diff --git a/docs/source/en/_toctree.yml b/docs/source/en/_toctree.yml
index e48378d8c25377..05b1af1b58da5e 100644
--- a/docs/source/en/_toctree.yml
+++ b/docs/source/en/_toctree.yml
@@ -665,6 +665,8 @@
title: ViTMSN
- local: model_doc/yolos
title: YOLOS
+ - local: model_doc/zoedepth
+ title: ZoeDepth
title: Vision models
- isExpanded: false
sections:
diff --git a/docs/source/en/index.md b/docs/source/en/index.md
index ac026067ac24b7..99aa40bf995325 100644
--- a/docs/source/en/index.md
+++ b/docs/source/en/index.md
@@ -343,5 +343,6 @@ Flax), PyTorch, and/or TensorFlow.
| [XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2) | ✅ | ✅ | ✅ |
| [YOLOS](model_doc/yolos) | ✅ | ❌ | ❌ |
| [YOSO](model_doc/yoso) | ✅ | ❌ | ❌ |
+| [ZoeDepth](model_doc/zoedepth) | ✅ | ❌ | ❌ |
diff --git a/docs/source/en/model_doc/zoedepth.md b/docs/source/en/model_doc/zoedepth.md
new file mode 100644
index 00000000000000..d16da59ea98245
--- /dev/null
+++ b/docs/source/en/model_doc/zoedepth.md
@@ -0,0 +1,108 @@
+
+
+# ZoeDepth
+
+## Overview
+
+The ZoeDepth model was proposed in [ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth](https://arxiv.org/abs/2302.12288) by Shariq Farooq Bhat, Reiner Birkl, Diana Wofk, Peter Wonka, Matthias Müller. ZoeDepth extends the [DPT](dpt) framework for metric (also called absolute) depth estimation. ZoeDepth is pre-trained on 12 datasets using relative depth and fine-tuned on two domains (NYU and KITTI) using metric depth. A lightweight head is used with a novel bin adjustment design called metric bins module for each domain. During inference, each input image is automatically routed to the appropriate head using a latent classifier.
+
+The abstract from the paper is the following:
+
+*This paper tackles the problem of depth estimation from a single image. Existing work either focuses on generalization performance disregarding metric scale, i.e. relative depth estimation, or state-of-the-art results on specific datasets, i.e. metric depth estimation. We propose the first approach that combines both worlds, leading to a model with excellent generalization performance while maintaining metric scale. Our flagship model, ZoeD-M12-NK, is pre-trained on 12 datasets using relative depth and fine-tuned on two datasets using metric depth. We use a lightweight head with a novel bin adjustment design called metric bins module for each domain. During inference, each input image is automatically routed to the appropriate head using a latent classifier. Our framework admits multiple configurations depending on the datasets used for relative depth pre-training and metric fine-tuning. Without pre-training, we can already significantly improve the state of the art (SOTA) on the NYU Depth v2 indoor dataset. Pre-training on twelve datasets and fine-tuning on the NYU Depth v2 indoor dataset, we can further improve SOTA for a total of 21% in terms of relative absolute error (REL). Finally, ZoeD-M12-NK is the first model that can jointly train on multiple datasets (NYU Depth v2 and KITTI) without a significant drop in performance and achieve unprecedented zero-shot generalization performance to eight unseen datasets from both indoor and outdoor domains.*
+
+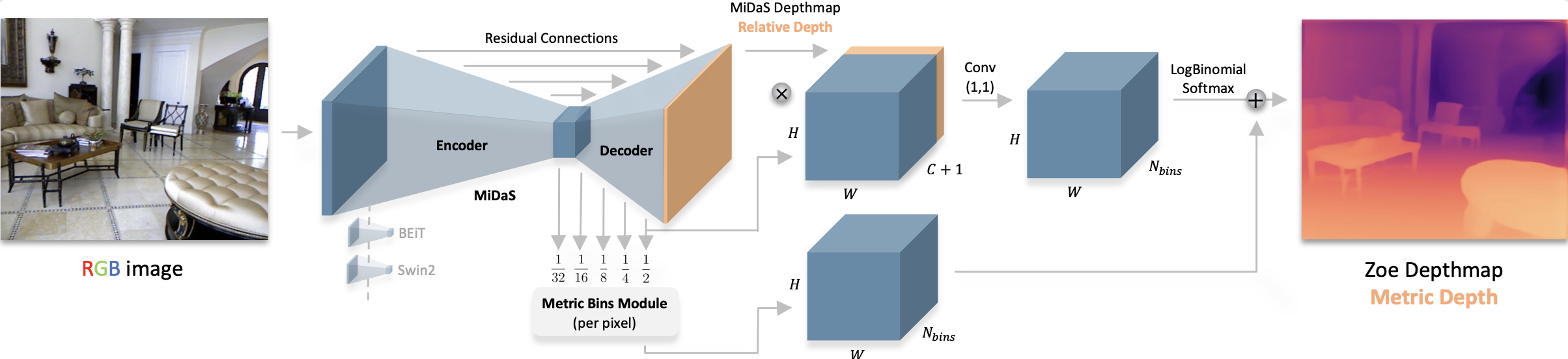 +
+ ZoeDepth architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/isl-org/ZoeDepth).
+
+## Usage tips
+
+- ZoeDepth is an absolute (also called metric) depth estimation model, unlike DPT which is a relative depth estimation model. This means that ZoeDepth is able to estimate depth in metric units like meters.
+
+The easiest to perform inference with ZoeDepth is by leveraging the [pipeline API](../main_classes/pipelines.md):
+
+```python
+from transformers import pipeline
+from PIL import Image
+import requests
+
+url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image = Image.open(requests.get(url, stream=True).raw)
+
+pipe = pipeline(task="depth-estimation", model="Intel/zoedepth-nyu-kitti")
+result = pipe(image)
+depth = result["depth"]
+```
+
+Alternatively, one can also perform inference using the classes:
+
+```python
+from transformers import AutoImageProcessor, ZoeDepthForDepthEstimation
+import torch
+import numpy as np
+from PIL import Image
+import requests
+
+url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image = Image.open(requests.get(url, stream=True).raw)
+
+image_processor = AutoImageProcessor.from_pretrained("Intel/zoedepth-nyu-kitti")
+model = ZoeDepthForDepthEstimation.from_pretrained("Intel/zoedepth-nyu-kitti")
+
+# prepare image for the model
+inputs = image_processor(images=image, return_tensors="pt")
+
+with torch.no_grad():
+ outputs = model(**inputs)
+ predicted_depth = outputs.predicted_depth
+
+# interpolate to original size
+prediction = torch.nn.functional.interpolate(
+ predicted_depth.unsqueeze(1),
+ size=image.size[::-1],
+ mode="bicubic",
+ align_corners=False,
+)
+
+# visualize the prediction
+output = prediction.squeeze().cpu().numpy()
+formatted = (output * 255 / np.max(output)).astype("uint8")
+depth = Image.fromarray(formatted)
+```
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ZoeDepth.
+
+- A demo notebook regarding inference with ZoeDepth models can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ZoeDepth). 🌎
+
+## ZoeDepthConfig
+
+[[autodoc]] ZoeDepthConfig
+
+## ZoeDepthImageProcessor
+
+[[autodoc]] ZoeDepthImageProcessor
+ - preprocess
+
+## ZoeDepthForDepthEstimation
+
+[[autodoc]] ZoeDepthForDepthEstimation
+ - forward
\ No newline at end of file
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index 42c5b713c55aef..c6679fa2f29428 100755
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -807,6 +807,7 @@
"models.xmod": ["XmodConfig"],
"models.yolos": ["YolosConfig"],
"models.yoso": ["YosoConfig"],
+ "models.zoedepth": ["ZoeDepthConfig"],
"onnx": [],
"pipelines": [
"AudioClassificationPipeline",
@@ -1182,6 +1183,7 @@
_import_structure["models.vitmatte"].append("VitMatteImageProcessor")
_import_structure["models.vivit"].append("VivitImageProcessor")
_import_structure["models.yolos"].extend(["YolosFeatureExtractor", "YolosImageProcessor"])
+ _import_structure["models.zoedepth"].append("ZoeDepthImageProcessor")
try:
if not is_torchvision_available():
@@ -3586,6 +3588,12 @@
"YosoPreTrainedModel",
]
)
+ _import_structure["models.zoedepth"].extend(
+ [
+ "ZoeDepthForDepthEstimation",
+ "ZoeDepthPreTrainedModel",
+ ]
+ )
_import_structure["optimization"] = [
"Adafactor",
"AdamW",
@@ -5497,6 +5505,7 @@
from .models.xmod import XmodConfig
from .models.yolos import YolosConfig
from .models.yoso import YosoConfig
+ from .models.zoedepth import ZoeDepthConfig
# Pipelines
from .pipelines import (
@@ -5872,6 +5881,7 @@
from .models.vitmatte import VitMatteImageProcessor
from .models.vivit import VivitImageProcessor
from .models.yolos import YolosFeatureExtractor, YolosImageProcessor
+ from .models.zoedepth import ZoeDepthImageProcessor
try:
if not is_torchvision_available():
@@ -7798,6 +7808,10 @@
YosoModel,
YosoPreTrainedModel,
)
+ from .models.zoedepth import (
+ ZoeDepthForDepthEstimation,
+ ZoeDepthPreTrainedModel,
+ )
# Optimization
from .optimization import (
diff --git a/src/transformers/image_utils.py b/src/transformers/image_utils.py
index a5d8f6f872aabd..0a1a73f5c63e11 100644
--- a/src/transformers/image_utils.py
+++ b/src/transformers/image_utils.py
@@ -409,22 +409,22 @@ def validate_preprocess_arguments(
"""
if do_rescale and rescale_factor is None:
- raise ValueError("rescale_factor must be specified if do_rescale is True.")
+ raise ValueError("`rescale_factor` must be specified if `do_rescale` is `True`.")
if do_pad and size_divisibility is None:
# Here, size_divisor might be passed as the value of size
raise ValueError(
- "Depending on moel, size_divisibility, size_divisor, pad_size or size must be specified if do_pad is True."
+ "Depending on the model, `size_divisibility`, `size_divisor`, `pad_size` or `size` must be specified if `do_pad` is `True`."
)
if do_normalize and (image_mean is None or image_std is None):
- raise ValueError("image_mean and image_std must both be specified if do_normalize is True.")
+ raise ValueError("`image_mean` and `image_std` must both be specified if `do_normalize` is `True`.")
if do_center_crop and crop_size is None:
- raise ValueError("crop_size must be specified if do_center_crop is True.")
+ raise ValueError("`crop_size` must be specified if `do_center_crop` is `True`.")
if do_resize and (size is None or resample is None):
- raise ValueError("size and resample must be specified if do_resize is True.")
+ raise ValueError("`size` and `resample` must be specified if `do_resize` is `True`.")
# In the future we can add a TF implementation here when we have TF models.
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index f4c33491472833..043c02a8d3f5ca 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -263,4 +263,5 @@
xmod,
yolos,
yoso,
+ zoedepth,
)
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index 7f52b3dc280ac6..53d817ca9c02ce 100755
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -291,6 +291,7 @@
("xmod", "XmodConfig"),
("yolos", "YolosConfig"),
("yoso", "YosoConfig"),
+ ("zoedepth", "ZoeDepthConfig"),
]
)
@@ -588,6 +589,7 @@
("xmod", "X-MOD"),
("yolos", "YOLOS"),
("yoso", "YOSO"),
+ ("zoedepth", "ZoeDepth"),
]
)
diff --git a/src/transformers/models/auto/image_processing_auto.py b/src/transformers/models/auto/image_processing_auto.py
index efc2d4d998ccdd..8ad9a3034b64e0 100644
--- a/src/transformers/models/auto/image_processing_auto.py
+++ b/src/transformers/models/auto/image_processing_auto.py
@@ -142,6 +142,7 @@
("vitmatte", ("VitMatteImageProcessor",)),
("xclip", ("CLIPImageProcessor",)),
("yolos", ("YolosImageProcessor",)),
+ ("zoedepth", ("ZoeDepthImageProcessor",)),
]
)
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index f674b777fca7be..8c4cea1539d55e 100755
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -792,6 +792,7 @@
("depth_anything", "DepthAnythingForDepthEstimation"),
("dpt", "DPTForDepthEstimation"),
("glpn", "GLPNForDepthEstimation"),
+ ("zoedepth", "ZoeDepthForDepthEstimation"),
]
)
MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING_NAMES = OrderedDict(
diff --git a/src/transformers/models/beit/modeling_beit.py b/src/transformers/models/beit/modeling_beit.py
index 184ab558228620..58b28866646091 100755
--- a/src/transformers/models/beit/modeling_beit.py
+++ b/src/transformers/models/beit/modeling_beit.py
@@ -34,7 +34,7 @@
SemanticSegmenterOutput,
)
from ...modeling_utils import PreTrainedModel
-from ...pytorch_utils import find_pruneable_heads_and_indices, meshgrid, prune_linear_layer
+from ...pytorch_utils import find_pruneable_heads_and_indices, prune_linear_layer
from ...utils import (
add_code_sample_docstrings,
add_start_docstrings,
@@ -193,12 +193,6 @@ def forward(
interpolate_pos_encoding: bool = False,
) -> torch.Tensor:
_, _, height, width = pixel_values.shape
- if not interpolate_pos_encoding and (height != self.image_size[0] or width != self.image_size[1]):
- raise ValueError(
- f"Input image size ({height}*{width}) doesn't match model"
- f" ({self.image_size[0]}*{self.image_size[1]})."
- )
-
embeddings, (patch_height, patch_width) = self.patch_embeddings(
pixel_values, self.position_embeddings[:, 1:, :] if self.position_embeddings is not None else None
)
@@ -280,6 +274,7 @@ def forward(
class BeitSelfAttention(nn.Module):
def __init__(self, config: BeitConfig, window_size: Optional[tuple] = None) -> None:
super().__init__()
+ self.config = config
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
raise ValueError(
f"The hidden size {config.hidden_size,} is not a multiple of the number of attention "
@@ -313,6 +308,7 @@ def forward(
output_attentions: bool = False,
relative_position_bias: Optional["BeitRelativePositionBias"] = None,
interpolate_pos_encoding: bool = False,
+ resolution: Optional[Tuple[int]] = None,
) -> Union[Tuple[torch.Tensor], Tuple[torch.Tensor, torch.Tensor]]:
mixed_query_layer = self.query(hidden_states)
@@ -327,9 +323,11 @@ def forward(
# Add relative position bias if present.
if self.relative_position_bias is not None:
+ height, width = resolution
+ window_size = (height // self.config.patch_size, width // self.config.patch_size)
attention_scores = attention_scores + self.relative_position_bias(
- interpolate_pos_encoding, attention_scores.shape[2]
- ).unsqueeze(0)
+ window_size, interpolate_pos_encoding, dim_size=hidden_states.shape[1]
+ )
# Add shared relative position bias if provided.
if relative_position_bias is not None:
@@ -407,9 +405,10 @@ def forward(
output_attentions: bool = False,
relative_position_bias: Optional["BeitRelativePositionBias"] = None,
interpolate_pos_encoding: bool = False,
+ resolution: Optional[Tuple[int]] = None,
) -> Union[Tuple[torch.Tensor], Tuple[torch.Tensor, torch.Tensor]]:
self_outputs = self.attention(
- hidden_states, head_mask, output_attentions, relative_position_bias, interpolate_pos_encoding
+ hidden_states, head_mask, output_attentions, relative_position_bias, interpolate_pos_encoding, resolution
)
attention_output = self.output(self_outputs[0], hidden_states)
@@ -475,6 +474,7 @@ def forward(
output_attentions: bool = False,
relative_position_bias: Optional["BeitRelativePositionBias"] = None,
interpolate_pos_encoding: bool = False,
+ resolution: Optional[Tuple[int]] = None,
) -> Union[Tuple[torch.Tensor], Tuple[torch.Tensor, torch.Tensor]]:
self_attention_outputs = self.attention(
self.layernorm_before(hidden_states), # in BEiT, layernorm is applied before self-attention
@@ -482,6 +482,7 @@ def forward(
output_attentions=output_attentions,
relative_position_bias=relative_position_bias,
interpolate_pos_encoding=interpolate_pos_encoding,
+ resolution=resolution,
)
attention_output = self_attention_outputs[0]
outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
@@ -520,32 +521,71 @@ def __init__(self, config: BeitConfig, window_size: tuple) -> None:
) # 2*Wh-1 * 2*Ww-1, nH
# cls to token & token 2 cls & cls to cls
+ self.relative_position_indices = {}
+
+ def generate_relative_position_index(self, window_size: Tuple[int, int]) -> torch.Tensor:
+ """
+ This method creates the relative position index, modified to support arbitrary window sizes,
+ as introduced in [MiDaS v3.1](https://arxiv.org/abs/2307.14460).
+ """
+ num_relative_distance = (2 * window_size[0] - 1) * (2 * window_size[1] - 1) + 3
+ # cls to token & token 2 cls & cls to cls
# get pair-wise relative position index for each token inside the window
- coords_h = torch.arange(window_size[0])
- coords_w = torch.arange(window_size[1])
- coords = torch.stack(meshgrid([coords_h, coords_w], indexing="ij")) # 2, Wh, Ww
+ window_area = window_size[0] * window_size[1]
+ grid = torch.meshgrid(torch.arange(window_size[0]), torch.arange(window_size[1]), indexing="ij")
+ coords = torch.stack(grid) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += window_size[1] - 1
relative_coords[:, :, 0] *= 2 * window_size[1] - 1
- relative_position_index = torch.zeros(
- size=(window_size[0] * window_size[1] + 1,) * 2, dtype=relative_coords.dtype
- )
+ relative_position_index = torch.zeros(size=(window_area + 1,) * 2, dtype=relative_coords.dtype)
relative_position_index[1:, 1:] = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
- relative_position_index[0, 0:] = self.num_relative_distance - 3
- relative_position_index[0:, 0] = self.num_relative_distance - 2
- relative_position_index[0, 0] = self.num_relative_distance - 1
+ relative_position_index[0, 0:] = num_relative_distance - 3
+ relative_position_index[0:, 0] = num_relative_distance - 2
+ relative_position_index[0, 0] = num_relative_distance - 1
+ return relative_position_index
+
+ def forward(self, window_size, interpolate_pos_encoding: bool = False, dim_size=None) -> torch.Tensor:
+ """
+ Modification of timm.models.beit.py: Attention._get_rel_pos_bias to support arbitrary window sizes.
+ """
+ old_height = 2 * self.window_size[0] - 1
+ old_width = 2 * self.window_size[1] - 1
+
+ new_height = 2 * window_size[0] - 1
+ new_width = 2 * window_size[1] - 1
- self.register_buffer("relative_position_index", relative_position_index, persistent=False)
+ old_relative_position_bias_table = self.relative_position_bias_table
- def forward(self, interpolate_pos_encoding: bool = False, dim_size: Optional[int] = None) -> torch.Tensor:
- relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
- self.window_size[0] * self.window_size[1] + 1, self.window_size[0] * self.window_size[1] + 1, -1
- ) # Wh*Ww,Wh*Ww,nH
+ old_num_relative_distance = self.num_relative_distance
+ new_num_relative_distance = new_height * new_width + 3
+
+ old_sub_table = old_relative_position_bias_table[: old_num_relative_distance - 3]
+
+ old_sub_table = old_sub_table.reshape(1, old_width, old_height, -1).permute(0, 3, 1, 2)
+ new_sub_table = nn.functional.interpolate(
+ old_sub_table, size=(int(new_height), int(new_width)), mode="bilinear"
+ )
+ new_sub_table = new_sub_table.permute(0, 2, 3, 1).reshape(new_num_relative_distance - 3, -1)
+
+ new_relative_position_bias_table = torch.cat(
+ [new_sub_table, old_relative_position_bias_table[old_num_relative_distance - 3 :]]
+ )
+
+ key = window_size
+ if key not in self.relative_position_indices.keys():
+ self.relative_position_indices[key] = self.generate_relative_position_index(window_size)
+
+ relative_position_bias = new_relative_position_bias_table[self.relative_position_indices[key].view(-1)]
+ # patch_size*num_patches_height, patch_size*num_patches_width, num_attention_heads
+ relative_position_bias = relative_position_bias.view(
+ window_size[0] * window_size[1] + 1, window_size[0] * window_size[1] + 1, -1
+ )
+ # num_attention_heads, patch_size*num_patches_width, patch_size*num_patches_height
+ relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous()
- relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
if interpolate_pos_encoding:
relative_position_bias = nn.functional.interpolate(
relative_position_bias.unsqueeze(1),
@@ -554,7 +594,7 @@ def forward(self, interpolate_pos_encoding: bool = False, dim_size: Optional[int
align_corners=False,
).squeeze(1)
- return relative_position_bias
+ return relative_position_bias.unsqueeze(0)
class BeitEncoder(nn.Module):
@@ -587,6 +627,7 @@ def forward(
output_attentions: bool = False,
output_hidden_states: bool = False,
interpolate_pos_encoding: bool = False,
+ resolution: Optional[Tuple[int]] = None,
return_dict: bool = True,
) -> Union[tuple, BaseModelOutput]:
all_hidden_states = () if output_hidden_states else None
@@ -606,13 +647,22 @@ def forward(
output_attentions,
)
else:
+ height, width = resolution
+ window_size = (height // self.config.patch_size, width // self.config.patch_size)
relative_position_bias = (
- self.relative_position_bias(interpolate_pos_encoding, hidden_states.shape[1])
+ self.relative_position_bias(
+ window_size, interpolate_pos_encoding=interpolate_pos_encoding, dim_size=hidden_states.shape[1]
+ )
if self.relative_position_bias is not None
else None
)
layer_outputs = layer_module(
- hidden_states, layer_head_mask, output_attentions, relative_position_bias, interpolate_pos_encoding
+ hidden_states,
+ layer_head_mask,
+ output_attentions,
+ relative_position_bias,
+ interpolate_pos_encoding,
+ resolution,
)
hidden_states = layer_outputs[0]
@@ -643,6 +693,7 @@ class BeitPreTrainedModel(PreTrainedModel):
main_input_name = "pixel_values"
supports_gradient_checkpointing = True
_no_split_modules = ["BeitLayer"]
+ _keys_to_ignore_on_load_unexpected = [r".*relative_position_index.*"]
def _init_weights(self, module):
"""Initialize the weights"""
@@ -738,7 +789,7 @@ class PreTrainedModel
)
def forward(
self,
- pixel_values: Optional[torch.Tensor] = None,
+ pixel_values: torch.Tensor,
bool_masked_pos: Optional[torch.BoolTensor] = None,
head_mask: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
@@ -756,9 +807,6 @@ def forward(
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
- if pixel_values is None:
- raise ValueError("You have to specify pixel_values")
-
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
@@ -766,15 +814,17 @@ def forward(
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
- embedding_output, (patch_height, patch_width) = self.embeddings(
+ embedding_output, _ = self.embeddings(
pixel_values, bool_masked_pos=bool_masked_pos, interpolate_pos_encoding=interpolate_pos_encoding
)
+ resolution = pixel_values.shape[2:]
encoder_outputs = self.encoder(
embedding_output,
head_mask=head_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
+ resolution=resolution,
return_dict=return_dict,
interpolate_pos_encoding=interpolate_pos_encoding,
)
@@ -1477,9 +1527,14 @@ def forward(
batch_size = pixel_values.shape[0]
embedding_output, (patch_height, patch_width) = self.embeddings(pixel_values)
+ resolution = pixel_values.shape[2:]
outputs = self.encoder(
- embedding_output, output_hidden_states=True, output_attentions=output_attentions, return_dict=return_dict
+ embedding_output,
+ output_hidden_states=True,
+ output_attentions=output_attentions,
+ resolution=resolution,
+ return_dict=return_dict,
)
hidden_states = outputs.hidden_states if return_dict else outputs[1]
diff --git a/src/transformers/models/data2vec/modeling_data2vec_vision.py b/src/transformers/models/data2vec/modeling_data2vec_vision.py
index a79810d0c5bb57..fca47c524e5146 100644
--- a/src/transformers/models/data2vec/modeling_data2vec_vision.py
+++ b/src/transformers/models/data2vec/modeling_data2vec_vision.py
@@ -32,7 +32,7 @@
SemanticSegmenterOutput,
)
from ...modeling_utils import PreTrainedModel
-from ...pytorch_utils import find_pruneable_heads_and_indices, meshgrid, prune_linear_layer
+from ...pytorch_utils import find_pruneable_heads_and_indices, prune_linear_layer
from ...utils import (
add_code_sample_docstrings,
add_start_docstrings,
@@ -192,12 +192,6 @@ def forward(
interpolate_pos_encoding: bool = False,
) -> torch.Tensor:
_, _, height, width = pixel_values.shape
- if not interpolate_pos_encoding and (height != self.image_size[0] or width != self.image_size[1]):
- raise ValueError(
- f"Input image size ({height}*{width}) doesn't match model"
- f" ({self.image_size[0]}*{self.image_size[1]})."
- )
-
embeddings, (patch_height, patch_width) = self.patch_embeddings(
pixel_values, self.position_embeddings[:, 1:, :] if self.position_embeddings is not None else None
)
@@ -281,6 +275,7 @@ def forward(
class Data2VecVisionSelfAttention(nn.Module):
def __init__(self, config: Data2VecVisionConfig, window_size: Optional[tuple] = None) -> None:
super().__init__()
+ self.config = config
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
raise ValueError(
f"The hidden size {config.hidden_size,} is not a multiple of the number of attention "
@@ -314,6 +309,7 @@ def forward(
output_attentions: bool = False,
relative_position_bias: Optional["Data2VecVisionRelativePositionBias"] = None,
interpolate_pos_encoding: bool = False,
+ resolution: Optional[Tuple[int]] = None,
) -> Union[Tuple[torch.Tensor], Tuple[torch.Tensor, torch.Tensor]]:
mixed_query_layer = self.query(hidden_states)
@@ -328,9 +324,11 @@ def forward(
# Add relative position bias if present.
if self.relative_position_bias is not None:
+ height, width = resolution
+ window_size = (height // self.config.patch_size, width // self.config.patch_size)
attention_scores = attention_scores + self.relative_position_bias(
- interpolate_pos_encoding, attention_scores.shape[2]
- ).unsqueeze(0)
+ window_size, interpolate_pos_encoding, dim_size=hidden_states.shape[1]
+ )
# Add shared relative position bias if provided.
if relative_position_bias is not None:
@@ -410,9 +408,10 @@ def forward(
output_attentions: bool = False,
relative_position_bias: Optional["Data2VecVisionRelativePositionBias"] = None,
interpolate_pos_encoding: bool = False,
+ resolution: Optional[Tuple[int]] = None,
) -> Union[Tuple[torch.Tensor], Tuple[torch.Tensor, torch.Tensor]]:
self_outputs = self.attention(
- hidden_states, head_mask, output_attentions, relative_position_bias, interpolate_pos_encoding
+ hidden_states, head_mask, output_attentions, relative_position_bias, interpolate_pos_encoding, resolution
)
attention_output = self.output(self_outputs[0], hidden_states)
@@ -483,6 +482,7 @@ def forward(
output_attentions: bool = False,
relative_position_bias: Optional["Data2VecVisionRelativePositionBias"] = None,
interpolate_pos_encoding: bool = False,
+ resolution: Optional[Tuple[int]] = None,
) -> Union[Tuple[torch.Tensor], Tuple[torch.Tensor, torch.Tensor]]:
self_attention_outputs = self.attention(
self.layernorm_before(hidden_states), # in Data2VecVision, layernorm is applied before self-attention
@@ -490,6 +490,7 @@ def forward(
output_attentions=output_attentions,
relative_position_bias=relative_position_bias,
interpolate_pos_encoding=interpolate_pos_encoding,
+ resolution=resolution,
)
attention_output = self_attention_outputs[0]
outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
@@ -529,32 +530,71 @@ def __init__(self, config: Data2VecVisionConfig, window_size: tuple) -> None:
) # 2*Wh-1 * 2*Ww-1, nH
# cls to token & token 2 cls & cls to cls
+ self.relative_position_indices = {}
+
+ def generate_relative_position_index(self, window_size: Tuple[int, int]) -> torch.Tensor:
+ """
+ This method creates the relative position index, modified to support arbitrary window sizes,
+ as introduced in [MiDaS v3.1](https://arxiv.org/abs/2307.14460).
+ """
+ num_relative_distance = (2 * window_size[0] - 1) * (2 * window_size[1] - 1) + 3
+ # cls to token & token 2 cls & cls to cls
# get pair-wise relative position index for each token inside the window
- coords_h = torch.arange(window_size[0])
- coords_w = torch.arange(window_size[1])
- coords = torch.stack(meshgrid([coords_h, coords_w], indexing="ij")) # 2, Wh, Ww
+ window_area = window_size[0] * window_size[1]
+ grid = torch.meshgrid(torch.arange(window_size[0]), torch.arange(window_size[1]), indexing="ij")
+ coords = torch.stack(grid) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += window_size[1] - 1
relative_coords[:, :, 0] *= 2 * window_size[1] - 1
- relative_position_index = torch.zeros(
- size=(window_size[0] * window_size[1] + 1,) * 2, dtype=relative_coords.dtype
- )
+ relative_position_index = torch.zeros(size=(window_area + 1,) * 2, dtype=relative_coords.dtype)
relative_position_index[1:, 1:] = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
- relative_position_index[0, 0:] = self.num_relative_distance - 3
- relative_position_index[0:, 0] = self.num_relative_distance - 2
- relative_position_index[0, 0] = self.num_relative_distance - 1
+ relative_position_index[0, 0:] = num_relative_distance - 3
+ relative_position_index[0:, 0] = num_relative_distance - 2
+ relative_position_index[0, 0] = num_relative_distance - 1
+ return relative_position_index
+
+ def forward(self, window_size, interpolate_pos_encoding: bool = False, dim_size=None) -> torch.Tensor:
+ """
+ Modification of timm.models.beit.py: Attention._get_rel_pos_bias to support arbitrary window sizes.
+ """
+ old_height = 2 * self.window_size[0] - 1
+ old_width = 2 * self.window_size[1] - 1
+
+ new_height = 2 * window_size[0] - 1
+ new_width = 2 * window_size[1] - 1
- self.register_buffer("relative_position_index", relative_position_index, persistent=False)
+ old_relative_position_bias_table = self.relative_position_bias_table
- def forward(self, interpolate_pos_encoding: bool = False, dim_size: Optional[int] = None) -> torch.Tensor:
- relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
- self.window_size[0] * self.window_size[1] + 1, self.window_size[0] * self.window_size[1] + 1, -1
- ) # Wh*Ww,Wh*Ww,nH
+ old_num_relative_distance = self.num_relative_distance
+ new_num_relative_distance = new_height * new_width + 3
+
+ old_sub_table = old_relative_position_bias_table[: old_num_relative_distance - 3]
+
+ old_sub_table = old_sub_table.reshape(1, old_width, old_height, -1).permute(0, 3, 1, 2)
+ new_sub_table = nn.functional.interpolate(
+ old_sub_table, size=(int(new_height), int(new_width)), mode="bilinear"
+ )
+ new_sub_table = new_sub_table.permute(0, 2, 3, 1).reshape(new_num_relative_distance - 3, -1)
+
+ new_relative_position_bias_table = torch.cat(
+ [new_sub_table, old_relative_position_bias_table[old_num_relative_distance - 3 :]]
+ )
+
+ key = window_size
+ if key not in self.relative_position_indices.keys():
+ self.relative_position_indices[key] = self.generate_relative_position_index(window_size)
+
+ relative_position_bias = new_relative_position_bias_table[self.relative_position_indices[key].view(-1)]
+ # patch_size*num_patches_height, patch_size*num_patches_width, num_attention_heads
+ relative_position_bias = relative_position_bias.view(
+ window_size[0] * window_size[1] + 1, window_size[0] * window_size[1] + 1, -1
+ )
+ # num_attention_heads, patch_size*num_patches_width, patch_size*num_patches_height
+ relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous()
- relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
if interpolate_pos_encoding:
relative_position_bias = nn.functional.interpolate(
relative_position_bias.unsqueeze(1),
@@ -563,7 +603,7 @@ def forward(self, interpolate_pos_encoding: bool = False, dim_size: Optional[int
align_corners=False,
).squeeze(1)
- return relative_position_bias
+ return relative_position_bias.unsqueeze(0)
# Copied from transformers.models.beit.modeling_beit.BeitEncoder with Beit->Data2VecVision
@@ -597,6 +637,7 @@ def forward(
output_attentions: bool = False,
output_hidden_states: bool = False,
interpolate_pos_encoding: bool = False,
+ resolution: Optional[Tuple[int]] = None,
return_dict: bool = True,
) -> Union[tuple, BaseModelOutput]:
all_hidden_states = () if output_hidden_states else None
@@ -616,13 +657,22 @@ def forward(
output_attentions,
)
else:
+ height, width = resolution
+ window_size = (height // self.config.patch_size, width // self.config.patch_size)
relative_position_bias = (
- self.relative_position_bias(interpolate_pos_encoding, hidden_states.shape[1])
+ self.relative_position_bias(
+ window_size, interpolate_pos_encoding=interpolate_pos_encoding, dim_size=hidden_states.shape[1]
+ )
if self.relative_position_bias is not None
else None
)
layer_outputs = layer_module(
- hidden_states, layer_head_mask, output_attentions, relative_position_bias, interpolate_pos_encoding
+ hidden_states,
+ layer_head_mask,
+ output_attentions,
+ relative_position_bias,
+ interpolate_pos_encoding,
+ resolution,
)
hidden_states = layer_outputs[0]
@@ -654,6 +704,7 @@ class Data2VecVisionPreTrainedModel(PreTrainedModel):
main_input_name = "pixel_values"
supports_gradient_checkpointing = True
_no_split_modules = ["Data2VecVisionLayer"]
+ _keys_to_ignore_on_load_unexpected = [r".*relative_position_index.*"]
def _init_weights(self, module):
"""Initialize the weights"""
@@ -750,7 +801,7 @@ class PreTrainedModel
)
def forward(
self,
- pixel_values: Optional[torch.Tensor] = None,
+ pixel_values: torch.Tensor,
bool_masked_pos: Optional[torch.BoolTensor] = None,
head_mask: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
@@ -768,9 +819,6 @@ def forward(
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
- if pixel_values is None:
- raise ValueError("You have to specify pixel_values")
-
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
@@ -778,15 +826,17 @@ def forward(
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
- embedding_output, (patch_height, patch_width) = self.embeddings(
+ embedding_output, _ = self.embeddings(
pixel_values, bool_masked_pos=bool_masked_pos, interpolate_pos_encoding=interpolate_pos_encoding
)
+ resolution = pixel_values.shape[2:]
encoder_outputs = self.encoder(
embedding_output,
head_mask=head_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
+ resolution=resolution,
return_dict=return_dict,
interpolate_pos_encoding=interpolate_pos_encoding,
)
diff --git a/src/transformers/models/dpt/image_processing_dpt.py b/src/transformers/models/dpt/image_processing_dpt.py
index 96f43a796e3886..a4e3da1528ec0b 100644
--- a/src/transformers/models/dpt/image_processing_dpt.py
+++ b/src/transformers/models/dpt/image_processing_dpt.py
@@ -58,7 +58,7 @@ def get_resize_output_image_size(
multiple: int,
input_data_format: Optional[Union[str, ChannelDimension]] = None,
) -> Tuple[int, int]:
- def constraint_to_multiple_of(val, multiple, min_val=0, max_val=None):
+ def constrain_to_multiple_of(val, multiple, min_val=0, max_val=None):
x = round(val / multiple) * multiple
if max_val is not None and x > max_val:
@@ -87,8 +87,8 @@ def constraint_to_multiple_of(val, multiple, min_val=0, max_val=None):
# fit height
scale_width = scale_height
- new_height = constraint_to_multiple_of(scale_height * input_height, multiple=multiple)
- new_width = constraint_to_multiple_of(scale_width * input_width, multiple=multiple)
+ new_height = constrain_to_multiple_of(scale_height * input_height, multiple=multiple)
+ new_width = constrain_to_multiple_of(scale_width * input_width, multiple=multiple)
return (new_height, new_width)
diff --git a/src/transformers/models/dpt/modeling_dpt.py b/src/transformers/models/dpt/modeling_dpt.py
index db5db0eae1189b..b2b88855669a76 100755
--- a/src/transformers/models/dpt/modeling_dpt.py
+++ b/src/transformers/models/dpt/modeling_dpt.py
@@ -1021,7 +1021,7 @@ def forward(self, hidden_states: List[torch.Tensor], patch_height=None, patch_wi
class DPTDepthEstimationHead(nn.Module):
"""
- Output head head consisting of 3 convolutional layers. It progressively halves the feature dimension and upsamples
+ Output head consisting of 3 convolutional layers. It progressively halves the feature dimension and upsamples
the predictions to the input resolution after the first convolutional layer (details can be found in the paper's
supplementary material).
"""
diff --git a/src/transformers/models/zoedepth/__init__.py b/src/transformers/models/zoedepth/__init__.py
new file mode 100644
index 00000000000000..15ba0883d83241
--- /dev/null
+++ b/src/transformers/models/zoedepth/__init__.py
@@ -0,0 +1,67 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...file_utils import _LazyModule, is_torch_available, is_vision_available
+from ...utils import OptionalDependencyNotAvailable
+
+
+_import_structure = {"configuration_zoedepth": ["ZOEDEPTH_PRETRAINED_CONFIG_ARCHIVE_MAP", "ZoeDepthConfig"]}
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["modeling_zoedepth"] = [
+ "ZoeDepthForDepthEstimation",
+ "ZoeDepthPreTrainedModel",
+ ]
+
+try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["image_processing_zoedepth"] = ["ZoeDepthImageProcessor"]
+
+
+if TYPE_CHECKING:
+ from .configuration_zoedepth import ZOEDEPTH_PRETRAINED_CONFIG_ARCHIVE_MAP, ZoeDepthConfig
+
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .modeling_zoedepth import (
+ ZoeDepthForDepthEstimation,
+ ZoeDepthPreTrainedModel,
+ )
+
+ try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .image_processing_zoedepth import ZoeDepthImageProcessor
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
diff --git a/src/transformers/models/zoedepth/configuration_zoedepth.py b/src/transformers/models/zoedepth/configuration_zoedepth.py
new file mode 100644
index 00000000000000..1b7e2695eb98c9
--- /dev/null
+++ b/src/transformers/models/zoedepth/configuration_zoedepth.py
@@ -0,0 +1,234 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""ZoeDepth model configuration"""
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+from ..auto.configuration_auto import CONFIG_MAPPING
+
+
+logger = logging.get_logger(__name__)
+
+ZOEDEPTH_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "Intel/zoedepth-nyu": "https://huggingface.co/Intel/zoedepth-nyu/resolve/main/config.json",
+}
+
+
+class ZoeDepthConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`ZoeDepthForDepthEstimation`]. It is used to instantiate an ZoeDepth
+ model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
+ defaults will yield a similar configuration to that of the ZoeDepth
+ [Intel/zoedepth-nyu](https://huggingface.co/Intel/zoedepth-nyu) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ backbone_config (`Union[Dict[str, Any], PretrainedConfig]`, *optional*, defaults to `BeitConfig()`):
+ The configuration of the backbone model.
+ backbone (`str`, *optional*):
+ Name of backbone to use when `backbone_config` is `None`. If `use_pretrained_backbone` is `True`, this
+ will load the corresponding pretrained weights from the timm or transformers library. If `use_pretrained_backbone`
+ is `False`, this loads the backbone's config and uses that to initialize the backbone with random weights.
+ use_pretrained_backbone (`bool`, *optional*, defaults to `False`):
+ Whether to use pretrained weights for the backbone.
+ backbone_kwargs (`dict`, *optional*):
+ Keyword arguments to be passed to AutoBackbone when loading from a checkpoint
+ e.g. `{'out_indices': (0, 1, 2, 3)}`. Cannot be specified if `backbone_config` is set.
+ hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"selu"` and `"gelu_new"` are supported.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ batch_norm_eps (`float`, *optional*, defaults to 1e-05):
+ The epsilon used by the batch normalization layers.
+ readout_type (`str`, *optional*, defaults to `"project"`):
+ The readout type to use when processing the readout token (CLS token) of the intermediate hidden states of
+ the ViT backbone. Can be one of [`"ignore"`, `"add"`, `"project"`].
+
+ - "ignore" simply ignores the CLS token.
+ - "add" passes the information from the CLS token to all other tokens by adding the representations.
+ - "project" passes information to the other tokens by concatenating the readout to all other tokens before
+ projecting the
+ representation to the original feature dimension D using a linear layer followed by a GELU non-linearity.
+ reassemble_factors (`List[int]`, *optional*, defaults to `[4, 2, 1, 0.5]`):
+ The up/downsampling factors of the reassemble layers.
+ neck_hidden_sizes (`List[str]`, *optional*, defaults to `[96, 192, 384, 768]`):
+ The hidden sizes to project to for the feature maps of the backbone.
+ fusion_hidden_size (`int`, *optional*, defaults to 256):
+ The number of channels before fusion.
+ head_in_index (`int`, *optional*, defaults to -1):
+ The index of the features to use in the heads.
+ use_batch_norm_in_fusion_residual (`bool`, *optional*, defaults to `False`):
+ Whether to use batch normalization in the pre-activate residual units of the fusion blocks.
+ use_bias_in_fusion_residual (`bool`, *optional*, defaults to `True`):
+ Whether to use bias in the pre-activate residual units of the fusion blocks.
+ num_relative_features (`int`, *optional*, defaults to 32):
+ The number of features to use in the relative depth estimation head.
+ add_projection (`bool`, *optional*, defaults to `False`):
+ Whether to add a projection layer before the depth estimation head.
+ bottleneck_features (`int`, *optional*, defaults to 256):
+ The number of features in the bottleneck layer.
+ num_attractors (`List[int], *optional*, defaults to `[16, 8, 4, 1]`):
+ The number of attractors to use in each stage.
+ bin_embedding_dim (`int`, *optional*, defaults to 128):
+ The dimension of the bin embeddings.
+ attractor_alpha (`int`, *optional*, defaults to 1000):
+ The alpha value to use in the attractor.
+ attractor_gamma (`int`, *optional*, defaults to 2):
+ The gamma value to use in the attractor.
+ attractor_kind (`str`, *optional*, defaults to `"mean"`):
+ The kind of attractor to use. Can be one of [`"mean"`, `"sum"`].
+ min_temp (`float`, *optional*, defaults to 0.0212):
+ The minimum temperature value to consider.
+ max_temp (`float`, *optional*, defaults to 50.0):
+ The maximum temperature value to consider.
+ bin_centers_type (`str`, *optional*, defaults to `"softplus"`):
+ Activation type used for bin centers. Can be "normed" or "softplus". For "normed" bin centers, linear normalization trick
+ is applied. This results in bounded bin centers. For "softplus", softplus activation is used and thus are unbounded.
+ bin_configurations (`List[dict]`, *optional*, defaults to `[{'n_bins': 64, 'min_depth': 0.001, 'max_depth': 10.0}]`):
+ Configuration for each of the bin heads.
+ Each configuration should consist of the following keys:
+ - name (`str`): The name of the bin head - only required in case of multiple bin configurations.
+ - `n_bins` (`int`): The number of bins to use.
+ - `min_depth` (`float`): The minimum depth value to consider.
+ - `max_depth` (`float`): The maximum depth value to consider.
+ In case only a single configuration is passed, the model will use a single head with the specified configuration.
+ In case multiple configurations are passed, the model will use multiple heads with the specified configurations.
+ num_patch_transformer_layers (`int`, *optional*):
+ The number of transformer layers to use in the patch transformer. Only used in case of multiple bin configurations.
+ patch_transformer_hidden_size (`int`, *optional*):
+ The hidden size to use in the patch transformer. Only used in case of multiple bin configurations.
+ patch_transformer_intermediate_size (`int`, *optional*):
+ The intermediate size to use in the patch transformer. Only used in case of multiple bin configurations.
+ patch_transformer_num_attention_heads (`int`, *optional*):
+ The number of attention heads to use in the patch transformer. Only used in case of multiple bin configurations.
+
+ Example:
+
+ ```python
+ >>> from transformers import ZoeDepthConfig, ZoeDepthForDepthEstimation
+
+ >>> # Initializing a ZoeDepth zoedepth-large style configuration
+ >>> configuration = ZoeDepthConfig()
+
+ >>> # Initializing a model from the zoedepth-large style configuration
+ >>> model = ZoeDepthForDepthEstimation(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = "zoedepth"
+
+ def __init__(
+ self,
+ backbone_config=None,
+ backbone=None,
+ use_pretrained_backbone=False,
+ backbone_kwargs=None,
+ hidden_act="gelu",
+ initializer_range=0.02,
+ batch_norm_eps=1e-05,
+ readout_type="project",
+ reassemble_factors=[4, 2, 1, 0.5],
+ neck_hidden_sizes=[96, 192, 384, 768],
+ fusion_hidden_size=256,
+ head_in_index=-1,
+ use_batch_norm_in_fusion_residual=False,
+ use_bias_in_fusion_residual=None,
+ num_relative_features=32,
+ add_projection=False,
+ bottleneck_features=256,
+ num_attractors=[16, 8, 4, 1],
+ bin_embedding_dim=128,
+ attractor_alpha=1000,
+ attractor_gamma=2,
+ attractor_kind="mean",
+ min_temp=0.0212,
+ max_temp=50.0,
+ bin_centers_type="softplus",
+ bin_configurations=[{"n_bins": 64, "min_depth": 0.001, "max_depth": 10.0}],
+ num_patch_transformer_layers=None,
+ patch_transformer_hidden_size=None,
+ patch_transformer_intermediate_size=None,
+ patch_transformer_num_attention_heads=None,
+ **kwargs,
+ ):
+ super().__init__(**kwargs)
+
+ if readout_type not in ["ignore", "add", "project"]:
+ raise ValueError("Readout_type must be one of ['ignore', 'add', 'project']")
+
+ if attractor_kind not in ["mean", "sum"]:
+ raise ValueError("Attractor_kind must be one of ['mean', 'sum']")
+
+ if use_pretrained_backbone:
+ raise ValueError("Pretrained backbones are not supported yet.")
+
+ if backbone_config is not None and backbone is not None:
+ raise ValueError("You can't specify both `backbone` and `backbone_config`.")
+
+ if backbone_config is None and backbone is None:
+ logger.info("`backbone_config` is `None`. Initializing the config with the default `BEiT` backbone.")
+ backbone_config = CONFIG_MAPPING["beit"](
+ image_size=384,
+ num_hidden_layers=24,
+ hidden_size=1024,
+ intermediate_size=4096,
+ num_attention_heads=16,
+ use_relative_position_bias=True,
+ reshape_hidden_states=False,
+ out_features=["stage6", "stage12", "stage18", "stage24"],
+ )
+ elif isinstance(backbone_config, dict):
+ backbone_model_type = backbone_config.get("model_type")
+ config_class = CONFIG_MAPPING[backbone_model_type]
+ backbone_config = config_class.from_dict(backbone_config)
+
+ if backbone_kwargs is not None and backbone_kwargs and backbone_config is not None:
+ raise ValueError("You can't specify both `backbone_kwargs` and `backbone_config`.")
+
+ self.backbone_config = backbone_config
+ self.backbone = backbone
+ self.hidden_act = hidden_act
+ self.use_pretrained_backbone = use_pretrained_backbone
+ self.initializer_range = initializer_range
+ self.batch_norm_eps = batch_norm_eps
+ self.readout_type = readout_type
+ self.reassemble_factors = reassemble_factors
+ self.neck_hidden_sizes = neck_hidden_sizes
+ self.fusion_hidden_size = fusion_hidden_size
+ self.head_in_index = head_in_index
+ self.use_batch_norm_in_fusion_residual = use_batch_norm_in_fusion_residual
+ self.use_bias_in_fusion_residual = use_bias_in_fusion_residual
+ self.num_relative_features = num_relative_features
+ self.add_projection = add_projection
+
+ self.bottleneck_features = bottleneck_features
+ self.num_attractors = num_attractors
+ self.bin_embedding_dim = bin_embedding_dim
+ self.attractor_alpha = attractor_alpha
+ self.attractor_gamma = attractor_gamma
+ self.attractor_kind = attractor_kind
+ self.min_temp = min_temp
+ self.max_temp = max_temp
+ self.bin_centers_type = bin_centers_type
+ self.bin_configurations = bin_configurations
+ self.num_patch_transformer_layers = num_patch_transformer_layers
+ self.patch_transformer_hidden_size = patch_transformer_hidden_size
+ self.patch_transformer_intermediate_size = patch_transformer_intermediate_size
+ self.patch_transformer_num_attention_heads = patch_transformer_num_attention_heads
diff --git a/src/transformers/models/zoedepth/convert_zoedepth_to_hf.py b/src/transformers/models/zoedepth/convert_zoedepth_to_hf.py
new file mode 100644
index 00000000000000..9a6701c35bcdf9
--- /dev/null
+++ b/src/transformers/models/zoedepth/convert_zoedepth_to_hf.py
@@ -0,0 +1,426 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Convert ZoeDepth checkpoints from the original repository. URL: https://github.com/isl-org/ZoeDepth.
+
+Original logits where obtained by running the following code:
+!git clone -b understanding_zoedepth https://github.com/NielsRogge/ZoeDepth
+!python inference.py
+"""
+
+import argparse
+from pathlib import Path
+
+import torch
+from huggingface_hub import hf_hub_download
+from PIL import Image
+
+from transformers import BeitConfig, ZoeDepthConfig, ZoeDepthForDepthEstimation, ZoeDepthImageProcessor
+from transformers.utils import logging
+
+
+logging.set_verbosity_info()
+logger = logging.get_logger(__name__)
+
+
+def get_zoedepth_config(model_name):
+ image_size = 384
+ backbone_config = BeitConfig(
+ image_size=image_size,
+ num_hidden_layers=24,
+ hidden_size=1024,
+ intermediate_size=4096,
+ num_attention_heads=16,
+ use_relative_position_bias=True,
+ reshape_hidden_states=False,
+ out_features=["stage6", "stage12", "stage18", "stage24"], # beit-large-512 uses [5, 11, 17, 23],
+ )
+
+ neck_hidden_sizes = [256, 512, 1024, 1024]
+ bin_centers_type = "softplus" if model_name in ["ZoeD_N", "ZoeD_NK"] else "normed"
+ if model_name == "ZoeD_NK":
+ bin_configurations = [
+ {"name": "nyu", "n_bins": 64, "min_depth": 1e-3, "max_depth": 10.0},
+ {"name": "kitti", "n_bins": 64, "min_depth": 1e-3, "max_depth": 80.0},
+ ]
+ elif model_name in ["ZoeD_N", "ZoeD_K"]:
+ bin_configurations = [
+ {"name": "nyu", "n_bins": 64, "min_depth": 1e-3, "max_depth": 10.0},
+ ]
+ config = ZoeDepthConfig(
+ backbone_config=backbone_config,
+ neck_hidden_sizes=neck_hidden_sizes,
+ bin_centers_type=bin_centers_type,
+ bin_configurations=bin_configurations,
+ num_patch_transformer_layers=4 if model_name == "ZoeD_NK" else None,
+ patch_transformer_hidden_size=128 if model_name == "ZoeD_NK" else None,
+ patch_transformer_intermediate_size=1024 if model_name == "ZoeD_NK" else None,
+ patch_transformer_num_attention_heads=4 if model_name == "ZoeD_NK" else None,
+ )
+
+ return config, image_size
+
+
+def rename_key(name):
+ # Transformer backbone
+ if "core.core.pretrained.model.blocks" in name:
+ name = name.replace("core.core.pretrained.model.blocks", "backbone.encoder.layer")
+ if "core.core.pretrained.model.patch_embed.proj" in name:
+ name = name.replace(
+ "core.core.pretrained.model.patch_embed.proj", "backbone.embeddings.patch_embeddings.projection"
+ )
+ if "core.core.pretrained.model.cls_token" in name:
+ name = name.replace("core.core.pretrained.model.cls_token", "backbone.embeddings.cls_token")
+ if "norm1" in name and "patch_transformer" not in name:
+ name = name.replace("norm1", "layernorm_before")
+ if "norm2" in name and "patch_transformer" not in name:
+ name = name.replace("norm2", "layernorm_after")
+ if "mlp.fc1" in name:
+ name = name.replace("mlp.fc1", "intermediate.dense")
+ if "mlp.fc2" in name:
+ name = name.replace("mlp.fc2", "output.dense")
+ if "gamma_1" in name:
+ name = name.replace("gamma_1", "lambda_1")
+ if "gamma_2" in name:
+ name = name.replace("gamma_2", "lambda_2")
+ if "attn.proj" in name:
+ name = name.replace("attn.proj", "attention.output.dense")
+ if "attn.relative_position_bias_table" in name:
+ name = name.replace(
+ "attn.relative_position_bias_table",
+ "attention.attention.relative_position_bias.relative_position_bias_table",
+ )
+ if "attn.relative_position_index" in name:
+ name = name.replace(
+ "attn.relative_position_index", "attention.attention.relative_position_bias.relative_position_index"
+ )
+
+ # activation postprocessing (readout projections + resize blocks)
+ if "core.core.pretrained.act_postprocess1.0.project" in name:
+ name = name.replace(
+ "core.core.pretrained.act_postprocess1.0.project", "neck.reassemble_stage.readout_projects.0"
+ )
+ if "core.core.pretrained.act_postprocess2.0.project" in name:
+ name = name.replace(
+ "core.core.pretrained.act_postprocess2.0.project", "neck.reassemble_stage.readout_projects.1"
+ )
+ if "core.core.pretrained.act_postprocess3.0.project" in name:
+ name = name.replace(
+ "core.core.pretrained.act_postprocess3.0.project", "neck.reassemble_stage.readout_projects.2"
+ )
+ if "core.core.pretrained.act_postprocess4.0.project" in name:
+ name = name.replace(
+ "core.core.pretrained.act_postprocess4.0.project", "neck.reassemble_stage.readout_projects.3"
+ )
+
+ if "core.core.pretrained.act_postprocess1.3" in name:
+ name = name.replace("core.core.pretrained.act_postprocess1.3", "neck.reassemble_stage.layers.0.projection")
+ if "core.core.pretrained.act_postprocess2.3" in name:
+ name = name.replace("core.core.pretrained.act_postprocess2.3", "neck.reassemble_stage.layers.1.projection")
+ if "core.core.pretrained.act_postprocess3.3" in name:
+ name = name.replace("core.core.pretrained.act_postprocess3.3", "neck.reassemble_stage.layers.2.projection")
+ if "core.core.pretrained.act_postprocess4.3" in name:
+ name = name.replace("core.core.pretrained.act_postprocess4.3", "neck.reassemble_stage.layers.3.projection")
+
+ if "core.core.pretrained.act_postprocess1.4" in name:
+ name = name.replace("core.core.pretrained.act_postprocess1.4", "neck.reassemble_stage.layers.0.resize")
+ if "core.core.pretrained.act_postprocess2.4" in name:
+ name = name.replace("core.core.pretrained.act_postprocess2.4", "neck.reassemble_stage.layers.1.resize")
+ if "core.core.pretrained.act_postprocess4.4" in name:
+ name = name.replace("core.core.pretrained.act_postprocess4.4", "neck.reassemble_stage.layers.3.resize")
+
+ # scratch convolutions
+ if "core.core.scratch.layer1_rn.weight" in name:
+ name = name.replace("core.core.scratch.layer1_rn.weight", "neck.convs.0.weight")
+ if "core.core.scratch.layer2_rn.weight" in name:
+ name = name.replace("core.core.scratch.layer2_rn.weight", "neck.convs.1.weight")
+ if "core.core.scratch.layer3_rn.weight" in name:
+ name = name.replace("core.core.scratch.layer3_rn.weight", "neck.convs.2.weight")
+ if "core.core.scratch.layer4_rn.weight" in name:
+ name = name.replace("core.core.scratch.layer4_rn.weight", "neck.convs.3.weight")
+
+ # fusion layers
+ # tricky here: mapping = {1:3, 2:2, 3:1, 4:0}
+ if "core.core.scratch.refinenet1" in name:
+ name = name.replace("core.core.scratch.refinenet1", "neck.fusion_stage.layers.3")
+ if "core.core.scratch.refinenet2" in name:
+ name = name.replace("core.core.scratch.refinenet2", "neck.fusion_stage.layers.2")
+ if "core.core.scratch.refinenet3" in name:
+ name = name.replace("core.core.scratch.refinenet3", "neck.fusion_stage.layers.1")
+ if "core.core.scratch.refinenet4" in name:
+ name = name.replace("core.core.scratch.refinenet4", "neck.fusion_stage.layers.0")
+
+ if "resConfUnit1" in name:
+ name = name.replace("resConfUnit1", "residual_layer1")
+
+ if "resConfUnit2" in name:
+ name = name.replace("resConfUnit2", "residual_layer2")
+
+ if "conv1" in name:
+ name = name.replace("conv1", "convolution1")
+
+ if "conv2" in name and "residual_layer" in name:
+ name = name.replace("conv2", "convolution2")
+
+ if "out_conv" in name:
+ name = name.replace("out_conv", "projection")
+
+ # relative depth estimation head
+ if "core.core.scratch.output_conv.0" in name:
+ name = name.replace("core.core.scratch.output_conv.0", "relative_head.conv1")
+
+ if "core.core.scratch.output_conv.2" in name:
+ name = name.replace("core.core.scratch.output_conv.2", "relative_head.conv2")
+
+ if "core.core.scratch.output_conv.4" in name:
+ name = name.replace("core.core.scratch.output_conv.4", "relative_head.conv3")
+
+ # patch transformer
+ if "patch_transformer" in name:
+ name = name.replace("patch_transformer", "metric_head.patch_transformer")
+
+ if "mlp_classifier.0" in name:
+ name = name.replace("mlp_classifier.0", "metric_head.mlp_classifier.linear1")
+ if "mlp_classifier.2" in name:
+ name = name.replace("mlp_classifier.2", "metric_head.mlp_classifier.linear2")
+
+ if "projectors" in name:
+ name = name.replace("projectors", "metric_head.projectors")
+
+ if "seed_bin_regressors" in name:
+ name = name.replace("seed_bin_regressors", "metric_head.seed_bin_regressors")
+
+ if "seed_bin_regressor" in name and "seed_bin_regressors" not in name:
+ name = name.replace("seed_bin_regressor", "metric_head.seed_bin_regressor")
+
+ if "seed_projector" in name:
+ name = name.replace("seed_projector", "metric_head.seed_projector")
+
+ if "_net.0" in name:
+ name = name.replace("_net.0", "conv1")
+
+ if "_net.2" in name:
+ name = name.replace("_net.2", "conv2")
+
+ if "attractors" in name:
+ name = name.replace("attractors", "metric_head.attractors")
+
+ if "conditional_log_binomial" in name:
+ name = name.replace("conditional_log_binomial", "metric_head.conditional_log_binomial")
+
+ # metric depth estimation head
+ if "conv2" in name and "metric_head" not in name and "attractors" not in name and "relative_head" not in name:
+ name = name.replace("conv2", "metric_head.conv2")
+
+ if "transformer_encoder.layers" in name:
+ name = name.replace("transformer_encoder.layers", "transformer_encoder")
+
+ return name
+
+
+def read_in_q_k_v_metric_head(state_dict):
+ hidden_size = 128
+ for i in range(4):
+ # read in weights + bias of input projection layer (in original implementation, this is a single matrix + bias)
+ in_proj_weight = state_dict.pop(f"patch_transformer.transformer_encoder.layers.{i}.self_attn.in_proj_weight")
+ in_proj_bias = state_dict.pop(f"patch_transformer.transformer_encoder.layers.{i}.self_attn.in_proj_bias")
+ # next, add query, keys and values (in that order) to the state dict
+ state_dict[f"patch_transformer.transformer_encoder.{i}.self_attn.query.weight"] = in_proj_weight[
+ :hidden_size, :
+ ]
+ state_dict[f"patch_transformer.transformer_encoder.{i}.self_attn.query.bias"] = in_proj_bias[:hidden_size]
+
+ state_dict[f"patch_transformer.transformer_encoder.{i}.self_attn.key.weight"] = in_proj_weight[
+ hidden_size : hidden_size * 2, :
+ ]
+ state_dict[f"patch_transformer.transformer_encoder.{i}.self_attn.key.bias"] = in_proj_bias[
+ hidden_size : hidden_size * 2
+ ]
+
+ state_dict[f"patch_transformer.transformer_encoder.{i}.self_attn.value.weight"] = in_proj_weight[
+ -hidden_size:, :
+ ]
+ state_dict[f"patch_transformer.transformer_encoder.{i}.self_attn.value.bias"] = in_proj_bias[-hidden_size:]
+
+
+def convert_state_dict(orig_state_dict):
+ for key in orig_state_dict.copy().keys():
+ val = orig_state_dict.pop(key)
+
+ # rename key
+ new_name = rename_key(key)
+ orig_state_dict[new_name] = val
+
+ return orig_state_dict
+
+
+def remove_ignore_keys(state_dict):
+ for key, _ in state_dict.copy().items():
+ if (
+ "fc_norm" in key
+ or "relative_position_index" in key
+ or "k_idx" in key
+ or "K_minus_1" in key
+ or "core.core.pretrained.model.head" in key
+ ):
+ state_dict.pop(key, None)
+
+
+# we split up the matrix of each encoder layer into queries, keys and values
+def read_in_q_k_v(state_dict, config):
+ hidden_size = config.backbone_config.hidden_size
+ for i in range(config.backbone_config.num_hidden_layers):
+ # read in weights + bias of input projection layer (in original implementation, this is a single matrix + bias)
+ in_proj_weight = state_dict.pop(f"core.core.pretrained.model.blocks.{i}.attn.qkv.weight")
+ q_bias = state_dict.pop(f"core.core.pretrained.model.blocks.{i}.attn.q_bias")
+ v_bias = state_dict.pop(f"core.core.pretrained.model.blocks.{i}.attn.v_bias")
+ # next, add query, keys and values (in that order) to the state dict
+ state_dict[f"backbone.encoder.layer.{i}.attention.attention.query.weight"] = in_proj_weight[:hidden_size, :]
+ state_dict[f"backbone.encoder.layer.{i}.attention.attention.query.bias"] = q_bias
+ state_dict[f"backbone.encoder.layer.{i}.attention.attention.key.weight"] = in_proj_weight[
+ hidden_size : hidden_size * 2, :
+ ]
+ state_dict[f"backbone.encoder.layer.{i}.attention.attention.value.weight"] = in_proj_weight[-hidden_size:, :]
+ state_dict[f"backbone.encoder.layer.{i}.attention.attention.value.bias"] = v_bias
+
+
+# We will verify our results on an image
+def prepare_img():
+ filepath = hf_hub_download(repo_id="shariqfarooq/ZoeDepth", filename="examples/person_1.jpeg", repo_type="space")
+ image = Image.open(filepath).convert("RGB")
+ return image
+
+
+@torch.no_grad()
+def convert_zoedepth_checkpoint(model_name, pytorch_dump_folder_path, push_to_hub):
+ """
+ Copy/paste/tweak model's weights to our ZoeDepth structure.
+ """
+
+ # define ZoeDepth configuration based on URL
+ config, _ = get_zoedepth_config(model_name)
+
+ # load original model
+ original_model = torch.hub.load(
+ "NielsRogge/ZoeDepth:understanding_zoedepth", model_name, pretrained=True, force_reload=True
+ )
+ original_model.eval()
+ state_dict = original_model.state_dict()
+
+ print("Original state dict:")
+ for name, param in state_dict.items():
+ print(name, param.shape)
+
+ # read in qkv matrices
+ read_in_q_k_v(state_dict, config)
+ if model_name == "ZoeD_NK":
+ read_in_q_k_v_metric_head(state_dict)
+
+ # rename keys
+ state_dict = convert_state_dict(state_dict)
+ # remove certain keys
+ remove_ignore_keys(state_dict)
+
+ # load HuggingFace model
+ model = ZoeDepthForDepthEstimation(config)
+ model.load_state_dict(state_dict)
+ model.eval()
+
+ # verify image processor
+ image = prepare_img()
+
+ image_processor = ZoeDepthImageProcessor()
+ pixel_values = image_processor(image, return_tensors="pt").pixel_values
+ filepath = hf_hub_download(
+ repo_id="nielsr/test-image",
+ filename="zoedepth_pixel_values.pt",
+ repo_type="dataset",
+ )
+ original_pixel_values = torch.load(filepath, map_location="cpu")
+ assert torch.allclose(pixel_values, original_pixel_values)
+
+ # verify logits
+ # this was done on a resized version of the cats image (384x384)
+ filepath = hf_hub_download(
+ repo_id="nielsr/test-image",
+ filename="zoedepth_pixel_values.pt",
+ repo_type="dataset",
+ revision="1865dbb81984f01c89e83eec10f8d07efd10743d",
+ )
+ cats_pixel_values = torch.load(filepath, map_location="cpu")
+ depth = model(cats_pixel_values).predicted_depth
+
+ # Verify logits
+ # These were obtained by inserting the pixel_values at the patch embeddings of BEiT
+ if model_name == "ZoeD_N":
+ expected_shape = torch.Size([1, 384, 384])
+ expected_slice = torch.tensor([[1.0328, 1.0604, 1.0747], [1.0816, 1.1293, 1.1456], [1.1117, 1.1629, 1.1766]])
+ elif model_name == "ZoeD_K":
+ expected_shape = torch.Size([1, 384, 384])
+ expected_slice = torch.tensor([[1.6567, 1.6852, 1.7065], [1.6707, 1.6764, 1.6713], [1.7195, 1.7166, 1.7118]])
+ elif model_name == "ZoeD_NK":
+ expected_shape = torch.Size([1, 384, 384])
+ expected_slice = torch.tensor([[1.1228, 1.1079, 1.1382], [1.1807, 1.1658, 1.1891], [1.2344, 1.2094, 1.2317]])
+
+ print("Shape of depth:", depth.shape)
+ print("First 3x3 slice of depth:", depth[0, :3, :3])
+
+ assert depth.shape == torch.Size(expected_shape)
+ assert torch.allclose(depth[0, :3, :3], expected_slice, atol=1e-4)
+ print("Looks ok!")
+
+ if pytorch_dump_folder_path is not None:
+ print(f"Saving model and processor to {pytorch_dump_folder_path}")
+ Path(pytorch_dump_folder_path).mkdir(exist_ok=True)
+ model.save_pretrained(pytorch_dump_folder_path)
+ image_processor.save_pretrained(pytorch_dump_folder_path)
+
+ if push_to_hub:
+ model_name_to_repo_id = {
+ "ZoeD_N": "zoedepth-nyu",
+ "ZoeD_K": "zoedepth-kitti",
+ "ZoeD_NK": "zoedepth-nyu-kitti",
+ }
+
+ print("Pushing model and processor to the hub...")
+ repo_id = model_name_to_repo_id[model_name]
+ model.push_to_hub(f"Intel/{repo_id}")
+ image_processor = ZoeDepthImageProcessor()
+ image_processor.push_to_hub(f"Intel/{repo_id}")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ # Required parameters
+ parser.add_argument(
+ "--model_name",
+ default="ZoeD_N",
+ choices=["ZoeD_N", "ZoeD_K", "ZoeD_NK"],
+ type=str,
+ help="Name of the original ZoeDepth checkpoint you'd like to convert.",
+ )
+ parser.add_argument(
+ "--pytorch_dump_folder_path",
+ default=None,
+ type=str,
+ required=False,
+ help="Path to the output PyTorch model directory.",
+ )
+ parser.add_argument(
+ "--push_to_hub",
+ action="store_true",
+ )
+
+ args = parser.parse_args()
+ convert_zoedepth_checkpoint(args.model_name, args.pytorch_dump_folder_path, args.push_to_hub)
diff --git a/src/transformers/models/zoedepth/image_processing_zoedepth.py b/src/transformers/models/zoedepth/image_processing_zoedepth.py
new file mode 100644
index 00000000000000..5276f2239151e8
--- /dev/null
+++ b/src/transformers/models/zoedepth/image_processing_zoedepth.py
@@ -0,0 +1,454 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Image processor class for ZoeDepth."""
+
+import math
+from typing import Dict, Iterable, List, Optional, Tuple, Union
+
+import numpy as np
+
+from ...image_processing_utils import BaseImageProcessor, BatchFeature, get_size_dict
+from ...image_transforms import PaddingMode, pad, to_channel_dimension_format
+from ...image_utils import (
+ IMAGENET_STANDARD_MEAN,
+ IMAGENET_STANDARD_STD,
+ ChannelDimension,
+ ImageInput,
+ PILImageResampling,
+ get_image_size,
+ infer_channel_dimension_format,
+ is_scaled_image,
+ make_list_of_images,
+ to_numpy_array,
+ valid_images,
+ validate_preprocess_arguments,
+)
+from ...utils import TensorType, is_torch_available, is_vision_available, logging, requires_backends
+
+
+if is_vision_available():
+ import PIL
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+
+logger = logging.get_logger(__name__)
+
+
+def get_resize_output_image_size(
+ input_image: np.ndarray,
+ output_size: Union[int, Iterable[int]],
+ keep_aspect_ratio: bool,
+ multiple: int,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+) -> Tuple[int, int]:
+ def constrain_to_multiple_of(val, multiple, min_val=0):
+ x = (np.round(val / multiple) * multiple).astype(int)
+
+ if x < min_val:
+ x = math.ceil(val / multiple) * multiple
+
+ return x
+
+ output_size = (output_size, output_size) if isinstance(output_size, int) else output_size
+
+ input_height, input_width = get_image_size(input_image, input_data_format)
+ output_height, output_width = output_size
+
+ # determine new height and width
+ scale_height = output_height / input_height
+ scale_width = output_width / input_width
+
+ if keep_aspect_ratio:
+ # scale as little as possible
+ if abs(1 - scale_width) < abs(1 - scale_height):
+ # fit width
+ scale_height = scale_width
+ else:
+ # fit height
+ scale_width = scale_height
+
+ new_height = constrain_to_multiple_of(scale_height * input_height, multiple=multiple)
+ new_width = constrain_to_multiple_of(scale_width * input_width, multiple=multiple)
+
+ return (new_height, new_width)
+
+
+class ZoeDepthImageProcessor(BaseImageProcessor):
+ r"""
+ Constructs a ZoeDepth image processor.
+
+ Args:
+ do_pad (`bool`, *optional*, defaults to `True`):
+ Whether to apply pad the input.
+ do_rescale (`bool`, *optional*, defaults to `True`):
+ Whether to rescale the image by the specified scale `rescale_factor`. Can be overidden by `do_rescale` in
+ `preprocess`.
+ rescale_factor (`int` or `float`, *optional*, defaults to `1/255`):
+ Scale factor to use if rescaling the image. Can be overidden by `rescale_factor` in `preprocess`.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether to normalize the image. Can be overridden by the `do_normalize` parameter in the `preprocess`
+ method.
+ image_mean (`float` or `List[float]`, *optional*, defaults to `IMAGENET_STANDARD_MEAN`):
+ Mean to use if normalizing the image. This is a float or list of floats the length of the number of
+ channels in the image. Can be overridden by the `image_mean` parameter in the `preprocess` method.
+ image_std (`float` or `List[float]`, *optional*, defaults to `IMAGENET_STANDARD_STD`):
+ Standard deviation to use if normalizing the image. This is a float or list of floats the length of the
+ number of channels in the image. Can be overridden by the `image_std` parameter in the `preprocess` method.
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Whether to resize the image's (height, width) dimensions. Can be overidden by `do_resize` in `preprocess`.
+ size (`Dict[str, int]` *optional*, defaults to `{"height": 384, "width": 512}`):
+ Size of the image after resizing. Size of the image after resizing. If `keep_aspect_ratio` is `True`,
+ the image is resized by choosing the smaller of the height and width scaling factors and using it for both dimensions.
+ If `ensure_multiple_of` is also set, the image is further resized to a size that is a multiple of this value.
+ Can be overidden by `size` in `preprocess`.
+ resample (`PILImageResampling`, *optional*, defaults to `Resampling.BILINEAR`):
+ Defines the resampling filter to use if resizing the image. Can be overidden by `resample` in `preprocess`.
+ keep_aspect_ratio (`bool`, *optional*, defaults to `True`):
+ If `True`, the image is resized by choosing the smaller of the height and width scaling factors and using it for
+ both dimensions. This ensures that the image is scaled down as little as possible while still fitting within the
+ desired output size. In case `ensure_multiple_of` is also set, the image is further resized to a size that is a
+ multiple of this value by flooring the height and width to the nearest multiple of this value.
+ Can be overidden by `keep_aspect_ratio` in `preprocess`.
+ ensure_multiple_of (`int`, *optional*, defaults to 32):
+ If `do_resize` is `True`, the image is resized to a size that is a multiple of this value. Works by flooring
+ the height and width to the nearest multiple of this value.
+
+ Works both with and without `keep_aspect_ratio` being set to `True`. Can be overidden by `ensure_multiple_of`
+ in `preprocess`.
+ """
+
+ model_input_names = ["pixel_values"]
+
+ def __init__(
+ self,
+ do_pad: bool = True,
+ do_rescale: bool = True,
+ rescale_factor: Union[int, float] = 1 / 255,
+ do_normalize: bool = True,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ do_resize: bool = True,
+ size: Dict[str, int] = None,
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ keep_aspect_ratio: bool = True,
+ ensure_multiple_of: int = 32,
+ **kwargs,
+ ) -> None:
+ super().__init__(**kwargs)
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_pad = do_pad
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean if image_mean is not None else IMAGENET_STANDARD_MEAN
+ self.image_std = image_std if image_std is not None else IMAGENET_STANDARD_STD
+ size = size if size is not None else {"height": 384, "width": 512}
+ size = get_size_dict(size)
+ self.do_resize = do_resize
+ self.size = size
+ self.keep_aspect_ratio = keep_aspect_ratio
+ self.ensure_multiple_of = ensure_multiple_of
+ self.resample = resample
+
+ self._valid_processor_keys = [
+ "images",
+ "do_resize",
+ "size",
+ "keep_aspect_ratio",
+ "ensure_multiple_of",
+ "resample",
+ "do_rescale",
+ "rescale_factor",
+ "do_normalize",
+ "image_mean",
+ "image_std",
+ "do_pad",
+ "return_tensors",
+ "data_format",
+ "input_data_format",
+ ]
+
+ def resize(
+ self,
+ image: np.ndarray,
+ size: Dict[str, int],
+ keep_aspect_ratio: bool = False,
+ ensure_multiple_of: int = 1,
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ data_format: Optional[Union[str, ChannelDimension]] = None,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ ) -> np.ndarray:
+ """
+ Resize an image to target size `(size["height"], size["width"])`. If `keep_aspect_ratio` is `True`, the image
+ is resized to the largest possible size such that the aspect ratio is preserved. If `ensure_multiple_of` is
+ set, the image is resized to a size that is a multiple of this value.
+
+ Args:
+ image (`np.ndarray`):
+ Image to resize.
+ size (`Dict[str, int]`):
+ Target size of the output image.
+ keep_aspect_ratio (`bool`, *optional*, defaults to `False`):
+ If `True`, the image is resized to the largest possible size such that the aspect ratio is preserved.
+ ensure_multiple_of (`int`, *optional*, defaults to 1):
+ The image is resized to a size that is a multiple of this value.
+ resample (`PILImageResampling`, *optional*, defaults to `PILImageResampling.BILINEAR`):
+ Defines the resampling filter to use if resizing the image. Otherwise, the image is resized to size
+ specified in `size`.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be the same as the input image.
+ input_data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format of the input image. If not provided, it will be inferred.
+ """
+ if input_data_format is None:
+ input_data_format = infer_channel_dimension_format(image)
+
+ data_format = data_format if data_format is not None else input_data_format
+
+ size = get_size_dict(size)
+ if "height" not in size or "width" not in size:
+ raise ValueError(f"The size dictionary must contain the keys 'height' and 'width'. Got {size.keys()}")
+
+ output_size = get_resize_output_image_size(
+ image,
+ output_size=(size["height"], size["width"]),
+ keep_aspect_ratio=keep_aspect_ratio,
+ multiple=ensure_multiple_of,
+ input_data_format=input_data_format,
+ )
+
+ height, width = output_size
+
+ torch_image = torch.from_numpy(image).unsqueeze(0)
+ torch_image = torch_image.permute(0, 3, 1, 2) if input_data_format == "channels_last" else torch_image
+
+ # TODO support align_corners=True in image_transforms.resize
+ requires_backends(self, "torch")
+ resample_to_mode = {PILImageResampling.BILINEAR: "bilinear", PILImageResampling.BICUBIC: "bicubic"}
+ mode = resample_to_mode[resample]
+ resized_image = nn.functional.interpolate(
+ torch_image, (int(height), int(width)), mode=mode, align_corners=True
+ )
+ resized_image = resized_image.squeeze().numpy()
+
+ resized_image = to_channel_dimension_format(
+ resized_image, data_format, input_channel_dim=ChannelDimension.FIRST
+ )
+
+ return resized_image
+
+ def pad_image(
+ self,
+ image: np.array,
+ mode: PaddingMode = PaddingMode.REFLECT,
+ data_format: Optional[Union[str, ChannelDimension]] = None,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ ):
+ """
+ Pad an image as done in the original ZoeDepth implementation.
+
+ Padding fixes the boundary artifacts in the output depth map.
+ Boundary artifacts are sometimes caused by the fact that the model is trained on NYU raw dataset
+ which has a black or white border around the image. This function pads the input image and crops
+ the prediction back to the original size / view.
+
+ Args:
+ image (`np.ndarray`):
+ Image to pad.
+ mode (`PaddingMode`):
+ The padding mode to use. Can be one of:
+ - `"constant"`: pads with a constant value.
+ - `"reflect"`: pads with the reflection of the vector mirrored on the first and last values of the
+ vector along each axis.
+ - `"replicate"`: pads with the replication of the last value on the edge of the array along each axis.
+ - `"symmetric"`: pads with the reflection of the vector mirrored along the edge of the array.
+ data_format (`ChannelDimension` or `str`, *optional*, defaults to `ChannelDimension.FIRST`):
+ The channel dimension format for the output image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - Unset: Use the channel dimension format of the input image.
+ input_data_format (`ChannelDimension` or `str`, *optional*):
+ The channel dimension format for the input image. If unset, the channel dimension format is inferred
+ from the input image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - `"none"` or `ChannelDimension.NONE`: image in (height, width) format.
+ """
+ height, width = get_image_size(image, input_data_format)
+
+ pad_height = int(np.sqrt(height / 2) * 3)
+ pad_width = int(np.sqrt(width / 2) * 3)
+
+ return pad(
+ image,
+ padding=((pad_height, pad_height), (pad_width, pad_width)),
+ mode=mode,
+ data_format=data_format,
+ input_data_format=input_data_format,
+ )
+
+ def preprocess(
+ self,
+ images: ImageInput,
+ do_pad: bool = None,
+ do_rescale: bool = None,
+ rescale_factor: float = None,
+ do_normalize: bool = None,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ do_resize: bool = None,
+ size: int = None,
+ keep_aspect_ratio: bool = None,
+ ensure_multiple_of: int = None,
+ resample: PILImageResampling = None,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ data_format: ChannelDimension = ChannelDimension.FIRST,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ ) -> PIL.Image.Image:
+ """
+ Preprocess an image or batch of images.
+
+ Args:
+ images (`ImageInput`):
+ Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If
+ passing in images with pixel values between 0 and 1, set `do_rescale=False`.
+ do_pad (`bool`, *optional*, defaults to `self.do_pad`):
+ Whether to pad the input image.
+ do_rescale (`bool`, *optional*, defaults to `self.do_rescale`):
+ Whether to rescale the image values between [0 - 1].
+ rescale_factor (`float`, *optional*, defaults to `self.rescale_factor`):
+ Rescale factor to rescale the image by if `do_rescale` is set to `True`.
+ do_normalize (`bool`, *optional*, defaults to `self.do_normalize`):
+ Whether to normalize the image.
+ image_mean (`float` or `List[float]`, *optional*, defaults to `self.image_mean`):
+ Image mean.
+ image_std (`float` or `List[float]`, *optional*, defaults to `self.image_std`):
+ Image standard deviation.
+ do_resize (`bool`, *optional*, defaults to `self.do_resize`):
+ Whether to resize the image.
+ size (`Dict[str, int]`, *optional*, defaults to `self.size`):
+ Size of the image after resizing. If `keep_aspect_ratio` is `True`, he image is resized by choosing the smaller of
+ the height and width scaling factors and using it for both dimensions. If `ensure_multiple_of` is also set,
+ the image is further resized to a size that is a multiple of this value.
+ keep_aspect_ratio (`bool`, *optional*, defaults to `self.keep_aspect_ratio`):
+ If `True` and `do_resize=True`, the image is resized by choosing the smaller of the height and width scaling factors and using it for
+ both dimensions. This ensures that the image is scaled down as little as possible while still fitting within the
+ desired output size. In case `ensure_multiple_of` is also set, the image is further resized to a size that is a
+ multiple of this value by flooring the height and width to the nearest multiple of this value.
+ ensure_multiple_of (`int`, *optional*, defaults to `self.ensure_multiple_of`):
+ If `do_resize` is `True`, the image is resized to a size that is a multiple of this value. Works by flooring
+ the height and width to the nearest multiple of this value.
+
+ Works both with and without `keep_aspect_ratio` being set to `True`. Can be overidden by `ensure_multiple_of` in `preprocess`.
+ resample (`int`, *optional*, defaults to `self.resample`):
+ Resampling filter to use if resizing the image. This can be one of the enum `PILImageResampling`, Only
+ has an effect if `do_resize` is set to `True`.
+ return_tensors (`str` or `TensorType`, *optional*):
+ The type of tensors to return. Can be one of:
+ - Unset: Return a list of `np.ndarray`.
+ - `TensorType.TENSORFLOW` or `'tf'`: Return a batch of type `tf.Tensor`.
+ - `TensorType.PYTORCH` or `'pt'`: Return a batch of type `torch.Tensor`.
+ - `TensorType.NUMPY` or `'np'`: Return a batch of type `np.ndarray`.
+ - `TensorType.JAX` or `'jax'`: Return a batch of type `jax.numpy.ndarray`.
+ data_format (`ChannelDimension` or `str`, *optional*, defaults to `ChannelDimension.FIRST`):
+ The channel dimension format for the output image. Can be one of:
+ - `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ input_data_format (`ChannelDimension` or `str`, *optional*):
+ The channel dimension format for the input image. If unset, the channel dimension format is inferred
+ from the input image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - `"none"` or `ChannelDimension.NONE`: image in (height, width) format.
+ """
+ do_resize = do_resize if do_resize is not None else self.do_resize
+ size = size if size is not None else self.size
+ size = get_size_dict(size)
+ keep_aspect_ratio = keep_aspect_ratio if keep_aspect_ratio is not None else self.keep_aspect_ratio
+ ensure_multiple_of = ensure_multiple_of if ensure_multiple_of is not None else self.ensure_multiple_of
+ resample = resample if resample is not None else self.resample
+ do_rescale = do_rescale if do_rescale is not None else self.do_rescale
+ rescale_factor = rescale_factor if rescale_factor is not None else self.rescale_factor
+ do_normalize = do_normalize if do_normalize is not None else self.do_normalize
+ image_mean = image_mean if image_mean is not None else self.image_mean
+ image_std = image_std if image_std is not None else self.image_std
+ do_pad = do_pad if do_pad is not None else self.do_pad
+
+ images = make_list_of_images(images)
+
+ if not valid_images(images):
+ raise ValueError(
+ "Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
+ "torch.Tensor, tf.Tensor or jax.ndarray."
+ )
+ validate_preprocess_arguments(
+ do_rescale=do_rescale,
+ rescale_factor=rescale_factor,
+ do_normalize=do_normalize,
+ image_mean=image_mean,
+ image_std=image_std,
+ do_resize=do_resize,
+ size=size,
+ resample=resample,
+ )
+ # All transformations expect numpy arrays.
+ images = [to_numpy_array(image) for image in images]
+
+ if is_scaled_image(images[0]) and do_rescale:
+ logger.warning_once(
+ "It looks like you are trying to rescale already rescaled images. If the input"
+ " images have pixel values between 0 and 1, set `do_rescale=False` to avoid rescaling them again."
+ )
+
+ if input_data_format is None:
+ # We assume that all images have the same channel dimension format.
+ input_data_format = infer_channel_dimension_format(images[0])
+
+ if do_rescale:
+ images = [
+ self.rescale(image=image, scale=rescale_factor, input_data_format=input_data_format)
+ for image in images
+ ]
+
+ if do_pad:
+ images = [self.pad_image(image=image, input_data_format=input_data_format) for image in images]
+
+ if do_resize:
+ images = [
+ self.resize(
+ image=image,
+ size=size,
+ resample=resample,
+ keep_aspect_ratio=keep_aspect_ratio,
+ ensure_multiple_of=ensure_multiple_of,
+ input_data_format=input_data_format,
+ )
+ for image in images
+ ]
+
+ if do_normalize:
+ images = [
+ self.normalize(image=image, mean=image_mean, std=image_std, input_data_format=input_data_format)
+ for image in images
+ ]
+
+ images = [
+ to_channel_dimension_format(image, data_format, input_channel_dim=input_data_format) for image in images
+ ]
+
+ data = {"pixel_values": images}
+ return BatchFeature(data=data, tensor_type=return_tensors)
diff --git a/src/transformers/models/zoedepth/modeling_zoedepth.py b/src/transformers/models/zoedepth/modeling_zoedepth.py
new file mode 100644
index 00000000000000..f03f775d1e4faf
--- /dev/null
+++ b/src/transformers/models/zoedepth/modeling_zoedepth.py
@@ -0,0 +1,1403 @@
+# coding=utf-8
+# Copyright 2024 Intel Labs and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""PyTorch ZoeDepth model."""
+
+import math
+from dataclasses import dataclass
+from typing import List, Optional, Tuple, Union
+
+import torch
+import torch.utils.checkpoint
+from torch import nn
+
+from ...activations import ACT2FN
+from ...file_utils import (
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ replace_return_docstrings,
+)
+from ...modeling_outputs import DepthEstimatorOutput
+from ...modeling_utils import PreTrainedModel
+from ...utils import ModelOutput, logging
+from ...utils.backbone_utils import load_backbone
+from .configuration_zoedepth import ZoeDepthConfig
+
+
+logger = logging.get_logger(__name__)
+
+# General docstring
+_CONFIG_FOR_DOC = "ZoeDepthConfig"
+
+
+@dataclass
+class ZoeDepthDepthEstimatorOutput(ModelOutput):
+ """
+ Extension of `DepthEstimatorOutput` to include domain logits (ZoeDepth specific).
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Classification (or regression if config.num_labels==1) loss.
+ predicted_depth (`torch.FloatTensor` of shape `(batch_size, height, width)`):
+ Predicted depth for each pixel.
+
+ domain_logits (`torch.FloatTensor` of shape `(batch_size, num_domains)`):
+ Logits for each domain (e.g. NYU and KITTI) in case multiple metric heads are used.
+
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, num_channels, height, width)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, patch_size,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ predicted_depth: torch.FloatTensor = None
+ domain_logits: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+class ZoeDepthReassembleStage(nn.Module):
+ """
+ This class reassembles the hidden states of the backbone into image-like feature representations at various
+ resolutions.
+
+ This happens in 3 stages:
+ 1. Map the N + 1 tokens to a set of N tokens, by taking into account the readout ([CLS]) token according to
+ `config.readout_type`.
+ 2. Project the channel dimension of the hidden states according to `config.neck_hidden_sizes`.
+ 3. Resizing the spatial dimensions (height, width).
+
+ Args:
+ config (`[ZoeDepthConfig]`):
+ Model configuration class defining the model architecture.
+ """
+
+ def __init__(self, config):
+ super().__init__()
+
+ self.readout_type = config.readout_type
+ self.layers = nn.ModuleList()
+
+ for neck_hidden_size, factor in zip(config.neck_hidden_sizes, config.reassemble_factors):
+ self.layers.append(ZoeDepthReassembleLayer(config, channels=neck_hidden_size, factor=factor))
+
+ if config.readout_type == "project":
+ self.readout_projects = nn.ModuleList()
+ hidden_size = config.backbone_hidden_size
+ for _ in config.neck_hidden_sizes:
+ self.readout_projects.append(
+ nn.Sequential(nn.Linear(2 * hidden_size, hidden_size), ACT2FN[config.hidden_act])
+ )
+
+ def forward(self, hidden_states: List[torch.Tensor], patch_height, patch_width) -> List[torch.Tensor]:
+ """
+ Args:
+ hidden_states (`List[torch.FloatTensor]`, each of shape `(batch_size, sequence_length + 1, hidden_size)`):
+ List of hidden states from the backbone.
+ """
+ batch_size = hidden_states[0].shape[0]
+
+ # stack along batch dimension
+ # shape (batch_size*num_stages, sequence_length + 1, hidden_size)
+ hidden_states = torch.cat(hidden_states, dim=0)
+
+ cls_token, hidden_states = hidden_states[:, 0], hidden_states[:, 1:]
+ # reshape hidden_states to (batch_size*num_stages, num_channels, height, width)
+ total_batch_size, sequence_length, num_channels = hidden_states.shape
+ hidden_states = hidden_states.reshape(total_batch_size, patch_height, patch_width, num_channels)
+ hidden_states = hidden_states.permute(0, 3, 1, 2).contiguous()
+
+ if self.readout_type == "project":
+ # reshape to (batch_size*num_stages, height*width, num_channels)
+ hidden_states = hidden_states.flatten(2).permute((0, 2, 1))
+ readout = cls_token.unsqueeze(dim=1).expand_as(hidden_states)
+ # concatenate the readout token to the hidden states
+ # to get (batch_size*num_stages, height*width, 2*num_channels)
+ hidden_states = torch.cat((hidden_states, readout), -1)
+ elif self.readout_type == "add":
+ hidden_states = hidden_states + cls_token.unsqueeze(-1)
+
+ out = []
+ for stage_idx, hidden_state in enumerate(hidden_states.split(batch_size, dim=0)):
+ if self.readout_type == "project":
+ hidden_state = self.readout_projects[stage_idx](hidden_state)
+
+ # reshape back to (batch_size, num_channels, height, width)
+ hidden_state = hidden_state.permute(0, 2, 1).reshape(batch_size, -1, patch_height, patch_width)
+ hidden_state = self.layers[stage_idx](hidden_state)
+ out.append(hidden_state)
+
+ return out
+
+
+class ZoeDepthReassembleLayer(nn.Module):
+ def __init__(self, config, channels, factor):
+ super().__init__()
+ # projection
+ hidden_size = config.backbone_hidden_size
+ self.projection = nn.Conv2d(in_channels=hidden_size, out_channels=channels, kernel_size=1)
+
+ # up/down sampling depending on factor
+ if factor > 1:
+ self.resize = nn.ConvTranspose2d(channels, channels, kernel_size=factor, stride=factor, padding=0)
+ elif factor == 1:
+ self.resize = nn.Identity()
+ elif factor < 1:
+ # so should downsample
+ self.resize = nn.Conv2d(channels, channels, kernel_size=3, stride=int(1 / factor), padding=1)
+
+ # Copied from transformers.models.dpt.modeling_dpt.DPTReassembleLayer.forward with DPT->ZoeDepth
+ def forward(self, hidden_state):
+ hidden_state = self.projection(hidden_state)
+ hidden_state = self.resize(hidden_state)
+ return hidden_state
+
+
+# Copied from transformers.models.dpt.modeling_dpt.DPTFeatureFusionStage with DPT->ZoeDepth
+class ZoeDepthFeatureFusionStage(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.layers = nn.ModuleList()
+ for _ in range(len(config.neck_hidden_sizes)):
+ self.layers.append(ZoeDepthFeatureFusionLayer(config))
+
+ def forward(self, hidden_states):
+ # reversing the hidden_states, we start from the last
+ hidden_states = hidden_states[::-1]
+
+ fused_hidden_states = []
+ # first layer only uses the last hidden_state
+ fused_hidden_state = self.layers[0](hidden_states[0])
+ fused_hidden_states.append(fused_hidden_state)
+ # looping from the last layer to the second
+ for hidden_state, layer in zip(hidden_states[1:], self.layers[1:]):
+ fused_hidden_state = layer(fused_hidden_state, hidden_state)
+ fused_hidden_states.append(fused_hidden_state)
+
+ return fused_hidden_states
+
+
+# Copied from transformers.models.dpt.modeling_dpt.DPTPreActResidualLayer with DPT->ZoeDepth
+class ZoeDepthPreActResidualLayer(nn.Module):
+ """
+ ResidualConvUnit, pre-activate residual unit.
+
+ Args:
+ config (`[ZoeDepthConfig]`):
+ Model configuration class defining the model architecture.
+ """
+
+ # Ignore copy
+ def __init__(self, config):
+ super().__init__()
+
+ self.use_batch_norm = config.use_batch_norm_in_fusion_residual
+ use_bias_in_fusion_residual = (
+ config.use_bias_in_fusion_residual
+ if config.use_bias_in_fusion_residual is not None
+ else not self.use_batch_norm
+ )
+
+ self.activation1 = nn.ReLU()
+ self.convolution1 = nn.Conv2d(
+ config.fusion_hidden_size,
+ config.fusion_hidden_size,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=use_bias_in_fusion_residual,
+ )
+
+ self.activation2 = nn.ReLU()
+ self.convolution2 = nn.Conv2d(
+ config.fusion_hidden_size,
+ config.fusion_hidden_size,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=use_bias_in_fusion_residual,
+ )
+
+ if self.use_batch_norm:
+ self.batch_norm1 = nn.BatchNorm2d(config.fusion_hidden_size, eps=config.batch_norm_eps)
+ self.batch_norm2 = nn.BatchNorm2d(config.fusion_hidden_size, eps=config.batch_norm_eps)
+
+ def forward(self, hidden_state: torch.Tensor) -> torch.Tensor:
+ residual = hidden_state
+ hidden_state = self.activation1(hidden_state)
+
+ hidden_state = self.convolution1(hidden_state)
+
+ if self.use_batch_norm:
+ hidden_state = self.batch_norm1(hidden_state)
+
+ hidden_state = self.activation2(hidden_state)
+ hidden_state = self.convolution2(hidden_state)
+
+ if self.use_batch_norm:
+ hidden_state = self.batch_norm2(hidden_state)
+
+ return hidden_state + residual
+
+
+# Copied from transformers.models.dpt.modeling_dpt.DPTFeatureFusionLayer with DPT->ZoeDepth
+class ZoeDepthFeatureFusionLayer(nn.Module):
+ """Feature fusion layer, merges feature maps from different stages.
+
+ Args:
+ config (`[ZoeDepthConfig]`):
+ Model configuration class defining the model architecture.
+ align_corners (`bool`, *optional*, defaults to `True`):
+ The align_corner setting for bilinear upsample.
+ """
+
+ def __init__(self, config, align_corners=True):
+ super().__init__()
+
+ self.align_corners = align_corners
+
+ self.projection = nn.Conv2d(config.fusion_hidden_size, config.fusion_hidden_size, kernel_size=1, bias=True)
+
+ self.residual_layer1 = ZoeDepthPreActResidualLayer(config)
+ self.residual_layer2 = ZoeDepthPreActResidualLayer(config)
+
+ def forward(self, hidden_state, residual=None):
+ if residual is not None:
+ if hidden_state.shape != residual.shape:
+ residual = nn.functional.interpolate(
+ residual, size=(hidden_state.shape[2], hidden_state.shape[3]), mode="bilinear", align_corners=False
+ )
+ hidden_state = hidden_state + self.residual_layer1(residual)
+
+ hidden_state = self.residual_layer2(hidden_state)
+ hidden_state = nn.functional.interpolate(
+ hidden_state, scale_factor=2, mode="bilinear", align_corners=self.align_corners
+ )
+ hidden_state = self.projection(hidden_state)
+
+ return hidden_state
+
+
+class ZoeDepthNeck(nn.Module):
+ """
+ ZoeDepthNeck. A neck is a module that is normally used between the backbone and the head. It takes a list of tensors as
+ input and produces another list of tensors as output. For ZoeDepth, it includes 2 stages:
+
+ * ZoeDepthReassembleStage
+ * ZoeDepthFeatureFusionStage.
+
+ Args:
+ config (dict): config dict.
+ """
+
+ # Copied from transformers.models.dpt.modeling_dpt.DPTNeck.__init__ with DPT->ZoeDepth
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+
+ # postprocessing: only required in case of a non-hierarchical backbone (e.g. ViT, BEiT)
+ if config.backbone_config is not None and config.backbone_config.model_type in ["swinv2"]:
+ self.reassemble_stage = None
+ else:
+ self.reassemble_stage = ZoeDepthReassembleStage(config)
+
+ self.convs = nn.ModuleList()
+ for channel in config.neck_hidden_sizes:
+ self.convs.append(nn.Conv2d(channel, config.fusion_hidden_size, kernel_size=3, padding=1, bias=False))
+
+ # fusion
+ self.fusion_stage = ZoeDepthFeatureFusionStage(config)
+
+ def forward(self, hidden_states: List[torch.Tensor], patch_height, patch_width) -> List[torch.Tensor]:
+ """
+ Args:
+ hidden_states (`List[torch.FloatTensor]`, each of shape `(batch_size, sequence_length, hidden_size)` or `(batch_size, hidden_size, height, width)`):
+ List of hidden states from the backbone.
+ """
+ if not isinstance(hidden_states, (tuple, list)):
+ raise ValueError("hidden_states should be a tuple or list of tensors")
+
+ if len(hidden_states) != len(self.config.neck_hidden_sizes):
+ raise ValueError("The number of hidden states should be equal to the number of neck hidden sizes.")
+
+ # postprocess hidden states
+ if self.reassemble_stage is not None:
+ hidden_states = self.reassemble_stage(hidden_states, patch_height, patch_width)
+
+ features = [self.convs[i](feature) for i, feature in enumerate(hidden_states)]
+
+ # fusion blocks
+ output = self.fusion_stage(features)
+
+ return output, features[-1]
+
+
+class ZoeDepthRelativeDepthEstimationHead(nn.Module):
+ """
+ Relative depth estimation head consisting of 3 convolutional layers. It progressively halves the feature dimension and upsamples
+ the predictions to the input resolution after the first convolutional layer (details can be found in DPT's paper's
+ supplementary material).
+ """
+
+ def __init__(self, config):
+ super().__init__()
+
+ self.head_in_index = config.head_in_index
+
+ self.projection = None
+ if config.add_projection:
+ self.projection = nn.Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+
+ features = config.fusion_hidden_size
+ self.conv1 = nn.Conv2d(features, features // 2, kernel_size=3, stride=1, padding=1)
+ self.upsample = nn.Upsample(scale_factor=2, mode="bilinear", align_corners=True)
+ self.conv2 = nn.Conv2d(features // 2, config.num_relative_features, kernel_size=3, stride=1, padding=1)
+ self.conv3 = nn.Conv2d(config.num_relative_features, 1, kernel_size=1, stride=1, padding=0)
+
+ def forward(self, hidden_states: List[torch.Tensor]) -> torch.Tensor:
+ # use last features
+ hidden_states = hidden_states[self.head_in_index]
+
+ if self.projection is not None:
+ hidden_states = self.projection(hidden_states)
+ hidden_states = nn.ReLU()(hidden_states)
+
+ hidden_states = self.conv1(hidden_states)
+ hidden_states = self.upsample(hidden_states)
+ hidden_states = self.conv2(hidden_states)
+ hidden_states = nn.ReLU()(hidden_states)
+ # we need the features here (after second conv + ReLu)
+ features = hidden_states
+ hidden_states = self.conv3(hidden_states)
+ hidden_states = nn.ReLU()(hidden_states)
+
+ predicted_depth = hidden_states.squeeze(dim=1)
+
+ return predicted_depth, features
+
+
+def log_binom(n, k, eps=1e-7):
+ """log(nCk) using stirling approximation"""
+ n = n + eps
+ k = k + eps
+ return n * torch.log(n) - k * torch.log(k) - (n - k) * torch.log(n - k + eps)
+
+
+class LogBinomialSoftmax(nn.Module):
+ def __init__(self, n_classes=256, act=torch.softmax):
+ """Compute log binomial distribution for n_classes
+
+ Args:
+ n_classes (`int`, *optional*, defaults to 256):
+ Number of output classes.
+ act (`torch.nn.Module`, *optional*, defaults to `torch.softmax`):
+ Activation function to apply to the output.
+ """
+ super().__init__()
+ self.k = n_classes
+ self.act = act
+ self.register_buffer("k_idx", torch.arange(0, n_classes).view(1, -1, 1, 1), persistent=False)
+ self.register_buffer("k_minus_1", torch.Tensor([self.k - 1]).view(1, -1, 1, 1), persistent=False)
+
+ def forward(self, probabilities, temperature=1.0, eps=1e-4):
+ """Compute the log binomial distribution for probabilities.
+
+ Args:
+ probabilities (`torch.Tensor` of shape `(batch_size, num_channels, height, width)`):
+ Tensor containing probabilities of each class.
+ temperature (`float` or `torch.Tensor` of shape `(batch_size, num_channels, height, width)`, *optional*, defaults to 1):
+ Temperature of distribution.
+ eps (`float`, *optional*, defaults to 1e-4):
+ Small number for numerical stability.
+
+ Returns:
+ `torch.Tensor` of shape `(batch_size, num_channels, height, width)`:
+ Log binomial distribution logbinomial(p;t).
+ """
+ if probabilities.ndim == 3:
+ probabilities = probabilities.unsqueeze(1) # make it (batch_size, num_channels, height, width)
+
+ one_minus_probabilities = torch.clamp(1 - probabilities, eps, 1)
+ probabilities = torch.clamp(probabilities, eps, 1)
+ y = (
+ log_binom(self.k_minus_1, self.k_idx)
+ + self.k_idx * torch.log(probabilities)
+ + (self.k_minus_1 - self.k_idx) * torch.log(one_minus_probabilities)
+ )
+ return self.act(y / temperature, dim=1)
+
+
+class ZoeDepthConditionalLogBinomialSoftmax(nn.Module):
+ def __init__(
+ self,
+ config,
+ in_features,
+ condition_dim,
+ n_classes=256,
+ bottleneck_factor=2,
+ ):
+ """Per-pixel MLP followed by a Conditional Log Binomial softmax.
+
+ Args:
+ in_features (`int`):
+ Number of input channels in the main feature.
+ condition_dim (`int`):
+ Number of input channels in the condition feature.
+ n_classes (`int`, *optional*, defaults to 256):
+ Number of classes.
+ bottleneck_factor (`int`, *optional*, defaults to 2):
+ Hidden dim factor.
+
+ """
+ super().__init__()
+
+ bottleneck = (in_features + condition_dim) // bottleneck_factor
+ self.mlp = nn.Sequential(
+ nn.Conv2d(in_features + condition_dim, bottleneck, kernel_size=1, stride=1, padding=0),
+ nn.GELU(),
+ # 2 for probabilities linear norm, 2 for temperature linear norm
+ nn.Conv2d(bottleneck, 2 + 2, kernel_size=1, stride=1, padding=0),
+ nn.Softplus(),
+ )
+
+ self.p_eps = 1e-4
+ self.max_temp = config.max_temp
+ self.min_temp = config.min_temp
+ self.log_binomial_transform = LogBinomialSoftmax(n_classes, act=torch.softmax)
+
+ def forward(self, main_feature, condition_feature):
+ """
+ Args:
+ main_feature (`torch.Tensor` of shape `(batch_size, num_channels, height, width)`):
+ Main feature.
+ condition_feature (torch.Tensor of shape `(batch_size, num_channels, height, width)`):
+ Condition feature.
+
+ Returns:
+ `torch.Tensor`:
+ Output log binomial distribution
+ """
+ probabilities_and_temperature = self.mlp(torch.concat((main_feature, condition_feature), dim=1))
+ probabilities, temperature = (
+ probabilities_and_temperature[:, :2, ...],
+ probabilities_and_temperature[:, 2:, ...],
+ )
+
+ probabilities = probabilities + self.p_eps
+ probabilities = probabilities[:, 0, ...] / (probabilities[:, 0, ...] + probabilities[:, 1, ...])
+
+ temperature = temperature + self.p_eps
+ temperature = temperature[:, 0, ...] / (temperature[:, 0, ...] + temperature[:, 1, ...])
+ temperature = temperature.unsqueeze(1)
+ temperature = (self.max_temp - self.min_temp) * temperature + self.min_temp
+
+ return self.log_binomial_transform(probabilities, temperature)
+
+
+class ZoeDepthSeedBinRegressor(nn.Module):
+ def __init__(self, config, n_bins=16, mlp_dim=256, min_depth=1e-3, max_depth=10):
+ """Bin center regressor network.
+
+ Can be "normed" or "unnormed". If "normed", bin centers are bounded on the (min_depth, max_depth) interval.
+
+ Args:
+ config (`int`):
+ Model configuration.
+ n_bins (`int`, *optional*, defaults to 16):
+ Number of bin centers.
+ mlp_dim (`int`, *optional*, defaults to 256):
+ Hidden dimension.
+ min_depth (`float`, *optional*, defaults to 1e-3):
+ Min depth value.
+ max_depth (`float`, *optional*, defaults to 10):
+ Max depth value.
+ """
+ super().__init__()
+
+ self.in_features = config.bottleneck_features
+ self.bin_centers_type = config.bin_centers_type
+ self.min_depth = min_depth
+ self.max_depth = max_depth
+
+ self.conv1 = nn.Conv2d(self.in_features, mlp_dim, 1, 1, 0)
+ self.act1 = nn.ReLU(inplace=True)
+ self.conv2 = nn.Conv2d(mlp_dim, n_bins, 1, 1, 0)
+ self.act2 = nn.ReLU(inplace=True) if self.bin_centers_type == "normed" else nn.Softplus()
+
+ def forward(self, x):
+ """
+ Returns tensor of bin_width vectors (centers). One vector b for every pixel
+ """
+ x = self.conv1(x)
+ x = self.act1(x)
+ x = self.conv2(x)
+ bin_centers = self.act2(x)
+
+ if self.bin_centers_type == "normed":
+ bin_centers = bin_centers + 1e-3
+ bin_widths_normed = bin_centers / bin_centers.sum(dim=1, keepdim=True)
+ # shape (batch_size, num_channels, height, width)
+ bin_widths = (self.max_depth - self.min_depth) * bin_widths_normed
+ # pad has the form (left, right, top, bottom, front, back)
+ bin_widths = nn.functional.pad(bin_widths, (0, 0, 0, 0, 1, 0), mode="constant", value=self.min_depth)
+ # shape (batch_size, num_channels, height, width)
+ bin_edges = torch.cumsum(bin_widths, dim=1)
+
+ bin_centers = 0.5 * (bin_edges[:, :-1, ...] + bin_edges[:, 1:, ...])
+ return bin_widths_normed, bin_centers
+
+ else:
+ return bin_centers, bin_centers
+
+
+@torch.jit.script
+def inv_attractor(dx, alpha: float = 300, gamma: int = 2):
+ """Inverse attractor: dc = dx / (1 + alpha*dx^gamma), where dx = a - c, a = attractor point, c = bin center, dc = shift in bin center
+ This is the default one according to the accompanying paper.
+
+ Args:
+ dx (`torch.Tensor`):
+ The difference tensor dx = Ai - Cj, where Ai is the attractor point and Cj is the bin center.
+ alpha (`float`, *optional*, defaults to 300):
+ Proportional Attractor strength. Determines the absolute strength. Lower alpha = greater attraction.
+ gamma (`int`, *optional*, defaults to 2):
+ Exponential Attractor strength. Determines the "region of influence" and indirectly number of bin centers affected.
+ Lower gamma = farther reach.
+
+ Returns:
+ torch.Tensor: Delta shifts - dc; New bin centers = Old bin centers + dc
+ """
+ return dx.div(1 + alpha * dx.pow(gamma))
+
+
+class ZoeDepthAttractorLayer(nn.Module):
+ def __init__(
+ self,
+ config,
+ n_bins,
+ n_attractors=16,
+ min_depth=1e-3,
+ max_depth=10,
+ memory_efficient=False,
+ ):
+ """
+ Attractor layer for bin centers. Bin centers are bounded on the interval (min_depth, max_depth)
+ """
+ super().__init__()
+
+ self.alpha = config.attractor_alpha
+ self.gemma = config.attractor_gamma
+ self.kind = config.attractor_kind
+
+ self.n_attractors = n_attractors
+ self.n_bins = n_bins
+ self.min_depth = min_depth
+ self.max_depth = max_depth
+ self.memory_efficient = memory_efficient
+
+ # MLP to predict attractor points
+ in_features = mlp_dim = config.bin_embedding_dim
+ self.conv1 = nn.Conv2d(in_features, mlp_dim, 1, 1, 0)
+ self.act1 = nn.ReLU(inplace=True)
+ self.conv2 = nn.Conv2d(mlp_dim, n_attractors * 2, 1, 1, 0) # x2 for linear norm
+ self.act2 = nn.ReLU(inplace=True)
+
+ def forward(self, x, prev_bin, prev_bin_embedding=None, interpolate=True):
+ """
+ The forward pass of the attractor layer. This layer predicts the new bin centers based on the previous bin centers
+ and the attractor points (the latter are predicted by the MLP).
+
+ Args:
+ x (`torch.Tensor` of shape `(batch_size, num_channels, height, width)`):
+ Feature block.
+ prev_bin (`torch.Tensor` of shape `(batch_size, prev_number_of_bins, height, width)`):
+ Previous bin centers normed.
+ prev_bin_embedding (`torch.Tensor`, *optional*):
+ Optional previous bin embeddings.
+ interpolate (`bool`, *optional*, defaults to `True`):
+ Whether to interpolate the previous bin embeddings to the size of the input features.
+
+ Returns:
+ `Tuple[`torch.Tensor`, `torch.Tensor`]:
+ New bin centers normed and scaled.
+ """
+ if prev_bin_embedding is not None:
+ if interpolate:
+ prev_bin_embedding = nn.functional.interpolate(
+ prev_bin_embedding, x.shape[-2:], mode="bilinear", align_corners=True
+ )
+ x = x + prev_bin_embedding
+
+ x = self.conv1(x)
+ x = self.act1(x)
+ x = self.conv2(x)
+ attractors = self.act2(x)
+
+ attractors = attractors + 1e-3
+ batch_size, _, height, width = attractors.shape
+ attractors = attractors.view(batch_size, self.n_attractors, 2, height, width)
+ # batch_size, num_attractors, 2, height, width
+ # note: original repo had a bug here: https://github.com/isl-org/ZoeDepth/blame/edb6daf45458569e24f50250ef1ed08c015f17a7/zoedepth/models/layers/attractor.py#L105C9-L106C50
+ # we include the bug to maintain compatibility with the weights
+ attractors_normed = attractors[:, :, 0, ...] # batch_size, batch_size*num_attractors, height, width
+
+ bin_centers = nn.functional.interpolate(prev_bin, (height, width), mode="bilinear", align_corners=True)
+
+ # note: only attractor_type = "exp" is supported here, since no checkpoints were released with other attractor types
+
+ if not self.memory_efficient:
+ func = {"mean": torch.mean, "sum": torch.sum}[self.kind]
+ # shape (batch_size, num_bins, height, width)
+ delta_c = func(inv_attractor(attractors_normed.unsqueeze(2) - bin_centers.unsqueeze(1)), dim=1)
+ else:
+ delta_c = torch.zeros_like(bin_centers, device=bin_centers.device)
+ for i in range(self.n_attractors):
+ # shape (batch_size, num_bins, height, width)
+ delta_c += inv_attractor(attractors_normed[:, i, ...].unsqueeze(1) - bin_centers)
+
+ if self.kind == "mean":
+ delta_c = delta_c / self.n_attractors
+
+ bin_new_centers = bin_centers + delta_c
+ bin_centers = (self.max_depth - self.min_depth) * bin_new_centers + self.min_depth
+ bin_centers, _ = torch.sort(bin_centers, dim=1)
+ bin_centers = torch.clip(bin_centers, self.min_depth, self.max_depth)
+ return bin_new_centers, bin_centers
+
+
+class ZoeDepthAttractorLayerUnnormed(nn.Module):
+ def __init__(
+ self,
+ config,
+ n_bins,
+ n_attractors=16,
+ min_depth=1e-3,
+ max_depth=10,
+ memory_efficient=True,
+ ):
+ """
+ Attractor layer for bin centers. Bin centers are unbounded
+ """
+ super().__init__()
+
+ self.n_attractors = n_attractors
+ self.n_bins = n_bins
+ self.min_depth = min_depth
+ self.max_depth = max_depth
+ self.alpha = config.attractor_alpha
+ self.gamma = config.attractor_alpha
+ self.kind = config.attractor_kind
+ self.memory_efficient = memory_efficient
+
+ in_features = mlp_dim = config.bin_embedding_dim
+ self.conv1 = nn.Conv2d(in_features, mlp_dim, 1, 1, 0)
+ self.act1 = nn.ReLU(inplace=True)
+ self.conv2 = nn.Conv2d(mlp_dim, n_attractors, 1, 1, 0)
+ self.act2 = nn.Softplus()
+
+ def forward(self, x, prev_bin, prev_bin_embedding=None, interpolate=True):
+ """
+ The forward pass of the attractor layer. This layer predicts the new bin centers based on the previous bin centers
+ and the attractor points (the latter are predicted by the MLP).
+
+ Args:
+ x (`torch.Tensor` of shape (batch_size, num_channels, height, width)`):
+ Feature block.
+ prev_bin (`torch.Tensor` of shape (batch_size, prev_num_bins, height, width)`):
+ Previous bin centers normed.
+ prev_bin_embedding (`torch.Tensor`, *optional*):
+ Optional previous bin embeddings.
+ interpolate (`bool`, *optional*, defaults to `True`):
+ Whether to interpolate the previous bin embeddings to the size of the input features.
+
+ Returns:
+ `Tuple[`torch.Tensor`, `torch.Tensor`]:
+ New bin centers unbounded. Two outputs just to keep the API consistent with the normed version.
+ """
+ if prev_bin_embedding is not None:
+ if interpolate:
+ prev_bin_embedding = nn.functional.interpolate(
+ prev_bin_embedding, x.shape[-2:], mode="bilinear", align_corners=True
+ )
+ x = x + prev_bin_embedding
+
+ x = self.conv1(x)
+ x = self.act1(x)
+ x = self.conv2(x)
+ attractors = self.act2(x)
+
+ height, width = attractors.shape[-2:]
+
+ bin_centers = nn.functional.interpolate(prev_bin, (height, width), mode="bilinear", align_corners=True)
+
+ if not self.memory_efficient:
+ func = {"mean": torch.mean, "sum": torch.sum}[self.kind]
+ # shape batch_size, num_bins, height, width
+ delta_c = func(inv_attractor(attractors.unsqueeze(2) - bin_centers.unsqueeze(1)), dim=1)
+ else:
+ delta_c = torch.zeros_like(bin_centers, device=bin_centers.device)
+ for i in range(self.n_attractors):
+ # shape batch_size, num_bins, height, width
+ delta_c += inv_attractor(attractors[:, i, ...].unsqueeze(1) - bin_centers)
+
+ if self.kind == "mean":
+ delta_c = delta_c / self.n_attractors
+
+ bin_new_centers = bin_centers + delta_c
+ bin_centers = bin_new_centers
+
+ return bin_new_centers, bin_centers
+
+
+class ZoeDepthProjector(nn.Module):
+ def __init__(self, in_features, out_features, mlp_dim=128):
+ """Projector MLP.
+
+ Args:
+ in_features (`int`):
+ Number of input channels.
+ out_features (`int`):
+ Number of output channels.
+ mlp_dim (`int`, *optional*, defaults to 128):
+ Hidden dimension.
+ """
+ super().__init__()
+
+ self.conv1 = nn.Conv2d(in_features, mlp_dim, 1, 1, 0)
+ self.act = nn.ReLU(inplace=True)
+ self.conv2 = nn.Conv2d(mlp_dim, out_features, 1, 1, 0)
+
+ def forward(self, hidden_state: torch.Tensor) -> torch.Tensor:
+ hidden_state = self.conv1(hidden_state)
+ hidden_state = self.act(hidden_state)
+ hidden_state = self.conv2(hidden_state)
+
+ return hidden_state
+
+
+# Copied from transformers.models.grounding_dino.modeling_grounding_dino.GroundingDinoMultiheadAttention with GroundingDino->ZoeDepth
+class ZoeDepthMultiheadAttention(nn.Module):
+ """Equivalent implementation of nn.MultiheadAttention with `batch_first=True`."""
+
+ # Ignore copy
+ def __init__(self, hidden_size, num_attention_heads, dropout):
+ super().__init__()
+ if hidden_size % num_attention_heads != 0:
+ raise ValueError(
+ f"The hidden size ({hidden_size}) is not a multiple of the number of attention "
+ f"heads ({num_attention_heads})"
+ )
+
+ self.num_attention_heads = num_attention_heads
+ self.attention_head_size = int(hidden_size / num_attention_heads)
+ self.all_head_size = self.num_attention_heads * self.attention_head_size
+
+ self.query = nn.Linear(hidden_size, self.all_head_size)
+ self.key = nn.Linear(hidden_size, self.all_head_size)
+ self.value = nn.Linear(hidden_size, self.all_head_size)
+
+ self.out_proj = nn.Linear(hidden_size, hidden_size)
+
+ self.dropout = nn.Dropout(dropout)
+
+ def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
+ new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
+ x = x.view(new_x_shape)
+ return x.permute(0, 2, 1, 3)
+
+ def forward(
+ self,
+ queries: torch.Tensor,
+ keys: torch.Tensor,
+ values: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor]:
+ query_layer = self.transpose_for_scores(self.query(queries))
+ key_layer = self.transpose_for_scores(self.key(keys))
+ value_layer = self.transpose_for_scores(self.value(values))
+
+ # Take the dot product between "query" and "key" to get the raw attention scores.
+ attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
+
+ attention_scores = attention_scores / math.sqrt(self.attention_head_size)
+ if attention_mask is not None:
+ # Apply the attention mask is (precomputed for all layers in ZoeDepthModel forward() function)
+ attention_scores = attention_scores + attention_mask
+
+ # Normalize the attention scores to probabilities.
+ attention_probs = nn.functional.softmax(attention_scores, dim=-1)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs = self.dropout(attention_probs)
+
+ context_layer = torch.matmul(attention_probs, value_layer)
+
+ context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
+ new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
+ context_layer = context_layer.view(new_context_layer_shape)
+
+ context_layer = self.out_proj(context_layer)
+
+ outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
+
+ return outputs
+
+
+class ZoeDepthTransformerEncoderLayer(nn.Module):
+ def __init__(self, config, dropout=0.1, activation="relu"):
+ super().__init__()
+
+ hidden_size = config.patch_transformer_hidden_size
+ intermediate_size = config.patch_transformer_intermediate_size
+ num_attention_heads = config.patch_transformer_num_attention_heads
+
+ self.self_attn = ZoeDepthMultiheadAttention(hidden_size, num_attention_heads, dropout=dropout)
+
+ self.linear1 = nn.Linear(hidden_size, intermediate_size)
+ self.dropout = nn.Dropout(dropout)
+ self.linear2 = nn.Linear(intermediate_size, hidden_size)
+
+ self.norm1 = nn.LayerNorm(hidden_size)
+ self.norm2 = nn.LayerNorm(hidden_size)
+ self.dropout1 = nn.Dropout(dropout)
+ self.dropout2 = nn.Dropout(dropout)
+
+ self.activation = ACT2FN[activation]
+
+ def forward(
+ self,
+ src,
+ src_mask: Optional[torch.Tensor] = None,
+ ):
+ queries = keys = src
+ src2 = self.self_attn(queries=queries, keys=keys, values=src, attention_mask=src_mask)[0]
+ src = src + self.dropout1(src2)
+ src = self.norm1(src)
+ src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
+ src = src + self.dropout2(src2)
+ src = self.norm2(src)
+ return src
+
+
+class ZoeDepthPatchTransformerEncoder(nn.Module):
+ def __init__(self, config):
+ """ViT-like transformer block
+
+ Args:
+ config (`ZoeDepthConfig`):
+ Model configuration class defining the model architecture.
+ """
+ super().__init__()
+
+ in_channels = config.bottleneck_features
+
+ self.transformer_encoder = nn.ModuleList(
+ [ZoeDepthTransformerEncoderLayer(config) for _ in range(config.num_patch_transformer_layers)]
+ )
+
+ self.embedding_convPxP = nn.Conv2d(
+ in_channels, config.patch_transformer_hidden_size, kernel_size=1, stride=1, padding=0
+ )
+
+ def positional_encoding_1d(self, batch_size, sequence_length, embedding_dim, device="cpu", dtype=torch.float32):
+ """Generate positional encodings
+
+ Args:
+ sequence_length (int): Sequence length
+ embedding_dim (int): Embedding dimension
+
+ Returns:
+ torch.Tensor: Positional encodings.
+ """
+ position = torch.arange(0, sequence_length, dtype=dtype, device=device).unsqueeze(1)
+ index = torch.arange(0, embedding_dim, 2, dtype=dtype, device=device).unsqueeze(0)
+ div_term = torch.exp(index * (-torch.log(torch.tensor(10000.0, device=device)) / embedding_dim))
+ pos_encoding = position * div_term
+ pos_encoding = torch.cat([torch.sin(pos_encoding), torch.cos(pos_encoding)], dim=1)
+ pos_encoding = pos_encoding.unsqueeze(dim=0).repeat(batch_size, 1, 1)
+ return pos_encoding
+
+ def forward(self, x):
+ """Forward pass
+
+ Args:
+ x (torch.Tensor - NCHW): Input feature tensor
+
+ Returns:
+ torch.Tensor - Transformer output embeddings of shape (batch_size, sequence_length, embedding_dim)
+ """
+ embeddings = self.embedding_convPxP(x).flatten(2) # shape (batch_size, num_channels, sequence_length)
+ # add an extra special CLS token at the start for global accumulation
+ embeddings = nn.functional.pad(embeddings, (1, 0))
+
+ embeddings = embeddings.permute(0, 2, 1)
+ batch_size, sequence_length, embedding_dim = embeddings.shape
+ embeddings = embeddings + self.positional_encoding_1d(
+ batch_size, sequence_length, embedding_dim, device=embeddings.device, dtype=embeddings.dtype
+ )
+
+ for i in range(4):
+ embeddings = self.transformer_encoder[i](embeddings)
+
+ return embeddings
+
+
+class ZoeDepthMLPClassifier(nn.Module):
+ def __init__(self, in_features, out_features) -> None:
+ super().__init__()
+
+ hidden_features = in_features
+ self.linear1 = nn.Linear(in_features, hidden_features)
+ self.activation = nn.ReLU()
+ self.linear2 = nn.Linear(hidden_features, out_features)
+
+ def forward(self, hidden_state):
+ hidden_state = self.linear1(hidden_state)
+ hidden_state = self.activation(hidden_state)
+ domain_logits = self.linear2(hidden_state)
+
+ return domain_logits
+
+
+class ZoeDepthMultipleMetricDepthEstimationHeads(nn.Module):
+ """
+ Multiple metric depth estimation heads. A MLP classifier is used to route between 2 different heads.
+ """
+
+ def __init__(self, config):
+ super().__init__()
+
+ bin_embedding_dim = config.bin_embedding_dim
+ n_attractors = config.num_attractors
+ self.bin_configurations = config.bin_configurations
+ self.bin_centers_type = config.bin_centers_type
+
+ # Bottleneck convolution
+ bottleneck_features = config.bottleneck_features
+ self.conv2 = nn.Conv2d(bottleneck_features, bottleneck_features, kernel_size=1, stride=1, padding=0)
+
+ # Transformer classifier on the bottleneck
+ self.patch_transformer = ZoeDepthPatchTransformerEncoder(config)
+ # MLP classifier
+ self.mlp_classifier = ZoeDepthMLPClassifier(in_features=128, out_features=2)
+
+ # Regressor and attractor
+ if self.bin_centers_type == "normed":
+ Attractor = ZoeDepthAttractorLayer
+ elif self.bin_centers_type == "softplus":
+ Attractor = ZoeDepthAttractorLayerUnnormed
+ # We have bins for each bin configuration
+ # Create a map (ModuleDict) of 'name' -> seed_bin_regressor
+ self.seed_bin_regressors = nn.ModuleDict(
+ {
+ conf["name"]: ZoeDepthSeedBinRegressor(
+ config,
+ n_bins=conf["n_bins"],
+ mlp_dim=bin_embedding_dim // 2,
+ min_depth=conf["min_depth"],
+ max_depth=conf["max_depth"],
+ )
+ for conf in config.bin_configurations
+ }
+ )
+
+ self.seed_projector = ZoeDepthProjector(
+ in_features=bottleneck_features, out_features=bin_embedding_dim, mlp_dim=bin_embedding_dim // 2
+ )
+ self.projectors = nn.ModuleList(
+ [
+ ZoeDepthProjector(
+ in_features=config.fusion_hidden_size,
+ out_features=bin_embedding_dim,
+ mlp_dim=bin_embedding_dim // 2,
+ )
+ for _ in range(4)
+ ]
+ )
+
+ # Create a map (ModuleDict) of 'name' -> attractors (ModuleList)
+ self.attractors = nn.ModuleDict(
+ {
+ configuration["name"]: nn.ModuleList(
+ [
+ Attractor(
+ config,
+ n_bins=n_attractors[i],
+ min_depth=configuration["min_depth"],
+ max_depth=configuration["max_depth"],
+ )
+ for i in range(len(n_attractors))
+ ]
+ )
+ for configuration in config.bin_configurations
+ }
+ )
+
+ last_in = config.num_relative_features
+ # conditional log binomial for each bin configuration
+ self.conditional_log_binomial = nn.ModuleDict(
+ {
+ configuration["name"]: ZoeDepthConditionalLogBinomialSoftmax(
+ config,
+ last_in,
+ bin_embedding_dim,
+ configuration["n_bins"],
+ bottleneck_factor=4,
+ )
+ for configuration in config.bin_configurations
+ }
+ )
+
+ def forward(self, outconv_activation, bottleneck, feature_blocks, relative_depth):
+ x = self.conv2(bottleneck)
+
+ # Predict which path to take
+ # Embedding is of shape (batch_size, hidden_size)
+ embedding = self.patch_transformer(x)[:, 0, :]
+
+ # MLP classifier to get logits of shape (batch_size, 2)
+ domain_logits = self.mlp_classifier(embedding)
+ domain_vote = torch.softmax(domain_logits.sum(dim=0, keepdim=True), dim=-1)
+
+ # Get the path
+ names = [configuration["name"] for configuration in self.bin_configurations]
+ bin_configurations_name = names[torch.argmax(domain_vote, dim=-1).squeeze().item()]
+
+ try:
+ conf = [config for config in self.bin_configurations if config["name"] == bin_configurations_name][0]
+ except IndexError:
+ raise ValueError(f"bin_configurations_name {bin_configurations_name} not found in bin_configurationss")
+
+ min_depth = conf["min_depth"]
+ max_depth = conf["max_depth"]
+
+ seed_bin_regressor = self.seed_bin_regressors[bin_configurations_name]
+ _, seed_bin_centers = seed_bin_regressor(x)
+ if self.bin_centers_type in ["normed", "hybrid2"]:
+ prev_bin = (seed_bin_centers - min_depth) / (max_depth - min_depth)
+ else:
+ prev_bin = seed_bin_centers
+ prev_bin_embedding = self.seed_projector(x)
+
+ attractors = self.attractors[bin_configurations_name]
+ for projector, attractor, feature in zip(self.projectors, attractors, feature_blocks):
+ bin_embedding = projector(feature)
+ bin, bin_centers = attractor(bin_embedding, prev_bin, prev_bin_embedding, interpolate=True)
+ prev_bin = bin
+ prev_bin_embedding = bin_embedding
+
+ last = outconv_activation
+
+ bin_centers = nn.functional.interpolate(bin_centers, last.shape[-2:], mode="bilinear", align_corners=True)
+ bin_embedding = nn.functional.interpolate(bin_embedding, last.shape[-2:], mode="bilinear", align_corners=True)
+
+ conditional_log_binomial = self.conditional_log_binomial[bin_configurations_name]
+ x = conditional_log_binomial(last, bin_embedding)
+
+ # Now depth value is Sum px * cx , where cx are bin_centers from the last bin tensor
+ out = torch.sum(x * bin_centers, dim=1, keepdim=True)
+
+ return out, domain_logits
+
+
+class ZoeDepthMetricDepthEstimationHead(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+
+ bin_configuration = config.bin_configurations[0]
+ n_bins = bin_configuration["n_bins"]
+ min_depth = bin_configuration["min_depth"]
+ max_depth = bin_configuration["max_depth"]
+ bin_embedding_dim = config.bin_embedding_dim
+ n_attractors = config.num_attractors
+ bin_centers_type = config.bin_centers_type
+
+ self.min_depth = min_depth
+ self.max_depth = max_depth
+ self.bin_centers_type = bin_centers_type
+
+ # Bottleneck convolution
+ bottleneck_features = config.bottleneck_features
+ self.conv2 = nn.Conv2d(bottleneck_features, bottleneck_features, kernel_size=1, stride=1, padding=0)
+
+ # Regressor and attractor
+ if self.bin_centers_type == "normed":
+ Attractor = ZoeDepthAttractorLayer
+ elif self.bin_centers_type == "softplus":
+ Attractor = ZoeDepthAttractorLayerUnnormed
+
+ self.seed_bin_regressor = ZoeDepthSeedBinRegressor(
+ config, n_bins=n_bins, min_depth=min_depth, max_depth=max_depth
+ )
+ self.seed_projector = ZoeDepthProjector(in_features=bottleneck_features, out_features=bin_embedding_dim)
+
+ self.projectors = nn.ModuleList(
+ [
+ ZoeDepthProjector(in_features=config.fusion_hidden_size, out_features=bin_embedding_dim)
+ for _ in range(4)
+ ]
+ )
+ self.attractors = nn.ModuleList(
+ [
+ Attractor(
+ config,
+ n_bins=n_bins,
+ n_attractors=n_attractors[i],
+ min_depth=min_depth,
+ max_depth=max_depth,
+ )
+ for i in range(4)
+ ]
+ )
+
+ last_in = config.num_relative_features + 1 # +1 for relative depth
+
+ # use log binomial instead of softmax
+ self.conditional_log_binomial = ZoeDepthConditionalLogBinomialSoftmax(
+ config,
+ last_in,
+ bin_embedding_dim,
+ n_classes=n_bins,
+ )
+
+ def forward(self, outconv_activation, bottleneck, feature_blocks, relative_depth):
+ x = self.conv2(bottleneck)
+ _, seed_bin_centers = self.seed_bin_regressor(x)
+
+ if self.bin_centers_type in ["normed", "hybrid2"]:
+ prev_bin = (seed_bin_centers - self.min_depth) / (self.max_depth - self.min_depth)
+ else:
+ prev_bin = seed_bin_centers
+
+ prev_bin_embedding = self.seed_projector(x)
+
+ # unroll this loop for better performance
+ for projector, attractor, feature in zip(self.projectors, self.attractors, feature_blocks):
+ bin_embedding = projector(feature)
+ bin, bin_centers = attractor(bin_embedding, prev_bin, prev_bin_embedding, interpolate=True)
+ prev_bin = bin.clone()
+ prev_bin_embedding = bin_embedding.clone()
+
+ last = outconv_activation
+
+ # concatenative relative depth with last. First interpolate relative depth to last size
+ relative_conditioning = relative_depth.unsqueeze(1)
+ relative_conditioning = nn.functional.interpolate(
+ relative_conditioning, size=last.shape[2:], mode="bilinear", align_corners=True
+ )
+ last = torch.cat([last, relative_conditioning], dim=1)
+
+ bin_embedding = nn.functional.interpolate(bin_embedding, last.shape[-2:], mode="bilinear", align_corners=True)
+ x = self.conditional_log_binomial(last, bin_embedding)
+
+ # Now depth value is Sum px * cx , where cx are bin_centers from the last bin tensor
+ bin_centers = nn.functional.interpolate(bin_centers, x.shape[-2:], mode="bilinear", align_corners=True)
+ out = torch.sum(x * bin_centers, dim=1, keepdim=True)
+
+ return out, None
+
+
+# Copied from transformers.models.dpt.modeling_dpt.DPTPreTrainedModel with DPT->ZoeDepth,dpt->zoedepth
+class ZoeDepthPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = ZoeDepthConfig
+ base_model_prefix = "zoedepth"
+ main_input_name = "pixel_values"
+ supports_gradient_checkpointing = True
+
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ if isinstance(module, (nn.Linear, nn.Conv2d, nn.ConvTranspose2d)):
+ # Slightly different from the TF version which uses truncated_normal for initialization
+ # cf https://github.com/pytorch/pytorch/pull/5617
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+
+
+ZOEDEPTH_START_DOCSTRING = r"""
+ This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it
+ as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
+ behavior.
+
+ Parameters:
+ config ([`ViTConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+ZOEDEPTH_INPUTS_DOCSTRING = r"""
+ Args:
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See [`DPTImageProcessor.__call__`]
+ for details.
+
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~file_utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ """
+ ZoeDepth model with one or multiple metric depth estimation head(s) on top.
+ """,
+ ZOEDEPTH_START_DOCSTRING,
+)
+class ZoeDepthForDepthEstimation(ZoeDepthPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+
+ self.backbone = load_backbone(config)
+
+ if hasattr(self.backbone.config, "hidden_size") and hasattr(self.backbone.config, "patch_size"):
+ config.backbone_hidden_size = self.backbone.config.hidden_size
+ self.patch_size = self.backbone.config.patch_size
+ else:
+ raise ValueError(
+ "ZoeDepth assumes the backbone's config to have `hidden_size` and `patch_size` attributes"
+ )
+
+ self.neck = ZoeDepthNeck(config)
+ self.relative_head = ZoeDepthRelativeDepthEstimationHead(config)
+
+ self.metric_head = (
+ ZoeDepthMultipleMetricDepthEstimationHeads(config)
+ if len(config.bin_configurations) > 1
+ else ZoeDepthMetricDepthEstimationHead(config)
+ )
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(ZOEDEPTH_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=DepthEstimatorOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ pixel_values: torch.FloatTensor,
+ labels: Optional[torch.LongTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple[torch.Tensor], DepthEstimatorOutput]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*):
+ Ground truth depth estimation maps for computing the loss.
+
+ Returns:
+
+ Examples:
+ ```python
+ >>> from transformers import AutoImageProcessor, ZoeDepthForDepthEstimation
+ >>> import torch
+ >>> import numpy as np
+ >>> from PIL import Image
+ >>> import requests
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> image_processor = AutoImageProcessor.from_pretrained("Intel/zoedepth-nyu-kitti")
+ >>> model = ZoeDepthForDepthEstimation.from_pretrained("Intel/zoedepth-nyu-kitti")
+
+ >>> # prepare image for the model
+ >>> inputs = image_processor(images=image, return_tensors="pt")
+
+ >>> with torch.no_grad():
+ ... outputs = model(**inputs)
+ ... predicted_depth = outputs.predicted_depth
+
+ >>> # interpolate to original size
+ >>> prediction = torch.nn.functional.interpolate(
+ ... predicted_depth.unsqueeze(1),
+ ... size=image.size[::-1],
+ ... mode="bicubic",
+ ... align_corners=False,
+ ... )
+
+ >>> # visualize the prediction
+ >>> output = prediction.squeeze().cpu().numpy()
+ >>> formatted = (output * 255 / np.max(output)).astype("uint8")
+ >>> depth = Image.fromarray(formatted)
+ ```"""
+ loss = None
+ if labels is not None:
+ raise NotImplementedError("Training is not implemented yet")
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+
+ outputs = self.backbone.forward_with_filtered_kwargs(
+ pixel_values, output_hidden_states=output_hidden_states, output_attentions=output_attentions
+ )
+ hidden_states = outputs.feature_maps
+
+ _, _, height, width = pixel_values.shape
+ patch_size = self.patch_size
+ patch_height = height // patch_size
+ patch_width = width // patch_size
+
+ hidden_states, features = self.neck(hidden_states, patch_height, patch_width)
+
+ out = [features] + hidden_states
+
+ relative_depth, features = self.relative_head(hidden_states)
+
+ out = [features] + out
+
+ metric_depth, domain_logits = self.metric_head(
+ outconv_activation=out[0], bottleneck=out[1], feature_blocks=out[2:], relative_depth=relative_depth
+ )
+ metric_depth = metric_depth.squeeze(dim=1)
+
+ if not return_dict:
+ if domain_logits is not None:
+ output = (metric_depth, domain_logits) + outputs[1:]
+ else:
+ output = (metric_depth,) + outputs[1:]
+
+ return ((loss,) + output) if loss is not None else output
+
+ return ZoeDepthDepthEstimatorOutput(
+ loss=loss,
+ predicted_depth=metric_depth,
+ domain_logits=domain_logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index 925d8bbb2f6547..edc4c95b1a35ed 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -9660,6 +9660,20 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
+class ZoeDepthForDepthEstimation(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class ZoeDepthPreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
class Adafactor(metaclass=DummyObject):
_backends = ["torch"]
diff --git a/src/transformers/utils/dummy_vision_objects.py b/src/transformers/utils/dummy_vision_objects.py
index 359c5481757d67..9d5175ed2aeab9 100644
--- a/src/transformers/utils/dummy_vision_objects.py
+++ b/src/transformers/utils/dummy_vision_objects.py
@@ -651,3 +651,10 @@ class YolosImageProcessor(metaclass=DummyObject):
def __init__(self, *args, **kwargs):
requires_backends(self, ["vision"])
+
+
+class ZoeDepthImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
diff --git a/tests/models/zoedepth/__init__.py b/tests/models/zoedepth/__init__.py
new file mode 100644
index 00000000000000..e69de29bb2d1d6
diff --git a/tests/models/zoedepth/test_image_processing_zoedepth.py b/tests/models/zoedepth/test_image_processing_zoedepth.py
new file mode 100644
index 00000000000000..7dd82daf0d5f24
--- /dev/null
+++ b/tests/models/zoedepth/test_image_processing_zoedepth.py
@@ -0,0 +1,187 @@
+# coding=utf-8
+# Copyright 2024 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+import numpy as np
+
+from transformers.file_utils import is_vision_available
+from transformers.testing_utils import require_torch, require_vision
+
+from ...test_image_processing_common import ImageProcessingTestMixin, prepare_image_inputs
+
+
+if is_vision_available():
+ from transformers import ZoeDepthImageProcessor
+
+
+class ZoeDepthImageProcessingTester(unittest.TestCase):
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ image_size=18,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size=None,
+ ensure_multiple_of=32,
+ keep_aspect_ratio=False,
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ do_pad=False,
+ ):
+ size = size if size is not None else {"height": 18, "width": 18}
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.ensure_multiple_of = ensure_multiple_of
+ self.keep_aspect_ratio = keep_aspect_ratio
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+ self.do_pad = do_pad
+
+ def prepare_image_processor_dict(self):
+ return {
+ "do_resize": self.do_resize,
+ "size": self.size,
+ "ensure_multiple_of": self.ensure_multiple_of,
+ "keep_aspect_ratio": self.keep_aspect_ratio,
+ "do_normalize": self.do_normalize,
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ "do_pad": self.do_pad,
+ }
+
+ def expected_output_image_shape(self, images):
+ return self.num_channels, self.ensure_multiple_of, self.ensure_multiple_of
+
+ def prepare_image_inputs(self, equal_resolution=False, numpify=False, torchify=False):
+ return prepare_image_inputs(
+ batch_size=self.batch_size,
+ num_channels=self.num_channels,
+ min_resolution=self.min_resolution,
+ max_resolution=self.max_resolution,
+ equal_resolution=equal_resolution,
+ numpify=numpify,
+ torchify=torchify,
+ )
+
+
+@require_torch
+@require_vision
+class ZoeDepthImageProcessingTest(ImageProcessingTestMixin, unittest.TestCase):
+ image_processing_class = ZoeDepthImageProcessor if is_vision_available() else None
+
+ def setUp(self):
+ super().setUp()
+
+ self.image_processor_tester = ZoeDepthImageProcessingTester(self)
+
+ @property
+ def image_processor_dict(self):
+ return self.image_processor_tester.prepare_image_processor_dict()
+
+ def test_image_processor_properties(self):
+ image_processing = self.image_processing_class(**self.image_processor_dict)
+ self.assertTrue(hasattr(image_processing, "image_mean"))
+ self.assertTrue(hasattr(image_processing, "image_std"))
+ self.assertTrue(hasattr(image_processing, "do_normalize"))
+ self.assertTrue(hasattr(image_processing, "do_resize"))
+ self.assertTrue(hasattr(image_processing, "size"))
+ self.assertTrue(hasattr(image_processing, "ensure_multiple_of"))
+ self.assertTrue(hasattr(image_processing, "do_rescale"))
+ self.assertTrue(hasattr(image_processing, "rescale_factor"))
+ self.assertTrue(hasattr(image_processing, "do_pad"))
+
+ def test_image_processor_from_dict_with_kwargs(self):
+ image_processor = self.image_processing_class.from_dict(self.image_processor_dict)
+ self.assertEqual(image_processor.size, {"height": 18, "width": 18})
+
+ image_processor = self.image_processing_class.from_dict(self.image_processor_dict, size=42)
+ self.assertEqual(image_processor.size, {"height": 42, "width": 42})
+
+ def test_ensure_multiple_of(self):
+ # Test variable by turning off all other variables which affect the size, size which is not multiple of 32
+ image = np.zeros((489, 640, 3))
+
+ size = {"height": 380, "width": 513}
+ multiple = 32
+ image_processor = ZoeDepthImageProcessor(
+ do_pad=False, ensure_multiple_of=multiple, size=size, keep_aspect_ratio=False
+ )
+ pixel_values = image_processor(image, return_tensors="pt").pixel_values
+
+ self.assertEqual(list(pixel_values.shape), [1, 3, 384, 512])
+ self.assertTrue(pixel_values.shape[2] % multiple == 0)
+ self.assertTrue(pixel_values.shape[3] % multiple == 0)
+
+ # Test variable by turning off all other variables which affect the size, size which is already multiple of 32
+ image = np.zeros((511, 511, 3))
+
+ height, width = 512, 512
+ size = {"height": height, "width": width}
+ multiple = 32
+ image_processor = ZoeDepthImageProcessor(
+ do_pad=False, ensure_multiple_of=multiple, size=size, keep_aspect_ratio=False
+ )
+ pixel_values = image_processor(image, return_tensors="pt").pixel_values
+
+ self.assertEqual(list(pixel_values.shape), [1, 3, height, width])
+ self.assertTrue(pixel_values.shape[2] % multiple == 0)
+ self.assertTrue(pixel_values.shape[3] % multiple == 0)
+
+ def test_keep_aspect_ratio(self):
+ # Test `keep_aspect_ratio=True` by turning off all other variables which affect the size
+ height, width = 489, 640
+ image = np.zeros((height, width, 3))
+
+ size = {"height": 512, "width": 512}
+ image_processor = ZoeDepthImageProcessor(do_pad=False, keep_aspect_ratio=True, size=size, ensure_multiple_of=1)
+ pixel_values = image_processor(image, return_tensors="pt").pixel_values
+
+ # As can be seen, the image is resized to the maximum size that fits in the specified size
+ self.assertEqual(list(pixel_values.shape), [1, 3, 512, 670])
+
+ # Test `keep_aspect_ratio=False` by turning off all other variables which affect the size
+ image_processor = ZoeDepthImageProcessor(
+ do_pad=False, keep_aspect_ratio=False, size=size, ensure_multiple_of=1
+ )
+ pixel_values = image_processor(image, return_tensors="pt").pixel_values
+
+ # As can be seen, the size is respected
+ self.assertEqual(list(pixel_values.shape), [1, 3, size["height"], size["width"]])
+
+ # Test `keep_aspect_ratio=True` with `ensure_multiple_of` set
+ image = np.zeros((489, 640, 3))
+
+ size = {"height": 511, "width": 511}
+ multiple = 32
+ image_processor = ZoeDepthImageProcessor(size=size, keep_aspect_ratio=True, ensure_multiple_of=multiple)
+
+ pixel_values = image_processor(image, return_tensors="pt").pixel_values
+
+ self.assertEqual(list(pixel_values.shape), [1, 3, 512, 672])
+ self.assertTrue(pixel_values.shape[2] % multiple == 0)
+ self.assertTrue(pixel_values.shape[3] % multiple == 0)
diff --git a/tests/models/zoedepth/test_modeling_zoedepth.py b/tests/models/zoedepth/test_modeling_zoedepth.py
new file mode 100644
index 00000000000000..571c44f2f47266
--- /dev/null
+++ b/tests/models/zoedepth/test_modeling_zoedepth.py
@@ -0,0 +1,257 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch ZoeDepth model."""
+
+import unittest
+
+from transformers import Dinov2Config, ZoeDepthConfig
+from transformers.file_utils import is_torch_available, is_vision_available
+from transformers.testing_utils import require_torch, require_vision, slow, torch_device
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import ZoeDepthForDepthEstimation
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import ZoeDepthImageProcessor
+
+
+class ZoeDepthModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=2,
+ num_channels=3,
+ image_size=32,
+ patch_size=16,
+ use_labels=True,
+ num_labels=3,
+ is_training=True,
+ hidden_size=4,
+ num_hidden_layers=2,
+ num_attention_heads=2,
+ intermediate_size=8,
+ out_features=["stage1", "stage2"],
+ apply_layernorm=False,
+ reshape_hidden_states=False,
+ neck_hidden_sizes=[2, 2],
+ fusion_hidden_size=6,
+ bottleneck_features=6,
+ num_out_features=[6, 6, 6, 6],
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.out_features = out_features
+ self.apply_layernorm = apply_layernorm
+ self.reshape_hidden_states = reshape_hidden_states
+ self.use_labels = use_labels
+ self.num_labels = num_labels
+ self.is_training = is_training
+ self.neck_hidden_sizes = neck_hidden_sizes
+ self.fusion_hidden_size = fusion_hidden_size
+ self.bottleneck_features = bottleneck_features
+ self.num_out_features = num_out_features
+ # ZoeDepth's sequence length
+ self.seq_length = (self.image_size // self.patch_size) ** 2 + 1
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+
+ labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size, self.image_size, self.image_size], self.num_labels)
+
+ config = self.get_config()
+
+ return config, pixel_values, labels
+
+ def get_config(self):
+ return ZoeDepthConfig(
+ backbone_config=self.get_backbone_config(),
+ backbone=None,
+ neck_hidden_sizes=self.neck_hidden_sizes,
+ fusion_hidden_size=self.fusion_hidden_size,
+ bottleneck_features=self.bottleneck_features,
+ num_out_features=self.num_out_features,
+ )
+
+ def get_backbone_config(self):
+ return Dinov2Config(
+ image_size=self.image_size,
+ patch_size=self.patch_size,
+ num_channels=self.num_channels,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ is_training=self.is_training,
+ out_features=self.out_features,
+ reshape_hidden_states=self.reshape_hidden_states,
+ )
+
+ def create_and_check_for_depth_estimation(self, config, pixel_values, labels):
+ config.num_labels = self.num_labels
+ model = ZoeDepthForDepthEstimation(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ self.parent.assertEqual(result.predicted_depth.shape, (self.batch_size, self.image_size, self.image_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values, labels = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class ZoeDepthModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as ZoeDepth does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (ZoeDepthForDepthEstimation,) if is_torch_available() else ()
+ pipeline_model_mapping = {"depth-estimation": ZoeDepthForDepthEstimation} if is_torch_available() else {}
+
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = ZoeDepthModelTester(self)
+ self.config_tester = ConfigTester(
+ self, config_class=ZoeDepthConfig, has_text_modality=False, hidden_size=37, common_properties=[]
+ )
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="ZoeDepth with AutoBackbone does not have a base model and hence no input_embeddings")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="ZoeDepth with AutoBackbone does not have a base model and hence no input_embeddings")
+ def test_model_get_set_embeddings(self):
+ pass
+
+ def test_for_depth_estimation(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_depth_estimation(*config_and_inputs)
+
+ @unittest.skip(reason="ZoeDepth with AutoBackbone does not have a base model and hence no input_embeddings")
+ def test_model_common_attributes(self):
+ pass
+
+ @unittest.skip(reason="ZoeDepth with AutoBackbone does not have a base model")
+ def test_save_load_fast_init_from_base(self):
+ pass
+
+ @unittest.skip(reason="ZoeDepth with AutoBackbone does not have a base model")
+ def test_save_load_fast_init_to_base(self):
+ pass
+
+ @unittest.skip(reason="ZoeDepth does not support training yet")
+ def test_training(self):
+ pass
+
+ @unittest.skip(reason="ZoeDepth does not support training yet")
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(reason="ZoeDepth does not support training yet")
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(reason="ZoeDepth does not support training yet")
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "Intel/zoedepth-nyu"
+ model = ZoeDepthForDepthEstimation.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+@require_torch
+@require_vision
+@slow
+class ZoeDepthModelIntegrationTest(unittest.TestCase):
+ def test_inference_depth_estimation(self):
+ image_processor = ZoeDepthImageProcessor.from_pretrained("Intel/zoedepth-nyu")
+ model = ZoeDepthForDepthEstimation.from_pretrained("Intel/zoedepth-nyu").to(torch_device)
+
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+ predicted_depth = outputs.predicted_depth
+
+ # verify the predicted depth
+ expected_shape = torch.Size((1, 384, 512))
+ self.assertEqual(predicted_depth.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[1.0020, 1.0219, 1.0389], [1.0349, 1.0816, 1.1000], [1.0576, 1.1094, 1.1249]],
+ ).to(torch_device)
+
+ self.assertTrue(torch.allclose(outputs.predicted_depth[0, :3, :3], expected_slice, atol=1e-4))
+
+ def test_inference_depth_estimation_multiple_heads(self):
+ image_processor = ZoeDepthImageProcessor.from_pretrained("Intel/zoedepth-nyu-kitti")
+ model = ZoeDepthForDepthEstimation.from_pretrained("Intel/zoedepth-nyu-kitti").to(torch_device)
+
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+ predicted_depth = outputs.predicted_depth
+
+ # verify the predicted depth
+ expected_shape = torch.Size((1, 384, 512))
+ self.assertEqual(predicted_depth.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[1.1571, 1.1438, 1.1783], [1.2163, 1.2036, 1.2320], [1.2688, 1.2461, 1.2734]],
+ ).to(torch_device)
+
+ self.assertTrue(torch.allclose(outputs.predicted_depth[0, :3, :3], expected_slice, atol=1e-4))
+
+ ZoeDepth architecture. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/isl-org/ZoeDepth).
+
+## Usage tips
+
+- ZoeDepth is an absolute (also called metric) depth estimation model, unlike DPT which is a relative depth estimation model. This means that ZoeDepth is able to estimate depth in metric units like meters.
+
+The easiest to perform inference with ZoeDepth is by leveraging the [pipeline API](../main_classes/pipelines.md):
+
+```python
+from transformers import pipeline
+from PIL import Image
+import requests
+
+url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image = Image.open(requests.get(url, stream=True).raw)
+
+pipe = pipeline(task="depth-estimation", model="Intel/zoedepth-nyu-kitti")
+result = pipe(image)
+depth = result["depth"]
+```
+
+Alternatively, one can also perform inference using the classes:
+
+```python
+from transformers import AutoImageProcessor, ZoeDepthForDepthEstimation
+import torch
+import numpy as np
+from PIL import Image
+import requests
+
+url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image = Image.open(requests.get(url, stream=True).raw)
+
+image_processor = AutoImageProcessor.from_pretrained("Intel/zoedepth-nyu-kitti")
+model = ZoeDepthForDepthEstimation.from_pretrained("Intel/zoedepth-nyu-kitti")
+
+# prepare image for the model
+inputs = image_processor(images=image, return_tensors="pt")
+
+with torch.no_grad():
+ outputs = model(**inputs)
+ predicted_depth = outputs.predicted_depth
+
+# interpolate to original size
+prediction = torch.nn.functional.interpolate(
+ predicted_depth.unsqueeze(1),
+ size=image.size[::-1],
+ mode="bicubic",
+ align_corners=False,
+)
+
+# visualize the prediction
+output = prediction.squeeze().cpu().numpy()
+formatted = (output * 255 / np.max(output)).astype("uint8")
+depth = Image.fromarray(formatted)
+```
+
+## Resources
+
+A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ZoeDepth.
+
+- A demo notebook regarding inference with ZoeDepth models can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ZoeDepth). 🌎
+
+## ZoeDepthConfig
+
+[[autodoc]] ZoeDepthConfig
+
+## ZoeDepthImageProcessor
+
+[[autodoc]] ZoeDepthImageProcessor
+ - preprocess
+
+## ZoeDepthForDepthEstimation
+
+[[autodoc]] ZoeDepthForDepthEstimation
+ - forward
\ No newline at end of file
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index 42c5b713c55aef..c6679fa2f29428 100755
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -807,6 +807,7 @@
"models.xmod": ["XmodConfig"],
"models.yolos": ["YolosConfig"],
"models.yoso": ["YosoConfig"],
+ "models.zoedepth": ["ZoeDepthConfig"],
"onnx": [],
"pipelines": [
"AudioClassificationPipeline",
@@ -1182,6 +1183,7 @@
_import_structure["models.vitmatte"].append("VitMatteImageProcessor")
_import_structure["models.vivit"].append("VivitImageProcessor")
_import_structure["models.yolos"].extend(["YolosFeatureExtractor", "YolosImageProcessor"])
+ _import_structure["models.zoedepth"].append("ZoeDepthImageProcessor")
try:
if not is_torchvision_available():
@@ -3586,6 +3588,12 @@
"YosoPreTrainedModel",
]
)
+ _import_structure["models.zoedepth"].extend(
+ [
+ "ZoeDepthForDepthEstimation",
+ "ZoeDepthPreTrainedModel",
+ ]
+ )
_import_structure["optimization"] = [
"Adafactor",
"AdamW",
@@ -5497,6 +5505,7 @@
from .models.xmod import XmodConfig
from .models.yolos import YolosConfig
from .models.yoso import YosoConfig
+ from .models.zoedepth import ZoeDepthConfig
# Pipelines
from .pipelines import (
@@ -5872,6 +5881,7 @@
from .models.vitmatte import VitMatteImageProcessor
from .models.vivit import VivitImageProcessor
from .models.yolos import YolosFeatureExtractor, YolosImageProcessor
+ from .models.zoedepth import ZoeDepthImageProcessor
try:
if not is_torchvision_available():
@@ -7798,6 +7808,10 @@
YosoModel,
YosoPreTrainedModel,
)
+ from .models.zoedepth import (
+ ZoeDepthForDepthEstimation,
+ ZoeDepthPreTrainedModel,
+ )
# Optimization
from .optimization import (
diff --git a/src/transformers/image_utils.py b/src/transformers/image_utils.py
index a5d8f6f872aabd..0a1a73f5c63e11 100644
--- a/src/transformers/image_utils.py
+++ b/src/transformers/image_utils.py
@@ -409,22 +409,22 @@ def validate_preprocess_arguments(
"""
if do_rescale and rescale_factor is None:
- raise ValueError("rescale_factor must be specified if do_rescale is True.")
+ raise ValueError("`rescale_factor` must be specified if `do_rescale` is `True`.")
if do_pad and size_divisibility is None:
# Here, size_divisor might be passed as the value of size
raise ValueError(
- "Depending on moel, size_divisibility, size_divisor, pad_size or size must be specified if do_pad is True."
+ "Depending on the model, `size_divisibility`, `size_divisor`, `pad_size` or `size` must be specified if `do_pad` is `True`."
)
if do_normalize and (image_mean is None or image_std is None):
- raise ValueError("image_mean and image_std must both be specified if do_normalize is True.")
+ raise ValueError("`image_mean` and `image_std` must both be specified if `do_normalize` is `True`.")
if do_center_crop and crop_size is None:
- raise ValueError("crop_size must be specified if do_center_crop is True.")
+ raise ValueError("`crop_size` must be specified if `do_center_crop` is `True`.")
if do_resize and (size is None or resample is None):
- raise ValueError("size and resample must be specified if do_resize is True.")
+ raise ValueError("`size` and `resample` must be specified if `do_resize` is `True`.")
# In the future we can add a TF implementation here when we have TF models.
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index f4c33491472833..043c02a8d3f5ca 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -263,4 +263,5 @@
xmod,
yolos,
yoso,
+ zoedepth,
)
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index 7f52b3dc280ac6..53d817ca9c02ce 100755
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -291,6 +291,7 @@
("xmod", "XmodConfig"),
("yolos", "YolosConfig"),
("yoso", "YosoConfig"),
+ ("zoedepth", "ZoeDepthConfig"),
]
)
@@ -588,6 +589,7 @@
("xmod", "X-MOD"),
("yolos", "YOLOS"),
("yoso", "YOSO"),
+ ("zoedepth", "ZoeDepth"),
]
)
diff --git a/src/transformers/models/auto/image_processing_auto.py b/src/transformers/models/auto/image_processing_auto.py
index efc2d4d998ccdd..8ad9a3034b64e0 100644
--- a/src/transformers/models/auto/image_processing_auto.py
+++ b/src/transformers/models/auto/image_processing_auto.py
@@ -142,6 +142,7 @@
("vitmatte", ("VitMatteImageProcessor",)),
("xclip", ("CLIPImageProcessor",)),
("yolos", ("YolosImageProcessor",)),
+ ("zoedepth", ("ZoeDepthImageProcessor",)),
]
)
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index f674b777fca7be..8c4cea1539d55e 100755
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -792,6 +792,7 @@
("depth_anything", "DepthAnythingForDepthEstimation"),
("dpt", "DPTForDepthEstimation"),
("glpn", "GLPNForDepthEstimation"),
+ ("zoedepth", "ZoeDepthForDepthEstimation"),
]
)
MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING_NAMES = OrderedDict(
diff --git a/src/transformers/models/beit/modeling_beit.py b/src/transformers/models/beit/modeling_beit.py
index 184ab558228620..58b28866646091 100755
--- a/src/transformers/models/beit/modeling_beit.py
+++ b/src/transformers/models/beit/modeling_beit.py
@@ -34,7 +34,7 @@
SemanticSegmenterOutput,
)
from ...modeling_utils import PreTrainedModel
-from ...pytorch_utils import find_pruneable_heads_and_indices, meshgrid, prune_linear_layer
+from ...pytorch_utils import find_pruneable_heads_and_indices, prune_linear_layer
from ...utils import (
add_code_sample_docstrings,
add_start_docstrings,
@@ -193,12 +193,6 @@ def forward(
interpolate_pos_encoding: bool = False,
) -> torch.Tensor:
_, _, height, width = pixel_values.shape
- if not interpolate_pos_encoding and (height != self.image_size[0] or width != self.image_size[1]):
- raise ValueError(
- f"Input image size ({height}*{width}) doesn't match model"
- f" ({self.image_size[0]}*{self.image_size[1]})."
- )
-
embeddings, (patch_height, patch_width) = self.patch_embeddings(
pixel_values, self.position_embeddings[:, 1:, :] if self.position_embeddings is not None else None
)
@@ -280,6 +274,7 @@ def forward(
class BeitSelfAttention(nn.Module):
def __init__(self, config: BeitConfig, window_size: Optional[tuple] = None) -> None:
super().__init__()
+ self.config = config
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
raise ValueError(
f"The hidden size {config.hidden_size,} is not a multiple of the number of attention "
@@ -313,6 +308,7 @@ def forward(
output_attentions: bool = False,
relative_position_bias: Optional["BeitRelativePositionBias"] = None,
interpolate_pos_encoding: bool = False,
+ resolution: Optional[Tuple[int]] = None,
) -> Union[Tuple[torch.Tensor], Tuple[torch.Tensor, torch.Tensor]]:
mixed_query_layer = self.query(hidden_states)
@@ -327,9 +323,11 @@ def forward(
# Add relative position bias if present.
if self.relative_position_bias is not None:
+ height, width = resolution
+ window_size = (height // self.config.patch_size, width // self.config.patch_size)
attention_scores = attention_scores + self.relative_position_bias(
- interpolate_pos_encoding, attention_scores.shape[2]
- ).unsqueeze(0)
+ window_size, interpolate_pos_encoding, dim_size=hidden_states.shape[1]
+ )
# Add shared relative position bias if provided.
if relative_position_bias is not None:
@@ -407,9 +405,10 @@ def forward(
output_attentions: bool = False,
relative_position_bias: Optional["BeitRelativePositionBias"] = None,
interpolate_pos_encoding: bool = False,
+ resolution: Optional[Tuple[int]] = None,
) -> Union[Tuple[torch.Tensor], Tuple[torch.Tensor, torch.Tensor]]:
self_outputs = self.attention(
- hidden_states, head_mask, output_attentions, relative_position_bias, interpolate_pos_encoding
+ hidden_states, head_mask, output_attentions, relative_position_bias, interpolate_pos_encoding, resolution
)
attention_output = self.output(self_outputs[0], hidden_states)
@@ -475,6 +474,7 @@ def forward(
output_attentions: bool = False,
relative_position_bias: Optional["BeitRelativePositionBias"] = None,
interpolate_pos_encoding: bool = False,
+ resolution: Optional[Tuple[int]] = None,
) -> Union[Tuple[torch.Tensor], Tuple[torch.Tensor, torch.Tensor]]:
self_attention_outputs = self.attention(
self.layernorm_before(hidden_states), # in BEiT, layernorm is applied before self-attention
@@ -482,6 +482,7 @@ def forward(
output_attentions=output_attentions,
relative_position_bias=relative_position_bias,
interpolate_pos_encoding=interpolate_pos_encoding,
+ resolution=resolution,
)
attention_output = self_attention_outputs[0]
outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
@@ -520,32 +521,71 @@ def __init__(self, config: BeitConfig, window_size: tuple) -> None:
) # 2*Wh-1 * 2*Ww-1, nH
# cls to token & token 2 cls & cls to cls
+ self.relative_position_indices = {}
+
+ def generate_relative_position_index(self, window_size: Tuple[int, int]) -> torch.Tensor:
+ """
+ This method creates the relative position index, modified to support arbitrary window sizes,
+ as introduced in [MiDaS v3.1](https://arxiv.org/abs/2307.14460).
+ """
+ num_relative_distance = (2 * window_size[0] - 1) * (2 * window_size[1] - 1) + 3
+ # cls to token & token 2 cls & cls to cls
# get pair-wise relative position index for each token inside the window
- coords_h = torch.arange(window_size[0])
- coords_w = torch.arange(window_size[1])
- coords = torch.stack(meshgrid([coords_h, coords_w], indexing="ij")) # 2, Wh, Ww
+ window_area = window_size[0] * window_size[1]
+ grid = torch.meshgrid(torch.arange(window_size[0]), torch.arange(window_size[1]), indexing="ij")
+ coords = torch.stack(grid) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += window_size[1] - 1
relative_coords[:, :, 0] *= 2 * window_size[1] - 1
- relative_position_index = torch.zeros(
- size=(window_size[0] * window_size[1] + 1,) * 2, dtype=relative_coords.dtype
- )
+ relative_position_index = torch.zeros(size=(window_area + 1,) * 2, dtype=relative_coords.dtype)
relative_position_index[1:, 1:] = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
- relative_position_index[0, 0:] = self.num_relative_distance - 3
- relative_position_index[0:, 0] = self.num_relative_distance - 2
- relative_position_index[0, 0] = self.num_relative_distance - 1
+ relative_position_index[0, 0:] = num_relative_distance - 3
+ relative_position_index[0:, 0] = num_relative_distance - 2
+ relative_position_index[0, 0] = num_relative_distance - 1
+ return relative_position_index
+
+ def forward(self, window_size, interpolate_pos_encoding: bool = False, dim_size=None) -> torch.Tensor:
+ """
+ Modification of timm.models.beit.py: Attention._get_rel_pos_bias to support arbitrary window sizes.
+ """
+ old_height = 2 * self.window_size[0] - 1
+ old_width = 2 * self.window_size[1] - 1
+
+ new_height = 2 * window_size[0] - 1
+ new_width = 2 * window_size[1] - 1
- self.register_buffer("relative_position_index", relative_position_index, persistent=False)
+ old_relative_position_bias_table = self.relative_position_bias_table
- def forward(self, interpolate_pos_encoding: bool = False, dim_size: Optional[int] = None) -> torch.Tensor:
- relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
- self.window_size[0] * self.window_size[1] + 1, self.window_size[0] * self.window_size[1] + 1, -1
- ) # Wh*Ww,Wh*Ww,nH
+ old_num_relative_distance = self.num_relative_distance
+ new_num_relative_distance = new_height * new_width + 3
+
+ old_sub_table = old_relative_position_bias_table[: old_num_relative_distance - 3]
+
+ old_sub_table = old_sub_table.reshape(1, old_width, old_height, -1).permute(0, 3, 1, 2)
+ new_sub_table = nn.functional.interpolate(
+ old_sub_table, size=(int(new_height), int(new_width)), mode="bilinear"
+ )
+ new_sub_table = new_sub_table.permute(0, 2, 3, 1).reshape(new_num_relative_distance - 3, -1)
+
+ new_relative_position_bias_table = torch.cat(
+ [new_sub_table, old_relative_position_bias_table[old_num_relative_distance - 3 :]]
+ )
+
+ key = window_size
+ if key not in self.relative_position_indices.keys():
+ self.relative_position_indices[key] = self.generate_relative_position_index(window_size)
+
+ relative_position_bias = new_relative_position_bias_table[self.relative_position_indices[key].view(-1)]
+ # patch_size*num_patches_height, patch_size*num_patches_width, num_attention_heads
+ relative_position_bias = relative_position_bias.view(
+ window_size[0] * window_size[1] + 1, window_size[0] * window_size[1] + 1, -1
+ )
+ # num_attention_heads, patch_size*num_patches_width, patch_size*num_patches_height
+ relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous()
- relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
if interpolate_pos_encoding:
relative_position_bias = nn.functional.interpolate(
relative_position_bias.unsqueeze(1),
@@ -554,7 +594,7 @@ def forward(self, interpolate_pos_encoding: bool = False, dim_size: Optional[int
align_corners=False,
).squeeze(1)
- return relative_position_bias
+ return relative_position_bias.unsqueeze(0)
class BeitEncoder(nn.Module):
@@ -587,6 +627,7 @@ def forward(
output_attentions: bool = False,
output_hidden_states: bool = False,
interpolate_pos_encoding: bool = False,
+ resolution: Optional[Tuple[int]] = None,
return_dict: bool = True,
) -> Union[tuple, BaseModelOutput]:
all_hidden_states = () if output_hidden_states else None
@@ -606,13 +647,22 @@ def forward(
output_attentions,
)
else:
+ height, width = resolution
+ window_size = (height // self.config.patch_size, width // self.config.patch_size)
relative_position_bias = (
- self.relative_position_bias(interpolate_pos_encoding, hidden_states.shape[1])
+ self.relative_position_bias(
+ window_size, interpolate_pos_encoding=interpolate_pos_encoding, dim_size=hidden_states.shape[1]
+ )
if self.relative_position_bias is not None
else None
)
layer_outputs = layer_module(
- hidden_states, layer_head_mask, output_attentions, relative_position_bias, interpolate_pos_encoding
+ hidden_states,
+ layer_head_mask,
+ output_attentions,
+ relative_position_bias,
+ interpolate_pos_encoding,
+ resolution,
)
hidden_states = layer_outputs[0]
@@ -643,6 +693,7 @@ class BeitPreTrainedModel(PreTrainedModel):
main_input_name = "pixel_values"
supports_gradient_checkpointing = True
_no_split_modules = ["BeitLayer"]
+ _keys_to_ignore_on_load_unexpected = [r".*relative_position_index.*"]
def _init_weights(self, module):
"""Initialize the weights"""
@@ -738,7 +789,7 @@ class PreTrainedModel
)
def forward(
self,
- pixel_values: Optional[torch.Tensor] = None,
+ pixel_values: torch.Tensor,
bool_masked_pos: Optional[torch.BoolTensor] = None,
head_mask: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
@@ -756,9 +807,6 @@ def forward(
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
- if pixel_values is None:
- raise ValueError("You have to specify pixel_values")
-
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
@@ -766,15 +814,17 @@ def forward(
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
- embedding_output, (patch_height, patch_width) = self.embeddings(
+ embedding_output, _ = self.embeddings(
pixel_values, bool_masked_pos=bool_masked_pos, interpolate_pos_encoding=interpolate_pos_encoding
)
+ resolution = pixel_values.shape[2:]
encoder_outputs = self.encoder(
embedding_output,
head_mask=head_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
+ resolution=resolution,
return_dict=return_dict,
interpolate_pos_encoding=interpolate_pos_encoding,
)
@@ -1477,9 +1527,14 @@ def forward(
batch_size = pixel_values.shape[0]
embedding_output, (patch_height, patch_width) = self.embeddings(pixel_values)
+ resolution = pixel_values.shape[2:]
outputs = self.encoder(
- embedding_output, output_hidden_states=True, output_attentions=output_attentions, return_dict=return_dict
+ embedding_output,
+ output_hidden_states=True,
+ output_attentions=output_attentions,
+ resolution=resolution,
+ return_dict=return_dict,
)
hidden_states = outputs.hidden_states if return_dict else outputs[1]
diff --git a/src/transformers/models/data2vec/modeling_data2vec_vision.py b/src/transformers/models/data2vec/modeling_data2vec_vision.py
index a79810d0c5bb57..fca47c524e5146 100644
--- a/src/transformers/models/data2vec/modeling_data2vec_vision.py
+++ b/src/transformers/models/data2vec/modeling_data2vec_vision.py
@@ -32,7 +32,7 @@
SemanticSegmenterOutput,
)
from ...modeling_utils import PreTrainedModel
-from ...pytorch_utils import find_pruneable_heads_and_indices, meshgrid, prune_linear_layer
+from ...pytorch_utils import find_pruneable_heads_and_indices, prune_linear_layer
from ...utils import (
add_code_sample_docstrings,
add_start_docstrings,
@@ -192,12 +192,6 @@ def forward(
interpolate_pos_encoding: bool = False,
) -> torch.Tensor:
_, _, height, width = pixel_values.shape
- if not interpolate_pos_encoding and (height != self.image_size[0] or width != self.image_size[1]):
- raise ValueError(
- f"Input image size ({height}*{width}) doesn't match model"
- f" ({self.image_size[0]}*{self.image_size[1]})."
- )
-
embeddings, (patch_height, patch_width) = self.patch_embeddings(
pixel_values, self.position_embeddings[:, 1:, :] if self.position_embeddings is not None else None
)
@@ -281,6 +275,7 @@ def forward(
class Data2VecVisionSelfAttention(nn.Module):
def __init__(self, config: Data2VecVisionConfig, window_size: Optional[tuple] = None) -> None:
super().__init__()
+ self.config = config
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
raise ValueError(
f"The hidden size {config.hidden_size,} is not a multiple of the number of attention "
@@ -314,6 +309,7 @@ def forward(
output_attentions: bool = False,
relative_position_bias: Optional["Data2VecVisionRelativePositionBias"] = None,
interpolate_pos_encoding: bool = False,
+ resolution: Optional[Tuple[int]] = None,
) -> Union[Tuple[torch.Tensor], Tuple[torch.Tensor, torch.Tensor]]:
mixed_query_layer = self.query(hidden_states)
@@ -328,9 +324,11 @@ def forward(
# Add relative position bias if present.
if self.relative_position_bias is not None:
+ height, width = resolution
+ window_size = (height // self.config.patch_size, width // self.config.patch_size)
attention_scores = attention_scores + self.relative_position_bias(
- interpolate_pos_encoding, attention_scores.shape[2]
- ).unsqueeze(0)
+ window_size, interpolate_pos_encoding, dim_size=hidden_states.shape[1]
+ )
# Add shared relative position bias if provided.
if relative_position_bias is not None:
@@ -410,9 +408,10 @@ def forward(
output_attentions: bool = False,
relative_position_bias: Optional["Data2VecVisionRelativePositionBias"] = None,
interpolate_pos_encoding: bool = False,
+ resolution: Optional[Tuple[int]] = None,
) -> Union[Tuple[torch.Tensor], Tuple[torch.Tensor, torch.Tensor]]:
self_outputs = self.attention(
- hidden_states, head_mask, output_attentions, relative_position_bias, interpolate_pos_encoding
+ hidden_states, head_mask, output_attentions, relative_position_bias, interpolate_pos_encoding, resolution
)
attention_output = self.output(self_outputs[0], hidden_states)
@@ -483,6 +482,7 @@ def forward(
output_attentions: bool = False,
relative_position_bias: Optional["Data2VecVisionRelativePositionBias"] = None,
interpolate_pos_encoding: bool = False,
+ resolution: Optional[Tuple[int]] = None,
) -> Union[Tuple[torch.Tensor], Tuple[torch.Tensor, torch.Tensor]]:
self_attention_outputs = self.attention(
self.layernorm_before(hidden_states), # in Data2VecVision, layernorm is applied before self-attention
@@ -490,6 +490,7 @@ def forward(
output_attentions=output_attentions,
relative_position_bias=relative_position_bias,
interpolate_pos_encoding=interpolate_pos_encoding,
+ resolution=resolution,
)
attention_output = self_attention_outputs[0]
outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
@@ -529,32 +530,71 @@ def __init__(self, config: Data2VecVisionConfig, window_size: tuple) -> None:
) # 2*Wh-1 * 2*Ww-1, nH
# cls to token & token 2 cls & cls to cls
+ self.relative_position_indices = {}
+
+ def generate_relative_position_index(self, window_size: Tuple[int, int]) -> torch.Tensor:
+ """
+ This method creates the relative position index, modified to support arbitrary window sizes,
+ as introduced in [MiDaS v3.1](https://arxiv.org/abs/2307.14460).
+ """
+ num_relative_distance = (2 * window_size[0] - 1) * (2 * window_size[1] - 1) + 3
+ # cls to token & token 2 cls & cls to cls
# get pair-wise relative position index for each token inside the window
- coords_h = torch.arange(window_size[0])
- coords_w = torch.arange(window_size[1])
- coords = torch.stack(meshgrid([coords_h, coords_w], indexing="ij")) # 2, Wh, Ww
+ window_area = window_size[0] * window_size[1]
+ grid = torch.meshgrid(torch.arange(window_size[0]), torch.arange(window_size[1]), indexing="ij")
+ coords = torch.stack(grid) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += window_size[1] - 1
relative_coords[:, :, 0] *= 2 * window_size[1] - 1
- relative_position_index = torch.zeros(
- size=(window_size[0] * window_size[1] + 1,) * 2, dtype=relative_coords.dtype
- )
+ relative_position_index = torch.zeros(size=(window_area + 1,) * 2, dtype=relative_coords.dtype)
relative_position_index[1:, 1:] = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
- relative_position_index[0, 0:] = self.num_relative_distance - 3
- relative_position_index[0:, 0] = self.num_relative_distance - 2
- relative_position_index[0, 0] = self.num_relative_distance - 1
+ relative_position_index[0, 0:] = num_relative_distance - 3
+ relative_position_index[0:, 0] = num_relative_distance - 2
+ relative_position_index[0, 0] = num_relative_distance - 1
+ return relative_position_index
+
+ def forward(self, window_size, interpolate_pos_encoding: bool = False, dim_size=None) -> torch.Tensor:
+ """
+ Modification of timm.models.beit.py: Attention._get_rel_pos_bias to support arbitrary window sizes.
+ """
+ old_height = 2 * self.window_size[0] - 1
+ old_width = 2 * self.window_size[1] - 1
+
+ new_height = 2 * window_size[0] - 1
+ new_width = 2 * window_size[1] - 1
- self.register_buffer("relative_position_index", relative_position_index, persistent=False)
+ old_relative_position_bias_table = self.relative_position_bias_table
- def forward(self, interpolate_pos_encoding: bool = False, dim_size: Optional[int] = None) -> torch.Tensor:
- relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
- self.window_size[0] * self.window_size[1] + 1, self.window_size[0] * self.window_size[1] + 1, -1
- ) # Wh*Ww,Wh*Ww,nH
+ old_num_relative_distance = self.num_relative_distance
+ new_num_relative_distance = new_height * new_width + 3
+
+ old_sub_table = old_relative_position_bias_table[: old_num_relative_distance - 3]
+
+ old_sub_table = old_sub_table.reshape(1, old_width, old_height, -1).permute(0, 3, 1, 2)
+ new_sub_table = nn.functional.interpolate(
+ old_sub_table, size=(int(new_height), int(new_width)), mode="bilinear"
+ )
+ new_sub_table = new_sub_table.permute(0, 2, 3, 1).reshape(new_num_relative_distance - 3, -1)
+
+ new_relative_position_bias_table = torch.cat(
+ [new_sub_table, old_relative_position_bias_table[old_num_relative_distance - 3 :]]
+ )
+
+ key = window_size
+ if key not in self.relative_position_indices.keys():
+ self.relative_position_indices[key] = self.generate_relative_position_index(window_size)
+
+ relative_position_bias = new_relative_position_bias_table[self.relative_position_indices[key].view(-1)]
+ # patch_size*num_patches_height, patch_size*num_patches_width, num_attention_heads
+ relative_position_bias = relative_position_bias.view(
+ window_size[0] * window_size[1] + 1, window_size[0] * window_size[1] + 1, -1
+ )
+ # num_attention_heads, patch_size*num_patches_width, patch_size*num_patches_height
+ relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous()
- relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
if interpolate_pos_encoding:
relative_position_bias = nn.functional.interpolate(
relative_position_bias.unsqueeze(1),
@@ -563,7 +603,7 @@ def forward(self, interpolate_pos_encoding: bool = False, dim_size: Optional[int
align_corners=False,
).squeeze(1)
- return relative_position_bias
+ return relative_position_bias.unsqueeze(0)
# Copied from transformers.models.beit.modeling_beit.BeitEncoder with Beit->Data2VecVision
@@ -597,6 +637,7 @@ def forward(
output_attentions: bool = False,
output_hidden_states: bool = False,
interpolate_pos_encoding: bool = False,
+ resolution: Optional[Tuple[int]] = None,
return_dict: bool = True,
) -> Union[tuple, BaseModelOutput]:
all_hidden_states = () if output_hidden_states else None
@@ -616,13 +657,22 @@ def forward(
output_attentions,
)
else:
+ height, width = resolution
+ window_size = (height // self.config.patch_size, width // self.config.patch_size)
relative_position_bias = (
- self.relative_position_bias(interpolate_pos_encoding, hidden_states.shape[1])
+ self.relative_position_bias(
+ window_size, interpolate_pos_encoding=interpolate_pos_encoding, dim_size=hidden_states.shape[1]
+ )
if self.relative_position_bias is not None
else None
)
layer_outputs = layer_module(
- hidden_states, layer_head_mask, output_attentions, relative_position_bias, interpolate_pos_encoding
+ hidden_states,
+ layer_head_mask,
+ output_attentions,
+ relative_position_bias,
+ interpolate_pos_encoding,
+ resolution,
)
hidden_states = layer_outputs[0]
@@ -654,6 +704,7 @@ class Data2VecVisionPreTrainedModel(PreTrainedModel):
main_input_name = "pixel_values"
supports_gradient_checkpointing = True
_no_split_modules = ["Data2VecVisionLayer"]
+ _keys_to_ignore_on_load_unexpected = [r".*relative_position_index.*"]
def _init_weights(self, module):
"""Initialize the weights"""
@@ -750,7 +801,7 @@ class PreTrainedModel
)
def forward(
self,
- pixel_values: Optional[torch.Tensor] = None,
+ pixel_values: torch.Tensor,
bool_masked_pos: Optional[torch.BoolTensor] = None,
head_mask: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
@@ -768,9 +819,6 @@ def forward(
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
- if pixel_values is None:
- raise ValueError("You have to specify pixel_values")
-
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
@@ -778,15 +826,17 @@ def forward(
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
- embedding_output, (patch_height, patch_width) = self.embeddings(
+ embedding_output, _ = self.embeddings(
pixel_values, bool_masked_pos=bool_masked_pos, interpolate_pos_encoding=interpolate_pos_encoding
)
+ resolution = pixel_values.shape[2:]
encoder_outputs = self.encoder(
embedding_output,
head_mask=head_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
+ resolution=resolution,
return_dict=return_dict,
interpolate_pos_encoding=interpolate_pos_encoding,
)
diff --git a/src/transformers/models/dpt/image_processing_dpt.py b/src/transformers/models/dpt/image_processing_dpt.py
index 96f43a796e3886..a4e3da1528ec0b 100644
--- a/src/transformers/models/dpt/image_processing_dpt.py
+++ b/src/transformers/models/dpt/image_processing_dpt.py
@@ -58,7 +58,7 @@ def get_resize_output_image_size(
multiple: int,
input_data_format: Optional[Union[str, ChannelDimension]] = None,
) -> Tuple[int, int]:
- def constraint_to_multiple_of(val, multiple, min_val=0, max_val=None):
+ def constrain_to_multiple_of(val, multiple, min_val=0, max_val=None):
x = round(val / multiple) * multiple
if max_val is not None and x > max_val:
@@ -87,8 +87,8 @@ def constraint_to_multiple_of(val, multiple, min_val=0, max_val=None):
# fit height
scale_width = scale_height
- new_height = constraint_to_multiple_of(scale_height * input_height, multiple=multiple)
- new_width = constraint_to_multiple_of(scale_width * input_width, multiple=multiple)
+ new_height = constrain_to_multiple_of(scale_height * input_height, multiple=multiple)
+ new_width = constrain_to_multiple_of(scale_width * input_width, multiple=multiple)
return (new_height, new_width)
diff --git a/src/transformers/models/dpt/modeling_dpt.py b/src/transformers/models/dpt/modeling_dpt.py
index db5db0eae1189b..b2b88855669a76 100755
--- a/src/transformers/models/dpt/modeling_dpt.py
+++ b/src/transformers/models/dpt/modeling_dpt.py
@@ -1021,7 +1021,7 @@ def forward(self, hidden_states: List[torch.Tensor], patch_height=None, patch_wi
class DPTDepthEstimationHead(nn.Module):
"""
- Output head head consisting of 3 convolutional layers. It progressively halves the feature dimension and upsamples
+ Output head consisting of 3 convolutional layers. It progressively halves the feature dimension and upsamples
the predictions to the input resolution after the first convolutional layer (details can be found in the paper's
supplementary material).
"""
diff --git a/src/transformers/models/zoedepth/__init__.py b/src/transformers/models/zoedepth/__init__.py
new file mode 100644
index 00000000000000..15ba0883d83241
--- /dev/null
+++ b/src/transformers/models/zoedepth/__init__.py
@@ -0,0 +1,67 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...file_utils import _LazyModule, is_torch_available, is_vision_available
+from ...utils import OptionalDependencyNotAvailable
+
+
+_import_structure = {"configuration_zoedepth": ["ZOEDEPTH_PRETRAINED_CONFIG_ARCHIVE_MAP", "ZoeDepthConfig"]}
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["modeling_zoedepth"] = [
+ "ZoeDepthForDepthEstimation",
+ "ZoeDepthPreTrainedModel",
+ ]
+
+try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["image_processing_zoedepth"] = ["ZoeDepthImageProcessor"]
+
+
+if TYPE_CHECKING:
+ from .configuration_zoedepth import ZOEDEPTH_PRETRAINED_CONFIG_ARCHIVE_MAP, ZoeDepthConfig
+
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .modeling_zoedepth import (
+ ZoeDepthForDepthEstimation,
+ ZoeDepthPreTrainedModel,
+ )
+
+ try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .image_processing_zoedepth import ZoeDepthImageProcessor
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
diff --git a/src/transformers/models/zoedepth/configuration_zoedepth.py b/src/transformers/models/zoedepth/configuration_zoedepth.py
new file mode 100644
index 00000000000000..1b7e2695eb98c9
--- /dev/null
+++ b/src/transformers/models/zoedepth/configuration_zoedepth.py
@@ -0,0 +1,234 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""ZoeDepth model configuration"""
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+from ..auto.configuration_auto import CONFIG_MAPPING
+
+
+logger = logging.get_logger(__name__)
+
+ZOEDEPTH_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "Intel/zoedepth-nyu": "https://huggingface.co/Intel/zoedepth-nyu/resolve/main/config.json",
+}
+
+
+class ZoeDepthConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`ZoeDepthForDepthEstimation`]. It is used to instantiate an ZoeDepth
+ model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
+ defaults will yield a similar configuration to that of the ZoeDepth
+ [Intel/zoedepth-nyu](https://huggingface.co/Intel/zoedepth-nyu) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ backbone_config (`Union[Dict[str, Any], PretrainedConfig]`, *optional*, defaults to `BeitConfig()`):
+ The configuration of the backbone model.
+ backbone (`str`, *optional*):
+ Name of backbone to use when `backbone_config` is `None`. If `use_pretrained_backbone` is `True`, this
+ will load the corresponding pretrained weights from the timm or transformers library. If `use_pretrained_backbone`
+ is `False`, this loads the backbone's config and uses that to initialize the backbone with random weights.
+ use_pretrained_backbone (`bool`, *optional*, defaults to `False`):
+ Whether to use pretrained weights for the backbone.
+ backbone_kwargs (`dict`, *optional*):
+ Keyword arguments to be passed to AutoBackbone when loading from a checkpoint
+ e.g. `{'out_indices': (0, 1, 2, 3)}`. Cannot be specified if `backbone_config` is set.
+ hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"selu"` and `"gelu_new"` are supported.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ batch_norm_eps (`float`, *optional*, defaults to 1e-05):
+ The epsilon used by the batch normalization layers.
+ readout_type (`str`, *optional*, defaults to `"project"`):
+ The readout type to use when processing the readout token (CLS token) of the intermediate hidden states of
+ the ViT backbone. Can be one of [`"ignore"`, `"add"`, `"project"`].
+
+ - "ignore" simply ignores the CLS token.
+ - "add" passes the information from the CLS token to all other tokens by adding the representations.
+ - "project" passes information to the other tokens by concatenating the readout to all other tokens before
+ projecting the
+ representation to the original feature dimension D using a linear layer followed by a GELU non-linearity.
+ reassemble_factors (`List[int]`, *optional*, defaults to `[4, 2, 1, 0.5]`):
+ The up/downsampling factors of the reassemble layers.
+ neck_hidden_sizes (`List[str]`, *optional*, defaults to `[96, 192, 384, 768]`):
+ The hidden sizes to project to for the feature maps of the backbone.
+ fusion_hidden_size (`int`, *optional*, defaults to 256):
+ The number of channels before fusion.
+ head_in_index (`int`, *optional*, defaults to -1):
+ The index of the features to use in the heads.
+ use_batch_norm_in_fusion_residual (`bool`, *optional*, defaults to `False`):
+ Whether to use batch normalization in the pre-activate residual units of the fusion blocks.
+ use_bias_in_fusion_residual (`bool`, *optional*, defaults to `True`):
+ Whether to use bias in the pre-activate residual units of the fusion blocks.
+ num_relative_features (`int`, *optional*, defaults to 32):
+ The number of features to use in the relative depth estimation head.
+ add_projection (`bool`, *optional*, defaults to `False`):
+ Whether to add a projection layer before the depth estimation head.
+ bottleneck_features (`int`, *optional*, defaults to 256):
+ The number of features in the bottleneck layer.
+ num_attractors (`List[int], *optional*, defaults to `[16, 8, 4, 1]`):
+ The number of attractors to use in each stage.
+ bin_embedding_dim (`int`, *optional*, defaults to 128):
+ The dimension of the bin embeddings.
+ attractor_alpha (`int`, *optional*, defaults to 1000):
+ The alpha value to use in the attractor.
+ attractor_gamma (`int`, *optional*, defaults to 2):
+ The gamma value to use in the attractor.
+ attractor_kind (`str`, *optional*, defaults to `"mean"`):
+ The kind of attractor to use. Can be one of [`"mean"`, `"sum"`].
+ min_temp (`float`, *optional*, defaults to 0.0212):
+ The minimum temperature value to consider.
+ max_temp (`float`, *optional*, defaults to 50.0):
+ The maximum temperature value to consider.
+ bin_centers_type (`str`, *optional*, defaults to `"softplus"`):
+ Activation type used for bin centers. Can be "normed" or "softplus". For "normed" bin centers, linear normalization trick
+ is applied. This results in bounded bin centers. For "softplus", softplus activation is used and thus are unbounded.
+ bin_configurations (`List[dict]`, *optional*, defaults to `[{'n_bins': 64, 'min_depth': 0.001, 'max_depth': 10.0}]`):
+ Configuration for each of the bin heads.
+ Each configuration should consist of the following keys:
+ - name (`str`): The name of the bin head - only required in case of multiple bin configurations.
+ - `n_bins` (`int`): The number of bins to use.
+ - `min_depth` (`float`): The minimum depth value to consider.
+ - `max_depth` (`float`): The maximum depth value to consider.
+ In case only a single configuration is passed, the model will use a single head with the specified configuration.
+ In case multiple configurations are passed, the model will use multiple heads with the specified configurations.
+ num_patch_transformer_layers (`int`, *optional*):
+ The number of transformer layers to use in the patch transformer. Only used in case of multiple bin configurations.
+ patch_transformer_hidden_size (`int`, *optional*):
+ The hidden size to use in the patch transformer. Only used in case of multiple bin configurations.
+ patch_transformer_intermediate_size (`int`, *optional*):
+ The intermediate size to use in the patch transformer. Only used in case of multiple bin configurations.
+ patch_transformer_num_attention_heads (`int`, *optional*):
+ The number of attention heads to use in the patch transformer. Only used in case of multiple bin configurations.
+
+ Example:
+
+ ```python
+ >>> from transformers import ZoeDepthConfig, ZoeDepthForDepthEstimation
+
+ >>> # Initializing a ZoeDepth zoedepth-large style configuration
+ >>> configuration = ZoeDepthConfig()
+
+ >>> # Initializing a model from the zoedepth-large style configuration
+ >>> model = ZoeDepthForDepthEstimation(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+
+ model_type = "zoedepth"
+
+ def __init__(
+ self,
+ backbone_config=None,
+ backbone=None,
+ use_pretrained_backbone=False,
+ backbone_kwargs=None,
+ hidden_act="gelu",
+ initializer_range=0.02,
+ batch_norm_eps=1e-05,
+ readout_type="project",
+ reassemble_factors=[4, 2, 1, 0.5],
+ neck_hidden_sizes=[96, 192, 384, 768],
+ fusion_hidden_size=256,
+ head_in_index=-1,
+ use_batch_norm_in_fusion_residual=False,
+ use_bias_in_fusion_residual=None,
+ num_relative_features=32,
+ add_projection=False,
+ bottleneck_features=256,
+ num_attractors=[16, 8, 4, 1],
+ bin_embedding_dim=128,
+ attractor_alpha=1000,
+ attractor_gamma=2,
+ attractor_kind="mean",
+ min_temp=0.0212,
+ max_temp=50.0,
+ bin_centers_type="softplus",
+ bin_configurations=[{"n_bins": 64, "min_depth": 0.001, "max_depth": 10.0}],
+ num_patch_transformer_layers=None,
+ patch_transformer_hidden_size=None,
+ patch_transformer_intermediate_size=None,
+ patch_transformer_num_attention_heads=None,
+ **kwargs,
+ ):
+ super().__init__(**kwargs)
+
+ if readout_type not in ["ignore", "add", "project"]:
+ raise ValueError("Readout_type must be one of ['ignore', 'add', 'project']")
+
+ if attractor_kind not in ["mean", "sum"]:
+ raise ValueError("Attractor_kind must be one of ['mean', 'sum']")
+
+ if use_pretrained_backbone:
+ raise ValueError("Pretrained backbones are not supported yet.")
+
+ if backbone_config is not None and backbone is not None:
+ raise ValueError("You can't specify both `backbone` and `backbone_config`.")
+
+ if backbone_config is None and backbone is None:
+ logger.info("`backbone_config` is `None`. Initializing the config with the default `BEiT` backbone.")
+ backbone_config = CONFIG_MAPPING["beit"](
+ image_size=384,
+ num_hidden_layers=24,
+ hidden_size=1024,
+ intermediate_size=4096,
+ num_attention_heads=16,
+ use_relative_position_bias=True,
+ reshape_hidden_states=False,
+ out_features=["stage6", "stage12", "stage18", "stage24"],
+ )
+ elif isinstance(backbone_config, dict):
+ backbone_model_type = backbone_config.get("model_type")
+ config_class = CONFIG_MAPPING[backbone_model_type]
+ backbone_config = config_class.from_dict(backbone_config)
+
+ if backbone_kwargs is not None and backbone_kwargs and backbone_config is not None:
+ raise ValueError("You can't specify both `backbone_kwargs` and `backbone_config`.")
+
+ self.backbone_config = backbone_config
+ self.backbone = backbone
+ self.hidden_act = hidden_act
+ self.use_pretrained_backbone = use_pretrained_backbone
+ self.initializer_range = initializer_range
+ self.batch_norm_eps = batch_norm_eps
+ self.readout_type = readout_type
+ self.reassemble_factors = reassemble_factors
+ self.neck_hidden_sizes = neck_hidden_sizes
+ self.fusion_hidden_size = fusion_hidden_size
+ self.head_in_index = head_in_index
+ self.use_batch_norm_in_fusion_residual = use_batch_norm_in_fusion_residual
+ self.use_bias_in_fusion_residual = use_bias_in_fusion_residual
+ self.num_relative_features = num_relative_features
+ self.add_projection = add_projection
+
+ self.bottleneck_features = bottleneck_features
+ self.num_attractors = num_attractors
+ self.bin_embedding_dim = bin_embedding_dim
+ self.attractor_alpha = attractor_alpha
+ self.attractor_gamma = attractor_gamma
+ self.attractor_kind = attractor_kind
+ self.min_temp = min_temp
+ self.max_temp = max_temp
+ self.bin_centers_type = bin_centers_type
+ self.bin_configurations = bin_configurations
+ self.num_patch_transformer_layers = num_patch_transformer_layers
+ self.patch_transformer_hidden_size = patch_transformer_hidden_size
+ self.patch_transformer_intermediate_size = patch_transformer_intermediate_size
+ self.patch_transformer_num_attention_heads = patch_transformer_num_attention_heads
diff --git a/src/transformers/models/zoedepth/convert_zoedepth_to_hf.py b/src/transformers/models/zoedepth/convert_zoedepth_to_hf.py
new file mode 100644
index 00000000000000..9a6701c35bcdf9
--- /dev/null
+++ b/src/transformers/models/zoedepth/convert_zoedepth_to_hf.py
@@ -0,0 +1,426 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Convert ZoeDepth checkpoints from the original repository. URL: https://github.com/isl-org/ZoeDepth.
+
+Original logits where obtained by running the following code:
+!git clone -b understanding_zoedepth https://github.com/NielsRogge/ZoeDepth
+!python inference.py
+"""
+
+import argparse
+from pathlib import Path
+
+import torch
+from huggingface_hub import hf_hub_download
+from PIL import Image
+
+from transformers import BeitConfig, ZoeDepthConfig, ZoeDepthForDepthEstimation, ZoeDepthImageProcessor
+from transformers.utils import logging
+
+
+logging.set_verbosity_info()
+logger = logging.get_logger(__name__)
+
+
+def get_zoedepth_config(model_name):
+ image_size = 384
+ backbone_config = BeitConfig(
+ image_size=image_size,
+ num_hidden_layers=24,
+ hidden_size=1024,
+ intermediate_size=4096,
+ num_attention_heads=16,
+ use_relative_position_bias=True,
+ reshape_hidden_states=False,
+ out_features=["stage6", "stage12", "stage18", "stage24"], # beit-large-512 uses [5, 11, 17, 23],
+ )
+
+ neck_hidden_sizes = [256, 512, 1024, 1024]
+ bin_centers_type = "softplus" if model_name in ["ZoeD_N", "ZoeD_NK"] else "normed"
+ if model_name == "ZoeD_NK":
+ bin_configurations = [
+ {"name": "nyu", "n_bins": 64, "min_depth": 1e-3, "max_depth": 10.0},
+ {"name": "kitti", "n_bins": 64, "min_depth": 1e-3, "max_depth": 80.0},
+ ]
+ elif model_name in ["ZoeD_N", "ZoeD_K"]:
+ bin_configurations = [
+ {"name": "nyu", "n_bins": 64, "min_depth": 1e-3, "max_depth": 10.0},
+ ]
+ config = ZoeDepthConfig(
+ backbone_config=backbone_config,
+ neck_hidden_sizes=neck_hidden_sizes,
+ bin_centers_type=bin_centers_type,
+ bin_configurations=bin_configurations,
+ num_patch_transformer_layers=4 if model_name == "ZoeD_NK" else None,
+ patch_transformer_hidden_size=128 if model_name == "ZoeD_NK" else None,
+ patch_transformer_intermediate_size=1024 if model_name == "ZoeD_NK" else None,
+ patch_transformer_num_attention_heads=4 if model_name == "ZoeD_NK" else None,
+ )
+
+ return config, image_size
+
+
+def rename_key(name):
+ # Transformer backbone
+ if "core.core.pretrained.model.blocks" in name:
+ name = name.replace("core.core.pretrained.model.blocks", "backbone.encoder.layer")
+ if "core.core.pretrained.model.patch_embed.proj" in name:
+ name = name.replace(
+ "core.core.pretrained.model.patch_embed.proj", "backbone.embeddings.patch_embeddings.projection"
+ )
+ if "core.core.pretrained.model.cls_token" in name:
+ name = name.replace("core.core.pretrained.model.cls_token", "backbone.embeddings.cls_token")
+ if "norm1" in name and "patch_transformer" not in name:
+ name = name.replace("norm1", "layernorm_before")
+ if "norm2" in name and "patch_transformer" not in name:
+ name = name.replace("norm2", "layernorm_after")
+ if "mlp.fc1" in name:
+ name = name.replace("mlp.fc1", "intermediate.dense")
+ if "mlp.fc2" in name:
+ name = name.replace("mlp.fc2", "output.dense")
+ if "gamma_1" in name:
+ name = name.replace("gamma_1", "lambda_1")
+ if "gamma_2" in name:
+ name = name.replace("gamma_2", "lambda_2")
+ if "attn.proj" in name:
+ name = name.replace("attn.proj", "attention.output.dense")
+ if "attn.relative_position_bias_table" in name:
+ name = name.replace(
+ "attn.relative_position_bias_table",
+ "attention.attention.relative_position_bias.relative_position_bias_table",
+ )
+ if "attn.relative_position_index" in name:
+ name = name.replace(
+ "attn.relative_position_index", "attention.attention.relative_position_bias.relative_position_index"
+ )
+
+ # activation postprocessing (readout projections + resize blocks)
+ if "core.core.pretrained.act_postprocess1.0.project" in name:
+ name = name.replace(
+ "core.core.pretrained.act_postprocess1.0.project", "neck.reassemble_stage.readout_projects.0"
+ )
+ if "core.core.pretrained.act_postprocess2.0.project" in name:
+ name = name.replace(
+ "core.core.pretrained.act_postprocess2.0.project", "neck.reassemble_stage.readout_projects.1"
+ )
+ if "core.core.pretrained.act_postprocess3.0.project" in name:
+ name = name.replace(
+ "core.core.pretrained.act_postprocess3.0.project", "neck.reassemble_stage.readout_projects.2"
+ )
+ if "core.core.pretrained.act_postprocess4.0.project" in name:
+ name = name.replace(
+ "core.core.pretrained.act_postprocess4.0.project", "neck.reassemble_stage.readout_projects.3"
+ )
+
+ if "core.core.pretrained.act_postprocess1.3" in name:
+ name = name.replace("core.core.pretrained.act_postprocess1.3", "neck.reassemble_stage.layers.0.projection")
+ if "core.core.pretrained.act_postprocess2.3" in name:
+ name = name.replace("core.core.pretrained.act_postprocess2.3", "neck.reassemble_stage.layers.1.projection")
+ if "core.core.pretrained.act_postprocess3.3" in name:
+ name = name.replace("core.core.pretrained.act_postprocess3.3", "neck.reassemble_stage.layers.2.projection")
+ if "core.core.pretrained.act_postprocess4.3" in name:
+ name = name.replace("core.core.pretrained.act_postprocess4.3", "neck.reassemble_stage.layers.3.projection")
+
+ if "core.core.pretrained.act_postprocess1.4" in name:
+ name = name.replace("core.core.pretrained.act_postprocess1.4", "neck.reassemble_stage.layers.0.resize")
+ if "core.core.pretrained.act_postprocess2.4" in name:
+ name = name.replace("core.core.pretrained.act_postprocess2.4", "neck.reassemble_stage.layers.1.resize")
+ if "core.core.pretrained.act_postprocess4.4" in name:
+ name = name.replace("core.core.pretrained.act_postprocess4.4", "neck.reassemble_stage.layers.3.resize")
+
+ # scratch convolutions
+ if "core.core.scratch.layer1_rn.weight" in name:
+ name = name.replace("core.core.scratch.layer1_rn.weight", "neck.convs.0.weight")
+ if "core.core.scratch.layer2_rn.weight" in name:
+ name = name.replace("core.core.scratch.layer2_rn.weight", "neck.convs.1.weight")
+ if "core.core.scratch.layer3_rn.weight" in name:
+ name = name.replace("core.core.scratch.layer3_rn.weight", "neck.convs.2.weight")
+ if "core.core.scratch.layer4_rn.weight" in name:
+ name = name.replace("core.core.scratch.layer4_rn.weight", "neck.convs.3.weight")
+
+ # fusion layers
+ # tricky here: mapping = {1:3, 2:2, 3:1, 4:0}
+ if "core.core.scratch.refinenet1" in name:
+ name = name.replace("core.core.scratch.refinenet1", "neck.fusion_stage.layers.3")
+ if "core.core.scratch.refinenet2" in name:
+ name = name.replace("core.core.scratch.refinenet2", "neck.fusion_stage.layers.2")
+ if "core.core.scratch.refinenet3" in name:
+ name = name.replace("core.core.scratch.refinenet3", "neck.fusion_stage.layers.1")
+ if "core.core.scratch.refinenet4" in name:
+ name = name.replace("core.core.scratch.refinenet4", "neck.fusion_stage.layers.0")
+
+ if "resConfUnit1" in name:
+ name = name.replace("resConfUnit1", "residual_layer1")
+
+ if "resConfUnit2" in name:
+ name = name.replace("resConfUnit2", "residual_layer2")
+
+ if "conv1" in name:
+ name = name.replace("conv1", "convolution1")
+
+ if "conv2" in name and "residual_layer" in name:
+ name = name.replace("conv2", "convolution2")
+
+ if "out_conv" in name:
+ name = name.replace("out_conv", "projection")
+
+ # relative depth estimation head
+ if "core.core.scratch.output_conv.0" in name:
+ name = name.replace("core.core.scratch.output_conv.0", "relative_head.conv1")
+
+ if "core.core.scratch.output_conv.2" in name:
+ name = name.replace("core.core.scratch.output_conv.2", "relative_head.conv2")
+
+ if "core.core.scratch.output_conv.4" in name:
+ name = name.replace("core.core.scratch.output_conv.4", "relative_head.conv3")
+
+ # patch transformer
+ if "patch_transformer" in name:
+ name = name.replace("patch_transformer", "metric_head.patch_transformer")
+
+ if "mlp_classifier.0" in name:
+ name = name.replace("mlp_classifier.0", "metric_head.mlp_classifier.linear1")
+ if "mlp_classifier.2" in name:
+ name = name.replace("mlp_classifier.2", "metric_head.mlp_classifier.linear2")
+
+ if "projectors" in name:
+ name = name.replace("projectors", "metric_head.projectors")
+
+ if "seed_bin_regressors" in name:
+ name = name.replace("seed_bin_regressors", "metric_head.seed_bin_regressors")
+
+ if "seed_bin_regressor" in name and "seed_bin_regressors" not in name:
+ name = name.replace("seed_bin_regressor", "metric_head.seed_bin_regressor")
+
+ if "seed_projector" in name:
+ name = name.replace("seed_projector", "metric_head.seed_projector")
+
+ if "_net.0" in name:
+ name = name.replace("_net.0", "conv1")
+
+ if "_net.2" in name:
+ name = name.replace("_net.2", "conv2")
+
+ if "attractors" in name:
+ name = name.replace("attractors", "metric_head.attractors")
+
+ if "conditional_log_binomial" in name:
+ name = name.replace("conditional_log_binomial", "metric_head.conditional_log_binomial")
+
+ # metric depth estimation head
+ if "conv2" in name and "metric_head" not in name and "attractors" not in name and "relative_head" not in name:
+ name = name.replace("conv2", "metric_head.conv2")
+
+ if "transformer_encoder.layers" in name:
+ name = name.replace("transformer_encoder.layers", "transformer_encoder")
+
+ return name
+
+
+def read_in_q_k_v_metric_head(state_dict):
+ hidden_size = 128
+ for i in range(4):
+ # read in weights + bias of input projection layer (in original implementation, this is a single matrix + bias)
+ in_proj_weight = state_dict.pop(f"patch_transformer.transformer_encoder.layers.{i}.self_attn.in_proj_weight")
+ in_proj_bias = state_dict.pop(f"patch_transformer.transformer_encoder.layers.{i}.self_attn.in_proj_bias")
+ # next, add query, keys and values (in that order) to the state dict
+ state_dict[f"patch_transformer.transformer_encoder.{i}.self_attn.query.weight"] = in_proj_weight[
+ :hidden_size, :
+ ]
+ state_dict[f"patch_transformer.transformer_encoder.{i}.self_attn.query.bias"] = in_proj_bias[:hidden_size]
+
+ state_dict[f"patch_transformer.transformer_encoder.{i}.self_attn.key.weight"] = in_proj_weight[
+ hidden_size : hidden_size * 2, :
+ ]
+ state_dict[f"patch_transformer.transformer_encoder.{i}.self_attn.key.bias"] = in_proj_bias[
+ hidden_size : hidden_size * 2
+ ]
+
+ state_dict[f"patch_transformer.transformer_encoder.{i}.self_attn.value.weight"] = in_proj_weight[
+ -hidden_size:, :
+ ]
+ state_dict[f"patch_transformer.transformer_encoder.{i}.self_attn.value.bias"] = in_proj_bias[-hidden_size:]
+
+
+def convert_state_dict(orig_state_dict):
+ for key in orig_state_dict.copy().keys():
+ val = orig_state_dict.pop(key)
+
+ # rename key
+ new_name = rename_key(key)
+ orig_state_dict[new_name] = val
+
+ return orig_state_dict
+
+
+def remove_ignore_keys(state_dict):
+ for key, _ in state_dict.copy().items():
+ if (
+ "fc_norm" in key
+ or "relative_position_index" in key
+ or "k_idx" in key
+ or "K_minus_1" in key
+ or "core.core.pretrained.model.head" in key
+ ):
+ state_dict.pop(key, None)
+
+
+# we split up the matrix of each encoder layer into queries, keys and values
+def read_in_q_k_v(state_dict, config):
+ hidden_size = config.backbone_config.hidden_size
+ for i in range(config.backbone_config.num_hidden_layers):
+ # read in weights + bias of input projection layer (in original implementation, this is a single matrix + bias)
+ in_proj_weight = state_dict.pop(f"core.core.pretrained.model.blocks.{i}.attn.qkv.weight")
+ q_bias = state_dict.pop(f"core.core.pretrained.model.blocks.{i}.attn.q_bias")
+ v_bias = state_dict.pop(f"core.core.pretrained.model.blocks.{i}.attn.v_bias")
+ # next, add query, keys and values (in that order) to the state dict
+ state_dict[f"backbone.encoder.layer.{i}.attention.attention.query.weight"] = in_proj_weight[:hidden_size, :]
+ state_dict[f"backbone.encoder.layer.{i}.attention.attention.query.bias"] = q_bias
+ state_dict[f"backbone.encoder.layer.{i}.attention.attention.key.weight"] = in_proj_weight[
+ hidden_size : hidden_size * 2, :
+ ]
+ state_dict[f"backbone.encoder.layer.{i}.attention.attention.value.weight"] = in_proj_weight[-hidden_size:, :]
+ state_dict[f"backbone.encoder.layer.{i}.attention.attention.value.bias"] = v_bias
+
+
+# We will verify our results on an image
+def prepare_img():
+ filepath = hf_hub_download(repo_id="shariqfarooq/ZoeDepth", filename="examples/person_1.jpeg", repo_type="space")
+ image = Image.open(filepath).convert("RGB")
+ return image
+
+
+@torch.no_grad()
+def convert_zoedepth_checkpoint(model_name, pytorch_dump_folder_path, push_to_hub):
+ """
+ Copy/paste/tweak model's weights to our ZoeDepth structure.
+ """
+
+ # define ZoeDepth configuration based on URL
+ config, _ = get_zoedepth_config(model_name)
+
+ # load original model
+ original_model = torch.hub.load(
+ "NielsRogge/ZoeDepth:understanding_zoedepth", model_name, pretrained=True, force_reload=True
+ )
+ original_model.eval()
+ state_dict = original_model.state_dict()
+
+ print("Original state dict:")
+ for name, param in state_dict.items():
+ print(name, param.shape)
+
+ # read in qkv matrices
+ read_in_q_k_v(state_dict, config)
+ if model_name == "ZoeD_NK":
+ read_in_q_k_v_metric_head(state_dict)
+
+ # rename keys
+ state_dict = convert_state_dict(state_dict)
+ # remove certain keys
+ remove_ignore_keys(state_dict)
+
+ # load HuggingFace model
+ model = ZoeDepthForDepthEstimation(config)
+ model.load_state_dict(state_dict)
+ model.eval()
+
+ # verify image processor
+ image = prepare_img()
+
+ image_processor = ZoeDepthImageProcessor()
+ pixel_values = image_processor(image, return_tensors="pt").pixel_values
+ filepath = hf_hub_download(
+ repo_id="nielsr/test-image",
+ filename="zoedepth_pixel_values.pt",
+ repo_type="dataset",
+ )
+ original_pixel_values = torch.load(filepath, map_location="cpu")
+ assert torch.allclose(pixel_values, original_pixel_values)
+
+ # verify logits
+ # this was done on a resized version of the cats image (384x384)
+ filepath = hf_hub_download(
+ repo_id="nielsr/test-image",
+ filename="zoedepth_pixel_values.pt",
+ repo_type="dataset",
+ revision="1865dbb81984f01c89e83eec10f8d07efd10743d",
+ )
+ cats_pixel_values = torch.load(filepath, map_location="cpu")
+ depth = model(cats_pixel_values).predicted_depth
+
+ # Verify logits
+ # These were obtained by inserting the pixel_values at the patch embeddings of BEiT
+ if model_name == "ZoeD_N":
+ expected_shape = torch.Size([1, 384, 384])
+ expected_slice = torch.tensor([[1.0328, 1.0604, 1.0747], [1.0816, 1.1293, 1.1456], [1.1117, 1.1629, 1.1766]])
+ elif model_name == "ZoeD_K":
+ expected_shape = torch.Size([1, 384, 384])
+ expected_slice = torch.tensor([[1.6567, 1.6852, 1.7065], [1.6707, 1.6764, 1.6713], [1.7195, 1.7166, 1.7118]])
+ elif model_name == "ZoeD_NK":
+ expected_shape = torch.Size([1, 384, 384])
+ expected_slice = torch.tensor([[1.1228, 1.1079, 1.1382], [1.1807, 1.1658, 1.1891], [1.2344, 1.2094, 1.2317]])
+
+ print("Shape of depth:", depth.shape)
+ print("First 3x3 slice of depth:", depth[0, :3, :3])
+
+ assert depth.shape == torch.Size(expected_shape)
+ assert torch.allclose(depth[0, :3, :3], expected_slice, atol=1e-4)
+ print("Looks ok!")
+
+ if pytorch_dump_folder_path is not None:
+ print(f"Saving model and processor to {pytorch_dump_folder_path}")
+ Path(pytorch_dump_folder_path).mkdir(exist_ok=True)
+ model.save_pretrained(pytorch_dump_folder_path)
+ image_processor.save_pretrained(pytorch_dump_folder_path)
+
+ if push_to_hub:
+ model_name_to_repo_id = {
+ "ZoeD_N": "zoedepth-nyu",
+ "ZoeD_K": "zoedepth-kitti",
+ "ZoeD_NK": "zoedepth-nyu-kitti",
+ }
+
+ print("Pushing model and processor to the hub...")
+ repo_id = model_name_to_repo_id[model_name]
+ model.push_to_hub(f"Intel/{repo_id}")
+ image_processor = ZoeDepthImageProcessor()
+ image_processor.push_to_hub(f"Intel/{repo_id}")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ # Required parameters
+ parser.add_argument(
+ "--model_name",
+ default="ZoeD_N",
+ choices=["ZoeD_N", "ZoeD_K", "ZoeD_NK"],
+ type=str,
+ help="Name of the original ZoeDepth checkpoint you'd like to convert.",
+ )
+ parser.add_argument(
+ "--pytorch_dump_folder_path",
+ default=None,
+ type=str,
+ required=False,
+ help="Path to the output PyTorch model directory.",
+ )
+ parser.add_argument(
+ "--push_to_hub",
+ action="store_true",
+ )
+
+ args = parser.parse_args()
+ convert_zoedepth_checkpoint(args.model_name, args.pytorch_dump_folder_path, args.push_to_hub)
diff --git a/src/transformers/models/zoedepth/image_processing_zoedepth.py b/src/transformers/models/zoedepth/image_processing_zoedepth.py
new file mode 100644
index 00000000000000..5276f2239151e8
--- /dev/null
+++ b/src/transformers/models/zoedepth/image_processing_zoedepth.py
@@ -0,0 +1,454 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Image processor class for ZoeDepth."""
+
+import math
+from typing import Dict, Iterable, List, Optional, Tuple, Union
+
+import numpy as np
+
+from ...image_processing_utils import BaseImageProcessor, BatchFeature, get_size_dict
+from ...image_transforms import PaddingMode, pad, to_channel_dimension_format
+from ...image_utils import (
+ IMAGENET_STANDARD_MEAN,
+ IMAGENET_STANDARD_STD,
+ ChannelDimension,
+ ImageInput,
+ PILImageResampling,
+ get_image_size,
+ infer_channel_dimension_format,
+ is_scaled_image,
+ make_list_of_images,
+ to_numpy_array,
+ valid_images,
+ validate_preprocess_arguments,
+)
+from ...utils import TensorType, is_torch_available, is_vision_available, logging, requires_backends
+
+
+if is_vision_available():
+ import PIL
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+
+logger = logging.get_logger(__name__)
+
+
+def get_resize_output_image_size(
+ input_image: np.ndarray,
+ output_size: Union[int, Iterable[int]],
+ keep_aspect_ratio: bool,
+ multiple: int,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+) -> Tuple[int, int]:
+ def constrain_to_multiple_of(val, multiple, min_val=0):
+ x = (np.round(val / multiple) * multiple).astype(int)
+
+ if x < min_val:
+ x = math.ceil(val / multiple) * multiple
+
+ return x
+
+ output_size = (output_size, output_size) if isinstance(output_size, int) else output_size
+
+ input_height, input_width = get_image_size(input_image, input_data_format)
+ output_height, output_width = output_size
+
+ # determine new height and width
+ scale_height = output_height / input_height
+ scale_width = output_width / input_width
+
+ if keep_aspect_ratio:
+ # scale as little as possible
+ if abs(1 - scale_width) < abs(1 - scale_height):
+ # fit width
+ scale_height = scale_width
+ else:
+ # fit height
+ scale_width = scale_height
+
+ new_height = constrain_to_multiple_of(scale_height * input_height, multiple=multiple)
+ new_width = constrain_to_multiple_of(scale_width * input_width, multiple=multiple)
+
+ return (new_height, new_width)
+
+
+class ZoeDepthImageProcessor(BaseImageProcessor):
+ r"""
+ Constructs a ZoeDepth image processor.
+
+ Args:
+ do_pad (`bool`, *optional*, defaults to `True`):
+ Whether to apply pad the input.
+ do_rescale (`bool`, *optional*, defaults to `True`):
+ Whether to rescale the image by the specified scale `rescale_factor`. Can be overidden by `do_rescale` in
+ `preprocess`.
+ rescale_factor (`int` or `float`, *optional*, defaults to `1/255`):
+ Scale factor to use if rescaling the image. Can be overidden by `rescale_factor` in `preprocess`.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether to normalize the image. Can be overridden by the `do_normalize` parameter in the `preprocess`
+ method.
+ image_mean (`float` or `List[float]`, *optional*, defaults to `IMAGENET_STANDARD_MEAN`):
+ Mean to use if normalizing the image. This is a float or list of floats the length of the number of
+ channels in the image. Can be overridden by the `image_mean` parameter in the `preprocess` method.
+ image_std (`float` or `List[float]`, *optional*, defaults to `IMAGENET_STANDARD_STD`):
+ Standard deviation to use if normalizing the image. This is a float or list of floats the length of the
+ number of channels in the image. Can be overridden by the `image_std` parameter in the `preprocess` method.
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Whether to resize the image's (height, width) dimensions. Can be overidden by `do_resize` in `preprocess`.
+ size (`Dict[str, int]` *optional*, defaults to `{"height": 384, "width": 512}`):
+ Size of the image after resizing. Size of the image after resizing. If `keep_aspect_ratio` is `True`,
+ the image is resized by choosing the smaller of the height and width scaling factors and using it for both dimensions.
+ If `ensure_multiple_of` is also set, the image is further resized to a size that is a multiple of this value.
+ Can be overidden by `size` in `preprocess`.
+ resample (`PILImageResampling`, *optional*, defaults to `Resampling.BILINEAR`):
+ Defines the resampling filter to use if resizing the image. Can be overidden by `resample` in `preprocess`.
+ keep_aspect_ratio (`bool`, *optional*, defaults to `True`):
+ If `True`, the image is resized by choosing the smaller of the height and width scaling factors and using it for
+ both dimensions. This ensures that the image is scaled down as little as possible while still fitting within the
+ desired output size. In case `ensure_multiple_of` is also set, the image is further resized to a size that is a
+ multiple of this value by flooring the height and width to the nearest multiple of this value.
+ Can be overidden by `keep_aspect_ratio` in `preprocess`.
+ ensure_multiple_of (`int`, *optional*, defaults to 32):
+ If `do_resize` is `True`, the image is resized to a size that is a multiple of this value. Works by flooring
+ the height and width to the nearest multiple of this value.
+
+ Works both with and without `keep_aspect_ratio` being set to `True`. Can be overidden by `ensure_multiple_of`
+ in `preprocess`.
+ """
+
+ model_input_names = ["pixel_values"]
+
+ def __init__(
+ self,
+ do_pad: bool = True,
+ do_rescale: bool = True,
+ rescale_factor: Union[int, float] = 1 / 255,
+ do_normalize: bool = True,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ do_resize: bool = True,
+ size: Dict[str, int] = None,
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ keep_aspect_ratio: bool = True,
+ ensure_multiple_of: int = 32,
+ **kwargs,
+ ) -> None:
+ super().__init__(**kwargs)
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_pad = do_pad
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean if image_mean is not None else IMAGENET_STANDARD_MEAN
+ self.image_std = image_std if image_std is not None else IMAGENET_STANDARD_STD
+ size = size if size is not None else {"height": 384, "width": 512}
+ size = get_size_dict(size)
+ self.do_resize = do_resize
+ self.size = size
+ self.keep_aspect_ratio = keep_aspect_ratio
+ self.ensure_multiple_of = ensure_multiple_of
+ self.resample = resample
+
+ self._valid_processor_keys = [
+ "images",
+ "do_resize",
+ "size",
+ "keep_aspect_ratio",
+ "ensure_multiple_of",
+ "resample",
+ "do_rescale",
+ "rescale_factor",
+ "do_normalize",
+ "image_mean",
+ "image_std",
+ "do_pad",
+ "return_tensors",
+ "data_format",
+ "input_data_format",
+ ]
+
+ def resize(
+ self,
+ image: np.ndarray,
+ size: Dict[str, int],
+ keep_aspect_ratio: bool = False,
+ ensure_multiple_of: int = 1,
+ resample: PILImageResampling = PILImageResampling.BILINEAR,
+ data_format: Optional[Union[str, ChannelDimension]] = None,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ ) -> np.ndarray:
+ """
+ Resize an image to target size `(size["height"], size["width"])`. If `keep_aspect_ratio` is `True`, the image
+ is resized to the largest possible size such that the aspect ratio is preserved. If `ensure_multiple_of` is
+ set, the image is resized to a size that is a multiple of this value.
+
+ Args:
+ image (`np.ndarray`):
+ Image to resize.
+ size (`Dict[str, int]`):
+ Target size of the output image.
+ keep_aspect_ratio (`bool`, *optional*, defaults to `False`):
+ If `True`, the image is resized to the largest possible size such that the aspect ratio is preserved.
+ ensure_multiple_of (`int`, *optional*, defaults to 1):
+ The image is resized to a size that is a multiple of this value.
+ resample (`PILImageResampling`, *optional*, defaults to `PILImageResampling.BILINEAR`):
+ Defines the resampling filter to use if resizing the image. Otherwise, the image is resized to size
+ specified in `size`.
+ data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format of the image. If not provided, it will be the same as the input image.
+ input_data_format (`str` or `ChannelDimension`, *optional*):
+ The channel dimension format of the input image. If not provided, it will be inferred.
+ """
+ if input_data_format is None:
+ input_data_format = infer_channel_dimension_format(image)
+
+ data_format = data_format if data_format is not None else input_data_format
+
+ size = get_size_dict(size)
+ if "height" not in size or "width" not in size:
+ raise ValueError(f"The size dictionary must contain the keys 'height' and 'width'. Got {size.keys()}")
+
+ output_size = get_resize_output_image_size(
+ image,
+ output_size=(size["height"], size["width"]),
+ keep_aspect_ratio=keep_aspect_ratio,
+ multiple=ensure_multiple_of,
+ input_data_format=input_data_format,
+ )
+
+ height, width = output_size
+
+ torch_image = torch.from_numpy(image).unsqueeze(0)
+ torch_image = torch_image.permute(0, 3, 1, 2) if input_data_format == "channels_last" else torch_image
+
+ # TODO support align_corners=True in image_transforms.resize
+ requires_backends(self, "torch")
+ resample_to_mode = {PILImageResampling.BILINEAR: "bilinear", PILImageResampling.BICUBIC: "bicubic"}
+ mode = resample_to_mode[resample]
+ resized_image = nn.functional.interpolate(
+ torch_image, (int(height), int(width)), mode=mode, align_corners=True
+ )
+ resized_image = resized_image.squeeze().numpy()
+
+ resized_image = to_channel_dimension_format(
+ resized_image, data_format, input_channel_dim=ChannelDimension.FIRST
+ )
+
+ return resized_image
+
+ def pad_image(
+ self,
+ image: np.array,
+ mode: PaddingMode = PaddingMode.REFLECT,
+ data_format: Optional[Union[str, ChannelDimension]] = None,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ ):
+ """
+ Pad an image as done in the original ZoeDepth implementation.
+
+ Padding fixes the boundary artifacts in the output depth map.
+ Boundary artifacts are sometimes caused by the fact that the model is trained on NYU raw dataset
+ which has a black or white border around the image. This function pads the input image and crops
+ the prediction back to the original size / view.
+
+ Args:
+ image (`np.ndarray`):
+ Image to pad.
+ mode (`PaddingMode`):
+ The padding mode to use. Can be one of:
+ - `"constant"`: pads with a constant value.
+ - `"reflect"`: pads with the reflection of the vector mirrored on the first and last values of the
+ vector along each axis.
+ - `"replicate"`: pads with the replication of the last value on the edge of the array along each axis.
+ - `"symmetric"`: pads with the reflection of the vector mirrored along the edge of the array.
+ data_format (`ChannelDimension` or `str`, *optional*, defaults to `ChannelDimension.FIRST`):
+ The channel dimension format for the output image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - Unset: Use the channel dimension format of the input image.
+ input_data_format (`ChannelDimension` or `str`, *optional*):
+ The channel dimension format for the input image. If unset, the channel dimension format is inferred
+ from the input image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - `"none"` or `ChannelDimension.NONE`: image in (height, width) format.
+ """
+ height, width = get_image_size(image, input_data_format)
+
+ pad_height = int(np.sqrt(height / 2) * 3)
+ pad_width = int(np.sqrt(width / 2) * 3)
+
+ return pad(
+ image,
+ padding=((pad_height, pad_height), (pad_width, pad_width)),
+ mode=mode,
+ data_format=data_format,
+ input_data_format=input_data_format,
+ )
+
+ def preprocess(
+ self,
+ images: ImageInput,
+ do_pad: bool = None,
+ do_rescale: bool = None,
+ rescale_factor: float = None,
+ do_normalize: bool = None,
+ image_mean: Optional[Union[float, List[float]]] = None,
+ image_std: Optional[Union[float, List[float]]] = None,
+ do_resize: bool = None,
+ size: int = None,
+ keep_aspect_ratio: bool = None,
+ ensure_multiple_of: int = None,
+ resample: PILImageResampling = None,
+ return_tensors: Optional[Union[str, TensorType]] = None,
+ data_format: ChannelDimension = ChannelDimension.FIRST,
+ input_data_format: Optional[Union[str, ChannelDimension]] = None,
+ ) -> PIL.Image.Image:
+ """
+ Preprocess an image or batch of images.
+
+ Args:
+ images (`ImageInput`):
+ Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If
+ passing in images with pixel values between 0 and 1, set `do_rescale=False`.
+ do_pad (`bool`, *optional*, defaults to `self.do_pad`):
+ Whether to pad the input image.
+ do_rescale (`bool`, *optional*, defaults to `self.do_rescale`):
+ Whether to rescale the image values between [0 - 1].
+ rescale_factor (`float`, *optional*, defaults to `self.rescale_factor`):
+ Rescale factor to rescale the image by if `do_rescale` is set to `True`.
+ do_normalize (`bool`, *optional*, defaults to `self.do_normalize`):
+ Whether to normalize the image.
+ image_mean (`float` or `List[float]`, *optional*, defaults to `self.image_mean`):
+ Image mean.
+ image_std (`float` or `List[float]`, *optional*, defaults to `self.image_std`):
+ Image standard deviation.
+ do_resize (`bool`, *optional*, defaults to `self.do_resize`):
+ Whether to resize the image.
+ size (`Dict[str, int]`, *optional*, defaults to `self.size`):
+ Size of the image after resizing. If `keep_aspect_ratio` is `True`, he image is resized by choosing the smaller of
+ the height and width scaling factors and using it for both dimensions. If `ensure_multiple_of` is also set,
+ the image is further resized to a size that is a multiple of this value.
+ keep_aspect_ratio (`bool`, *optional*, defaults to `self.keep_aspect_ratio`):
+ If `True` and `do_resize=True`, the image is resized by choosing the smaller of the height and width scaling factors and using it for
+ both dimensions. This ensures that the image is scaled down as little as possible while still fitting within the
+ desired output size. In case `ensure_multiple_of` is also set, the image is further resized to a size that is a
+ multiple of this value by flooring the height and width to the nearest multiple of this value.
+ ensure_multiple_of (`int`, *optional*, defaults to `self.ensure_multiple_of`):
+ If `do_resize` is `True`, the image is resized to a size that is a multiple of this value. Works by flooring
+ the height and width to the nearest multiple of this value.
+
+ Works both with and without `keep_aspect_ratio` being set to `True`. Can be overidden by `ensure_multiple_of` in `preprocess`.
+ resample (`int`, *optional*, defaults to `self.resample`):
+ Resampling filter to use if resizing the image. This can be one of the enum `PILImageResampling`, Only
+ has an effect if `do_resize` is set to `True`.
+ return_tensors (`str` or `TensorType`, *optional*):
+ The type of tensors to return. Can be one of:
+ - Unset: Return a list of `np.ndarray`.
+ - `TensorType.TENSORFLOW` or `'tf'`: Return a batch of type `tf.Tensor`.
+ - `TensorType.PYTORCH` or `'pt'`: Return a batch of type `torch.Tensor`.
+ - `TensorType.NUMPY` or `'np'`: Return a batch of type `np.ndarray`.
+ - `TensorType.JAX` or `'jax'`: Return a batch of type `jax.numpy.ndarray`.
+ data_format (`ChannelDimension` or `str`, *optional*, defaults to `ChannelDimension.FIRST`):
+ The channel dimension format for the output image. Can be one of:
+ - `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ input_data_format (`ChannelDimension` or `str`, *optional*):
+ The channel dimension format for the input image. If unset, the channel dimension format is inferred
+ from the input image. Can be one of:
+ - `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
+ - `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
+ - `"none"` or `ChannelDimension.NONE`: image in (height, width) format.
+ """
+ do_resize = do_resize if do_resize is not None else self.do_resize
+ size = size if size is not None else self.size
+ size = get_size_dict(size)
+ keep_aspect_ratio = keep_aspect_ratio if keep_aspect_ratio is not None else self.keep_aspect_ratio
+ ensure_multiple_of = ensure_multiple_of if ensure_multiple_of is not None else self.ensure_multiple_of
+ resample = resample if resample is not None else self.resample
+ do_rescale = do_rescale if do_rescale is not None else self.do_rescale
+ rescale_factor = rescale_factor if rescale_factor is not None else self.rescale_factor
+ do_normalize = do_normalize if do_normalize is not None else self.do_normalize
+ image_mean = image_mean if image_mean is not None else self.image_mean
+ image_std = image_std if image_std is not None else self.image_std
+ do_pad = do_pad if do_pad is not None else self.do_pad
+
+ images = make_list_of_images(images)
+
+ if not valid_images(images):
+ raise ValueError(
+ "Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
+ "torch.Tensor, tf.Tensor or jax.ndarray."
+ )
+ validate_preprocess_arguments(
+ do_rescale=do_rescale,
+ rescale_factor=rescale_factor,
+ do_normalize=do_normalize,
+ image_mean=image_mean,
+ image_std=image_std,
+ do_resize=do_resize,
+ size=size,
+ resample=resample,
+ )
+ # All transformations expect numpy arrays.
+ images = [to_numpy_array(image) for image in images]
+
+ if is_scaled_image(images[0]) and do_rescale:
+ logger.warning_once(
+ "It looks like you are trying to rescale already rescaled images. If the input"
+ " images have pixel values between 0 and 1, set `do_rescale=False` to avoid rescaling them again."
+ )
+
+ if input_data_format is None:
+ # We assume that all images have the same channel dimension format.
+ input_data_format = infer_channel_dimension_format(images[0])
+
+ if do_rescale:
+ images = [
+ self.rescale(image=image, scale=rescale_factor, input_data_format=input_data_format)
+ for image in images
+ ]
+
+ if do_pad:
+ images = [self.pad_image(image=image, input_data_format=input_data_format) for image in images]
+
+ if do_resize:
+ images = [
+ self.resize(
+ image=image,
+ size=size,
+ resample=resample,
+ keep_aspect_ratio=keep_aspect_ratio,
+ ensure_multiple_of=ensure_multiple_of,
+ input_data_format=input_data_format,
+ )
+ for image in images
+ ]
+
+ if do_normalize:
+ images = [
+ self.normalize(image=image, mean=image_mean, std=image_std, input_data_format=input_data_format)
+ for image in images
+ ]
+
+ images = [
+ to_channel_dimension_format(image, data_format, input_channel_dim=input_data_format) for image in images
+ ]
+
+ data = {"pixel_values": images}
+ return BatchFeature(data=data, tensor_type=return_tensors)
diff --git a/src/transformers/models/zoedepth/modeling_zoedepth.py b/src/transformers/models/zoedepth/modeling_zoedepth.py
new file mode 100644
index 00000000000000..f03f775d1e4faf
--- /dev/null
+++ b/src/transformers/models/zoedepth/modeling_zoedepth.py
@@ -0,0 +1,1403 @@
+# coding=utf-8
+# Copyright 2024 Intel Labs and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""PyTorch ZoeDepth model."""
+
+import math
+from dataclasses import dataclass
+from typing import List, Optional, Tuple, Union
+
+import torch
+import torch.utils.checkpoint
+from torch import nn
+
+from ...activations import ACT2FN
+from ...file_utils import (
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ replace_return_docstrings,
+)
+from ...modeling_outputs import DepthEstimatorOutput
+from ...modeling_utils import PreTrainedModel
+from ...utils import ModelOutput, logging
+from ...utils.backbone_utils import load_backbone
+from .configuration_zoedepth import ZoeDepthConfig
+
+
+logger = logging.get_logger(__name__)
+
+# General docstring
+_CONFIG_FOR_DOC = "ZoeDepthConfig"
+
+
+@dataclass
+class ZoeDepthDepthEstimatorOutput(ModelOutput):
+ """
+ Extension of `DepthEstimatorOutput` to include domain logits (ZoeDepth specific).
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided):
+ Classification (or regression if config.num_labels==1) loss.
+ predicted_depth (`torch.FloatTensor` of shape `(batch_size, height, width)`):
+ Predicted depth for each pixel.
+
+ domain_logits (`torch.FloatTensor` of shape `(batch_size, num_domains)`):
+ Logits for each domain (e.g. NYU and KITTI) in case multiple metric heads are used.
+
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
+ one for the output of each layer) of shape `(batch_size, num_channels, height, width)`.
+
+ Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, patch_size,
+ sequence_length)`.
+
+ Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
+ heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ predicted_depth: torch.FloatTensor = None
+ domain_logits: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
+ attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
+
+
+class ZoeDepthReassembleStage(nn.Module):
+ """
+ This class reassembles the hidden states of the backbone into image-like feature representations at various
+ resolutions.
+
+ This happens in 3 stages:
+ 1. Map the N + 1 tokens to a set of N tokens, by taking into account the readout ([CLS]) token according to
+ `config.readout_type`.
+ 2. Project the channel dimension of the hidden states according to `config.neck_hidden_sizes`.
+ 3. Resizing the spatial dimensions (height, width).
+
+ Args:
+ config (`[ZoeDepthConfig]`):
+ Model configuration class defining the model architecture.
+ """
+
+ def __init__(self, config):
+ super().__init__()
+
+ self.readout_type = config.readout_type
+ self.layers = nn.ModuleList()
+
+ for neck_hidden_size, factor in zip(config.neck_hidden_sizes, config.reassemble_factors):
+ self.layers.append(ZoeDepthReassembleLayer(config, channels=neck_hidden_size, factor=factor))
+
+ if config.readout_type == "project":
+ self.readout_projects = nn.ModuleList()
+ hidden_size = config.backbone_hidden_size
+ for _ in config.neck_hidden_sizes:
+ self.readout_projects.append(
+ nn.Sequential(nn.Linear(2 * hidden_size, hidden_size), ACT2FN[config.hidden_act])
+ )
+
+ def forward(self, hidden_states: List[torch.Tensor], patch_height, patch_width) -> List[torch.Tensor]:
+ """
+ Args:
+ hidden_states (`List[torch.FloatTensor]`, each of shape `(batch_size, sequence_length + 1, hidden_size)`):
+ List of hidden states from the backbone.
+ """
+ batch_size = hidden_states[0].shape[0]
+
+ # stack along batch dimension
+ # shape (batch_size*num_stages, sequence_length + 1, hidden_size)
+ hidden_states = torch.cat(hidden_states, dim=0)
+
+ cls_token, hidden_states = hidden_states[:, 0], hidden_states[:, 1:]
+ # reshape hidden_states to (batch_size*num_stages, num_channels, height, width)
+ total_batch_size, sequence_length, num_channels = hidden_states.shape
+ hidden_states = hidden_states.reshape(total_batch_size, patch_height, patch_width, num_channels)
+ hidden_states = hidden_states.permute(0, 3, 1, 2).contiguous()
+
+ if self.readout_type == "project":
+ # reshape to (batch_size*num_stages, height*width, num_channels)
+ hidden_states = hidden_states.flatten(2).permute((0, 2, 1))
+ readout = cls_token.unsqueeze(dim=1).expand_as(hidden_states)
+ # concatenate the readout token to the hidden states
+ # to get (batch_size*num_stages, height*width, 2*num_channels)
+ hidden_states = torch.cat((hidden_states, readout), -1)
+ elif self.readout_type == "add":
+ hidden_states = hidden_states + cls_token.unsqueeze(-1)
+
+ out = []
+ for stage_idx, hidden_state in enumerate(hidden_states.split(batch_size, dim=0)):
+ if self.readout_type == "project":
+ hidden_state = self.readout_projects[stage_idx](hidden_state)
+
+ # reshape back to (batch_size, num_channels, height, width)
+ hidden_state = hidden_state.permute(0, 2, 1).reshape(batch_size, -1, patch_height, patch_width)
+ hidden_state = self.layers[stage_idx](hidden_state)
+ out.append(hidden_state)
+
+ return out
+
+
+class ZoeDepthReassembleLayer(nn.Module):
+ def __init__(self, config, channels, factor):
+ super().__init__()
+ # projection
+ hidden_size = config.backbone_hidden_size
+ self.projection = nn.Conv2d(in_channels=hidden_size, out_channels=channels, kernel_size=1)
+
+ # up/down sampling depending on factor
+ if factor > 1:
+ self.resize = nn.ConvTranspose2d(channels, channels, kernel_size=factor, stride=factor, padding=0)
+ elif factor == 1:
+ self.resize = nn.Identity()
+ elif factor < 1:
+ # so should downsample
+ self.resize = nn.Conv2d(channels, channels, kernel_size=3, stride=int(1 / factor), padding=1)
+
+ # Copied from transformers.models.dpt.modeling_dpt.DPTReassembleLayer.forward with DPT->ZoeDepth
+ def forward(self, hidden_state):
+ hidden_state = self.projection(hidden_state)
+ hidden_state = self.resize(hidden_state)
+ return hidden_state
+
+
+# Copied from transformers.models.dpt.modeling_dpt.DPTFeatureFusionStage with DPT->ZoeDepth
+class ZoeDepthFeatureFusionStage(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.layers = nn.ModuleList()
+ for _ in range(len(config.neck_hidden_sizes)):
+ self.layers.append(ZoeDepthFeatureFusionLayer(config))
+
+ def forward(self, hidden_states):
+ # reversing the hidden_states, we start from the last
+ hidden_states = hidden_states[::-1]
+
+ fused_hidden_states = []
+ # first layer only uses the last hidden_state
+ fused_hidden_state = self.layers[0](hidden_states[0])
+ fused_hidden_states.append(fused_hidden_state)
+ # looping from the last layer to the second
+ for hidden_state, layer in zip(hidden_states[1:], self.layers[1:]):
+ fused_hidden_state = layer(fused_hidden_state, hidden_state)
+ fused_hidden_states.append(fused_hidden_state)
+
+ return fused_hidden_states
+
+
+# Copied from transformers.models.dpt.modeling_dpt.DPTPreActResidualLayer with DPT->ZoeDepth
+class ZoeDepthPreActResidualLayer(nn.Module):
+ """
+ ResidualConvUnit, pre-activate residual unit.
+
+ Args:
+ config (`[ZoeDepthConfig]`):
+ Model configuration class defining the model architecture.
+ """
+
+ # Ignore copy
+ def __init__(self, config):
+ super().__init__()
+
+ self.use_batch_norm = config.use_batch_norm_in_fusion_residual
+ use_bias_in_fusion_residual = (
+ config.use_bias_in_fusion_residual
+ if config.use_bias_in_fusion_residual is not None
+ else not self.use_batch_norm
+ )
+
+ self.activation1 = nn.ReLU()
+ self.convolution1 = nn.Conv2d(
+ config.fusion_hidden_size,
+ config.fusion_hidden_size,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=use_bias_in_fusion_residual,
+ )
+
+ self.activation2 = nn.ReLU()
+ self.convolution2 = nn.Conv2d(
+ config.fusion_hidden_size,
+ config.fusion_hidden_size,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias=use_bias_in_fusion_residual,
+ )
+
+ if self.use_batch_norm:
+ self.batch_norm1 = nn.BatchNorm2d(config.fusion_hidden_size, eps=config.batch_norm_eps)
+ self.batch_norm2 = nn.BatchNorm2d(config.fusion_hidden_size, eps=config.batch_norm_eps)
+
+ def forward(self, hidden_state: torch.Tensor) -> torch.Tensor:
+ residual = hidden_state
+ hidden_state = self.activation1(hidden_state)
+
+ hidden_state = self.convolution1(hidden_state)
+
+ if self.use_batch_norm:
+ hidden_state = self.batch_norm1(hidden_state)
+
+ hidden_state = self.activation2(hidden_state)
+ hidden_state = self.convolution2(hidden_state)
+
+ if self.use_batch_norm:
+ hidden_state = self.batch_norm2(hidden_state)
+
+ return hidden_state + residual
+
+
+# Copied from transformers.models.dpt.modeling_dpt.DPTFeatureFusionLayer with DPT->ZoeDepth
+class ZoeDepthFeatureFusionLayer(nn.Module):
+ """Feature fusion layer, merges feature maps from different stages.
+
+ Args:
+ config (`[ZoeDepthConfig]`):
+ Model configuration class defining the model architecture.
+ align_corners (`bool`, *optional*, defaults to `True`):
+ The align_corner setting for bilinear upsample.
+ """
+
+ def __init__(self, config, align_corners=True):
+ super().__init__()
+
+ self.align_corners = align_corners
+
+ self.projection = nn.Conv2d(config.fusion_hidden_size, config.fusion_hidden_size, kernel_size=1, bias=True)
+
+ self.residual_layer1 = ZoeDepthPreActResidualLayer(config)
+ self.residual_layer2 = ZoeDepthPreActResidualLayer(config)
+
+ def forward(self, hidden_state, residual=None):
+ if residual is not None:
+ if hidden_state.shape != residual.shape:
+ residual = nn.functional.interpolate(
+ residual, size=(hidden_state.shape[2], hidden_state.shape[3]), mode="bilinear", align_corners=False
+ )
+ hidden_state = hidden_state + self.residual_layer1(residual)
+
+ hidden_state = self.residual_layer2(hidden_state)
+ hidden_state = nn.functional.interpolate(
+ hidden_state, scale_factor=2, mode="bilinear", align_corners=self.align_corners
+ )
+ hidden_state = self.projection(hidden_state)
+
+ return hidden_state
+
+
+class ZoeDepthNeck(nn.Module):
+ """
+ ZoeDepthNeck. A neck is a module that is normally used between the backbone and the head. It takes a list of tensors as
+ input and produces another list of tensors as output. For ZoeDepth, it includes 2 stages:
+
+ * ZoeDepthReassembleStage
+ * ZoeDepthFeatureFusionStage.
+
+ Args:
+ config (dict): config dict.
+ """
+
+ # Copied from transformers.models.dpt.modeling_dpt.DPTNeck.__init__ with DPT->ZoeDepth
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+
+ # postprocessing: only required in case of a non-hierarchical backbone (e.g. ViT, BEiT)
+ if config.backbone_config is not None and config.backbone_config.model_type in ["swinv2"]:
+ self.reassemble_stage = None
+ else:
+ self.reassemble_stage = ZoeDepthReassembleStage(config)
+
+ self.convs = nn.ModuleList()
+ for channel in config.neck_hidden_sizes:
+ self.convs.append(nn.Conv2d(channel, config.fusion_hidden_size, kernel_size=3, padding=1, bias=False))
+
+ # fusion
+ self.fusion_stage = ZoeDepthFeatureFusionStage(config)
+
+ def forward(self, hidden_states: List[torch.Tensor], patch_height, patch_width) -> List[torch.Tensor]:
+ """
+ Args:
+ hidden_states (`List[torch.FloatTensor]`, each of shape `(batch_size, sequence_length, hidden_size)` or `(batch_size, hidden_size, height, width)`):
+ List of hidden states from the backbone.
+ """
+ if not isinstance(hidden_states, (tuple, list)):
+ raise ValueError("hidden_states should be a tuple or list of tensors")
+
+ if len(hidden_states) != len(self.config.neck_hidden_sizes):
+ raise ValueError("The number of hidden states should be equal to the number of neck hidden sizes.")
+
+ # postprocess hidden states
+ if self.reassemble_stage is not None:
+ hidden_states = self.reassemble_stage(hidden_states, patch_height, patch_width)
+
+ features = [self.convs[i](feature) for i, feature in enumerate(hidden_states)]
+
+ # fusion blocks
+ output = self.fusion_stage(features)
+
+ return output, features[-1]
+
+
+class ZoeDepthRelativeDepthEstimationHead(nn.Module):
+ """
+ Relative depth estimation head consisting of 3 convolutional layers. It progressively halves the feature dimension and upsamples
+ the predictions to the input resolution after the first convolutional layer (details can be found in DPT's paper's
+ supplementary material).
+ """
+
+ def __init__(self, config):
+ super().__init__()
+
+ self.head_in_index = config.head_in_index
+
+ self.projection = None
+ if config.add_projection:
+ self.projection = nn.Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+
+ features = config.fusion_hidden_size
+ self.conv1 = nn.Conv2d(features, features // 2, kernel_size=3, stride=1, padding=1)
+ self.upsample = nn.Upsample(scale_factor=2, mode="bilinear", align_corners=True)
+ self.conv2 = nn.Conv2d(features // 2, config.num_relative_features, kernel_size=3, stride=1, padding=1)
+ self.conv3 = nn.Conv2d(config.num_relative_features, 1, kernel_size=1, stride=1, padding=0)
+
+ def forward(self, hidden_states: List[torch.Tensor]) -> torch.Tensor:
+ # use last features
+ hidden_states = hidden_states[self.head_in_index]
+
+ if self.projection is not None:
+ hidden_states = self.projection(hidden_states)
+ hidden_states = nn.ReLU()(hidden_states)
+
+ hidden_states = self.conv1(hidden_states)
+ hidden_states = self.upsample(hidden_states)
+ hidden_states = self.conv2(hidden_states)
+ hidden_states = nn.ReLU()(hidden_states)
+ # we need the features here (after second conv + ReLu)
+ features = hidden_states
+ hidden_states = self.conv3(hidden_states)
+ hidden_states = nn.ReLU()(hidden_states)
+
+ predicted_depth = hidden_states.squeeze(dim=1)
+
+ return predicted_depth, features
+
+
+def log_binom(n, k, eps=1e-7):
+ """log(nCk) using stirling approximation"""
+ n = n + eps
+ k = k + eps
+ return n * torch.log(n) - k * torch.log(k) - (n - k) * torch.log(n - k + eps)
+
+
+class LogBinomialSoftmax(nn.Module):
+ def __init__(self, n_classes=256, act=torch.softmax):
+ """Compute log binomial distribution for n_classes
+
+ Args:
+ n_classes (`int`, *optional*, defaults to 256):
+ Number of output classes.
+ act (`torch.nn.Module`, *optional*, defaults to `torch.softmax`):
+ Activation function to apply to the output.
+ """
+ super().__init__()
+ self.k = n_classes
+ self.act = act
+ self.register_buffer("k_idx", torch.arange(0, n_classes).view(1, -1, 1, 1), persistent=False)
+ self.register_buffer("k_minus_1", torch.Tensor([self.k - 1]).view(1, -1, 1, 1), persistent=False)
+
+ def forward(self, probabilities, temperature=1.0, eps=1e-4):
+ """Compute the log binomial distribution for probabilities.
+
+ Args:
+ probabilities (`torch.Tensor` of shape `(batch_size, num_channels, height, width)`):
+ Tensor containing probabilities of each class.
+ temperature (`float` or `torch.Tensor` of shape `(batch_size, num_channels, height, width)`, *optional*, defaults to 1):
+ Temperature of distribution.
+ eps (`float`, *optional*, defaults to 1e-4):
+ Small number for numerical stability.
+
+ Returns:
+ `torch.Tensor` of shape `(batch_size, num_channels, height, width)`:
+ Log binomial distribution logbinomial(p;t).
+ """
+ if probabilities.ndim == 3:
+ probabilities = probabilities.unsqueeze(1) # make it (batch_size, num_channels, height, width)
+
+ one_minus_probabilities = torch.clamp(1 - probabilities, eps, 1)
+ probabilities = torch.clamp(probabilities, eps, 1)
+ y = (
+ log_binom(self.k_minus_1, self.k_idx)
+ + self.k_idx * torch.log(probabilities)
+ + (self.k_minus_1 - self.k_idx) * torch.log(one_minus_probabilities)
+ )
+ return self.act(y / temperature, dim=1)
+
+
+class ZoeDepthConditionalLogBinomialSoftmax(nn.Module):
+ def __init__(
+ self,
+ config,
+ in_features,
+ condition_dim,
+ n_classes=256,
+ bottleneck_factor=2,
+ ):
+ """Per-pixel MLP followed by a Conditional Log Binomial softmax.
+
+ Args:
+ in_features (`int`):
+ Number of input channels in the main feature.
+ condition_dim (`int`):
+ Number of input channels in the condition feature.
+ n_classes (`int`, *optional*, defaults to 256):
+ Number of classes.
+ bottleneck_factor (`int`, *optional*, defaults to 2):
+ Hidden dim factor.
+
+ """
+ super().__init__()
+
+ bottleneck = (in_features + condition_dim) // bottleneck_factor
+ self.mlp = nn.Sequential(
+ nn.Conv2d(in_features + condition_dim, bottleneck, kernel_size=1, stride=1, padding=0),
+ nn.GELU(),
+ # 2 for probabilities linear norm, 2 for temperature linear norm
+ nn.Conv2d(bottleneck, 2 + 2, kernel_size=1, stride=1, padding=0),
+ nn.Softplus(),
+ )
+
+ self.p_eps = 1e-4
+ self.max_temp = config.max_temp
+ self.min_temp = config.min_temp
+ self.log_binomial_transform = LogBinomialSoftmax(n_classes, act=torch.softmax)
+
+ def forward(self, main_feature, condition_feature):
+ """
+ Args:
+ main_feature (`torch.Tensor` of shape `(batch_size, num_channels, height, width)`):
+ Main feature.
+ condition_feature (torch.Tensor of shape `(batch_size, num_channels, height, width)`):
+ Condition feature.
+
+ Returns:
+ `torch.Tensor`:
+ Output log binomial distribution
+ """
+ probabilities_and_temperature = self.mlp(torch.concat((main_feature, condition_feature), dim=1))
+ probabilities, temperature = (
+ probabilities_and_temperature[:, :2, ...],
+ probabilities_and_temperature[:, 2:, ...],
+ )
+
+ probabilities = probabilities + self.p_eps
+ probabilities = probabilities[:, 0, ...] / (probabilities[:, 0, ...] + probabilities[:, 1, ...])
+
+ temperature = temperature + self.p_eps
+ temperature = temperature[:, 0, ...] / (temperature[:, 0, ...] + temperature[:, 1, ...])
+ temperature = temperature.unsqueeze(1)
+ temperature = (self.max_temp - self.min_temp) * temperature + self.min_temp
+
+ return self.log_binomial_transform(probabilities, temperature)
+
+
+class ZoeDepthSeedBinRegressor(nn.Module):
+ def __init__(self, config, n_bins=16, mlp_dim=256, min_depth=1e-3, max_depth=10):
+ """Bin center regressor network.
+
+ Can be "normed" or "unnormed". If "normed", bin centers are bounded on the (min_depth, max_depth) interval.
+
+ Args:
+ config (`int`):
+ Model configuration.
+ n_bins (`int`, *optional*, defaults to 16):
+ Number of bin centers.
+ mlp_dim (`int`, *optional*, defaults to 256):
+ Hidden dimension.
+ min_depth (`float`, *optional*, defaults to 1e-3):
+ Min depth value.
+ max_depth (`float`, *optional*, defaults to 10):
+ Max depth value.
+ """
+ super().__init__()
+
+ self.in_features = config.bottleneck_features
+ self.bin_centers_type = config.bin_centers_type
+ self.min_depth = min_depth
+ self.max_depth = max_depth
+
+ self.conv1 = nn.Conv2d(self.in_features, mlp_dim, 1, 1, 0)
+ self.act1 = nn.ReLU(inplace=True)
+ self.conv2 = nn.Conv2d(mlp_dim, n_bins, 1, 1, 0)
+ self.act2 = nn.ReLU(inplace=True) if self.bin_centers_type == "normed" else nn.Softplus()
+
+ def forward(self, x):
+ """
+ Returns tensor of bin_width vectors (centers). One vector b for every pixel
+ """
+ x = self.conv1(x)
+ x = self.act1(x)
+ x = self.conv2(x)
+ bin_centers = self.act2(x)
+
+ if self.bin_centers_type == "normed":
+ bin_centers = bin_centers + 1e-3
+ bin_widths_normed = bin_centers / bin_centers.sum(dim=1, keepdim=True)
+ # shape (batch_size, num_channels, height, width)
+ bin_widths = (self.max_depth - self.min_depth) * bin_widths_normed
+ # pad has the form (left, right, top, bottom, front, back)
+ bin_widths = nn.functional.pad(bin_widths, (0, 0, 0, 0, 1, 0), mode="constant", value=self.min_depth)
+ # shape (batch_size, num_channels, height, width)
+ bin_edges = torch.cumsum(bin_widths, dim=1)
+
+ bin_centers = 0.5 * (bin_edges[:, :-1, ...] + bin_edges[:, 1:, ...])
+ return bin_widths_normed, bin_centers
+
+ else:
+ return bin_centers, bin_centers
+
+
+@torch.jit.script
+def inv_attractor(dx, alpha: float = 300, gamma: int = 2):
+ """Inverse attractor: dc = dx / (1 + alpha*dx^gamma), where dx = a - c, a = attractor point, c = bin center, dc = shift in bin center
+ This is the default one according to the accompanying paper.
+
+ Args:
+ dx (`torch.Tensor`):
+ The difference tensor dx = Ai - Cj, where Ai is the attractor point and Cj is the bin center.
+ alpha (`float`, *optional*, defaults to 300):
+ Proportional Attractor strength. Determines the absolute strength. Lower alpha = greater attraction.
+ gamma (`int`, *optional*, defaults to 2):
+ Exponential Attractor strength. Determines the "region of influence" and indirectly number of bin centers affected.
+ Lower gamma = farther reach.
+
+ Returns:
+ torch.Tensor: Delta shifts - dc; New bin centers = Old bin centers + dc
+ """
+ return dx.div(1 + alpha * dx.pow(gamma))
+
+
+class ZoeDepthAttractorLayer(nn.Module):
+ def __init__(
+ self,
+ config,
+ n_bins,
+ n_attractors=16,
+ min_depth=1e-3,
+ max_depth=10,
+ memory_efficient=False,
+ ):
+ """
+ Attractor layer for bin centers. Bin centers are bounded on the interval (min_depth, max_depth)
+ """
+ super().__init__()
+
+ self.alpha = config.attractor_alpha
+ self.gemma = config.attractor_gamma
+ self.kind = config.attractor_kind
+
+ self.n_attractors = n_attractors
+ self.n_bins = n_bins
+ self.min_depth = min_depth
+ self.max_depth = max_depth
+ self.memory_efficient = memory_efficient
+
+ # MLP to predict attractor points
+ in_features = mlp_dim = config.bin_embedding_dim
+ self.conv1 = nn.Conv2d(in_features, mlp_dim, 1, 1, 0)
+ self.act1 = nn.ReLU(inplace=True)
+ self.conv2 = nn.Conv2d(mlp_dim, n_attractors * 2, 1, 1, 0) # x2 for linear norm
+ self.act2 = nn.ReLU(inplace=True)
+
+ def forward(self, x, prev_bin, prev_bin_embedding=None, interpolate=True):
+ """
+ The forward pass of the attractor layer. This layer predicts the new bin centers based on the previous bin centers
+ and the attractor points (the latter are predicted by the MLP).
+
+ Args:
+ x (`torch.Tensor` of shape `(batch_size, num_channels, height, width)`):
+ Feature block.
+ prev_bin (`torch.Tensor` of shape `(batch_size, prev_number_of_bins, height, width)`):
+ Previous bin centers normed.
+ prev_bin_embedding (`torch.Tensor`, *optional*):
+ Optional previous bin embeddings.
+ interpolate (`bool`, *optional*, defaults to `True`):
+ Whether to interpolate the previous bin embeddings to the size of the input features.
+
+ Returns:
+ `Tuple[`torch.Tensor`, `torch.Tensor`]:
+ New bin centers normed and scaled.
+ """
+ if prev_bin_embedding is not None:
+ if interpolate:
+ prev_bin_embedding = nn.functional.interpolate(
+ prev_bin_embedding, x.shape[-2:], mode="bilinear", align_corners=True
+ )
+ x = x + prev_bin_embedding
+
+ x = self.conv1(x)
+ x = self.act1(x)
+ x = self.conv2(x)
+ attractors = self.act2(x)
+
+ attractors = attractors + 1e-3
+ batch_size, _, height, width = attractors.shape
+ attractors = attractors.view(batch_size, self.n_attractors, 2, height, width)
+ # batch_size, num_attractors, 2, height, width
+ # note: original repo had a bug here: https://github.com/isl-org/ZoeDepth/blame/edb6daf45458569e24f50250ef1ed08c015f17a7/zoedepth/models/layers/attractor.py#L105C9-L106C50
+ # we include the bug to maintain compatibility with the weights
+ attractors_normed = attractors[:, :, 0, ...] # batch_size, batch_size*num_attractors, height, width
+
+ bin_centers = nn.functional.interpolate(prev_bin, (height, width), mode="bilinear", align_corners=True)
+
+ # note: only attractor_type = "exp" is supported here, since no checkpoints were released with other attractor types
+
+ if not self.memory_efficient:
+ func = {"mean": torch.mean, "sum": torch.sum}[self.kind]
+ # shape (batch_size, num_bins, height, width)
+ delta_c = func(inv_attractor(attractors_normed.unsqueeze(2) - bin_centers.unsqueeze(1)), dim=1)
+ else:
+ delta_c = torch.zeros_like(bin_centers, device=bin_centers.device)
+ for i in range(self.n_attractors):
+ # shape (batch_size, num_bins, height, width)
+ delta_c += inv_attractor(attractors_normed[:, i, ...].unsqueeze(1) - bin_centers)
+
+ if self.kind == "mean":
+ delta_c = delta_c / self.n_attractors
+
+ bin_new_centers = bin_centers + delta_c
+ bin_centers = (self.max_depth - self.min_depth) * bin_new_centers + self.min_depth
+ bin_centers, _ = torch.sort(bin_centers, dim=1)
+ bin_centers = torch.clip(bin_centers, self.min_depth, self.max_depth)
+ return bin_new_centers, bin_centers
+
+
+class ZoeDepthAttractorLayerUnnormed(nn.Module):
+ def __init__(
+ self,
+ config,
+ n_bins,
+ n_attractors=16,
+ min_depth=1e-3,
+ max_depth=10,
+ memory_efficient=True,
+ ):
+ """
+ Attractor layer for bin centers. Bin centers are unbounded
+ """
+ super().__init__()
+
+ self.n_attractors = n_attractors
+ self.n_bins = n_bins
+ self.min_depth = min_depth
+ self.max_depth = max_depth
+ self.alpha = config.attractor_alpha
+ self.gamma = config.attractor_alpha
+ self.kind = config.attractor_kind
+ self.memory_efficient = memory_efficient
+
+ in_features = mlp_dim = config.bin_embedding_dim
+ self.conv1 = nn.Conv2d(in_features, mlp_dim, 1, 1, 0)
+ self.act1 = nn.ReLU(inplace=True)
+ self.conv2 = nn.Conv2d(mlp_dim, n_attractors, 1, 1, 0)
+ self.act2 = nn.Softplus()
+
+ def forward(self, x, prev_bin, prev_bin_embedding=None, interpolate=True):
+ """
+ The forward pass of the attractor layer. This layer predicts the new bin centers based on the previous bin centers
+ and the attractor points (the latter are predicted by the MLP).
+
+ Args:
+ x (`torch.Tensor` of shape (batch_size, num_channels, height, width)`):
+ Feature block.
+ prev_bin (`torch.Tensor` of shape (batch_size, prev_num_bins, height, width)`):
+ Previous bin centers normed.
+ prev_bin_embedding (`torch.Tensor`, *optional*):
+ Optional previous bin embeddings.
+ interpolate (`bool`, *optional*, defaults to `True`):
+ Whether to interpolate the previous bin embeddings to the size of the input features.
+
+ Returns:
+ `Tuple[`torch.Tensor`, `torch.Tensor`]:
+ New bin centers unbounded. Two outputs just to keep the API consistent with the normed version.
+ """
+ if prev_bin_embedding is not None:
+ if interpolate:
+ prev_bin_embedding = nn.functional.interpolate(
+ prev_bin_embedding, x.shape[-2:], mode="bilinear", align_corners=True
+ )
+ x = x + prev_bin_embedding
+
+ x = self.conv1(x)
+ x = self.act1(x)
+ x = self.conv2(x)
+ attractors = self.act2(x)
+
+ height, width = attractors.shape[-2:]
+
+ bin_centers = nn.functional.interpolate(prev_bin, (height, width), mode="bilinear", align_corners=True)
+
+ if not self.memory_efficient:
+ func = {"mean": torch.mean, "sum": torch.sum}[self.kind]
+ # shape batch_size, num_bins, height, width
+ delta_c = func(inv_attractor(attractors.unsqueeze(2) - bin_centers.unsqueeze(1)), dim=1)
+ else:
+ delta_c = torch.zeros_like(bin_centers, device=bin_centers.device)
+ for i in range(self.n_attractors):
+ # shape batch_size, num_bins, height, width
+ delta_c += inv_attractor(attractors[:, i, ...].unsqueeze(1) - bin_centers)
+
+ if self.kind == "mean":
+ delta_c = delta_c / self.n_attractors
+
+ bin_new_centers = bin_centers + delta_c
+ bin_centers = bin_new_centers
+
+ return bin_new_centers, bin_centers
+
+
+class ZoeDepthProjector(nn.Module):
+ def __init__(self, in_features, out_features, mlp_dim=128):
+ """Projector MLP.
+
+ Args:
+ in_features (`int`):
+ Number of input channels.
+ out_features (`int`):
+ Number of output channels.
+ mlp_dim (`int`, *optional*, defaults to 128):
+ Hidden dimension.
+ """
+ super().__init__()
+
+ self.conv1 = nn.Conv2d(in_features, mlp_dim, 1, 1, 0)
+ self.act = nn.ReLU(inplace=True)
+ self.conv2 = nn.Conv2d(mlp_dim, out_features, 1, 1, 0)
+
+ def forward(self, hidden_state: torch.Tensor) -> torch.Tensor:
+ hidden_state = self.conv1(hidden_state)
+ hidden_state = self.act(hidden_state)
+ hidden_state = self.conv2(hidden_state)
+
+ return hidden_state
+
+
+# Copied from transformers.models.grounding_dino.modeling_grounding_dino.GroundingDinoMultiheadAttention with GroundingDino->ZoeDepth
+class ZoeDepthMultiheadAttention(nn.Module):
+ """Equivalent implementation of nn.MultiheadAttention with `batch_first=True`."""
+
+ # Ignore copy
+ def __init__(self, hidden_size, num_attention_heads, dropout):
+ super().__init__()
+ if hidden_size % num_attention_heads != 0:
+ raise ValueError(
+ f"The hidden size ({hidden_size}) is not a multiple of the number of attention "
+ f"heads ({num_attention_heads})"
+ )
+
+ self.num_attention_heads = num_attention_heads
+ self.attention_head_size = int(hidden_size / num_attention_heads)
+ self.all_head_size = self.num_attention_heads * self.attention_head_size
+
+ self.query = nn.Linear(hidden_size, self.all_head_size)
+ self.key = nn.Linear(hidden_size, self.all_head_size)
+ self.value = nn.Linear(hidden_size, self.all_head_size)
+
+ self.out_proj = nn.Linear(hidden_size, hidden_size)
+
+ self.dropout = nn.Dropout(dropout)
+
+ def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
+ new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
+ x = x.view(new_x_shape)
+ return x.permute(0, 2, 1, 3)
+
+ def forward(
+ self,
+ queries: torch.Tensor,
+ keys: torch.Tensor,
+ values: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor]:
+ query_layer = self.transpose_for_scores(self.query(queries))
+ key_layer = self.transpose_for_scores(self.key(keys))
+ value_layer = self.transpose_for_scores(self.value(values))
+
+ # Take the dot product between "query" and "key" to get the raw attention scores.
+ attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
+
+ attention_scores = attention_scores / math.sqrt(self.attention_head_size)
+ if attention_mask is not None:
+ # Apply the attention mask is (precomputed for all layers in ZoeDepthModel forward() function)
+ attention_scores = attention_scores + attention_mask
+
+ # Normalize the attention scores to probabilities.
+ attention_probs = nn.functional.softmax(attention_scores, dim=-1)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs = self.dropout(attention_probs)
+
+ context_layer = torch.matmul(attention_probs, value_layer)
+
+ context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
+ new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
+ context_layer = context_layer.view(new_context_layer_shape)
+
+ context_layer = self.out_proj(context_layer)
+
+ outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
+
+ return outputs
+
+
+class ZoeDepthTransformerEncoderLayer(nn.Module):
+ def __init__(self, config, dropout=0.1, activation="relu"):
+ super().__init__()
+
+ hidden_size = config.patch_transformer_hidden_size
+ intermediate_size = config.patch_transformer_intermediate_size
+ num_attention_heads = config.patch_transformer_num_attention_heads
+
+ self.self_attn = ZoeDepthMultiheadAttention(hidden_size, num_attention_heads, dropout=dropout)
+
+ self.linear1 = nn.Linear(hidden_size, intermediate_size)
+ self.dropout = nn.Dropout(dropout)
+ self.linear2 = nn.Linear(intermediate_size, hidden_size)
+
+ self.norm1 = nn.LayerNorm(hidden_size)
+ self.norm2 = nn.LayerNorm(hidden_size)
+ self.dropout1 = nn.Dropout(dropout)
+ self.dropout2 = nn.Dropout(dropout)
+
+ self.activation = ACT2FN[activation]
+
+ def forward(
+ self,
+ src,
+ src_mask: Optional[torch.Tensor] = None,
+ ):
+ queries = keys = src
+ src2 = self.self_attn(queries=queries, keys=keys, values=src, attention_mask=src_mask)[0]
+ src = src + self.dropout1(src2)
+ src = self.norm1(src)
+ src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
+ src = src + self.dropout2(src2)
+ src = self.norm2(src)
+ return src
+
+
+class ZoeDepthPatchTransformerEncoder(nn.Module):
+ def __init__(self, config):
+ """ViT-like transformer block
+
+ Args:
+ config (`ZoeDepthConfig`):
+ Model configuration class defining the model architecture.
+ """
+ super().__init__()
+
+ in_channels = config.bottleneck_features
+
+ self.transformer_encoder = nn.ModuleList(
+ [ZoeDepthTransformerEncoderLayer(config) for _ in range(config.num_patch_transformer_layers)]
+ )
+
+ self.embedding_convPxP = nn.Conv2d(
+ in_channels, config.patch_transformer_hidden_size, kernel_size=1, stride=1, padding=0
+ )
+
+ def positional_encoding_1d(self, batch_size, sequence_length, embedding_dim, device="cpu", dtype=torch.float32):
+ """Generate positional encodings
+
+ Args:
+ sequence_length (int): Sequence length
+ embedding_dim (int): Embedding dimension
+
+ Returns:
+ torch.Tensor: Positional encodings.
+ """
+ position = torch.arange(0, sequence_length, dtype=dtype, device=device).unsqueeze(1)
+ index = torch.arange(0, embedding_dim, 2, dtype=dtype, device=device).unsqueeze(0)
+ div_term = torch.exp(index * (-torch.log(torch.tensor(10000.0, device=device)) / embedding_dim))
+ pos_encoding = position * div_term
+ pos_encoding = torch.cat([torch.sin(pos_encoding), torch.cos(pos_encoding)], dim=1)
+ pos_encoding = pos_encoding.unsqueeze(dim=0).repeat(batch_size, 1, 1)
+ return pos_encoding
+
+ def forward(self, x):
+ """Forward pass
+
+ Args:
+ x (torch.Tensor - NCHW): Input feature tensor
+
+ Returns:
+ torch.Tensor - Transformer output embeddings of shape (batch_size, sequence_length, embedding_dim)
+ """
+ embeddings = self.embedding_convPxP(x).flatten(2) # shape (batch_size, num_channels, sequence_length)
+ # add an extra special CLS token at the start for global accumulation
+ embeddings = nn.functional.pad(embeddings, (1, 0))
+
+ embeddings = embeddings.permute(0, 2, 1)
+ batch_size, sequence_length, embedding_dim = embeddings.shape
+ embeddings = embeddings + self.positional_encoding_1d(
+ batch_size, sequence_length, embedding_dim, device=embeddings.device, dtype=embeddings.dtype
+ )
+
+ for i in range(4):
+ embeddings = self.transformer_encoder[i](embeddings)
+
+ return embeddings
+
+
+class ZoeDepthMLPClassifier(nn.Module):
+ def __init__(self, in_features, out_features) -> None:
+ super().__init__()
+
+ hidden_features = in_features
+ self.linear1 = nn.Linear(in_features, hidden_features)
+ self.activation = nn.ReLU()
+ self.linear2 = nn.Linear(hidden_features, out_features)
+
+ def forward(self, hidden_state):
+ hidden_state = self.linear1(hidden_state)
+ hidden_state = self.activation(hidden_state)
+ domain_logits = self.linear2(hidden_state)
+
+ return domain_logits
+
+
+class ZoeDepthMultipleMetricDepthEstimationHeads(nn.Module):
+ """
+ Multiple metric depth estimation heads. A MLP classifier is used to route between 2 different heads.
+ """
+
+ def __init__(self, config):
+ super().__init__()
+
+ bin_embedding_dim = config.bin_embedding_dim
+ n_attractors = config.num_attractors
+ self.bin_configurations = config.bin_configurations
+ self.bin_centers_type = config.bin_centers_type
+
+ # Bottleneck convolution
+ bottleneck_features = config.bottleneck_features
+ self.conv2 = nn.Conv2d(bottleneck_features, bottleneck_features, kernel_size=1, stride=1, padding=0)
+
+ # Transformer classifier on the bottleneck
+ self.patch_transformer = ZoeDepthPatchTransformerEncoder(config)
+ # MLP classifier
+ self.mlp_classifier = ZoeDepthMLPClassifier(in_features=128, out_features=2)
+
+ # Regressor and attractor
+ if self.bin_centers_type == "normed":
+ Attractor = ZoeDepthAttractorLayer
+ elif self.bin_centers_type == "softplus":
+ Attractor = ZoeDepthAttractorLayerUnnormed
+ # We have bins for each bin configuration
+ # Create a map (ModuleDict) of 'name' -> seed_bin_regressor
+ self.seed_bin_regressors = nn.ModuleDict(
+ {
+ conf["name"]: ZoeDepthSeedBinRegressor(
+ config,
+ n_bins=conf["n_bins"],
+ mlp_dim=bin_embedding_dim // 2,
+ min_depth=conf["min_depth"],
+ max_depth=conf["max_depth"],
+ )
+ for conf in config.bin_configurations
+ }
+ )
+
+ self.seed_projector = ZoeDepthProjector(
+ in_features=bottleneck_features, out_features=bin_embedding_dim, mlp_dim=bin_embedding_dim // 2
+ )
+ self.projectors = nn.ModuleList(
+ [
+ ZoeDepthProjector(
+ in_features=config.fusion_hidden_size,
+ out_features=bin_embedding_dim,
+ mlp_dim=bin_embedding_dim // 2,
+ )
+ for _ in range(4)
+ ]
+ )
+
+ # Create a map (ModuleDict) of 'name' -> attractors (ModuleList)
+ self.attractors = nn.ModuleDict(
+ {
+ configuration["name"]: nn.ModuleList(
+ [
+ Attractor(
+ config,
+ n_bins=n_attractors[i],
+ min_depth=configuration["min_depth"],
+ max_depth=configuration["max_depth"],
+ )
+ for i in range(len(n_attractors))
+ ]
+ )
+ for configuration in config.bin_configurations
+ }
+ )
+
+ last_in = config.num_relative_features
+ # conditional log binomial for each bin configuration
+ self.conditional_log_binomial = nn.ModuleDict(
+ {
+ configuration["name"]: ZoeDepthConditionalLogBinomialSoftmax(
+ config,
+ last_in,
+ bin_embedding_dim,
+ configuration["n_bins"],
+ bottleneck_factor=4,
+ )
+ for configuration in config.bin_configurations
+ }
+ )
+
+ def forward(self, outconv_activation, bottleneck, feature_blocks, relative_depth):
+ x = self.conv2(bottleneck)
+
+ # Predict which path to take
+ # Embedding is of shape (batch_size, hidden_size)
+ embedding = self.patch_transformer(x)[:, 0, :]
+
+ # MLP classifier to get logits of shape (batch_size, 2)
+ domain_logits = self.mlp_classifier(embedding)
+ domain_vote = torch.softmax(domain_logits.sum(dim=0, keepdim=True), dim=-1)
+
+ # Get the path
+ names = [configuration["name"] for configuration in self.bin_configurations]
+ bin_configurations_name = names[torch.argmax(domain_vote, dim=-1).squeeze().item()]
+
+ try:
+ conf = [config for config in self.bin_configurations if config["name"] == bin_configurations_name][0]
+ except IndexError:
+ raise ValueError(f"bin_configurations_name {bin_configurations_name} not found in bin_configurationss")
+
+ min_depth = conf["min_depth"]
+ max_depth = conf["max_depth"]
+
+ seed_bin_regressor = self.seed_bin_regressors[bin_configurations_name]
+ _, seed_bin_centers = seed_bin_regressor(x)
+ if self.bin_centers_type in ["normed", "hybrid2"]:
+ prev_bin = (seed_bin_centers - min_depth) / (max_depth - min_depth)
+ else:
+ prev_bin = seed_bin_centers
+ prev_bin_embedding = self.seed_projector(x)
+
+ attractors = self.attractors[bin_configurations_name]
+ for projector, attractor, feature in zip(self.projectors, attractors, feature_blocks):
+ bin_embedding = projector(feature)
+ bin, bin_centers = attractor(bin_embedding, prev_bin, prev_bin_embedding, interpolate=True)
+ prev_bin = bin
+ prev_bin_embedding = bin_embedding
+
+ last = outconv_activation
+
+ bin_centers = nn.functional.interpolate(bin_centers, last.shape[-2:], mode="bilinear", align_corners=True)
+ bin_embedding = nn.functional.interpolate(bin_embedding, last.shape[-2:], mode="bilinear", align_corners=True)
+
+ conditional_log_binomial = self.conditional_log_binomial[bin_configurations_name]
+ x = conditional_log_binomial(last, bin_embedding)
+
+ # Now depth value is Sum px * cx , where cx are bin_centers from the last bin tensor
+ out = torch.sum(x * bin_centers, dim=1, keepdim=True)
+
+ return out, domain_logits
+
+
+class ZoeDepthMetricDepthEstimationHead(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+
+ bin_configuration = config.bin_configurations[0]
+ n_bins = bin_configuration["n_bins"]
+ min_depth = bin_configuration["min_depth"]
+ max_depth = bin_configuration["max_depth"]
+ bin_embedding_dim = config.bin_embedding_dim
+ n_attractors = config.num_attractors
+ bin_centers_type = config.bin_centers_type
+
+ self.min_depth = min_depth
+ self.max_depth = max_depth
+ self.bin_centers_type = bin_centers_type
+
+ # Bottleneck convolution
+ bottleneck_features = config.bottleneck_features
+ self.conv2 = nn.Conv2d(bottleneck_features, bottleneck_features, kernel_size=1, stride=1, padding=0)
+
+ # Regressor and attractor
+ if self.bin_centers_type == "normed":
+ Attractor = ZoeDepthAttractorLayer
+ elif self.bin_centers_type == "softplus":
+ Attractor = ZoeDepthAttractorLayerUnnormed
+
+ self.seed_bin_regressor = ZoeDepthSeedBinRegressor(
+ config, n_bins=n_bins, min_depth=min_depth, max_depth=max_depth
+ )
+ self.seed_projector = ZoeDepthProjector(in_features=bottleneck_features, out_features=bin_embedding_dim)
+
+ self.projectors = nn.ModuleList(
+ [
+ ZoeDepthProjector(in_features=config.fusion_hidden_size, out_features=bin_embedding_dim)
+ for _ in range(4)
+ ]
+ )
+ self.attractors = nn.ModuleList(
+ [
+ Attractor(
+ config,
+ n_bins=n_bins,
+ n_attractors=n_attractors[i],
+ min_depth=min_depth,
+ max_depth=max_depth,
+ )
+ for i in range(4)
+ ]
+ )
+
+ last_in = config.num_relative_features + 1 # +1 for relative depth
+
+ # use log binomial instead of softmax
+ self.conditional_log_binomial = ZoeDepthConditionalLogBinomialSoftmax(
+ config,
+ last_in,
+ bin_embedding_dim,
+ n_classes=n_bins,
+ )
+
+ def forward(self, outconv_activation, bottleneck, feature_blocks, relative_depth):
+ x = self.conv2(bottleneck)
+ _, seed_bin_centers = self.seed_bin_regressor(x)
+
+ if self.bin_centers_type in ["normed", "hybrid2"]:
+ prev_bin = (seed_bin_centers - self.min_depth) / (self.max_depth - self.min_depth)
+ else:
+ prev_bin = seed_bin_centers
+
+ prev_bin_embedding = self.seed_projector(x)
+
+ # unroll this loop for better performance
+ for projector, attractor, feature in zip(self.projectors, self.attractors, feature_blocks):
+ bin_embedding = projector(feature)
+ bin, bin_centers = attractor(bin_embedding, prev_bin, prev_bin_embedding, interpolate=True)
+ prev_bin = bin.clone()
+ prev_bin_embedding = bin_embedding.clone()
+
+ last = outconv_activation
+
+ # concatenative relative depth with last. First interpolate relative depth to last size
+ relative_conditioning = relative_depth.unsqueeze(1)
+ relative_conditioning = nn.functional.interpolate(
+ relative_conditioning, size=last.shape[2:], mode="bilinear", align_corners=True
+ )
+ last = torch.cat([last, relative_conditioning], dim=1)
+
+ bin_embedding = nn.functional.interpolate(bin_embedding, last.shape[-2:], mode="bilinear", align_corners=True)
+ x = self.conditional_log_binomial(last, bin_embedding)
+
+ # Now depth value is Sum px * cx , where cx are bin_centers from the last bin tensor
+ bin_centers = nn.functional.interpolate(bin_centers, x.shape[-2:], mode="bilinear", align_corners=True)
+ out = torch.sum(x * bin_centers, dim=1, keepdim=True)
+
+ return out, None
+
+
+# Copied from transformers.models.dpt.modeling_dpt.DPTPreTrainedModel with DPT->ZoeDepth,dpt->zoedepth
+class ZoeDepthPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = ZoeDepthConfig
+ base_model_prefix = "zoedepth"
+ main_input_name = "pixel_values"
+ supports_gradient_checkpointing = True
+
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ if isinstance(module, (nn.Linear, nn.Conv2d, nn.ConvTranspose2d)):
+ # Slightly different from the TF version which uses truncated_normal for initialization
+ # cf https://github.com/pytorch/pytorch/pull/5617
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+
+
+ZOEDEPTH_START_DOCSTRING = r"""
+ This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it
+ as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
+ behavior.
+
+ Parameters:
+ config ([`ViTConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+ZOEDEPTH_INPUTS_DOCSTRING = r"""
+ Args:
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
+ Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See [`DPTImageProcessor.__call__`]
+ for details.
+
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~file_utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ """
+ ZoeDepth model with one or multiple metric depth estimation head(s) on top.
+ """,
+ ZOEDEPTH_START_DOCSTRING,
+)
+class ZoeDepthForDepthEstimation(ZoeDepthPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+
+ self.backbone = load_backbone(config)
+
+ if hasattr(self.backbone.config, "hidden_size") and hasattr(self.backbone.config, "patch_size"):
+ config.backbone_hidden_size = self.backbone.config.hidden_size
+ self.patch_size = self.backbone.config.patch_size
+ else:
+ raise ValueError(
+ "ZoeDepth assumes the backbone's config to have `hidden_size` and `patch_size` attributes"
+ )
+
+ self.neck = ZoeDepthNeck(config)
+ self.relative_head = ZoeDepthRelativeDepthEstimationHead(config)
+
+ self.metric_head = (
+ ZoeDepthMultipleMetricDepthEstimationHeads(config)
+ if len(config.bin_configurations) > 1
+ else ZoeDepthMetricDepthEstimationHead(config)
+ )
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(ZOEDEPTH_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=DepthEstimatorOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ pixel_values: torch.FloatTensor,
+ labels: Optional[torch.LongTensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple[torch.Tensor], DepthEstimatorOutput]:
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*):
+ Ground truth depth estimation maps for computing the loss.
+
+ Returns:
+
+ Examples:
+ ```python
+ >>> from transformers import AutoImageProcessor, ZoeDepthForDepthEstimation
+ >>> import torch
+ >>> import numpy as np
+ >>> from PIL import Image
+ >>> import requests
+
+ >>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ >>> image = Image.open(requests.get(url, stream=True).raw)
+
+ >>> image_processor = AutoImageProcessor.from_pretrained("Intel/zoedepth-nyu-kitti")
+ >>> model = ZoeDepthForDepthEstimation.from_pretrained("Intel/zoedepth-nyu-kitti")
+
+ >>> # prepare image for the model
+ >>> inputs = image_processor(images=image, return_tensors="pt")
+
+ >>> with torch.no_grad():
+ ... outputs = model(**inputs)
+ ... predicted_depth = outputs.predicted_depth
+
+ >>> # interpolate to original size
+ >>> prediction = torch.nn.functional.interpolate(
+ ... predicted_depth.unsqueeze(1),
+ ... size=image.size[::-1],
+ ... mode="bicubic",
+ ... align_corners=False,
+ ... )
+
+ >>> # visualize the prediction
+ >>> output = prediction.squeeze().cpu().numpy()
+ >>> formatted = (output * 255 / np.max(output)).astype("uint8")
+ >>> depth = Image.fromarray(formatted)
+ ```"""
+ loss = None
+ if labels is not None:
+ raise NotImplementedError("Training is not implemented yet")
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+
+ outputs = self.backbone.forward_with_filtered_kwargs(
+ pixel_values, output_hidden_states=output_hidden_states, output_attentions=output_attentions
+ )
+ hidden_states = outputs.feature_maps
+
+ _, _, height, width = pixel_values.shape
+ patch_size = self.patch_size
+ patch_height = height // patch_size
+ patch_width = width // patch_size
+
+ hidden_states, features = self.neck(hidden_states, patch_height, patch_width)
+
+ out = [features] + hidden_states
+
+ relative_depth, features = self.relative_head(hidden_states)
+
+ out = [features] + out
+
+ metric_depth, domain_logits = self.metric_head(
+ outconv_activation=out[0], bottleneck=out[1], feature_blocks=out[2:], relative_depth=relative_depth
+ )
+ metric_depth = metric_depth.squeeze(dim=1)
+
+ if not return_dict:
+ if domain_logits is not None:
+ output = (metric_depth, domain_logits) + outputs[1:]
+ else:
+ output = (metric_depth,) + outputs[1:]
+
+ return ((loss,) + output) if loss is not None else output
+
+ return ZoeDepthDepthEstimatorOutput(
+ loss=loss,
+ predicted_depth=metric_depth,
+ domain_logits=domain_logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index 925d8bbb2f6547..edc4c95b1a35ed 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -9660,6 +9660,20 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
+class ZoeDepthForDepthEstimation(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class ZoeDepthPreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
class Adafactor(metaclass=DummyObject):
_backends = ["torch"]
diff --git a/src/transformers/utils/dummy_vision_objects.py b/src/transformers/utils/dummy_vision_objects.py
index 359c5481757d67..9d5175ed2aeab9 100644
--- a/src/transformers/utils/dummy_vision_objects.py
+++ b/src/transformers/utils/dummy_vision_objects.py
@@ -651,3 +651,10 @@ class YolosImageProcessor(metaclass=DummyObject):
def __init__(self, *args, **kwargs):
requires_backends(self, ["vision"])
+
+
+class ZoeDepthImageProcessor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
diff --git a/tests/models/zoedepth/__init__.py b/tests/models/zoedepth/__init__.py
new file mode 100644
index 00000000000000..e69de29bb2d1d6
diff --git a/tests/models/zoedepth/test_image_processing_zoedepth.py b/tests/models/zoedepth/test_image_processing_zoedepth.py
new file mode 100644
index 00000000000000..7dd82daf0d5f24
--- /dev/null
+++ b/tests/models/zoedepth/test_image_processing_zoedepth.py
@@ -0,0 +1,187 @@
+# coding=utf-8
+# Copyright 2024 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+import numpy as np
+
+from transformers.file_utils import is_vision_available
+from transformers.testing_utils import require_torch, require_vision
+
+from ...test_image_processing_common import ImageProcessingTestMixin, prepare_image_inputs
+
+
+if is_vision_available():
+ from transformers import ZoeDepthImageProcessor
+
+
+class ZoeDepthImageProcessingTester(unittest.TestCase):
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ image_size=18,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size=None,
+ ensure_multiple_of=32,
+ keep_aspect_ratio=False,
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ do_pad=False,
+ ):
+ size = size if size is not None else {"height": 18, "width": 18}
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.ensure_multiple_of = ensure_multiple_of
+ self.keep_aspect_ratio = keep_aspect_ratio
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+ self.do_pad = do_pad
+
+ def prepare_image_processor_dict(self):
+ return {
+ "do_resize": self.do_resize,
+ "size": self.size,
+ "ensure_multiple_of": self.ensure_multiple_of,
+ "keep_aspect_ratio": self.keep_aspect_ratio,
+ "do_normalize": self.do_normalize,
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ "do_pad": self.do_pad,
+ }
+
+ def expected_output_image_shape(self, images):
+ return self.num_channels, self.ensure_multiple_of, self.ensure_multiple_of
+
+ def prepare_image_inputs(self, equal_resolution=False, numpify=False, torchify=False):
+ return prepare_image_inputs(
+ batch_size=self.batch_size,
+ num_channels=self.num_channels,
+ min_resolution=self.min_resolution,
+ max_resolution=self.max_resolution,
+ equal_resolution=equal_resolution,
+ numpify=numpify,
+ torchify=torchify,
+ )
+
+
+@require_torch
+@require_vision
+class ZoeDepthImageProcessingTest(ImageProcessingTestMixin, unittest.TestCase):
+ image_processing_class = ZoeDepthImageProcessor if is_vision_available() else None
+
+ def setUp(self):
+ super().setUp()
+
+ self.image_processor_tester = ZoeDepthImageProcessingTester(self)
+
+ @property
+ def image_processor_dict(self):
+ return self.image_processor_tester.prepare_image_processor_dict()
+
+ def test_image_processor_properties(self):
+ image_processing = self.image_processing_class(**self.image_processor_dict)
+ self.assertTrue(hasattr(image_processing, "image_mean"))
+ self.assertTrue(hasattr(image_processing, "image_std"))
+ self.assertTrue(hasattr(image_processing, "do_normalize"))
+ self.assertTrue(hasattr(image_processing, "do_resize"))
+ self.assertTrue(hasattr(image_processing, "size"))
+ self.assertTrue(hasattr(image_processing, "ensure_multiple_of"))
+ self.assertTrue(hasattr(image_processing, "do_rescale"))
+ self.assertTrue(hasattr(image_processing, "rescale_factor"))
+ self.assertTrue(hasattr(image_processing, "do_pad"))
+
+ def test_image_processor_from_dict_with_kwargs(self):
+ image_processor = self.image_processing_class.from_dict(self.image_processor_dict)
+ self.assertEqual(image_processor.size, {"height": 18, "width": 18})
+
+ image_processor = self.image_processing_class.from_dict(self.image_processor_dict, size=42)
+ self.assertEqual(image_processor.size, {"height": 42, "width": 42})
+
+ def test_ensure_multiple_of(self):
+ # Test variable by turning off all other variables which affect the size, size which is not multiple of 32
+ image = np.zeros((489, 640, 3))
+
+ size = {"height": 380, "width": 513}
+ multiple = 32
+ image_processor = ZoeDepthImageProcessor(
+ do_pad=False, ensure_multiple_of=multiple, size=size, keep_aspect_ratio=False
+ )
+ pixel_values = image_processor(image, return_tensors="pt").pixel_values
+
+ self.assertEqual(list(pixel_values.shape), [1, 3, 384, 512])
+ self.assertTrue(pixel_values.shape[2] % multiple == 0)
+ self.assertTrue(pixel_values.shape[3] % multiple == 0)
+
+ # Test variable by turning off all other variables which affect the size, size which is already multiple of 32
+ image = np.zeros((511, 511, 3))
+
+ height, width = 512, 512
+ size = {"height": height, "width": width}
+ multiple = 32
+ image_processor = ZoeDepthImageProcessor(
+ do_pad=False, ensure_multiple_of=multiple, size=size, keep_aspect_ratio=False
+ )
+ pixel_values = image_processor(image, return_tensors="pt").pixel_values
+
+ self.assertEqual(list(pixel_values.shape), [1, 3, height, width])
+ self.assertTrue(pixel_values.shape[2] % multiple == 0)
+ self.assertTrue(pixel_values.shape[3] % multiple == 0)
+
+ def test_keep_aspect_ratio(self):
+ # Test `keep_aspect_ratio=True` by turning off all other variables which affect the size
+ height, width = 489, 640
+ image = np.zeros((height, width, 3))
+
+ size = {"height": 512, "width": 512}
+ image_processor = ZoeDepthImageProcessor(do_pad=False, keep_aspect_ratio=True, size=size, ensure_multiple_of=1)
+ pixel_values = image_processor(image, return_tensors="pt").pixel_values
+
+ # As can be seen, the image is resized to the maximum size that fits in the specified size
+ self.assertEqual(list(pixel_values.shape), [1, 3, 512, 670])
+
+ # Test `keep_aspect_ratio=False` by turning off all other variables which affect the size
+ image_processor = ZoeDepthImageProcessor(
+ do_pad=False, keep_aspect_ratio=False, size=size, ensure_multiple_of=1
+ )
+ pixel_values = image_processor(image, return_tensors="pt").pixel_values
+
+ # As can be seen, the size is respected
+ self.assertEqual(list(pixel_values.shape), [1, 3, size["height"], size["width"]])
+
+ # Test `keep_aspect_ratio=True` with `ensure_multiple_of` set
+ image = np.zeros((489, 640, 3))
+
+ size = {"height": 511, "width": 511}
+ multiple = 32
+ image_processor = ZoeDepthImageProcessor(size=size, keep_aspect_ratio=True, ensure_multiple_of=multiple)
+
+ pixel_values = image_processor(image, return_tensors="pt").pixel_values
+
+ self.assertEqual(list(pixel_values.shape), [1, 3, 512, 672])
+ self.assertTrue(pixel_values.shape[2] % multiple == 0)
+ self.assertTrue(pixel_values.shape[3] % multiple == 0)
diff --git a/tests/models/zoedepth/test_modeling_zoedepth.py b/tests/models/zoedepth/test_modeling_zoedepth.py
new file mode 100644
index 00000000000000..571c44f2f47266
--- /dev/null
+++ b/tests/models/zoedepth/test_modeling_zoedepth.py
@@ -0,0 +1,257 @@
+# coding=utf-8
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch ZoeDepth model."""
+
+import unittest
+
+from transformers import Dinov2Config, ZoeDepthConfig
+from transformers.file_utils import is_torch_available, is_vision_available
+from transformers.testing_utils import require_torch, require_vision, slow, torch_device
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import ZoeDepthForDepthEstimation
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import ZoeDepthImageProcessor
+
+
+class ZoeDepthModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=2,
+ num_channels=3,
+ image_size=32,
+ patch_size=16,
+ use_labels=True,
+ num_labels=3,
+ is_training=True,
+ hidden_size=4,
+ num_hidden_layers=2,
+ num_attention_heads=2,
+ intermediate_size=8,
+ out_features=["stage1", "stage2"],
+ apply_layernorm=False,
+ reshape_hidden_states=False,
+ neck_hidden_sizes=[2, 2],
+ fusion_hidden_size=6,
+ bottleneck_features=6,
+ num_out_features=[6, 6, 6, 6],
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.out_features = out_features
+ self.apply_layernorm = apply_layernorm
+ self.reshape_hidden_states = reshape_hidden_states
+ self.use_labels = use_labels
+ self.num_labels = num_labels
+ self.is_training = is_training
+ self.neck_hidden_sizes = neck_hidden_sizes
+ self.fusion_hidden_size = fusion_hidden_size
+ self.bottleneck_features = bottleneck_features
+ self.num_out_features = num_out_features
+ # ZoeDepth's sequence length
+ self.seq_length = (self.image_size // self.patch_size) ** 2 + 1
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+
+ labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size, self.image_size, self.image_size], self.num_labels)
+
+ config = self.get_config()
+
+ return config, pixel_values, labels
+
+ def get_config(self):
+ return ZoeDepthConfig(
+ backbone_config=self.get_backbone_config(),
+ backbone=None,
+ neck_hidden_sizes=self.neck_hidden_sizes,
+ fusion_hidden_size=self.fusion_hidden_size,
+ bottleneck_features=self.bottleneck_features,
+ num_out_features=self.num_out_features,
+ )
+
+ def get_backbone_config(self):
+ return Dinov2Config(
+ image_size=self.image_size,
+ patch_size=self.patch_size,
+ num_channels=self.num_channels,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ is_training=self.is_training,
+ out_features=self.out_features,
+ reshape_hidden_states=self.reshape_hidden_states,
+ )
+
+ def create_and_check_for_depth_estimation(self, config, pixel_values, labels):
+ config.num_labels = self.num_labels
+ model = ZoeDepthForDepthEstimation(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ self.parent.assertEqual(result.predicted_depth.shape, (self.batch_size, self.image_size, self.image_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values, labels = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class ZoeDepthModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as ZoeDepth does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (ZoeDepthForDepthEstimation,) if is_torch_available() else ()
+ pipeline_model_mapping = {"depth-estimation": ZoeDepthForDepthEstimation} if is_torch_available() else {}
+
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = ZoeDepthModelTester(self)
+ self.config_tester = ConfigTester(
+ self, config_class=ZoeDepthConfig, has_text_modality=False, hidden_size=37, common_properties=[]
+ )
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="ZoeDepth with AutoBackbone does not have a base model and hence no input_embeddings")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="ZoeDepth with AutoBackbone does not have a base model and hence no input_embeddings")
+ def test_model_get_set_embeddings(self):
+ pass
+
+ def test_for_depth_estimation(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_depth_estimation(*config_and_inputs)
+
+ @unittest.skip(reason="ZoeDepth with AutoBackbone does not have a base model and hence no input_embeddings")
+ def test_model_common_attributes(self):
+ pass
+
+ @unittest.skip(reason="ZoeDepth with AutoBackbone does not have a base model")
+ def test_save_load_fast_init_from_base(self):
+ pass
+
+ @unittest.skip(reason="ZoeDepth with AutoBackbone does not have a base model")
+ def test_save_load_fast_init_to_base(self):
+ pass
+
+ @unittest.skip(reason="ZoeDepth does not support training yet")
+ def test_training(self):
+ pass
+
+ @unittest.skip(reason="ZoeDepth does not support training yet")
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(reason="ZoeDepth does not support training yet")
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(reason="ZoeDepth does not support training yet")
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "Intel/zoedepth-nyu"
+ model = ZoeDepthForDepthEstimation.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+@require_torch
+@require_vision
+@slow
+class ZoeDepthModelIntegrationTest(unittest.TestCase):
+ def test_inference_depth_estimation(self):
+ image_processor = ZoeDepthImageProcessor.from_pretrained("Intel/zoedepth-nyu")
+ model = ZoeDepthForDepthEstimation.from_pretrained("Intel/zoedepth-nyu").to(torch_device)
+
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+ predicted_depth = outputs.predicted_depth
+
+ # verify the predicted depth
+ expected_shape = torch.Size((1, 384, 512))
+ self.assertEqual(predicted_depth.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[1.0020, 1.0219, 1.0389], [1.0349, 1.0816, 1.1000], [1.0576, 1.1094, 1.1249]],
+ ).to(torch_device)
+
+ self.assertTrue(torch.allclose(outputs.predicted_depth[0, :3, :3], expected_slice, atol=1e-4))
+
+ def test_inference_depth_estimation_multiple_heads(self):
+ image_processor = ZoeDepthImageProcessor.from_pretrained("Intel/zoedepth-nyu-kitti")
+ model = ZoeDepthForDepthEstimation.from_pretrained("Intel/zoedepth-nyu-kitti").to(torch_device)
+
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+ predicted_depth = outputs.predicted_depth
+
+ # verify the predicted depth
+ expected_shape = torch.Size((1, 384, 512))
+ self.assertEqual(predicted_depth.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[1.1571, 1.1438, 1.1783], [1.2163, 1.2036, 1.2320], [1.2688, 1.2461, 1.2734]],
+ ).to(torch_device)
+
+ self.assertTrue(torch.allclose(outputs.predicted_depth[0, :3, :3], expected_slice, atol=1e-4))