Make pinset sharding deterministic #3640
Conversation
Making this deterministic keeps us from creating an exponential amount of objects as the number of pins in the set increases. License: MIT Signed-off-by: Jeromy <[email protected]>
|
Confirmed there is no longer exponential explosion, |
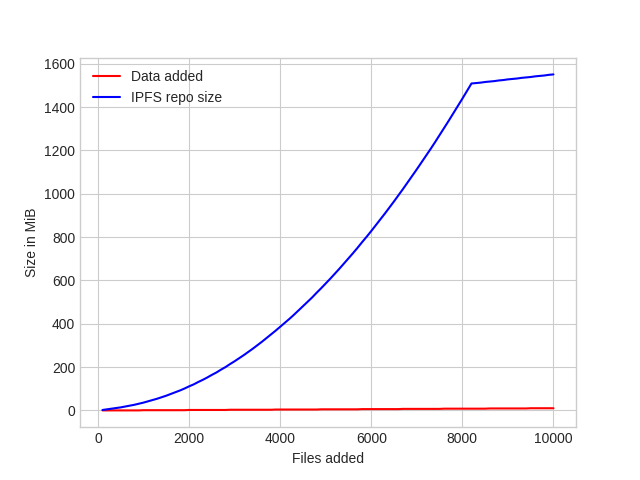
What you mean by that? |
|
From that graph it seems for me that we should start sharding the pinset a bit more early. |
|
I meant: the storage-saving effect of the block-dedup is shadowed by the storage-requirement of the pin set. In short, files in an ipFS repo take more space than they were in unixFS. |
|
IDK if we should go with fully static seed, it allows for same attacks that all languages protect their hash maps against (precalcing which items would go to which buckets and causing requests that would cause many items in one bucket) but in our case it would be causing the tree to have one deep branch. |
|
@Kubuxu I don't think this is an issue, You would have to find 257 items that all share a hash prefix of length n, where the hash function changes at each byte index. And then convince another node to pin each of them individually. |
|
Yeah, the split to sub buckets helps in comparison to hash maps. |
|
@Kubuxu 👍 here? |
Making this deterministic keeps us from creating an exponential amount
of objects as the number of pins in the set increases.
closes #3621 for the most part
License: MIT
Signed-off-by: Jeromy [email protected]