-
네이버 영화 리뷰 데이터에 대한 카테고리(긍/부정)를 분류하는 예제 소스코드입니다.
-
기본적인 Bag of Words부터, LSTM까지 다양한 방법으로 영화 리뷰의 카테고리 분류를 시도하였습니다.
-
자연어처리(NLP)에서 분류(Classification) task 입문자를 위해 작성되었습니다.
- 데이터는 e9t(Lucy Park)님께서 github에 공유해주신 네이버 영화 리뷰 데이터를 사용하였습니다.
- 모든 코드는
Scikit-learn과Pytorch패키지를 사용하여 구현되었습니다. - 전처리 과정은 생략하였습니다.
- Python : 3.5.5
- Scikit-learn : 0.20.2
- Pytorch : 1.0.0
- Cuda : Not used
- 가장 기본적인 BOW와 Logistic Regression을 활용한 예제입니다.
- 전체 과정을 표현하기 위해 예외적으로
scipy패키지를 사용하여 BOW를 모델링 하였습니다. scikit-learn의CountVectorizer를 사용하면 더욱 쉽게 구현하실 수 있습니다.
- TF-IDF와 Logistic Regression을 활용한 예제입니다.
- 쉬운 방법론이지만, 일반적으로 굉장히 우수한 성능을 보입니다.
- 문장에 포함된 모든 단어를 k차원 벡터로 임베딩하고, 변환된 벡터를 모두 합하는 방식으로 문장을 수치화하는 방법론입니다.
- 단어 임베딩은 random하게 initialize 하였습니다.
- pre-train된 임베딩 모델은 사용하지 않았습니다.
- Yoon Kim, 2014, Convolutional Neural Networks for Sentence Classification
- CNN을 NLP task에 활용한 Yoon Kim 교수님의 논문
- 커널의 열(column) 사이즈를 임베딩 차원에 맞추어, 단어 벡터를 n-gram형태로 컨볼루션
- rand 모델만 구현하였습니다. (pre-trained 임베딩 모델은 사용하지 않았습니다.
- hyper-parameter와 optimization-algorithm은 원문과 다르게 적용하였습니다.

- N Kalchbrenner, 2014, A Convolutional Neural Network for Modelling Sentences)
- Dynamic k-max-pooling을 적용하여, 다양한 길이의 문장을 input으로 받을 수 있는 것이 특징
- Convolution과 Pooling을 행(row) 단위로 적용하여, 특징을 추출하고 Folding 과정을 통해, 행(row) 사이의 결합 관계를 획득
- 문장의 길이에 상관 없이 input으로 받을 수 있지만, Pytorch Variable로 변환하기 위해 모든 문장의 길이를 동일하게 맞춰야 하는 문제를 해결하지 못하였습니다.
- 코드 개선을 위한 의견을 Issue에 남겨주시면 진심으로 감사하겠습니다.

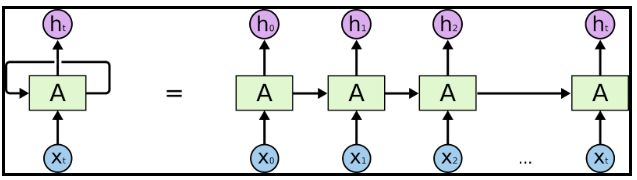
- Sequence(순서) 데이터를 입력받는 RNN 구조를 활용하여, 단어를 순서대로 입력 받아 레이블(긍/부정)을 분류
- Sequence한 데이터에 적합한 형태의 인공 신경망으로, 시계열 분석, 자연어 처리에 적합한 구조
- 과거 정보에 대한 memory가 빠르게 망각되어(BPTT : tanh 함수를 미분값은 최대 1, 이를 chain rule로 누적곱 하였기 때문에 값이 계속 작아짐), Long Term Dependancy를 잡아내지 못한다는 단점이 존재
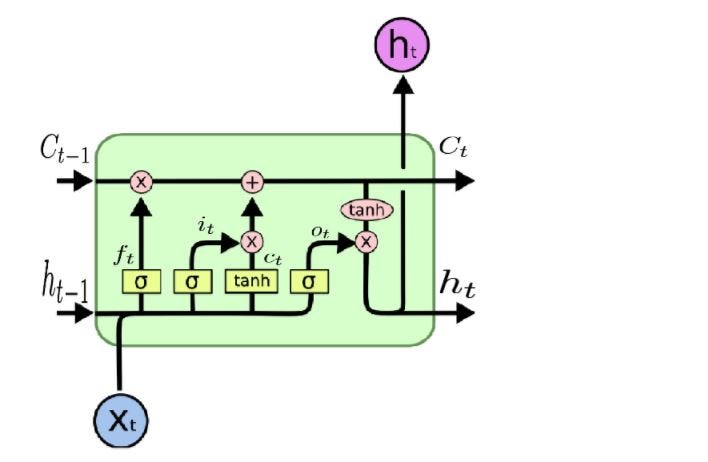
- RNN의 변형된 형태로, 과거 Cell-State에 대해, forget-gate와 input-gate를 활용하여 선별적으로 정보를 제거하고, 새로운 정보를 저장하기 때문에 RNN의 Vanishing Gradient의 문제를 개선한 모델
- 현재 기계번역, 개체명 인식 등 다양한 NLP Task에서 널리 활용되고 있으며, 우수한 성능을 입증 받았다