메인메모리와 CPU의 속도 차로 인해 발생하는 병목현상을 줄이기 위한 메모리
- CPU가 원하는 데이터가 캐시에 존재하는 경우 -> 캐시 Hit
- CPU가 원하는 데이터가 캐시에 없는 경우 -> 캐시 Miss
- CPU가 원하는 데이터가 캐시에 존재할 확률 -> Hit Ratio(캐시 적중률)
- L1
- CPU와 가장 가까우며 가장 빠른 캐시
- 속도를 위해 IC(Instrunction Cache)와 DC(Data Cache)로 나뉨
- IC : 메모리에서 Text 영역 데이터만 다룸
- DC : 메모리에서 Text 영역 이외의 데이터를 다룸
- L2
- L1보다 용량이 크지만 속도는 느림
- L3
- 멀티 코어 시스템에서 코어가 공유하는 캐시
- Write Through(동시에 쓰기)
- CPU가 데이터를 사용하면 캐시와 메인 메모리에 동시에 저장되는 방식
- 캐시와 메인메모리의 데이터 일관성 유지는 가능하지만 데이터 쓰기 마다 메인메모리에 접근해야 해서 캐시의 접근 시간 개선이 무의미 해짐.
- Write back(나중에 쓰기)
- 캐시의 데이터를 비울 때 메인 메모리에 기입하는 방식
- 동시에 쓰기에 비해 빠르지만 캐시와 메인메모리의 데이터가 서로 다른 경우가 발생할 수 있음
지역성 : 데이터의 접근을 균등하게 하지 않고 특정 부분을 집중적으로 하는 특성
- 캐시의 효율을 올릴려면 캐시 적중률을 올려야 하고, 캐시 적중률을 올릴려면 캐시에 저장할 데이터가 지역성을 가져야 한다.
- 공간적 지역성
- 참조된 주소의 인접한 주소가 참조되는 특성
- 배열
- 해당 특성으로 인해 캐시는 메인메모리로부터 데이터를 가져올 때 원하는 데이터 하나만 가져오는 것이 아니라 그 데이터가 위치한 라인 전체를 가져옴. 그 때 가져오는 라인의 크기를 캐시라인이라 함.
- 시간적 지역성
- 참조된 주소가 다시 참조되는 특성
- 반복문(for, whlie...)
캐시에 데이터를 저장하는 방법
- Direct Mapping
- 캐시에 데이터를 저장할 때 이미 자리가 정해진 방법
- ex) 메인 메모리 1 에서 100, 캐시 1 에서 10이 있다고 가정하면 메인 메모리의 1 에서 10은 캐시의 1에 메인메모리의 11 에서 20은 캐시의 2에 저장되는 방법
- 데이터를 찾을 때 정해진 자리로 바로 가면 되서 빠르지만 겹치는 부분에 데이터가 없으면 계속 교체를 해줘야 하므로 적중률이 낮음
- Associate Mapping
- Direct Mapping과 다르게 자리가 정해져 있지 않고 비어있다면 어디든지 데이터를 저장할 수 있는 방법
- 데이터를 찾을 때 tag를 일일이 비교해줘야해서 속도는 느리지만 적중률은 높음
- Set Associate Mapping
- Direct Mapping의 장점 + Associate Mapping의 장점
- 여러개의 캐시 라인을 하나의 set으로 묶고 그렇게 만들어진 set들을 정해진 자리대로 저장 -> Direct Mapping
- set 안에서는 순서가 정해져 있지 않고 어디든지 데이터 저장 가능 -> Associate Mapping
- 데이터를 찾을 때 set번호를 참조해서 찾음
캐시 메모리에서 가장 오랫동안 사용하지 않은 데이터 순으로 제거하는 알고리즘
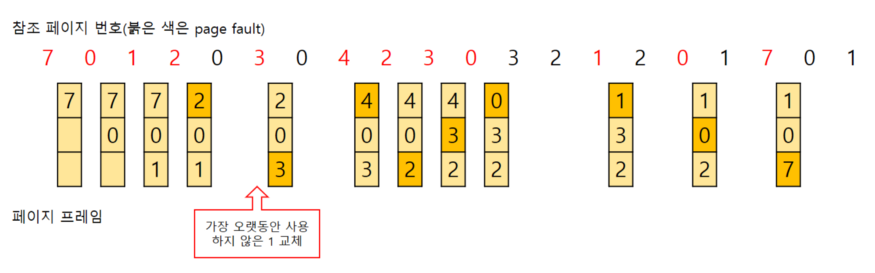
- Doubly Linked List 사용
- head일수록 자주 사용, tail일수록 사용 빈도 적음
- 교체가 필요할 때 tail쪽의 데이터 교체 후 새로운 데이터는 head쪽으로 배치
- 시간 복잡도 O(1)
- 구현이 간단하고 가장 보편적인 방식임

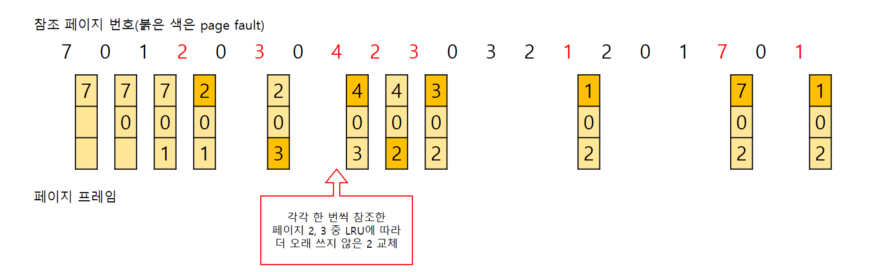
캐시 메모리에서 사용 횟수가 가장 적은 데이터부터 교체하는 알고리즘
교체 대상이 여렷(횟수 동일)이면 LRU 알고리즘을 따름
- 단점
- 구현이 복잡함
- 적재된 초반에 집중적으로 쓰여 사용 횟수가 많아졌으나 이후 거의 쓰이지 않는데도 잔존해버려 메모리 낭비 가능성이 있음
- 최근 적재된 데이터가 교체될 수도 있음
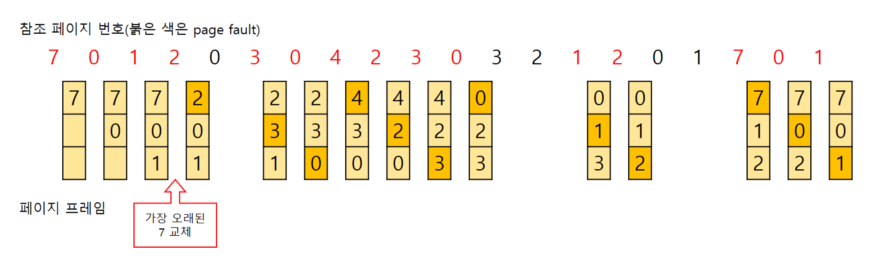
캐시 메모리에 올라온 가장 오래된 데이터를 교체
- Queue를 통해 구현
- 구현이 간단함
- 잦은 교체가 발생할 수 있음