(Draft as 08/28/2022)
Xarray is an open source project in Python that extends Pandas, to handle multidimensional data structures that are used in the physical sciences. Xarray integrates labels in the form of dimensions, coordinates and attributes to multidimensional arrays.
Xarray expands on the capabilities on NumPy arrays, providing a lot of streamlined data manipulation. It is similar in that respect to Pandas, but whereas Pandas excels at working with dataframes, Xarray is focused on N-dimensional arrays of data (i.e. grids). Its interface is based largely on the netCDF data model (variables, attributes, and dimensions), but it goes beyond the traditional netCDF interfaces to provide functionality similar to netCDF-java’s Common Data Model (CDM).
Xarrays have two core data structures:
- DataArray, which is a N-dimensional array with labeled coordinates and dimensions. It is a N-dimenisonal generalization of a Pandas.Series.
- Dataset, which is a multidimensional in-memory array database.
xarray.DataArray is xarray’s implementation of a labeled, multi-dimensional array. It has several key properties:
- values: a numpy.ndarray holding the array’s values
- dims: dimension names for each axis (e.g., ('x', 'y', 'z'))
- coords: a dict-like container of arrays (coordinates) that label each point (e.g., 1-dimensional arrays of numbers, datetime objects or strings)
- attrs: dict to hold arbitrary metadata (attributes)
Xarray uses dims and coords to enable its core metadata aware operations. Dimensions provide names that xarray uses instead of the axis argument found in many numpy functions. Coordinates enable fast label based indexing and alignment, building on the functionality of the index found on a pandas DataFrame or Series.
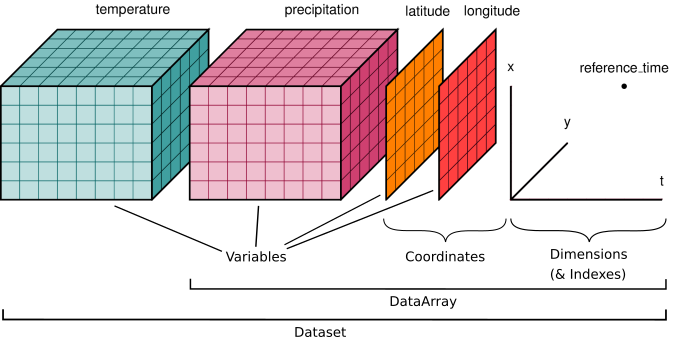
DataArray objects also can have a name and can hold arbitrary metadata in the form of their attrs property. Names and attributes are strictly for users and user-written code: xarray makes no attempt to interpret them, and propagates them only in unambiguous cases.
To start, load xarray into the working memory.
import xarray as xr
You can find the complete set of xarray function in the online documentation. Here is a short list of possible functions:
| Function | Description |
|---|---|
| Read / Write | |
xr.load_dataset() |
Open, load into memory, and close a Dataset from a netCDF file (*.nc) or file-like object. |
xr.open_dataset() |
Open and decode a dataset from a netCDF file or file-like object. |
xr.DataArray.to_netcdf() |
Write dataset contents to a netCDF file. |
| File information | |
Dataset |
Will return the structure and values of the xarray Dataset |
Dataset.info() |
Concise summary of a xarray Dataset variables and attributes. |
Dataset.head() / Dataset.tail() |
Returns a new dataset with the first / last n values of each array for the specified dimension(s) |
Dataset.dims |
Mapping from dimension names to lengths |
Dataset.coords |
Dictionary of xarray DataArray objects corresponding to coordinate variables |
Dataset.attrs |
Dictionary of global attributes on this dataset |
| Selection | |
Dataset.sel() |
Returns a new dataset with each array indexed by labels along the specified dimension(s). |
Dataset.isel() |
Returns a new dataset with each array indexed along the specified dimension(s). |
DataArray.where() |
Filter elements from this object according to a condition. |
Dataset.drop_sel() |
Drop index labels from this dataset. |
Dataset.drop_isel() |
Drop index positions from this Dataset. |
Dataset.drop_dims() |
Drop dimensions and associated variables from this dataset. |
Dataset.drop_vars() |
Drop variables from this dataset. |
| Basic array Math | |
arr+3, arr*3,... |
Arithmetic operations by a constant (+, -, *, /) |
np.abs(arr), np.sqrt(arr), np.sin(arr), ... |
Apply any Numpy mathematical function to the dataset array values. |
arr@arr |
Array muliplication @ |
arr.round(2) |
Round array values to 2 decomals. |
arr.T |
The transposed array. |
arr |
The array accepts any attributes and methods as any N-dimensional array described in numpy.ndarray |
Xarray objects borrow the isnull(), notnull(), count(), dropna(), fillna(), ffill(), and bfill() methods for working with missing data from the pandas library.
Xarray supports indexing routines that combine the best features of NumPy and pandas for data selection.:
- label-based indexing using
.sel - position-based indexing using
.isel
Lets create the following xarray.DataArray
da = xr.DataArray(
np.random.rand(4, 3),
[
("time", pd.date_range("2000-01-01", periods=4)),
("space", ["IA", "IL", "IN"]),
],
)
We enter da to see the DataArray
xarray.DataArray (time: 4, space: 3)
array([[0.1459828 , 0.5703558 , 0.74967209],
[0.80313568, 0.83131726, 0.94946361],
[0.62060118, 0.77879503, 0.57976898],
[0.82277328, 0.5918192 , 0.57177288]])
Coordinates:
time (time) datetime64[ns] 2000-01-01 ... 2000-01-04
space (space) <U2 'IA' 'IL' 'IN'
Attributes: (0)
Example of position based selection:
If we enter da[:2], we get rows 0 and 1 of the array, and everything else.
xarray.DataArray (time: 2, space: 3)
array([[0.1459828 , 0.5703558 , 0.74967209],
[0.80313568, 0.83131726, 0.94946361]])
Coordinates:
time (time) datetime64[ns] 2000-01-01 2000-01-02
space (space) <U2 'IA' 'IL' 'IN'
Attributes: (0)
By entering da[0,0] we will get the 0-th element of every variable in the DataArray
xarray.DataArray
array(0.1459828)
Coordinates:
time () datetime64[ns] 2000-01-01
space () <U2 'IA'
Attributes: (0)
Finally if we enter da[:, [2,1]], we get all the values of the time variable and select the third and second values of the space variable in that order.
xarray.DataArray (time: 4, space: 2)
array([[0.74967209, 0.5703558 ],
[0.94946361, 0.83131726],
[0.57976898, 0.77879503],
[0.57177288, 0.5918192 ]])
Coordinates:
time (time) datetime64[ns] 2000-01-01 ... 2000-01-04
space (space) <U2 'IN' 'IL'
Attributes: (0)
Example of label-based indexing using .isel
Index by integer array indices:
da.isel(space=0, time=slice(None, 2))
xarray.DataArray (time: 2)
array([0.1459828 , 0.80313568])
Coordinates:
time (time) datetime64[ns] 2000-01-01 2000-01-02
space () <U2 'IA'
Attributes: (0)
index by dimension coordinate labels:
da.sel(time=slice("2000-01-01", "2000-01-02"))
xarray.DataArray (time: 2, space: 3)
array([[0.1459828 , 0.5703558 , 0.74967209],
[0.80313568, 0.83131726, 0.94946361]])
Coordinates:
time (time) datetime64[ns] 2000-01-01 2000-01-02
space (space) <U2 'IA' 'IL' 'IN'
Attributes: (0)
Selecting the 0-th element: da.isel(space=[0], time=[0]) (same as da[0,0])
xarray.DataArray (time: 1, space: 1)
array([[0.1459828]])
Coordinates:
time (time) datetime64[ns] 2000-01-01
space (space) <U2 'IA'
Attributes: (0)
Selecting a time slice: da.sel(time="2000-01-01")
xarray.DataArray (space: 3)
array([0.1459828 , 0.5703558 , 0.74967209])
Coordinates:
time () datetime64[ns] 2000-01-01
space (space) <U2 'IA' 'IL' 'IN'
Attributes: (0)
The drop_sel() method returns a new object with the listed index labels along a dimension dropped
Drop 2 space coordinates: da.drop_sel(space=["IN", "IL"])
xarray.DataArray (time: 4, space: 1)
array([[0.22300306],
[0.55091584],
[0.46223584],
[0.14886755]])
Coordinates:
time (time) datetime64[ns] 2000-01-01 ... 2000-01-04
space (space) <U2 'IA'
Attributes: (0)
Next, we drop the first value of the timeand space coordinates: da.drop_isel(space=[0], time=[0])
xarray.DataArray (time: 3, space: 2)
array([[0.25754302, 0.18756148],
[0.53243459, 0.876909 ],
[0.19766897, 0.19531781]])
Coordinates:
time (time) datetime64[ns] 2000-01-02 2000-01-03 2000-01-04
space (space) <U2 'IL' 'IN'
Attributes: (0)
Use drop_vars() to drop a full variable from a Dataset. Any variables depending on it are also dropped: da.drop_vars("time")
xarray.DataArray (time: 4, space: 3)
array([[0.22300306, 0.91809559, 0.79787847],
[0.55091584, 0.25754302, 0.18756148],
[0.46223584, 0.53243459, 0.876909 ],
[0.14886755, 0.19766897, 0.19531781]])
Coordinates:
space (space) <U2 'IA' 'IL' 'IN'
Attributes: (0)
The DataArray is one of the basic building blocks of Xarray. It provides a numpy.ndarray-like object that expands to provide two critical pieces of functionality:
- Coordinate names and values are stored with the data, making slicing and indexing much more powerful.
- It has a built-in container for attributes.
Xarray comes with a collection of datasets to explore: xarray.tutorial.open_dataset
Available datasets:
"air_temperature": NCEP reanalysis subset
"air_temperature_gradient": NCEP reanalysis subset with approximate x,y gradients
"basin_mask": Dataset with ocean basins marked using integers
"ASE_ice_velocity": MEaSUREs InSAR-Based Ice Velocity of the Amundsen Sea Embayment, Antarctica, Version 1
"rasm": Output of the Regional Arctic System Model (RASM)
"ROMS_example": Regional Ocean Model System (ROMS) output
"tiny": small synthetic dataset with a 1D data variable
"era5-2mt-2019-03-uk.grib": ERA5 temperature data over the UK
"eraint_uvz": data from ERA-Interim reanalysis, monthly averages of upper level data
"ersstv5": NOAA’s Extended Reconstructed Sea Surface Temperature monthly averages
Example from Physical Sciences Lab at NOAA.

# Load the air_temperature dataset and define a xarray dataarray ds
# 4 x Daily Air temperature in degrees K at sigma level 995
# Spatial Coverage
# 2.5 degree x 2.5 degree global grids (144x73) [2.5 degree = 172.5 miles]
# 0.0E to 357.5E, 90.0N to 90.0S
import numpy as np
import pandas as pd
import dask.array as da
import dask.dataframe as dd
import pooch
import xarray as xr
# Load one of the tutorial datasets
ds = xr.tutorial.open_dataset('air_temperature')
ds.info()
We can inquiry about the array's ds.values
ds.values
<bound method Mapping.values of <xarray.Dataset>
Dimensions: (lat: 25, time: 2920, lon: 53)
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00
Data variables:
air (time, lat, lon) float32 ...
Attributes:
Conventions: COARDS
title: 4x daily NMC reanalysis (1948)
description: Data is from NMC initialized reanalysis\n(4x/day). These a...
platform: Model
references: http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reanaly...>
The dimension names and sizes for each axis: ds.dims
ds.dims
Frozen({'lat': 25, 'time': 2920, 'lon': 53})
Coordinate variable labels and time for each point: ds.coords
ds.coords
Coordinates:
* lat (lat) float32 75.0 72.5 70.0 67.5 65.0 ... 25.0 22.5 20.0 17.5 15.0
* lon (lon) float32 200.0 202.5 205.0 207.5 ... 322.5 325.0 327.5 330.0
* time (time) datetime64[ns] 2013-01-01 ... 2014-12-31T18:00:00
And lastly, the dictionary of atributes: ds.attrs
ds.attrs
{'Conventions': 'COARDS',
'title': '4x daily NMC reanalysis (1948)',
'description': 'Data is from NMC initialized reanalysis\n(4x/day). These are the 0.9950 sigma level values.',
'platform': 'Model',
'references': 'http://www.esrl.noaa.gov/psd/data/gridded/data.ncep.reanalysis.html'}
Then, for example we can use xarray.DataArray.groupby to caculate average monthly temperatures and anomalies.
# calculate monthly climatology
climatology = ds.groupby('time.month').mean('time')
# calculate anomalies
anomalies = ds.groupby('time.month') - climatology
📝 Please see Jupyter Notebook Xarray Example
For netDCF and IO: There is a set of optional dependencies when installing Xarray:
For accelerating Xarray:
- scipy for enabling interpolation features for xarray objects.
- bottleneck fast NumPy functions for xarray.
For parallel computing:
- dask.array for parallel computing in Python.
- Xarray Documentation.
- Xarray Tutorial
- Xarray User Guide
- Xarray API Reference
- Xarray. Project Pythia.
- Introduction to Python - ARGO float data. Ocean Data Labs. Rutgers University.
Created: 08/18/2022; Updated: 08/22/2022
Carlos Lizárraga.

