- Introduction to Spark
- Initializing Spark
- Spark DataFrame
- Spark SQL
- Spark Core
- Spark Submit
- Internals of Spark
- Spark Memory Management
Spark is a an open-source, distributed computation engine that:
- Distributes workloads: Splits data across multiple machines / nodes, enabling parallel processing and faster analysis.
- Handles diverse data: Works with various data formats, from structured databases to unstructured text files.
- Offers multiple languages: Can be program with Scala, Java, Python, R, or SQL.
- Supports multiple use cases: Tackle batch processing, real-time streaming, machine learning, and more.
In this module, we would be using PySpark, a Python API for Apache Spark. It enables you to perform real-time, large-scale data processing in a distributed environment using Python. PySpark supports all of Spark’s features such as Spark SQL, DataFrames, Structured Streaming, Machine Learning (MLlib) and Spark Core.
The entry point into all functionality in Spark is the SparkSession class. We could use the code below to initialize a SparkSession.
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.master("local[*]") \
.appName("Python Spark SQL basic example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()Spark configuration can be set with SparkConf(). Various Spark parameters can be set with key-value pairs.
Spark dataframe is an immutable distributed collection of data conceptually equivalent to a table in a relational database or a Pandas DataFrame, but with richer optimizations under the hood.
Spark dataframe can be manipulated with untyped dataset operations (aka DataFrame Operations). There are two types of dataframe operations, namely transformations and actions. Transformations are lazily evaluated, which means no Spark jobs are triggered, no matter the number of transformations are scheduled. Actions are executed in eager manner, where all unevaluated transformations are executed prior to the action.
Some common transformations and actions are shown in the table below.
| Transformations | Select, Filter, Distinct, Repartition, Joins, GroupBy, udf |
| Actions | Count, Show, Take, Head, Write |
| Narrow Transformations | Wide Transformations |
|---|---|
| Each partition at the parent RDD is used by at most one partition of the child RDD | Each partition at the parent RDD is used by multiple partitions of the child RDD |
| Fast | Slow |
| Does not require any data shuffling over the cluster network | Might require data shuffling over the cluster network |
| Example: filter, map | Example: join, repartition |
Spark SQL is Spark’s module for working with structured data. Spark SQL code tells Spark what to do in a declarative manner. Code written in Spark SQL benefits from Spark’s catalyst, which optimizes the performance. Thus, using Spark SQL with the structured APIs is easier to write performant code.
Note
Some common Spark SQL syntax can be found here.
Spark Core is the underlying general execution engine for the Spark platform that all other functionality is built on top of. It provides RDDs (Resilient Distributed Datasets) and in-memory computing capabilities.
RDD is a distributed collection of elements that can be operated on in parallel. It is the following properties
- Resilient - Fault-tolerant with the help of RDD lineage graph [DAG] and so able to recompute missing or damaged partitions due to node failures.
- Lazy evaluated - Data inside RDD is not available or transformed until an action triggers the execution.
- Cacheablec - All the data can be hold in a persistent “storage” like memory (default and the most preferred) or disk (the least preferred due to access speed).
- Immutable or Read-Only - It does not change once created and can only be transformed using transformations to new RDDs.
Spark Submit is a command-line tool provided by Apache Spark for submitting Spark applications to a cluster. It is used to launch applications on a standalone Spark cluster, a Hadoop YARN cluster, or a Mesos cluster.
| Cluster | Client | |
|---|---|---|
| Driver | Runs on one of the worker nodes | Runs locally from where you are submitting your application using spark-submit command |
| When to use | Production | Interactive and debugging purposes |
Note
Default deployment mode is client mode
Note
In client mode only the driver runs locally and all tasks run on cluster worker nodes.
In Spark application, cluster manager does the resource allocating work.
To run on a cluster, SparkContext connect to several types of cluster managers (either Spark’s own standalone cluster manager, Mesos, YARN or Kubernetes). Once connected with cluster, SparkContext sends the application code (defined by JAR for JAVA and Scala or Python files passed to SparkContext) to the executors. Finally, SparkContext sends tasks to the executors to run.

| Cluster Manager | --master | Description |
|---|---|---|
| Yarn | yarn | Use yarn if cluster resources are managed by Hadoop Yarn |
| Mesos | mesos://HOST:PORT | Use mesos://HOST:PORT for Mesos cluster manager |
| Standalone | spark://HOST:PORT | Use spark://HOST:PORT for Standalone cluster |
| Kubernetes | k8s://HOST:PORT or k8s://https://HOST:PORT | Use k8s://HOST:PORT for Kubernetes |
| local | local or local[k] or local[k, F] | k = number of cores, which translate to number of workers, F = number of attempts it should run when failed |
Note
In local mode, all driver and executor run inside of a single JVM. Only setting driver behaviour matters.
Refer this page for more info on spark-submit.
A groupby operation in Spark's physical plan will go through HashAggregate -> Exchange -> HashAggregate. The operations is as follows.
- The first HashAggregate is responsible for doing partial aggregation where GroupBy operation is done locally on the data in each executor (One partition of data as each executor will only have one partition of data).
- Exchange represents shuffle, which is the process of exchanging data between partitions. Data rows can move between worker nodes when their source partition and the target partition reside on a different machine.
- The second HashAggregate represents the final aggregation (final merge) after the shuffle.
For the query below, the operation is as follows
query = f"""
SELECT
PULocationID AS zone,
date_trunc('HOUR', lpep_pickup_datetime) AS pickup_datetime,
DECIMAL(SUM(total_amount)) AS revenue,
COUNT(1) AS number_of_records
FROM
green_taxi
WHERE lpep_pickup_datetime > '2019-01-01 00:00:00'
GROUP BY
zone, pickup_datetime
"""
spark.sql(query).show()Stage 1 - Filtering of lpep_pickpup_datetime. Filtering in Spark is done by predicate pushdown. Then, partial aggregation of local data in each executor is performed.

Exchange - Shuffling of data

Stage 2 - Final merge of data where data with same key is put into same partition. Then final aggregation of data (sum, count, etc) is done here.

Spark Join Strategies can be thought of in 2 phases, Data Exchange Strategies and Join Algorithms.
- Broadcast
- The driver will collect all the data partitions for table A, and broadcast the entire table A to all of the executors. This
avoids an all-to-all communication (shuffle) between the executorswhich is expensive. The data partitions for table B do not need to move unless explicitly told to do so.
- The driver will collect all the data partitions for table A, and broadcast the entire table A to all of the executors. This
- Shuffle
- All the executors will communicate with every other executor to share the data partition of table A and table B. All the records with the same join keys will then be in the same executors. As this is an all-to-all communication, this is
expensive as the network can become congested and involve I/O. After the shuffle, each executor holds data partitions (with the same join key) of table A and table B.
- All the executors will communicate with every other executor to share the data partition of table A and table B. All the records with the same join keys will then be in the same executors. As this is an all-to-all communication, this is
Two most common join strategy in Spark is sort-merge join and broadcast hash join.
Sort-merge join uses Sort Merge Algorithm and shuffle data exchange. The algorithm is done as follows:
- Sort all the data partitions accordingly to the Join Key
- Perform merge operation based on the sorted Join Key.
Sort-merge join is useful for large tables. However, it might cause spilling to disk if there is not enough execution memory.
Broadcast Hash join uses Hash Join Algorithm and broadcast data exchange. The algorithm is done as follows:
- A Hash Table is built on the smaller table of the join. The Join Column value is used as the key in the Hash Table
- For every row in the other data partitions, the Join Column value is used to query the Hash Table built in (1). When Hash Table returns some value, then there is a match.
Broadcast Hash join is useful if one of the table is able to fit into executor memory. The default broadcast size is 10mb. Broadcast Hash is the preferred way of joining tables as shuffling is not required. One disadvantage is that it doeese not support FULL OUTER JOIN.
Spark advantage over MapReduce is it's ability to store data reliably in-memory and this makes repeatedly accessing it (ie. for iterative algorithms) incomparably faster.
Spark memory management model is summarized in the following figure.
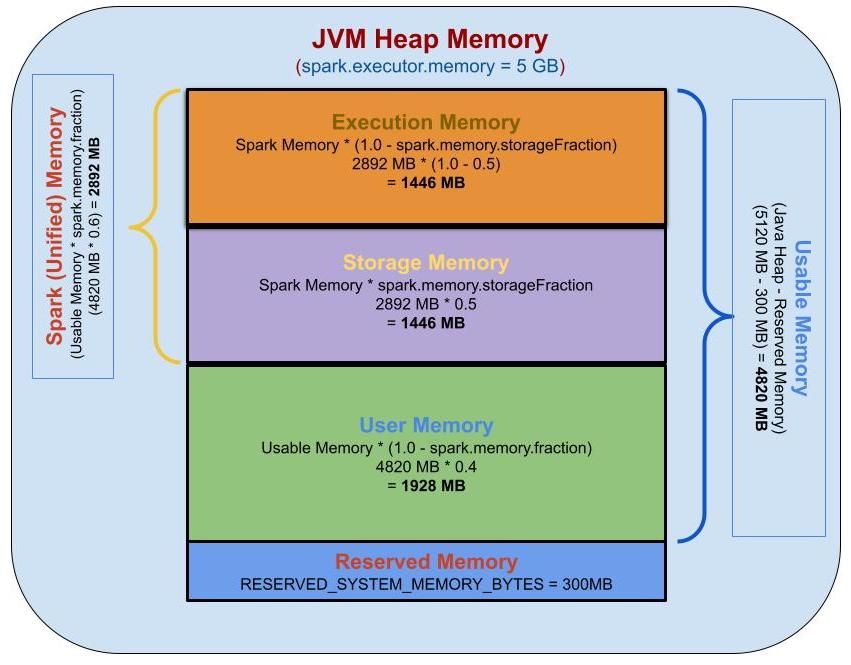
- Reserved Memory
- Memory reserved for the system and is used to store Spark's internal objects. Typically around 300mb.
- User Memory
- Memory used to store user-defined data structures, Spark internal metadata, any UDFs created by the user, and the data needed for RDD conversion operations, such as RDD dependency information, etc.
- This memory segment is not managed by Spark. Spark will not be aware of or maintain this memory segment.
- Formula :
(Java Heap — Reserved Memory) * (1.0—Spark.memory.fraction)
- Spark Memory (Unified Memory)
- Memory pool managed by Apache Spark.
- Responsible for storing intermediate states while doing task execution like joins or storing broadcast variables. All the cached or persistent data will be stored in this segment, specifically in the storage memory of this segment.
- Formula :
(Java Heap — Reserved Memory) * spark.memory.fraction - Spark tasks operate in two main memory regions:
- Execution: Used for shuffles, joins, sorts, and aggregations.
- Storage: used to cache partitions of data, cached data, broadcast variables, etc..
- The boundary between them is set by spark.memory.storageFraction parameter, which defaults to 0.5 or 50%.