1 | |
1 | package testthread41; |

xtfp这软件上手很容易
只需要左右拖拽文件即刻互相传输
-1 | |
1 | yum install nginx -y |
1 | |
1 | nginx |
1 | |
1 | 1.进入/etc/nginx文件夹 |
1 | |
1 | # For more information on configuration, see: |
其中8001端口为我的静态资源访问端口
/usr/local/java/resources 为我的静态资源存放位置
1 | |
1 | nginx -s reload |
1 | |
1 | 例如:/usr/local/java/resources下有一个index.html文件 |
如果还不能使用的话 是服务器没有开放端口问题
进入阿里云
diff --git a/2021/10/13/leetcode_412/index.html b/2021/10/13/leetcode_412/index.html index d02aff148..a5b2368bf 100644 --- a/2021/10/13/leetcode_412/index.html +++ b/2021/10/13/leetcode_412/index.html @@ -222,7 +222,7 @@输入:n = 3
输出:[“1”,”2”,”Fizz”]
示例 2:
输入:n = 5
输出:[“1”,”2”,”Fizz”,”4”,”Buzz”]
示例 3:
输入:n = 15
输出:[“1”,”2”,”Fizz”,”4”,”Buzz”,”Fizz”,”7”,”8”,”Fizz”,”Buzz”,”11”,”Fizz”,”13”,”14”,”FizzBuzz”]
1 | |
1 | class Solution { |
所以自己想了一下自己可以写一个绩点计算器出来吗 好像也不是很难的样子
所以自己用了差不多20分钟帮这个写出来了
下面是源码
-1 | |
1 |
|
功能样图
欢迎关注微信公众号 :打码少年风萧
程序链接
链接:https://pan.baidu.com/s/1MzkRQ3XCtWadlWFxFDef4g
提取码:30qf
题目
-1 | |
1 | 符合下列属性的数组 arr 称为 山峰数组(山脉数组) : |
我写的想法 第一次就想到for循环遍历 写出了O(n)的学法
-1 | |
1 | int peakIndexInMountainArray(int* arr, int arrSize){ |
三叶姐姐的解法
二分
往常我们使用「二分」进行查值,需要确保序列本身满足「二段性」:当选定一个端点(基准值)后,结合「一段满足 & 另一段不满足」的特性来实现“折半”的查找效果。
1 | |
1 | class Solution { |
时间复杂度:O(\log{n})O(logn)
diff --git "a/2021/10/14/\347\210\254\350\231\253/index.html" "b/2021/10/14/\347\210\254\350\231\253/index.html" index 578b2194c..e61879cd5 100644 --- "a/2021/10/14/\347\210\254\350\231\253/index.html" +++ "b/2021/10/14/\347\210\254\350\231\253/index.html" @@ -215,7 +215,7 @@1 | |
1 | package testthread41; |
二分算法基本框架
-1 | |
1 | class Solution { |
分析二分查找的一个技巧是:不要出现 else,而是把所有情况用 else if 写清楚,这样可以清楚地展现所有细节。本文都会使用 else if,旨在讲清楚,读者理解后可自行简化。
其中 … 标记的部分,就是可能出现细节问题的地方,当你见到一个二分查找的代码时,首先注意这几个地方。后文用实例分析这些地方能有什么样的变化。
另外声明一下,计算 mid 时需要技巧防止溢出,即 mid=left+(right-left)/2。本文暂时忽略这个问题。
一、寻找一个数(基本的二分搜索)
这个场景是最简单的,可能也是大家最熟悉的,即搜索一个数,如果存在,返回其索引,否则返回 -1。
-1 | |
1 | int binarySearch(int[] nums, int target) { |
1. 为什么 while 循环的条件中是 <=,而不是 < ?
答:因为初始化 right 的赋值是 nums.length-1,即最后一个元素的索引,而不是 nums.length。
这二者可能出现在不同功能的二分查找中,区别是:前者相当于两端都闭区间 [left, right],后者相当于左闭右开区间 [left, right),因为索引大小为 nums.length 是越界的。
我们这个算法中使用的是前者 [left, right] 两端都闭的区间。这个区间其实就是每次进行搜索的区间,我们不妨称为「搜索区间」。
什么时候应该停止搜索呢?当然,找到了目标值的时候可以终止:
-1 | |
1 | if(nums[mid] == target) |
但如果没找到,就需要 while 循环终止,然后返回 -1。那 while 循环什么时候应该终止?搜索区间为空的时候应该终止,意味着你没得找了,就等于没找到嘛。
while(left <= right) 的终止条件是 left == right + 1,写成区间的形式就是 [right + 1, right],或者带个具体的数字进去 [3, 2],可见这时候搜索区间为空,因为没有数字既大于等于 3 又小于等于 2 的吧。所以这时候 while 循环终止是正确的,直接返回 -1 即可。
while(left < right) 的终止条件是 left == right,写成区间的形式就是 [left, right],或者带个具体的数字进去 [2, 2],这时候搜索区间非空,还有一个数 2,但此时 while 循环终止了。也就是说这区间 [2, 2] 被漏掉了,索引 2 没有被搜索,如果这时候直接返回 -1 就是错误的。
当然,如果你非要用 while(left < right) 也可以,我们已经知道了出错的原因,就打个补丁好了:
-1 | |
1 | //... |
详解解析看 [https://www.cnblogs.com/mxj961116/p/11945444.html]
leetcode_剑指 Offer II 069. 山峰数组的顶部

二分题解
-1 | |
1 | class Solution { |
leetcode_35

题解
-1 | |
1 | class Solution { |

题解
-1 | |
1 | class Solution { |
左括号必须用相同类型的右括号闭合。
左括号必须以正确的顺序闭合。
示例 1:
-1 | |
1 | 输入:s = "()" |
示例 2:
-1 | |
1 | 输入:s = "()[]{}" |
示例 3:
-1 | |
1 | 输入:s = "(]" |
示例 4:
-1 | |
1 | 输入:s = "([)]" |
示例 5:
-1 | |
1 | 输入:s = "{[]}" |
提示:
-1 | |
1 | 1 <= s.length <= 104 |
题解
-1 | |
1 | class Solution { |
先就s字符串的长度奇数还是偶数进行判断
如果长度是奇数 直接返回false 因为不满足闭合条件
diff --git a/2021/10/20/SpringMvc/index.html b/2021/10/20/SpringMvc/index.html index bf30600cf..ec38d312e 100644 --- a/2021/10/20/SpringMvc/index.html +++ b/2021/10/20/SpringMvc/index.html @@ -219,7 +219,7 @@Model :实体类Bean 专门做存储业务数据
- 业务处理Bean 指Servicw或Dao对象,专门用于处理业务逻辑和数据访问
+ 业务处理Bean 指Servicw或Dao对象,专门用于处理业务逻辑和数据访问
View :视图层 指工程中的html+jsp等页面
Controller : 控制层 servelt
diff --git a/2021/10/20/leetcode_453/index.html b/2021/10/20/leetcode_453/index.html
index 447615381..da0a4ad62 100644
--- a/2021/10/20/leetcode_453/index.html
+++ b/2021/10/20/leetcode_453/index.html
@@ -217,27 +217,27 @@
453. 最小操作次数使数组元素相等
给你一个长度为 n 的整数数组,每次操作将会使 n - 1 个元素增加 1 。返回让数组所有元素相等的最小操作次数。
示例 1:
-1
2
3
4
5
6
输入:nums = [1,2,3]
输出:3
解释:
只需要3次操作(注意每次操作会增加两个元素的值):
[1,2,3] => [2,3,3] => [3,4,3] => [4,4,4]
+1
2
3
4
5
6
输入:nums = [1,2,3]
输出:3
解释:
只需要3次操作(注意每次操作会增加两个元素的值):
[1,2,3] => [2,3,3] => [3,4,3] => [4,4,4]
示例 2:
-1
2
输入:nums = [1,1,1]
输出:0
+1
2
输入:nums = [1,1,1]
输出:0
-1
+1
解析
每一步除了最大的那个数不加1 相等于最大的数减1 参考相对运动理解
每一次操作总和都会-1
那么最后的结果肯定是n个最小数
那么
-1
return sum - min * n;
+1
return sum - min * n;
即可得到结果
利用for each语句遍历数组
找出数组里面最小的数和总和sum
-1
2
3
4
for (int i : nums) {
min = Math.min(min, i);
sum += i;
}
+1
2
3
4
for (int i : nums) {
min = Math.min(min, i);
sum += i;
}
题解
-1
2
3
4
5
6
7
8
9
10
11
class Solution {
public int minMoves(int[] nums) {
int n = nums.length;
int min = nums[0], sum = 0;
for (int i : nums) {
min = Math.min(min, i);
sum += i;
}
return sum - min * n;
}
}
+1
2
3
4
5
6
7
8
9
10
11
class Solution {
public int minMoves(int[] nums) {
int n = nums.length;
int min = nums[0], sum = 0;
for (int i : nums) {
min = Math.min(min, i);
sum += i;
}
return sum - min * n;
}
}
diff --git "a/2021/10/23/\346\271\226\345\215\227\347\234\201\350\264\242\345\212\241\345\244\247\345\255\246\347\224\237\347\253\236\350\265\233/index.html" "b/2021/10/23/\346\271\226\345\215\227\347\234\201\350\264\242\345\212\241\345\244\247\345\255\246\347\224\237\347\253\236\350\265\233/index.html"
index 30a90a66e..3bee54aa3 100644
--- "a/2021/10/23/\346\271\226\345\215\227\347\234\201\350\264\242\345\212\241\345\244\247\345\255\246\347\224\237\347\253\236\350\265\233/index.html"
+++ "b/2021/10/23/\346\271\226\345\215\227\347\234\201\350\264\242\345\212\241\345\244\247\345\255\246\347\224\237\347\253\236\350\265\233/index.html"
@@ -220,7 +220,7 @@
被拉去参加财务大学生竞赛 让我当大数据分析师
刷了几套题发现是考查找数据能力以及利用python tushare库做分析

-1
2
3
4
5
6
import tushare as ts
ts.set_token('41addd8c3955aea5623099855def5d5ae794632258ad289d8fd02fb6')
ds = ts.pro_bar(ts_code='000425.SZ', start_date='20130101', end_date='20171231', freq='M', adj='hfq')
ds = ds[['trade_date', 'close']]
ds.to_excel('D:/bigdata/000425.xlsx')
print(ds)
+1
2
3
4
5
6
import tushare as ts
ts.set_token('41addd8c3955aea5623099855def5d5ae794632258ad289d8fd02fb6')
ds = ts.pro_bar(ts_code='000425.SZ', start_date='20130101', end_date='20171231', freq='M', adj='hfq')
ds = ds[['trade_date', 'close']]
ds.to_excel('D:/bigdata/000425.xlsx')
print(ds)
刚好在1024节这天参加了学校的校赛,讲讲这次作为大数据分析师的感受把 ,题目不难,但是有些题数据很多很费时间,我就是因为没有正确的选择以及没有得知大数据分析师考完后其他人能看到正确答案的要求,不然我也不会死耗在第一题第二题数据多分少但是对队友很重要的地方了。两个利用tushare库的问题,其实编程很简单,简单导个库,然后找到接口依葫芦画瓢就好了。
虽然过程很曲折,但是结果还是比较符合人意的,队伍排名10/102 刚好拿到三等奖的最后一个名次 刚出来成绩的时候看到分数还是很自责的 因为要是我发挥稳定的话,可能我们就是第一了 或者没看错那个题 我们就是二等奖了 好在队友小雪 佳佳 子怡都挺好的 也很高兴经过四天训练之后能拿到这一个校奖。虽然自己的大数据分析师好像被别人拉爆了 已经被拉到10名开外了 有点丢我们计院的脸了hhh。但是好像也免了去拒绝停课去打这个几乎和我本专业无关的比赛了。
diff --git "a/2021/10/26/leetcode_496 \344\270\213\344\270\200\344\270\252\346\233\264\345\244\247\345\205\203\347\264\240/index.html" "b/2021/10/26/leetcode_496 \344\270\213\344\270\200\344\270\252\346\233\264\345\244\247\345\205\203\347\264\240/index.html"
index 62b091b07..71777a5c2 100644
--- "a/2021/10/26/leetcode_496 \344\270\213\344\270\200\344\270\252\346\233\264\345\244\247\345\205\203\347\264\240/index.html"
+++ "b/2021/10/26/leetcode_496 \344\270\213\344\270\200\344\270\252\346\233\264\345\244\247\345\205\203\347\264\240/index.html"
@@ -210,29 +210,29 @@
496. 下一个更大元素 I
难度 :简单
-1
2
3
4
5
给你两个 没有重复元素 的数组 nums1 和 nums2 ,其中nums1 是 nums2 的子集。
请你找出 nums1 中每个元素在 nums2 中的下一个比其大的值。
nums1 中数字 x 的下一个更大元素是指 x 在 nums2 中对应位置的右边的第一个比 x 大的元素。如果不存在,对应位置输出 -1 。
+1
2
3
4
5
给你两个 没有重复元素 的数组 nums1 和 nums2 ,其中nums1 是 nums2 的子集。
请你找出 nums1 中每个元素在 nums2 中的下一个比其大的值。
nums1 中数字 x 的下一个更大元素是指 x 在 nums2 中对应位置的右边的第一个比 x 大的元素。如果不存在,对应位置输出 -1 。
示例 1:
-1
2
3
4
5
6
输入: nums1 = [4,1,2], nums2 = [1,3,4,2].
输出: [-1,3,-1]
解释:
对于 num1 中的数字 4 ,你无法在第二个数组中找到下一个更大的数字,因此输出 -1 。
对于 num1 中的数字 1 ,第二个数组中数字1右边的下一个较大数字是 3 。
对于 num1 中的数字 2 ,第二个数组中没有下一个更大的数字,因此输出 -1 。
+1
2
3
4
5
6
输入: nums1 = [4,1,2], nums2 = [1,3,4,2].
输出: [-1,3,-1]
解释:
对于 num1 中的数字 4 ,你无法在第二个数组中找到下一个更大的数字,因此输出 -1 。
对于 num1 中的数字 1 ,第二个数组中数字1右边的下一个较大数字是 3 。
对于 num1 中的数字 2 ,第二个数组中没有下一个更大的数字,因此输出 -1 。
示例 2:
-1
2
3
4
5
6
输入: nums1 = [2,4], nums2 = [1,2,3,4].
输出: [3,-1]
解释:
对于 num1 中的数字 2 ,第二个数组中的下一个较大数字是 3 。
对于 num1 中的数字 4 ,第二个数组中没有下一个更大的数字,因此输出 -1 。
+1
2
3
4
5
6
输入: nums1 = [2,4], nums2 = [1,2,3,4].
输出: [3,-1]
解释:
对于 num1 中的数字 2 ,第二个数组中的下一个较大数字是 3 。
对于 num1 中的数字 4 ,第二个数组中没有下一个更大的数字,因此输出 -1 。
提示:
-1
2
3
4
1 <= nums1.length <= nums2.length <= 1000
0 <= nums1[i], nums2[i] <= 104
nums1和nums2中所有整数 互不相同
nums1 中的所有整数同样出现在 nums2 中
+1
2
3
4
1 <= nums1.length <= nums2.length <= 1000
0 <= nums1[i], nums2[i] <= 104
nums1和nums2中所有整数 互不相同
nums1 中的所有整数同样出现在 nums2 中
看到题目第一时间就想的遍历然后匹配 虽然写的很垃圾 但是是自己独立debug写出来的还是很高兴
-方法一 :暴力
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class Solution {
public int[] nextGreaterElement(int[] nums1, int[] nums2) {
int n = nums1.length;
int nums3[] = new int[n];
for(int i = 0 ; i < n ; i++ )
for(int j = 0 ; j < nums2.length ; j++ )
if(nums1[i] == nums2[j])
for(int k = j;k<nums2.length;k++)
if( nums2[k] > nums1[i])
{
nums3[i] = nums2[k];
break;
}
else
nums3[i] = -1;
return nums3;
}
}
+方法一 :暴力
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class Solution {
public int[] nextGreaterElement(int[] nums1, int[] nums2) {
int n = nums1.length;
int nums3[] = new int[n];
for(int i = 0 ; i < n ; i++ )
for(int j = 0 ; j < nums2.length ; j++ )
if(nums1[i] == nums2[j])
for(int k = j;k<nums2.length;k++)
if( nums2[k] > nums1[i])
{
nums3[i] = nums2[k];
break;
}
else
nums3[i] = -1;
return nums3;
}
}
有几个地方需要注意 就是当遇见一个数比他大的时候 需要赋值后立即跳出
官方题解
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class Solution {
public int[] nextGreaterElement(int[] nums1, int[] nums2) {
int m = nums1.length, n = nums2.length;
int[] res = new int[m];
for (int i = 0; i < m; ++i) {
int j = 0;
while (j < n && nums2[j] != nums1[i]) {
++j;
}
int k = j + 1;
while (k < n && nums2[k] < nums2[j]) {
++k;
}
res[i] = k < n ? nums2[k] : -1;
}
return res;
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class Solution {
public int[] nextGreaterElement(int[] nums1, int[] nums2) {
int m = nums1.length, n = nums2.length;
int[] res = new int[m];
for (int i = 0; i < m; ++i) {
int j = 0;
while (j < n && nums2[j] != nums1[i]) {
++j;
}
int k = j + 1;
while (k < n && nums2[k] < nums2[j]) {
++k;
}
res[i] = k < n ? nums2[k] : -1;
}
return res;
}
}
不得不感叹一下 同样是暴力遍历 官方写的比我写的好得多
-方法二:单调栈 + 哈希表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
class Solution {
public int[] nextGreaterElement(int[] nums1, int[] nums2) {
Map<Integer, Integer> map = new HashMap<Integer, Integer>();
Deque<Integer> stack = new ArrayDeque<Integer>();
for (int i = nums2.length - 1; i >= 0; --i) {
int num = nums2[i];
while (!stack.isEmpty() && num >= stack.peek()) {
stack.pop();
}
map.put(num, stack.isEmpty() ? -1 : stack.peek());
stack.push(num);
}
int[] res = new int[nums1.length];
for (int i = 0; i < nums1.length; ++i) {
res[i] = map.get(nums1[i]);
}
return res;
}
}
+方法二:单调栈 + 哈希表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
class Solution {
public int[] nextGreaterElement(int[] nums1, int[] nums2) {
Map<Integer, Integer> map = new HashMap<Integer, Integer>();
Deque<Integer> stack = new ArrayDeque<Integer>();
for (int i = nums2.length - 1; i >= 0; --i) {
int num = nums2[i];
while (!stack.isEmpty() && num >= stack.peek()) {
stack.pop();
}
map.put(num, stack.isEmpty() ? -1 : stack.peek());
stack.push(num);
}
int[] res = new int[nums1.length];
for (int i = 0; i < nums1.length; ++i) {
res[i] = map.get(nums1[i]);
}
return res;
}
}
三叶姐题解
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class Solution {
public int[] nextGreaterElement(int[] nums1, int[] nums2) {
int n = nums1.length, m = nums2.length;
Deque<Integer> d = new ArrayDeque<>();
Map<Integer, Integer> map = new HashMap<>();
for (int i = m - 1; i >= 0; i--) {
int x = nums2[i];
while (!d.isEmpty() && d.peekLast() <= x) d.pollLast();
map.put(x, d.isEmpty() ? -1 : d.peekLast());
d.addLast(x);
}
int[] ans = new int[n];
for (int i = 0; i < n; i++) ans[i] = map.get(nums1[i]);
return ans;
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class Solution {
public int[] nextGreaterElement(int[] nums1, int[] nums2) {
int n = nums1.length, m = nums2.length;
Deque<Integer> d = new ArrayDeque<>();
Map<Integer, Integer> map = new HashMap<>();
for (int i = m - 1; i >= 0; i--) {
int x = nums2[i];
while (!d.isEmpty() && d.peekLast() <= x) d.pollLast();
map.put(x, d.isEmpty() ? -1 : d.peekLast());
d.addLast(x);
}
int[] ans = new int[n];
for (int i = 0; i < n; i++) ans[i] = map.get(nums1[i]);
return ans;
}
}
diff --git "a/2021/11/01/ArrayList\344\270\216HashSet\347\232\204\345\214\272\345\210\253/index.html" "b/2021/11/01/ArrayList\344\270\216HashSet\347\232\204\345\214\272\345\210\253/index.html"
index 122888f8e..21d4bb0df 100644
--- "a/2021/11/01/ArrayList\344\270\216HashSet\347\232\204\345\214\272\345\210\253/index.html"
+++ "b/2021/11/01/ArrayList\344\270\216HashSet\347\232\204\345\214\272\345\210\253/index.html"
@@ -222,7 +222,7 @@ ArrayList与Hashset
Hashset 具有去重的功能 利用size()方法可以得到里面元素的种类
ArrayList是有序的 元素可以重复
HashSet是无序不重复的
-575. 分糖果
1
2
3
4
5
6
7
class Solution {
public int distributeCandies(int[] candyType) {
Set<Integer> set = new HashSet<>();
for (int i : candyType) set.add(i);
return Math.min(candyType.length / 2, set.size());
}
}
+575. 分糖果
1
2
3
4
5
6
7
class Solution {
public int distributeCandies(int[] candyType) {
Set<Integer> set = new HashSet<>();
for (int i : candyType) set.add(i);
return Math.min(candyType.length / 2, set.size());
}
}
利用set去重,再用set.size()得到糖果的种类
创建ArrayList表
diff --git a/2021/11/01/leetcode_1221/index.html b/2021/11/01/leetcode_1221/index.html
index 6736cd2d8..1ac4e40a6 100644
--- a/2021/11/01/leetcode_1221/index.html
+++ b/2021/11/01/leetcode_1221/index.html
@@ -210,10 +210,10 @@
- 1221. 分割平衡字符串
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
在一个 平衡字符串 中,'L' 和 'R' 字符的数量是相同的。
给你一个平衡字符串 s,请你将它分割成尽可能多的平衡字符串。
注意:分割得到的每个字符串都必须是平衡字符串,且分割得到的平衡字符串是原平衡字符串的连续子串。
返回可以通过分割得到的平衡字符串的 最大数量 。
示例 1:
输入:s = "RLRRLLRLRL"
输出:4
解释:s 可以分割为 "RL"、"RRLL"、"RL"、"RL" ,每个子字符串中都包含相同数量的 'L' 和 'R' 。
示例 2:
输入:s = "RLLLLRRRLR"
输出:3
解释:s 可以分割为 "RL"、"LLLRRR"、"LR" ,每个子字符串中都包含相同数量的 'L' 和 'R' 。
示例 3:
输入:s = "LLLLRRRR"
输出:1
解释:s 只能保持原样 "LLLLRRRR".
示例 4:
输入:s = "RLRRRLLRLL"
输出:2
解释:s 可以分割为 "RL"、"RRRLLRLL" ,每个子字符串中都包含相同数量的 'L' 和 'R' 。
提示:
1 <= s.length <= 1000
s[i] = 'L' 或 'R'
s 是一个 平衡 字符串
+ 1221. 分割平衡字符串
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
在一个 平衡字符串 中,'L' 和 'R' 字符的数量是相同的。
给你一个平衡字符串 s,请你将它分割成尽可能多的平衡字符串。
注意:分割得到的每个字符串都必须是平衡字符串,且分割得到的平衡字符串是原平衡字符串的连续子串。
返回可以通过分割得到的平衡字符串的 最大数量 。
示例 1:
输入:s = "RLRRLLRLRL"
输出:4
解释:s 可以分割为 "RL"、"RRLL"、"RL"、"RL" ,每个子字符串中都包含相同数量的 'L' 和 'R' 。
示例 2:
输入:s = "RLLLLRRRLR"
输出:3
解释:s 可以分割为 "RL"、"LLLRRR"、"LR" ,每个子字符串中都包含相同数量的 'L' 和 'R' 。
示例 3:
输入:s = "LLLLRRRR"
输出:1
解释:s 只能保持原样 "LLLLRRRR".
示例 4:
输入:s = "RLRRRLLRLL"
输出:2
解释:s 可以分割为 "RL"、"RRRLLRLL" ,每个子字符串中都包含相同数量的 'L' 和 'R' 。
提示:
1 <= s.length <= 1000
s[i] = 'L' 或 'R'
s 是一个 平衡 字符串
题解
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
class Solution {
public int balancedStringSplit(String s) {
int n = s.length();
int j=0,ans=0;
for(int i = 0 ; i < n ; i++ )
{
if (s.charAt(i)=='R')
{
j++;
}
if (s.charAt(i)=='L')
{
j--;
}
if(j==0)
{
ans++;
}
}
return ans;
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
class Solution {
public int balancedStringSplit(String s) {
int n = s.length();
int j=0,ans=0;
for(int i = 0 ; i < n ; i++ )
{
if (s.charAt(i)=='R')
{
j++;
}
if (s.charAt(i)=='L')
{
j--;
}
if(j==0)
{
ans++;
}
}
return ans;
}
}
diff --git a/2021/11/01/leetcode_561/index.html b/2021/11/01/leetcode_561/index.html
index ad3136d1d..91807cbfa 100644
--- a/2021/11/01/leetcode_561/index.html
+++ b/2021/11/01/leetcode_561/index.html
@@ -210,10 +210,10 @@
- 561. 数组拆分 I
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
给定长度为 2n 的整数数组 nums ,你的任务是将这些数分成 n 对, 例如 (a1, b1), (a2, b2), ..., (an, bn) ,使得从 1 到 n 的 min(ai, bi) 总和最大。
返回该 最大总和 。
示例 1:
输入:nums = [1,4,3,2]
输出:4
解释:所有可能的分法(忽略元素顺序)为:
1. (1, 4), (2, 3) -> min(1, 4) + min(2, 3) = 1 + 2 = 3
2. (1, 3), (2, 4) -> min(1, 3) + min(2, 4) = 1 + 2 = 3
3. (1, 2), (3, 4) -> min(1, 2) + min(3, 4) = 1 + 3 = 4
所以最大总和为 4
示例 2:
输入:nums = [6,2,6,5,1,2]
输出:9
解释:最优的分法为 (2, 1), (2, 5), (6, 6). min(2, 1) + min(2, 5) + min(6, 6) = 1 + 2 + 6 = 9
+ 561. 数组拆分 I
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
给定长度为 2n 的整数数组 nums ,你的任务是将这些数分成 n 对, 例如 (a1, b1), (a2, b2), ..., (an, bn) ,使得从 1 到 n 的 min(ai, bi) 总和最大。
返回该 最大总和 。
示例 1:
输入:nums = [1,4,3,2]
输出:4
解释:所有可能的分法(忽略元素顺序)为:
1. (1, 4), (2, 3) -> min(1, 4) + min(2, 3) = 1 + 2 = 3
2. (1, 3), (2, 4) -> min(1, 3) + min(2, 4) = 1 + 2 = 3
3. (1, 2), (3, 4) -> min(1, 2) + min(3, 4) = 1 + 3 = 4
所以最大总和为 4
示例 2:
输入:nums = [6,2,6,5,1,2]
输出:9
解释:最优的分法为 (2, 1), (2, 5), (6, 6). min(2, 1) + min(2, 5) + min(6, 6) = 1 + 2 + 6 = 9
题解
-1
2
3
4
5
6
7
8
9
10
11
12
class Solution {
public int arrayPairSum(int[] nums) {
Arrays.sort(nums);
int n = nums.length;
int ans = 0;
for(int i = 0 ; i < n ; i+=2)
{
ans+=nums[i];
}
return ans;
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
class Solution {
public int arrayPairSum(int[] nums) {
Arrays.sort(nums);
int n = nums.length;
int ans = 0;
for(int i = 0 ; i < n ; i+=2)
{
ans+=nums[i];
}
return ans;
}
}
diff --git a/2021/11/01/leetcode_575/index.html b/2021/11/01/leetcode_575/index.html
index 3d1ce1434..8bf13b522 100644
--- a/2021/11/01/leetcode_575/index.html
+++ b/2021/11/01/leetcode_575/index.html
@@ -210,17 +210,17 @@
- 575. 分糖果
1
2
3
4
5
6
Alice 有 n 枚糖,其中第 i 枚糖的类型为 candyType[i] 。Alice 注意到她的体重正在增长,所以前去拜访了一位医生。
医生建议 Alice 要少摄入糖分,只吃掉她所有糖的 n / 2 即可(n 是一个偶数)。Alice 非常喜欢这些糖,她想要在遵循医生建议的情况下,尽可能吃到最多不同种类的糖。
给你一个长度为 n 的整数数组 candyType ,返回: Alice 在仅吃掉 n / 2 枚糖的情况下,可以吃到糖的最多种类数。
+ 575. 分糖果
1
2
3
4
5
6
Alice 有 n 枚糖,其中第 i 枚糖的类型为 candyType[i] 。Alice 注意到她的体重正在增长,所以前去拜访了一位医生。
医生建议 Alice 要少摄入糖分,只吃掉她所有糖的 n / 2 即可(n 是一个偶数)。Alice 非常喜欢这些糖,她想要在遵循医生建议的情况下,尽可能吃到最多不同种类的糖。
给你一个长度为 n 的整数数组 candyType ,返回: Alice 在仅吃掉 n / 2 枚糖的情况下,可以吃到糖的最多种类数。
示例 1:
-1
2
3
输入:candyType = [1,1,2,2,3,3]
输出:3
解释:Alice 只能吃 6 / 2 = 3 枚糖,由于只有 3 种糖,她可以每种吃一枚。
+1
2
3
输入:candyType = [1,1,2,2,3,3]
输出:3
解释:Alice 只能吃 6 / 2 = 3 枚糖,由于只有 3 种糖,她可以每种吃一枚。
示例 2:
-1
2
3
输入:candyType = [1,1,2,3]
输出:2
解释:Alice 只能吃 4 / 2 = 2 枚糖,不管她选择吃的种类是 [1,2]、[1,3] 还是 [2,3],她只能吃到两种不同类的糖。
+1
2
3
输入:candyType = [1,1,2,3]
输出:2
解释:Alice 只能吃 4 / 2 = 2 枚糖,不管她选择吃的种类是 [1,2]、[1,3] 还是 [2,3],她只能吃到两种不同类的糖。
-1
2
3
4
5
示例 3:
输入:candyType = [6,6,6,6]
输出:1
解释:Alice 只能吃 4 / 2 = 2 枚糖,尽管她能吃 2 枚,但只能吃到 1 种糖。
+1
2
3
4
5
示例 3:
输入:candyType = [6,6,6,6]
输出:1
解释:Alice 只能吃 4 / 2 = 2 枚糖,尽管她能吃 2 枚,但只能吃到 1 种糖。
-1
2
3
4
5
6
7
class Solution {
public int distributeCandies(int[] candyType) {
Set<Integer> set = new HashSet<>();
for (int i : candyType) set.add(i);
return Math.min(candyType.length / 2, set.size());
}
}
+1
2
3
4
5
6
7
class Solution {
public int distributeCandies(int[] candyType) {
Set<Integer> set = new HashSet<>();
for (int i : candyType) set.add(i);
return Math.min(candyType.length / 2, set.size());
}
}
diff --git "a/2021/11/02/java\345\256\236\347\216\260pdf\350\275\254\344\270\272\345\233\276\347\211\207/index.html" "b/2021/11/02/java\345\256\236\347\216\260pdf\350\275\254\344\270\272\345\233\276\347\211\207/index.html"
index 032db0d50..1544bddf6 100644
--- "a/2021/11/02/java\345\256\236\347\216\260pdf\350\275\254\344\270\272\345\233\276\347\211\207/index.html"
+++ "b/2021/11/02/java\345\256\236\347\216\260pdf\350\275\254\344\270\272\345\233\276\347\211\207/index.html"
@@ -218,18 +218,18 @@
[toc]Java实现pdf转为图片
首先创建一个maven工程 在pom.xml文件导入包的依赖
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
<dependencies>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>fontbox</artifactId>
<version>2.0.1</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.develouz.view/pdfreader -->
<!-- pdf水印 -->
<dependency>
<groupId>com.lowagie</groupId>
<artifactId>itext</artifactId>
<version>2.1.7</version>
</dependency>
</dependencies>>
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
<dependencies>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>fontbox</artifactId>
<version>2.0.1</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.develouz.view/pdfreader -->
<!-- pdf水印 -->
<dependency>
<groupId>com.lowagie</groupId>
<artifactId>itext</artifactId>
<version>2.1.7</version>
</dependency>
</dependencies>>
第二步 在Java路径下创建一个子类PDF2IMAGE
然后导入包
-1
2
3
4
5
6
7
8
9
10
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import javax.imageio.ImageIO;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.rendering.PDFRenderer;
import com.lowagie.text.pdf.PdfReader;
+1
2
3
4
5
6
7
8
9
10
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import javax.imageio.ImageIO;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.rendering.PDFRenderer;
import com.lowagie.text.pdf.PdfReader;
主体结构
-1
2
3
4
public class PDF2IMAGE {
public static void main(String[] args) {
pdf2Image("C:/Users/peng/Downloads/1.pdf", "D:/pdf2", 300);
}
+1
2
3
4
public class PDF2IMAGE {
public static void main(String[] args) {
pdf2Image("C:/Users/peng/Downloads/1.pdf", "D:/pdf2", 300);
}
主要利用pdf2Image方法
代码见下
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
public static void pdf2Image(String PdfFilePath, String dstImgFolder, int dpi) {
File file = new File(PdfFilePath);
PDDocument pdDocument;
try {
String imgPDFPath = file.getParent();
int dot = file.getName().lastIndexOf('.');
String imagePDFName = file.getName().substring(0, dot); // 获取图片文件名
String imgFolderPath = null;
if (dstImgFolder.equals("")) {
imgFolderPath = imgPDFPath + File.separator + imagePDFName;// 获取图片存放的文件夹路径
} else {
imgFolderPath = dstImgFolder + File.separator + imagePDFName;
}
if (createDirectory(imgFolderPath)) {
pdDocument = PDDocument.load(file);
PDFRenderer renderer = new PDFRenderer(pdDocument);
/* dpi越大转换后越清晰,相对转换速度越慢 */
PdfReader reader = new PdfReader(PdfFilePath);
int pages = reader.getNumberOfPages();
StringBuffer imgFilePath = null;
for (int i = 0; i < pages; i++) {
String imgFilePathPrefix = imgFolderPath + File.separator + imagePDFName;
imgFilePath = new StringBuffer();
imgFilePath.append(imgFilePathPrefix);
imgFilePath.append("_");
imgFilePath.append(String.valueOf(i + 1));
imgFilePath.append(".png");
File dstFile = new File(imgFilePath.toString());
BufferedImage image = renderer.renderImageWithDPI(i, dpi);
ImageIO.write(image, "png", dstFile);
}
System.out.println("PDF文档转PNG图片成功!");
} else {
System.out.println("PDF文档转PNG图片失败:" + "创建" + imgFolderPath + "失败");
}
} catch (IOException e) {
e.printStackTrace();
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
public static void pdf2Image(String PdfFilePath, String dstImgFolder, int dpi) {
File file = new File(PdfFilePath);
PDDocument pdDocument;
try {
String imgPDFPath = file.getParent();
int dot = file.getName().lastIndexOf('.');
String imagePDFName = file.getName().substring(0, dot); // 获取图片文件名
String imgFolderPath = null;
if (dstImgFolder.equals("")) {
imgFolderPath = imgPDFPath + File.separator + imagePDFName;// 获取图片存放的文件夹路径
} else {
imgFolderPath = dstImgFolder + File.separator + imagePDFName;
}
if (createDirectory(imgFolderPath)) {
pdDocument = PDDocument.load(file);
PDFRenderer renderer = new PDFRenderer(pdDocument);
/* dpi越大转换后越清晰,相对转换速度越慢 */
PdfReader reader = new PdfReader(PdfFilePath);
int pages = reader.getNumberOfPages();
StringBuffer imgFilePath = null;
for (int i = 0; i < pages; i++) {
String imgFilePathPrefix = imgFolderPath + File.separator + imagePDFName;
imgFilePath = new StringBuffer();
imgFilePath.append(imgFilePathPrefix);
imgFilePath.append("_");
imgFilePath.append(String.valueOf(i + 1));
imgFilePath.append(".png");
File dstFile = new File(imgFilePath.toString());
BufferedImage image = renderer.renderImageWithDPI(i, dpi);
ImageIO.write(image, "png", dstFile);
}
System.out.println("PDF文档转PNG图片成功!");
} else {
System.out.println("PDF文档转PNG图片失败:" + "创建" + imgFolderPath + "失败");
}
} catch (IOException e) {
e.printStackTrace();
}
}
diff --git "a/2021/11/02/pyautogui\346\214\202\345\256\236\351\252\214\345\256\244\346\227\266\351\225\277/index.html" "b/2021/11/02/pyautogui\346\214\202\345\256\236\351\252\214\345\256\244\346\227\266\351\225\277/index.html"
index 26b87ba04..8af58ed71 100644
--- "a/2021/11/02/pyautogui\346\214\202\345\256\236\351\252\214\345\256\244\346\227\266\351\225\277/index.html"
+++ "b/2021/11/02/pyautogui\346\214\202\345\256\236\351\252\214\345\256\244\346\227\266\351\225\277/index.html"
@@ -216,10 +216,10 @@
第一步
先导包
-1
2
3
import pyautogui
import time
+1
2
3
import pyautogui
import time
第二部写个for循环
-1
2
3
4
for i in range(0,100):
print(i)
pyautogui.click(1113,209, clicks=5,interval=1,duration=0.5)
time.sleep(298)
+1
2
3
4
for i in range(0,100):
print(i)
pyautogui.click(1113,209, clicks=5,interval=1,duration=0.5)
time.sleep(298)
github仓库源代码 https://github.com/fengxiaop/pyautogui
有用的话记得点个 star
diff --git a/2021/11/04/leetcode/index.html b/2021/11/04/leetcode/index.html
index ac5b5ff7d..dcd4f534c 100644
--- a/2021/11/04/leetcode/index.html
+++ b/2021/11/04/leetcode/index.html
@@ -220,24 +220,24 @@
第一次直接想的就是暴力遍历
-1
2
3
4
5
6
7
8
9
10
11
12
13
class Solution {
public boolean isPerfectSquare(int num) {
for(int i = 1 ;i <= num/2 ; i++)
{
if(i*i == num)
return true;
}
if(num == 1)
return true;
else
return false;
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
class Solution {
public boolean isPerfectSquare(int num) {
for(int i = 1 ;i <= num/2 ; i++)
{
if(i*i == num)
return true;
}
if(num == 1)
return true;
else
return false;
}
}
样例是全过了 但是超时了
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
class Solution {
public boolean isPerfectSquare(int num) {
for(int i = 1 ;i <= num/2 ; i++)
{
if(num / i == i && num % i == 0)
return true;
if (num / i < i) return false;
}
if(num == 1 ||num==4)
return true;
else
return false;
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
class Solution {
public boolean isPerfectSquare(int num) {
for(int i = 1 ;i <= num/2 ; i++)
{
if(num / i == i && num % i == 0)
return true;
if (num / i < i) return false;
}
if(num == 1 ||num==4)
return true;
else
return false;
}
}
后面参考评论区
速度是以除代乘 速度大大提升。
-1
2
3
4
5
6
7
8
class Solution {
public boolean isPerfectSquare(int num) {
for(int i = num / 2 + 1;i >= 1; i--){
if(num == i * i) return true;
}
return false;
}
}
+1
2
3
4
5
6
7
8
class Solution {
public boolean isPerfectSquare(int num) {
for(int i = num / 2 + 1;i >= 1; i--){
if(num == i * i) return true;
}
return false;
}
}
这是第一版的改进 从后面开始遍历 提升下速率 数越大越明显
二分法
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class Solution {
public boolean isPerfectSquare(int num) {
int low = 1;
int high = num;
while(low <= high){
int mid = low + (high - low) / 2;
int t = num / mid;
if(t == mid){
if(num % mid==0) return true;
low = mid+1;}
else if(t<mid)
{
high = mid-1;
}
else{
low = mid+1;
}
}
return false;
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class Solution {
public boolean isPerfectSquare(int num) {
int low = 1;
int high = num;
while(low <= high){
int mid = low + (high - low) / 2;
int t = num / mid;
if(t == mid){
if(num % mid==0) return true;
low = mid+1;}
else if(t<mid)
{
high = mid-1;
}
else{
low = mid+1;
}
}
return false;
}
}
数学方法
所有平方数都是可以由奇数和构成的
1=1 4=1+3 9=1+3+5
则只需要每次从1开始减 每次加2 以num>0为判断条件
-1
2
3
4
5
6
7
8
9
10
11
class Solution {
public boolean isPerfectSquare(int num) {
int ans=1;
while(num > 0)
{
num -= ans;
ans += 2;
}
return num==0;
}
}
+1
2
3
4
5
6
7
8
9
10
11
class Solution {
public boolean isPerfectSquare(int num) {
int ans=1;
while(num > 0)
{
num -= ans;
ans += 2;
}
return num==0;
}
}
diff --git "a/2021/11/08/Arrays\345\267\245\345\205\267\347\261\273/index.html" "b/2021/11/08/Arrays\345\267\245\345\205\267\347\261\273/index.html"
index 3690818f5..329d2dded 100644
--- "a/2021/11/08/Arrays\345\267\245\345\205\267\347\261\273/index.html"
+++ "b/2021/11/08/Arrays\345\267\245\345\205\267\347\261\273/index.html"
@@ -213,7 +213,7 @@
Arrays.sort(arr)
给数组arr排序
二分法查找的使用
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
package com.leetcode;
import java.util.Arrays;
public class ArraysTest {
public static void main(String[] args) {
int [] arr = {1,11,22,33,45,35};
Arrays.sort(arr);
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
int index = Arrays.binarySearch(arr,333);
System.out.println(index);
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
package com.leetcode;
import java.util.Arrays;
public class ArraysTest {
public static void main(String[] args) {
int [] arr = {1,11,22,33,45,35};
Arrays.sort(arr);
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
int index = Arrays.binarySearch(arr,333);
System.out.println(index);
}
}
diff --git "a/2021/11/08/Thread\347\261\273/index.html" "b/2021/11/08/Thread\347\261\273/index.html"
index cf825d74b..631aa7401 100644
--- "a/2021/11/08/Thread\347\261\273/index.html"
+++ "b/2021/11/08/Thread\347\261\273/index.html"
@@ -219,7 +219,7 @@
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
// 1. 创建一个继承于Thread类的子类
class MyThread1 extends Thread {
// 2. 重写Thread类的run()
@Override
public void run() {
for (int i = 0; i <= 100; i++) {
if (i % 2 == 0) {
System.out.println(Thread.currentThread().getName() + ": " + i);
}
}
}
}
public class ThreadTest1 {
public static void main(String[] args) {
// 3. 创建Thread类的子类的对象
MyThread1 t1 = new MyThread1();
t1.setName("线程1");
// 4.通过此对象调用start():
// ①启动当前线程 ② 调用当前线程的run()
t1.start();
// 再启动一个线程
MyThread1 t2 = new MyThread1();
t2.setName("线程2");
t2.start();
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
// 1. 创建一个继承于Thread类的子类
class MyThread1 extends Thread {
// 2. 重写Thread类的run()
public void run() {
for (int i = 0; i <= 100; i++) {
if (i % 2 == 0) {
System.out.println(Thread.currentThread().getName() + ": " + i);
}
}
}
}
public class ThreadTest1 {
public static void main(String[] args) {
// 3. 创建Thread类的子类的对象
MyThread1 t1 = new MyThread1();
t1.setName("线程1");
// 4.通过此对象调用start():
// ①启动当前线程 ② 调用当前线程的run()
t1.start();
// 再启动一个线程
MyThread1 t2 = new MyThread1();
t2.setName("线程2");
t2.start();
}
}
方式2:实现 Runnable 接口
创建步骤
1、创建一个实现了 Runnable 接口的类;
@@ -227,7 +227,7 @@
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
// 1. 创建一个实现了Runnable接口的类
class MyThread implements Runnable {
// 2. 实现类去实现Runnable中的抽象方法:run()
@Override
public void run() {
for (int i = 0; i < 100; i++) {
if (i % 2 == 0) {
System.out.println(Thread.currentThread().getName() + ": " +i);
}
}
}
}
public class ThreadTest {
public static void main(String[] args) {
// 3. 创建实现类的对象
MyThread myThread = new MyThread();
// 4. 将此对象作为参数传递到Thread类的构造器中,创建Thread类的对象
Thread t1 = new Thread(myThread);
t1.setName("线程1");
// 5. 通过Thread类的对象调用start():
// ① 启动线程 ②调用当前线程的run()-->调用了Runnable类型的target的run()
t1.start();
// 再启动一个线程:
Thread t2 = new Thread(myThread);
t2.setName("线程2");
t2.start();
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
// 1. 创建一个实现了Runnable接口的类
class MyThread implements Runnable {
// 2. 实现类去实现Runnable中的抽象方法:run()
public void run() {
for (int i = 0; i < 100; i++) {
if (i % 2 == 0) {
System.out.println(Thread.currentThread().getName() + ": " +i);
}
}
}
}
public class ThreadTest {
public static void main(String[] args) {
// 3. 创建实现类的对象
MyThread myThread = new MyThread();
// 4. 将此对象作为参数传递到Thread类的构造器中,创建Thread类的对象
Thread t1 = new Thread(myThread);
t1.setName("线程1");
// 5. 通过Thread类的对象调用start():
// ① 启动线程 ②调用当前线程的run()-->调用了Runnable类型的target的run()
t1.start();
// 再启动一个线程:
Thread t2 = new Thread(myThread);
t2.setName("线程2");
t2.start();
}
}
方式3:实现 Callable 接口
创建步骤
1、创建一个实现Callable接口的实现类;
@@ -235,14 +235,14 @@
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
// 1.创建一个实现Callable的实现类
class NumThread implements Callable<Integer> {
// 2.实现call方法,将此线程需要执行的操作声明在call()中
@Override
public Integer call() throws Exception {
int sum = 0;
for (int i = 0; i <=100; i++) {
if (i % 2 == 0) {
System.out.println(i);
sum += i;
}
}
return sum;
}
}
public class ThreadNew {
public static void main(String[] args) {
// 3.创建Callable接口实现类的对象
NumThread numThread = new NumThread();
// 4.将此Callable接口实现类的对象作为传递到FutureTask构造器中,创建FutureTask的对象
FutureTask<Integer> futureTask = new FutureTask<Integer>(numThread);
// 5.将FutureTask的对象作为参数传递到Thread类的构造器中,创建Thread对象,并调用start()
new Thread(futureTask).start();
try {
// 6.获取Callable中call方法的返回值
// get()返回值即为FutureTask构造器参数Callable实现类重写的call()的返回值。
Integer sum = futureTask.get();
System.out.println("总和为:" + sum);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
// 1.创建一个实现Callable的实现类
class NumThread implements Callable<Integer> {
// 2.实现call方法,将此线程需要执行的操作声明在call()中
public Integer call() throws Exception {
int sum = 0;
for (int i = 0; i <=100; i++) {
if (i % 2 == 0) {
System.out.println(i);
sum += i;
}
}
return sum;
}
}
public class ThreadNew {
public static void main(String[] args) {
// 3.创建Callable接口实现类的对象
NumThread numThread = new NumThread();
// 4.将此Callable接口实现类的对象作为传递到FutureTask构造器中,创建FutureTask的对象
FutureTask<Integer> futureTask = new FutureTask<Integer>(numThread);
// 5.将FutureTask的对象作为参数传递到Thread类的构造器中,创建Thread对象,并调用start()
new Thread(futureTask).start();
try {
// 6.获取Callable中call方法的返回值
// get()返回值即为FutureTask构造器参数Callable实现类重写的call()的返回值。
Integer sum = futureTask.get();
System.out.println("总和为:" + sum);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
方式4:使用线程池
创建步骤
1、提供指定线程数量的线程池;
2、设置线程池的属性;
3、执行指定的线程的操作。需要提供实现Runnable接口或Callable接口实现类的对象;
4、关闭连接池。
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
class NumberThread1 implements Runnable {
@Override
public void run() {
for (int i = 0; i <= 100; i++) {
if (i % 2 == 0) {
System.out.println(Thread.currentThread().getName() + ": " + i);
}
}
}
}
class NumberThread2 implements Runnable {
@Override
public void run() {
for (int i = 0; i <= 100; i++) {
if (i % 2 != 0) {
System.out.println(Thread.currentThread().getName() + ": " + i);
}
}
}
}
public class ThreadPoolTest {
public static void main(String[] args) {
//1.提供指定线程数量的线程池
ExecutorService service = Executors.newFixedThreadPool(10);
ThreadPoolExecutor service1 = (ThreadPoolExecutor) service;
//设置线程池的属性
// System.out.println(service.getClass());
// service1.setCorePoolSize(15);
// service1.setKeepAliveTime();
//2.执行指定的线程的操作。需要提供实现Runnable接口或Callable接口实现类的对象
service.execute(new NumberThread1());
service.execute(new NumberThread2());
//3.关闭连接池
service.shutdown();
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
class NumberThread1 implements Runnable {
public void run() {
for (int i = 0; i <= 100; i++) {
if (i % 2 == 0) {
System.out.println(Thread.currentThread().getName() + ": " + i);
}
}
}
}
class NumberThread2 implements Runnable {
public void run() {
for (int i = 0; i <= 100; i++) {
if (i % 2 != 0) {
System.out.println(Thread.currentThread().getName() + ": " + i);
}
}
}
}
public class ThreadPoolTest {
public static void main(String[] args) {
//1.提供指定线程数量的线程池
ExecutorService service = Executors.newFixedThreadPool(10);
ThreadPoolExecutor service1 = (ThreadPoolExecutor) service;
//设置线程池的属性
// System.out.println(service.getClass());
// service1.setCorePoolSize(15);
// service1.setKeepAliveTime();
//2.执行指定的线程的操作。需要提供实现Runnable接口或Callable接口实现类的对象
service.execute(new NumberThread1());
service.execute(new NumberThread2());
//3.关闭连接池
service.shutdown();
diff --git "a/2021/11/08/equals\344\270\216==\347\232\204\345\214\272\345\210\253/index.html" "b/2021/11/08/equals\344\270\216==\347\232\204\345\214\272\345\210\253/index.html"
index 57f59f17a..72f5c8636 100644
--- "a/2021/11/08/equals\344\270\216==\347\232\204\345\214\272\345\210\253/index.html"
+++ "b/2021/11/08/equals\344\270\216==\347\232\204\345\214\272\345\210\253/index.html"
@@ -214,13 +214,13 @@

String类中equals和==的区别
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
package com.leetcode;
public class StringTest {
public static void main(String[] args) {
String abc = "abc";
String cde = "abc";
String cda = new String("abc");
System.out.println(abc.equals(cde));
System.out.println(abc.equals(cda));
System.out.println(abc == cda);
System.out.println(abc==cde);
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
package com.leetcode;
public class StringTest {
public static void main(String[] args) {
String abc = "abc";
String cde = "abc";
String cda = new String("abc");
System.out.println(abc.equals(cde));
System.out.println(abc.equals(cda));
System.out.println(abc == cda);
System.out.println(abc==cde);
}
}
想一下答案

为什么呢
使用new对象的一定会在堆内存中开辟空间
-1
String abc = "abc";
+1
String abc = "abc";
使用这种方法会放入字符串池中
当已经存在时,不在开辟空间
diff --git "a/2021/11/10/\345\217\214\346\214\207\351\222\210/index.html" "b/2021/11/10/\345\217\214\346\214\207\351\222\210/index.html"
index e06a2c2b2..af50071b5 100644
--- "a/2021/11/10/\345\217\214\346\214\207\351\222\210/index.html"
+++ "b/2021/11/10/\345\217\214\346\214\207\351\222\210/index.html"
@@ -210,11 +210,11 @@
双指针
26. 删除有序数组中的重复项
这题典型的双指针 一个指针是用来遍历 另外一个用来存储
-1
2
3
4
5
6
7
8
9
10
11
12
13
class Solution {
public int removeDuplicates(int[] nums) {
int t = 0;
for (int i = 0; i < nums.length; i ++ ) {
if (i == 0 || nums[i] != nums[i - 1])
{
nums[t] = nums[i];
t++;
}
}
return t;
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
class Solution {
public int removeDuplicates(int[] nums) {
int t = 0;
for (int i = 0; i < nums.length; i ++ ) {
if (i == 0 || nums[i] != nums[i - 1])
{
nums[t] = nums[i];
t++;
}
}
return t;
}
}
i用来遍历数组 而t用来存储新的数组
通用解法拓展
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class Solution {
public int removeDuplicates(int[] nums) {
int n = nums.length;
if (n <= 1) return n;
return process(nums, 1, nums[n - 1]);
}
int process(int[] nums, int k, int max) {
int idx = 0;
for (int x : nums) {
if (idx < k || nums[idx - k] != x) nums[idx++] = x;
if (idx - k >= 0 && nums[idx - k] == max) break;
}
return idx;
}
}
作者:AC_OIer
链接:https://leetcode-cn.com/problems/remove-duplicates-from-sorted-array/solution/shua-chuan-lc-jian-ji-shuang-zhi-zhen-ji-2eg8/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class Solution {
public int removeDuplicates(int[] nums) {
int n = nums.length;
if (n <= 1) return n;
return process(nums, 1, nums[n - 1]);
}
int process(int[] nums, int k, int max) {
int idx = 0;
for (int x : nums) {
if (idx < k || nums[idx - k] != x) nums[idx++] = x;
if (idx - k >= 0 && nums[idx - k] == max) break;
}
return idx;
}
}
作者:AC_OIer
链接:https://leetcode-cn.com/problems/remove-duplicates-from-sorted-array/solution/shua-chuan-lc-jian-ji-shuang-zhi-zhen-ji-2eg8/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
diff --git "a/2021/11/11/pdf\345\212\240\346\260\264\345\215\260/index.html" "b/2021/11/11/pdf\345\212\240\346\260\264\345\215\260/index.html"
index f96cf5afc..9ba767459 100644
--- "a/2021/11/11/pdf\345\212\240\346\260\264\345\215\260/index.html"
+++ "b/2021/11/11/pdf\345\212\240\346\260\264\345\215\260/index.html"
@@ -211,10 +211,10 @@
首先导入依赖
-1
2
3
4
5
6
7
8
9
10
11
12
<!-- https://mvnrepository.com/artifact/com.itextpdf/itextpdf -->
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itextpdf</artifactId>
<version>5.5.13</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.lowagie/itext -->
<dependency>
<groupId>com.lowagie</groupId>
<artifactId>itext</artifactId>
<version>2.1.7</version>
</dependency>
+1
2
3
4
5
6
7
8
9
10
11
12
<!-- https://mvnrepository.com/artifact/com.itextpdf/itextpdf -->
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itextpdf</artifactId>
<version>5.5.13</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.lowagie/itext -->
<dependency>
<groupId>com.lowagie</groupId>
<artifactId>itext</artifactId>
<version>2.1.7</version>
</dependency>
代码如下
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
import java.awt.AlphaComposite;
import java.awt.Color;
import java.awt.Font;
import java.awt.Graphics2D;
import java.awt.Image;
import java.awt.RenderingHints;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.OutputStream;
import javax.imageio.ImageIO;
import javax.swing.ImageIcon;
/*******************************************************************************
* Description: 图片水印工具类
* @author zengshunyao
* @version 1.0
*/
public class ImageRemarkUtil {
// 水印透明度
private static float alpha = 0.5f;
// 水印横向位置
private static int positionWidth = 150;
// 水印纵向位置
private static int positionHeight = 300;
// 水印文字字体
private static Font font = new Font("宋体", Font.BOLD, 100);
// 水印文字颜色
private static Color color = Color.red;
/**
*
* @param alpha
* 水印透明度
* @param positionWidth
* 水印横向位置
* @param positionHeight
* 水印纵向位置
* @param font
* 水印文字字体
* @param color
* 水印文字颜色
*/
public static void setImageMarkOptions(float alpha, int positionWidth,
int positionHeight, Font font, Color color) {
if (alpha != 0.0f)
ImageRemarkUtil.alpha = alpha;
if (positionWidth != 0)
ImageRemarkUtil.positionWidth = positionWidth;
if (positionHeight != 0)
ImageRemarkUtil.positionHeight = positionHeight;
if (font != null)
ImageRemarkUtil.font = font;
if (color != null)
ImageRemarkUtil.color = color;
}
/**
* 给图片添加水印图片
*
* @param iconPath
* 水印图片路径
* @param srcImgPath
* 源图片路径
* @param targerPath
* 目标图片路径
*/
public static void markImageByIcon(String iconPath, String srcImgPath,
String targerPath) {
markImageByIcon(iconPath, srcImgPath, targerPath, null);
}
/**
* 给图片添加水印图片、可设置水印图片旋转角度
*
* @param iconPath
* 水印图片路径
* @param srcImgPath
* 源图片路径
* @param targerPath
* 目标图片路径
* @param degree
* 水印图片旋转角度
*/
public static void markImageByIcon(String iconPath, String srcImgPath,
String targerPath, Integer degree) {
OutputStream os = null;
try {
Image srcImg = ImageIO.read(new File(srcImgPath));
BufferedImage buffImg = new BufferedImage(srcImg.getWidth(null),
srcImg.getHeight(null), BufferedImage.TYPE_INT_RGB);
// 1、得到画笔对象
Graphics2D g = buffImg.createGraphics();
// 2、设置对线段的锯齿状边缘处理
g.setRenderingHint(RenderingHints.KEY_INTERPOLATION,
RenderingHints.VALUE_INTERPOLATION_BILINEAR);
g.drawImage(
srcImg.getScaledInstance(srcImg.getWidth(null),
srcImg.getHeight(null), Image.SCALE_SMOOTH), 0, 0,
null);
// 3、设置水印旋转
if (null != degree) {
g.rotate(Math.toRadians(degree),
(double) buffImg.getWidth() / 2,
(double) buffImg.getHeight() / 2);
}
// 4、水印图片的路径 水印图片一般为gif或者png的,这样可设置透明度
ImageIcon imgIcon = new ImageIcon(iconPath);
// 5、得到Image对象。
Image img = imgIcon.getImage();
g.setComposite(AlphaComposite.getInstance(AlphaComposite.SRC_ATOP,
alpha));
// 6、水印图片的位置
g.drawImage(img, positionWidth, positionHeight, null);
g.setComposite(AlphaComposite.getInstance(AlphaComposite.SRC_OVER));
// 7、释放资源
g.dispose();
// 8、生成图片
os = new FileOutputStream(targerPath);
ImageIO.write(buffImg, "JPG", os);
System.out.println("图片完成添加水印图片");
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (null != os)
os.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
/**
* 给图片添加水印文字
*
* @param logoText
* 水印文字
* @param srcImgPath
* 源图片路径
* @param targerPath
* 目标图片路径
*/
public static void markImageByText(String logoText, String srcImgPath,
String targerPath) {
markImageByText(logoText, srcImgPath, targerPath, null);
}
/**
* 给图片添加水印文字、可设置水印文字的旋转角度
*
* @param logoText
* @param srcImgPath
* @param targerPath
* @param degree
*/
public static void markImageByText(String logoText, String srcImgPath,
String targerPath, Integer degree) {
InputStream is = null;
OutputStream os = null;
try {
// 1、源图片
Image srcImg = ImageIO.read(new File(srcImgPath));
BufferedImage buffImg = new BufferedImage(srcImg.getWidth(null),
srcImg.getHeight(null), BufferedImage.TYPE_INT_RGB);
// 2、得到画笔对象
Graphics2D g = buffImg.createGraphics();
// 3、设置对线段的锯齿状边缘处理
g.setRenderingHint(RenderingHints.KEY_INTERPOLATION,
RenderingHints.VALUE_INTERPOLATION_BILINEAR);
g.drawImage(
srcImg.getScaledInstance(srcImg.getWidth(null),
srcImg.getHeight(null), Image.SCALE_SMOOTH), 0, 0,
null);
// 4、设置水印旋转
if (null != degree) {
g.rotate(Math.toRadians(degree),
(double) buffImg.getWidth() / 2,
(double) buffImg.getHeight() / 2);
}
// 5、设置水印文字颜色
g.setColor(color);
// 6、设置水印文字Font
g.setFont(font);
// 7、设置水印文字透明度
g.setComposite(AlphaComposite.getInstance(AlphaComposite.SRC_ATOP,
alpha));
// 8、第一参数->设置的内容,后面两个参数->文字在图片上的坐标位置(x,y)
g.drawString(logoText, positionWidth, positionHeight);
// 9、释放资源
g.dispose();
// 10、生成图片
os = new FileOutputStream(targerPath);
ImageIO.write(buffImg, "JPG", os);
System.out.println("图片完成添加水印文字");
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (null != is)
is.close();
} catch (Exception e) {
e.printStackTrace();
}
try {
if (null != os)
os.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
String logoText = "三 年 一 梦";
String iconPath = "D:/pdf/dp/dp_1.png";
String targerTextPath2 = "d:/qie_text_rotate.jpg";
String targerIconPath = "d:/qie_icon.jpg";
String targerIconPath2 = "d:/qie_icon_rotate.jpg";
System.out.println("给图片添加水印文字开始...");
for (int i = 1; i < 10; i++) {
String srcImgPath = "D:/pdf/1/1_"+i+".png";
String targerTextPath = "d:/水印/qie_text"+i+".jpg";
// 给图片添加水印文字
markImageByText(logoText, srcImgPath, targerTextPath);
// 给图片添加水印文字,水印文字旋转-45
//markImageByText(logoText, srcImgPath, targerTextPath2, -45);
}
System.out.println("给图片添加水印文字结束...");
//System.out.println("给图片添加水印图片开始...");
//setImageMarkOptions(0.3f, 1, 1, null, null);
// 给图片添加水印图片
//markImageByIcon(iconPath, srcImgPath, targerIconPath);
// 给图片添加水印图片,水印图片旋转-45
//markImageByIcon(iconPath, srcImgPath, targerIconPath2, -45);
//System.out.println("给图片添加水印图片结束...");
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
import java.awt.AlphaComposite;
import java.awt.Color;
import java.awt.Font;
import java.awt.Graphics2D;
import java.awt.Image;
import java.awt.RenderingHints;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.OutputStream;
import javax.imageio.ImageIO;
import javax.swing.ImageIcon;
/*******************************************************************************
* Description: 图片水印工具类
* @author zengshunyao
* @version 1.0
*/
public class ImageRemarkUtil {
// 水印透明度
private static float alpha = 0.5f;
// 水印横向位置
private static int positionWidth = 150;
// 水印纵向位置
private static int positionHeight = 300;
// 水印文字字体
private static Font font = new Font("宋体", Font.BOLD, 100);
// 水印文字颜色
private static Color color = Color.red;
/**
*
* @param alpha
* 水印透明度
* @param positionWidth
* 水印横向位置
* @param positionHeight
* 水印纵向位置
* @param font
* 水印文字字体
* @param color
* 水印文字颜色
*/
public static void setImageMarkOptions(float alpha, int positionWidth,
int positionHeight, Font font, Color color) {
if (alpha != 0.0f)
ImageRemarkUtil.alpha = alpha;
if (positionWidth != 0)
ImageRemarkUtil.positionWidth = positionWidth;
if (positionHeight != 0)
ImageRemarkUtil.positionHeight = positionHeight;
if (font != null)
ImageRemarkUtil.font = font;
if (color != null)
ImageRemarkUtil.color = color;
}
/**
* 给图片添加水印图片
*
* @param iconPath
* 水印图片路径
* @param srcImgPath
* 源图片路径
* @param targerPath
* 目标图片路径
*/
public static void markImageByIcon(String iconPath, String srcImgPath,
String targerPath) {
markImageByIcon(iconPath, srcImgPath, targerPath, null);
}
/**
* 给图片添加水印图片、可设置水印图片旋转角度
*
* @param iconPath
* 水印图片路径
* @param srcImgPath
* 源图片路径
* @param targerPath
* 目标图片路径
* @param degree
* 水印图片旋转角度
*/
public static void markImageByIcon(String iconPath, String srcImgPath,
String targerPath, Integer degree) {
OutputStream os = null;
try {
Image srcImg = ImageIO.read(new File(srcImgPath));
BufferedImage buffImg = new BufferedImage(srcImg.getWidth(null),
srcImg.getHeight(null), BufferedImage.TYPE_INT_RGB);
// 1、得到画笔对象
Graphics2D g = buffImg.createGraphics();
// 2、设置对线段的锯齿状边缘处理
g.setRenderingHint(RenderingHints.KEY_INTERPOLATION,
RenderingHints.VALUE_INTERPOLATION_BILINEAR);
g.drawImage(
srcImg.getScaledInstance(srcImg.getWidth(null),
srcImg.getHeight(null), Image.SCALE_SMOOTH), 0, 0,
null);
// 3、设置水印旋转
if (null != degree) {
g.rotate(Math.toRadians(degree),
(double) buffImg.getWidth() / 2,
(double) buffImg.getHeight() / 2);
}
// 4、水印图片的路径 水印图片一般为gif或者png的,这样可设置透明度
ImageIcon imgIcon = new ImageIcon(iconPath);
// 5、得到Image对象。
Image img = imgIcon.getImage();
g.setComposite(AlphaComposite.getInstance(AlphaComposite.SRC_ATOP,
alpha));
// 6、水印图片的位置
g.drawImage(img, positionWidth, positionHeight, null);
g.setComposite(AlphaComposite.getInstance(AlphaComposite.SRC_OVER));
// 7、释放资源
g.dispose();
// 8、生成图片
os = new FileOutputStream(targerPath);
ImageIO.write(buffImg, "JPG", os);
System.out.println("图片完成添加水印图片");
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (null != os)
os.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
/**
* 给图片添加水印文字
*
* @param logoText
* 水印文字
* @param srcImgPath
* 源图片路径
* @param targerPath
* 目标图片路径
*/
public static void markImageByText(String logoText, String srcImgPath,
String targerPath) {
markImageByText(logoText, srcImgPath, targerPath, null);
}
/**
* 给图片添加水印文字、可设置水印文字的旋转角度
*
* @param logoText
* @param srcImgPath
* @param targerPath
* @param degree
*/
public static void markImageByText(String logoText, String srcImgPath,
String targerPath, Integer degree) {
InputStream is = null;
OutputStream os = null;
try {
// 1、源图片
Image srcImg = ImageIO.read(new File(srcImgPath));
BufferedImage buffImg = new BufferedImage(srcImg.getWidth(null),
srcImg.getHeight(null), BufferedImage.TYPE_INT_RGB);
// 2、得到画笔对象
Graphics2D g = buffImg.createGraphics();
// 3、设置对线段的锯齿状边缘处理
g.setRenderingHint(RenderingHints.KEY_INTERPOLATION,
RenderingHints.VALUE_INTERPOLATION_BILINEAR);
g.drawImage(
srcImg.getScaledInstance(srcImg.getWidth(null),
srcImg.getHeight(null), Image.SCALE_SMOOTH), 0, 0,
null);
// 4、设置水印旋转
if (null != degree) {
g.rotate(Math.toRadians(degree),
(double) buffImg.getWidth() / 2,
(double) buffImg.getHeight() / 2);
}
// 5、设置水印文字颜色
g.setColor(color);
// 6、设置水印文字Font
g.setFont(font);
// 7、设置水印文字透明度
g.setComposite(AlphaComposite.getInstance(AlphaComposite.SRC_ATOP,
alpha));
// 8、第一参数->设置的内容,后面两个参数->文字在图片上的坐标位置(x,y)
g.drawString(logoText, positionWidth, positionHeight);
// 9、释放资源
g.dispose();
// 10、生成图片
os = new FileOutputStream(targerPath);
ImageIO.write(buffImg, "JPG", os);
System.out.println("图片完成添加水印文字");
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (null != is)
is.close();
} catch (Exception e) {
e.printStackTrace();
}
try {
if (null != os)
os.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
String logoText = "三 年 一 梦";
String iconPath = "D:/pdf/dp/dp_1.png";
String targerTextPath2 = "d:/qie_text_rotate.jpg";
String targerIconPath = "d:/qie_icon.jpg";
String targerIconPath2 = "d:/qie_icon_rotate.jpg";
System.out.println("给图片添加水印文字开始...");
for (int i = 1; i < 10; i++) {
String srcImgPath = "D:/pdf/1/1_"+i+".png";
String targerTextPath = "d:/水印/qie_text"+i+".jpg";
// 给图片添加水印文字
markImageByText(logoText, srcImgPath, targerTextPath);
// 给图片添加水印文字,水印文字旋转-45
//markImageByText(logoText, srcImgPath, targerTextPath2, -45);
}
System.out.println("给图片添加水印文字结束...");
//System.out.println("给图片添加水印图片开始...");
//setImageMarkOptions(0.3f, 1, 1, null, null);
// 给图片添加水印图片
//markImageByIcon(iconPath, srcImgPath, targerIconPath);
// 给图片添加水印图片,水印图片旋转-45
//markImageByIcon(iconPath, srcImgPath, targerIconPath2, -45);
//System.out.println("给图片添加水印图片结束...");
}
}
diff --git "a/2021/11/15/pdf\346\260\264\345\215\260\351\241\271\347\233\256\345\210\233\345\273\272/index.html" "b/2021/11/15/pdf\346\260\264\345\215\260\351\241\271\347\233\256\345\210\233\345\273\272/index.html"
index 7403de80f..e60e1c5f6 100644
--- "a/2021/11/15/pdf\346\260\264\345\215\260\351\241\271\347\233\256\345\210\233\345\273\272/index.html"
+++ "b/2021/11/15/pdf\346\260\264\345\215\260\351\241\271\347\233\256\345\210\233\345\273\272/index.html"
@@ -222,17 +222,17 @@
所需要的工具 一台服务器 一个可以编译jar的java环境 nginx用来正向代理
xshell连接服务器
安装java环境
-1
yum install java-1.8.0-openjdk
+1
yum install java-1.8.0-openjdk
查看java是否安装好
-1
java -version
+1
java -version
创建自己项目的路径并且cd到该路径
-1
2
mkdir java
cd java
+1
2
mkdir java
cd java
用命令让他跑起来
Linux启动
-1
2
3
4
5
6
nohup java -jar pdf-service-0.0.1-SNAPSHOT.jar
--host=http://161.117.229.248/
--pdfPassword=2021 --footerDesc=\u9875\u811a\u6587\u5b57
--watermarkPic=https://www.wwei.cn/yasuotu/images/logo.png
--basicUrl=tmp/resources/static/pdf/
--location=10,10,30,30 > nohup.out 2>&1 &
+1
2
3
4
5
6
nohup java -jar pdf-service-0.0.1-SNAPSHOT.jar
--host=http://161.117.229.248/
--pdfPassword=2021 --footerDesc=\u9875\u811a\u6587\u5b57
--watermarkPic=https://www.wwei.cn/yasuotu/images/logo.png
--basicUrl=tmp/resources/static/pdf/
--location=10,10,30,30 > nohup.out 2>&1 &
这里注意把它copy去浏览器 变成一行去粘贴 这里只是方便看的参数的意义
Linux查看日志
tail -f nohup.out
diff --git "a/2021/11/17/nginx\345\222\214servelt/index.html" "b/2021/11/17/nginx\345\222\214servelt/index.html"
index 30f36175d..bdc32132d 100644
--- "a/2021/11/17/nginx\345\222\214servelt/index.html"
+++ "b/2021/11/17/nginx\345\222\214servelt/index.html"
@@ -214,7 +214,7 @@
最近遇见了ip+端口转换为域名的问题
本来我用境外服务器可以直接用80端口 用起来也很方便 不用备案啥的 但是就是太容易挂了
所以下定决心撸了个腾讯云的服务器
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
# For more information on configuration, see:
# * Official English Documentation: http://nginx.org/en/docs/
# * Official Russian Documentation: http://nginx.org/ru/docs/
user root;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
# Load dynamic modules. See /usr/share/nginx/README.dynamic.
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 1024;
}
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 2048;
include /etc/nginx/mime.types;
default_type application/octet-stream;
# Load modular configuration files from the /etc/nginx/conf.d directory.
# See http://nginx.org/en/docs/ngx_core_module.html#include
# for more information.
include /etc/nginx/conf.d/*.conf;
server {
listen 8080 default_server;
listen [::]:8080 default_server;
server_name www.sy.huttop.top;
root /root/java/; #修改为root /data/www;
include /etc/nginx/default.d/*.conf;
location / {
}
error_page 404 /404.html;
location = /40x.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}
server {
listen 8888 default_server;
listen [::]:8888 default_server;
server_name www.huttop.top;
root /root/zhuye/; #修改为root /data/www;
include /etc/nginx/default.d/*.conf;
location / {
}
error_page 404 /404.html;
location = /40x.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
# For more information on configuration, see:
# * Official English Documentation: http://nginx.org/en/docs/
# * Official Russian Documentation: http://nginx.org/ru/docs/
user root;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
# Load dynamic modules. See /usr/share/nginx/README.dynamic.
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 1024;
}
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 2048;
include /etc/nginx/mime.types;
default_type application/octet-stream;
# Load modular configuration files from the /etc/nginx/conf.d directory.
# See http://nginx.org/en/docs/ngx_core_module.html#include
# for more information.
include /etc/nginx/conf.d/*.conf;
server {
listen 8080 default_server;
listen [::]:8080 default_server;
server_name www.sy.huttop.top;
root /root/java/; #修改为root /data/www;
include /etc/nginx/default.d/*.conf;
location / {
}
error_page 404 /404.html;
location = /40x.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}
server {
listen 8888 default_server;
listen [::]:8888 default_server;
server_name www.huttop.top;
root /root/zhuye/; #修改为root /data/www;
include /etc/nginx/default.d/*.conf;
location / {
}
error_page 404 /404.html;
location = /40x.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}
}
这是配置文件
diff --git "a/2021/11/19/springboot\347\250\213\345\272\217/index.html" "b/2021/11/19/springboot\347\250\213\345\272\217/index.html"
index c57fa3037..e9ff80e52 100644
--- "a/2021/11/19/springboot\347\250\213\345\272\217/index.html"
+++ "b/2021/11/19/springboot\347\250\213\345\272\217/index.html"
@@ -225,14 +225,14 @@
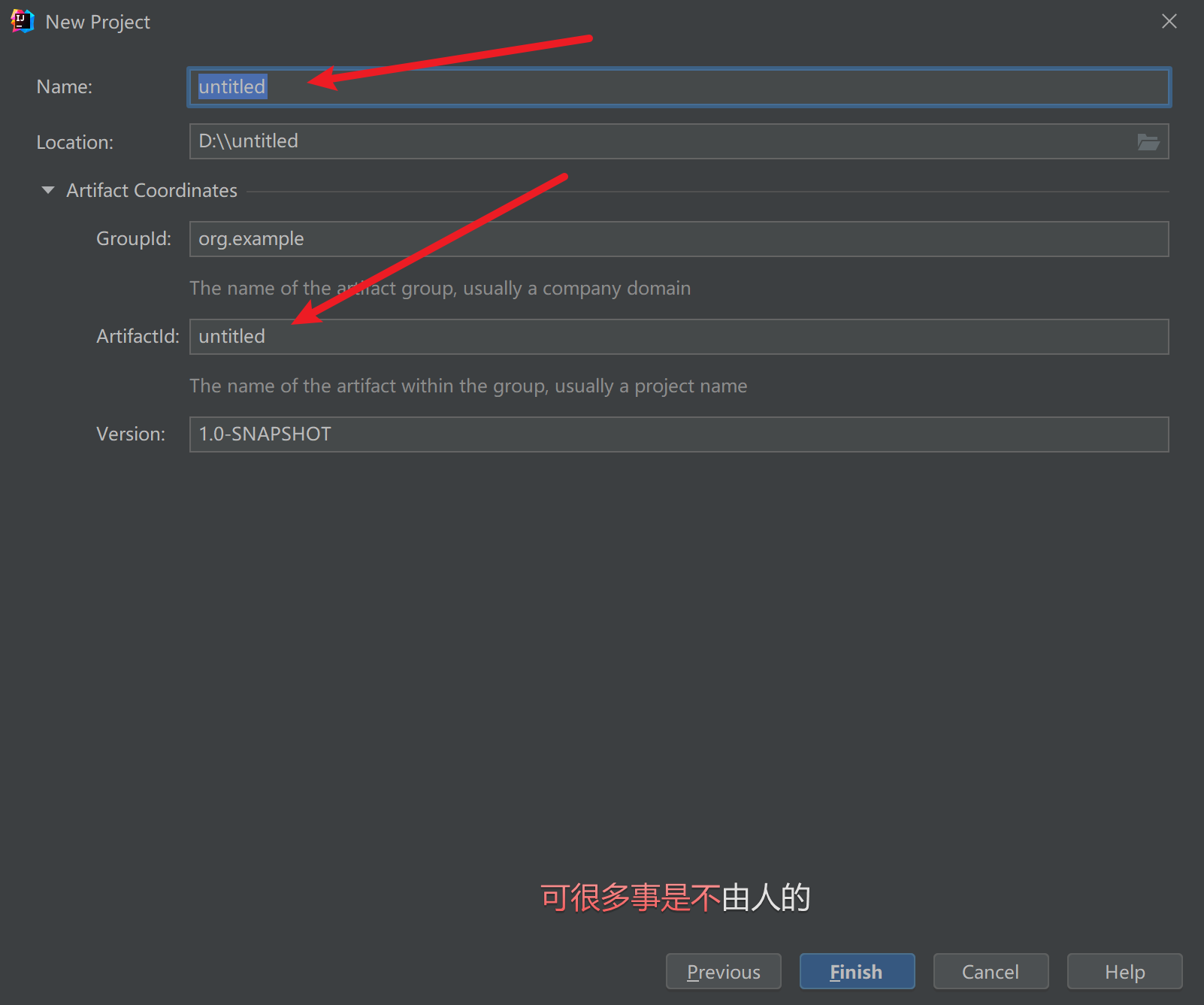
新建一个包boot
在boot包下创建一个类 MainApplication
-1
2
3
4
5
6
7
8
9
10
11
12
package org.example.boot;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class MainApplication {
public static void main(String[] args) {
SpringApplication.run(MainApplication.class,args);
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
package org.example.boot;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
public class MainApplication {
public static void main(String[] args) {
SpringApplication.run(MainApplication.class,args);
}
}
点击pom.xml 进行导包
-1
2
3
4
5
6
7
8
9
10
11
12
13
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.4.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
+1
2
3
4
5
6
7
8
9
10
11
12
13
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.4.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
建立controller层
创建了类HelloController
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
package org.example.boot.Controller;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class HelloController {
@RequestMapping("/hello")
public String hello01(){
return "第一个springboot hello ";
System.out.println("Springboot程序启动成功");
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
package org.example.boot.Controller;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
public class HelloController {
public String hello01(){
return "第一个springboot hello ";
System.out.println("Springboot程序启动成功");
}
}
点击启动MainApplication
diff --git "a/2021/11/22/java\345\210\267\351\242\230\346\250\241\347\211\210/index.html" "b/2021/11/22/java\345\210\267\351\242\230\346\250\241\347\211\210/index.html"
index 814c968d1..f05e1194c 100644
--- "a/2021/11/22/java\345\210\267\351\242\230\346\250\241\347\211\210/index.html"
+++ "b/2021/11/22/java\345\210\267\351\242\230\346\250\241\347\211\210/index.html"
@@ -211,70 +211,70 @@
数据输入
一般我常用的数据输入方法有两种,Scanner和BufferedReader。BufferedReader可以读一行,速度比Scanner快,所以数据较多的时候使用。注意BufferedReader用完记得关。
Scanner
-1
2
3
4
5
6
7
8
9
10
11
12
import java.util.*;
public class Main{
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
int n = scan.nextInt(); // String: next(), double: nextDouble()
int[] nums = new int[n];
for (int i = 0; i < n; i++)
nums[i] = scan.nextInt();
// ...
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
import java.util.*;
public class Main{
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
int n = scan.nextInt(); // String: next(), double: nextDouble()
int[] nums = new int[n];
for (int i = 0; i < n; i++)
nums[i] = scan.nextInt();
// ...
}
}
BufferedReader
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import java.util.*;
import java.io.*;
public class Main{
public static void main(String[] args) throws IOException {
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(reader.readLine());
int[] nums = new int[n];
String[] strs = reader.readLine().split(" ");
for (int i = 0; i < n; i++)
nums[i] = Integer.parseInt(strs[i]);
// ...
reader.close(); // 记得关闭
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import java.util.*;
import java.io.*;
public class Main{
public static void main(String[] args) throws IOException {
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(reader.readLine());
int[] nums = new int[n];
String[] strs = reader.readLine().split(" ");
for (int i = 0; i < n; i++)
nums[i] = Integer.parseInt(strs[i]);
// ...
reader.close(); // 记得关闭
}
}
快速排序quickSort
快速排序要注意x取值的边界情况。取x = nums[left], nums分为[left, j]和[j + 1, right],或x = nums[right], nums分为[left, i - 1]和[i, right],否则会StackOverflow。
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public void quickSort(int[] nums, int left, int right) {
if (left >= right)
return;
int i = left - 1, j = right + 1, x = nums[left];
while (i < j) {
do i++; while (nums[i] < x);
do j--; while (nums[j] > x);
if (i < j) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
}
quickSort(nums, left, j);
quickSort(nums, j + 1, right);
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public void quickSort(int[] nums, int left, int right) {
if (left >= right)
return;
int i = left - 1, j = right + 1, x = nums[left];
while (i < j) {
do i++; while (nums[i] < x);
do j--; while (nums[j] > x);
if (i < j) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
}
quickSort(nums, left, j);
quickSort(nums, j + 1, right);
}
例题:AcWing 785, LeetCode 912
归并排序mergeSort
mergeSort时间复杂度是稳定O(nlogn),空间复杂度O(n),稳定的。quickSort时间复杂度平均O(nlogn),最坏O(n^2),最好O(nlogn),空间复杂度O(nlogn),不稳定的。
public void mergeSort(int[] nums, int left, int right) {
if (left >= right)
return;
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
int mid = left + (right - left) / 2;
mergeSort(nums, left, mid);
mergeSort(nums, mid + 1, right);
int k = 0, i = left, j = mid + 1;
int[] temp = new int[right - left + 1];
while (i <= mid && j <= right)
if (nums[i] < nums[j])
temp[k++] = nums[i++];
else
temp[k++] = nums[j++];
while (i <= mid)
temp[k++] = nums[i++];
while (j <= right)
temp[k++] = nums[j++];
for (i = left, j = 0; i <= right; i++, j++)
nums[i] = temp[j];
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
int mid = left + (right - left) / 2;
mergeSort(nums, left, mid);
mergeSort(nums, mid + 1, right);
int k = 0, i = left, j = mid + 1;
int[] temp = new int[right - left + 1];
while (i <= mid && j <= right)
if (nums[i] < nums[j])
temp[k++] = nums[i++];
else
temp[k++] = nums[j++];
while (i <= mid)
temp[k++] = nums[i++];
while (j <= right)
temp[k++] = nums[j++];
for (i = left, j = 0; i <= right; i++, j++)
nums[i] = temp[j];
}
例题:AcWing 787, LeetCode 912
二分搜索binarySearch
二分搜索逼近左边界,区间[left, right]被分为左区间[left, mid]和右区间[mid + 1, right]。
-1
2
3
4
5
6
7
8
9
10
11
public int binarySearchLeft(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while (left < right) {
int mid = left + (right - left) / 2;
if (check(mid))
right = mid;
else
left = mid + 1;
}
return nums[left];
}
+1
2
3
4
5
6
7
8
9
10
11
public int binarySearchLeft(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while (left < right) {
int mid = left + (right - left) / 2;
if (check(mid))
right = mid;
else
left = mid + 1;
}
return nums[left];
}
二分搜索逼近右边界,区间[left, right]被分为左区间[left, mid - 1]和右区间[mid, right]。
-1
2
3
4
5
6
7
8
9
10
11
public int binarySearchRight(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while (left < right) {
int mid = left + (right - left) / 2 + 1;
if (check(mid))
left = mid;
else
right = mid - 1;
}
return nums[left];
}
+1
2
3
4
5
6
7
8
9
10
11
public int binarySearchRight(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while (left < right) {
int mid = left + (right - left) / 2 + 1;
if (check(mid))
left = mid;
else
right = mid - 1;
}
return nums[left];
}
暑假在LeetCode打卡的时候发现还有第三种模板,nums[mid] == target 直接return,区间[left, right]被分为[left, mid - 1]和[mid + 1, right]。
-1
2
3
4
5
6
7
8
9
10
11
12
13
public int searchInsert(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target)
return mid;
else if (check(mid))
right = mid - 1;
else
left = mid + 1;
}
return left;
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
public int searchInsert(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target)
return mid;
else if (check(mid))
right = mid - 1;
else
left = mid + 1;
}
return left;
}
例题:AcWing 789, LeetCode 34, LeetCode 35
KMP
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public int kmp(String text, String pattern) {
int m = pattern.length();
if (m == 0)
return 0;
int n = text.length();
int[] next = new int[m + 1];
for (int i = 2, j = 0; i <= m; i++) {
while (j > 0 && pattern.charAt(i - 1) != pattern.charAt(j))
j = next[j];
if (pattern.charAt(i - 1) == pattern.charAt(j))
j++;
next[i] = j;
}
for (int i = 1, j = 0; i <= n; i++) {
while (j > 0 && text.charAt(i - 1) != pattern.charAt(j))
j = next[j];
if (text.charAt(i - 1) == pattern.charAt(j))
j++;
if (j == m)
return i - m;
}
return -1;
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public int kmp(String text, String pattern) {
int m = pattern.length();
if (m == 0)
return 0;
int n = text.length();
int[] next = new int[m + 1];
for (int i = 2, j = 0; i <= m; i++) {
while (j > 0 && pattern.charAt(i - 1) != pattern.charAt(j))
j = next[j];
if (pattern.charAt(i - 1) == pattern.charAt(j))
j++;
next[i] = j;
}
for (int i = 1, j = 0; i <= n; i++) {
while (j > 0 && text.charAt(i - 1) != pattern.charAt(j))
j = next[j];
if (text.charAt(i - 1) == pattern.charAt(j))
j++;
if (j == m)
return i - m;
}
return -1;
}
例题:AcWing 831, LeetCode 28
Trie
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
public static final int SIZE = 26;
public static class TrieNode {
TrieNode[] children = new TrieNode[SIZE];
int times;
TrieNode() {
times = 0;
for (int i = 0; i < SIZE; i++)
children[i] = null;
}
}
public static TrieNode root = new TrieNode();
public static void insert(String word) {
TrieNode node = root;
for (int i = 0; i < word.length(); i++) {
int index = word.charAt(i) - 'a';
if (node.children[index] == null)
node.children[index] = new TrieNode();
node = node.children[index];
}
node.times++;
}
public static int query(String word) {
TrieNode node = root;
for (int i = 0; i < word.length(); i++) {
int index = word.charAt(i) - 'a';
if (node.children[index] == null)
return 0;
node = node.children[index];
}
return node.times;
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
public static final int SIZE = 26;
public static class TrieNode {
TrieNode[] children = new TrieNode[SIZE];
int times;
TrieNode() {
times = 0;
for (int i = 0; i < SIZE; i++)
children[i] = null;
}
}
public static TrieNode root = new TrieNode();
public static void insert(String word) {
TrieNode node = root;
for (int i = 0; i < word.length(); i++) {
int index = word.charAt(i) - 'a';
if (node.children[index] == null)
node.children[index] = new TrieNode();
node = node.children[index];
}
node.times++;
}
public static int query(String word) {
TrieNode node = root;
for (int i = 0; i < word.length(); i++) {
int index = word.charAt(i) - 'a';
if (node.children[index] == null)
return 0;
node = node.children[index];
}
return node.times;
}
例题:AcWing 835
并查集
朴素并查集
-1
2
3
4
5
6
7
8
9
public static int[] p;
public static int find(int x) {
if (p[x] != x)
p[x] = find(p[x]);
return p[x];
}
p[find(a)] = find(b);
+1
2
3
4
5
6
7
8
9
public static int[] p;
public static int find(int x) {
if (p[x] != x)
p[x] = find(p[x]);
return p[x];
}
p[find(a)] = find(b);
例题:AcWing 836
图的存储
n个点,m条边,m约等于n2n2叫做稠密图,用邻接矩阵存储;n个点,m条边,m远小于n2n2叫做稀疏图,用邻接表存储。
邻接矩阵
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
public class Main{
public static final int INF = 0x3f3f3f3f;
public static int n;
public static int[][] g;
public static int[] dist;
public static boolean[] visit;
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
n = scan.nextInt();
int m = scan.nextInt();
g = new int[n + 1][n + 1];
dist = new int[n + 1];
visit = new boolean[n + 1];
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++)
if (i == j)
g[i][j] = 0;
else
g[i][j] = INF;
for (int i = 0; i < m; i++) {
int x = scan.nextInt(), y = scan.nextInt(), z = scan.nextInt();
g[a][b] = Math.min(g[a][b], c);
}
int res = dijkstra();
System.out.println(res);
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
public class Main{
public static final int INF = 0x3f3f3f3f;
public static int n;
public static int[][] g;
public static int[] dist;
public static boolean[] visit;
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
n = scan.nextInt();
int m = scan.nextInt();
g = new int[n + 1][n + 1];
dist = new int[n + 1];
visit = new boolean[n + 1];
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++)
if (i == j)
g[i][j] = 0;
else
g[i][j] = INF;
for (int i = 0; i < m; i++) {
int x = scan.nextInt(), y = scan.nextInt(), z = scan.nextInt();
g[a][b] = Math.min(g[a][b], c);
}
int res = dijkstra();
System.out.println(res);
}
}
邻接表
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
import java.util.*;
public class Main{
public static int INF = 0x3f3f3f3f;
public static int n;
public static Map<Integer, List<Node>> map = new HashMap<>();
public static int[] dist;
public static boolean[] visit;
public static class Node {
public int node;
public int length;
public Node(int node, int length) {
this.node = node;
this.length = length;
}
}
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
n = scan.nextInt();
dist = new int[n + 1];
visit = new boolean[n + 1];
int m = scan.nextInt();
for (int i = 1; i <= n; i++)
map.put(i, new ArrayList<>());
for (int i = 0; i < m; i++) {
int x = scan.nextInt(), y = scan.nextInt(), z = scan.nextInt();
map.get(x).add(new Node(y, z));
}
int res = dijkstra();
System.out.println(res);
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
import java.util.*;
public class Main{
public static int INF = 0x3f3f3f3f;
public static int n;
public static Map<Integer, List<Node>> map = new HashMap<>();
public static int[] dist;
public static boolean[] visit;
public static class Node {
public int node;
public int length;
public Node(int node, int length) {
this.node = node;
this.length = length;
}
}
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
n = scan.nextInt();
dist = new int[n + 1];
visit = new boolean[n + 1];
int m = scan.nextInt();
for (int i = 1; i <= n; i++)
map.put(i, new ArrayList<>());
for (int i = 0; i < m; i++) {
int x = scan.nextInt(), y = scan.nextInt(), z = scan.nextInt();
map.get(x).add(new Node(y, z));
}
int res = dijkstra();
System.out.println(res);
}
}
Dijkstra
边权不能是负数!
1.dist[1] = 0, dist[i] = +∞
2.for i 1 ~ n
t <- 不在s中的,距离最近的点 – n2n2 / n
s <- t – n
用t更新其他点的距离 – m / mlogn
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public static int dijkstra() {
for (int i = 1; i <= n; i++)
dist[i] = INF;
dist[1] = 0;
for (int i = 0; i < n - 1; i++) {
int t = -1;
for (int j = 1; j <= n; j++)
if (!visit[j] && (t == -1 || dist[t] > dist[j]))
t = j;
if (t == n)
break;
for (int j = 1; j <= n; j++)
dist[j] = Math.min(dist[j], dist[t] + g[t][j]);
visit[t] = true;
}
if (dist[n] == INF)
return -1;
return dist[n];
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public static int dijkstra() {
for (int i = 1; i <= n; i++)
dist[i] = INF;
dist[1] = 0;
for (int i = 0; i < n - 1; i++) {
int t = -1;
for (int j = 1; j <= n; j++)
if (!visit[j] && (t == -1 || dist[t] > dist[j]))
t = j;
if (t == n)
break;
for (int j = 1; j <= n; j++)
dist[j] = Math.min(dist[j], dist[t] + g[t][j]);
visit[t] = true;
}
if (dist[n] == INF)
return -1;
return dist[n];
}
例题:AcWing 849
优化Dijkstra
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
public static int dijkstra() {
for (int i = 1; i <= n; i++)
dist[i] = INF;
dist[1] = 0;
PriorityQueue<Node> heap = new PriorityQueue<>((node1, node2) -> node1.length - node2.length);
heap.add(new Node(1, 0));
while (!heap.isEmpty()) {
Node top = heap.poll();
int length = top.length, cur = top.node;
if (visit[cur])
continue;
visit[cur] = true;
for (Node next: map.get(cur)) {
int node = next.node, cost = next.length;
if (dist[node] > length + cost) {
dist[node] = length + cost;
heap.add(new Node(node, dist[node]));
}
}
}
if (dist[n] == INF)
return -1;
return dist[n];
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
public static int dijkstra() {
for (int i = 1; i <= n; i++)
dist[i] = INF;
dist[1] = 0;
PriorityQueue<Node> heap = new PriorityQueue<>((node1, node2) -> node1.length - node2.length);
heap.add(new Node(1, 0));
while (!heap.isEmpty()) {
Node top = heap.poll();
int length = top.length, cur = top.node;
if (visit[cur])
continue;
visit[cur] = true;
for (Node next: map.get(cur)) {
int node = next.node, cost = next.length;
if (dist[node] > length + cost) {
dist[node] = length + cost;
heap.add(new Node(node, dist[node]));
}
}
}
if (dist[n] == INF)
return -1;
return dist[n];
}
例题:AcWing 850
Bellman-ford
O(nm)
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public static int bellman_ford() {
for (int i = 1; i <= n; i++)
dist[i] = INF;
dist[1] = 0;
for (int i = 0; i < k; i++) {
for (int j = 1; j <= n; j++)
backup[j] = dist[j]; // deep copy
for (int k = 0; k < m; k++) {
int x = edges[k].x;
int y = edges[k].y;
int z = edges[k].z;
dist[y] = Math.min(dist[y], backup[x] + z);
}
}
if (dist[n] > INF / 2)
return -1;
else
return dist[n];
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public static int bellman_ford() {
for (int i = 1; i <= n; i++)
dist[i] = INF;
dist[1] = 0;
for (int i = 0; i < k; i++) {
for (int j = 1; j <= n; j++)
backup[j] = dist[j]; // deep copy
for (int k = 0; k < m; k++) {
int x = edges[k].x;
int y = edges[k].y;
int z = edges[k].z;
dist[y] = Math.min(dist[y], backup[x] + z);
}
}
if (dist[n] > INF / 2)
return -1;
else
return dist[n];
}
例题:AcWing 853
SPFA (队列优化的Bellman-ford算法)
一般O(m),最坏O(nm)。n表示点数,m表示边数。
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public static int spfa() {
for (int i = 1; i <= n; i++)
dist[i] = INF;
dist[1] = 0;
Queue<Integer> queue = new LinkedList<>();
queue.add(1);
visit[1] = true;
while (!queue.isEmpty()) {
int t = queue.poll();
visit[t] = false;
for (Node cur: map.get(t)) {
int node = cur.node, length = cur.length;
if (dist[node] > dist[t] + length) {
dist[node] = dist[t] + length;
if (!visit[node]) {
queue.add(node);
visit[node] = true;
}
}
}
}
return dist[n];
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public static int spfa() {
for (int i = 1; i <= n; i++)
dist[i] = INF;
dist[1] = 0;
Queue<Integer> queue = new LinkedList<>();
queue.add(1);
visit[1] = true;
while (!queue.isEmpty()) {
int t = queue.poll();
visit[t] = false;
for (Node cur: map.get(t)) {
int node = cur.node, length = cur.length;
if (dist[node] > dist[t] + length) {
dist[node] = dist[t] + length;
if (!visit[node]) {
queue.add(node);
visit[node] = true;
}
}
}
}
return dist[n];
}
例题:AcWing 851
SPFA 判断图中是否存在负环
O(nm),n表示点数,m表示边数。
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
public static boolean spfa() {
Queue<Integer> queue = new LinkedList<>();
for (int i = 1; i <= n; i++) {
queue.add(i);
visit[i] = true;
}
while (!queue.isEmpty()) {
int t = queue.poll();
visit[t] = false;
for (Node cur: map.get(t)) {
int node = cur.node, length = cur.length;
if (dist[node] > dist[t] + length) {
dist[node] = dist[t] + length;
count[node] = count[t] + 1;
if (count[node] >= n)
return true;
if (!visit[node]) {
queue.add(node);
visit[node] = true;
}
}
}
}
return false;
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
public static boolean spfa() {
Queue<Integer> queue = new LinkedList<>();
for (int i = 1; i <= n; i++) {
queue.add(i);
visit[i] = true;
}
while (!queue.isEmpty()) {
int t = queue.poll();
visit[t] = false;
for (Node cur: map.get(t)) {
int node = cur.node, length = cur.length;
if (dist[node] > dist[t] + length) {
dist[node] = dist[t] + length;
count[node] = count[t] + 1;
if (count[node] >= n)
return true;
if (!visit[node]) {
queue.add(node);
visit[node] = true;
}
}
}
}
return false;
}
例题:AcWing 852
Floyd
O(n3)O(n3)
-1
2
3
4
5
6
7
public static void floyd() {
for (int k = 1; k <= n; k++)
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++)
d[i][j] = Math.min(d[i][j], d[i][k] + d[k][j]);
}
+1
2
3
4
5
6
7
public static void floyd() {
for (int k = 1; k <= n; k++)
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++)
d[i][j] = Math.min(d[i][j], d[i][k] + d[k][j]);
}
例题:AcWing 854
作者:Lic
链接:https://www.acwing.com/file_system/file/content/whole/index/content/5873/
来源:AcWing
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
diff --git "a/2021/11/23/\345\237\272\344\272\216BigInteger\347\232\204\345\206\231\351\242\230/index.html" "b/2021/11/23/\345\237\272\344\272\216BigInteger\347\232\204\345\206\231\351\242\230/index.html"
index d6cbd7d03..c317927bc 100644
--- "a/2021/11/23/\345\237\272\344\272\216BigInteger\347\232\204\345\206\231\351\242\230/index.html"
+++ "b/2021/11/23/\345\237\272\344\272\216BigInteger\347\232\204\345\206\231\351\242\230/index.html"
@@ -218,11 +218,11 @@
题目其实很容易 但是这个输入卡的人傻了
用nextInt() nextLong()都会爆
后面我写的是字符串
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
import java.util.Scanner;
class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt();
for (int i = 0; i < n; i++) {
String s = scanner.next();
int m = s.length();
if(m == 1){
int k = s.charAt(0)-'0';
if(k%8==0) System.out.println("yes");
else System.out.println("no");
}
else if(m==2)
{
int q = s.charAt(0)-'0';
int w = s.charAt(1)-'0';
int k = q*10+w;
if(k%8==0) System.out.println("yes");
else System.out.println("no");
}
else if (m == 3) {
int q = s.charAt(0)-'0';
int w = s.charAt(1)-'0';
int e = s.charAt(2)-'0';
int k = q*100+w*10+e;
if (k % 8 == 0) System.out.println("yes");
else System.out.println("no");
} else if(m > 3) {
int st = s.charAt(m - 1) - '0';
int st1 = s.charAt(m - 2) - '0';
int st2 = s.charAt(m - 3) - '0';
int ans = st + st1*10 + st2*100;
if (ans % 8 == 0) System.out.println("yes");
else System.out.println("no");
}
}
scanner.close();
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
import java.util.Scanner;
class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt();
for (int i = 0; i < n; i++) {
String s = scanner.next();
int m = s.length();
if(m == 1){
int k = s.charAt(0)-'0';
if(k%8==0) System.out.println("yes");
else System.out.println("no");
}
else if(m==2)
{
int q = s.charAt(0)-'0';
int w = s.charAt(1)-'0';
int k = q*10+w;
if(k%8==0) System.out.println("yes");
else System.out.println("no");
}
else if (m == 3) {
int q = s.charAt(0)-'0';
int w = s.charAt(1)-'0';
int e = s.charAt(2)-'0';
int k = q*100+w*10+e;
if (k % 8 == 0) System.out.println("yes");
else System.out.println("no");
} else if(m > 3) {
int st = s.charAt(m - 1) - '0';
int st1 = s.charAt(m - 2) - '0';
int st2 = s.charAt(m - 3) - '0';
int ans = st + st1*10 + st2*100;
if (ans % 8 == 0) System.out.println("yes");
else System.out.println("no");
}
}
scanner.close();
}
}
刚开始 判断k的位数是1位是 我用的判定条件是 if(k == 8) 漏了k==0的这种情况 0也是0的倍数
看了一位学弟的代码 让我尤为惊人
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import java.math.BigInteger;
import java.util.Scanner;
public class B {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt();
BigInteger a = scanner.nextBigInteger();
BigInteger b=new BigInteger("8");
BigInteger c=BigInteger.ZERO;
if(a.mod(b)==c) System.out.println("yes");
else System.out.println("no");
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import java.math.BigInteger;
import java.util.Scanner;
public class B {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt();
BigInteger a = scanner.nextBigInteger();
BigInteger b=new BigInteger("8");
BigInteger c=BigInteger.ZERO;
if(a.mod(b)==c) System.out.println("yes");
else System.out.println("no");
}
}
青出如蓝 让我觉得学弟学妹太优秀了
diff --git "a/2021/11/25/PDF\346\260\264\345\215\260demo/index.html" "b/2021/11/25/PDF\346\260\264\345\215\260demo/index.html"
index cc637dc33..95afc514b 100644
--- "a/2021/11/25/PDF\346\260\264\345\215\260demo/index.html"
+++ "b/2021/11/25/PDF\346\260\264\345\215\260demo/index.html"
@@ -217,7 +217,7 @@
第一步创建一个Application类 加上@SpringBootApplication的注解
打印控制台消息
System.out.println("SpringBoot启动成功");
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
package com.example;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
System.out.println("SpringBoot启动成功");
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
package com.example;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
System.out.println("SpringBoot启动成功");
}
}
水印程序
@@ -226,12 +226,12 @@
文件序号 index
文件路径 path
构造有参无参
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
{
/**
* 文件序号
*/
private Integer index;
/**
* 文件路径
*/
private String path;
public Integer getIndex() {
return index;
}
public void setIndex(Integer index) {
this.index = index;
}
public String getPath() {
return path;
}
public void setPath(String path) {
this.path = path;
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
{
/**
* 文件序号
*/
private Integer index;
/**
* 文件路径
*/
private String path;
public Integer getIndex() {
return index;
}
public void setIndex(Integer index) {
this.index = index;
}
public String getPath() {
return path;
}
public void setPath(String path) {
this.path = path;
}
}
PDF拆分为image
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
package com.example.pdfwatermark;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.rendering.ImageType;
import org.apache.pdfbox.rendering.PDFRenderer;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.*;
import java.util.ArrayList;
import java.util.List;
public class Pdf2Image {
/**
* 将File PDF文件转化为每一张图片
* @param file PDF文件
* @return 返回每一张图片的实体对象集合
*/
public static List<FileDTO> generate(File file) {
try {
Long now = System.currentTimeMillis();
//读取PDF
PDDocument document = PDDocument.load(file);
//加载PDF对象
PDFRenderer pdfRenderer = new PDFRenderer(document);
//存储的PDF每一张图片的路径以及索引
List<FileDTO> dataList = new ArrayList<>();
for (int page = 0;page<document.getNumberOfPages();page++){
//读取PDF每一页的图片
BufferedImage img = pdfRenderer.renderImageWithDPI(page, 300, ImageType.RGB);
//生成图片的本地路径
String pathname = PdfWatermarkConstants.PDF_2_IMAGE + now + "/" + file.getName() + page + ".png";
//创建本地文件
File imageFile = new File(pathname);
//创建文件夹
imageFile.mkdirs();
//创建文件
imageFile.createNewFile();
FileDTO dto = new FileDTO();
dataList.add(dto);
dto.setIndex(page);
dto.setPath(pathname);
//生成PNG格式的图片
ImageIO.write(img, "png", imageFile);
}
//关闭Doc流
document.close();
return dataList;
} catch (Exception e) {
e.printStackTrace();
}
return new ArrayList<>();
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
package com.example.pdfwatermark;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.rendering.ImageType;
import org.apache.pdfbox.rendering.PDFRenderer;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.*;
import java.util.ArrayList;
import java.util.List;
public class Pdf2Image {
/**
* 将File PDF文件转化为每一张图片
* @param file PDF文件
* @return 返回每一张图片的实体对象集合
*/
public static List<FileDTO> generate(File file) {
try {
Long now = System.currentTimeMillis();
//读取PDF
PDDocument document = PDDocument.load(file);
//加载PDF对象
PDFRenderer pdfRenderer = new PDFRenderer(document);
//存储的PDF每一张图片的路径以及索引
List<FileDTO> dataList = new ArrayList<>();
for (int page = 0;page<document.getNumberOfPages();page++){
//读取PDF每一页的图片
BufferedImage img = pdfRenderer.renderImageWithDPI(page, 300, ImageType.RGB);
//生成图片的本地路径
String pathname = PdfWatermarkConstants.PDF_2_IMAGE + now + "/" + file.getName() + page + ".png";
//创建本地文件
File imageFile = new File(pathname);
//创建文件夹
imageFile.mkdirs();
//创建文件
imageFile.createNewFile();
FileDTO dto = new FileDTO();
dataList.add(dto);
dto.setIndex(page);
dto.setPath(pathname);
//生成PNG格式的图片
ImageIO.write(img, "png", imageFile);
}
//关闭Doc流
document.close();
return dataList;
} catch (Exception e) {
e.printStackTrace();
}
return new ArrayList<>();
}
}
diff --git "a/2021/11/28/\346\226\260\347\224\237\350\265\233/index.html" "b/2021/11/28/\346\226\260\347\224\237\350\265\233/index.html"
index 54cb988ec..c751029f5 100644
--- "a/2021/11/28/\346\226\260\347\224\237\350\265\233/index.html"
+++ "b/2021/11/28/\346\226\260\347\224\237\350\265\233/index.html"
@@ -212,10 +212,10 @@
L. 恭喜edg夺得S11冠军
纯属签到题 细致一点就好了
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
#include<stdio.h>
int main(){
printf("EDGNBEDGNBEDGNBEDGNBEDGNBEDGNBEDGNB\n");
printf("EDGNBEDGNBEDGNBEDGNBEDGNBEDGNBEDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf("EDGNB");
return 0;
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
int main(){
printf("EDGNBEDGNBEDGNBEDGNBEDGNBEDGNBEDGNB\n");
printf("EDGNBEDGNBEDGNBEDGNBEDGNBEDGNBEDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf(" EDGNB\n");
printf("EDGNB");
return 0;
}
A. 阳阳姐的魔力数
描述
对于我们的出色的冒险者阳阳姐来说,魔力数对他有奇特的作用,能在战斗中助他一臂之力,所以他知道的魔力数越多越好,但是令他头疼的是,他不知道范围NN之内的自然数有多少个魔力数,于是他向你求助,你能帮帮他吗。 一个自然数有魔力,当且仅当这个自然数数可以由两个相同的自然数拼接起来,比如”2020”这个数字就是由两个”20”拼接而成,但是”2002”却不是魔力数,因为”20”和”02”是两个不同的数字。
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
import java.util.*;
class Main{
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
long n = scan.nextLong();
long sum =0;
String s = n+"";
String[] str = {"9","99","999","9999","99999","999999","9999999","99999999","999999999","9999999999"};
int m = s.length();
int k = m/2;
if(n<100){
if(n<11) System.out.print(0);
else if(n<22) System.out.print(1);
else if(n<33) System.out.print(2);
else if(n<44) System.out.print(3);
else if(n<55) System.out.print(4);
else if(n<66) System.out.print(5);
else if(n<77) System.out.print(6);
else if(n<88) System.out.print(7);
else if(n<99) System.out.print(8);
else if(n==99) System.out.print(9);
}
else{
if(m%2==1)
{
System.out.print(str[k-1]);
}
else{
String string ="";
String string1 ="";
for(int i = 0,j=k;i < k;i++,j++)
{
String t = s.charAt(i)+"";
String t1 = s.charAt(j)+"";
string = string+t;
string1 = string1+t1;
}
int a = Integer.parseInt(string);
int b = Integer.parseInt(string1);
if(a<=b)
{int q = (int) (Integer.parseInt(string)-Math.pow(10,(m/2)-1)+1);
int p = Integer.parseInt(str[(m/2)-2]);
System.out.print(q+p);}
else{
int q = (int) (Integer.parseInt(string)-Math.pow(10, (m/2)-1));
int p = Integer.parseInt(str[(m/2)-2]);
System.out.print(q+p);
}
}
}
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
import java.util.*;
class Main{
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
long n = scan.nextLong();
long sum =0;
String s = n+"";
String[] str = {"9","99","999","9999","99999","999999","9999999","99999999","999999999","9999999999"};
int m = s.length();
int k = m/2;
if(n<100){
if(n<11) System.out.print(0);
else if(n<22) System.out.print(1);
else if(n<33) System.out.print(2);
else if(n<44) System.out.print(3);
else if(n<55) System.out.print(4);
else if(n<66) System.out.print(5);
else if(n<77) System.out.print(6);
else if(n<88) System.out.print(7);
else if(n<99) System.out.print(8);
else if(n==99) System.out.print(9);
}
else{
if(m%2==1)
{
System.out.print(str[k-1]);
}
else{
String string ="";
String string1 ="";
for(int i = 0,j=k;i < k;i++,j++)
{
String t = s.charAt(i)+"";
String t1 = s.charAt(j)+"";
string = string+t;
string1 = string1+t1;
}
int a = Integer.parseInt(string);
int b = Integer.parseInt(string1);
if(a<=b)
{int q = (int) (Integer.parseInt(string)-Math.pow(10,(m/2)-1)+1);
int p = Integer.parseInt(str[(m/2)-2]);
System.out.print(q+p);}
else{
int q = (int) (Integer.parseInt(string)-Math.pow(10, (m/2)-1));
int p = Integer.parseInt(str[(m/2)-2]);
System.out.print(q+p);
}
}
}
}
}
这题有着更好的方法 纯数学题 我直接吧所有情况考虑上了
奇数位的时候为固定数 不满足魔力数
@@ -224,7 +224,7 @@
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
import java.util.*;
class Main{
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
int n = scan.nextInt();
String s = scan.next();
if(n < 10){ System.out.print("Yuuki is unhappy");}
else{
int l = 0,r=10;
while(r <=n)
{
int p=0,q=0;
for(;l<r;l++){
if(s.charAt(l)=='a') p++;
else q++;
}
if(p==5&&q==5) {System.out.println(r-9+" "+r);
break;}
else {
r++;
l = r-10;
}
}
if(r > n) System.out.print("Yuuki is unhappy");
}
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
import java.util.*;
class Main{
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
int n = scan.nextInt();
String s = scan.next();
if(n < 10){ System.out.print("Yuuki is unhappy");}
else{
int l = 0,r=10;
while(r <=n)
{
int p=0,q=0;
for(;l<r;l++){
if(s.charAt(l)=='a') p++;
else q++;
}
if(p==5&&q==5) {System.out.println(r-9+" "+r);
break;}
else {
r++;
l = r-10;
}
}
if(r > n) System.out.print("Yuuki is unhappy");
}
}
}
这题卡回车
卡了半个小时 挺恶心的 。。。。
@@ -241,23 +241,23 @@ 输出第一行输出能否到达目的地。
如果能,输出”YES”(不包含引号),否则输出”NO“(不包含引号)。
如果能够到达目的地,在第二行输出所需的最小步数,定义每一步为坐标加一或者减一。
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
import java.util.*;
class Main{
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
int n = scan.nextInt();
long []arr = new long[2];
long []arr2 = new long[2];
for(int i = 0;i < n;i++)
{
arr[0] = scan.nextLong();
arr[1] = scan.nextLong();
arr2[0] = scan.nextLong();
arr2[1] = scan.nextLong();
long x = Math.abs(arr[0]-arr2[0]);
long y = Math.abs(arr[1]-arr2[1]);
long z = Math.min(x, y);
long sum = z*2;
long p = Math.max(x,y);
p = p-z;
if(p%2==0) sum = sum + p*2;
else sum = sum +(p*2)-1;
System.out.println("YES");
System.out.println(sum);
}
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
import java.util.*;
class Main{
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
int n = scan.nextInt();
long []arr = new long[2];
long []arr2 = new long[2];
for(int i = 0;i < n;i++)
{
arr[0] = scan.nextLong();
arr[1] = scan.nextLong();
arr2[0] = scan.nextLong();
arr2[1] = scan.nextLong();
long x = Math.abs(arr[0]-arr2[0]);
long y = Math.abs(arr[1]-arr2[1]);
long z = Math.min(x, y);
long sum = z*2;
long p = Math.max(x,y);
p = p-z;
if(p%2==0) sum = sum + p*2;
else sum = sum +(p*2)-1;
System.out.println("YES");
System.out.println(sum);
}
}
}
单纯的模拟题 只是这里就需要回车了 卡的我头大了
K. 樊学长的馈赠
描述
fzx学长是一位非常厉害的老学长,他在备战考研时依旧挂念着我们的小萌新们,于是他特意给大家出了一道有意思的题目:
在茫茫大海中有n座独立的岛屿,岛上生活着一些淳朴善良的村民。
但是有一天,大海上出现了一群可怕的海盗,海盗们虽然不敢直接攻击岛屿,但是会在海上等待他们出来捕鱼,然后趁机袭击他们。
村民们为了抵御海盗,决定与其他岛屿结成攻守同盟,现在你需要为他们规划航线,使得n个岛屿形成一个整体(从任意一个岛屿出发,都能到达其他的n-1个岛屿)。
但是由于村民们没有接受过现代化的教育,所以他们看不懂你画的航线图,所以你只能告诉他们要设立一些航线,村民们会随机选择两个之前没有建立过航线的岛屿,在两个岛屿之间建立一条航线。
但是设立航线也是很麻烦的事情,为了尽快组成同盟抵御海盗,你需要找到一个最小的航线数量m,确保n个岛屿一定能形成一个整体。
***注意:一条航线可以看作连接两个岛屿**u**和*v*的一条边,相同的两个岛屿之间不会有重复的航线,同时也不会有岛屿规划到自己本身的航线*
输入
第一行输入一个整数t(t\leq 5 \times 10^5)t(t≤5×105),代表有tt个样例。
每组样例有一行,输入一个整数n(1 < n \leq 10^9)n(1<n≤109),代表有nn个独立的岛屿。
输出
每个样例输出一行,一行包含一个正整数mm代表生成的航线数量。
-样例
输入复制
1
2
1
3
+样例
输入复制
1
2
1
3
-输出复制
1
2
+输出复制
1
2
-输入复制
1
2
3
2
4
5
+输入复制
1
2
3
2
4
5
-输出复制
1
2
4
7
+输出复制
1
2
4
7
-输入复制
1
2
1
65536
+输入复制
1
2
1
65536
-输出复制
1
2147385346
+输出复制
1
2147385346
这题看题目根本没用 直接撸样例 还是能够通过65536和2147385346
后者的位数是前者的两倍
diff --git "a/2021/12/01/\351\233\206\345\220\210/index.html" "b/2021/12/01/\351\233\206\345\220\210/index.html"
index 16267f5ef..11cf518ed 100644
--- "a/2021/12/01/\351\233\206\345\220\210/index.html"
+++ "b/2021/12/01/\351\233\206\345\220\210/index.html"
@@ -254,10 +254,10 @@
Interator为对象 可以用hasNext和next
hasNext下一个是不是还有
next下一个
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public class Main {
public static void main(String[] args){
ArrayList list = new ArrayList();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
list.add(4);
list.add(3);
list.add(2);
list.add(1);
Iterator iterator = list.iterator();
while (iterator.hasNext())
{
System.out.println(iterator.next());
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public class Main {
public static void main(String[] args){
ArrayList list = new ArrayList();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
list.add(4);
list.add(3);
list.add(2);
list.add(1);
Iterator iterator = list.iterator();
while (iterator.hasNext())
{
System.out.println(iterator.next());
}
}
输出顺序也就是输入的顺序
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
package com.HUToh;
import java.io.BufferedInputStream;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.* ;
public class Main {
public static void main(String[] args){
Set list = new HashSet();
list.add(1);
list.add(2);
list.add(3);
list.add(5);
list.add(4);
list.add(4);
list.add(3);
list.add(2);
list.add(1);
Iterator iterator = list.iterator();
while (iterator.hasNext())
{
System.out.println(iterator.next());
}
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
package com.HUToh;
import java.io.BufferedInputStream;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.* ;
public class Main {
public static void main(String[] args){
Set list = new HashSet();
list.add(1);
list.add(2);
list.add(3);
list.add(5);
list.add(4);
list.add(4);
list.add(3);
list.add(2);
list.add(1);
Iterator iterator = list.iterator();
while (iterator.hasNext())
{
System.out.println(iterator.next());
}
}
}
输出顺序和输入顺序并不一样
所以说Set是无序的 而且Set是不重复的
diff --git "a/2021/12/02/contains\350\257\246\350\247\243/index.html" "b/2021/12/02/contains\350\257\246\350\247\243/index.html"
index a569b7a96..798703d49 100644
--- "a/2021/12/02/contains\350\257\246\350\247\243/index.html"
+++ "b/2021/12/02/contains\350\257\246\350\247\243/index.html"
@@ -211,7 +211,7 @@
Contains方法
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
package com.HUToh;
import java.io.BufferedInputStream;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.* ;
public class Main {
public static void main(String[] args){
ArrayList arrayList = new ArrayList();
String s1 = new String("abc");
String s2 = new String("abc");
arrayList.add(s1);
arrayList.add(s2);
String s3 = new String("abc");
System.out.println(s1==s2);
System.out.println(s1.equals(s2));
System.out.println(arrayList.contains(s1));
System.out.println(arrayList.contains(s3));
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
package com.HUToh;
import java.io.BufferedInputStream;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.* ;
public class Main {
public static void main(String[] args){
ArrayList arrayList = new ArrayList();
String s1 = new String("abc");
String s2 = new String("abc");
arrayList.add(s1);
arrayList.add(s2);
String s3 = new String("abc");
System.out.println(s1==s2);
System.out.println(s1.equals(s2));
System.out.println(arrayList.contains(s1));
System.out.println(arrayList.contains(s3));
}
}
这段代码输出的是什么是
是false true true true
diff --git "a/2021/12/05/\345\277\253\351\200\237\345\271\202/index.html" "b/2021/12/05/\345\277\253\351\200\237\345\271\202/index.html"
index 1e6dd2ed7..d11111ef3 100644
--- "a/2021/12/05/\345\277\253\351\200\237\345\271\202/index.html"
+++ "b/2021/12/05/\345\277\253\351\200\237\345\271\202/index.html"
@@ -215,13 +215,13 @@
50. Pow(x, n)
难度中等8
实现 pow(x, n) ,即计算 x 的 n 次幂函数(即,xn)。
示例 1:
-1
2
输入:x = 2.00000, n = 10
输出:1024.00000
+1
2
输入:x = 2.00000, n = 10
输出:1024.00000
示例 2:
-1
2
输入:x = 2.10000, n = 3
输出:9.26100
+1
2
输入:x = 2.10000, n = 3
输出:9.26100
示例 3:
-1
2
3
输入:x = 2.00000, n = -2
输出:0.25000
解释:2-2 = 1/22 = 1/4 = 0.25
+1
2
3
输入:x = 2.00000, n = -2
输出:0.25000
解释:2-2 = 1/22 = 1/4 = 0.25
提示:
@@ -231,29 +231,29 @@
1
1->2->4->8->16->32->64->128->256->512->1024
+1
1->2->4->8->16->32->64->128->256->512->1024
时间复杂的为O(log 1024)也就是10

算法板子
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
class Solution {
public double myPow(double x, int n) {
long N = n;
return N >= 0 ? quickMul(x, N) : 1.0 / quickMul(x, -N);
}
public double quickMul(double x, long N) {
if (N == 0) {
return 1.0;
}
double y = quickMul(x, N / 2);
return N % 2 == 0 ? y * y : y * y * x;
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
class Solution {
public double myPow(double x, int n) {
long N = n;
return N >= 0 ? quickMul(x, N) : 1.0 / quickMul(x, -N);
}
public double quickMul(double x, long N) {
if (N == 0) {
return 1.0;
}
double y = quickMul(x, N / 2);
return N % 2 == 0 ? y * y : y * y * x;
}
}
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class Solution {
public double myPow(double x, int n) {
long N = n;
double ans = quickMul(x,N);
if(N>=0) return ans;
else return 1.0/ans;
}
public double quickMul(double x, long N) {
if (N == 0) {
return 1.0;
}
double y = quickMul(x, N / 2);
if(N%2==0) return y*y;
else return y*y*x;
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class Solution {
public double myPow(double x, int n) {
long N = n;
double ans = quickMul(x,N);
if(N>=0) return ans;
else return 1.0/ans;
}
public double quickMul(double x, long N) {
if (N == 0) {
return 1.0;
}
double y = quickMul(x, N / 2);
if(N%2==0) return y*y;
else return y*y*x;
}
}
进阶
372. 超级次方
难度 中等
你的任务是计算 ab 对 1337 取模,a 是一个正整数,b 是一个非常大的正整数且会以数组形式给出。
示例 1:
-1
2
输入:a = 2, b = [3]
输出:8
+1
2
输入:a = 2, b = [3]
输出:8
示例 2:
-1
2
输入:a = 2, b = [1,0]
输出:1024
+1
2
输入:a = 2, b = [1,0]
输出:1024
示例 3:
-1
2
输入:a = 1, b = [4,3,3,8,5,2]
输出:1
+1
2
输入:a = 1, b = [4,3,3,8,5,2]
输出:1
示例 4:
-1
2
输入:a = 2147483647, b = [2,0,0]
输出:1198
+1
2
输入:a = 2147483647, b = [2,0,0]
输出:1198
提示:
@@ -262,7 +262,7 @@
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
class Solution {
static final int MOD = 1337;
public int superPow(int a, int[] b) {
int ans = 1;
for (int i = b.length - 1; i >= 0; --i) {
ans = (int) ((long) ans * pow(a, b[i]) % MOD);
a = pow(a, 10);
}
return ans;
}
public int pow(int x, int n) {
int res = 1;
while (n != 0) {
if (n % 2 != 0) {
res = (int) ((long) res * x % MOD);
}
x = (int) ((long) x * x % MOD);
n /= 2;
}
return res;
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
class Solution {
static final int MOD = 1337;
public int superPow(int a, int[] b) {
int ans = 1;
for (int i = b.length - 1; i >= 0; --i) {
ans = (int) ((long) ans * pow(a, b[i]) % MOD);
a = pow(a, 10);
}
return ans;
}
public int pow(int x, int n) {
int res = 1;
while (n != 0) {
if (n % 2 != 0) {
res = (int) ((long) res * x % MOD);
}
x = (int) ((long) x * x % MOD);
n /= 2;
}
return res;
}
}
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/super-pow/solution/chao-ji-ci-fang-by-leetcode-solution-ow8j/
diff --git "a/2021/12/31/\345\256\214\347\276\216\346\225\260/index.html" "b/2021/12/31/\345\256\214\347\276\216\346\225\260/index.html"
index 6ca966b62..48fb832e8 100644
--- "a/2021/12/31/\345\256\214\347\276\216\346\225\260/index.html"
+++ "b/2021/12/31/\345\256\214\347\276\216\346\225\260/index.html"
@@ -218,14 +218,14 @@
我试了一下我的打表方式 20分钟还没打出最后一个数
直接搬官方的吧
-1
2
3
4
5
class Solution {
public boolean checkPerfectNumber(int num) {
return num == 6 || num == 28 || num == 496 || num == 8128 || num == 33550336;
}
}
+1
2
3
4
5
class Solution {
public boolean checkPerfectNumber(int num) {
return num == 6 || num == 28 || num == 496 || num == 8128 || num == 33550336;
}
}
方法二 枚举
-1
2
3
4
5
6
7
8
9
10
11
12
class Solution {
public boolean checkPerfectNumber(int num) {
int sum = 0;
if(num==1) return false;
for(int i = 1;i <= num/2;i++)
{
if(num%i==0)
sum+=i;
}
return sum==num;
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
class Solution {
public boolean checkPerfectNumber(int num) {
int sum = 0;
if(num==1) return false;
for(int i = 1;i <= num/2;i++)
{
if(num%i==0)
sum+=i;
}
return sum==num;
}
}
这个稍微时间稍微长了一点
-1
2
3
4
5
6
7
8
9
10
11
12
13
class Solution {
public boolean checkPerfectNumber(int num) {
if (num == 1) return false;
int ans = 1;
for (int i = 2; i <= num / i; i++) {
if (num % i == 0) {
ans += i;
if (i * i != num) ans += num / i;
}
}
return ans == num;
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
class Solution {
public boolean checkPerfectNumber(int num) {
if (num == 1) return false;
int ans = 1;
for (int i = 2; i <= num / i; i++) {
if (num % i == 0) {
ans += i;
if (i * i != num) ans += num / i;
}
}
return ans == num;
}
}
这个就很快了
同样是枚举 别人写的和我写的 感觉自己在时间复杂度方法还得加强
diff --git "a/2022/01/11/\347\210\254\345\217\226\345\274\272\345\210\266\347\247\221\346\212\200\346\225\231\345\212\241\347\263\273\347\273\237\342\200\224\344\273\245\346\271\226\345\215\227\345\267\245\344\270\232\345\244\247\345\255\246\344\270\272\344\276\213/index.html" "b/2022/01/11/\347\210\254\345\217\226\345\274\272\345\210\266\347\247\221\346\212\200\346\225\231\345\212\241\347\263\273\347\273\237\342\200\224\344\273\245\346\271\226\345\215\227\345\267\245\344\270\232\345\244\247\345\255\246\344\270\272\344\276\213/index.html"
index f8170e43f..878ee2a4c 100644
--- "a/2022/01/11/\347\210\254\345\217\226\345\274\272\345\210\266\347\247\221\346\212\200\346\225\231\345\212\241\347\263\273\347\273\237\342\200\224\344\273\245\346\271\226\345\215\227\345\267\245\344\270\232\345\244\247\345\255\246\344\270\272\344\276\213/index.html"
+++ "b/2022/01/11/\347\210\254\345\217\226\345\274\272\345\210\266\347\247\221\346\212\200\346\225\231\345\212\241\347\263\273\347\273\237\342\200\224\344\273\245\346\271\226\345\215\227\345\267\245\344\270\232\345\244\247\345\255\246\344\270\272\344\276\213/index.html"
@@ -234,26 +234,26 @@ 准备找到这一项 点开 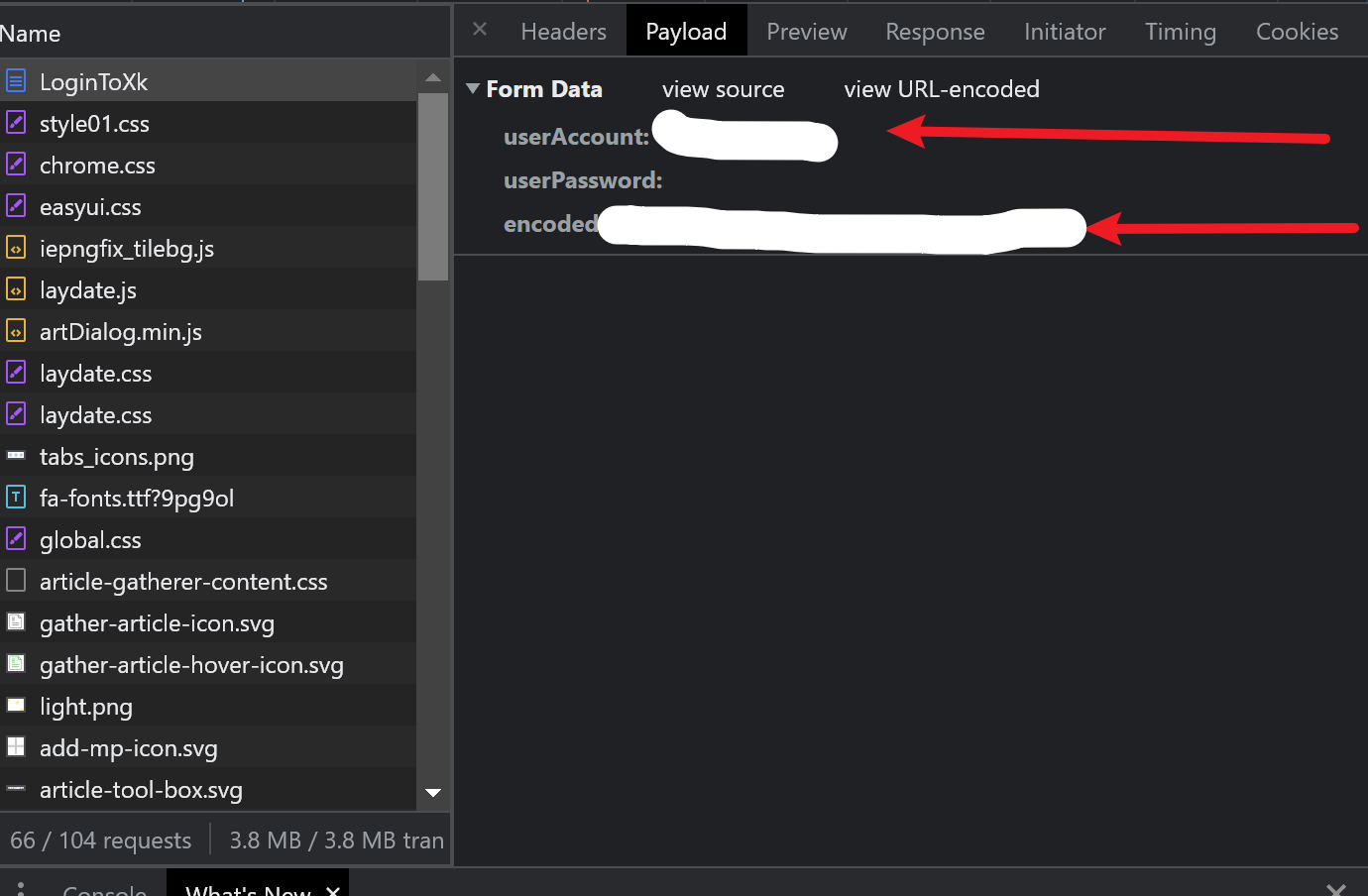
记录下这个的信息 userAccount即是学号 encodedd是学号+密码的base64加密
maven依赖
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.6.2</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.example</groupId>
<artifactId>JWXT</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>JWXT</name>
<description>JWXT</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-mail -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-mail</artifactId>
<version>2.5.4</version>
</dependency>
<!--Lang3工具类-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.7</version>
</dependency>
<!-- 发送邮件 -->
<dependency>
<groupId>javax.mail</groupId>
<artifactId>mail</artifactId>
<version>1.4.7</version>
</dependency>
<!--HttpClient-->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.6</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.3.4</version>
</dependency>
<!--阿里巴巴 json-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.51</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.1.0</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.6.2</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.example</groupId>
<artifactId>JWXT</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>JWXT</name>
<description>JWXT</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-mail -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-mail</artifactId>
<version>2.5.4</version>
</dependency>
<!--Lang3工具类-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.7</version>
</dependency>
<!-- 发送邮件 -->
<dependency>
<groupId>javax.mail</groupId>
<artifactId>mail</artifactId>
<version>1.4.7</version>
</dependency>
<!--HttpClient-->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.6</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.3.4</version>
</dependency>
<!--阿里巴巴 json-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.51</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.1.0</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
在IDEA新建Springboot框架 然后在新建类LoginPZ
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
package com.example.jwxt;
import org.apache.http.NameValuePair;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.client.protocol.HttpClientContext;
import org.apache.http.cookie.Cookie;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.message.BasicNameValuePair;
import java.io.IOException;
import java.net.URI;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* 登录
*/
public class LoginPz {
public static String hello() {
Map<String,String> param = new HashMap<>();
String userAccount = "你的学号";
String userPassword = "密码";
String encoded = "上文提到的加密信息";//加密信息
param.put("userAccount",userAccount);
param.put("userPassword",userPassword);
param.put("encoded",encoded);
List<URI> redirectLocations = null;
// 创建Httpclient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
String resultString = "";
try {
// 创建Http Post请求
HttpPost httpPost = new HttpPost("http://218.75.197.123:83/jsxsd/xk/LoginToXk");
//请求头
httpPost.addHeader("Content-Type","application/x-www-form-urlencoded");
httpPost.addHeader("Cookie","JSESSIONID=22B4C4CE6240C6C53FF6BC3C197E3B83; SERVERID=121; JSESSIONID=8FFFAEA49DC840CE5A3135330C06CED3");
// 创建参数列表
if (param != null) {
List<NameValuePair> paramList = new ArrayList<>();
for (String key : param.keySet()) {
paramList.add(new BasicNameValuePair(key, param.get(key)));
}
// 模拟表单登录
UrlEncodedFormEntity entity = new UrlEncodedFormEntity(paramList);
httpPost.setEntity(entity);
}
// 执行http请求
HttpClientContext context = HttpClientContext.create();
response = httpClient.execute(httpPost,context);
//获取Cookie信息,得到两个参数 JSESSIONID 、 Serverid
List<Cookie> cookies = context.getCookieStore().getCookies();
for (Cookie cookie : cookies) {
String name = cookie.getName();
String value = cookie.getValue();
// System.out.println("name:"+name+","+value);
return value;
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
response.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return " ";
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
package com.example.jwxt;
import org.apache.http.NameValuePair;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.client.protocol.HttpClientContext;
import org.apache.http.cookie.Cookie;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.message.BasicNameValuePair;
import java.io.IOException;
import java.net.URI;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* 登录
*/
public class LoginPz {
public static String hello() {
Map<String,String> param = new HashMap<>();
String userAccount = "你的学号";
String userPassword = "密码";
String encoded = "上文提到的加密信息";//加密信息
param.put("userAccount",userAccount);
param.put("userPassword",userPassword);
param.put("encoded",encoded);
List<URI> redirectLocations = null;
// 创建Httpclient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
String resultString = "";
try {
// 创建Http Post请求
HttpPost httpPost = new HttpPost("http://218.75.197.123:83/jsxsd/xk/LoginToXk");
//请求头
httpPost.addHeader("Content-Type","application/x-www-form-urlencoded");
httpPost.addHeader("Cookie","JSESSIONID=22B4C4CE6240C6C53FF6BC3C197E3B83; SERVERID=121; JSESSIONID=8FFFAEA49DC840CE5A3135330C06CED3");
// 创建参数列表
if (param != null) {
List<NameValuePair> paramList = new ArrayList<>();
for (String key : param.keySet()) {
paramList.add(new BasicNameValuePair(key, param.get(key)));
}
// 模拟表单登录
UrlEncodedFormEntity entity = new UrlEncodedFormEntity(paramList);
httpPost.setEntity(entity);
}
// 执行http请求
HttpClientContext context = HttpClientContext.create();
response = httpClient.execute(httpPost,context);
//获取Cookie信息,得到两个参数 JSESSIONID 、 Serverid
List<Cookie> cookies = context.getCookieStore().getCookies();
for (Cookie cookie : cookies) {
String name = cookie.getName();
String value = cookie.getValue();
// System.out.println("name:"+name+","+value);
return value;
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
response.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return " ";
}
}
这是模拟教务系统登陆 然后我们新建类GetUserInfo
代码如下
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
package com.example.jwxt;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.util.ArrayList;
import java.util.List;
import java.util.Timer;
import java.util.stream.Collectors;
/**
* 登录后获取用户信息
* 相关解析HTMl的操作不是固定的
* 需要结合自己的需求来操作
* 此处仅作为演示。
*/
public class GetUserInfo {
static int idx = 0;
public static void cj() throws Exception {
for (int i = 0; i < 1000000000; ) {
LoginPz loginPz = new LoginPz();
String cookies = loginPz.hello();
CloseableHttpClient httpClient = HttpClients.createDefault();
try {
HttpGet httpGet = new HttpGet("http://218.75.197.123:83/jsxsd/kscj/cjcx_list?kksj=2021-2022-1");//2021-2022-1为学期信息 可自行更改
//增加头信息
//注意此处需要修改为正确的JSESSIONID 和 SERVERID
httpGet.addHeader("Cookie", "JSESSIONID" + "=" + cookies + "; SERVERID=121; JSESSIONID=8FFFAEA49DC840CE5A3135330C06CED3");
httpGet.addHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36");
httpGet.addHeader("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9");
httpGet.addHeader("Connection", "keep-alive");
//执行
CloseableHttpResponse response = httpClient.execute(httpGet);
String html = EntityUtils.toString(response.getEntity(), "utf8");
Document parse = Jsoup.parse(html);
parseHtml(parse);
Thread thread = new Thread();
thread.sleep(600000);
} catch (Exception e) {
}
}
}
private static void parseHtml(Document parse) throws Exception {
// int idx = 2;//目前已出成绩科目
//选择table
Element table = parse.getElementById("dataList");
//选择tr
Elements cells = table.select("tr");
StringBuilder stringBuilder = new StringBuilder(); //用来存储成绩信息
//自己存储的每一行数据
List<List<String>> tables = new ArrayList<>();
for (int index = 1; index < cells.size(); index++) {
//第一行是表头 index = 0 跳过
//第二行开始table数据
Element row = cells.get(index);
//搜索tr下的所有的td
Elements rows = row.select("td");
//每一行的数据
List<String> dataList = new ArrayList<>();
for (Element element : rows) {
dataList.add(element.text());
}
tables.add(dataList);
}
//获取表头
Elements headers = cells.get(0).select("th");
List<String> tableHeader = headers.stream()
.map(Element::text)
.collect(Collectors.toList());
//打印数据
for (String str : tableHeader) {
System.out.printf(str + " ");
stringBuilder.append(str + " ");
}
stringBuilder.append("\r\n");
System.out.println("");
for (List<String> strs : tables) {
for (String str : strs) {
System.out.printf(str + " ");
stringBuilder.append(str + " ");
}
stringBuilder.append("\r\n");
System.out.println("");
}
System.out.println();
// System.out.println(tables.size());
if (tables.size() > idx)//idx 为原先的成绩数量123
{
//发送邮件给自己
System.out.println("这是一个标志");
SendMailUtil.sendEmail("你的邮箱 xxxx@qq.com", "成绩更新", stringBuilder.toString());
idx = tables.size();
}
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
package com.example.jwxt;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.util.ArrayList;
import java.util.List;
import java.util.Timer;
import java.util.stream.Collectors;
/**
* 登录后获取用户信息
* 相关解析HTMl的操作不是固定的
* 需要结合自己的需求来操作
* 此处仅作为演示。
*/
public class GetUserInfo {
static int idx = 0;
public static void cj() throws Exception {
for (int i = 0; i < 1000000000; ) {
LoginPz loginPz = new LoginPz();
String cookies = loginPz.hello();
CloseableHttpClient httpClient = HttpClients.createDefault();
try {
HttpGet httpGet = new HttpGet("http://218.75.197.123:83/jsxsd/kscj/cjcx_list?kksj=2021-2022-1");//2021-2022-1为学期信息 可自行更改
//增加头信息
//注意此处需要修改为正确的JSESSIONID 和 SERVERID
httpGet.addHeader("Cookie", "JSESSIONID" + "=" + cookies + "; SERVERID=121; JSESSIONID=8FFFAEA49DC840CE5A3135330C06CED3");
httpGet.addHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36");
httpGet.addHeader("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9");
httpGet.addHeader("Connection", "keep-alive");
//执行
CloseableHttpResponse response = httpClient.execute(httpGet);
String html = EntityUtils.toString(response.getEntity(), "utf8");
Document parse = Jsoup.parse(html);
parseHtml(parse);
Thread thread = new Thread();
thread.sleep(600000);
} catch (Exception e) {
}
}
}
private static void parseHtml(Document parse) throws Exception {
// int idx = 2;//目前已出成绩科目
//选择table
Element table = parse.getElementById("dataList");
//选择tr
Elements cells = table.select("tr");
StringBuilder stringBuilder = new StringBuilder(); //用来存储成绩信息
//自己存储的每一行数据
List<List<String>> tables = new ArrayList<>();
for (int index = 1; index < cells.size(); index++) {
//第一行是表头 index = 0 跳过
//第二行开始table数据
Element row = cells.get(index);
//搜索tr下的所有的td
Elements rows = row.select("td");
//每一行的数据
List<String> dataList = new ArrayList<>();
for (Element element : rows) {
dataList.add(element.text());
}
tables.add(dataList);
}
//获取表头
Elements headers = cells.get(0).select("th");
List<String> tableHeader = headers.stream()
.map(Element::text)
.collect(Collectors.toList());
//打印数据
for (String str : tableHeader) {
System.out.printf(str + " ");
stringBuilder.append(str + " ");
}
stringBuilder.append("\r\n");
System.out.println("");
for (List<String> strs : tables) {
for (String str : strs) {
System.out.printf(str + " ");
stringBuilder.append(str + " ");
}
stringBuilder.append("\r\n");
System.out.println("");
}
System.out.println();
// System.out.println(tables.size());
if (tables.size() > idx)//idx 为原先的成绩数量123
{
//发送邮件给自己
System.out.println("这是一个标志");
SendMailUtil.sendEmail("你的邮箱 xxxx@qq.com", "成绩更新", stringBuilder.toString());
idx = tables.size();
}
}
}
新建发邮件的类SendMailUtil
邮箱建议使用qq邮箱 需要拿到授权码
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
package com.example.jwxt;
import java.io.FileOutputStream;
import java.io.OutputStream;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Properties;
import javax.mail.Address;
import javax.mail.Message;
import javax.mail.Session;
import javax.mail.Transport;
import javax.mail.internet.InternetAddress;
import javax.mail.internet.MimeMessage;
import com.sun.mail.util.MailSSLSocketFactory;
public class SendMailUtil {
//邮件服务器主机名
// QQ邮箱的 SMTP 服务器地址为: smtp.qq.com
private static String myEmailSMTPHost = "smtp.qq.com";
//发件人邮箱
private static String myEmailAccount = "xx@qq.com";
//发件人邮箱密码(授权码)
//在开启SMTP服务时会获取到一个授权码,把授权码填在这里
private static String myEmailPassword = "授权码 需要自己去qq邮箱拿";
/**
* 邮件单发(自由编辑短信,并发送,适用于私信)
*
* @param toEmailAddress 收件箱地址
* @param emailTitle 邮件主题
* @param emailContent 邮件内容
* @throws Exception
*/
public static void sendEmail(String toEmailAddress, String emailTitle, String emailContent) throws Exception{
Properties props = new Properties();
// 开启debug调试
props.setProperty("mail.debug", "true");
// 发送服务器需要身份验证
props.setProperty("mail.smtp.auth", "true");
// 端口号
props.put("mail.smtp.port", 465);
// 设置邮件服务器主机名
props.setProperty("mail.smtp.host", myEmailSMTPHost);
// 发送邮件协议名称
props.setProperty("mail.transport.protocol", "smtp");
/**SSL认证,注意腾讯邮箱是基于SSL加密的,所以需要开启才可以使用**/
MailSSLSocketFactory sf = new MailSSLSocketFactory();
sf.setTrustAllHosts(true);
//设置是否使用ssl安全连接(一般都使用)
props.put("mail.smtp.ssl.enable", "true");
props.put("mail.smtp.ssl.socketFactory", sf);
//创建会话
Session session = Session.getInstance(props);
//获取邮件对象
//发送的消息,基于观察者模式进行设计的
Message msg = new MimeMessage(session);
//设置邮件标题
msg.setSubject(emailTitle);
//设置邮件内容
//使用StringBuilder,因为StringBuilder加载速度会比String快,而且线程安全性也不错
StringBuilder builder = new StringBuilder();
//写入内容
builder.append("\n" + emailContent);
//设置显示的发件时间
msg.setSentDate(new Date());
//设置邮件内容
msg.setText(builder.toString());
//设置发件人邮箱
// InternetAddress 的三个参数分别为: 发件人邮箱, 显示的昵称(只用于显示, 没有特别的要求), 昵称的字符集编码
msg.setFrom(new InternetAddress(myEmailAccount,"我的工作站", "UTF-8"));
//得到邮差对象
Transport transport = session.getTransport();
//连接自己的邮箱账户
//密码不是自己QQ邮箱的密码,而是在开启SMTP服务时所获取到的授权码
//connect(host, user, password)
transport.connect( myEmailSMTPHost, myEmailAccount, myEmailPassword);
//发送邮件
transport.sendMessage(msg, new Address[] { new InternetAddress(toEmailAddress) });
//将该邮件保存到本地
OutputStream out = new FileOutputStream("MyEmail.eml");
msg.writeTo(out);
out.flush();
out.close();
transport.close();
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
package com.example.jwxt;
import java.io.FileOutputStream;
import java.io.OutputStream;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Properties;
import javax.mail.Address;
import javax.mail.Message;
import javax.mail.Session;
import javax.mail.Transport;
import javax.mail.internet.InternetAddress;
import javax.mail.internet.MimeMessage;
import com.sun.mail.util.MailSSLSocketFactory;
public class SendMailUtil {
//邮件服务器主机名
// QQ邮箱的 SMTP 服务器地址为: smtp.qq.com
private static String myEmailSMTPHost = "smtp.qq.com";
//发件人邮箱
private static String myEmailAccount = "xx@qq.com";
//发件人邮箱密码(授权码)
//在开启SMTP服务时会获取到一个授权码,把授权码填在这里
private static String myEmailPassword = "授权码 需要自己去qq邮箱拿";
/**
* 邮件单发(自由编辑短信,并发送,适用于私信)
*
* @param toEmailAddress 收件箱地址
* @param emailTitle 邮件主题
* @param emailContent 邮件内容
* @throws Exception
*/
public static void sendEmail(String toEmailAddress, String emailTitle, String emailContent) throws Exception{
Properties props = new Properties();
// 开启debug调试
props.setProperty("mail.debug", "true");
// 发送服务器需要身份验证
props.setProperty("mail.smtp.auth", "true");
// 端口号
props.put("mail.smtp.port", 465);
// 设置邮件服务器主机名
props.setProperty("mail.smtp.host", myEmailSMTPHost);
// 发送邮件协议名称
props.setProperty("mail.transport.protocol", "smtp");
/**SSL认证,注意腾讯邮箱是基于SSL加密的,所以需要开启才可以使用**/
MailSSLSocketFactory sf = new MailSSLSocketFactory();
sf.setTrustAllHosts(true);
//设置是否使用ssl安全连接(一般都使用)
props.put("mail.smtp.ssl.enable", "true");
props.put("mail.smtp.ssl.socketFactory", sf);
//创建会话
Session session = Session.getInstance(props);
//获取邮件对象
//发送的消息,基于观察者模式进行设计的
Message msg = new MimeMessage(session);
//设置邮件标题
msg.setSubject(emailTitle);
//设置邮件内容
//使用StringBuilder,因为StringBuilder加载速度会比String快,而且线程安全性也不错
StringBuilder builder = new StringBuilder();
//写入内容
builder.append("\n" + emailContent);
//设置显示的发件时间
msg.setSentDate(new Date());
//设置邮件内容
msg.setText(builder.toString());
//设置发件人邮箱
// InternetAddress 的三个参数分别为: 发件人邮箱, 显示的昵称(只用于显示, 没有特别的要求), 昵称的字符集编码
msg.setFrom(new InternetAddress(myEmailAccount,"我的工作站", "UTF-8"));
//得到邮差对象
Transport transport = session.getTransport();
//连接自己的邮箱账户
//密码不是自己QQ邮箱的密码,而是在开启SMTP服务时所获取到的授权码
//connect(host, user, password)
transport.connect( myEmailSMTPHost, myEmailAccount, myEmailPassword);
//发送邮件
transport.sendMessage(msg, new Address[] { new InternetAddress(toEmailAddress) });
//将该邮件保存到本地
OutputStream out = new FileOutputStream("MyEmail.eml");
msg.writeTo(out);
out.flush();
out.close();
transport.close();
}
}
拿授权码过程
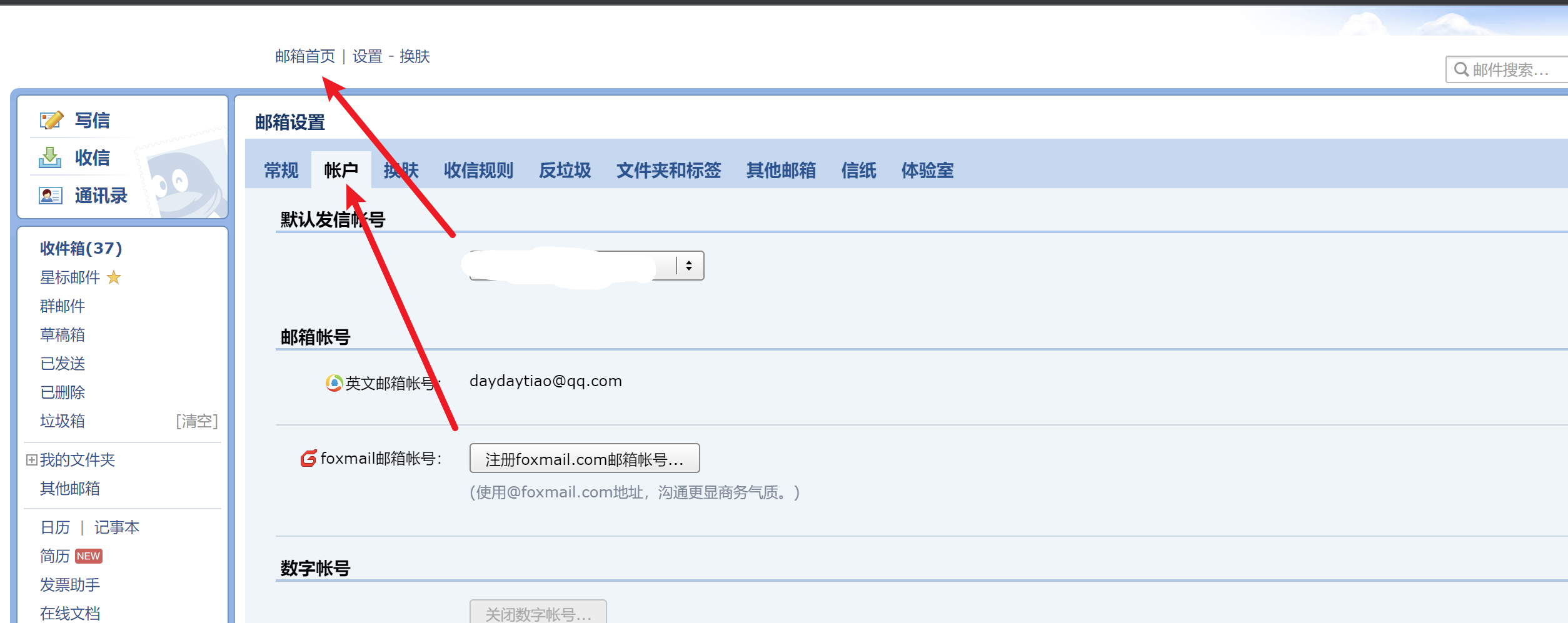
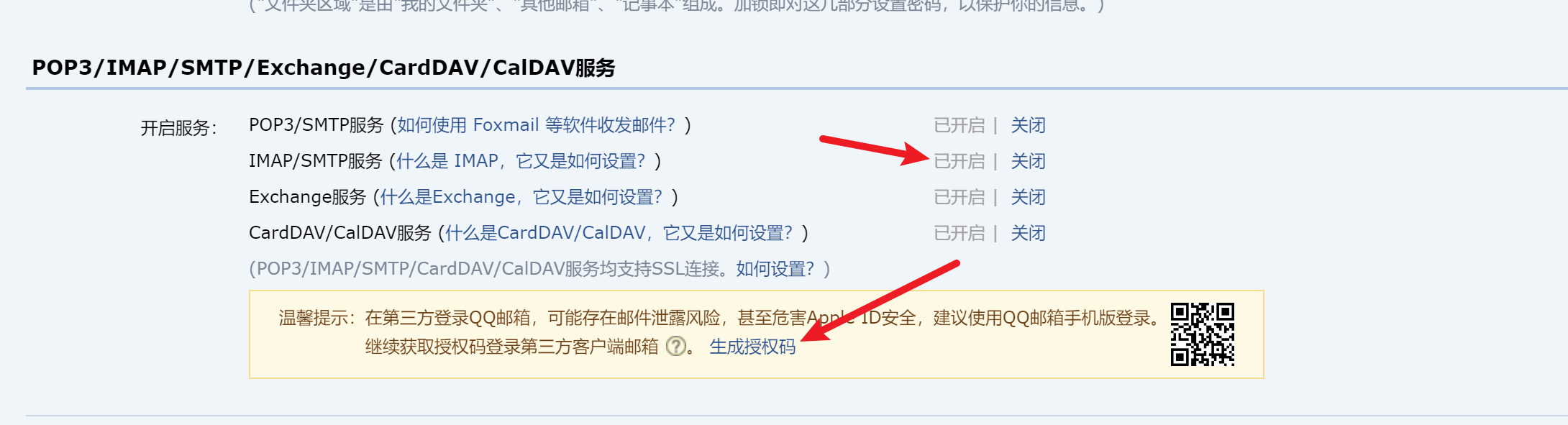
拿到授权码之后复制到上面去
再到Application添加启动类
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
package com.example.jwxt;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class JwxtApplication {
public static void main(String[] args) throws Exception {
SpringApplication.run(JwxtApplication.class, args);
GetUserInfo getUserInfo = new GetUserInfo();
getUserInfo.cj();
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
package com.example.jwxt;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
public class JwxtApplication {
public static void main(String[] args) throws Exception {
SpringApplication.run(JwxtApplication.class, args);
GetUserInfo getUserInfo = new GetUserInfo();
getUserInfo.cj();
}
}
如果自己有服务器就把这个项目打包成jar包上跑起来
没有的话只能把项目一直跑着不关
@@ -265,7 +265,7 @@ 准备然后用xshell 一直cd到jar包所在的路径
使用命令
-1
nohup java -jar JWXT-0.0.1-SNAPSHOT.jar 2>&1 &
+1
nohup java -jar JWXT-0.0.1-SNAPSHOT.jar 2>&1 &
然后就大功告成了 一般你跑起来之后就会收到一封邮件提醒
github的项目地址 https://github.com/fengxiaop/JWXT
diff --git "a/2022/03/12/JAVA\351\235\242\345\220\221\345\257\271\350\261\241/index.html" "b/2022/03/12/JAVA\351\235\242\345\220\221\345\257\271\350\261\241/index.html"
index 81d9b43cb..1199273ed 100644
--- "a/2022/03/12/JAVA\351\235\242\345\220\221\345\257\271\350\261\241/index.html"
+++ "b/2022/03/12/JAVA\351\235\242\345\220\221\345\257\271\350\261\241/index.html"
@@ -257,7 +257,7 @@ == 与 equals
String类中的equals方法是重写过的 因为Object的equals类方法是比较的对象的内存地址 而String类中的equals方法比较的是对象的值
当创建 String 类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创建一个 String 对象
String类equals()方法:
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
HashCode() 与 equals()
diff --git "a/2022/03/12/Lambda\350\241\250\350\276\276\345\274\217/index.html" "b/2022/03/12/Lambda\350\241\250\350\276\276\345\274\217/index.html"
index 81274aab5..9ca50e34c 100644
--- "a/2022/03/12/Lambda\350\241\250\350\276\276\345\274\217/index.html"
+++ "b/2022/03/12/Lambda\350\241\250\350\276\276\345\274\217/index.html"
@@ -221,16 +221,16 @@ 语法1.无参数,无返回值
1
2
Runnable t = () -> System.out.println("Hello Lambda")
t.run();
+语法
1.无参数,无返回值
1
2
Runnable t = () -> System.out.println("Hello Lambda")
t.run();
-2.有参数,无返回值
1
(x)-> System.out.println(x)
+2.有参数,无返回值
1
(x)-> System.out.println(x)
若只有一个参数,小括号可以省略不写
-1
x-> System.out.println(x)
+1
x-> System.out.println(x)
3.有两个以上的参数,有返回值,并且 Lambda体中有多条语句
-1
Comparator<Integer> com =(x,y)->(System.out.print1n("函数式接口") return Integer.compare(x,y)
+1
Comparator<Integer> com =(x,y)->(System.out.print1n("函数式接口") return Integer.compare(x,y)
…待续
diff --git "a/2022/03/20/\347\254\254\344\270\200\345\261\212ACC(AcWing Cup)\345\205\250\345\233\275\351\253\230\346\240\241\350\201\224\350\265\233/index.html" "b/2022/03/20/\347\254\254\344\270\200\345\261\212ACC(AcWing Cup)\345\205\250\345\233\275\351\253\230\346\240\241\350\201\224\350\265\233/index.html"
index 40451e95b..6a2255799 100644
--- "a/2022/03/20/\347\254\254\344\270\200\345\261\212ACC(AcWing Cup)\345\205\250\345\233\275\351\253\230\346\240\241\350\201\224\350\265\233/index.html"
+++ "b/2022/03/20/\347\254\254\344\270\200\345\261\212ACC(AcWing Cup)\345\205\250\345\233\275\351\253\230\346\240\241\350\201\224\350\265\233/index.html"
@@ -228,16 +228,16 @@ 题
输入格式
一个整数 nn。
输出格式
一个整数,表示整数 nn 的十六进制表示包含的圈圈总数。
数据范围
前三个测试点满足 0≤n≤1000≤n≤100,
所有测试点满足 0≤n≤2×1090≤n≤2×109。
-输入样例1:
1
11
+输入样例1:
1
11
-输出样例1:
1
2
+输出样例1:
1
2
-输入样例2:
1
14
+输入样例2:
1
14
-输出样例2:
1
0
+输出样例2:
1
0
简单模拟即可 注意特判0 每次都在这里栽跟头…
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
// package com.ACC;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
long n = scanner.nextLong();
long ans = 0;
if(n == 0) System.out.println(1);
else{while(n > 0)
{
long m = n% 16;
// System.out.println(m);
if(m == 0|| m == 4 || m == 6 || m==9 || m== 10||m == 13) ans++;
else if(m == 8 || m == 11) ans +=2;
n = n / 16;
}
System.out.println(ans);
}
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
// package com.ACC;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
long n = scanner.nextLong();
long ans = 0;
if(n == 0) System.out.println(1);
else{while(n > 0)
{
long m = n% 16;
// System.out.println(m);
if(m == 0|| m == 4 || m == 6 || m==9 || m== 10||m == 13) ans++;
else if(m == 8 || m == 11) ans +=2;
n = n / 16;
}
System.out.println(ans);
}
}
}
题目B
农夫约翰有 nn 片连续的农田,编号依次为 1∼n1∼n。
其中有 kk 片农田中装有洒水器。
@@ -253,12 +253,12 @@ 输出格式
每组数据输出一行答案。
数据范围
前三个测试点满足 1≤n≤51≤n≤5,
所有测试点满足 1≤T≤2001≤T≤200,1≤n≤2001≤n≤200,1≤k≤n1≤k≤n,1≤xi≤n1≤xi≤n,xi−1<xixi−1<xi,TT 组数据的 nn 相加之和不超过 200200。
-输入样例:
1
2
3
4
5
6
7
3
5 1
3
3 3
1 2 3
4 1
1
+输入样例:
1
2
3
4
5
6
7
3
5 1
3
3 3
1 2 3
4 1
1
-输出样例:
1
2
3
3
1
4
+输出样例:
1
2
3
3
1
4
模拟即可
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
// package com.ACC;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int T = scanner.nextInt();
int[] n = new int[T];
int[] k = new int[T];
for (int i = 0; i < T; i++) {
n[i] = scanner.nextInt();
k[i] = scanner.nextInt();
int[] a = new int[k[i]];
for (int j = 0; j < k[i]; j++) {
a[j] = scanner.nextInt();
}
int q = n[i] - a[k[i] -1]+1;
int ans = Math.max(a[0],q);
if(k[i] == 1) ans =Math.max(a[0],n[i] - a[0]+1);
else {
for (int j = 0; j + 1 < k[i]; j++) {
ans = Math.max(ans, (a[j + 1] - a[j]+2)/2);
}
}
System.out.println(ans);
}
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
// package com.ACC;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int T = scanner.nextInt();
int[] n = new int[T];
int[] k = new int[T];
for (int i = 0; i < T; i++) {
n[i] = scanner.nextInt();
k[i] = scanner.nextInt();
int[] a = new int[k[i]];
for (int j = 0; j < k[i]; j++) {
a[j] = scanner.nextInt();
}
int q = n[i] - a[k[i] -1]+1;
int ans = Math.max(a[0],q);
if(k[i] == 1) ans =Math.max(a[0],n[i] - a[0]+1);
else {
for (int j = 0; j + 1 < k[i]; j++) {
ans = Math.max(ans, (a[j + 1] - a[j]+2)/2);
}
}
System.out.println(ans);
}
}
}
题目C
diff --git "a/2022/04/01/\345\233\236\346\272\257\351\227\256\351\242\230/index.html" "b/2022/04/01/\345\233\236\346\272\257\351\227\256\351\242\230/index.html"
index 89d87e3eb..eb2470775 100644
--- "a/2022/04/01/\345\233\236\346\272\257\351\227\256\351\242\230/index.html"
+++ "b/2022/04/01/\345\233\236\346\272\257\351\227\256\351\242\230/index.html"
@@ -229,14 +229,14 @@
1
2
3
4
5
6
7
8
9
10
result = []
def backtrack(路径, 选择列表):
if 满足结束条件:
result.add(路径)
return
for 选择 in 选择列表:
做选择
backtrack(路径, 选择列表)
撤销选择
+1
2
3
4
5
6
7
8
9
10
result = []
def backtrack(路径, 选择列表):
if 满足结束条件:
result.add(路径)
return
for 选择 in 选择列表:
做选择
backtrack(路径, 选择列表)
撤销选择
核心在于for循环里面的递归,在递归调用之前做选择,在递归调用之后撤销选择。
例子1 全排列问题
有n个数 每个数都只能用一次 求出所有能排列的可能性。全排列个数为n!个
PS:为了简单清晰起见,我们这次讨论的全排列问题不包含重复的数字。
如果已知有多少个数的情况下,我们通常可以使用n层for循环暴力遍历所有数
例如3个数 我们可以暴力写法为
-1
2
3
4
5
6
7
8
9
10
11
12
13
for(int i = 0;i < n;i++)
for(int j = 0;j < n;j++)
for(int k = 0;k < n;k++)
{
if(i!=j && i!=k && j!=k)
{
// 1 2 3 1 3 2 2 1 3 2 3 1 3 2 1 3 1 2
list.add(nums[i]);
list.add(nums[j]);
list.add(nums[k]);
res.add(list);
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
for(int i = 0;i < n;i++)
for(int j = 0;j < n;j++)
for(int k = 0;k < n;k++)
{
if(i!=j && i!=k && j!=k)
{
// 1 2 3 1 3 2 2 1 3 2 3 1 3 2 1 3 1 2
list.add(nums[i]);
list.add(nums[j]);
list.add(nums[k]);
res.add(list);
}
}
@@ -248,7 +248,7 @@
我们定义的backtrack函数就是指针一样,在这棵树上游走,同时要正确维护每个节点的属性,每当走到树的底层,其路径就是一个全排列。
再进一步,如何遍历一颗树,
-1
2
3
4
5
6
void traverse(TreeNode root) {
for (TreeNode child : root.childern)
// 前序遍历需要的操作
traverse(child);
// 后序遍历需要的操作
}
+1
2
3
4
5
6
void traverse(TreeNode root) {
for (TreeNode child : root.childern)
// 前序遍历需要的操作
traverse(child);
// 后序遍历需要的操作
}
@@ -257,12 +257,12 @@
回溯代码核心框架
-1
2
3
4
5
6
7
8
9
for 选择 in 选择列表:
# 做选择
将该选择从选择列表移除
路径.add(选择)
backtrack(路径, 选择列表)
# 撤销选择
路径.remove(选择)
将该选择再加入选择列表
+1
2
3
4
5
6
7
8
9
for 选择 in 选择列表:
# 做选择
将该选择从选择列表移除
路径.add(选择)
backtrack(路径, 选择列表)
# 撤销选择
路径.remove(选择)
将该选择再加入选择列表
我们只要在递归之前做出选择,在递归之后撤销自己的选择,就能得到每个节点的选择路径和列表。
-全排列代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
List<List<Integer>> res = new LinkedList<>();
/* 主函数,输入一组不重复的数字,返回它们的全排列 */
List<List<Integer>> permute(int[] nums) {
// 记录「路径」
LinkedList<Integer> track = new LinkedList<>();
backtrack(nums, track);
return res;
}
// 路径:记录在 track 中
// 选择列表:nums 中不存在于 track 的那些元素
// 结束条件:nums 中的元素全都在 track 中出现
void backtrack(int[] nums, LinkedList<Integer> track) {
// 触发结束条件
if (track.size() == nums.length) {
res.add(new LinkedList(track));
return;
}
for (int i = 0; i < nums.length; i++) {
// 排除不合法的选择
if (track.contains(nums[i]))
continue;
// 做选择
track.add(nums[i]);
// 进入下一层决策树
backtrack(nums, track);
// 取消选择
track.removeLast();
}
}
+全排列代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
List<List<Integer>> res = new LinkedList<>();
/* 主函数,输入一组不重复的数字,返回它们的全排列 */
List<List<Integer>> permute(int[] nums) {
// 记录「路径」
LinkedList<Integer> track = new LinkedList<>();
backtrack(nums, track);
return res;
}
// 路径:记录在 track 中
// 选择列表:nums 中不存在于 track 的那些元素
// 结束条件:nums 中的元素全都在 track 中出现
void backtrack(int[] nums, LinkedList<Integer> track) {
// 触发结束条件
if (track.size() == nums.length) {
res.add(new LinkedList(track));
return;
}
for (int i = 0; i < nums.length; i++) {
// 排除不合法的选择
if (track.contains(nums[i]))
continue;
// 做选择
track.add(nums[i]);
// 进入下一层决策树
backtrack(nums, track);
// 取消选择
track.removeLast();
}
}
我们这里稍微做了些变通,没有显式记录「选择列表」,而是通过 nums 和 track 推导出当前的选择列表:
通过contains函数来判断该数是否已经被使用。
@@ -273,10 +273,10 @@ 例子2 N皇后问题
题意
给你一个N*N的棋盘,,让你放置 N 个皇后,使得它们不能互相攻击。
PS:皇后可以攻击同一行、同一列、左上左下右上右下四个方向的任意单位。
这个问题本质上跟全排列问题差不多,决策树的每一层表示棋盘上的每一行;每个节点可以做出的选择是,在该行的任意一列放置一个皇后。
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
vector<vector<string>> res;
/* 输入棋盘边长 n,返回所有合法的放置 */
vector<vector<string>> solveNQueens(int n) {
// '.' 表示空,'Q' 表示皇后,初始化空棋盘。
vector<string> board(n, string(n, '.'));
backtrack(board, 0);
return res;
}
// 路径:board 中小于 row 的那些行都已经成功放置了皇后
// 选择列表:第 row 行的所有列都是放置皇后的选择
// 结束条件:row 超过 board 的最后一行
void backtrack(vector<string>& board, int row) {
// 触发结束条件
if (row == board.size()) {
res.push_back(board);
return;
}
int n = board[row].size();
for (int col = 0; col < n; col++) {
// 排除不合法选择
if (!isValid(board, row, col))
continue;
// 做选择
board[row][col] = 'Q';
// 进入下一行决策
backtrack(board, row + 1);
// 撤销选择
board[row][col] = '.';
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
vector<vector<string>> res;
/* 输入棋盘边长 n,返回所有合法的放置 */
vector<vector<string>> solveNQueens(int n) {
// '.' 表示空,'Q' 表示皇后,初始化空棋盘。
vector<string> board(n, string(n, '.'));
backtrack(board, 0);
return res;
}
// 路径:board 中小于 row 的那些行都已经成功放置了皇后
// 选择列表:第 row 行的所有列都是放置皇后的选择
// 结束条件:row 超过 board 的最后一行
void backtrack(vector<string>& board, int row) {
// 触发结束条件
if (row == board.size()) {
res.push_back(board);
return;
}
int n = board[row].size();
for (int col = 0; col < n; col++) {
// 排除不合法选择
if (!isValid(board, row, col))
continue;
// 做选择
board[row][col] = 'Q';
// 进入下一行决策
backtrack(board, row + 1);
// 撤销选择
board[row][col] = '.';
}
}
IsValid()函数
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
/* 是否可以在 board[row][col] 放置皇后? */
bool isValid(vector<string>& board, int row, int col) {
int n = board.size();
// 检查列是否有皇后互相冲突
for (int i = 0; i < n; i++) {
if (board[i][col] == 'Q')
return false;
}
// 检查右上方是否有皇后互相冲突
for (int i = row - 1, j = col + 1;
i >= 0 && j < n; i--, j++) {
if (board[i][j] == 'Q')
return false;
}
// 检查左上方是否有皇后互相冲突
for (int i = row - 1, j = col - 1;
i >= 0 && j >= 0; i--, j--) {
if (board[i][j] == 'Q')
return false;
}
return true;
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
/* 是否可以在 board[row][col] 放置皇后? */
bool isValid(vector<string>& board, int row, int col) {
int n = board.size();
// 检查列是否有皇后互相冲突
for (int i = 0; i < n; i++) {
if (board[i][col] == 'Q')
return false;
}
// 检查右上方是否有皇后互相冲突
for (int i = row - 1, j = col + 1;
i >= 0 && j < n; i--, j++) {
if (board[i][j] == 'Q')
return false;
}
// 检查左上方是否有皇后互相冲突
for (int i = row - 1, j = col - 1;
i >= 0 && j >= 0; i--, j--) {
if (board[i][j] == 'Q')
return false;
}
return true;
}
函数 backtrack 依然像个在决策树上游走的指针,通过 row 和 col 就可以表示函数遍历到的位置,通过 isValid 函数可以将不符合条件的情况剪枝:
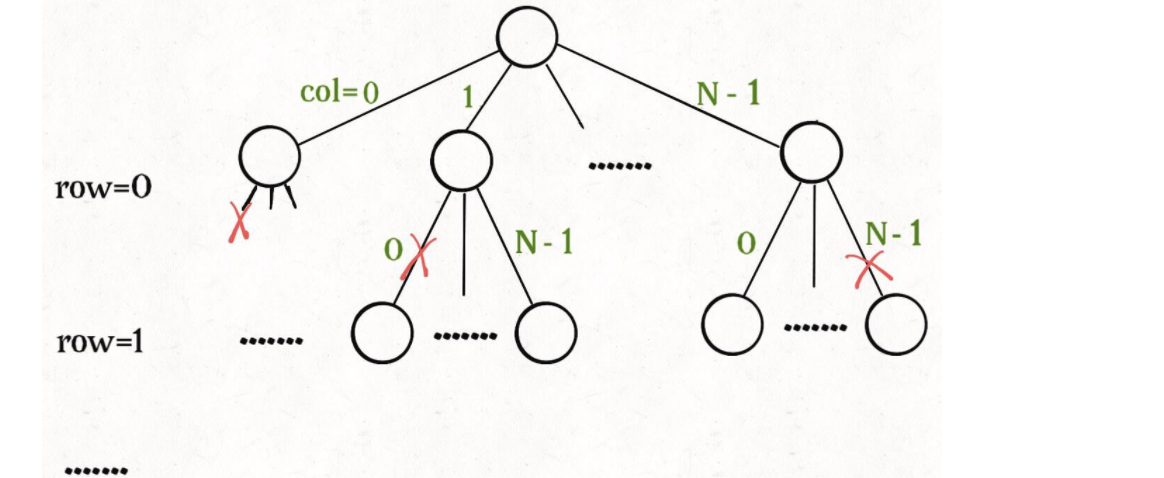
diff --git "a/2022/04/02/\345\205\250\346\216\222\345\210\227/index.html" "b/2022/04/02/\345\205\250\346\216\222\345\210\227/index.html"
index fef6478d5..d3679ac9b 100644
--- "a/2022/04/02/\345\205\250\346\216\222\345\210\227/index.html"
+++ "b/2022/04/02/\345\205\250\346\216\222\345\210\227/index.html"
@@ -222,14 +222,14 @@
1
2
3
4
5
6
7
8
9
10
result = []
def backtrack(路径, 选择列表):
if 满足结束条件:
result.add(路径)
return
for 选择 in 选择列表:
做选择
backtrack(路径, 选择列表)
撤销选择
+1
2
3
4
5
6
7
8
9
10
result = []
def backtrack(路径, 选择列表):
if 满足结束条件:
result.add(路径)
return
for 选择 in 选择列表:
做选择
backtrack(路径, 选择列表)
撤销选择
核心在于for循环里面的递归,在递归调用之前做选择,在递归调用之后撤销选择。
例子1 全排列问题
有n个数 每个数都只能用一次 求出所有能排列的可能性。全排列个数为n!个
PS:为了简单清晰起见,我们这次讨论的全排列问题不包含重复的数字。
如果已知有多少个数的情况下,我们通常可以使用n层for循环暴力遍历所有数
例如3个数 我们可以暴力写法为
-1
2
3
4
5
6
7
8
9
10
11
12
13
for(int i = 0;i < n;i++)
for(int j = 0;j < n;j++)
for(int k = 0;k < n;k++)
{
if(i!=j && i!=k && j!=k)
{
// 1 2 3 1 3 2 2 1 3 2 3 1 3 2 1 3 1 2
list.add(nums[i]);
list.add(nums[j]);
list.add(nums[k]);
res.add(list);
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
for(int i = 0;i < n;i++)
for(int j = 0;j < n;j++)
for(int k = 0;k < n;k++)
{
if(i!=j && i!=k && j!=k)
{
// 1 2 3 1 3 2 2 1 3 2 3 1 3 2 1 3 1 2
list.add(nums[i]);
list.add(nums[j]);
list.add(nums[k]);
res.add(list);
}
}
@@ -241,7 +241,7 @@
我们定义的backtrack函数就是指针一样,在这棵树上游走,同时要正确维护每个节点的属性,每当走到树的底层,其路径就是一个全排列。
再进一步,如何遍历一颗树,
-1
2
3
4
5
6
void traverse(TreeNode root) {
for (TreeNode child : root.childern)
// 前序遍历需要的操作
traverse(child);
// 后序遍历需要的操作
}
+1
2
3
4
5
6
void traverse(TreeNode root) {
for (TreeNode child : root.childern)
// 前序遍历需要的操作
traverse(child);
// 后序遍历需要的操作
}
@@ -250,12 +250,12 @@
回溯代码核心框架
-1
2
3
4
5
6
7
8
9
for 选择 in 选择列表:
# 做选择
将该选择从选择列表移除
路径.add(选择)
backtrack(路径, 选择列表)
# 撤销选择
路径.remove(选择)
将该选择再加入选择列表
+1
2
3
4
5
6
7
8
9
for 选择 in 选择列表:
# 做选择
将该选择从选择列表移除
路径.add(选择)
backtrack(路径, 选择列表)
# 撤销选择
路径.remove(选择)
将该选择再加入选择列表
我们只要在递归之前做出选择,在递归之后撤销自己的选择,就能得到每个节点的选择路径和列表。
-全排列代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
List<List<Integer>> res = new LinkedList<>();
/* 主函数,输入一组不重复的数字,返回它们的全排列 */
List<List<Integer>> permute(int[] nums) {
// 记录「路径」
LinkedList<Integer> track = new LinkedList<>();
backtrack(nums, track);
return res;
}
// 路径:记录在 track 中
// 选择列表:nums 中不存在于 track 的那些元素
// 结束条件:nums 中的元素全都在 track 中出现
void backtrack(int[] nums, LinkedList<Integer> track) {
// 触发结束条件
if (track.size() == nums.length) {
res.add(new LinkedList(track));
return;
}
for (int i = 0; i < nums.length; i++) {
// 排除不合法的选择
if (track.contains(nums[i]))
continue;
// 做选择
track.add(nums[i]);
// 进入下一层决策树
backtrack(nums, track);
// 取消选择
track.removeLast();
}
}
+全排列代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
List<List<Integer>> res = new LinkedList<>();
/* 主函数,输入一组不重复的数字,返回它们的全排列 */
List<List<Integer>> permute(int[] nums) {
// 记录「路径」
LinkedList<Integer> track = new LinkedList<>();
backtrack(nums, track);
return res;
}
// 路径:记录在 track 中
// 选择列表:nums 中不存在于 track 的那些元素
// 结束条件:nums 中的元素全都在 track 中出现
void backtrack(int[] nums, LinkedList<Integer> track) {
// 触发结束条件
if (track.size() == nums.length) {
res.add(new LinkedList(track));
return;
}
for (int i = 0; i < nums.length; i++) {
// 排除不合法的选择
if (track.contains(nums[i]))
continue;
// 做选择
track.add(nums[i]);
// 进入下一层决策树
backtrack(nums, track);
// 取消选择
track.removeLast();
}
}
我们这里稍微做了些变通,没有显式记录「选择列表」,而是通过 nums 和 track 推导出当前的选择列表:
通过contains函数来判断该数是否已经被使用。
@@ -266,10 +266,10 @@ 例子2 N皇后问题
题意
给你一个N*N的棋盘,,让你放置 N 个皇后,使得它们不能互相攻击。
PS:皇后可以攻击同一行、同一列、左上左下右上右下四个方向的任意单位。
这个问题本质上跟全排列问题差不多,决策树的每一层表示棋盘上的每一行;每个节点可以做出的选择是,在该行的任意一列放置一个皇后。
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
vector<vector<string>> res;
/* 输入棋盘边长 n,返回所有合法的放置 */
vector<vector<string>> solveNQueens(int n) {
// '.' 表示空,'Q' 表示皇后,初始化空棋盘。
vector<string> board(n, string(n, '.'));
backtrack(board, 0);
return res;
}
// 路径:board 中小于 row 的那些行都已经成功放置了皇后
// 选择列表:第 row 行的所有列都是放置皇后的选择
// 结束条件:row 超过 board 的最后一行
void backtrack(vector<string>& board, int row) {
// 触发结束条件
if (row == board.size()) {
res.push_back(board);
return;
}
int n = board[row].size();
for (int col = 0; col < n; col++) {
// 排除不合法选择
if (!isValid(board, row, col))
continue;
// 做选择
board[row][col] = 'Q';
// 进入下一行决策
backtrack(board, row + 1);
// 撤销选择
board[row][col] = '.';
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
vector<vector<string>> res;
/* 输入棋盘边长 n,返回所有合法的放置 */
vector<vector<string>> solveNQueens(int n) {
// '.' 表示空,'Q' 表示皇后,初始化空棋盘。
vector<string> board(n, string(n, '.'));
backtrack(board, 0);
return res;
}
// 路径:board 中小于 row 的那些行都已经成功放置了皇后
// 选择列表:第 row 行的所有列都是放置皇后的选择
// 结束条件:row 超过 board 的最后一行
void backtrack(vector<string>& board, int row) {
// 触发结束条件
if (row == board.size()) {
res.push_back(board);
return;
}
int n = board[row].size();
for (int col = 0; col < n; col++) {
// 排除不合法选择
if (!isValid(board, row, col))
continue;
// 做选择
board[row][col] = 'Q';
// 进入下一行决策
backtrack(board, row + 1);
// 撤销选择
board[row][col] = '.';
}
}
IsValid()函数
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
/* 是否可以在 board[row][col] 放置皇后? */
bool isValid(vector<string>& board, int row, int col) {
int n = board.size();
// 检查列是否有皇后互相冲突
for (int i = 0; i < n; i++) {
if (board[i][col] == 'Q')
return false;
}
// 检查右上方是否有皇后互相冲突
for (int i = row - 1, j = col + 1;
i >= 0 && j < n; i--, j++) {
if (board[i][j] == 'Q')
return false;
}
// 检查左上方是否有皇后互相冲突
for (int i = row - 1, j = col - 1;
i >= 0 && j >= 0; i--, j--) {
if (board[i][j] == 'Q')
return false;
}
return true;
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
/* 是否可以在 board[row][col] 放置皇后? */
bool isValid(vector<string>& board, int row, int col) {
int n = board.size();
// 检查列是否有皇后互相冲突
for (int i = 0; i < n; i++) {
if (board[i][col] == 'Q')
return false;
}
// 检查右上方是否有皇后互相冲突
for (int i = row - 1, j = col + 1;
i >= 0 && j < n; i--, j++) {
if (board[i][j] == 'Q')
return false;
}
// 检查左上方是否有皇后互相冲突
for (int i = row - 1, j = col - 1;
i >= 0 && j >= 0; i--, j--) {
if (board[i][j] == 'Q')
return false;
}
return true;
}
函数 backtrack 依然像个在决策树上游走的指针,通过 row 和 col 就可以表示函数遍历到的位置,通过 isValid 函数可以将不符合条件的情况剪枝:
diff --git a/2022/04/03/AOP/index.html b/2022/04/03/AOP/index.html
index e8dadeff5..63e7c7da1 100644
--- a/2022/04/03/AOP/index.html
+++ b/2022/04/03/AOP/index.html
@@ -215,7 +215,7 @@ 有接口情况:使用 JDK 动态代理,创建接口实现类代理对象,增强类的方法。
1 | |
1 | newProxyInstance(ClassLoader loader,类<?>[] interfaces,InvacationHandle) |
方法有三个参数
第一个参数:类加载器
diff --git "a/2022/04/06/\347\273\217\345\205\270DP---\350\243\205\351\233\266\351\243\237/index.html" "b/2022/04/06/\347\273\217\345\205\270DP---\350\243\205\351\233\266\351\243\237/index.html" index b6f67d328..834d579dd 100644 --- "a/2022/04/06/\347\273\217\345\205\270DP---\350\243\205\351\233\266\351\243\237/index.html" +++ "b/2022/04/06/\347\273\217\345\205\270DP---\350\243\205\351\233\266\351\243\237/index.html" @@ -210,24 +210,24 @@题干
-1 | |
1 | 秋天快到啦,天气慢慢凉爽了下来,所以实验室要组织去骊山进行一次野餐活动。 |
Input
输入:一个整数v,表示背包容量 一个整数n,表示有n个物品 接下来 n 个整数,分别表示这 n 个物品的各自体积
Output
输出:一个整数,表示背包最小的剩余空间
Sample Input
-1 | |
1 | 24 |
Sample Output
-1 | |
1 | 0 |
看到这道理的第一时刻想的是暴力枚举出所有零食混合装的重量 可复杂度太高 遂放弃。
然后看了一下大佬们的代码
-1 | |
1 |
|
刚开始我用Java实现的时候,
-1 | |
1 |
|
形式一下子就清楚了 dp是为了统计零食能够组成的重量
拿本题例子来说
@@ -240,7 +240,7 @@从最大的量递减便利 当dp[i] 不为0 时 也就是为1 代表着这是能够装载着最大的重量 直接输出V-i
感叹算法的奇妙与精彩,只恨自己接触晚与学校氛围不好,蹉跎了许久时光。
JAVA版代码
-1 | |
1 | package com.VG; |
1.Servlet初始化后调用Init()方法
2.Servlet调用service()方法来处理客户端的请求。
3.Servlet销毁前调用destroy()方法终止
-1 | |
1 | package com.yuewen; |
1 | |
1 | public class Singleton{ |
1 | |
1 | package com.yuewen; |
1 | |
1 | public static Object mapToObject(Map<String,Object> map,Class<?> beanClass){ |
数据库中存在个用户表:users ,表结构如下:
-1 | |
1 | CREATE TABLE `users` ( |
完善以下方法
public boolean verifyPassword(String username,String password) {
Connection con = getConnection () ;// getConnection() 方法是个已有的方法可以获取到数据库连接 ,
// here is your code
}
1 | |
1 | public boolean verifyPassword(String username,String password){ |
HashMap JDK1.8之前 数组+链表
JDK1.8之后 数组+链表+红黑树
@@ -298,7 +298,7 @@1 | |
1 | package com.yuewen; |
1 | |
1 | import org.junit.Test; |
1 | |
1 | package com.yuewen; |
1 | |
1 | public static String dateSub(String a, String b) { |
1 | |
1 | public static Map<String, Integer> sortMap(Map<String, Integer> map) { |
把6-10位的数字替换成””;
-1 | |
1 | public static String filterQQ(String s) { |
1 | |
1 | package leecode; |
经典爬楼梯问题
-1 | |
1 | package com.yuewen; |
1 | |
1 | import java.util.*; |
24 将一个给定的单链表反转,例:1-2-3-4-5,反转为5-4-3-2-1
-1 | |
1 | import java.util.*; |
例:图中给定树 {3,5,1,6,2,0,8,#,#,7,4} 中,节点6、节点4的最近公共祖先为5。
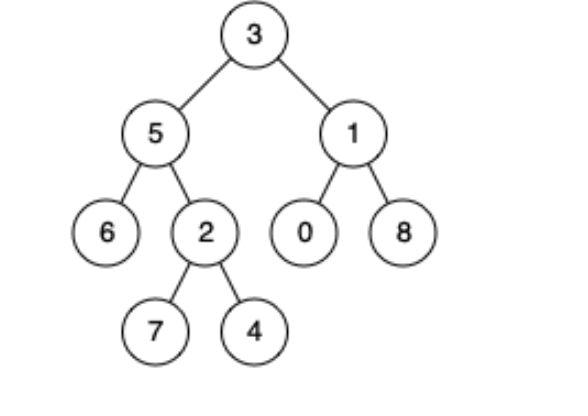
1 | |
1 | import java.util.*; |
好像是错误的!
-1 | |
1 | int binarySearch(int* arr, int arrLen, int a) { |

1 | |
1 | import java.util.*; |
例:数字23转为二进制为 10111,其中1的个数为4
-1 | |
1 | public static int binaryTo(int num) { int sum = 0; while (num > 0) { |
例:输入abcbdde,输出abcde。
-1 | |
1 | import java.util.*; |
30 给定一个整型数组,移除数组的某个元素使其剩下的元素乘积最大,如果数组出现相同的元素 ,请输出第一次出现的元素
-1 | |
1 | public class Main { |
1 | |
1 | public static int[][] rotationMatrix(int[][] matrix) { |
例:对于字符串“hellohehe”,第一个不重复的字符是“o”。如果每个字符都有重复,则抛出运行时异常。
-1 | |
1 | public char findFirstNonRepeatChar (String str) { |
给定一个 N * N 的矩阵 M,表示用户之间的朋友关系。如果M[i][j] = 1,表示已知第 i 个和 j 个人互为朋友关系,否则为不知道。你必须输出所有用户中的已知的朋友圈总数。
-1 | |
1 | import java.util.HashSet; |
id,category,words,updatetime
id 表示书id,long类型,id不重复;
@@ -365,20 +365,20 @@1 | |
1 | import java.text.ParseException; |
为自动测试方便,使用每行输入模拟操作:
1) push 1 表明向队列里面新增一个元素 1 , push 和元素之间用空格表示;
2) pop 表明输出当前队列里面的第一个元素,如果当前队列为空请输出null
请将每个输出以英文逗号拼接到一个字符串中。
-1 | |
1 | static class MyQueue { |
1) 所有的参数值必须经过urlencode,编码为utf-8;
2) 对编码后数据按照key值进行字典升序排序;
3)将所有的参数按照排序的顺序拼接成字符串 ,格式如下: k1=v1&k2=v2&k3=v3;
\4) 将第三步的算出的值计算md5值,md5加密的值小写
请你编写一段方法计算token值
-1 | |
1 | public String getToken(Map<String, String> params) { |
1 | |
1 | <!-- AMQP依赖 --> |
1 | |
1 | application.yml |

很容易出现ClassCastException,因为容易“误转型”:
-1 | |
1 | public class Main { |

则控制台会报错ClassCastException
String单独编写一种ArrayList
StringArrayList stringarraylist = new Stringarraylist()
底层就是String类型的数组了
-1 | |
1 | public class StringArrayList { |
这样一来,存入的必须是String,取出的也一定是String,不需要强制转型,因为编译器会强制检查放入的类型:
但是我们总不能针对Integer类型再写个IngtegerArrayList类型 针对Character再写个。。。
工程量十分的巨大 以及累赘
所以泛型的出现解决了这个问题
我们必须把ArrayList变成一种模板:ArrayList
1 | |
1 | public class ArrayList<T> { |
T可以是任何class。这样一来,我们就实现了:编写一次模版,可以创建任意类型的ArrayList:
我们可以定义任何一种类型的ArrayList啦
-1 | |
1 | ArrayList<String> stringArrayList = new ArrayList<>(); |
这样一来,既实现了编写一次,万能匹配,又通过编译器保证了类型安全:这就是泛型。
在Java标准库中的ArrayList<T>实现了List<T>接口,它可以向上转型为List<T>:
使用ArrayList时,如果不定义泛型类型时,泛型类型实际上就是Object:
1 | |
1 | ArrayList list = new ArrayList();//此为Object |
1 | |
1 | List list = new ArrayList(); |

当我们定义泛型 List<String> list = new List<>();
1 | |
1 | //无编译器警告: |
当我们定义泛型类型<Number>后,List<T>的泛型接口变为强类型List<Number>:
1 | |
1 | List<Number> list = new ArrayList<>(); |
除了ArrayList<T>使用了泛型,还可以在接口中使用泛型。例如,Arrays.sort(Object[])可以对任意数组进行排序,但待排序的元素必须实现Comparable<T>这个泛型接口:
1 | |
1 | public interface Comparable<T> { |
1 | |
1 | synchronized void method() { |
synchronized 方法,而线程 B 需要调用这个实例对象所属类的静态 synchronized 方法,是允许的,不会发生互斥现象,因为访问静态 synchronized 方法占用的锁是当前类的锁,而访问非静态 synchronized 方法占用的锁是当前实例对象锁。1 | |
1 | synchronized void staic method() { |
synchronized(this|object) 表示进入同步代码库前要获得给定对象的锁。synchronized(类.class) 表示进入同步代码前要获得 当前 class 的锁1 | |
1 | synchronized(this) { |
当初始长度为10已经加入了十个元素之后,我们需要再加一个元素的时候,我们就需要扩容

1 | |
1 | private void add(E e, Object[] elementData, int s) { |
这段源代码就是ArrayList的add()方法 如果添加的元素已经满了 则调用grow()函数 很明显 这是一个扩容函数
grow函数有两个 一个有参函数 一个无参函数

无参参数会调用有参参数 进行1.5倍的扩容
-1 | |
1 | ArrayList list1 = new ArrayList(23); |
这表示着生成了一个初始长度为23的ArrayList数组
和ArrayList数组类似 线程安全 效率低 用的很少
@@ -287,7 +287,7 @@HashMap 是无序的,即不会记录插入的顺序。
HashMap 继承于AbstractMap,实现了 Map、Cloneable、java.io.Serializable 接口。

1 | |
1 | public class Main { |
起初我验证Map的无序的时候 输出的总是有序的 增加了样本之后才变得无序

多线程demo
-1 | |
1 | public class deno01 { |
很明显得到的结果是交替打印1 和 2。
拓展
diff --git "a/2022/08/10/leetcode\344\272\224\347\231\276\351\242\230\344\273\245\345\217\212\345\256\236\344\271\240\346\216\245\350\277\221\344\272\206\345\260\276\345\243\260/index.html" "b/2022/08/10/leetcode\344\272\224\347\231\276\351\242\230\344\273\245\345\217\212\345\256\236\344\271\240\346\216\245\350\277\221\344\272\206\345\260\276\345\243\260/index.html" index 3811d16fd..f30c4ea7c 100644 --- "a/2022/08/10/leetcode\344\272\224\347\231\276\351\242\230\344\273\245\345\217\212\345\256\236\344\271\240\346\216\245\350\277\221\344\272\206\345\260\276\345\243\260/index.html" +++ "b/2022/08/10/leetcode\344\272\224\347\231\276\351\242\230\344\273\245\345\217\212\345\256\236\344\271\240\346\216\245\350\277\221\344\272\206\345\260\276\345\243\260/index.html" @@ -29,7 +29,7 @@ - + @@ -183,7 +183,7 @@六月中旬 自己坐高铁独自北上,人生中第一次离开了自己生活了20年没离开过的湖南省。
遥想三年前,自己和当时一起考入一个大学的同桌坐高铁一起从那个湘西南的小县城去往湖南株洲。
当时两个从来没有离开过那个小县城的我们用着惊叹的眼神看着高铁站外面的高楼大厦,人来人往以及车让我们迷失了方向。
好在学校在高铁站有接待点,上了学校包的公交车,和不同地方五湖四海不同学院,和他们一起前往了那个我大学生涯待在那里的学校
如果八月中旬,我决定结束我的实习之旅 本周五完成工作交接并且正式离职。今天自己刷leetocde也达到了500道题 也想发点什么给自己记录一下,也想大学毕业的时候还能够继续看一下这些记录

自己刷力扣是从9月份那时候大三刚开学 感觉自己要为工作准备一些 以前一直知道leetcode这个网站。
但是一直没有勇气坚持下去,我记得我大二的时候尝试过,但是被我想像中的两数之和以及核心代码不适应劝退了。
大二一年忙着家教挣生活费,当时没时间去弄这样。记得刷了力扣两个月 大概11月份的样子 我去参加了学院组织的程序竞赛 获得了非新生组的二等奖 。
离一等奖仅有一名只差 当然这要感谢我们学校的ACM大神们不屑于来欺负我们。但是的那个二等奖给了我很大的信心,后面断断续续的刷了一些题目。
后面加了宫水三叶姐的刷题群后,发现氛围真的是一个极其重要的东西。那里们有很多人细心的指导着新手对一些很常见问题的提问。
再后面跟着做每日一题 但是题太难了就会直接copy 老是想着有时间再去复习 实际上并没有坐到。
自己的水平再慢慢的提升,但是进步的空间依旧很大。
需要自己继续努力 秋招已经开始了。今年好像是过去十年最难的一届 好像也是将来十年最好的一年,听的人很焦虑,除了工作压力大之外 我承受受了这个的影响 想早一点的准备秋招。
在实习遇见了很多nice的同事 当然也会遇见很多不是很高兴的事情 比如比较push的组长 自己一直是一个想做到工作生活分离的人 不想在下班的时候被打扰 结果生活往往不是那么的如意。
也给我要步入社会的我上了一课。
在这里希望秋招顺利!工作顺心 万事如意。
也祝各位看到这的人天天开心!
]]> @@ -133,9 +133,9 @@Java Web开发 Web服务器
slf4j打印日志是好的实践
才用lombok简化Java bean编写
给线程取一个好名字
Rob Pike(Golang语言创始者)的一段描述
多线程demo
1 | |
很明显得到的结果是交替打印1 和 2。
拓展
tasklist 查看进程
taskkill 杀死进程
Jdk自带的命令 jps
可以查看java运行的程序类名

tasklist | findstr java 可以查看java的程序

taskkill /F /PID pid端口号 可以杀死进程
top命令查看服务器资源占有情况

synchronized关键字解决的是多个线程之间访问资源的同步性
Java Web开发 Web服务器
slf4j打印日志是好的实践
才用lombok简化Java bean编写
给线程取一个好名字
Rob Pike(Golang语言创始者)的一段描述
多线程demo
1 | public class deno01 { |
很明显得到的结果是交替打印1 和 2。
拓展
tasklist 查看进程
taskkill 杀死进程
Jdk自带的命令 jps
可以查看java运行的程序类名
tasklist | findstr java 可以查看java的程序
taskkill /F /PID pid端口号 可以杀死进程
top命令查看服务器资源占有情况
synchronized关键字解决的是多个线程之间访问资源的同步性
对于八种基本数据类型来说(byte short int long float double boolean char) == 是比较的值 而八种基本数据类型 是没有equals方法的
对于引用数据类型来说 == 比较的是对象的内存地址 而equals比较的字面值(例:String类型)
synchronized修饰的类或对象的所有操作都是原子的,因为在执行操作之前必须先获得类或对象的锁,直到执行完才能释放。Synchronized主要有三种用法:
1 | |
synchronized 方法,而线程 B 需要调用这个实例对象所属类的静态 synchronized 方法,是允许的,不会发生互斥现象,因为访问静态 synchronized 方法占用的锁是当前类的锁,而访问非静态 synchronized 方法占用的锁是当前实例对象锁。1 | |
synchronized(this|object) 表示进入同步代码库前要获得给定对象的锁。synchronized(类.class) 表示进入同步代码前要获得 当前 class 的锁1 | |
简单来说就是单个集合的元素
分为List、Set、Queue三大类
List有ArrayList(底层由数组组成 查找快 支持随机访问) LinkedList(底层由双向链表组成 修改快 还可以做栈 队列 以及双向队列) 以及Vector(线程安全 但是效率低 很少用)
JDK 7 以无参数构造方法创建 ArrayList 时,直接创建了长度是10的Object[]数组elementData 。
JDK 8 以无参数构造方法创建 ArrayList 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量。即向数组中添加第一个元素时,数组容量扩为 10。
底层为一个Object类型的数组 初始长度为0;若采用了泛型 ArrayList
则生成的是String[]类型的数组 初始长度为0
当初始长度为10已经加入了十个元素之后,我们需要再加一个元素的时候,我们就需要扩容
1 | |
这段源代码就是ArrayList的add()方法 如果添加的元素已经满了 则调用grow()函数 很明显 这是一个扩容函数
grow函数有两个 一个有参函数 一个无参函数
无参参数会调用有参参数 进行1.5倍的扩容
1 | |
这表示着生成了一个初始长度为23的ArrayList数组
和ArrayList数组类似 线程安全 效率低 用的很少
但是我们用的Stack(栈)则是基于Vector设计的
实现栈
Stack继承Vector 是Vector的子类

基于双向链表实现 增删元素效率高 查询效率低
LinkedList可以用作栈 队列 以及双向队列
集合 无序可去重的集合
无序 不可重复 自动排序 相当于存放在TreeMap的Key部分
无序 不可重复 支持快速查找 存放在HashMap中相当于key部分
基于双向链表实现,具有HashSet的查找效率
可以用他来实现双向队列
用于堆实现 可以用它实现优先队列
映射类型 Key - Value类型结构、
比如最为常见的HashMap
JDK 1.7 底层是数组+链表
JDK 1.8 底层是数组+链表+红黑树 加入红黑树的目的是增加HashMap的插入和查询速率
HaashMap通过key进行hashcode与 与运算 得到下标。
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。
HashMap 实现了 Map 接口,根据键的 HashCode 值存储数据,具有很快的访问速度,最多允许一条记录的键为 null,不支持线程同步。
HashMap 是无序的,即不会记录插入的顺序。
HashMap 继承于AbstractMap,实现了 Map、Cloneable、java.io.Serializable 接口。
1 | |
起初我验证Map的无序的时候 输出的总是有序的 增加了样本之后才变得无序
但是输入 它内部就有机构形成 无论你是输出十遍还是一百遍 他都是输出一样的顺序
这就是HashMap的无序性和有序性
采用拉链法解决哈希冲突
JDK1.7采用头插法,有可能形成回路
JDK1.8以后采用尾插法
HashMap的默认初始容量为16
必须是 2 的次幂,这也是 jdk 官⽅推荐的
这是因为达到散列均匀,为了提⾼ HashMap 集合的存取效率,所必须的
HashMap 默认加载因⼦:0.75
数组容器达到 3/4 时,开始扩容
JDK 8 之后,对 HashMap 底层数据结构(单链表)进⾏了改进
如果单链表元素超过8个,则将单链表转变为红⿊树;
如果红⿊树节点数量⼩于6时,会将红⿊树重新变为单链表。
hashcode() :通过调用Hashcode()方法得到key的哈希值
通过哈希函数/哈希算法 转换成数组的下表
重写Hashcode()和equals()的原因是
需要达到散列分布均匀
总的来说 JVM包括JRE JRE包括JVM
Java 虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM 有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。字节码和不同系统的 JVM 实现是 Java 语言“一次编译,随处可以运行”的关键所在。
]]>对于八种基本数据类型来说(byte short int long float double boolean char) == 是比较的值 而八种基本数据类型 是没有equals方法的
对于引用数据类型来说 == 比较的是对象的内存地址 而equals比较的字面值(例:String类型)
synchronized修饰的类或对象的所有操作都是原子的,因为在执行操作之前必须先获得类或对象的锁,直到执行完才能释放。Synchronized主要有三种用法:
1 | synchronized void method() { |
synchronized 方法,而线程 B 需要调用这个实例对象所属类的静态 synchronized 方法,是允许的,不会发生互斥现象,因为访问静态 synchronized 方法占用的锁是当前类的锁,而访问非静态 synchronized 方法占用的锁是当前实例对象锁。1 | synchronized void staic method() { |
synchronized(this|object) 表示进入同步代码库前要获得给定对象的锁。synchronized(类.class) 表示进入同步代码前要获得 当前 class 的锁1 | synchronized(this) { |
简单来说就是单个集合的元素
分为List、Set、Queue三大类
List有ArrayList(底层由数组组成 查找快 支持随机访问) LinkedList(底层由双向链表组成 修改快 还可以做栈 队列 以及双向队列) 以及Vector(线程安全 但是效率低 很少用)
JDK 7 以无参数构造方法创建 ArrayList 时,直接创建了长度是10的Object[]数组elementData 。
JDK 8 以无参数构造方法创建 ArrayList 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量。即向数组中添加第一个元素时,数组容量扩为 10。
底层为一个Object类型的数组 初始长度为0;若采用了泛型 ArrayList
则生成的是String[]类型的数组 初始长度为0
当初始长度为10已经加入了十个元素之后,我们需要再加一个元素的时候,我们就需要扩容
1 | private void add(E e, Object[] elementData, int s) { |
这段源代码就是ArrayList的add()方法 如果添加的元素已经满了 则调用grow()函数 很明显 这是一个扩容函数
grow函数有两个 一个有参函数 一个无参函数
无参参数会调用有参参数 进行1.5倍的扩容
1 | ArrayList list1 = new ArrayList(23); |
这表示着生成了一个初始长度为23的ArrayList数组
和ArrayList数组类似 线程安全 效率低 用的很少
但是我们用的Stack(栈)则是基于Vector设计的
实现栈
Stack继承Vector 是Vector的子类
基于双向链表实现 增删元素效率高 查询效率低
LinkedList可以用作栈 队列 以及双向队列
集合 无序可去重的集合
无序 不可重复 自动排序 相当于存放在TreeMap的Key部分
无序 不可重复 支持快速查找 存放在HashMap中相当于key部分
基于双向链表实现,具有HashSet的查找效率
可以用他来实现双向队列
用于堆实现 可以用它实现优先队列
映射类型 Key - Value类型结构、
比如最为常见的HashMap
JDK 1.7 底层是数组+链表
JDK 1.8 底层是数组+链表+红黑树 加入红黑树的目的是增加HashMap的插入和查询速率
HaashMap通过key进行hashcode与 与运算 得到下标。
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。
HashMap 实现了 Map 接口,根据键的 HashCode 值存储数据,具有很快的访问速度,最多允许一条记录的键为 null,不支持线程同步。
HashMap 是无序的,即不会记录插入的顺序。
HashMap 继承于AbstractMap,实现了 Map、Cloneable、java.io.Serializable 接口。
1 | public class Main { |
起初我验证Map的无序的时候 输出的总是有序的 增加了样本之后才变得无序
但是输入 它内部就有机构形成 无论你是输出十遍还是一百遍 他都是输出一样的顺序
这就是HashMap的无序性和有序性
采用拉链法解决哈希冲突
JDK1.7采用头插法,有可能形成回路
JDK1.8以后采用尾插法
HashMap的默认初始容量为16
必须是 2 的次幂,这也是 jdk 官⽅推荐的
这是因为达到散列均匀,为了提⾼ HashMap 集合的存取效率,所必须的
HashMap 默认加载因⼦:0.75
数组容器达到 3/4 时,开始扩容
JDK 8 之后,对 HashMap 底层数据结构(单链表)进⾏了改进
如果单链表元素超过8个,则将单链表转变为红⿊树;
如果红⿊树节点数量⼩于6时,会将红⿊树重新变为单链表。
hashcode() :通过调用Hashcode()方法得到key的哈希值
通过哈希函数/哈希算法 转换成数组的下表
重写Hashcode()和equals()的原因是
需要达到散列分布均匀
总的来说 JVM包括JRE JRE包括JVM
Java 虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM 有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。字节码和不同系统的 JVM 实现是 Java 语言“一次编译,随处可以运行”的关键所在。
]]>ArrayList大家都肯定很熟悉 在需要存储一个不定长度的时候,我们通常第一时间想的就是ArrayList。
实际上
ArrayList内部就是一个Object[]数组,配合存储一个当前分配的长度,就可以充当“可变数组”:引用自廖雪峰老师的博客
我们翻开他的底层源码 我们会发现

原型是创建了一个Object[]的数组(初始容量为空 如果add第一个元素则会吧数组大小赋成10) 刚开始的 DEFAULT_CAPACITY 为10
未指定泛型前 我们需要这样写来获取对象
很容易出现ClassCastException,因为容易“误转型”:
1 | |
则控制台会报错ClassCastException

要解决上述问题,我们可以为String单独编写一种ArrayList
StringArrayList stringarraylist = new Stringarraylist()
底层就是String类型的数组了
1 | |
这样一来,存入的必须是String,取出的也一定是String,不需要强制转型,因为编译器会强制检查放入的类型:
但是我们总不能针对Integer类型再写个IngtegerArrayList类型 针对Character再写个。。。
工程量十分的巨大 以及累赘
所以泛型的出现解决了这个问题
我们必须把ArrayList变成一种模板:ArrayList
1 | |
T可以是任何class。这样一来,我们就实现了:编写一次模版,可以创建任意类型的ArrayList:
我们可以定义任何一种类型的ArrayList啦
1 | |
这样一来,既实现了编写一次,万能匹配,又通过编译器保证了类型安全:这就是泛型。
在Java标准库中的ArrayList<T>实现了List<T>接口,它可以向上转型为List<T>:
使用ArrayList时,如果不定义泛型类型时,泛型类型实际上就是Object:
1 | |
1 | |
当我们定义泛型 List<String> list = new List<>();
1 | |
当我们定义泛型类型<Number>后,List<T>的泛型接口变为强类型List<Number>:
1 | |
除了ArrayList<T>使用了泛型,还可以在接口中使用泛型。例如,Arrays.sort(Object[])可以对任意数组进行排序,但待排序的元素必须实现Comparable<T>这个泛型接口:
1 | |
ArrayList大家都肯定很熟悉 在需要存储一个不定长度的时候,我们通常第一时间想的就是ArrayList。
实际上
ArrayList内部就是一个Object[]数组,配合存储一个当前分配的长度,就可以充当“可变数组”:引用自廖雪峰老师的博客
我们翻开他的底层源码 我们会发现
原型是创建了一个Object[]的数组(初始容量为空 如果add第一个元素则会吧数组大小赋成10) 刚开始的 DEFAULT_CAPACITY 为10
未指定泛型前 我们需要这样写来获取对象
很容易出现ClassCastException,因为容易“误转型”:
1 | public class Main { |
则控制台会报错ClassCastException
要解决上述问题,我们可以为String单独编写一种ArrayList
StringArrayList stringarraylist = new Stringarraylist()
底层就是String类型的数组了
1 | public class StringArrayList { |
这样一来,存入的必须是String,取出的也一定是String,不需要强制转型,因为编译器会强制检查放入的类型:
但是我们总不能针对Integer类型再写个IngtegerArrayList类型 针对Character再写个。。。
工程量十分的巨大 以及累赘
所以泛型的出现解决了这个问题
我们必须把ArrayList变成一种模板:ArrayList
1 | public class ArrayList<T> { |
T可以是任何class。这样一来,我们就实现了:编写一次模版,可以创建任意类型的ArrayList:
我们可以定义任何一种类型的ArrayList啦
1 | ArrayList<String> stringArrayList = new ArrayList<>(); |
这样一来,既实现了编写一次,万能匹配,又通过编译器保证了类型安全:这就是泛型。
在Java标准库中的ArrayList<T>实现了List<T>接口,它可以向上转型为List<T>:
使用ArrayList时,如果不定义泛型类型时,泛型类型实际上就是Object:
1 | ArrayList list = new ArrayList();//此为Object |
1 | List list = new ArrayList(); |
当我们定义泛型 List<String> list = new List<>();
1 | //无编译器警告: |
当我们定义泛型类型<Number>后,List<T>的泛型接口变为强类型List<Number>:
1 | List<Number> list = new ArrayList<>(); |
除了ArrayList<T>使用了泛型,还可以在接口中使用泛型。例如,Arrays.sort(Object[])可以对任意数组进行排序,但待排序的元素必须实现Comparable<T>这个泛型接口:
1 | public interface Comparable<T> { |

先创建两个路径 先安装erlang环境
rabbitmq资源地址https://wwb.lanzoum.com/igycS04nk2ej
erlang资源 https://wwb.lanzoum.com/ic3df04nk6sh 密码:emig
yum -y install esl-erlang_23.0.2-1_centos_7_amd64.rpm

rabbitmq-plugins enable rabbitmq_management systemctl start rabbitmq-server.service systemctl status rabbitmq-server.service
!!!这个很重要 我安装的时候排查了很久 发现就是忘记敲了这个命令

systemctl start rabbitmq-server.service
systemctl status rabbitmq-server.service

查看是否是绿色的running
打开防火墙


默认账号guest 密码 guest
但是是默认不是本机是登不上去的
在rabbitmq的配置文件目录下(默认为:/etc/rabbitmq)创建一个rabbitmq.config文件。 文件中添加如下配置(请不要忘记那个“.”):
cd /etc/rabbitmq
vim rabbitmq.config
加入下面一句话
[{rabbit, [{loopback_users, []}]}].
重启rabbitmq服务
systemctl restart rabbitmq-server.service
1 | |
1 | |
先创建两个路径 先安装erlang环境
rabbitmq资源地址https://wwb.lanzoum.com/igycS04nk2ej
erlang资源 https://wwb.lanzoum.com/ic3df04nk6sh 密码:emig
yum -y install esl-erlang_23.0.2-1_centos_7_amd64.rpm
rabbitmq-plugins enable rabbitmq_management systemctl start rabbitmq-server.service systemctl status rabbitmq-server.service
!!!这个很重要 我安装的时候排查了很久 发现就是忘记敲了这个命令
systemctl start rabbitmq-server.service
systemctl status rabbitmq-server.service
查看是否是绿色的running
打开防火墙
默认账号guest 密码 guest
但是是默认不是本机是登不上去的
在rabbitmq的配置文件目录下(默认为:/etc/rabbitmq)创建一个rabbitmq.config文件。 文件中添加如下配置(请不要忘记那个“.”):
cd /etc/rabbitmq
vim rabbitmq.config
加入下面一句话
[{rabbit, [{loopback_users, []}]}].
重启rabbitmq服务
systemctl restart rabbitmq-server.service
1 | <!-- AMQP依赖 --> |
1 | application.yml |
corePoolSize : 线程池的核心大小,也可以理解为最小的线程池大小。
maximinPoolSize : 最大线程池大小
keepAliveTime:空余线程存活时间,指的是超过corePoolSize的空余线程达到多长时间才进行销毁。
util:销毁时间单位
WorkQueue:存储等待执行线程的工作队列。
threadFactory:创建线程的工厂,一般用默认即可。
handle:拒绝策略,当工厂队列,线程池全满时如何拒绝新任务,默认抛出异常
1.Servlet初始化后调用Init()方法
2.Servlet调用service()方法来处理客户端的请求。
3.Servlet销毁前调用destroy()方法终止
1 | |
1 | |
1 | |
1 | |
数据库中存在个用户表:users ,表结构如下:
1 | |
完善以下方法
public boolean verifyPassword(String username,String password) {
Connection con = getConnection () ;// getConnection() 方法是个已有的方法可以获取到数据库连接 ,
// here is your code
}
1 | |
HashMap JDK1.8之前 数组+链表
JDK1.8之后 数组+链表+红黑树
数组用于存储内容,链表(红黑树)用于解决hash冲突。如果链表长度大于阈值8,但是当前数组长度小于树化阈值64,则进行数组扩容操作;如果数组长度大于树化阈值64,则进行链表树化操作,将单向链表转化为红黑树结构。
如果不指定容量,则初始容量默认为16。如果指定容量,则初始容量设置为大于指定容量的最小2的幂数。当当前容量大于容量*负载因子(默认为0.75)时进行扩容操作,扩容为原容量的2倍。
1)数据结构区别:HashMap为数组+链表(红黑树),HashTable为数组+链表,HashTable没有树化操作。
2)扩容机制区别:未指定容量情况下,HashMap容量默认16,每次扩容为2n(n:原容量)。HashTable容量默认为11,每次扩容为2n+1(n:原容量)。指定容量情况下,HashMap将保证容量为2的幂数,HashTable将直接使用指定容量。
3)数据插入方式的区别:当发生hash冲突时,HashMap使用尾插法插入链表,HashTable使用头插法插入链表。
4)线程安全区别:HashMap是非线程安全的,HashTable因为使用synchronized修饰方法,所以HashTable是线程安全的。
ConcurrentHashMap的实现机制
1)ConcurrentHashMap通过synchronized关键字和CAS操作实现线程安全,若插入的槽没有数据,使用CAS操作执行插入操作,若插入的槽有数据,通过synchronized锁住链表的头节点,从而实现效率与线程安全的平衡
1.用户给servlet发送请求,请求Dao要Connection
2.Dao从“连接池”中取出Connection资源,与DB的通讯
3.当用户离开之后,释放该Connection,那么该Connection被释放到连接池中,等待下一个用户来
Demo目标:
通过简单的增删改查来做到下面几个关于连接池的方式,让我们更了解几种优化的方式
1.自定义一个Pool,来实现类似于现在开源连接池为我们做的一些操作
2.使用Tomcat内置的连接池(apache dbcp)
3.使用DBCP数据库连接池
4.使用C3P0数据库连接池(推荐)
1. 资源重用
由于数据库连接得到重用,避免了频繁创建、释放连接引起的大量性能开销。在减少系统消耗的基础上,另一方面也增进了系统运行环境的平稳性(减少内存碎片以及数据库临时进程/线程的数量)。
2. 更快的系统响应速度
数据库连接池在初始化过程中,往往已经创建了若干数据库连接置于池中备用。此时连接的初始化工作均已完成。对于业务请求处理而言,直接利用现有可用连接,避免了数据库连接初始化和释放过程的时间开销,从而缩减了系统整体响应时间。
3. 新的资源分配手段
对于多应用共享同一数据库的系统而言,可在应用层通过数据库连接的配置,实现数据库连接池技术,几年钱也许还是个新鲜话题,对于目前的业务系统而言,如果设计中还没有考虑到连接池的应用,那么…….快在设计文档中加上这部分的内容吧。某一应用最大可用数据库连接数的限制,避免某一应用独占所有数据库资源。
4. 统一的连接管理,避免数据库连接泄漏
在较为完备的数据库连接池实现中,可根据预先的连接占用超时设定,强制收回被占用连接。从而避免了常规数据库连接操作中可能出现的资源泄漏。一个最小化的数据库连接池实现:
死锁是一种特定的程序状态,在实体之间,由于循环依赖导致彼此一直处于等待之中,没有任何个体可以继续前进。死锁不仅仅会发生在线程之间,存在资源独占的进程之间同样也可能出现死锁。通常来说,我们大多是聚焦在多线程场景中的死锁,指两个或多个线程之间,由于互相持有对方需要的锁,而永久处于阻塞的状态。
基本上死锁的发生是因为:互斥条件,类似Java中Monitor都是独占的,要么是我用,要么是你用。互斥条件是长期持有的,在使用结束之前,自己不会释放,也不能被其它线程抢占。循环依赖关系,两个或者多个个体之间出现了锁的链条环。免死锁的思路和方法。****1、如果可能的话,尽量避免使用多个锁,并且只有需要时才持有锁。2、如果必须使用多个锁,尽量设计好锁的获取顺序。
3、使用带超时的方法,为程序带来更多可控性
分布式锁一般有三种实现方式:
1、 数据库锁
2、基于Redis的分布式锁
3、基于ZooKeeper的分布式锁
如果客户端连续不断的向服务端发送数据包时,服务端接收的数据会出现两个数据包粘在一起的情况,这就是TCP协议中经常会遇到的粘包以及拆包的问题。
1、TCP是基于字节流的,虽然应用层和传输层之间的数据交互是大小不等的数据块,但是TCP把这些数据块仅仅看成一连串无结构的字节流,没有边界;
2、在TCP的首部没有表示数据长度的字段,
基于上面两点,在使用TCP传输数据时,才有粘包或者拆包现象发生的可能。
解决
1、发送端给每个数据包添加包首部,首部中应该至少包含数据包的长度,这样接收端在接收到数据后,通过读取包首部的长度字段,便知道每一个数据包的实际长度了。
2、发送端将每个数据包封装为固定长度(不够的可以通过补0填充),这样接收端每次从接收缓冲区中读取固定长度的数据就自然而然的把每个数据包拆分开来。
3、可以在数据包之间设置边界,如添加特殊符号,这样,接收端通过这个边界就可以将不同的数据包拆分开。
BIO:同步阻塞式IO,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。
NIO:同步非阻塞式IO,服务器实现模式为一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。
AIO:异步非阻塞式IO,服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由OS先完成了再通知服务器应用去启动线程进行处理。
1、创建类的实例(开辟地址空间)
2、访问某个静态类或接口的静态常量,或者对该静态变量赋值(类初始化)
3、调用类的静态访问(new,也会占用空间)
4、反射(类初始化)
5、初始化一个类的子类(继承)
6、JAVA虚拟机启动被称标明为启动类的类
7、调用某个 ClassLoader 实例的 loadClass() 方法(类不会初始化)
1 | |
1 | |
1 | |
1 | |
1 | |
把6-10位的数字替换成””;
1 | |
1 | |
经典爬楼梯问题
1 | |
1 | |
24 将一个给定的单链表反转,例:1-2-3-4-5,反转为5-4-3-2-1
1 | |
例:图中给定树 {3,5,1,6,2,0,8,#,#,7,4} 中,节点6、节点4的最近公共祖先为5。
1 | |
好像是错误的!
1 | |
1 | |
例:数字23转为二进制为 10111,其中1的个数为4
1 | |
例:输入abcbdde,输出abcde。
1 | |
30 给定一个整型数组,移除数组的某个元素使其剩下的元素乘积最大,如果数组出现相同的元素 ,请输出第一次出现的元素
1 | |
1 | |
例:对于字符串“hellohehe”,第一个不重复的字符是“o”。如果每个字符都有重复,则抛出运行时异常。
1 | |
给定一个 N * N 的矩阵 M,表示用户之间的朋友关系。如果M[i][j] = 1,表示已知第 i 个和 j 个人互为朋友关系,否则为不知道。你必须输出所有用户中的已知的朋友圈总数。
1 | |
id,category,words,updatetime
id 表示书id,long类型,id不重复;
category 表示书的分类,int类型,请注意全部数据的分类只有几个
words 表示书的字数,int类型
updatetime 表示书的更新时间 ,格式为2020-02-01 23:00:00
请编写程序对文件数据进行排序后输出id,排序优先级为: category>updatetime > words > id , 增序排序
1 | |
为自动测试方便,使用每行输入模拟操作:
1) push 1 表明向队列里面新增一个元素 1 , push 和元素之间用空格表示;
2) pop 表明输出当前队列里面的第一个元素,如果当前队列为空请输出null
请将每个输出以英文逗号拼接到一个字符串中。
1 | |
1) 所有的参数值必须经过urlencode,编码为utf-8;
2) 对编码后数据按照key值进行字典升序排序;
3)将所有的参数按照排序的顺序拼接成字符串 ,格式如下: k1=v1&k2=v2&k3=v3;
\4) 将第三步的算出的值计算md5值,md5加密的值小写
请你编写一段方法计算token值
1 | |
corePoolSize : 线程池的核心大小,也可以理解为最小的线程池大小。
maximinPoolSize : 最大线程池大小
keepAliveTime:空余线程存活时间,指的是超过corePoolSize的空余线程达到多长时间才进行销毁。
util:销毁时间单位
WorkQueue:存储等待执行线程的工作队列。
threadFactory:创建线程的工厂,一般用默认即可。
handle:拒绝策略,当工厂队列,线程池全满时如何拒绝新任务,默认抛出异常
1.Servlet初始化后调用Init()方法
2.Servlet调用service()方法来处理客户端的请求。
3.Servlet销毁前调用destroy()方法终止
1 | package com.yuewen; |
1 | public class Singleton{ |
1 | package com.yuewen; |
1 | public static Object mapToObject(Map<String,Object> map,Class<?> beanClass){ |
数据库中存在个用户表:users ,表结构如下:
1 | CREATE TABLE `users` ( |
完善以下方法
public boolean verifyPassword(String username,String password) {
Connection con = getConnection () ;// getConnection() 方法是个已有的方法可以获取到数据库连接 ,
// here is your code
}
1 | public boolean verifyPassword(String username,String password){ |
HashMap JDK1.8之前 数组+链表
JDK1.8之后 数组+链表+红黑树
数组用于存储内容,链表(红黑树)用于解决hash冲突。如果链表长度大于阈值8,但是当前数组长度小于树化阈值64,则进行数组扩容操作;如果数组长度大于树化阈值64,则进行链表树化操作,将单向链表转化为红黑树结构。
如果不指定容量,则初始容量默认为16。如果指定容量,则初始容量设置为大于指定容量的最小2的幂数。当当前容量大于容量*负载因子(默认为0.75)时进行扩容操作,扩容为原容量的2倍。
1)数据结构区别:HashMap为数组+链表(红黑树),HashTable为数组+链表,HashTable没有树化操作。
2)扩容机制区别:未指定容量情况下,HashMap容量默认16,每次扩容为2n(n:原容量)。HashTable容量默认为11,每次扩容为2n+1(n:原容量)。指定容量情况下,HashMap将保证容量为2的幂数,HashTable将直接使用指定容量。
3)数据插入方式的区别:当发生hash冲突时,HashMap使用尾插法插入链表,HashTable使用头插法插入链表。
4)线程安全区别:HashMap是非线程安全的,HashTable因为使用synchronized修饰方法,所以HashTable是线程安全的。
ConcurrentHashMap的实现机制
1)ConcurrentHashMap通过synchronized关键字和CAS操作实现线程安全,若插入的槽没有数据,使用CAS操作执行插入操作,若插入的槽有数据,通过synchronized锁住链表的头节点,从而实现效率与线程安全的平衡
1.用户给servlet发送请求,请求Dao要Connection
2.Dao从“连接池”中取出Connection资源,与DB的通讯
3.当用户离开之后,释放该Connection,那么该Connection被释放到连接池中,等待下一个用户来
Demo目标:
通过简单的增删改查来做到下面几个关于连接池的方式,让我们更了解几种优化的方式
1.自定义一个Pool,来实现类似于现在开源连接池为我们做的一些操作
2.使用Tomcat内置的连接池(apache dbcp)
3.使用DBCP数据库连接池
4.使用C3P0数据库连接池(推荐)
1. 资源重用
由于数据库连接得到重用,避免了频繁创建、释放连接引起的大量性能开销。在减少系统消耗的基础上,另一方面也增进了系统运行环境的平稳性(减少内存碎片以及数据库临时进程/线程的数量)。
2. 更快的系统响应速度
数据库连接池在初始化过程中,往往已经创建了若干数据库连接置于池中备用。此时连接的初始化工作均已完成。对于业务请求处理而言,直接利用现有可用连接,避免了数据库连接初始化和释放过程的时间开销,从而缩减了系统整体响应时间。
3. 新的资源分配手段
对于多应用共享同一数据库的系统而言,可在应用层通过数据库连接的配置,实现数据库连接池技术,几年钱也许还是个新鲜话题,对于目前的业务系统而言,如果设计中还没有考虑到连接池的应用,那么…….快在设计文档中加上这部分的内容吧。某一应用最大可用数据库连接数的限制,避免某一应用独占所有数据库资源。
4. 统一的连接管理,避免数据库连接泄漏
在较为完备的数据库连接池实现中,可根据预先的连接占用超时设定,强制收回被占用连接。从而避免了常规数据库连接操作中可能出现的资源泄漏。一个最小化的数据库连接池实现:
死锁是一种特定的程序状态,在实体之间,由于循环依赖导致彼此一直处于等待之中,没有任何个体可以继续前进。死锁不仅仅会发生在线程之间,存在资源独占的进程之间同样也可能出现死锁。通常来说,我们大多是聚焦在多线程场景中的死锁,指两个或多个线程之间,由于互相持有对方需要的锁,而永久处于阻塞的状态。
基本上死锁的发生是因为:互斥条件,类似Java中Monitor都是独占的,要么是我用,要么是你用。互斥条件是长期持有的,在使用结束之前,自己不会释放,也不能被其它线程抢占。循环依赖关系,两个或者多个个体之间出现了锁的链条环。免死锁的思路和方法。****1、如果可能的话,尽量避免使用多个锁,并且只有需要时才持有锁。2、如果必须使用多个锁,尽量设计好锁的获取顺序。
3、使用带超时的方法,为程序带来更多可控性
分布式锁一般有三种实现方式:
1、 数据库锁
2、基于Redis的分布式锁
3、基于ZooKeeper的分布式锁
如果客户端连续不断的向服务端发送数据包时,服务端接收的数据会出现两个数据包粘在一起的情况,这就是TCP协议中经常会遇到的粘包以及拆包的问题。
1、TCP是基于字节流的,虽然应用层和传输层之间的数据交互是大小不等的数据块,但是TCP把这些数据块仅仅看成一连串无结构的字节流,没有边界;
2、在TCP的首部没有表示数据长度的字段,
基于上面两点,在使用TCP传输数据时,才有粘包或者拆包现象发生的可能。
解决
1、发送端给每个数据包添加包首部,首部中应该至少包含数据包的长度,这样接收端在接收到数据后,通过读取包首部的长度字段,便知道每一个数据包的实际长度了。
2、发送端将每个数据包封装为固定长度(不够的可以通过补0填充),这样接收端每次从接收缓冲区中读取固定长度的数据就自然而然的把每个数据包拆分开来。
3、可以在数据包之间设置边界,如添加特殊符号,这样,接收端通过这个边界就可以将不同的数据包拆分开。
BIO:同步阻塞式IO,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。
NIO:同步非阻塞式IO,服务器实现模式为一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。
AIO:异步非阻塞式IO,服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由OS先完成了再通知服务器应用去启动线程进行处理。
1、创建类的实例(开辟地址空间)
2、访问某个静态类或接口的静态常量,或者对该静态变量赋值(类初始化)
3、调用类的静态访问(new,也会占用空间)
4、反射(类初始化)
5、初始化一个类的子类(继承)
6、JAVA虚拟机启动被称标明为启动类的类
7、调用某个 ClassLoader 实例的 loadClass() 方法(类不会初始化)
1 | package com.yuewen; |
1 | import org.junit.Test; |
1 | package com.yuewen; |
1 | public static String dateSub(String a, String b) { |
1 | public static Map<String, Integer> sortMap(Map<String, Integer> map) { |
把6-10位的数字替换成””;
1 | public static String filterQQ(String s) { |
1 | package leecode; |
经典爬楼梯问题
1 | package com.yuewen; |
1 | import java.util.*; |
24 将一个给定的单链表反转,例:1-2-3-4-5,反转为5-4-3-2-1
1 | import java.util.*; |
例:图中给定树 {3,5,1,6,2,0,8,#,#,7,4} 中,节点6、节点4的最近公共祖先为5。
1 | import java.util.*; |
好像是错误的!
1 | int binarySearch(int* arr, int arrLen, int a) { |
1 | import java.util.*; |
例:数字23转为二进制为 10111,其中1的个数为4
1 | public static int binaryTo(int num) { int sum = 0; while (num > 0) { |
例:输入abcbdde,输出abcde。
1 | import java.util.*; |
30 给定一个整型数组,移除数组的某个元素使其剩下的元素乘积最大,如果数组出现相同的元素 ,请输出第一次出现的元素
1 | public class Main { |
1 | public static int[][] rotationMatrix(int[][] matrix) { |
例:对于字符串“hellohehe”,第一个不重复的字符是“o”。如果每个字符都有重复,则抛出运行时异常。
1 | public char findFirstNonRepeatChar (String str) { |
给定一个 N * N 的矩阵 M,表示用户之间的朋友关系。如果M[i][j] = 1,表示已知第 i 个和 j 个人互为朋友关系,否则为不知道。你必须输出所有用户中的已知的朋友圈总数。
1 | import java.util.HashSet; |
id,category,words,updatetime
id 表示书id,long类型,id不重复;
category 表示书的分类,int类型,请注意全部数据的分类只有几个
words 表示书的字数,int类型
updatetime 表示书的更新时间 ,格式为2020-02-01 23:00:00
请编写程序对文件数据进行排序后输出id,排序优先级为: category>updatetime > words > id , 增序排序
1 | import java.text.ParseException; |
为自动测试方便,使用每行输入模拟操作:
1) push 1 表明向队列里面新增一个元素 1 , push 和元素之间用空格表示;
2) pop 表明输出当前队列里面的第一个元素,如果当前队列为空请输出null
请将每个输出以英文逗号拼接到一个字符串中。
1 | static class MyQueue { |
1) 所有的参数值必须经过urlencode,编码为utf-8;
2) 对编码后数据按照key值进行字典升序排序;
3)将所有的参数按照排序的顺序拼接成字符串 ,格式如下: k1=v1&k2=v2&k3=v3;
\4) 将第三步的算出的值计算md5值,md5加密的值小写
请你编写一段方法计算token值
1 | public String getToken(Map<String, String> params) { |
1 | |
Input
输入:一个整数v,表示背包容量 一个整数n,表示有n个物品 接下来 n 个整数,分别表示这 n 个物品的各自体积
Output
输出:一个整数,表示背包最小的剩余空间
Sample Input
1 | |
Sample Output
1 | |
看到这道理的第一时刻想的是暴力枚举出所有零食混合装的重量 可复杂度太高 遂放弃。
然后看了一下大佬们的代码
1 | |
刚开始我用Java实现的时候,
1 | |
形式一下子就清楚了 dp是为了统计零食能够组成的重量
拿本题例子来说
输入 t = 8 时 只有dp[8] = dp[8] | dp[0] 才变成1 这代表着能够组成8的重量
输入 t = 3 时 有了dp[11] = dp[11] | dp[11 - 3] dp[3] = dp[3] | dp[0] 这次增加 11(8+3) 3(3+0)l两种可能
输入t = 12时 有dp[23] = 1 ,dp[20] = 1 dp[15] =1 dp[12] = 1
输入t = 7时 有 dp[22] = 1,dp[22] = 1 dp[19] = 1 dp[18] = 1 dp[15] = 1 dp[10] = 1
。。。。
到最后会使所有能够凑出重量的dp数都为1
从最大的量递减便利 当dp[i] 不为0 时 也就是为1 代表着这是能够装载着最大的重量 直接输出V-i
感叹算法的奇妙与精彩,只恨自己接触晚与学校氛围不好,蹉跎了许久时光。
JAVA版代码
1 | |
1 | 秋天快到啦,天气慢慢凉爽了下来,所以实验室要组织去骊山进行一次野餐活动。 |
Input
输入:一个整数v,表示背包容量 一个整数n,表示有n个物品 接下来 n 个整数,分别表示这 n 个物品的各自体积
Output
输出:一个整数,表示背包最小的剩余空间
Sample Input
1 | 24 |
Sample Output
1 | 0 |
看到这道理的第一时刻想的是暴力枚举出所有零食混合装的重量 可复杂度太高 遂放弃。
然后看了一下大佬们的代码
1 |
|
刚开始我用Java实现的时候,
1 |
|
形式一下子就清楚了 dp是为了统计零食能够组成的重量
拿本题例子来说
输入 t = 8 时 只有dp[8] = dp[8] | dp[0] 才变成1 这代表着能够组成8的重量
输入 t = 3 时 有了dp[11] = dp[11] | dp[11 - 3] dp[3] = dp[3] | dp[0] 这次增加 11(8+3) 3(3+0)l两种可能
输入t = 12时 有dp[23] = 1 ,dp[20] = 1 dp[15] =1 dp[12] = 1
输入t = 7时 有 dp[22] = 1,dp[22] = 1 dp[19] = 1 dp[18] = 1 dp[15] = 1 dp[10] = 1
。。。。
到最后会使所有能够凑出重量的dp数都为1
从最大的量递减便利 当dp[i] 不为0 时 也就是为1 代表着这是能够装载着最大的重量 直接输出V-i
感叹算法的奇妙与精彩,只恨自己接触晚与学校氛围不好,蹉跎了许久时光。
JAVA版代码
1 | package com.VG; |
面向切面编程(方面), 利用 AOP 可以对业务逻辑的各个部分进行隔离,从而使得业务逻辑各部分之间的耦合度降低,提高程序的可重用性,同时提高了开发的效率。
通俗描述:不通过修改源代码方式,在主干功能里面添加新功能。
1 | |
方法有三个参数
第一个参数:类加载器
第二个参数:增加方法所在的类。
第三个参数:
]]>面向切面编程(方面), 利用 AOP 可以对业务逻辑的各个部分进行隔离,从而使得业务逻辑各部分之间的耦合度降低,提高程序的可重用性,同时提高了开发的效率。
通俗描述:不通过修改源代码方式,在主干功能里面添加新功能。
1 | newProxyInstance(ClassLoader loader,类<?>[] interfaces,InvacationHandle) |
方法有三个参数
第一个参数:类加载器
第二个参数:增加方法所在的类。
第三个参数:
]]>解决一个回溯问题,实际上就是一个决策树的遍历过程,需要思考三个问题
回溯算法框架
1 | |
核心在于for循环里面的递归,在递归调用之前做选择,在递归调用之后撤销选择。
有n个数 每个数都只能用一次 求出所有能排列的可能性。全排列个数为n!个
PS:为了简单清晰起见,我们这次讨论的全排列问题不包含重复的数字。
如果已知有多少个数的情况下,我们通常可以使用n层for循环暴力遍历所有数
例如3个数 我们可以暴力写法为
1 | |
回溯数如下图所示,只要从根遍历这棵树,记录路径下的数字,其实就是所有的全排列,我们不妨把这棵树称之为回溯算法的决策树
为什么叫决策树呢,顾名思义,每次遍历的时候都需要做决策来去避开那些已经走过的路。
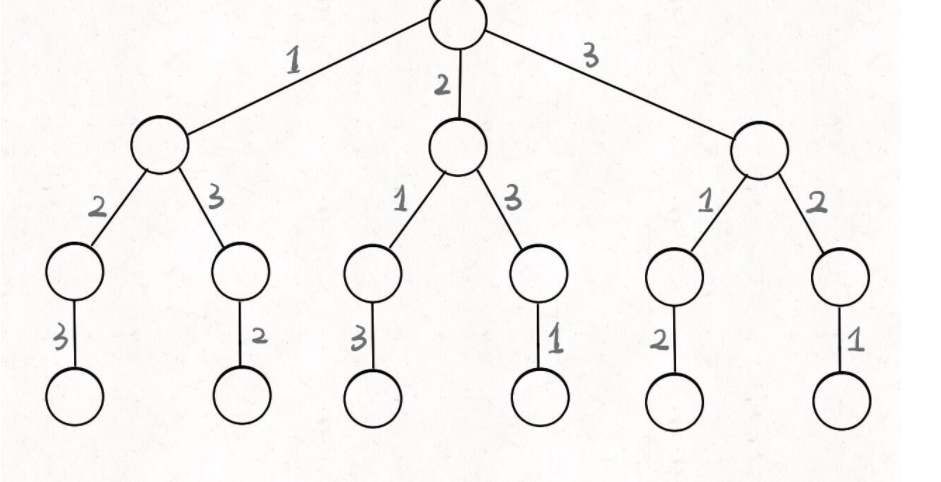
现在可以解答开头的几个名词:[2] 就是「路径」,记录你已经做过的选择;[1,3] 就是「选择列表」,表示你当前可以做出的选择;「结束条件」就是遍历到树的底层,在这里就是选择列表为空的时候。
如果明白了这几个名词,可以把「路径」和「选择」列表作为决策树上每个节点的属性,比如下图列出了几个节点的属性:
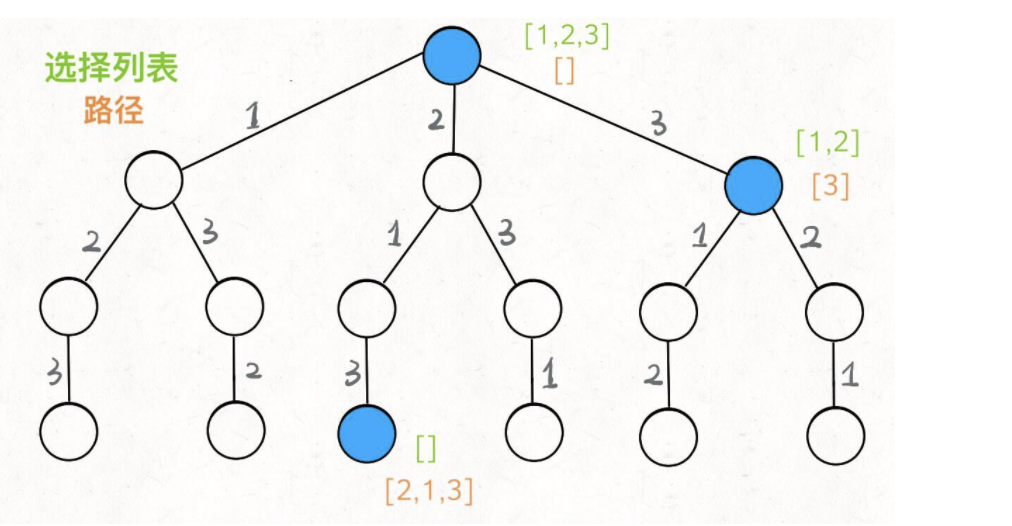
我们定义的backtrack函数就是指针一样,在这棵树上游走,同时要正确维护每个节点的属性,每当走到树的底层,其路径就是一个全排列。
再进一步,如何遍历一颗树,
1 | |
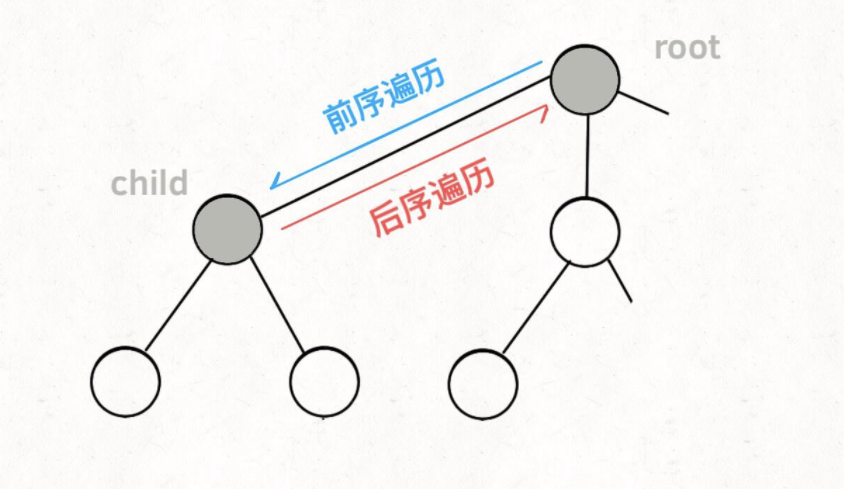
前序遍历的代码在进入某一个节点之前的那个时间点执行,后序遍历代码在离开某个节点之后的那个时间点执行。
回想我们刚才说的,「路径」和「选择」是每个节点的属性,函数在树上游走要正确维护节点的属性,那么就要在这两个特殊时间点搞点动作:
回溯代码核心框架
1 | |
我们只要在递归之前做出选择,在递归之后撤销自己的选择,就能得到每个节点的选择路径和列表。
1 | |
我们这里稍微做了些变通,没有显式记录「选择列表」,而是通过 nums 和 track 推导出当前的选择列表:
通过contains函数来判断该数是否已经被使用。
至此,我们就通过全排列问题详解了回溯算法的底层原理。当然,这个算法解决全排列不是很高效,应为对链表使用 contains 方法需要 O(N) 的时间复杂度。有更好的方法通过交换元素达到目的,但是难理解一些,这里就不写了,有兴趣可以自行搜索一下。
但是必须说明的是,不管怎么优化,都符合回溯框架,而且时间复杂度都不可能低于 O(N!),因为穷举整棵决策树是无法避免的。这也是回溯算法的一个特点,不像动态规划存在重叠子问题可以优化,回溯算法就是纯暴力穷举,复杂度一般都很高。
明白了全排列问题,就可以直接套回溯算法框架了,下面简单看看 N 皇后问题。
给你一个N*N的棋盘,,让你放置 N 个皇后,使得它们不能互相攻击。
PS:皇后可以攻击同一行、同一列、左上左下右上右下四个方向的任意单位。
这个问题本质上跟全排列问题差不多,决策树的每一层表示棋盘上的每一行;每个节点可以做出的选择是,在该行的任意一列放置一个皇后。
1 | |
IsValid()函数
1 | |
函数 backtrack 依然像个在决策树上游走的指针,通过 row 和 col 就可以表示函数遍历到的位置,通过 isValid 函数可以将不符合条件的情况剪枝:
某种程度上说,动态规划的暴力求解阶段就是回溯算法。只是有的问题具有重叠子问题性质,可以用 dp table 或者备忘录优化,将递归树大幅剪枝,这就变成了动态规划。而今天的两个问题,都没有重叠子问题,也就是回溯算法问题了,复杂度非常高是不可避免的。
参考链接:https://leetcode-cn.com/problems/permutations/solution/hui-su-suan-fa-xiang-jie-by-labuladong-2/
]]>解决一个回溯问题,实际上就是一个决策树的遍历过程,需要思考三个问题
回溯算法框架
1 | result = [] |
核心在于for循环里面的递归,在递归调用之前做选择,在递归调用之后撤销选择。
有n个数 每个数都只能用一次 求出所有能排列的可能性。全排列个数为n!个
PS:为了简单清晰起见,我们这次讨论的全排列问题不包含重复的数字。
如果已知有多少个数的情况下,我们通常可以使用n层for循环暴力遍历所有数
例如3个数 我们可以暴力写法为
1 | for(int i = 0;i < n;i++) |
回溯数如下图所示,只要从根遍历这棵树,记录路径下的数字,其实就是所有的全排列,我们不妨把这棵树称之为回溯算法的决策树
为什么叫决策树呢,顾名思义,每次遍历的时候都需要做决策来去避开那些已经走过的路。
现在可以解答开头的几个名词:[2] 就是「路径」,记录你已经做过的选择;[1,3] 就是「选择列表」,表示你当前可以做出的选择;「结束条件」就是遍历到树的底层,在这里就是选择列表为空的时候。
如果明白了这几个名词,可以把「路径」和「选择」列表作为决策树上每个节点的属性,比如下图列出了几个节点的属性:
我们定义的backtrack函数就是指针一样,在这棵树上游走,同时要正确维护每个节点的属性,每当走到树的底层,其路径就是一个全排列。
再进一步,如何遍历一颗树,
1 | void traverse(TreeNode root) { |
前序遍历的代码在进入某一个节点之前的那个时间点执行,后序遍历代码在离开某个节点之后的那个时间点执行。
回想我们刚才说的,「路径」和「选择」是每个节点的属性,函数在树上游走要正确维护节点的属性,那么就要在这两个特殊时间点搞点动作:
回溯代码核心框架
1 | for 选择 in 选择列表: |
我们只要在递归之前做出选择,在递归之后撤销自己的选择,就能得到每个节点的选择路径和列表。
1 | List<List<Integer>> res = new LinkedList<>(); |
我们这里稍微做了些变通,没有显式记录「选择列表」,而是通过 nums 和 track 推导出当前的选择列表:
通过contains函数来判断该数是否已经被使用。
至此,我们就通过全排列问题详解了回溯算法的底层原理。当然,这个算法解决全排列不是很高效,应为对链表使用 contains 方法需要 O(N) 的时间复杂度。有更好的方法通过交换元素达到目的,但是难理解一些,这里就不写了,有兴趣可以自行搜索一下。
但是必须说明的是,不管怎么优化,都符合回溯框架,而且时间复杂度都不可能低于 O(N!),因为穷举整棵决策树是无法避免的。这也是回溯算法的一个特点,不像动态规划存在重叠子问题可以优化,回溯算法就是纯暴力穷举,复杂度一般都很高。
明白了全排列问题,就可以直接套回溯算法框架了,下面简单看看 N 皇后问题。
给你一个N*N的棋盘,,让你放置 N 个皇后,使得它们不能互相攻击。
PS:皇后可以攻击同一行、同一列、左上左下右上右下四个方向的任意单位。
这个问题本质上跟全排列问题差不多,决策树的每一层表示棋盘上的每一行;每个节点可以做出的选择是,在该行的任意一列放置一个皇后。
1 | vector<vector<string>> res; |
IsValid()函数
1 | /* 是否可以在 board[row][col] 放置皇后? */ |
函数 backtrack 依然像个在决策树上游走的指针,通过 row 和 col 就可以表示函数遍历到的位置,通过 isValid 函数可以将不符合条件的情况剪枝:
某种程度上说,动态规划的暴力求解阶段就是回溯算法。只是有的问题具有重叠子问题性质,可以用 dp table 或者备忘录优化,将递归树大幅剪枝,这就变成了动态规划。而今天的两个问题,都没有重叠子问题,也就是回溯算法问题了,复杂度非常高是不可避免的。
参考链接:https://leetcode-cn.com/problems/permutations/solution/hui-su-suan-fa-xiang-jie-by-labuladong-2/
]]>解决一个回溯问题,实际上就是一个决策树的遍历过程,需要思考三个问题
回溯算法框架
1 | |
核心在于for循环里面的递归,在递归调用之前做选择,在递归调用之后撤销选择。
有n个数 每个数都只能用一次 求出所有能排列的可能性。全排列个数为n!个
PS:为了简单清晰起见,我们这次讨论的全排列问题不包含重复的数字。
如果已知有多少个数的情况下,我们通常可以使用n层for循环暴力遍历所有数
例如3个数 我们可以暴力写法为
1 | |
回溯数如下图所示,只要从根遍历这棵树,记录路径下的数字,其实就是所有的全排列,我们不妨把这棵树称之为回溯算法的决策树
为什么叫决策树呢,顾名思义,每次遍历的时候都需要做决策来去避开那些已经走过的路。
现在可以解答开头的几个名词:[2] 就是「路径」,记录你已经做过的选择;[1,3] 就是「选择列表」,表示你当前可以做出的选择;「结束条件」就是遍历到树的底层,在这里就是选择列表为空的时候。
如果明白了这几个名词,可以把「路径」和「选择」列表作为决策树上每个节点的属性,比如下图列出了几个节点的属性:
我们定义的backtrack函数就是指针一样,在这棵树上游走,同时要正确维护每个节点的属性,每当走到树的底层,其路径就是一个全排列。
再进一步,如何遍历一颗树,
1 | |
前序遍历的代码在进入某一个节点之前的那个时间点执行,后序遍历代码在离开某个节点之后的那个时间点执行。
回想我们刚才说的,「路径」和「选择」是每个节点的属性,函数在树上游走要正确维护节点的属性,那么就要在这两个特殊时间点搞点动作:
回溯代码核心框架
1 | |
我们只要在递归之前做出选择,在递归之后撤销自己的选择,就能得到每个节点的选择路径和列表。
1 | |
我们这里稍微做了些变通,没有显式记录「选择列表」,而是通过 nums 和 track 推导出当前的选择列表:
通过contains函数来判断该数是否已经被使用。
至此,我们就通过全排列问题详解了回溯算法的底层原理。当然,这个算法解决全排列不是很高效,应为对链表使用 contains 方法需要 O(N) 的时间复杂度。有更好的方法通过交换元素达到目的,但是难理解一些,这里就不写了,有兴趣可以自行搜索一下。
但是必须说明的是,不管怎么优化,都符合回溯框架,而且时间复杂度都不可能低于 O(N!),因为穷举整棵决策树是无法避免的。这也是回溯算法的一个特点,不像动态规划存在重叠子问题可以优化,回溯算法就是纯暴力穷举,复杂度一般都很高。
明白了全排列问题,就可以直接套回溯算法框架了,下面简单看看 N 皇后问题。
给你一个N*N的棋盘,,让你放置 N 个皇后,使得它们不能互相攻击。
PS:皇后可以攻击同一行、同一列、左上左下右上右下四个方向的任意单位。
这个问题本质上跟全排列问题差不多,决策树的每一层表示棋盘上的每一行;每个节点可以做出的选择是,在该行的任意一列放置一个皇后。
1 | |
IsValid()函数
1 | |
函数 backtrack 依然像个在决策树上游走的指针,通过 row 和 col 就可以表示函数遍历到的位置,通过 isValid 函数可以将不符合条件的情况剪枝:
某种程度上说,动态规划的暴力求解阶段就是回溯算法。只是有的问题具有重叠子问题性质,可以用 dp table 或者备忘录优化,将递归树大幅剪枝,这就变成了动态规划。而今天的两个问题,都没有重叠子问题,也就是回溯算法问题了,复杂度非常高是不可避免的。
参考链接:https://leetcode-cn.com/problems/permutations/solution/hui-su-suan-fa-xiang-jie-by-labuladong-2/
]]>解决一个回溯问题,实际上就是一个决策树的遍历过程,需要思考三个问题
回溯算法框架
1 | result = [] |
核心在于for循环里面的递归,在递归调用之前做选择,在递归调用之后撤销选择。
有n个数 每个数都只能用一次 求出所有能排列的可能性。全排列个数为n!个
PS:为了简单清晰起见,我们这次讨论的全排列问题不包含重复的数字。
如果已知有多少个数的情况下,我们通常可以使用n层for循环暴力遍历所有数
例如3个数 我们可以暴力写法为
1 | for(int i = 0;i < n;i++) |
回溯数如下图所示,只要从根遍历这棵树,记录路径下的数字,其实就是所有的全排列,我们不妨把这棵树称之为回溯算法的决策树
为什么叫决策树呢,顾名思义,每次遍历的时候都需要做决策来去避开那些已经走过的路。
现在可以解答开头的几个名词:[2] 就是「路径」,记录你已经做过的选择;[1,3] 就是「选择列表」,表示你当前可以做出的选择;「结束条件」就是遍历到树的底层,在这里就是选择列表为空的时候。
如果明白了这几个名词,可以把「路径」和「选择」列表作为决策树上每个节点的属性,比如下图列出了几个节点的属性:
我们定义的backtrack函数就是指针一样,在这棵树上游走,同时要正确维护每个节点的属性,每当走到树的底层,其路径就是一个全排列。
再进一步,如何遍历一颗树,
1 | void traverse(TreeNode root) { |
前序遍历的代码在进入某一个节点之前的那个时间点执行,后序遍历代码在离开某个节点之后的那个时间点执行。
回想我们刚才说的,「路径」和「选择」是每个节点的属性,函数在树上游走要正确维护节点的属性,那么就要在这两个特殊时间点搞点动作:
回溯代码核心框架
1 | for 选择 in 选择列表: |
我们只要在递归之前做出选择,在递归之后撤销自己的选择,就能得到每个节点的选择路径和列表。
1 | List<List<Integer>> res = new LinkedList<>(); |
我们这里稍微做了些变通,没有显式记录「选择列表」,而是通过 nums 和 track 推导出当前的选择列表:
通过contains函数来判断该数是否已经被使用。
至此,我们就通过全排列问题详解了回溯算法的底层原理。当然,这个算法解决全排列不是很高效,应为对链表使用 contains 方法需要 O(N) 的时间复杂度。有更好的方法通过交换元素达到目的,但是难理解一些,这里就不写了,有兴趣可以自行搜索一下。
但是必须说明的是,不管怎么优化,都符合回溯框架,而且时间复杂度都不可能低于 O(N!),因为穷举整棵决策树是无法避免的。这也是回溯算法的一个特点,不像动态规划存在重叠子问题可以优化,回溯算法就是纯暴力穷举,复杂度一般都很高。
明白了全排列问题,就可以直接套回溯算法框架了,下面简单看看 N 皇后问题。
给你一个N*N的棋盘,,让你放置 N 个皇后,使得它们不能互相攻击。
PS:皇后可以攻击同一行、同一列、左上左下右上右下四个方向的任意单位。
这个问题本质上跟全排列问题差不多,决策树的每一层表示棋盘上的每一行;每个节点可以做出的选择是,在该行的任意一列放置一个皇后。
1 | vector<vector<string>> res; |
IsValid()函数
1 | /* 是否可以在 board[row][col] 放置皇后? */ |
函数 backtrack 依然像个在决策树上游走的指针,通过 row 和 col 就可以表示函数遍历到的位置,通过 isValid 函数可以将不符合条件的情况剪枝:
某种程度上说,动态规划的暴力求解阶段就是回溯算法。只是有的问题具有重叠子问题性质,可以用 dp table 或者备忘录优化,将递归树大幅剪枝,这就变成了动态规划。而今天的两个问题,都没有重叠子问题,也就是回溯算法问题了,复杂度非常高是不可避免的。
参考链接:https://leetcode-cn.com/problems/permutations/solution/hui-su-suan-fa-xiang-jie-by-labuladong-2/
]]>多线程demo
-1 | |
1 | public class deno01 { |
很明显得到的结果是交替打印1 和 2。
拓展
@@ -835,17 +841,17 @@1 | |
1 | synchronized void method() { |
synchronized 方法,而线程 B 需要调用这个实例对象所属类的静态 synchronized 方法,是允许的,不会发生互斥现象,因为访问静态 synchronized 方法占用的锁是当前类的锁,而访问非静态 synchronized 方法占用的锁是当前实例对象锁。1 | |
1 | synchronized void staic method() { |
synchronized(this|object) 表示进入同步代码库前要获得给定对象的锁。synchronized(类.class) 表示进入同步代码前要获得 当前 class 的锁1 | |
1 | synchronized(this) { |
当初始长度为10已经加入了十个元素之后,我们需要再加一个元素的时候,我们就需要扩容
1 | |
1 | private void add(E e, Object[] elementData, int s) { |
这段源代码就是ArrayList的add()方法 如果添加的元素已经满了 则调用grow()函数 很明显 这是一个扩容函数
grow函数有两个 一个有参函数 一个无参函数
无参参数会调用有参参数 进行1.5倍的扩容
-1 | |
1 | ArrayList list1 = new ArrayList(23); |
这表示着生成了一个初始长度为23的ArrayList数组
和ArrayList数组类似 线程安全 效率低 用的很少
@@ -890,7 +896,7 @@HashMap 是无序的,即不会记录插入的顺序。
HashMap 继承于AbstractMap,实现了 Map、Cloneable、java.io.Serializable 接口。
1 | |
1 | public class Main { |
起初我验证Map的无序的时候 输出的总是有序的 增加了样本之后才变得无序
很容易出现ClassCastException,因为容易“误转型”:
-1 | |
1 | public class Main { |
则控制台会报错ClassCastException
String单独编写一种ArrayList
StringArrayList stringarraylist = new Stringarraylist()
底层就是String类型的数组了
-1 | |
1 | public class StringArrayList { |
这样一来,存入的必须是String,取出的也一定是String,不需要强制转型,因为编译器会强制检查放入的类型:
但是我们总不能针对Integer类型再写个IngtegerArrayList类型 针对Character再写个。。。
工程量十分的巨大 以及累赘
所以泛型的出现解决了这个问题
我们必须把ArrayList变成一种模板:ArrayList
1 | |
1 | public class ArrayList<T> { |
T可以是任何class。这样一来,我们就实现了:编写一次模版,可以创建任意类型的ArrayList:
我们可以定义任何一种类型的ArrayList啦
-1 | |
1 | ArrayList<String> stringArrayList = new ArrayList<>(); |
这样一来,既实现了编写一次,万能匹配,又通过编译器保证了类型安全:这就是泛型。
在Java标准库中的ArrayList<T>实现了List<T>接口,它可以向上转型为List<T>:
使用ArrayList时,如果不定义泛型类型时,泛型类型实际上就是Object:
1 | |
1 | ArrayList list = new ArrayList();//此为Object |
1 | |
1 | List list = new ArrayList(); |
当我们定义泛型 List<String> list = new List<>();
1 | |
1 | //无编译器警告: |
当我们定义泛型类型<Number>后,List<T>的泛型接口变为强类型List<Number>:
1 | |
1 | List<Number> list = new ArrayList<>(); |
除了ArrayList<T>使用了泛型,还可以在接口中使用泛型。例如,Arrays.sort(Object[])可以对任意数组进行排序,但待排序的元素必须实现Comparable<T>这个泛型接口:
1 | |
1 | public interface Comparable<T> { |
1 | |
1 | <!-- AMQP依赖 --> |
1 | |
1 | application.yml |
1.Servlet初始化后调用Init()方法
2.Servlet调用service()方法来处理客户端的请求。
3.Servlet销毁前调用destroy()方法终止
-1 | |
1 | package com.yuewen; |
1 | |
1 | public class Singleton{ |
1 | |
1 | package com.yuewen; |
1 | |
1 | public static Object mapToObject(Map<String,Object> map,Class<?> beanClass){ |
数据库中存在个用户表:users ,表结构如下:
-1 | |
1 | CREATE TABLE `users` ( |
完善以下方法
public boolean verifyPassword(String username,String password) {
Connection con = getConnection () ;// getConnection() 方法是个已有的方法可以获取到数据库连接 ,
// here is your code
}
1 | |
1 | public boolean verifyPassword(String username,String password){ |
HashMap JDK1.8之前 数组+链表
JDK1.8之后 数组+链表+红黑树
@@ -817,7 +817,7 @@1 | |
1 | package com.yuewen; |
1 | |
1 | import org.junit.Test; |
1 | |
1 | package com.yuewen; |
1 | |
1 | public static String dateSub(String a, String b) { |
1 | |
1 | public static Map<String, Integer> sortMap(Map<String, Integer> map) { |
把6-10位的数字替换成””;
-1 | |
1 | public static String filterQQ(String s) { |
1 | |
1 | package leecode; |
经典爬楼梯问题
-1 | |
1 | package com.yuewen; |
1 | |
1 | import java.util.*; |
24 将一个给定的单链表反转,例:1-2-3-4-5,反转为5-4-3-2-1
-1 | |
1 | import java.util.*; |
例:图中给定树 {3,5,1,6,2,0,8,#,#,7,4} 中,节点6、节点4的最近公共祖先为5。
1 | |
1 | import java.util.*; |
好像是错误的!
-1 | |
1 | int binarySearch(int* arr, int arrLen, int a) { |
1 | |
1 | import java.util.*; |
例:数字23转为二进制为 10111,其中1的个数为4
-1 | |
1 | public static int binaryTo(int num) { int sum = 0; while (num > 0) { |
例:输入abcbdde,输出abcde。
-1 | |
1 | import java.util.*; |
30 给定一个整型数组,移除数组的某个元素使其剩下的元素乘积最大,如果数组出现相同的元素 ,请输出第一次出现的元素
-1 | |
1 | public class Main { |
1 | |
1 | public static int[][] rotationMatrix(int[][] matrix) { |
例:对于字符串“hellohehe”,第一个不重复的字符是“o”。如果每个字符都有重复,则抛出运行时异常。
-1 | |
1 | public char findFirstNonRepeatChar (String str) { |
给定一个 N * N 的矩阵 M,表示用户之间的朋友关系。如果M[i][j] = 1,表示已知第 i 个和 j 个人互为朋友关系,否则为不知道。你必须输出所有用户中的已知的朋友圈总数。
-1 | |
1 | import java.util.HashSet; |
id,category,words,updatetime
id 表示书id,long类型,id不重复;
@@ -884,20 +884,20 @@1 | |
1 | import java.text.ParseException; |
为自动测试方便,使用每行输入模拟操作:
1) push 1 表明向队列里面新增一个元素 1 , push 和元素之间用空格表示;
2) pop 表明输出当前队列里面的第一个元素,如果当前队列为空请输出null
请将每个输出以英文逗号拼接到一个字符串中。
-1 | |
1 | static class MyQueue { |
1) 所有的参数值必须经过urlencode,编码为utf-8;
2) 对编码后数据按照key值进行字典升序排序;
3)将所有的参数按照排序的顺序拼接成字符串 ,格式如下: k1=v1&k2=v2&k3=v3;
\4) 将第三步的算出的值计算md5值,md5加密的值小写
请你编写一段方法计算token值
-1 | |
1 | public String getToken(Map<String, String> params) { |
题干
-1 | |
1 | 秋天快到啦,天气慢慢凉爽了下来,所以实验室要组织去骊山进行一次野餐活动。 |
Input
输入:一个整数v,表示背包容量 一个整数n,表示有n个物品 接下来 n 个整数,分别表示这 n 个物品的各自体积
Output
输出:一个整数,表示背包最小的剩余空间
Sample Input
-1 | |
1 | 24 |
Sample Output
-1 | |
1 | 0 |
看到这道理的第一时刻想的是暴力枚举出所有零食混合装的重量 可复杂度太高 遂放弃。
然后看了一下大佬们的代码
-1 | |
1 |
|
刚开始我用Java实现的时候,
-1 | |
1 |
|
形式一下子就清楚了 dp是为了统计零食能够组成的重量
拿本题例子来说
@@ -1002,7 +1002,7 @@从最大的量递减便利 当dp[i] 不为0 时 也就是为1 代表着这是能够装载着最大的重量 直接输出V-i
感叹算法的奇妙与精彩,只恨自己接触晚与学校氛围不好,蹉跎了许久时光。
JAVA版代码
-1 | |
1 | package com.VG; |
1 | |
1 | newProxyInstance(ClassLoader loader,类<?>[] interfaces,InvacationHandle) |
方法有三个参数
第一个参数:类加载器
@@ -1166,14 +1166,14 @@1 | |
1 | result = [] |
核心在于for循环里面的递归,在递归调用之前做选择,在递归调用之后撤销选择。
有n个数 每个数都只能用一次 求出所有能排列的可能性。全排列个数为n!个
PS:为了简单清晰起见,我们这次讨论的全排列问题不包含重复的数字。
如果已知有多少个数的情况下,我们通常可以使用n层for循环暴力遍历所有数
例如3个数 我们可以暴力写法为
-1 | |
1 | for(int i = 0;i < n;i++) |
我们定义的backtrack函数就是指针一样,在这棵树上游走,同时要正确维护每个节点的属性,每当走到树的底层,其路径就是一个全排列。
再进一步,如何遍历一颗树,
-1 | |
1 | void traverse(TreeNode root) { |
回溯代码核心框架
-1 | |
1 | for 选择 in 选择列表: |
我们只要在递归之前做出选择,在递归之后撤销自己的选择,就能得到每个节点的选择路径和列表。
-1 | |
1 | List<List<Integer>> res = new LinkedList<>(); |
我们这里稍微做了些变通,没有显式记录「选择列表」,而是通过 nums 和 track 推导出当前的选择列表:
通过contains函数来判断该数是否已经被使用。
@@ -1210,10 +1210,10 @@给你一个N*N的棋盘,,让你放置 N 个皇后,使得它们不能互相攻击。
PS:皇后可以攻击同一行、同一列、左上左下右上右下四个方向的任意单位。
这个问题本质上跟全排列问题差不多,决策树的每一层表示棋盘上的每一行;每个节点可以做出的选择是,在该行的任意一列放置一个皇后。
-1 | |
1 | vector<vector<string>> res; |
IsValid()函数
-1 | |
1 | /* 是否可以在 board[row][col] 放置皇后? */ |
函数 backtrack 依然像个在决策树上游走的指针,通过 row 和 col 就可以表示函数遍历到的位置,通过 isValid 函数可以将不符合条件的情况剪枝:
1 | |
1 | result = [] |
核心在于for循环里面的递归,在递归调用之前做选择,在递归调用之后撤销选择。
有n个数 每个数都只能用一次 求出所有能排列的可能性。全排列个数为n!个
PS:为了简单清晰起见,我们这次讨论的全排列问题不包含重复的数字。
如果已知有多少个数的情况下,我们通常可以使用n层for循环暴力遍历所有数
例如3个数 我们可以暴力写法为
-1 | |
1 | for(int i = 0;i < n;i++) |
我们定义的backtrack函数就是指针一样,在这棵树上游走,同时要正确维护每个节点的属性,每当走到树的底层,其路径就是一个全排列。
再进一步,如何遍历一颗树,
-1 | |
1 | void traverse(TreeNode root) { |
回溯代码核心框架
-1 | |
1 | for 选择 in 选择列表: |
我们只要在递归之前做出选择,在递归之后撤销自己的选择,就能得到每个节点的选择路径和列表。
-1 | |
1 | List<List<Integer>> res = new LinkedList<>(); |
我们这里稍微做了些变通,没有显式记录「选择列表」,而是通过 nums 和 track 推导出当前的选择列表:
通过contains函数来判断该数是否已经被使用。
@@ -1348,10 +1348,10 @@给你一个N*N的棋盘,,让你放置 N 个皇后,使得它们不能互相攻击。
PS:皇后可以攻击同一行、同一列、左上左下右上右下四个方向的任意单位。
这个问题本质上跟全排列问题差不多,决策树的每一层表示棋盘上的每一行;每个节点可以做出的选择是,在该行的任意一列放置一个皇后。
-1 | |
1 | vector<vector<string>> res; |
IsValid()函数
-1 | |
1 | /* 是否可以在 board[row][col] 放置皇后? */ |
函数 backtrack 依然像个在决策树上游走的指针,通过 row 和 col 就可以表示函数遍历到的位置,通过 isValid 函数可以将不符合条件的情况剪枝:
一个整数 nn。
一个整数,表示整数 nn 的十六进制表示包含的圈圈总数。
前三个测试点满足 0≤n≤1000≤n≤100,
所有测试点满足 0≤n≤2×1090≤n≤2×109。
1 | |
1 | 11 |
1 | |
1 | 2 |
1 | |
1 | 14 |
1 | |
1 | 0 |
简单模拟即可 注意特判0 每次都在这里栽跟头…
-1 | |
1 | // package com.ACC; |
农夫约翰有 nn 片连续的农田,编号依次为 1∼n1∼n。
其中有 kk 片农田中装有洒水器。
@@ -600,12 +600,12 @@每组数据输出一行答案。
前三个测试点满足 1≤n≤51≤n≤5,
所有测试点满足 1≤T≤2001≤T≤200,1≤n≤2001≤n≤200,1≤k≤n1≤k≤n,1≤xi≤n1≤xi≤n,xi−1<xixi−1<xi,TT 组数据的 nn 相加之和不超过 200200。
1 | |
1 | 3 |
1 | |
1 | 3 |
模拟即可
-1 | |
1 | // package com.ACC; |
题目C
@@ -1338,16 +1338,16 @@1 | |
1 | Runnable t = () -> System.out.println("Hello Lambda") |
1 | |
1 | (x)-> System.out.println(x) |
若只有一个参数,小括号可以省略不写
-1 | |
1 | x-> System.out.println(x) |
1 | |
1 | Comparator<Integer> com =(x,y)->(System.out.print1n("函数式接口") return Integer.compare(x,y) |
…待续
diff --git a/page/4/index.html b/page/4/index.html index fbf5ec7dd..e0bd05500 100644 --- a/page/4/index.html +++ b/page/4/index.html @@ -252,7 +252,7 @@String类中的equals方法是重写过的 因为Object的equals类方法是比较的对象的内存地址 而String类中的equals方法比较的是对象的值
当创建 String 类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创建一个 String 对象
String类equals()方法:
1 | |
1 | public boolean equals(Object anObject) { |
记录下这个的信息 userAccount即是学号 encodedd是学号+密码的base64加密
maven依赖
-1 | |
1 |
|
在IDEA新建Springboot框架 然后在新建类LoginPZ
-1 | |
1 | package com.example.jwxt; |
这是模拟教务系统登陆 然后我们新建类GetUserInfo
代码如下
-1 | |
1 | package com.example.jwxt; |
新建发邮件的类SendMailUtil
邮箱建议使用qq邮箱 需要拿到授权码
1 | |
1 | package com.example.jwxt; |
拿授权码过程
拿到授权码之后复制到上面去
再到Application添加启动类
-1 | |
1 | package com.example.jwxt; |
如果自己有服务器就把这个项目打包成jar包上跑起来
没有的话只能把项目一直跑着不关
@@ -558,7 +558,7 @@
使用命令
-1 | |
1 | nohup java -jar JWXT-0.0.1-SNAPSHOT.jar 2>&1 & |
然后就大功告成了 一般你跑起来之后就会收到一封邮件提醒
github的项目地址 https://github.com/fengxiaop/JWXT
@@ -721,14 +721,14 @@
我试了一下我的打表方式 20分钟还没打出最后一个数
直接搬官方的吧
-1 | |
1 | class Solution { |
方法二 枚举
-1 | |
1 | class Solution { |
这个稍微时间稍微长了一点
-1 | |
1 | class Solution { |
这个就很快了
同样是枚举 别人写的和我写的 感觉自己在时间复杂度方法还得加强
@@ -960,13 +960,13 @@难度中等8
实现 pow(x, n) ,即计算 x 的 n 次幂函数(即,xn)。
示例 1:
-1 | |
1 | 输入:x = 2.00000, n = 10 |
示例 2:
-1 | |
1 | 输入:x = 2.10000, n = 3 |
示例 3:
-1 | |
1 | 输入:x = 2.00000, n = -2 |
提示:
1 | |
1 | 1->2->4->8->16->32->64->128->256->512->1024 |
时间复杂的为O(log 1024)也就是10
算法板子
-1 | |
1 | class Solution { |
1 | |
1 | class Solution { |
进阶
难度 中等
你的任务是计算 ab 对 1337 取模,a 是一个正整数,b 是一个非常大的正整数且会以数组形式给出。
示例 1:
-1 | |
1 | 输入:a = 2, b = [3] |
示例 2:
-1 | |
1 | 输入:a = 2, b = [1,0] |
示例 3:
-1 | |
1 | 输入:a = 1, b = [4,3,3,8,5,2] |
示例 4:
-1 | |
1 | 输入:a = 2147483647, b = [2,0,0] |
提示:
1 | |
1 | class Solution { |
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/super-pow/solution/chao-ji-ci-fang-by-leetcode-solution-ow8j/
Contains方法
-1 | |
1 | package com.HUToh; |
这段代码输出的是什么是
是false true true true
diff --git a/page/5/index.html b/page/5/index.html index 87070f9f2..6ba4c12b8 100644 --- a/page/5/index.html +++ b/page/5/index.html @@ -246,10 +246,10 @@Interator为对象 可以用hasNext和next
hasNext下一个是不是还有
next下一个
-1 | |
1 | public class Main { |
输出顺序也就是输入的顺序
-1 | |
1 | package com.HUToh; |
输出顺序和输入顺序并不一样
所以说Set是无序的 而且Set是不重复的
@@ -327,10 +327,10 @@纯属签到题 细致一点就好了
-1 | |
1 |
|
对于我们的出色的冒险者阳阳姐来说,魔力数对他有奇特的作用,能在战斗中助他一臂之力,所以他知道的魔力数越多越好,但是令他头疼的是,他不知道范围NN之内的自然数有多少个魔力数,于是他向你求助,你能帮帮他吗。 一个自然数有魔力,当且仅当这个自然数数可以由两个相同的自然数拼接起来,比如”2020”这个数字就是由两个”20”拼接而成,但是”2002”却不是魔力数,因为”20”和”02”是两个不同的数字。
-1 | |
1 | import java.util.*; |
这题有着更好的方法 纯数学题 我直接吧所有情况考虑上了
奇数位的时候为固定数 不满足魔力数
@@ -339,7 +339,7 @@1 | |
1 | import java.util.*; |
这题卡回车
卡了半个小时 挺恶心的 。。。。
@@ -356,23 +356,23 @@如果能,输出”YES”(不包含引号),否则输出”NO“(不包含引号)。
如果能够到达目的地,在第二行输出所需的最小步数,定义每一步为坐标加一或者减一。
-1 | |
1 | import java.util.*; |
单纯的模拟题 只是这里就需要回车了 卡的我头大了
fzx学长是一位非常厉害的老学长,他在备战考研时依旧挂念着我们的小萌新们,于是他特意给大家出了一道有意思的题目:
在茫茫大海中有n座独立的岛屿,岛上生活着一些淳朴善良的村民。
但是有一天,大海上出现了一群可怕的海盗,海盗们虽然不敢直接攻击岛屿,但是会在海上等待他们出来捕鱼,然后趁机袭击他们。
村民们为了抵御海盗,决定与其他岛屿结成攻守同盟,现在你需要为他们规划航线,使得n个岛屿形成一个整体(从任意一个岛屿出发,都能到达其他的n-1个岛屿)。
但是由于村民们没有接受过现代化的教育,所以他们看不懂你画的航线图,所以你只能告诉他们要设立一些航线,村民们会随机选择两个之前没有建立过航线的岛屿,在两个岛屿之间建立一条航线。
但是设立航线也是很麻烦的事情,为了尽快组成同盟抵御海盗,你需要找到一个最小的航线数量m,确保n个岛屿一定能形成一个整体。
***注意:一条航线可以看作连接两个岛屿**u**和*v*的一条边,相同的两个岛屿之间不会有重复的航线,同时也不会有岛屿规划到自己本身的航线*
第一行输入一个整数t(t\leq 5 \times 10^5)t(t≤5×105),代表有tt个样例。
每组样例有一行,输入一个整数n(1 < n \leq 10^9)n(1<n≤109),代表有nn个独立的岛屿。
每个样例输出一行,一行包含一个正整数mm代表生成的航线数量。
-1 | |
1 | 1 |
1 | |
1 | 2 |
1 | |
1 | 2 |
1 | |
1 | 4 |
1 | |
1 | 1 |
1 | |
1 | 2147385346 |
这题看题目根本没用 直接撸样例 还是能够通过65536和2147385346
后者的位数是前者的两倍
@@ -458,7 +458,7 @@第一步创建一个Application类 加上@SpringBootApplication的注解
打印控制台消息
System.out.println("SpringBoot启动成功");
1 | |
1 | package com.example; |
水印程序
@@ -467,12 +467,12 @@文件序号 index
文件路径 path
构造有参无参
-1 | |
1 | { |
PDF拆分为image
-1 | |
1 | package com.example.pdfwatermark; |
题目其实很容易 但是这个输入卡的人傻了
用nextInt() nextLong()都会爆
后面我写的是字符串
-1 | |
1 | import java.util.Scanner; |
刚开始 判断k的位数是1位是 我用的判定条件是 if(k == 8) 漏了k==0的这种情况 0也是0的倍数
看了一位学弟的代码 让我尤为惊人
-1 | |
1 | import java.math.BigInteger; |
青出如蓝 让我觉得学弟学妹太优秀了
@@ -774,70 +774,70 @@数据输入
一般我常用的数据输入方法有两种,Scanner和BufferedReader。BufferedReader可以读一行,速度比Scanner快,所以数据较多的时候使用。注意BufferedReader用完记得关。
Scanner
-1 | |
1 | import java.util.*; |
BufferedReader
-1 | |
1 | import java.util.*; |
快速排序quickSort
快速排序要注意x取值的边界情况。取x = nums[left], nums分为[left, j]和[j + 1, right],或x = nums[right], nums分为[left, i - 1]和[i, right],否则会StackOverflow。
1 | |
1 | public void quickSort(int[] nums, int left, int right) { |
例题:AcWing 785, LeetCode 912
归并排序mergeSort
mergeSort时间复杂度是稳定O(nlogn),空间复杂度O(n),稳定的。quickSort时间复杂度平均O(nlogn),最坏O(n^2),最好O(nlogn),空间复杂度O(nlogn),不稳定的。
public void mergeSort(int[] nums, int left, int right) {
if (left >= right)
return;
1 | |
1 | int mid = left + (right - left) / 2; |
}
例题:AcWing 787, LeetCode 912
二分搜索binarySearch
二分搜索逼近左边界,区间[left, right]被分为左区间[left, mid]和右区间[mid + 1, right]。
1 | |
1 | public int binarySearchLeft(int[] nums, int target) { |
二分搜索逼近右边界,区间[left, right]被分为左区间[left, mid - 1]和右区间[mid, right]。
-1 | |
1 | public int binarySearchRight(int[] nums, int target) { |
暑假在LeetCode打卡的时候发现还有第三种模板,nums[mid] == target 直接return,区间[left, right]被分为[left, mid - 1]和[mid + 1, right]。
-1 | |
1 | public int searchInsert(int[] nums, int target) { |
例题:AcWing 789, LeetCode 34, LeetCode 35
KMP
-1 | |
1 | public int kmp(String text, String pattern) { |
例题:AcWing 831, LeetCode 28
Trie
-1 | |
1 | public static final int SIZE = 26; |
例题:AcWing 835
并查集
朴素并查集
1 | |
1 | public static int[] p; |
例题:AcWing 836
图的存储
n个点,m条边,m约等于n2n2叫做稠密图,用邻接矩阵存储;n个点,m条边,m远小于n2n2叫做稀疏图,用邻接表存储。
邻接矩阵
-1 | |
1 | public class Main{ |
邻接表
-1 | |
1 | import java.util.*; |
Dijkstra
边权不能是负数!
1.dist[1] = 0, dist[i] = +∞
2.for i 1 ~ n
t <- 不在s中的,距离最近的点 – n2n2 / n
s <- t – n
用t更新其他点的距离 – m / mlogn
1 | |
1 | public static int dijkstra() { |
例题:AcWing 849
优化Dijkstra
-1 | |
1 | public static int dijkstra() { |
例题:AcWing 850
Bellman-ford
O(nm)
1 | |
1 | public static int bellman_ford() { |
例题:AcWing 853
SPFA (队列优化的Bellman-ford算法)
一般O(m),最坏O(nm)。n表示点数,m表示边数。
1 | |
1 | public static int spfa() { |
例题:AcWing 851
SPFA 判断图中是否存在负环
O(nm),n表示点数,m表示边数。
1 | |
1 | public static boolean spfa() { |
例题:AcWing 852
Floyd
O(n3)O(n3)
1 | |
1 | public static void floyd() { |
例题:AcWing 854
作者:Lic
链接:https://www.acwing.com/file_system/file/content/whole/index/content/5873/
来源:AcWing
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
新建一个包boot
在boot包下创建一个类 MainApplication
-1 | |
1 | package org.example.boot; |
点击pom.xml 进行导包
-1 | |
1 | <parent> |
建立controller层
创建了类HelloController
-1 | |
1 | package org.example.boot.Controller; |
点击启动MainApplication
最近遇见了ip+端口转换为域名的问题
本来我用境外服务器可以直接用80端口 用起来也很方便 不用备案啥的 但是就是太容易挂了
所以下定决心撸了个腾讯云的服务器
-1 | |
1 | # For more information on configuration, see: |
这是配置文件
@@ -1102,17 +1102,17 @@所需要的工具 一台服务器 一个可以编译jar的java环境 nginx用来正向代理
xshell连接服务器
安装java环境
-1 | |
1 | yum install java-1.8.0-openjdk |
查看java是否安装好
-1 | |
1 | java -version |
创建自己项目的路径并且cd到该路径
-1 | |
1 | mkdir java |
用命令让他跑起来
Linux启动
-1 | |
1 | nohup java -jar pdf-service-0.0.1-SNAPSHOT.jar |
这里注意把它copy去浏览器 变成一行去粘贴 这里只是方便看的参数的意义
Linux查看日志tail -f nohup.out
首先导入依赖
-1 | |
1 | <!-- https://mvnrepository.com/artifact/com.itextpdf/itextpdf --> |
代码如下
-1 | |
1 | import java.awt.AlphaComposite; |
这题典型的双指针 一个指针是用来遍历 另外一个用来存储
-1 | |
1 | class Solution { |
i用来遍历数组 而t用来存储新的数组
通用解法拓展
-1 | |
1 | class Solution { |
1 | |
1 | // 1. 创建一个继承于Thread类的子类 |
创建步骤
1、创建一个实现了 Runnable 接口的类;
1 | |
1 | // 1. 创建一个实现了Runnable接口的类 |
创建步骤
1、创建一个实现Callable接口的实现类;
1 | |
1 | // 1.创建一个实现Callable的实现类 |
创建步骤
1、提供指定线程数量的线程池;
2、设置线程池的属性;
3、执行指定的线程的操作。需要提供实现Runnable接口或Callable接口实现类的对象;
4、关闭连接池。
-1 | |
1 | class NumberThread1 implements Runnable { |
String类中equals和==的区别
-1 | |
1 | package com.leetcode; |
想一下答案
为什么呢
使用new对象的一定会在堆内存中开辟空间
-1 | |
1 | String abc = "abc"; |
使用这种方法会放入字符串池中
当已经存在时,不在开辟空间
@@ -570,7 +570,7 @@Arrays.sort(arr)
给数组arr排序
二分法查找的使用
-1 | |
1 | package com.leetcode; |
第一次直接想的就是暴力遍历
-1 | |
1 | class Solution { |
样例是全过了 但是超时了
-1 | |
1 | class Solution { |
后面参考评论区
速度是以除代乘 速度大大提升。
-1 | |
1 | class Solution { |
这是第一版的改进 从后面开始遍历 提升下速率 数越大越明显
二分法
-1 | |
1 | class Solution { |
数学方法
所有平方数都是可以由奇数和构成的
1=1 4=1+3 9=1+3+5
则只需要每次从1开始减 每次加2 以num>0为判断条件
-1 | |
1 | class Solution { |
[toc]Java实现pdf转为图片
首先创建一个maven工程 在pom.xml文件导入包的依赖
-1 | |
1 | <dependencies> |
第二步 在Java路径下创建一个子类PDF2IMAGE
然后导入包
-1 | |
1 | import java.awt.image.BufferedImage; |
主体结构
-1 | |
1 | public class PDF2IMAGE { |
主要利用pdf2Image方法
代码见下
-1 | |
1 | public static void pdf2Image(String PdfFilePath, String dstImgFolder, int dpi) { |
先导包
-1 | |
1 | import pyautogui |
第二部写个for循环
-1 | |
1 | for i in range(0,100): |
github仓库源代码 https://github.com/fengxiaop/pyautogui
有用的话记得点个 star
@@ -1019,10 +1019,10 @@1 | |
1 | 在一个 平衡字符串 中,'L' 和 'R' 字符的数量是相同的。 |
题解
-1 | |
1 | class Solution { |
1 | |
1 | 给定长度为 2n 的整数数组 nums ,你的任务是将这些数分成 n 对, 例如 (a1, b1), (a2, b2), ..., (an, bn) ,使得从 1 到 n 的 min(ai, bi) 总和最大。 |
题解
-1 | |
1 | class Solution { |
1 | |
1 | Alice 有 n 枚糖,其中第 i 枚糖的类型为 candyType[i] 。Alice 注意到她的体重正在增长,所以前去拜访了一位医生。 |
示例 1:
-1 | |
1 | 输入:candyType = [1,1,2,2,3,3] |
示例 2:
-1 | |
1 | 输入:candyType = [1,1,2,3] |
1 | |
1 | 示例 3: |
1 | |
1 | class Solution { |
Hashset 具有去重的功能 利用size()方法可以得到里面元素的种类
ArrayList是有序的 元素可以重复
HashSet是无序不重复的
-1 | |
1 | class Solution { |
利用set去重,再用set.size()得到糖果的种类
创建ArrayList表
@@ -463,29 +463,29 @@难度 :简单
-1 | |
1 | 给你两个 没有重复元素 的数组 nums1 和 nums2 ,其中nums1 是 nums2 的子集。 |
示例 1:
-1 | |
1 | 输入: nums1 = [4,1,2], nums2 = [1,3,4,2]. |
示例 2:
-1 | |
1 | 输入: nums1 = [2,4], nums2 = [1,2,3,4]. |
提示:
-1 | |
1 | 1 <= nums1.length <= nums2.length <= 1000 |
看到题目第一时间就想的遍历然后匹配 虽然写的很垃圾 但是是自己独立debug写出来的还是很高兴
-1 | |
1 | class Solution { |
有几个地方需要注意 就是当遇见一个数比他大的时候 需要赋值后立即跳出
官方题解
-1 | |
1 | class Solution { |
不得不感叹一下 同样是暴力遍历 官方写的比我写的好得多
-1 | |
1 | class Solution { |
三叶姐题解
-1 | |
1 | class Solution { |
被拉去参加财务大学生竞赛 让我当大数据分析师
刷了几套题发现是考查找数据能力以及利用python tushare库做分析
1 | |
1 | import tushare as ts |
刚好在1024节这天参加了学校的校赛,讲讲这次作为大数据分析师的感受把 ,题目不难,但是有些题数据很多很费时间,我就是因为没有正确的选择以及没有得知大数据分析师考完后其他人能看到正确答案的要求,不然我也不会死耗在第一题第二题数据多分少但是对队友很重要的地方了。两个利用tushare库的问题,其实编程很简单,简单导个库,然后找到接口依葫芦画瓢就好了。
虽然过程很曲折,但是结果还是比较符合人意的,队伍排名10/102 刚好拿到三等奖的最后一个名次 刚出来成绩的时候看到分数还是很自责的 因为要是我发挥稳定的话,可能我们就是第一了 或者没看错那个题 我们就是二等奖了 好在队友小雪 佳佳 子怡都挺好的 也很高兴经过四天训练之后能拿到这一个校奖。虽然自己的大数据分析师好像被别人拉爆了 已经被拉到10名开外了 有点丢我们计院的脸了hhh。但是好像也免了去拒绝停课去打这个几乎和我本专业无关的比赛了。
@@ -654,7 +654,7 @@Model :实体类Bean 专门做存储业务数据
- 业务处理Bean 指Servicw或Dao对象,专门用于处理业务逻辑和数据访问
+ 业务处理Bean 指Servicw或Dao对象,专门用于处理业务逻辑和数据访问
View :视图层 指工程中的html+jsp等页面
Controller : 控制层 servelt
@@ -741,27 +741,27 @@
453. 最小操作次数使数组元素相等
给你一个长度为 n 的整数数组,每次操作将会使 n - 1 个元素增加 1 。返回让数组所有元素相等的最小操作次数。
示例 1:
-1
2
3
4
5
6
输入:nums = [1,2,3]
输出:3
解释:
只需要3次操作(注意每次操作会增加两个元素的值):
[1,2,3] => [2,3,3] => [3,4,3] => [4,4,4]
+1
2
3
4
5
6
输入:nums = [1,2,3]
输出:3
解释:
只需要3次操作(注意每次操作会增加两个元素的值):
[1,2,3] => [2,3,3] => [3,4,3] => [4,4,4]
示例 2:
-1
2
输入:nums = [1,1,1]
输出:0
+1
2
输入:nums = [1,1,1]
输出:0
-1
+1
解析
每一步除了最大的那个数不加1 相等于最大的数减1 参考相对运动理解
每一次操作总和都会-1
那么最后的结果肯定是n个最小数
那么
-1
return sum - min * n;
+1
return sum - min * n;
即可得到结果
利用for each语句遍历数组
找出数组里面最小的数和总和sum
-1
2
3
4
for (int i : nums) {
min = Math.min(min, i);
sum += i;
}
+1
2
3
4
for (int i : nums) {
min = Math.min(min, i);
sum += i;
}
题解
-1
2
3
4
5
6
7
8
9
10
11
class Solution {
public int minMoves(int[] nums) {
int n = nums.length;
int min = nums[0], sum = 0;
for (int i : nums) {
min = Math.min(min, i);
sum += i;
}
return sum - min * n;
}
}
+1
2
3
4
5
6
7
8
9
10
11
class Solution {
public int minMoves(int[] nums) {
int n = nums.length;
int min = nums[0], sum = 0;
for (int i : nums) {
min = Math.min(min, i);
sum += i;
}
return sum - min * n;
}
}
@@ -845,26 +845,26 @@ 有效字符串需满足:
左括号必须用相同类型的右括号闭合。
左括号必须以正确的顺序闭合。
示例 1:
-1
2
输入:s = "()"
输出:true
+1
2
输入:s = "()"
输出:true
示例 2:
-1
2
输入:s = "()[]{}"
输出:true
+1
2
输入:s = "()[]{}"
输出:true
示例 3:
-1
2
输入:s = "(]"
输出:false
+1
2
输入:s = "(]"
输出:false
示例 4:
-1
2
输入:s = "([)]"
输出:false
+1
2
输入:s = "([)]"
输出:false
示例 5:
-1
2
输入:s = "{[]}"
输出:true
+1
2
输入:s = "{[]}"
输出:true
提示:
-1
2
1 <= s.length <= 104
s 仅由括号 '()[]{}' 组成
+1
2
1 <= s.length <= 104
s 仅由括号 '()[]{}' 组成
题解
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
class Solution {
public boolean isValid(String s) {
int n = s.length();
if (n % 2 == 1) {
return false;
}
Map<Character, Character> pairs = new HashMap<Character, Character>() {{
put(')', '(');
put(']', '[');
put('}', '{');
}};
Deque<Character> stack = new LinkedList<Character>();
for (int i = 0; i < n; i++) {
char ch = s.charAt(i);
if (pairs.containsKey(ch)) {
if (stack.isEmpty() || stack.peek() != pairs.get(ch)) {
return false;
}
stack.pop();
} else {
stack.push(ch);
}
}
return stack.isEmpty();
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
class Solution {
public boolean isValid(String s) {
int n = s.length();
if (n % 2 == 1) {
return false;
}
Map<Character, Character> pairs = new HashMap<Character, Character>() {{
put(')', '(');
put(']', '[');
put('}', '{');
}};
Deque<Character> stack = new LinkedList<Character>();
for (int i = 0; i < n; i++) {
char ch = s.charAt(i);
if (pairs.containsKey(ch)) {
if (stack.isEmpty() || stack.peek() != pairs.get(ch)) {
return false;
}
stack.pop();
} else {
stack.push(ch);
}
}
return stack.isEmpty();
}
}
先就s字符串的长度奇数还是偶数进行判断
如果长度是奇数 直接返回false 因为不满足闭合条件
@@ -947,42 +947,42 @@
二分算法
二分算法基本框架
-1
2
3
4
5
6
7
8
9
10
11
12
13
class Solution {
public int searchInsert(int[] nums, int target) {
int left = 0,right=nums.length-1,ans=right+1;
while(left<=right){
int mid = (left + right)/2;
if(nums[mid]>=target){
ans=mid;
right=mid-1;}
else
left=mid+1;
}
return ans;
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
class Solution {
public int searchInsert(int[] nums, int target) {
int left = 0,right=nums.length-1,ans=right+1;
while(left<=right){
int mid = (left + right)/2;
if(nums[mid]>=target){
ans=mid;
right=mid-1;}
else
left=mid+1;
}
return ans;
}
分析二分查找的一个技巧是:不要出现 else,而是把所有情况用 else if 写清楚,这样可以清楚地展现所有细节。本文都会使用 else if,旨在讲清楚,读者理解后可自行简化。
其中 … 标记的部分,就是可能出现细节问题的地方,当你见到一个二分查找的代码时,首先注意这几个地方。后文用实例分析这些地方能有什么样的变化。
另外声明一下,计算 mid 时需要技巧防止溢出,即 mid=left+(right-left)/2。本文暂时忽略这个问题。
一、寻找一个数(基本的二分搜索)
这个场景是最简单的,可能也是大家最熟悉的,即搜索一个数,如果存在,返回其索引,否则返回 -1。
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
int binarySearch(int[] nums, int target) {
int left = 0;
int right = nums.length - 1; // 注意
while(left <= right) {
int mid = (right + left) / 2;
if(nums[mid] == target)
return mid;
else if (nums[mid] < target)
left = mid + 1; // 注意
else if (nums[mid] > target)
right = mid - 1; // 注意
}
return -1;
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
int binarySearch(int[] nums, int target) {
int left = 0;
int right = nums.length - 1; // 注意
while(left <= right) {
int mid = (right + left) / 2;
if(nums[mid] == target)
return mid;
else if (nums[mid] < target)
left = mid + 1; // 注意
else if (nums[mid] > target)
right = mid - 1; // 注意
}
return -1;
}
1. 为什么 while 循环的条件中是 <=,而不是 < ?
答:因为初始化 right 的赋值是 nums.length-1,即最后一个元素的索引,而不是 nums.length。
这二者可能出现在不同功能的二分查找中,区别是:前者相当于两端都闭区间 [left, right],后者相当于左闭右开区间 [left, right),因为索引大小为 nums.length 是越界的。
我们这个算法中使用的是前者 [left, right] 两端都闭的区间。这个区间其实就是每次进行搜索的区间,我们不妨称为「搜索区间」。
什么时候应该停止搜索呢?当然,找到了目标值的时候可以终止:
-1
2
if(nums[mid] == target)
return mid;
+1
2
if(nums[mid] == target)
return mid;
但如果没找到,就需要 while 循环终止,然后返回 -1。那 while 循环什么时候应该终止?搜索区间为空的时候应该终止,意味着你没得找了,就等于没找到嘛。
while(left <= right) 的终止条件是 left == right + 1,写成区间的形式就是 [right + 1, right],或者带个具体的数字进去 [3, 2],可见这时候搜索区间为空,因为没有数字既大于等于 3 又小于等于 2 的吧。所以这时候 while 循环终止是正确的,直接返回 -1 即可。
while(left < right) 的终止条件是 left == right,写成区间的形式就是 [left, right],或者带个具体的数字进去 [2, 2],这时候搜索区间非空,还有一个数 2,但此时 while 循环终止了。也就是说这区间 [2, 2] 被漏掉了,索引 2 没有被搜索,如果这时候直接返回 -1 就是错误的。
当然,如果你非要用 while(left < right) 也可以,我们已经知道了出错的原因,就打个补丁好了:
-1
2
3
4
5
//...
while(left < right) {
// ...
}
return nums[left] == target ? left : -1;
+1
2
3
4
5
//...
while(left < right) {
// ...
}
return nums[left] == target ? left : -1;
详解解析看 [https://www.cnblogs.com/mxj961116/p/11945444.html]
leetcode_剑指 Offer II 069. 山峰数组的顶部
二分题解
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class Solution {
public int peakIndexInMountainArray(int[] arr) {
int left = 0 , rigth = arr.length-1,ans = 0;
while(left<=rigth)
{
int mid = (left+rigth)/2;
if(arr[mid]>arr[mid+1])
{ans = mid;
rigth = mid-1;}
else
left = mid+1;
}
return ans;
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class Solution {
public int peakIndexInMountainArray(int[] arr) {
int left = 0 , rigth = arr.length-1,ans = 0;
while(left<=rigth)
{
int mid = (left+rigth)/2;
if(arr[mid]>arr[mid+1])
{ans = mid;
rigth = mid-1;}
else
left = mid+1;
}
return ans;
}
}
leetcode_35
35. 搜索插入位置
题解
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
class Solution {
public int searchInsert(int[] nums, int target) {
int left = 0,right=nums.length-1,ans=right+1;
while(left<=right){
int mid = (left + right)/2;
if(nums[mid]>=target){
ans=mid;
right=mid-1;}
else
left=mid+1;
}
return ans;
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
class Solution {
public int searchInsert(int[] nums, int target) {
int left = 0,right=nums.length-1,ans=right+1;
while(left<=right){
int mid = (left + right)/2;
if(nums[mid]>=target){
ans=mid;
right=mid-1;}
else
left=mid+1;
}
return ans;
}
}
33. 搜索旋转排序数组
题解
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
class Solution {
public int search(int[] nums, int target) {
int left = 0, right = nums.length - 1,ans = 0;
while(left <= right)
{
int mid=(left+right);
if(nums[mid] > nums[right]){
if(target > nums[mid])
{
left = mid+1;
}
else if(target < nums[mid])
{
right = mid-1;
}
else
ans = mid;
}
if(nums[mid] <nums[right]){
if(target<nums[mid])
{
left=mid+1;
}
else if(target > nums[mid])
{
right=mid-1;
}
else
ans=mid;
}
}
return ans;
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
class Solution {
public int search(int[] nums, int target) {
int left = 0, right = nums.length - 1,ans = 0;
while(left <= right)
{
int mid=(left+right);
if(nums[mid] > nums[right]){
if(target > nums[mid])
{
left = mid+1;
}
else if(target < nums[mid])
{
right = mid-1;
}
else
ans = mid;
}
if(nums[mid] <nums[right]){
if(target<nums[mid])
{
left=mid+1;
}
else if(target > nums[mid])
{
right=mid-1;
}
else
ans=mid;
}
}
return ans;
}
}
@@ -1062,7 +1062,7 @@
- 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
package testthread41;
import org.apache.commons.io.FileUtils;
import java.io.File;
import java.io.IOException;
import java.net.URL;
//练习Thread 实现多线程同步下载
public class TestThread2 extends Thread {
private String url;//图片地址
private String name;
public TestThread2 (String url,String name){
this.url = url;
this.name = name;
}
@Override
public void run() {
WebDownload webDownload = new WebDownload();
webDownload.downloader(url,name);
System.out.println("下载了文件名:"+name);
}
public static void main(String[] args) {
TestThread2 t1 = new TestThread2("https://img.lianzhixiu.com/uploads/allimg/150827/9-150RH11Z00-L.jpg","美女1.jpg");
TestThread2 t2 = new TestThread2("https://img.lianzhixiu.com/uploads/allimg/202105/9999/rnf45aa76447.jpg","美女2.jpg");
TestThread2 t3 = new TestThread2("https://img.lianzhixiu.com/uploads/allimg/202104/9999/rndb598b8b76.jpg","美女3.jpg");
t1.start();
t2.start();
t3.start();
}
}
class WebDownload{
public void downloader(String url,String name){
try {
FileUtils.copyURLToFile(new URL(url),new File(name));
} catch (IOException e) {
e.printStackTrace();
System.out.println("IO异常,downloader方法出现问题");
}
}
}
+ 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
package testthread41;
import org.apache.commons.io.FileUtils;
import java.io.File;
import java.io.IOException;
import java.net.URL;
//练习Thread 实现多线程同步下载
public class TestThread2 extends Thread {
private String url;//图片地址
private String name;
public TestThread2 (String url,String name){
this.url = url;
this.name = name;
}
public void run() {
WebDownload webDownload = new WebDownload();
webDownload.downloader(url,name);
System.out.println("下载了文件名:"+name);
}
public static void main(String[] args) {
TestThread2 t1 = new TestThread2("https://img.lianzhixiu.com/uploads/allimg/150827/9-150RH11Z00-L.jpg","美女1.jpg");
TestThread2 t2 = new TestThread2("https://img.lianzhixiu.com/uploads/allimg/202105/9999/rnf45aa76447.jpg","美女2.jpg");
TestThread2 t3 = new TestThread2("https://img.lianzhixiu.com/uploads/allimg/202104/9999/rndb598b8b76.jpg","美女3.jpg");
t1.start();
t2.start();
t3.start();
}
}
class WebDownload{
public void downloader(String url,String name){
try {
FileUtils.copyURLToFile(new URL(url),new File(name));
} catch (IOException e) {
e.printStackTrace();
System.out.println("IO异常,downloader方法出现问题");
}
}
}
diff --git a/page/8/index.html b/page/8/index.html
index 42a5a4ab8..0faaa0418 100644
--- a/page/8/index.html
+++ b/page/8/index.html
@@ -211,10 +211,10 @@
剑指 Offer II 069. 山峰数组的顶部
题目
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
符合下列属性的数组 arr 称为 山峰数组(山脉数组) :
arr.length >= 3
存在 i(0 < i < arr.length - 1)使得:
arr[0] < arr[1] < ... arr[i-1] < arr[i]
arr[i] > arr[i+1] > ... > arr[arr.length - 1]
给定由整数组成的山峰数组 arr ,返回任何满足 arr[0] < arr[1] < ... arr[i - 1] < arr[i] > arr[i + 1] > ... > arr[arr.length - 1] 的下标 i ,即山峰顶部。
示例 1:
输入:arr = [0,1,0]
输出:1
示例 2:
输入:arr = [1,3,5,4,2]
输出:2
示例 3:
输入:arr = [0,10,5,2]
输出:1
示例 4:
输入:arr = [3,4,5,1]
输出:2
示例 5:
输入:arr = [24,69,100,99,79,78,67,36,26,19]
输出:2
提示:
3 <= arr.length <= 104
0 <= arr[i] <= 106
题目数据保证 arr 是一个山脉数组
进阶:很容易想到时间复杂度 O(n) 的解决方案,你可以设计一个 O(log(n)) 的解决方案吗?
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
符合下列属性的数组 arr 称为 山峰数组(山脉数组) :
arr.length >= 3
存在 i(0 < i < arr.length - 1)使得:
arr[0] < arr[1] < ... arr[i-1] < arr[i]
arr[i] > arr[i+1] > ... > arr[arr.length - 1]
给定由整数组成的山峰数组 arr ,返回任何满足 arr[0] < arr[1] < ... arr[i - 1] < arr[i] > arr[i + 1] > ... > arr[arr.length - 1] 的下标 i ,即山峰顶部。
示例 1:
输入:arr = [0,1,0]
输出:1
示例 2:
输入:arr = [1,3,5,4,2]
输出:2
示例 3:
输入:arr = [0,10,5,2]
输出:1
示例 4:
输入:arr = [3,4,5,1]
输出:2
示例 5:
输入:arr = [24,69,100,99,79,78,67,36,26,19]
输出:2
提示:
3 <= arr.length <= 104
0 <= arr[i] <= 106
题目数据保证 arr 是一个山脉数组
进阶:很容易想到时间复杂度 O(n) 的解决方案,你可以设计一个 O(log(n)) 的解决方案吗?
我写的想法 第一次就想到for循环遍历 写出了O(n)的学法
-1
2
3
4
5
6
7
8
int peakIndexInMountainArray(int* arr, int arrSize){
int temp=0;
for(;temp<arrSize-1;temp++){
if(arr[temp]>arr[temp+1])
break;
}
return temp;
}
+1
2
3
4
5
6
7
8
int peakIndexInMountainArray(int* arr, int arrSize){
int temp=0;
for(;temp<arrSize-1;temp++){
if(arr[temp]>arr[temp+1])
break;
}
return temp;
}
三叶姐姐的解法
二分
往常我们使用「二分」进行查值,需要确保序列本身满足「二段性」:当选定一个端点(基准值)后,结合「一段满足 & 另一段不满足」的特性来实现“折半”的查找效果。
@@ -223,7 +223,7 @@
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class Solution {
// 根据 arr[i-1] < arr[i] 在 [1,n-1] 范围内找值
// 峰顶元素为符合条件的最靠近中心的元素
public int peakIndexInMountainArray(int[] arr) {
int n = arr.length;
int l = 1, r = n - 1;
while (l < r) {
int mid = l + r + 1 >> 1;
if (arr[mid - 1] < arr[mid]) l = mid;
else r = mid - 1;
}
return r;
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
class Solution {
// 根据 arr[i-1] < arr[i] 在 [1,n-1] 范围内找值
// 峰顶元素为符合条件的最靠近中心的元素
public int peakIndexInMountainArray(int[] arr) {
int n = arr.length;
int l = 1, r = n - 1;
while (l < r) {
int mid = l + r + 1 >> 1;
if (arr[mid - 1] < arr[mid]) l = mid;
else r = mid - 1;
}
return r;
}
}
时间复杂度:O(\log{n})O(logn)
@@ -336,7 +336,7 @@
所以自己想了一下自己可以写一个绩点计算器出来吗 好像也不是很难的样子
所以自己用了差不多20分钟帮这个写出来了
下面是源码
-1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
#include<stdio.h>
int main()
{
int number;
float score;
float credit,creditsum=0;
float gpasum=0.0,GPA=0.0;
printf("请输入需要计算的科目数量");
scanf("%d",&number);
int count=1;
for(int i=0;i<number;i++)
{
printf("请输入第%d科的成绩和学分",count);
scanf("%f %f",&score,&credit);
creditsum+=credit;
// printf("%.1f",(score/10-5)*credit);
gpasum+=(score/10-5)*credit;
GPA=gpasum/creditsum;
count++;
}
// printf("学分总和:%.1f",creditsum);
// printf("总分:%.1f",gpasum);
printf("您的GPA是%.1f",GPA);
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
int main()
{
int number;
float score;
float credit,creditsum=0;
float gpasum=0.0,GPA=0.0;
printf("请输入需要计算的科目数量");
scanf("%d",&number);
int count=1;
for(int i=0;i<number;i++)
{
printf("请输入第%d科的成绩和学分",count);
scanf("%f %f",&score,&credit);
creditsum+=credit;
// printf("%.1f",(score/10-5)*credit);
gpasum+=(score/10-5)*credit;
GPA=gpasum/creditsum;
count++;
}
// printf("学分总和:%.1f",creditsum);
// printf("总分:%.1f",gpasum);
printf("您的GPA是%.1f",GPA);
}
功能样图
欢迎关注微信公众号 :打码少年风萧
程序链接
链接:https://pan.baidu.com/s/1MzkRQ3XCtWadlWFxFDef4g
提取码:30qf
@@ -424,7 +424,7 @@
输入:n = 3
输出:[“1”,”2”,”Fizz”]
示例 2:
输入:n = 5
输出:[“1”,”2”,”Fizz”,”4”,”Buzz”]
示例 3:
输入:n = 15
输出:[“1”,”2”,”Fizz”,”4”,”Buzz”,”Fizz”,”7”,”8”,”Fizz”,”Buzz”,”11”,”Fizz”,”13”,”14”,”FizzBuzz”]
-1
2
3
4
5
6
7
8
9
10
11
12
13
class Solution {
public List<String> fizzBuzz(int n) {
List<String> li = new ArrayList<>();
for(Integer i=1;i<=n;i++)
{
if(i % 3 == 0 && i % 5 == 0) li.add("FizzBuzz");
else if(i%3==0)li.add("Fizz");
else if(i%5==0)li.add("Buzz");
else li.add(i.toString());
}
return li;
}
}
+1
2
3
4
5
6
7
8
9
10
11
12
13
class Solution {
public List<String> fizzBuzz(int n) {
List<String> li = new ArrayList<>();
for(Integer i=1;i<=n;i++)
{
if(i % 3 == 0 && i % 5 == 0) li.add("FizzBuzz");
else if(i%3==0)li.add("Fizz");
else if(i%5==0)li.add("Buzz");
else li.add(i.toString());
}
return li;
}
}
@@ -511,18 +511,18 @@
xtfp这软件上手很容易
只需要左右拖拽文件即刻互相传输
-1.首先在Xshell上利用yum工具下载nginx
1
yum install nginx -y
+1.首先在Xshell上利用yum工具下载nginx
1
yum install nginx -y
-2.测试启动nginx
1
nginx
+2.测试启动nginx
1
nginx
-3.配置nginx配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
1.进入/etc/nginx文件夹
cd /etc/nginx
2.编辑nginx.conf
vim nginx.conf
3.添加一个server
server实例:
server {
listen 80 default_server;
listen [::]:80 default_server;
server_name _;
root /usr/share/nginx/html; #修改为root /data/www;
include /etc/nginx/default.d/*.conf;
location / {
}
error_page 404 /404.html;
location = /40x.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}
+3.配置nginx配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
1.进入/etc/nginx文件夹
cd /etc/nginx
2.编辑nginx.conf
vim nginx.conf
3.添加一个server
server实例:
server {
listen 80 default_server;
listen [::]:80 default_server;
server_name _;
root /usr/share/nginx/html; #修改为root /data/www;
include /etc/nginx/default.d/*.conf;
location / {
}
error_page 404 /404.html;
location = /40x.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}
-4.贴上我自己的nginx.conf完整配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
# For more information on configuration, see:
# * Official English Documentation: http://nginx.org/en/docs/
# * Official Russian Documentation: http://nginx.org/ru/docs/
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
# Load dynamic modules. See /usr/share/nginx/README.dynamic.
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 1024;
}
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 2048;
include /etc/nginx/mime.types;
default_type application/octet-stream;
# Load modular configuration files from the /etc/nginx/conf.d directory.
# See http://nginx.org/en/docs/ngx_core_module.html#include
# for more information.
include /etc/nginx/conf.d/*.conf;
server {
listen 80 default_server;
listen [::]:80 default_server;
server_name _;
root /usr/share/nginx/html;
# Load configuration files for the default server block.
include /etc/nginx/default.d/*.conf;
location / {
}
error_page 404 /404.html;
location = /40x.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}
server {
listen 8001 default_server;
listen [::]:8001 default_server;
server_name _;
root /usr/local/java/resources; #修改为root /data/www;
include /etc/nginx/default.d/*.conf;
location / {
}
error_page 404 /404.html;
location = /40x.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}
# Settings for a TLS enabled server.
#
# server {
# listen 443 ssl http2 default_server;
# listen [::]:443 ssl http2 default_server;
# server_name _;
# root /usr/share/nginx/html;
#
# ssl_certificate "/etc/pki/nginx/server.crt";
# ssl_certificate_key "/etc/pki/nginx/private/server.key";
# ssl_session_cache shared:SSL:1m;
# ssl_session_timeout 10m;
# ssl_ciphers HIGH:!aNULL:!MD5;
# ssl_prefer_server_ciphers on;
#
# # Load configuration files for the default server block.
# include /etc/nginx/default.d/*.conf;
#
# location / {
# }
#
# error_page 404 /404.html;
# location = /40x.html {
# }
#
# error_page 500 502 503 504 /50x.html;
# location = /50x.html {
# }
# }
}
+4.贴上我自己的nginx.conf完整配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
# For more information on configuration, see:
# * Official English Documentation: http://nginx.org/en/docs/
# * Official Russian Documentation: http://nginx.org/ru/docs/
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
# Load dynamic modules. See /usr/share/nginx/README.dynamic.
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 1024;
}
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 2048;
include /etc/nginx/mime.types;
default_type application/octet-stream;
# Load modular configuration files from the /etc/nginx/conf.d directory.
# See http://nginx.org/en/docs/ngx_core_module.html#include
# for more information.
include /etc/nginx/conf.d/*.conf;
server {
listen 80 default_server;
listen [::]:80 default_server;
server_name _;
root /usr/share/nginx/html;
# Load configuration files for the default server block.
include /etc/nginx/default.d/*.conf;
location / {
}
error_page 404 /404.html;
location = /40x.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}
server {
listen 8001 default_server;
listen [::]:8001 default_server;
server_name _;
root /usr/local/java/resources; #修改为root /data/www;
include /etc/nginx/default.d/*.conf;
location / {
}
error_page 404 /404.html;
location = /40x.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}
# Settings for a TLS enabled server.
#
# server {
# listen 443 ssl http2 default_server;
# listen [::]:443 ssl http2 default_server;
# server_name _;
# root /usr/share/nginx/html;
#
# ssl_certificate "/etc/pki/nginx/server.crt";
# ssl_certificate_key "/etc/pki/nginx/private/server.key";
# ssl_session_cache shared:SSL:1m;
# ssl_session_timeout 10m;
# ssl_ciphers HIGH:!aNULL:!MD5;
# ssl_prefer_server_ciphers on;
#
# # Load configuration files for the default server block.
# include /etc/nginx/default.d/*.conf;
#
# location / {
# }
#
# error_page 404 /404.html;
# location = /40x.html {
# }
#
# error_page 500 502 503 504 /50x.html;
# location = /50x.html {
# }
# }
}
其中8001端口为我的静态资源访问端口
/usr/local/java/resources 为我的静态资源存放位置
-5.重启nginx
1
nginx -s reload
+5.重启nginx
1
nginx -s reload
-6.测试nginx静态资源访问是否成功
1
2
例如:/usr/local/java/resources下有一个index.html文件
访问则是:www.huhdcc.top:8001/index.html
+6.测试nginx静态资源访问是否成功
1
2
例如:/usr/local/java/resources下有一个index.html文件
访问则是:www.huhdcc.top:8001/index.html
如果还不能使用的话 是服务器没有开放端口问题
进入阿里云
diff --git a/sitemap.xml b/sitemap.xml
index dc65946c8..7402d33e8 100644
--- a/sitemap.xml
+++ b/sitemap.xml
@@ -662,14 +662,14 @@
- http://example.com/tags/%E6%95%B0%E6%8D%AE%E5%BA%93/
+ http://example.com/tags/Thread/
2023-09-24
daily
0.6
- http://example.com/tags/Thread/
+ http://example.com/tags/%E6%95%B0%E6%8D%AE%E5%BA%93/
2023-09-24
daily
0.6
@@ -731,6 +731,13 @@
0.6
+
+ http://example.com/tags/%E6%89%80%E6%83%B3/
+ 2023-09-24
+ daily
+ 0.6
+
+
http://example.com/tags/nginx/
2023-09-24
@@ -753,21 +760,21 @@
- http://example.com/tags/linux/
+ http://example.com/tags/pdf/
2023-09-24
daily
0.6
- http://example.com/tags/pdf/
+ http://example.com/tags/%E5%B0%8F%E4%BD%9C%E4%B8%9A/
2023-09-24
daily
0.6
- http://example.com/tags/%E5%B0%8F%E4%BD%9C%E4%B8%9A/
+ http://example.com/tags/linux/
2023-09-24
daily
0.6
@@ -787,6 +794,13 @@
0.6
+
+ http://example.com/tags/%E5%AE%9E%E4%B9%A0/
+ 2023-09-24
+ daily
+ 0.6
+
+
http://example.com/tags/leetcode-507-%E5%AE%8C%E7%BE%8E%E6%95%B0/
2023-09-24
@@ -864,20 +878,6 @@
0.6
-
- http://example.com/tags/%E5%AE%9E%E4%B9%A0/
- 2023-09-24
- daily
- 0.6
-
-
-
- http://example.com/tags/%E6%89%80%E6%83%B3/
- 2023-09-24
- daily
- 0.6
-
-
diff --git a/tags/java/index.html b/tags/java/index.html
index d52192edf..80de3d282 100644
--- a/tags/java/index.html
+++ b/tags/java/index.html
@@ -475,6 +475,107 @@ Java
+
+
+
+
+
+
+
+