列表 ops,其中 ops[i] 是你需要记录的第 i 项操作,ops 遵循下述规则:
- 整数
x- 表示本回合新获得分数x "+"- 表示本回合新获得的得分是前两次得分的总和。题目数据保证记录此操作时前面总是存在两个有效的分数。"D"- 表示本回合新获得的得分是前一次得分的两倍。题目数据保证记录此操作时前面总是存在一个有效的分数。"C"- 表示前一次得分无效,将其从记录中移除。题目数据保证记录此操作时前面总是存在一个有效的分数
请你返回记录中所有得分的总和。
示例 1:
输入:ops = ["5","2","C","D","+"]
输出:30
解释:
"5" - 记录加 5 ,记录现在是 [5]
"2" - 记录加 2 ,记录现在是 [5, 2]
"C" - 使前一次得分的记录无效并将其移除,记录现在是 [5].
"D" - 记录加 2 * 5 = 10 ,记录现在是 [5, 10].
"+" - 记录加 5 + 10 = 15 ,记录现在是 [5, 10, 15].
所有得分的总和 5 + 10 + 15 = 30
示例 2:
输入:ops = ["5","-2","4","C","D","9","+","+"]
输出:27
"5" - 记录加 5 ,记录现在是 [5]
"-2" - 记录加 -2 ,记录现在是 [5, -2]
"4" - 记录加 4 ,记录现在是 [5, -2, 4]
"C" - 使前一次得分的记录无效并将其移除,记录现在是 [5, -2]
"D" - 记录加 2 * -2 = -4 ,记录现在是 [5, -2, -4]
"9" - 记录加 9 ,记录现在是 [5, -2, -4, 9]
"+" - 记录加 -4 + 9 = 5 ,记录现在是 [5, -2, -4, 9, 5]
"+" - 记录加 9 + 5 = 14 ,记录现在是 [5, -2, -4, 9, 5, 14]
所有得分的总和 5 + -2 + -4 + 9 + 5 + 14 = 27
示例 3:
输入:ops = ["1"]
输出:1
给你一个字符串 path ,表示指向某一文件或目录的 Unix 风格 绝对路径 (以 '/' 开头),请你将其转化为更加简洁的规范路径。
在 Unix 风格的文件系统中,一个点(.)表示当前目录本身;此外,两个点 (..) 表示将目录切换到上一级(指向父目录);两者都可以是复杂相对路径的组成部分。任意多个连续的斜杠(即,'//')都被视为单个斜杠 '/' 。对于此问题,任何其他格式的点(例如,'...')均被视为文件/目录名称。
请注意,返回的 规范路径 必须遵循下述格式:
- 始终以斜杠
'/'开头。 - 两个目录名之间必须只有一个斜杠
'/'。 - 最后一个目录名(如果存在)不能 以
'/'结尾。 - 此外,路径仅包含从根目录到目标文件或目录的路径上的目录(即,不含
'.'或'..')。
返回简化后得到的 规范路径 。
示例 1:
输入:path = "/home/"
输出:"/home"
解释:注意,最后一个目录名后面没有斜杠。
示例 2:
输入:path = "/../"
输出:"/"
解释:从根目录向上一级是不可行的,因为根目录是你可以到达的最高级。
示例 3:
输入:path = "/home//foo/"
输出:"/home/foo"
解释:在规范路径中,多个连续斜杠需要用一个斜杠替换。
示例 4:
输入:path = "/a/./b/../../c/"
输出:"/c"
提示:
- 1 <= path.length <= 3000
- path 由英文字母,数字,'.','/' 或 '_' 组成。
- path 是一个有效的 Unix 风格绝对路径。
假设有一个同时存储文件和目录的文件系统。下图展示了文件系统的一个示例:
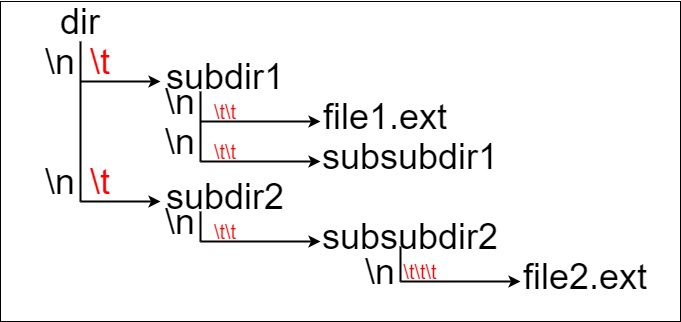
这里将 dir 作为根目录中的唯一目录。dir 包含两个子目录 subdir1 和 subdir2 。subdir1 包含文件 file1.ext 和子目录 subsubdir1;
subdir2 包含子目录 subsubdir2,该子目录下包含文件 file2.ext 。
在文本格式中,如下所示(⟶表示制表符):
dir
⟶ subdir1
⟶ ⟶ file1.ext
⟶ ⟶ subsubdir1
⟶ subdir2
⟶ ⟶ subsubdir2
⟶ ⟶ ⟶ file2.ext
如果是代码表示,上面的文件系统可以写为
"dir\n\tsubdir1\n\t\tfile1.ext\n\t\tsubsubdir1\n\tsubdir2\n\t\tsubsubdir2\n\t\t\tfile2.ext"。'\n' 和 '\t' 分别是换行符和制表符。
文件系统中的每个文件和文件夹都有一个唯一的 绝对路径 ,即必须打开才能到达文件/目录所在位置的目录顺序,所有路径用 '/' 连接。上面例子中,指向 file2.ext 的绝对路径是 "dir/subdir2/subsubdir2/file2.ext"。每个目录名由字母、数字和/或空格组成,每个文件名遵循 name.extension 的格式,其中名称和扩展名由字母、数字和/或空格组成。
给定一个以上述格式表示文件系统的字符串 input ,返回文件系统中 指向文件的最长绝对路径 的长度。 如果系统中没有文件,返回 0。
示例 1:
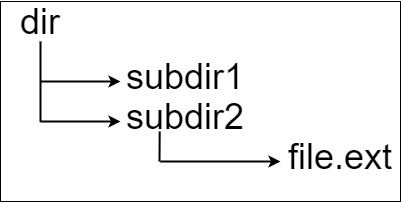
输入:input = "dir\n\tsubdir1\n\tsubdir2\n\t\tfile.ext"
输出:20
解释:只有一个文件,绝对路径为 "dir/subdir2/file.ext" ,路径长度 20
示例 2:
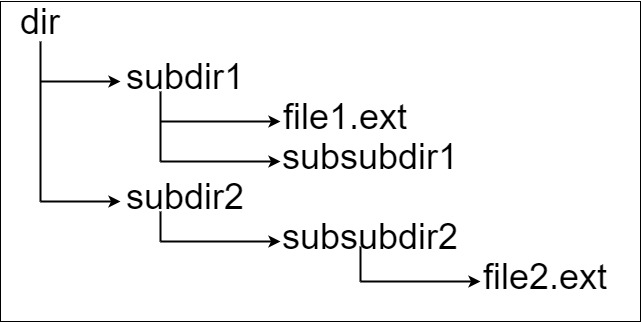
输入:input = "dir\n\tsubdir1\n\t\tfile1.ext\n\t\tsubsubdir1\n\tsubdir2\n\t\tsubsubdir2\n\t\t\tfile2.ext"
输出:32
解释:存在两个文件:
"dir/subdir1/file1.ext" ,路径长度 21
"dir/subdir2/subsubdir2/file2.ext" ,路径长度 32
返回 32 ,因为这是最长的路径
示例 3:
输入:input = "a"
输出:0
解释:不存在任何文件
示例 4:
输入:input = "file1.txt\nfile2.txt\nlongfile.txt"
输出:12
解释:根目录下有 3 个文件。
因为根目录中任何东西的绝对路径只是名称本身,所以答案是 "longfile.txt" ,路径长度为 12
给你一个字符串表达式 s ,请你实现一个基本计算器来计算并返回它的值。
整数除法仅保留整数部分。
示例 1:
输入:s = "3+2*2"
输出:7
示例 2:
输入:s = " 3/2 "
输出:1
示例 3:
输入:s = " 3+5 / 2 "
输出:5
给你一个字符串表达式 s ,请你实现一个基本计算器来计算并返回它的值。
示例 1:
输入:s = "1 + 1"
输出:2
示例 2:
输入:s = " 2-1 + 2 "
输出:3
示例 3:
输入:s = "(1+(4+5+2)-3)+(6+8)"
输出:23
有一个 单线程 CPU 正在运行一个含有 n 道函数的程序。每道函数都有一个位于 0 和 n-1 之间的唯一标识符。
函数调用 存储在一个 调用栈 上 :当一个函数调用开始时,它的标识符将会推入栈中。而当一个函数调用结束时,它的标识符将会从栈中弹出。标识符位于栈顶的函数是 当前正在执行的函数 。每当一个函数开始或者结束时,将会记录一条日志,包括函数标识符、是开始还是结束、以及相应的时间戳。
给你一个由日志组成的列表 logs ,其中 logs[i] 表示第 i 条日志消息,该消息是一个按 "{function_id}:{"start" | "end"}:{timestamp}" 进行格式化的字符串。例如,"0:start:3" 意味着标识符为 0 的函数调用在时间戳 3 的 起始开始执行 ;而 "1:end:2" 意味着标识符为 1 的函数调用在时间戳 2 的 末尾结束执行。注意,函数可以 调用多次,可能存在递归调用 。
函数的 独占时间 定义是在这个函数在程序所有函数调用中执行时间的总和,调用其他函数花费的时间不算该函数的独占时间。例如,如果一个函数被调用两次,一次调用执行 2 单位时间,另一次调用执行 1 单位时间,那么该函数的 独占时间 为 2 + 1 = 3 。
以数组形式返回每个函数的 独占时间 ,其中第 i 个下标对应的值表示标识符 i 的函数的独占时间。
示例 1:

输入:n = 2, logs = ["0:start:0","1:start:2","1:end:5","0:end:6"]
输出:[3,4]
解释:
函数 0 在时间戳 0 的起始开始执行,执行 2 个单位时间,于时间戳 1 的末尾结束执行。
函数 1 在时间戳 2 的起始开始执行,执行 4 个单位时间,于时间戳 5 的末尾结束执行。
函数 0 在时间戳 6 的开始恢复执行,执行 1 个单位时间。
所以函数 0 总共执行 2 + 1 = 3 个单位时间,函数 1 总共执行 4 个单位时间。
示例 2:
输入:n = 2, logs = ["0:start:0","0:start:2","0:end:5","1:start:6","1:end:6","0:end:7"]
输出:[7,1]
解释:
函数 0 在时间戳 0 的起始开始执行,执行 2 个单位时间,并递归调用它自身。
函数 0(递归调用)在时间戳 2 的起始开始执行,执行 4 个单位时间。
函数 0(初始调用)恢复执行,并立刻调用函数 1 。
函数 1在时间戳 6 的起始开始执行,执行 1 个单位时间,于时间戳 6 的末尾结束执行。
函数 0(初始调用)在时间戳 7 的起始恢复执行,执行 1 个单位时间,于时间戳 7 的末尾结束执行。
所以函数 0 总共执行 2 + 4 + 1 = 7 个单位时间,函数 1 总共执行 1 个单位时间。
示例 4:
输入:n = 2, logs = ["0:start:0","0:start:2","0:end:5","1:start:7","1:end:7","0:end:8"]
输出:[8,1]
示例 5:
输入:n = 1, logs =["0:start:0","0:end:0"]
输出:[1]
给定一个表示代码片段的字符串,你需要实现一个验证器来解析这段代码,并返回它是否合法。合法的代码片段需要遵守以下的所有规则:
- 代码必须被合法的闭合标签包围。否则,代码是无效的。
- 闭合标签(不一定合法)要严格符合格式:
<TAG_NAME>TAG_CONTENT</TAG_NAME>。其中,<TAG_NAME>是起始标签,</TAG_NAME>是结束标签。起始和结束标签中的 TAG_NAME 应当相同。当且仅当 TAG_NAME 和 TAG_CONTENT 都是合法的,闭合标签才是合法的。 - 合法的
TAG_NAME仅含有大写字母,长度在范围 [1,9] 之间。否则,该TAG_NAME是不合法的。 - 合法的
TAG_CONTENT可以包含其他合法的闭合标签,cdata (请参考规则7)和任意字符(注意参考规则1)除了不匹配的<、不匹配的起始和结束标签、不匹配的或带有不合法 TAG_NAME 的闭合标签。否则,TAG_CONTENT是不合法的。 - 一个起始标签,如果没有具有相同 TAG_NAME 的结束标签与之匹配,是不合法的。反之亦然。不过,你也需要考虑标签嵌套的问题。
- 一个
<,如果你找不到一个后续的>与之匹配,是不合法的。并且当你找到一个<或</时,所有直到下一个>的前的字符,都应当被解析为 TAG_NAME(不一定合法)。 - cdata 有如下格式:
<![CDATA[CDATA_CONTENT]]>。CDATA_CONTENT的范围被定义成<![CDATA[和后续的第一个]]>之间的字符。 CDATA_CONTENT可以包含任意字符。cdata 的功能是阻止验证器解析CDATA_CONTENT,所以即使其中有一些字符可以被解析为标签(无论合法还是不合法),也应该将它们视为常规字符。
合法代码的例子:
输入: "<DIV>This is the first line <![CDATA[<div>]]></DIV>"
输出: True
解释:
代码被包含在了闭合的标签内: <DIV> 和 </DIV> 。
TAG_NAME 是合法的,TAG_CONTENT 包含了一些字符和 cdata 。
即使 CDATA_CONTENT 含有不匹配的起始标签和不合法的 TAG_NAME,它应该被视为普通的文本,而不是标签。
所以 TAG_CONTENT 是合法的,因此代码是合法的。最终返回True。
输入: "<DIV>>> ![cdata[]] <![CDATA[<div>]>]]>]]>>]</DIV>"
输出: True
解释:
我们首先将代码分割为: start_tag|tag_content|end_tag 。
start_tag -> "<DIV>"
end_tag -> "</DIV>"
tag_content 也可被分割为: text1|cdata|text2 。
text1 -> ">> ![cdata[]] "
cdata -> "<![CDATA[<div>]>]]>" ,其中 CDATA_CONTENT 为 "<div>]>"
text2 -> "]]>>]"
start_tag 不是 "<DIV>>>" 的原因参照规则 6 。
cdata 不是 "<![CDATA[<div>]>]]>]]>" 的原因参照规则 7 。
不合法代码的例子:
输入: "<A> <B> </A> </B>"
输出: False
解释: 不合法。如果 "<A>" 是闭合的,那么 "<B>" 一定是不匹配的,反之亦然。
输入: "<DIV> div tag is not closed <DIV>"
输出: False
输入: "<DIV> unmatched < </DIV>"
输出: False
输入: "<DIV> closed tags with invalid tag name <b>123</b> </DIV>"
输出: False
输入: "<DIV> unmatched tags with invalid tag name </1234567890> and <CDATA[[]]> </DIV>"
输出: False
输入: "<DIV> unmatched start tag <B> and unmatched end tag </C> </DIV>"
输出: False
注意:
- 为简明起见,你可以假设输入的代码(包括提到的任意字符)只包含
数字, 字母,'<','>','/','!','[',']'和' '。
给你一个只包含 '(' 和 ')' 的字符串,找出最长有效(格式正确且连续)括号子串的长度。
示例 1:
输入:s = "(()"
输出:2
解释:最长有效括号子串是 "()"
示例 2:
输入:s = ")()())"
输出:4
解释:最长有效括号子串是 "()()"
示例 3:
输入:s = ""
输出:0
提示:
0 <= s.length <= 3 * 104s[i]为'('或')'
给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
不允许修改 链表。
示例 1:
输入:head = [3,2,0,-4], pos = 1
输出:返回索引为 1 的链表节点
解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
输入:head = [1,2], pos = 0
输出:返回索引为 0 的链表节点
解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:
输入:head = [1], pos = -1
输出:返回 null
解释:链表中没有环。
给定一个经过编码的字符串,返回它解码后的字符串。
编码规则为: k[encoded_string],表示其中方括号内部的 encoded_string 正好重复 k 次。注意 k 保证为正整数。
你可以认为输入字符串总是有效的;输入字符串中没有额外的空格,且输入的方括号总是符合格式要求的。
此外,你可以认为原始数据不包含数字,所有的数字只表示重复的次数 k ,例如不会出现像 3a 或 2[4] 的输入。
示例 1:
输入:s = "3[a]2[bc]"
输出:"aaabcbc"
示例 2:
输入:s = "3[a2[c]]"
输出:"accaccacc"
示例 3:
输入:s = "2[abc]3[cd]ef"
输出:"abcabccdcdcdef"
示例 4:
输入:s = "abc3[cd]xyz"
输出:"abccdcdcdxyz"
你会得到一个双链表,其中包含的节点有一个下一个指针、一个前一个指针和一个额外的 子指针 。这个子指针可能指向一个单独的双向链表,也包含这些特殊的节点。这些子列表可以有一个或多个自己的子列表,以此类推,以生成如下面的示例所示的 多层数据结构 。
给定链表的头节点 head ,将链表 扁平化 ,以便所有节点都出现在单层双链表中。让 curr 是一个带有子列表的节点。子列表中的节点应该出现在扁平化列表中的 curr 之后 和 curr.next 之前 。
返回 扁平列表的 head 。列表中的节点必须将其 所有 子指针设置为 null 。
示例 1:
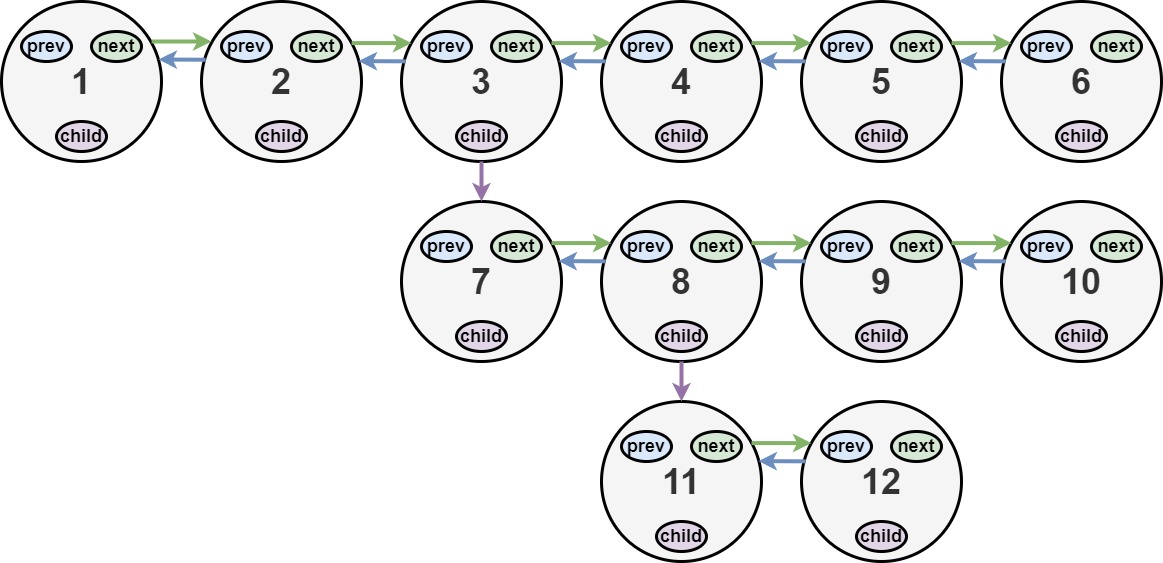
输入:head = [1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12]
输出:[1,2,3,7,8,11,12,9,10,4,5,6]
解释:输入的多级列表如上图所示。
扁平化后的链表如下图:

示例 2:
输入:head = [1,2,null,3]
输出:[1,3,2]
解释:输入的多级列表如上图所示。
扁平化后的链表如下图:
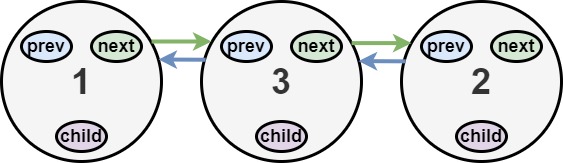
示例 3:
输入:head = []
输出:[]
说明:输入中可能存在空列表。
在一个 n x n 的国际象棋棋盘上,一个骑士从单元格 (row, column) 开始,并尝试进行 k 次移动。行和列是 从 0 开始 的,所以左上单元格是 (0,0) ,右下单元格是 (n - 1, n - 1) 。
象棋骑士有8种可能的走法,如下图所示。每次移动在基本方向上是两个单元格,然后在正交方向上是一个单元格。

每次骑士要移动时,它都会随机从8种可能的移动中选择一种(即使棋子会离开棋盘),然后移动到那里。
骑士继续移动,直到它走了 k 步或离开了棋盘。
返回 骑士在棋盘停止移动后仍留在棋盘上的概率 。
示例 1:
输入: n = 3, k = 2, row = 0, column = 0
输出: 0.0625
解释: 有两步(到(1,2),(2,1))可以让骑士留在棋盘上。
在每一个位置上,也有两种移动可以让骑士留在棋盘上。
骑士留在棋盘上的总概率是0.0625。
示例 2:
输入: n = 1, k = 0, row = 0, column = 0
输出: 1.00000
给你两个 非空 链表来代表两个非负整数。数字最高位位于链表开始位置。它们的每个节点只存储一位数字。将这两数相加会返回一个新的链表。
你可以假设除了数字 0 之外,这两个数字都不会以零开头。
示例1:
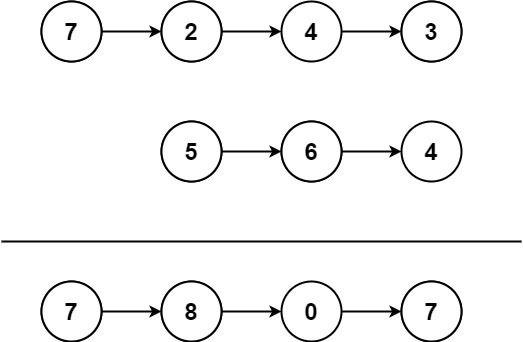
输入:l1 = [7,2,4,3], l2 = [5,6,4]
输出:[7,8,0,7]
示例2:
输入:l1 = [2,4,3], l2 = [5,6,4]
输出:[8,0,7]
示例3:
输入:l1 = [0], l2 = [0]
输出:[0]
编写一个算法来判断一个数 n 是不是快乐数。 「快乐数」 定义为:
- 对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。
- 然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。
- 如果这个过程 结果为 1,那么这个数就是快乐数。 如果 n 是 快乐数 就返回 true ;不是,则返回 false 。
示例 1:
输入:n = 19
输出:true
解释:
12 + 92 = 82
82 + 22 = 68
62 + 82 = 100
12 + 02 + 02 = 1
示例 2:
输入:n = 2
输出:false
给你一个字符串数组 words ,只返回可以使用在 美式键盘 同一行的字母打印出来的单词。键盘如下图所示。
美式键盘 中:
- 第一行由字符
"qwertyuiop"组成。 - 第二行由字符
"asdfghjkl"组成。 - 第三行由字符
"zxcvbnm"组成。

示例 1:
输入:words = ["Hello","Alaska","Dad","Peace"]
输出:["Alaska","Dad"]
示例 2:
输入:words = ["omk"]
输出:[]
示例 3:
输入:words = ["adsdf","sfd"]
输出:["adsdf","sfd"]
提示:
1 <= words.length <= 201 <= words[i].length <= 100words[i]由英文字母(小写和大写字母)组成
给定一个整数数组和一个整数 **k**,你需要在数组里找到 不同的 k-diff 数对,并返回不同的 k-diff 数对 的数目。
这里将 k-diff 数对定义为一个整数对 (nums[i], nums[j]),并满足下述全部条件:
0 <= i < j < nums.length|nums[i] - nums[j]| == k
注意,|val| 表示 val 的绝对值。
示例 1:
输入:nums = [3, 1, 4, 1, 5], k = 2
输出:2
解释:数组中有两个 2-diff 数对, (1, 3) 和 (3, 5)。
尽管数组中有两个1,但我们只应返回不同的数对的数量。
示例 2:
输入:nums = [1, 2, 3, 4, 5], k = 1
输出:4
解释:数组中有四个 1-diff 数对, (1, 2), (2, 3), (3, 4) 和 (4, 5)。
示例 3:
输入:nums = [1, 3, 1, 5, 4], k = 0
输出:1
解释:数组中只有一个 0-diff 数对,(1, 1)。
提示:
1 <= nums.length <= 104-107 <= nums[i] <= 1070 <= k <= 107
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示Node.val的整数。random_index:随机指针指向的节点索引(范围从0到n-1);如果不指向任何节点,则为null。
你的代码 只 接受原链表的头节点 head 作为传入参数。
示例 1:

输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
示例 2:

输入:head = [[1,1],[2,1]]
输出:[[1,1],[2,1]]
示例 3:

输入:head = [[3,null],[3,0],[3,null]]
输出:[[3,null],[3,0],[3,null]]
假设 Andy 和 Doris 想在晚餐时选择一家餐厅,并且他们都有一个表示最喜爱餐厅的列表,每个餐厅的名字用字符串表示。
你需要帮助他们用最少的索引和找出他们共同喜爱的餐厅。 如果答案不止一个,则输出所有答案并且不考虑顺序。 你可以假设答案总是存在。
示例 1:
输入: list1 = ["Shogun", "Tapioca Express", "Burger King", "KFC"],list2 = ["Piatti", "The Grill at Torrey Pines", "Hungry Hunter Steakhouse", "Shogun"]
输出: ["Shogun"]
解释: 他们唯一共同喜爱的餐厅是“Shogun”。
示例 2:
输入:list1 = ["Shogun", "Tapioca Express", "Burger King", "KFC"],list2 = ["KFC", "Shogun", "Burger King"]
输出: ["Shogun"]
解释: 他们共同喜爱且具有最小索引和的餐厅是“Shogun”,它有最小的索引和1(0+1)。
给你一个整数数组 nums 和一个整数 k ,判断数组中是否存在两个 不同的索引 i 和 j ,满足 nums[i] == nums[j] 且 abs(i - j) <= k 。如果存在,返回 true ;否则,返回 false 。
示例 1:
输入:nums = [1,2,3,1], k = 3
输出:true
示例 2:
输入:nums = [1,0,1,1], k = 1
输出:true
示例 3:
输入:nums = [1,2,3,1,2,3], k = 2
输出:false
给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c *,*使得 a + b + c = 0 ?请你找出所有和为 0 且不重复的三元组。**注意:**答案中不可以包含重复的三元组。
示例 1:
输入:nums = [-1,0,1,2,-1,-4]
输出:[[-1,-1,2],[-1,0,1]]
示例 2:
输入:nums = []
输出:[]
示例 3:
输入:nums = [0]
输出:[]
路径 被定义为一条从树中任意节点出发,沿父节点-子节点连接,达到任意节点的序列。
同一个节点在一条路径序列中 至多出现一次 。该路径 至少包含一个 节点,且不一定经过根节点。路径和 是路径中各节点值的总和。
给定一个二叉树的根节点 root ,返回其 最大路径和,即所有路径上节点值之和的最大值。
示例 1:
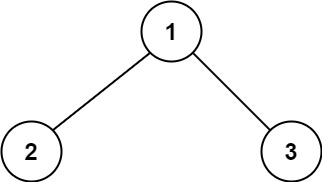
输入:root = [1,2,3]
输出:6
解释:最优路径是 2 -> 1 -> 3 ,路径和为 2 + 1 + 3 = 6
示例 2:
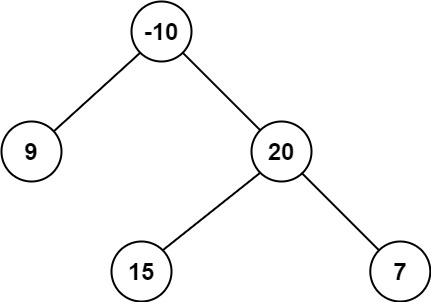
输入:root = [-10,9,20,null,null,15,7]
输出:42
解释:最优路径是 15 -> 20 -> 7 ,路径和为 15 + 20 + 7 = 42
提示:
- 树中节点数目范围是
[1, 3 * 104] -1000 <= Node.val <= 1000
给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: s = "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
示例 2:
输入: s = "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
示例 3:
输入: s = "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。
示例 1:

输入:root = [3,9,20,null,null,15,7]
输出:[[3],[9,20],[15,7]]
示例 2:
输入:root = [1]
输出:[[1]]
示例 3:
输入:root = []
输出:[]
假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。
对每个孩子 i,都有一个胃口值 g[i],这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干 j,都有一个尺寸 s[j] 。如果 s[j] >= g[i],我们可以将这个饼干 j 分配给孩子 i ,这个孩子会得到满足。你的目标是尽可能满足越多数量的孩子,并输出这个最大数值。
示例 1:
输入: g = [1,2,3], s = [1,1]
输出: 1
解释:
你有三个孩子和两块小饼干,3个孩子的胃口值分别是:1,2,3。
虽然你有两块小饼干,由于他们的尺寸都是1,你只能让胃口值是1的孩子满足。
所以你应该输出1。
示例 2:
输入: g = [1,2], s = [1,2,3]
输出: 2
解释:
你有两个孩子和三块小饼干,2个孩子的胃口值分别是1,2。
你拥有的饼干数量和尺寸都足以让所有孩子满足。
所以你应该输出2.
给定一个 正整数 num ,编写一个函数,如果 num 是一个完全平方数,则返回 true ,否则返回 false 。
进阶:不要 使用任何内置的库函数,如 sqrt 。
示例 1:
输入:num = 16
输出:true
示例 2:
输入:num = 14
输出:false
提示:
1 <= num <= 2^31 - 1
给定一个整数数组 asteroids,表示在同一行的行星。
对于数组中的每一个元素,其绝对值表示行星的大小,正负表示行星的移动方向(正表示向右移动,负表示向左移动)。每一颗行星以相同的速度移动。
找出碰撞后剩下的所有行星。碰撞规则:两个行星相互碰撞,较小的行星会爆炸。如果两颗行星大小相同,则两颗行星都会爆炸。两颗移动方向相同的行星,永远不会发生碰撞。
示例 1:
输入:asteroids = [5,10,-5]
输出:[5,10]
解释:10 和 -5 碰撞后只剩下 10 。 5 和 10 永远不会发生碰撞。
示例 2:
输入:asteroids = [8,-8]
输出:[]
解释:8 和 -8 碰撞后,两者都发生爆炸。
示例 3:
输入:asteroids = [10,2,-5]
输出:[10]
解释:2 和 -5 发生碰撞后剩下 -5 。10 和 -5 发生碰撞后剩下 10 。
给定一个区间的集合 intervals ,其中 intervals[i] = [starti, endi] 。返回 需要移除区间的最小数量,使剩余区间互不重叠 。
示例 1:
输入: intervals = [[1,2],[2,3],[3,4],[1,3]]
输出: 1
解释: 移除 [1,3] 后,剩下的区间没有重叠。
示例 2:
输入: intervals = [ [1,2], [1,2], [1,2] ]
输出: 2
解释: 你需要移除两个 [1,2] 来使剩下的区间没有重叠。
示例 3:
输入: intervals = [ [1,2], [2,3] ]
输出: 0
解释: 你不需要移除任何区间,因为它们已经是无重叠的了。
给定一个大小为 n 的数组,找到其中的多数元素。多数元素是指在数组中出现次数 大于 ⌊ n/2 ⌋ 的元素。
你可以假设数组是非空的,并且给定的数组总是存在多数元素。
示例 1:
输入:[3,2,3]
输出:3
示例 2:
输入:[2,2,1,1,1,2,2]
输出:2
进阶:
- 尝试设计时间复杂度为 O(n)、空间复杂度为 O(1) 的算法解决此问题。
给定一个 N 叉树,返回其节点值的层序遍历。(即从左到右,逐层遍历)。
树的序列化输入是用层序遍历,每组子节点都由 null 值分隔(参见示例)。
示例 1:
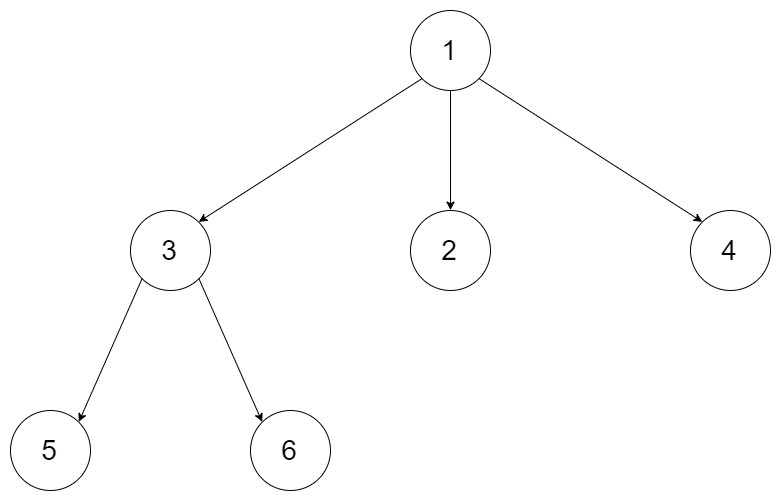
输入:root = [1,null,3,2,4,null,5,6]
输出:[[1],[3,2,4],[5,6]]
示例 2:
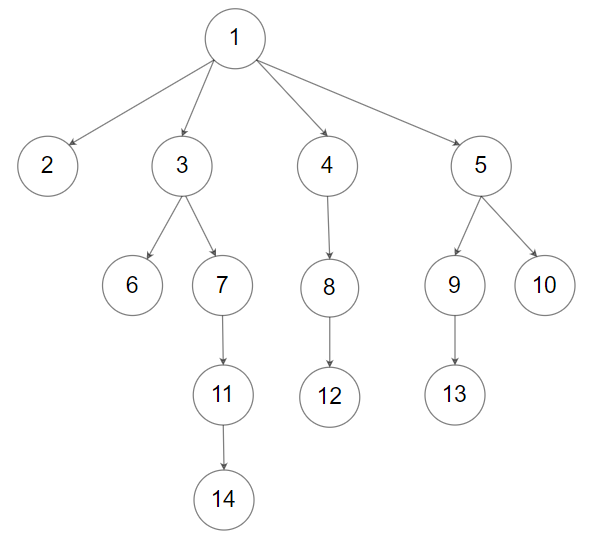
输入:root =[1,null,2,3,4,5,null,null,6,7,null,8,null,9,10,null,null,11,null,12,null,13,null,null,14]
输出:[[1],[2,3,4,5],[6,7,8,9,10],[11,12,13],[14]]
提示:
- 树的高度不会超过
1000 - 树的节点总数在
[0, 10^4]之间
给定一个正整数 n ,将其拆分为 k 个 正整数 的和( k >= 2 ),并使这些整数的乘积最大化。
返回 你可以获得的最大乘积 。
示例 1:
输入: n = 2
输出: 1
解释: 2 = 1 + 1, 1 × 1 = 1。
示例 2:
输入: n = 10
输出: 36
解释: 10 = 3 + 3 + 4, 3 × 3 × 4 = 36。
提示:
2 <= n <= 58
给定一个非空字符串 s,最多删除一个字符。判断是否能成为回文字符串。
示例 1:
输入: s = "aba"
输出: true
示例 2:
输入: s = "abca"
输出: true
解释: 你可以删除c字符。
示例 3:
输入: s = "abc"
输出: false
给你一个整数数组 nums,将 nums 中的的所有偶数元素移动到数组的前面,后跟所有奇数元素。
返回满足此条件的 任一数组 作为答案。
示例 1:
输入:nums = [3,1,2,4]
输出:[2,4,3,1]
解释:[4,2,3,1]、[2,4,1,3] 和 [4,2,1,3] 也会被视作正确答案。
示例 2:
输入:nums = [0]
输出:[0]
给你一棵 完全二叉树 的根节点 root ,求出该树的节点个数。
完全二叉树 的定义如下:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层,则该层包含 1~ 2h 个节点。
示例 1:

输入:root = [1,2,3,4,5,6]
输出:6
示例 2:
输入:root = []
输出:0
示例 3:
输入:root = [1]
输出:1
提示:
- 树中节点的数目范围是
[0, 5 * 104] 0 <= Node.val <= 5 * 104- 题目数据保证输入的树是 完全二叉树
给你一个整数数组 nums 和一个整数 k ,请你返回子数组内所有元素的乘积严格小于 k 的连续子数组的数目。
示例 1:
输入:nums = [10,5,2,6], k = 100
输出:8
解释:8 个乘积小于 100 的子数组分别为:[10]、[5]、[2],、[6]、[10,5]、[5,2]、[2,6]、[5,2,6]。
需要注意的是 [10,5,2] 并不是乘积小于 100 的子数组。
示例 2:
输入:nums = [1,2,3], k = 0
输出:0
提示:
1 <= nums.length <= 3 * 1041 <= nums[i] <= 10000 <= k <= 106
字符串有三种编辑操作:插入一个字符、删除一个字符或者替换一个字符。 给定两个字符串,编写一个函数判定它们是否只需要一次(或者零次)编辑。
示例 1:
输入:
first = "pale"
second = "ple"
输出: True
示例 2:
输入:
first = "pales"
second = "pal"
输出: False
设计一个算法,找出二叉搜索树中指定节点的“下一个”节点(也即中序后继)。
如果指定节点没有对应的“下一个”节点,则返回null。
示例 1:
输入: root = [2,1,3], p = 1
2
/ \
1 3
输出: 2
示例 2:
输入: root = [5,3,6,2,4,null,null,1], p = 6
5
/ \
3 6
/ \
2 4
/
1
输出: null
如果二叉树每个节点都具有相同的值,那么该二叉树就是单值二叉树。
只有给定的树是单值二叉树时,才返回 true;否则返回 false。
示例 1:
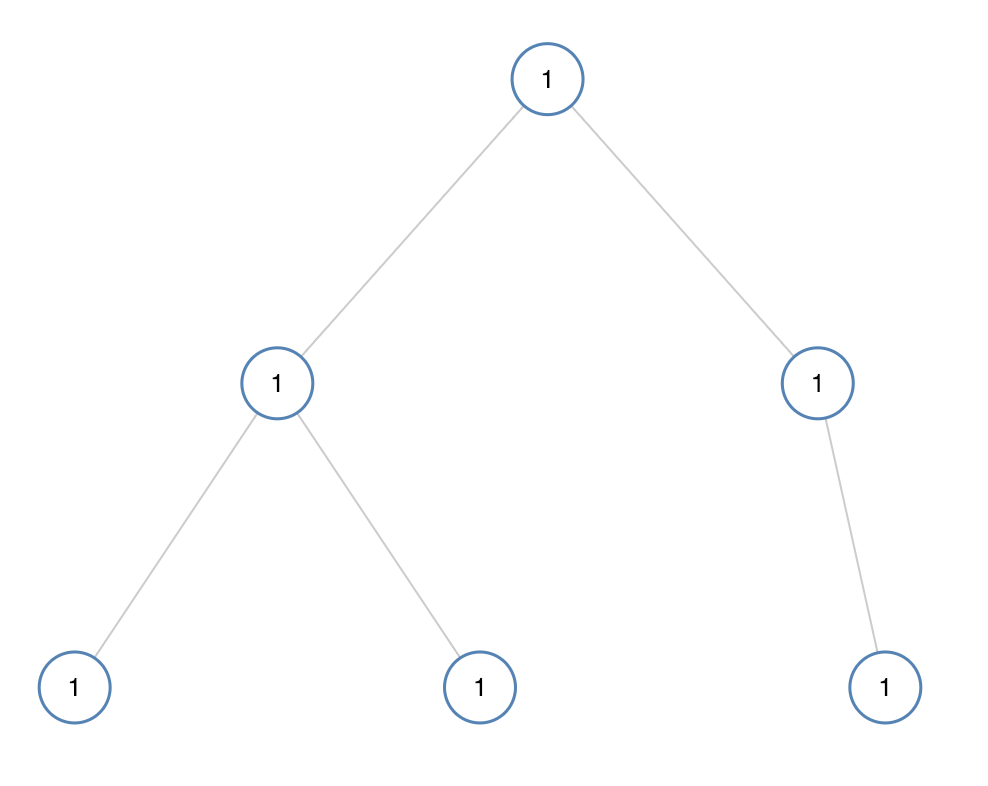
输入:[1,1,1,1,1,null,1]
输出:true
示例 2:
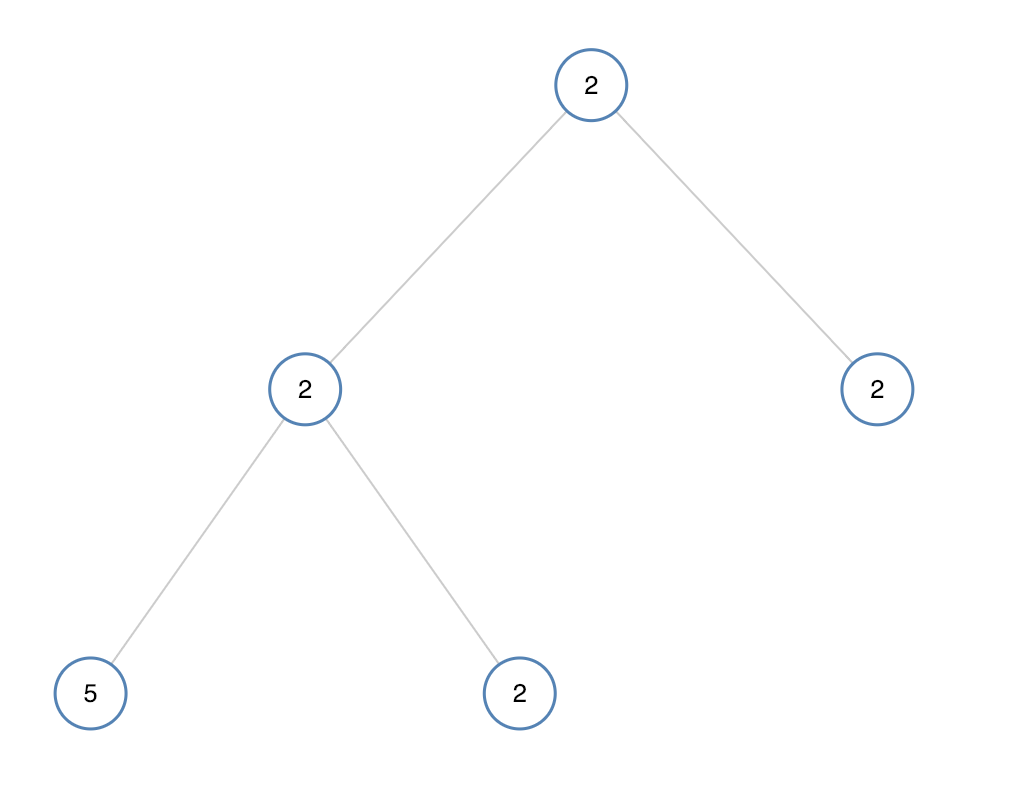
输入:[2,2,2,5,2]
输出:false
提示:
- 给定树的节点数范围是
[1, 100]。 - 每个节点的值都是整数,范围为
[0, 99]。