Introduce IVFFlat to Lucene for ANN similarity search [LUCENE-9136] #10177
Comments
|
Xin-Chun Zhang (migrated from JIRA) I worked on this issue for about three to four days. And it now works fine for searching. My personal dev branch is available in github https://github.com/irvingzhang/lucene-solr/tree/jira/LUCENE-9136. The index format (only one meta file with suffix .ifi) of IVFFlat is shown in the class Lucene90IvfFlatIndexFormat. In my implementation, the clustering process was optimized when the number of vectors is sufficient large (e.g. > 200,000 per segment). A subset after shuffling is selected for training, thereby saving time and memory. The insertion performance of IVFFlat is better due to no extra executions on insertion while HNSW need to maintain the graph. However, IVFFlat consumes more time in flushing because of the k-means clustering. My test cases show that the query performance of IVFFlat is better than HNSW, even if HNSW uses a cache for graphs while IVFFlat has no cache. And its recall is pretty high (avg time <10ms and recall>96% over a set of 50000 random vectors with 100 dimensions). My test class for IVFFlat is under the directory https://github.com/irvingzhang/lucene-solr/blob/jira/LUCENE-9136/lucene/core/src/test/org/apache/lucene/util/ivfflat/. Performance comparison between IVFFlat and HNSW is in the class TestKnnGraphAndIvfFlat. The work is still in its early stage. There must be some bugs that need to be fixed and and I would like to hear more comments. Everyone is welcomed to participate in this issue. |
|
Julie Tibshirani (@jtibshirani) (migrated from JIRA) Hello Xin-Chun Zhang, to me this looks like a really interesting direction! We also found in our research that k-means clustering (IVFFlat) could achieve high recall with a relatively low number of distance computations. It performs well compared to KD-trees and LSH, although it tends to require substantially more distance computations than HNSW. A nice property of the approach is that it's based on a classic algorithm, k-means – it is easy to understand, and has few tuning parameters. I wonder if this clustering-based approach could fit more closely in the current search framework. In the current prototype, we keep all the cluster information on-heap. We could instead try storing each cluster as its own 'term' with a postings list. The kNN query would then be modelled as an 'OR' over these terms. A major concern about clustering-based approaches is the high indexing cost. K-means is a heavy operation in itself. And even if we only use subsample of documents during k-means, we must compare each indexed document to all centroids to assign it to the right cluster. With the heuristic of using sqrt(n) centroids, this could give poor scaling behavior when indexing large segments. Because of this concern, it could be nice to include benchmarks for index time (in addition to QPS). A couple more thoughts on this point:
|
|
Julie Tibshirani (@jtibshirani) (migrated from JIRA) Hello Xin-Chun Zhang, thanks for the updates and for trying out the idea. I was thinking we could actually reuse the existing
I created this draft PR to sketch out the approach: apache/lucene-solr#1314. I’m looking forward to hearing your thoughts! I included some benchmarks, and the QPS looks okay. The indexing time is ~1 hour for 1 million points – as we discussed earlier this is a major concern, and it will be important to think about how it can be improved. |
|
Tomoko Uchida (@mocobeta) (migrated from JIRA) @jtibshirani Xin-Chun Zhang thanks for your hard work here!
Actually the first implementation (by Michael Sokolov) for the HNSW was wrapping DocValuesFormat to avoid code duplication. However, this approach - reusing existing code - could lead another concern from the perspective of maintenance. (From the beginning, Adrien Grand suggested a dedicated format instead of hacking doc values.) This is the main reason why I introduced a new format for knn search in #10047. I'm not strongly against to the "reusing existing format" strategy if it's the best way here, just would like to share my feeling that it could be a bit controversial and you might need to convince maintainers that the (pretty new) feature does not cause any problems/concerns on future maintenance for Lucene core, if you implement it on existing formats/readers. I have not closely looked at your PR yet - sorry if my comments completely besides the point (you might already talk with other committers about the implementation in another channel, eg. private chats?). |
|
Julie Tibshirani (@jtibshirani) (migrated from JIRA) Hello @mocobeta! My explanation before was way too brief, I'm still getting used to the joint JIRA/ GitHub set-up :) I'll give more context on the suggested direction. The draft adds a new format VectorsFormat, which simply delegates to DocValuesFormat and PostingsFormat under the hood:
Given a query vector, we first iterate through all the centroid terms to find a small number of closest centroids. We then take the disjunction of all those postings enums to obtain a DocIdSetIterator of candidate nearest neighbors. To produce the score for each candidate, we load its vector from BinaryDocValues and compute the distance to the query vector. I liked that this approach didn't introduce major new data structures and could re-use the existing formats. To respond to your point, one difference between this approach and HNSW is that it’s able to re-use the formats without modifications to their APIs or implementations. In particular, it doesn’t require random access for doc values, they are only accessed through forward iteration. So to keep the code as simple as possible, I stuck with BinaryDocValues and didn’t create a new way to store the vector values. However, the PR does introduce a new top-level VectorsFormat as I thought this gave nice flexibility while prototyping. There are two main hacks in the draft that would need addressing:
Even apart from code-level concerns, I don't think the draft PR would be ready to integrate immediately. There are some areas where I think further work is needed to determine if coarse quantization (IVFFlat) is the right approach:
|
|
Xin-Chun Zhang (migrated from JIRA) Hi, @jtibshirani, thanks for you excellent work!
Yes, the codes could be simple by reusing these formats. But I agree with @mocobeta that ANN search is a pretty new feature to Lucene, it's better to use a dedicated format for maintaining reasons. Moreover, If we are going to use a dedicated vector format for HNSW, this format should also be applied to IVFFlat because IVFFlat and HNSW are used for the same purpose of ANN search. It may be strange to users if IVFFlat and HNSW perform completely different.
Actually, we need random access to the vector values! For a typical search engine, we are going to retrieving the best matched documents after obtaining the TopK docIDs. Retrieving vectors via these docIDs requires random access to the vector values. |
|
Xin-Chun Zhang (migrated from JIRA)
Structure of IVF index meta is as follows,
Structure of IVF data:
Benchmark results (Single Thread, 2.5GHz * 2CPU, 16GB RAM, nprobe=8,16,32,64,128,256, centroids=4*sqrt(N), where N the size of dataset):
|
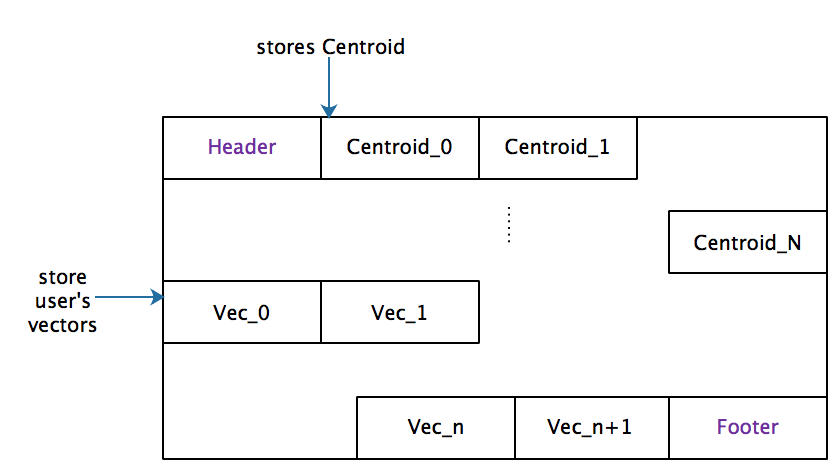
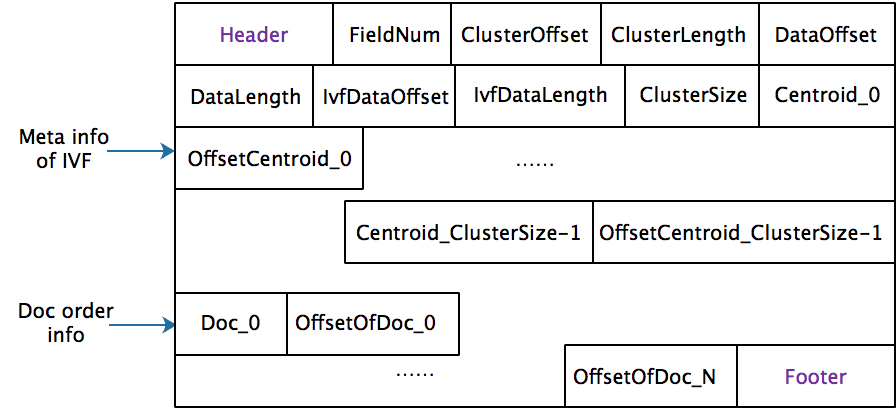
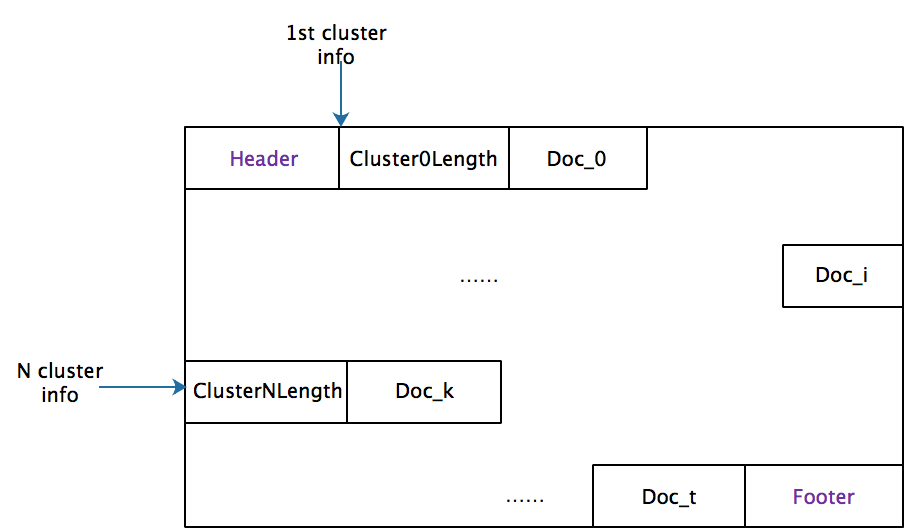
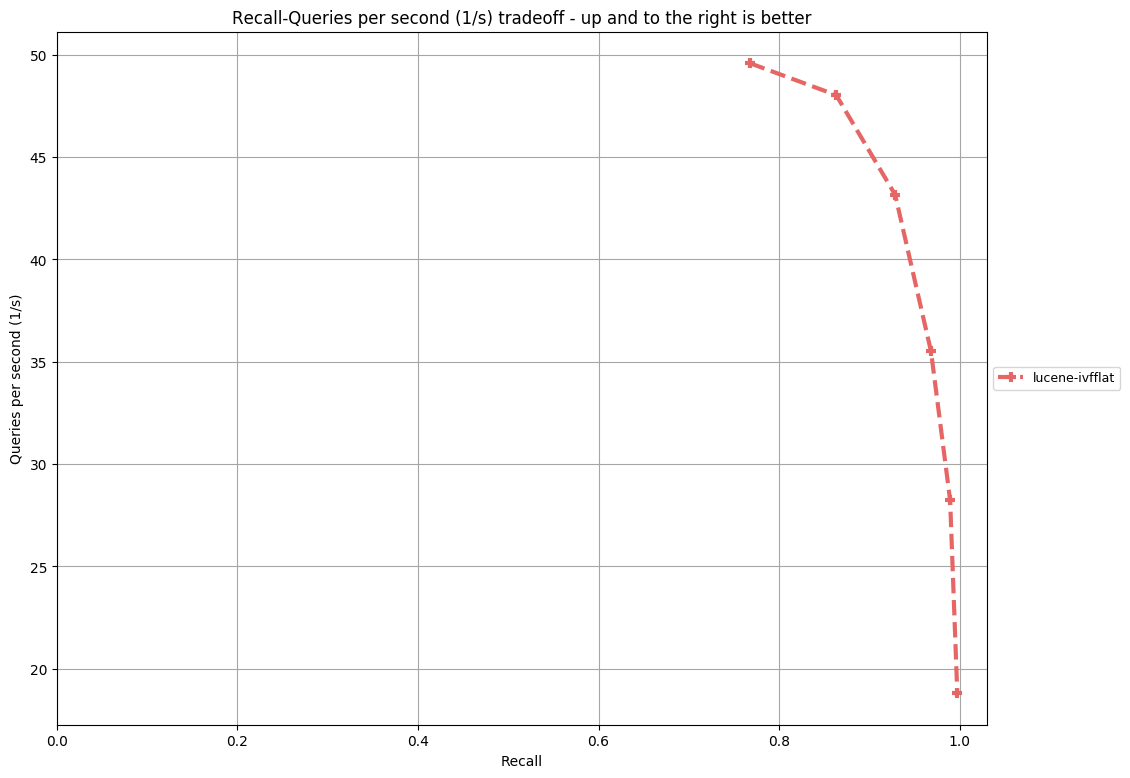
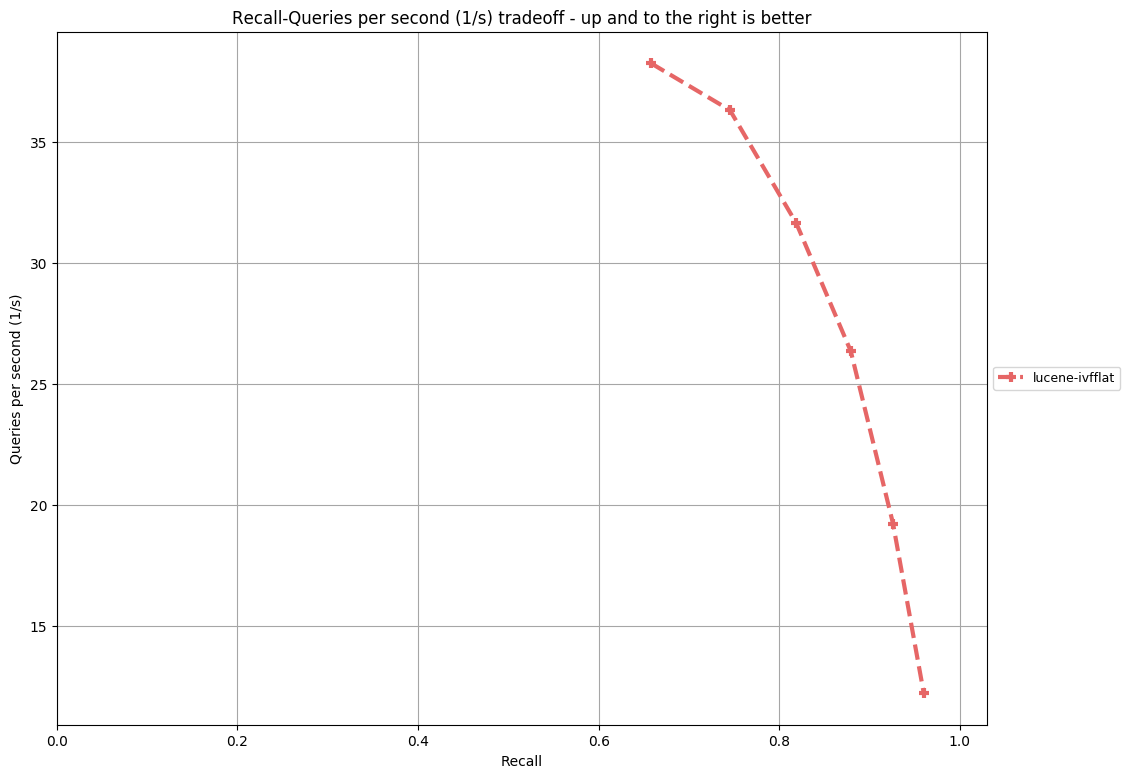
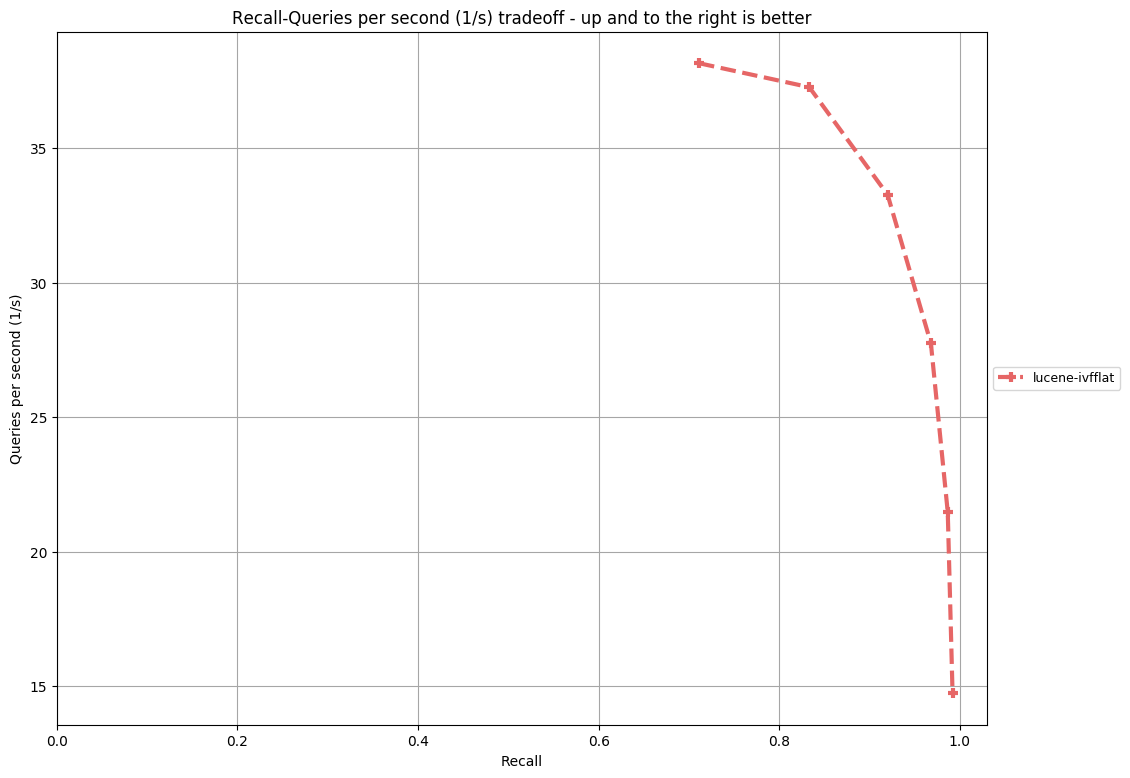
|
Jim Ferenczi (@jimczi) (migrated from JIRA) > That's the one of the main reason why this approach is interesting for Lucene. The main operation at query time is a basic inverted lists search so it would be a shame to not reuse the existing formats that were designed for this purpose. In general I think that this approach (k-means clustering at index time) is very compelling since it's a light layer on top of existing functionalities. The computational cost is big (running k-means and assigning vectors to centroids) but we can ensure that it remains acceptable by capping the number of centroids or by using an hybrid approach with a small-world graph like Julie suggested. Regarding the link with the graph-based approach, I wonder what the new ANN Codec should expose. If the goal is to provide approximate nearest neighbors capabilities to Lucene I don't think we want to leak any implementation details there. It's difficult to tell now since both effort are in the design phase but I think we should aim at something very simple that only exposes an approximate nearest neighbor search. Something like: interface VectorFormat {
TopDocs ann(int topN, int maxDocsToVisit);
float[] getVector(int docID);
}should be enough. Most of the format we have in Lucene have sensible defaults or compute parameters based on the shape of the data so I don't think we should expose tons of options here. This is another advantage of this approach in my opinion since we can compute the number of centroids needed for each segment automatically. The research in this area are also moving fast so we need to remain open to new approaches without requiring to add a new format all the time. > Actually, we need random access to the vector values! For a typical search engine, we are going to retrieving the best matched documents after obtaining the TopK docIDs. Retrieving vectors via these docIDs requires random access to the vector values. You can sort the TopK (which should be small) by docIDs and then perform the lookup sequentially ? That's how we retrieve stored fields from top documents in the normal search. This is again an advantage against the graph based approach because it is compliant with the search model in Lucene that requires forward iteration. To move forward on this issue I'd like to list the things that need clarifications in my opinion:
** Lots of optimizations have been mentioned in both issues but I think we should drive for simplicity first. In general I feel like the branch proposed by Xin-Chun Zhang and the additional changes by @jtibshirani are moving toward the right direction. The qps improvement over a brute-force approach are already compelling as outlined in apache/lucene-solr#1314 so I don't think it will be difficult to have a consensus whether this would be useful to add in Lucene. |
|
Tomoko Uchida (@mocobeta) (migrated from JIRA) Do we need a new VectorFormat that can be shared with the graph-based approach ?About this point, I think we don't need to consider both approaches at once. |
|
Jim Ferenczi (@jimczi) (migrated from JIRA) Thanks for chiming in @mocobeta. Although I still think it would be valuable to discuss the minimal signature needed to share a new codec in both approaches. I also think that there is a consensus around the fact that multiple strategies could be needed depending on the trade-offs that users are willing to take. If we start adding codecs and formats for every strategy that we think valuable I am afraid that this will block us sooner that we expect. If we agree that having a new codec for vectors and ann is valuable in Lucene, my proposal is to have a generic codec that can be used to test different strategies (k-means, hsnw, ...). IMO this could also changed the goal for these approaches since we don't want to require users to tune tons of internal options (numbers of neighbors, numbers of levels, ...) upfront. |
|
Tomoko Uchida (@mocobeta) (migrated from JIRA) @jimczi Thank you for elaborating. I agree with you, it's great if we have some abstraction for vectors (interface or abstract base class with default implementation?) for experimenting different ann search algorithms. |
|
Julie Tibshirani (@jtibshirani) (migrated from JIRA) A note that I filed #10362 to start a discussion around a unified format API. |
|
Alessandro Benedetti (@alessandrobenedetti) (migrated from JIRA) Now that #10362 has been resolved, what's remaining in this issue to be merged? |
|
Hi guys Any progress on this issue? We're trying to use vector search, but HNSW seems to take too much memory... |
Representation learning (RL) has been an established discipline in the machine learning space for decades but it draws tremendous attention lately with the emergence of deep learning. The central problem of RL is to determine an optimal representation of the input data. By embedding the data into a high dimensional vector, the vector retrieval (VR) method is then applied to search the relevant items.
With the rapid development of RL over the past few years, the technique has been used extensively in industry from online advertising to computer vision and speech recognition. There exist many open source implementations of VR algorithms, such as Facebook's FAISS and Microsoft's SPTAG, providing various choices for potential users. However, the aforementioned implementations are all written in C+, and no plan for supporting Java interface, making it hard to be integrated in Java projects or those who are not familier with C/C+ [[https://github.com/facebookresearch/faiss/issues/105]].
The algorithms for vector retrieval can be roughly classified into four categories,
where IVFFlat and HNSW are the most popular ones among all the VR algorithms.
IVFFlat is better for high-precision applications such as face recognition, while HNSW performs better in general scenarios including recommendation and personalized advertisement. The recall ratio of IVFFlat could be gradually increased by adjusting the query parameter (nprobe), while it's hard for HNSW to improve its accuracy. In theory, IVFFlat could achieve 100% recall ratio.
Recently, the implementation of HNSW (Hierarchical Navigable Small World, LUCENE-9004) for Lucene, has made great progress. The issue draws attention of those who are interested in Lucene or hope to use HNSW with Solr/Lucene.
As an alternative for solving ANN similarity search problems, IVFFlat is also very popular with many users and supporters. Compared with HNSW, IVFFlat has smaller index size but requires k-means clustering, while HNSW is faster in query (no training required) but requires extra storage for saving graphs [indexing 1M vectors|[https://github.com/facebookresearch/faiss/wiki/Indexing-1M-vectors]]. Another advantage is that IVFFlat can be faster and more accurate when enables GPU parallel computing (current not support in Java). Both algorithms have their merits and demerits. Since HNSW is now under development, it may be better to provide both implementations (HNSW && IVFFlat) for potential users who are faced with very different scenarios and want to more choices.
The latest branch is lucene-9136-ann-ivfflat](https://github.com/irvingzhang/lucene-solr/commits/jira/lucene-9136-ann-ivfflat)
Migrated from LUCENE-9136 by Xin-Chun Zhang, 3 votes, updated Dec 09 2020
Attachments: glove-100-angular.png, glove-25-angular.png, image-2020-03-07-01-22-06-132.png, image-2020-03-07-01-25-58-047.png, image-2020-03-07-01-27-12-859.png, sift-128-euclidean.png
The text was updated successfully, but these errors were encountered: