
Hydra is open source, column-oriented Postgres. You can query billions of rows instantly on Postgres without code changes. Parallelized analytics in minutes, not weeks.
Try the Hydra Free Tier to create a column-oriented Postgres instance. Then connect to it with your preferred Postgres client (psql, dbeaver, etc).
Alternatively, you can run Hydra locally.
Benchmarks were run on a c6a.4xlarge (16 vCPU, 32 GB RAM) with 500 GB of GP2 storage. Results in seconds, smaller is better.
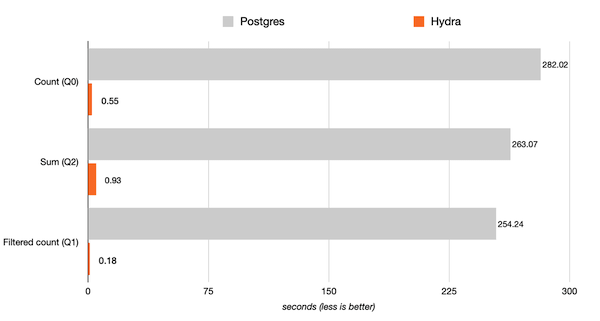
Review Clickbench for comprehensive results and the list of 42 queries tested.
This benchmark represents typical workload in the following areas: clickstream and traffic analysis, web analytics, machine-generated data, structured logs, and events data.
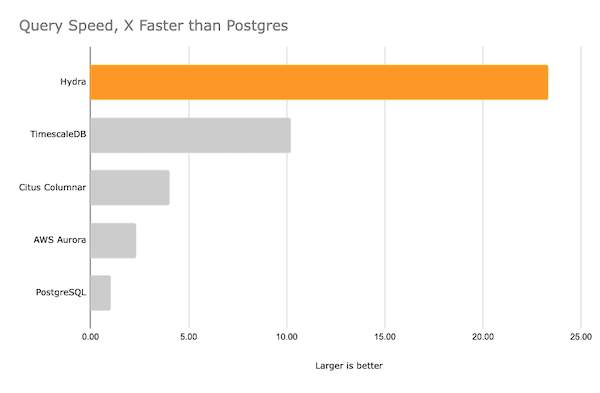
For our continuous benchmark results, see BENCHMARKS.
View complete answers in our documentation.
A: Columnar storage, query parallelization, vectorized execution, column-level caching, and tuning Postgres.
A: Data is loaded into columnar format by default. Use Postgres normally.
A: Aggregates (COUNT, SUM, AVG), WHERE clauses, bulk INSERTS, UPDATE, DELETE…
A: Frequent large updates, small transactions…
- Logical replication.
- Columnar tables don’t typically use indexes, only supporting btree and hash indexes, and their associated constraints.
A: Hydra is a Postgres extension, not a fork. Hydra makes use of tableam (table access method API), which was added in Postgres 12 released in 2019.
- Alpha: Limited to select design partners
- Public Alpha: available for use, but with noted frictions
- Hydra 1.0 beta: Stable for non-enterprise use cases
- Hydra 1.0 Release: Generally Available (GA) and ready for production use
- CHANGELOG for details of recent changes
- GitHub Issues for bugs and missing features
- Discord discussion with the Community and Hydra team
- Docs for Hydra features and warehouse ops
The Hydra Docker image is a drop-in replacement for postgres Docker image.
You can try out Hydra locally using docker-compose.
git clone https://github.com/hydradatabase/hydra && cd hydra
cp .env.example .env
docker compose up
psql postgres://postgres:[email protected]:5432Hydra is only possible by building on the shoulders of giants.
The code in this repo is licensed under:
- AGPL 3.0 for Hydra Columnar
- All other code is Apache 2.0
The docker image is built on the Postgres docker image, which contains a large number of open source projects, including:
- Postgres - the Postgres license
- Debian or Alpine Linux image, depending on the image used
- Hydra includes the following additional software in the image:
- multicorn - BSD license
- mysql_fdw - MIT-style license
- parquet_s3_fdw - MIT-style license
- pgsql-http - MIT license
As for any pre-built image usage, it is the image user's responsibility to ensure that any use of this image complies with any relevant licenses for all software contained within.