diff --git a/docs/source/ko/_toctree.yml b/docs/source/ko/_toctree.yml
index 06ece415a82481..f23d04695c56e8 100644
--- a/docs/source/ko/_toctree.yml
+++ b/docs/source/ko/_toctree.yml
@@ -149,8 +149,8 @@
title: (번역중) AWQ
- local: in_translation
title: (번역중) AQLM
- - local: in_translation
- title: (번역중) Quanto
+ - local: quantization/quanto
+ title: Quanto
- local: in_translation
title: (번역중) EETQ
- local: in_translation
diff --git a/docs/source/ko/quantization/quanto.md b/docs/source/ko/quantization/quanto.md
new file mode 100644
index 00000000000000..7eff695051d6b8
--- /dev/null
+++ b/docs/source/ko/quantization/quanto.md
@@ -0,0 +1,67 @@
+
+
+# Quanto[[quanto]]
+
+
+
+이 [노트북](https://colab.research.google.com/drive/16CXfVmtdQvciSh9BopZUDYcmXCDpvgrT?usp=sharing)으로 Quanto와 transformers를 사용해 보세요!
+
+
+
+
+[🤗 Quanto](https://github.com/huggingface/optimum-quanto) 라이브러리는 다목적 파이토치 양자화 툴킷입니다. 이 라이브러리에서 사용되는 양자화 방법은 선형 양자화입니다. Quanto는 다음과 같은 여러 가지 기능을 제공합니다:
+
+- 가중치 양자화 (`float8`,`int8`,`int4`,`int2`)
+- 활성화 양자화 (`float8`,`int8`)
+- 모달리티에 구애받지 않음 (e.g CV,LLM)
+- 장치에 구애받지 않음 (e.g CUDA,MPS,CPU)
+- `torch.compile` 호환성
+- 특정 장치에 대한 사용자 정의 커널의 쉬운 추가
+- QAT(양자화를 고려한 학습) 지원
+
+
+시작하기 전에 다음 라이브러리가 설치되어 있는지 확인하세요:
+
+```bash
+pip install quanto accelerate transformers
+```
+
+이제 [`~PreTrainedModel.from_pretrained`] 메소드에 [`QuantoConfig`] 객체를 전달하여 모델을 양자화할 수 있습니다. 이 방식은 `torch.nn.Linear` 레이어를 포함하는 모든 모달리티의 모든 모델에서 잘 작동합니다.
+
+허깅페이스의 transformers 라이브러리는 개발자 편의를 위해 quanto의 인터페이스를 일부 통합하여 지원하고 있으며, 이 방식으로는 가중치 양자화만 지원합니다. 활성화 양자화, 캘리브레이션, QAT 같은 더 복잡한 기능을 수행하기 위해서는 [quanto](https://github.com/huggingface/optimum-quanto) 라이브러리의 해당 함수를 직접 호출해야 합니다.
+
+```py
+from transformers import AutoModelForCausalLM, AutoTokenizer, QuantoConfig
+
+model_id = "facebook/opt-125m"
+tokenizer = AutoTokenizer.from_pretrained(model_id)
+quantization_config = QuantoConfig(weights="int8")
+quantized_model = AutoModelForCausalLM.from_pretrained(model_id, device_map="cuda:0", quantization_config=quantization_config)
+```
+
+참고로, transformers에서는 아직 직렬화가 지원되지 않지만 곧 지원될 예정입니다!
+모델을 저장하고 싶으면 quanto 라이브러리를 대신 사용할 수 있습니다.
+
+Quanto 라이브러리는 양자화를 위해 선형 양자화 알고리즘을 사용합니다. 비록 기본적인 양자화 기술이지만, 좋은 결과를 얻는데 아주 큰 도움이 됩니다! 바로 아래에 있는 벤치마크(llama-2-7b의 펄플렉서티 지표)를 확인해 보세요. 더 많은 벤치마크는 [여기](https://github.com/huggingface/quanto/tree/main/bench/generation) 에서 찾을 수 있습니다.
+
+
+
+
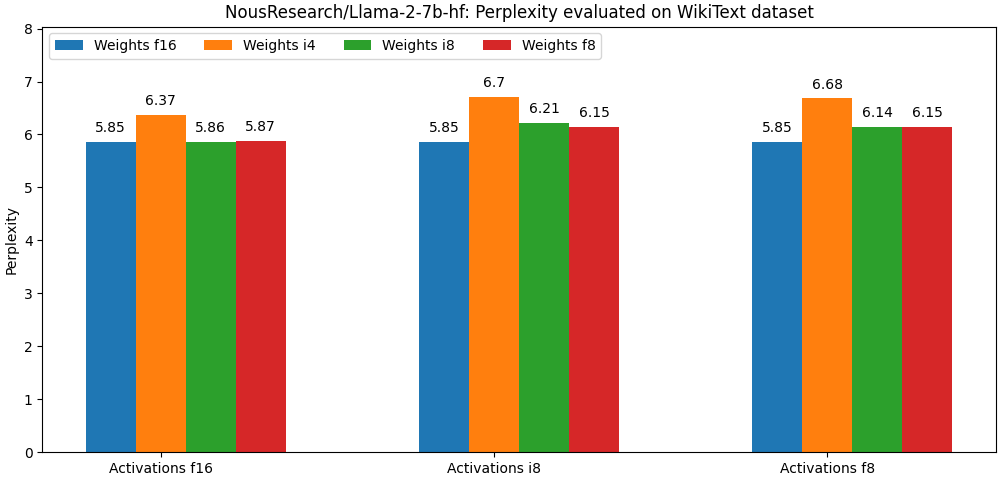
+
+