Слова русского языка и варианты их неправильного написания. Включает в себя как орфографические ошибки, так и опечатки. Все ошибочные написания снабжены весами, позволяющими оценить относительную частоту встречаемости тех или иных ошибок.
Все данные представлены в двух форматах — HDP и CSV (разделённый точкой с запятой). Каждая запись включает в себя словарное слово-эталон, ошибочное написание и вес:
путешественница
путешествиница 0.1304
путишественница 0.087
путешествинница 0.0435
...
Вес — это отношение количества употреблений слова-ошибки к количеству употреблений слова-эталона. Соответственно веса можно сравнивать как в рамках одного слова-эталона, так и для разных слов. Например при подсчёте частоты ошибочного употребления одной буквы вместо другой.
- Скачать на диск и положить в папку под названием "Интересные датасеты. Посмотреть потом" (нет)
- Протестировать свой алгоритм спеллчекинга и автокоррекции.
- Собрать объединённую статистику по ошибочным написаниям букв и буквенных сочетаний.
- Используя машинное обучение, построить филигранную систему правил для фонетического алгоритма, учитывающую предшествующую и последующую буквы, а также умеющую работать с буквенными сочетаниями.
- Исследовать фонетические особенности русского языка и написать по результатам научную работу.
Сырые данные представляют собой непересекающиеся наборы слов, где для каждого набора известно, что в нём содержатся как правильные, так и ошибочные написания слов. Слова-эталоны с верным написанием в каждом наборе искались по словарю. Далее ошибки "подцеплялись" к словам-эталонам по двум метрикам.
Слова считаются эквивалентными по этой метрике тогда и только тогда, когда:
- одно слово полностью не содержит другое;
- можно получить одно слово из другого:
- вставкой/удалением подряд идущих одного или двух символов;
- заменой одного символа в одном из слов одним или двумя символами в другом.
Простым языком это немного ослабленная метрика "расстояние Левенштейна равно одному". Первый пункт о невключении одного слова в другое диктуется особенностями морфемного строя русского языка — чтобы исключить случаи неверного отнесения слова-ошибки к слову-эталону с другой приставкой/окончанием.
Если расстояние Левенштейна ограничивать двумя или тремя, то данные начинают быстро зашумляться — появляется много случаев ложного отнесения слова-ошибки к эталонному написанию. Для поиска мульти-орф-ошибок, т.е. где пользователь ошибается в нескольких местах одновременно, применяется фонетический алгоритм.
Данный датасет содержит все те же ошибки, что и L1_5 + ошибки, совпадающие с эталонами по фонетическим меткам.
Матрица ошибок — это матрица относительных частот того, что вместо верного употребления буквы X будет ошибочно употреблена буква Y. Причиной ошибки может быть как орфография, так и опечатка.
По строкам идут верные употребления, по столбцам — ошибочные. Каждая строка в отдельности отнормирована к единице по максимальному значению. Таким образом самая частотная ошибка в каждой строке будет иметь вес 1.0.
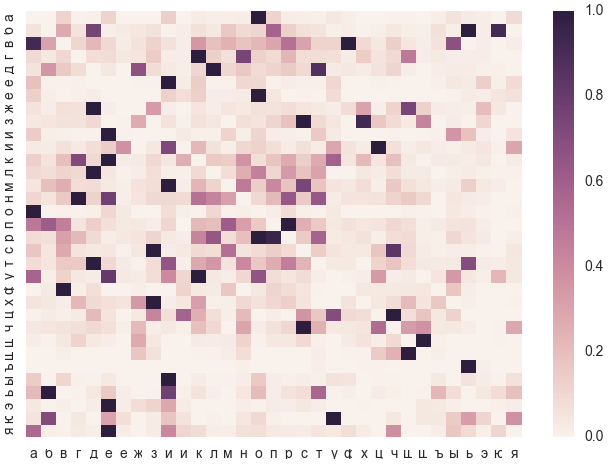
Тепловая карта читается по строкам. Например для буквы а наиболее вероятная ошибка — о. Все остальные ошибки существенно менее вероятны.
А, например, для б наиболее вероятными будут опечатки ь, ю и, реже, д. Фонетическая ошибка п уступает по частоте предыдущим трём.
Для отрисовки тепловой карты ошибок, можно использовать следующий код на Python:
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/dkulagin/kartaslov/master/dataset/orfo_and_typos/letter.matrix.csv', sep=';', index_col='INDEX_LETTER')
sns.heatmap(df)
plt.show()Данный датасет распространяется по лицензии CC BY-NC-SA 4.0. Простыми словами — вы можете свободно использовать его в личных, научных, исследовательских и любых других целях, не подразумевающих получения дохода коммерческим путём. При этом от вас требуется указать ссылку на лицензию и на этот репозиторий. Производные работы должны распространятся под аналогичной лицензией.
Будем признательны, если вы скинете несколько строк на [email protected] о том, как вы планируете использовать датасет — нам это интересно, как исследователям, и поможет сделать датасет лучше в будущем.
По вопросам использования датасета в коммерческих целях смотрите развёрнутый комментарий: использование данных в коммерческих целях.