❤️💕💕算法学习笔记和LeetCode的刷题笔记与记录。Myblog:http://nsddd.top
[TOC]
Class Node(v) {
V value;
Node next;
}
由以上结点依次连接起来的所形成的链叫做单链表结构
Class Node(v) {
V value;
Node next;
node last;
}
由以上结点依次连接起来的所形成的链叫做双链表结构
单链表和双链表都只需要给一个头部结点head,就可以找到剩下的所有结点
Given the head of a singly linked list, reverse the list, and return the reversed list.
Example 1:

Input: head = [1,2,3,4,5]
Output: [5,4,3,2,1]
Example 2:

Input: head = [1,2]
Output: [2,1]
Example 3:
Input: head = []
Output: []
关于这道题,我们可以考虑将数据放在栈里面,用到栈的先进后出的原则依次弹出

/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func reverseList(head *ListNode) *ListNode {
var prev *ListNode //定义一个链表
curr := head
for curr != nil {
next := curr.Next
curr.Next = prev //改变链表
prev = curr //
curr = next
}
return prev
}# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def reverseList(self, head: Optional[ListNode]) -> Optional[ListNode]:
pre, cur = None, head
while cur:
tmp = cur.next #保存当前结点
cur.next = pre
pre = cur
cur = tmp #当前结点是之前保存的结点 后移一位
return pre #返回的是前一个结点
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode reverseList(ListNode head) {
ListNode pre = null;
ListNode cur = head;
while(cur != null){
ListNode tmp = cur.next; //保存下一个结点
cur.next = pre; //指向前一个结点
pre = cur; //保存后续的结点
cur = tmp; //当前结点是之前保存的哪个结点
}
return pre;
}
}/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode* pre = nullptr;
ListNode* cur = head;
while(cur != nullptr){
ListNode* tmp = cur->next; //保存下一个结点
cur->next = pre; //指向前一个结点
pre = cur; //保存后续的结点
cur = tmp; //当前结点是之前保存的哪个结点
}
return pre;
}
};/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* reverseList(struct ListNode* head){
struct ListNode* pre = NULL;
struct ListNode* cur = head;
while(cur != NULL)
{
struct ListNode* tmp = cur->next; //保存下一个结点
cur->next = pre; //指向前一个结点
pre = cur; //保存后续的结点
cur = tmp; //当前结点是之前保存的哪个结点
}
return pre;
}/**
* Definition for singly-linked list.
* function ListNode(val, next) {
* this.val = (val===undefined ? 0 : val)
* this.next = (next===undefined ? null : next)
* }
*/
/**
* @param {ListNode} head
* @return {ListNode}
*/
var reverseList = function(head) {
var prev = null //定义一个链表
var curr = head
while(curr) {
const next = curr.next;
curr.next = prev; //改变链表
prev = curr;
curr = next;
}
return prev;
};
- 对于笔试,不用太在乎空间复杂度,一切为了时间复杂度
- 对于面试,时间复杂度依然放在第一位,但是一定要找到空间最省的方法
重要技巧
- 额外数据结构记录(哈希表等)
- 快慢指针
给定一个链表的 头节点 head ,请判断其是否为回文链表。
如果一个链表是回文,那么链表节点序列从前往后看和从后往前看是相同的。
示例 1:

输入: head = [1,2,3,3,2,1]
输出: true
示例 2:

输入: head = [1,2]
输出: false
笔试方法
- 笔试中我们可以考虑放在栈中,先进后出(可以只放一半的数据进去)
- 设置快慢指针,都从
0下标开始,快指针一次两步,慢指针一次一步,快指针走完的时候慢指针开始放入链表(判断奇偶性)。
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public boolean isPalindrome(ListNode head) {
Stack<ListNode> stack = new Stack<ListNode>(); //准备一个栈
ListNode cur = head;
while(cur != null) {
//如果结点不为空,就全部压入栈
stack.push(cur);
cur = cur.next;
}
while(head != null) {
//头结点不为空
if(head.val != stack.pop().val) {
return false;
}
head = head.next;
}
return true;
}
}面试方法
- 面试中我们使用改链表的方式(前面一半的数据不变,后面一半的数据反过来 – 反转链表),改完后我们再把链表调回来.
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public boolean isPalindrome(ListNode head) {
if(head == null || head.next == null) {
return true;
}
ListNode n1 = head;
ListNode n2 = head;
//设置快慢指针开始都指向的是头结点head
while(n2.next != null && n2.next.next != null) {
//快慢指针下一节点不为空,继续走
n1 = n1.next;
n2 = n2.next.next;
}
//快指针走到头了就没有价值了,可以记录慢指针的位置
n2 = n1.next;
n1.next = null;
ListNode n3 = null;
while(n2 != null) {
//n2不断地向前走
n3 = n2.next; //n3指向下一个结点
n2.next = n1;
n1 = n2; //n1 move
n2 = n3; //n2 move
}
n3 = n1;
n2 = head;
boolean res = true;
while(n1 != null && n2 != null) {
if(n1.val != n2.val) {
//左右不相等说明了不是回文
res = false;
break;
}
n1 = n1.next;
n2 = n2.next;
}
//返回之前不要忘记把右部分逆序回来
n1 = n3.next;
n3.next = null;
while(n1 != null) {
n2 = n1.next;
n1.next = n3;
n3 = n1;
n1 = n2;
}
return res;
}
}- 普通方法,将链表节点放到数组然后partition
- 进阶方法,将链表划分成三个子链表,然后合并
普通方法,将链表节点放到数组然后partition 这个方法比较简单,直接将链表中的值保存到一个数组中,然后按照荷兰国旗的划分方式,将数组划分成左边小于那个数,中间等于那个数,右边大于那个数的形式,(荷兰国旗问题用于快速排序中的partition过程);
划分完之后,再把数组中的值用链表的形式连接起来。 但是这个方法需要额外的O(n)的空间复杂度,而且partition不能达到稳定性(就是会改变原来的相对顺序);
static class Node {
public int value;
public Node next;
public Node(int value) {
this.value = value;
}
}
//普通的需要额外空间O(n)且不能达到稳定性的 方法
static Node partitionList_1(Node head, int pivot) { //pivot表示 枢轴;中心点;旋转运动
if (head == null) return null;
Node cur = head;
int len = 0;
while (cur != null) {
len++;
cur = cur.next;
}
Node[] nodeArr = new Node[len];
cur = head;
for (int i = 0; i < nodeArr.length; i++) {
nodeArr[i] = cur;
cur = cur.next;
}
arrPartition(nodeArr, pivot);
for (int i = 1; i < nodeArr.length; i++) {
nodeArr[i - 1].next = nodeArr[i];
}
nodeArr[nodeArr.length - 1].next = null; //一定要记得把最后一个指针指向null
return nodeArr[0];
}
//数组划分的paration
static void arrPartition(Node[] nodeArr, int pivot) {
int less = -1;
int more = nodeArr.length;
int cur = 0;
while (cur < more) {
if (nodeArr[cur].value < pivot) {
swap(nodeArr, ++less, cur++);
} else if (nodeArr[cur].value > pivot) {
swap(nodeArr, --more, cur); //注意放到大于区域的时候cur不能++
} else {
cur++;
}
}
}
//交换两个结点
static void swap(Node[] arrNode, int a, int b) {
Node temp = arrNode[a];
arrNode[a] = arrNode[b];
arrNode[b] = temp;
}进阶方法,将链表划分成三个子链表,然后合并 这个方法是将原来的链表依次划分成三个链表,三个链表分别为small代表的是左边小于的部分,equal代表的是中间相等的部分,big代表的是右边的大于部分; 这三个链表都有自己的两个指针Head和Tail分别代表各自的头部和尾部,分成三个子链表之后,我们只需要遍历链表,然后和给定的值比较,按照条件,向三个链表中添加值就可以了,最后把三个链表连接起来就可以了;

//第二种 进阶的方法 不需要额外的空间复杂度,且能达到稳定性
static Node partitionList_2(Node head,int piovt){
if(head == null)return null;
Node sH = null,sT = null; //小于部分链表的 head 和tail
Node eH = null,eT = null; //等于部分链表的 head 和tail
Node bH = null,bT = null; //大于部分链表的 head 和tail
Node next = null; //用来保存下一个结点
//划分到 三个不同的链表
while(head != null){
next = head.next;
head.next = null; //这个是为了链表拼接后 最后一个就不用再去赋值其next域为null 了
if(head.value < piovt){ //向 small 部分 分布
if(sH == null){ //如果是small部分的第一个结点
sH = head; //小于区块的头和尾
sT = head;
}else {
sT.next = head; //把head放到small最后一个
sT = head; //更新small部分的sT
}
}else if(head.value == piovt){ //等于区域
if(eH == null){
eH = head;
eT = head;
}else{
eT.next = head;
eT = head;
}
}else { //大于区域
if(bH == null){
bH = head;
bT = head;
}else {
bT.next = head;
bT = head;
}
}
head = next;
}
//将三个链表合并(注意边界的判断)
if(null != sT) { //合并small和equal部分
sT.next = eH;
eT = eT == null ? sT : eT;
}
if(null != eT){
eT.next = bH;
}
return sH != null ? sH : eH != null ? eH : bH;
}请实现 copyRandomList 函数,复制一个复杂链表。在复杂链表中,每个节点除了有一个 next 指针指向下一个节点,还有一个 random 指针指向链表中的任意节点或者 null。
示例 1:

输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
示例 2:

输入:head = [[1,1],[2,1]]
输出:[[1,1],[2,1]]
示例 3:

输入:head = [[3,null],[3,0],[3,null]]
输出:[[3,null],[3,0],[3,null]]
示例 4:
输入:head = []
输出:[]
解释:给定的链表为空(空指针),因此返回 null。
- 如果是笔试的话,使用额外的空间很好解决,用hash表的方法
/*
// Definition for a Node.
class Node {
int val;
Node next;
Node random;
public Node(int val) {
this.val = val;
this.next = null;
this.random = null;
}
}
*/
class Solution {
public Node copyRandomList(Node head) {
HashMap<Node,Node> map = new HashMap<Node,Node>();
//生成哈希表
Node cur = head;
while(cur != null) {
map.put(cur, new Node(cur.val));
cur = cur.next;
//做出克隆结点划分到map,每个结点都是如此
}
cur = head;
while(cur != null) {
// cur 老
// map.ger(cur) 新
map.get(cur).next = map.get(cur.next);
map.get(cur).random = map.get(cur.random);
cur = cur.next;
}
return map.get(head);
}
}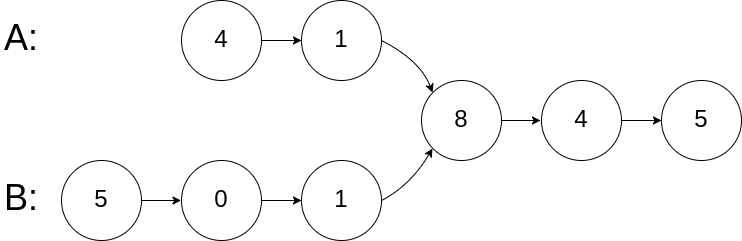
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3
输出:Reference of the node with value = 8
输入解释:相交节点的值为 8 (注意,如果两个列表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,0,1,8,4,5]。在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
- 单链表可能有环, 也可能无环. 两个链表可能相交, 可能不相交. 实现一个函数, 如果两个链表相交, 则返回相交的第一个节点; 如果不相交, 返回null即可.
- 链表的长度为M, N. 要求时间复杂度达到O(M+N), 额外空间复杂度达到O(1).
- 此题目可以拆分成三个子问题:
- 如何判断一个链表是否有环, 如果有, 则返回第一个进入环的节点, 没有则返回null.
- 如何判断两个无环链表是否相交, 相交则返回第一个相交节点, 不相交则返回null.
- 如何判断两个有环链表是否相交, 相交则返回第一个相交节点, 不相交则返回null.
- 简单方法:使用哈希表的方法判断是否有环,第一个就是入环结点
- 有环的链表一定走不出来,如果能走出来,就一定没有环
- 进阶方法:使用快慢指针

- 采取快慢指针法. 设置快指针fast和慢指针slow.
- 第一次循环, fast走两步, slow走一步. 如果fast = null, 则无环返回null. 否则fast = slow.
- 当fast = slow时候, 让fast回到头节点, 然后fast和slow每次走一步. 当fast == slow时候, 相遇的节点就是第一次入环的节点.
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
Set<ListNode> visited = new HashSet<ListNode>();
for(ListNode temp = headA; temp != null; temp = temp.next){
visited.add(temp);
}
for(ListNode temp = headB; temp != null; temp = temp.next){
if(visited.contains(temp)){
return temp;
}
}
return null;
}
}-
第一种情况是两个链表没有相交的结点
- 找到最后一个结点,以及求出当前的链表最后一个结点长度
- 链表二的最后一个结点和长度
-
第二种情况是两个链表之间有相同重合的结点
- 最后一个结点相同
- 先求长度和最后一个end结点
-
end相同说明是情况二
-
end不同说明是情况一
golang
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func getIntersectionNode(headA, headB *ListNode) *ListNode {
//进阶方法 -- 和一个链表不一样的是:第一个结点有可能是一样的
if headA == nil || headB == nil {
return nil
}
var n int = 0;
pa, pb := headA, headB //pb.Next.Next
for pa.Next != nil { //发现空结点就停下
n++
pa = pa.Next
}
for pb.Next != nil {
n-- //统计pb和pa长度做差
pb = pb.Next
}
if pa != pb {
//最后的结点1不相等
return nil
}
//找到长的链
if n > 0 { //pa长
pa = headA
pb = headB
}else{
pa = headB
pb = headA
}
if n < 0 {
//取绝对值
n = (-n)
}
//pb = headB
for n != 0 {
n--
pa = pa.Next
//往回走,直到找到pa相同的结点
}
for pb != pa { //再次相遇说明找到了第一个结点
pa = pa.Next
pb = pb.Next
}
return pa
}func getIntersectionNode(head *ListNode) *ListNode {
//进阶方法
if head == nil || head.Next == nil || head.Next.Next == nil {
return nil
}
pa, pb := head.Next, head.Next.Next //pb.Next.Next
for pa != pb {
if pa.Next == nil || pb.Next.Next == nil {
return nil
}
//不相等,就一直往下走
pa, pb = pa.Next, pb.Next.Next
}
// 找到了相等的结点
pb = head //相遇了快结点跳到开头
for pb != pa {
pa, pb = pa.Next, pb.Next
}
return pa
}