1 5 透過 RISC V 模擬器搞懂指令管線化
本篇文章藉由閱讀 rv32emu-next 這個開源的 risc-v emulator 原始碼介紹處理器如何執行組合語言,了解其工作原理後再看看如何透過 pinpline 和 branch-prediction 提升處理器效能。
- IO 以及記憶體、虛擬機初始化。
-
run()orrun_and_trace()根據不同情況決定每個 cycle 要執行多少個指令後再呼叫rv_step()。 -
rv_step()拿出指令並判斷其類型 (load, jump, store, branch...) 後呼叫op(),讓其做 dispatch 和後續動作。
-
rv_step()達到 cycle 目標之前重複以下動作:- 將指令從 pc 指向的記憶體位置讀取出來。
- 讀取出來之後,將指令交給 op handler: op() 進行處理。
- op()
在
riscv.c的第 787 行處有預先定義好 RV32I 各類指令的 opcode (前五碼)。
static const opcode_t opcodes[] = { // 000 001 010 011 100 101 110 111 op_load, op_load_fp, NULL, op_misc_mem, op_op_imm, op_auipc, NULL, NULL, // 00 op_store, op_store_fp, NULL, op_amo, op_op, op_lui, NULL, NULL, // 01 op_madd, op_msub, op_nmsub, op_nmadd, op_fp, NULL, NULL, NULL, // 10 op_branch, op_jalr, NULL, op_jal, op_system, NULL, NULL, NULL, // 11 };只定義前 5 碼是因為 RV32I opcode 的後兩碼都是固定的 (
xxxxx11),我們也可以在rv_step()中看到待執行指令inst的預處理:// standard uncompressed instruction if ((inst & 3) == 3) { const uint32_t index = (inst & INST_6_2) >> 2;簡單來說就是判斷
inst是否屬於 RV32I 指令(末兩碼是否為11。),如果是的話我們就將末兩碼移除並且做right_shift。補充 1 :
INST_6_2定義在riscv_private.h中,其值為0b00000000000000000000000001111100。補充 2 : 除了 RVC 指令集外,其他合法 RISC-V 指令集的 OPCODE 末兩碼都是
11。題外話: 在上面的原始碼中就有大量的 bitwise 操作,再次凸顯它的重要性。
-
op()op其實只是函式指標,透過rv_step()指定指令的 handler 後,再去做相關操作。 這邊以op_op_imm()這個關於整數操作的 handler 舉例:static bool op_op_imm(struct riscv_t *rv, uint32_t inst) { // i-type decode const int32_t imm = dec_itype_imm(inst); const uint32_t rd = dec_rd(inst); const uint32_t rs1 = dec_rs1(inst); const uint32_t funct3 = dec_funct3(inst); // dispatch operation type switch (funct3) { case 0: // ADDI rv->X[rd] = (int32_t)(rv->X[rs1]) + imm; break; case 1: // SLLI rv->X[rd] = rv->X[rs1] << (imm & 0x1f); break; case 2: // SLTI rv->X[rd] = ((int32_t)(rv->X[rs1]) < imm) ? 1 : 0; break; case 3: // SLTIU rv->X[rd] = (rv->X[rs1] < (uint32_t) imm) ? 1 : 0; break; case 4: // XORI rv->X[rd] = rv->X[rs1] ^ imm; break; case 5: if (imm & ~0x1f) { // SRAI rv->X[rd] = ((int32_t) rv->X[rs1]) >> (imm & 0x1f); } else { // SRLI rv->X[rd] = rv->X[rs1] >> (imm & 0x1f); } break; case 6: // ORI rv->X[rd] = rv->X[rs1] | imm; break; case 7: // ANDI rv->X[rd] = rv->X[rs1] & imm; break; default: rv_except_illegal_inst(rv); return false; } // step over instruction rv->PC += 4; // enforce zero register if (rd == rv_reg_zero) rv->X[rv_reg_zero] = 0; return true; }handler 會將傳入指令做解碼,也就是將傳入的
inst根據上圖的 I type 切割成四塊:- funct3
- imm
- rs1
- rd
funct3會決定要做哪一種操作,如: ADDI, SLLI, ORI... 。 假設現在要做的是 ADDI 操作,模擬器就會按照 RISC-V 中 ADDI 指令所定義的行為執行。
定義: 常數部分為 sign-extended 12-bit ,會將 12-bit 做 sign-extension 成 32-bit 後,再與 rs1 暫存器做加法運算,將結果寫入 rd 暫存器,addi rd, rs1, 0 可被用來當做 mov 指令。
將結果寫回相關暫存器後, handler 會將 Program counter 指到下一個記憶體位置後回傳結果。
 handler 會將傳入指令做解碼,也就是將傳入的
handler 會將傳入指令做解碼,也就是將傳入的 上面的工作流程涵蓋了處理器的部分行為:
- Fetch
- Decode
- Execute
- Write-back
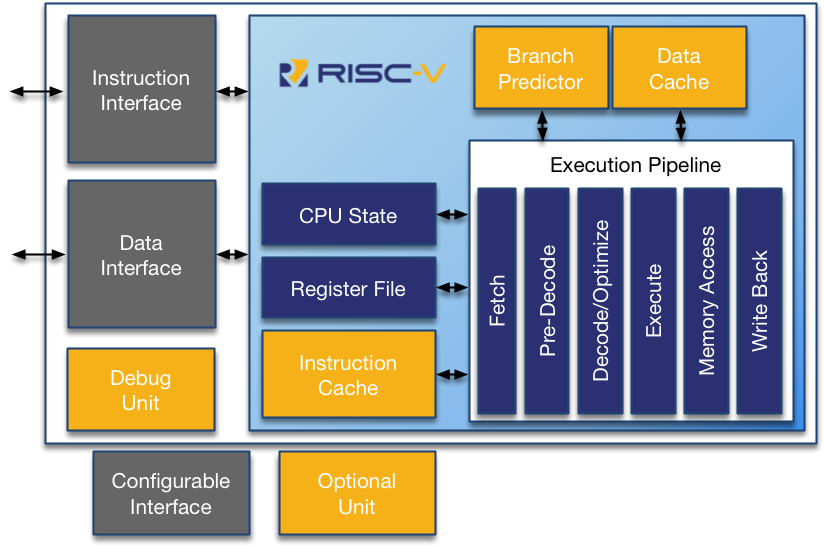
恰好呼應到了本文開頭提到的 RISC-V Arch 架構圖。
就 rv32emu-next 的原始碼來看,我們不難知道它會逐步處理 Fetch, Decode, Execute, Write-back ,假設每個階段耗費 1ms ,那一個指令需要 4ms 才能完成,若處理十個指令就需要 40ms 。由於其中一個階段在執行時,其他的邏輯電路都是閒置的,這樣未免有些浪費。
流水線 (pinpline) ,又稱為指令管線化。被設計來加速指令通過的速度。
如果以指令管線化的技術實現,第一個指令仍會耗費 4ms ,之後每 1ms 便能完成一條指令。

上圖為一個 5 級流水線的示意圖,我們可以清楚的看到在 Clock Cycle = 2 時,指令 1 已經進入解碼階段 (ID),而讀取指令的電路也沒閒著,已經準備將指令 2 從記憶體讀進處理器了。
使用管線可以有效加速指令的流通速。不過,在現實中還是會遇到一些問題以及缺陷:
-
週期同步問題 前面假設各個層級的耗費時間都相同。實際上,各層級所耗時間並不是相等的。因此,時鐘週期就需要以最慢的 stage 下去做考量,若流水線設計過長,反而會因為過長的等待時間造成反效果。
-
電路體積加大 將一塊電路拆成多塊電路實現管線,需要在每個階層都放上大量的暫存器以保存前一層的輸出。暫存器在邏輯電路中是用正反器去實現的,越長的流水線就會有越多的正反器,這樣便會造成電路體積加大以及廢熱的問題需要解決。
-
指令延遲問題 利用大量的暫存器去保存前一個階層的結果也會間接造成指令的延遲問題。
-
分支預測問題
分支問題可被歸類在 Control Hazards 。
以
rv32emu-next來看,在一般情況下,當一個指令完成後,程式計數器 (PC, Program Counter) 會讀取記憶體中的下一個地址 (PC = PC + 4) 。 實際情況中,還會有分支的可能需要考慮進去,像是常見的無條件轉跳指令jump和條件轉跳指令branch都會造成問題,像是,當指令 1 進入執行階段時發現該指令會進行轉跳,那指令 2 和指令 3 已經分別在解碼和讀取階段了該怎麼辦呢?這時處理器便會將前面的流水線清空並將正確的指令放回來。要知道,清除流水線是十分浪費效能的(做白工)。因此,隨著流水線加長,分支預測也是電腦科學家一直一來想去探討的議題。關於 Hazards ,在本系列的淺談分支預測與 Hazards 議題會有更進一步的探討。
在本篇章中,讀者快速的向各位介紹完了處理器的部分行為以及指令管線化的技術,如果對分支預測有興趣可以參考本篇的延伸閱讀。兩篇都提到了分支預測的問題並且使用不同的方式解決加快了程式碼的執行速度。