diff --git a/README.md b/README.md
index 99c90a3916ddda..0cda209bdfc32c 100644
--- a/README.md
+++ b/README.md
@@ -368,6 +368,7 @@ Current number of checkpoints: ** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
+1. **[VideoMAE](https://huggingface.co/docs/transformers/main/model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
diff --git a/README_ko.md b/README_ko.md
index adfaefddf628ca..c63fdca749da8f 100644
--- a/README_ko.md
+++ b/README_ko.md
@@ -324,6 +324,7 @@ Flax, PyTorch, TensorFlow 설치 페이지에서 이들을 conda로 설치하는
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/pdf/2202.09741.pdf) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
+1. **[VideoMAE](https://huggingface.co/docs/transformers/main/model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
diff --git a/README_zh-hans.md b/README_zh-hans.md
index 0e51441b407b44..0ab06bd96ad99f 100644
--- a/README_zh-hans.md
+++ b/README_zh-hans.md
@@ -348,6 +348,7 @@ conda install -c huggingface transformers
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (来自 Microsoft Research) 伴随论文 [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) 由 Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang 发布。
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (来自 Microsoft Research) 伴随论文 [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) 由 Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu 发布。
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (来自 Tsinghua University and Nankai University) 伴随论文 [Visual Attention Network](https://arxiv.org/pdf/2202.09741.pdf) 由 Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu 发布。
+1. **[VideoMAE](https://huggingface.co/docs/transformers/main/model_doc/videomae)** (来自 Multimedia Computing Group, Nanjing University) 伴随论文 [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) 由 Zhan Tong, Yibing Song, Jue Wang, Limin Wang 发布。
1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (来自 NAVER AI Lab/Kakao Enterprise/Kakao Brain) 伴随论文 [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) 由 Wonjae Kim, Bokyung Son, Ildoo Kim 发布。
1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (来自 Google AI) 伴随论文 [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) 由 Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby 发布。
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (来自 UCLA NLP) 伴随论文 [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) 由 Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang 发布。
diff --git a/README_zh-hant.md b/README_zh-hant.md
index 1fbff9fa1741bd..90f29ad031b8b0 100644
--- a/README_zh-hant.md
+++ b/README_zh-hant.md
@@ -360,6 +360,7 @@ conda install -c huggingface transformers
1. **[UniSpeech](https://huggingface.co/docs/transformers/model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
1. **[UniSpeechSat](https://huggingface.co/docs/transformers/model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
1. **[VAN](https://huggingface.co/docs/transformers/model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/pdf/2202.09741.pdf) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
+1. **[VideoMAE](https://huggingface.co/docs/transformers/main/model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
1. **[ViLT](https://huggingface.co/docs/transformers/model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
1. **[Vision Transformer (ViT)](https://huggingface.co/docs/transformers/model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
1. **[VisualBERT](https://huggingface.co/docs/transformers/model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
diff --git a/docs/source/en/_toctree.yml b/docs/source/en/_toctree.yml
index 2be8f650738079..32ab4c6361d3a7 100644
--- a/docs/source/en/_toctree.yml
+++ b/docs/source/en/_toctree.yml
@@ -381,6 +381,8 @@
title: Swin Transformer V2
- local: model_doc/van
title: VAN
+ - local: model_doc/videomae
+ title: VideoMAE
- local: model_doc/vit
title: Vision Transformer (ViT)
- local: model_doc/vit_mae
diff --git a/docs/source/en/index.mdx b/docs/source/en/index.mdx
index e8c3ed2928a7c6..5c0d51d8b7afb2 100644
--- a/docs/source/en/index.mdx
+++ b/docs/source/en/index.mdx
@@ -166,6 +166,7 @@ The library currently contains JAX, PyTorch and TensorFlow implementations, pret
1. **[UniSpeech](model_doc/unispeech)** (from Microsoft Research) released with the paper [UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597) by Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang.
1. **[UniSpeechSat](model_doc/unispeech-sat)** (from Microsoft Research) released with the paper [UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752) by Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu.
1. **[VAN](model_doc/van)** (from Tsinghua University and Nankai University) released with the paper [Visual Attention Network](https://arxiv.org/abs/2202.09741) by Meng-Hao Guo, Cheng-Ze Lu, Zheng-Ning Liu, Ming-Ming Cheng, Shi-Min Hu.
+1. **[VideoMAE](model_doc/videomae)** (from Multimedia Computing Group, Nanjing University) released with the paper [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
1. **[ViLT](model_doc/vilt)** (from NAVER AI Lab/Kakao Enterprise/Kakao Brain) released with the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Wonjae Kim, Bokyung Son, Ildoo Kim.
1. **[Vision Transformer (ViT)](model_doc/vit)** (from Google AI) released with the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby.
1. **[VisualBERT](model_doc/visual_bert)** (from UCLA NLP) released with the paper [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
@@ -299,6 +300,7 @@ Flax), PyTorch, and/or TensorFlow.
| UniSpeech | ❌ | ❌ | ✅ | ❌ | ❌ |
| UniSpeechSat | ❌ | ❌ | ✅ | ❌ | ❌ |
| VAN | ❌ | ❌ | ✅ | ❌ | ❌ |
+| VideoMAE | ❌ | ❌ | ✅ | ❌ | ❌ |
| ViLT | ❌ | ❌ | ✅ | ❌ | ❌ |
| Vision Encoder decoder | ❌ | ❌ | ✅ | ✅ | ✅ |
| VisionTextDualEncoder | ❌ | ❌ | ✅ | ❌ | ✅ |
diff --git a/docs/source/en/model_doc/auto.mdx b/docs/source/en/model_doc/auto.mdx
index 6c32166389614e..67fc81d280a79b 100644
--- a/docs/source/en/model_doc/auto.mdx
+++ b/docs/source/en/model_doc/auto.mdx
@@ -118,6 +118,10 @@ Likewise, if your `NewModel` is a subclass of [`PreTrainedModel`], make sure its
[[autodoc]] AutoModelForImageClassification
+## AutoModelForVideoClassification
+
+[[autodoc]] AutoModelForVideoClassification
+
## AutoModelForVision2Seq
[[autodoc]] AutoModelForVision2Seq
diff --git a/docs/source/en/model_doc/videomae.mdx b/docs/source/en/model_doc/videomae.mdx
new file mode 100644
index 00000000000000..c319944dc8ed43
--- /dev/null
+++ b/docs/source/en/model_doc/videomae.mdx
@@ -0,0 +1,60 @@
+
+
+# VideoMAE
+
+## Overview
+
+The VideoMAE model was proposed in [VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training](https://arxiv.org/abs/2203.12602) by Zhan Tong, Yibing Song, Jue Wang, Limin Wang.
+VideoMAE extends masked auto encoders ([MAE](vit_mae)) to video, claiming state-of-the-art performance on several video classification benchmarks.
+
+The abstract from the paper is the following:
+
+*Pre-training video transformers on extra large-scale datasets is generally required to achieve premier performance on relatively small datasets. In this paper, we show that video masked autoencoders (VideoMAE) are data-efficient learners for self-supervised video pre-training (SSVP). We are inspired by the recent ImageMAE and propose customized video tube masking and reconstruction. These simple designs turn out to be effective for overcoming information leakage caused by the temporal correlation during video reconstruction. We obtain three important findings on SSVP: (1) An extremely high proportion of masking ratio (i.e., 90% to 95%) still yields favorable performance of VideoMAE. The temporally redundant video content enables higher masking ratio than that of images. (2) VideoMAE achieves impressive results on very small datasets (i.e., around 3k-4k videos) without using any extra data. This is partially ascribed to the challenging task of video reconstruction to enforce high-level structure learning. (3) VideoMAE shows that data quality is more important than data quantity for SSVP. Domain shift between pre-training and target datasets are important issues in SSVP. Notably, our VideoMAE with the vanilla ViT backbone can achieve 83.9% on Kinects-400, 75.3% on Something-Something V2, 90.8% on UCF101, and 61.1% on HMDB51 without using any extra data.*
+
+Tips:
+
+- One can use [`VideoMAEFeatureExtractor`] to prepare videos for the model. It will resize + normalize all frames of a video for you.
+- [`VideoMAEForPreTraining`] includes the decoder on top for self-supervised pre-training.
+
+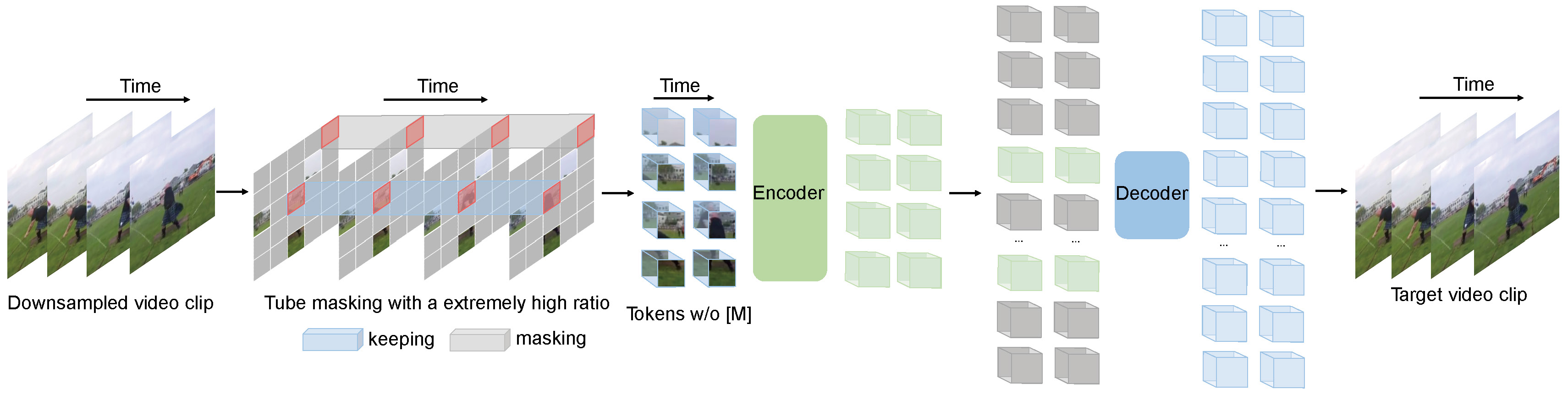 +
+ VideoMAE pre-training. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/MCG-NJU/VideoMAE).
+
+
+## VideoMAEConfig
+
+[[autodoc]] VideoMAEConfig
+
+## VideoMAEFeatureExtractor
+
+[[autodoc]] VideoMAEFeatureExtractor
+ - __call__
+
+## VideoMAEModel
+
+[[autodoc]] VideoMAEModel
+ - forward
+
+## VideoMAEForPreTraining
+
+[[autodoc]] transformers.VideoMAEForPreTraining
+ - forward
+
+## VideoMAEForVideoClassification
+
+[[autodoc]] transformers.VideoMAEForVideoClassification
+ - forward
\ No newline at end of file
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index 75784ce4637659..e8cfd47f3d3b37 100755
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -341,6 +341,7 @@
"UniSpeechSatConfig",
],
"models.van": ["VAN_PRETRAINED_CONFIG_ARCHIVE_MAP", "VanConfig"],
+ "models.videomae": ["VIDEOMAE_PRETRAINED_CONFIG_ARCHIVE_MAP", "VideoMAEConfig"],
"models.vilt": ["VILT_PRETRAINED_CONFIG_ARCHIVE_MAP", "ViltConfig", "ViltFeatureExtractor", "ViltProcessor"],
"models.vision_encoder_decoder": ["VisionEncoderDecoderConfig"],
"models.vision_text_dual_encoder": ["VisionTextDualEncoderConfig", "VisionTextDualEncoderProcessor"],
@@ -653,6 +654,7 @@
_import_structure["models.perceiver"].append("PerceiverFeatureExtractor")
_import_structure["models.poolformer"].append("PoolFormerFeatureExtractor")
_import_structure["models.segformer"].append("SegformerFeatureExtractor")
+ _import_structure["models.videomae"].append("VideoMAEFeatureExtractor")
_import_structure["models.vilt"].append("ViltFeatureExtractor")
_import_structure["models.vilt"].append("ViltProcessor")
_import_structure["models.vit"].append("ViTFeatureExtractor")
@@ -799,6 +801,7 @@
"MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING",
"MODEL_FOR_TABLE_QUESTION_ANSWERING_MAPPING",
"MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING",
+ "MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING",
"MODEL_FOR_VISION_2_SEQ_MAPPING",
"MODEL_FOR_VISUAL_QUESTION_ANSWERING_MAPPING",
"MODEL_MAPPING",
@@ -825,6 +828,7 @@
"AutoModelForSpeechSeq2Seq",
"AutoModelForTableQuestionAnswering",
"AutoModelForTokenClassification",
+ "AutoModelForVideoClassification",
"AutoModelForVision2Seq",
"AutoModelForVisualQuestionAnswering",
"AutoModelWithLMHead",
@@ -1871,6 +1875,15 @@
"ViTMAEPreTrainedModel",
]
)
+ _import_structure["models.videomae"].extend(
+ [
+ "VIDEOMAE_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "VideoMAEForPreTraining",
+ "VideoMAEModel",
+ "VideoMAEPreTrainedModel",
+ "VideoMAEForVideoClassification",
+ ]
+ )
_import_structure["models.wav2vec2"].extend(
[
"WAV_2_VEC_2_PRETRAINED_MODEL_ARCHIVE_LIST",
@@ -3100,6 +3113,7 @@
from .models.unispeech import UNISPEECH_PRETRAINED_CONFIG_ARCHIVE_MAP, UniSpeechConfig
from .models.unispeech_sat import UNISPEECH_SAT_PRETRAINED_CONFIG_ARCHIVE_MAP, UniSpeechSatConfig
from .models.van import VAN_PRETRAINED_CONFIG_ARCHIVE_MAP, VanConfig
+ from .models.videomae import VIDEOMAE_PRETRAINED_CONFIG_ARCHIVE_MAP, VideoMAEConfig
from .models.vilt import VILT_PRETRAINED_CONFIG_ARCHIVE_MAP, ViltConfig, ViltFeatureExtractor, ViltProcessor
from .models.vision_encoder_decoder import VisionEncoderDecoderConfig
from .models.vision_text_dual_encoder import VisionTextDualEncoderConfig, VisionTextDualEncoderProcessor
@@ -3373,6 +3387,7 @@
from .models.perceiver import PerceiverFeatureExtractor
from .models.poolformer import PoolFormerFeatureExtractor
from .models.segformer import SegformerFeatureExtractor
+ from .models.videomae import VideoMAEFeatureExtractor
from .models.vilt import ViltFeatureExtractor, ViltProcessor
from .models.vit import ViTFeatureExtractor
from .models.yolos import YolosFeatureExtractor
@@ -3497,6 +3512,7 @@
MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING,
MODEL_FOR_TABLE_QUESTION_ANSWERING_MAPPING,
MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING,
+ MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING,
MODEL_FOR_VISION_2_SEQ_MAPPING,
MODEL_FOR_VISUAL_QUESTION_ANSWERING_MAPPING,
MODEL_MAPPING,
@@ -3523,6 +3539,7 @@
AutoModelForSpeechSeq2Seq,
AutoModelForTableQuestionAnswering,
AutoModelForTokenClassification,
+ AutoModelForVideoClassification,
AutoModelForVision2Seq,
AutoModelForVisualQuestionAnswering,
AutoModelWithLMHead,
@@ -4338,6 +4355,13 @@
VanModel,
VanPreTrainedModel,
)
+ from .models.videomae import (
+ VIDEOMAE_PRETRAINED_MODEL_ARCHIVE_LIST,
+ VideoMAEForPreTraining,
+ VideoMAEForVideoClassification,
+ VideoMAEModel,
+ VideoMAEPreTrainedModel,
+ )
from .models.vilt import (
VILT_PRETRAINED_MODEL_ARCHIVE_LIST,
ViltForImageAndTextRetrieval,
diff --git a/src/transformers/image_utils.py b/src/transformers/image_utils.py
index ddef7a3a777e93..dd7bb326993d34 100644
--- a/src/transformers/image_utils.py
+++ b/src/transformers/image_utils.py
@@ -23,14 +23,15 @@
import requests
from .utils import is_torch_available
+from .utils.constants import ( # noqa: F401
+ IMAGENET_DEFAULT_MEAN,
+ IMAGENET_DEFAULT_STD,
+ IMAGENET_STANDARD_MEAN,
+ IMAGENET_STANDARD_STD,
+)
from .utils.generic import _is_torch
-IMAGENET_DEFAULT_MEAN = [0.485, 0.456, 0.406]
-IMAGENET_DEFAULT_STD = [0.229, 0.224, 0.225]
-IMAGENET_STANDARD_MEAN = [0.5, 0.5, 0.5]
-IMAGENET_STANDARD_STD = [0.5, 0.5, 0.5]
-
ImageInput = Union[
PIL.Image.Image, np.ndarray, "torch.Tensor", List[PIL.Image.Image], List[np.ndarray], List["torch.Tensor"] # noqa
]
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index 1b81ce7d8fab1d..11887db91f8393 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -137,6 +137,7 @@
unispeech,
unispeech_sat,
van,
+ videomae,
vilt,
vision_encoder_decoder,
vision_text_dual_encoder,
diff --git a/src/transformers/models/auto/__init__.py b/src/transformers/models/auto/__init__.py
index 09961bae14fdeb..b04c2420ef963e 100644
--- a/src/transformers/models/auto/__init__.py
+++ b/src/transformers/models/auto/__init__.py
@@ -63,6 +63,7 @@
"MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING",
"MODEL_FOR_TABLE_QUESTION_ANSWERING_MAPPING",
"MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING",
+ "MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING",
"MODEL_FOR_VISION_2_SEQ_MAPPING",
"MODEL_FOR_VISUAL_QUESTION_ANSWERING_MAPPING",
"MODEL_MAPPING",
@@ -89,6 +90,7 @@
"AutoModelForSpeechSeq2Seq",
"AutoModelForTableQuestionAnswering",
"AutoModelForTokenClassification",
+ "AutoModelForVideoClassification",
"AutoModelForVision2Seq",
"AutoModelForVisualQuestionAnswering",
"AutoModelWithLMHead",
@@ -203,6 +205,7 @@
MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING,
MODEL_FOR_TABLE_QUESTION_ANSWERING_MAPPING,
MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING,
+ MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING,
MODEL_FOR_VISION_2_SEQ_MAPPING,
MODEL_FOR_VISUAL_QUESTION_ANSWERING_MAPPING,
MODEL_MAPPING,
@@ -229,6 +232,7 @@
AutoModelForSpeechSeq2Seq,
AutoModelForTableQuestionAnswering,
AutoModelForTokenClassification,
+ AutoModelForVideoClassification,
AutoModelForVision2Seq,
AutoModelForVisualQuestionAnswering,
AutoModelWithLMHead,
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index 13f69c024a9a0d..d8ecbb49e64f29 100644
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -132,6 +132,7 @@
("unispeech", "UniSpeechConfig"),
("unispeech-sat", "UniSpeechSatConfig"),
("van", "VanConfig"),
+ ("videomae", "VideoMAEConfig"),
("vilt", "ViltConfig"),
("vision-encoder-decoder", "VisionEncoderDecoderConfig"),
("vision-text-dual-encoder", "VisionTextDualEncoderConfig"),
@@ -247,6 +248,7 @@
("unispeech", "UNISPEECH_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("unispeech-sat", "UNISPEECH_SAT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("van", "VAN_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("videomae", "VIDEOMAE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("vilt", "VILT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("visual_bert", "VISUAL_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("vit", "VIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
@@ -388,6 +390,7 @@
("unispeech", "UniSpeech"),
("unispeech-sat", "UniSpeechSat"),
("van", "VAN"),
+ ("videomae", "VideoMAE"),
("vilt", "ViLT"),
("vision-encoder-decoder", "Vision Encoder decoder"),
("vision-text-dual-encoder", "VisionTextDualEncoder"),
diff --git a/src/transformers/models/auto/feature_extraction_auto.py b/src/transformers/models/auto/feature_extraction_auto.py
index 8c4564e261c616..ed526369df4f38 100644
--- a/src/transformers/models/auto/feature_extraction_auto.py
+++ b/src/transformers/models/auto/feature_extraction_auto.py
@@ -68,6 +68,7 @@
("swin", "ViTFeatureExtractor"),
("swinv2", "ViTFeatureExtractor"),
("van", "ConvNextFeatureExtractor"),
+ ("videomae", "ViTFeatureExtractor"),
("vilt", "ViltFeatureExtractor"),
("vit", "ViTFeatureExtractor"),
("vit_mae", "ViTFeatureExtractor"),
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index a86e8bc56da34b..bd4774c245b07b 100644
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -127,6 +127,7 @@
("unispeech", "UniSpeechModel"),
("unispeech-sat", "UniSpeechSatModel"),
("van", "VanModel"),
+ ("videomae", "VideoMAEModel"),
("vilt", "ViltModel"),
("vision-text-dual-encoder", "VisionTextDualEncoderModel"),
("visual_bert", "VisualBertModel"),
@@ -187,6 +188,7 @@
("transfo-xl", "TransfoXLLMHeadModel"),
("unispeech", "UniSpeechForPreTraining"),
("unispeech-sat", "UniSpeechSatForPreTraining"),
+ ("videomae", "VideoMAEForPreTraining"),
("visual_bert", "VisualBertForPreTraining"),
("vit_mae", "ViTMAEForPreTraining"),
("wav2vec2", "Wav2Vec2ForPreTraining"),
@@ -381,6 +383,12 @@
]
)
+MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
+ [
+ ("videomae", "VideoMAEForVideoClassification"),
+ ]
+)
+
MODEL_FOR_VISION_2_SEQ_MAPPING_NAMES = OrderedDict(
[
("vision-encoder-decoder", "VisionEncoderDecoderModel"),
@@ -754,6 +762,9 @@
MODEL_FOR_INSTANCE_SEGMENTATION_MAPPING = _LazyAutoMapping(
CONFIG_MAPPING_NAMES, MODEL_FOR_INSTANCE_SEGMENTATION_MAPPING_NAMES
)
+MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING_NAMES
+)
MODEL_FOR_VISION_2_SEQ_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_VISION_2_SEQ_MAPPING_NAMES)
MODEL_FOR_VISUAL_QUESTION_ANSWERING_MAPPING = _LazyAutoMapping(
CONFIG_MAPPING_NAMES, MODEL_FOR_VISUAL_QUESTION_ANSWERING_MAPPING_NAMES
@@ -938,6 +949,13 @@ class AutoModelForObjectDetection(_BaseAutoModelClass):
AutoModelForObjectDetection = auto_class_update(AutoModelForObjectDetection, head_doc="object detection")
+class AutoModelForVideoClassification(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING
+
+
+AutoModelForVideoClassification = auto_class_update(AutoModelForVideoClassification, head_doc="video classification")
+
+
class AutoModelForVision2Seq(_BaseAutoModelClass):
_model_mapping = MODEL_FOR_VISION_2_SEQ_MAPPING
diff --git a/src/transformers/models/videomae/__init__.py b/src/transformers/models/videomae/__init__.py
new file mode 100644
index 00000000000000..fb239c6063ba80
--- /dev/null
+++ b/src/transformers/models/videomae/__init__.py
@@ -0,0 +1,77 @@
+# flake8: noqa
+# There's no way to ignore "F401 '...' imported but unused" warnings in this
+# module, but to preserve other warnings. So, don't check this module at all.
+
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...utils import OptionalDependencyNotAvailable, _LazyModule, is_torch_available, is_vision_available
+
+
+_import_structure = {
+ "configuration_videomae": ["VIDEOMAE_PRETRAINED_CONFIG_ARCHIVE_MAP", "VideoMAEConfig"],
+}
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["modeling_videomae"] = [
+ "VIDEOMAE_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "VideoMAEForPreTraining",
+ "VideoMAEModel",
+ "VideoMAEPreTrainedModel",
+ "VideoMAEForVideoClassification",
+ ]
+
+try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["feature_extraction_videomae"] = ["VideoMAEFeatureExtractor"]
+
+if TYPE_CHECKING:
+ from .configuration_videomae import VIDEOMAE_PRETRAINED_CONFIG_ARCHIVE_MAP, VideoMAEConfig
+
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .modeling_videomae import (
+ VIDEOMAE_PRETRAINED_MODEL_ARCHIVE_LIST,
+ VideoMAEForPreTraining,
+ VideoMAEForVideoClassification,
+ VideoMAEModel,
+ VideoMAEPreTrainedModel,
+ )
+
+ try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .feature_extraction_videomae import VideoMAEFeatureExtractor
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
diff --git a/src/transformers/models/videomae/configuration_videomae.py b/src/transformers/models/videomae/configuration_videomae.py
new file mode 100644
index 00000000000000..932c4c1d98cabf
--- /dev/null
+++ b/src/transformers/models/videomae/configuration_videomae.py
@@ -0,0 +1,148 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" VideoMAE model configuration"""
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+VIDEOMAE_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "MCG-NJU/videomae-base": "https://huggingface.co/MCG-NJU/videomae-base/resolve/main/config.json",
+}
+
+
+class VideoMAEConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`VideoMAEModel`]. It is used to instantiate a
+ VideoMAE model according to the specified arguments, defining the model architecture. Instantiating a configuration
+ with the defaults will yield a similar configuration to that of the VideoMAE
+ [MCG-NJU/videomae-base](https://huggingface.co/MCG-NJU/videomae-base) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ image_size (`int`, *optional*, defaults to 224):
+ The size (resolution) of each image.
+ patch_size (`int`, *optional*, defaults to 16):
+ The size (resolution) of each patch.
+ num_channels (`int`, *optional*, defaults to 3):
+ The number of input channels.
+ num_frames (`int`, *optional*, defaults to 16):
+ The number of frames in each video.
+ tubelet_size (`int`, *optional*, defaults to 2):
+ The number of tubelets.
+ hidden_size (`int`, *optional*, defaults to 768):
+ Dimensionality of the encoder layers and the pooler layer.
+ num_hidden_layers (`int`, *optional*, defaults to 12):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 12):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ intermediate_size (`int`, *optional*, defaults to 3072):
+ Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
+ hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"selu"` and `"gelu_new"` are supported.
+ hidden_dropout_prob (`float`, *optional*, defaults to 0.0):
+ The dropout probabilitiy for all fully connected layers in the embeddings, encoder, and pooler.
+ attention_probs_dropout_prob (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ layer_norm_eps (`float`, *optional*, defaults to 1e-12):
+ The epsilon used by the layer normalization layers.
+ qkv_bias (`bool`, *optional*, defaults to `True`):
+ Whether to add a bias to the queries, keys and values.
+ use_mean_pooling (`bool`, *optional*, defaults to `True`):
+ Whether to mean pool the final hidden states instead of using the final hidden state of the [CLS] token.
+ decoder_num_attention_heads (`int`, *optional*, defaults to 6):
+ Number of attention heads for each attention layer in the decoder.
+ decoder_hidden_size (`int`, *optional*, defaults to 384):
+ Dimensionality of the decoder.
+ decoder_num_hidden_layers (`int`, *optional*, defaults to 4):
+ Number of hidden layers in the decoder.
+ decoder_intermediate_size (`int`, *optional*, defaults to 1536):
+ Dimensionality of the "intermediate" (i.e., feed-forward) layer in the decoder.
+ norm_pix_loss (`bool`, *optional*, defaults to `True`):
+ Whether to normalize the target patch pixels.
+
+ Example:
+
+ ```python
+ >>> from transformers import VideoMAEConfig, VideoMAEModel
+
+ >>> # Initializing a VideoMAE videomae-base style configuration
+ >>> configuration = VideoMAEConfig()
+
+ >>> # Randomly initializing a model from the configuration
+ >>> model = VideoMAEModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+ model_type = "videomae"
+
+ def __init__(
+ self,
+ image_size=224,
+ patch_size=16,
+ num_channels=3,
+ num_frames=16,
+ tubelet_size=2,
+ hidden_size=768,
+ num_hidden_layers=12,
+ num_attention_heads=12,
+ intermediate_size=3072,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.0,
+ attention_probs_dropout_prob=0.0,
+ initializer_range=0.02,
+ layer_norm_eps=1e-12,
+ qkv_bias=True,
+ use_mean_pooling=True,
+ decoder_num_attention_heads=6,
+ decoder_hidden_size=384,
+ decoder_num_hidden_layers=4,
+ decoder_intermediate_size=1536,
+ norm_pix_loss=True,
+ **kwargs
+ ):
+ super().__init__(**kwargs)
+
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.num_frames = num_frames
+ self.tubelet_size = tubelet_size
+
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.initializer_range = initializer_range
+ self.layer_norm_eps = layer_norm_eps
+ self.qkv_bias = qkv_bias
+ self.use_mean_pooling = use_mean_pooling
+
+ self.decoder_num_attention_heads = decoder_num_attention_heads
+ self.decoder_hidden_size = decoder_hidden_size
+ self.decoder_num_hidden_layers = decoder_num_hidden_layers
+ self.decoder_intermediate_size = decoder_intermediate_size
+ self.norm_pix_loss = norm_pix_loss
diff --git a/src/transformers/models/videomae/convert_videomae_to_pytorch.py b/src/transformers/models/videomae/convert_videomae_to_pytorch.py
new file mode 100644
index 00000000000000..60e5ae8f5f41c0
--- /dev/null
+++ b/src/transformers/models/videomae/convert_videomae_to_pytorch.py
@@ -0,0 +1,286 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Convert VideoMAE checkpoints from the original repository: https://github.com/MCG-NJU/VideoMAE"""
+
+import argparse
+import json
+
+import numpy as np
+import torch
+
+import gdown
+from huggingface_hub import hf_hub_download
+from transformers import (
+ VideoMAEConfig,
+ VideoMAEFeatureExtractor,
+ VideoMAEForPreTraining,
+ VideoMAEForVideoClassification,
+)
+
+
+def get_videomae_config(model_name):
+ config = VideoMAEConfig()
+
+ if "large" in model_name:
+ config.hidden_size = 1024
+ config.intermediate_size = 4096
+ config.num_hidden_layers = 24
+ config.num_attention_heads = 16
+ config.decoder_num_hidden_layers = 12
+ config.decoder_num_attention_heads = 8
+ config.decoder_hidden_size = 512
+ config.decoder_intermediate_size = 2048
+
+ if "finetuned" not in model_name:
+ config.use_mean_pooling = False
+
+ if "finetuned" in model_name:
+ repo_id = "datasets/huggingface/label-files"
+ if "kinetics" in model_name:
+ config.num_labels = 400
+ filename = "kinetics400-id2label.json"
+ elif "ssv2" in model_name:
+ config.num_labels = 174
+ filename = "something-something-v2-id2label.json"
+ else:
+ raise ValueError("Model name should either contain 'kinetics' or 'ssv2' in case it's fine-tuned.")
+ id2label = json.load(open(hf_hub_download(repo_id, filename), "r"))
+ id2label = {int(k): v for k, v in id2label.items()}
+ config.id2label = id2label
+ config.label2id = {v: k for k, v in id2label.items()}
+
+ return config
+
+
+def rename_key(name):
+ if "encoder." in name:
+ name = name.replace("encoder.", "")
+ if "cls_token" in name:
+ name = name.replace("cls_token", "videomae.embeddings.cls_token")
+ if "decoder_pos_embed" in name:
+ name = name.replace("decoder_pos_embed", "decoder.decoder_pos_embed")
+ if "pos_embed" in name and "decoder" not in name:
+ name = name.replace("pos_embed", "videomae.embeddings.position_embeddings")
+ if "patch_embed.proj" in name:
+ name = name.replace("patch_embed.proj", "videomae.embeddings.patch_embeddings.projection")
+ if "patch_embed.norm" in name:
+ name = name.replace("patch_embed.norm", "videomae.embeddings.norm")
+ if "decoder.blocks" in name:
+ name = name.replace("decoder.blocks", "decoder.decoder_layers")
+ if "blocks" in name:
+ name = name.replace("blocks", "videomae.encoder.layer")
+ if "attn.proj" in name:
+ name = name.replace("attn.proj", "attention.output.dense")
+ if "attn" in name and "bias" not in name:
+ name = name.replace("attn", "attention.self")
+ if "attn" in name:
+ name = name.replace("attn", "attention.attention")
+ if "norm1" in name:
+ name = name.replace("norm1", "layernorm_before")
+ if "norm2" in name:
+ name = name.replace("norm2", "layernorm_after")
+ if "mlp.fc1" in name:
+ name = name.replace("mlp.fc1", "intermediate.dense")
+ if "mlp.fc2" in name:
+ name = name.replace("mlp.fc2", "output.dense")
+ if "decoder_embed" in name:
+ name = name.replace("decoder_embed", "decoder.decoder_embed")
+ if "decoder_norm" in name:
+ name = name.replace("decoder_norm", "decoder.decoder_norm")
+ if "decoder_pred" in name:
+ name = name.replace("decoder_pred", "decoder.decoder_pred")
+ if "norm.weight" in name and "decoder" not in name and "fc" not in name:
+ name = name.replace("norm.weight", "videomae.layernorm.weight")
+ if "norm.bias" in name and "decoder" not in name and "fc" not in name:
+ name = name.replace("norm.bias", "videomae.layernorm.bias")
+ if "head" in name and "decoder" not in name:
+ name = name.replace("head", "classifier")
+
+ return name
+
+
+def convert_state_dict(orig_state_dict, config):
+ for key in orig_state_dict.copy().keys():
+ val = orig_state_dict.pop(key)
+
+ if key.startswith("encoder."):
+ key = key.replace("encoder.", "")
+
+ if "qkv" in key:
+ key_split = key.split(".")
+ if key.startswith("decoder.blocks"):
+ dim = config.decoder_hidden_size
+ layer_num = int(key_split[2])
+ prefix = "decoder.decoder_layers."
+ if "weight" in key:
+ orig_state_dict[f"{prefix}{layer_num}.attention.attention.query.weight"] = val[:dim, :]
+ orig_state_dict[f"{prefix}{layer_num}.attention.attention.key.weight"] = val[dim : dim * 2, :]
+ orig_state_dict[f"{prefix}{layer_num}.attention.attention.value.weight"] = val[-dim:, :]
+ else:
+ dim = config.hidden_size
+ layer_num = int(key_split[1])
+ prefix = "videomae.encoder.layer."
+ if "weight" in key:
+ orig_state_dict[f"{prefix}{layer_num}.attention.attention.query.weight"] = val[:dim, :]
+ orig_state_dict[f"{prefix}{layer_num}.attention.attention.key.weight"] = val[dim : dim * 2, :]
+ orig_state_dict[f"{prefix}{layer_num}.attention.attention.value.weight"] = val[-dim:, :]
+ else:
+ orig_state_dict[rename_key(key)] = val
+
+ return orig_state_dict
+
+
+# We will verify our results on a video of eating spaghetti
+# Frame indices used: [164 168 172 176 181 185 189 193 198 202 206 210 215 219 223 227]
+def prepare_video():
+ file = hf_hub_download(repo_id="datasets/hf-internal-testing/spaghetti-video", filename="eating_spaghetti.npy")
+ video = np.load(file)
+ return list(video)
+
+
+def convert_videomae_checkpoint(checkpoint_url, pytorch_dump_folder_path, model_name, push_to_hub):
+ config = get_videomae_config(model_name)
+
+ if "finetuned" in model_name:
+ model = VideoMAEForVideoClassification(config)
+ else:
+ model = VideoMAEForPreTraining(config)
+
+ # download original checkpoint, hosted on Google Drive
+ output = "pytorch_model.bin"
+ gdown.cached_download(checkpoint_url, output, quiet=False)
+ files = torch.load(output, map_location="cpu")
+ if "model" in files:
+ state_dict = files["model"]
+ else:
+ state_dict = files["module"]
+ new_state_dict = convert_state_dict(state_dict, config)
+
+ model.load_state_dict(new_state_dict)
+ model.eval()
+
+ # verify model on basic input
+ feature_extractor = VideoMAEFeatureExtractor(image_mean=[0.5, 0.5, 0.5], image_std=[0.5, 0.5, 0.5])
+ video = prepare_video()
+ inputs = feature_extractor(video, return_tensors="pt")
+
+ if "finetuned" not in model_name:
+ local_path = hf_hub_download(repo_id="hf-internal-testing/bool-masked-pos", filename="bool_masked_pos.pt")
+ inputs["bool_masked_pos"] = torch.load(local_path)
+
+ outputs = model(**inputs)
+ logits = outputs.logits
+
+ model_names = [
+ # Kinetics-400 checkpoints (short = pretrained only for 800 epochs instead of 1600)
+ "videomae-base-short",
+ "videomae-base-short-finetuned-kinetics",
+ "videomae-base",
+ "videomae-base-finetuned-kinetics",
+ "videomae-large",
+ "videomae-large-finetuned-kinetics",
+ # Something-Something-v2 checkpoints (short = pretrained only for 800 epochs instead of 2400)
+ "videomae-base-short-ssv2",
+ "videomae-base-short-finetuned-ssv2",
+ "videomae-base-ssv2",
+ "videomae-base-finetuned-ssv2",
+ ]
+
+ # NOTE: logits were tested with image_mean and image_std equal to [0.5, 0.5, 0.5] and [0.5, 0.5, 0.5]
+ if model_name == "videomae-base":
+ expected_shape = torch.Size([1, 1408, 1536])
+ expected_slice = torch.tensor([[0.7739, 0.7968, 0.7089], [0.6701, 0.7487, 0.6209], [0.4287, 0.5158, 0.4773]])
+ elif model_name == "videomae-base-short":
+ expected_shape = torch.Size([1, 1408, 1536])
+ expected_slice = torch.tensor([[0.7994, 0.9612, 0.8508], [0.7401, 0.8958, 0.8302], [0.5862, 0.7468, 0.7325]])
+ # we verified the loss both for normalized and unnormalized targets for this one
+ expected_loss = torch.tensor([0.5142]) if config.norm_pix_loss else torch.tensor([0.6469])
+ elif model_name == "videomae-large":
+ expected_shape = torch.Size([1, 1408, 1536])
+ expected_slice = torch.tensor([[0.7149, 0.7997, 0.6966], [0.6768, 0.7869, 0.6948], [0.5139, 0.6221, 0.5605]])
+ elif model_name == "videomae-large-finetuned-kinetics":
+ expected_shape = torch.Size([1, 400])
+ expected_slice = torch.tensor([0.0771, 0.0011, -0.3625])
+ elif model_name == "videomae-base-short-finetuned-kinetics":
+ expected_shape = torch.Size([1, 400])
+ expected_slice = torch.tensor([0.6588, 0.0990, -0.2493])
+ elif model_name == "videomae-base-finetuned-kinetics":
+ expected_shape = torch.Size([1, 400])
+ expected_slice = torch.tensor([0.3669, -0.0688, -0.2421])
+ elif model_name == "videomae-base-short-ssv2":
+ expected_shape = torch.Size([1, 1408, 1536])
+ expected_slice = torch.tensor([[0.4712, 0.5296, 0.5786], [0.2278, 0.2729, 0.4026], [0.0352, 0.0730, 0.2506]])
+ elif model_name == "videomae-base-short-finetuned-ssv2":
+ expected_shape = torch.Size([1, 174])
+ expected_slice = torch.tensor([-0.0537, -0.1539, -0.3266])
+ elif model_name == "videomae-base-ssv2":
+ expected_shape = torch.Size([1, 1408, 1536])
+ expected_slice = torch.tensor([[0.8131, 0.8727, 0.8546], [0.7366, 0.9377, 0.8870], [0.5935, 0.8874, 0.8564]])
+ elif model_name == "videomae-base-finetuned-ssv2":
+ expected_shape = torch.Size([1, 174])
+ expected_slice = torch.tensor([0.1961, -0.8337, -0.6389])
+ else:
+ raise ValueError(f"Model name not supported. Should be one of {model_names}")
+
+ # verify logits
+ assert logits.shape == expected_shape
+ if "finetuned" in model_name:
+ assert torch.allclose(logits[0, :3], expected_slice, atol=1e-4)
+ else:
+ print("Logits:", logits[0, :3, :3])
+ assert torch.allclose(logits[0, :3, :3], expected_slice, atol=1e-4)
+ print("Logits ok!")
+
+ # verify loss, if applicable
+ if model_name == "videomae-base-short":
+ loss = outputs.loss
+ assert torch.allclose(loss, expected_loss, atol=1e-4)
+ print("Loss ok!")
+
+ if pytorch_dump_folder_path is not None:
+ print(f"Saving model and feature extractor to {pytorch_dump_folder_path}")
+ feature_extractor.save_pretrained(pytorch_dump_folder_path)
+ model.save_pretrained(pytorch_dump_folder_path)
+
+ if push_to_hub:
+ print("Pushing to the hub...")
+ model.push_to_hub(model_name, organization="nielsr")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ # Required parameters
+ parser.add_argument(
+ "--checkpoint_url",
+ default="https://drive.google.com/u/1/uc?id=1tEhLyskjb755TJ65ptsrafUG2llSwQE1&export=download&confirm=t&uuid=aa3276eb-fb7e-482a-adec-dc7171df14c4",
+ type=str,
+ help=(
+ "URL of the original PyTorch checkpoint (on Google Drive) you'd like to convert. Should be a direct"
+ " download link."
+ ),
+ )
+ parser.add_argument(
+ "--pytorch_dump_folder_path",
+ default="/Users/nielsrogge/Documents/VideoMAE/Test",
+ type=str,
+ help="Path to the output PyTorch model directory.",
+ )
+ parser.add_argument("--model_name", default="videomae-base", type=str, help="Name of the model.")
+ parser.add_argument(
+ "--push_to_hub", action="store_true", help="Whether or not to push the converted model to the 🤗 hub."
+ )
+
+ args = parser.parse_args()
+ convert_videomae_checkpoint(args.checkpoint_url, args.pytorch_dump_folder_path, args.model_name, args.push_to_hub)
diff --git a/src/transformers/models/videomae/feature_extraction_videomae.py b/src/transformers/models/videomae/feature_extraction_videomae.py
new file mode 100644
index 00000000000000..132dabda8c6833
--- /dev/null
+++ b/src/transformers/models/videomae/feature_extraction_videomae.py
@@ -0,0 +1,169 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Feature extractor class for VideoMAE."""
+
+from typing import Optional, Union
+
+import numpy as np
+from PIL import Image
+
+from ...feature_extraction_utils import BatchFeature, FeatureExtractionMixin
+from ...image_utils import ImageFeatureExtractionMixin, ImageInput, is_torch_tensor
+from ...utils import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD, TensorType, logging
+
+
+logger = logging.get_logger(__name__)
+
+
+class VideoMAEFeatureExtractor(FeatureExtractionMixin, ImageFeatureExtractionMixin):
+ r"""
+ Constructs a VideoMAE feature extractor. This feature extractor can be used to prepare videos for the model.
+
+ This feature extractor inherits from [`FeatureExtractionMixin`] which contains most of the main methods. Users
+ should refer to this superclass for more information regarding those methods.
+
+ Args:
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Whether to resize the shorter edge of the input to a certain `size`.
+ size (`int`, *optional*, defaults to 224):
+ Resize the shorter edge of the input to the given size. Only has an effect if `do_resize` is set to `True`.
+ resample (`int`, *optional*, defaults to `PIL.Image.BILINEAR`):
+ An optional resampling filter. This can be one of `PIL.Image.NEAREST`, `PIL.Image.BOX`,
+ `PIL.Image.BILINEAR`, `PIL.Image.HAMMING`, `PIL.Image.BICUBIC` or `PIL.Image.LANCZOS`. Only has an effect
+ if `do_resize` is set to `True`.
+ do_center_crop (`bool`, *optional*, defaults to `True`):
+ Whether to center crop the input to a certain `size`.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether or not to normalize the input with mean and standard deviation.
+ image_mean (`List[int]`, defaults to `[0.485, 0.456, 0.406]`):
+ The sequence of means for each channel, to be used when normalizing images.
+ image_std (`List[int]`, defaults to `[0.229, 0.224, 0.225]`):
+ The sequence of standard deviations for each channel, to be used when normalizing images.
+ """
+
+ model_input_names = ["pixel_values"]
+
+ def __init__(
+ self,
+ do_resize=True,
+ size=224,
+ resample=Image.BILINEAR,
+ do_center_crop=True,
+ do_normalize=True,
+ image_mean=None,
+ image_std=None,
+ **kwargs
+ ):
+ super().__init__(**kwargs)
+ self.do_resize = do_resize
+ self.size = size
+ self.resample = resample
+ self.do_center_crop = do_center_crop
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean if image_mean is not None else IMAGENET_DEFAULT_MEAN
+ self.image_std = image_std if image_std is not None else IMAGENET_DEFAULT_STD
+
+ def resize_video(self, video, size, resample="bilinear"):
+ return [self.resize(frame, size, resample, default_to_square=False) for frame in video]
+
+ def crop_video(self, video, size):
+ return [self.center_crop(frame, size) for frame in video]
+
+ def normalize_video(self, video, mean, std):
+ # video can be a list of PIL images, list of NumPy arrays or list of PyTorch tensors
+ # first: convert to list of NumPy arrays
+ video = [self.to_numpy_array(frame) for frame in video]
+
+ # second: stack to get (num_frames, num_channels, height, width)
+ video = np.stack(video, axis=0)
+
+ # third: normalize
+ if not isinstance(mean, np.ndarray):
+ mean = np.array(mean).astype(video.dtype)
+ if not isinstance(std, np.ndarray):
+ std = np.array(std).astype(video.dtype)
+
+ return (video - mean[None, :, None, None]) / std[None, :, None, None]
+
+ def __call__(
+ self, videos: ImageInput, return_tensors: Optional[Union[str, TensorType]] = None, **kwargs
+ ) -> BatchFeature:
+ """
+ Main method to prepare for the model one or several video(s).
+
+
+
+ NumPy arrays are converted to PIL images when resizing, so the most efficient is to pass PIL images.
+
+
+
+ Args:
+ videos (`List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`, `List[List[PIL.Image.Image]]`, `List[List[np.ndarrray]]`,:
+ `List[List[torch.Tensor]]`): The video or batch of videos to be prepared. Each video should be a list
+ of frames, which can be either PIL images or NumPy arrays. In case of NumPy arrays/PyTorch tensors,
+ each frame should be of shape (H, W, C), where H and W are frame height and width, and C is a number of
+ channels.
+
+ return_tensors (`str` or [`~utils.TensorType`], *optional*, defaults to `'np'`):
+ If set, will return tensors of a particular framework. Acceptable values are:
+
+ - `'tf'`: Return TensorFlow `tf.constant` objects.
+ - `'pt'`: Return PyTorch `torch.Tensor` objects.
+ - `'np'`: Return NumPy `np.ndarray` objects.
+ - `'jax'`: Return JAX `jnp.ndarray` objects.
+
+ Returns:
+ [`BatchFeature`]: A [`BatchFeature`] with the following fields:
+
+ - **pixel_values** -- Pixel values to be fed to a model, of shape (batch_size, num_channels, num_frames,
+ height, width).
+ """
+ # Input type checking for clearer error
+ valid_videos = False
+ is_batched = False
+
+ # Check that videos have a valid type
+ if isinstance(videos, (list, tuple)):
+ if isinstance(videos[0], (Image.Image, np.ndarray)) or is_torch_tensor(videos[0]):
+ valid_videos = True
+ elif isinstance(videos[0], (list, tuple)) and (
+ isinstance(videos[0][0], (Image.Image, np.ndarray)) or is_torch_tensor(videos[0][0])
+ ):
+ valid_videos = True
+ is_batched = True
+
+ if not valid_videos:
+ raise ValueError(
+ "Videos must of type `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]` (single"
+ " example), `List[List[PIL.Image.Image]]`, `List[List[np.ndarray]]`, `List[List[torch.Tensor]]` (batch"
+ " of examples)."
+ )
+
+ if not is_batched:
+ videos = [videos]
+
+ # transformations (resizing + center cropping + normalization)
+ if self.do_resize and self.size is not None:
+ videos = [self.resize_video(video, size=self.size, resample=self.resample) for video in videos]
+ if self.do_center_crop and self.size is not None:
+ videos = [self.crop_video(video, size=self.size) for video in videos]
+ if self.do_normalize:
+ videos = [self.normalize_video(video, mean=self.image_mean, std=self.image_std) for video in videos]
+
+ # return as BatchFeature
+ data = {"pixel_values": videos}
+ encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
+
+ return encoded_inputs
diff --git a/src/transformers/models/videomae/modeling_videomae.py b/src/transformers/models/videomae/modeling_videomae.py
new file mode 100644
index 00000000000000..a807ed7208fccb
--- /dev/null
+++ b/src/transformers/models/videomae/modeling_videomae.py
@@ -0,0 +1,1039 @@
+# coding=utf-8
+# Copyright 2022 Multimedia Computing Group, Nanjing University and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch VideoMAE (masked autoencoder) model."""
+
+
+import collections.abc
+import math
+from copy import deepcopy
+from dataclasses import dataclass
+from typing import Optional, Set, Tuple, Union
+
+import numpy as np
+import torch
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+
+from ...activations import ACT2FN
+from ...modeling_outputs import BaseModelOutput, ImageClassifierOutput
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import find_pruneable_heads_and_indices, prune_linear_layer
+from ...utils import (
+ ModelOutput,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ logging,
+ replace_return_docstrings,
+)
+from ...utils.constants import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
+from .configuration_videomae import VideoMAEConfig
+
+
+logger = logging.get_logger(__name__)
+
+_CONFIG_FOR_DOC = "VideoMAEConfig"
+_CHECKPOINT_FOR_DOC = "MCG-NJU/videomae-base"
+
+VIDEOMAE_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "MCG-NJU/videomae-base",
+ # See all VideoMAE models at https://huggingface.co/models?filter=videomae
+]
+
+
+@dataclass
+class VideoMAEDecoderOutput(ModelOutput):
+ """
+ Class for VideoMAEDecoder's outputs, with potential hidden states and attentions.
+
+ Args:
+ logits (`torch.FloatTensor` of shape `(batch_size, patch_size ** 2 * num_channels)`):
+ Pixel reconstruction logits.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
+ shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the model at the output of each layer
+ plus the initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`. Attentions weights after the attention softmax, used to compute the weighted average in
+ the self-attention heads.
+ """
+
+ logits: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[torch.FloatTensor]] = None
+
+
+@dataclass
+class VideoMAEForPreTrainingOutput(ModelOutput):
+ """
+ Class for VideoMAEForPreTraining's outputs, with potential hidden states and attentions.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`):
+ Pixel reconstruction loss.
+ logits (`torch.FloatTensor` of shape `(batch_size, patch_size ** 2 * num_channels)`):
+ Pixel reconstruction logits.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
+ shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the model at the output of each layer
+ plus the initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`. Attentions weights after the attention softmax, used to compute the weighted average in
+ the self-attention heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[torch.FloatTensor]] = None
+
+
+# sin-cos position encoding
+# https://github.com/jadore801120/attention-is-all-you-need-pytorch/blob/master/transformer/Models.py#L31
+def get_sinusoid_encoding_table(n_position, d_hid):
+ """Sinusoid position encoding table"""
+ # TODO: make it with torch instead of numpy
+ def get_position_angle_vec(position):
+ return [position / np.power(10000, 2 * (hid_j // 2) / d_hid) for hid_j in range(d_hid)]
+
+ sinusoid_table = np.array([get_position_angle_vec(pos_i) for pos_i in range(n_position)])
+ sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i
+ sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1
+
+ return torch.FloatTensor(sinusoid_table).unsqueeze(0)
+
+
+class VideoMAEEmbeddings(nn.Module):
+ """
+ Construct the patch and position embeddings.
+
+ """
+
+ def __init__(self, config):
+ super().__init__()
+
+ self.patch_embeddings = VideoMAEPatchEmbeddings(config)
+ self.num_patches = self.patch_embeddings.num_patches
+ # fixed sin-cos embedding
+ self.position_embeddings = get_sinusoid_encoding_table(self.num_patches, config.hidden_size)
+ self.config = config
+
+ def forward(self, pixel_values, bool_masked_pos):
+ # create patch embeddings
+ embeddings = self.patch_embeddings(pixel_values)
+
+ # add position embeddings
+ embeddings = embeddings + self.position_embeddings.type_as(embeddings).to(embeddings.device).clone().detach()
+
+ # only keep visible patches
+ # ~bool_masked_pos means visible
+ if bool_masked_pos is not None:
+ batch_size, _, num_channels = embeddings.shape
+ embeddings = embeddings[~bool_masked_pos]
+ embeddings = embeddings.reshape(batch_size, -1, num_channels)
+
+ return embeddings
+
+
+class VideoMAEPatchEmbeddings(nn.Module):
+ """
+ Video to Patch Embedding. This module turns a batch of videos of shape (batch_size, num_frames, num_channels,
+ height, width) into a tensor of shape (batch_size, seq_len, hidden_size) to be consumed by a Transformer encoder.
+
+ The seq_len (the number of patches) equals (number of frames // tubelet_size) * (height // patch_size) * (width //
+ patch_size).
+
+ """
+
+ def __init__(self, config):
+ super().__init__()
+
+ image_size = config.image_size
+ patch_size = config.patch_size
+ num_channels = config.num_channels
+ hidden_size = config.hidden_size
+ num_frames = config.num_frames
+ tubelet_size = config.tubelet_size
+
+ image_size = image_size if isinstance(image_size, collections.abc.Iterable) else (image_size, image_size)
+ patch_size = patch_size if isinstance(patch_size, collections.abc.Iterable) else (patch_size, patch_size)
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.tubelet_size = int(tubelet_size)
+ num_patches = (
+ (image_size[1] // patch_size[1]) * (image_size[0] // patch_size[0]) * (num_frames // self.tubelet_size)
+ )
+ self.num_channels = num_channels
+ self.num_patches = num_patches
+ self.projection = nn.Conv3d(
+ in_channels=num_channels,
+ out_channels=hidden_size,
+ kernel_size=(self.tubelet_size, patch_size[0], patch_size[1]),
+ stride=(self.tubelet_size, patch_size[0], patch_size[1]),
+ )
+
+ def forward(self, pixel_values):
+ batch_size, num_frames, num_channels, height, width = pixel_values.shape
+ if num_channels != self.num_channels:
+ raise ValueError(
+ "Make sure that the channel dimension of the pixel values match with the one set in the configuration."
+ )
+ if height != self.image_size[0] or width != self.image_size[1]:
+ raise ValueError(
+ f"Input image size ({height}*{width}) doesn't match model ({self.image_size[0]}*{self.image_size[1]})."
+ )
+ # permute to (batch_size, num_channels, num_frames, height, width)
+ pixel_values = pixel_values.permute(0, 2, 1, 3, 4)
+ embeddings = self.projection(pixel_values).flatten(2).transpose(1, 2)
+ return embeddings
+
+
+class VideoMAESelfAttention(nn.Module):
+ def __init__(self, config: VideoMAEConfig) -> None:
+ super().__init__()
+ if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
+ raise ValueError(
+ f"The hidden size {config.hidden_size,} is not a multiple of the number of attention "
+ f"heads {config.num_attention_heads}."
+ )
+
+ self.num_attention_heads = config.num_attention_heads
+ self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
+ self.all_head_size = self.num_attention_heads * self.attention_head_size
+
+ self.query = nn.Linear(config.hidden_size, self.all_head_size, bias=False)
+ self.key = nn.Linear(config.hidden_size, self.all_head_size, bias=False)
+ self.value = nn.Linear(config.hidden_size, self.all_head_size, bias=False)
+
+ if config.qkv_bias:
+ self.q_bias = nn.Parameter(torch.zeros(self.all_head_size))
+ self.v_bias = nn.Parameter(torch.zeros(self.all_head_size))
+ else:
+ self.q_bias = None
+ self.v_bias = None
+
+ self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
+
+ def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
+ new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
+ x = x.view(new_x_shape)
+ return x.permute(0, 2, 1, 3)
+
+ def forward(
+ self, hidden_states, head_mask: Optional[torch.Tensor] = None, output_attentions: bool = False
+ ) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+
+ k_bias = torch.zeros_like(self.v_bias, requires_grad=False) if self.q_bias is not None else None
+ keys = nn.functional.linear(input=hidden_states, weight=self.key.weight, bias=k_bias)
+ values = nn.functional.linear(input=hidden_states, weight=self.value.weight, bias=self.v_bias)
+ queries = nn.functional.linear(input=hidden_states, weight=self.query.weight, bias=self.q_bias)
+
+ key_layer = self.transpose_for_scores(keys)
+ value_layer = self.transpose_for_scores(values)
+ query_layer = self.transpose_for_scores(queries)
+
+ # Take the dot product between "query" and "key" to get the raw attention scores.
+ attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
+
+ attention_scores = attention_scores / math.sqrt(self.attention_head_size)
+
+ # Normalize the attention scores to probabilities.
+ attention_probs = nn.functional.softmax(attention_scores, dim=-1)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs = self.dropout(attention_probs)
+
+ # Mask heads if we want to
+ if head_mask is not None:
+ attention_probs = attention_probs * head_mask
+
+ context_layer = torch.matmul(attention_probs, value_layer)
+
+ context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
+ new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
+ context_layer = context_layer.view(new_context_layer_shape)
+
+ outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
+
+ return outputs
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTSelfOutput with ViT->VideoMAE
+class VideoMAESelfOutput(nn.Module):
+ """
+ The residual connection is defined in VideoMAELayer instead of here (as is the case with other models), due to the
+ layernorm applied before each block.
+ """
+
+ def __init__(self, config: VideoMAEConfig) -> None:
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+
+ return hidden_states
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTAttention with ViT->VideoMAE
+class VideoMAEAttention(nn.Module):
+ def __init__(self, config: VideoMAEConfig) -> None:
+ super().__init__()
+ self.attention = VideoMAESelfAttention(config)
+ self.output = VideoMAESelfOutput(config)
+ self.pruned_heads = set()
+
+ def prune_heads(self, heads: Set[int]) -> None:
+ if len(heads) == 0:
+ return
+ heads, index = find_pruneable_heads_and_indices(
+ heads, self.attention.num_attention_heads, self.attention.attention_head_size, self.pruned_heads
+ )
+
+ # Prune linear layers
+ self.attention.query = prune_linear_layer(self.attention.query, index)
+ self.attention.key = prune_linear_layer(self.attention.key, index)
+ self.attention.value = prune_linear_layer(self.attention.value, index)
+ self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
+
+ # Update hyper params and store pruned heads
+ self.attention.num_attention_heads = self.attention.num_attention_heads - len(heads)
+ self.attention.all_head_size = self.attention.attention_head_size * self.attention.num_attention_heads
+ self.pruned_heads = self.pruned_heads.union(heads)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ self_outputs = self.attention(hidden_states, head_mask, output_attentions)
+
+ attention_output = self.output(self_outputs[0], hidden_states)
+
+ outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
+ return outputs
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTIntermediate ViT->VideoMAE
+class VideoMAEIntermediate(nn.Module):
+ def __init__(self, config: VideoMAEConfig) -> None:
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
+ if isinstance(config.hidden_act, str):
+ self.intermediate_act_fn = ACT2FN[config.hidden_act]
+ else:
+ self.intermediate_act_fn = config.hidden_act
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.intermediate_act_fn(hidden_states)
+
+ return hidden_states
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTOutput ViT->VideoMAE
+class VideoMAEOutput(nn.Module):
+ def __init__(self, config: VideoMAEConfig) -> None:
+ super().__init__()
+ self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+
+ hidden_states = hidden_states + input_tensor
+
+ return hidden_states
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTLayer with ViT->VideoMAE
+class VideoMAELayer(nn.Module):
+ """This corresponds to the Block class in the timm implementation."""
+
+ def __init__(self, config: VideoMAEConfig) -> None:
+ super().__init__()
+ self.chunk_size_feed_forward = config.chunk_size_feed_forward
+ self.seq_len_dim = 1
+ self.attention = VideoMAEAttention(config)
+ self.intermediate = VideoMAEIntermediate(config)
+ self.output = VideoMAEOutput(config)
+ self.layernorm_before = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.layernorm_after = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ self_attention_outputs = self.attention(
+ self.layernorm_before(hidden_states), # in VideoMAE, layernorm is applied before self-attention
+ head_mask,
+ output_attentions=output_attentions,
+ )
+ attention_output = self_attention_outputs[0]
+ outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
+
+ # first residual connection
+ hidden_states = attention_output + hidden_states
+
+ # in VideoMAE, layernorm is also applied after self-attention
+ layer_output = self.layernorm_after(hidden_states)
+ layer_output = self.intermediate(layer_output)
+
+ # second residual connection is done here
+ layer_output = self.output(layer_output, hidden_states)
+
+ outputs = (layer_output,) + outputs
+
+ return outputs
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTEncoder with ViT->VideoMAE
+class VideoMAEEncoder(nn.Module):
+ def __init__(self, config: VideoMAEConfig) -> None:
+ super().__init__()
+ self.config = config
+ self.layer = nn.ModuleList([VideoMAELayer(config) for _ in range(config.num_hidden_layers)])
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ output_hidden_states: bool = False,
+ return_dict: bool = True,
+ ) -> Union[tuple, BaseModelOutput]:
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attentions = () if output_attentions else None
+
+ for i, layer_module in enumerate(self.layer):
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ layer_head_mask = head_mask[i] if head_mask is not None else None
+
+ if self.gradient_checkpointing and self.training:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs, output_attentions)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(layer_module),
+ hidden_states,
+ layer_head_mask,
+ )
+ else:
+ layer_outputs = layer_module(hidden_states, layer_head_mask, output_attentions)
+
+ hidden_states = layer_outputs[0]
+
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (layer_outputs[1],)
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, all_hidden_states, all_self_attentions] if v is not None)
+ return BaseModelOutput(
+ last_hidden_state=hidden_states,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ )
+
+
+class VideoMAEPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = VideoMAEConfig
+ base_model_prefix = "videomae"
+ main_input_name = "pixel_values"
+ supports_gradient_checkpointing = True
+
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ if isinstance(module, (nn.Linear, nn.Conv3d)):
+ # Slightly different from the TF version which uses truncated_normal for initialization
+ # cf https://github.com/pytorch/pytorch/pull/5617
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, VideoMAEEncoder):
+ module.gradient_checkpointing = value
+
+
+VIDEOMAE_START_DOCSTRING = r"""
+ This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it
+ as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
+ behavior.
+
+ Parameters:
+ config ([`VideoMAEConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+VIDEOMAE_INPUTS_DOCSTRING = r"""
+ Args:
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_frames, num_channels, height, width)`):
+ Pixel values. Pixel values can be obtained using [`VideoMAEFeatureExtractor`]. See
+ [`VideoMAEFeatureExtractor.__call__`] for details.
+
+ head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
+ Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ "The bare VideoMAE Model transformer outputting raw hidden-states without any specific head on top.",
+ VIDEOMAE_START_DOCSTRING,
+)
+class VideoMAEModel(VideoMAEPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.config = config
+
+ self.embeddings = VideoMAEEmbeddings(config)
+ self.encoder = VideoMAEEncoder(config)
+
+ if config.use_mean_pooling:
+ self.layernorm = None
+ else:
+ self.layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embeddings.patch_embeddings
+
+ def _prune_heads(self, heads_to_prune):
+ """
+ Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
+ class PreTrainedModel
+ """
+ for layer, heads in heads_to_prune.items():
+ self.encoder.layer[layer].attention.prune_heads(heads)
+
+ @add_start_docstrings_to_model_forward(VIDEOMAE_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=BaseModelOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ pixel_values,
+ bool_masked_pos=None,
+ head_mask=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ ):
+ r"""
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from decord import VideoReader, cpu
+ >>> import numpy as np
+
+ >>> from transformers import VideoMAEFeatureExtractor, VideoMAEModel
+ >>> from huggingface_hub import hf_hub_download
+
+
+ >>> def sample_frame_indices(clip_len, frame_sample_rate, seg_len):
+ ... converted_len = int(clip_len * frame_sample_rate)
+ ... end_idx = np.random.randint(converted_len, seg_len)
+ ... start_idx = end_idx - converted_len
+ ... indices = np.linspace(start_idx, end_idx, num=clip_len)
+ ... indices = np.clip(indices, start_idx, end_idx - 1).astype(np.int64)
+ ... return indices
+
+
+ >>> # video clip consists of 300 frames (10 seconds at 30 FPS)
+ >>> file_path = hf_hub_download(
+ ... repo_id="nielsr/video-demo", filename="eating_spaghetti.mp4", repo_type="dataset"
+ ... )
+ >>> vr = VideoReader(file_path, num_threads=1, ctx=cpu(0))
+
+ >>> # sample 16 frames
+ >>> vr.seek(0)
+ >>> indices = sample_frame_indices(clip_len=16, frame_sample_rate=4, seg_len=len(vr))
+ >>> buffer = vr.get_batch(indices).asnumpy()
+
+ >>> # create a list of NumPy arrays
+ >>> video = [buffer[i] for i in range(buffer.shape[0])]
+
+ >>> feature_extractor = VideoMAEFeatureExtractor.from_pretrained("MCG-NJU/videomae-base")
+ >>> model = VideoMAEModel.from_pretrained("MCG-NJU/videomae-base")
+
+ >>> # prepare video for the model
+ >>> inputs = feature_extractor(video, return_tensors="pt")
+
+ >>> # forward pass
+ >>> outputs = model(**inputs)
+ >>> last_hidden_states = outputs.last_hidden_state
+ >>> list(last_hidden_states.shape)
+ [1, 1568, 768]
+ ```"""
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape bsz x n_heads x N x N
+ # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
+ # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
+ head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
+
+ embedding_output = self.embeddings(pixel_values, bool_masked_pos)
+
+ encoder_outputs = self.encoder(
+ embedding_output,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ sequence_output = encoder_outputs[0]
+ if self.layernorm is not None:
+ sequence_output = self.layernorm(sequence_output)
+
+ if not return_dict:
+ return (sequence_output,) + encoder_outputs[1:]
+
+ return BaseModelOutput(
+ last_hidden_state=sequence_output,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ )
+
+
+class VideoMAEDecoder(nn.Module):
+ def __init__(self, config, num_patches):
+ super().__init__()
+
+ decoder_num_labels = config.num_channels * config.tubelet_size * config.patch_size**2
+
+ decoder_config = deepcopy(config)
+ decoder_config.hidden_size = config.decoder_hidden_size
+ decoder_config.num_hidden_layers = config.decoder_num_hidden_layers
+ decoder_config.num_attention_heads = config.decoder_num_attention_heads
+ decoder_config.intermediate_size = config.decoder_intermediate_size
+ self.decoder_layers = nn.ModuleList(
+ [VideoMAELayer(decoder_config) for _ in range(config.decoder_num_hidden_layers)]
+ )
+
+ self.norm = nn.LayerNorm(config.decoder_hidden_size)
+ self.head = (
+ nn.Linear(config.decoder_hidden_size, decoder_num_labels) if decoder_num_labels > 0 else nn.Identity()
+ )
+
+ self.gradient_checkpointing = False
+ self.config = config
+
+ def forward(
+ self,
+ hidden_states,
+ return_token_num,
+ output_attentions=False,
+ output_hidden_states=False,
+ return_dict=True,
+ ):
+ # apply Transformer layers (blocks)
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attentions = () if output_attentions else None
+ for i, layer_module in enumerate(self.decoder_layers):
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if self.gradient_checkpointing and self.training:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs, output_attentions)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(layer_module),
+ hidden_states,
+ None,
+ )
+ else:
+ layer_outputs = layer_module(hidden_states, head_mask=None, output_attentions=output_attentions)
+
+ hidden_states = layer_outputs[0]
+
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (layer_outputs[1],)
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if return_token_num > 0:
+ hidden_states = hidden_states[:, -return_token_num:]
+
+ # predictor projection
+ hidden_states = self.norm(hidden_states)
+ logits = self.head(hidden_states)
+
+ if not return_dict:
+ return tuple(v for v in [logits, all_hidden_states, all_self_attentions] if v is not None)
+ return VideoMAEDecoderOutput(logits=logits, hidden_states=all_hidden_states, attentions=all_self_attentions)
+
+
+@add_start_docstrings(
+ "The VideoMAE Model transformer with the decoder on top for self-supervised pre-training.",
+ VIDEOMAE_START_DOCSTRING,
+)
+class VideoMAEForPreTraining(VideoMAEPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.config = config
+
+ self.videomae = VideoMAEModel(config)
+
+ self.encoder_to_decoder = nn.Linear(config.hidden_size, config.decoder_hidden_size, bias=False)
+ self.mask_token = nn.Parameter(torch.zeros(1, 1, config.decoder_hidden_size))
+ self.position_embeddings = get_sinusoid_encoding_table(
+ self.videomae.embeddings.num_patches, config.decoder_hidden_size
+ )
+
+ self.decoder = VideoMAEDecoder(config, num_patches=self.videomae.embeddings.num_patches)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(VIDEOMAE_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=VideoMAEForPreTrainingOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ pixel_values,
+ bool_masked_pos,
+ head_mask=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ ):
+ r"""
+ Returns:
+
+ Examples:
+ ```python
+ >>> from transformers import VideoMAEFeatureExtractor, VideoMAEForPreTraining
+ >>> import numpy as np
+ >>> import torch
+
+ >>> num_frames = 16
+ >>> video = list(np.random.randn(16, 3, 224, 224))
+
+ >>> feature_extractor = VideoMAEFeatureExtractor.from_pretrained("MCG-NJU/videomae-base")
+ >>> model = VideoMAEForPreTraining.from_pretrained("MCG-NJU/videomae-base")
+
+ >>> pixel_values = feature_extractor(video, return_tensors="pt").pixel_values
+
+ >>> num_patches_per_frame = (model.config.image_size // model.config.patch_size) ** 2
+ >>> seq_length = (num_frames // model.config.tubelet_size) * num_patches_per_frame
+ >>> bool_masked_pos = torch.randint(0, 2, (1, seq_length)).bool()
+
+ >>> outputs = model(pixel_values, bool_masked_pos=bool_masked_pos)
+ >>> loss = outputs.loss
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.videomae(
+ pixel_values,
+ bool_masked_pos=bool_masked_pos,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ sequence_output = outputs[0]
+ sequence_output = self.encoder_to_decoder(
+ sequence_output
+ ) # [batch_size, num_visible_patches, decoder_hidden_size]
+ batch_size, seq_len, num_channels = sequence_output.shape
+
+ # we don't unshuffle the correct visible token order, but shuffle the position embeddings accordingly.
+ if bool_masked_pos is None:
+ raise ValueError("One must provided a boolean mask ")
+ expanded_position_embeddings = self.position_embeddings.expand(batch_size, -1, -1).type_as(pixel_values)
+ expanded_position_embeddings = expanded_position_embeddings.to(pixel_values.device).clone().detach()
+ pos_emb_visible = expanded_position_embeddings[~bool_masked_pos].reshape(batch_size, -1, num_channels)
+ pos_emb_mask = expanded_position_embeddings[bool_masked_pos].reshape(batch_size, -1, num_channels)
+
+ # [batch_size, num_patches, decoder_hidden_size]
+ x_full = torch.cat([sequence_output + pos_emb_visible, self.mask_token + pos_emb_mask], dim=1)
+
+ # [batch_size, num_masked_patches, num_channels * patch_size * patch_size]
+ decoder_outputs = self.decoder(x_full, pos_emb_mask.shape[1])
+ logits = decoder_outputs.logits
+
+ loss = None
+ with torch.no_grad():
+ # calculate the labels to be predicted
+ # first, unnormalize the frames
+ device = pixel_values.device
+ mean = torch.as_tensor(IMAGENET_DEFAULT_MEAN).to(device)[None, None, :, None, None]
+ std = torch.as_tensor(IMAGENET_DEFAULT_STD).to(device)[None, None, :, None, None]
+ frames = pixel_values * std + mean # in [0, 1]
+
+ batch_size, time, num_channels, height, width = frames.shape
+ tubelet_size, patch_size = self.config.tubelet_size, self.config.patch_size
+ if self.config.norm_pix_loss:
+ # step 1: split up dimensions (time by tubelet_size, height by patch_size, width by patch_size)
+ frames = frames.view(
+ batch_size,
+ time // tubelet_size,
+ tubelet_size,
+ num_channels,
+ height // patch_size,
+ patch_size,
+ width // patch_size,
+ patch_size,
+ )
+ # step 2: move dimensions to concatenate:
+ frames = frames.permute(0, 1, 4, 6, 2, 5, 7, 3).contiguous()
+ # step 3: concatenate:
+ frames = frames.view(
+ batch_size,
+ time // tubelet_size * height // patch_size * width // patch_size,
+ tubelet_size * patch_size * patch_size,
+ num_channels,
+ )
+ # step 4: normalize. The authors find that the mean is about 0.48 and standard deviation is about 0.08.
+ frames_norm = (frames - frames.mean(dim=-2, keepdim=True)) / (
+ frames.var(dim=-2, unbiased=True, keepdim=True).sqrt() + 1e-6
+ )
+ # step 5: reshape to (batch_size, T//ts * H//ps * W//ps, ts * ps * ps * C)
+ videos_patch = frames_norm.view(
+ batch_size,
+ time // tubelet_size * height // patch_size * width // patch_size,
+ tubelet_size * patch_size * patch_size * num_channels,
+ )
+ else:
+ # step 1: split up dimensions (time by tubelet_size, height by patch_size, width by patch_size)
+ frames = frames.view(
+ batch_size,
+ time // tubelet_size,
+ tubelet_size,
+ num_channels,
+ height // patch_size,
+ patch_size,
+ width // patch_size,
+ patch_size,
+ )
+ # step 2: move dimensions to concatenate: (batch_size, T//ts, H//ps, W//ps, ts, ps, ps, C)
+ frames = frames.permute(0, 1, 4, 6, 2, 5, 7, 3).contiguous()
+ # step 3: concatenate
+ videos_patch = frames.view(
+ batch_size,
+ time // tubelet_size * height // patch_size * width // patch_size,
+ tubelet_size * patch_size * patch_size * num_channels,
+ )
+
+ batch_size, _, num_channels = videos_patch.shape
+ labels = videos_patch[bool_masked_pos].reshape(batch_size, -1, num_channels)
+
+ loss_fct = MSELoss()
+ loss = loss_fct(logits, labels)
+
+ if not return_dict:
+ output = (logits,) + outputs[1:]
+ return ((loss,) + output) if loss is not None else output
+
+ return VideoMAEForPreTrainingOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+@add_start_docstrings(
+ """VideoMAE Model transformer with a video classification head on top (a linear layer on top of the final hidden state of
+ the [CLS] token) e.g. for ImageNet.""",
+ VIDEOMAE_START_DOCSTRING,
+)
+class VideoMAEForVideoClassification(VideoMAEPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+
+ self.num_labels = config.num_labels
+ self.videomae = VideoMAEModel(config)
+
+ # Classifier head
+ self.fc_norm = nn.LayerNorm(config.hidden_size) if config.use_mean_pooling else None
+ self.classifier = nn.Linear(config.hidden_size, config.num_labels) if config.num_labels > 0 else nn.Identity()
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(VIDEOMAE_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=ImageClassifierOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ pixel_values: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ):
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the image classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from decord import VideoReader, cpu
+ >>> import torch
+
+ >>> from transformers import VideoMAEFeatureExtractor, VideoMAEForVideoClassification
+ >>> from huggingface_hub import hf_hub_download
+
+
+ >>> def sample_frame_indices(clip_len, frame_sample_rate, seg_len):
+ ... converted_len = int(clip_len * frame_sample_rate)
+ ... end_idx = np.random.randint(converted_len, seg_len)
+ ... start_idx = end_idx - converted_len
+ ... indices = np.linspace(start_idx, end_idx, num=clip_len)
+ ... indices = np.clip(indices, start_idx, end_idx - 1).astype(np.int64)
+ ... return indices
+
+
+ >>> # video clip consists of 300 frames (10 seconds at 30 FPS)
+ >>> file_path = hf_hub_download(
+ ... repo_id="nielsr/video-demo", filename="eating_spaghetti.mp4", repo_type="dataset"
+ ... )
+ >>> vr = VideoReader(file_path, num_threads=1, ctx=cpu(0))
+
+ >>> # sample 16 frames
+ >>> vr.seek(0)
+ >>> indices = sample_frame_indices(clip_len=16, frame_sample_rate=4, seg_len=len(vr))
+ >>> buffer = vr.get_batch(indices).asnumpy()
+
+ >>> # create a list of NumPy arrays
+ >>> video = [buffer[i] for i in range(buffer.shape[0])]
+
+ >>> feature_extractor = VideoMAEFeatureExtractor.from_pretrained("MCG-NJU/videomae-base-finetuned-kinetics")
+ >>> model = VideoMAEForVideoClassification.from_pretrained("MCG-NJU/videomae-base-finetuned-kinetics")
+
+ >>> inputs = feature_extractor(video, return_tensors="pt")
+
+ >>> with torch.no_grad():
+ ... outputs = model(**inputs)
+ ... logits = outputs.logits
+
+ >>> # model predicts one of the 400 Kinetics-400 classes
+ >>> predicted_label = logits.argmax(-1).item()
+ >>> print(model.config.id2label[predicted_label])
+ eating spaghetti
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.videomae(
+ pixel_values,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ sequence_output = outputs[0]
+
+ if self.fc_norm is not None:
+ sequence_output = self.fc_norm(sequence_output.mean(1))
+ else:
+ sequence_output = sequence_output[:, 0]
+
+ logits = self.classifier(sequence_output)
+
+ loss = None
+ if labels is not None:
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = "regression"
+ elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
+ self.config.problem_type = "single_label_classification"
+ else:
+ self.config.problem_type = "multi_label_classification"
+
+ if self.config.problem_type == "regression":
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(logits, labels)
+ elif self.config.problem_type == "single_label_classification":
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == "multi_label_classification":
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(logits, labels)
+
+ if not return_dict:
+ output = (logits,) + outputs[1:]
+ return ((loss,) + output) if loss is not None else output
+
+ return ImageClassifierOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
diff --git a/src/transformers/utils/__init__.py b/src/transformers/utils/__init__.py
index 2334c351cc5120..377932e2d490e7 100644
--- a/src/transformers/utils/__init__.py
+++ b/src/transformers/utils/__init__.py
@@ -22,6 +22,7 @@
from packaging import version
from .. import __version__
+from .constants import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD, IMAGENET_STANDARD_MEAN, IMAGENET_STANDARD_STD
from .doc import (
add_code_sample_docstrings,
add_end_docstrings,
diff --git a/src/transformers/utils/constants.py b/src/transformers/utils/constants.py
new file mode 100644
index 00000000000000..af2e48ab0a8be3
--- /dev/null
+++ b/src/transformers/utils/constants.py
@@ -0,0 +1,4 @@
+IMAGENET_DEFAULT_MEAN = [0.485, 0.456, 0.406]
+IMAGENET_DEFAULT_STD = [0.229, 0.224, 0.225]
+IMAGENET_STANDARD_MEAN = [0.5, 0.5, 0.5]
+IMAGENET_STANDARD_STD = [0.5, 0.5, 0.5]
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index c1dfc6b6b7ca64..d636be655af284 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -406,6 +406,9 @@ def load_tf_weights_in_albert(*args, **kwargs):
MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING = None
+MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING = None
+
+
MODEL_FOR_VISION_2_SEQ_MAPPING = None
@@ -572,6 +575,13 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
+class AutoModelForVideoClassification(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
class AutoModelForVision2Seq(metaclass=DummyObject):
_backends = ["torch"]
@@ -4753,6 +4763,37 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
+VIDEOMAE_PRETRAINED_MODEL_ARCHIVE_LIST = None
+
+
+class VideoMAEForPreTraining(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class VideoMAEForVideoClassification(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class VideoMAEModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class VideoMAEPreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
VILT_PRETRAINED_MODEL_ARCHIVE_LIST = None
diff --git a/src/transformers/utils/dummy_vision_objects.py b/src/transformers/utils/dummy_vision_objects.py
index e5d2bced9e0415..30228e022222bf 100644
--- a/src/transformers/utils/dummy_vision_objects.py
+++ b/src/transformers/utils/dummy_vision_objects.py
@@ -150,6 +150,13 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["vision"])
+class VideoMAEFeatureExtractor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class ViltFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
diff --git a/tests/models/videomae/__init__.py b/tests/models/videomae/__init__.py
new file mode 100644
index 00000000000000..e69de29bb2d1d6
diff --git a/tests/models/videomae/test_feature_extraction_videomae.py b/tests/models/videomae/test_feature_extraction_videomae.py
new file mode 100644
index 00000000000000..cfe00f51e5e529
--- /dev/null
+++ b/tests/models/videomae/test_feature_extraction_videomae.py
@@ -0,0 +1,202 @@
+# coding=utf-8
+# Copyright 2022 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+import numpy as np
+
+from transformers.testing_utils import require_torch, require_vision
+from transformers.utils import is_torch_available, is_vision_available
+
+from ...test_feature_extraction_common import FeatureExtractionSavingTestMixin, prepare_video_inputs
+
+
+if is_torch_available():
+ import torch
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import VideoMAEFeatureExtractor
+
+
+class VideoMAEFeatureExtractionTester(unittest.TestCase):
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ num_frames=10,
+ image_size=18,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size=18,
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.num_frames = num_frames
+ self.image_size = image_size
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+
+ def prepare_feat_extract_dict(self):
+ return {
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ "do_normalize": self.do_normalize,
+ "do_resize": self.do_resize,
+ "size": self.size,
+ }
+
+
+@require_torch
+@require_vision
+class VideoMAEFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.TestCase):
+
+ feature_extraction_class = VideoMAEFeatureExtractor if is_vision_available() else None
+
+ def setUp(self):
+ self.feature_extract_tester = VideoMAEFeatureExtractionTester(self)
+
+ @property
+ def feat_extract_dict(self):
+ return self.feature_extract_tester.prepare_feat_extract_dict()
+
+ def test_feat_extract_properties(self):
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ self.assertTrue(hasattr(feature_extractor, "image_mean"))
+ self.assertTrue(hasattr(feature_extractor, "image_std"))
+ self.assertTrue(hasattr(feature_extractor, "do_normalize"))
+ self.assertTrue(hasattr(feature_extractor, "do_resize"))
+ self.assertTrue(hasattr(feature_extractor, "size"))
+
+ def test_batch_feature(self):
+ pass
+
+ def test_call_pil(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random PIL videos
+ video_inputs = prepare_video_inputs(self.feature_extract_tester, equal_resolution=False)
+ for video in video_inputs:
+ self.assertIsInstance(video, list)
+ self.assertIsInstance(video[0], Image.Image)
+
+ # Test not batched input
+ encoded_videos = feature_extractor(video_inputs[0], return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_videos.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_frames,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ # Test batched
+ encoded_videos = feature_extractor(video_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_videos.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_frames,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ def test_call_numpy(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random numpy tensors
+ video_inputs = prepare_video_inputs(self.feature_extract_tester, equal_resolution=False, numpify=True)
+ for video in video_inputs:
+ self.assertIsInstance(video, list)
+ self.assertIsInstance(video[0], np.ndarray)
+
+ # Test not batched input
+ encoded_videos = feature_extractor(video_inputs[0], return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_videos.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_frames,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ # Test batched
+ encoded_videos = feature_extractor(video_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_videos.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_frames,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ def test_call_pytorch(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random PyTorch tensors
+ video_inputs = prepare_video_inputs(self.feature_extract_tester, equal_resolution=False, torchify=True)
+ for video in video_inputs:
+ self.assertIsInstance(video, list)
+ self.assertIsInstance(video[0], torch.Tensor)
+
+ # Test not batched input
+ encoded_videos = feature_extractor(video_inputs[0], return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_videos.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_frames,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ # Test batched
+ encoded_videos = feature_extractor(video_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_videos.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_frames,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
diff --git a/tests/models/videomae/test_modeling_videomae.py b/tests/models/videomae/test_modeling_videomae.py
new file mode 100644
index 00000000000000..adce62021c9ded
--- /dev/null
+++ b/tests/models/videomae/test_modeling_videomae.py
@@ -0,0 +1,421 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch VideoMAE model. """
+
+
+import copy
+import inspect
+import unittest
+
+import numpy as np
+
+from huggingface_hub import hf_hub_download
+from transformers import VideoMAEConfig
+from transformers.models.auto import get_values
+from transformers.testing_utils import require_torch, require_vision, slow, torch_device
+from transformers.utils import cached_property, is_torch_available, is_vision_available
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import (
+ MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING,
+ VideoMAEForPreTraining,
+ VideoMAEForVideoClassification,
+ VideoMAEModel,
+ )
+ from transformers.models.videomae.modeling_videomae import VIDEOMAE_PRETRAINED_MODEL_ARCHIVE_LIST
+
+
+if is_vision_available():
+ from transformers import VideoMAEFeatureExtractor
+
+
+class VideoMAEModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ image_size=10,
+ num_channels=3,
+ patch_size=2,
+ tubelet_size=2,
+ num_frames=2,
+ is_training=True,
+ use_labels=True,
+ hidden_size=32,
+ num_hidden_layers=5,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ type_sequence_label_size=10,
+ initializer_range=0.02,
+ mask_ratio=0.9,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.num_channels = num_channels
+ self.patch_size = patch_size
+ self.tubelet_size = tubelet_size
+ self.num_frames = num_frames
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.mask_ratio = mask_ratio
+ self.scope = scope
+
+ # in VideoMAE, the number of tokens equals num_frames/tubelet_size * num_patches per frame
+ self.num_patches_per_frame = (image_size // patch_size) ** 2
+ self.seq_length = (num_frames // tubelet_size) * self.num_patches_per_frame
+
+ # use this variable to define bool_masked_pos
+ self.num_masks = int(mask_ratio * self.seq_length)
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor(
+ [self.batch_size, self.num_frames, self.num_channels, self.image_size, self.image_size]
+ )
+
+ labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+
+ config = self.get_config()
+
+ return config, pixel_values, labels
+
+ def get_config(self):
+ return VideoMAEConfig(
+ image_size=self.image_size,
+ patch_size=self.patch_size,
+ num_channels=self.num_channels,
+ num_frames=self.num_frames,
+ tubelet_size=self.tubelet_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ )
+
+ def create_and_check_model(self, config, pixel_values, labels):
+ model = VideoMAEModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def create_and_check_for_pretraining(self, config, pixel_values, labels):
+ model = VideoMAEForPreTraining(config)
+ model.to(torch_device)
+ model.eval()
+ # important: each video needs to have the same number of masked patches
+ # hence we define a single mask, which we then repeat for each example in the batch
+ mask = torch.ones((self.num_masks,))
+ mask = torch.cat([mask, torch.zeros(self.seq_length - mask.size(0))])
+ bool_masked_pos = mask.expand(self.batch_size, -1).bool()
+
+ result = model(pixel_values, bool_masked_pos)
+ # model only returns predictions for masked patches
+ num_masked_patches = mask.sum().item()
+ decoder_num_labels = 3 * self.tubelet_size * self.patch_size**2
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, num_masked_patches, decoder_num_labels))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values, labels = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class VideoMAEModelTest(ModelTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as VideoMAE does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (
+ (VideoMAEModel, VideoMAEForPreTraining, VideoMAEForVideoClassification) if is_torch_available() else ()
+ )
+
+ test_pruning = False
+ test_torchscript = False
+ test_resize_embeddings = False
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = VideoMAEModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=VideoMAEConfig, has_text_modality=False, hidden_size=37)
+
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ inputs_dict = copy.deepcopy(inputs_dict)
+
+ if model_class == VideoMAEForPreTraining:
+ # important: each video needs to have the same number of masked patches
+ # hence we define a single mask, which we then repeat for each example in the batch
+ mask = torch.ones((self.model_tester.num_masks,))
+ mask = torch.cat([mask, torch.zeros(self.model_tester.seq_length - mask.size(0))])
+ bool_masked_pos = mask.expand(self.model_tester.batch_size, -1).bool()
+ inputs_dict["bool_masked_pos"] = bool_masked_pos.to(torch_device)
+
+ if return_labels:
+ if model_class in [
+ *get_values(MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING),
+ ]:
+ inputs_dict["labels"] = torch.zeros(
+ self.model_tester.batch_size, dtype=torch.long, device=torch_device
+ )
+
+ return inputs_dict
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="VideoMAE does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ def test_model_common_attributes(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_for_pretraining(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_pretraining(*config_and_inputs)
+
+ @slow
+ def test_model_from_pretrained(self):
+ for model_name in VIDEOMAE_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ model = VideoMAEModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+ def test_attention_outputs(self):
+ if not self.has_attentions:
+ pass
+
+ else:
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ for model_class in self.all_model_classes:
+ num_visible_patches = self.model_tester.seq_length - self.model_tester.num_masks
+ seq_len = (
+ num_visible_patches if model_class == VideoMAEForPreTraining else self.model_tester.seq_length
+ )
+
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = False
+ config.return_dict = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.attentions
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ # check that output_attentions also work using config
+ del inputs_dict["output_attentions"]
+ config.output_attentions = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.attentions
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ self.assertListEqual(
+ list(attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, seq_len, seq_len],
+ )
+ out_len = len(outputs)
+
+ # Check attention is always last and order is fine
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ self.assertEqual(out_len + 1, len(outputs))
+
+ self_attentions = outputs.attentions
+
+ self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(self_attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, seq_len, seq_len],
+ )
+
+ def test_hidden_states_output(self):
+ def check_hidden_states_output(inputs_dict, config, model_class):
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ hidden_states = outputs.hidden_states
+ expected_num_layers = self.model_tester.num_hidden_layers + 1
+ self.assertEqual(len(hidden_states), expected_num_layers)
+
+ num_visible_patches = self.model_tester.seq_length - self.model_tester.num_masks
+ seq_length = num_visible_patches if model_class == VideoMAEForPreTraining else self.model_tester.seq_length
+
+ self.assertListEqual(
+ list(hidden_states[0].shape[-2:]),
+ [seq_length, self.model_tester.hidden_size],
+ )
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_hidden_states"] = True
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ # check that output_hidden_states also work using config
+ del inputs_dict["output_hidden_states"]
+ config.output_hidden_states = True
+
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+
+# We will verify our results on a video of eating spaghetti
+# Frame indices used: [164 168 172 176 181 185 189 193 198 202 206 210 215 219 223 227]
+def prepare_video():
+ file = hf_hub_download(repo_id="datasets/hf-internal-testing/spaghetti-video", filename="eating_spaghetti.npy")
+ video = np.load(file)
+ return list(video)
+
+
+@require_torch
+@require_vision
+class VideoMAEModelIntegrationTest(unittest.TestCase):
+ @cached_property
+ def default_feature_extractor(self):
+ # logits were tested with a different mean and std, so we use the same here
+ return (
+ VideoMAEFeatureExtractor(image_mean=[0.5, 0.5, 0.5], image_std=[0.5, 0.5, 0.5])
+ if is_vision_available()
+ else None
+ )
+
+ @slow
+ def test_inference_for_video_classification(self):
+ model = VideoMAEForVideoClassification.from_pretrained("MCG-NJU/videomae-base-finetuned-kinetics").to(
+ torch_device
+ )
+
+ feature_extractor = self.default_feature_extractor
+ video = prepare_video()
+ inputs = feature_extractor(video, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the logits
+ expected_shape = torch.Size((1, 400))
+ self.assertEqual(outputs.logits.shape, expected_shape)
+
+ expected_slice = torch.tensor([0.3669, -0.0688, -0.2421]).to(torch_device)
+
+ self.assertTrue(torch.allclose(outputs.logits[0, :3], expected_slice, atol=1e-4))
+
+ @slow
+ def test_inference_for_pretraining(self):
+ model = VideoMAEForPreTraining.from_pretrained("MCG-NJU/videomae-base-short").to(torch_device)
+
+ feature_extractor = self.default_feature_extractor
+ video = prepare_video()
+ inputs = feature_extractor(video, return_tensors="pt").to(torch_device)
+
+ # add boolean mask, indicating which patches to mask
+ local_path = hf_hub_download(repo_id="hf-internal-testing/bool-masked-pos", filename="bool_masked_pos.pt")
+ inputs["bool_masked_pos"] = torch.load(local_path)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the logits
+ expected_shape = torch.Size([1, 1408, 1536])
+ expected_slice = torch.tensor(
+ [[0.7994, 0.9612, 0.8508], [0.7401, 0.8958, 0.8302], [0.5862, 0.7468, 0.7325]], device=torch_device
+ )
+ self.assertEqual(outputs.logits.shape, expected_shape)
+ self.assertTrue(torch.allclose(outputs.logits[0, :3, :3], expected_slice, atol=1e-4))
+
+ # verify the loss (`config.norm_pix_loss` = `True`)
+ expected_loss = torch.tensor([0.5142], device=torch_device)
+ self.assertTrue(torch.allclose(outputs.loss, expected_loss, atol=1e-4))
+
+ # verify the loss (`config.norm_pix_loss` = `False`)
+ model = VideoMAEForPreTraining.from_pretrained("MCG-NJU/videomae-base-short", norm_pix_loss=False).to(
+ torch_device
+ )
+
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ expected_loss = torch.tensor(torch.tensor([0.6469]), device=torch_device)
+ self.assertTrue(torch.allclose(outputs.loss, expected_loss, atol=1e-4))
diff --git a/tests/test_feature_extraction_common.py b/tests/test_feature_extraction_common.py
index 16ab3c6459544c..a822b75cc5eb62 100644
--- a/tests/test_feature_extraction_common.py
+++ b/tests/test_feature_extraction_common.py
@@ -48,49 +48,91 @@
def prepare_image_inputs(feature_extract_tester, equal_resolution=False, numpify=False, torchify=False):
"""This function prepares a list of PIL images, or a list of numpy arrays if one specifies numpify=True,
or a list of PyTorch tensors if one specifies torchify=True.
+
+ One can specify whether the images are of the same resolution or not.
"""
assert not (numpify and torchify), "You cannot specify both numpy and PyTorch tensors at the same time"
- if equal_resolution:
- image_inputs = []
- for i in range(feature_extract_tester.batch_size):
- image_inputs.append(
- np.random.randint(
- 255,
- size=(
- feature_extract_tester.num_channels,
- feature_extract_tester.max_resolution,
- feature_extract_tester.max_resolution,
- ),
- dtype=np.uint8,
- )
- )
- else:
- image_inputs = []
-
- # To avoid getting image width/height 0
- min_resolution = feature_extract_tester.min_resolution
- if getattr(feature_extract_tester, "size_divisor", None):
- # If `size_divisor` is defined, the image needs to have width/size >= `size_divisor`
- min_resolution = max(feature_extract_tester.size_divisor, min_resolution)
-
- for i in range(feature_extract_tester.batch_size):
+ image_inputs = []
+ for i in range(feature_extract_tester.batch_size):
+ if equal_resolution:
+ width = height = feature_extract_tester.max_resolution
+ else:
+ # To avoid getting image width/height 0
+ min_resolution = feature_extract_tester.min_resolution
+ if getattr(feature_extract_tester, "size_divisor", None):
+ # If `size_divisor` is defined, the image needs to have width/size >= `size_divisor`
+ min_resolution = max(feature_extract_tester.size_divisor, min_resolution)
width, height = np.random.choice(np.arange(min_resolution, feature_extract_tester.max_resolution), 2)
- image_inputs.append(
- np.random.randint(255, size=(feature_extract_tester.num_channels, width, height), dtype=np.uint8)
+ image_inputs.append(
+ np.random.randint(
+ 255,
+ size=(
+ feature_extract_tester.num_channels,
+ width,
+ height,
+ ),
+ dtype=np.uint8,
)
+ )
if not numpify and not torchify:
# PIL expects the channel dimension as last dimension
- image_inputs = [Image.fromarray(np.moveaxis(x, 0, -1)) for x in image_inputs]
+ image_inputs = [Image.fromarray(np.moveaxis(image, 0, -1)) for image in image_inputs]
if torchify:
- image_inputs = [torch.from_numpy(x) for x in image_inputs]
+ image_inputs = [torch.from_numpy(image) for image in image_inputs]
return image_inputs
+def prepare_video(feature_extract_tester, width=10, height=10, numpify=False, torchify=False):
+ """This function prepares a video as a list of PIL images/NumPy arrays/PyTorch tensors."""
+
+ video = []
+ for i in range(feature_extract_tester.num_frames):
+ video.append(np.random.randint(255, size=(feature_extract_tester.num_channels, width, height), dtype=np.uint8))
+
+ if not numpify and not torchify:
+ # PIL expects the channel dimension as last dimension
+ video = [Image.fromarray(np.moveaxis(frame, 0, -1)) for frame in video]
+
+ if torchify:
+ video = [torch.from_numpy(frame) for frame in video]
+
+ return video
+
+
+def prepare_video_inputs(feature_extract_tester, equal_resolution=False, numpify=False, torchify=False):
+ """This function prepares a batch of videos: a list of list of PIL images, or a list of list of numpy arrays if
+ one specifies numpify=True, or a list of list of PyTorch tensors if one specifies torchify=True.
+
+ One can specify whether the videos are of the same resolution or not.
+ """
+
+ assert not (numpify and torchify), "You cannot specify both numpy and PyTorch tensors at the same time"
+
+ video_inputs = []
+ for i in range(feature_extract_tester.batch_size):
+ if equal_resolution:
+ width = height = feature_extract_tester.max_resolution
+ else:
+ width, height = np.random.choice(
+ np.arange(feature_extract_tester.min_resolution, feature_extract_tester.max_resolution), 2
+ )
+ video = prepare_video(
+ feature_extract_tester=feature_extract_tester,
+ width=width,
+ height=height,
+ numpify=numpify,
+ torchify=torchify,
+ )
+ video_inputs.append(video)
+
+ return video_inputs
+
+
class FeatureExtractionSavingTestMixin:
def test_feat_extract_to_json_string(self):
feat_extract = self.feature_extraction_class(**self.feat_extract_dict)
diff --git a/tests/test_modeling_common.py b/tests/test_modeling_common.py
index a86b33e88ff2a0..c05771336e6365 100755
--- a/tests/test_modeling_common.py
+++ b/tests/test_modeling_common.py
@@ -99,6 +99,7 @@
MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING,
MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING,
MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING,
+ MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING,
MODEL_MAPPING,
AdaptiveEmbedding,
AutoModelForCausalLM,
@@ -182,6 +183,7 @@ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
*get_values(MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING),
*get_values(MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING),
*get_values(MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING),
+ *get_values(MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING),
]:
inputs_dict["labels"] = torch.zeros(
self.model_tester.batch_size, dtype=torch.long, device=torch_device
+
+ VideoMAE pre-training. Taken from the original paper.
+
+This model was contributed by [nielsr](https://huggingface.co/nielsr).
+The original code can be found [here](https://github.com/MCG-NJU/VideoMAE).
+
+
+## VideoMAEConfig
+
+[[autodoc]] VideoMAEConfig
+
+## VideoMAEFeatureExtractor
+
+[[autodoc]] VideoMAEFeatureExtractor
+ - __call__
+
+## VideoMAEModel
+
+[[autodoc]] VideoMAEModel
+ - forward
+
+## VideoMAEForPreTraining
+
+[[autodoc]] transformers.VideoMAEForPreTraining
+ - forward
+
+## VideoMAEForVideoClassification
+
+[[autodoc]] transformers.VideoMAEForVideoClassification
+ - forward
\ No newline at end of file
diff --git a/src/transformers/__init__.py b/src/transformers/__init__.py
index 75784ce4637659..e8cfd47f3d3b37 100755
--- a/src/transformers/__init__.py
+++ b/src/transformers/__init__.py
@@ -341,6 +341,7 @@
"UniSpeechSatConfig",
],
"models.van": ["VAN_PRETRAINED_CONFIG_ARCHIVE_MAP", "VanConfig"],
+ "models.videomae": ["VIDEOMAE_PRETRAINED_CONFIG_ARCHIVE_MAP", "VideoMAEConfig"],
"models.vilt": ["VILT_PRETRAINED_CONFIG_ARCHIVE_MAP", "ViltConfig", "ViltFeatureExtractor", "ViltProcessor"],
"models.vision_encoder_decoder": ["VisionEncoderDecoderConfig"],
"models.vision_text_dual_encoder": ["VisionTextDualEncoderConfig", "VisionTextDualEncoderProcessor"],
@@ -653,6 +654,7 @@
_import_structure["models.perceiver"].append("PerceiverFeatureExtractor")
_import_structure["models.poolformer"].append("PoolFormerFeatureExtractor")
_import_structure["models.segformer"].append("SegformerFeatureExtractor")
+ _import_structure["models.videomae"].append("VideoMAEFeatureExtractor")
_import_structure["models.vilt"].append("ViltFeatureExtractor")
_import_structure["models.vilt"].append("ViltProcessor")
_import_structure["models.vit"].append("ViTFeatureExtractor")
@@ -799,6 +801,7 @@
"MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING",
"MODEL_FOR_TABLE_QUESTION_ANSWERING_MAPPING",
"MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING",
+ "MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING",
"MODEL_FOR_VISION_2_SEQ_MAPPING",
"MODEL_FOR_VISUAL_QUESTION_ANSWERING_MAPPING",
"MODEL_MAPPING",
@@ -825,6 +828,7 @@
"AutoModelForSpeechSeq2Seq",
"AutoModelForTableQuestionAnswering",
"AutoModelForTokenClassification",
+ "AutoModelForVideoClassification",
"AutoModelForVision2Seq",
"AutoModelForVisualQuestionAnswering",
"AutoModelWithLMHead",
@@ -1871,6 +1875,15 @@
"ViTMAEPreTrainedModel",
]
)
+ _import_structure["models.videomae"].extend(
+ [
+ "VIDEOMAE_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "VideoMAEForPreTraining",
+ "VideoMAEModel",
+ "VideoMAEPreTrainedModel",
+ "VideoMAEForVideoClassification",
+ ]
+ )
_import_structure["models.wav2vec2"].extend(
[
"WAV_2_VEC_2_PRETRAINED_MODEL_ARCHIVE_LIST",
@@ -3100,6 +3113,7 @@
from .models.unispeech import UNISPEECH_PRETRAINED_CONFIG_ARCHIVE_MAP, UniSpeechConfig
from .models.unispeech_sat import UNISPEECH_SAT_PRETRAINED_CONFIG_ARCHIVE_MAP, UniSpeechSatConfig
from .models.van import VAN_PRETRAINED_CONFIG_ARCHIVE_MAP, VanConfig
+ from .models.videomae import VIDEOMAE_PRETRAINED_CONFIG_ARCHIVE_MAP, VideoMAEConfig
from .models.vilt import VILT_PRETRAINED_CONFIG_ARCHIVE_MAP, ViltConfig, ViltFeatureExtractor, ViltProcessor
from .models.vision_encoder_decoder import VisionEncoderDecoderConfig
from .models.vision_text_dual_encoder import VisionTextDualEncoderConfig, VisionTextDualEncoderProcessor
@@ -3373,6 +3387,7 @@
from .models.perceiver import PerceiverFeatureExtractor
from .models.poolformer import PoolFormerFeatureExtractor
from .models.segformer import SegformerFeatureExtractor
+ from .models.videomae import VideoMAEFeatureExtractor
from .models.vilt import ViltFeatureExtractor, ViltProcessor
from .models.vit import ViTFeatureExtractor
from .models.yolos import YolosFeatureExtractor
@@ -3497,6 +3512,7 @@
MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING,
MODEL_FOR_TABLE_QUESTION_ANSWERING_MAPPING,
MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING,
+ MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING,
MODEL_FOR_VISION_2_SEQ_MAPPING,
MODEL_FOR_VISUAL_QUESTION_ANSWERING_MAPPING,
MODEL_MAPPING,
@@ -3523,6 +3539,7 @@
AutoModelForSpeechSeq2Seq,
AutoModelForTableQuestionAnswering,
AutoModelForTokenClassification,
+ AutoModelForVideoClassification,
AutoModelForVision2Seq,
AutoModelForVisualQuestionAnswering,
AutoModelWithLMHead,
@@ -4338,6 +4355,13 @@
VanModel,
VanPreTrainedModel,
)
+ from .models.videomae import (
+ VIDEOMAE_PRETRAINED_MODEL_ARCHIVE_LIST,
+ VideoMAEForPreTraining,
+ VideoMAEForVideoClassification,
+ VideoMAEModel,
+ VideoMAEPreTrainedModel,
+ )
from .models.vilt import (
VILT_PRETRAINED_MODEL_ARCHIVE_LIST,
ViltForImageAndTextRetrieval,
diff --git a/src/transformers/image_utils.py b/src/transformers/image_utils.py
index ddef7a3a777e93..dd7bb326993d34 100644
--- a/src/transformers/image_utils.py
+++ b/src/transformers/image_utils.py
@@ -23,14 +23,15 @@
import requests
from .utils import is_torch_available
+from .utils.constants import ( # noqa: F401
+ IMAGENET_DEFAULT_MEAN,
+ IMAGENET_DEFAULT_STD,
+ IMAGENET_STANDARD_MEAN,
+ IMAGENET_STANDARD_STD,
+)
from .utils.generic import _is_torch
-IMAGENET_DEFAULT_MEAN = [0.485, 0.456, 0.406]
-IMAGENET_DEFAULT_STD = [0.229, 0.224, 0.225]
-IMAGENET_STANDARD_MEAN = [0.5, 0.5, 0.5]
-IMAGENET_STANDARD_STD = [0.5, 0.5, 0.5]
-
ImageInput = Union[
PIL.Image.Image, np.ndarray, "torch.Tensor", List[PIL.Image.Image], List[np.ndarray], List["torch.Tensor"] # noqa
]
diff --git a/src/transformers/models/__init__.py b/src/transformers/models/__init__.py
index 1b81ce7d8fab1d..11887db91f8393 100644
--- a/src/transformers/models/__init__.py
+++ b/src/transformers/models/__init__.py
@@ -137,6 +137,7 @@
unispeech,
unispeech_sat,
van,
+ videomae,
vilt,
vision_encoder_decoder,
vision_text_dual_encoder,
diff --git a/src/transformers/models/auto/__init__.py b/src/transformers/models/auto/__init__.py
index 09961bae14fdeb..b04c2420ef963e 100644
--- a/src/transformers/models/auto/__init__.py
+++ b/src/transformers/models/auto/__init__.py
@@ -63,6 +63,7 @@
"MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING",
"MODEL_FOR_TABLE_QUESTION_ANSWERING_MAPPING",
"MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING",
+ "MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING",
"MODEL_FOR_VISION_2_SEQ_MAPPING",
"MODEL_FOR_VISUAL_QUESTION_ANSWERING_MAPPING",
"MODEL_MAPPING",
@@ -89,6 +90,7 @@
"AutoModelForSpeechSeq2Seq",
"AutoModelForTableQuestionAnswering",
"AutoModelForTokenClassification",
+ "AutoModelForVideoClassification",
"AutoModelForVision2Seq",
"AutoModelForVisualQuestionAnswering",
"AutoModelWithLMHead",
@@ -203,6 +205,7 @@
MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING,
MODEL_FOR_TABLE_QUESTION_ANSWERING_MAPPING,
MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING,
+ MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING,
MODEL_FOR_VISION_2_SEQ_MAPPING,
MODEL_FOR_VISUAL_QUESTION_ANSWERING_MAPPING,
MODEL_MAPPING,
@@ -229,6 +232,7 @@
AutoModelForSpeechSeq2Seq,
AutoModelForTableQuestionAnswering,
AutoModelForTokenClassification,
+ AutoModelForVideoClassification,
AutoModelForVision2Seq,
AutoModelForVisualQuestionAnswering,
AutoModelWithLMHead,
diff --git a/src/transformers/models/auto/configuration_auto.py b/src/transformers/models/auto/configuration_auto.py
index 13f69c024a9a0d..d8ecbb49e64f29 100644
--- a/src/transformers/models/auto/configuration_auto.py
+++ b/src/transformers/models/auto/configuration_auto.py
@@ -132,6 +132,7 @@
("unispeech", "UniSpeechConfig"),
("unispeech-sat", "UniSpeechSatConfig"),
("van", "VanConfig"),
+ ("videomae", "VideoMAEConfig"),
("vilt", "ViltConfig"),
("vision-encoder-decoder", "VisionEncoderDecoderConfig"),
("vision-text-dual-encoder", "VisionTextDualEncoderConfig"),
@@ -247,6 +248,7 @@
("unispeech", "UNISPEECH_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("unispeech-sat", "UNISPEECH_SAT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("van", "VAN_PRETRAINED_CONFIG_ARCHIVE_MAP"),
+ ("videomae", "VIDEOMAE_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("vilt", "VILT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("visual_bert", "VISUAL_BERT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
("vit", "VIT_PRETRAINED_CONFIG_ARCHIVE_MAP"),
@@ -388,6 +390,7 @@
("unispeech", "UniSpeech"),
("unispeech-sat", "UniSpeechSat"),
("van", "VAN"),
+ ("videomae", "VideoMAE"),
("vilt", "ViLT"),
("vision-encoder-decoder", "Vision Encoder decoder"),
("vision-text-dual-encoder", "VisionTextDualEncoder"),
diff --git a/src/transformers/models/auto/feature_extraction_auto.py b/src/transformers/models/auto/feature_extraction_auto.py
index 8c4564e261c616..ed526369df4f38 100644
--- a/src/transformers/models/auto/feature_extraction_auto.py
+++ b/src/transformers/models/auto/feature_extraction_auto.py
@@ -68,6 +68,7 @@
("swin", "ViTFeatureExtractor"),
("swinv2", "ViTFeatureExtractor"),
("van", "ConvNextFeatureExtractor"),
+ ("videomae", "ViTFeatureExtractor"),
("vilt", "ViltFeatureExtractor"),
("vit", "ViTFeatureExtractor"),
("vit_mae", "ViTFeatureExtractor"),
diff --git a/src/transformers/models/auto/modeling_auto.py b/src/transformers/models/auto/modeling_auto.py
index a86e8bc56da34b..bd4774c245b07b 100644
--- a/src/transformers/models/auto/modeling_auto.py
+++ b/src/transformers/models/auto/modeling_auto.py
@@ -127,6 +127,7 @@
("unispeech", "UniSpeechModel"),
("unispeech-sat", "UniSpeechSatModel"),
("van", "VanModel"),
+ ("videomae", "VideoMAEModel"),
("vilt", "ViltModel"),
("vision-text-dual-encoder", "VisionTextDualEncoderModel"),
("visual_bert", "VisualBertModel"),
@@ -187,6 +188,7 @@
("transfo-xl", "TransfoXLLMHeadModel"),
("unispeech", "UniSpeechForPreTraining"),
("unispeech-sat", "UniSpeechSatForPreTraining"),
+ ("videomae", "VideoMAEForPreTraining"),
("visual_bert", "VisualBertForPreTraining"),
("vit_mae", "ViTMAEForPreTraining"),
("wav2vec2", "Wav2Vec2ForPreTraining"),
@@ -381,6 +383,12 @@
]
)
+MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
+ [
+ ("videomae", "VideoMAEForVideoClassification"),
+ ]
+)
+
MODEL_FOR_VISION_2_SEQ_MAPPING_NAMES = OrderedDict(
[
("vision-encoder-decoder", "VisionEncoderDecoderModel"),
@@ -754,6 +762,9 @@
MODEL_FOR_INSTANCE_SEGMENTATION_MAPPING = _LazyAutoMapping(
CONFIG_MAPPING_NAMES, MODEL_FOR_INSTANCE_SEGMENTATION_MAPPING_NAMES
)
+MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING = _LazyAutoMapping(
+ CONFIG_MAPPING_NAMES, MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING_NAMES
+)
MODEL_FOR_VISION_2_SEQ_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_VISION_2_SEQ_MAPPING_NAMES)
MODEL_FOR_VISUAL_QUESTION_ANSWERING_MAPPING = _LazyAutoMapping(
CONFIG_MAPPING_NAMES, MODEL_FOR_VISUAL_QUESTION_ANSWERING_MAPPING_NAMES
@@ -938,6 +949,13 @@ class AutoModelForObjectDetection(_BaseAutoModelClass):
AutoModelForObjectDetection = auto_class_update(AutoModelForObjectDetection, head_doc="object detection")
+class AutoModelForVideoClassification(_BaseAutoModelClass):
+ _model_mapping = MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING
+
+
+AutoModelForVideoClassification = auto_class_update(AutoModelForVideoClassification, head_doc="video classification")
+
+
class AutoModelForVision2Seq(_BaseAutoModelClass):
_model_mapping = MODEL_FOR_VISION_2_SEQ_MAPPING
diff --git a/src/transformers/models/videomae/__init__.py b/src/transformers/models/videomae/__init__.py
new file mode 100644
index 00000000000000..fb239c6063ba80
--- /dev/null
+++ b/src/transformers/models/videomae/__init__.py
@@ -0,0 +1,77 @@
+# flake8: noqa
+# There's no way to ignore "F401 '...' imported but unused" warnings in this
+# module, but to preserve other warnings. So, don't check this module at all.
+
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from typing import TYPE_CHECKING
+
+from ...utils import OptionalDependencyNotAvailable, _LazyModule, is_torch_available, is_vision_available
+
+
+_import_structure = {
+ "configuration_videomae": ["VIDEOMAE_PRETRAINED_CONFIG_ARCHIVE_MAP", "VideoMAEConfig"],
+}
+
+try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["modeling_videomae"] = [
+ "VIDEOMAE_PRETRAINED_MODEL_ARCHIVE_LIST",
+ "VideoMAEForPreTraining",
+ "VideoMAEModel",
+ "VideoMAEPreTrainedModel",
+ "VideoMAEForVideoClassification",
+ ]
+
+try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+except OptionalDependencyNotAvailable:
+ pass
+else:
+ _import_structure["feature_extraction_videomae"] = ["VideoMAEFeatureExtractor"]
+
+if TYPE_CHECKING:
+ from .configuration_videomae import VIDEOMAE_PRETRAINED_CONFIG_ARCHIVE_MAP, VideoMAEConfig
+
+ try:
+ if not is_torch_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .modeling_videomae import (
+ VIDEOMAE_PRETRAINED_MODEL_ARCHIVE_LIST,
+ VideoMAEForPreTraining,
+ VideoMAEForVideoClassification,
+ VideoMAEModel,
+ VideoMAEPreTrainedModel,
+ )
+
+ try:
+ if not is_vision_available():
+ raise OptionalDependencyNotAvailable()
+ except OptionalDependencyNotAvailable:
+ pass
+ else:
+ from .feature_extraction_videomae import VideoMAEFeatureExtractor
+
+else:
+ import sys
+
+ sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
diff --git a/src/transformers/models/videomae/configuration_videomae.py b/src/transformers/models/videomae/configuration_videomae.py
new file mode 100644
index 00000000000000..932c4c1d98cabf
--- /dev/null
+++ b/src/transformers/models/videomae/configuration_videomae.py
@@ -0,0 +1,148 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" VideoMAE model configuration"""
+
+from ...configuration_utils import PretrainedConfig
+from ...utils import logging
+
+
+logger = logging.get_logger(__name__)
+
+VIDEOMAE_PRETRAINED_CONFIG_ARCHIVE_MAP = {
+ "MCG-NJU/videomae-base": "https://huggingface.co/MCG-NJU/videomae-base/resolve/main/config.json",
+}
+
+
+class VideoMAEConfig(PretrainedConfig):
+ r"""
+ This is the configuration class to store the configuration of a [`VideoMAEModel`]. It is used to instantiate a
+ VideoMAE model according to the specified arguments, defining the model architecture. Instantiating a configuration
+ with the defaults will yield a similar configuration to that of the VideoMAE
+ [MCG-NJU/videomae-base](https://huggingface.co/MCG-NJU/videomae-base) architecture.
+
+ Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
+ documentation from [`PretrainedConfig`] for more information.
+
+ Args:
+ image_size (`int`, *optional*, defaults to 224):
+ The size (resolution) of each image.
+ patch_size (`int`, *optional*, defaults to 16):
+ The size (resolution) of each patch.
+ num_channels (`int`, *optional*, defaults to 3):
+ The number of input channels.
+ num_frames (`int`, *optional*, defaults to 16):
+ The number of frames in each video.
+ tubelet_size (`int`, *optional*, defaults to 2):
+ The number of tubelets.
+ hidden_size (`int`, *optional*, defaults to 768):
+ Dimensionality of the encoder layers and the pooler layer.
+ num_hidden_layers (`int`, *optional*, defaults to 12):
+ Number of hidden layers in the Transformer encoder.
+ num_attention_heads (`int`, *optional*, defaults to 12):
+ Number of attention heads for each attention layer in the Transformer encoder.
+ intermediate_size (`int`, *optional*, defaults to 3072):
+ Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
+ hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
+ The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
+ `"relu"`, `"selu"` and `"gelu_new"` are supported.
+ hidden_dropout_prob (`float`, *optional*, defaults to 0.0):
+ The dropout probabilitiy for all fully connected layers in the embeddings, encoder, and pooler.
+ attention_probs_dropout_prob (`float`, *optional*, defaults to 0.0):
+ The dropout ratio for the attention probabilities.
+ initializer_range (`float`, *optional*, defaults to 0.02):
+ The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
+ layer_norm_eps (`float`, *optional*, defaults to 1e-12):
+ The epsilon used by the layer normalization layers.
+ qkv_bias (`bool`, *optional*, defaults to `True`):
+ Whether to add a bias to the queries, keys and values.
+ use_mean_pooling (`bool`, *optional*, defaults to `True`):
+ Whether to mean pool the final hidden states instead of using the final hidden state of the [CLS] token.
+ decoder_num_attention_heads (`int`, *optional*, defaults to 6):
+ Number of attention heads for each attention layer in the decoder.
+ decoder_hidden_size (`int`, *optional*, defaults to 384):
+ Dimensionality of the decoder.
+ decoder_num_hidden_layers (`int`, *optional*, defaults to 4):
+ Number of hidden layers in the decoder.
+ decoder_intermediate_size (`int`, *optional*, defaults to 1536):
+ Dimensionality of the "intermediate" (i.e., feed-forward) layer in the decoder.
+ norm_pix_loss (`bool`, *optional*, defaults to `True`):
+ Whether to normalize the target patch pixels.
+
+ Example:
+
+ ```python
+ >>> from transformers import VideoMAEConfig, VideoMAEModel
+
+ >>> # Initializing a VideoMAE videomae-base style configuration
+ >>> configuration = VideoMAEConfig()
+
+ >>> # Randomly initializing a model from the configuration
+ >>> model = VideoMAEModel(configuration)
+
+ >>> # Accessing the model configuration
+ >>> configuration = model.config
+ ```"""
+ model_type = "videomae"
+
+ def __init__(
+ self,
+ image_size=224,
+ patch_size=16,
+ num_channels=3,
+ num_frames=16,
+ tubelet_size=2,
+ hidden_size=768,
+ num_hidden_layers=12,
+ num_attention_heads=12,
+ intermediate_size=3072,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.0,
+ attention_probs_dropout_prob=0.0,
+ initializer_range=0.02,
+ layer_norm_eps=1e-12,
+ qkv_bias=True,
+ use_mean_pooling=True,
+ decoder_num_attention_heads=6,
+ decoder_hidden_size=384,
+ decoder_num_hidden_layers=4,
+ decoder_intermediate_size=1536,
+ norm_pix_loss=True,
+ **kwargs
+ ):
+ super().__init__(**kwargs)
+
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.num_frames = num_frames
+ self.tubelet_size = tubelet_size
+
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.initializer_range = initializer_range
+ self.layer_norm_eps = layer_norm_eps
+ self.qkv_bias = qkv_bias
+ self.use_mean_pooling = use_mean_pooling
+
+ self.decoder_num_attention_heads = decoder_num_attention_heads
+ self.decoder_hidden_size = decoder_hidden_size
+ self.decoder_num_hidden_layers = decoder_num_hidden_layers
+ self.decoder_intermediate_size = decoder_intermediate_size
+ self.norm_pix_loss = norm_pix_loss
diff --git a/src/transformers/models/videomae/convert_videomae_to_pytorch.py b/src/transformers/models/videomae/convert_videomae_to_pytorch.py
new file mode 100644
index 00000000000000..60e5ae8f5f41c0
--- /dev/null
+++ b/src/transformers/models/videomae/convert_videomae_to_pytorch.py
@@ -0,0 +1,286 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Convert VideoMAE checkpoints from the original repository: https://github.com/MCG-NJU/VideoMAE"""
+
+import argparse
+import json
+
+import numpy as np
+import torch
+
+import gdown
+from huggingface_hub import hf_hub_download
+from transformers import (
+ VideoMAEConfig,
+ VideoMAEFeatureExtractor,
+ VideoMAEForPreTraining,
+ VideoMAEForVideoClassification,
+)
+
+
+def get_videomae_config(model_name):
+ config = VideoMAEConfig()
+
+ if "large" in model_name:
+ config.hidden_size = 1024
+ config.intermediate_size = 4096
+ config.num_hidden_layers = 24
+ config.num_attention_heads = 16
+ config.decoder_num_hidden_layers = 12
+ config.decoder_num_attention_heads = 8
+ config.decoder_hidden_size = 512
+ config.decoder_intermediate_size = 2048
+
+ if "finetuned" not in model_name:
+ config.use_mean_pooling = False
+
+ if "finetuned" in model_name:
+ repo_id = "datasets/huggingface/label-files"
+ if "kinetics" in model_name:
+ config.num_labels = 400
+ filename = "kinetics400-id2label.json"
+ elif "ssv2" in model_name:
+ config.num_labels = 174
+ filename = "something-something-v2-id2label.json"
+ else:
+ raise ValueError("Model name should either contain 'kinetics' or 'ssv2' in case it's fine-tuned.")
+ id2label = json.load(open(hf_hub_download(repo_id, filename), "r"))
+ id2label = {int(k): v for k, v in id2label.items()}
+ config.id2label = id2label
+ config.label2id = {v: k for k, v in id2label.items()}
+
+ return config
+
+
+def rename_key(name):
+ if "encoder." in name:
+ name = name.replace("encoder.", "")
+ if "cls_token" in name:
+ name = name.replace("cls_token", "videomae.embeddings.cls_token")
+ if "decoder_pos_embed" in name:
+ name = name.replace("decoder_pos_embed", "decoder.decoder_pos_embed")
+ if "pos_embed" in name and "decoder" not in name:
+ name = name.replace("pos_embed", "videomae.embeddings.position_embeddings")
+ if "patch_embed.proj" in name:
+ name = name.replace("patch_embed.proj", "videomae.embeddings.patch_embeddings.projection")
+ if "patch_embed.norm" in name:
+ name = name.replace("patch_embed.norm", "videomae.embeddings.norm")
+ if "decoder.blocks" in name:
+ name = name.replace("decoder.blocks", "decoder.decoder_layers")
+ if "blocks" in name:
+ name = name.replace("blocks", "videomae.encoder.layer")
+ if "attn.proj" in name:
+ name = name.replace("attn.proj", "attention.output.dense")
+ if "attn" in name and "bias" not in name:
+ name = name.replace("attn", "attention.self")
+ if "attn" in name:
+ name = name.replace("attn", "attention.attention")
+ if "norm1" in name:
+ name = name.replace("norm1", "layernorm_before")
+ if "norm2" in name:
+ name = name.replace("norm2", "layernorm_after")
+ if "mlp.fc1" in name:
+ name = name.replace("mlp.fc1", "intermediate.dense")
+ if "mlp.fc2" in name:
+ name = name.replace("mlp.fc2", "output.dense")
+ if "decoder_embed" in name:
+ name = name.replace("decoder_embed", "decoder.decoder_embed")
+ if "decoder_norm" in name:
+ name = name.replace("decoder_norm", "decoder.decoder_norm")
+ if "decoder_pred" in name:
+ name = name.replace("decoder_pred", "decoder.decoder_pred")
+ if "norm.weight" in name and "decoder" not in name and "fc" not in name:
+ name = name.replace("norm.weight", "videomae.layernorm.weight")
+ if "norm.bias" in name and "decoder" not in name and "fc" not in name:
+ name = name.replace("norm.bias", "videomae.layernorm.bias")
+ if "head" in name and "decoder" not in name:
+ name = name.replace("head", "classifier")
+
+ return name
+
+
+def convert_state_dict(orig_state_dict, config):
+ for key in orig_state_dict.copy().keys():
+ val = orig_state_dict.pop(key)
+
+ if key.startswith("encoder."):
+ key = key.replace("encoder.", "")
+
+ if "qkv" in key:
+ key_split = key.split(".")
+ if key.startswith("decoder.blocks"):
+ dim = config.decoder_hidden_size
+ layer_num = int(key_split[2])
+ prefix = "decoder.decoder_layers."
+ if "weight" in key:
+ orig_state_dict[f"{prefix}{layer_num}.attention.attention.query.weight"] = val[:dim, :]
+ orig_state_dict[f"{prefix}{layer_num}.attention.attention.key.weight"] = val[dim : dim * 2, :]
+ orig_state_dict[f"{prefix}{layer_num}.attention.attention.value.weight"] = val[-dim:, :]
+ else:
+ dim = config.hidden_size
+ layer_num = int(key_split[1])
+ prefix = "videomae.encoder.layer."
+ if "weight" in key:
+ orig_state_dict[f"{prefix}{layer_num}.attention.attention.query.weight"] = val[:dim, :]
+ orig_state_dict[f"{prefix}{layer_num}.attention.attention.key.weight"] = val[dim : dim * 2, :]
+ orig_state_dict[f"{prefix}{layer_num}.attention.attention.value.weight"] = val[-dim:, :]
+ else:
+ orig_state_dict[rename_key(key)] = val
+
+ return orig_state_dict
+
+
+# We will verify our results on a video of eating spaghetti
+# Frame indices used: [164 168 172 176 181 185 189 193 198 202 206 210 215 219 223 227]
+def prepare_video():
+ file = hf_hub_download(repo_id="datasets/hf-internal-testing/spaghetti-video", filename="eating_spaghetti.npy")
+ video = np.load(file)
+ return list(video)
+
+
+def convert_videomae_checkpoint(checkpoint_url, pytorch_dump_folder_path, model_name, push_to_hub):
+ config = get_videomae_config(model_name)
+
+ if "finetuned" in model_name:
+ model = VideoMAEForVideoClassification(config)
+ else:
+ model = VideoMAEForPreTraining(config)
+
+ # download original checkpoint, hosted on Google Drive
+ output = "pytorch_model.bin"
+ gdown.cached_download(checkpoint_url, output, quiet=False)
+ files = torch.load(output, map_location="cpu")
+ if "model" in files:
+ state_dict = files["model"]
+ else:
+ state_dict = files["module"]
+ new_state_dict = convert_state_dict(state_dict, config)
+
+ model.load_state_dict(new_state_dict)
+ model.eval()
+
+ # verify model on basic input
+ feature_extractor = VideoMAEFeatureExtractor(image_mean=[0.5, 0.5, 0.5], image_std=[0.5, 0.5, 0.5])
+ video = prepare_video()
+ inputs = feature_extractor(video, return_tensors="pt")
+
+ if "finetuned" not in model_name:
+ local_path = hf_hub_download(repo_id="hf-internal-testing/bool-masked-pos", filename="bool_masked_pos.pt")
+ inputs["bool_masked_pos"] = torch.load(local_path)
+
+ outputs = model(**inputs)
+ logits = outputs.logits
+
+ model_names = [
+ # Kinetics-400 checkpoints (short = pretrained only for 800 epochs instead of 1600)
+ "videomae-base-short",
+ "videomae-base-short-finetuned-kinetics",
+ "videomae-base",
+ "videomae-base-finetuned-kinetics",
+ "videomae-large",
+ "videomae-large-finetuned-kinetics",
+ # Something-Something-v2 checkpoints (short = pretrained only for 800 epochs instead of 2400)
+ "videomae-base-short-ssv2",
+ "videomae-base-short-finetuned-ssv2",
+ "videomae-base-ssv2",
+ "videomae-base-finetuned-ssv2",
+ ]
+
+ # NOTE: logits were tested with image_mean and image_std equal to [0.5, 0.5, 0.5] and [0.5, 0.5, 0.5]
+ if model_name == "videomae-base":
+ expected_shape = torch.Size([1, 1408, 1536])
+ expected_slice = torch.tensor([[0.7739, 0.7968, 0.7089], [0.6701, 0.7487, 0.6209], [0.4287, 0.5158, 0.4773]])
+ elif model_name == "videomae-base-short":
+ expected_shape = torch.Size([1, 1408, 1536])
+ expected_slice = torch.tensor([[0.7994, 0.9612, 0.8508], [0.7401, 0.8958, 0.8302], [0.5862, 0.7468, 0.7325]])
+ # we verified the loss both for normalized and unnormalized targets for this one
+ expected_loss = torch.tensor([0.5142]) if config.norm_pix_loss else torch.tensor([0.6469])
+ elif model_name == "videomae-large":
+ expected_shape = torch.Size([1, 1408, 1536])
+ expected_slice = torch.tensor([[0.7149, 0.7997, 0.6966], [0.6768, 0.7869, 0.6948], [0.5139, 0.6221, 0.5605]])
+ elif model_name == "videomae-large-finetuned-kinetics":
+ expected_shape = torch.Size([1, 400])
+ expected_slice = torch.tensor([0.0771, 0.0011, -0.3625])
+ elif model_name == "videomae-base-short-finetuned-kinetics":
+ expected_shape = torch.Size([1, 400])
+ expected_slice = torch.tensor([0.6588, 0.0990, -0.2493])
+ elif model_name == "videomae-base-finetuned-kinetics":
+ expected_shape = torch.Size([1, 400])
+ expected_slice = torch.tensor([0.3669, -0.0688, -0.2421])
+ elif model_name == "videomae-base-short-ssv2":
+ expected_shape = torch.Size([1, 1408, 1536])
+ expected_slice = torch.tensor([[0.4712, 0.5296, 0.5786], [0.2278, 0.2729, 0.4026], [0.0352, 0.0730, 0.2506]])
+ elif model_name == "videomae-base-short-finetuned-ssv2":
+ expected_shape = torch.Size([1, 174])
+ expected_slice = torch.tensor([-0.0537, -0.1539, -0.3266])
+ elif model_name == "videomae-base-ssv2":
+ expected_shape = torch.Size([1, 1408, 1536])
+ expected_slice = torch.tensor([[0.8131, 0.8727, 0.8546], [0.7366, 0.9377, 0.8870], [0.5935, 0.8874, 0.8564]])
+ elif model_name == "videomae-base-finetuned-ssv2":
+ expected_shape = torch.Size([1, 174])
+ expected_slice = torch.tensor([0.1961, -0.8337, -0.6389])
+ else:
+ raise ValueError(f"Model name not supported. Should be one of {model_names}")
+
+ # verify logits
+ assert logits.shape == expected_shape
+ if "finetuned" in model_name:
+ assert torch.allclose(logits[0, :3], expected_slice, atol=1e-4)
+ else:
+ print("Logits:", logits[0, :3, :3])
+ assert torch.allclose(logits[0, :3, :3], expected_slice, atol=1e-4)
+ print("Logits ok!")
+
+ # verify loss, if applicable
+ if model_name == "videomae-base-short":
+ loss = outputs.loss
+ assert torch.allclose(loss, expected_loss, atol=1e-4)
+ print("Loss ok!")
+
+ if pytorch_dump_folder_path is not None:
+ print(f"Saving model and feature extractor to {pytorch_dump_folder_path}")
+ feature_extractor.save_pretrained(pytorch_dump_folder_path)
+ model.save_pretrained(pytorch_dump_folder_path)
+
+ if push_to_hub:
+ print("Pushing to the hub...")
+ model.push_to_hub(model_name, organization="nielsr")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ # Required parameters
+ parser.add_argument(
+ "--checkpoint_url",
+ default="https://drive.google.com/u/1/uc?id=1tEhLyskjb755TJ65ptsrafUG2llSwQE1&export=download&confirm=t&uuid=aa3276eb-fb7e-482a-adec-dc7171df14c4",
+ type=str,
+ help=(
+ "URL of the original PyTorch checkpoint (on Google Drive) you'd like to convert. Should be a direct"
+ " download link."
+ ),
+ )
+ parser.add_argument(
+ "--pytorch_dump_folder_path",
+ default="/Users/nielsrogge/Documents/VideoMAE/Test",
+ type=str,
+ help="Path to the output PyTorch model directory.",
+ )
+ parser.add_argument("--model_name", default="videomae-base", type=str, help="Name of the model.")
+ parser.add_argument(
+ "--push_to_hub", action="store_true", help="Whether or not to push the converted model to the 🤗 hub."
+ )
+
+ args = parser.parse_args()
+ convert_videomae_checkpoint(args.checkpoint_url, args.pytorch_dump_folder_path, args.model_name, args.push_to_hub)
diff --git a/src/transformers/models/videomae/feature_extraction_videomae.py b/src/transformers/models/videomae/feature_extraction_videomae.py
new file mode 100644
index 00000000000000..132dabda8c6833
--- /dev/null
+++ b/src/transformers/models/videomae/feature_extraction_videomae.py
@@ -0,0 +1,169 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Feature extractor class for VideoMAE."""
+
+from typing import Optional, Union
+
+import numpy as np
+from PIL import Image
+
+from ...feature_extraction_utils import BatchFeature, FeatureExtractionMixin
+from ...image_utils import ImageFeatureExtractionMixin, ImageInput, is_torch_tensor
+from ...utils import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD, TensorType, logging
+
+
+logger = logging.get_logger(__name__)
+
+
+class VideoMAEFeatureExtractor(FeatureExtractionMixin, ImageFeatureExtractionMixin):
+ r"""
+ Constructs a VideoMAE feature extractor. This feature extractor can be used to prepare videos for the model.
+
+ This feature extractor inherits from [`FeatureExtractionMixin`] which contains most of the main methods. Users
+ should refer to this superclass for more information regarding those methods.
+
+ Args:
+ do_resize (`bool`, *optional*, defaults to `True`):
+ Whether to resize the shorter edge of the input to a certain `size`.
+ size (`int`, *optional*, defaults to 224):
+ Resize the shorter edge of the input to the given size. Only has an effect if `do_resize` is set to `True`.
+ resample (`int`, *optional*, defaults to `PIL.Image.BILINEAR`):
+ An optional resampling filter. This can be one of `PIL.Image.NEAREST`, `PIL.Image.BOX`,
+ `PIL.Image.BILINEAR`, `PIL.Image.HAMMING`, `PIL.Image.BICUBIC` or `PIL.Image.LANCZOS`. Only has an effect
+ if `do_resize` is set to `True`.
+ do_center_crop (`bool`, *optional*, defaults to `True`):
+ Whether to center crop the input to a certain `size`.
+ do_normalize (`bool`, *optional*, defaults to `True`):
+ Whether or not to normalize the input with mean and standard deviation.
+ image_mean (`List[int]`, defaults to `[0.485, 0.456, 0.406]`):
+ The sequence of means for each channel, to be used when normalizing images.
+ image_std (`List[int]`, defaults to `[0.229, 0.224, 0.225]`):
+ The sequence of standard deviations for each channel, to be used when normalizing images.
+ """
+
+ model_input_names = ["pixel_values"]
+
+ def __init__(
+ self,
+ do_resize=True,
+ size=224,
+ resample=Image.BILINEAR,
+ do_center_crop=True,
+ do_normalize=True,
+ image_mean=None,
+ image_std=None,
+ **kwargs
+ ):
+ super().__init__(**kwargs)
+ self.do_resize = do_resize
+ self.size = size
+ self.resample = resample
+ self.do_center_crop = do_center_crop
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean if image_mean is not None else IMAGENET_DEFAULT_MEAN
+ self.image_std = image_std if image_std is not None else IMAGENET_DEFAULT_STD
+
+ def resize_video(self, video, size, resample="bilinear"):
+ return [self.resize(frame, size, resample, default_to_square=False) for frame in video]
+
+ def crop_video(self, video, size):
+ return [self.center_crop(frame, size) for frame in video]
+
+ def normalize_video(self, video, mean, std):
+ # video can be a list of PIL images, list of NumPy arrays or list of PyTorch tensors
+ # first: convert to list of NumPy arrays
+ video = [self.to_numpy_array(frame) for frame in video]
+
+ # second: stack to get (num_frames, num_channels, height, width)
+ video = np.stack(video, axis=0)
+
+ # third: normalize
+ if not isinstance(mean, np.ndarray):
+ mean = np.array(mean).astype(video.dtype)
+ if not isinstance(std, np.ndarray):
+ std = np.array(std).astype(video.dtype)
+
+ return (video - mean[None, :, None, None]) / std[None, :, None, None]
+
+ def __call__(
+ self, videos: ImageInput, return_tensors: Optional[Union[str, TensorType]] = None, **kwargs
+ ) -> BatchFeature:
+ """
+ Main method to prepare for the model one or several video(s).
+
+
+
+ NumPy arrays are converted to PIL images when resizing, so the most efficient is to pass PIL images.
+
+
+
+ Args:
+ videos (`List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`, `List[List[PIL.Image.Image]]`, `List[List[np.ndarrray]]`,:
+ `List[List[torch.Tensor]]`): The video or batch of videos to be prepared. Each video should be a list
+ of frames, which can be either PIL images or NumPy arrays. In case of NumPy arrays/PyTorch tensors,
+ each frame should be of shape (H, W, C), where H and W are frame height and width, and C is a number of
+ channels.
+
+ return_tensors (`str` or [`~utils.TensorType`], *optional*, defaults to `'np'`):
+ If set, will return tensors of a particular framework. Acceptable values are:
+
+ - `'tf'`: Return TensorFlow `tf.constant` objects.
+ - `'pt'`: Return PyTorch `torch.Tensor` objects.
+ - `'np'`: Return NumPy `np.ndarray` objects.
+ - `'jax'`: Return JAX `jnp.ndarray` objects.
+
+ Returns:
+ [`BatchFeature`]: A [`BatchFeature`] with the following fields:
+
+ - **pixel_values** -- Pixel values to be fed to a model, of shape (batch_size, num_channels, num_frames,
+ height, width).
+ """
+ # Input type checking for clearer error
+ valid_videos = False
+ is_batched = False
+
+ # Check that videos have a valid type
+ if isinstance(videos, (list, tuple)):
+ if isinstance(videos[0], (Image.Image, np.ndarray)) or is_torch_tensor(videos[0]):
+ valid_videos = True
+ elif isinstance(videos[0], (list, tuple)) and (
+ isinstance(videos[0][0], (Image.Image, np.ndarray)) or is_torch_tensor(videos[0][0])
+ ):
+ valid_videos = True
+ is_batched = True
+
+ if not valid_videos:
+ raise ValueError(
+ "Videos must of type `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]` (single"
+ " example), `List[List[PIL.Image.Image]]`, `List[List[np.ndarray]]`, `List[List[torch.Tensor]]` (batch"
+ " of examples)."
+ )
+
+ if not is_batched:
+ videos = [videos]
+
+ # transformations (resizing + center cropping + normalization)
+ if self.do_resize and self.size is not None:
+ videos = [self.resize_video(video, size=self.size, resample=self.resample) for video in videos]
+ if self.do_center_crop and self.size is not None:
+ videos = [self.crop_video(video, size=self.size) for video in videos]
+ if self.do_normalize:
+ videos = [self.normalize_video(video, mean=self.image_mean, std=self.image_std) for video in videos]
+
+ # return as BatchFeature
+ data = {"pixel_values": videos}
+ encoded_inputs = BatchFeature(data=data, tensor_type=return_tensors)
+
+ return encoded_inputs
diff --git a/src/transformers/models/videomae/modeling_videomae.py b/src/transformers/models/videomae/modeling_videomae.py
new file mode 100644
index 00000000000000..a807ed7208fccb
--- /dev/null
+++ b/src/transformers/models/videomae/modeling_videomae.py
@@ -0,0 +1,1039 @@
+# coding=utf-8
+# Copyright 2022 Multimedia Computing Group, Nanjing University and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" PyTorch VideoMAE (masked autoencoder) model."""
+
+
+import collections.abc
+import math
+from copy import deepcopy
+from dataclasses import dataclass
+from typing import Optional, Set, Tuple, Union
+
+import numpy as np
+import torch
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+
+from ...activations import ACT2FN
+from ...modeling_outputs import BaseModelOutput, ImageClassifierOutput
+from ...modeling_utils import PreTrainedModel
+from ...pytorch_utils import find_pruneable_heads_and_indices, prune_linear_layer
+from ...utils import (
+ ModelOutput,
+ add_start_docstrings,
+ add_start_docstrings_to_model_forward,
+ logging,
+ replace_return_docstrings,
+)
+from ...utils.constants import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
+from .configuration_videomae import VideoMAEConfig
+
+
+logger = logging.get_logger(__name__)
+
+_CONFIG_FOR_DOC = "VideoMAEConfig"
+_CHECKPOINT_FOR_DOC = "MCG-NJU/videomae-base"
+
+VIDEOMAE_PRETRAINED_MODEL_ARCHIVE_LIST = [
+ "MCG-NJU/videomae-base",
+ # See all VideoMAE models at https://huggingface.co/models?filter=videomae
+]
+
+
+@dataclass
+class VideoMAEDecoderOutput(ModelOutput):
+ """
+ Class for VideoMAEDecoder's outputs, with potential hidden states and attentions.
+
+ Args:
+ logits (`torch.FloatTensor` of shape `(batch_size, patch_size ** 2 * num_channels)`):
+ Pixel reconstruction logits.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
+ shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the model at the output of each layer
+ plus the initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`. Attentions weights after the attention softmax, used to compute the weighted average in
+ the self-attention heads.
+ """
+
+ logits: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[torch.FloatTensor]] = None
+
+
+@dataclass
+class VideoMAEForPreTrainingOutput(ModelOutput):
+ """
+ Class for VideoMAEForPreTraining's outputs, with potential hidden states and attentions.
+
+ Args:
+ loss (`torch.FloatTensor` of shape `(1,)`):
+ Pixel reconstruction loss.
+ logits (`torch.FloatTensor` of shape `(batch_size, patch_size ** 2 * num_channels)`):
+ Pixel reconstruction logits.
+ hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
+ shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the model at the output of each layer
+ plus the initial embedding outputs.
+ attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
+ sequence_length)`. Attentions weights after the attention softmax, used to compute the weighted average in
+ the self-attention heads.
+ """
+
+ loss: Optional[torch.FloatTensor] = None
+ logits: torch.FloatTensor = None
+ hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[torch.FloatTensor]] = None
+
+
+# sin-cos position encoding
+# https://github.com/jadore801120/attention-is-all-you-need-pytorch/blob/master/transformer/Models.py#L31
+def get_sinusoid_encoding_table(n_position, d_hid):
+ """Sinusoid position encoding table"""
+ # TODO: make it with torch instead of numpy
+ def get_position_angle_vec(position):
+ return [position / np.power(10000, 2 * (hid_j // 2) / d_hid) for hid_j in range(d_hid)]
+
+ sinusoid_table = np.array([get_position_angle_vec(pos_i) for pos_i in range(n_position)])
+ sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i
+ sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1
+
+ return torch.FloatTensor(sinusoid_table).unsqueeze(0)
+
+
+class VideoMAEEmbeddings(nn.Module):
+ """
+ Construct the patch and position embeddings.
+
+ """
+
+ def __init__(self, config):
+ super().__init__()
+
+ self.patch_embeddings = VideoMAEPatchEmbeddings(config)
+ self.num_patches = self.patch_embeddings.num_patches
+ # fixed sin-cos embedding
+ self.position_embeddings = get_sinusoid_encoding_table(self.num_patches, config.hidden_size)
+ self.config = config
+
+ def forward(self, pixel_values, bool_masked_pos):
+ # create patch embeddings
+ embeddings = self.patch_embeddings(pixel_values)
+
+ # add position embeddings
+ embeddings = embeddings + self.position_embeddings.type_as(embeddings).to(embeddings.device).clone().detach()
+
+ # only keep visible patches
+ # ~bool_masked_pos means visible
+ if bool_masked_pos is not None:
+ batch_size, _, num_channels = embeddings.shape
+ embeddings = embeddings[~bool_masked_pos]
+ embeddings = embeddings.reshape(batch_size, -1, num_channels)
+
+ return embeddings
+
+
+class VideoMAEPatchEmbeddings(nn.Module):
+ """
+ Video to Patch Embedding. This module turns a batch of videos of shape (batch_size, num_frames, num_channels,
+ height, width) into a tensor of shape (batch_size, seq_len, hidden_size) to be consumed by a Transformer encoder.
+
+ The seq_len (the number of patches) equals (number of frames // tubelet_size) * (height // patch_size) * (width //
+ patch_size).
+
+ """
+
+ def __init__(self, config):
+ super().__init__()
+
+ image_size = config.image_size
+ patch_size = config.patch_size
+ num_channels = config.num_channels
+ hidden_size = config.hidden_size
+ num_frames = config.num_frames
+ tubelet_size = config.tubelet_size
+
+ image_size = image_size if isinstance(image_size, collections.abc.Iterable) else (image_size, image_size)
+ patch_size = patch_size if isinstance(patch_size, collections.abc.Iterable) else (patch_size, patch_size)
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.tubelet_size = int(tubelet_size)
+ num_patches = (
+ (image_size[1] // patch_size[1]) * (image_size[0] // patch_size[0]) * (num_frames // self.tubelet_size)
+ )
+ self.num_channels = num_channels
+ self.num_patches = num_patches
+ self.projection = nn.Conv3d(
+ in_channels=num_channels,
+ out_channels=hidden_size,
+ kernel_size=(self.tubelet_size, patch_size[0], patch_size[1]),
+ stride=(self.tubelet_size, patch_size[0], patch_size[1]),
+ )
+
+ def forward(self, pixel_values):
+ batch_size, num_frames, num_channels, height, width = pixel_values.shape
+ if num_channels != self.num_channels:
+ raise ValueError(
+ "Make sure that the channel dimension of the pixel values match with the one set in the configuration."
+ )
+ if height != self.image_size[0] or width != self.image_size[1]:
+ raise ValueError(
+ f"Input image size ({height}*{width}) doesn't match model ({self.image_size[0]}*{self.image_size[1]})."
+ )
+ # permute to (batch_size, num_channels, num_frames, height, width)
+ pixel_values = pixel_values.permute(0, 2, 1, 3, 4)
+ embeddings = self.projection(pixel_values).flatten(2).transpose(1, 2)
+ return embeddings
+
+
+class VideoMAESelfAttention(nn.Module):
+ def __init__(self, config: VideoMAEConfig) -> None:
+ super().__init__()
+ if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
+ raise ValueError(
+ f"The hidden size {config.hidden_size,} is not a multiple of the number of attention "
+ f"heads {config.num_attention_heads}."
+ )
+
+ self.num_attention_heads = config.num_attention_heads
+ self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
+ self.all_head_size = self.num_attention_heads * self.attention_head_size
+
+ self.query = nn.Linear(config.hidden_size, self.all_head_size, bias=False)
+ self.key = nn.Linear(config.hidden_size, self.all_head_size, bias=False)
+ self.value = nn.Linear(config.hidden_size, self.all_head_size, bias=False)
+
+ if config.qkv_bias:
+ self.q_bias = nn.Parameter(torch.zeros(self.all_head_size))
+ self.v_bias = nn.Parameter(torch.zeros(self.all_head_size))
+ else:
+ self.q_bias = None
+ self.v_bias = None
+
+ self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
+
+ def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
+ new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
+ x = x.view(new_x_shape)
+ return x.permute(0, 2, 1, 3)
+
+ def forward(
+ self, hidden_states, head_mask: Optional[torch.Tensor] = None, output_attentions: bool = False
+ ) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+
+ k_bias = torch.zeros_like(self.v_bias, requires_grad=False) if self.q_bias is not None else None
+ keys = nn.functional.linear(input=hidden_states, weight=self.key.weight, bias=k_bias)
+ values = nn.functional.linear(input=hidden_states, weight=self.value.weight, bias=self.v_bias)
+ queries = nn.functional.linear(input=hidden_states, weight=self.query.weight, bias=self.q_bias)
+
+ key_layer = self.transpose_for_scores(keys)
+ value_layer = self.transpose_for_scores(values)
+ query_layer = self.transpose_for_scores(queries)
+
+ # Take the dot product between "query" and "key" to get the raw attention scores.
+ attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
+
+ attention_scores = attention_scores / math.sqrt(self.attention_head_size)
+
+ # Normalize the attention scores to probabilities.
+ attention_probs = nn.functional.softmax(attention_scores, dim=-1)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs = self.dropout(attention_probs)
+
+ # Mask heads if we want to
+ if head_mask is not None:
+ attention_probs = attention_probs * head_mask
+
+ context_layer = torch.matmul(attention_probs, value_layer)
+
+ context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
+ new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
+ context_layer = context_layer.view(new_context_layer_shape)
+
+ outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
+
+ return outputs
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTSelfOutput with ViT->VideoMAE
+class VideoMAESelfOutput(nn.Module):
+ """
+ The residual connection is defined in VideoMAELayer instead of here (as is the case with other models), due to the
+ layernorm applied before each block.
+ """
+
+ def __init__(self, config: VideoMAEConfig) -> None:
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+
+ return hidden_states
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTAttention with ViT->VideoMAE
+class VideoMAEAttention(nn.Module):
+ def __init__(self, config: VideoMAEConfig) -> None:
+ super().__init__()
+ self.attention = VideoMAESelfAttention(config)
+ self.output = VideoMAESelfOutput(config)
+ self.pruned_heads = set()
+
+ def prune_heads(self, heads: Set[int]) -> None:
+ if len(heads) == 0:
+ return
+ heads, index = find_pruneable_heads_and_indices(
+ heads, self.attention.num_attention_heads, self.attention.attention_head_size, self.pruned_heads
+ )
+
+ # Prune linear layers
+ self.attention.query = prune_linear_layer(self.attention.query, index)
+ self.attention.key = prune_linear_layer(self.attention.key, index)
+ self.attention.value = prune_linear_layer(self.attention.value, index)
+ self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
+
+ # Update hyper params and store pruned heads
+ self.attention.num_attention_heads = self.attention.num_attention_heads - len(heads)
+ self.attention.all_head_size = self.attention.attention_head_size * self.attention.num_attention_heads
+ self.pruned_heads = self.pruned_heads.union(heads)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ self_outputs = self.attention(hidden_states, head_mask, output_attentions)
+
+ attention_output = self.output(self_outputs[0], hidden_states)
+
+ outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
+ return outputs
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTIntermediate ViT->VideoMAE
+class VideoMAEIntermediate(nn.Module):
+ def __init__(self, config: VideoMAEConfig) -> None:
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
+ if isinstance(config.hidden_act, str):
+ self.intermediate_act_fn = ACT2FN[config.hidden_act]
+ else:
+ self.intermediate_act_fn = config.hidden_act
+
+ def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
+
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.intermediate_act_fn(hidden_states)
+
+ return hidden_states
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTOutput ViT->VideoMAE
+class VideoMAEOutput(nn.Module):
+ def __init__(self, config: VideoMAEConfig) -> None:
+ super().__init__()
+ self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+
+ hidden_states = hidden_states + input_tensor
+
+ return hidden_states
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTLayer with ViT->VideoMAE
+class VideoMAELayer(nn.Module):
+ """This corresponds to the Block class in the timm implementation."""
+
+ def __init__(self, config: VideoMAEConfig) -> None:
+ super().__init__()
+ self.chunk_size_feed_forward = config.chunk_size_feed_forward
+ self.seq_len_dim = 1
+ self.attention = VideoMAEAttention(config)
+ self.intermediate = VideoMAEIntermediate(config)
+ self.output = VideoMAEOutput(config)
+ self.layernorm_before = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.layernorm_after = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ self_attention_outputs = self.attention(
+ self.layernorm_before(hidden_states), # in VideoMAE, layernorm is applied before self-attention
+ head_mask,
+ output_attentions=output_attentions,
+ )
+ attention_output = self_attention_outputs[0]
+ outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
+
+ # first residual connection
+ hidden_states = attention_output + hidden_states
+
+ # in VideoMAE, layernorm is also applied after self-attention
+ layer_output = self.layernorm_after(hidden_states)
+ layer_output = self.intermediate(layer_output)
+
+ # second residual connection is done here
+ layer_output = self.output(layer_output, hidden_states)
+
+ outputs = (layer_output,) + outputs
+
+ return outputs
+
+
+# Copied from transformers.models.vit.modeling_vit.ViTEncoder with ViT->VideoMAE
+class VideoMAEEncoder(nn.Module):
+ def __init__(self, config: VideoMAEConfig) -> None:
+ super().__init__()
+ self.config = config
+ self.layer = nn.ModuleList([VideoMAELayer(config) for _ in range(config.num_hidden_layers)])
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ output_hidden_states: bool = False,
+ return_dict: bool = True,
+ ) -> Union[tuple, BaseModelOutput]:
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attentions = () if output_attentions else None
+
+ for i, layer_module in enumerate(self.layer):
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ layer_head_mask = head_mask[i] if head_mask is not None else None
+
+ if self.gradient_checkpointing and self.training:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs, output_attentions)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(layer_module),
+ hidden_states,
+ layer_head_mask,
+ )
+ else:
+ layer_outputs = layer_module(hidden_states, layer_head_mask, output_attentions)
+
+ hidden_states = layer_outputs[0]
+
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (layer_outputs[1],)
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(v for v in [hidden_states, all_hidden_states, all_self_attentions] if v is not None)
+ return BaseModelOutput(
+ last_hidden_state=hidden_states,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ )
+
+
+class VideoMAEPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = VideoMAEConfig
+ base_model_prefix = "videomae"
+ main_input_name = "pixel_values"
+ supports_gradient_checkpointing = True
+
+ def _init_weights(self, module):
+ """Initialize the weights"""
+ if isinstance(module, (nn.Linear, nn.Conv3d)):
+ # Slightly different from the TF version which uses truncated_normal for initialization
+ # cf https://github.com/pytorch/pytorch/pull/5617
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, VideoMAEEncoder):
+ module.gradient_checkpointing = value
+
+
+VIDEOMAE_START_DOCSTRING = r"""
+ This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it
+ as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
+ behavior.
+
+ Parameters:
+ config ([`VideoMAEConfig`]): Model configuration class with all the parameters of the model.
+ Initializing with a config file does not load the weights associated with the model, only the
+ configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+VIDEOMAE_INPUTS_DOCSTRING = r"""
+ Args:
+ pixel_values (`torch.FloatTensor` of shape `(batch_size, num_frames, num_channels, height, width)`):
+ Pixel values. Pixel values can be obtained using [`VideoMAEFeatureExtractor`]. See
+ [`VideoMAEFeatureExtractor.__call__`] for details.
+
+ head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
+ Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ "The bare VideoMAE Model transformer outputting raw hidden-states without any specific head on top.",
+ VIDEOMAE_START_DOCSTRING,
+)
+class VideoMAEModel(VideoMAEPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.config = config
+
+ self.embeddings = VideoMAEEmbeddings(config)
+ self.encoder = VideoMAEEncoder(config)
+
+ if config.use_mean_pooling:
+ self.layernorm = None
+ else:
+ self.layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embeddings.patch_embeddings
+
+ def _prune_heads(self, heads_to_prune):
+ """
+ Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
+ class PreTrainedModel
+ """
+ for layer, heads in heads_to_prune.items():
+ self.encoder.layer[layer].attention.prune_heads(heads)
+
+ @add_start_docstrings_to_model_forward(VIDEOMAE_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=BaseModelOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ pixel_values,
+ bool_masked_pos=None,
+ head_mask=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ ):
+ r"""
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from decord import VideoReader, cpu
+ >>> import numpy as np
+
+ >>> from transformers import VideoMAEFeatureExtractor, VideoMAEModel
+ >>> from huggingface_hub import hf_hub_download
+
+
+ >>> def sample_frame_indices(clip_len, frame_sample_rate, seg_len):
+ ... converted_len = int(clip_len * frame_sample_rate)
+ ... end_idx = np.random.randint(converted_len, seg_len)
+ ... start_idx = end_idx - converted_len
+ ... indices = np.linspace(start_idx, end_idx, num=clip_len)
+ ... indices = np.clip(indices, start_idx, end_idx - 1).astype(np.int64)
+ ... return indices
+
+
+ >>> # video clip consists of 300 frames (10 seconds at 30 FPS)
+ >>> file_path = hf_hub_download(
+ ... repo_id="nielsr/video-demo", filename="eating_spaghetti.mp4", repo_type="dataset"
+ ... )
+ >>> vr = VideoReader(file_path, num_threads=1, ctx=cpu(0))
+
+ >>> # sample 16 frames
+ >>> vr.seek(0)
+ >>> indices = sample_frame_indices(clip_len=16, frame_sample_rate=4, seg_len=len(vr))
+ >>> buffer = vr.get_batch(indices).asnumpy()
+
+ >>> # create a list of NumPy arrays
+ >>> video = [buffer[i] for i in range(buffer.shape[0])]
+
+ >>> feature_extractor = VideoMAEFeatureExtractor.from_pretrained("MCG-NJU/videomae-base")
+ >>> model = VideoMAEModel.from_pretrained("MCG-NJU/videomae-base")
+
+ >>> # prepare video for the model
+ >>> inputs = feature_extractor(video, return_tensors="pt")
+
+ >>> # forward pass
+ >>> outputs = model(**inputs)
+ >>> last_hidden_states = outputs.last_hidden_state
+ >>> list(last_hidden_states.shape)
+ [1, 1568, 768]
+ ```"""
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape bsz x n_heads x N x N
+ # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
+ # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
+ head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
+
+ embedding_output = self.embeddings(pixel_values, bool_masked_pos)
+
+ encoder_outputs = self.encoder(
+ embedding_output,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+ sequence_output = encoder_outputs[0]
+ if self.layernorm is not None:
+ sequence_output = self.layernorm(sequence_output)
+
+ if not return_dict:
+ return (sequence_output,) + encoder_outputs[1:]
+
+ return BaseModelOutput(
+ last_hidden_state=sequence_output,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ )
+
+
+class VideoMAEDecoder(nn.Module):
+ def __init__(self, config, num_patches):
+ super().__init__()
+
+ decoder_num_labels = config.num_channels * config.tubelet_size * config.patch_size**2
+
+ decoder_config = deepcopy(config)
+ decoder_config.hidden_size = config.decoder_hidden_size
+ decoder_config.num_hidden_layers = config.decoder_num_hidden_layers
+ decoder_config.num_attention_heads = config.decoder_num_attention_heads
+ decoder_config.intermediate_size = config.decoder_intermediate_size
+ self.decoder_layers = nn.ModuleList(
+ [VideoMAELayer(decoder_config) for _ in range(config.decoder_num_hidden_layers)]
+ )
+
+ self.norm = nn.LayerNorm(config.decoder_hidden_size)
+ self.head = (
+ nn.Linear(config.decoder_hidden_size, decoder_num_labels) if decoder_num_labels > 0 else nn.Identity()
+ )
+
+ self.gradient_checkpointing = False
+ self.config = config
+
+ def forward(
+ self,
+ hidden_states,
+ return_token_num,
+ output_attentions=False,
+ output_hidden_states=False,
+ return_dict=True,
+ ):
+ # apply Transformer layers (blocks)
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attentions = () if output_attentions else None
+ for i, layer_module in enumerate(self.decoder_layers):
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if self.gradient_checkpointing and self.training:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs, output_attentions)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(layer_module),
+ hidden_states,
+ None,
+ )
+ else:
+ layer_outputs = layer_module(hidden_states, head_mask=None, output_attentions=output_attentions)
+
+ hidden_states = layer_outputs[0]
+
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (layer_outputs[1],)
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if return_token_num > 0:
+ hidden_states = hidden_states[:, -return_token_num:]
+
+ # predictor projection
+ hidden_states = self.norm(hidden_states)
+ logits = self.head(hidden_states)
+
+ if not return_dict:
+ return tuple(v for v in [logits, all_hidden_states, all_self_attentions] if v is not None)
+ return VideoMAEDecoderOutput(logits=logits, hidden_states=all_hidden_states, attentions=all_self_attentions)
+
+
+@add_start_docstrings(
+ "The VideoMAE Model transformer with the decoder on top for self-supervised pre-training.",
+ VIDEOMAE_START_DOCSTRING,
+)
+class VideoMAEForPreTraining(VideoMAEPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.config = config
+
+ self.videomae = VideoMAEModel(config)
+
+ self.encoder_to_decoder = nn.Linear(config.hidden_size, config.decoder_hidden_size, bias=False)
+ self.mask_token = nn.Parameter(torch.zeros(1, 1, config.decoder_hidden_size))
+ self.position_embeddings = get_sinusoid_encoding_table(
+ self.videomae.embeddings.num_patches, config.decoder_hidden_size
+ )
+
+ self.decoder = VideoMAEDecoder(config, num_patches=self.videomae.embeddings.num_patches)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(VIDEOMAE_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=VideoMAEForPreTrainingOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ pixel_values,
+ bool_masked_pos,
+ head_mask=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ ):
+ r"""
+ Returns:
+
+ Examples:
+ ```python
+ >>> from transformers import VideoMAEFeatureExtractor, VideoMAEForPreTraining
+ >>> import numpy as np
+ >>> import torch
+
+ >>> num_frames = 16
+ >>> video = list(np.random.randn(16, 3, 224, 224))
+
+ >>> feature_extractor = VideoMAEFeatureExtractor.from_pretrained("MCG-NJU/videomae-base")
+ >>> model = VideoMAEForPreTraining.from_pretrained("MCG-NJU/videomae-base")
+
+ >>> pixel_values = feature_extractor(video, return_tensors="pt").pixel_values
+
+ >>> num_patches_per_frame = (model.config.image_size // model.config.patch_size) ** 2
+ >>> seq_length = (num_frames // model.config.tubelet_size) * num_patches_per_frame
+ >>> bool_masked_pos = torch.randint(0, 2, (1, seq_length)).bool()
+
+ >>> outputs = model(pixel_values, bool_masked_pos=bool_masked_pos)
+ >>> loss = outputs.loss
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.videomae(
+ pixel_values,
+ bool_masked_pos=bool_masked_pos,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ sequence_output = outputs[0]
+ sequence_output = self.encoder_to_decoder(
+ sequence_output
+ ) # [batch_size, num_visible_patches, decoder_hidden_size]
+ batch_size, seq_len, num_channels = sequence_output.shape
+
+ # we don't unshuffle the correct visible token order, but shuffle the position embeddings accordingly.
+ if bool_masked_pos is None:
+ raise ValueError("One must provided a boolean mask ")
+ expanded_position_embeddings = self.position_embeddings.expand(batch_size, -1, -1).type_as(pixel_values)
+ expanded_position_embeddings = expanded_position_embeddings.to(pixel_values.device).clone().detach()
+ pos_emb_visible = expanded_position_embeddings[~bool_masked_pos].reshape(batch_size, -1, num_channels)
+ pos_emb_mask = expanded_position_embeddings[bool_masked_pos].reshape(batch_size, -1, num_channels)
+
+ # [batch_size, num_patches, decoder_hidden_size]
+ x_full = torch.cat([sequence_output + pos_emb_visible, self.mask_token + pos_emb_mask], dim=1)
+
+ # [batch_size, num_masked_patches, num_channels * patch_size * patch_size]
+ decoder_outputs = self.decoder(x_full, pos_emb_mask.shape[1])
+ logits = decoder_outputs.logits
+
+ loss = None
+ with torch.no_grad():
+ # calculate the labels to be predicted
+ # first, unnormalize the frames
+ device = pixel_values.device
+ mean = torch.as_tensor(IMAGENET_DEFAULT_MEAN).to(device)[None, None, :, None, None]
+ std = torch.as_tensor(IMAGENET_DEFAULT_STD).to(device)[None, None, :, None, None]
+ frames = pixel_values * std + mean # in [0, 1]
+
+ batch_size, time, num_channels, height, width = frames.shape
+ tubelet_size, patch_size = self.config.tubelet_size, self.config.patch_size
+ if self.config.norm_pix_loss:
+ # step 1: split up dimensions (time by tubelet_size, height by patch_size, width by patch_size)
+ frames = frames.view(
+ batch_size,
+ time // tubelet_size,
+ tubelet_size,
+ num_channels,
+ height // patch_size,
+ patch_size,
+ width // patch_size,
+ patch_size,
+ )
+ # step 2: move dimensions to concatenate:
+ frames = frames.permute(0, 1, 4, 6, 2, 5, 7, 3).contiguous()
+ # step 3: concatenate:
+ frames = frames.view(
+ batch_size,
+ time // tubelet_size * height // patch_size * width // patch_size,
+ tubelet_size * patch_size * patch_size,
+ num_channels,
+ )
+ # step 4: normalize. The authors find that the mean is about 0.48 and standard deviation is about 0.08.
+ frames_norm = (frames - frames.mean(dim=-2, keepdim=True)) / (
+ frames.var(dim=-2, unbiased=True, keepdim=True).sqrt() + 1e-6
+ )
+ # step 5: reshape to (batch_size, T//ts * H//ps * W//ps, ts * ps * ps * C)
+ videos_patch = frames_norm.view(
+ batch_size,
+ time // tubelet_size * height // patch_size * width // patch_size,
+ tubelet_size * patch_size * patch_size * num_channels,
+ )
+ else:
+ # step 1: split up dimensions (time by tubelet_size, height by patch_size, width by patch_size)
+ frames = frames.view(
+ batch_size,
+ time // tubelet_size,
+ tubelet_size,
+ num_channels,
+ height // patch_size,
+ patch_size,
+ width // patch_size,
+ patch_size,
+ )
+ # step 2: move dimensions to concatenate: (batch_size, T//ts, H//ps, W//ps, ts, ps, ps, C)
+ frames = frames.permute(0, 1, 4, 6, 2, 5, 7, 3).contiguous()
+ # step 3: concatenate
+ videos_patch = frames.view(
+ batch_size,
+ time // tubelet_size * height // patch_size * width // patch_size,
+ tubelet_size * patch_size * patch_size * num_channels,
+ )
+
+ batch_size, _, num_channels = videos_patch.shape
+ labels = videos_patch[bool_masked_pos].reshape(batch_size, -1, num_channels)
+
+ loss_fct = MSELoss()
+ loss = loss_fct(logits, labels)
+
+ if not return_dict:
+ output = (logits,) + outputs[1:]
+ return ((loss,) + output) if loss is not None else output
+
+ return VideoMAEForPreTrainingOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+
+@add_start_docstrings(
+ """VideoMAE Model transformer with a video classification head on top (a linear layer on top of the final hidden state of
+ the [CLS] token) e.g. for ImageNet.""",
+ VIDEOMAE_START_DOCSTRING,
+)
+class VideoMAEForVideoClassification(VideoMAEPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+
+ self.num_labels = config.num_labels
+ self.videomae = VideoMAEModel(config)
+
+ # Classifier head
+ self.fc_norm = nn.LayerNorm(config.hidden_size) if config.use_mean_pooling else None
+ self.classifier = nn.Linear(config.hidden_size, config.num_labels) if config.num_labels > 0 else nn.Identity()
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ @add_start_docstrings_to_model_forward(VIDEOMAE_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=ImageClassifierOutput, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ pixel_values: Optional[torch.Tensor] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ labels: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ):
+ r"""
+ labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
+ Labels for computing the image classification/regression loss. Indices should be in `[0, ...,
+ config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
+ `config.num_labels > 1` a classification loss is computed (Cross-Entropy).
+
+ Returns:
+
+ Examples:
+
+ ```python
+ >>> from decord import VideoReader, cpu
+ >>> import torch
+
+ >>> from transformers import VideoMAEFeatureExtractor, VideoMAEForVideoClassification
+ >>> from huggingface_hub import hf_hub_download
+
+
+ >>> def sample_frame_indices(clip_len, frame_sample_rate, seg_len):
+ ... converted_len = int(clip_len * frame_sample_rate)
+ ... end_idx = np.random.randint(converted_len, seg_len)
+ ... start_idx = end_idx - converted_len
+ ... indices = np.linspace(start_idx, end_idx, num=clip_len)
+ ... indices = np.clip(indices, start_idx, end_idx - 1).astype(np.int64)
+ ... return indices
+
+
+ >>> # video clip consists of 300 frames (10 seconds at 30 FPS)
+ >>> file_path = hf_hub_download(
+ ... repo_id="nielsr/video-demo", filename="eating_spaghetti.mp4", repo_type="dataset"
+ ... )
+ >>> vr = VideoReader(file_path, num_threads=1, ctx=cpu(0))
+
+ >>> # sample 16 frames
+ >>> vr.seek(0)
+ >>> indices = sample_frame_indices(clip_len=16, frame_sample_rate=4, seg_len=len(vr))
+ >>> buffer = vr.get_batch(indices).asnumpy()
+
+ >>> # create a list of NumPy arrays
+ >>> video = [buffer[i] for i in range(buffer.shape[0])]
+
+ >>> feature_extractor = VideoMAEFeatureExtractor.from_pretrained("MCG-NJU/videomae-base-finetuned-kinetics")
+ >>> model = VideoMAEForVideoClassification.from_pretrained("MCG-NJU/videomae-base-finetuned-kinetics")
+
+ >>> inputs = feature_extractor(video, return_tensors="pt")
+
+ >>> with torch.no_grad():
+ ... outputs = model(**inputs)
+ ... logits = outputs.logits
+
+ >>> # model predicts one of the 400 Kinetics-400 classes
+ >>> predicted_label = logits.argmax(-1).item()
+ >>> print(model.config.id2label[predicted_label])
+ eating spaghetti
+ ```"""
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ outputs = self.videomae(
+ pixel_values,
+ head_mask=head_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ sequence_output = outputs[0]
+
+ if self.fc_norm is not None:
+ sequence_output = self.fc_norm(sequence_output.mean(1))
+ else:
+ sequence_output = sequence_output[:, 0]
+
+ logits = self.classifier(sequence_output)
+
+ loss = None
+ if labels is not None:
+ if self.config.problem_type is None:
+ if self.num_labels == 1:
+ self.config.problem_type = "regression"
+ elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
+ self.config.problem_type = "single_label_classification"
+ else:
+ self.config.problem_type = "multi_label_classification"
+
+ if self.config.problem_type == "regression":
+ loss_fct = MSELoss()
+ if self.num_labels == 1:
+ loss = loss_fct(logits.squeeze(), labels.squeeze())
+ else:
+ loss = loss_fct(logits, labels)
+ elif self.config.problem_type == "single_label_classification":
+ loss_fct = CrossEntropyLoss()
+ loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
+ elif self.config.problem_type == "multi_label_classification":
+ loss_fct = BCEWithLogitsLoss()
+ loss = loss_fct(logits, labels)
+
+ if not return_dict:
+ output = (logits,) + outputs[1:]
+ return ((loss,) + output) if loss is not None else output
+
+ return ImageClassifierOutput(
+ loss=loss,
+ logits=logits,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
diff --git a/src/transformers/utils/__init__.py b/src/transformers/utils/__init__.py
index 2334c351cc5120..377932e2d490e7 100644
--- a/src/transformers/utils/__init__.py
+++ b/src/transformers/utils/__init__.py
@@ -22,6 +22,7 @@
from packaging import version
from .. import __version__
+from .constants import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD, IMAGENET_STANDARD_MEAN, IMAGENET_STANDARD_STD
from .doc import (
add_code_sample_docstrings,
add_end_docstrings,
diff --git a/src/transformers/utils/constants.py b/src/transformers/utils/constants.py
new file mode 100644
index 00000000000000..af2e48ab0a8be3
--- /dev/null
+++ b/src/transformers/utils/constants.py
@@ -0,0 +1,4 @@
+IMAGENET_DEFAULT_MEAN = [0.485, 0.456, 0.406]
+IMAGENET_DEFAULT_STD = [0.229, 0.224, 0.225]
+IMAGENET_STANDARD_MEAN = [0.5, 0.5, 0.5]
+IMAGENET_STANDARD_STD = [0.5, 0.5, 0.5]
diff --git a/src/transformers/utils/dummy_pt_objects.py b/src/transformers/utils/dummy_pt_objects.py
index c1dfc6b6b7ca64..d636be655af284 100644
--- a/src/transformers/utils/dummy_pt_objects.py
+++ b/src/transformers/utils/dummy_pt_objects.py
@@ -406,6 +406,9 @@ def load_tf_weights_in_albert(*args, **kwargs):
MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING = None
+MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING = None
+
+
MODEL_FOR_VISION_2_SEQ_MAPPING = None
@@ -572,6 +575,13 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
+class AutoModelForVideoClassification(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
class AutoModelForVision2Seq(metaclass=DummyObject):
_backends = ["torch"]
@@ -4753,6 +4763,37 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
+VIDEOMAE_PRETRAINED_MODEL_ARCHIVE_LIST = None
+
+
+class VideoMAEForPreTraining(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class VideoMAEForVideoClassification(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class VideoMAEModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
+class VideoMAEPreTrainedModel(metaclass=DummyObject):
+ _backends = ["torch"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["torch"])
+
+
VILT_PRETRAINED_MODEL_ARCHIVE_LIST = None
diff --git a/src/transformers/utils/dummy_vision_objects.py b/src/transformers/utils/dummy_vision_objects.py
index e5d2bced9e0415..30228e022222bf 100644
--- a/src/transformers/utils/dummy_vision_objects.py
+++ b/src/transformers/utils/dummy_vision_objects.py
@@ -150,6 +150,13 @@ def __init__(self, *args, **kwargs):
requires_backends(self, ["vision"])
+class VideoMAEFeatureExtractor(metaclass=DummyObject):
+ _backends = ["vision"]
+
+ def __init__(self, *args, **kwargs):
+ requires_backends(self, ["vision"])
+
+
class ViltFeatureExtractor(metaclass=DummyObject):
_backends = ["vision"]
diff --git a/tests/models/videomae/__init__.py b/tests/models/videomae/__init__.py
new file mode 100644
index 00000000000000..e69de29bb2d1d6
diff --git a/tests/models/videomae/test_feature_extraction_videomae.py b/tests/models/videomae/test_feature_extraction_videomae.py
new file mode 100644
index 00000000000000..cfe00f51e5e529
--- /dev/null
+++ b/tests/models/videomae/test_feature_extraction_videomae.py
@@ -0,0 +1,202 @@
+# coding=utf-8
+# Copyright 2022 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+import numpy as np
+
+from transformers.testing_utils import require_torch, require_vision
+from transformers.utils import is_torch_available, is_vision_available
+
+from ...test_feature_extraction_common import FeatureExtractionSavingTestMixin, prepare_video_inputs
+
+
+if is_torch_available():
+ import torch
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import VideoMAEFeatureExtractor
+
+
+class VideoMAEFeatureExtractionTester(unittest.TestCase):
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ num_frames=10,
+ image_size=18,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size=18,
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.num_frames = num_frames
+ self.image_size = image_size
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+
+ def prepare_feat_extract_dict(self):
+ return {
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ "do_normalize": self.do_normalize,
+ "do_resize": self.do_resize,
+ "size": self.size,
+ }
+
+
+@require_torch
+@require_vision
+class VideoMAEFeatureExtractionTest(FeatureExtractionSavingTestMixin, unittest.TestCase):
+
+ feature_extraction_class = VideoMAEFeatureExtractor if is_vision_available() else None
+
+ def setUp(self):
+ self.feature_extract_tester = VideoMAEFeatureExtractionTester(self)
+
+ @property
+ def feat_extract_dict(self):
+ return self.feature_extract_tester.prepare_feat_extract_dict()
+
+ def test_feat_extract_properties(self):
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ self.assertTrue(hasattr(feature_extractor, "image_mean"))
+ self.assertTrue(hasattr(feature_extractor, "image_std"))
+ self.assertTrue(hasattr(feature_extractor, "do_normalize"))
+ self.assertTrue(hasattr(feature_extractor, "do_resize"))
+ self.assertTrue(hasattr(feature_extractor, "size"))
+
+ def test_batch_feature(self):
+ pass
+
+ def test_call_pil(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random PIL videos
+ video_inputs = prepare_video_inputs(self.feature_extract_tester, equal_resolution=False)
+ for video in video_inputs:
+ self.assertIsInstance(video, list)
+ self.assertIsInstance(video[0], Image.Image)
+
+ # Test not batched input
+ encoded_videos = feature_extractor(video_inputs[0], return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_videos.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_frames,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ # Test batched
+ encoded_videos = feature_extractor(video_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_videos.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_frames,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ def test_call_numpy(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random numpy tensors
+ video_inputs = prepare_video_inputs(self.feature_extract_tester, equal_resolution=False, numpify=True)
+ for video in video_inputs:
+ self.assertIsInstance(video, list)
+ self.assertIsInstance(video[0], np.ndarray)
+
+ # Test not batched input
+ encoded_videos = feature_extractor(video_inputs[0], return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_videos.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_frames,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ # Test batched
+ encoded_videos = feature_extractor(video_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_videos.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_frames,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ def test_call_pytorch(self):
+ # Initialize feature_extractor
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_dict)
+ # create random PyTorch tensors
+ video_inputs = prepare_video_inputs(self.feature_extract_tester, equal_resolution=False, torchify=True)
+ for video in video_inputs:
+ self.assertIsInstance(video, list)
+ self.assertIsInstance(video[0], torch.Tensor)
+
+ # Test not batched input
+ encoded_videos = feature_extractor(video_inputs[0], return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_videos.shape,
+ (
+ 1,
+ self.feature_extract_tester.num_frames,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
+
+ # Test batched
+ encoded_videos = feature_extractor(video_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ encoded_videos.shape,
+ (
+ self.feature_extract_tester.batch_size,
+ self.feature_extract_tester.num_frames,
+ self.feature_extract_tester.num_channels,
+ self.feature_extract_tester.size,
+ self.feature_extract_tester.size,
+ ),
+ )
diff --git a/tests/models/videomae/test_modeling_videomae.py b/tests/models/videomae/test_modeling_videomae.py
new file mode 100644
index 00000000000000..adce62021c9ded
--- /dev/null
+++ b/tests/models/videomae/test_modeling_videomae.py
@@ -0,0 +1,421 @@
+# coding=utf-8
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the PyTorch VideoMAE model. """
+
+
+import copy
+import inspect
+import unittest
+
+import numpy as np
+
+from huggingface_hub import hf_hub_download
+from transformers import VideoMAEConfig
+from transformers.models.auto import get_values
+from transformers.testing_utils import require_torch, require_vision, slow, torch_device
+from transformers.utils import cached_property, is_torch_available, is_vision_available
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import (
+ MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING,
+ VideoMAEForPreTraining,
+ VideoMAEForVideoClassification,
+ VideoMAEModel,
+ )
+ from transformers.models.videomae.modeling_videomae import VIDEOMAE_PRETRAINED_MODEL_ARCHIVE_LIST
+
+
+if is_vision_available():
+ from transformers import VideoMAEFeatureExtractor
+
+
+class VideoMAEModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ image_size=10,
+ num_channels=3,
+ patch_size=2,
+ tubelet_size=2,
+ num_frames=2,
+ is_training=True,
+ use_labels=True,
+ hidden_size=32,
+ num_hidden_layers=5,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ type_sequence_label_size=10,
+ initializer_range=0.02,
+ mask_ratio=0.9,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.num_channels = num_channels
+ self.patch_size = patch_size
+ self.tubelet_size = tubelet_size
+ self.num_frames = num_frames
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.mask_ratio = mask_ratio
+ self.scope = scope
+
+ # in VideoMAE, the number of tokens equals num_frames/tubelet_size * num_patches per frame
+ self.num_patches_per_frame = (image_size // patch_size) ** 2
+ self.seq_length = (num_frames // tubelet_size) * self.num_patches_per_frame
+
+ # use this variable to define bool_masked_pos
+ self.num_masks = int(mask_ratio * self.seq_length)
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor(
+ [self.batch_size, self.num_frames, self.num_channels, self.image_size, self.image_size]
+ )
+
+ labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+
+ config = self.get_config()
+
+ return config, pixel_values, labels
+
+ def get_config(self):
+ return VideoMAEConfig(
+ image_size=self.image_size,
+ patch_size=self.patch_size,
+ num_channels=self.num_channels,
+ num_frames=self.num_frames,
+ tubelet_size=self.tubelet_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ )
+
+ def create_and_check_model(self, config, pixel_values, labels):
+ model = VideoMAEModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def create_and_check_for_pretraining(self, config, pixel_values, labels):
+ model = VideoMAEForPreTraining(config)
+ model.to(torch_device)
+ model.eval()
+ # important: each video needs to have the same number of masked patches
+ # hence we define a single mask, which we then repeat for each example in the batch
+ mask = torch.ones((self.num_masks,))
+ mask = torch.cat([mask, torch.zeros(self.seq_length - mask.size(0))])
+ bool_masked_pos = mask.expand(self.batch_size, -1).bool()
+
+ result = model(pixel_values, bool_masked_pos)
+ # model only returns predictions for masked patches
+ num_masked_patches = mask.sum().item()
+ decoder_num_labels = 3 * self.tubelet_size * self.patch_size**2
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, num_masked_patches, decoder_num_labels))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values, labels = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class VideoMAEModelTest(ModelTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as VideoMAE does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (
+ (VideoMAEModel, VideoMAEForPreTraining, VideoMAEForVideoClassification) if is_torch_available() else ()
+ )
+
+ test_pruning = False
+ test_torchscript = False
+ test_resize_embeddings = False
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = VideoMAEModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=VideoMAEConfig, has_text_modality=False, hidden_size=37)
+
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ inputs_dict = copy.deepcopy(inputs_dict)
+
+ if model_class == VideoMAEForPreTraining:
+ # important: each video needs to have the same number of masked patches
+ # hence we define a single mask, which we then repeat for each example in the batch
+ mask = torch.ones((self.model_tester.num_masks,))
+ mask = torch.cat([mask, torch.zeros(self.model_tester.seq_length - mask.size(0))])
+ bool_masked_pos = mask.expand(self.model_tester.batch_size, -1).bool()
+ inputs_dict["bool_masked_pos"] = bool_masked_pos.to(torch_device)
+
+ if return_labels:
+ if model_class in [
+ *get_values(MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING),
+ ]:
+ inputs_dict["labels"] = torch.zeros(
+ self.model_tester.batch_size, dtype=torch.long, device=torch_device
+ )
+
+ return inputs_dict
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="VideoMAE does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ def test_model_common_attributes(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_for_pretraining(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_pretraining(*config_and_inputs)
+
+ @slow
+ def test_model_from_pretrained(self):
+ for model_name in VIDEOMAE_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
+ model = VideoMAEModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+ def test_attention_outputs(self):
+ if not self.has_attentions:
+ pass
+
+ else:
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ for model_class in self.all_model_classes:
+ num_visible_patches = self.model_tester.seq_length - self.model_tester.num_masks
+ seq_len = (
+ num_visible_patches if model_class == VideoMAEForPreTraining else self.model_tester.seq_length
+ )
+
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = False
+ config.return_dict = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.attentions
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ # check that output_attentions also work using config
+ del inputs_dict["output_attentions"]
+ config.output_attentions = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.attentions
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ self.assertListEqual(
+ list(attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, seq_len, seq_len],
+ )
+ out_len = len(outputs)
+
+ # Check attention is always last and order is fine
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ self.assertEqual(out_len + 1, len(outputs))
+
+ self_attentions = outputs.attentions
+
+ self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(self_attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, seq_len, seq_len],
+ )
+
+ def test_hidden_states_output(self):
+ def check_hidden_states_output(inputs_dict, config, model_class):
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ hidden_states = outputs.hidden_states
+ expected_num_layers = self.model_tester.num_hidden_layers + 1
+ self.assertEqual(len(hidden_states), expected_num_layers)
+
+ num_visible_patches = self.model_tester.seq_length - self.model_tester.num_masks
+ seq_length = num_visible_patches if model_class == VideoMAEForPreTraining else self.model_tester.seq_length
+
+ self.assertListEqual(
+ list(hidden_states[0].shape[-2:]),
+ [seq_length, self.model_tester.hidden_size],
+ )
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_hidden_states"] = True
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ # check that output_hidden_states also work using config
+ del inputs_dict["output_hidden_states"]
+ config.output_hidden_states = True
+
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+
+# We will verify our results on a video of eating spaghetti
+# Frame indices used: [164 168 172 176 181 185 189 193 198 202 206 210 215 219 223 227]
+def prepare_video():
+ file = hf_hub_download(repo_id="datasets/hf-internal-testing/spaghetti-video", filename="eating_spaghetti.npy")
+ video = np.load(file)
+ return list(video)
+
+
+@require_torch
+@require_vision
+class VideoMAEModelIntegrationTest(unittest.TestCase):
+ @cached_property
+ def default_feature_extractor(self):
+ # logits were tested with a different mean and std, so we use the same here
+ return (
+ VideoMAEFeatureExtractor(image_mean=[0.5, 0.5, 0.5], image_std=[0.5, 0.5, 0.5])
+ if is_vision_available()
+ else None
+ )
+
+ @slow
+ def test_inference_for_video_classification(self):
+ model = VideoMAEForVideoClassification.from_pretrained("MCG-NJU/videomae-base-finetuned-kinetics").to(
+ torch_device
+ )
+
+ feature_extractor = self.default_feature_extractor
+ video = prepare_video()
+ inputs = feature_extractor(video, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the logits
+ expected_shape = torch.Size((1, 400))
+ self.assertEqual(outputs.logits.shape, expected_shape)
+
+ expected_slice = torch.tensor([0.3669, -0.0688, -0.2421]).to(torch_device)
+
+ self.assertTrue(torch.allclose(outputs.logits[0, :3], expected_slice, atol=1e-4))
+
+ @slow
+ def test_inference_for_pretraining(self):
+ model = VideoMAEForPreTraining.from_pretrained("MCG-NJU/videomae-base-short").to(torch_device)
+
+ feature_extractor = self.default_feature_extractor
+ video = prepare_video()
+ inputs = feature_extractor(video, return_tensors="pt").to(torch_device)
+
+ # add boolean mask, indicating which patches to mask
+ local_path = hf_hub_download(repo_id="hf-internal-testing/bool-masked-pos", filename="bool_masked_pos.pt")
+ inputs["bool_masked_pos"] = torch.load(local_path)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the logits
+ expected_shape = torch.Size([1, 1408, 1536])
+ expected_slice = torch.tensor(
+ [[0.7994, 0.9612, 0.8508], [0.7401, 0.8958, 0.8302], [0.5862, 0.7468, 0.7325]], device=torch_device
+ )
+ self.assertEqual(outputs.logits.shape, expected_shape)
+ self.assertTrue(torch.allclose(outputs.logits[0, :3, :3], expected_slice, atol=1e-4))
+
+ # verify the loss (`config.norm_pix_loss` = `True`)
+ expected_loss = torch.tensor([0.5142], device=torch_device)
+ self.assertTrue(torch.allclose(outputs.loss, expected_loss, atol=1e-4))
+
+ # verify the loss (`config.norm_pix_loss` = `False`)
+ model = VideoMAEForPreTraining.from_pretrained("MCG-NJU/videomae-base-short", norm_pix_loss=False).to(
+ torch_device
+ )
+
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ expected_loss = torch.tensor(torch.tensor([0.6469]), device=torch_device)
+ self.assertTrue(torch.allclose(outputs.loss, expected_loss, atol=1e-4))
diff --git a/tests/test_feature_extraction_common.py b/tests/test_feature_extraction_common.py
index 16ab3c6459544c..a822b75cc5eb62 100644
--- a/tests/test_feature_extraction_common.py
+++ b/tests/test_feature_extraction_common.py
@@ -48,49 +48,91 @@
def prepare_image_inputs(feature_extract_tester, equal_resolution=False, numpify=False, torchify=False):
"""This function prepares a list of PIL images, or a list of numpy arrays if one specifies numpify=True,
or a list of PyTorch tensors if one specifies torchify=True.
+
+ One can specify whether the images are of the same resolution or not.
"""
assert not (numpify and torchify), "You cannot specify both numpy and PyTorch tensors at the same time"
- if equal_resolution:
- image_inputs = []
- for i in range(feature_extract_tester.batch_size):
- image_inputs.append(
- np.random.randint(
- 255,
- size=(
- feature_extract_tester.num_channels,
- feature_extract_tester.max_resolution,
- feature_extract_tester.max_resolution,
- ),
- dtype=np.uint8,
- )
- )
- else:
- image_inputs = []
-
- # To avoid getting image width/height 0
- min_resolution = feature_extract_tester.min_resolution
- if getattr(feature_extract_tester, "size_divisor", None):
- # If `size_divisor` is defined, the image needs to have width/size >= `size_divisor`
- min_resolution = max(feature_extract_tester.size_divisor, min_resolution)
-
- for i in range(feature_extract_tester.batch_size):
+ image_inputs = []
+ for i in range(feature_extract_tester.batch_size):
+ if equal_resolution:
+ width = height = feature_extract_tester.max_resolution
+ else:
+ # To avoid getting image width/height 0
+ min_resolution = feature_extract_tester.min_resolution
+ if getattr(feature_extract_tester, "size_divisor", None):
+ # If `size_divisor` is defined, the image needs to have width/size >= `size_divisor`
+ min_resolution = max(feature_extract_tester.size_divisor, min_resolution)
width, height = np.random.choice(np.arange(min_resolution, feature_extract_tester.max_resolution), 2)
- image_inputs.append(
- np.random.randint(255, size=(feature_extract_tester.num_channels, width, height), dtype=np.uint8)
+ image_inputs.append(
+ np.random.randint(
+ 255,
+ size=(
+ feature_extract_tester.num_channels,
+ width,
+ height,
+ ),
+ dtype=np.uint8,
)
+ )
if not numpify and not torchify:
# PIL expects the channel dimension as last dimension
- image_inputs = [Image.fromarray(np.moveaxis(x, 0, -1)) for x in image_inputs]
+ image_inputs = [Image.fromarray(np.moveaxis(image, 0, -1)) for image in image_inputs]
if torchify:
- image_inputs = [torch.from_numpy(x) for x in image_inputs]
+ image_inputs = [torch.from_numpy(image) for image in image_inputs]
return image_inputs
+def prepare_video(feature_extract_tester, width=10, height=10, numpify=False, torchify=False):
+ """This function prepares a video as a list of PIL images/NumPy arrays/PyTorch tensors."""
+
+ video = []
+ for i in range(feature_extract_tester.num_frames):
+ video.append(np.random.randint(255, size=(feature_extract_tester.num_channels, width, height), dtype=np.uint8))
+
+ if not numpify and not torchify:
+ # PIL expects the channel dimension as last dimension
+ video = [Image.fromarray(np.moveaxis(frame, 0, -1)) for frame in video]
+
+ if torchify:
+ video = [torch.from_numpy(frame) for frame in video]
+
+ return video
+
+
+def prepare_video_inputs(feature_extract_tester, equal_resolution=False, numpify=False, torchify=False):
+ """This function prepares a batch of videos: a list of list of PIL images, or a list of list of numpy arrays if
+ one specifies numpify=True, or a list of list of PyTorch tensors if one specifies torchify=True.
+
+ One can specify whether the videos are of the same resolution or not.
+ """
+
+ assert not (numpify and torchify), "You cannot specify both numpy and PyTorch tensors at the same time"
+
+ video_inputs = []
+ for i in range(feature_extract_tester.batch_size):
+ if equal_resolution:
+ width = height = feature_extract_tester.max_resolution
+ else:
+ width, height = np.random.choice(
+ np.arange(feature_extract_tester.min_resolution, feature_extract_tester.max_resolution), 2
+ )
+ video = prepare_video(
+ feature_extract_tester=feature_extract_tester,
+ width=width,
+ height=height,
+ numpify=numpify,
+ torchify=torchify,
+ )
+ video_inputs.append(video)
+
+ return video_inputs
+
+
class FeatureExtractionSavingTestMixin:
def test_feat_extract_to_json_string(self):
feat_extract = self.feature_extraction_class(**self.feat_extract_dict)
diff --git a/tests/test_modeling_common.py b/tests/test_modeling_common.py
index a86b33e88ff2a0..c05771336e6365 100755
--- a/tests/test_modeling_common.py
+++ b/tests/test_modeling_common.py
@@ -99,6 +99,7 @@
MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING,
MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING,
MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING,
+ MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING,
MODEL_MAPPING,
AdaptiveEmbedding,
AutoModelForCausalLM,
@@ -182,6 +183,7 @@ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
*get_values(MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING),
*get_values(MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING),
*get_values(MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING),
+ *get_values(MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING),
]:
inputs_dict["labels"] = torch.zeros(
self.model_tester.batch_size, dtype=torch.long, device=torch_device