{kind=link}
MusicGen is a single-stage auto-regressive Transformer model capable of generating high-quality music samples conditioned on text descriptions or audio prompts. The text prompt is passed to a text encoder model (T5) to obtain a sequence of hidden-state representations. These hidden states are fed to MusicGen, which predicts discrete audio tokens (audio codes). Finally, audio tokens are then decoded using an audio compression model (EnCodec) to recover the audio waveform.
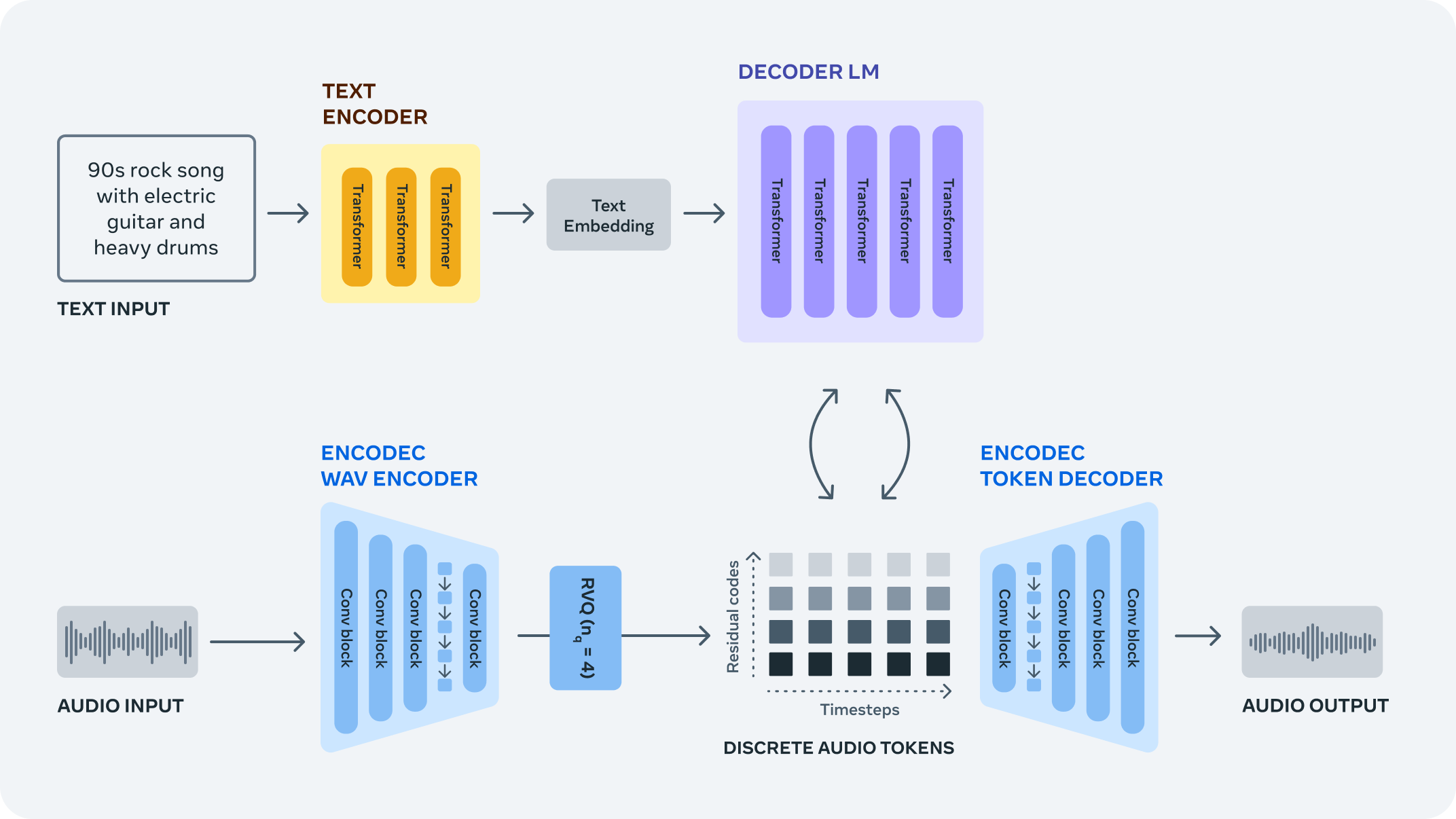
The tutorial consists of the following steps:
- Install and import prerequisite packages
- Download the MusicGen Small model from a public source using the Hugging Face Hub.
- Run the text-conditioned music generation pipeline
- Convert three models backing the MusicGen pipeline
- Run the music generation pipeline again using OpenVINO
This is a self-contained example that relies solely on its own code.
We recommend running the notebook in a virtual environment. You only need a Jupyter server to start.
For details, please refer to Installation Guide.