diff --git a/doc/md/versioned/down.mdx b/doc/md/versioned/down.mdx
index 65f3cb2f51a..d22bf26e4c0 100644
--- a/doc/md/versioned/down.mdx
+++ b/doc/md/versioned/down.mdx
@@ -154,7 +154,7 @@ atlas migrate down \
3\. After downgrading your database to the desired version, you can safely delete the migration file `20240305171146.sql`
-from the migration directory and then run `atlas migrate hash` to update the `atlas.sum` file.
+from the migration directory by running `atlas migrate rm 20240305171146`.
4\. After the file was deleted and the database downgraded, you can generate a new migration using the `atlas migrate diff`
command with the optional `--edit` flag to open the generated file in your default editor.
diff --git a/doc/website/blog/2024-04-01-migrate-down.mdx b/doc/website/blog/2024-04-01-migrate-down.mdx
new file mode 100644
index 00000000000..27771b65ffd
--- /dev/null
+++ b/doc/website/blog/2024-04-01-migrate-down.mdx
@@ -0,0 +1,394 @@
+---
+title: The Myth of Down Migrations; Introducing Atlas Migrate Down
+authors: a8m
+tags: [down migrations, rollback, undo migrations, revert migrations, migrate down]
+---
+
+import Tabs from '@theme/Tabs';
+import TabItem from '@theme/TabItem';
+
+### TL;DR
+
+Ever since my first job as a junior engineer, the seniors on my team told me that whenever I make a schema change
+I must write the corresponding "down migration", so it can be reverted at a later time if needed. But what if that advice,
+while well-intentioned, deserves a second look?
+
+Today, I want to argue that contrary to popular belief, down migration files are actually a bad idea and should be actively avoided.
+
+In the final section, I'll introduce an alternative that may sound completely contradictory: the new `migrate down` command. I will explain the
+thought process behind its creation and show examples of how to use it.
+
+### Background
+
+Since the beginning of my career, I have worked in teams where, whenever it came to database migrations,
+we were writing "down files" (ending with the `.down.sql` file extension). This was considered good practice and
+an example of how a "well-organized project should be."
+
+Over the years, as my career shifted to focus mainly on infrastructure and database tooling
+in large software projects (at companies like [Meta](https://meta.com)), I had the opportunity to question
+this practice and the reasoning behind it.
+
+Down migrations were an odd thing. In my entire career, working on projects with thousands of down files, I never applied
+them on a real environment. As simple as that: not even once.
+
+Furthermore, since we have started Atlas and to this very day, we have interviewed countless software
+engineers from virtually every industry. In all of these interviews, we have only met with _a single team_ that routinely applied down
+files in production (and even they were not happy with how it worked).
+
+Why is that? Why is it that down files are so popular, yet so rarely used? Let's dive in.
+
+#### Down migrations are the naively optimistic plan for a grim and unexpected world
+
+Down migrations are supposed to be the "undo" counterpart of the "up" migration. Why do "undo" buttons exist?
+Because mistakes happen, things fail, and then we want a way to quickly and safely revert them.
+Database migrations are considered something we should do with caution, they are super risky! So, it makes sense
+to have a plan for reverting them, right?
+
+But consider this: when we write a down file, we are essentially writing a script that will be executed in the future
+to revert the changes we are about to make. This script is written _before_ the changes are applied, and it is based on
+the assumption that the changes will be applied correctly. But what if they are not?
+
+When do we need to revert a migration? When it fails. But if it fails, it means that the database might be in an unknown state.
+It is quite likely that the database is not in the state that the down file expects it to be. For example, if the "up" migration was supposed to add
+two columns, the down file would be written to remove these two columns. But what if the migration was partially applied and only one
+column was added? Running the down file would fail, and we would be stuck in an unknown state.
+
+#### Rolling back additive changes is a destructive operation
+
+When you are working on a local database, without real traffic, having the up/down mechanism for migrations
+might feel like hitting Undo and Redo in your favorite text editor. But in a real environment, it is not the case.
+
+If you successfully rolled out a migration that added a column to a table, and then decided to revert it, its inverse
+operation (`DROP COLUMN`) does not merely remove the column. It deletes all the data in that column. Re-applying the
+migration would not bring back the data, as it was lost when the column was dropped.
+
+For this reason, teams that want to temporarily deploy a previous version of the application, usually do not revert the
+database changes, because doing so will result in data loss for their users. Instead, they need to assess the situation
+on the ground and figure out some other way to handle the situation.
+
+#### Down migrations are incompatible with modern deployment practices
+
+Many modern deployment practices like Continuous Delivery (CD) and GitOps advocate for the
+software delivery process to be automated and repeatable. This means that the deployment process should be
+deterministic and should not require manual intervention. A common way of doing this is to have a pipeline that
+receives a commit, and then automatically deploys the build artifacts from that commit to the target environment.
+
+As it is very rare to encounter a project with a 0% change failure rate, rolling back a deployment is a common scenario.
+
+In theory, rolling back a deployment should be as simple as deploying the previous version of the application. When
+it comes to versions of our application code, this works perfectly. We pull the container image that corresponds to
+the previous version, and we deploy it.
+
+But what about the database? When we pull artifacts from a previous version, they do not contain the down files that
+are needed to revert the database changes back to the necessary schema - they were only created in a future commit!
+
+For this reason, rollbacks to versions that require reverting database changes are usually done manually, going against
+the efforts to automate the deployment process by modern deployment practices.
+
+### How do teams work around this?
+
+In previous companies I worked for, we faced the same challenges. The tools we used to manage our database migrations
+advocated for down migrations, but we never used them. Instead, we had to develop some practices to support
+a safe and automated way of deploying database changes. Here are some of the practices we used:
+
+#### Migration Rollbacks
+
+When we worked with PostgreSQL, we always tried to make migrations transactional and made sure to isolate the DDLs that prevent it,
+like `CREATE INDEX CONCURRENTLY`, to separate migrations. In case the deployment failed, for instance, due to a
+[data-dependent](/lint/analyzers#data-dependent-changes) change, the entire migration was rolled back, and the application
+was not promoted to the next version. By doing this, we avoided the need to run down migrations, as the database was left in
+the same state as bit was before the deployment.
+
+#### Non-transactional DDLs
+
+When we worked with MySQL, which I really like as a database but hate when it come to migrations, it was challenging.
+Since MySQL [does not support](https://dev.mysql.com/doc/refman/8.3/en/implicit-commit.html) transactional DDLs, failures
+were more complex to handle. In case the migration contains more than one DDL and unexpectedly failed in the middle,
+because of a constraint violation or another error, we were stuck in an intermediate state that couldn't be
+automatically reverted by applying a "revert file".
+
+Most of the time, it required special handling and expertise in the data and product. We mainly preferred fixing
+the data and moving forward rather than dropping or altering the changes that were applied - which was also impossible if the
+migration introduced [destructive changes](/lint/analyzers#destructive-changes) (e.g., `DROP` commands).
+
+#### Making changes Backwards Compatible
+
+A common practice in schema migrations is to make them backwards compatible (BC). We stuck to this approach, and also made
+it the default behavior in [Ent](https://github.com/ent/ent). When schema changes are BC, applying them before starting a
+deployment should not affect older instances of the app, and they should continue to work without any issues (in rolling deployments,
+there is a period where two versions of the app are running at the same time).
+
+When there is a need to revert a deployment, the previous version of the app remains fully functional without any issues -
+if you are an Ent user, this is one of the reasons we avoid `SELECT *` in Ent. Using `SELECT *` can also break the BC
+for additive changes, like adding a new column, as the application expects to retrieve N columns but unexpectedly receives N+1.
+
+### Deciding Atlas would not support down migrations
+
+When we started Atlas, we had the opportunity to design a new tool from scratch. Seeing as "down files" never helped us
+solve failures in production, from the very beginning of Atlas, Rotem and I agreed that down files should not be generated - except for
+cases where users use Atlas to generate migrations for other tools that expect these files, such as Flyway or golang-migrate.
+
+#### Listening to community feedback
+
+Immediately after Atlas' initial release some two years ago, we started receiving feedback from the community
+that put this decision in question. The main questions were: _"Why doesn't Atlas support down migrations?"_ and _"How do I
+revert local changes?"_.
+
+Whenever the opportunity came to engage in such discussions, we eagerly participated and even pursued verbal discussions
+to better understand the use cases. The feedback and the motivation behind these questions were mainly:
+
+1. It is challenging to experiment with local changes without some way to revert them.
+2. There is a need to reset dev, staging or test-like environments to a specific schema version.
+
+#### Declarative Roll-forward
+
+Considering this feedback and the use cases, we went back to the drawing board. We came up with an approach that was
+primarily about improving developer ergonomics and was in line with the declarative approach that we were advocating
+for with Atlas. We named this approach "declarative roll-forward".
+
+Albeit, it was not a "down migration" in the traditional sense, it helped to revert applied migrations in an
+automated way. The concept is based on a three-step process:
+
+1. Use `atlas schema apply` to plan a declarative migration, using a target revision as the desired state:
+
+ ```shell
+ atlas schema apply \
+ --url "mysql://root:pass@localhost:3306/example" \
+ --to "file://migrations?version=20220925094437" \
+ --dev-url "docker://mysql/8/example" \
+ --exclude "atlas_schema_revisions"
+ ```
+ This step requires excluding the `atlas_schema_revisions` table, which tracks the applied migrations, to avoid
+ deleting it when reverting the schema.
+
+2. Review the generated plan and apply it to the database.
+
+3. Use the `atlas migrate set` command to update the revisions table to the desired version:
+
+ ```shell
+ atlas migrate set 20220925094437 \
+ --url "mysql://root:pass@localhost:3306/example" \
+ --dir "file://migrations"
+ ```
+
+This worked for the defined use cases. However, we felt that our workaround was a bit clunky as it required a
+three-step process to achieve the result. We agreed to revisit this decision in the future.
+
+### Revisiting the down migrations
+
+In recent months, the question of down migrations was raised again by a few of our customers, and we dove into it again with them.
+I always try to approach these discussions with an open mind, and listen to the different points of view and use cases that I personally
+haven't encountered before.
+
+Our discussions highlighted the need for a more elegant and automated way to perform deployment rollbacks in remote environments. The solution
+should address situations where applied migrations need to be reverted, regardless of their success, failure, or partial application,
+which could leave the database in an unknown state.
+
+The solution needs to be **automated**, **correct**, and **reviewable**, as it could involve data deletion. The solution can't be
+the "down files", because although their generation can be automated by Atlas and reviewed in the PR stage, they cannot guarantee
+correctness when applied to the database at runtime.
+
+After weeks of design and experimentation, we introduced a new command to Atlas named `migrate down`.
+
+### Introducing: `migrate down`
+
+The `atlas migrate down` command allows reverting applied migrations. Unlike the traditional approach, where down files
+are "pre-planned", Atlas computes a migration plan based on the current state of the database. Atlas reverts previously
+applied migrations and executes them until the desired version is reached, regardless of the state of the latest applied
+migration — whether it succeeded, failed, or was partially applied and left the database in an unknown version.
+
+By default, Atlas generates and executes a set of [pre-migration checks](/versioned/checks) to ensure the computed plan
+does not introduce data deletion. Users can review the plan and execute the checks before the plan is applied to the
+database by using the `--dry-run` flag or the Cloud as described below. Let's see it in action on local databases:
+
+#### Reverting locally applied migrations
+
+
+
+Assuming a migration file named `20240305171146.sql` was last applied to the database and needs to be
+reverted. Before deleting it, run the `atlas migrate down` to revert the last applied migration:
+
+
+
+
+
+
+```shell
+atlas migrate down \
+ --dir "file://migrations" \
+ --url "mysql://root:pass@localhost:3306/example" \
+ --dev-url "docker://mysql/8/dev"
+```
+
+
+
+
+```shell
+atlas migrate down \
+ --dir "file://migrations" \
+ --url "mysql://root:pass@localhost:3306/example" \
+ --dev-url "docker://mariadb/latest/dev"
+```
+
+
+
+
+```shell
+atlas migrate down \
+ --dir "file://migrations" \
+ --url "postgres://postgres:pass@:5432/example?search_path=public&sslmode=disable" \
+ --dev-url "docker://postgres/15/dev?search_path=public"
+```
+
+
+
+
+```shell
+atlas migrate down \
+ --dir "file://migrations" \
+ --url "sqlite://file.db" \
+ --dev-url "sqlite://dev?mode=memory"
+```
+
+
+
+
+```shell
+atlas migrate down \
+ --dir "file://migrations" \
+ --url "sqlserver://sa:P@ssw0rd0995@:1433?database=master" \
+ --dev-url "docker://sqlserver/2022-latest/dev"
+```
+
+
+
+
+```shell
+atlas migrate down \
+ --dir "file://migrations" \
+ --url "clickhouse://root:pass@:9000/default" \
+ --dev-url "docker://clickhouse/23.11/dev"
+```
+
+
+
+
+
+```applylog
+Migrating down from version 20240305171146 to 20240305160718 (1 migration in total):
+
+ -- checks before reverting version 20240305171146
+ -> SELECT NOT EXISTS (SELECT 1 FROM `logs`) AS `is_empty`
+ -- ok (50.472µs)
+
+ -- reverting version 20240305171146
+ -> DROP TABLE `logs`
+ -- ok (53.245µs)
+
+ -------------------------
+ -- 57.097µs
+ -- 1 migration
+ -- 1 sql statement
+```
+
+Notice two important things in the output:
+1. Atlas automatically generated a migration plan to revert the applied migration `20240305171146.sql`.
+2. Before executing the plan, Atlas ran a pre-migration check to ensure the plan does not introduce data deletion.
+
+After downgrading your database to the desired version, you can safely delete the migration file `20240305171146.sql`
+from the migration directory by running `atlas migrate rm 20240305171146`.
+
+Then, you can generate a new migration version using the `atlas migrate diff` command with the optional `--edit` flag to
+open the generated file in your default editor.
+
+For local development, the command met our expectations. It is indeed automated, correct, in the sense that it undoes
+only the reverted files, and can be reviewed using the `--dry-run` flag or the Cloud. But what about real environments?
+
+### Reverting real environments
+
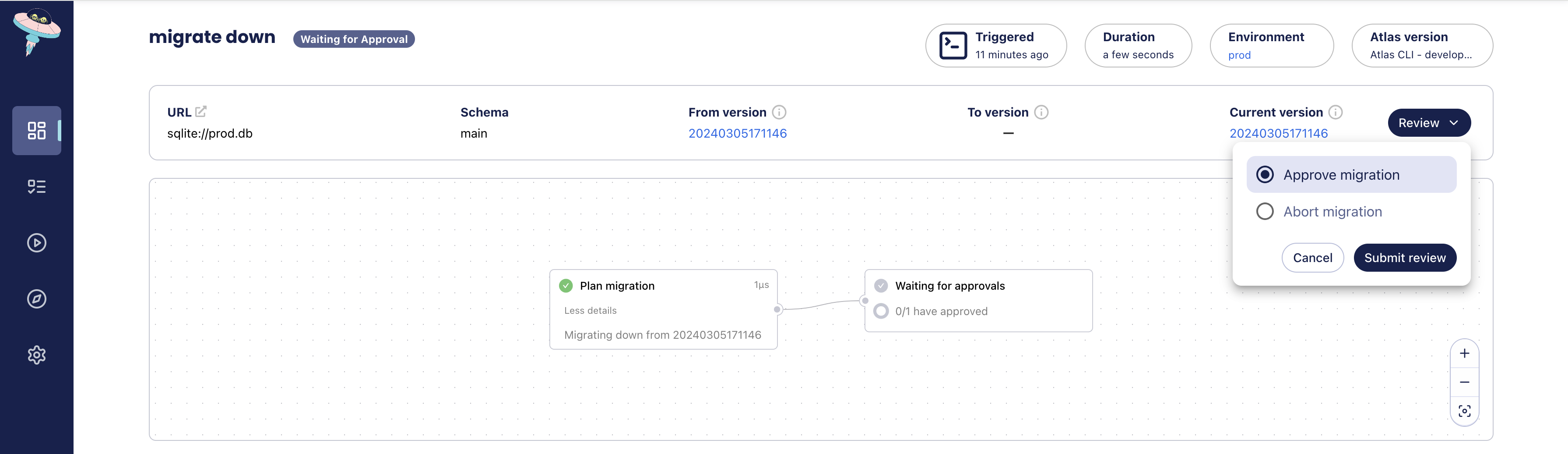
+For real environments, we're introducing another feature in Atlas Cloud today: the ability to review and approve changes
+for specific projects and commands. In practice, this means if we trigger a workflow that reverts schema changes in real environments,
+we can configure Atlas to wait for approval from one or more reviewers.
+
+Here's what it looks like:
+
+
+
+
+
+
+
+
+
+
+
+
+
+
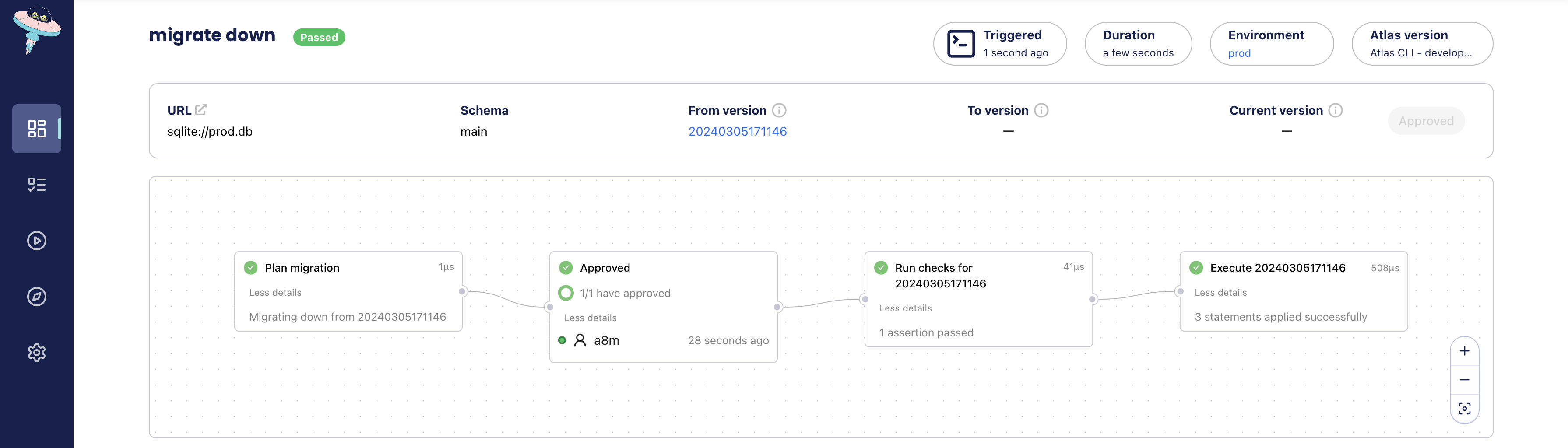
+With this new feature, down migrations are reviewable. But what about their safety and automation? As mentioned above,
+non-transactional DDLs can really leave us in trouble in case they fail, potentially keeping the database in an unknown
+state that is hard to recover from - it takes time and requires caution. However, this is true not only for applied (up)
+migrations but also for their inverse: down migrations. If the database we operate on does not support transactional DDLs,
+and we fail in the middle of the execution, we are in trouble.
+
+For this reason, when Atlas generates a down migration plan, it considers the database (and its version) and the
+necessary changes. If a transactional plan that is executable as a single unit can be created, Atlas will opt for this
+approach. If not, Atlas reverts the applied statements one at a time, ensuring that the database is not left in an unknown
+state in case a failure occurs midway. If we fail for any reason during the migration, we can rerun Atlas to
+continue from where it failed. Let's explain this with an example:
+
+Suppose we want to revert these two versions:
+
+```sql title="migrations/20240329000000.sql"
+ALTER TABLE users DROP COLUMN account_name;
+```
+
+```sql title="migrations/20240328000000.sql"
+ALTER TABLE users ADD COLUMN account_id int;
+ALTER TABLE accounts ADD COLUMN plan_id int;
+```
+
+Let's see how Atlas handles this for databases that support transactional DDLs, like PostgreSQL, and those that don't,
+like MySQL:
+
+- For PostgreSQL, Atlas starts a transaction and checks that `account_id` and `plan_id` do not contain data before
+ they are dropped. Then, Atlas applies one `ALTER` statement on the `users` table to add back the `account_name` column
+ but drops the `account_id` column. Then, Atlas executes the other `ALTER` statement to drop the `plan_id` column from the `accounts` table.
+ If any of these statements fail, the transaction is rolled back, and the database is left in the same state as before.
+ In case we succeed, the revisions table is updated, and the transaction is committed.
+
+- For MySQL, we can't execute the entire plan as a single unit. This means the same plan cannot be executed, because if we
+ fail in the middle, this intermediate state does not represent any version of the database or the migration directory. Thus, when migrating down,
+ Atlas first applies the `ALTER` statement to undo `20240329000000` and updates the revisions table. Then, it will undo `20240328000000` statement by statement, and update the revisions
+ table after each successful step. If we fail in the middle, we can re-run Atlas to continue from where it failed.
+
+What we achieved with the new `migrate down` command, is a safer and more automated way to revert applied migrations.
+
+:::info Down options
+By default, `atlas migrate down` reverts the last applied file. However, you can pass the amount of migrations to revert
+as an argument, or a target version or a tag as a flag. For instance, `atlas migrate down 2` will revert up to 2 pending
+migrations while `atlas migrate down --to-tag 297cc2c` will undo all migrations up to the state of the migration directory
+at this tag.
+:::
+
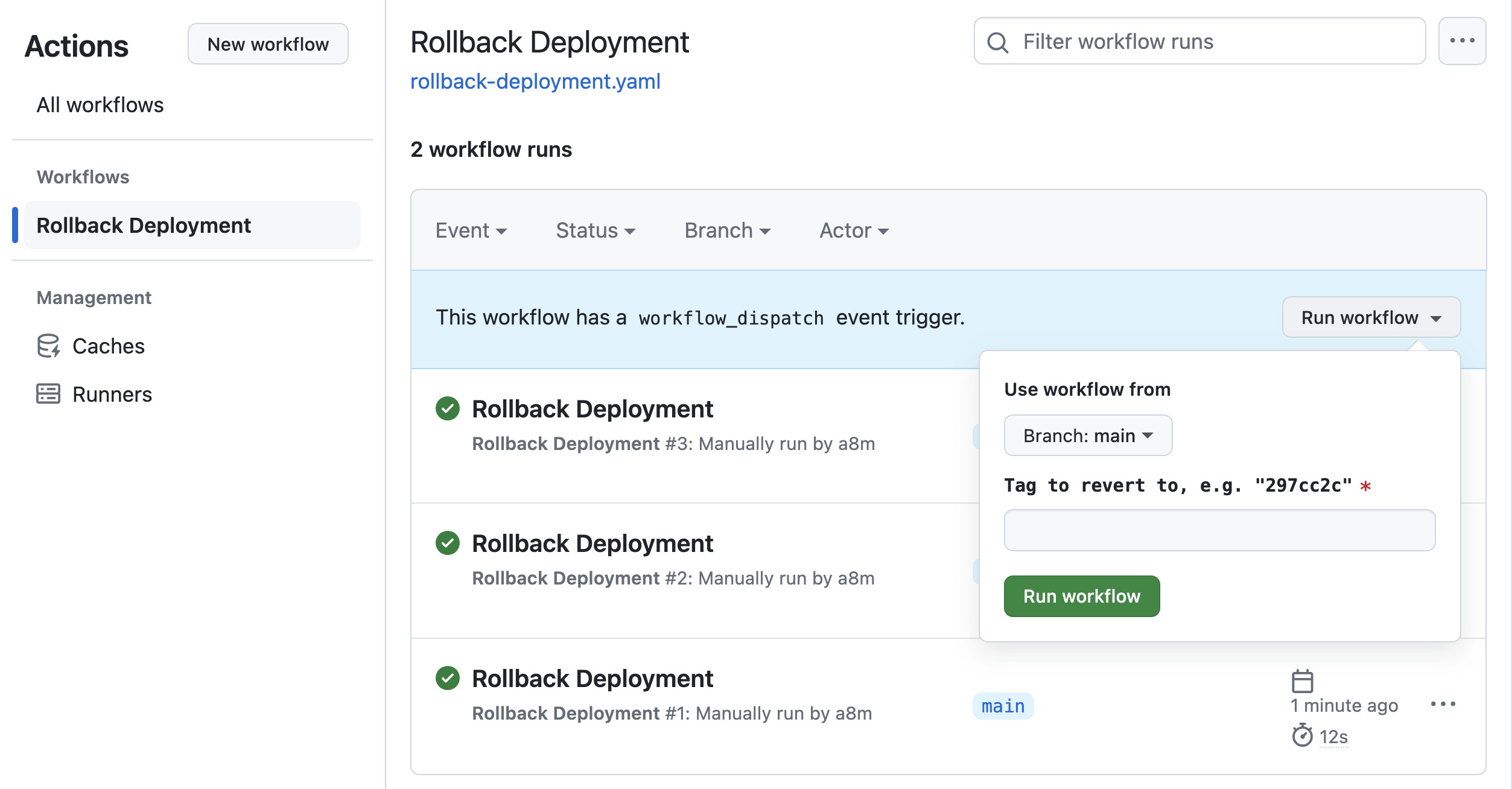
+#### GitHub Actions Integration
+
+In addition to the CLI, we also added an integration with GitHub Actions. If you have already connected your project to the
+[Schema Registry](https://atlasgo.io/cloud/features/registry) and use GitHub Actions, you can set up a workflow that
+gets a commit and triggers [Atlas](https://github.com/ariga/atlas-action) to migrate down the database to the version defined by the commit.
+The workflow will wait for approval and then apply the plan
+to the database once approved. For more info, see the [Down Action documentation](https://github.com/ariga/atlas-action?tab=readme-ov-file#arigaatlas-actionmigratedown).
+
+
+
+## Wrapping up
+
+In retrospect, I'm glad we did not implement the traditional approach in the first place. When meeting with users, we
+listened to their problems and focused on their expected outcomes rather than the features they expected. This helped us
+better understand the problem space instead of focusing the discussion on the implementation. The result we came up with
+is elegant, probably not perfect (yet), but it successfully avoided the issues that bother me most about pre-planned files.
+
+What's next? We're opening it for GA today and invite you to share your feedback and suggestions for improvements on
+our [Discord server](https://discord.gg/zZ6sWVg6NT).
+
+