\n```\n\nNesse exemplo, estamos combinando flexbox (classe `flex`) com unidades percentuais (`width: 100%`). Isso pode funcionar em navegadores mais recentes, mas causa problemas em versões mais antigas do Safari, como o iPhone 10, 11 e 12.\n\nPara solucionar esse problema, recomendamos substituir `w-full` por classes relacionadas ao flexbox:\n\n ```html\n
\n
\n
\n```\n\nIsso garantirá que o layout funcione corretamente em todos os navegadores.\n\n\nEstamos sempre acompanhando os novos projetos, coletando os apresentados e melhorando o template [Storefront](https://github.com/deco-sites/storefront).","seo":{"image":"https://github.com/deco-cx/blog/assets/1753396/20fb996b-4d04-417c-af69-5beb2a7e7969","title":"6 meses de lojas em produçāo - Uma jornada de aprendizados","description":"Nos últimos seis meses acumulamos um valioso conjunto de lições ao levar lojas para produção. Nesse período, aprendemos o que deve ser evitado, o que não funciona e a melhor maneira de iniciar o desenvolvimento de uma loja online. A seguir, compartilhamos um resumo das lições que adquirimos durante essa jornada."}}},"date":"10/10/2023","path":"licoes-6-meses.md","author":"Gui Tavano, Tiago Gimenes"},{"body":{"pt":{"title":"Partials","descr":"Revolucionando o Desenvolvimento Web","content":"[Fresh](https://fresh.deno.dev/), o framework web utilizado pela Deco, é conhecido por possibilitar a criação de páginas de altíssimo desempenho. Uma das razões pelas quais as páginas criadas na Deco são tão eficientes é devido à arquitetura de ilhas. Essa arquitetura permite que os desenvolvedores removam partes não interativas do pacote final de JavaScript, reduzindo a quantidade total de JavaScript na página e aliviando o navegador para realizar outras tarefas.\n\nNo entanto, uma das limitações dessa arquitetura é que páginas muito complexas, com muita interatividade e, portanto, muitas ilhas, ainda exigem uma grande quantidade de JavaScript. Felizmente, essa limitação agora é coisa do passado, graças à introdução dos Partials.\n\n## Como Funciona?\n\nOs Partials, inspirados no [htmx](https://htmx.org/docs/), operam com um runtime que intercepta as interações do usuário com elementos de botão, âncora e formulário. Essas interações são enviadas para nosso servidor, que calcula o novo estado da página e responde ao navegador. O navegador recebe o novo estado da IU em HTML puro, que é então processado e as diferenças são aplicadas, alterando a página para o seu estado final. Para obter informações mais detalhadas sobre os Partials, consulte a [documentação](https://github.com/denoland/fresh/issues/1609) do Fresh.\n\n## Partials em Ação\n\nEstamos migrando os componentes da loja da Deco para a nova solução de Partials. Até o momento, migramos o seletor de SKU, que pode ser visualizado em ação [aqui](http://storefront-vtex.deco.site/camisa-masculina-xadrez-sun-e-azul/p?skuId=120). Mais mudanças, como `infinite scroll` e melhorias nos filtros, estão por vir.\n\nOutra funcionalidade desbloqueada é a possibilidade de criar dobras na página. As páginas de comércio eletrônico geralmente são longas e contêm muitos elementos. Os navegadores costumam enfrentar problemas quando há muitos elementos no HTML. Para lidar com isso, foi inventada a técnica de dobra.\n\nA ideia básica dessa técnica é dividir o conteúdo da página em duas partes: o conteúdo acima e o conteúdo abaixo da dobra. O conteúdo acima da dobra é carregado na primeira solicitação ao servidor. O conteúdo abaixo da dobra é carregado assim que a primeira solicitação é concluída. Esse tipo de funcionalidade costumava ser difícil de implementar em arquiteturas mais antigas. Felizmente, embutimos essa lógica em uma nova seção chamada `Deferred`. Esta seção aceita uma lista de seções como parâmetro que devem ter seu carregamento adiado para um momento posterior.\n\nPara usar essa nova seção:\n\n1. Acesse o painel de administração da Deco e adicione a seção `Rendering > Deferred` à sua página.\n2. Mova as seções que deseja adiar para a seção `Deferred`.\n3. Salve e publique a página.\n4. Pronto! As seções agora estão adiadas sem a necessidade de alterar o código!\n\nVeja `Deferred` em ação neste [link](https://storefront-vtex.deco.site/home-partial).\n\n> Observe que, para a seção `Deferred` aparecer, você deve estar na versão mais recente do `fresh`, `apps` e deco!\n\nUma pergunta que você pode estar se fazendo agora é: Como escolher as seções que devo incluir no deferred? Para isso, use a aba de desempenho e comece pelas seções mais pesadas que oferecem o maior retorno!\n\nPara mais informações, veja nossas [docs](https://www.deco.cx/docs/en/developing-capabilities/interactive-sections/partial)"},"en":{"title":"Partials","descr":"Revolutionizing Web Development","content":"[Fresh](https://fresh.deno.dev/), the web framework used by Deco, is known for enabling the creation of high-performance pages. One of the reasons why pages created in Deco are so efficient is due to the island architecture. This architecture allows developers to remove non-interactive parts of the final JavaScript package, reducing the total amount of JavaScript on the page and freeing up the browser to perform other tasks.\n\nHowever, one of the limitations of this architecture is that very complex pages, with a lot of interactivity and therefore many islands, still require a large amount of JavaScript. Fortunately, this limitation is now a thing of the past, thanks to the introduction of Partials.\n\n## How It Works\n\nPartials, inspired by [htmx](https://htmx.org/docs/), operate with a runtime that intercepts user interactions with button, anchor, and form elements. These interactions are sent to our server, which calculates the new state of the page and responds to the browser. The browser receives the new UI state in pure HTML, which is then processed and the differences are applied, changing the page to its final state. For more detailed information about Partials, see the [Fresh documentation](https://github.com/denoland/fresh/issues/1609).\n\n## Partials in Action\n\nWe are migrating the components of the Deco store to the new Partials solution. So far, we have migrated the SKU selector, which can be viewed in action [here](http://storefront-vtex.deco.site/camisa-masculina-xadrez-sun-e-azul/p?skuId=120). More changes, such as `infinite scroll` and improvements to filters, are coming soon.\n\nAnother unlocked feature is the ability to create folds on the page. E-commerce pages are usually long and contain many elements. Browsers often face problems when there are many elements in the HTML. To deal with this, the fold technique was invented.\n\nThe basic idea of this technique is to divide the content of the page into two parts: the content above and the content below the fold. The content above the fold is loaded on the first request to the server. The content below the fold is loaded as soon as the first request is completed. This type of functionality used to be difficult to implement in older architectures. Fortunately, we have embedded this logic in a new section called `Deferred`. This section accepts a list of sections as a parameter that should have their loading delayed until a later time.\n\nTo use this new section:\n\n1. Access the Deco administration panel and add the `Rendering > Deferred` section to your page.\n2. Move the sections you want to defer to the `Deferred` section.\n3. Save and publish the page.\n4. Done! The sections are now deferred without the need to change the code!\n\nSee `Deferred` in action at this [link](https://storefront-vtex.deco.site/home-partial).\n\n> Note that, for the `Deferred` section to appear, you must be on the latest version of `fresh`, `apps`, and deco!\n\nA question you may be asking yourself now is: How do I choose the sections I should include in the deferred? To do this, use the performance tab and start with the heaviest sections that offer the greatest return!\n\nFor more information, see our [docs](https://www.deco.cx/docs/en/developing-capabilities/interactive-sections/partial)"}},"path":"partials.md","img":"https://user-images.githubusercontent.com/121065272/278023987-b7ab4ae9-6669-4e38-94b8-268049fa6569.png","date":"10/06/2023","author":"Marcos Candeia, Tiago Gimenes"},{"img":"https://user-images.githubusercontent.com/121065272/278021874-91a4ffea-3a22-4631-a4b3-c21bbc056386.png","body":{"en":{"descr":"Como a Lojas Torra dobrou sua taxa de conversão após migrar o front do seu ecommerce para a deco.cx","title":"A nova fase da Lojas Torra com a deco.cx."},"pt":{"descr":"Como a Lojas Torra dobrou sua taxa de conversão após migrar o front do seu ecommerce para a deco.cx","title":"A nova fase da Lojas Torra com a deco.cx."}},"date":"08/31/2023","path":"case-lojas-torra","author":"Por Maria Cecilia Marques"},{"body":{"pt":{"title":"AR&Co kickstarts digital shift: Baw goes headless with deco.cx","descr":"AR&Co. is getting its headless strategy off the ground, with both quality and speed by trusting deco.cx as its frontend solution."},"en":{"title":"AR&Co kickstarts digital shift: Baw goes headless with deco.cx","descr":"AR&Co. is getting its headless strategy off the ground, with both quality and speed by trusting deco.cx as its frontend solution."}},"path":"customer-story-baw","date":"04/25/2023","author":"Maria Cecilia Marques","img":"https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/ec116700-62ee-408d-8621-3f8b2db72e8b","tags":[]},{"body":{"pt":{"content":"Com dezenas de milhões de e-commerces, o varejo digital nunca enfrentou tanta competição. Por outro lado, com o grande aumento do número de consumidores online, nunca houve maior oportunidade pra crescer. Neste contexto, **oferecer experiências distintas é crucial.**\n\nContudo, mesmo as maiores marcas tem dificuldade construir algo além do previsível - páginas lentas e estáticas para todos os usuários. O resultado todos já sabem: **baixa conversão** -- pessoas deixam de comprar na loja porque não viram um conteúdo que lhe agrada ou porquê as páginas demoraram pra carregar em seus celulares.\n\nVamos entender primeiro porque isso acontece.\n\n\n## Por quê seu site performa mal?\n\n### 1. Sua loja demora para construir\n\nO time de tecnologia para ecommerce é pouco produtivo pois trabalha com frameworks e tech stacks complexas de aprender e fazer manutenção - e que vão ficando ainda mais complexas com o tempo, além do talento em tech ser escasso.\n\nPessoas desenvolvedoras gastam horas e horas cada mês com a complexidade acidental das tecnologias usadas: esperando o tempo de deploy, cuidando de milhares de linhas de código, ou lidando com dependências no npm - sobra pouco tempo para codar de verdade.\n\nResultado: o custo de novas funcionalidades é caro e a entrega é demorada, além de ser operacionalmente complexo contratar e treinar devs.\n\n\n### 2. Sua loja demora para carregar\n\nSabe-se que a velocidade de carregamento de uma página afeta drastricamente a taxa de conversão e o SEO. Em um site \"médio\", é esperado que cada 100ms a menos no tempo de carregamento de uma página, aumente em 1% a conversão.\n\nAinda assim, a maior parte das lojas tem storefronts (frentes de loja de ecommerce) com nota abaixo de 50 no [Google Lighthouse](https://developer.chrome.com/docs/lighthouse/overview/). E poucos parecem saber resolver.\n\nCom isso, o ecommerce global perde trilhões (!) de dólares em vendas.\n\nParte do problema é a escolha do framework e das tecnologias envolvidas:\n\n- a. SPA (Single Page Application) não é a tecnologia ideal para ecommerce, especialmente para performance e SEO.\n\n- b. A complexidade de criar código com esse paradigma cria bases de código difíceis de manter e adicionar novas funcionalidades.\n\n\n### 3. Sua loja demora para evoluir\n\nNos negócios e na vida, a evolução contínua e o aprendizado diário é o que gera sucesso. Especialmente no varejo, que vive de otimização contínua de margem.\n\nContudo, times de ecommerce dependem de devs para editar, testar, aprender e evoluir suas lojas.\n\nDevs, por sua vez, estão geralmente sobrecarregadas de demandas, e demoram demais para entregar o que foi pedido, ainda que sejam tasks simples.\n\nPara piorar, as ferramentas necessárias para realizar o ciclo completo de CRO (conversion rate optimization) como teste A/B, analytics, personalização e content management system (CMS) estão fragmentadas, o que exige ter que lidar com várias integrações e diversos serviços terceirizados diferentes.\n\nTudo isso aumenta drasticamente a complexidade operacional, especialmente em storefronts de alta escala, onde o ciclo de evolução é lento e ineficaz.\n\n\n## Nossa solução\n\nNosso time ficou mais de 10 anos lidando com estes mesmo problemas. Sabemos que existem tecnologias para criar sites e lojas de alto desempenho, mas a maioria parece não ter a coragem de utilizá-las.\n\nFoi quando decidimos criar a deco.cx.\n\nPara habilitarmos a criação de experiências de alto desempenho foi necessário um novo paradigma, que simplifique a criação de lojas rápidas, sem sacrificar a capacidade de **personalização e de evolução contínua.**\n\nCriamos uma plataforma headless que integra tudo o que uma marca ou agência precisa para gerenciar e otimizar sua experiência digital, tornando fácil tomar decisões em cima de dados reais, e aumentando continuamente as taxas de conversão.\n\n## Como fazemos isso:\n\n### 1. Com deco.cx fica rápido de construir\n\nAceleramos desenvolvimento de lojas, apostando em uma combinação de tecnologias de ponta que oferecem uma experiência de desenvolvimento frontend otimizada e eficiente. A stack inclui:\n\n- [**Deno**](https://deno.land)\n Um runtime seguro para JavaScript e TypeScript, criado para resolver problemas do Node.js, como gerenciamento de dependências e configurações TypeScript.\n\n- [**Fresh**](https://fresh.deno.dev)\nUm framework web minimalista e rápido, que proporciona uma experiência de desenvolvimento mais dinâmica e eficiente, com tempos de compilação rápidos ou inexistentes.\n\n- [**Twind**](https://twind.dev)\nUma biblioteca de CSS-in-JS que permite a criação de estilos dinâmicos, sem sacrificar o desempenho, e oferece compatibilidade com o popular framework Tailwind CSS.\n\n- [**Preact**](https://deno.land)\nUma alternativa leve ao React, que oferece desempenho superior e menor tamanho de pacote para aplicações web modernas.\n\nEssa combinação de tecnologias permite que a deco.cx ofereça uma plataforma de desenvolvimento frontend que melhora a produtividade e reduz o tempo de implementação, além de proporcionar sites de alto desempenho.\n\nOs principais ganhos de produtividade da plataforma e tecnologia deco são:\n\n- O deploy (e rollback) instantâneo na edge oferecido pelo [deno Deploy](https://deno.com/deploy)\n\n- A bibliotecas de componentes universais e extensíveis ([Sections](https://www.deco.cx/docs/en/concepts/section)), além de funções pré-construídas e totalmente customizáveis ([Loaders](https://www.deco.cx/docs/en/concepts/loader)).\n\n- A facilidade de aprendizado. Qualquer desenvolvedor junior que sabe codar em React, Javascript, HTML e CSS consegue aprender rapidamente a nossa stack, que foi desenhada pensando na melhor experiência de desenvolvimento.\n\n\n### 2. Com deco.cx fica ultrarrápido de navegar\n\nAs tecnologias escolhidas pela deco também facilitam drasticamente a criação de lojas ultrarrápidas.\n\nNormalmente os storesfronts são criados com React e Next.Js - frameworks JavaScript que usam a abordagem de Single-Page Applications (SPA) para construir aplicativos web. Ou seja, o site é carregado em uma única página e o conteúdo é transportado dinamicamente com JavaScript.\n\nDeno e Fresh, tecnologias que usamos aqui, são frameworks de JavaScript que trabalham com outro paradigma: o server-side-rendering, ou seja, o processamento dos componentes da página é feito em servidores antes de ser enviado para o navegador, ao invés de ser processado apenas no lado do cliente.\n\nIsso significa que a página já vem pronta para ser exibida quando é carregada no navegador, o que resulta em um carregamento mais rápido e uma melhor experiência do usuário.\n\nAlém disso, essas tecnologias trabalham nativamente com computação na edge, o que significa que a maior parte da lógica é executada em servidores perto do usuário, reduzindo a latência e melhorando a velocidade de resposta. Como o processamento é feito em servidores na edge, ele é capaz de realizar tarefas mais pesadas, como buscar e processar dados de fontes externas, de forma mais eficiente.\n\nAo usar essas ferramentas em conjunto, é possível construir e-commerces de alto desempenho, com tempos de carregamento de página mais rápidos e uma experiência geral melhorada.\n\n\n### 3. Com deco.cx fica fácil de evoluir\n\nA plataforma deco oferece, em um mesmo produto, tudo o que as agências e marcas precisam para rodar o ciclo completo de evolução da loja:\n\n- **Library**: Onde os desenvolvedores criam (ou customizam) [loaders](https://www.deco.cx/docs/en/concepts/loader) que puxam dados de qualquer API externa, e usam os dados coletados para criar componentes de interface totalmente editáveis pelos usuários de negócio ([Sections](https://www.deco.cx/docs/en/concepts/section)).\n\n- **Pages**: Nosso CMS integrado, para que o time de negócio consiga [compor e editar experiências rapidamente](https://www.deco.cx/docs/en/concepts/page), usando as funções e componentes de alto desempenho pré-construidos pelos seus desenvolvedores, sem precisar de uma linha de código.\n\n- **Campanhas**: Nossa ferramenta de personalização que te permite agendar ou customizar a mudança que quiser por data ou audiência. Seja uma landing page para a Black Friday ou uma sessão para um público específico, você decide como e quando seu site se comporta para cada usuário.\n\n- **Experimentos**: Testes A/B ou multivariados em 5 segundos - nossa ferramenta te permite acompanhar, em tempo real, a performance dos seus experimentos e relação à versão de controle.\n\n- **Analytics**: Dados em tempo real sobre toda a jornada de compra e a performance da loja. Aqui você cria relatórios personalizados, que consolidam dados de qualquer API externa.\n\n\n## O que está por vir\n\nEstamos só começando. Nossa primeira linha de código na deco foi em Setembro 2022. De lá pra cá montamos [uma comunidade no Discord](https://deco.cx/discord), que já conta com 1.050+ membros, entre agências, estudantes, marcas e experts.\n\nSe você está atrás de uma forma de criar sites e lojas ultrarrápidos, relevantes para cada audiência, e que evoluem diariamente através de experimentos e dados, [agende uma demo](https://deco.cx).","title":"Como a deco.cx faz sua loja converter mais","descr":"Descubra como a nossa plataforma headless ajuda lojas virtuais a converter mais clientes, simplificando a criação e manutenção de lojas rápidas e personalizáveis. "},"en":{"title":"Como a deco.cx faz sua loja converter mais","descr":"Descubra como a nossa plataforma headless ajuda lojas virtuais a converter mais clientes, simplificando a criação e manutenção de lojas rápidas e personalizáveis. ","content":"Com dezenas de milhões de e-commerces, o varejo digital nunca enfrentou tanta competição. Por outro lado, com o grande aumento do número de consumidores online, nunca houve maior oportunidade pra crescer. Neste contexto, **oferecer experiências distintas é crucial.**\n\nContudo, mesmo as maiores marcas tem dificuldade construir algo além do previsível - páginas lentas e estáticas para todos os usuários. O resultado todos já sabem: **baixa conversão** -- pessoas deixam de comprar na loja porque não viram um conteúdo que lhe agrada ou porquê as páginas demoraram pra carregar em seus celulares.\n\nVamos entender primeiro porque isso acontece.\n\n\n## Por quê seu site performa mal?\n\n### 1. Sua loja demora para construir\n\nO time de tecnologia para ecommerce é pouco produtivo pois trabalha com frameworks e tech stacks complexas de aprender e fazer manutenção - e que vão ficando ainda mais complexas com o tempo, além do talento em tech ser escasso.\n\nPessoas desenvolvedoras gastam horas e horas cada mês com a complexidade acidental das tecnologias usadas: esperando o tempo de deploy, cuidando de milhares de linhas de código, ou lidando com dependências no npm - sobra pouco tempo para codar de verdade.\n\nResultado: o custo de novas funcionalidades é caro e a entrega é demorada, além de ser operacionalmente complexo contratar e treinar devs.\n\n\n### 2. Sua loja demora para carregar\n\nSabe-se que a velocidade de carregamento de uma página afeta drastricamente a taxa de conversão e o SEO. Em um site \"médio\", é esperado que cada 100ms a menos no tempo de carregamento de uma página, aumente em 1% a conversão.\n\nAinda assim, a maior parte das lojas tem storefronts (frentes de loja de ecommerce) com nota abaixo de 50 no [Google Lighthouse](https://developer.chrome.com/docs/lighthouse/overview/). E poucos parecem saber resolver.\n\nCom isso, o ecommerce global perde trilhões (!) de dólares em vendas.\n\nParte do problema é a escolha do framework e das tecnologias envolvidas:\n\n- a. SPA (Single Page Application) não é a tecnologia ideal para ecommerce, especialmente para performance e SEO.\n\n- b. A complexidade de criar código com esse paradigma cria bases de código difíceis de manter e adicionar novas funcionalidades.\n\n\n### 3. Sua loja demora para evoluir\n\nNos negócios e na vida, a evolução contínua e o aprendizado diário é o que gera sucesso. Especialmente no varejo, que vive de otimização contínua de margem.\n\nContudo, times de ecommerce dependem de devs para editar, testar, aprender e evoluir suas lojas.\n\nDevs, por sua vez, estão geralmente sobrecarregadas de demandas, e demoram demais para entregar o que foi pedido, ainda que sejam tasks simples.\n\nPara piorar, as ferramentas necessárias para realizar o ciclo completo de CRO (conversion rate optimization) como teste A/B, analytics, personalização e content management system (CMS) estão fragmentadas, o que exige ter que lidar com várias integrações e diversos serviços terceirizados diferentes.\n\nTudo isso aumenta drasticamente a complexidade operacional, especialmente em storefronts de alta escala, onde o ciclo de evolução é lento e ineficaz.\n\n\n## Nossa solução\n\nNosso time ficou mais de 10 anos lidando com estes mesmo problemas. Sabemos que existem tecnologias para criar sites e lojas de alto desempenho, mas a maioria parece não ter a coragem de utilizá-las.\n\nFoi quando decidimos criar a deco.cx.\n\nPara habilitarmos a criação de experiências de alto desempenho foi necessário um novo paradigma, que simplifique a criação de lojas rápidas, sem sacrificar a capacidade de **personalização e de evolução contínua.**\n\nCriamos uma plataforma headless que integra tudo o que uma marca ou agência precisa para gerenciar e otimizar sua experiência digital, tornando fácil tomar decisões em cima de dados reais, e aumentando continuamente as taxas de conversão.\n\n## Como fazemos isso:\n\n### 1. Com deco.cx fica rápido de construir\n\nAceleramos desenvolvimento de lojas, apostando em uma combinação de tecnologias de ponta que oferecem uma experiência de desenvolvimento frontend otimizada e eficiente. A stack inclui:\n\n- [**Deno**](https://deno.land)\n Um runtime seguro para JavaScript e TypeScript, criado para resolver problemas do Node.js, como gerenciamento de dependências e configurações TypeScript.\n\n- [**Fresh**](https://fresh.deno.dev)\nUm framework web minimalista e rápido, que proporciona uma experiência de desenvolvimento mais dinâmica e eficiente, com tempos de compilação rápidos ou inexistentes.\n\n- [**Twind**](https://twind.dev)\nUma biblioteca de CSS-in-JS que permite a criação de estilos dinâmicos, sem sacrificar o desempenho, e oferece compatibilidade com o popular framework Tailwind CSS.\n\n- [**Preact**](https://deno.land)\nUma alternativa leve ao React, que oferece desempenho superior e menor tamanho de pacote para aplicações web modernas.\n\nEssa combinação de tecnologias permite que a deco.cx ofereça uma plataforma de desenvolvimento frontend que melhora a produtividade e reduz o tempo de implementação, além de proporcionar sites de alto desempenho.\n\nOs principais ganhos de produtividade da plataforma e tecnologia deco são:\n\n- O deploy (e rollback) instantâneo na edge oferecido pelo [deno Deploy](https://deno.com/deploy)\n\n- A bibliotecas de componentes universais e extensíveis ([Sections](https://www.deco.cx/docs/en/concepts/section)), além de funções pré-construídas e totalmente customizáveis ([Loaders](https://www.deco.cx/docs/en/concepts/loader)).\n\n- A facilidade de aprendizado. Qualquer desenvolvedor junior que sabe codar em React, Javascript, HTML e CSS consegue aprender rapidamente a nossa stack, que foi desenhada pensando na melhor experiência de desenvolvimento.\n\n\n### 2. Com deco.cx fica ultrarrápido de navegar\n\nAs tecnologias escolhidas pela deco também facilitam drasticamente a criação de lojas ultrarrápidas.\n\nNormalmente os storesfronts são criados com React e Next.Js - frameworks JavaScript que usam a abordagem de Single-Page Applications (SPA) para construir aplicativos web. Ou seja, o site é carregado em uma única página e o conteúdo é transportado dinamicamente com JavaScript.\n\nDeno e Fresh, tecnologias que usamos aqui, são frameworks de JavaScript que trabalham com outro paradigma: o server-side-rendering, ou seja, o processamento dos componentes da página é feito em servidores antes de ser enviado para o navegador, ao invés de ser processado apenas no lado do cliente.\n\nIsso significa que a página já vem pronta para ser exibida quando é carregada no navegador, o que resulta em um carregamento mais rápido e uma melhor experiência do usuário.\n\nAlém disso, essas tecnologias trabalham nativamente com computação na edge, o que significa que a maior parte da lógica é executada em servidores perto do usuário, reduzindo a latência e melhorando a velocidade de resposta. Como o processamento é feito em servidores na edge, ele é capaz de realizar tarefas mais pesadas, como buscar e processar dados de fontes externas, de forma mais eficiente.\n\nAo usar essas ferramentas em conjunto, é possível construir e-commerces de alto desempenho, com tempos de carregamento de página mais rápidos e uma experiência geral melhorada.\n\n\n### 3. Com deco.cx fica fácil de evoluir\n\nA plataforma deco oferece, em um mesmo produto, tudo o que as agências e marcas precisam para rodar o ciclo completo de evolução da loja:\n\n- **Library**: Onde os desenvolvedores criam (ou customizam) [loaders](https://www.deco.cx/docs/en/concepts/loader) que puxam dados de qualquer API externa, e usam os dados coletados para criar componentes de interface totalmente editáveis pelos usuários de negócio ([Sections](https://www.deco.cx/docs/en/concepts/section)).\n\n- **Pages**: Nosso CMS integrado, para que o time de negócio consiga [compor e editar experiências rapidamente](https://www.deco.cx/docs/en/concepts/page), usando as funções e componentes de alto desempenho pré-construidos pelos seus desenvolvedores, sem precisar de uma linha de código.\n\n- **Campanhas**: Nossa ferramenta de personalização que te permite agendar ou customizar a mudança que quiser por data ou audiência. Seja uma landing page para a Black Friday ou uma sessão para um público específico, você decide como e quando seu site se comporta para cada usuário.\n\n- **Experimentos**: Testes A/B ou multivariados em 5 segundos - nossa ferramenta te permite acompanhar, em tempo real, a performance dos seus experimentos e relação à versão de controle.\n\n- **Analytics**: Dados em tempo real sobre toda a jornada de compra e a performance da loja. Aqui você cria relatórios personalizados, que consolidam dados de qualquer API externa.\n\n\n## O que está por vir\n\nEstamos só começando. Nossa primeira linha de código na deco foi em Setembro 2022. De lá pra cá montamos [uma comunidade no Discord](https://deco.cx/discord), que já conta com 1.050+ membros, entre agências, estudantes, marcas e experts.\n\nSe você está atrás de uma forma de criar sites e lojas ultrarrápidos, relevantes para cada audiência, e que evoluem diariamente através de experimentos e dados, [agende uma demo](https://deco.cx)."}},"path":"como-a-deco-faz-sua-loja-converter-mais.md","date":"04/14/2023","author":"Rafael Crespo","img":"https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/450efa63-082e-427a-b218-e8b3690823cc"},{"body":{"pt":{"content":"## Desafio\n\nRecentemente aceitei um desafio e quero compartilhar como foi a minha experiência.\n\nO desafio era reconstruir a Home da [https://deno.land/](https://deno.land/) utilizando a plataforma deco.cx como CMS.\n\n## O que é deco.cx?\n\nÉ uma plataforma criada por um time de pessoas que trabalharam na Vtex, para construir páginas e lojas virtuais performáticas e em um curto período de tempo.\n\nCom o slogan \"Crie, teste e evolua sua loja. Todos os dias.\", a plataforma foca na simplicidade no desenvolvimento, autonomia para edições/testes e foco em performance.\n\n## Primeira etapa - Conhecendo a Stack\n\nAntes de iniciar o desenvolvimento, precisei correr atrás das tecnologias que a deco.cx sugere para utilização.\n\nSão elas:\n\n### Preact\n\nPreact é uma biblioteca JS baseada no React, mas que promete ser mais leve e mais performática.\n\nA adaptação aqui, para quem já tem o React, não tende a ser complicada.\n\n### Deno\n\nDeno é um ambiente de execução de Javascript e Typescript, criado pelo mesmo criador do Node.js.\n\nCom uma boa aceitação entre os devs, a alternativa melhorada do Node.js promete se destacar no futuro.\n\n### Fresh\n\nFresh é um Framework que me deixou bem curioso. Nessa stack, podemos dizer que ele atua como um Next.\n\nApesar de não ter me aprofundado no Framework, não tive problemas aqui, afinal um dos pilares do Fresh é não precisar de configuração, além de não ter etapa de build.\n\n### Twind\n\nTwind é uma alternativa mais leve, rápida e completa do tão conhecido Tailwind.\n\nA adaptação é extremamente fácil para quem já trabalha com Tailwind, mas não era o meu caso.\n\nPequenos gargalos no começo, mas a curva de aprendizagem é curta e nas últimas seções eu já estava sentindo os efeitos (positivos).\n\n## Segunda Etapa - Conhecendo a ferramenta da deco.cx\n\nMeu objetivo aqui, era entender como a ferramenta me ajudaria a recriar a página deno.land, tornando os componentes editáveis pelo painel CMS.\n\n### Criação da Conta\n\nO Login foi bem simples, pode ser feito com Github ou Google.\n\n### Criação do Projeto\n\nNa primeira página, após logado, temos a opção de Criar um Novo Site.\n\nTive que dar um nome ao projeto e escolher o template padrão para ser iniciado.\n\n\n\nAssim que o site é criado, **automaticamente** um repositório é montado no GitHub da [deco-sites](https://github.com/deco-sites) e um link da sua página na internet também.\n\nA partir dai, cada push que você fizer resultará no Deploy da aplicação no servidor e rapidamente será refletido em produção\n\n### Entendendo páginas e seções\n\nDentro do painel, podemos acessar a aba de \"Pages\"\n\n\n\nNessa parte, cada página do seu site estará listada, e assim que você clicar, você pode ver as seções que estão sendo utilizadas.\n\n\n\nDessa forma, fica fácil para uma pessoa não técnica conseguir criar novas páginas e adicionar/editar as seções.\n\nMas para entender como criar um modelo de seção, vamos para a terceira etapa.\n\n## Terceira Etapa - Integração do Código com a deco.cx\n\nComo eu tinha o objetivo de tornar as seções da página editáveis, eu precisei entender como isso deveria ser escrito no código.\n\nE é tão simples, quanto tipagem em Typescript, literalmente.\n\nDentro da estrutura no GitHub, temos uma pasta chamada _sections_, e cada arquivo _.tsx_ lá dentro se tornará uma daquelas seções no painel.\n\n\n\nEm cada arquivo, deve ser exportado uma função default, que retorna um código HTML.\n\nDentro desse HTML, podemos utilizar dados que vem do painel, e para definir quais dados deverão vir de lá, fazemos dessa forma:\n\nexport interface Props {\n image: LiveImage;\n imageMobile: LiveImage;\n altText: string;\n title: string;\n subTitle: string;\n}\n\nEsses são os campos que configurei para a seção _Banner_, e o resultado é esse no painel:\n\n\n\nDepois recebi esses dados como Props, assim:\n\nexport default function Banner({ image, imageMobile, altText, subTitle, title }: Props,) {\n return (\n <>\n //Your HTML code here\n \n );\n}\n\nE o resultado final da seção é:\n\n\n\n### Dev Mode\n\nÉ importante ressaltar, que durante o desenvolvimento, a ferramenta oferece uma função \"Dev Mode\".\n\nIsso faz com que os campos editáveis do painel se baseiem no código feito no localhost e não do repositório no Github.\n\nGarantindo a possibilidade de testes durante a criação.\n\n## Resultado Final + Conclusão\n\nO resultado final, pode ser conferido em: [https://deno-land.deco.site/](https://deno-land.deco.site/)\n\nConsegui atingir nota 97 no Pagespeed Mobile e isso me impressionou bastante.\n\nParticularmente, gostei muito dos pilares que a deco.cx está buscando entregar, em especial a autonomia de edição e o foco na velocidade de carregamento.\n\nA ferramenta é nova e já entrega muita coisa legal. A realização desse desafio foi feita após 3 meses do início do desenvolvimento da plataforma da deco.\n\nMinha recomendação a todos é que entrem na [Comunidade no Discord](https://discord.gg/RZkvt5AE) e acompanhem as novidades para não ficar para trás.\n\nSe possível, criem um site na ferramenta e façam os seus próprios testes.\n\nEm parceria com [TavanoBlog](https://tavanoblog.com.br/).","title":"Minha experiência com deco.cx","descr":"Recriando a página da deno-land utilizando a plataforma da deco.cx com as tecnologias: Deno, Fresh, Preact e Twind."},"en":{"title":"Minha experiência com deco.cx","descr":"Recriando a página da deno-land utilizando a plataforma da deco.cx com as tecnologias: Deno, Fresh, Preact e Twind.","content":"## Desafio\n\nRecentemente aceitei um desafio e quero compartilhar como foi a minha experiência.\n\nO desafio era reconstruir a Home da [https://deno.land/](https://deno.land/) utilizando a plataforma deco.cx como CMS.\n\n## O que é deco.cx?\n\nÉ uma plataforma criada por um time de pessoas que trabalharam na Vtex, para construir páginas e lojas virtuais performáticas e em um curto período de tempo.\n\nCom o slogan \"Crie, teste e evolua sua loja. Todos os dias.\", a plataforma foca na simplicidade no desenvolvimento, autonomia para edições/testes e foco em performance.\n\n## Primeira etapa - Conhecendo a Stack\n\nAntes de iniciar o desenvolvimento, precisei correr atrás das tecnologias que a deco.cx sugere para utilização.\n\nSão elas:\n\n### Preact\n\nPreact é uma biblioteca JS baseada no React, mas que promete ser mais leve e mais performática.\n\nA adaptação aqui, para quem já tem o React, não tende a ser complicada.\n\n### Deno\n\nDeno é um ambiente de execução de Javascript e Typescript, criado pelo mesmo criador do Node.js.\n\nCom uma boa aceitação entre os devs, a alternativa melhorada do Node.js promete se destacar no futuro.\n\n### Fresh\n\nFresh é um Framework que me deixou bem curioso. Nessa stack, podemos dizer que ele atua como um Next.\n\nApesar de não ter me aprofundado no Framework, não tive problemas aqui, afinal um dos pilares do Fresh é não precisar de configuração, além de não ter etapa de build.\n\n### Twind\n\nTwind é uma alternativa mais leve, rápida e completa do tão conhecido Tailwind.\n\nA adaptação é extremamente fácil para quem já trabalha com Tailwind, mas não era o meu caso.\n\nPequenos gargalos no começo, mas a curva de aprendizagem é curta e nas últimas seções eu já estava sentindo os efeitos (positivos).\n\n## Segunda Etapa - Conhecendo a ferramenta da deco.cx\n\nMeu objetivo aqui, era entender como a ferramenta me ajudaria a recriar a página deno.land, tornando os componentes editáveis pelo painel CMS.\n\n### Criação da Conta\n\nO Login foi bem simples, pode ser feito com Github ou Google.\n\n### Criação do Projeto\n\nNa primeira página, após logado, temos a opção de Criar um Novo Site.\n\nTive que dar um nome ao projeto e escolher o template padrão para ser iniciado.\n\n\n\nAssim que o site é criado, **automaticamente** um repositório é montado no GitHub da [deco-sites](https://github.com/deco-sites) e um link da sua página na internet também.\n\nA partir dai, cada push que você fizer resultará no Deploy da aplicação no servidor e rapidamente será refletido em produção\n\n### Entendendo páginas e seções\n\nDentro do painel, podemos acessar a aba de \"Pages\"\n\n\n\nNessa parte, cada página do seu site estará listada, e assim que você clicar, você pode ver as seções que estão sendo utilizadas.\n\n\n\nDessa forma, fica fácil para uma pessoa não técnica conseguir criar novas páginas e adicionar/editar as seções.\n\nMas para entender como criar um modelo de seção, vamos para a terceira etapa.\n\n## Terceira Etapa - Integração do Código com a deco.cx\n\nComo eu tinha o objetivo de tornar as seções da página editáveis, eu precisei entender como isso deveria ser escrito no código.\n\nE é tão simples, quanto tipagem em Typescript, literalmente.\n\nDentro da estrutura no GitHub, temos uma pasta chamada _sections_, e cada arquivo _.tsx_ lá dentro se tornará uma daquelas seções no painel.\n\n\n\nEm cada arquivo, deve ser exportado uma função default, que retorna um código HTML.\n\nDentro desse HTML, podemos utilizar dados que vem do painel, e para definir quais dados deverão vir de lá, fazemos dessa forma:\n\nexport interface Props {\n image: LiveImage;\n imageMobile: LiveImage;\n altText: string;\n title: string;\n subTitle: string;\n}\n\nEsses são os campos que configurei para a seção _Banner_, e o resultado é esse no painel:\n\n\n\nDepois recebi esses dados como Props, assim:\n\nexport default function Banner({ image, imageMobile, altText, subTitle, title }: Props,) {\n return (\n <>\n //Your HTML code here\n \n );\n}\n\nE o resultado final da seção é:\n\n\n\n### Dev Mode\n\nÉ importante ressaltar, que durante o desenvolvimento, a ferramenta oferece uma função \"Dev Mode\".\n\nIsso faz com que os campos editáveis do painel se baseiem no código feito no localhost e não do repositório no Github.\n\nGarantindo a possibilidade de testes durante a criação.\n\n## Resultado Final + Conclusão\n\nO resultado final, pode ser conferido em: [https://deno-land.deco.site/](https://deno-land.deco.site/)\n\nConsegui atingir nota 97 no Pagespeed Mobile e isso me impressionou bastante.\n\nParticularmente, gostei muito dos pilares que a deco.cx está buscando entregar, em especial a autonomia de edição e o foco na velocidade de carregamento.\n\nA ferramenta é nova e já entrega muita coisa legal. A realização desse desafio foi feita após 3 meses do início do desenvolvimento da plataforma da deco.\n\nMinha recomendação a todos é que entrem na [Comunidade no Discord](https://discord.gg/RZkvt5AE) e acompanhem as novidades para não ficar para trás.\n\nSe possível, criem um site na ferramenta e façam os seus próprios testes.\n\nEm parceria com [TavanoBlog](https://tavanoblog.com.br/)."}},"path":"criando-uma-pagina-com-decocx.md","date":"03/01/2023","author":"Guilherme Tavano","img":"https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/179d2e1f-8214-46f4-bc85-497f2313145e"},{"body":{"pt":{"content":"Nesta última versão, a deco está revolucionando a forma como você adiciona funcionalidades em seus **sites**. Dê as boas-vindas à era dos Apps.\n\n**O que são Apps?**\n\nAs Apps são poderosos conjuntos de capacidades de negócios que podem ser importados e configurados em sites deco. Uma App na deco é essencialmente uma coleção de vários componentes, como **Actions**, **Sections**, **Loaders**, **Workflows**, **Handlers**, ou quaisquer outros tipos de blocks que podem ser usados para estender a funcionalidade dos seus sites.\n\nCom as apps, você tem o poder de definir propriedades necessárias para a funcionalidade como um todo, como chaves de aplicação, nomes de contas entre outros.\n\n**Templates de Loja**\n\nIntroduzimos vários templates de lojas integradas com plataformas como - Vnda., VTEX e Shopify. Agora, você tem a flexibilidade de escolher o template que melhor se adapta às suas necessidades e pode criar facilmente sua loja a partir desses templates.\n\n
\n\n**DecoHub: Seu Hub de Apps**\n\nCom a estreia do DecoHub, você pode descobrir e instalar uma variedade de apps com base em suas necessidades do seu negócio. Se você é um desenvolvedor, pode criar seus próprios apps fora do repositório do [deco-cx/apps](http://github.com/deco-cx/apps) e enviar um PR para adicioná-los ao DecoHub.\n\n**Transição de Deco-Sites/Std para Apps**\n\nMigramos do hub central de integrações do [deco-sites/std](https://github.com/deco-sites/std) para uma abordagem mais modular com o [deco-cx/apps](http://github.com/deco-cx/apps). O STD agora está em modo de manutenção, portanto, certifique-se de migrar sua loja e seguir as etapas de instalação em nossa [documentação](https://www.deco.cx/docs/en/getting-started/installing-an-app) para aproveitar o novo ecossistema de Apps.\n\n**Comece a Usar os Apps Agora Mesmo!**\n\nDesenvolvedores, mergulhem em nosso [guia](https://www.deco.cx/docs/en/developing-capabilities/apps/creating-an-app) sobre como criar seu primeiro App no Deco. Para lojas existentes, faça a migração executando `deno run -A -r https://deco.cx/upgrade`.\n\nIsso é apenas o começo. Estamos trabalhando continuamente para aprimorar nosso ecossistema de Apps e explorar novos recursos, como transições de visualização e soluções de estilo.\n\nFiquem ligados e vamos construir juntos o futuro do desenvolvimento web!","title":"Como utilizar apps para adicionar funcionalidades aos seus sites.","descr":"Descubra como a nossa plataforma headless ajuda lojas virtuais a converter mais clientes, simplificando a criação e manutenção de lojas rápidas e personalizáveis."},"en":{"title":"How to use apps to add functionality to your sites.","descr":"Discover how our headless platform helps e-commerce stores convert more customers by simplifying the creation and maintenance of fast, customizable stores.","content":"In this latest release, deco is revolutionizing the way you add functionality to your **sites**. Welcome to the era of Apps.\n\n**What are Apps?**\n\nApps are powerful sets of business capabilities that can be imported and configured in deco sites. An App in deco is essentially a collection of various components, such as **Actions**, **Sections**, **Loaders**, **Workflows**, **Handlers**, or any other types of blocks that can be used to extend the functionality of your sites.\n\nWith apps, you have the power to define properties necessary for the functionality as a whole, such as application keys, account names, and more.\n\n**Store Templates**\n\nWe've introduced several store templates integrated with platforms like - Vnda., VTEX, and Shopify. Now, you have the flexibility to choose the template that best suits your needs and can easily create your store from these templates.\n\n
\n\n**DecoHub: Your App Hub**\n\nWith the debut of DecoHub, you can discover and install a variety of apps based on your business needs. If you're a developer, you can create your own apps outside of the [deco-cx/apps](http://github.com/deco-cx/apps) repository and submit a PR to add them to DecoHub.\n\n**Transition from Deco-Sites/Std to Apps**\n\nWe've migrated from the central integration hub of [deco-sites/std](https://github.com/deco-sites/std) to a more modular approach with [deco-cx/apps](http://github.com/deco-cx/apps). STD is now in maintenance mode, so be sure to migrate your store and follow the installation steps in our [documentation](https://www.deco.cx/docs/en/getting-started/installing-an-app) to take advantage of the new Apps ecosystem.\n\n**Start Using Apps Now!**\n\nDevelopers, dive into our [guide](https://www.deco.cx/docs/en/developing-capabilities/apps/creating-an-app) on how to create your first App in Deco. For existing stores, make the migration by running `deno run -A -r https://deco.cx/upgrade`.\n\nThis is just the beginning. We're continuously working to enhance our Apps ecosystem and explore new features, such as view transitions and styling solutions.\n\nStay tuned and let's build the future of web development together!"}},"path":"apps-era.md","date":"01/23/2023","author":"Marcos Candeia, Tiago Gimenes","img":"https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/5a07de58-ba83-4c6c-92e1-bea033350318","descr":"A era dos Apps!"},{"body":{"pt":{"title":"A vida é curta","descr":"Por Paul Graham, traduzido por ChatGPT.","content":"A vida é curta, como todos sabem. Quando era criança, costumava me perguntar sobre isso. A vida realmente é curta ou estamos realmente nos queixando de sua finitude? Seríamos tão propensos a sentir que a vida é curta se vivêssemos 10 vezes mais tempo?\n\nComo não parecia haver maneira de responder a essa pergunta, parei de me perguntar sobre isso. Depois tive filhos. Isso me deu uma maneira de responder à pergunta e a resposta é que a vida realmente é curta.\n\nTer filhos me mostrou como converter uma quantidade contínua, o tempo, em quantidades discretas. Você só tem 52 fins de semana com seu filho de 2 anos. Se o Natal-como-mágica dure, digamos, dos 3 aos 10 anos, só poderá ver seu filho experimentá-lo 8 vezes. E enquanto é impossível dizer o que é muito ou pouco de uma quantidade contínua como o tempo, 8 não é muito de alguma coisa. Se você tivesse uma punhado de 8 amendoins ou uma prateleira de 8 livros para escolher, a quantidade definitivamente pareceria limitada, independentemente da sua expectativa de vida.\n\nOk, então a vida realmente é curta. Isso faz alguma diferença saber disso?\n\nFez para mim. Isso significa que argumentos do tipo \"A vida é muito curta para x\" têm muita força. Não é apenas uma figura de linguagem dizer que a vida é muito curta para alguma coisa. Não é apenas um sinônimo de chato. Se você achar que a vida é muito curta para alguma coisa, deve tentar eliminá-la se puder.\n\nQuando me pergunto o que descobri que a vida é muito curta, a palavra que me vem à cabeça é \"besteira\". Eu percebo que essa resposta é um pouco tautológica. Quase é a definição de besteira que é a coisa de que a vida é muito curta. E ainda assim a besteira tem um caráter distintivo. Há algo falso nela. É o alimento junk da experiência. [1]\n\nSe você perguntar a si mesmo o que gasta o seu tempo em besteira, provavelmente já sabe a resposta. Reuniões desnecessárias, disputas sem sentido, burocracia, postura, lidar com os erros de outras pessoas, engarrafamentos, passatempos viciantes mas pouco gratificantes.\n\nHá duas maneiras pelas quais esse tipo de coisa entra em sua vida: ou é imposto a você ou o engana. Até certo ponto, você tem que suportar as besteiras impostas por circunstâncias. Você precisa ganhar dinheiro e ganhar dinheiro consiste principalmente em realizar tarefas. De fato, a lei da oferta e da demanda garante isso: quanto mais gratificante é algum tipo de trabalho, mais barato as pessoas o farão. Pode ser que menos tarefas sejam impostas a você do que você pensa, no entanto. Sempre houve uma corrente de pessoas que optam por sair da rotina padrão e vão viver em algum lugar onde as oportunidades são menores no sentido convencional, mas a vida parece mais autêntica. Isso pode se tornar mais comum.\n\nVocê pode reduzir a quantidade de besteira em sua vida sem precisar se mudar. A quantidade de tempo que você precisa gastar com besteiras varia entre empregadores. A maioria das grandes organizações (e muitas pequenas) está imersa nelas. Mas se você priorizar conscientemente a redução de besteiras acima de outros fatores, como dinheiro e prestígio, pode encontrar empregadores que irão desperdiçar menos do seu tempo.\n\nSe você é freelancer ou uma pequena empresa, pode fazer isso no nível de clientes individuais. Se você demitir ou evitar clientes tóxicos, pode diminuir a quantidade de besteira em sua vida mais do que diminui sua renda.\n\nMas, enquanto alguma quantidade de besteira é inevitavelmente imposta a você, a besteira que se infiltra em sua vida enganando-o não é culpa de ninguém, mas sua própria. E ainda assim, a besteira que você escolhe pode ser mais difícil de eliminar do que a besteira que é imposta a você. Coisas que o atraem para desperdiçar seu tempo precisam ser muito boas em enganá-lo. Um exemplo que será familiar para muitas pessoas é discutir online. Quando alguém contradiz você, está, de certa forma, atacando você. Às vezes bastante abertamente. Seu instinto quando é atacado é se defender. Mas, assim como muitos instintos, esse não foi projetado para o mundo em que vivemos agora. Contrariamente ao que parece, é melhor, na maioria das vezes, não se defender. Caso contrário, essas pessoas estão literalmente tomando sua vida. [2]\n\nDiscutir online é apenas incidentalmente viciante. Há coisas mais perigosas do que isso. Como já escrevi antes, um subproduto do progresso técnico é que as coisas que gostamos tendem a se tornar mais viciantes. Isso significa que precisaremos fazer um esforço consciente para evitar vícios, para nos colocarmos fora de nós mesmos e perguntarmos: \"é assim que quero estar gastando meu tempo?\"\n\nAlém de evitar besteiras, devemos procurar ativamente coisas que importam. Mas coisas diferentes importam para pessoas diferentes e a maioria precisa aprender o que importa para elas. Alguns são afortunados e percebem cedo que adoram matemática, cuidar de animais ou escrever e, então, descobrem uma maneira de passar muito tempo fazendo isso. Mas a maioria das pessoas começa com uma vida que é uma mistura de coisas que importam e coisas que não importam e só gradualmente aprende a distinguir entre elas.\n\nPara os jovens, especialmente, muita dessa confusão é induzida pelas situações artificiais em que se encontram. Na escola intermediária e na escola secundária, o que os outros estudantes acham de você parece ser a coisa mais importante do mundo. Mas quando você pergunta aos adultos o que eles fizeram de errado nessa idade, quase todos dizem que se importavam demais com o que os outros estudantes achavam deles.\n\nUma heurística para distinguir coisas que importam é perguntar a si mesmo se você se importará com elas no futuro. A coisa falsa que importa geralmente tem um pico afiado de parecer importar. É assim que o engana. A área sob a curva é pequena, mas sua forma se crava em sua consciência como uma alfinete.\n\nAs coisas que importam nem sempre são aquelas que as pessoas chamariam de \"importantes\". Tomar café com um amigo importa. Você não vai sentir depois que isso foi um desperdício de tempo.\n\nUma coisa ótima em ter crianças pequenas é que elas fazem você gastar tempo em coisas que importam: elas. Elas puxam sua manga enquanto você está olhando para o seu celular e dizem: \"você vai brincar comigo?\". E as chances são de que essa seja, de fato, a opção de minimização de besteira.\n\nSe a vida é curta, devemos esperar que sua brevidade nos surpreenda. E é exatamente isso que costuma acontecer. Você assume as coisas como garantidas e, então, elas desaparecem. Você acha que sempre pode escrever aquele livro, ou subir aquela montanha, ou o que quer que seja, e então percebe que a janela se fechou. As janelas mais tristes fecham quando outras pessoas morrem. Suas vidas também são curtas. Depois que minha mãe morreu, eu desejei ter passado mais tempo com ela. Eu vivi como se ela sempre estivesse lá. E, de maneira típica e discreta, ela incentivou essa ilusão. Mas era uma ilusão. Acho que muitas pessoas cometem o mesmo erro que eu cometi.\n\nA maneira usual de evitar ser surpreendido por algo é estar consciente disso. Quando a vida era mais precária, as pessoas costumavam ser conscientes da morte em um grau que agora pareceria um pouco morboso. Não tenho certeza do porquê, mas não parece ser a resposta certa lembrar constantemente da caveira pairando no ombro de todos. Talvez uma solução melhor seja olhar o problema pelo outro lado. Cultive o hábito de ser impaciente com as coisas que mais quer fazer. Não espere antes de subir aquela montanha ou escrever aquele livro ou visitar sua mãe. Você não precisa se lembrar constantemente por que não deve esperar. Apenas não espere.\n\nPosso pensar em mais duas coisas que alguém faz quando não tem muito de algo: tentar obter mais disso e saborear o que tem. Ambos fazem sentido aqui.\n\nComo você vive afeta por quanto tempo você vive. A maioria das pessoas poderia fazer melhor. Eu entre elas.\n\nMas você provavelmente pode obter ainda mais efeito prestando mais atenção ao tempo que tem. É fácil deixar os dias passarem voando. O \"fluxo\" que as pessoas imaginativas adoram tanto tem um parente mais sombrio que impede você de pausar para saborear a vida no meio da rotina diária de tarefas e alarmes. Uma das coisas mais impressionantes que já li não estava em um livro, mas no título de um: Burning the Days (Queimando os Dias), de James Salter.\n\nÉ possível diminuir um pouco o tempo. Eu melhorei nisso. As crianças ajudam. Quando você tem crianças pequenas, há muitos momentos tão perfeitos que você não consegue deixar de notar.\n\nTambém ajuda sentir que você tirou tudo de alguma experiência. O motivo pelo qual estou triste por minha mãe não é apenas porque sinto falta dela, mas porque penso em tudo o que poderíamos ter feito e não fizemos. Meu filho mais velho vai fazer 7 anos em breve. E, embora sinta falta da versão dele de 3 anos, pelo menos não tenho nenhum arrependimento pelo que poderia ter sido. Tivemos o melhor tempo que um pai e um filho de 3 anos poderiam ter.\n\nCorte implacavelmente as besteiras, não espere para fazer coisas que importam e saboreie o tempo que tem. É isso o que você faz quando a vida é curta. \n\n---\n\nNotas\n\n[1] No começo, eu não gostei que a palavra que me veio à mente tivesse outros significados. Mas então percebi que os outros significados estão bastante relacionados. Besteira no sentido de coisas em que você desperdiça seu tempo é bastante parecida com besteira intelectual.\n\n[2] Escolhi esse exemplo de forma deliberada como uma nota para mim mesmo. Eu sou atacado muito online. As pessoas contam as mentiras mais loucas sobre mim. E até agora eu fiz um trabalho bastante medíocre de suprimir a inclinação natural do ser humano de dizer \"Ei, isso não é verdade!\".\n\nObrigado a Jessica Livingston e Geoff Ralston por ler rascunhos deste."},"en":{"title":"A vida é curta","descr":"Por Paul Graham, traduzido por ChatGPT.","content":"A vida é curta, como todos sabem. Quando era criança, costumava me perguntar sobre isso. A vida realmente é curta ou estamos realmente nos queixando de sua finitude? Seríamos tão propensos a sentir que a vida é curta se vivêssemos 10 vezes mais tempo?\n\nComo não parecia haver maneira de responder a essa pergunta, parei de me perguntar sobre isso. Depois tive filhos. Isso me deu uma maneira de responder à pergunta e a resposta é que a vida realmente é curta.\n\nTer filhos me mostrou como converter uma quantidade contínua, o tempo, em quantidades discretas. Você só tem 52 fins de semana com seu filho de 2 anos. Se o Natal-como-mágica dure, digamos, dos 3 aos 10 anos, só poderá ver seu filho experimentá-lo 8 vezes. E enquanto é impossível dizer o que é muito ou pouco de uma quantidade contínua como o tempo, 8 não é muito de alguma coisa. Se você tivesse uma punhado de 8 amendoins ou uma prateleira de 8 livros para escolher, a quantidade definitivamente pareceria limitada, independentemente da sua expectativa de vida.\n\nOk, então a vida realmente é curta. Isso faz alguma diferença saber disso?\n\nFez para mim. Isso significa que argumentos do tipo \"A vida é muito curta para x\" têm muita força. Não é apenas uma figura de linguagem dizer que a vida é muito curta para alguma coisa. Não é apenas um sinônimo de chato. Se você achar que a vida é muito curta para alguma coisa, deve tentar eliminá-la se puder.\n\nQuando me pergunto o que descobri que a vida é muito curta, a palavra que me vem à cabeça é \"besteira\". Eu percebo que essa resposta é um pouco tautológica. Quase é a definição de besteira que é a coisa de que a vida é muito curta. E ainda assim a besteira tem um caráter distintivo. Há algo falso nela. É o alimento junk da experiência. [1]\n\nSe você perguntar a si mesmo o que gasta o seu tempo em besteira, provavelmente já sabe a resposta. Reuniões desnecessárias, disputas sem sentido, burocracia, postura, lidar com os erros de outras pessoas, engarrafamentos, passatempos viciantes mas pouco gratificantes.\n\nHá duas maneiras pelas quais esse tipo de coisa entra em sua vida: ou é imposto a você ou o engana. Até certo ponto, você tem que suportar as besteiras impostas por circunstâncias. Você precisa ganhar dinheiro e ganhar dinheiro consiste principalmente em realizar tarefas. De fato, a lei da oferta e da demanda garante isso: quanto mais gratificante é algum tipo de trabalho, mais barato as pessoas o farão. Pode ser que menos tarefas sejam impostas a você do que você pensa, no entanto. Sempre houve uma corrente de pessoas que optam por sair da rotina padrão e vão viver em algum lugar onde as oportunidades são menores no sentido convencional, mas a vida parece mais autêntica. Isso pode se tornar mais comum.\n\nVocê pode reduzir a quantidade de besteira em sua vida sem precisar se mudar. A quantidade de tempo que você precisa gastar com besteiras varia entre empregadores. A maioria das grandes organizações (e muitas pequenas) está imersa nelas. Mas se você priorizar conscientemente a redução de besteiras acima de outros fatores, como dinheiro e prestígio, pode encontrar empregadores que irão desperdiçar menos do seu tempo.\n\nSe você é freelancer ou uma pequena empresa, pode fazer isso no nível de clientes individuais. Se você demitir ou evitar clientes tóxicos, pode diminuir a quantidade de besteira em sua vida mais do que diminui sua renda.\n\nMas, enquanto alguma quantidade de besteira é inevitavelmente imposta a você, a besteira que se infiltra em sua vida enganando-o não é culpa de ninguém, mas sua própria. E ainda assim, a besteira que você escolhe pode ser mais difícil de eliminar do que a besteira que é imposta a você. Coisas que o atraem para desperdiçar seu tempo precisam ser muito boas em enganá-lo. Um exemplo que será familiar para muitas pessoas é discutir online. Quando alguém contradiz você, está, de certa forma, atacando você. Às vezes bastante abertamente. Seu instinto quando é atacado é se defender. Mas, assim como muitos instintos, esse não foi projetado para o mundo em que vivemos agora. Contrariamente ao que parece, é melhor, na maioria das vezes, não se defender. Caso contrário, essas pessoas estão literalmente tomando sua vida. [2]\n\nDiscutir online é apenas incidentalmente viciante. Há coisas mais perigosas do que isso. Como já escrevi antes, um subproduto do progresso técnico é que as coisas que gostamos tendem a se tornar mais viciantes. Isso significa que precisaremos fazer um esforço consciente para evitar vícios, para nos colocarmos fora de nós mesmos e perguntarmos: \"é assim que quero estar gastando meu tempo?\"\n\nAlém de evitar besteiras, devemos procurar ativamente coisas que importam. Mas coisas diferentes importam para pessoas diferentes e a maioria precisa aprender o que importa para elas. Alguns são afortunados e percebem cedo que adoram matemática, cuidar de animais ou escrever e, então, descobrem uma maneira de passar muito tempo fazendo isso. Mas a maioria das pessoas começa com uma vida que é uma mistura de coisas que importam e coisas que não importam e só gradualmente aprende a distinguir entre elas.\n\nPara os jovens, especialmente, muita dessa confusão é induzida pelas situações artificiais em que se encontram. Na escola intermediária e na escola secundária, o que os outros estudantes acham de você parece ser a coisa mais importante do mundo. Mas quando você pergunta aos adultos o que eles fizeram de errado nessa idade, quase todos dizem que se importavam demais com o que os outros estudantes achavam deles.\n\nUma heurística para distinguir coisas que importam é perguntar a si mesmo se você se importará com elas no futuro. A coisa falsa que importa geralmente tem um pico afiado de parecer importar. É assim que o engana. A área sob a curva é pequena, mas sua forma se crava em sua consciência como uma alfinete.\n\nAs coisas que importam nem sempre são aquelas que as pessoas chamariam de \"importantes\". Tomar café com um amigo importa. Você não vai sentir depois que isso foi um desperdício de tempo.\n\nUma coisa ótima em ter crianças pequenas é que elas fazem você gastar tempo em coisas que importam: elas. Elas puxam sua manga enquanto você está olhando para o seu celular e dizem: \"você vai brincar comigo?\". E as chances são de que essa seja, de fato, a opção de minimização de besteira.\n\nSe a vida é curta, devemos esperar que sua brevidade nos surpreenda. E é exatamente isso que costuma acontecer. Você assume as coisas como garantidas e, então, elas desaparecem. Você acha que sempre pode escrever aquele livro, ou subir aquela montanha, ou o que quer que seja, e então percebe que a janela se fechou. As janelas mais tristes fecham quando outras pessoas morrem. Suas vidas também são curtas. Depois que minha mãe morreu, eu desejei ter passado mais tempo com ela. Eu vivi como se ela sempre estivesse lá. E, de maneira típica e discreta, ela incentivou essa ilusão. Mas era uma ilusão. Acho que muitas pessoas cometem o mesmo erro que eu cometi.\n\nA maneira usual de evitar ser surpreendido por algo é estar consciente disso. Quando a vida era mais precária, as pessoas costumavam ser conscientes da morte em um grau que agora pareceria um pouco morboso. Não tenho certeza do porquê, mas não parece ser a resposta certa lembrar constantemente da caveira pairando no ombro de todos. Talvez uma solução melhor seja olhar o problema pelo outro lado. Cultive o hábito de ser impaciente com as coisas que mais quer fazer. Não espere antes de subir aquela montanha ou escrever aquele livro ou visitar sua mãe. Você não precisa se lembrar constantemente por que não deve esperar. Apenas não espere.\n\nPosso pensar em mais duas coisas que alguém faz quando não tem muito de algo: tentar obter mais disso e saborear o que tem. Ambos fazem sentido aqui.\n\nComo você vive afeta por quanto tempo você vive. A maioria das pessoas poderia fazer melhor. Eu entre elas.\n\nMas você provavelmente pode obter ainda mais efeito prestando mais atenção ao tempo que tem. É fácil deixar os dias passarem voando. O \"fluxo\" que as pessoas imaginativas adoram tanto tem um parente mais sombrio que impede você de pausar para saborear a vida no meio da rotina diária de tarefas e alarmes. Uma das coisas mais impressionantes que já li não estava em um livro, mas no título de um: Burning the Days (Queimando os Dias), de James Salter.\n\nÉ possível diminuir um pouco o tempo. Eu melhorei nisso. As crianças ajudam. Quando você tem crianças pequenas, há muitos momentos tão perfeitos que você não consegue deixar de notar.\n\nTambém ajuda sentir que você tirou tudo de alguma experiência. O motivo pelo qual estou triste por minha mãe não é apenas porque sinto falta dela, mas porque penso em tudo o que poderíamos ter feito e não fizemos. Meu filho mais velho vai fazer 7 anos em breve. E, embora sinta falta da versão dele de 3 anos, pelo menos não tenho nenhum arrependimento pelo que poderia ter sido. Tivemos o melhor tempo que um pai e um filho de 3 anos poderiam ter.\n\nCorte implacavelmente as besteiras, não espere para fazer coisas que importam e saboreie o tempo que tem. É isso o que você faz quando a vida é curta. \n\n---\n\nNotas\n\n[1] No começo, eu não gostei que a palavra que me veio à mente tivesse outros significados. Mas então percebi que os outros significados estão bastante relacionados. Besteira no sentido de coisas em que você desperdiça seu tempo é bastante parecida com besteira intelectual.\n\n[2] Escolhi esse exemplo de forma deliberada como uma nota para mim mesmo. Eu sou atacado muito online. As pessoas contam as mentiras mais loucas sobre mim. E até agora eu fiz um trabalho bastante medíocre de suprimir a inclinação natural do ser humano de dizer \"Ei, isso não é verdade!\".\n\nObrigado a Jessica Livingston e Geoff Ralston por ler rascunhos deste."}},"path":"pg-vb-pt-br.md","author":"Chat GPT","img":"https://i.insider.com/5e6bb1bd84159f39f736ee32?width=2000&format=jpeg&auto=webp","date":"11/29/2022"},{"tags":[],"body":{"en":{"content":"Maximus Tecidos, a prominent name in the textile industry, faced critical challenges with their existing e-commerce platform that hindered their operational efficiency and customer experience. This article outlines how Maximus Tecidos, in collaboration with Agência 2B Digital, successfully transitioned to deco.cx, resulting in significant improvements in site performance and management ease.\n\n### The Challenges\n\nPrior to the migration, Maximus Tecidos encountered several issues:\n\n- **Difficulty in Managing Site Content:** The existing CMS platform didn't allow for quick content updates.\n- **Performance Issues:** The website's performance, particularly page load times, was subpar, affecting user experience and engagement.\n\n### The Solution\n\nAgência 2B Digital, leveraging their longstanding partnership with Maximus Tecidos, facilitated a strategic transition to deco.cx. This move was designed to address the critical pain points and provide a more efficient platform.\n\n- **Enhanced Manageability:** deco.cx offers a user-friendly platform, simplifying the management of configurations and site maintenance.\n- **Improved Performance:** The new platform significantly boosted site performance, ensuring faster load times and a smoother user experience.\n\nThe migration occurred on December 5, 2023.\n\n### The Results\n\n- **Keyword Index Stability:** Post-migration, there was no drop in the number of indexed keywords.\n- **Improved SEO Metrics:** There was an increase in the Top 3 keyword rankings and the total number of indexed keywords.\n- **Increased Conversion Rates:** The improved site performance contributed to a notable rise in conversion rates.\n\n### Conclusion\n\nFor businesses seeking to optimize their digital operations and improve site performance, the experience of Maximus Tecidos offers valuable insights and a proven path to success. The partnership with Agência 2B Digital and the transition to deco.cx have empowered Maximus Tecidos to overcome their e-commerce challenges and achieve substantial performance gains.","title":"Maximus Tecidos, 2B Digital & deco.cx","descr":"A Seamless Transition to Enhanced E-commerce Performance","seo":{"title":"Maximus Tecidos, 2B Digital & deco.cx: A Seamless Transition to Enhanced E-commerce Performance","description":"This article outlines how Maximus Tecidos, in collaboration with Agência 2B Digital, successfully transitioned to deco.cx, resulting in significant improvements in site performance and management ease.","image":"https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/341e8759-7fbd-42fd-821b-5382f7cc053a"}},"pt":{"title":"Maximus Tecidos, 2B Digital & deco.cx","descr":"Uma Transição Suave para Melhor Desempenho no E-commerce","content":"A Maximus Tecidos, um nome proeminente na indústria têxtil, enfrentava desafios críticos com sua plataforma de e-commerce existente, que prejudicavam sua eficiência operacional e a experiência do cliente. Este artigo descreve como a Maximus Tecidos, em colaboração com a Agência 2B Digital, realizou com sucesso a transição para a deco.cx, resultando em melhorias significativas no desempenho do site e na facilidade de gestão.\n\n### Os Desafios\n\nAntes da migração, a Maximus Tecidos encontrava vários problemas:\n\n- **Dificuldade em Gerenciar o Conteúdo do Site: A plataforma CMS existente não permitia atualizações rápidas de conteúdo.\n- **Problemas de Desempenho: O desempenho do site, especialmente os tempos de carregamento de página, era insatisfatório, afetando a experiência do usuário e o engajamento.\n\n### A Solução\n\nA Agência 2B Digital, aproveitando sua parceria de longa data com a Maximus Tecidos, facilitou uma transição estratégica para a deco.cx. Este movimento foi projetado para abordar os pontos críticos e fornecer uma plataforma mais eficiente.\n\n- **Maior Facilidade de Gestão: A deco.cx oferece uma plataforma amigável, simplificando a gestão de configurações e a manutenção do site.\n- **Desempenho Melhorado: A nova plataforma melhorou significativamente o desempenho do site, garantindo tempos de carregamento mais rápidos e uma experiência de usuário mais suave.\n\nA migração ocorreu em 5 de dezembro de 2023.\n\n### Os Resultados\n\n- **Estabilidade no Índice de Palavras-Chave: Após a migração, não houve queda no número de palavras-chave indexadas.\n- **Melhoria nas Métricas de SEO: Houve um aumento nas classificações das palavras-chave no Top 3 e no número total de palavras-chave indexadas.\n- **Aumento nas Taxas de Conversão: O melhor desempenho do site contribuiu para um aumento notável nas taxas de conversão.\n\n### Conclusão\n\nPara empresas que buscam otimizar suas operações digitais e melhorar o desempenho do site, a experiência da Maximus Tecidos oferece insights valiosos e um caminho comprovado para o sucesso. A parceria com a Agência 2B Digital e a transição para a deco.cx permitiram que a Maximus Tecidos superasse seus desafios no e-commerce e alcançasse ganhos substanciais de desempenho.","seo":{"title":"Maximus Tecidos, 2B Digital & deco.cx: Uma Transição Suave para Melhor Desempenho no E-commerce","description":"Este artigo descreve como a Maximus Tecidos, em colaboração com a Agência 2B Digital, realizou com sucesso a transição para a deco.cx, resultando em melhorias significativas no desempenho do site e na facilidade de gestão","image":"https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/72426ea0-ebee-45a1-9701-79c7cd007bb4"}}},"path":"maximus-tecidos","date":"05/08/2024","author":"Maria Cecília Marques","img":"https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/8903bdfe-fda3-4a79-8b3b-544f64e8f9d6"}]},"__resolveType":"site/loaders/blogPostLoader.ts"}
\ No newline at end of file
+{
+ "list": {
+ "posts": [
+ {
+ "body": {
+ "en": {
+ "title": "Introducing My Account VTEX Headless at deco.cx!",
+ "descr": "Expand Your E-commerce Potential with Greater Flexibility",
+ "content": "We’re excited to announce a significant upgrade to deco.cx: the addition of My Account VTEX Headless, a solution designed to help you create highly customized and high-performing customer-account experiences. \n\nThis feature currently works via proxy to ensure seamless integration with VTEX systems. However, we’re taking it a step further by transitioning to a fully headless approach. This improvement will enhance flexibility, empowering you to deliver an even better user experience. \n\nWith My Account VTEX Headless, you can design unique account-management experiences tailored to your brand while harnessing the full power of headless architecture, all integrated effortlessly with VTEX. \n\n### **What’s New with My Account VTEX Headless? ** \n\n- **Flexible Customization:** Adapt the account interface to reflect your brand’s identity. Create layouts and functionalities that meet your business’s specific needs. \n\n- **Enhanced Performance:** deco.cx’s architecture ensures fast, responsive interfaces, providing a smooth experience for your customers. \n\n- **A/B Testing and Segmentation:** Test different versions of your designs and segment users to deliver tailored experiences that increase engagement and optimize results.\n\n\n### **How It Benefits Your Business**\n\n- **Agility and Control:** Quickly implement and test new features without affecting system stability.\n\n- **Personalized Experiences:** Offer relevant, engaging customer interactions that strengthen your brand’s appeal and competitive edge. \n\n- **Simplified Management:** Streamline customer-account interactions in a unified, intuitive interface.\n\n### **Use Cases for My Account VTEX Headless**\n\n- **Reimagine My Account as a Sales Tool:** Follow Amazon's lead by offering product recommendations and similar items within the My Account section, transforming it into a powerful sales channel rather than just a list of past orders.\n\n- **Custom Delivery and Return Tracking Interface:** Build your own interface to enhance the customer experience for tracking deliveries or processing returns.\n\n- **\"Buy Again\" Button:** Add a convenient \"Buy Again\" button to the order history, simplifying repeat purchases for your customers.\n\n- **Personalized Management of Gift Cards, Subscriptions, and Coupons:** Create tailored experiences for managing gift cards, subscriptions, and promotional coupons directly within the My Account interface.\n\n### **Ready to Take Your E-commerce to the Next Level? **\n\nContact us at professional-services@deco.cx to learn how My Account VTEX Headless can help you create stand-out customer experiences and drive meaningful results for your business.",
+ "seo": {
+ "title": "Introducing My Account VTEX Headless at deco.cx!",
+ "description": "Expand Your E-commerce Potential with Greater Flexibility"
+ }
+ }
+ },
+ "tags": [],
+ "path": "my-account-headless",
+ "date": "04/12/2024",
+ "author": "Guilherme Tavano",
+ "img": "https://deco-sites-assets.s3.sa-east-1.amazonaws.com/starting/ed8a10c6-69f7-41e6-9f3d-101ebdad975c/thumbnail.png"
+ },
+ {
+ "img": "https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/971f5e4d-fc34-4b4e-98a3-fd09eeae079a",
+ "body": {
+ "en": {
+ "descr": "How They’re Draining Your Website’s Resources",
+ "title": "🚀 A New Era of Bots and Crawlers",
+ "content": "\n\nYour website’s traffic doesn’t just come from human visitors; bots play a significant role too. **Search engines, social media platforms, and even AI systems deploy automated tools (robots, or 'bots') to crawl your site, extracting content and valuable information.** To rank well on Google, for example, your content must be well-structured, with clear titles, readable text, and highly relevant information. This entire analysis is conducted by bots crawling your site!\n\nBut here’s the catch: **Every time a bot crawls your site, it’s not “free.”** Each request made by a bot consumes resources—whether it's computational power or bandwidth. Most major bots respect a special file (`robots.txt`) that tells them which parts of your site they can or cannot access. As a site owner, you can control which bots are allowed to crawl your site.\n\n```\nUser-agent: *\nAllow: /\n```\n\n_A simple rule that allows all bots to access all pages._\n\nLet’s look at the impact this can have. \n\nIn May, across various Deco sites, bots were responsible for **over 50% of the bandwidth consumed**, even though they didn’t make up the majority of the requests.\n\n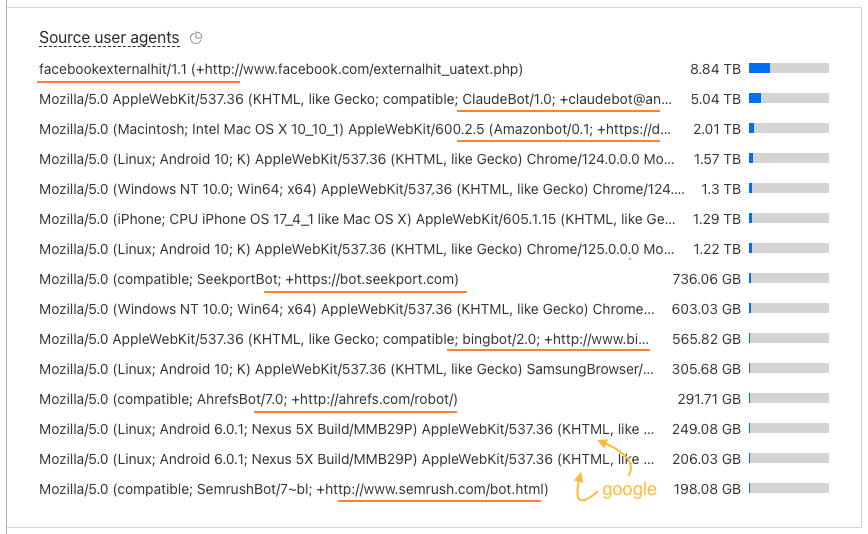\n\nDespite accounting for less than 20% of traffic, **bots often consume significantly more bandwidth due to the specific pages they access.** They tend to spend more time on larger pages, such as category pages in online stores, which naturally load more data. These pages often feature product variations and filters, making them even more data-heavy.\n\nWhile Google’s bot respects the `nofollow` attribute, which prevents links from being crawled, not all bots do. \nThis means that pages with filter variations also need a `noindex` meta tag or a more specialized `robots.txt` configuration.\n\n## AI: The New Gold Rush\n\nAI is changing the game when it comes to data extraction, release, and value. \n\nThe demand for massive amounts of data for processing has led to the creation of more bots, particularly crawlers operating on the web. **Data is more valuable than ever, yet there’s no guarantee of immediate returns for those who hand over their data to third parties.** The third-largest consumer of bandwidth (Amazonbot) and several others (Ahrefs, Semrush, Bing) are known as “good bots.” **These verified bots respect the `robots.txt` file, allowing you to control how and what they access.** A possible configuration for managing these bots is shown below:\n\n```\nUser-agent: googlebot\nUser-agent: bingbot\nAllow: /\nDisallow: /search\n\nUser-agent: *\nAllow: /$\nDisallow: /\n```\n\n_This allows Google and Bing bots to crawl your site, except for search pages, while restricting all other bots to the site’s root._\n\nThis setup grants broad access to valuable, known bots but limits overly aggressive crawling of all your site’s pages. However, notice how the second-highest bandwidth consumer is ClaudeBot—an **AI bot notorious for consuming large amounts of data while disregarding the `robots.txt` file.** In this new AI-driven world, we’re seeing more of these kinds of bots.\n\nAt deco.cx, we offer a standard `robots.txt` similar to the example above for our sites, but for bots that don’t respect this standard, the only way to control access is through blocking them at the CDN (in our case, Cloudflare). At Deco, we use three approaches to block these bots:\n\n- **Block by User-Agent**: Bots that ignore `robots.txt` but have a consistent user-agent can be blocked directly at our CDN.\n\n- **Challenge by ASN**: Some bots, especially malicious ones, come from networks known for such attacks. We place a challenge on these networks, making it difficult for machines to solve.\n\n- **Limit Requests by IP**: After a certain number of requests from a single origin, we present a challenge that users must solve correctly or face a temporary block.\n\nThese rules have effectively controlled most bots…\n\n…except Facebook.\n\n## “Facebook, Are You Okay?”\n\nWe’ve discussed bots that respect `robots.txt`. And then there’s Facebook.\n\nJust before Facebook’s new privacy policy went into effect—allowing user data to be used for AI training—we noticed a significant spike in the behavior of Facebook’s bot on our networks. This resulted in a substantial increase in data consumption, as shown in the graph below.\n\n[More details on Facebook’s new privacy policy](https://www.gov.br/anpd/pt-br/assuntos/noticias/anpd-determina-suspensao-cautelar-do-tratamento-de-dados-pessoais-para-treinamento-da-ia-da-meta)\n\n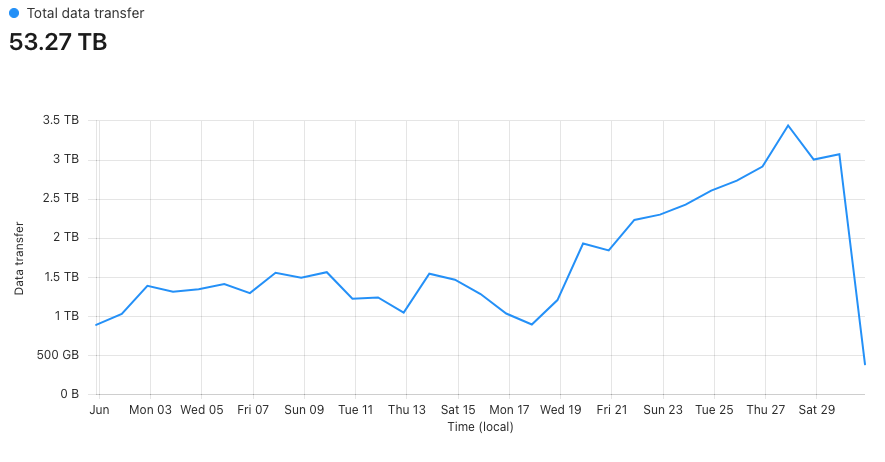\n\n_Aggregate data traffic for a set of sites in June 2024._\n\nThe Facebook bot typically fetches data when a link is shared on the platform, including details about the image and site information. However, we discovered that the bot wasn’t just fetching this data—it was performing a full crawl of sites, aggressively and without respecting `robots.txt`!\n\nMoreover, Facebook uses various IPv6 addresses, meaning the crawl doesn’t come from a single or a few IPs, making it difficult to block with our existing controls. \nWe didn’t want to block Facebook entirely, as this would disrupt sharing, but we also didn’t want to allow their bots to consume excessive resources. To address this, we implemented more specific control rules, limiting access across Facebook’s entire network…\n\n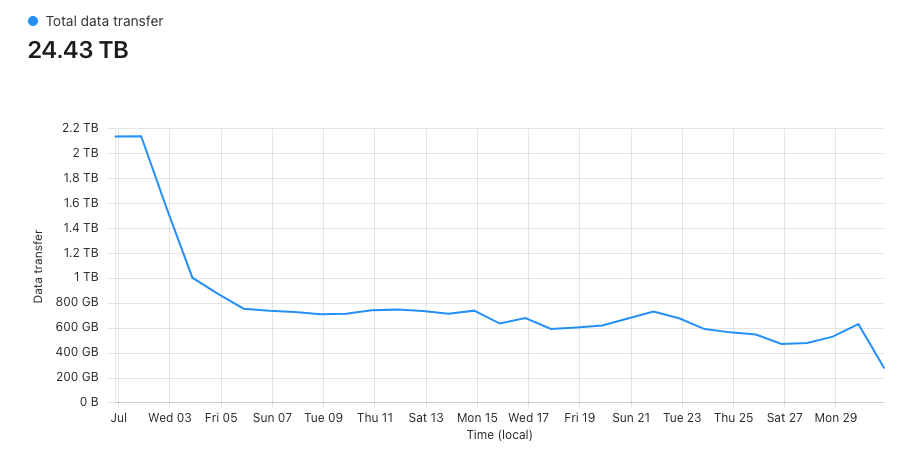\n_Aggregate data traffic for a set of sites in July 2024._\n\n…which proved to be highly effective.\n\n## Blocking Too Much Could Hurt Your Presence in Emerging Bots or Technologies\n\nA final word of caution: adopting an overly aggressive approach has its downsides. \nRestricting access to unknown bots might prevent new technologies and tools that could benefit your site from interacting with it. For example, a new AI that could recommend specific products to visitors might be inadvertently blocked. \nIt’s crucial to strike a balance, allowing selective bot access in line with market evolution and your business needs.\n\nIn summary, bots and crawlers are valuable allies, but managing their access requires strategic thinking. \nThe key is to allow only beneficial bots to interact with your site while staying alert to new technologies that might emerge. This balanced approach will ensure that your business maximizes return on traffic and resource consumption."
+ }
+ },
+ "date": "08/15/2024",
+ "path": "bots",
+ "tags": [],
+ "author": "Matheus Gaudêncio"
+ },
+ {
+ "img": "https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/05ed5d60-22c1-459a-8323-53d3b2b3b3d9",
+ "body": {
+ "en": {
+ "descr": "How to refactor common design patterns from React into Native Web",
+ "title": "Leveraging native web APIs to reduce bundle size and improve performance",
+ "content": "\n\nIn modern web development, libraries like React have become the norm for building dynamic and interactive user interfaces. However, relying heavily on such libraries can sometimes lead to larger bundle sizes and reduced performance. By leveraging native web APIs, we can accomplish common design patterns more efficiently, enhancing performance and overall web compatibility. In this article, we will explore how to use these APIs to reduce our dependence on React hooks like `useState`.\n\n### Case Study: The Hidden `
` Hack\n\nOne often overlooked technique in native web development is the hidden `
` hack. This trick, which has been around for a while, offers a way to control UI state without relying on JavaScript, reducing bundle size and potentially improving performance.\n\n#### The React Approach\n\nLet’s start with a typical example in React:\n\n\n\n\n```tsx\nimport { useState } from \"preact/hooks\";\n\nexport default function Section() {\n const [display, setDisplay] = useState(false);\n\n return (\n
\n
setDisplay(!display)} class=\"btn\">Click Me \n {display &&
Hello!
}\n
\n );\n}\n```\n\nIn this example, the `useState` hook and the `onClick` handler are used to toggle the visibility of a piece of UI. While this approach is effective, it involves additional JavaScript, which can contribute to a larger bundle size.\n\n#### The Native Web API Approach\n\nNow, let’s refactor this example to use only native web APIs:\n\n```tsx\nexport default function Section() {\n return (\n
\n
\n
Click Me \n
Hello!
\n
\n );\n}\n```\n\n#### Explanation\n\nSo, what’s happening here? We’ve replaced the `useState` hook with a hidden `
` element. Here’s a breakdown of the changes:\n\n1. **Hidden Checkbox**: We introduce an `
` with an `id` and the `hidden` class. This checkbox will control the state.\n2. **Label for Toggle**: The `
` is linked to the checkbox using the `for` attribute, which toggles the checkbox state when clicked.\n3. **Peer Class**: Using Tailwind CSS's `peer` class, we can style elements based on the state of the checkbox. The `peer-checked:inline` class makes the `` appear when the checkbox is checked.\n\n\nThis final result from both the React and Native Web API are indistinguishable to the final user, only changing the performance/compatibility characteristics of the application. Also, this trick can be applied in Drawers, Modals and any other kind of boolean UI. Bellow are some examples of this usage:\n\n#### More Examples\n\n1. Drawer\n\n\n2. Modal\n\n\n3. Coupon code\n\n\n\n\n### Case Study: The Forgotten `
` Hack\n\nAnother powerful yet often overlooked HTML element is the `
`. This can be especially useful for creating SKU selectors or similar UI components. Let’s examine how we can refactor a React component to use native radio inputs.\n\n\n\n#### The React Approach\n\nFirst, let’s look at a typical React component for a SKU selector:\n\n```tsx\nimport { useState } from \"preact/hooks\";\n\nconst options = [\"1\", \"2\", \"3\"];\n\nexport default function Section() {\n const [selected, setSelected] = useState(0);\n\n return (\n
\n {options.map((o, index) => (\n \n setSelected(index)}\n class={`btn btn-circle ${index === selected ? \"btn-primary\" : \"\"}`}\n >\n {o}\n \n \n ))}\n \n );\n}\n```\n\nIn this example, the `useState` hook and `onClick` handlers are used to manage and update the selected state. This approach, while effective, involves additional JavaScript.\n\n#### The Native Web API Approach\n\nNow, let’s refactor this example to use `
` elements:\n\n```tsx\nconst options = [\"1\", \"2\", \"3\"];\n\nexport default function Section() {\n return (\n
\n {options.map((o, index) => (\n \n \n {o}\n \n \n ))}\n \n );\n}\n```\n\n#### Explanation\n\nHere’s a breakdown of how we refactored the React component to use native web APIs:\n\n1. **Radio Inputs**: We introduce `
` elements, each with a unique `id` and the same `name` attribute. The `name` property ensures that only one radio button can be selected at a time within the group.\n2. **Hidden Class**: The `hidden` class hides the radio buttons from view.\n3. **Label for Toggle**: The `
` is linked to the corresponding radio input using the `for` attribute, making the label clickable to change the radio button’s state.\n4. **Default Checked**: We use the `defaultChecked` attribute to set the initial checked radio button.\n5. **Peer Class**: With Tailwind CSS’s `peer` class, we can style the labels based on the state of the radio inputs. The `peer-checked:btn-primary` class applies the `btn-primary` style to the selected label.\n\n#### Benefits and Drawbacks\n\nUsing the techniques presented in this article can lead to significant performance improvements for your website. By reducing the amount of JavaScript required, you decrease parse and compile times, thereby improving Total Blocking Time (TBT). Additionally, adding animations and transitions becomes simpler, as these can be managed directly within the DOM, eliminating the need for third-party libraries often required in React.\n\nAnother advantage of these native web API hacks is enhanced browser compatibility. Since these techniques are supported by all major browsers, your website will function consistently across different platforms, providing a seamless experience for all users. Furthermore, reducing dependency on external libraries can simplify your project and reduce potential security vulnerabilities, while better performance on low-end devices ensures a broader audience can have a good user experience.\n\nHowever, there are some tradeoffs to consider. One drawback is the potential increase in initial DOM size, as all states must be represented in the DOM. This can lead to a higher First Contentful Paint (FCP), as the browser has to load more content initially. Additionally, while native web APIs are great for many use cases, they might not be suitable for highly interactive applications where complex state management and frequent updates are necessary. In such cases, frameworks like React offer more powerful and flexible solutions. SEO considerations also come into play, as you need to ensure that content visibility managed through the DOM is still accessible and indexable by search engines. Lastly, as your application scales, maintaining complex UI interactions purely through native web APIs and CSS might become challenging, making the abstractions provided by frameworks beneficial for managing complexity.\n\n### Conclusion\n\nUsing native web APIs like `\n
setDisplay(!display)} class=\"btn\">Click Me \n {display &&
Hello!
}\n
\n
\n
Click Me \n
Hello!
\n
` está vinculado ao checkbox usando o atributo `for`, que alterna o estado do checkbox quando clicado.\n3. **Classe Peer**: Usando a classe `peer` do Tailwind CSS, podemos estilizar elementos com base no estado do checkbox. A classe `peer-checked:inline` faz o `` aparecer quando o checkbox está marcado.\n\nO resultado final tanto no React quanto na API Nativa da Web é indistinguível para o usuário final, mudando apenas as características de desempenho/compatibilidade da aplicação. Além disso, esse truque pode ser aplicado em gavetas, modais e qualquer outro tipo de interface booleana. Abaixo estão alguns exemplos desse uso:\n\n##### Mais Exemplos\n\n1. Gaveta\n2. Modal\n3. Código de Cupom\n\n### Estudo de Caso: O Truque Esquecido do `
`\n\nOutro elemento HTML poderoso, mas muitas vezes negligenciado, é o `
`. Isso pode ser especialmente útil para criar seletores de SKU ou componentes de interface semelhantes. Vamos examinar como podemos refatorar um componente React para usar entradas de rádio nativas.\n\n#### A Abordagem com React\n\nPrimeiro, vejamos um componente React típico para um seletor de SKU:\n\n```tsx\nimport { useState } from \"preact/hooks\";\n\nconst options = [\"1\", \"2\", \"3\"];\n\nexport default function Section() {\n const [selected, setSelected] = useState(0);\n\n return (\n
\n {options.map((o, index) => (\n \n setSelected(index)}\n class={`btn btn-circle ${index === selected ? \"btn-primary\" : \"\"}`}\n >\n {o}\n \n \n ))}\n \n );\n}\n```\n\nNeste exemplo, o hook `useState` e os manipuladores `onClick` são usados para gerenciar e atualizar o estado selecionado. Esta abordagem, embora eficaz, envolve JavaScript adicional.\n\n#### A Abordagem com API Nativa da Web\n\nAgora, vamos refatorar este exemplo para usar elementos `
`:\n\n```tsx\nconst options = [\"1\", \"2\", \"3\"];\n\nexport default function Section() {\n return (\n
\n {options.map((o, index) => (\n \n \n {o}\n \n \n ))}\n \n );\n}\n```\n\n#### Explicação\n\nAqui está um detalhamento de como refatoramos o componente React para usar APIs nativas da web:\n\n1. **Entradas de Rádio**: Introduzimos elementos `
`, cada um com um `id` único e o mesmo atributo `name`. A propriedade `name` garante que apenas um botão de rádio possa ser selecionado por vez dentro do grupo.\n2. **Classe Oculta**: A classe `hidden` oculta os botões de rádio da visualização.\n3. **Rótulo para Alternar**: O `
` está vinculado à entrada de rádio correspondente usando o atributo `for`, tornando o rótulo clicável para alterar o estado do botão de rádio.\n4. **Default Checked**: Usamos o atributo `defaultChecked` para definir o botão de rádio inicialmente marcado.\n5. **Classe Peer**: Com a classe `peer` do Tailwind CSS, podemos estilizar os rótulos com base no estado das entradas de rádio. A classe `peer-checked:btn-primary` aplica o estilo `btn-primary` ao rótulo selecionado.\n\n#### Benefícios e Desvantagens\n\nUsar as técnicas apresentadas neste artigo pode levar a melhorias significativas no desempenho do seu site. Ao reduzir a quantidade de JavaScript necessário, você diminui os tempos de análise e compilação, melhorando assim o Tempo Total de Bloqueio (TBT). Além disso, adicionar animações e transições se torna mais simples, pois estas podem ser gerenciadas diretamente no DOM, eliminando a necessidade de bibliotecas de terceiros frequentemente necessárias no React.\n\nOutra vantagem desses truques com APIs nativas da web é a compatibilidade aprimorada com navegadores. Como essas técnicas são suportadas por todos os principais navegadores, seu site funcionará de maneira consistente em diferentes plataformas, proporcionando uma experiência perfeita para todos os usuários. Além disso, reduzir a dependência de bibliotecas externas pode simplificar seu projeto e reduzir potenciais vulnerabilidades de segurança, enquanto um melhor desempenho em dispositivos de baixo custo garante que um público mais amplo tenha uma boa experiência de usuário.\n\nNo entanto, há algumas compensações a considerar. Uma desvantagem é o potencial aumento no tamanho inicial do DOM, pois todos os estados devem ser representados no DOM. Isso pode levar a um Maior Tempo para Primeiro Conteúdo (FCP), já que o navegador precisa carregar mais conteúdo inicialmente. Além disso, embora as APIs nativas da web sejam ótimas para muitos casos de uso, elas podem não ser adequadas para aplicações altamente interativas, onde o gerenciamento complexo de estado e atualizações frequentes são necessários. Nesses casos, frameworks como React oferecem soluções mais poderosas e flexíveis. Considerações de SEO também entram em jogo, pois você precisa garantir que a visibilidade do conteúdo gerenciada através do DOM ainda seja acessível e indexável pelos mecanismos de busca. Por último, à medida que sua aplicação cresce, manter interações complexas de interface puramente através de APIs nativas da web e CSS pode se tornar desafiador, tornando as abstrações fornecidas pelos frameworks benéficas para gerenciar a complexidade.\n\n### Conclusão\n\nUsar APIs nativas da web como `\n Click me\n \n );\n}\n\nexport default ExampleButton;\n```\n\nIn this example, `useScript` takes the `onClick` function and inlines it into the `hx-on:click` attribute, making the button interactive without loading a large JavaScript framework.\n\n### Bridging the gap between server and client\n\n`useScript` offers a unique balance between server-rendered and client-side interactions. By combining the strengths of HTMX for processing large HTML chunks on the server with the ability to add small, targeted JavaScript interactions, `useScript` delivers the best of both worlds. This approach allows developers to build performant, interactive web applications without the need for complex toolsets like React.\n\n### Notes and Limitations\n\nWhile `useScript` is a powerful tool, there are a few things to keep in mind:\n\n1. **No Build Tool**: Since we don’t use a build tool, developers must ensure that their JavaScript functions are compatible with their target browsers. This means keeping your code in sync with your [browserslist](https://browsersl.ist/) target.\n2. **Scope and Dependencies**: The function you pass to `useScript` should not rely on external variables or closures that won’t be available when the script is executed inline. Make sure the function is self-contained and does not depend on external state.\n3. **Attribute Length**: When using `hx-on:` handlers, ensure the minified function does not exceed any attribute length limits imposed by browsers or HTML specifications.\n\n### Conclusion\n\n`useScript` is a valuable addition to our toolkit, enabling developers to add small, targeted JavaScript interactions to their server-rendered HTML. By leveraging the power of HTMX for large chunks of HTML and using `useScript` for small event handlers, you can create efficient, interactive web applications without the overhead of a full client-side framework. Try out `useScript` today and experience the best of both worlds in your web development projects.\n\nFor more details visit the [useScript API reference](https://deco.cx/docs/en/api-reference/use-script).\n\nHappy coding!"
+ }
+ },
+ "date": "06/21/2024",
+ "path": "introducing-use-script",
+ "author": "Tiago Gimenes",
+ "tags": [],
+ "authorRole": "Developer"
+ },
+ {
+ "img": "https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/ce8eaf0a-71df-4e9f-b629-96b997daaf51",
+ "body": {
+ "en": {
+ "descr": "Unleash the power of native web APIs",
+ "title": "HTMX first class support on deco.cx",
+ "content": "We are thrilled to announce a new HTMX App on deco hub. HTMX has been gaining popularity for its ability to create dynamic web applications without relying heavily on JavaScript. By leveraging HTML attributes, HTMX simplifies the development process, making it easier to build interactive user interfaces.\n\n#### Why support HTMX now?\n\nAt deco.cx, we intend to support all major frameworks, including Angular, Next.JS, SvelteKit, and more. However, we started with HTMX because we see a significant potential in simplifying both the development and production of simple web pages. HTMX shines in scenarios where developers want to avoid the complexities of build steps, hot module replacement (HMR), and other tooling. With HTMX, what you write in HTML is exactly what you see in both development and production environments.\n\nBy combining HTMX with the strengths of HTML5 and CSS3, developers can deliver good user experiences and top-class performance without the overhead of downloading, parsing, and compiling heavy JavaScript libraries. Additionally, using HTMX can result in more robust web applications. Testing JavaScript across all devices and browsers (Safari, Samsung browser, etc.) is time-consuming and expensive. Having your UI rendered on the server saves you countless hours of debugging across different environments, ultimately reducing Sentry bills.\n\n#### How deco.cx Integrates with HTMX\n\nIf HTMX offers so many advantages, why isn't it the standard for web application development? The primary challenge with HTMX lies in the need to create routes for each UI state, which can complicate the development process. Each interactive element or dynamic update often requires a corresponding server route, leading to a proliferation of endpoints and increased maintenance complexity.\n\nMoreover, the web is mostly comprised of centralized servers, and computing new UI states on a centralized server can penalize peripheral users due to latency issues. This is not the case with deco.cx, where our edge-first infrastructure distributes the code globally. This ensures that computing new UI states is much cheaper and faster, thanks to our low latency and globally distributed infrastructure.\n\nFor us at deco.cx, the most difficult part of using HTMX is having to create a route for each UI state. To address this challenge, we developed a new hook called `useSection`. This hook automatically creates routes for rendering your UI states without requiring developers to handle routing manually.\n\nTo demonstrate the power and simplicity of the `useSection` hook, let's explore an example by building a counter component.\n\n#### Building a Counter with `useSection` on deco.cx\n\nIn this guide, we'll build a simple counter component using HTMX and the `useSection` hook on deco.cx.\n\n\n\n\n#### Preact Version\n\nFirst, let's look at the usual Preact code for this component using the `useState` hook:\n\n```jsx\nimport { useState } from \"preact/hooks\";\n\nexport default function Section() {\n const [count, setCount] = useState(0);\n\n return (\n \n setCount(count - 1)}\n >\n - \n \n {count} \n setCount(count + 1)}\n >\n + \n \n
\n );\n}\n```\n\n#### Refactoring to HTMX\n\nTo refactor this component into HTMX, we follow three simple rules:\n\n1. Client-side hooks like `useState` and `useEffect` are removed.\n2. All variables started by a `useState` hook are placed on the component's props.\n3. Client-side event handlers like `onClick` and `onChange` are removed\n\nBy applying rules 1 and 2 to the Section component, we move the `count` variable to the component's props, leaving us with:\n\n```jsx\nexport default function Section({ count }: { count: number }) {\n return (\n \n setCount(count - 1)}\n >\n - \n \n {count} \n setCount(count + 1)}\n >\n + \n \n
\n );\n}\n```\n\nNotice we don't need the import of `useState` anymore. To apply rule number 3, we need to remove the onClick handler, however, how can we keep the interactivity? That’s where the `useSection` hook is handy.\n\n#### Integrating `useSection`\n\nTo implement the `onClick` functionality, start by importing `useSection` from `deco/hooks/useSection.ts`. This hook lets you create a link for the current section instance and override any props this section receives. By refactoring this component, we get:\n\n```jsx\nimport { useSection } from \"deco/hooks/useSection.ts\";\n\nexport default function Section({ count = 0 }:{ count: number }) {\n return (\n \n \n - \n \n {count} \n \n + \n \n
\n );\n}\n```\n\n#### Explanation\n\nLet’s dissect each part starting with the `hx-get` attribute. `useSection({ props: { count: count - 1 }})` creates a link for the current section instance, but overrides the `count` prop. This means that if we had other props, the new `count` value would be merged with the other prop values, and a link for this section would be returned. This is beneficial as the developer can now override some props inserted by the deco.cx CMS.\n\nThe `hx-target` and `hx-swap` combo is useful when you want to replace the whole section at deco.cx, as sections are rendered under a `` element.\n\n\n\n\n#### Handling Slow Connections\n\nFor 3G connections, where performing a request to increase/decrease the counter can be slow, we need to add a loading state. HTMX provides the `htmx-request` indicator class for this purpose. When HTMX is performing a request, the `htmx-request` class is added to the DOM. With TailwindCSS v3, we can create specific rules activated once this class is present. Here's the updated button:\n\n```jsx\n\n - \n \n setCount(count - 1)}\n >\n - \n \n {count} \n setCount(count + 1)}\n >\n + \n \n
\n );\n}\n```\n\n##### Refatorando para HTMX\n\nPara refatorar este componente para HTMX, seguimos três regras simples:\n\n1. Hooks do lado do cliente, como `useState` e `useEffect`, são removidos.\n2. Todas as variáveis iniciadas por um hook `useState` são colocadas nas props do componente.\n3. Manipuladores de eventos do lado do cliente, como `onClick` e `onChange`, são removidos.\n\nAplicando as regras 1 e 2 ao componente Section, movemos a variável `count` para as props do componente, deixando-nos com:\n\n```jsx\nexport default function Section({ count }: { count: number }) {\n return (\n \n setCount(count - 1)}\n >\n - \n \n {count} \n setCount(count + 1)}\n >\n + \n \n
\n );\n}\n```\n\nNote que não precisamos mais da importação do `useState`. Para aplicar a regra número 3, precisamos remover o manipulador `onClick`, mas como manter a interatividade? É aí que o hook `useSection` é útil.\n\n##### Integrando o `useSection`\n\nPara implementar a funcionalidade `onClick`, começamos importando `useSection` de `deco/hooks/useSection.ts`. Este hook permite criar um link para a instância atual da seção e substituir quaisquer props que esta seção recebe. Refatorando este componente, obtemos:\n\n```jsx\nimport { useSection } from \"deco/hooks/useSection.ts\";\n\nexport default function Section({ count = 0 }:{ count: number }) {\n return (\n \n \n - \n \n {count} \n \n + \n \n
\n );\n}\n```\n\n##### Explicação\n\nVamos dissecar cada parte começando pelo atributo `hx-get`. `useSection({ props: { count: count - 1 }})` cria um link para a instância atual da seção, mas substitui a prop `count`. Isso significa que, se tivéssemos outras props, o novo valor de `count` seria mesclado com os outros valores de prop, e um link para esta seção seria retornado. Isso é benéfico, pois o desenvolvedor pode agora substituir algumas props inseridas pelo CMS deco.cx.\n\nA combinação `hx-target` e `hx-swap` é útil quando você quer substituir toda a seção no deco.cx, já que as seções são renderizadas sob um elemento ``.\n\n\n\n##### Lidando com Conexões Lentas\n\nPara conexões 3G, onde realizar uma solicitação para aumentar/diminuir o contador pode ser lento, precisamos adicionar um estado de carregamento. O HTMX fornece a classe indicadora `htmx-request` para este propósito. Quando o HTMX está realizando uma solicitação, a classe `htmx-request` é adicionada ao DOM. Com o TailwindCSS v3, podemos criar regras específicas ativadas quando esta classe está presente. Aqui está o botão atualizado:\n\n```jsx\n\n - \n \n
\n A header leading to 30+ links with 3 level menu navigation \n 1 full-banner carousel with 2 high definition images (1200x1200) \n 1 Campaign Timer \n 3 Product Shelfs fetching 12 products each \n 1 Shoppable Banner \n 1 Category grid \n 1 Blog post section \n A footer with 4 columns and 20+ links \n \n
\n
\n **Total Blocking Time:** One of Core Web Vitals metrics, it measures the total amount of time after First Contentful Paint (FCP) where the main thread was blocked for long enough to prevent input responsiveness. \n **Performance Grade:** We used https://pagespeed.web.dev/ API to run tests because it guarantees isonomy of the overall conditions (CPU, connection, etc). More over, since it's an universal tool, anyone can double check this study on their own. \n \n
\nAvoiding Google Page Speed cache (servers are all USA based) \nAvoiding outliers* that could miss lead results \n \n\n## Scenario 1: Perfectly Optimized Storefront (no tags)\n\nThis is a storefront built on top of deco.cx without any third-party tags, only with our built-in Analytics Tools (weights 1kb).\n\n\n
\n The most damaged Core Web Vital metric is the TBT, since each tag typically involves additional JavaScript execution, which can delay the rendering of a webpage and cause blocking of other critical tasks, such as user interaction or resource loading. \n There is a trade-off between adding third-party tags and your website performance \n \n
\n
\n Um cabeçalho com mais de 30 links com navegação de menu de 3 níveis \n 1 carrossel de banner completo com 2 imagens de alta definição (1200x1200) \n 1 Contador de Campanha \n 3 Prateleiras de Produtos exibindo 12 produtos cada \n 1 Banner Comercializável \n 1 Grade de Categoria \n 1 Seção de postagens de blog \n 1 rodapé com 4 colunas e mais de 20 links \n \n
\n
\n **Tempo Total de Bloqueio:** Uma das métricas do Core Web Vitals, mede o tempo total após o Primeiro Conteúdo Exibido (FCP) em que a thread principal foi bloqueada tempo suficiente para evitar a responsividade de entrada. \n **Nota de Desempenho:** Usamos a API https://pagespeed.web.dev/ para executar testes porque garante a isonomia das condições gerais (CPU, conexão, etc). Além disso, como é uma ferramenta universal, qualquer um pode verificar este estudo por conta própria. \n \n
\nEvitar o cache do Google Page Speed (os servidores são todos baseados nos EUA) \nEvitar outliers que poderiam distorcer os resultados \n \n\n## Cenário 1: Loja Perfeitamente Otimizada (sem tags)\n\nEsta é uma loja construída em cima da deco.cx sem nenhuma tag de terceiros, apenas com nossas Ferramentas de Análise integradas (peso 1kb).\n\n\n
\n A métrica Core Web Vital mais prejudicada é o TBT, pois cada tag geralmente envolve execução adicional de JavaScript, o que pode atrasar a renderização de uma página da web e causar bloqueio de outras tarefas críticas, como interação do usuário ou carregamento de recursos. \n Há um equilíbrio entre adicionar tags de terceiros e o desempenho do seu site \n \n
loading...
\n}\n```\n\n> Tip: try exporting a component named ErrorFallback to handle any possible error this section may encounter\n\nto learn more, check out or [docs](https://deco.cx/docs/en/developing-capabilities/sections/loading-fallback)\n\n## Seo\n\nAs you may know, partially rendering a page's content is not ideal to SEO. For this reason, whenever our system detects it's google or any other search engine bot requesting your page, out system will fallback to fetch-then-render approach, delivering the best SEO possible. \n\n## Taking a Tour of Async Rendering in Deco.cx's Admin:\n\nReady to experience the power of Async Rendering firsthand? Join us for a guided tour on activating this feature within Deco.cx's admin interface. Discover how easy it is to enhance your website's performance with a few simple steps.\n\n1. Make sure your project is up-to-date to the latest deco and apps versions by running:\n\n```sh\ndeno run -A https://deco.cx/update\n```\n\n2. Open your site's app on deco.cx admin and look for Async Rendering option. Set it to 0 to disable or any other value to enable it. \ncarregando...
\n}\n```\n\n> Dica: tente exportar um componente chamado ErrorFallback para lidar com qualquer possível erro que esta seção possa encontrar\n\nPara saber mais, confira nossos [docs](https://deco.cx/docs/en/developing-capabilities/sections/loading-fallback)\n\n## SEO\n\nComo você deve saber, renderizar parcialmente o conteúdo de uma página não é ideal para SEO. Por esse motivo, sempre que nosso sistema detectar que é o Google ou qualquer outro mecanismo de busca solicitando sua página, nosso sistema recorrerá à abordagem fetch-then-render, oferecendo o melhor SEO possível.\n\n## Faça um Tour pela Renderização Assíncrona no Admin da Deco.cx:\n\nPronto para experimentar o poder da Renderização Assíncrona em primeira mão? Junte-se a nós para um tour guiado sobre como ativar este recurso dentro da interface de administração da Deco.cx. Descubra como é fácil melhorar o desempenho do seu site com alguns passos simples.\n\n1. Certifique-se de que seu projeto esteja atualizado para as últimas versões do deco e dos aplicativos executando:\n\n```sh\ndeno run -A https://deco.cx/update\n```\n\n2. Abra o aplicativo do seu site no admin da deco.cx e procure pela opção de Renderização Assíncrona. Defina-o como 0 para desativar ou qualquer outro valor para ativá-lo.\n\n\n💨 Every site built on
deco.cx is inherently responsive. Migrating to deco.cx typically results in a 5x boost in PageSpeed, and being approved by Google's Core Web Vitals (CWV) standards. deco.cx supports high website performance through:\n\n
\n Server Side Rendering \n Edge deployment \n Optimized images\n \n Automatic conversion to light formats (webp/avif) \n Different sizes to each device \n Pre-load the main image (LCP of CWV) \n Lazy loading \n \n \n Cacheable fonts \n \n
Click here to read more! \n
🔗 By exposing both backend and frontend code to site creators,
deco.cx allows for full control over the URL structure, enabling optimal SEO customization.\n
🧩 On
deco.cx , you can seamlessly blend text, images, videos, and other HTML elements into Product Detail Pages (PDPs), as well as manage satellite content within your domain, leveraging built-in blogging and frontend/backend customization for superior SEO results.\n
🛍️
deco.cx , enables the creation of product collections and landing pages on custom URLs not directly linked to the main catalog tree, facilitating creation of content that is more likely to convert buyers.\n
🎯 [deco.cx](https://deco.cx) allows for full control over meta elements throughout your site (title, description, meta image, and more). When it comes to canonical tags, deco.cx not only assigns canonicals by default to make sure search engines know how to prioritize the most relevant URLs, it also makes these tags totally customizable. This flexibility means that you can avoid secondary URLs created through pagination or filters from being indexed by search engines.\n
\n\n\nFor example, on deco.cx, only option A is indexed by default (although this is 100% editable):\n\nA. yoursite.com/categories/category-1\n\nB. yoursite.com/categories/category-1/?ordenation=true&page=3\n\n\n\n_Form created on deco.cx by [Zee.Dog](http://Zee.Dog) to edit SEO meta elements_\n\n### **7. SEO-friendly frameworks**\n\nSites built with frameworks that ensure search engines can accurately crawl and index pages are generally ranked higher. \n\n ⚙️
deco.cx 's framework is 100% server side by default, meaning that no JavaScript is sent to the client browser. Even if you add client side scripts, they are first rendered on the server side. This guarantees that search engines have access to all the content in your site.\n
🚫 Many platforms allow you to redirect missing URLs to similar addresses or to your site's homepage. On
deco.cx , you can go a step further, keeping the original URL available and directing your visitor to similar products in your store. This practice prevents errors in searches for missing products and enables out-of-stock items to keep on bringing organic traffic into your site.\n
✅ Sites on
deco.cx are guaranteed 99.99% uptime on average, ensuring that they are always available to both customers and search engines.
\n💨 Todo site construído na
deco.cx é inerentemente responsivo. Migrar para a deco.cx geralmente resulta em um aumento de 5x no PageSpeed e em ser aprovado pelos padrões de Core Web Vitals (CWV) do Google. A deco.cx suporta alto desempenho do website por meio de:\n\n
\n Renderização Server Side \n Deploy na Edge \n Otimização de imagens\n \n Conversão automática para formatos leves (webp/avif) \n Diferentes tamanhos para cada tipo de dispositivo \n Pré-carregamento da imagem principal (LCP do CWV) \n Lazy loading das imagens \n \n \n Fontes armazenáveis em cache \n \n
Clique aqui para ler mais! \n
🔗 Ao expor o código backend e frontend aos criadores do site,
deco.cx permite controle total sobre a estrutura da URL, possibilitando a personalização ideal de SEO.\n
🧩 Na
deco.cx , você pode mesclar textos, imagens, vídeos e outros elementos HTML em Páginas de Detalhes do Produto (PDPs), além de gerenciar conteúdo de satélite dentro do seu domínio, aproveitando a escrita integrada de blog e a personalização frontend/backend para resultados de SEO superiores.\n
🛍️
deco.cx , permite a criação de coleções de produtos e landing pages em URLs personalizadas que não estão diretamente vinculadas à árvore de catálogo principal, facilitando a criação de conteúdo que tem mais chances de converter compradores.\n
🎯 A [deco.cx](https://deco.cx) permite controle total sobre elementos meta em todo o seu site (título, descrição, imagem meta e mais). Quando se trata de tags canônicas, a deco.cx não apenas atribui canônicos por padrão para garantir que os mecanismos de busca saibam como priorizar as URLs mais relevantes, mas também torna essas tags totalmente personalizáveis. Essa flexibilidade significa que você pode evitar que URLs secundárias criadas por paginação ou filtros sejam indexadas pelos mecanismos de busca.\n
\n\n\nPor exemplo, na deco.cx só a opção A é indexada por padrão (embora isso seja 100% editável):\n\nA. yoursite.com/categories/category-1\n\nB. yoursite.com/categories/category-1/?ordenation=true&page=3\n\n\n\n_Formulário criado na deco.cx pela [Zee.Dog](http://Zee.Dog) para editar elementos meta de SEO_\n\n### **7. Frameworks SEO-friendly**\n\nSites construídos com frameworks que garantem que os mecanismos de busca possam rastrear e indexar páginas geralmente são classificados em posições mais altas. \n\n ⚙️ O framework da
deco.cx é 100% server side por padrão, o que significa que nenhum JavaScript é enviado para o navegador do cliente. Mesmo que você adicione scripts do lado do cliente, eles são primeiro renderizados no lado do servidor. Isso garante que os mecanismos de busca tenham acesso a todo o conteúdo do seu site.\n
🚫 Muitas plataformas permitem que você redirecione URLs ausentes para endereços semelhantes ou para a página inicial do seu site. Na
deco.cx , você pode ir um passo além, mantendo a URL original disponível e direcionando seu visitante para produtos similares em sua loja. Essa prática evita erros em buscas por produtos indisponíveis e permite que itens fora de estoque continuem trazendo tráfego orgânico para seu site.\n
✅ Os sites na
deco.cx têm garantia de 99,99% de tempo de atividade em média, assegurando que estejam sempre disponíveis tanto para clientes quanto para mecanismos de busca.\n
\n
\n\n### **2 - URL Support**\n\nAs unimportant as it may seem, a platform that offers support to customize URLs as much as possible is always better when it comes to SEO.\n\nA clear example is a platform where category pages must necessarily contain, at the second level, the classification /collection/, and products must necessarily contain, at the second level, the classification /products/.\n\nNo matter how small the detail, we will be at a disadvantage in the competition when the platform offers more flexible URL customization, considering that the use of the keyword in the URL is a good optimization practice recommended by Google.\n\nIn the Bolsa Já site, we customized 100% of the Category and Subcategory URLs so that they all remained at the first level of URL navigation. With this, we increased the relevance of the pages in relation to the home page.\n\nCategory: [https://bolsasja.com.br/bolsas-femininas](https://bolsasja.com.br/bolsas-femininas)\n\nSubcategory:\n[https://bolsasja.com.br/bolsa-casual](https://bolsasja.com.br/bolsa-casual)\n\n### **3 - Content Structure**\n\nSuccessful SEO projects increasingly bring e-commerce closer to content. See some examples below:\n\n\n
\n\nNotice that on the category page of the site, there is significant space for content insertion. \n\nToday having an e-commerce on one side and a blog created and used on a subdomain [blog.site.com.br](http://blog.site.com.br/) is no longer a guarantee of successful SEO work. Therefore, if the e-commerce platform offers this type of support for content creation, it will be a differentiator in terms of SEO.\n\nThe Bolsas Já site is an example where we can apply content, images, and HTML elements in categories and subcategories, while working with the products at the same time.\n\n\n
\n\n### **4 - HTML Content Application Support**\n\nFollowing the above example, if the platform offers support for creating a content structure in e-commerce in HTML, it will be possible to insert images, internal links, and other HTML attributes that will be favorable for an SEO project.\n\n### **5 – Blog Creation in Directory**\n\nThere are platforms that allow the creation of content components or a blog directly at the second level of the URL.\n\nExample: [yoursite.com.br/blog](http://yoursite.com.br/blog)\n\nThis option allows you to work with content directly on the URL, avoiding the creation of a subdomain outside of the site. As mentioned above, the closer the content is to the domain, the better the chances of results.\n\nThe example of Bolsa Já uses the [Fashion Tips](https://bolsasja.com.br/dicas-de-moda/) subdirectory to display content related to the segment within without the need to create a subdomain.\n\n\n
\n\n### **6 – Collection Creation**\n\nLook at this URL: https://www.dafiti.com.br/rasteiras-com-pedras/.\n\nBasically, a collection of products was created in a personalized URL that is not directly linked to the catalog and the product menu. This is only possible because the platform allows new product collections to be created without needing to be associated with the navigation menu or the category tree.\n\nWith this, it will be possible to create content and collections that are not directly associated with the menu (for example, \"Carnival clothes\", \"dog outfits\", etc.) and enhance work with long-tail keywords highly prone to conversion.\n\nIn addition, it will also be possible to create a menu or an exclusive section for this type of page. The example in the image below ([cea.com.br](http://cea.com.br/)) is the creation of a glossary only with terms that are not contained in the menu but are considered relevant in terms of organic search traffic.\n\n\n
\n\n### **7 – Custom Landing Pages Creation**\n\nThe URL https://www.kabum.com.br/hotsite/blackfriday/ is an example where it is possible to create a 100% customized Landing Page without direct association for viewing products.\n\nGenerally, this strategy is used for creating seasonal pages for specific content. Precisely on the date of the occasion (Christmas, Black Friday, Mother's Day, etc.), this page is redirected to a product showcase URL, leveraging the organic traffic developed throughout the year.\n\nIn the Bolsas Já website, it is possible to create both collections and customized Landing Pages:\n\nhttps://bolsasja.com.br/bolsa-caramelo/: These are collections created based on keywords and search volume, and, as explained above, there is no direct relationship with the navigation tree.\n\nhttps://bolsasja.com.br/bolsas-dia-das-maes: A Landing Page created exclusively to meet a seasonal demand with keywords and search volume for an SEO project.\n\n\n
\n\n### **8 – WEBp Support**\n\nAccording to Google (https://developers.google.com/speed/webp/faq), images in Webp format have a size reduction of up to 30% compared to traditional image formats (PNG, JPG, GIF). The Webp format itself already makes the site faster and, consequently, more advantageous in terms of SEO. A platform that supports this format is highly recommended.\n\n### **9 – Free Editing for Meta Description, Title Tags, and Headers**\n\nEven today, there are platforms where the titles and meta descriptions of pages are created automatically, not allowing customization. This mainly occurs with product pages, specifically with the h1 headers.\n\nAs a result, we lose control of all the titles and meta descriptions that exceed the character limit for display in search engines. Consider manually customizing the 20% most important products in your e-commerce if you have many products.\n\n\n
\n\n### **10 – Organization of Third-party Tags and Codes**\n\nThere are platforms where all insertions of third-party tags and codes (Google Analytics, conversion pixels, etc.) are supported only at the beginning of the page, in many cases hindering the site's loading time. Consequently, this can be a disadvantage in an SEO project.\n\nIdeally, platforms should offer support for inserting third-party tags and codes at the bottom of the site, facilitating the loading of what really matters: the content of the site.\n\n### **11 – Handling of Custom Filters (to prevent them from being transformed into an indexable URL)**\n\nThere are several platforms that do not offer support for avoiding pagination results or filters used on the site to be indexed by search engines, harming the most relevant pages. For example:\n\n[seusite.com.br/categorias/categoria-1](http://seusite.com.br/categorias/categoria-1)\n\n[seusite.com.br/categorias/categoria-1/?ordenacao=true&pagina=3](http://seusite.com.br/categorias/categoria-1/?ordenacao=true&pagina=3)\n\nBoth URLs are indexing and being displayed in search engines. However, the only one that should be displayed is [seusite.com.br/categorias/categoria-1](http://seusite.com.br/categorias/categoria-1). The platform should have a solution so that these filter and pagination URLs are not shown in the search results.\n\n### **12 – Framework Support for Search Engines**\n\nThere are platforms that use Javascript frameworks (for more information visit: https://www.excellentwebworld.com/what-is-a-single-page-application/) to improve the user experience, making navigation more efficient and facilitating the development process. Widely used frameworks such as Angular, Vue, and React already have support for search engines to properly crawl and index all pages.\n\nHowever, there are still platforms that use frameworks that compromise the site's performance in search engines. It is extremely important to make sure that the platform has the appropriate support. Generally, this practice occurs on proprietary sites, where the company is 100% responsible for the development.\n\n### **13 - Headless Architecture**\n\nAnother important point is the use of e-commerce in a headless format, where the back-end and front-end are completely separate and integrated via API. This brings more autonomy to the development of the front-end and also creates independence from a single platform for SEO work.\n\nDeco is an example of a 100% headless platform where it is possible to integrate the front-end with the main platforms (VTEX, Linx, Shopify, VNDA, Wake), conceived enable development of an e-commerce where all SEO premises are met.\n\nCurrently, we have the Bolsas Já site being developed with the back-end in Shopify and the front-end on Deco. This gives us more autonomy to implement features and execute all the technical tasks on the front-end without impacting the operation of the e-commerce.\n\n### **14 – Organization and Availability of Products**\n\nIn most e-commerces, when a product is out of stock or permanently withdrawn from sale, both the product and its URL are removed, leading all organic visits to 404 error pages. In some platforms, the only possible option is to redirect this URL to another similar URL or to the homepage.\n\nThis practice works in the short term, until Google naturally removes the result from the organic search, since the page no longer matches the keyword. But what if we had the option to keep the URL available even with the product missing, and direct the visitor's navigation to similar products in the site?\n\nThis practice would allow the product to continue in organic searches and also continue bringing organic traffic into the site, guiding the visitor to a product close to what they were looking for.\n\n### **15 – Site Availability**\n\nShockingly, there are still large e-commerces that have to go offline for minutes or even hours during the night to run internal processes. \n\nThere is even a concern in the market regarding one of the largest Brazilian e-commerce platforms during Black Friday: the platform has been offline during the Black Friday period, leaving the sites inaccessible and compromising the performance of client sales.\n\nIf you hear from any platform that this is normal, run away! Analyze the contract well and be sure that your site is 100% available and functional. Of course, unavailability can occur, but it should be treated as an exception, not a rule. ERP update routines, integration with marketplaces, product updates, and inventory cannot stop the e-commerce under any circumstances.\n\n**Why is this bad for SEO?**\n\nImagine a site that, for some reason mentioned above, is offline daily between 2 a.m. and 3 a.m. In terms of visits and revenue, it may not have such a big impact, but there is no prediction of when the indexing robots will scan the site. Surely, at some point, the site will be scanned and not be online. The consequence? Moving down on rankings and loss of organic traffic.\n\nAll e-commerce platforms have their pros and cons, and most of them will not meet all of the above requirements. So, when deciding on the platform, consider that the more support it gives, the easier it will be to execute a successful SEO project, avoiding future headaches.\n\n## **After all, what is the best e-commerce platform in terms of SEO?**\n\nWe conducted a study with the main e-commerce platforms and considered all the technical tasks we have performed on them.\n\nWe grouped all the technical tasks we have worked on and defined the following criteria: the feasibility of applying complex SEO techniques and the complexity of these technical applications. For the first, we simply considered the possibility of implementing a particular task or not. For complexity, we considered the time and effort required to perform these technical tasks.\n\n\n
\n\nAs shown on the graph above, the few technical tasks that we managed to implement using Loja Integrada, for example, were simple and easy to apply, (robots.txt configuration, titles, meta descriptions, etc.). With Deco, it is possible to apply the largest number of technical recommendations with low implementation complexity.\n\nRemember that the platform alone will not be responsible for 100% of the success of an SEO project, but it should at least offer the support for this project to evolve satisfactorily.\n\n## **Development and Implementation Costs**\n\nBecause Deco is 100% independent and integrable with the main platforms on the market, it brings development flexibility to agencies like ours that execute SEO projects. Instead of having to become specialists in developing on specific platforms, where we have to follow guidelines that are not always favorable to our work, we can execute entire projects using Deco only, regardless of the other platforms and systems used by the client. \n\nThis flexibility has brought a different dynamic in the application of technical tasks and also changes to our business model. At Gear SEO, for example, the entire development process with Deco is based on activities and implementations and not just on hours worked. This point is positive because the price is not defined by the number of hours invested in a task, but in the resolution of each task.\n\nLikewise, there will no longer be a need for an agency specialized in a particular platform to meet the technical and SEO needs of an e-commerce. At Gear SEO, we have a complete solution for the development of the entire front-end.\n\n## **Conclusion**\n\nAs mentioned at the beginning of this article there is no platform that is 100% adherent to SEO technical applications. However, there are platforms that are closer to this reality. Deco, for example, is the platform closest to supporting the application of all the technical tasks we have already performed on an e-commerce platform.\n\nThe Deco platform was designed and built to meet specific SEO needs. In this scenario, Gear SEO has a specialized team in creating, developing, and maintaining e-commerces using the Deco platform.\n\nThe advantages of working with Gear SEO in the development of an e-commerce using the Deco platform are numerous:\n\n- Ability to customize the front-end through Deco's CMS module;\n\n- Gear SEO is 100% responsible for the development and maintenance of the e-commerce front-end, eliminating the need to hire multiple agencies. \n\n- Gear SEO will be able to perform all technical applications directly in the e-commerce, ensuring the quality and organization of all implementations;\n\n- Ease of integration and organization with third-party applications;\n\n- Agility in updating layout, design, and, most importantly, in monitoring technical recommendations due to the changes of search algorithms;\n\n- It is important to consider the role of SEO in a project from its conception, taking into account the work needed on each front (Strategy, On-Page, Content Production, and Link Building).\n\nThis is why an e-commerce platform should be chosen as a basis to meet SEO needs, instead of being just another acquisition channel, working partially or limitedly. A project where SEO technical recommendations work partially or limitedly is most of the time unsuccessful, especially when it comes to increasing conversion rates. \n\nDo you know of any other important points that should be considered? Comment below and participate."
+ },
+ "pt": {
+ "descr": "Descubra os fatores essenciais a considerar ao escolher uma plataforma de e-commerce com forte suporte de SEO",
+ "title": "Qual é a melhor plataforma de e-commerce para SEO?",
+ "seo": {
+ "title": "Qual é a melhor plataforma de e-commerce para SEO?",
+ "description": "Descubra os fatores essenciais a considerar ao escolher uma plataforma de e-commerce com forte suporte de SEO"
+ },
+ "content": "## **Sumário**\n\nIntrodução\n\nQuais pontos devem ser considerados?\n\n1 - Suporte Móvel\n\n2 - Suporte de URL\n\n3 - Estrutura de Conteúdo\n\n4 - Suporte de Aplicação de Conteúdo HTML\n\n5 – Criação de Blog no Diretório\n\n6 – Criação de Coleção\n\n7 – Criação de Landing Pages Customizadas\n\n8 – Suporte WEBp\n\n9 – Edição Gratuita para Meta Descrição, Tag de Título e Cabeçalhos\n\n10 – Organização de Tags e Códigos de Terceiros\n\n11 – Manipulação de Filtro Personalizado (para evitar tornar-se uma URL indexável)\n\n12 – Suporte de Framework para Mecanismos de Busca\n\n13 – Arquitetura Headless\n\n14 – Organização e Disponibilidade de Produtos\n\n15 – Disponibilidade do Site\n\nAfinal, qual é a melhor plataforma de e-commerce em termos de SEO?\n\nCustos de desenvolvimento e implementação\n\nConclusão\n\n## **Introdução**\n\nCom a popularização e difusão das estratégias e projetos de SEO, é essencial considerar uma plataforma eficiente com suporte para todas as recomendações de mecanismos de busca. Mas a principal questão é: qual é a melhor plataforma de e-commerce em termos de SEO?\n\nNós, da Gear SEO, acreditamos que essa pergunta só pode ser respondida por meio da experiência acumulada de trabalho de SEO com todas elas. Entre as plataformas com as quais trabalhamos, podemos afirmar que todas têm seus prós e contras.\n\nExistem plataformas que atendem às recomendações técnicas básicas de SEO e plataformas que atendem a quase todas as recomendações técnicas com as quais trabalhamos.\n\nDiante desse cenário, compilamos uma lista das principais recomendações técnicas que consideramos que uma plataforma de e-commerce deve conter em termos de suporte de SEO. Esta pesquisa é baseada em nossa experiência trabalhando com as principais plataformas de e-commerce ao longo dos anos.\n\nIsso será importante porque pode orientar a escolha da plataforma de acordo com os pontos que ela aborda ou os pontos que devem ser considerados no desenvolvimento de uma plataforma própria. Neste universo, consideramos tanto plataformas comerciais de e-commerce quanto plataformas de e-commerce de código aberto.\n\nTambém temos nosso e-commerce demonstrativo onde aplicamos todos os fundamentos de SEO por meio de nosso programa \"SEO na Prática\". Bolsas Já é um e-commerce headless usando a plataforma Deco com um backend Shopify.\n\n## **Quais pontos devem ser considerados?**\n\nAbaixo está uma lista com os pontos que consideramos importantes para que um e-commerce produza resultados de SEO mais eficazes, levando em consideração um projeto onde todas as páginas são trabalhadas.\n\n### **1 - Suporte Móvel**\n\nEste ponto é um dos mais importantes, se não o mais importante. É essencial que a plataforma considere um site responsivo com tempo de carregamento satisfatório.\n\nQuando falamos de um site responsivo, significa que ele deve ser o mesmo para desktop e mobile, incluindo a mesma URL. O Google já está comprometido em mudar completamente a forma como os sites são rastreados, priorizando as versões móveis de todos eles.\n\nNesta dinâmica, sites específicos para mobile ([m.site.com.br](http://m.site.com.br/)) deixarão de existir, dando lugar a sites responsivos. Na verdade, o Google já possui documentação e recomendações para essa mudança.\n\nBolsas Já é um exemplo de um aplicativo móvel 100% responsivo, atendendo a todos os requisitos técnicos de SEO.\n\n\n
\n\n### **2 - Suporte de URL**\n\nPor menos importante que possa parecer, uma plataforma que oferece suporte para personalizar as URLs o máximo possível é sempre melhor quando se trata de SEO.\n\nUm exemplo claro é uma plataforma onde as páginas de categoria devem necessariamente conter, no segundo nível, a classificação /coleção/, e os produtos devem necessariamente conter, no segundo nível, a classificação /produtos/.\n\nPor menor que seja o detalhe, estaremos em desvantagem na competição quando a plataforma oferecer mais flexibilidade na personalização de URLs, considerando que o uso da palavra-chave na URL é uma boa prática de otimização recomendada pelo Google.\n\nNo site Bolsas Já, personalizamos 100% das URLs de Categoria e Subcategoria para que todas permanecessem no primeiro nível de navegação de URL. Com isso, aumentamos a relevância das páginas em relação à página inicial.\n\nCategoria: [https://bolsasja.com.br/bolsas-femininas](https://bolsasja.com.br/bolsas-femininas)\n\nSubcategoria:\n[https://bolsasja.com.br/bolsa-casual](https://bolsasja.com.br/bolsa-casual)\n\n### **3 - Estrutura de Conteúdo**\n\nProjetos bem-sucedidos de SEO aproximam cada vez mais o e-commerce do conteúdo. Veja alguns exemplos abaixo:\n\n\n
\n\nObserve que na página de categoria do site, há um espaço significativo para inserção de conteúdo.\n\nHoje, ter um e-commerce de um lado e um blog criado e utilizado em um subdomínio [blog.site.com.br](http://blog.site.com.br/) não é mais garantia de um trabalho de SEO bem-sucedido. Portanto, se a plataforma de e-commerce oferecer esse tipo de suporte para criação de conteúdo, será um diferencial em termos de SEO.\n\nO site Bolsas Já é um exemplo onde podemos aplicar conteúdo, imagens e elementos HTML em categorias e subcategorias, enquanto trabalhamos com os produtos ao mesmo tempo.\n\n\n
\n\n### **4 - Suporte para Aplicação de Conteúdo HTML**\n\nSeguindo o exemplo acima, se a plataforma oferecer suporte para criação de uma estrutura de conteúdo em HTML no e-commerce, será possível inserir imagens, links internos e outros atributos HTML que serão favoráveis para um projeto de SEO.\n\n### **5 – Criação de Blog no Diretório**\n\nExistem plataformas que permitem a criação de componentes de conteúdo ou um blog diretamente no segundo nível da URL.\n\nExemplo: [yoursite.com.br/blog](http://yoursite.com.br/blog)\n\nEssa opção permite trabalhar com conteúdo diretamente na URL, evitando a criação de um subdomínio fora do site. Como mencionado acima, quanto mais próximo o conteúdo estiver do domínio, melhores serão as chances de resultados.\n\nO exemplo do Bolsa Já utiliza o subdiretório [Fashion Tips](https://bolsasja.com.br/dicas-de-moda/) para exibir conteúdo relacionado ao segmento dentro do próprio site, sem a necessidade de criar um subdomínio.\n\n\n
\n\n### **6 – Criação de Coleção**\n\nObserve esta URL: https://www.dafiti.com.br/rasteiras-com-pedras/.\n\nBasicamente, uma coleção de produtos foi criada em uma URL personalizada que não está diretamente vinculada ao catálogo e ao menu de produtos. Isso só é possível porque a plataforma permite a criação de novas coleções de produtos sem precisar estar associada ao menu de navegação ou à árvore de categorias.\n\nCom isso, será possível criar conteúdo e coleções que não estão diretamente associadas ao menu (por exemplo, \"Roupas de Carnaval\", \"roupas para cachorro\", etc.) e aprimorar o trabalho com palavras-chave de cauda longa altamente propensas à conversão.\n\nAlém disso, também será possível criar um menu ou uma seção exclusiva para este tipo de página. O exemplo na imagem abaixo ([cea.com.br](http://cea.com.br/)) é a criação de um glossário apenas com termos que não estão contidos no menu, mas são considerados relevantes em termos de tráfego orgânico de pesquisa.\n\n\n
\n\n### **7 – Criação de Landing Pages Personalizadas**\n\nA https://www.kabum.com.br/hotsite/blackfriday/ é um exemplo onde é possível criar uma Landing Page 100% personalizada sem associação direta para visualização de produtos.\n\nGeralmente, essa estratégia é usada para criar páginas sazonais para conteúdo específico. Precisamente na data da ocasião (Natal, Black Friday, Dia das Mães, etc.), esta página é redirecionada para uma URL de vitrine de produtos, alavancando o tráfego orgânico desenvolvido ao longo do ano.\n\nNo site Bolsas Já, é possível criar tanto coleções quanto Landing Pages personalizadas:\n\nhttps://bolsasja.com.br/bolsa-caramelo/: Estas são coleções criadas com base em palavras-chave e volume de busca e, como explicado acima, não há relação direta com a árvore de navegação.\n\nhttps://bolsasja.com.br/bolsas-dia-das-maes: Uma Landing Page criada exclusivamente para atender a uma demanda sazonal com palavras-chave e volume de busca para um projeto de SEO.\n\n\n
\n\n### **8 – Suporte WEBp**\n\nDe acordo com o Google (https://developers.google.com/speed/webp/faq), imagens no formato Webp têm uma redução de tamanho de até 30% em comparação com os formatos tradicionais de imagem (PNG, JPG, GIF). O próprio formato Webp já torna o site mais rápido e, consequentemente, mais vantajoso em termos de SEO. Uma plataforma que suporta esse formato é altamente recomendada.\n\n### **9 – Edição Gratuita para Meta Descrição, Títulos e Cabeçalhos**\n\nAinda hoje, existem plataformas onde os títulos e meta descrições das páginas são criados automaticamente, não permitindo personalização. Isso ocorre principalmente com as páginas de produtos, especificamente com os cabeçalhos h1.\n\nComo resultado, perdemos o controle de todos os títulos e meta descrições que excedem o limite de caracteres para exibição nos mecanismos de busca. Considere personalizar manualmente os 20% dos produtos mais importantes em seu e-commerce se você tiver muitos produtos.\n\n\n
\n\n### **10 – Organização de Tags e Códigos de Terceiros**\n\nExistem plataformas onde todas as inserções de tags e códigos de terceiros (Google Analytics, pixels de conversão, etc.) são suportadas apenas no início da página, em muitos casos prejudicando o tempo de carregamento do site. Consequentemente, isso pode ser uma desvantagem em um projeto de SEO.\n\nIdealmente, as plataformas devem oferecer suporte para inserir tags e códigos de terceiros no final do site, facilitando o carregamento do que realmente importa: o conteúdo do site.\n\n### **11 – Manipulação de Filtros Personalizados (para evitar que sejam transformados em uma URL indexável)**\n\nExistem várias plataformas que não oferecem suporte para evitar que os resultados de paginação ou filtros usados no site sejam indexados pelos mecanismos de busca, prejudicando as páginas mais relevantes. Por exemplo:\n\n[seusite.com.br/categorias/categoria-1](http://seusite.com.br/categorias/categoria-1)\n\n[seusite.com.br/categorias/categoria-1/?ordenacao=true&pagina=3](http://seusite.com.br/categorias/categoria-1/?ordenacao=true&pagina=3)\n\nAmbas as URLs estão sendo indexadas e exibidas nos mecanismos de busca. No entanto, apenas a que deve ser exibida é [seusite.com.br/categorias/categoria-1](http://seusite.com.br/categorias/categoria-1). A plataforma deve ter uma solução para que essas URLs de filtro e paginação não sejam mostradas nos resultados da pesquisa.\n\n### **12 – Suporte de Framework para Mecanismos de Busca**\n\nExistem plataformas que utilizam frameworks Javascript (para mais informações, visite: https://www.excellentwebworld.com/what-is-a-single-page-application/) para melhorar a experiência do usuário, tornando a navegação mais eficiente e facilitando o processo de desenvolvimento. Frameworks amplamente utilizados como Angular, Vue e React já têm suporte para os mecanismos de busca rastrearem e indexarem corretamente todas as páginas.\n\nNo entanto, ainda existem plataformas que usam frameworks que comprometem o desempenho do site nos mecanismos de busca. É extremamente importante garantir que a plataforma tenha o suporte apropriado. Geralmente, essa prática ocorre em sites proprietários, onde a empresa é 100% responsável pelo desenvolvimento.\n\n### **13 - Arquitetura Headless**\n\nOutro ponto importante é o uso de e-commerce em um formato headless, onde o back-end e o front-end são completamente separados e integrados via API. Isso traz mais autonomia para o desenvolvimento do front-end e também cria independência de uma única plataforma para o trabalho de SEO.\n\nDeco é um exemplo de uma plataforma 100% headless onde é possível integrar o front-end com as principais plataformas (VTEX, Linx, Shopify, VNDA, Wake), concebida para permitir o desenvolvimento de um e-commerce onde todos os preceitos de SEO são atendidos.\n\nAtualmente, temos o site Bolsas Já sendo desenvolvido com o back-end no Shopify e o front-end na Deco. Isso nos dá mais autonomia para implementar recursos e executar todas as tarefas técnicas no front-end sem impactar o funcionamento do e-commerce.\n\n### **14 – Organização e Disponibilidade de Produtos**\n\nNa maioria dos e-commerces, quando um produto está fora de estoque ou é retirado permanentemente da venda, tanto o produto quanto sua URL são removidos, levando todas as visitas orgânicas a páginas de erro 404. Em algumas plataformas, a única opção possível é redirecionar essa URL para outra URL semelhante ou para a página inicial.\n\nEssa prática funciona a curto prazo, até que o Google remova naturalmente o resultado da pesquisa orgânica, pois a página não corresponde mais à palavra-chave. Mas e se tivéssemos a opção de manter a URL disponível mesmo com o produto ausente e direcionar a navegação do visitante para produtos similares no site?\n\nEssa prática permitiria que o produto continuasse nas pesquisas orgânicas e também continuasse trazendo tráfego orgânico para o site, orientando o visitante para um produto próximo ao que ele estava procurando.\n\n### **15 – Disponibilidade do Site**\n\nSurpreendentemente, ainda existem grandes e-commerces que precisam ficar offline por minutos ou até horas durante a noite para executar processos internos.\n\nHá até mesmo uma preocupação no mercado em relação a uma das maiores plataformas de e-commerce brasileiras durante a Black Friday: a plataforma ficou offline durante o período da Black Friday, deixando os sites inacessíveis e comprometendo o desempenho das vendas dos clientes.\n\nSe você ouvir de alguma plataforma que isso é normal, fuja! Analise bem o contrato e certifique-se de que seu site está 100% disponível e funcional. Claro, a indisponibilidade pode ocorrer, mas deve ser tratada como uma exceção, não uma regra. Rotinas de atualização do ERP, integração com marketplaces, atualizações de produtos e inventário não podem interromper o e-commerce sob nenhuma circunstância.\n\n**Por que isso é ruim para o SEO?**\n\nImagine um site que, por algum motivo mencionado acima, fica offline diariamente entre 2h e 3h. Em termos de visitas e receita, pode não ter um impacto tão grande, mas não há previsão de quando os robôs de indexação vão escanear o site. Certamente, em algum momento, o site será escaneado e não estará online. A consequência? Queda nos rankings e perda de tráfego orgânico.\n\nTodas as plataformas de e-commerce têm seus prós e contras, e a maioria delas não atenderá a todos os requisitos acima. Portanto, ao decidir sobre a plataforma, considere que quanto mais suporte ela oferecer, mais fácil será executar um projeto de SEO bem-sucedido, evitando dores de cabeça futuras.\n\n## **Afinal, qual é a melhor plataforma de e-commerce em termos de SEO?**\n\nRealizamos um estudo com as principais plataformas de e-commerce e consideramos todas as tarefas técnicas que realizamos nelas.\n\nAgrupamos todas as tarefas técnicas que trabalhamos e definimos os seguintes critérios: a viabilidade de aplicar técnicas de SEO complexas e a complexidade dessas aplicações técnicas. Para o primeiro, simplesmente consideramos a possibilidade de implementar uma tarefa específica ou não. Para a complexidade, consideramos o tempo e o esforço necessários para realizar essas tarefas técnicas.\n\n\n
\n\nConforme mostrado no gráfico acima, as poucas tarefas técnicas que conseguimos implementar usando a Loja Integrada, por exemplo, foram simples e fáceis de aplicar (configuração de robots.txt, títulos, meta descrições, etc.). Com a Deco, é possível aplicar o maior número de recomendações técnicas com baixa complexidade de implementação.\n\nLembre-se de que a plataforma por si só não será responsável por 100% do sucesso de um projeto de SEO, mas deve pelo menos oferecer o suporte para que este projeto evolua satisfatoriamente.\n\n## **Custos de Desenvolvimento e Implementação**\n\nPor ser 100% independente e integrável com as principais plataformas do mercado, a Deco traz flexibilidade de desenvolvimento para agências como a nossa que executam projetos de SEO. Em vez de precisar se tornar especialistas em desenvolver em plataformas específicas, onde temos que seguir diretrizes que nem sempre são favoráveis ao nosso trabalho, podemos executar projetos inteiros usando apenas a Deco, independentemente das outras plataformas e sistemas usados pelo cliente.\n\nEssa flexibilidade trouxe uma dinâmica diferente na aplicação de tarefas técnicas e também mudanças em nosso modelo de negócios. Na Gear SEO, por exemplo, todo o processo de desenvolvimento com a Deco é baseado em atividades e implementações e não apenas em horas trabalhadas. Este ponto é positivo porque o preço não é definido pelo número de horas investidas em uma tarefa, mas na resolução de cada tarefa.\n\nDa mesma forma, não será mais necessário uma agência especializada em uma plataforma específica para atender às necessidades técnicas e de SEO de um e-commerce. Na Gear SEO, temos uma solução completa para o desenvolvimento de todo o front-end.\n\n## **Conclusão**\n\nComo mencionado no início deste artigo, não há uma plataforma que seja 100% aderente às aplicações técnicas de SEO. No entanto, existem plataformas que estão mais próximas dessa realidade. A Deco, por exemplo, é a plataforma mais próxima de oferecer suporte para a aplicação de todas as tarefas técnicas que já realizamos em uma plataforma de e-commerce.\n\nA plataforma Deco foi projetada e construída para atender às necessidades específicas de SEO. Neste cenário, a Gear SEO possui uma equipe especializada na criação, desenvolvimento e manutenção de e-commerces usando a plataforma Deco.\n\nAs vantagens de trabalhar com a Gear SEO no desenvolvimento de um e-commerce usando a plataforma Deco são numerosas:\n\n- Capacidade de personalizar o front-end por meio do módulo CMS da Deco;\n\n- A Gear SEO é 100% responsável pelo desenvolvimento e manutenção do front-end do e-commerce, eliminando a necessidade de contratar várias agências.\n\n- A Gear SEO poderá realizar todas as aplicações técnicas diretamente no e-commerce, garantindo a qualidade e organização de todas as implementações;\n\n- Facilidade de integração e organização com aplicativos de terceiros;\n\n- Agilidade na atualização do layout, design e, o mais importante, no monitoramento das recomendações técnicas devido às mudanças nos algoritmos de busca;\n\n- É importante considerar o papel do SEO em um projeto desde sua concepção, levando em conta o trabalho necessário em cada frente (Estratégia, On-Page, Produção de Conteúdo e Construção de Links).\n\nPor isso, uma plataforma de e-commerce deve ser escolhida como base para atender às necessidades de SEO, em vez de ser apenas mais um canal de aquisição, trabalhando parcialmente ou de forma limitada. Um projeto onde as recomendações técnicas de SEO funcionam parcialmente ou de forma limitada é na maioria das vezes malsucedido, especialmente quando se trata de aumentar as taxas de conversão.\n\nVocê conhece outros pontos importantes que devem ser considerados? Comente abaixo e participe."
+ }
+ },
+ "date": "02/02/2024",
+ "path": "gear-seo-article-en",
+ "author": "Rodrigo Botinhão",
+ "tags": []
+ },
+ {
+ "body": {
+ "pt": {
+ "title": "A melhor experiência digital da Euro Colchões aumenta as vendas em loja",
+ "descr": "A equipe de três pessoas da Euro Colchões aumentou a pontuação de PageSpeed de seu e-commerce de 7 para 80, transformando a presença online e física da Euro",
+ "seo": {
+ "title": "A melhor experiência digital da Euro Colchões aumenta as vendas em loja",
+ "description": "A equipe de três pessoas da Euro Colchões aumentou a pontuação de PageSpeed de seu e-commerce de 7 para 80, transformando a presença online e física da Euro"
+ }
+ },
+ "en": {
+ "title": "Euro Colchões’ top digital experience increases in-store sales",
+ "descr": "Euro Colchões' three-person team increased its ecommerce PageSpeed score from 7 to 80, transforming Euro's online and physical presence",
+ "seo": {
+ "image": "https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/acc51bf5-3243-4ce6-950f-6dd30634339a",
+ "title": "Euro Colchões’ top digital experience increases in-store sales",
+ "description": "Euro Colchões' three-person team increased its ecommerce PageSpeed score from 7 to 80, transforming Euro's online and physical presence"
+ }
+ }
+ },
+ "path": "case-eurocolchoes",
+ "img": "https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/a668b07e-356e-4b6b-b1d1-bb7d4a11e608",
+ "date": "01/12/2024",
+ "author": "By Maria Cecilia Marques",
+ "tags": []
+ },
+ {
+ "img": "https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/a9db4aff-6729-4c81-bb8f-1a57c8dd9ee8",
+ "body": {
+ "en": {
+ "descr": "New App to see your Core Web Vitals results",
+ "title": "Core Web Vitals App",
+ "content": "In recent years, web performance has become a crucial factor for the success of websites and online applications. Core Web Vitals, introduced by Google, has been a benchmark for measuring user experience on the web.\n\nToday, we announce an App on [deco.cx](https://deco.cx) that allows you to bring up a complete report of Core Web Vitals.\n\n\n Click here\n \n```\n\nIn this example with pure Tailwind CSS, you need to specify all the classes for button styling, from the background color (bg-blue-500 and hover:bg-blue-700 for the hover state) to the rounding of the corners (rounded).\n\n### With DaisyUI\n\n\n```html\n\n\n Click here\n \n```\n\nWith DaisyUI, we simplify the markup using the btn class for basic button styling and btn-primary to apply the primary style predefined by the DaisyUI theme. The library takes care of all button interaction states, such as hover and focus, without the need to add additional classes.\n\nWhen you install DaisyUI, it provides a series of pre-defined classes that already come with a range of style settings. This allows for a substantial reduction in the code effort and increases readability at the same time.\n\n## How does DaisyUI fit into the Storefront?\n\nIt is common knowledge that our sites already have DaisyUI in them. The difference now is that with the 'daisy' components folder, you can find the UI components offered by the library adapted to become components with props in our editor.\nThese 'deco' components are advanced versions of DaisyUI components that can now be used as Preact components (a lightweight alternative to React), offering the flexibility to accept 'props' - a powerful Preact feature for passing data and configuring the component. This allows them to adapt or change according to the needs of the context in which they are used, which is especially useful for creating dynamic 'sections' in an application.\n\nFor example, if we have a Toast component, instead of using them in different ways in different contexts, you can use the Toast.tsx component that already anticipates some behavioral changes.\n\n\n```jsx\n\n\n Clique Aqui\n \n```\n\nNeste exemplo com Tailwind CSS puro, é preciso especificar todas as classes para estilização do botão, desde a cor do fundo (`bg-blue-500` e `hover:bg-blue-700` para o estado de hover) até o arredondamento das bordas (`rounded`).\n\n### Com DaisyUI\n\n```html\n\n\n Clique Aqui\n \n```\n\nCom o DaisyUI, simplificamos a marcação usando a classe `btn` para um estilo básico de botão e `btn-primary` para aplicar o estilo primário predefinido pelo tema do DaisyUI. A biblioteca cuida de todos os estados de interação do botão, como hover e foco, sem a necessidade de adicionar classes adicionais.\n\nQuando você instala o DaisyUI, ele disponibiliza uma série de classes pré-definidas que já levam consigo uma série de configurações de estilo. Isso permite uma redução substancial do esforço necessário no código e aumenta a legibilidade ao mesmo tempo.\n\n## E como o Daisy UI se encontra no Storefront?\n\nÉ comum o conhecimento de que nossos sites já tem Daisy UI neles. A diferença agora é que com a pasta de componentes “daisy” você pode encontrar os componentes de UI oferecidos pela biblioteca adaptados para virarem componentes com props no nosso editor. \n\nEstes componentes 'deco' são versões avançadas dos componentes do DaisyUI que agora podem ser usados como componentes Preact (uma alternativa leve ao React), oferecendo a flexibilidade de aceitar 'props' - um recurso poderoso do Preact para passar dados e configurar o componente. Isso permite que eles se adaptem ou mudem de acordo com as necessidades do contexto em que são utilizados, o que é especialmente útil para criar 'sections' dinâmicas numa aplicação.\n\nPor exemplo, se temos um componente Toast, ao invés de usar eles de diferentes formas em diferentes contextos, você pode usar o componente `Toast.tsx` que já prevê algumas mudanças de comportamento.\n\n\n```jsx\n\n- Aline Augusto, Head of ecommerce, marketplace and media at [Embelleze](http://embelleze.com/)
\n\n\n_Graph showing revenue from Embelleze's ecommerce in the 24 hours of BF 2023. The lines show this year's revenue vs. last year's vs. the target sales for this year._\n\n\n> This Black Friday was a great one for all of our clients that are on [deco.cx](https://deco.cx/). I have seen firsthand how deco's platform enables better customer experiences and more efficiency in the day to day management of ecommerces. I've been gaining a lot through out partnership - they actually listen to our feedbacks about the platform's performance optimization tools. \n\n- Henrique Reis, Co-Founder and CEO of [Sourei Digital Services](http://sourei.com.br/)
\n\n> Our ecommerce grew a lot last year and our 2022 Black Friday results were amazing. This year, we chose to dose down on our promotion strategy with less expressive discounts. Even so, we exceeded our original target (to maintain last year's results), increasing our sales in 15%! \n\n- Guilherme Ladowsky, Partner at [Aviator](http://aviator.com.br/)
\n\n> We migrated to deco on September and the impact on performance was instantaneous - we went from an average PageSpeed of 20 on mobile to over 80. This was especially important to us since over half of our sales are through mobile devices. On top of the improvement in performance, we worked with the[ eplus agency](https://www.agenciaeplus.com.br/) and other partners to increase our storefront conversion rate. And now we are reaping the benefits of these investments - we sold 100% more on this BF vs. the same period last year! \n\n- Tania Puglisi, Head of ecommerce at [OpenBox2](http://openbox2.com.br/)
\n\n## Next Black Friday\n\nAs for next year's BFCM period, we are looking to have thousands of live projects on [deco.cx](https://deco.cx/), from AI-generated landing pages to the biggest ecommerce operations in the world. \n"
+ },
+ "pt": {
+ "descr": "Preparo, uptime, testemunhos de clientes e mais.",
+ "title": "Dos desafios aos saltos: nossa Black Friday 2023",
+ "content": "Desde a sua fundação em agosto de 2022, a [deco.cx](https://deco.cx/) tem visto um crescimento muito acelerado. Nossa primeira loja foi para o ar em maio (zeedog.com.br), e até o período da Black Friday e Cyber Monday (24 a 27 de novembro de 2023) alcançamos mais de 20 projetos _live_.\n\n👏🏻 Em primeiro lugar, queremos agradecer aos nossos clientes pelo apoio e confiança! Todos os projetos _live_ podem ser vistos em: [deco.cx/pt/projetos-ao-vivo](https://deco.cx/en/live-projects)\n\nEstamos muito orgulhosos das mais de 20 marcas que estão na nossa plataforma: muitas são líderes de suas indústrias, com tráfego e GMV significativos. Juntas, geraram um total de **15M** de visualizações de página durante o período BFCM, atingindo o pico às **21:01 (GMT-3) na quarta-feira, 22 de novembro.**\n\n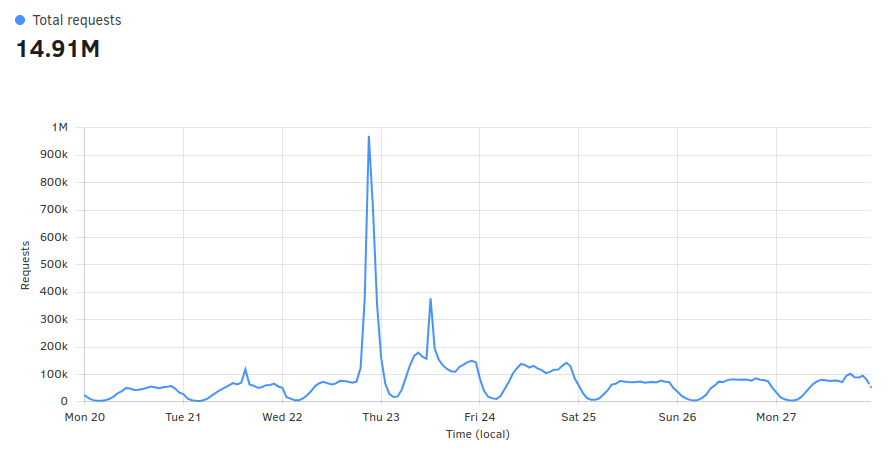\n\n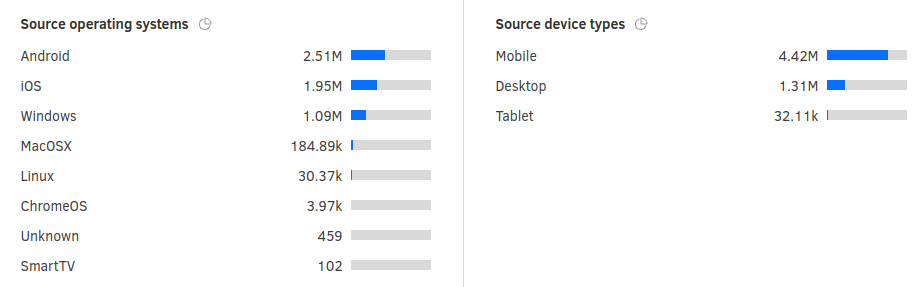\n\n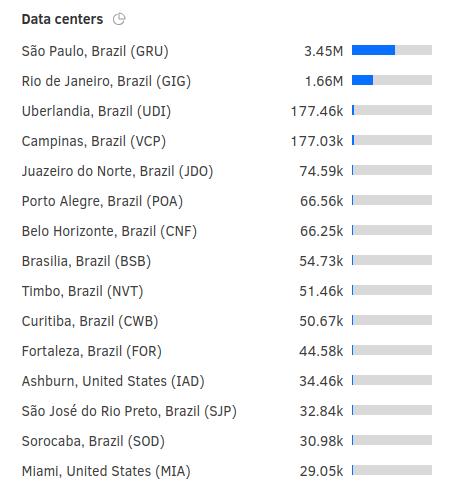\n\n_Requisições totais de 20 a 27 de novembro de 2023_\n\nConseguimos manter nosso _uptime_ em 99,99% durante o período BFCM. No entanto, enfrentamos uma [degradação de desempenho por 1 hora na noite de quarta-feira,](https://deco.instatus.com/clpagkpn724079bbom1qcbc3fh) em que um de nossos clientes experimentou até 30% de falhas nas requisições para “adicionar ao carrinho” e navegação mais lenta.\n\n⚠️ _Isso significa que, enquanto o incidente ocorreu, uma parcela dos visitantes teve uma experiência de compra abaixo da média. O motivo foi que [Deno](http://deno.com/), nosso provedor de infraestrutura, demorou mais do que o esperado para escalar corretamente sua infraestrutura à medida que o tráfego aumentava. Embora todos os preparativos estivessem no lugar, houve um limite imprevisto em sua própria infraestrutura, que foi então abordado e permitiu um escalonamento suficiente._\n\nLamentamos profundamente essa degradação do serviço e tomamos as medidas para evitar problemas semelhantes no futuro. A confiabilidade dos sites de nossos clientes é a prioridade número um para a equipe de engenharia da Deco. Fora este incidente, ficamos satisfeitos com o desempenho sólido de nossos sistemas durante todo o período crítico de vendas da Black Friday.\n\n## Como nos preparamos?\n\nEsta foi a nossa primeira BFCM como [deco.cx](https://deco.cx/), mas individualmente nossos engenheiros têm muita experiência anterior. À medida que nos aproximávamos deste período chave do ano, tomamos algumas medidas para garantir o sucesso de nossos clientes:\n\n- **Otimizando Lojas de Maior Tráfego:** Revisamos meticulosamente e otimizamos o uso de recursos para nossas lojas de maior tráfego.\n\n- **Colaboração com a Deno:** Nos tornamos um [estudo de caso da Deno](https://deno.com/blog/deco-cx-subhosting-serve-their-clients-storefronts-fast) e aproveitamos nosso relacionamento com eles para ter um canal de comunicação direto com sua liderança, o que foi crucial para resolver o problema de serviço degradado o mais rápido possível.\n\n- **Infraestrutura de Backup na AWS:** Construímos uma infraestrutura de backup usando a AWS para ter uma rede de segurança caso a Deno enfrentasse problemas mais profundos.\n\n- **Canal de Suporte Aprimorado:** Introduzimos um novo [canal de suporte centralizado em nosso servidor Discord](https://discord.com/channels/985687648595243068/1176583956573999114) para comunicação eficiente com parceiros e clientes em momentos de alta demanda.\n\n## Principais resultados\n\nApós o período BFCM, nos reunimos com alguns de nossos clientes para falar de suas experiências. Segue um pouco de suas histórias:\n\n> A Embelleze superou todas as expectativas de vendas no ecommerce durante esta BF. No dia 24, alcançamos as maiores vendas da história da loja virtual da Embelleze! Isso foi graças à plataforma deco, que proporcionou uma experiência de compra prática, rápida e amigável ao usuário, a [Tec4u](https://www.tec4udigital.com/), que nos apoiou na transição para deco, e a expertise da [Sourei](http://sourei.com.br/), que nos permitiu otimizar nossos gastos com mídia e ter total observabilidade dos resultados. Essas mudanças levaram a um aumento de 125% em nosso Retorno sobre Investimento (ROI) e um crescimento de 144% na receita.\n\n- Aline Augusto, Head de ecommerce, marketplace e mídia na [Embelleze](http://embelleze.com/)
\n\n\n\n_Gráfico mostrando a receita do ecommerce da Embelleze nas 24 horas da Black Friday 2023. As linhas mostram a receita deste ano vs. o ano passado vs. a meta para este ano._\n\n> Esta Black Friday foi ótima para todos os nossos clientes que estão na [deco.cx](https://deco.cx/). Eu vi pessoalmente como a plataforma da deco possibilita melhores experiências de compra e mais eficiência no gerenciamento diário de ecommerces. Tenho ganhado muito com nossa parceria - eles de fato ouvem nossos feedbacks sobre as ferramentas de otimização de desempenho da plataforma.\n\n- Henrique Reis, Co-Fundador e CEO da [Sourei Digital Services](http://sourei.com.br/)
\n\n> Nosso ecommerce cresceu muito no ano passado e nossos resultados da Black Friday de 2022 foram incríveis. Este ano, escolhemos reduzir nossa estratégia de promoção com descontos menos expressivos. Mesmo assim, superamos nossa meta original (manter os resultados do ano passado), aumentando nossas vendas em 15%!\n\n- Guilherme Ladowsky, Sócio na [Aviator](http://aviator.com.br/)
\n\n> Migramos para a deco em setembro e o impacto na performance do site foi instantâneo - passamos de uma média de PageSpeed de 20 em dispositivos móveis para mais de 80. Isso foi especialmente importante para nós, já que mais da metade de nossas vendas são feitas por dispositivos móveis. Além da melhoria no desempenho, trabalhamos com a [agência eplus](https://www.agenciaeplus.com.br/) e outros parceiros para aumentar a taxa de conversão da nossa loja. E agora estamos colhendo os benefícios desses investimentos - vendemos 100% a mais nesta BF em comparação com o mesmo período do ano passado!\n\n- Tania Puglisi, Head de ecommerce na [OpenBox2](http://openbox2.com.br/)
\n\n## Próxima Black Friday\n\nQuanto ao período BFCM do próximo ano, pretendemos ter milhares de projetos ao vivo na [deco.cx](https://deco.cx/), desde _landing pages_ geradas por IA até as maiores operações de ecommerce do mundo.\n",
+ "seo": {
+ "image": "https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/64896cb4-327b-4c6d-a7b7-9a97a6df4bff"
+ }
+ }
+ },
+ "date": "12/13/2023",
+ "path": "black-friday-23-results",
+ "author": "Maria Cecilia Marques",
+ "tags": [],
+ "readTime": "3"
+ },
+ {
+ "img": "https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/1d6078d8-29e6-4bdc-8d3a-9c8b5566de69",
+ "body": {
+ "en": {
+ "descr": "Leverage stale caching and tracing on all loaders at deco.cx",
+ "title": "New Loaders API: Enhancing Stale Caching and Tracing",
+ "content": "## Introduction\n\nStale caching has long been the secret behind the speed and reliability of deco.cx websites. With ecommerce APIs often experiencing latency between 1 to 7 seconds, crafting a rendering engine that responds in a sub-second timescale requires a meticulously designed caching layer. Today, we're excited to announce a pivotal shift in how stale caching operates on deco.cx, introducing a simpler API for developers and significantly improving observability.\n\nIn the past, utilizing deco.cx's stale caching layer meant developers had to employ a custom `fetch` implementation provided by the deco.cx framework. This custom fetch modified the fetched URL, routing the request through deco's CDN and incorporating stale caching. For example, when fetching `https://example.com`, the framework would actually retrieve `https://decocache.com?src=\"https://example.com\"`. However, with the growing number of apps on our deco.store, some services already provided libraries for interacting with their APIs, making our custom fetch implementation impractical. Moreover, integrating tracing was challenging due to the framework's lack of control over HTTP connections. Consequently, we're transitioning away from the custom `fetch` implementation, relocating the caching layer to our loaders. This new API offers seamless support for both stale caching and tracing.\n\n## Opting into the new features: a simplified transition process\n\nTo start using the new loaders API, set the environment variable:\n\n```sh\nexport ENABLE_LOADER_CACHE=true\n```\n\n## Enable stale caching\n\nBy default, stale caching remains inactive in loaders. Activating this feature requires a simple modification in your loader's code:\n\n```ts\n// ... loader code\n\nexport const cache = 'stale-while-revalidate'\n```\n\nYou have the option to set the cache variable to either `stale-while-revalidate` or `no-store`, with the default being `no-store`.\n\nNow, your loader is stale cached! To confirm, open a page where your loader is used, add a `?__d` query string to the URL, and observe tracing information in the terminal, including cache states such as `HIT`, `MISS`, `STALE`, and `BYPASS`.\n\n```sh\n[200] 1312ms /camisa-masc-classic-linen-ml-verde-forest-46661-206/p\n[====================] 1312ms 200 /camisa-masc-classic-linen-ml-verde-forest-46661-206/p\n[ ] 0ms load-page\n[ ] 23ms router\n[ ===================] 1234ms load-data\n[ ===================] 1233ms Product Page@sections\n[ ] 0ms PDP Loader@data.slug\n[ ===================] 1231ms STALE PDP Loader@extensions.0\n[ ] 47ms render-to-string\n```\n\n**HIT**: Cache considered fresh (standard max-age: 60 seconds). **STALE**: Cache not fresh, but stale content served (background validation triggered). **MISS**: Loader is cacheable, but data not in the cache. **BYPASS**: Loader not cacheable, possibly due to specific configurations.\n\nNote that the cache key varies with the props content passed to the loader. To vary the loader's response with the `Request` object, read the next section.\n\n## Varying the Cache\n\nSome loaders may need to vary based on properties available only in the `Request` object, such as query strings, cookies, etc. To achieve this, open your loader's file and export the `cacheKey` function:\n\n```ts\nexport const cacheKey = (req: Request, ctx: AppContext): string => '';\n```\n\nThis function allows the developer to precisely describe how the cache should vary.\n\n\n## Example\n\nTo illustrate, let's consider a practical scenario. Suppose you're building a loader for fetching a paginated response, with the pagination information stored in a `?page=` parameter. Here's how you can correctly implement this loader:\n\n```ts\ninterface Props {\n // ... loader props\n}\n\nconst loader = (props: Props, req: Request, ctx: AppContext) {\n // Implementation details for fetching paginated response\n}\n\nexport const cache = 'stale-while-revalidate'\n\n// Vary the cache with the page parameter\nexport const cacheKey = (req: Request, ctx: AppContext) => {\n const url = new URL(req.url)\n return url.searchParams.get('page')\n}\n```\n\nIn this example, the `loader` function encapsulates the logic for fetching a paginated response, while the `cache` setting ensures stale-while-revalidate caching. The `cacheKey` function intelligently varies the cache based on the `page` parameter, allowing for a dynamic and efficient caching strategy tailored to your specific use case.\n\n## Conclusion\n\nThese changes mark the beginning of forthcoming improvements in both performance and observability for websites built on deco.cx. We'll start testing this new feature and gradually roll it out for our customers by default.\n\nFor more info, check out the [original PR](https://github.com/deco-cx/deco/pull/502) on GitHub.",
+ "seo": {
+ "title": "New Loaders API: Enhancing Stale Caching and Tracing",
+ "description": "Leverage stale caching and tracing on all loaders at deco.cx"
+ }
+ },
+ "pt": {
+ "descr": "Mudanças na camada de cache da deco e melhorias no tracing",
+ "title": "Nova API de Loaders: Aprimorando Stale Caching e Tracing",
+ "content": "## Introdução\n\nStale caching tem sido há muito tempo o segredo por trás da velocidade e confiabilidade dos sites deco.cx. Com APIs de comércio eletrônico frequentemente enfrentando latência entre 1 a 7 segundos, criar um mecanismo de renderização que responda em uma escala de sub-segundos requer uma camada de caching meticulosamente projetada. Hoje, estamos animados em anunciar uma mudança fundamental na forma como o stale caching opera no deco.cx, introduzindo uma API mais simples para desenvolvedores e melhorando significativamente a observabilidade.\n\nNo passado, utilizar a camada de stale caching do deco.cx significava que os desenvolvedores tinham que empregar uma implementação customizada de `fetch` fornecida pelo framework deco.cx. Esse fetch customizado modificava a URL solicitada, direcionando a requisição através do CDN do deco e incorporando stale caching. Por exemplo, ao buscar `https://example.com`, o framework realmente recuperaria `https://decocache.com?src=\"https://example.com\"`. No entanto, com o crescente número de aplicativos no decohub, alguns serviços já forneciam bibliotecas para interagir com suas APIs, tornando impraticável nossa implementação customizada de `fetch`. Além disso, a integração do tracing era desafiadora devido à falta de controle do framework sobre as conexões HTTP. Consequentemente, estamos nos afastando da implementação customizada de `fetch`, realocando a camada de caching para nossos loaders. Esta nova API oferece suporte perfeito tanto para o stale caching quanto para o tracing.\n\n## Optando pelas Novas Funcionalidades: Um Processo de Transição Simplificado\n\nPara começar a usar a nova API de loaders, configure a variável de ambiente:\n\n```sh\nexport ENABLE_LOADER_CACHE=true\n```\n\n## Habilitar o Stale Caching\n\nPor padrão, o stale caching permanece inativo nos loaders. Ativar essa funcionalidade requer uma modificação simples no código do seu loader:\n\n```ts\n// ... código do loader\n\nexport const cache = 'stale-while-revalidate'\n```\n\nVocê tem a opção de configurar a variável de cache para `stale-while-revalidate` ou `no-store`, sendo o padrão `no-store`.\n\nAgora, seu loader está com stale caching! Para confirmar, abra uma página onde seu loader é usado, adicione uma string de consulta `?__d` à URL e observe as informações de tracing no terminal, incluindo os estados de cache como `HIT`, `MISS`, `STALE` e `BYPASS`.\n\n```sh\n[200] 1312ms /camisa-masc-classic-linen-ml-verde-forest-46661-206/p\n[====================] 1312ms 200 /camisa-masc-classic-linen-ml-verde-forest-46661-206/p\n[ ] 0ms load-page\n[ ] 23ms router\n[ ===================] 1234ms load-data\n[ ===================] 1233ms Product Page@sections\n[ ] 0ms PDP Loader@data.slug\n[ ===================] 1231ms STALE PDP Loader@extensions.0\n[ ] 47ms render-to-string\n```\n\n**HIT**: Cache considerado fresco (max-age padrão: 60 segundos). **STALE**: Cache não está fresco, mas conteúdo antigo servido (validação em segundo plano acionada). **MISS**: Loader é cacheável, mas dados não estão no cache. **BYPASS**: Loader não é cacheável, possivelmente devido a configurações específicas.\n\nObserve que a chave de cache varia com o conteúdo de props passado para o loader. Para variar a resposta do loader com o objeto `Request`, leia a próxima seção.\n\n## Variando o Cache\n\nAlguns loaders podem precisar variar com base em propriedades disponíveis apenas no objeto `Request`, como strings de consulta, cookies, etc. Para alcançar isso, abra o arquivo do seu loader e exporte a função `cacheKey`:\n\n```ts\nexport const cacheKey = (req: Request, ctx: AppContext): string => '';\n```\n\nEssa função permite que o desenvolvedor descreva precisamente como o cache deve variar.\n\n## Exemplo\n\nPara ilustrar, considere um cenário prático. Suponha que você esteja construindo um loader para buscar uma resposta paginada, com informações de paginação armazenadas em um parâmetro `?page=`. Veja como você pode implementar corretamente esse loader:\n\n```ts\ninterface Props {\n // ... props do loader\n}\n\nconst loader = (props: Props, req: Request, ctx: AppContext) {\n // Detalhes de implementação para buscar resposta paginada\n}\n\nexport const cache = 'stale-while-revalidate'\n\n// Varie o cache com o parâmetro de página\nexport const cacheKey = (req: Request, ctx: AppContext) => {\n const url = new URL(req.url)\n return url.searchParams.get('page')\n}\n```\n\nNeste exemplo, a função `loader` encapsula a lógica para buscar uma resposta paginada, enquanto a configuração `cache` garante caching stale-while-revalidate. A função `cacheKey` varia inteligentemente o cache com base no parâmetro `page`, permitindo uma estratégia de caching dinâmica e eficiente adaptada ao seu caso de uso específico.\n\n## Conclusão\n\nEssas mudanças marcam o início de melhorias futuras tanto em desempenho quanto em observabilidade para sites construídos no deco.cx. Vamos começar a testar esse novo recurso e implementá-lo gradualmente para nossos clientes por padrão.\n\nPara mais informações, confira o [PR original](https://github.com/deco-cx/deco/pull/502) no GitHub.",
+ "seo": {
+ "title": "Nova API de Loaders: Aprimorando Stale Caching e Tracing",
+ "description": "Mudanças na camada de cache da deco e melhorias no tracing"
+ }
+ }
+ },
+ "date": "05/12/2023",
+ "path": "new-loaders-api",
+ "author": "Tiago Gimenes",
+ "authorAvatar": "https://avatars.githubusercontent.com/u/1753396?v=4",
+ "tags": [
+ "loaders"
+ ]
+ },
+ {
+ "img": "https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/9cd72d58-1a57-443f-83a3-d263105670ff",
+ "body": {
+ "en": {
+ "descr": "Discurso da abertura da segunda Hackathon deco.cx.",
+ "title": "América Latina e o futuro das experiências digitais",
+ "content": "Estou extremamente empolgado em dar início à nossa segunda Hackathon deco.cx! Mas antes de começarmos, eu quero dividir algumas palavras com vocês.\n\nNós estamos reunidos aqui hoje para aprender, criar e, se tudo der certo, levar para casa um prêmio de 500 reais. Mas acreditem, esse prêmio não é o melhor que vocês vão levar daqui — longe disso.\n\nA verdadeira recompensa é a oportunidade de adquirir novas habilidades que os diferenciam e os elevam a outro patamar como desenvolvedores e desenvolvedoras. E ainda maior que isso: a oportunidade de protagonizar a próxima geração de desenvolvimento web global.\n\nO estado atual de complexidade acumulada no desenvolvimento web é insustentável. Os anos de desenvolvimento na \"câmara de eco\" dos frameworks JS gerou uma enorme fricção, uma grande barreira de entrada para desenvolver web apps.\n\nCada vez é necessário aprender mais frameworks, padrões e bibliotecas para ser minimamente produtivo. O tempo de build de sites baseados nessas stacks limitam nossa criatividade no dia a dia. Além disso, temos grandes dificuldades de entregar sites performáticos. Não precisa ser assim!\n\nVivemos em um momento único na história do desenvolvimento web. Deno está no início de uma revolução que transformará a maneira como criamos e entregamos experiências digitais. E nós temos a chance de aproveitar essa janela de oportunidade para nos destacarmos no mercado global.\n\nDeno, junto com tecnologias como Fresh e Tailwind, representam a esperança de uma nova direção. Essas tecnologias nos mostraram como é possível ser simples e eficiente. Estamos vendo nascer o próximo Node.js, diante de nossos olhos — e estamos convidados a participar e a co-criá-lo!\n\nPor outro lado, a demanda global por digitalização só acelera. Demanda por projetos, demanda por sites, demanda por pessoas desenvolvedoras. E nós temos muita oferta de talento brasileiro — jovens pessoas desenvolvedoras, muitas vezes com dificuldade de se colocar no mercado de trabalho apesar de seu grande potencial.\n\nNós temos a oportunidade de atender essa demanda, mostrando o incrível potencial dos desenvolvedores brasileiros. Não precisamos apenas seguir as tendências; podemos liderar e nos tornar referência mundial na criação de experiências digitais de alta performance.\n\nMas a nossa responsabilidade não termina com o domínio dessas tecnologias. Para promover uma mudança estrutural, não basta garantirmos o nosso próprio sucesso. Devemos nos esforçar para sermos mentores, treinarmos a próxima geração e multiplicarmos a tecnologia no Brasil, promovendo a inclusão e dando oportunidades a todos aqueles que desejam ingressar nesse mercado em constante crescimento: especialmente aqueles que previsivelmente não teriam acesso a elas.\n\nEntão, enquanto vocês participam desta Hackathon, lembrem-se do potencial que têm em mãos e da responsabilidade compartilhada. Que vocês aproveitem ao máximo essa oportunidade, tanto para o seu crescimento pessoal quanto para o desenvolvimento da nossa comunidade. Estamos construindo algo muito maior do que cada um de nós.\n\nDesejo a todos vocês um ótimo evento, repleto de aprendizado, colaboração e inovação. Que comecem os trabalhos!"
+ },
+ "pt": {
+ "descr": "Discurso da abertura da segunda Hackathon deco.cx.",
+ "title": "América Latina e o futuro das experiências digitais",
+ "content": "Estou extremamente empolgado em dar início à nossa segunda Hackathon deco.cx! Mas antes de começarmos, eu quero dividir algumas palavras com vocês.\n\nNós estamos reunidos aqui hoje para aprender, criar e, se tudo der certo, levar para casa um prêmio de 500 reais. Mas acreditem, esse prêmio não é o melhor que vocês vão levar daqui — longe disso.\n\nA verdadeira recompensa é a oportunidade de adquirir novas habilidades que os diferenciam e os elevam a outro patamar como desenvolvedores e desenvolvedoras. E ainda maior que isso: a oportunidade de protagonizar a próxima geração de desenvolvimento web global.\n\nO estado atual de complexidade acumulada no desenvolvimento web é insustentável. Os anos de desenvolvimento na \"câmara de eco\" dos frameworks JS gerou uma enorme fricção, uma grande barreira de entrada para desenvolver web apps.\n\nCada vez é necessário aprender mais frameworks, padrões e bibliotecas para ser minimamente produtivo. O tempo de build de sites baseados nessas stacks limitam nossa criatividade no dia a dia. Além disso, temos grandes dificuldades de entregar sites performáticos. Não precisa ser assim!\n\nVivemos em um momento único na história do desenvolvimento web. Deno está no início de uma revolução que transformará a maneira como criamos e entregamos experiências digitais. E nós temos a chance de aproveitar essa janela de oportunidade para nos destacarmos no mercado global.\n\nDeno, junto com tecnologias como Fresh e Tailwind, representam a esperança de uma nova direção. Essas tecnologias nos mostraram como é possível ser simples e eficiente. Estamos vendo nascer o próximo Node.js, diante de nossos olhos — e estamos convidados a participar e a co-criá-lo!\n\nPor outro lado, a demanda global por digitalização só acelera. Demanda por projetos, demanda por sites, demanda por pessoas desenvolvedoras. E nós temos muita oferta de talento brasileiro — jovens pessoas desenvolvedoras, muitas vezes com dificuldade de se colocar no mercado de trabalho apesar de seu grande potencial.\n\nNós temos a oportunidade de atender essa demanda, mostrando o incrível potencial dos desenvolvedores brasileiros. Não precisamos apenas seguir as tendências; podemos liderar e nos tornar referência mundial na criação de experiências digitais de alta performance.\n\nMas a nossa responsabilidade não termina com o domínio dessas tecnologias. Para promover uma mudança estrutural, não basta garantirmos o nosso próprio sucesso. Devemos nos esforçar para sermos mentores, treinarmos a próxima geração e multiplicarmos a tecnologia no Brasil, promovendo a inclusão e dando oportunidades a todos aqueles que desejam ingressar nesse mercado em constante crescimento: especialmente aqueles que previsivelmente não teriam acesso a elas.\n\nEntão, enquanto vocês participam desta Hackathon, lembrem-se do potencial que têm em mãos e da responsabilidade compartilhada. Que vocês aproveitem ao máximo essa oportunidade, tanto para o seu crescimento pessoal quanto para o desenvolvimento da nossa comunidade. Estamos construindo algo muito maior do que cada um de nós.\n\nDesejo a todos vocês um ótimo evento, repleto de aprendizado, colaboração e inovação. Que comecem os trabalhos!"
+ }
+ },
+ "date": "12/03/2023",
+ "path": "abertura-ii-hackathon-deco.md",
+ "author": "Guilherme Rodrigues"
+ },
+ {
+ "img": "https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/10a6a987-e88a-4d3b-b915-a6346d16f43c",
+ "body": {
+ "en": {
+ "descr": "Nuvemshop is now available on deco.cx",
+ "title": "Nuvemshop Integration",
+ "seo": {
+ "image": "https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/5160315f-a46c-4e15-977a-29f70ad7cc40"
+ },
+ "content": "We're thrilled to bring you the latest chapter in our journey to streamline your e-commerce experience. Introducing the new integration of [deco.cx](https://deco.cx/) with Nuvemshop, an e-commerce platform for growing businesses!\n\n## Seamless Integration for Growth\n\nOur goal is simple: to empower your e-commerce store with the robust capabilities of Nuvemshop, making it easier than ever to expand your business.\n\nSimply fill in your Nuvemshop store details on [deco.cx](https://deco.cx/), and you're all set to fetch your products and customize your frontend.\n\n## Available Features\n\n- Product Shelf\n\n` tag.\n\nEngage your developer to make the necessary adjustments to remove the `` tag and set Safari12 as the build target. We recommend performing this step after migrating to ahead-of-time builds to ensure a smooth transition.\n\nAs we kick off the holiday shopping season, the [Deco.cx](https://deco.cx/) team is dedicated to providing stability and reliability during this critical period. Starting this week, we will be actively working on stability improvements to enhance your experience on Black Friday. It's crucial to stay up-to-date with the latest Deco versions and keep an eye out for more informative posts on how to optimize your online store for success on Black Friday."
+ },
+ "pt": {
+ "descr": "Checklist para uma Black Friday tranquila",
+ "title": "Como se preparar para a Black Friday 2023",
+ "content": "A Black Friday está chegando e é uma oportunidade incrível para as marcas aumentarem suas vendas. Para ajudar você a aproveitar ao máximo esse período de compras, compilamos uma lista de tarefas essenciais para garantir que sua loja online esteja totalmente preparada para a Black Friday 2023.\n\n## Adote a Compilação Ahead-of-Time\n\nO Fresh recentemente introduziu um recurso inovador chamado \"compilações _ahead-of-time_\", projetado para transformar como você cria e entrega seu site. Essa abordagem não apenas estabiliza o JavaScript da sua loja, mas também melhora significativamente os tempos de inicialização do servidor. Para entender essa nova abordagem completamente, você pode explorar a documentação estruturada fornecida pelo Fresh **[aqui](https://fresh.deno.dev/docs/concepts/ahead-of-time-builds)**.\n\nNa [deco.cx](https://deco.cx/), recomendamos fortemente a adoção da versão _ahead-of-time_, pois ela fornece escalabilidade ao seu servidor, o que é essencial para lidar com as demandas de eventos como a Black Friday. Para migrar para essa nova versão, instrua seu desenvolvedor a realizar a atualização usando o seguinte comando:\n\n```sh\ndeno run -Ar https://deco.cx/upgrade\n```\n\nApós concluir a atualização, certifique-se de que:\n\n1. Sua loja está funcionando corretamente, incluindo a verificação das páginas inicial, detalhes do produto (PDP) e listagem de produtos (PLP), além de verificar a funcionalidade de adicionar ao carrinho e quaisquer outros fluxos críticos.\n2. A edição administrativa está funcionando sem problemas, permitindo que você edite as seções da sua loja e as publique.\n\nSe sua loja já estiver online, a equipe do [deco.cx](https://deco.cx/) já executou esse comando para você. Para verificar, peça ao seu desenvolvedor para procurar um Pull Request (PR) no GitHub com o título \"Preparations for Black Friday\". Se encontrar algum problema durante esse processo, não hesite em nos contatar no [deco.cx discord](https://deco.cx/discord).\n\n## Suporte ao Mobile Safari\n\nHá alguns meses, compartilhamos um post no blog detalhando as **[lições que aprendemos](https://www.deco.cx/en/blog/licoes-6-meses.md)** com nossas lojas em produção. Recomendamos fortemente a implementação de todas as sugestões mencionadas no post antes da Black Friday. No entanto, um dos passos mais importantes é garantir que sua loja funcione perfeitamente nas versões 12, 13 e 14 do Safari.\n\nPara isso, siga estas etapas:\n\n1. Verifique se seu arquivo **`fresh.config.ts`** inclui o destino de compilação Safari12.\n2. Certifique-se de que seu site não usa a tag **``**.\n\nPeça ao seu desenvolvedor para fazer os ajustes necessários para remover a tag **``** e configurar o Safari12 como destino de compilação. Recomendamos realizar esta etapa após migrar para as compilações *ahead-of-time* para garantir uma transição tranquila.\n\nAo iniciarmos a temporada de compras de fim de ano, a equipe da [deco.cx](https://deco.cx/) está empenhada em fornecer estabilidade e confiabilidade durante este período crítico. A partir desta semana, estaremos trabalhando ativamente em melhorias de estabilidade para aprimorar sua experiência na Black Friday. É crucial ficar atualizado com as últimas versões da deco e ficar atento a mais postagens informativas sobre como otimizar sua loja online para o sucesso na Black Friday.",
+ "seo": {
+ "image": "https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/8242aca6-5215-4321-8e9d-f876fc1d1d58",
+ "title": "Black Friday 2023",
+ "description": "Checklist para uma Black Friday tranquila",
+ "canonical": "/black-friday-2023"
+ }
+ }
+ },
+ "date": "11/06/2023",
+ "path": "black-friday-2023.md",
+ "author": "Tiago Gimenes",
+ "readTime": "5",
+ "authorAvatar": "https://avatars.githubusercontent.com/u/1753396?v=4",
+ "tags": []
+ },
+ {
+ "img": "https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/c4f791fe-9f43-400d-94a0-c203a6dc3b37",
+ "body": {
+ "en": {
+ "descr": "Use deco.cx's powerful CMS directly from the command line",
+ "title": "deco play",
+ "seo": {
+ "image": "https://github.com/deco-sites/std/assets/18706156/ec92362b-9d18-42d8-9c60-bcb5bfef0d71",
+ "title": "deco play is released",
+ "description": "Use deco.cx's powerful CMS directly from the command line with Preact, Tailwind and Deno"
+ },
+ "content": "## deco play\n\nMaking life easier for developers is at deco's core, and today we're proud to announce deco play, a new way to test our stack in record time!\n\nTo start testing deco play, go to [https://play.deco.cx](https://play.deco.cx) and follow the instructions.\n\n\n\nIt's the fastest way to spin up a deco site or app on your local machine and start developing with Preact, Tailwind, Deno and getting all the benefits of our CMS that automatically extracts the schema from your functions (UI components, loaders, actions…), makes them easily editable and composable on a Web UI that saves the data locally.\n\nAnd you don't need to be logged into [deco.cx](https://deco.cx) to use deco play, it's just one click away from the command line!"
+ },
+ "pt": {
+ "descr": "Use deco.cx's powerful CMS directly from the command line",
+ "title": "deco play",
+ "content": "## deco play\n\nMaking life easier for developers is at deco's core, and today we're proud to announce deco play, a new way to test our stack in record time!\n\nTo start testing deco play, go to [https://play.deco.cx](https://play.deco.cx) and follow the instructions.\n\n\n\nIt's the fastest way to spin up a deco site or app on your local machine and start developing with Preact, Tailwind, Deno and getting all the benefits of our CMS that automatically extracts the schema from your functions (UI components, loaders, actions…), makes them easily editable and composable on a Web UI that saves the data locally.\n\nAnd you don't need to be logged into [deco.cx](https://deco.cx) to use deco play, it's just one click away from the command line!",
+ "seo": {
+ "image": "https://github.com/deco-sites/std/assets/18706156/ec92362b-9d18-42d8-9c60-bcb5bfef0d71",
+ "title": "deco play is released",
+ "description": "Use deco.cx's powerful CMS directly from the command line with Preact, Tailwind and Deno"
+ }
+ }
+ },
+ "date": "10/31/2023",
+ "path": "deco-play.md",
+ "author": "Héricles Emanuel",
+ "readTime": "2",
+ "authorAvatar": "https://avatars.githubusercontent.com/u/30700596?v=4"
+ },
+ {
+ "img": "https://user-images.githubusercontent.com/121065272/278081341-14f42eff-92aa-46aa-b282-c3ce2823fcd5.png",
+ "body": {
+ "en": {
+ "descr": "Analytics with realtime, goals and conversions!",
+ "title": "New Analytics Tool",
+ "seo": {
+ "image": "https://github.com/deco-cx/apps/assets/882438/1b3f06d2-1d2d-4ec8-a9cf-2c14008229a6",
+ "title": "New Analytics Tool",
+ "description": "Analytics with realtime, goals and conversions!"
+ },
+ "content": "## Introduction\n\nFollowing up on [Updated Redirects configuration](https://www.deco.cx/en/blog/redirects.md), **we're releasing today the new analytics tool**. We comprehend the significance of tracking every step of website users, from their first access to the site, to viewing a product, completing a purchase, and more. That's why we have evolved our tool!\n\n## Analytics on deco\n\nWe understand that data collection tools can impact the platform's performance. For this reason, deco uses a tool that seeks to strike a balance between performance and the collection of essential data needed for the analysis of various website usage metrics.\n\nIn addition to a smaller and more efficient data collector, we also have some exciting updates with the new tool!\n\n### Better UI/UX\n\nOur new, user-friendly and visually appealing analytics tool provides metrics such as location, device, operating system, and bounce rate, making it a more enjoyable experience.\n\n\n\n### Realtime Analytics\n\n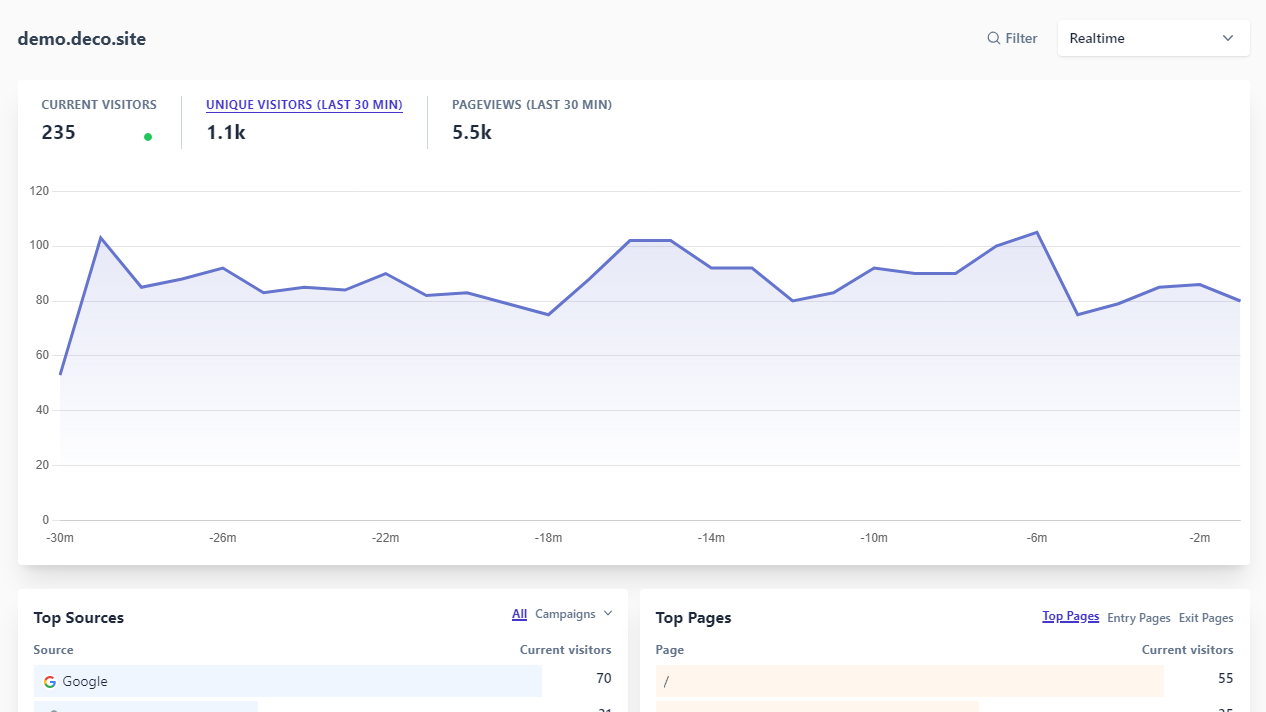\n\nSee your current visitors in real-time. No more waiting two days for data.\n\n### Goals and Funnels\n\n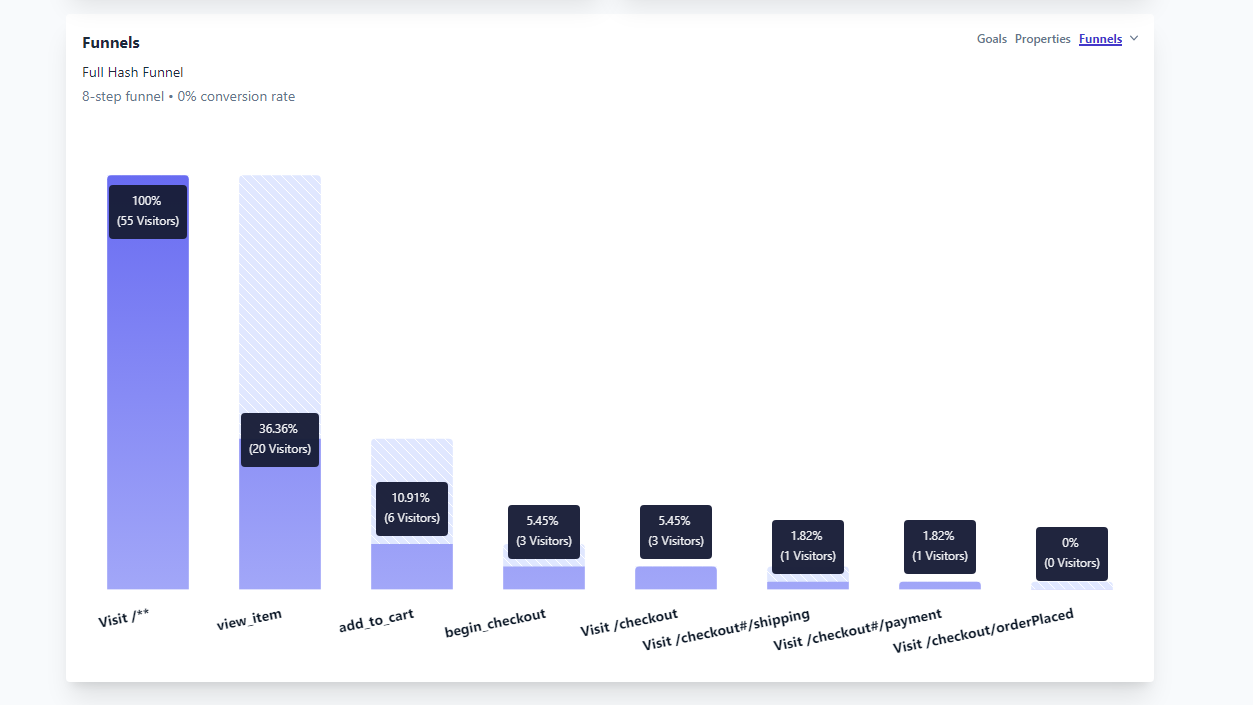\n\nIt's also possible to see at which point in the purchasing journey the user decides to interrupt the process. This can happen during the initial page view, immediately after adding a product to the cart, or even during the checkout!\n\n## Analytics Apps\n\n[You can view the code that powers Deco Analytics](https://github.com/deco-cx/apps/tree/main/analytics), and even make contributions!\n\nTo use this tool, you need to update the **deco-cx/apps** to version 0.17.3 or higher.\n\nIn the coming days, we will commence the roll-out to our production customers. That's it for today. Keep an eye out for our next release!"
+ },
+ "pt": {
+ "descr": "Analytics with realtime, goals and conversions!",
+ "title": "New Analytics Tool",
+ "content": "## Introduction\n\nFollowing up on [Updated Redirects configuration](https://www.deco.cx/en/blog/redirects.md), **we're releasing today the new analytics tool**. We comprehend the significance of tracking every step of website users, from their first access to the site, to viewing a product, completing a purchase, and more. That's why we have evolved our tool!\n\n## Analytics on deco\n\nWe understand that data collection tools can impact the platform's performance. For this reason, deco uses a tool that seeks to strike a balance between performance and the collection of essential data needed for the analysis of various website usage metrics.\n\nIn addition to a smaller and more efficient data collector, we also have some exciting updates with the new tool!\n\n### Better UI/UX\n\nOur new, user-friendly and visually appealing analytics tool provides metrics such as location, device, operating system, and bounce rate, making it a more enjoyable experience.\n\n\n\n### Realtime Analytics\n\n\n\nSee your current visitors in real-time. No more waiting two days for data.\n\n### Goals and Funnels\n\n\n\nIt's also possible to see at which point in the purchasing journey the user decides to interrupt the process. This can happen during the initial page view, immediately after adding a product to the cart, or even during the checkout!\n\n## Analytics Apps\n\n[You can view the code that powers Deco Analytics](https://github.com/deco-cx/apps/tree/main/analytics), and even make contributions!\n\nTo use this tool, you need to update the **deco-cx/apps** to version 0.17.3 or higher.\n\nIn the coming days, we will commence the roll-out to our production customers. That's it for today. Keep an eye out for our next release!"
+ }
+ },
+ "date": "10/24/2023",
+ "path": "analytics.md",
+ "author": "Matheus Gaudencio and Nathan Luiz",
+ "readTime": "2",
+ "authorAvatar": "https://lh3.googleusercontent.com/a/ACg8ocIjb0LttoalDQynwu_U2A43KTAulDjme3BwrvxzAOOBzQ=s96-c"
+ },
+ {
+ "img": "https://user-images.githubusercontent.com/121065272/278021160-f0fa7e72-ad95-4dfd-b201-fdbee639d7a0.png",
+ "body": {
+ "en": {
+ "descr": "Create and manage Redirects",
+ "title": "Redirects",
+ "seo": {
+ "image": "https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/be8ca70a-6e2f-42ed-965c-6771e1fcda39",
+ "title": "Redirects",
+ "description": "Create and manage Redirects on deco.cx"
+ },
+ "content": "\nToday, we're excited to introduce a new feature that allows our users to\n**manage redirects on their websites directly** on deco.cx's Admin. Now, users\ncan create, edit and delete redirects without any extra effort.\n\nYou can test this feature right now by accessing the admin panel at\n[https://admin.deco.cx](https://admin.deco.cx/).\n\n\n\n## Types of Redirect\n\nWhen it comes to creating redirects, you have two options: temporary or\npermanent.\n\n- **Temporary**: not indexed, stored or cached by crawlers (e.g: Google) and\n browsers. They provide a short-term solution and are ideal for situations\n where you might want to reroute traffic temporarily.\n\n- **Permanent**: stored by search engines and crawlers. They permanently update\n the path for the current page, and they are hard to undo. If you're unsure\n about which type of redirect to choose, we strongly recommend using temporary\n redirects.\n\n### **Enabling this Feature for Your Site**\n\nFor websites created after the date of this blog post (Oct 23 2023), this\nfeature will be enabled by default.\n\nIf your site was created before this blog post, you can enable this feature by\nupdating your site dependencies to `deco@1.41.11` and `apps@0.15.8`. (Run\n`deno task update`) Next, update your app's **`site`** by adding a new Site Map\nentry named `Redirects`. Once this is done, all managed redirects will function\nseamlessly on your site.\n\n\n\nIf you have any questions, feel free to reach us at\n[deco.cx Discord Server](https://deco.cx/discord).\n\nThat's all for today. Stay tuned for our next release!\n"
+ },
+ "pt": {
+ "descr": "Create and manage Redirects",
+ "title": "Redirects",
+ "seo": {
+ "image": "https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/be8ca70a-6e2f-42ed-965c-6771e1fcda39",
+ "title": "Redirects",
+ "description": "Create and manage Redirects on deco.cx"
+ },
+ "content": "\nToday, we're excited to introduce a new feature that allows our users to\n**manage redirects on their websites directly** on deco.cx's Admin. Now, users\ncan create, edit and delete redirects without any extra effort.\n\nYou can test this feature right now by accessing the admin panel at\n[https://admin.deco.cx](https://admin.deco.cx/).\n\n\n\n## Types of Redirect\n\nWhen it comes to creating redirects, you have two options: temporary or\npermanent.\n\n- **Temporary**: not indexed, stored or cached by crawlers (e.g: Google) and\n browsers. They provide a short-term solution and are ideal for situations\n where you might want to reroute traffic temporarily.\n\n- **Permanent**: stored by search engines and crawlers. They permanently update\n the path for the current page, and they are hard to undo. If you're unsure\n about which type of redirect to choose, we strongly recommend using temporary\n redirects.\n\n### **Enabling this Feature for Your Site**\n\nFor websites created after the date of this blog post (Oct 23 2023), this\nfeature will be enabled by default.\n\nIf your site was created before this blog post, you can enable this feature by\nupdating your site dependencies to `deco@1.41.11` and `apps@0.15.8`. (Run\n`deno task update`) Next, update your app's **`site`** by adding a new Site Map\nentry named `Redirects`. Once this is done, all managed redirects will function\nseamlessly on your site.\n\n\n\nIf you have any questions, feel free to reach us at\n[deco.cx Discord Server](https://deco.cx/discord).\n\nThat's all for today. Stay tuned for our next release!\n"
+ }
+ },
+ "date": "10/20/2023",
+ "path": "redirects.md",
+ "author": "Igor Brasileiro",
+ "readTime": "4",
+ "authorAvatar": "https://cdn.discordapp.com/avatars/87899733435088896/ae5525772e63fc0f47680e90b0902cd2.webp?size=240"
+ },
+ {
+ "img": "https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/b86b6a80-ca1a-478a-ba30-8499105f146b",
+ "body": {
+ "en": {
+ "descr": "Easier to use, refreshed UI, and better JSON editing ",
+ "title": "New Editor",
+ "seo": {
+ "image": "https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/7188c283-d2d7-4a38-bbbd-b4e3db275df4",
+ "title": "New Editor",
+ "description": "Easier to use, refreshed UI, and better JSON editing"
+ },
+ "content": "## New Editor\n\nFollowing up on our [Admin Reloaded](https://www.deco.cx/en/blog/admin-reloaded.md), we're **releasing today the new CMS editor.** This release includes a redesigned layout based on feedback from our users, an emphasis on content segmentation, and a new inline JSON editor.\n\n`\n\nEm versões anteriores de nossos templates, utilizávamos a tag HTML5 ``. Essa tag permitia a criação de modais com suporte à acessibilidade. No entanto, identificamos dois problemas principais relacionados a ela:\n\n1. Exigia JavaScript para funcionar corretamente, o que ia de encontro à nossa filosofia de minimizar o uso de JavaScript na página.\n2. Versões recentes do iPhone (10, 11 e 12) não oferecem suporte a essa tag, o que nos forçava a inserir \"polyfills\". Essa inserção era síncrona e prejudicava significativamente o desempenho dos sites.\n\nDevido a esses dois pontos mencionados, adotamos uma abordagem alternativa usando a tag ``, recomendamos fazer a migração o mais rápido possível para `\n
\n
\n```\n\nNesse exemplo, estamos combinando flexbox (classe `flex`) com unidades percentuais (`width: 100%`). Isso pode funcionar em navegadores mais recentes, mas causa problemas em versões mais antigas do Safari, como o iPhone 10, 11 e 12.\n\nPara solucionar esse problema, recomendamos substituir `w-full` por classes relacionadas ao flexbox:\n\n ```html\n
\n
\n
\n```\n\nIsso garantirá que o layout funcione corretamente em todos os navegadores.\n\n\nEstamos sempre acompanhando os novos projetos, coletando os apresentados e melhorando o template [Storefront](https://github.com/deco-sites/storefront).",
+ "seo": {
+ "image": "https://github.com/deco-cx/blog/assets/1753396/20fb996b-4d04-417c-af69-5beb2a7e7969",
+ "title": "6 meses de lojas em produçāo - Uma jornada de aprendizados",
+ "description": "Nos últimos seis meses acumulamos um valioso conjunto de lições ao levar lojas para produção. Nesse período, aprendemos o que deve ser evitado, o que não funciona e a melhor maneira de iniciar o desenvolvimento de uma loja online. A seguir, compartilhamos um resumo das lições que adquirimos durante essa jornada."
+ }
+ },
+ "en": {
+ "title": "6 months of stores in production",
+ "descr": "A journey of learning",
+ "content": "Over the past six months, we have accumulated a valuable set of lessons while taking stores into production. During this period, we have learned what to avoid, what doesn't work, and the best way to start developing an online store. Below, we share a summary of the lessons we have acquired during this journey.\n\n## **Starting the Development of a Store**\n\nAll projects created at Deco start from a pre-configured template with various components, integrations, and themes. We have noticed that after creating the store, some developers turn to GitHub to modify components and themes directly in the code. Although this is a natural reflex for a developer's work, we have noticed that projects in which development mainly focuses on the CMS (Content Management System) tend to be completed more quickly and with better performance.\n\nThe ideal flow that we have discovered is as follows:\n\n1. Create the project.\n2. Customize the theme, components, SEO optimization, among others through the Deco admin.\n3. Present the result to the end client and collect feedback.\n4. Based on the feedback, adjust the store in the CMS, using the predefined sections, and return to step 3.\n5. If the client is satisfied, migrate the domain to Deco.\n6. If it is necessary to make changes in the code, add specific sections for the use case in question.\n\n## **The `
` Tag**\n\nIn previous versions of our templates, we used the HTML5 tag **``**. This tag allowed the creation of modals with accessibility support. However, we identified two main problems related to it:\n\n1. It required JavaScript to work properly, which went against our philosophy of minimizing the use of JavaScript on the page.\n2. Recent versions of iPhones (10, 11, and 12) do not support this tag, which forced us to insert \"polyfills\". This insertion was synchronous and significantly affected the performance of the websites.\n\nDue to these two mentioned points, we have adopted an alternative approach using the **``** tag, we recommend migrating to **`\n
\n
\n\n```\n\nIn this example, we are combining flexbox (class **`flex`**) with percentage units (**`width: 100%`**). This may work in newer browsers but causes issues in older versions of Safari, such as iPhone 10, 11, and 12.\n\nTo solve this problem, we recommend replacing **`w-full`** with classes related to flexbox:\n\n```html\n
\n
\n
\n\n```\n\nThis will ensure that the layout works correctly in all browsers.\n\nWe are always keeping up with new projects, collecting feedback, and improving the **[Storefront](https://github.com/deco-sites/storefront)** template.",
+ "seo": {
+ "image": "https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/1bc67d75-698c-4d38-9035-64b097273881",
+ "title": "6 months of stores in production",
+ "description": "A journey of learning"
+ }
+ }
+ },
+ "path": "licoes-6-meses.md",
+ "img": "https://github.com/deco-cx/blog/assets/1753396/20fb996b-4d04-417c-af69-5beb2a7e7969",
+ "date": "10/10/2023",
+ "author": "Gui Tavano, Tiago Gimenes"
+ },
+ {
+ "img": "https://user-images.githubusercontent.com/121065272/278023987-b7ab4ae9-6669-4e38-94b8-268049fa6569.png",
+ "body": {
+ "en": {
+ "descr": "Revolutionizing Web Development",
+ "title": "Partials",
+ "content": "[Fresh](https://fresh.deno.dev/), the web framework used by Deco, is known for enabling the creation of high-performance pages. One of the reasons why pages created in Deco are so efficient is due to the island architecture. This architecture allows developers to remove non-interactive parts of the final JavaScript package, reducing the total amount of JavaScript on the page and freeing up the browser to perform other tasks.\n\nHowever, one of the limitations of this architecture is that very complex pages, with a lot of interactivity and therefore many islands, still require a large amount of JavaScript. Fortunately, this limitation is now a thing of the past, thanks to the introduction of Partials.\n\n## How It Works\n\nPartials, inspired by [htmx](https://htmx.org/docs/), operate with a runtime that intercepts user interactions with button, anchor, and form elements. These interactions are sent to our server, which calculates the new state of the page and responds to the browser. The browser receives the new UI state in pure HTML, which is then processed and the differences are applied, changing the page to its final state. For more detailed information about Partials, see the [Fresh documentation](https://github.com/denoland/fresh/issues/1609).\n\n## Partials in Action\n\nWe are migrating the components of the Deco store to the new Partials solution. So far, we have migrated the SKU selector, which can be viewed in action [here](http://storefront-vtex.deco.site/camisa-masculina-xadrez-sun-e-azul/p?skuId=120). More changes, such as `infinite scroll` and improvements to filters, are coming soon.\n\nAnother unlocked feature is the ability to create folds on the page. E-commerce pages are usually long and contain many elements. Browsers often face problems when there are many elements in the HTML. To deal with this, the fold technique was invented.\n\nThe basic idea of this technique is to divide the content of the page into two parts: the content above and the content below the fold. The content above the fold is loaded on the first request to the server. The content below the fold is loaded as soon as the first request is completed. This type of functionality used to be difficult to implement in older architectures. Fortunately, we have embedded this logic in a new section called `Deferred`. This section accepts a list of sections as a parameter that should have their loading delayed until a later time.\n\nTo use this new section:\n\n1. Access the Deco administration panel and add the `Rendering > Deferred` section to your page.\n2. Move the sections you want to defer to the `Deferred` section.\n3. Save and publish the page.\n4. Done! The sections are now deferred without the need to change the code!\n\nSee `Deferred` in action at this [link](https://storefront-vtex.deco.site/home-partial).\n\n> Note that, for the `Deferred` section to appear, you must be on the latest version of `fresh`, `apps`, and deco!\n\nA question you may be asking yourself now is: How do I choose the sections I should include in the deferred? To do this, use the performance tab and start with the heaviest sections that offer the greatest return!\n\nFor more information, see our [docs](https://www.deco.cx/docs/en/developing-capabilities/interactive-sections/partial)"
+ },
+ "pt": {
+ "descr": "Revolucionando o Desenvolvimento Web",
+ "title": "Partials",
+ "content": "[Fresh](https://fresh.deno.dev/), o framework web utilizado pela Deco, é conhecido por possibilitar a criação de páginas de altíssimo desempenho. Uma das razões pelas quais as páginas criadas na Deco são tão eficientes é devido à arquitetura de ilhas. Essa arquitetura permite que os desenvolvedores removam partes não interativas do pacote final de JavaScript, reduzindo a quantidade total de JavaScript na página e aliviando o navegador para realizar outras tarefas.\n\nNo entanto, uma das limitações dessa arquitetura é que páginas muito complexas, com muita interatividade e, portanto, muitas ilhas, ainda exigem uma grande quantidade de JavaScript. Felizmente, essa limitação agora é coisa do passado, graças à introdução dos Partials.\n\n## Como Funciona?\n\nOs Partials, inspirados no [htmx](https://htmx.org/docs/), operam com um runtime que intercepta as interações do usuário com elementos de botão, âncora e formulário. Essas interações são enviadas para nosso servidor, que calcula o novo estado da página e responde ao navegador. O navegador recebe o novo estado da IU em HTML puro, que é então processado e as diferenças são aplicadas, alterando a página para o seu estado final. Para obter informações mais detalhadas sobre os Partials, consulte a [documentação](https://github.com/denoland/fresh/issues/1609) do Fresh.\n\n## Partials em Ação\n\nEstamos migrando os componentes da loja da Deco para a nova solução de Partials. Até o momento, migramos o seletor de SKU, que pode ser visualizado em ação [aqui](http://storefront-vtex.deco.site/camisa-masculina-xadrez-sun-e-azul/p?skuId=120). Mais mudanças, como `infinite scroll` e melhorias nos filtros, estão por vir.\n\nOutra funcionalidade desbloqueada é a possibilidade de criar dobras na página. As páginas de comércio eletrônico geralmente são longas e contêm muitos elementos. Os navegadores costumam enfrentar problemas quando há muitos elementos no HTML. Para lidar com isso, foi inventada a técnica de dobra.\n\nA ideia básica dessa técnica é dividir o conteúdo da página em duas partes: o conteúdo acima e o conteúdo abaixo da dobra. O conteúdo acima da dobra é carregado na primeira solicitação ao servidor. O conteúdo abaixo da dobra é carregado assim que a primeira solicitação é concluída. Esse tipo de funcionalidade costumava ser difícil de implementar em arquiteturas mais antigas. Felizmente, embutimos essa lógica em uma nova seção chamada `Deferred`. Esta seção aceita uma lista de seções como parâmetro que devem ter seu carregamento adiado para um momento posterior.\n\nPara usar essa nova seção:\n\n1. Acesse o painel de administração da Deco e adicione a seção `Rendering > Deferred` à sua página.\n2. Mova as seções que deseja adiar para a seção `Deferred`.\n3. Salve e publique a página.\n4. Pronto! As seções agora estão adiadas sem a necessidade de alterar o código!\n\nVeja `Deferred` em ação neste [link](https://storefront-vtex.deco.site/home-partial).\n\n> Observe que, para a seção `Deferred` aparecer, você deve estar na versão mais recente do `fresh`, `apps` e deco!\n\nUma pergunta que você pode estar se fazendo agora é: Como escolher as seções que devo incluir no deferred? Para isso, use a aba de desempenho e comece pelas seções mais pesadas que oferecem o maior retorno!\n\nPara mais informações, veja nossas [docs](https://www.deco.cx/docs/en/developing-capabilities/interactive-sections/partial)"
+ }
+ },
+ "date": "10/06/2023",
+ "path": "partials.md",
+ "author": "Marcos Candeia, Tiago Gimenes"
+ },
+ {
+ "body": {
+ "pt": {
+ "title": "A nova fase da Lojas Torra com a deco.cx.",
+ "descr": "Como a Lojas Torra dobrou sua taxa de conversão após migrar o front do seu ecommerce para a deco.cx"
+ },
+ "en": {
+ "title": "A nova fase da Lojas Torra com a deco.cx.",
+ "descr": "Como a Lojas Torra dobrou sua taxa de conversão após migrar o front do seu ecommerce para a deco.cx"
+ }
+ },
+ "path": "case-lojas-torra",
+ "date": "08/31/2023",
+ "author": "Por Maria Cecilia Marques",
+ "img": "https://user-images.githubusercontent.com/121065272/278021874-91a4ffea-3a22-4631-a4b3-c21bbc056386.png"
+ },
+ {
+ "body": {
+ "pt": {
+ "title": "AR&Co kickstarts digital shift: Baw goes headless with deco.cx",
+ "descr": "AR&Co. is getting its headless strategy off the ground, with both quality and speed by trusting deco.cx as its frontend solution."
+ },
+ "en": {
+ "title": "AR&Co kickstarts digital shift: Baw goes headless with deco.cx",
+ "descr": "AR&Co. is getting its headless strategy off the ground, with both quality and speed by trusting deco.cx as its frontend solution."
+ }
+ },
+ "path": "customer-story-baw",
+ "date": "04/25/2023",
+ "author": "Maria Cecilia Marques",
+ "img": "https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/ec116700-62ee-408d-8621-3f8b2db72e8b",
+ "tags": []
+ },
+ {
+ "body": {
+ "pt": {
+ "content": "Com dezenas de milhões de e-commerces, o varejo digital nunca enfrentou tanta competição. Por outro lado, com o grande aumento do número de consumidores online, nunca houve maior oportunidade pra crescer. Neste contexto, **oferecer experiências distintas é crucial.**\n\nContudo, mesmo as maiores marcas tem dificuldade construir algo além do previsível - páginas lentas e estáticas para todos os usuários. O resultado todos já sabem: **baixa conversão** -- pessoas deixam de comprar na loja porque não viram um conteúdo que lhe agrada ou porquê as páginas demoraram pra carregar em seus celulares.\n\nVamos entender primeiro porque isso acontece.\n\n\n## Por quê seu site performa mal?\n\n### 1. Sua loja demora para construir\n\nO time de tecnologia para ecommerce é pouco produtivo pois trabalha com frameworks e tech stacks complexas de aprender e fazer manutenção - e que vão ficando ainda mais complexas com o tempo, além do talento em tech ser escasso.\n\nPessoas desenvolvedoras gastam horas e horas cada mês com a complexidade acidental das tecnologias usadas: esperando o tempo de deploy, cuidando de milhares de linhas de código, ou lidando com dependências no npm - sobra pouco tempo para codar de verdade.\n\nResultado: o custo de novas funcionalidades é caro e a entrega é demorada, além de ser operacionalmente complexo contratar e treinar devs.\n\n\n### 2. Sua loja demora para carregar\n\nSabe-se que a velocidade de carregamento de uma página afeta drastricamente a taxa de conversão e o SEO. Em um site \"médio\", é esperado que cada 100ms a menos no tempo de carregamento de uma página, aumente em 1% a conversão.\n\nAinda assim, a maior parte das lojas tem storefronts (frentes de loja de ecommerce) com nota abaixo de 50 no [Google Lighthouse](https://developer.chrome.com/docs/lighthouse/overview/). E poucos parecem saber resolver.\n\nCom isso, o ecommerce global perde trilhões (!) de dólares em vendas.\n\nParte do problema é a escolha do framework e das tecnologias envolvidas:\n\n- a. SPA (Single Page Application) não é a tecnologia ideal para ecommerce, especialmente para performance e SEO.\n\n- b. A complexidade de criar código com esse paradigma cria bases de código difíceis de manter e adicionar novas funcionalidades.\n\n\n### 3. Sua loja demora para evoluir\n\nNos negócios e na vida, a evolução contínua e o aprendizado diário é o que gera sucesso. Especialmente no varejo, que vive de otimização contínua de margem.\n\nContudo, times de ecommerce dependem de devs para editar, testar, aprender e evoluir suas lojas.\n\nDevs, por sua vez, estão geralmente sobrecarregadas de demandas, e demoram demais para entregar o que foi pedido, ainda que sejam tasks simples.\n\nPara piorar, as ferramentas necessárias para realizar o ciclo completo de CRO (conversion rate optimization) como teste A/B, analytics, personalização e content management system (CMS) estão fragmentadas, o que exige ter que lidar com várias integrações e diversos serviços terceirizados diferentes.\n\nTudo isso aumenta drasticamente a complexidade operacional, especialmente em storefronts de alta escala, onde o ciclo de evolução é lento e ineficaz.\n\n\n## Nossa solução\n\nNosso time ficou mais de 10 anos lidando com estes mesmo problemas. Sabemos que existem tecnologias para criar sites e lojas de alto desempenho, mas a maioria parece não ter a coragem de utilizá-las.\n\nFoi quando decidimos criar a deco.cx.\n\nPara habilitarmos a criação de experiências de alto desempenho foi necessário um novo paradigma, que simplifique a criação de lojas rápidas, sem sacrificar a capacidade de **personalização e de evolução contínua.**\n\nCriamos uma plataforma headless que integra tudo o que uma marca ou agência precisa para gerenciar e otimizar sua experiência digital, tornando fácil tomar decisões em cima de dados reais, e aumentando continuamente as taxas de conversão.\n\n## Como fazemos isso:\n\n### 1. Com deco.cx fica rápido de construir\n\nAceleramos desenvolvimento de lojas, apostando em uma combinação de tecnologias de ponta que oferecem uma experiência de desenvolvimento frontend otimizada e eficiente. A stack inclui:\n\n- [**Deno**](https://deno.land)\n Um runtime seguro para JavaScript e TypeScript, criado para resolver problemas do Node.js, como gerenciamento de dependências e configurações TypeScript.\n\n- [**Fresh**](https://fresh.deno.dev)\nUm framework web minimalista e rápido, que proporciona uma experiência de desenvolvimento mais dinâmica e eficiente, com tempos de compilação rápidos ou inexistentes.\n\n- [**Twind**](https://twind.dev)\nUma biblioteca de CSS-in-JS que permite a criação de estilos dinâmicos, sem sacrificar o desempenho, e oferece compatibilidade com o popular framework Tailwind CSS.\n\n- [**Preact**](https://deno.land)\nUma alternativa leve ao React, que oferece desempenho superior e menor tamanho de pacote para aplicações web modernas.\n\nEssa combinação de tecnologias permite que a deco.cx ofereça uma plataforma de desenvolvimento frontend que melhora a produtividade e reduz o tempo de implementação, além de proporcionar sites de alto desempenho.\n\nOs principais ganhos de produtividade da plataforma e tecnologia deco são:\n\n- O deploy (e rollback) instantâneo na edge oferecido pelo [deno Deploy](https://deno.com/deploy)\n\n- A bibliotecas de componentes universais e extensíveis ([Sections](https://www.deco.cx/docs/en/concepts/section)), além de funções pré-construídas e totalmente customizáveis ([Loaders](https://www.deco.cx/docs/en/concepts/loader)).\n\n- A facilidade de aprendizado. Qualquer desenvolvedor junior que sabe codar em React, Javascript, HTML e CSS consegue aprender rapidamente a nossa stack, que foi desenhada pensando na melhor experiência de desenvolvimento.\n\n\n### 2. Com deco.cx fica ultrarrápido de navegar\n\nAs tecnologias escolhidas pela deco também facilitam drasticamente a criação de lojas ultrarrápidas.\n\nNormalmente os storesfronts são criados com React e Next.Js - frameworks JavaScript que usam a abordagem de Single-Page Applications (SPA) para construir aplicativos web. Ou seja, o site é carregado em uma única página e o conteúdo é transportado dinamicamente com JavaScript.\n\nDeno e Fresh, tecnologias que usamos aqui, são frameworks de JavaScript que trabalham com outro paradigma: o server-side-rendering, ou seja, o processamento dos componentes da página é feito em servidores antes de ser enviado para o navegador, ao invés de ser processado apenas no lado do cliente.\n\nIsso significa que a página já vem pronta para ser exibida quando é carregada no navegador, o que resulta em um carregamento mais rápido e uma melhor experiência do usuário.\n\nAlém disso, essas tecnologias trabalham nativamente com computação na edge, o que significa que a maior parte da lógica é executada em servidores perto do usuário, reduzindo a latência e melhorando a velocidade de resposta. Como o processamento é feito em servidores na edge, ele é capaz de realizar tarefas mais pesadas, como buscar e processar dados de fontes externas, de forma mais eficiente.\n\nAo usar essas ferramentas em conjunto, é possível construir e-commerces de alto desempenho, com tempos de carregamento de página mais rápidos e uma experiência geral melhorada.\n\n\n### 3. Com deco.cx fica fácil de evoluir\n\nA plataforma deco oferece, em um mesmo produto, tudo o que as agências e marcas precisam para rodar o ciclo completo de evolução da loja:\n\n- **Library**: Onde os desenvolvedores criam (ou customizam) [loaders](https://www.deco.cx/docs/en/concepts/loader) que puxam dados de qualquer API externa, e usam os dados coletados para criar componentes de interface totalmente editáveis pelos usuários de negócio ([Sections](https://www.deco.cx/docs/en/concepts/section)).\n\n- **Pages**: Nosso CMS integrado, para que o time de negócio consiga [compor e editar experiências rapidamente](https://www.deco.cx/docs/en/concepts/page), usando as funções e componentes de alto desempenho pré-construidos pelos seus desenvolvedores, sem precisar de uma linha de código.\n\n- **Campanhas**: Nossa ferramenta de personalização que te permite agendar ou customizar a mudança que quiser por data ou audiência. Seja uma landing page para a Black Friday ou uma sessão para um público específico, você decide como e quando seu site se comporta para cada usuário.\n\n- **Experimentos**: Testes A/B ou multivariados em 5 segundos - nossa ferramenta te permite acompanhar, em tempo real, a performance dos seus experimentos e relação à versão de controle.\n\n- **Analytics**: Dados em tempo real sobre toda a jornada de compra e a performance da loja. Aqui você cria relatórios personalizados, que consolidam dados de qualquer API externa.\n\n\n## O que está por vir\n\nEstamos só começando. Nossa primeira linha de código na deco foi em Setembro 2022. De lá pra cá montamos [uma comunidade no Discord](https://deco.cx/discord), que já conta com 1.050+ membros, entre agências, estudantes, marcas e experts.\n\nSe você está atrás de uma forma de criar sites e lojas ultrarrápidos, relevantes para cada audiência, e que evoluem diariamente através de experimentos e dados, [agende uma demo](https://deco.cx).",
+ "title": "Como a deco.cx faz sua loja converter mais",
+ "descr": "Descubra como a nossa plataforma headless ajuda lojas virtuais a converter mais clientes, simplificando a criação e manutenção de lojas rápidas e personalizáveis. "
+ },
+ "en": {
+ "title": "Como a deco.cx faz sua loja converter mais",
+ "descr": "Descubra como a nossa plataforma headless ajuda lojas virtuais a converter mais clientes, simplificando a criação e manutenção de lojas rápidas e personalizáveis. ",
+ "content": "Com dezenas de milhões de e-commerces, o varejo digital nunca enfrentou tanta competição. Por outro lado, com o grande aumento do número de consumidores online, nunca houve maior oportunidade pra crescer. Neste contexto, **oferecer experiências distintas é crucial.**\n\nContudo, mesmo as maiores marcas tem dificuldade construir algo além do previsível - páginas lentas e estáticas para todos os usuários. O resultado todos já sabem: **baixa conversão** -- pessoas deixam de comprar na loja porque não viram um conteúdo que lhe agrada ou porquê as páginas demoraram pra carregar em seus celulares.\n\nVamos entender primeiro porque isso acontece.\n\n\n## Por quê seu site performa mal?\n\n### 1. Sua loja demora para construir\n\nO time de tecnologia para ecommerce é pouco produtivo pois trabalha com frameworks e tech stacks complexas de aprender e fazer manutenção - e que vão ficando ainda mais complexas com o tempo, além do talento em tech ser escasso.\n\nPessoas desenvolvedoras gastam horas e horas cada mês com a complexidade acidental das tecnologias usadas: esperando o tempo de deploy, cuidando de milhares de linhas de código, ou lidando com dependências no npm - sobra pouco tempo para codar de verdade.\n\nResultado: o custo de novas funcionalidades é caro e a entrega é demorada, além de ser operacionalmente complexo contratar e treinar devs.\n\n\n### 2. Sua loja demora para carregar\n\nSabe-se que a velocidade de carregamento de uma página afeta drastricamente a taxa de conversão e o SEO. Em um site \"médio\", é esperado que cada 100ms a menos no tempo de carregamento de uma página, aumente em 1% a conversão.\n\nAinda assim, a maior parte das lojas tem storefronts (frentes de loja de ecommerce) com nota abaixo de 50 no [Google Lighthouse](https://developer.chrome.com/docs/lighthouse/overview/). E poucos parecem saber resolver.\n\nCom isso, o ecommerce global perde trilhões (!) de dólares em vendas.\n\nParte do problema é a escolha do framework e das tecnologias envolvidas:\n\n- a. SPA (Single Page Application) não é a tecnologia ideal para ecommerce, especialmente para performance e SEO.\n\n- b. A complexidade de criar código com esse paradigma cria bases de código difíceis de manter e adicionar novas funcionalidades.\n\n\n### 3. Sua loja demora para evoluir\n\nNos negócios e na vida, a evolução contínua e o aprendizado diário é o que gera sucesso. Especialmente no varejo, que vive de otimização contínua de margem.\n\nContudo, times de ecommerce dependem de devs para editar, testar, aprender e evoluir suas lojas.\n\nDevs, por sua vez, estão geralmente sobrecarregadas de demandas, e demoram demais para entregar o que foi pedido, ainda que sejam tasks simples.\n\nPara piorar, as ferramentas necessárias para realizar o ciclo completo de CRO (conversion rate optimization) como teste A/B, analytics, personalização e content management system (CMS) estão fragmentadas, o que exige ter que lidar com várias integrações e diversos serviços terceirizados diferentes.\n\nTudo isso aumenta drasticamente a complexidade operacional, especialmente em storefronts de alta escala, onde o ciclo de evolução é lento e ineficaz.\n\n\n## Nossa solução\n\nNosso time ficou mais de 10 anos lidando com estes mesmo problemas. Sabemos que existem tecnologias para criar sites e lojas de alto desempenho, mas a maioria parece não ter a coragem de utilizá-las.\n\nFoi quando decidimos criar a deco.cx.\n\nPara habilitarmos a criação de experiências de alto desempenho foi necessário um novo paradigma, que simplifique a criação de lojas rápidas, sem sacrificar a capacidade de **personalização e de evolução contínua.**\n\nCriamos uma plataforma headless que integra tudo o que uma marca ou agência precisa para gerenciar e otimizar sua experiência digital, tornando fácil tomar decisões em cima de dados reais, e aumentando continuamente as taxas de conversão.\n\n## Como fazemos isso:\n\n### 1. Com deco.cx fica rápido de construir\n\nAceleramos desenvolvimento de lojas, apostando em uma combinação de tecnologias de ponta que oferecem uma experiência de desenvolvimento frontend otimizada e eficiente. A stack inclui:\n\n- [**Deno**](https://deno.land)\n Um runtime seguro para JavaScript e TypeScript, criado para resolver problemas do Node.js, como gerenciamento de dependências e configurações TypeScript.\n\n- [**Fresh**](https://fresh.deno.dev)\nUm framework web minimalista e rápido, que proporciona uma experiência de desenvolvimento mais dinâmica e eficiente, com tempos de compilação rápidos ou inexistentes.\n\n- [**Twind**](https://twind.dev)\nUma biblioteca de CSS-in-JS que permite a criação de estilos dinâmicos, sem sacrificar o desempenho, e oferece compatibilidade com o popular framework Tailwind CSS.\n\n- [**Preact**](https://deno.land)\nUma alternativa leve ao React, que oferece desempenho superior e menor tamanho de pacote para aplicações web modernas.\n\nEssa combinação de tecnologias permite que a deco.cx ofereça uma plataforma de desenvolvimento frontend que melhora a produtividade e reduz o tempo de implementação, além de proporcionar sites de alto desempenho.\n\nOs principais ganhos de produtividade da plataforma e tecnologia deco são:\n\n- O deploy (e rollback) instantâneo na edge oferecido pelo [deno Deploy](https://deno.com/deploy)\n\n- A bibliotecas de componentes universais e extensíveis ([Sections](https://www.deco.cx/docs/en/concepts/section)), além de funções pré-construídas e totalmente customizáveis ([Loaders](https://www.deco.cx/docs/en/concepts/loader)).\n\n- A facilidade de aprendizado. Qualquer desenvolvedor junior que sabe codar em React, Javascript, HTML e CSS consegue aprender rapidamente a nossa stack, que foi desenhada pensando na melhor experiência de desenvolvimento.\n\n\n### 2. Com deco.cx fica ultrarrápido de navegar\n\nAs tecnologias escolhidas pela deco também facilitam drasticamente a criação de lojas ultrarrápidas.\n\nNormalmente os storesfronts são criados com React e Next.Js - frameworks JavaScript que usam a abordagem de Single-Page Applications (SPA) para construir aplicativos web. Ou seja, o site é carregado em uma única página e o conteúdo é transportado dinamicamente com JavaScript.\n\nDeno e Fresh, tecnologias que usamos aqui, são frameworks de JavaScript que trabalham com outro paradigma: o server-side-rendering, ou seja, o processamento dos componentes da página é feito em servidores antes de ser enviado para o navegador, ao invés de ser processado apenas no lado do cliente.\n\nIsso significa que a página já vem pronta para ser exibida quando é carregada no navegador, o que resulta em um carregamento mais rápido e uma melhor experiência do usuário.\n\nAlém disso, essas tecnologias trabalham nativamente com computação na edge, o que significa que a maior parte da lógica é executada em servidores perto do usuário, reduzindo a latência e melhorando a velocidade de resposta. Como o processamento é feito em servidores na edge, ele é capaz de realizar tarefas mais pesadas, como buscar e processar dados de fontes externas, de forma mais eficiente.\n\nAo usar essas ferramentas em conjunto, é possível construir e-commerces de alto desempenho, com tempos de carregamento de página mais rápidos e uma experiência geral melhorada.\n\n\n### 3. Com deco.cx fica fácil de evoluir\n\nA plataforma deco oferece, em um mesmo produto, tudo o que as agências e marcas precisam para rodar o ciclo completo de evolução da loja:\n\n- **Library**: Onde os desenvolvedores criam (ou customizam) [loaders](https://www.deco.cx/docs/en/concepts/loader) que puxam dados de qualquer API externa, e usam os dados coletados para criar componentes de interface totalmente editáveis pelos usuários de negócio ([Sections](https://www.deco.cx/docs/en/concepts/section)).\n\n- **Pages**: Nosso CMS integrado, para que o time de negócio consiga [compor e editar experiências rapidamente](https://www.deco.cx/docs/en/concepts/page), usando as funções e componentes de alto desempenho pré-construidos pelos seus desenvolvedores, sem precisar de uma linha de código.\n\n- **Campanhas**: Nossa ferramenta de personalização que te permite agendar ou customizar a mudança que quiser por data ou audiência. Seja uma landing page para a Black Friday ou uma sessão para um público específico, você decide como e quando seu site se comporta para cada usuário.\n\n- **Experimentos**: Testes A/B ou multivariados em 5 segundos - nossa ferramenta te permite acompanhar, em tempo real, a performance dos seus experimentos e relação à versão de controle.\n\n- **Analytics**: Dados em tempo real sobre toda a jornada de compra e a performance da loja. Aqui você cria relatórios personalizados, que consolidam dados de qualquer API externa.\n\n\n## O que está por vir\n\nEstamos só começando. Nossa primeira linha de código na deco foi em Setembro 2022. De lá pra cá montamos [uma comunidade no Discord](https://deco.cx/discord), que já conta com 1.050+ membros, entre agências, estudantes, marcas e experts.\n\nSe você está atrás de uma forma de criar sites e lojas ultrarrápidos, relevantes para cada audiência, e que evoluem diariamente através de experimentos e dados, [agende uma demo](https://deco.cx)."
+ }
+ },
+ "path": "como-a-deco-faz-sua-loja-converter-mais.md",
+ "date": "04/14/2023",
+ "author": "Rafael Crespo",
+ "img": "https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/450efa63-082e-427a-b218-e8b3690823cc"
+ },
+ {
+ "body": {
+ "pt": {
+ "content": "## Desafio\n\nRecentemente aceitei um desafio e quero compartilhar como foi a minha experiência.\n\nO desafio era reconstruir a Home da [https://deno.land/](https://deno.land/) utilizando a plataforma deco.cx como CMS.\n\n## O que é deco.cx?\n\nÉ uma plataforma criada por um time de pessoas que trabalharam na Vtex, para construir páginas e lojas virtuais performáticas e em um curto período de tempo.\n\nCom o slogan \"Crie, teste e evolua sua loja. Todos os dias.\", a plataforma foca na simplicidade no desenvolvimento, autonomia para edições/testes e foco em performance.\n\n## Primeira etapa - Conhecendo a Stack\n\nAntes de iniciar o desenvolvimento, precisei correr atrás das tecnologias que a deco.cx sugere para utilização.\n\nSão elas:\n\n### Preact\n\nPreact é uma biblioteca JS baseada no React, mas que promete ser mais leve e mais performática.\n\nA adaptação aqui, para quem já tem o React, não tende a ser complicada.\n\n### Deno\n\nDeno é um ambiente de execução de Javascript e Typescript, criado pelo mesmo criador do Node.js.\n\nCom uma boa aceitação entre os devs, a alternativa melhorada do Node.js promete se destacar no futuro.\n\n### Fresh\n\nFresh é um Framework que me deixou bem curioso. Nessa stack, podemos dizer que ele atua como um Next.\n\nApesar de não ter me aprofundado no Framework, não tive problemas aqui, afinal um dos pilares do Fresh é não precisar de configuração, além de não ter etapa de build.\n\n### Twind\n\nTwind é uma alternativa mais leve, rápida e completa do tão conhecido Tailwind.\n\nA adaptação é extremamente fácil para quem já trabalha com Tailwind, mas não era o meu caso.\n\nPequenos gargalos no começo, mas a curva de aprendizagem é curta e nas últimas seções eu já estava sentindo os efeitos (positivos).\n\n## Segunda Etapa - Conhecendo a ferramenta da deco.cx\n\nMeu objetivo aqui, era entender como a ferramenta me ajudaria a recriar a página deno.land, tornando os componentes editáveis pelo painel CMS.\n\n### Criação da Conta\n\nO Login foi bem simples, pode ser feito com Github ou Google.\n\n### Criação do Projeto\n\nNa primeira página, após logado, temos a opção de Criar um Novo Site.\n\nTive que dar um nome ao projeto e escolher o template padrão para ser iniciado.\n\n\n\nAssim que o site é criado, **automaticamente** um repositório é montado no GitHub da [deco-sites](https://github.com/deco-sites) e um link da sua página na internet também.\n\nA partir dai, cada push que você fizer resultará no Deploy da aplicação no servidor e rapidamente será refletido em produção\n\n### Entendendo páginas e seções\n\nDentro do painel, podemos acessar a aba de \"Pages\"\n\n\n\nNessa parte, cada página do seu site estará listada, e assim que você clicar, você pode ver as seções que estão sendo utilizadas.\n\n\n\nDessa forma, fica fácil para uma pessoa não técnica conseguir criar novas páginas e adicionar/editar as seções.\n\nMas para entender como criar um modelo de seção, vamos para a terceira etapa.\n\n## Terceira Etapa - Integração do Código com a deco.cx\n\nComo eu tinha o objetivo de tornar as seções da página editáveis, eu precisei entender como isso deveria ser escrito no código.\n\nE é tão simples, quanto tipagem em Typescript, literalmente.\n\nDentro da estrutura no GitHub, temos uma pasta chamada _sections_, e cada arquivo _.tsx_ lá dentro se tornará uma daquelas seções no painel.\n\n\n\nEm cada arquivo, deve ser exportado uma função default, que retorna um código HTML.\n\nDentro desse HTML, podemos utilizar dados que vem do painel, e para definir quais dados deverão vir de lá, fazemos dessa forma:\n\nexport interface Props {\n image: LiveImage;\n imageMobile: LiveImage;\n altText: string;\n title: string;\n subTitle: string;\n}\n\nEsses são os campos que configurei para a seção _Banner_, e o resultado é esse no painel:\n\n\n\nDepois recebi esses dados como Props, assim:\n\nexport default function Banner({ image, imageMobile, altText, subTitle, title }: Props,) {\n return (\n <>\n //Your HTML code here\n \n );\n}\n\nE o resultado final da seção é:\n\n\n\n### Dev Mode\n\nÉ importante ressaltar, que durante o desenvolvimento, a ferramenta oferece uma função \"Dev Mode\".\n\nIsso faz com que os campos editáveis do painel se baseiem no código feito no localhost e não do repositório no Github.\n\nGarantindo a possibilidade de testes durante a criação.\n\n## Resultado Final + Conclusão\n\nO resultado final, pode ser conferido em: [https://deno-land.deco.site/](https://deno-land.deco.site/)\n\nConsegui atingir nota 97 no Pagespeed Mobile e isso me impressionou bastante.\n\nParticularmente, gostei muito dos pilares que a deco.cx está buscando entregar, em especial a autonomia de edição e o foco na velocidade de carregamento.\n\nA ferramenta é nova e já entrega muita coisa legal. A realização desse desafio foi feita após 3 meses do início do desenvolvimento da plataforma da deco.\n\nMinha recomendação a todos é que entrem na [Comunidade no Discord](https://discord.gg/RZkvt5AE) e acompanhem as novidades para não ficar para trás.\n\nSe possível, criem um site na ferramenta e façam os seus próprios testes.\n\nEm parceria com [TavanoBlog](https://tavanoblog.com.br/).",
+ "title": "Minha experiência com deco.cx",
+ "descr": "Recriando a página da deno-land utilizando a plataforma da deco.cx com as tecnologias: Deno, Fresh, Preact e Twind."
+ },
+ "en": {
+ "title": "Minha experiência com deco.cx",
+ "descr": "Recriando a página da deno-land utilizando a plataforma da deco.cx com as tecnologias: Deno, Fresh, Preact e Twind.",
+ "content": "## Desafio\n\nRecentemente aceitei um desafio e quero compartilhar como foi a minha experiência.\n\nO desafio era reconstruir a Home da [https://deno.land/](https://deno.land/) utilizando a plataforma deco.cx como CMS.\n\n## O que é deco.cx?\n\nÉ uma plataforma criada por um time de pessoas que trabalharam na Vtex, para construir páginas e lojas virtuais performáticas e em um curto período de tempo.\n\nCom o slogan \"Crie, teste e evolua sua loja. Todos os dias.\", a plataforma foca na simplicidade no desenvolvimento, autonomia para edições/testes e foco em performance.\n\n## Primeira etapa - Conhecendo a Stack\n\nAntes de iniciar o desenvolvimento, precisei correr atrás das tecnologias que a deco.cx sugere para utilização.\n\nSão elas:\n\n### Preact\n\nPreact é uma biblioteca JS baseada no React, mas que promete ser mais leve e mais performática.\n\nA adaptação aqui, para quem já tem o React, não tende a ser complicada.\n\n### Deno\n\nDeno é um ambiente de execução de Javascript e Typescript, criado pelo mesmo criador do Node.js.\n\nCom uma boa aceitação entre os devs, a alternativa melhorada do Node.js promete se destacar no futuro.\n\n### Fresh\n\nFresh é um Framework que me deixou bem curioso. Nessa stack, podemos dizer que ele atua como um Next.\n\nApesar de não ter me aprofundado no Framework, não tive problemas aqui, afinal um dos pilares do Fresh é não precisar de configuração, além de não ter etapa de build.\n\n### Twind\n\nTwind é uma alternativa mais leve, rápida e completa do tão conhecido Tailwind.\n\nA adaptação é extremamente fácil para quem já trabalha com Tailwind, mas não era o meu caso.\n\nPequenos gargalos no começo, mas a curva de aprendizagem é curta e nas últimas seções eu já estava sentindo os efeitos (positivos).\n\n## Segunda Etapa - Conhecendo a ferramenta da deco.cx\n\nMeu objetivo aqui, era entender como a ferramenta me ajudaria a recriar a página deno.land, tornando os componentes editáveis pelo painel CMS.\n\n### Criação da Conta\n\nO Login foi bem simples, pode ser feito com Github ou Google.\n\n### Criação do Projeto\n\nNa primeira página, após logado, temos a opção de Criar um Novo Site.\n\nTive que dar um nome ao projeto e escolher o template padrão para ser iniciado.\n\n\n\nAssim que o site é criado, **automaticamente** um repositório é montado no GitHub da [deco-sites](https://github.com/deco-sites) e um link da sua página na internet também.\n\nA partir dai, cada push que você fizer resultará no Deploy da aplicação no servidor e rapidamente será refletido em produção\n\n### Entendendo páginas e seções\n\nDentro do painel, podemos acessar a aba de \"Pages\"\n\n\n\nNessa parte, cada página do seu site estará listada, e assim que você clicar, você pode ver as seções que estão sendo utilizadas.\n\n\n\nDessa forma, fica fácil para uma pessoa não técnica conseguir criar novas páginas e adicionar/editar as seções.\n\nMas para entender como criar um modelo de seção, vamos para a terceira etapa.\n\n## Terceira Etapa - Integração do Código com a deco.cx\n\nComo eu tinha o objetivo de tornar as seções da página editáveis, eu precisei entender como isso deveria ser escrito no código.\n\nE é tão simples, quanto tipagem em Typescript, literalmente.\n\nDentro da estrutura no GitHub, temos uma pasta chamada _sections_, e cada arquivo _.tsx_ lá dentro se tornará uma daquelas seções no painel.\n\n\n\nEm cada arquivo, deve ser exportado uma função default, que retorna um código HTML.\n\nDentro desse HTML, podemos utilizar dados que vem do painel, e para definir quais dados deverão vir de lá, fazemos dessa forma:\n\nexport interface Props {\n image: LiveImage;\n imageMobile: LiveImage;\n altText: string;\n title: string;\n subTitle: string;\n}\n\nEsses são os campos que configurei para a seção _Banner_, e o resultado é esse no painel:\n\n\n\nDepois recebi esses dados como Props, assim:\n\nexport default function Banner({ image, imageMobile, altText, subTitle, title }: Props,) {\n return (\n <>\n //Your HTML code here\n \n );\n}\n\nE o resultado final da seção é:\n\n\n\n### Dev Mode\n\nÉ importante ressaltar, que durante o desenvolvimento, a ferramenta oferece uma função \"Dev Mode\".\n\nIsso faz com que os campos editáveis do painel se baseiem no código feito no localhost e não do repositório no Github.\n\nGarantindo a possibilidade de testes durante a criação.\n\n## Resultado Final + Conclusão\n\nO resultado final, pode ser conferido em: [https://deno-land.deco.site/](https://deno-land.deco.site/)\n\nConsegui atingir nota 97 no Pagespeed Mobile e isso me impressionou bastante.\n\nParticularmente, gostei muito dos pilares que a deco.cx está buscando entregar, em especial a autonomia de edição e o foco na velocidade de carregamento.\n\nA ferramenta é nova e já entrega muita coisa legal. A realização desse desafio foi feita após 3 meses do início do desenvolvimento da plataforma da deco.\n\nMinha recomendação a todos é que entrem na [Comunidade no Discord](https://discord.gg/RZkvt5AE) e acompanhem as novidades para não ficar para trás.\n\nSe possível, criem um site na ferramenta e façam os seus próprios testes.\n\nEm parceria com [TavanoBlog](https://tavanoblog.com.br/)."
+ }
+ },
+ "path": "criando-uma-pagina-com-decocx.md",
+ "date": "03/01/2023",
+ "author": "Guilherme Tavano",
+ "img": "https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/179d2e1f-8214-46f4-bc85-497f2313145e"
+ },
+ {
+ "body": {
+ "pt": {
+ "title": "Como utilizar apps para adicionar funcionalidades aos seus sites.",
+ "descr": "Descubra como a nossa plataforma headless ajuda lojas virtuais a converter mais clientes, simplificando a criação e manutenção de lojas rápidas e personalizáveis.",
+ "content": "Nesta última versão, a deco está revolucionando a forma como você adiciona funcionalidades em seus **sites**. Dê as boas-vindas à era dos Apps.\n\n**O que são Apps?**\n\nAs Apps são poderosos conjuntos de capacidades de negócios que podem ser importados e configurados em sites deco. Uma App na deco é essencialmente uma coleção de vários componentes, como **Actions**, **Sections**, **Loaders**, **Workflows**, **Handlers**, ou quaisquer outros tipos de blocks que podem ser usados para estender a funcionalidade dos seus sites.\n\nCom as apps, você tem o poder de definir propriedades necessárias para a funcionalidade como um todo, como chaves de aplicação, nomes de contas entre outros.\n\n**Templates de Loja**\n\nIntroduzimos vários templates de lojas integradas com plataformas como - Vnda., VTEX e Shopify. Agora, você tem a flexibilidade de escolher o template que melhor se adapta às suas necessidades e pode criar facilmente sua loja a partir desses templates.\n\n
\n\n**DecoHub: Seu Hub de Apps**\n\nCom a estreia do DecoHub, você pode descobrir e instalar uma variedade de apps com base em suas necessidades do seu negócio. Se você é um desenvolvedor, pode criar seus próprios apps fora do repositório do [deco-cx/apps](http://github.com/deco-cx/apps) e enviar um PR para adicioná-los ao DecoHub.\n\n**Transição de Deco-Sites/Std para Apps**\n\nMigramos do hub central de integrações do [deco-sites/std](https://github.com/deco-sites/std) para uma abordagem mais modular com o [deco-cx/apps](http://github.com/deco-cx/apps). O STD agora está em modo de manutenção, portanto, certifique-se de migrar sua loja e seguir as etapas de instalação em nossa [documentação](https://www.deco.cx/docs/en/getting-started/installing-an-app) para aproveitar o novo ecossistema de Apps.\n\n**Comece a Usar os Apps Agora Mesmo!**\n\nDesenvolvedores, mergulhem em nosso [guia](https://www.deco.cx/docs/en/developing-capabilities/apps/creating-an-app) sobre como criar seu primeiro App no Deco. Para lojas existentes, faça a migração executando `deno run -A -r https://deco.cx/upgrade`.\n\nIsso é apenas o começo. Estamos trabalhando continuamente para aprimorar nosso ecossistema de Apps e explorar novos recursos, como transições de visualização e soluções de estilo.\n\nFiquem ligados e vamos construir juntos o futuro do desenvolvimento web!"
+ },
+ "en": {
+ "title": "How to use apps to add functionality to your sites.",
+ "descr": "Discover how our headless platform helps e-commerce stores convert more customers by simplifying the creation and maintenance of fast, customizable stores.",
+ "content": "In this latest release, deco is revolutionizing the way you add functionality to your **sites**. Welcome to the era of Apps.\n\n**What are Apps?**\n\nApps are powerful sets of business capabilities that can be imported and configured in deco sites. An App in deco is essentially a collection of various components, such as **Actions**, **Sections**, **Loaders**, **Workflows**, **Handlers**, or any other types of blocks that can be used to extend the functionality of your sites.\n\nWith apps, you have the power to define properties necessary for the functionality as a whole, such as application keys, account names, and more.\n\n**Store Templates**\n\nWe've introduced several store templates integrated with platforms like - Vnda., VTEX, and Shopify. Now, you have the flexibility to choose the template that best suits your needs and can easily create your store from these templates.\n\n
\n\n**DecoHub: Your App Hub**\n\nWith the debut of DecoHub, you can discover and install a variety of apps based on your business needs. If you're a developer, you can create your own apps outside of the [deco-cx/apps](http://github.com/deco-cx/apps) repository and submit a PR to add them to DecoHub.\n\n**Transition from Deco-Sites/Std to Apps**\n\nWe've migrated from the central integration hub of [deco-sites/std](https://github.com/deco-sites/std) to a more modular approach with [deco-cx/apps](http://github.com/deco-cx/apps). STD is now in maintenance mode, so be sure to migrate your store and follow the installation steps in our [documentation](https://www.deco.cx/docs/en/getting-started/installing-an-app) to take advantage of the new Apps ecosystem.\n\n**Start Using Apps Now!**\n\nDevelopers, dive into our [guide](https://www.deco.cx/docs/en/developing-capabilities/apps/creating-an-app) on how to create your first App in Deco. For existing stores, make the migration by running `deno run -A -r https://deco.cx/upgrade`.\n\nThis is just the beginning. We're continuously working to enhance our Apps ecosystem and explore new features, such as view transitions and styling solutions.\n\nStay tuned and let's build the future of web development together!"
+ }
+ },
+ "path": "apps-era.md",
+ "author": "Marcos Candeia, Tiago Gimenes",
+ "img": "https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/5a07de58-ba83-4c6c-92e1-bea033350318",
+ "date": "01/23/2023",
+ "descr": "A era dos Apps!"
+ },
+ {
+ "body": {
+ "en": {
+ "content": "A vida é curta, como todos sabem. Quando era criança, costumava me perguntar sobre isso. A vida realmente é curta ou estamos realmente nos queixando de sua finitude? Seríamos tão propensos a sentir que a vida é curta se vivêssemos 10 vezes mais tempo?\n\nComo não parecia haver maneira de responder a essa pergunta, parei de me perguntar sobre isso. Depois tive filhos. Isso me deu uma maneira de responder à pergunta e a resposta é que a vida realmente é curta.\n\nTer filhos me mostrou como converter uma quantidade contínua, o tempo, em quantidades discretas. Você só tem 52 fins de semana com seu filho de 2 anos. Se o Natal-como-mágica dure, digamos, dos 3 aos 10 anos, só poderá ver seu filho experimentá-lo 8 vezes. E enquanto é impossível dizer o que é muito ou pouco de uma quantidade contínua como o tempo, 8 não é muito de alguma coisa. Se você tivesse uma punhado de 8 amendoins ou uma prateleira de 8 livros para escolher, a quantidade definitivamente pareceria limitada, independentemente da sua expectativa de vida.\n\nOk, então a vida realmente é curta. Isso faz alguma diferença saber disso?\n\nFez para mim. Isso significa que argumentos do tipo \"A vida é muito curta para x\" têm muita força. Não é apenas uma figura de linguagem dizer que a vida é muito curta para alguma coisa. Não é apenas um sinônimo de chato. Se você achar que a vida é muito curta para alguma coisa, deve tentar eliminá-la se puder.\n\nQuando me pergunto o que descobri que a vida é muito curta, a palavra que me vem à cabeça é \"besteira\". Eu percebo que essa resposta é um pouco tautológica. Quase é a definição de besteira que é a coisa de que a vida é muito curta. E ainda assim a besteira tem um caráter distintivo. Há algo falso nela. É o alimento junk da experiência. [1]\n\nSe você perguntar a si mesmo o que gasta o seu tempo em besteira, provavelmente já sabe a resposta. Reuniões desnecessárias, disputas sem sentido, burocracia, postura, lidar com os erros de outras pessoas, engarrafamentos, passatempos viciantes mas pouco gratificantes.\n\nHá duas maneiras pelas quais esse tipo de coisa entra em sua vida: ou é imposto a você ou o engana. Até certo ponto, você tem que suportar as besteiras impostas por circunstâncias. Você precisa ganhar dinheiro e ganhar dinheiro consiste principalmente em realizar tarefas. De fato, a lei da oferta e da demanda garante isso: quanto mais gratificante é algum tipo de trabalho, mais barato as pessoas o farão. Pode ser que menos tarefas sejam impostas a você do que você pensa, no entanto. Sempre houve uma corrente de pessoas que optam por sair da rotina padrão e vão viver em algum lugar onde as oportunidades são menores no sentido convencional, mas a vida parece mais autêntica. Isso pode se tornar mais comum.\n\nVocê pode reduzir a quantidade de besteira em sua vida sem precisar se mudar. A quantidade de tempo que você precisa gastar com besteiras varia entre empregadores. A maioria das grandes organizações (e muitas pequenas) está imersa nelas. Mas se você priorizar conscientemente a redução de besteiras acima de outros fatores, como dinheiro e prestígio, pode encontrar empregadores que irão desperdiçar menos do seu tempo.\n\nSe você é freelancer ou uma pequena empresa, pode fazer isso no nível de clientes individuais. Se você demitir ou evitar clientes tóxicos, pode diminuir a quantidade de besteira em sua vida mais do que diminui sua renda.\n\nMas, enquanto alguma quantidade de besteira é inevitavelmente imposta a você, a besteira que se infiltra em sua vida enganando-o não é culpa de ninguém, mas sua própria. E ainda assim, a besteira que você escolhe pode ser mais difícil de eliminar do que a besteira que é imposta a você. Coisas que o atraem para desperdiçar seu tempo precisam ser muito boas em enganá-lo. Um exemplo que será familiar para muitas pessoas é discutir online. Quando alguém contradiz você, está, de certa forma, atacando você. Às vezes bastante abertamente. Seu instinto quando é atacado é se defender. Mas, assim como muitos instintos, esse não foi projetado para o mundo em que vivemos agora. Contrariamente ao que parece, é melhor, na maioria das vezes, não se defender. Caso contrário, essas pessoas estão literalmente tomando sua vida. [2]\n\nDiscutir online é apenas incidentalmente viciante. Há coisas mais perigosas do que isso. Como já escrevi antes, um subproduto do progresso técnico é que as coisas que gostamos tendem a se tornar mais viciantes. Isso significa que precisaremos fazer um esforço consciente para evitar vícios, para nos colocarmos fora de nós mesmos e perguntarmos: \"é assim que quero estar gastando meu tempo?\"\n\nAlém de evitar besteiras, devemos procurar ativamente coisas que importam. Mas coisas diferentes importam para pessoas diferentes e a maioria precisa aprender o que importa para elas. Alguns são afortunados e percebem cedo que adoram matemática, cuidar de animais ou escrever e, então, descobrem uma maneira de passar muito tempo fazendo isso. Mas a maioria das pessoas começa com uma vida que é uma mistura de coisas que importam e coisas que não importam e só gradualmente aprende a distinguir entre elas.\n\nPara os jovens, especialmente, muita dessa confusão é induzida pelas situações artificiais em que se encontram. Na escola intermediária e na escola secundária, o que os outros estudantes acham de você parece ser a coisa mais importante do mundo. Mas quando você pergunta aos adultos o que eles fizeram de errado nessa idade, quase todos dizem que se importavam demais com o que os outros estudantes achavam deles.\n\nUma heurística para distinguir coisas que importam é perguntar a si mesmo se você se importará com elas no futuro. A coisa falsa que importa geralmente tem um pico afiado de parecer importar. É assim que o engana. A área sob a curva é pequena, mas sua forma se crava em sua consciência como uma alfinete.\n\nAs coisas que importam nem sempre são aquelas que as pessoas chamariam de \"importantes\". Tomar café com um amigo importa. Você não vai sentir depois que isso foi um desperdício de tempo.\n\nUma coisa ótima em ter crianças pequenas é que elas fazem você gastar tempo em coisas que importam: elas. Elas puxam sua manga enquanto você está olhando para o seu celular e dizem: \"você vai brincar comigo?\". E as chances são de que essa seja, de fato, a opção de minimização de besteira.\n\nSe a vida é curta, devemos esperar que sua brevidade nos surpreenda. E é exatamente isso que costuma acontecer. Você assume as coisas como garantidas e, então, elas desaparecem. Você acha que sempre pode escrever aquele livro, ou subir aquela montanha, ou o que quer que seja, e então percebe que a janela se fechou. As janelas mais tristes fecham quando outras pessoas morrem. Suas vidas também são curtas. Depois que minha mãe morreu, eu desejei ter passado mais tempo com ela. Eu vivi como se ela sempre estivesse lá. E, de maneira típica e discreta, ela incentivou essa ilusão. Mas era uma ilusão. Acho que muitas pessoas cometem o mesmo erro que eu cometi.\n\nA maneira usual de evitar ser surpreendido por algo é estar consciente disso. Quando a vida era mais precária, as pessoas costumavam ser conscientes da morte em um grau que agora pareceria um pouco morboso. Não tenho certeza do porquê, mas não parece ser a resposta certa lembrar constantemente da caveira pairando no ombro de todos. Talvez uma solução melhor seja olhar o problema pelo outro lado. Cultive o hábito de ser impaciente com as coisas que mais quer fazer. Não espere antes de subir aquela montanha ou escrever aquele livro ou visitar sua mãe. Você não precisa se lembrar constantemente por que não deve esperar. Apenas não espere.\n\nPosso pensar em mais duas coisas que alguém faz quando não tem muito de algo: tentar obter mais disso e saborear o que tem. Ambos fazem sentido aqui.\n\nComo você vive afeta por quanto tempo você vive. A maioria das pessoas poderia fazer melhor. Eu entre elas.\n\nMas você provavelmente pode obter ainda mais efeito prestando mais atenção ao tempo que tem. É fácil deixar os dias passarem voando. O \"fluxo\" que as pessoas imaginativas adoram tanto tem um parente mais sombrio que impede você de pausar para saborear a vida no meio da rotina diária de tarefas e alarmes. Uma das coisas mais impressionantes que já li não estava em um livro, mas no título de um: Burning the Days (Queimando os Dias), de James Salter.\n\nÉ possível diminuir um pouco o tempo. Eu melhorei nisso. As crianças ajudam. Quando você tem crianças pequenas, há muitos momentos tão perfeitos que você não consegue deixar de notar.\n\nTambém ajuda sentir que você tirou tudo de alguma experiência. O motivo pelo qual estou triste por minha mãe não é apenas porque sinto falta dela, mas porque penso em tudo o que poderíamos ter feito e não fizemos. Meu filho mais velho vai fazer 7 anos em breve. E, embora sinta falta da versão dele de 3 anos, pelo menos não tenho nenhum arrependimento pelo que poderia ter sido. Tivemos o melhor tempo que um pai e um filho de 3 anos poderiam ter.\n\nCorte implacavelmente as besteiras, não espere para fazer coisas que importam e saboreie o tempo que tem. É isso o que você faz quando a vida é curta. \n\n---\n\nNotas\n\n[1] No começo, eu não gostei que a palavra que me veio à mente tivesse outros significados. Mas então percebi que os outros significados estão bastante relacionados. Besteira no sentido de coisas em que você desperdiça seu tempo é bastante parecida com besteira intelectual.\n\n[2] Escolhi esse exemplo de forma deliberada como uma nota para mim mesmo. Eu sou atacado muito online. As pessoas contam as mentiras mais loucas sobre mim. E até agora eu fiz um trabalho bastante medíocre de suprimir a inclinação natural do ser humano de dizer \"Ei, isso não é verdade!\".\n\nObrigado a Jessica Livingston e Geoff Ralston por ler rascunhos deste.",
+ "title": "A vida é curta",
+ "descr": "Por Paul Graham, traduzido por ChatGPT."
+ },
+ "pt": {
+ "title": "A vida é curta",
+ "descr": "Por Paul Graham, traduzido por ChatGPT.",
+ "content": "A vida é curta, como todos sabem. Quando era criança, costumava me perguntar sobre isso. A vida realmente é curta ou estamos realmente nos queixando de sua finitude? Seríamos tão propensos a sentir que a vida é curta se vivêssemos 10 vezes mais tempo?\n\nComo não parecia haver maneira de responder a essa pergunta, parei de me perguntar sobre isso. Depois tive filhos. Isso me deu uma maneira de responder à pergunta e a resposta é que a vida realmente é curta.\n\nTer filhos me mostrou como converter uma quantidade contínua, o tempo, em quantidades discretas. Você só tem 52 fins de semana com seu filho de 2 anos. Se o Natal-como-mágica dure, digamos, dos 3 aos 10 anos, só poderá ver seu filho experimentá-lo 8 vezes. E enquanto é impossível dizer o que é muito ou pouco de uma quantidade contínua como o tempo, 8 não é muito de alguma coisa. Se você tivesse uma punhado de 8 amendoins ou uma prateleira de 8 livros para escolher, a quantidade definitivamente pareceria limitada, independentemente da sua expectativa de vida.\n\nOk, então a vida realmente é curta. Isso faz alguma diferença saber disso?\n\nFez para mim. Isso significa que argumentos do tipo \"A vida é muito curta para x\" têm muita força. Não é apenas uma figura de linguagem dizer que a vida é muito curta para alguma coisa. Não é apenas um sinônimo de chato. Se você achar que a vida é muito curta para alguma coisa, deve tentar eliminá-la se puder.\n\nQuando me pergunto o que descobri que a vida é muito curta, a palavra que me vem à cabeça é \"besteira\". Eu percebo que essa resposta é um pouco tautológica. Quase é a definição de besteira que é a coisa de que a vida é muito curta. E ainda assim a besteira tem um caráter distintivo. Há algo falso nela. É o alimento junk da experiência. [1]\n\nSe você perguntar a si mesmo o que gasta o seu tempo em besteira, provavelmente já sabe a resposta. Reuniões desnecessárias, disputas sem sentido, burocracia, postura, lidar com os erros de outras pessoas, engarrafamentos, passatempos viciantes mas pouco gratificantes.\n\nHá duas maneiras pelas quais esse tipo de coisa entra em sua vida: ou é imposto a você ou o engana. Até certo ponto, você tem que suportar as besteiras impostas por circunstâncias. Você precisa ganhar dinheiro e ganhar dinheiro consiste principalmente em realizar tarefas. De fato, a lei da oferta e da demanda garante isso: quanto mais gratificante é algum tipo de trabalho, mais barato as pessoas o farão. Pode ser que menos tarefas sejam impostas a você do que você pensa, no entanto. Sempre houve uma corrente de pessoas que optam por sair da rotina padrão e vão viver em algum lugar onde as oportunidades são menores no sentido convencional, mas a vida parece mais autêntica. Isso pode se tornar mais comum.\n\nVocê pode reduzir a quantidade de besteira em sua vida sem precisar se mudar. A quantidade de tempo que você precisa gastar com besteiras varia entre empregadores. A maioria das grandes organizações (e muitas pequenas) está imersa nelas. Mas se você priorizar conscientemente a redução de besteiras acima de outros fatores, como dinheiro e prestígio, pode encontrar empregadores que irão desperdiçar menos do seu tempo.\n\nSe você é freelancer ou uma pequena empresa, pode fazer isso no nível de clientes individuais. Se você demitir ou evitar clientes tóxicos, pode diminuir a quantidade de besteira em sua vida mais do que diminui sua renda.\n\nMas, enquanto alguma quantidade de besteira é inevitavelmente imposta a você, a besteira que se infiltra em sua vida enganando-o não é culpa de ninguém, mas sua própria. E ainda assim, a besteira que você escolhe pode ser mais difícil de eliminar do que a besteira que é imposta a você. Coisas que o atraem para desperdiçar seu tempo precisam ser muito boas em enganá-lo. Um exemplo que será familiar para muitas pessoas é discutir online. Quando alguém contradiz você, está, de certa forma, atacando você. Às vezes bastante abertamente. Seu instinto quando é atacado é se defender. Mas, assim como muitos instintos, esse não foi projetado para o mundo em que vivemos agora. Contrariamente ao que parece, é melhor, na maioria das vezes, não se defender. Caso contrário, essas pessoas estão literalmente tomando sua vida. [2]\n\nDiscutir online é apenas incidentalmente viciante. Há coisas mais perigosas do que isso. Como já escrevi antes, um subproduto do progresso técnico é que as coisas que gostamos tendem a se tornar mais viciantes. Isso significa que precisaremos fazer um esforço consciente para evitar vícios, para nos colocarmos fora de nós mesmos e perguntarmos: \"é assim que quero estar gastando meu tempo?\"\n\nAlém de evitar besteiras, devemos procurar ativamente coisas que importam. Mas coisas diferentes importam para pessoas diferentes e a maioria precisa aprender o que importa para elas. Alguns são afortunados e percebem cedo que adoram matemática, cuidar de animais ou escrever e, então, descobrem uma maneira de passar muito tempo fazendo isso. Mas a maioria das pessoas começa com uma vida que é uma mistura de coisas que importam e coisas que não importam e só gradualmente aprende a distinguir entre elas.\n\nPara os jovens, especialmente, muita dessa confusão é induzida pelas situações artificiais em que se encontram. Na escola intermediária e na escola secundária, o que os outros estudantes acham de você parece ser a coisa mais importante do mundo. Mas quando você pergunta aos adultos o que eles fizeram de errado nessa idade, quase todos dizem que se importavam demais com o que os outros estudantes achavam deles.\n\nUma heurística para distinguir coisas que importam é perguntar a si mesmo se você se importará com elas no futuro. A coisa falsa que importa geralmente tem um pico afiado de parecer importar. É assim que o engana. A área sob a curva é pequena, mas sua forma se crava em sua consciência como uma alfinete.\n\nAs coisas que importam nem sempre são aquelas que as pessoas chamariam de \"importantes\". Tomar café com um amigo importa. Você não vai sentir depois que isso foi um desperdício de tempo.\n\nUma coisa ótima em ter crianças pequenas é que elas fazem você gastar tempo em coisas que importam: elas. Elas puxam sua manga enquanto você está olhando para o seu celular e dizem: \"você vai brincar comigo?\". E as chances são de que essa seja, de fato, a opção de minimização de besteira.\n\nSe a vida é curta, devemos esperar que sua brevidade nos surpreenda. E é exatamente isso que costuma acontecer. Você assume as coisas como garantidas e, então, elas desaparecem. Você acha que sempre pode escrever aquele livro, ou subir aquela montanha, ou o que quer que seja, e então percebe que a janela se fechou. As janelas mais tristes fecham quando outras pessoas morrem. Suas vidas também são curtas. Depois que minha mãe morreu, eu desejei ter passado mais tempo com ela. Eu vivi como se ela sempre estivesse lá. E, de maneira típica e discreta, ela incentivou essa ilusão. Mas era uma ilusão. Acho que muitas pessoas cometem o mesmo erro que eu cometi.\n\nA maneira usual de evitar ser surpreendido por algo é estar consciente disso. Quando a vida era mais precária, as pessoas costumavam ser conscientes da morte em um grau que agora pareceria um pouco morboso. Não tenho certeza do porquê, mas não parece ser a resposta certa lembrar constantemente da caveira pairando no ombro de todos. Talvez uma solução melhor seja olhar o problema pelo outro lado. Cultive o hábito de ser impaciente com as coisas que mais quer fazer. Não espere antes de subir aquela montanha ou escrever aquele livro ou visitar sua mãe. Você não precisa se lembrar constantemente por que não deve esperar. Apenas não espere.\n\nPosso pensar em mais duas coisas que alguém faz quando não tem muito de algo: tentar obter mais disso e saborear o que tem. Ambos fazem sentido aqui.\n\nComo você vive afeta por quanto tempo você vive. A maioria das pessoas poderia fazer melhor. Eu entre elas.\n\nMas você provavelmente pode obter ainda mais efeito prestando mais atenção ao tempo que tem. É fácil deixar os dias passarem voando. O \"fluxo\" que as pessoas imaginativas adoram tanto tem um parente mais sombrio que impede você de pausar para saborear a vida no meio da rotina diária de tarefas e alarmes. Uma das coisas mais impressionantes que já li não estava em um livro, mas no título de um: Burning the Days (Queimando os Dias), de James Salter.\n\nÉ possível diminuir um pouco o tempo. Eu melhorei nisso. As crianças ajudam. Quando você tem crianças pequenas, há muitos momentos tão perfeitos que você não consegue deixar de notar.\n\nTambém ajuda sentir que você tirou tudo de alguma experiência. O motivo pelo qual estou triste por minha mãe não é apenas porque sinto falta dela, mas porque penso em tudo o que poderíamos ter feito e não fizemos. Meu filho mais velho vai fazer 7 anos em breve. E, embora sinta falta da versão dele de 3 anos, pelo menos não tenho nenhum arrependimento pelo que poderia ter sido. Tivemos o melhor tempo que um pai e um filho de 3 anos poderiam ter.\n\nCorte implacavelmente as besteiras, não espere para fazer coisas que importam e saboreie o tempo que tem. É isso o que você faz quando a vida é curta. \n\n---\n\nNotas\n\n[1] No começo, eu não gostei que a palavra que me veio à mente tivesse outros significados. Mas então percebi que os outros significados estão bastante relacionados. Besteira no sentido de coisas em que você desperdiça seu tempo é bastante parecida com besteira intelectual.\n\n[2] Escolhi esse exemplo de forma deliberada como uma nota para mim mesmo. Eu sou atacado muito online. As pessoas contam as mentiras mais loucas sobre mim. E até agora eu fiz um trabalho bastante medíocre de suprimir a inclinação natural do ser humano de dizer \"Ei, isso não é verdade!\".\n\nObrigado a Jessica Livingston e Geoff Ralston por ler rascunhos deste."
+ }
+ },
+ "path": "pg-vb-pt-br.md",
+ "date": "11/29/2022",
+ "author": "Chat GPT",
+ "img": "https://i.insider.com/5e6bb1bd84159f39f736ee32?width=2000&format=jpeg&auto=webp"
+ },
+ {
+ "tags": [],
+ "body": {
+ "en": {
+ "content": "Maximus Tecidos, a prominent name in the textile industry, faced critical challenges with their existing e-commerce platform that hindered their operational efficiency and customer experience. This article outlines how Maximus Tecidos, in collaboration with Agência 2B Digital, successfully transitioned to deco.cx, resulting in significant improvements in site performance and management ease.\n\n### The Challenges\n\nPrior to the migration, Maximus Tecidos encountered several issues:\n\n- **Difficulty in Managing Site Content:** The existing CMS platform didn't allow for quick content updates.\n- **Performance Issues:** The website's performance, particularly page load times, was subpar, affecting user experience and engagement.\n\n### The Solution\n\nAgência 2B Digital, leveraging their longstanding partnership with Maximus Tecidos, facilitated a strategic transition to deco.cx. This move was designed to address the critical pain points and provide a more efficient platform.\n\n- **Enhanced Manageability:** deco.cx offers a user-friendly platform, simplifying the management of configurations and site maintenance.\n- **Improved Performance:** The new platform significantly boosted site performance, ensuring faster load times and a smoother user experience.\n\nThe migration occurred on December 5, 2023.\n\n### The Results\n\n- **Keyword Index Stability:** Post-migration, there was no drop in the number of indexed keywords.\n- **Improved SEO Metrics:** There was an increase in the Top 3 keyword rankings and the total number of indexed keywords.\n- **Increased Conversion Rates:** The improved site performance contributed to a notable rise in conversion rates.\n\n### Conclusion\n\nFor businesses seeking to optimize their digital operations and improve site performance, the experience of Maximus Tecidos offers valuable insights and a proven path to success. The partnership with Agência 2B Digital and the transition to deco.cx have empowered Maximus Tecidos to overcome their e-commerce challenges and achieve substantial performance gains.",
+ "title": "Maximus Tecidos, 2B Digital & deco.cx",
+ "descr": "A Seamless Transition to Enhanced E-commerce Performance",
+ "seo": {
+ "title": "Maximus Tecidos, 2B Digital & deco.cx: A Seamless Transition to Enhanced E-commerce Performance",
+ "description": "This article outlines how Maximus Tecidos, in collaboration with Agência 2B Digital, successfully transitioned to deco.cx, resulting in significant improvements in site performance and management ease.",
+ "image": "https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/341e8759-7fbd-42fd-821b-5382f7cc053a"
+ }
+ },
+ "pt": {
+ "title": "Maximus Tecidos, 2B Digital & deco.cx",
+ "descr": "Uma Transição Suave para Melhor Desempenho no E-commerce",
+ "content": "A Maximus Tecidos, um nome proeminente na indústria têxtil, enfrentava desafios críticos com sua plataforma de e-commerce existente, que prejudicavam sua eficiência operacional e a experiência do cliente. Este artigo descreve como a Maximus Tecidos, em colaboração com a Agência 2B Digital, realizou com sucesso a transição para a deco.cx, resultando em melhorias significativas no desempenho do site e na facilidade de gestão.\n\n### Os Desafios\n\nAntes da migração, a Maximus Tecidos encontrava vários problemas:\n\n- **Dificuldade em Gerenciar o Conteúdo do Site: A plataforma CMS existente não permitia atualizações rápidas de conteúdo.\n- **Problemas de Desempenho: O desempenho do site, especialmente os tempos de carregamento de página, era insatisfatório, afetando a experiência do usuário e o engajamento.\n\n### A Solução\n\nA Agência 2B Digital, aproveitando sua parceria de longa data com a Maximus Tecidos, facilitou uma transição estratégica para a deco.cx. Este movimento foi projetado para abordar os pontos críticos e fornecer uma plataforma mais eficiente.\n\n- **Maior Facilidade de Gestão: A deco.cx oferece uma plataforma amigável, simplificando a gestão de configurações e a manutenção do site.\n- **Desempenho Melhorado: A nova plataforma melhorou significativamente o desempenho do site, garantindo tempos de carregamento mais rápidos e uma experiência de usuário mais suave.\n\nA migração ocorreu em 5 de dezembro de 2023.\n\n### Os Resultados\n\n- **Estabilidade no Índice de Palavras-Chave: Após a migração, não houve queda no número de palavras-chave indexadas.\n- **Melhoria nas Métricas de SEO: Houve um aumento nas classificações das palavras-chave no Top 3 e no número total de palavras-chave indexadas.\n- **Aumento nas Taxas de Conversão: O melhor desempenho do site contribuiu para um aumento notável nas taxas de conversão.\n\n### Conclusão\n\nPara empresas que buscam otimizar suas operações digitais e melhorar o desempenho do site, a experiência da Maximus Tecidos oferece insights valiosos e um caminho comprovado para o sucesso. A parceria com a Agência 2B Digital e a transição para a deco.cx permitiram que a Maximus Tecidos superasse seus desafios no e-commerce e alcançasse ganhos substanciais de desempenho.",
+ "seo": {
+ "title": "Maximus Tecidos, 2B Digital & deco.cx: Uma Transição Suave para Melhor Desempenho no E-commerce",
+ "description": "Este artigo descreve como a Maximus Tecidos, em colaboração com a Agência 2B Digital, realizou com sucesso a transição para a deco.cx, resultando em melhorias significativas no desempenho do site e na facilidade de gestão",
+ "image": "https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/72426ea0-ebee-45a1-9701-79c7cd007bb4"
+ }
+ }
+ },
+ "path": "maximus-tecidos",
+ "date": "05/08/2024",
+ "author": "Maria Cecília Marques",
+ "img": "https://ozksgdmyrqcxcwhnbepg.supabase.co/storage/v1/object/public/assets/530/8903bdfe-fda3-4a79-8b3b-544f64e8f9d6"
+ }
+ ]
+ },
+ "__resolveType": "site/loaders/blogPostLoader.ts"
+}
\ No newline at end of file