| layout | title | date | author | tags | modified_time | ||
|---|---|---|---|---|---|---|---|
post |
Processing realtime event stream with Apache Storm |
2015-09-25T12:34:00.001-07:00 |
Saptak Sen |
|
2015-09-25T15:11:18.054-07:00 |
In this tutorial, we will explore Apache Storm and use it with Apache Kafka to develop a multi-stage event processing pipeline.
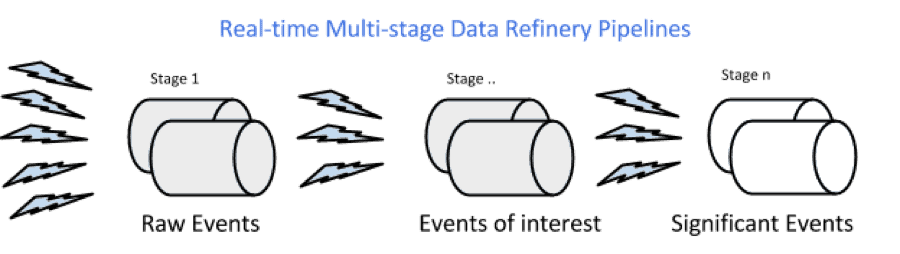
In an event processing pipeline, each stage is a purpose-built step that performs some real-time processing against upstream event streams for downstream analysis. This produces increasingly richer event streams, as data flows through the pipeline:
- raw events stream from many sources,
- those are processed to create events of interest, and
- events of interest are analyzed to detect significant events.
In the previous tutorial, we explored collecting and transporting data using Apache Kafka.
So the tutorial Transporting Realtime Event Stream with Apache Kafka needs to be completed before the next steps of this tutorial.
The Trucking business is a high-risk business in which truck drivers venture into remote areas, often in harsh weather conditions and chaotic traffic on a daily basis. Using this solution illustrating Modern Data Architecture with Hortonworks Data Platform, we have developed a centralized management system that can help reduce risk and lower the total cost of operations.
This system takes into consideration adverse weather conditions, the driver’s driving patterns, current traffic conditions and other criterions to alert and inform the management staff and the drivers themselves to mitigate risks.
In this tutorial, you will learn the following topics:
- Managing Storm on HDP.
- Creating a Storm spout to consume the Kafka ‘truckevents’ generated in Tutorial #1.
Apache Storm is a distributed real-time computation system for processing large volumes of high-velocity data in parallel and at scale. With its simple programming interface, Storm allows application developers to write applications that analyze streams comprised of tuples of data; a tuple may can contain object of any type.
At the core of Storm’s data stream processing is a computational topology. This topology of nodes dictates how tuples are processed, transformed, aggregated, stored, or re-emitted to other nodes in the topology for further processing.
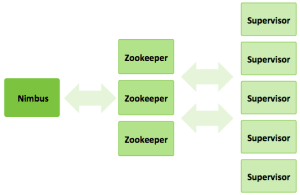
A storm cluster has three sets of nodes:
- Nimbus node (master node, similar to the Hadoop JobTracker):
- Uploads computations for execution
- Distributes code across the cluster
- Launches workers across the cluster
- Monitors computation and reallocates workers as needed
- ZooKeeper nodes – coordinates the Storm cluster
- Supervisor nodes – communicates with Nimbus through Zookeeper, starts and stops workers according to signals from Nimbus
Five key abstractions help to understand how Storm processes data:
- Tuples – an ordered list of elements. For example, a “4-tuple” might be (7, 1, 3, 7)
- Streams – an unbounded sequence of tuples.
- Spouts – sources of streams in a computation (e.g. a Twitter API)
- Bolts – process input streams and produce output streams. They can run functions, filter, aggregate, or join data, or talk to databases.
- Topologies – the overall calculation, represented visually as a network of spouts and bolts (as in the following diagram)
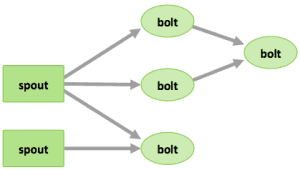
Storm users define topologies for how to process the data when it comes streaming in from the spout. When the data comes in, it is processed and the results are passed onto to other bolts or stored in Hadoop.
The core abstraction in Storm is the “stream.” It is an unbounded sequence of tuples. Storm provides the primitives for transforming a stream into a new stream in a distributed and reliable way. For example, you may transform a stream of tweets into a stream of trending topics.
The basic primitives Storm provides for doing stream transformations are “spouts” and “bolts.” Spouts and bolts have interfaces that you, as an application developer, implement to run your application-specific logic.
A spout is a source of streams. For example, a spout may read tuples off of a Kafka Topic and emit them as a stream, or a spout may even connect to the Twitter API and emit a stream of tweets.
A bolt consumes any number of input streams, does some processing, and possibly emits new streams. Complex stream transformations, like computing a stream of trending topics from a stream of tweets, require multiple steps and thus multiple bolts. Bolts can do anything from running functions, filtering tuples, do streaming aggregations, do streaming joins, talk to databases, and more.
A Storm cluster is similar to a Hadoop cluster. Whereas on Hadoop you run “MapReduce jobs,” on Storm you run “topologies.” “Jobs” and “topologies” are different in that a MapReduce job eventually finishes, whereas a topology processes messages forever (or until you terminate it).
Networks of spouts and bolts are packaged into a “topology,” which is the top-level abstraction that you submit to Storm clusters for execution. A topology is a graph of stream transformations where each node is a spout or bolt. Edges in the graph indicate which bolts are subscribing to which streams. When a spout or bolt emits a tuple to a stream, it sends the tuple to every bolt that subscribed to that stream.
Links between nodes in your topology indicate how tuples should be passed around. For example, if there is a link between Spout A and Bolt B, a link from Spout A to Bolt C, and a link from Bolt B to Bolt C, then every time Spout A emits a tuple, it will send the tuple to both Bolt B and Bolt C. All of Bolt B’s output tuples will go to Bolt C as well.
Each node in a Storm topology executes in parallel. In your topology, you can specify how much parallelism you want for each node, and then Storm will spawn that number of threads across the cluster to do the execution.
A topology runs indefinitely until you terminate it. Storm will automatically reassign any failed tasks. Additionally, Storm guarantees that there will be no data loss, even if machines go down and messages are dropped.
###Steps
####Step 1: Start and Configure Storm
- View the Storm Services page
Started by logging into Ambari as admin/admin. From the Dashboard page of Ambari, click on Storm from the list of installed services. (If you do not see Storm listed under Services, please follow click on Action->Add Service and select Storm and deploy it.)
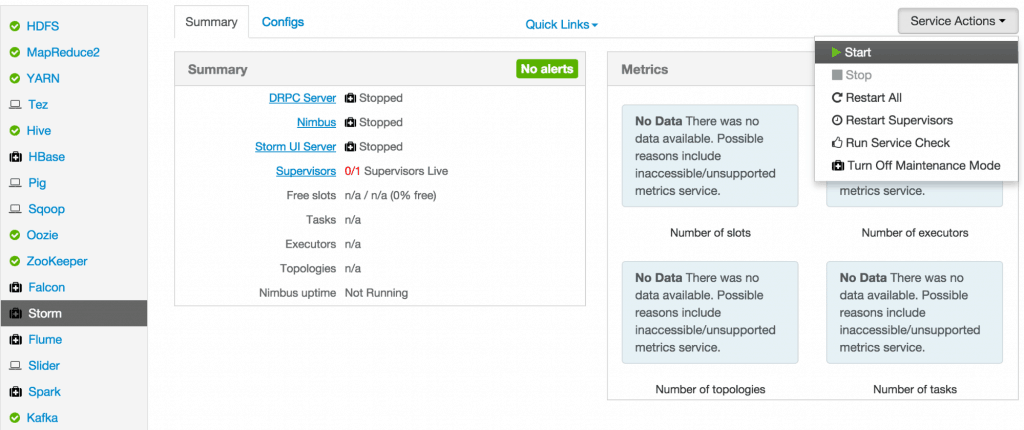
- Start Storm
From the Storm page, click on Service Actions -> Start
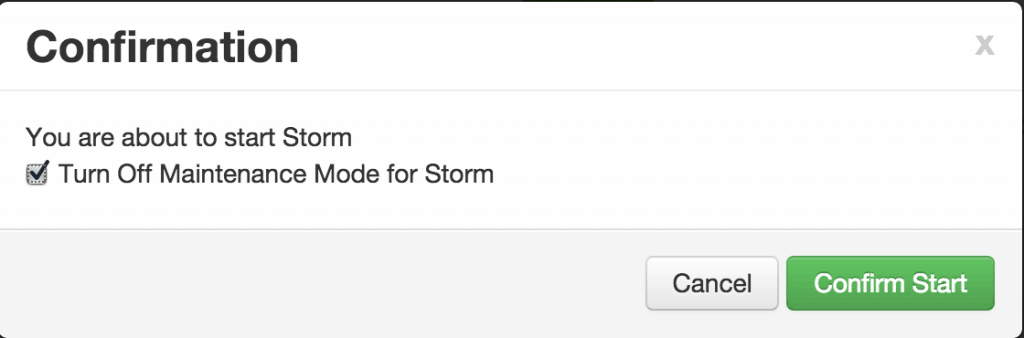
Check the box and click on Confirm Start:
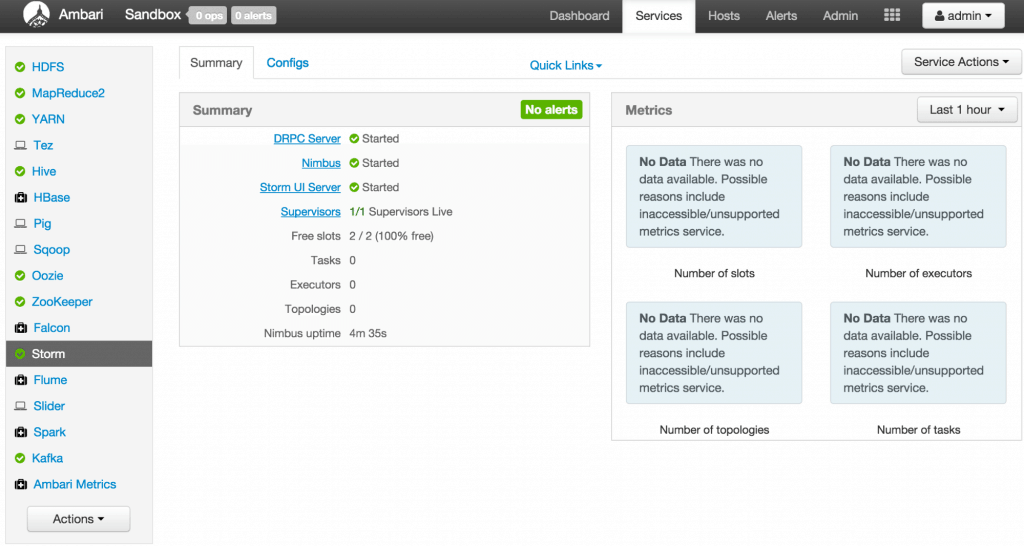
Wait for Storm to start.
- Configure Storm
You can check the below configurations by pasting them into the Filter text box under the Service Actions dropdown
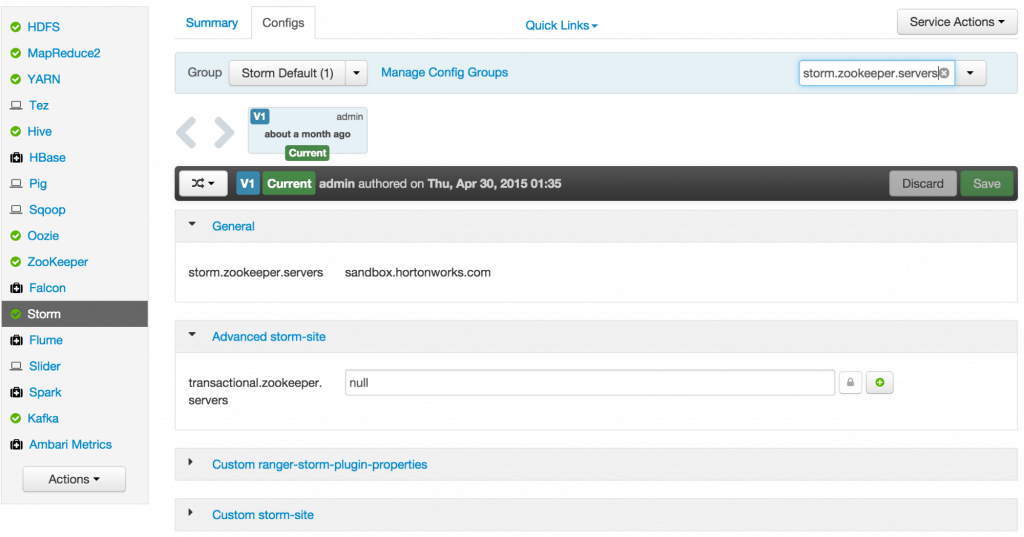
- Check zookeeper configuration: ensure
storm.zookeeper.serversis set to sandbox.hortonworks.com
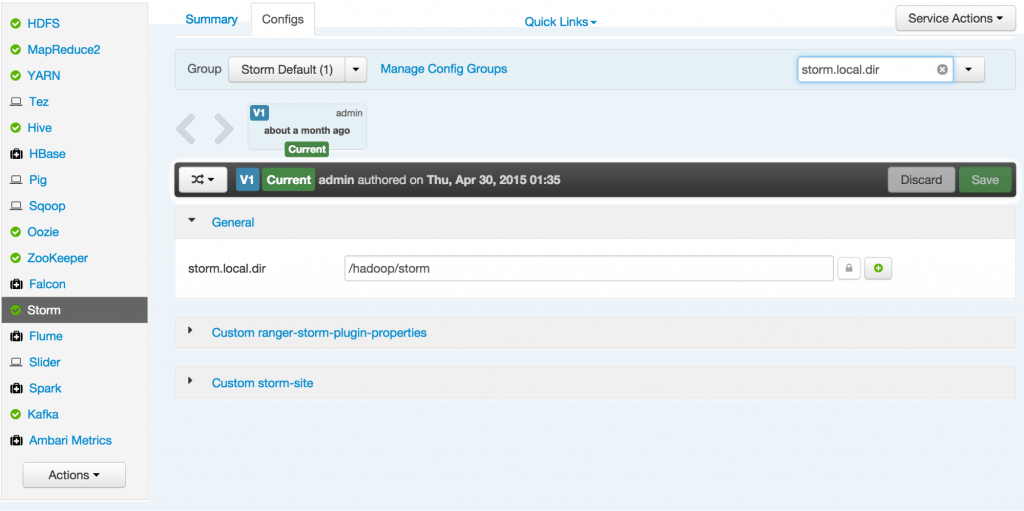
- Check the local directory configuration: ensure
storm.local.diris set to /hadoop/storm
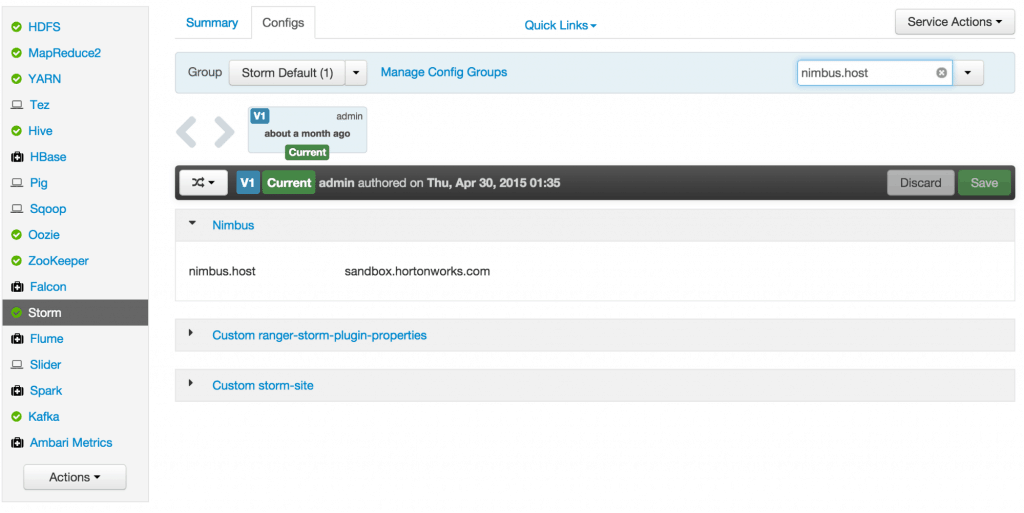
- Check the nimbus host configuration: ensure nimbus.host is set to sandbox.hortonworks.com
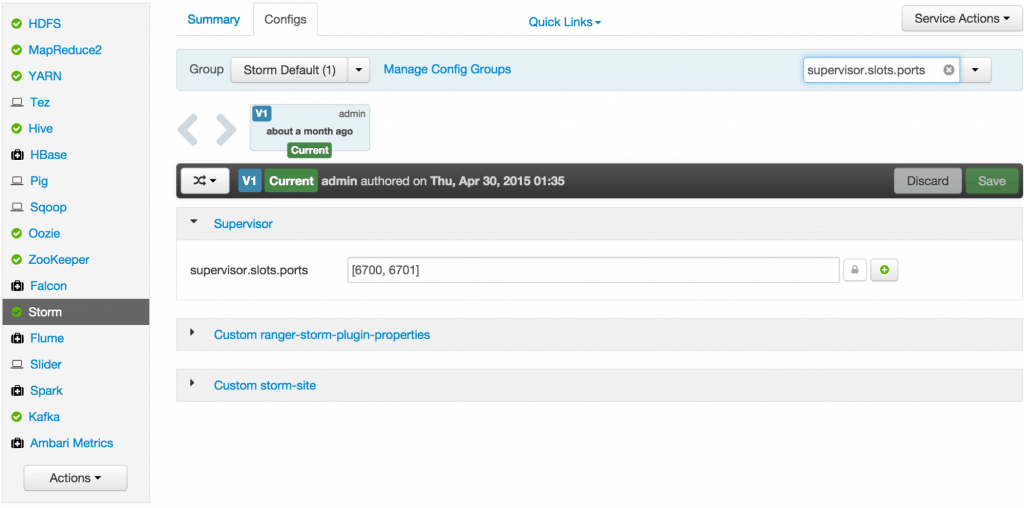
- Check the slots allocated: ensure supervisor.slots.ports is set to [6700, 6701]
- Check the UI configuration port: Ensure ui.port is set to 8744
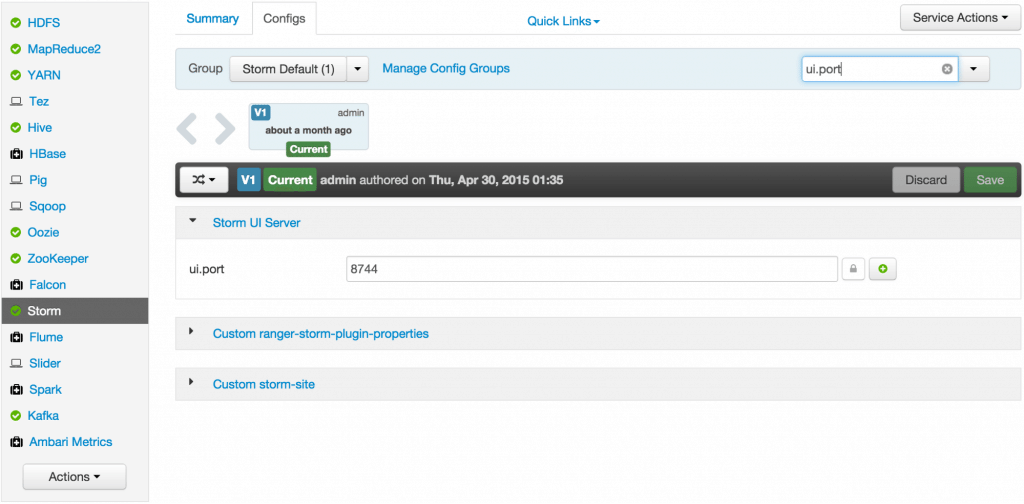
- Check the Storm UI from the Quick Links
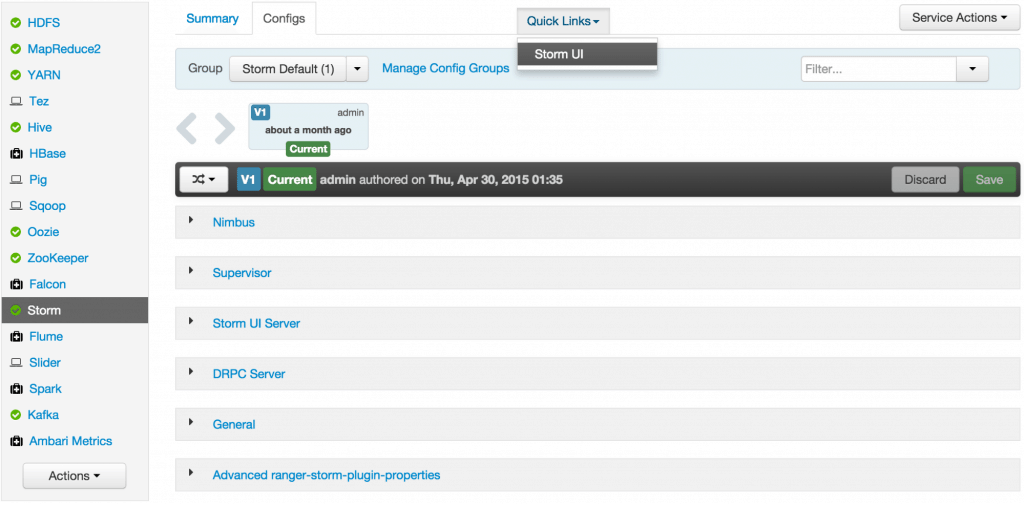
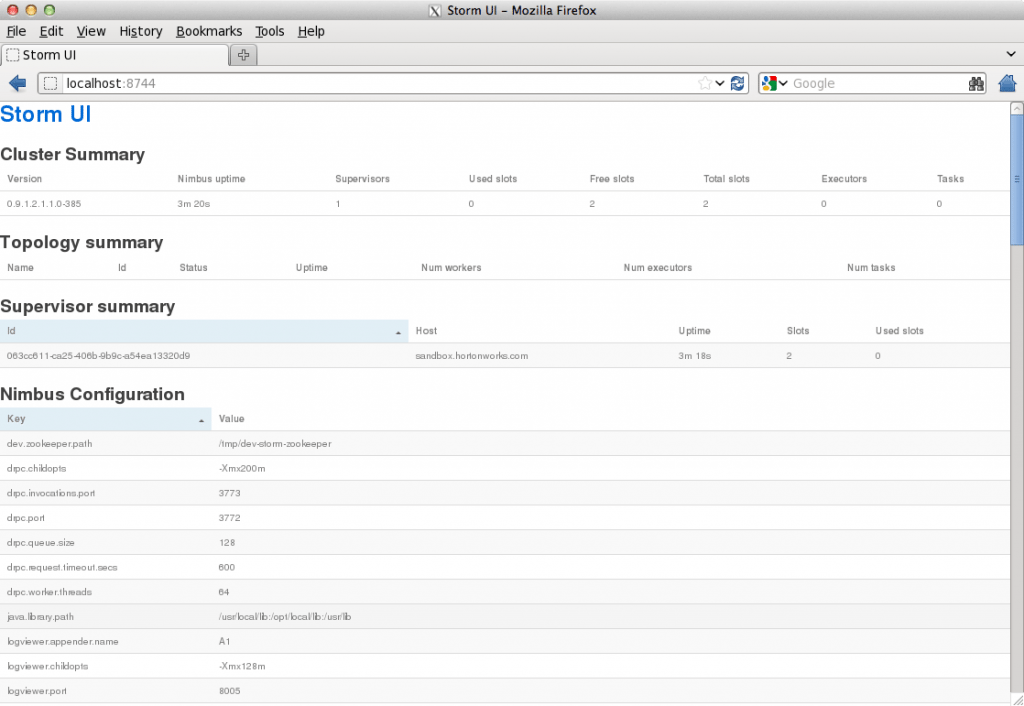
Now you can see the UI:
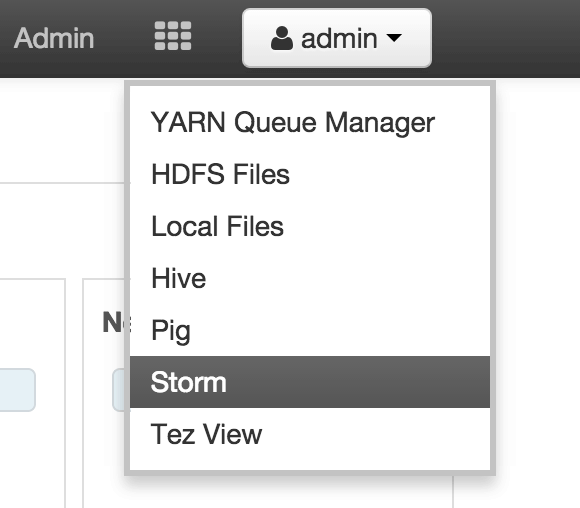
4. **Storm User View: **You can alternatively use Storm User View as well to view the topologies created by you.
- Go to the Ambari User VIew icon and select Storm :
- The Storm user view gives you the summary of topologies created by you. As of now we do not have any topologies created hence none are listed in the summary.

- Load data if required:
From tutorial #1 you already have the required New York City truck routes KML. If required, you can download the latest copy of the file with the following command.
wget http://www.nyc.gov/html/dot/downloads/misc/all_truck_routes_nyc.kml --directory-prefix=/opt/TruckEvents/Tutorials-master/src/main/resources/Recall that the source code is under /opt/TruckEvents/Tutorials-master/src directory
directory and pre-compiled jars are under the /opt/TruckEvents/Tutorials-master/target directory
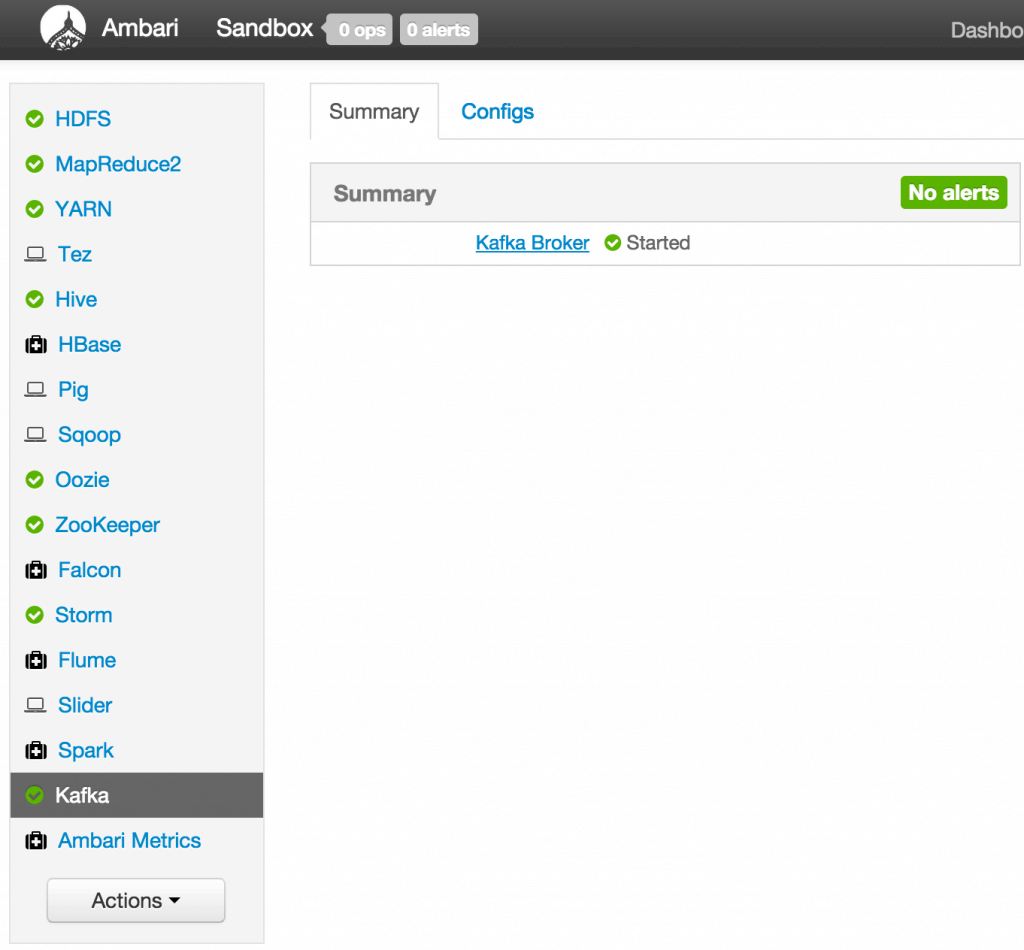
- Verify that Kafka process is running
Verify that Kafka is running using Ambari dashboard. If not, following the steps in tutorial #1
- Creating Storm Topology
We now have ‘supervisor’ daemon and Kafka processes running.
Running a topology is straightforward. First, you package all your code and dependencies into a single jar. Then, you run a command like the following: The command below will start a new Storm Topology for TruckEvents.
cd /opt/TruckEvents/Tutorials-master/
storm jar target/Tutorial-1.0-SNAPSHOT.jar.com.hortonworks.tutorials.tutorial2.TruckEventProcessingTopology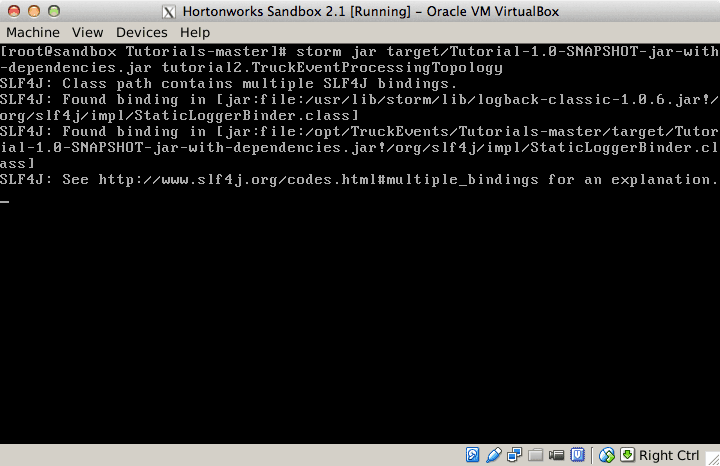
It should complete with “Finished submitting topology” as shown below.
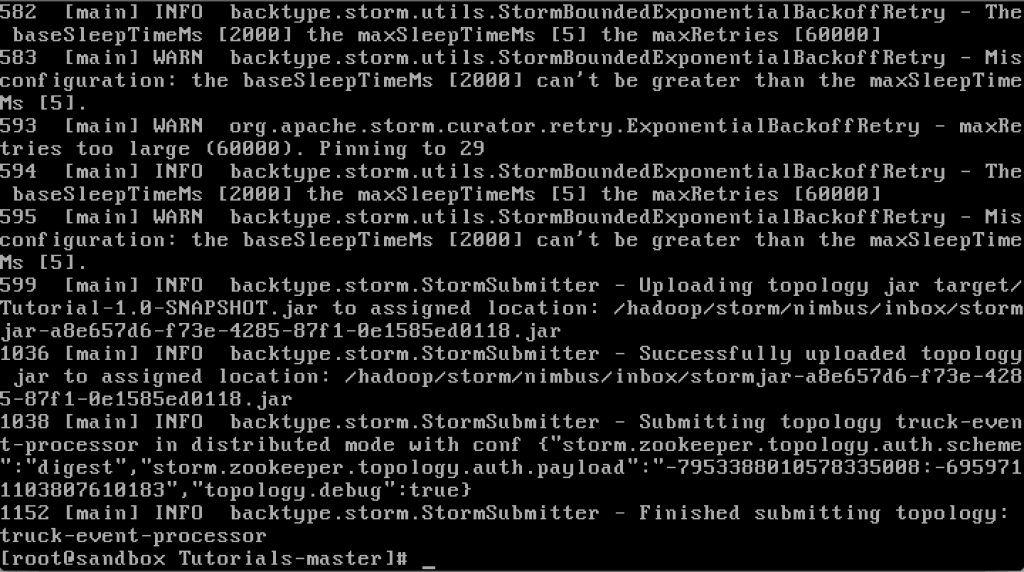
This runs the class TruckEventProcessingTopology . The main function of the class defines the topology and submits it to Nimbus. The storm jar part takes care of connecting to Nimbus and uploading the jar.
Refresh the Storm UI browser window to see new Topology ‘truck-event-processor’ in the browser.
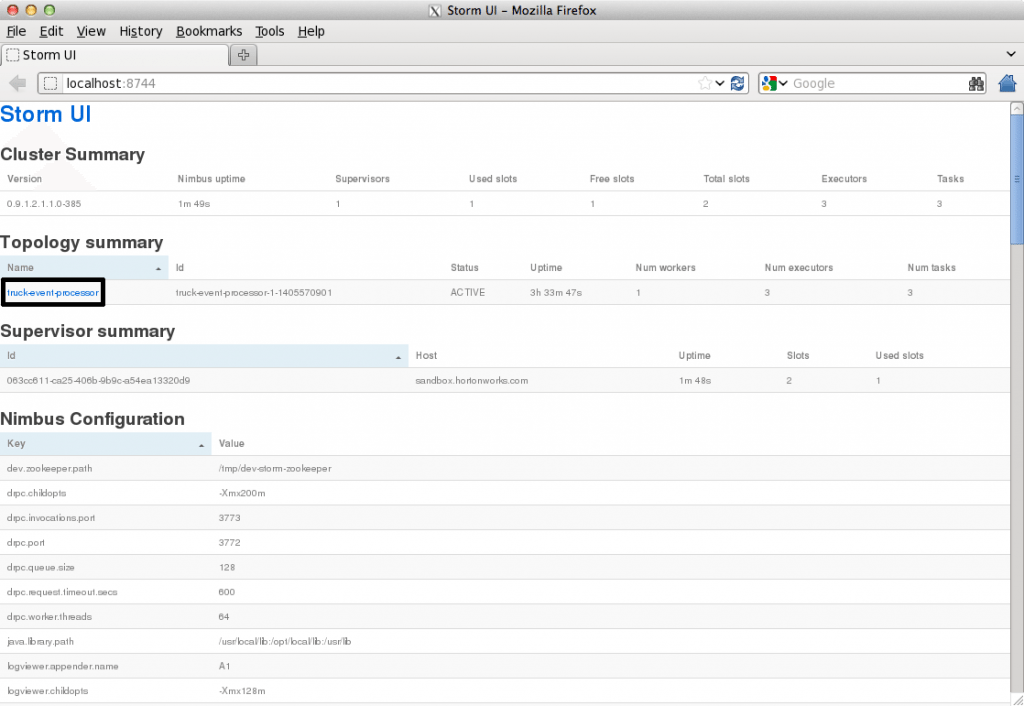
- Storm User View will now show a topology formed and running.
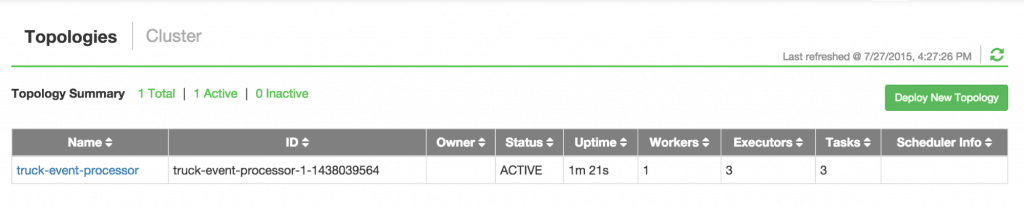
- Generating TruckEvents
The TruckEvents producer can now be executed as we did in Tutorial #1 from the same dir:
java -cp target/Tutorial-1.0-SNAPSHOT.jar com.hortonworks.tutorials.tutorial1.TruckEventsProducer sandbox.hortonworks.com:6667 sandbox.hortonworks.com:2181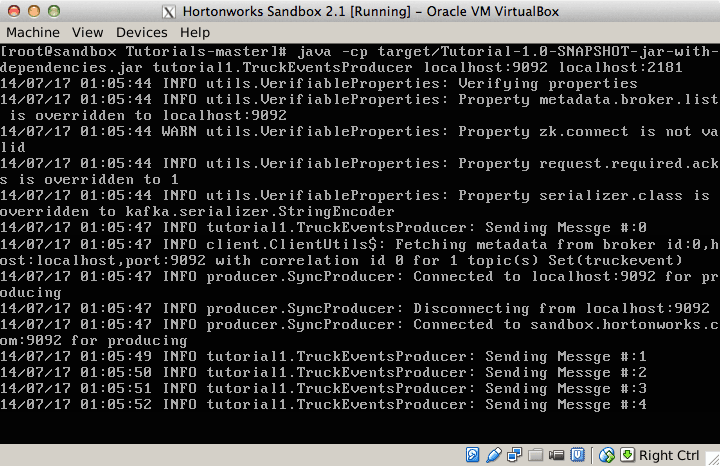
Go back to the Storm UI and click on “truck-event-processor” topology to drill into it. Under Spouts you should see that numbers of emitted and transferred tuples is increasing which shows that the messages are processed in real time by Spout

You can press Ctrl-C to stop the Kafka producer
** Under Storm User view: ** You should be able to see the topology created by you under storm user views.
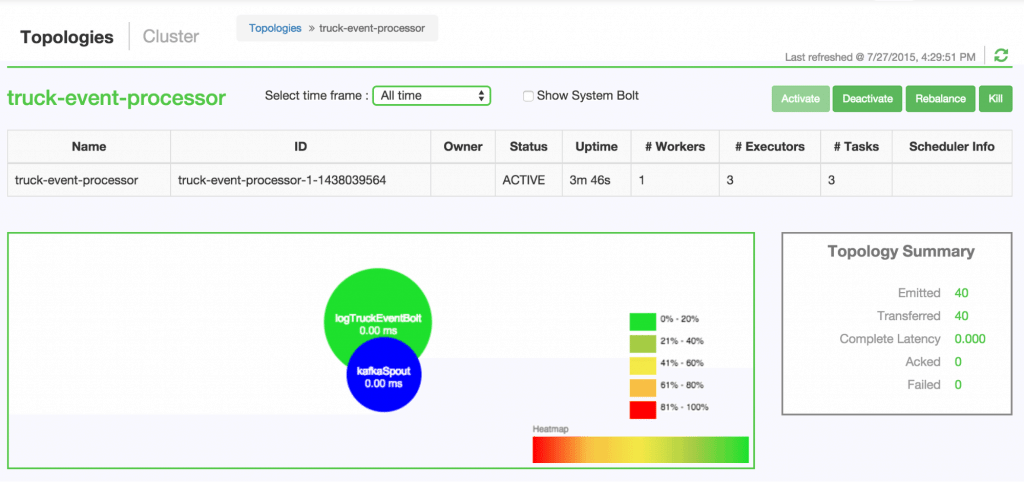
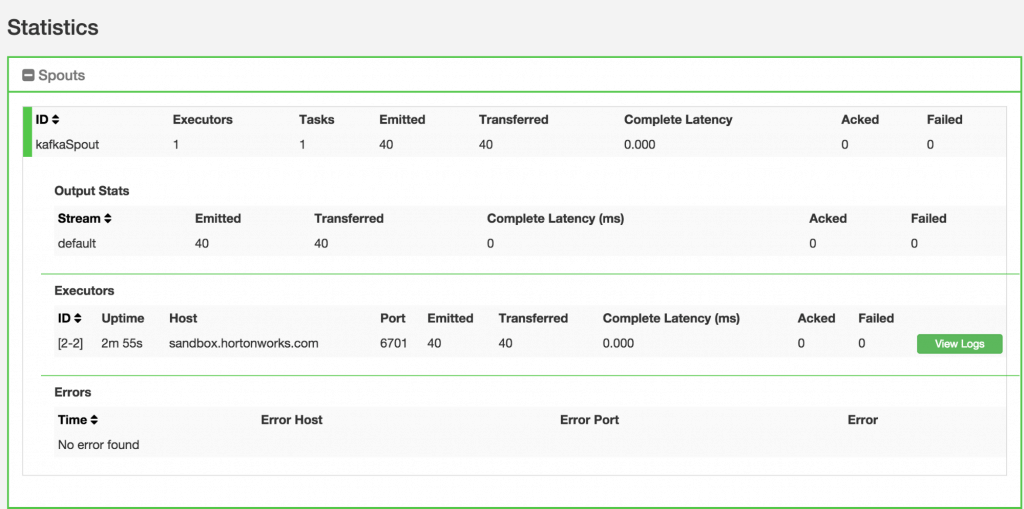
- You can also keep track of several statistics of Spouts and Bolts.

####Step 3: Code description
Let us review the code used in this tutorial. The source files are under the /opt/TruckEvents/Tutorials-master/src/main/java/com/hortonworks/tutorials/tutorial2/
[root@sandbox Tutorials-master]# ls -l src/main/java/com/hortonworks/tutorials/tutorial2/
total 16
-rw-r--r-- 1 root root 861 Jul 24 23:34 BaseTruckEventTopology.java
-rw-r--r-- 1 root root 1205 Jul 24 23:34 LogTruckEventsBolt.java
-rw-r--r-- 1 root root 2777 Jul 24 23:34 TruckEventProcessingTopology.java
-rw-r--r-- 1 root root 2233 Jul 24 23:34 TruckScheme.java
- BaseTruckEventTopology.java
topologyConfig.load(ClassLoader.getSystemResourceAsStream(configFileLocation));Is the base class, where the topology configurations is initialized from the /resource/truck_event_topology.properties files.
- TruckEventProcessingTopology.java
This is the storm topology configuration class, where the Kafka spout and LogTruckevent Bolts are initialized. In the following method the Kafka spout is configured.
private SpoutConfig constructKafkaSpoutConf()
{
…
SpoutConfig spoutConfig = new SpoutConfig(hosts, topic, zkRoot, consumerGroupId);
…
spoutConfig.scheme = new SchemeAsMultiScheme(new TruckScheme());
return spoutConfig;
}A logging bolt that prints the message from the Kafka spout was created for debugging purpose just for this tutorial.
public void configureLogTruckEventBolt(TopologyBuilder builder)
{
LogTruckEventsBolt logBolt = new LogTruckEventsBolt();
builder.setBolt(LOG_TRUCK_BOLT_ID, logBolt).globalGrouping(KAFKA_SPOUT_ID);
}The topology is built and submitted in the following method;
private void buildAndSubmit() throws Exception
{
...
StormSubmitter.submitTopology("truck-event-processor",
conf, builder.createTopology());
}- TruckScheme.java
Is the deserializer provided to the kafka spout to deserialize kafka byte message stream to Values objects.
public List<Object> deserialize(byte[] bytes)
{
try
{
String truckEvent = new String(bytes, "UTF-8");
String[] pieces = truckEvent.split("\\|");
Timestamp eventTime = Timestamp.valueOf(pieces[0]);
String truckId = pieces[1];
String driverId = pieces[2];
String eventType = pieces[3];
String longitude= pieces[4];
String latitude = pieces[5];
return new Values(cleanup(driverId), cleanup(truckId),
eventTime, cleanup(eventType), cleanup(longitude), cleanup(latitude));
}
catch (UnsupportedEncodingException e)
{
LOG.error(e);
throw new RuntimeException(e);
}
}- LogTruckEventsBolt.java
LogTruckEvent spout logs the kafka message received from the kafka spout to the log files under /var/log/storm/worker-*.log
public void execute(Tuple tuple)
{
LOG.info(tuple.getStringByField(TruckScheme.FIELD_DRIVER_ID) + "," +
tuple.getStringByField(TruckScheme.FIELD_TRUCK_ID) + "," +
tuple.getValueByField(TruckScheme.FIELD_EVENT_TIME) + "," +
tuple.getStringByField(TruckScheme.FIELD_EVENT_TYPE) + "," +
tuple.getStringByField(TruckScheme.FIELD_LATITUDE) + "," +
tuple.getStringByField(TruckScheme.FIELD_LONGITUDE));
}###Summary
In this tutorial we have learned to capture data from Kafka Producer into Storm Spout. This data can now be processed in real time. In our next Tutorial, using Storm Bolt, you will see how to store data into multiple sources for persistence.