Data quality api #2
Closed
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
## Summary Closes elastic#146574 <img width="1059" alt="image" src="https://user-images.githubusercontent.com/17003240/204623693-a2d17c66-cd86-450b-b50f-e2ced880e46f.png">
{kind=link}
## Summary Closes elastic#145378. The overview page has a [`<EuiSpacer />` at the bottom of the grid](https://github.com/elastic/kibana/blob/e8d77b3f0f46ac62e9220ffe28eb455880854906/x-pack/plugins/synthetics/public/apps/synthetics/components/monitors_page/overview/overview/overview_grid.tsx#L135-L137) to track the user's scroll position. This is done [with an `IntersectionObserver` (wrapped in a hook) and a `ref`](https://github.com/elastic/kibana/blob/e8d77b3f0f46ac62e9220ffe28eb455880854906/x-pack/plugins/synthetics/public/apps/synthetics/components/monitors_page/overview/overview/overview_grid.tsx#L70-L75). Sometimes the `ref` got destroyed, and with it the `IntersectionObserver` instance. This causes a race condition [in the code that checks for the intersection](https://github.com/elastic/kibana/blob/e8d77b3f0f46ac62e9220ffe28eb455880854906/x-pack/plugins/synthetics/public/apps/synthetics/components/monitors_page/overview/overview/overview_grid.tsx#L78-L88) to determine if the next page should be loaded or not. <img width="1278" alt="Screenshot 2022-11-29 at 16 35 42" src="https://user-images.githubusercontent.com/57448/204574461-5056391c-e96d-4b38-9c9e-4976e0d14a40.png"> The reason why the `ref` got destroyed was [this early return](https://github.com/elastic/kibana/blob/e8d77b3f0f46ac62e9220ffe28eb455880854906/x-pack/plugins/synthetics/public/apps/synthetics/components/monitors_page/overview/overview/overview_grid.tsx#L98-L100). With the code in `main` there is a brief moment in which the condition holds `true`, right after the monitors are loaded. In that brief instant the `status` is present but `monitorsSortedByStatus` is empty. <img width="1084" alt="Screenshot 2022-11-29 at 16 44 35" src="https://user-images.githubusercontent.com/57448/204575679-de4bc6bf-122b-4c6d-ae75-9c96a7c5fb85.png"> When this happens the `ref` is destroyed, because the underlying element used to track the intersection is destroyed due of the early return. This was caused because `monitorsSortedByStatus` was updated asynchronously [with `useEffect`](https://github.com/elastic/kibana/blob/2f3313371bc6d992a99accef1289dd035779d3e6/x-pack/plugins/synthetics/public/apps/synthetics/hooks/use_monitors_sorted_by_status.tsx#L30-L72) as part of the component lifecycle. This PR uses `useMemo` instead of `useEffect`, to update the `monitorsSortedByStatus` at the same time that `status` is present. This prevents the early return from ever firing in the normal load cycle and keeps the `ref`. Since the `ref` never gets destroyed there's no race condition anymore.
{kind=link}
{kind=link}
## Summary Closes elastic#144289 This PR just removes ts-ignore annotation where it's not needed anymore. ### How to test - Start local Kibana - Go to stack monitoring and try to access all the pages there. Co-authored-by: Kibana Machine <[email protected]>
…c#146158) ## Summary I noticed `agent_list_page/index.tsx` was quite large, so I have moved the agent list table to be its own component. Co-authored-by: Kibana Machine <[email protected]>
## Summary This PR is focusing on closing two tickets elastic#143503 and elastic#143421. There are a bunch of new icons for AWS and Azure architecture that are being added and would be visualized as a dependency. There is also a synthrace scenario added in this PR, which would allow for a better review of how it would look like. We can use this scenario for testing more things in the future. 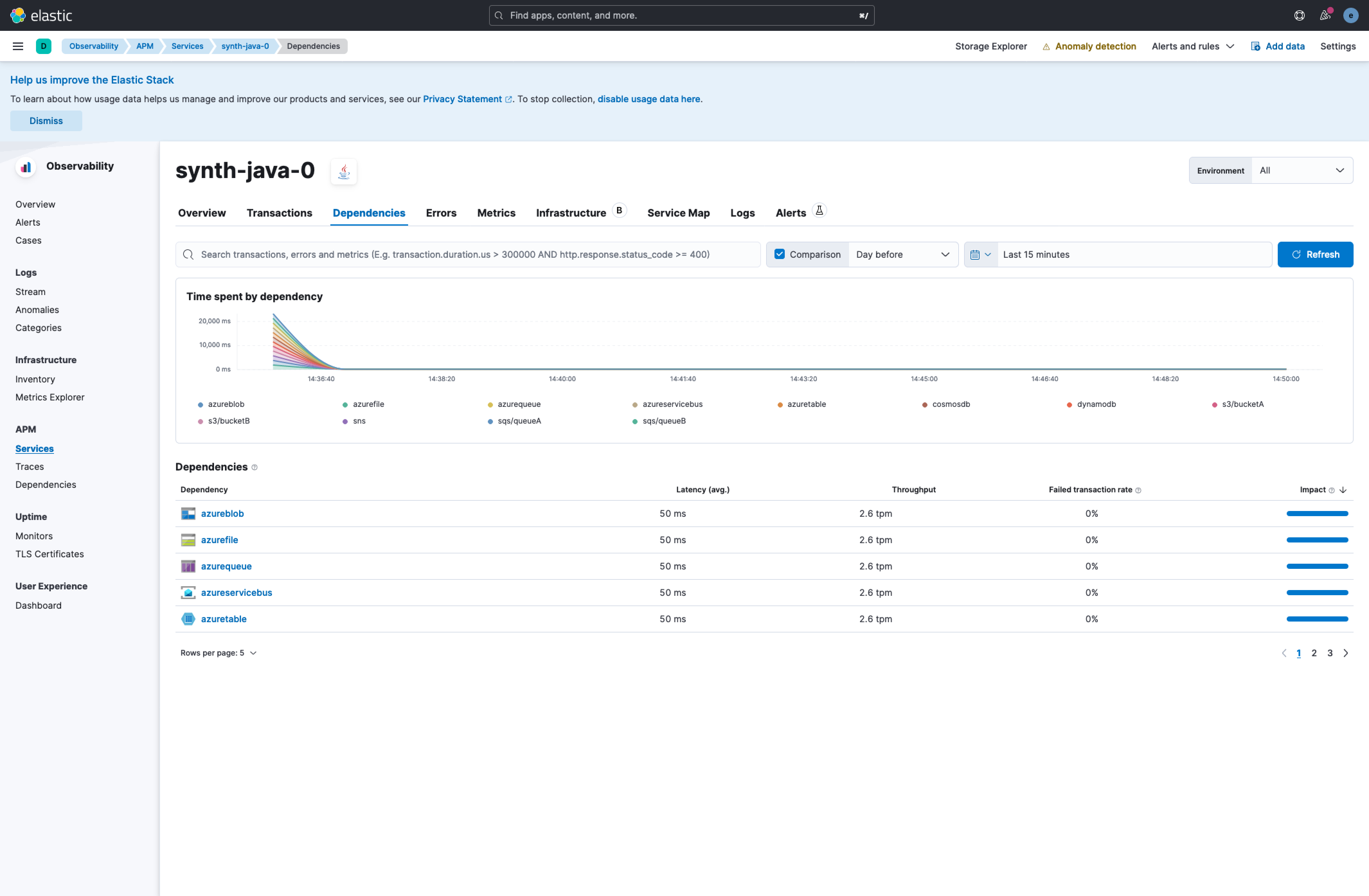  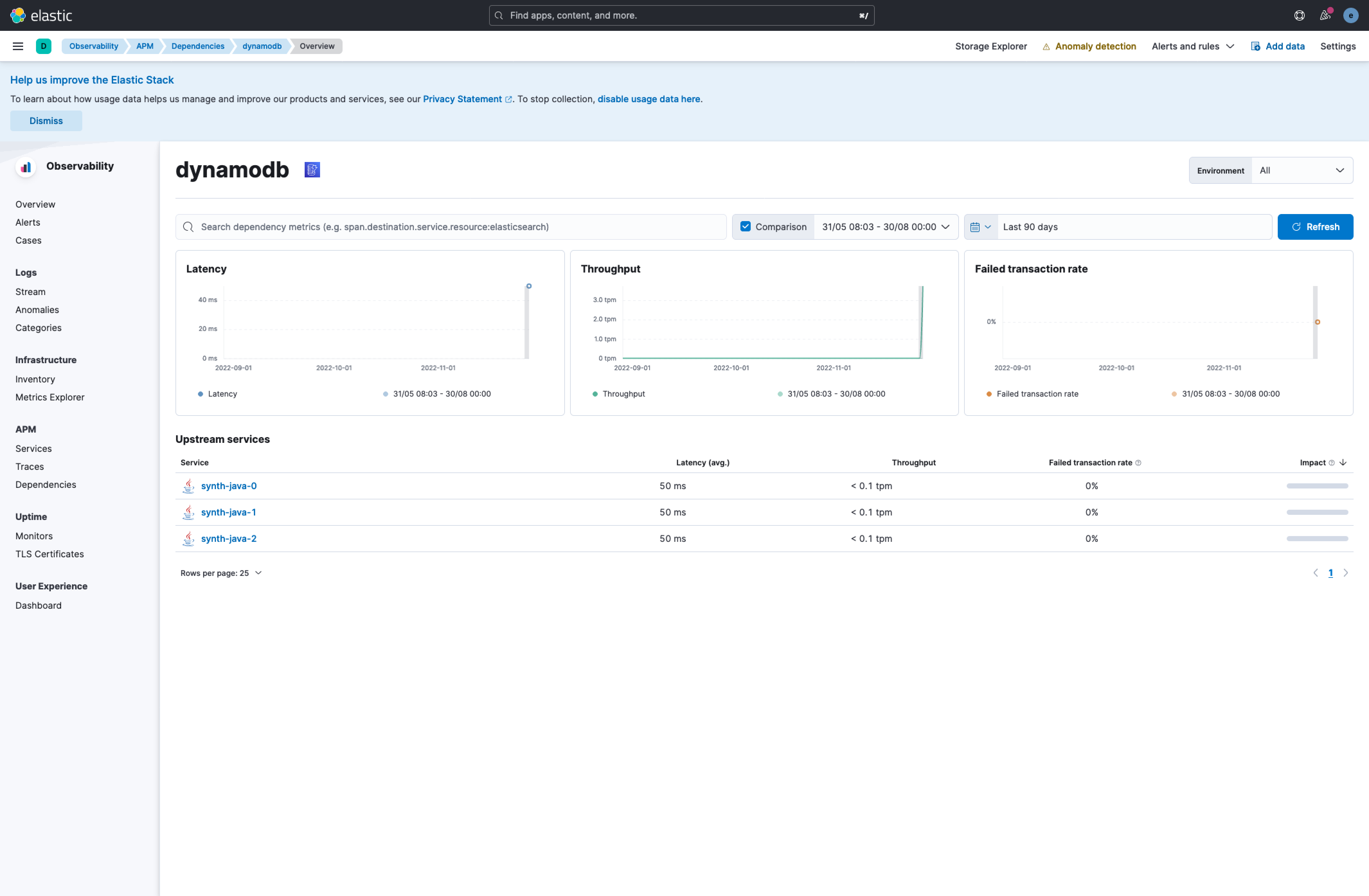 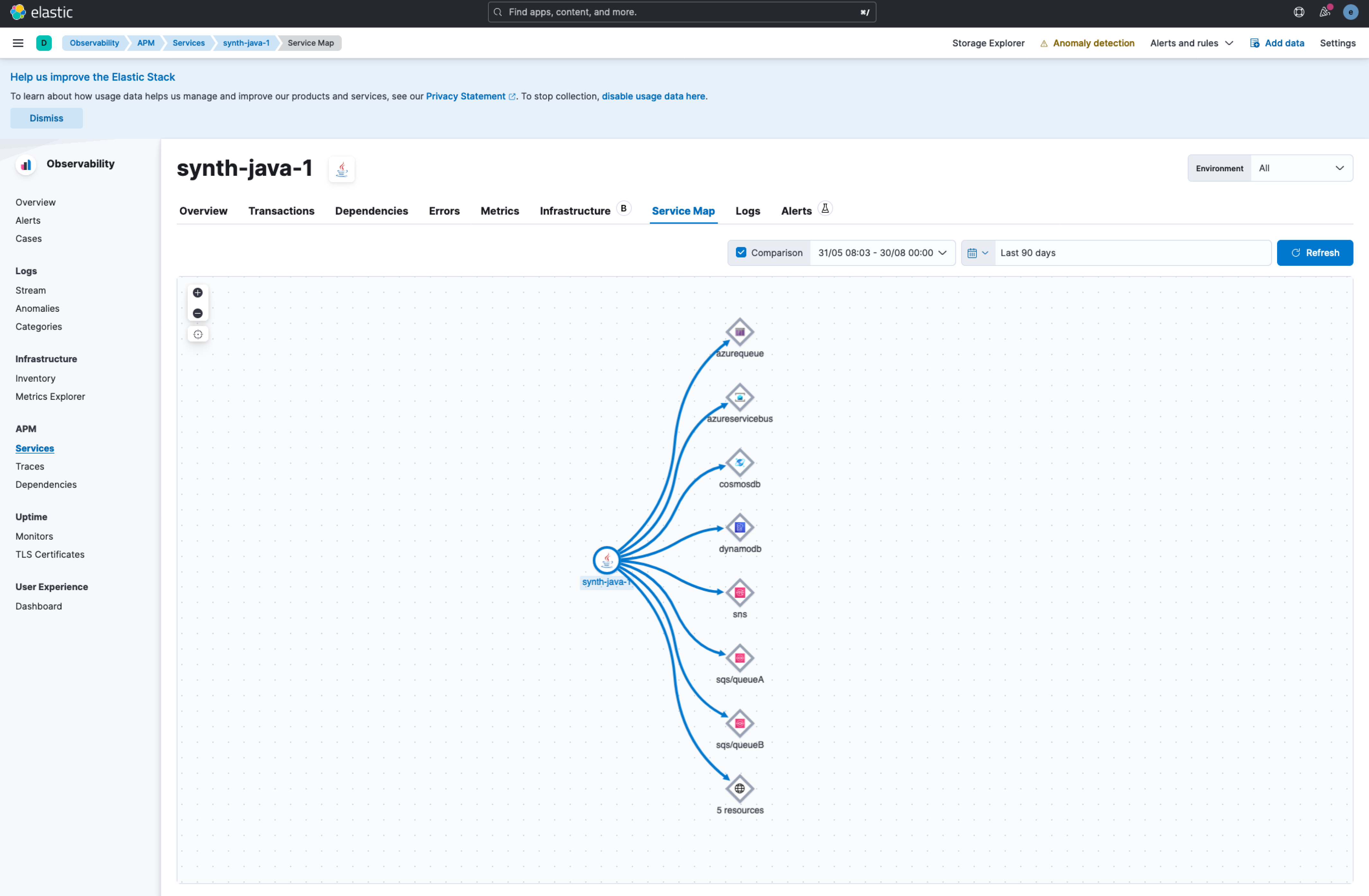 Co-authored-by: Kibana Machine <[email protected]>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Closes [elastic#140445](elastic#140445) ## Summary This PR adds 2 filters (Operating System and Cloud Provider) using [Kibana Controls API](https://github.com/elastic/kibana/tree/main/src/plugins/controls) to the Host view. ## Testing - Open Host View - The Operating System and Cloud Provider filters should be visible under the search bar. Supported values: - Filter Include/exclude OS name / Cloud Provider name - Exist / Does not exist - Any (also when clearing the filters) - The control filters should update the possible values when the other control filter or unified search query/filters are changes - When the control group filters are updated the table is loading the filtered result. - Combination with unified search query/filters should be possible. 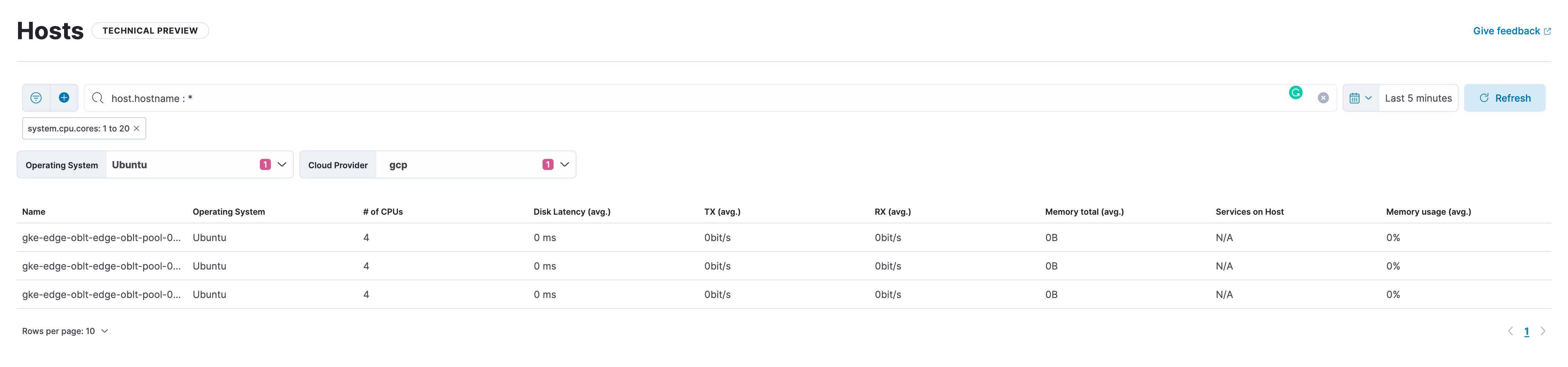 - Copy the url after adding the filters and paste it into a separate tab - The control group AND the other filters/query should be prefilled ## 🎉 UPDATE the control panels are prefilled from the URL ### The Workaround: Together with @ThomThomson we found a way to prefill the control group selections from the URL state by adding the panels' objects to the URL state (using a separate key to avoid the infinite loop issue) and keeping the output filters (used for updating the table) separately. ## Discovered issues with persisting the new filters to the URL state ~~⚠️ This PR does not support persisting those filters in the URL state. The reason behind this is that if we persist those filters inside the other filters parameter it will create an infinite loop (as those controls are relying on the filters to adjust the possible values).~~ In order to avoid that we can persist them in a different parameter (instead of adding them to the existing `_a` we can add a new one for example named `controlFilters`. This will work with filtering the table results. BUT If we go with the solution to persist them in another `urlStateKey` we also need to prefill those selections from the url state to the control filters (Operating System and Cloud Provide). Currently, the controls API supports setting `selectedOptions` as a string array. ### Workaraound Ideas Option 1: I tried first on a[ separate branch ](elastic/kibana@main...jennypavlova:kibana:140445-host-filtering-controls-with-url-state) - Persist the filters as an array of filter options. - on load prefill the control filters - extract the string values from the filters and set them as `selectedOptions` inside the control group input `panel` (based on the field name for example) Option 2 (Suggestion from Devon ) - on load pass in the selections from the URL to the control group input - Don't render the table right away - Wait until control group is ready .then - Get the filters from the control group output - Set filters from controls in the use state by doing controls.getOutput().filters - Render the table with ...unifiedSearchFilters, ...filtersFromControls ❌ The issue with both 1 & 2 - With `selectedOptions` we can prefill only **strings** so `Exist` and `Negate` won't be supported
{kind=link}
…146272) Closes [elastic#145238](elastic#145238) ## Summary These changes add validation to the Metric Indices passed into the Metrics settings page. New validation is added both in the UI and in the endpoint, performing the following checks: - Index pattern is not an empty string - Index pattern does not contain empty spaces (start, middle, end) (the pattern is not trimmed) - Index pattern does not contain empty entries, comma-separated values should have an acceptable value. In case the value is not valid, the UI will render an appropriate error message. If the `PATCH /api/metrics/source/{sourceId}` request to update the value is manually sent with an invalid value, the server will respond with a 400 status code and an error message. Also, for retro compatibility and to not block the user when the configuration can't be successfully retrieved, in case of internal error the `GET /api/metrics/source/{sourceId}` will return a 404 and on the UI, instead of rendering a blank page, the user will see the empty form and will be able to re-insert the right values. ## Testing Navigate to `Inventory`-> Click on `Settings` on the topbar -> Start writing different metric indices in the Metric Indices field. ### Editing Metric Indices validation https://user-images.githubusercontent.com/34506779/203763021-0f4d8926-ffa4-448a-a038-696732158f4e.mov ### Missing/Broken configuration response https://user-images.githubusercontent.com/34506779/203763120-ffc91cd3-9bf4-43da-a04f-5561ceabf591.mov Co-authored-by: Marco Antonio Ghiani <[email protected]> Co-authored-by: kibanamachine <[email protected]>
## Summary Reshuffles all remaining App Services CODEOWNERS paths to various teams. Co-authored-by: kibanamachine <[email protected]>
…ilable (elastic#139945) ## Summary In the integrations browser, put a notification on the installed integrations tab when we have unverified or out of date packages. Add a new callout for packages with upgrade available. <img width="1266" alt="Screenshot 2022-11-29 at 14 16 41" src="https://user-images.githubusercontent.com/3315046/204554172-71e9b37c-5d0a-4cc7-9eb1-27f6776ee808.png">
{kind=link}
## Summary Closes elastic#144289 PR resolves TS errors after enabling allowJs in tsconfig file. There are still ~40 files that unnecessarily use the @ts-gnore annotation and those can now be removed, but to avoid creating a gigantic PR, I've decided to open this one focusing only on the bare minimum to enable the allowJs parameter. ### How to test - Start local Kibana - Go to stack monitoring and try to access all the pages there. Co-authored-by: Kibana Machine <[email protected]> Co-authored-by: Kevin Lacabane <[email protected]>
…stic#146673) ## Summary Update the docker image used as Elastic Package Registry distribution for Package Storage V2, so it contains the latest packages published. Tested updating fleet_packages.json to use endpoint version 8.6.0 (and reverted).
## Summary Patch for elastic#146605 Currently if a test fails, ES is not killed, causing errors for all following tests ### Checklist Delete any items that are not applicable to this PR. - [ ] Any text added follows [EUI's writing guidelines](https://elastic.github.io/eui/#/guidelines/writing), uses sentence case text and includes [i18n support](https://github.com/elastic/kibana/blob/main/packages/kbn-i18n/README.md) - [ ] [Documentation](https://www.elastic.co/guide/en/kibana/master/development-documentation.html) was added for features that require explanation or tutorials - [ ] [Unit or functional tests](https://www.elastic.co/guide/en/kibana/master/development-tests.html) were updated or added to match the most common scenarios - [ ] Any UI touched in this PR is usable by keyboard only (learn more about [keyboard accessibility](https://webaim.org/techniques/keyboard/)) - [ ] Any UI touched in this PR does not create any new axe failures (run axe in browser: [FF](https://addons.mozilla.org/en-US/firefox/addon/axe-devtools/), [Chrome](https://chrome.google.com/webstore/detail/axe-web-accessibility-tes/lhdoppojpmngadmnindnejefpokejbdd?hl=en-US)) - [ ] If a plugin configuration key changed, check if it needs to be allowlisted in the cloud and added to the [docker list](https://github.com/elastic/kibana/blob/main/src/dev/build/tasks/os_packages/docker_generator/resources/base/bin/kibana-docker) - [ ] This renders correctly on smaller devices using a responsive layout. (You can test this [in your browser](https://www.browserstack.com/guide/responsive-testing-on-local-server)) - [ ] This was checked for [cross-browser compatibility](https://www.elastic.co/support/matrix#matrix_browsers) ### Risk Matrix Delete this section if it is not applicable to this PR. Before closing this PR, invite QA, stakeholders, and other developers to identify risks that should be tested prior to the change/feature release. When forming the risk matrix, consider some of the following examples and how they may potentially impact the change: | Risk | Probability | Severity | Mitigation/Notes | |---------------------------|-------------|----------|-------------------------| | Multiple Spaces—unexpected behavior in non-default Kibana Space. | Low | High | Integration tests will verify that all features are still supported in non-default Kibana Space and when user switches between spaces. | | Multiple nodes—Elasticsearch polling might have race conditions when multiple Kibana nodes are polling for the same tasks. | High | Low | Tasks are idempotent, so executing them multiple times will not result in logical error, but will degrade performance. To test for this case we add plenty of unit tests around this logic and document manual testing procedure. | | Code should gracefully handle cases when feature X or plugin Y are disabled. | Medium | High | Unit tests will verify that any feature flag or plugin combination still results in our service operational. | | [See more potential risk examples](https://github.com/elastic/kibana/blob/main/RISK_MATRIX.mdx) | ### For maintainers - [ ] This was checked for breaking API changes and was [labeled appropriately](https://www.elastic.co/guide/en/kibana/master/contributing.html#kibana-release-notes-process)
…stic#146303) ## Summary Closes elastic#141470 The source_uri parameter in agent policy should actually be `sourceURI`. I didn't change the parameter everywhere in the code but only where is exposed to the agent policy/actions, since in other places is only used internally by fleet. <img width="748" alt="Screenshot 2022-11-24 at 15 59 54" src="https://user-images.githubusercontent.com/16084106/203814663-b9e37be2-5017-4aba-94da-9f928de490c8.png"> ### Checklist - [ ] [Unit or functional tests](https://www.elastic.co/guide/en/kibana/master/development-tests.html) were updated or added to match the most common scenarios Co-authored-by: Kibana Machine <[email protected]>
{kind=link}
## Summary Removes the technical preview badge from the mosaic/waffle charts <img width="497" alt="image" src="https://user-images.githubusercontent.com/17003240/203747315-45a1e817-c1c4-4f72-9d8c-d2d564d1e721.png">
{kind=link}
…n hosts page (elastic#146671) Closes: elastic#146670 ## Summary This PR fixes the unified search bar size on the host view page.
… to remove flakiness (elastic#146677) Co-authored-by: Kibana Machine <[email protected]>
## Summary Part of elastic#142456 Adds functional tests for the Test model action ### Checklist - [x] [Unit or functional tests](https://www.elastic.co/guide/en/kibana/master/development-tests.html) were updated or added to match the most common scenarios
…elastic#146564) ## Summary Addresses elastic#146494 We only need the first document from the bucket to create the alert, not `maxSignals` documents. If `maxSignals` was greater than 100, this caused an error in the search.
## Remove id from item list when try to close alerts during update exceptions close: elastic#146661 Co-authored-by: Kibana Machine <[email protected]>
## Summary Resolves elastic#146932 Adjusts monitor delete logic for Uptime to ensure that multiple monitors are able to be deleted in a row. ### Testing 1. Create at least two monitors 2. Navigate to Uptime monitor management. Delete a monitor. Ensure the success toast appears and the monitor is removed from the monitor list 3. Delete a second monitor. Ensure the success toast appears and the monitor is removed from the list. Co-authored-by: shahzad31 <[email protected]>
…elastic#147040) ## Summary Closes elastic#147028 ## Testing instructions See steps to reproduce in linked issue. Verify AWS credential variables appear on this branch.  I took a pass at adding tests for our `parseAndVeryArchive` method but it's sort of a recursive chain of mocked `Buffer` -> `yaml.safeLoad` operations and got pretty involved to set up from scratch. The other option would be to add an FTR API test that catches this case, but we'd need a package with top-level variables loaded into the test registry, which we may not have readily available if elastic#146809 lands. I would love some alternative ideas on adding test coverage for this fix, but if it's going to involved I don't want to block this fix from landing in 8.6 on tests.
{kind=link}
…lastic#147039) ## Summary - Applying a max-height to the `Linked Rules` combobox in the List Shared details as well as in the Add Exception Items
…s within timeline (elastic#147024) ## Summary This pr is a bit of a hack to get around an issue with eui portals and the z-index of the timeline, as the tags super select that is displayed when the exceptions flyout is opened when not specifically for a rule instance, renders below the flyout due to z-index of 5000. This change makes it so that the flyout has a z-index of 1000 in that case, and 5000 in the timeline view, so that all elements are visible as expected. https://user-images.githubusercontent.com/56408403/205704409-9379e5af-2f01-45f0-b5d9-8479ac892b65.mov
…dpoint package (elastic#147052) ## Summary Change our query to use `prerelease` to correctly find dev endpoint packages in tests ### Checklist - [x] [Unit or functional tests](https://www.elastic.co/guide/en/kibana/master/development-tests.html) were updated or added to match the most common scenarios
## Summary - Single observable for internal state - Selector style creation of observables for individual usage in react code - internal `stateUpdate` fn that sets internal state and emits new observable value
## Summary Closes elastic#146442 Orders the date fields first when navigating from Lens to Discover.  ### Checklist - [x] [Unit or functional tests](https://www.elastic.co/guide/en/kibana/master/development-tests.html) were updated or added to match the most common scenarios Co-authored-by: Kibana Machine <[email protected]>
{kind=link}
Automated by https://internal-ci.elastic.co/job/package_storage/job/sync-bundled-packages-job/job/main/784/ Co-authored-by: apmmachine <[email protected]> Co-authored-by: Kyle Pollich <[email protected]>
These changes should make it simpler to add the search bar to the service map.
…onboarding is active (elastic#146902) Due to the location of the guided onboarding tour, it can overlap with the new features tour when a user is doing guided onboarding. This PR disables the new features tour if the user is in the middle of guided onboarding. There is still a remaining issue where after the user completes the 3 steps of the guided onboarding on the rules page, the `isGuideStepActive$` API returns `false` even though there is still a tooltip open for the `Continue with the guide` option. The new features tour overlaps with this option. 
{kind=link}
## Invalidate cache for rules, after adding shared exception Related: elastic#146962 Co-authored-by: Kibana Machine <[email protected]>
…spector panel (elastic#147026) ## Summary Fixes elastic#141199 Extends the `fetch$` method in the `handleRequest` to accept a custom title+description params to be used on the inspector request log method. In case params are not passed the old behaviour is kept as fallback. The annotation expression can now pass the request meta information about the Annotation request type, that will show up in the panel: <img width="709" alt="Screenshot 2022-12-05 at 18 40 14" src="https://user-images.githubusercontent.com/924948/205705862-45ae1070-d635-4519-9e4e-7d769d05b8d7.png"> ### Checklist Delete any items that are not applicable to this PR. - [ ] Any text added follows [EUI's writing guidelines](https://elastic.github.io/eui/#/guidelines/writing), uses sentence case text and includes [i18n support](https://github.com/elastic/kibana/blob/main/packages/kbn-i18n/README.md) - [ ] [Documentation](https://www.elastic.co/guide/en/kibana/master/development-documentation.html) was added for features that require explanation or tutorials - [ ] [Unit or functional tests](https://www.elastic.co/guide/en/kibana/master/development-tests.html) were updated or added to match the most common scenarios - [ ] Any UI touched in this PR is usable by keyboard only (learn more about [keyboard accessibility](https://webaim.org/techniques/keyboard/)) - [ ] Any UI touched in this PR does not create any new axe failures (run axe in browser: [FF](https://addons.mozilla.org/en-US/firefox/addon/axe-devtools/), [Chrome](https://chrome.google.com/webstore/detail/axe-web-accessibility-tes/lhdoppojpmngadmnindnejefpokejbdd?hl=en-US)) - [ ] If a plugin configuration key changed, check if it needs to be allowlisted in the cloud and added to the [docker list](https://github.com/elastic/kibana/blob/main/src/dev/build/tasks/os_packages/docker_generator/resources/base/bin/kibana-docker) - [ ] This renders correctly on smaller devices using a responsive layout. (You can test this [in your browser](https://www.browserstack.com/guide/responsive-testing-on-local-server)) - [ ] This was checked for [cross-browser compatibility](https://www.elastic.co/support/matrix#matrix_browsers) ### Risk Matrix Delete this section if it is not applicable to this PR. Before closing this PR, invite QA, stakeholders, and other developers to identify risks that should be tested prior to the change/feature release. When forming the risk matrix, consider some of the following examples and how they may potentially impact the change: | Risk | Probability | Severity | Mitigation/Notes | |---------------------------|-------------|----------|-------------------------| | Multiple Spaces—unexpected behavior in non-default Kibana Space. | Low | High | Integration tests will verify that all features are still supported in non-default Kibana Space and when user switches between spaces. | | Multiple nodes—Elasticsearch polling might have race conditions when multiple Kibana nodes are polling for the same tasks. | High | Low | Tasks are idempotent, so executing them multiple times will not result in logical error, but will degrade performance. To test for this case we add plenty of unit tests around this logic and document manual testing procedure. | | Code should gracefully handle cases when feature X or plugin Y are disabled. | Medium | High | Unit tests will verify that any feature flag or plugin combination still results in our service operational. | | [See more potential risk examples](https://github.com/elastic/kibana/blob/main/RISK_MATRIX.mdx) | ### For maintainers - [ ] This was checked for breaking API changes and was [labeled appropriately](https://www.elastic.co/guide/en/kibana/master/contributing.html#kibana-release-notes-process)
{kind=link}
andrew-goldstein
pushed a commit
that referenced
this pull request
Jan 3, 2023
## Summary Fixes elastic#144161 As discussed [here](elastic#144161 (comment)), the existing implementation of update tags doesn't work well with real agents, as there are many conflicts with checkin, even when trying to add/remove one tag. Refactored the logic to make retries more efficient: - Instead of aborting the whole bulk action on conflicts, changed the conflict strategy to 'proceed'. This means, if an action of 50k agents has 1k conflicts, not all 50k is retried, but only the 1k conflicts, this makes it less likely to conflict on retry. - Because of this, on retry we have to know which agents don't yet have the tag added/removed. For this, added an additional filter to the `updateByQuery` request. Only adding the filter if there is exactly one `tagsToAdd` or one `tagsToRemove`. This is the main use case from the UI, and handling other cases would complicate the logic more (each additional tag to add/remove would result in another OR query, which would match more agents, making conflicts more likely). - Added this additional query on the initial request as well (not only retries) to save on unnecessary work e.g. if the user tries to add a tag on 50k agents, but 48k already have it, it is enough to update the remaining 2k agents. - This improvement has the effect that 'Agent activity' shows the real updated agent count, not the total selected. I think this is not really a problem for update tags. - Cleaned up some of the UI logic, because the conflicts are fully handled now on the backend. - Locally I couldn't reproduce the conflict with agent checkins, even with 1k horde agents. I'll try to test in cloud with more real agents. To verify: - Enroll 50k agents (I used 50k with create_agents script, and 1k with horde). Enroll 50k with horde if possible. - Select all on UI and try to add/remove one or more tags - Expect the changes to propagate quickly (up to 1m). It might take a few refreshes to see the result on agent list and tags list, because the UI polls the agents every 30s. It is expected that the tags list temporarily shows incorrect data because the action is async. E.g. removed `test3` tag and added `add` tag quickly: <img width="1776" alt="image" src="https://user-images.githubusercontent.com/90178898/207824481-411f0f70-d7e8-42a6-b73f-ed80e77b7700.png"> <img width="422" alt="image" src="https://user-images.githubusercontent.com/90178898/207824550-582d43fc-87db-45e1-ba58-15915447fefd.png"> The logs show the details of how many `version_conflicts` were there, and it decreased with retries. ``` [2022-12-15T10:32:12.937+01:00][INFO ][plugins.fleet] Running action asynchronously, actionId: 90acd541-19ac-4738-b3d3-db32789233de, total agents: 52000 [2022-12-15T10:32:12.981+01:00][INFO ][plugins.fleet] Scheduling task fleet:update_agent_tags:retry:check:90acd541-19ac-4738-b3d3-db32789233de [2022-12-15T10:32:16.477+01:00][INFO ][plugins.fleet] Running action asynchronously, actionId: 29e9da70-7194-4e52-8004-2c1b19f6dfd5, total agents: 52000 [2022-12-15T10:32:16.537+01:00][INFO ][plugins.fleet] Scheduling task fleet:update_agent_tags:retry:check:29e9da70-7194-4e52-8004-2c1b19f6dfd5 [2022-12-15T10:32:22.893+01:00][DEBUG][plugins.fleet] {"took":9886,"timed_out":false,"total":52000,"updated":41143,"deleted":0,"batches":52,"version_conflicts":10857,"noops":0,"retries":{"bulk":0,"search":0},"throttled_millis":0,"requests_per_second":-1,"throttled_until_millis":0,"failures":[]} [2022-12-15T10:32:26.066+01:00][DEBUG][plugins.fleet] {"took":9518,"timed_out":false,"total":52000,"updated":25755,"deleted":0,"batches":52,"version_conflicts":26245,"noops":0,"retries":{"bulk":0,"search":0},"throttled_millis":0,"requests_per_second":-1,"throttled_until_millis":0,"failures":[]} [2022-12-15T10:32:27.401+01:00][ERROR][plugins.fleet] Action failed: version conflict of 10857 agents [2022-12-15T10:32:27.461+01:00][INFO ][plugins.fleet] Scheduling task fleet:update_agent_tags:retry:90acd541-19ac-4738-b3d3-db32789233de [2022-12-15T10:32:27.462+01:00][INFO ][plugins.fleet] Retrying in task: fleet:update_agent_tags:retry:90acd541-19ac-4738-b3d3-db32789233de [2022-12-15T10:32:29.274+01:00][ERROR][plugins.fleet] Action failed: version conflict of 26245 agents [2022-12-15T10:32:29.353+01:00][INFO ][plugins.fleet] Scheduling task fleet:update_agent_tags:retry:29e9da70-7194-4e52-8004-2c1b19f6dfd5 [2022-12-15T10:32:29.353+01:00][INFO ][plugins.fleet] Retrying in task: fleet:update_agent_tags:retry:29e9da70-7194-4e52-8004-2c1b19f6dfd5 [2022-12-15T10:32:31.480+01:00][INFO ][plugins.fleet] Running bulk action retry task [2022-12-15T10:32:31.481+01:00][DEBUG][plugins.fleet] Retry #1 of task fleet:update_agent_tags:retry:90acd541-19ac-4738-b3d3-db32789233de [2022-12-15T10:32:31.481+01:00][INFO ][plugins.fleet] Running action asynchronously, actionId: 90acd541-19ac-4738-b3d3-db32789233de, total agents: 52000 [2022-12-15T10:32:31.481+01:00][INFO ][plugins.fleet] Completed bulk action retry task [2022-12-15T10:32:31.485+01:00][INFO ][plugins.fleet] Scheduling task fleet:update_agent_tags:retry:check:90acd541-19ac-4738-b3d3-db32789233de [2022-12-15T10:32:33.841+01:00][DEBUG][plugins.fleet] {"took":2347,"timed_out":false,"total":10857,"updated":9857,"deleted":0,"batches":11,"version_conflicts":1000,"noops":0,"retries":{"bulk":0,"search":0},"throttled_millis":0,"requests_per_second":-1,"throttled_until_millis":0,"failures":[]} [2022-12-15T10:32:34.556+01:00][INFO ][plugins.fleet] Running bulk action retry task [2022-12-15T10:32:34.557+01:00][DEBUG][plugins.fleet] Retry #1 of task fleet:update_agent_tags:retry:29e9da70-7194-4e52-8004-2c1b19f6dfd5 [2022-12-15T10:32:34.557+01:00][INFO ][plugins.fleet] Running action asynchronously, actionId: 29e9da70-7194-4e52-8004-2c1b19f6dfd5, total agents: 52000 [2022-12-15T10:32:34.557+01:00][INFO ][plugins.fleet] Completed bulk action retry task [2022-12-15T10:32:34.560+01:00][INFO ][plugins.fleet] Scheduling task fleet:update_agent_tags:retry:check:29e9da70-7194-4e52-8004-2c1b19f6dfd5 [2022-12-15T10:32:35.388+01:00][ERROR][plugins.fleet] Retry #1 of task fleet:update_agent_tags:retry:90acd541-19ac-4738-b3d3-db32789233de failed: version conflict of 1000 agents [2022-12-15T10:32:35.468+01:00][INFO ][plugins.fleet] Scheduling task fleet:update_agent_tags:retry:90acd541-19ac-4738-b3d3-db32789233de [2022-12-15T10:32:35.468+01:00][INFO ][plugins.fleet] Retrying in task: fleet:update_agent_tags:retry:90acd541-19ac-4738-b3d3-db32789233de {"took":5509,"timed_out":false,"total":26245,"updated":26245,"deleted":0,"batches":27,"version_conflicts":0,"noops":0,"retries":{"bulk":0,"search":0},"throttled_millis":0,"requests_per_second":-1,"throttled_until_millis":0,"failures":[]} [2022-12-15T10:32:42.722+01:00][INFO ][plugins.fleet] processed 26245 agents, took 5509ms [2022-12-15T10:32:42.723+01:00][INFO ][plugins.fleet] Removing task fleet:update_agent_tags:retry:check:29e9da70-7194-4e52-8004-2c1b19f6dfd5 [2022-12-15T10:32:46.705+01:00][INFO ][plugins.fleet] Running bulk action retry task [2022-12-15T10:32:46.706+01:00][DEBUG][plugins.fleet] Retry #2 of task fleet:update_agent_tags:retry:90acd541-19ac-4738-b3d3-db32789233de [2022-12-15T10:32:46.707+01:00][INFO ][plugins.fleet] Running action asynchronously, actionId: 90acd541-19ac-4738-b3d3-db32789233de, total agents: 52000 [2022-12-15T10:32:46.707+01:00][INFO ][plugins.fleet] Completed bulk action retry task [2022-12-15T10:32:46.711+01:00][INFO ][plugins.fleet] Scheduling task fleet:update_agent_tags:retry:check:90acd541-19ac-4738-b3d3-db32789233de [2022-12-15T10:32:47.099+01:00][DEBUG][plugins.fleet] {"took":379,"timed_out":false,"total":1000,"updated":1000,"deleted":0,"batches":1,"version_conflicts":0,"noops":0,"retries":{"bulk":0,"search":0},"throttled_millis":0,"requests_per_second":-1,"throttled_until_millis":0,"failures":[]} [2022-12-15T10:32:47.623+01:00][INFO ][plugins.fleet] processed 1000 agents, took 379ms [2022-12-15T10:32:47.623+01:00][INFO ][plugins.fleet] Removing task fleet:update_agent_tags:retry:check:90acd541-19ac-4738-b3d3-db32789233de ``` ### Checklist - [x] [Unit or functional tests](https://www.elastic.co/guide/en/kibana/master/development-tests.html) were updated or added to match the most common scenarios Co-authored-by: Kibana Machine <[email protected]>
{kind=link}
{kind=link}
andrew-goldstein
pushed a commit
that referenced
this pull request
Jun 13, 2023
…lastic#159352) ## Summary Skip `Security Solution Tests #2 / rule snoozing Rule editing page / actions tab adds an action to a snoozed rule` [This test failed on `main` as soon as it was merged.](https://buildkite.com/elastic/kibana-on-merge-unsupported-ftrs/builds/2952) ### For maintainers - [ ] This was checked for breaking API changes and was [labeled appropriately](https://www.elastic.co/guide/en/kibana/master/contributing.html#kibana-release-notes-process)
andrew-goldstein
added a commit
that referenced
this pull request
Sep 25, 2023
… integration for ES|QL query generation via ELSER (elastic#167097) ## [Security Solution] [Elastic AI Assistant] LangChain Agents and Tools integration for ES|QL query generation via ELSER This PR integrates [LangChain](https://www.langchain.com/) [Agents](https://js.langchain.com/docs/modules/agents/) and [Tools](https://js.langchain.com/docs/modules/agents/tools/) with the [Elastic AI Assistant](https://www.elastic.co/blog/introducing-elastic-ai-assistant). These abstractions enable the LLM to dynamically choose whether or not to query, via [ELSER](https://www.elastic.co/guide/en/machine-learning/current/ml-nlp-elser.html), an [ES|QL](https://www.elastic.co/blog/elasticsearch-query-language-esql) knowledge base. Context from the knowledge base is used to generate `ES|QL` queries, or answer questions about `ES|QL`. Registration of the tool occurs in `x-pack/plugins/elastic_assistant/server/lib/langchain/execute_custom_llm_chain/index.ts`: ```typescript const tools: Tool[] = [ new ChainTool({ name: 'esql-language-knowledge-base', description: 'Call this for knowledge on how to build an ESQL query, or answer questions about the ES|QL query language.', chain, }), ]; ``` The `tools` array above may be updated in future PRs to include, for example, an `ES|QL` query validator endpoint. ### Details The `callAgentExecutor` function in `x-pack/plugins/elastic_assistant/server/lib/langchain/execute_custom_llm_chain/index.ts`: 1. Creates a `RetrievalQAChain` from an `ELSER` backed `ElasticsearchStore`, which serves as a knowledge base for `ES|QL`: ```typescript // ELSER backed ElasticsearchStore for Knowledge Base const esStore = new ElasticsearchStore(esClient, KNOWLEDGE_BASE_INDEX_PATTERN, logger); const chain = RetrievalQAChain.fromLLM(llm, esStore.asRetriever()); ``` 2. Registers the chain as a tool, which may be invoked by the LLM based on its description: ```typescript const tools: Tool[] = [ new ChainTool({ name: 'esql-language-knowledge-base', description: 'Call this for knowledge on how to build an ESQL query, or answer questions about the ES|QL query language.', chain, }), ]; ``` 3. Creates an Agent executor that combines the `tools` above, the `ActionsClientLlm` (an abstraction that calls `actionsClient.execute`), and memory of the previous messages in the conversation: ```typescript const executor = await initializeAgentExecutorWithOptions(tools, llm, { agentType: 'chat-conversational-react-description', memory, verbose: false, }); ``` Note: Set `verbose` above to `true` to for detailed debugging output from LangChain. 4. Calls the `executor`, kicking it off with `latestMessage`: ```typescript await executor.call({ input: latestMessage[0].content }); ``` ### Changes to `x-pack/packages/kbn-elastic-assistant` A client side change was required to the assistant, because the response returned from the agent executor is JSON. This response is parsed on the client in `x-pack/packages/kbn-elastic-assistant/impl/assistant/api.tsx`: ```typescript return assistantLangChain ? getFormattedMessageContent(result) : result; ``` Client-side parsing of the response only happens when then `assistantLangChain` feature flag is `true`. ## Desk testing Set ```typescript assistantLangChain={true} ``` in `x-pack/plugins/security_solution/public/assistant/provider.tsx` to enable this experimental feature in development environments. Also (optionally) set `verbose` to `true` in the following code in ``x-pack/plugins/elastic_assistant/server/lib/langchain/execute_custom_llm_chain/index.ts``: ```typescript const executor = await initializeAgentExecutorWithOptions(tools, llm, { agentType: 'chat-conversational-react-description', memory, verbose: true, }); ``` After setting the feature flag and optionally enabling verbose debugging output, you may ask the assistant to generate an `ES|QL` query, per the example in the next section. ### Example output When the Elastic AI Assistant is asked: ``` From employees, I want to see the 5 earliest employees (hire_date), I want to display only the month and the year that they were hired in and their employee number (emp_no). Format the date as e.g. "September 2019". Only show the query ``` it replies: ``` Here is the query to get the employee number and the formatted hire date for the 5 earliest employees by hire_date: FROM employees | KEEP emp_no, hire_date | EVAL month_year = DATE_FORMAT(hire_date, "MMMM YYYY") | SORT hire_date | LIMIT 5 ``` Per the screenshot below:  The `verbose: true` output from LangChain logged to the console reveals that the prompt sent to the LLM includes text like the following: ``` Assistant can ask the user to use tools to look up information that may be helpful in answering the users original question. The tools the human can use are:\\n\\nesql-language-knowledge-base: Call this for knowledge on how to build an ESQL query, or answer questions about the ES|QL query language. ``` along with instructions for "calling" the tool like a function. The debugging output also reveals the agent selecting the tool, and returning results from ESLR: ``` [agent/action] [1:chain:AgentExecutor] Agent selected action: { "tool": "esql-language-knowledge-base", "toolInput": "Display the 'emp_no', month and year of the 5 earliest employees by 'hire_date'. Format the date as 'Month Year'.", "log": "```json\n{\n \"action\": \"esql-language-knowledge-base\",\n \"action_input\": \"Display the 'emp_no', month and year of the 5 earliest employees by 'hire_date'. Format the date as 'Month Year'.\"\n}\n```" } [tool/start] [1:chain:AgentExecutor > 4:tool:ChainTool] Entering Tool run with input: "Display the 'emp_no', month and year of the 5 earliest employees by 'hire_date'. Format the date as 'Month Year'." [chain/start] [1:chain:AgentExecutor > 4:tool:ChainTool > 5:chain:RetrievalQAChain] Entering Chain run with input: { "query": "Display the 'emp_no', month and year of the 5 earliest employees by 'hire_date'. Format the date as 'Month Year'." } [retriever/start] [1:chain:AgentExecutor > 4:tool:ChainTool > 5:chain:RetrievalQAChain > 6:retriever:VectorStoreRetriever] Entering Retriever run with input: { "query": "Display the 'emp_no', month and year of the 5 earliest employees by 'hire_date'. Format the date as 'Month Year'." } [retriever/end] [1:chain:AgentExecutor > 4:tool:ChainTool > 5:chain:RetrievalQAChain > 6:retriever:VectorStoreRetriever] [115ms] Exiting Retriever run with output: { "documents": [ { "pageContent": "[[esql-date_format]]\n=== `DATE_FORMAT`\nReturns a string representation of a date in the provided format. If no format\nis specified, the `yyyy-MM-dd'T'HH:mm:ss.SSSZ` format is used.\n\n[source,esql]\n----\nFROM employees\n| KEEP first_name, last_name, hire_date\n| EVAL hired = DATE_FORMAT(hire_date, \"YYYY-MM-dd\")\n----\n", ``` The documents containing `ES|QL` examples, retrieved from ELSER, are sent back to the LLM to answer the original question, per the abridged output below: ``` [llm/start] [1:chain:AgentExecutor > 4:tool:ChainTool > 5:chain:RetrievalQAChain > 7:chain:StuffDocumentsChain > 8:chain:LLMChain > 9:llm:ActionsClientLlm] Entering LLM run with input: { "prompts": [ "Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.\n\n[[esql-date_format]]\n=== `DATE_FORMAT`\nReturns a string representation of a date in the provided format. If no format\nis specified, the `yyyy-MM-dd'T'HH:mm:ss.SSSZ` format is used.\n\n[source,esql]\n----\nFROM employees\n| KEEP first_name, last_name, hire_date\n| EVAL hired = DATE_FORMAT(hire_date, \"YYYY-MM-dd\")\n----\n\n\n[[esql-date_trunc]]\n=== `DATE_TRUNC`\nRounds down a date to the closest interval. Intervals can be expressed using the\n<<esql-timespan-literals,timespan literal syntax>>.\n\n[source,esql]\n----\nFROM employees\n| EVAL year_hired = DATE_TRUNC(1 year, hire_date)\n| STATS count(emp_no) BY year_hired\n| SORT year_hired\n----\n\n\n[[esql-from]]\n=== `FROM`\n\nThe `FROM` source command returns a table with up to 10,000 documents from a\ndata stream, index, ``` ### Complete (verbose) LangChain output from the example The following `verbose: true` output from LangChain below was produced via the example in the previous section: ``` [chain/start] [1:chain:AgentExecutor] Entering Chain run with input: { "input": "\n\n\n\nFrom employees, I want to see the 5 earliest employees (hire_date), I want to display only the month and the year that they were hired in and their employee number (emp_no). Format the date as e.g. \"September 2019\". Only show the query", "chat_history": [] } [chain/start] [1:chain:AgentExecutor > 2:chain:LLMChain] Entering Chain run with input: { "input": "\n\n\n\nFrom employees, I want to see the 5 earliest employees (hire_date), I want to display only the month and the year that they were hired in and their employee number (emp_no). Format the date as e.g. \"September 2019\". Only show the query", "chat_history": [], "agent_scratchpad": [], "stop": [ "Observation:" ] } [llm/start] [1:chain:AgentExecutor > 2:chain:LLMChain > 3:llm:ActionsClientLlm] Entering LLM run with input: { "prompts": [ "[{\"lc\":1,\"type\":\"constructor\",\"id\":[\"langchain\",\"schema\",\"SystemMessage\"],\"kwargs\":{\"content\":\"Assistant is a large language model trained by OpenAI.\\n\\nAssistant is designed to be able to assist with a wide range of tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics. As a language model, Assistant is able to generate human-like text based on the input it receives, allowing it to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand.\\n\\nAssistant is constantly learning and improving, and its capabilities are constantly evolving. It is able to process and understand large amounts of text, and can use this knowledge to provide accurate and informative responses to a wide range of questions. Additionally, Assistant is able to generate its own text based on the input it receives, allowing it to engage in discussions and provide explanations and descriptions on a wide range of topics.\\n\\nOverall, Assistant is a powerful system that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics. Whether you need help with a specific question or just want to have a conversation about a particular topic, Assistant is here to assist. However, above all else, all responses must adhere to the format of RESPONSE FORMAT INSTRUCTIONS.\",\"additional_kwargs\":{}}},{\"lc\":1,\"type\":\"constructor\",\"id\":[\"langchain\",\"schema\",\"HumanMessage\"],\"kwargs\":{\"content\":\"TOOLS\\n------\\nAssistant can ask the user to use tools to look up information that may be helpful in answering the users original question. The tools the human can use are:\\n\\nesql-language-knowledge-base: Call this for knowledge on how to build an ESQL query, or answer questions about the ES|QL query language.\\n\\nRESPONSE FORMAT INSTRUCTIONS\\n----------------------------\\n\\nOutput a JSON markdown code snippet containing a valid JSON object in one of two formats:\\n\\n**Option 1:**\\nUse this if you want the human to use a tool.\\nMarkdown code snippet formatted in the following schema:\\n\\n```json\\n{\\n \\\"action\\\": string, // The action to take. Must be one of [esql-language-knowledge-base]\\n \\\"action_input\\\": string // The input to the action. May be a stringified object.\\n}\\n```\\n\\n**Option #2:**\\nUse this if you want to respond directly and conversationally to the human. Markdown code snippet formatted in the following schema:\\n\\n```json\\n{\\n \\\"action\\\": \\\"Final Answer\\\",\\n \\\"action_input\\\": string // You should put what you want to return to use here and make sure to use valid json newline characters.\\n}\\n```\\n\\nFor both options, remember to always include the surrounding markdown code snippet delimiters (begin with \\\"```json\\\" and end with \\\"```\\\")!\\n\\n\\nUSER'S INPUT\\n--------------------\\nHere is the user's input (remember to respond with a markdown code snippet of a json blob with a single action, and NOTHING else):\\n\\n\\n\\n\\n\\nFrom employees, I want to see the 5 earliest employees (hire_date), I want to display only the month and the year that they were hired in and their employee number (emp_no). Format the date as e.g. \\\"September 2019\\\". Only show the query\",\"additional_kwargs\":{}}}]" ] } [llm/end] [1:chain:AgentExecutor > 2:chain:LLMChain > 3:llm:ActionsClientLlm] [3.08s] Exiting LLM run with output: { "generations": [ [ { "text": "```json\n{\n \"action\": \"esql-language-knowledge-base\",\n \"action_input\": \"Display the 'emp_no', month and year of the 5 earliest employees by 'hire_date'. Format the date as 'Month Year'.\"\n}\n```" } ] ] } [chain/end] [1:chain:AgentExecutor > 2:chain:LLMChain] [3.09s] Exiting Chain run with output: { "text": "```json\n{\n \"action\": \"esql-language-knowledge-base\",\n \"action_input\": \"Display the 'emp_no', month and year of the 5 earliest employees by 'hire_date'. Format the date as 'Month Year'.\"\n}\n```" } [agent/action] [1:chain:AgentExecutor] Agent selected action: { "tool": "esql-language-knowledge-base", "toolInput": "Display the 'emp_no', month and year of the 5 earliest employees by 'hire_date'. Format the date as 'Month Year'.", "log": "```json\n{\n \"action\": \"esql-language-knowledge-base\",\n \"action_input\": \"Display the 'emp_no', month and year of the 5 earliest employees by 'hire_date'. Format the date as 'Month Year'.\"\n}\n```" } [tool/start] [1:chain:AgentExecutor > 4:tool:ChainTool] Entering Tool run with input: "Display the 'emp_no', month and year of the 5 earliest employees by 'hire_date'. Format the date as 'Month Year'." [chain/start] [1:chain:AgentExecutor > 4:tool:ChainTool > 5:chain:RetrievalQAChain] Entering Chain run with input: { "query": "Display the 'emp_no', month and year of the 5 earliest employees by 'hire_date'. Format the date as 'Month Year'." } [retriever/start] [1:chain:AgentExecutor > 4:tool:ChainTool > 5:chain:RetrievalQAChain > 6:retriever:VectorStoreRetriever] Entering Retriever run with input: { "query": "Display the 'emp_no', month and year of the 5 earliest employees by 'hire_date'. Format the date as 'Month Year'." } [retriever/end] [1:chain:AgentExecutor > 4:tool:ChainTool > 5:chain:RetrievalQAChain > 6:retriever:VectorStoreRetriever] [115ms] Exiting Retriever run with output: { "documents": [ { "pageContent": "[[esql-date_format]]\n=== `DATE_FORMAT`\nReturns a string representation of a date in the provided format. If no format\nis specified, the `yyyy-MM-dd'T'HH:mm:ss.SSSZ` format is used.\n\n[source,esql]\n----\nFROM employees\n| KEEP first_name, last_name, hire_date\n| EVAL hired = DATE_FORMAT(hire_date, \"YYYY-MM-dd\")\n----\n", "metadata": { "source": "/Users/andrew.goldstein/Projects/forks/spong/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/docs/functions/date_format.asciidoc" } }, { "pageContent": "[[esql-date_trunc]]\n=== `DATE_TRUNC`\nRounds down a date to the closest interval. Intervals can be expressed using the\n<<esql-timespan-literals,timespan literal syntax>>.\n\n[source,esql]\n----\nFROM employees\n| EVAL year_hired = DATE_TRUNC(1 year, hire_date)\n| STATS count(emp_no) BY year_hired\n| SORT year_hired\n----\n", "metadata": { "source": "/Users/andrew.goldstein/Projects/forks/spong/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/docs/functions/date_trunc.asciidoc" } }, { "pageContent": "[[esql-from]]\n=== `FROM`\n\nThe `FROM` source command returns a table with up to 10,000 documents from a\ndata stream, index, or alias. Each row in the resulting table represents a\ndocument. Each column corresponds to a field, and can be accessed by the name\nof that field.\n\n[source,esql]\n----\nFROM employees\n----\n\nYou can use <<api-date-math-index-names,date math>> to refer to indices, aliases\nand data streams. This can be useful for time series data, for example to access\ntoday's index:\n\n[source,esql]\n----\nFROM <logs-{now/d}>\n----\n\nUse comma-separated lists or wildcards to query multiple data streams, indices,\nor aliases:\n\n[source,esql]\n----\nFROM employees-00001,employees-*\n----\n", "metadata": { "source": "/Users/andrew.goldstein/Projects/forks/spong/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/docs/source_commands/from.asciidoc" } }, { "pageContent": "[[esql-where]]\n=== `WHERE`\n\nUse `WHERE` to produce a table that contains all the rows from the input table\nfor which the provided condition evaluates to `true`:\n\n[source,esql]\n----\ninclude::{esql-specs}/docs.csv-spec[tag=where]\n----\n\nWhich, if `still_hired` is a boolean field, can be simplified to:\n\n[source,esql]\n----\ninclude::{esql-specs}/docs.csv-spec[tag=whereBoolean]\n----\n\n[discrete]\n==== Operators\n\nRefer to <<esql-operators>> for an overview of the supported operators.\n\n[discrete]\n==== Functions\n`WHERE` supports various functions for calculating values. Refer to\n<<esql-functions,Functions>> for more information.\n\n[source,esql]\n----\ninclude::{esql-specs}/docs.csv-spec[tag=whereFunction]\n----\n", "metadata": { "source": "/Users/andrew.goldstein/Projects/forks/spong/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/docs/processing_commands/where.asciidoc" } } ] } [chain/start] [1:chain:AgentExecutor > 4:tool:ChainTool > 5:chain:RetrievalQAChain > 7:chain:StuffDocumentsChain] Entering Chain run with input: { "question": "Display the 'emp_no', month and year of the 5 earliest employees by 'hire_date'. Format the date as 'Month Year'.", "input_documents": [ { "pageContent": "[[esql-date_format]]\n=== `DATE_FORMAT`\nReturns a string representation of a date in the provided format. If no format\nis specified, the `yyyy-MM-dd'T'HH:mm:ss.SSSZ` format is used.\n\n[source,esql]\n----\nFROM employees\n| KEEP first_name, last_name, hire_date\n| EVAL hired = DATE_FORMAT(hire_date, \"YYYY-MM-dd\")\n----\n", "metadata": { "source": "/Users/andrew.goldstein/Projects/forks/spong/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/docs/functions/date_format.asciidoc" } }, { "pageContent": "[[esql-date_trunc]]\n=== `DATE_TRUNC`\nRounds down a date to the closest interval. Intervals can be expressed using the\n<<esql-timespan-literals,timespan literal syntax>>.\n\n[source,esql]\n----\nFROM employees\n| EVAL year_hired = DATE_TRUNC(1 year, hire_date)\n| STATS count(emp_no) BY year_hired\n| SORT year_hired\n----\n", "metadata": { "source": "/Users/andrew.goldstein/Projects/forks/spong/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/docs/functions/date_trunc.asciidoc" } }, { "pageContent": "[[esql-from]]\n=== `FROM`\n\nThe `FROM` source command returns a table with up to 10,000 documents from a\ndata stream, index, or alias. Each row in the resulting table represents a\ndocument. Each column corresponds to a field, and can be accessed by the name\nof that field.\n\n[source,esql]\n----\nFROM employees\n----\n\nYou can use <<api-date-math-index-names,date math>> to refer to indices, aliases\nand data streams. This can be useful for time series data, for example to access\ntoday's index:\n\n[source,esql]\n----\nFROM <logs-{now/d}>\n----\n\nUse comma-separated lists or wildcards to query multiple data streams, indices,\nor aliases:\n\n[source,esql]\n----\nFROM employees-00001,employees-*\n----\n", "metadata": { "source": "/Users/andrew.goldstein/Projects/forks/spong/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/docs/source_commands/from.asciidoc" } }, { "pageContent": "[[esql-where]]\n=== `WHERE`\n\nUse `WHERE` to produce a table that contains all the rows from the input table\nfor which the provided condition evaluates to `true`:\n\n[source,esql]\n----\ninclude::{esql-specs}/docs.csv-spec[tag=where]\n----\n\nWhich, if `still_hired` is a boolean field, can be simplified to:\n\n[source,esql]\n----\ninclude::{esql-specs}/docs.csv-spec[tag=whereBoolean]\n----\n\n[discrete]\n==== Operators\n\nRefer to <<esql-operators>> for an overview of the supported operators.\n\n[discrete]\n==== Functions\n`WHERE` supports various functions for calculating values. Refer to\n<<esql-functions,Functions>> for more information.\n\n[source,esql]\n----\ninclude::{esql-specs}/docs.csv-spec[tag=whereFunction]\n----\n", "metadata": { "source": "/Users/andrew.goldstein/Projects/forks/spong/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/docs/processing_commands/where.asciidoc" } } ], "query": "Display the 'emp_no', month and year of the 5 earliest employees by 'hire_date'. Format the date as 'Month Year'." } [chain/start] [1:chain:AgentExecutor > 4:tool:ChainTool > 5:chain:RetrievalQAChain > 7:chain:StuffDocumentsChain > 8:chain:LLMChain] Entering Chain run with input: { "question": "Display the 'emp_no', month and year of the 5 earliest employees by 'hire_date'. Format the date as 'Month Year'.", "query": "Display the 'emp_no', month and year of the 5 earliest employees by 'hire_date'. Format the date as 'Month Year'.", "context": "[[esql-date_format]]\n=== `DATE_FORMAT`\nReturns a string representation of a date in the provided format. If no format\nis specified, the `yyyy-MM-dd'T'HH:mm:ss.SSSZ` format is used.\n\n[source,esql]\n----\nFROM employees\n| KEEP first_name, last_name, hire_date\n| EVAL hired = DATE_FORMAT(hire_date, \"YYYY-MM-dd\")\n----\n\n\n[[esql-date_trunc]]\n=== `DATE_TRUNC`\nRounds down a date to the closest interval. Intervals can be expressed using the\n<<esql-timespan-literals,timespan literal syntax>>.\n\n[source,esql]\n----\nFROM employees\n| EVAL year_hired = DATE_TRUNC(1 year, hire_date)\n| STATS count(emp_no) BY year_hired\n| SORT year_hired\n----\n\n\n[[esql-from]]\n=== `FROM`\n\nThe `FROM` source command returns a table with up to 10,000 documents from a\ndata stream, index, or alias. Each row in the resulting table represents a\ndocument. Each column corresponds to a field, and can be accessed by the name\nof that field.\n\n[source,esql]\n----\nFROM employees\n----\n\nYou can use <<api-date-math-index-names,date math>> to refer to indices, aliases\nand data streams. This can be useful for time series data, for example to access\ntoday's index:\n\n[source,esql]\n----\nFROM <logs-{now/d}>\n----\n\nUse comma-separated lists or wildcards to query multiple data streams, indices,\nor aliases:\n\n[source,esql]\n----\nFROM employees-00001,employees-*\n----\n\n\n[[esql-where]]\n=== `WHERE`\n\nUse `WHERE` to produce a table that contains all the rows from the input table\nfor which the provided condition evaluates to `true`:\n\n[source,esql]\n----\ninclude::{esql-specs}/docs.csv-spec[tag=where]\n----\n\nWhich, if `still_hired` is a boolean field, can be simplified to:\n\n[source,esql]\n----\ninclude::{esql-specs}/docs.csv-spec[tag=whereBoolean]\n----\n\n[discrete]\n==== Operators\n\nRefer to <<esql-operators>> for an overview of the supported operators.\n\n[discrete]\n==== Functions\n`WHERE` supports various functions for calculating values. Refer to\n<<esql-functions,Functions>> for more information.\n\n[source,esql]\n----\ninclude::{esql-specs}/docs.csv-spec[tag=whereFunction]\n----\n" } [llm/start] [1:chain:AgentExecutor > 4:tool:ChainTool > 5:chain:RetrievalQAChain > 7:chain:StuffDocumentsChain > 8:chain:LLMChain > 9:llm:ActionsClientLlm] Entering LLM run with input: { "prompts": [ "Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.\n\n[[esql-date_format]]\n=== `DATE_FORMAT`\nReturns a string representation of a date in the provided format. If no format\nis specified, the `yyyy-MM-dd'T'HH:mm:ss.SSSZ` format is used.\n\n[source,esql]\n----\nFROM employees\n| KEEP first_name, last_name, hire_date\n| EVAL hired = DATE_FORMAT(hire_date, \"YYYY-MM-dd\")\n----\n\n\n[[esql-date_trunc]]\n=== `DATE_TRUNC`\nRounds down a date to the closest interval. Intervals can be expressed using the\n<<esql-timespan-literals,timespan literal syntax>>.\n\n[source,esql]\n----\nFROM employees\n| EVAL year_hired = DATE_TRUNC(1 year, hire_date)\n| STATS count(emp_no) BY year_hired\n| SORT year_hired\n----\n\n\n[[esql-from]]\n=== `FROM`\n\nThe `FROM` source command returns a table with up to 10,000 documents from a\ndata stream, index, or alias. Each row in the resulting table represents a\ndocument. Each column corresponds to a field, and can be accessed by the name\nof that field.\n\n[source,esql]\n----\nFROM employees\n----\n\nYou can use <<api-date-math-index-names,date math>> to refer to indices, aliases\nand data streams. This can be useful for time series data, for example to access\ntoday's index:\n\n[source,esql]\n----\nFROM <logs-{now/d}>\n----\n\nUse comma-separated lists or wildcards to query multiple data streams, indices,\nor aliases:\n\n[source,esql]\n----\nFROM employees-00001,employees-*\n----\n\n\n[[esql-where]]\n=== `WHERE`\n\nUse `WHERE` to produce a table that contains all the rows from the input table\nfor which the provided condition evaluates to `true`:\n\n[source,esql]\n----\ninclude::{esql-specs}/docs.csv-spec[tag=where]\n----\n\nWhich, if `still_hired` is a boolean field, can be simplified to:\n\n[source,esql]\n----\ninclude::{esql-specs}/docs.csv-spec[tag=whereBoolean]\n----\n\n[discrete]\n==== Operators\n\nRefer to <<esql-operators>> for an overview of the supported operators.\n\n[discrete]\n==== Functions\n`WHERE` supports various functions for calculating values. Refer to\n<<esql-functions,Functions>> for more information.\n\n[source,esql]\n----\ninclude::{esql-specs}/docs.csv-spec[tag=whereFunction]\n----\n\n\nQuestion: Display the 'emp_no', month and year of the 5 earliest employees by 'hire_date'. Format the date as 'Month Year'.\nHelpful Answer:" ] } [llm/end] [1:chain:AgentExecutor > 4:tool:ChainTool > 5:chain:RetrievalQAChain > 7:chain:StuffDocumentsChain > 8:chain:LLMChain > 9:llm:ActionsClientLlm] [2.23s] Exiting LLM run with output: { "generations": [ [ { "text": "FROM employees\n| KEEP emp_no, hire_date\n| EVAL month_year = DATE_FORMAT(hire_date, \"MMMM YYYY\")\n| SORT hire_date\n| LIMIT 5" } ] ] } [chain/end] [1:chain:AgentExecutor > 4:tool:ChainTool > 5:chain:RetrievalQAChain > 7:chain:StuffDocumentsChain > 8:chain:LLMChain] [2.23s] Exiting Chain run with output: { "text": "FROM employees\n| KEEP emp_no, hire_date\n| EVAL month_year = DATE_FORMAT(hire_date, \"MMMM YYYY\")\n| SORT hire_date\n| LIMIT 5" } [chain/end] [1:chain:AgentExecutor > 4:tool:ChainTool > 5:chain:RetrievalQAChain > 7:chain:StuffDocumentsChain] [2.23s] Exiting Chain run with output: { "text": "FROM employees\n| KEEP emp_no, hire_date\n| EVAL month_year = DATE_FORMAT(hire_date, \"MMMM YYYY\")\n| SORT hire_date\n| LIMIT 5" } [chain/end] [1:chain:AgentExecutor > 4:tool:ChainTool > 5:chain:RetrievalQAChain] [2.35s] Exiting Chain run with output: { "text": "FROM employees\n| KEEP emp_no, hire_date\n| EVAL month_year = DATE_FORMAT(hire_date, \"MMMM YYYY\")\n| SORT hire_date\n| LIMIT 5" } [tool/end] [1:chain:AgentExecutor > 4:tool:ChainTool] [2.35s] Exiting Tool run with output: "FROM employees | KEEP emp_no, hire_date | EVAL month_year = DATE_FORMAT(hire_date, "MMMM YYYY") | SORT hire_date | LIMIT 5" [chain/start] [1:chain:AgentExecutor > 10:chain:LLMChain] Entering Chain run with input: { "input": "\n\n\n\nFrom employees, I want to see the 5 earliest employees (hire_date), I want to display only the month and the year that they were hired in and their employee number (emp_no). Format the date as e.g. \"September 2019\". Only show the query", "chat_history": [], "agent_scratchpad": [ { "lc": 1, "type": "constructor", "id": [ "langchain", "schema", "AIMessage" ], "kwargs": { "content": "```json\n{\n \"action\": \"esql-language-knowledge-base\",\n \"action_input\": \"Display the 'emp_no', month and year of the 5 earliest employees by 'hire_date'. Format the date as 'Month Year'.\"\n}\n```", "additional_kwargs": {} } }, { "lc": 1, "type": "constructor", "id": [ "langchain", "schema", "HumanMessage" ], "kwargs": { "content": "TOOL RESPONSE:\n---------------------\nFROM employees\n| KEEP emp_no, hire_date\n| EVAL month_year = DATE_FORMAT(hire_date, \"MMMM YYYY\")\n| SORT hire_date\n| LIMIT 5\n\nUSER'S INPUT\n--------------------\n\nOkay, so what is the response to my last comment? If using information obtained from the tools you must mention it explicitly without mentioning the tool names - I have forgotten all TOOL RESPONSES! Remember to respond with a markdown code snippet of a json blob with a single action, and NOTHING else.", "additional_kwargs": {} } } ], "stop": [ "Observation:" ] } [llm/start] [1:chain:AgentExecutor > 10:chain:LLMChain > 11:llm:ActionsClientLlm] Entering LLM run with input: { "prompts": [ "[{\"lc\":1,\"type\":\"constructor\",\"id\":[\"langchain\",\"schema\",\"SystemMessage\"],\"kwargs\":{\"content\":\"Assistant is a large language model trained by OpenAI.\\n\\nAssistant is designed to be able to assist with a wide range of tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics. As a language model, Assistant is able to generate human-like text based on the input it receives, allowing it to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand.\\n\\nAssistant is constantly learning and improving, and its capabilities are constantly evolving. It is able to process and understand large amounts of text, and can use this knowledge to provide accurate and informative responses to a wide range of questions. Additionally, Assistant is able to generate its own text based on the input it receives, allowing it to engage in discussions and provide explanations and descriptions on a wide range of topics.\\n\\nOverall, Assistant is a powerful system that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics. Whether you need help with a specific question or just want to have a conversation about a particular topic, Assistant is here to assist. However, above all else, all responses must adhere to the format of RESPONSE FORMAT INSTRUCTIONS.\",\"additional_kwargs\":{}}},{\"lc\":1,\"type\":\"constructor\",\"id\":[\"langchain\",\"schema\",\"HumanMessage\"],\"kwargs\":{\"content\":\"TOOLS\\n------\\nAssistant can ask the user to use tools to look up information that may be helpful in answering the users original question. The tools the human can use are:\\n\\nesql-language-knowledge-base: Call this for knowledge on how to build an ESQL query, or answer questions about the ES|QL query language.\\n\\nRESPONSE FORMAT INSTRUCTIONS\\n----------------------------\\n\\nOutput a JSON markdown code snippet containing a valid JSON object in one of two formats:\\n\\n**Option 1:**\\nUse this if you want the human to use a tool.\\nMarkdown code snippet formatted in the following schema:\\n\\n```json\\n{\\n \\\"action\\\": string, // The action to take. Must be one of [esql-language-knowledge-base]\\n \\\"action_input\\\": string // The input to the action. May be a stringified object.\\n}\\n```\\n\\n**Option #2:**\\nUse this if you want to respond directly and conversationally to the human. Markdown code snippet formatted in the following schema:\\n\\n```json\\n{\\n \\\"action\\\": \\\"Final Answer\\\",\\n \\\"action_input\\\": string // You should put what you want to return to use here and make sure to use valid json newline characters.\\n}\\n```\\n\\nFor both options, remember to always include the surrounding markdown code snippet delimiters (begin with \\\"```json\\\" and end with \\\"```\\\")!\\n\\n\\nUSER'S INPUT\\n--------------------\\nHere is the user's input (remember to respond with a markdown code snippet of a json blob with a single action, and NOTHING else):\\n\\n\\n\\n\\n\\nFrom employees, I want to see the 5 earliest employees (hire_date), I want to display only the month and the year that they were hired in and their employee number (emp_no). Format the date as e.g. \\\"September 2019\\\". Only show the query\",\"additional_kwargs\":{}}},{\"lc\":1,\"type\":\"constructor\",\"id\":[\"langchain\",\"schema\",\"AIMessage\"],\"kwargs\":{\"content\":\"```json\\n{\\n \\\"action\\\": \\\"esql-language-knowledge-base\\\",\\n \\\"action_input\\\": \\\"Display the 'emp_no', month and year of the 5 earliest employees by 'hire_date'. Format the date as 'Month Year'.\\\"\\n}\\n```\",\"additional_kwargs\":{}}},{\"lc\":1,\"type\":\"constructor\",\"id\":[\"langchain\",\"schema\",\"HumanMessage\"],\"kwargs\":{\"content\":\"TOOL RESPONSE:\\n---------------------\\nFROM employees\\n| KEEP emp_no, hire_date\\n| EVAL month_year = DATE_FORMAT(hire_date, \\\"MMMM YYYY\\\")\\n| SORT hire_date\\n| LIMIT 5\\n\\nUSER'S INPUT\\n--------------------\\n\\nOkay, so what is the response to my last comment? If using information obtained from the tools you must mention it explicitly without mentioning the tool names - I have forgotten all TOOL RESPONSES! Remember to respond with a markdown code snippet of a json blob with a single action, and NOTHING else.\",\"additional_kwargs\":{}}}]" ] } [llm/end] [1:chain:AgentExecutor > 10:chain:LLMChain > 11:llm:ActionsClientLlm] [6.47s] Exiting LLM run with output: { "generations": [ [ { "text": "```json\n{\n \"action\": \"Final Answer\",\n \"action_input\": \"Here is the query to get the employee number and the formatted hire date for the 5 earliest employees by hire_date:\\n\\nFROM employees\\n| KEEP emp_no, hire_date\\n| EVAL month_year = DATE_FORMAT(hire_date, \\\"MMMM YYYY\\\")\\n| SORT hire_date\\n| LIMIT 5\"\n}\n```" } ] ] } [chain/end] [1:chain:AgentExecutor > 10:chain:LLMChain] [6.47s] Exiting Chain run with output: { "text": "```json\n{\n \"action\": \"Final Answer\",\n \"action_input\": \"Here is the query to get the employee number and the formatted hire date for the 5 earliest employees by hire_date:\\n\\nFROM employees\\n| KEEP emp_no, hire_date\\n| EVAL month_year = DATE_FORMAT(hire_date, \\\"MMMM YYYY\\\")\\n| SORT hire_date\\n| LIMIT 5\"\n}\n```" } [chain/end] [1:chain:AgentExecutor] [11.91s] Exiting Chain run with output: { "output": "Here is the query to get the employee number and the formatted hire date for the 5 earliest employees by hire_date:\n\nFROM employees\n| KEEP emp_no, hire_date\n| EVAL month_year = DATE_FORMAT(hire_date, \"MMMM YYYY\")\n| SORT hire_date\n| LIMIT 5" } ```
andrew-goldstein
added a commit
that referenced
this pull request
Oct 16, 2023
… search for improved ES|QL query generation
This PR implements hybrid (vector + terms) search to improve the quality of `ES|QL` queries generated by the Elastic AI Assistant.
The hybrid search combines (from a single request to Elasticsearch):
- Vector search results from ELSER that vary depending on the query specified by the user
- Terms search results that return a set of Knowledge Base (KB) documents marked as "required" for a topic
The hybrid search results, when provided as context to an LLM, improve the quality of generated `ES|QL` queries by combining `ES|QL` parser grammar and documentation specific to the question asked by a user with additional examples of valid `ES|QL` queries that aren't specific to the query.
## Details
### Indexing additional `metadata`
The `loadESQL` function in `x-pack/plugins/elastic_assistant/server/lib/langchain/content_loaders/esql_loader.ts` loads a directory containing 13 valid, and one invalid example of `ES|QL` queries:
```typescript
const rawExampleQueries = await exampleQueriesLoader.load();
// Add additional metadata to the example queries that indicates they are required KB documents:
const requiredExampleQueries = addRequiredKbResourceMetadata({
docs: rawExampleQueries,
kbResource: ESQL_RESOURCE,
});
```
The `addRequiredKbResourceMetadata` function adds two additional fields to the `metadata` property of the document:
- `kbResource` - a `keyword` field that specifies the category of knowledge, e.g. `esql`
- `required` - a `boolean` field that when `true`, indicates the document should be returned in all searches for the `kbResource`
The additional metadata fields are shown below in the following abridged sample document:
```
{
"_index": ".kibana-elastic-ai-assistant-kb",
"_id": "e297e2d9-fb0e-4638-b4be-af31d1b31b9f",
"_version": 1,
"_seq_no": 129,
"_primary_term": 1,
"found": true,
"_source": {
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/example_queries/esql_example_query_0001.asciidoc",
"required": true,
"kbResource": "esql"
},
"vector": {
"tokens": {
"serial": 0.5612584,
"syntax": 0.006727545,
"user": 1.1184403,
// ...additional tokens
},
"model_id": ".elser_model_2"
},
"text": """[[esql-example-queries]]
The following is an example ES|QL query:
\`\`\`
FROM logs-*
| WHERE NOT CIDR_MATCH(destination.ip, "10.0.0.0/8", "172.16.0.0/12", "192.168.0.0/16")
| STATS destcount = COUNT(destination.ip) by user.name, host.name
| ENRICH ldap_lookup_new ON user.name
| WHERE group.name IS NOT NULL
| EVAL follow_up = CASE(
destcount >= 100, "true",
"false")
| SORT destcount desc
| KEEP destcount, host.name, user.name, group.name, follow_up
\`\`\`
"""
}
}
```
### Hybrid search
The `ElasticsearchStore.similaritySearch` function is invoked by LangChain's `VectorStoreRetriever.getRelevantDocuments` function when the `RetrievalQAChain` searches for documents.
A single request to Elasticsearch performs a hybrid search that combines the vector and terms searches into a single request with an [msearch](https://www.elastic.co/guide/en/elasticsearch/reference/current/search-multi-search.html):
```typescript
// requiredDocs is an array of filters that can be used in a `bool` Elasticsearch DSL query to filter in/out required KB documents:
const requiredDocs = getRequiredKbDocsTermsQueryDsl(this.kbResource);
// The `k` parameter is typically provided by LangChain's `VectorStoreRetriever._getRelevantDocuments`, which calls this function:
const vectorSearchQuerySize = k ?? FALLBACK_SIMILARITY_SEARCH_SIZE;
// build a vector search query:
const vectorSearchQuery = getVectorSearchQuery({
filter,
modelId: this.model,
mustNotTerms: requiredDocs,
query,
});
// build a (separate) terms search query:
const termsSearchQuery = getTermsSearchQuery(requiredDocs);
// combine the vector search query and the terms search queries into a single multi-search query:
const mSearchQueryBody = getMsearchQueryBody({
index: this.index,
termsSearchQuery,
termsSearchQuerySize: TERMS_QUERY_SIZE,
vectorSearchQuery,
vectorSearchQuerySize,
});
try {
// execute both queries via a single multi-search request:
const result = await this.esClient.msearch<MsearchResponse>(mSearchQueryBody);
// flatten the results of the combined queries into a single array of hits:
const results: FlattenedHit[] = result.responses.flatMap((response) =>
// ...
```
## Desk testing
1. Delete any previous instances of the Knowledge Base by executing the following query in Kibana's `Dev Tools`:
```
DELETE .kibana-elastic-ai-assistant-kb
```
2. In the Security Solution, open the Elastic AI Assistant
3. In the assistant, click the `Settings` gear
4. Click the `Knowledge Base` icon to view the KB settings
5. Toggle the `Knowledge Base` setting `off` if it's already on
6. Toggle the `Knowledge Base` setting `on` to load the KB documents
7. Click the `Save` button to close settings
8. Enter the following prompt, then press Enter:
```
Generate an ES|QL query that will count the number of connections made to external IP addresses, broken down by user. If the count is greater than 100 for a specific user, add a new field called "follow_up" that contains a value of "true", otherwise, it should contain "false". The user names should also be enriched with their respective group names.
```
**Expected result**
A response similar to the following is returned:
```
FROM logs-*
| WHERE NOT CIDR_MATCH(destination.ip, "10.0.0.0/8", "172.16.0.0/12", "192.168.0.0/16")
| STATS destcount = COUNT(destination.ip) BY user.name
| ENRICH ldap_lookup ON user.name
| EVAL follow_up = CASE(
destcount >= 100, "true",
"false")
| SORT destcount DESC
| KEEP destcount, user.name, group.name, follow_up
```
### Reference: Annotated `verbose: true` output
The following output, annotated with `// comments` was generating by setting `verbose: true` in the following code in `x-pack/plugins/elastic_assistant/server/lib/langchain/execute_custom_llm_chain/index.ts`:
```typescript
const executor = await initializeAgentExecutorWithOptions(tools, llm, {
agentType: 'chat-conversational-react-description',
memory,
verbose: true, // <--
});
```
<details>
<summary>Annotated verbose output</summary>
```json
// The chain starts with just the input from the user: a system prompt, plus the user's input:
[chain/start] [1:chain:AgentExecutor] Entering Chain run with input: {
"input": "You are a helpful, expert assistant who answers questions about Elastic Security. Do not answer questions unrelated to Elastic Security.\nIf you answer a question related to KQL, EQL, or ES|QL, it should be immediately usable within an Elastic Security timeline; please always format the output correctly with back ticks. Any answer provided for Query DSL should also be usable in a security timeline. This means you should only ever include the \"filter\" portion of the query.\nUse the following context to answer questions:\n\n\n\nGenerate an ES|QL query that will count the number of connections made to external IP addresses, broken down by user. If the count is greater than 100 for a specific user, add a new field called \"follow_up\" that contains a value of \"true\", otherwise, it should contain \"false\". The user names should also be enriched with their respective group names.",
"chat_history": []
}
// The input from the previous step is unchanged in this one:
[chain/start] [1:chain:AgentExecutor > 2:chain:LLMChain] Entering Chain run with input: {
"input": "You are a helpful, expert assistant who answers questions about Elastic Security. Do not answer questions unrelated to Elastic Security.\nIf you answer a question related to KQL, EQL, or ES|QL, it should be immediately usable within an Elastic Security timeline; please always format the output correctly with back ticks. Any answer provided for Query DSL should also be usable in a security timeline. This means you should only ever include the \"filter\" portion of the query.\nUse the following context to answer questions:\n\n\n\nGenerate an ES|QL query that will count the number of connections made to external IP addresses, broken down by user. If the count is greater than 100 for a specific user, add a new field called \"follow_up\" that contains a value of \"true\", otherwise, it should contain \"false\". The user names should also be enriched with their respective group names.",
"chat_history": [],
"agent_scratchpad": [],
"stop": [
"Observation:"
]
}
// The "prompts" array below contains content written by LangChain inform the LLM about the available tools, including the ES|QL knowledge base, and "teach" it how to use them:
[llm/start] [1:chain:AgentExecutor > 2:chain:LLMChain > 3:llm:ActionsClientLlm] Entering LLM run with input: {
"prompts": [
"[{\"lc\":1,\"type\":\"constructor\",\"id\":[\"langchain\",\"schema\",\"SystemMessage\"],\"kwargs\":{\"content\":\"Assistant is a large language model trained by OpenAI.\\n\\nAssistant is designed to be able to assist with a wide range of tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics. As a language model, Assistant is able to generate human-like text based on the input it receives, allowing it to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand.\\n\\nAssistant is constantly learning and improving, and its capabilities are constantly evolving. It is able to process and understand large amounts of text, and can use this knowledge to provide accurate and informative responses to a wide range of questions. Additionally, Assistant is able to generate its own text based on the input it receives, allowing it to engage in discussions and provide explanations and descriptions on a wide range of topics.\\n\\nOverall, Assistant is a powerful system that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics. Whether you need help with a specific question or just want to have a conversation about a particular topic, Assistant is here to assist. However, above all else, all responses must adhere to the format of RESPONSE FORMAT INSTRUCTIONS.\",\"additional_kwargs\":{}}},{\"lc\":1,\"type\":\"constructor\",\"id\":[\"langchain\",\"schema\",\"HumanMessage\"],\"kwargs\":{\"content\":\"TOOLS\\n------\\nAssistant can ask the user to use tools to look up information that may be helpful in answering the users original question. The tools the human can use are:\\n\\nesql-language-knowledge-base: Call this for knowledge on how to build an ESQL query, or answer questions about the ES|QL query language.\\n\\nRESPONSE FORMAT INSTRUCTIONS\\n----------------------------\\n\\nOutput a JSON markdown code snippet containing a valid JSON object in one of two formats:\\n\\n**Option 1:**\\nUse this if you want the human to use a tool.\\nMarkdown code snippet formatted in the following schema:\\n\\n```json\\n{\\n \\\"action\\\": string, // The action to take. Must be one of [esql-language-knowledge-base]\\n \\\"action_input\\\": string // The input to the action. May be a stringified object.\\n}\\n```\\n\\n**Option #2:**\\nUse this if you want to respond directly and conversationally to the human. Markdown code snippet formatted in the following schema:\\n\\n```json\\n{\\n \\\"action\\\": \\\"Final Answer\\\",\\n \\\"action_input\\\": string // You should put what you want to return to use here and make sure to use valid json newline characters.\\n}\\n```\\n\\nFor both options, remember to always include the surrounding markdown code snippet delimiters (begin with \\\"```json\\\" and end with \\\"```\\\")!\\n\\n\\nUSER'S INPUT\\n--------------------\\nHere is the user's input (remember to respond with a markdown code snippet of a json blob with a single action, and NOTHING else):\\n\\nYou are a helpful, expert assistant who answers questions about Elastic Security. Do not answer questions unrelated to Elastic Security.\\nIf you answer a question related to KQL, EQL, or ES|QL, it should be immediately usable within an Elastic Security timeline; please always format the output correctly with back ticks. Any answer provided for Query DSL should also be usable in a security timeline. This means you should only ever include the \\\"filter\\\" portion of the query.\\nUse the following context to answer questions:\\n\\n\\n\\nGenerate an ES|QL query that will count the number of connections made to external IP addresses, broken down by user. If the count is greater than 100 for a specific user, add a new field called \\\"follow_up\\\" that contains a value of \\\"true\\\", otherwise, it should contain \\\"false\\\". The user names should also be enriched with their respective group names.\",\"additional_kwargs\":{}}}]"
]
}
// The LLM then uses the prompt above, to generate a response (below), which is then passed to the Chain:
[llm/end] [1:chain:AgentExecutor > 2:chain:LLMChain > 3:llm:ActionsClientLlm] [5.48s] Exiting LLM run with output: {
"generations": [
[
{
"text": "```json\n{\n \"action\": \"esql-language-knowledge-base\",\n \"action_input\": \"Generate an ES|QL query that will count the number of connections made to external IP addresses, broken down by user. If the count is greater than 100 for a specific user, add a new field called \\\"follow_up\\\" that contains a value of \\\"true\\\", otherwise, it should contain \\\"false\\\". The user names should also be enriched with their respective group names.\"\n}\n```"
}
]
]
}
// It's worth noting that the LLM **ONLY** provided the actual question posed by the user. The LLM correctly omitted all the other instructions, including the system prompt, because the question asked by the user is the most relevant piece of information for the LLM to use to generate a response.
[chain/end] [1:chain:AgentExecutor > 2:chain:LLMChain] [5.49s] Exiting Chain run with output: {
"text": "```json\n{\n \"action\": \"esql-language-knowledge-base\",\n \"action_input\": \"Generate an ES|QL query that will count the number of connections made to external IP addresses, broken down by user. If the count is greater than 100 for a specific user, add a new field called \\\"follow_up\\\" that contains a value of \\\"true\\\", otherwise, it should contain \\\"false\\\". The user names should also be enriched with their respective group names.\"\n}\n```"
}
// In this step, the `AgentExecutor` takes the output from the previous step, and passes it to the `ChainTool`:
[agent/action] [1:chain:AgentExecutor] Agent selected action: {
"tool": "esql-language-knowledge-base",
"toolInput": "Generate an ES|QL query that will count the number of connections made to external IP addresses, broken down by user. If the count is greater than 100 for a specific user, add a new field called \"follow_up\" that contains a value of \"true\", otherwise, it should contain \"false\". The user names should also be enriched with their respective group names.",
"log": "```json\n{\n \"action\": \"esql-language-knowledge-base\",\n \"action_input\": \"Generate an ES|QL query that will count the number of connections made to external IP addresses, broken down by user. If the count is greater than 100 for a specific user, add a new field called \\\"follow_up\\\" that contains a value of \\\"true\\\", otherwise, it should contain \\\"false\\\". The user names should also be enriched with their respective group names.\"\n}\n```"
}
// The `ChainTool` then passes the input to the `RetrievalQAChain`:
[tool/start] [1:chain:AgentExecutor > 4:tool:ChainTool] Entering Tool run with input: "Generate an ES|QL query that will count the number of connections made to external IP addresses, broken down by user. If the count is greater than 100 for a specific user, add a new field called "follow_up" that contains a value of "true", otherwise, it should contain "false". The user names should also be enriched with their respective group names."
// The `RetrievalQAChain` then passes the input to the `VectorStoreRetriever`:
[chain/start] [1:chain:AgentExecutor > 4:tool:ChainTool > 5:chain:RetrievalQAChain] Entering Chain run with input: {
"query": "Generate an ES|QL query that will count the number of connections made to external IP addresses, broken down by user. If the count is greater than 100 for a specific user, add a new field called \"follow_up\" that contains a value of \"true\", otherwise, it should contain \"false\". The user names should also be enriched with their respective group names."
}
// The `VectorStoreRetriever` then passes the input to the `ElasticsearchStore`, and calls the `similaritySearch` method, in this example with a `k` value of `4`, which means that the `ElasticsearchStore` will return the top 4 results:
[retriever/start] [1:chain:AgentExecutor > 4:tool:ChainTool > 5:chain:RetrievalQAChain > 6:retriever:VectorStoreRetriever] Entering Retriever run with input: {
"query": "Generate an ES|QL query that will count the number of connections made to external IP addresses, broken down by user. If the count is greater than 100 for a specific user, add a new field called \"follow_up\" that contains a value of \"true\", otherwise, it should contain \"false\". The user names should also be enriched with their respective group names."
}
// The `VectorStoreRetriever]` returned 18 results, the first 4 results are from ELSER, because the LangChain `RetrievalQAChain` is configured to return 4 results. The other 14 results matched a terms query where "metadata.kbResource": "esql" AND "metadata.required": true:
[retriever/end] [1:chain:AgentExecutor > 4:tool:ChainTool > 5:chain:RetrievalQAChain > 6:retriever:VectorStoreRetriever] [23ms] Exiting Retriever run with output: {
"documents": [
{
"pageContent": "[[esql]]\n= {esql}\n\n:esql-tests: {xes-repo-dir}/../../plugin/esql/qa\n:esql-specs: {esql-tests}/testFixtures/src/main/resources\n\n[partintro]\n--\n\npreview::[]\n\nThe {es} Query Language ({esql}) is a query language that enables the iterative\nexploration of data.\n\nAn {esql} query consists of a series of commands, separated by pipes. Each query\nstarts with a <<esql-source-commands,source command>>. A source command produces\na table, typically with data from {es}.\n\nimage::images/esql/source-command.svg[A source command producing a table from {es},align=\"center\"]\n\nA source command can be followed by one or more\n<<esql-processing-commands,processing commands>>. Processing commands change an\ninput table by adding, removing, or changing rows and columns.\n\nimage::images/esql/processing-command.svg[A processing command changing an input table,align=\"center\"]\n\nYou can chain processing commands, separated by a pipe character: `|`. Each\nprocessing command works on the output table of the previous command.\n\nimage::images/esql/chaining-processing-commands.svg[Processing commands can be chained,align=\"center\"]\n\nThe result of a query is the table produced by the final processing command.\n\n[discrete]\n[[esql-console]]\n=== Run an {esql} query\n\n[discrete]\n==== The {esql} API\n\nUse the `_query` endpoint to run an {esql} query:\n\n[source,console]\n----\nPOST /_query\n{\n \"query\": \"\"\"\n FROM library\n | EVAL year = DATE_TRUNC(1 YEARS, release_date)\n | STATS MAX(page_count) BY year\n | SORT year\n | LIMIT 5\n \"\"\"\n}\n----\n// TEST[setup:library]\n\nThe results come back in rows:\n\n[source,console-result]\n----\n{\n \"columns\": [\n { \"name\": \"MAX(page_count)\", \"type\": \"integer\"},\n { \"name\": \"year\" , \"type\": \"date\"}\n ],\n \"values\": [\n [268, \"1932-01-01T00:00:00.000Z\"],\n [224, \"1951-01-01T00:00:00.000Z\"],\n [227, \"1953-01-01T00:00:00.000Z\"],\n [335, \"1959-01-01T00:00:00.000Z\"],\n [604, \"1965-01-01T00:00:00.000Z\"]\n ]\n}\n----\n\nBy default, results are returned as JSON. To return results formatted as text,\nCSV, or TSV, use the `format` parameter:\n\n[source,console]\n----\nPOST /_query?format=txt\n{\n \"query\": \"\"\"\n FROM library\n | EVAL year = DATE_TRUNC(1 YEARS, release_date)\n | STATS MAX(page_count) BY year\n | SORT year\n | LIMIT 5\n \"\"\"\n}\n----\n// TEST[setup:library]\n\n[discrete]\n==== {kib}\n\n{esql} can be used in Discover to explore a data set, and in Lens to visualize it.\nFirst, enable the `enableTextBased` setting in *Advanced Settings*. Next, in\nDiscover or Lens, from the data view dropdown, select *{esql}*.\n\nNOTE: {esql} queries in Discover and Lens are subject to the time range selected\nwith the time filter.\n\n[discrete]\n[[esql-limitations]]\n=== Limitations\n\n{esql} currently supports the following <<mapping-types,field types>>:\n\n- `alias`\n- `boolean`\n- `date`\n- `double` (`float`, `half_float`, `scaled_float` are represented as `double`)\n- `ip`\n- `keyword` family including `keyword`, `constant_keyword`, and `wildcard`\n- `int` (`short` and `byte` are represented as `int`)\n- `long`\n- `null`\n- `text`\n- `unsigned_long`\n- `version`\n--\n\ninclude::esql-get-started.asciidoc[]\n\ninclude::esql-syntax.asciidoc[]\n\ninclude::esql-source-commands.asciidoc[]\n\ninclude::esql-processing-commands.asciidoc[]\n\ninclude::esql-functions.asciidoc[]\n\ninclude::aggregation-functions.asciidoc[]\n\ninclude::multivalued-fields.asciidoc[]\n\ninclude::task-management.asciidoc[]\n\n:esql-tests!:\n:esql-specs!:\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/docs/index.asciidoc"
}
},
{
"pageContent": "[[esql-from]]\n=== `FROM`\n\nThe `FROM` source command returns a table with up to 10,000 documents from a\ndata stream, index, or alias. Each row in the resulting table represents a\ndocument. Each column corresponds to a field, and can be accessed by the name\nof that field.\n\n[source,esql]\n----\nFROM employees\n----\n\nYou can use <<api-date-math-index-names,date math>> to refer to indices, aliases\nand data streams. This can be useful for time series data, for example to access\ntoday's index:\n\n[source,esql]\n----\nFROM <logs-{now/d}>\n----\n\nUse comma-separated lists or wildcards to query multiple data streams, indices,\nor aliases:\n\n[source,esql]\n----\nFROM employees-00001,employees-*\n----\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/docs/source_commands/from.asciidoc"
}
},
{
"pageContent": "[[esql-agg-count]]\n=== `COUNT`\nCounts field values.\n\n[source.merge.styled,esql]\n----\ninclude::{esql-specs}/stats.csv-spec[tag=count]\n----\n[%header.monospaced.styled,format=dsv,separator=|]\n|===\ninclude::{esql-specs}/stats.csv-spec[tag=count-result]\n|===\n\nCan take any field type as input and the result is always a `long` not matter\nthe input type.\n\nNOTE: There isn't yet a `COUNT(*)`. Please count a single valued field if you\n need a count of rows.\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/docs/aggregation_functions/count.asciidoc"
}
},
{
"pageContent": "[[esql-agg-count-distinct]]\n=== `COUNT_DISTINCT`\nThe approximate number of distinct values.\n\n[source.merge.styled,esql]\n----\ninclude::{esql-specs}/stats_count_distinct.csv-spec[tag=count-distinct]\n----\n[%header.monospaced.styled,format=dsv,separator=|]\n|===\ninclude::{esql-specs}/stats_count_distinct.csv-spec[tag=count-distinct-result]\n|===\n\nCan take any field type as input and the result is always a `long` not matter\nthe input type.\n\n==== Counts are approximate\n\nComputing exact counts requires loading values into a set and returning its\nsize. This doesn't scale when working on high-cardinality sets and/or large\nvalues as the required memory usage and the need to communicate those\nper-shard sets between nodes would utilize too many resources of the cluster.\n\nThis `COUNT_DISTINCT` function is based on the\nhttps://static.googleusercontent.com/media/research.google.com/fr//pubs/archive/40671.pdf[HyperLogLog++]\nalgorithm, which counts based on the hashes of the values with some interesting\nproperties:\n\ninclude::../../aggregations/metrics/cardinality-aggregation.asciidoc[tag=explanation]\n\n==== Precision is configurable\n\nThe `COUNT_DISTINCT` function takes an optional second parameter to configure the\nprecision discussed previously.\n\n[source.merge.styled,esql]\n----\ninclude::{esql-specs}/stats_count_distinct.csv-spec[tag=count-distinct-precision]\n----\n[%header.monospaced.styled,format=dsv,separator=|]\n|===\ninclude::{esql-specs}/stats_count_distinct.csv-spec[tag=count-distinct-precision-result]\n|===\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/docs/aggregation_functions/count_distinct.asciidoc"
}
},
{
"pageContent": "[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nFROM logs-*\n| WHERE NOT CIDR_MATCH(destination.ip, \"10.0.0.0/8\", \"172.16.0.0/12\", \"192.168.0.0/16\")\n| STATS destcount = COUNT(destination.ip) by user.name, host.name\n| ENRICH ldap_lookup_new ON user.name\n| WHERE group.name IS NOT NULL\n| EVAL follow_up = CASE(\n destcount >= 100, \"true\",\n \"false\")\n| SORT destcount desc\n| KEEP destcount, host.name, user.name, group.name, follow_up\n```\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/example_queries/esql_example_query_0001.asciidoc"
}
},
{
"pageContent": "[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nfrom logs-*\n| grok dns.question.name \"%{DATA}\\\\.%{GREEDYDATA:dns.question.registered_domain:string}\"\n| stats unique_queries = count_distinct(dns.question.name) by dns.question.registered_domain, process.name\n| where unique_queries > 5\n| sort unique_queries desc\n```\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/example_queries/esql_example_query_0002.asciidoc"
}
},
{
"pageContent": "[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nfrom logs-*\n| where event.code is not null\n| stats event_code_count = count(event.code) by event.code,host.name\n| enrich win_events on event.code with EVENT_DESCRIPTION\n| where EVENT_DESCRIPTION is not null and host.name is not null\n| rename EVENT_DESCRIPTION as event.description\n| sort event_code_count desc\n| keep event_code_count,event.code,host.name,event.description\n```\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/example_queries/esql_example_query_0003.asciidoc"
}
},
{
"pageContent": "[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nfrom logs-*\n| where event.category == \"file\" and event.action == \"creation\"\n| stats filecount = count(file.name) by process.name,host.name\n| dissect process.name \"%{process}.%{extension}\"\n| eval proclength = length(process.name)\n| where proclength > 10\n| sort filecount,proclength desc\n| limit 10\n| keep host.name,process.name,filecount,process,extension,fullproc,proclength\n```\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/example_queries/esql_example_query_0004.asciidoc"
}
},
{
"pageContent": "[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nfrom logs-*\n| where process.name == \"curl.exe\"\n| stats bytes = sum(destination.bytes) by destination.address\n| eval kb = bytes/1024\n| sort kb desc\n| limit 10\n| keep kb,destination.address\n```\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/example_queries/esql_example_query_0005.asciidoc"
}
},
{
"pageContent": "[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nFROM metrics-apm*\n| WHERE metricset.name == \"transaction\" AND metricset.interval == \"1m\"\n| EVAL bucket = AUTO_BUCKET(transaction.duration.histogram, 50, <start-date>, <end-date>)\n| STATS avg_duration = AVG(transaction.duration.histogram) BY bucket\n```\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/example_queries/esql_example_query_0006.asciidoc"
}
},
{
"pageContent": "[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nFROM packetbeat-*\n| STATS doc_count = COUNT(destination.domain) BY destination.domain\n| SORT doc_count DESC\n| LIMIT 10\n```\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/example_queries/esql_example_query_0007.asciidoc"
}
},
{
"pageContent": "[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nFROM employees\n| EVAL hire_date_formatted = DATE_FORMAT(hire_date, \"MMMM yyyy\")\n| SORT hire_date\n| KEEP emp_no, hire_date_formatted\n| LIMIT 5\n```\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/example_queries/esql_example_query_0008.asciidoc"
}
},
{
"pageContent": "[[esql-example-queries]]\n\nThe following is NOT an example of an ES|QL query:\n\n```\nPagination is not supported\n```\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/example_queries/esql_example_query_0009.asciidoc"
}
},
{
"pageContent": "[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nFROM logs-*\n| WHERE @timestamp >= NOW() - 15 minutes\n| EVAL bucket = DATE_TRUNC(1 minute, @timestamp)\n| STATS avg_cpu = AVG(system.cpu.total.norm.pct) BY bucket, host.name\n| LIMIT 10\n```\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/example_queries/esql_example_query_0010.asciidoc"
}
},
{
"pageContent": "[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nFROM traces-apm*\n| WHERE @timestamp >= NOW() - 24 hours\n| EVAL successful = CASE(event.outcome == \"success\", 1, 0),\n failed = CASE(event.outcome == \"failure\", 1, 0)\n| STATS success_rate = AVG(successful),\n avg_duration = AVG(transaction.duration),\n total_requests = COUNT(transaction.id) BY service.name\n```\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/example_queries/esql_example_query_0011.asciidoc"
}
},
{
"pageContent": "[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nFROM metricbeat*\n| EVAL cpu_pct_normalized = (system.cpu.user.pct + system.cpu.system.pct) / system.cpu.cores\n| STATS AVG(cpu_pct_normalized) BY host.name\n```\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/example_queries/esql_example_query_0012.asciidoc"
}
},
{
"pageContent": "[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nFROM postgres-logs\n| DISSECT message \"%{} duration: %{query_duration} ms\"\n| EVAL query_duration_num = TO_DOUBLE(query_duration)\n| STATS avg_duration = AVG(query_duration_num)\n```\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/example_queries/esql_example_query_0013.asciidoc"
}
},
{
"pageContent": "[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nFROM nyc_taxis\n| WHERE DATE_EXTRACT(drop_off_time, \"hour\") >= 6 AND DATE_EXTRACT(drop_off_time, \"hour\") < 10\n| LIMIT 10\n```\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/example_queries/esql_example_query_0014.asciidoc"
}
}
]
}
// The search results are then transformed into documents:
[chain/start] [1:chain:AgentExecutor > 4:tool:ChainTool > 5:chain:RetrievalQAChain > 7:chain:StuffDocumentsChain] Entering Chain run with input: {
"question": "Generate an ES|QL query that will count the number of connections made to external IP addresses, broken down by user. If the count is greater than 100 for a specific user, add a new field called \"follow_up\" that contains a value of \"true\", otherwise, it should contain \"false\". The user names should also be enriched with their respective group names.",
"input_documents": [
{
"pageContent": "[[esql]]\n= {esql}\n\n:esql-tests: {xes-repo-dir}/../../plugin/esql/qa\n:esql-specs: {esql-tests}/testFixtures/src/main/resources\n\n[partintro]\n--\n\npreview::[]\n\nThe {es} Query Language ({esql}) is a query language that enables the iterative\nexploration of data.\n\nAn {esql} query consists of a series of commands, separated by pipes. Each query\nstarts with a <<esql-source-commands,source command>>. A source command produces\na table, typically with data from {es}.\n\nimage::images/esql/source-command.svg[A source command producing a table from {es},align=\"center\"]\n\nA source command can be followed by one or more\n<<esql-processing-commands,processing commands>>. Processing commands change an\ninput table by adding, removing, or changing rows and columns.\n\nimage::images/esql/processing-command.svg[A processing command changing an input table,align=\"center\"]\n\nYou can chain processing commands, separated by a pipe character: `|`. Each\nprocessing command works on the output table of the previous command.\n\nimage::images/esql/chaining-processing-commands.svg[Processing commands can be chained,align=\"center\"]\n\nThe result of a query is the table produced by the final processing command.\n\n[discrete]\n[[esql-console]]\n=== Run an {esql} query\n\n[discrete]\n==== The {esql} API\n\nUse the `_query` endpoint to run an {esql} query:\n\n[source,console]\n----\nPOST /_query\n{\n \"query\": \"\"\"\n FROM library\n | EVAL year = DATE_TRUNC(1 YEARS, release_date)\n | STATS MAX(page_count) BY year\n | SORT year\n | LIMIT 5\n \"\"\"\n}\n----\n// TEST[setup:library]\n\nThe results come back in rows:\n\n[source,console-result]\n----\n{\n \"columns\": [\n { \"name\": \"MAX(page_count)\", \"type\": \"integer\"},\n { \"name\": \"year\" , \"type\": \"date\"}\n ],\n \"values\": [\n [268, \"1932-01-01T00:00:00.000Z\"],\n [224, \"1951-01-01T00:00:00.000Z\"],\n [227, \"1953-01-01T00:00:00.000Z\"],\n [335, \"1959-01-01T00:00:00.000Z\"],\n [604, \"1965-01-01T00:00:00.000Z\"]\n ]\n}\n----\n\nBy default, results are returned as JSON. To return results formatted as text,\nCSV, or TSV, use the `format` parameter:\n\n[source,console]\n----\nPOST /_query?format=txt\n{\n \"query\": \"\"\"\n FROM library\n | EVAL year = DATE_TRUNC(1 YEARS, release_date)\n | STATS MAX(page_count) BY year\n | SORT year\n | LIMIT 5\n \"\"\"\n}\n----\n// TEST[setup:library]\n\n[discrete]\n==== {kib}\n\n{esql} can be used in Discover to explore a data set, and in Lens to visualize it.\nFirst, enable the `enableTextBased` setting in *Advanced Settings*. Next, in\nDiscover or Lens, from the data view dropdown, select *{esql}*.\n\nNOTE: {esql} queries in Discover and Lens are subject to the time range selected\nwith the time filter.\n\n[discrete]\n[[esql-limitations]]\n=== Limitations\n\n{esql} currently supports the following <<mapping-types,field types>>:\n\n- `alias`\n- `boolean`\n- `date`\n- `double` (`float`, `half_float`, `scaled_float` are represented as `double`)\n- `ip`\n- `keyword` family including `keyword`, `constant_keyword`, and `wildcard`\n- `int` (`short` and `byte` are represented as `int`)\n- `long`\n- `null`\n- `text`\n- `unsigned_long`\n- `version`\n--\n\ninclude::esql-get-started.asciidoc[]\n\ninclude::esql-syntax.asciidoc[]\n\ninclude::esql-source-commands.asciidoc[]\n\ninclude::esql-processing-commands.asciidoc[]\n\ninclude::esql-functions.asciidoc[]\n\ninclude::aggregation-functions.asciidoc[]\n\ninclude::multivalued-fields.asciidoc[]\n\ninclude::task-management.asciidoc[]\n\n:esql-tests!:\n:esql-specs!:\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/docs/index.asciidoc"
}
},
{
"pageContent": "[[esql-from]]\n=== `FROM`\n\nThe `FROM` source command returns a table with up to 10,000 documents from a\ndata stream, index, or alias. Each row in the resulting table represents a\ndocument. Each column corresponds to a field, and can be accessed by the name\nof that field.\n\n[source,esql]\n----\nFROM employees\n----\n\nYou can use <<api-date-math-index-names,date math>> to refer to indices, aliases\nand data streams. This can be useful for time series data, for example to access\ntoday's index:\n\n[source,esql]\n----\nFROM <logs-{now/d}>\n----\n\nUse comma-separated lists or wildcards to query multiple data streams, indices,\nor aliases:\n\n[source,esql]\n----\nFROM employees-00001,employees-*\n----\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/docs/source_commands/from.asciidoc"
}
},
{
"pageContent": "[[esql-agg-count]]\n=== `COUNT`\nCounts field values.\n\n[source.merge.styled,esql]\n----\ninclude::{esql-specs}/stats.csv-spec[tag=count]\n----\n[%header.monospaced.styled,format=dsv,separator=|]\n|===\ninclude::{esql-specs}/stats.csv-spec[tag=count-result]\n|===\n\nCan take any field type as input and the result is always a `long` not matter\nthe input type.\n\nNOTE: There isn't yet a `COUNT(*)`. Please count a single valued field if you\n need a count of rows.\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/docs/aggregation_functions/count.asciidoc"
}
},
{
"pageContent": "[[esql-agg-count-distinct]]\n=== `COUNT_DISTINCT`\nThe approximate number of distinct values.\n\n[source.merge.styled,esql]\n----\ninclude::{esql-specs}/stats_count_distinct.csv-spec[tag=count-distinct]\n----\n[%header.monospaced.styled,format=dsv,separator=|]\n|===\ninclude::{esql-specs}/stats_count_distinct.csv-spec[tag=count-distinct-result]\n|===\n\nCan take any field type as input and the result is always a `long` not matter\nthe input type.\n\n==== Counts are approximate\n\nComputing exact counts requires loading values into a set and returning its\nsize. This doesn't scale when working on high-cardinality sets and/or large\nvalues as the required memory usage and the need to communicate those\nper-shard sets between nodes would utilize too many resources of the cluster.\n\nThis `COUNT_DISTINCT` function is based on the\nhttps://static.googleusercontent.com/media/research.google.com/fr//pubs/archive/40671.pdf[HyperLogLog++]\nalgorithm, which counts based on the hashes of the values with some interesting\nproperties:\n\ninclude::../../aggregations/metrics/cardinality-aggregation.asciidoc[tag=explanation]\n\n==== Precision is configurable\n\nThe `COUNT_DISTINCT` function takes an optional second parameter to configure the\nprecision discussed previously.\n\n[source.merge.styled,esql]\n----\ninclude::{esql-specs}/stats_count_distinct.csv-spec[tag=count-distinct-precision]\n----\n[%header.monospaced.styled,format=dsv,separator=|]\n|===\ninclude::{esql-specs}/stats_count_distinct.csv-spec[tag=count-distinct-precision-result]\n|===\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/docs/aggregation_functions/count_distinct.asciidoc"
}
},
{
"pageContent": "[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nFROM logs-*\n| WHERE NOT CIDR_MATCH(destination.ip, \"10.0.0.0/8\", \"172.16.0.0/12\", \"192.168.0.0/16\")\n| STATS destcount = COUNT(destination.ip) by user.name, host.name\n| ENRICH ldap_lookup_new ON user.name\n| WHERE group.name IS NOT NULL\n| EVAL follow_up = CASE(\n destcount >= 100, \"true\",\n \"false\")\n| SORT destcount desc\n| KEEP destcount, host.name, user.name, group.name, follow_up\n```\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/example_queries/esql_example_query_0001.asciidoc"
}
},
{
"pageContent": "[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nfrom logs-*\n| grok dns.question.name \"%{DATA}\\\\.%{GREEDYDATA:dns.question.registered_domain:string}\"\n| stats unique_queries = count_distinct(dns.question.name) by dns.question.registered_domain, process.name\n| where unique_queries > 5\n| sort unique_queries desc\n```\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/example_queries/esql_example_query_0002.asciidoc"
}
},
{
"pageContent": "[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nfrom logs-*\n| where event.code is not null\n| stats event_code_count = count(event.code) by event.code,host.name\n| enrich win_events on event.code with EVENT_DESCRIPTION\n| where EVENT_DESCRIPTION is not null and host.name is not null\n| rename EVENT_DESCRIPTION as event.description\n| sort event_code_count desc\n| keep event_code_count,event.code,host.name,event.description\n```\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/example_queries/esql_example_query_0003.asciidoc"
}
},
{
"pageContent": "[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nfrom logs-*\n| where event.category == \"file\" and event.action == \"creation\"\n| stats filecount = count(file.name) by process.name,host.name\n| dissect process.name \"%{process}.%{extension}\"\n| eval proclength = length(process.name)\n| where proclength > 10\n| sort filecount,proclength desc\n| limit 10\n| keep host.name,process.name,filecount,process,extension,fullproc,proclength\n```\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/example_queries/esql_example_query_0004.asciidoc"
}
},
{
"pageContent": "[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nfrom logs-*\n| where process.name == \"curl.exe\"\n| stats bytes = sum(destination.bytes) by destination.address\n| eval kb = bytes/1024\n| sort kb desc\n| limit 10\n| keep kb,destination.address\n```\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/example_queries/esql_example_query_0005.asciidoc"
}
},
{
"pageContent": "[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nFROM metrics-apm*\n| WHERE metricset.name == \"transaction\" AND metricset.interval == \"1m\"\n| EVAL bucket = AUTO_BUCKET(transaction.duration.histogram, 50, <start-date>, <end-date>)\n| STATS avg_duration = AVG(transaction.duration.histogram) BY bucket\n```\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/example_queries/esql_example_query_0006.asciidoc"
}
},
{
"pageContent": "[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nFROM packetbeat-*\n| STATS doc_count = COUNT(destination.domain) BY destination.domain\n| SORT doc_count DESC\n| LIMIT 10\n```\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/example_queries/esql_example_query_0007.asciidoc"
}
},
{
"pageContent": "[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nFROM employees\n| EVAL hire_date_formatted = DATE_FORMAT(hire_date, \"MMMM yyyy\")\n| SORT hire_date\n| KEEP emp_no, hire_date_formatted\n| LIMIT 5\n```\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/example_queries/esql_example_query_0008.asciidoc"
}
},
{
"pageContent": "[[esql-example-queries]]\n\nThe following is NOT an example of an ES|QL query:\n\n```\nPagination is not supported\n```\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/example_queries/esql_example_query_0009.asciidoc"
}
},
{
"pageContent": "[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nFROM logs-*\n| WHERE @timestamp >= NOW() - 15 minutes\n| EVAL bucket = DATE_TRUNC(1 minute, @timestamp)\n| STATS avg_cpu = AVG(system.cpu.total.norm.pct) BY bucket, host.name\n| LIMIT 10\n```\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/example_queries/esql_example_query_0010.asciidoc"
}
},
{
"pageContent": "[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nFROM traces-apm*\n| WHERE @timestamp >= NOW() - 24 hours\n| EVAL successful = CASE(event.outcome == \"success\", 1, 0),\n failed = CASE(event.outcome == \"failure\", 1, 0)\n| STATS success_rate = AVG(successful),\n avg_duration = AVG(transaction.duration),\n total_requests = COUNT(transaction.id) BY service.name\n```\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/example_queries/esql_example_query_0011.asciidoc"
}
},
{
"pageContent": "[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nFROM metricbeat*\n| EVAL cpu_pct_normalized = (system.cpu.user.pct + system.cpu.system.pct) / system.cpu.cores\n| STATS AVG(cpu_pct_normalized) BY host.name\n```\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/example_queries/esql_example_query_0012.asciidoc"
}
},
{
"pageContent": "[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nFROM postgres-logs\n| DISSECT message \"%{} duration: %{query_duration} ms\"\n| EVAL query_duration_num = TO_DOUBLE(query_duration)\n| STATS avg_duration = AVG(query_duration_num)\n```\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/example_queries/esql_example_query_0013.asciidoc"
}
},
{
"pageContent": "[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nFROM nyc_taxis\n| WHERE DATE_EXTRACT(drop_off_time, \"hour\") >= 6 AND DATE_EXTRACT(drop_off_time, \"hour\") < 10\n| LIMIT 10\n```\n",
"metadata": {
"source": "/Users/andrew.goldstein/Projects/forks/andrew-goldstein/kibana/x-pack/plugins/elastic_assistant/server/knowledge_base/esql/example_queries/esql_example_query_0014.asciidoc"
}
}
],
"query": "Generate an ES|QL query that will count the number of connections made to external IP addresses, broken down by user. If the count is greater than 100 for a specific user, add a new field called \"follow_up\" that contains a value of \"true\", otherwise, it should contain \"false\". The user names should also be enriched with their respective group names."
}
// The `pageContent`, but not the `metadata`, is then passed back to the `LLMChain`:
[chain/start] [1:chain:AgentExecutor > 4:tool:ChainTool > 5:chain:RetrievalQAChain > 7:chain:StuffDocumentsChain > 8:chain:LLMChain] Entering Chain run with input: {
"question": "Generate an ES|QL query that will count the number of connections made to external IP addresses, broken down by user. If the count is greater than 100 for a specific user, add a new field called \"follow_up\" that contains a value of \"true\", otherwise, it should contain \"false\". The user names should also be enriched with their respective group names.",
"query": "Generate an ES|QL query that will count the number of connections made to external IP addresses, broken down by user. If the count is greater than 100 for a specific user, add a new field called \"follow_up\" that contains a value of \"true\", otherwise, it should contain \"false\". The user names should also be enriched with their respective group names.",
"context": "[[esql]]\n= {esql}\n\n:esql-tests: {xes-repo-dir}/../../plugin/esql/qa\n:esql-specs: {esql-tests}/testFixtures/src/main/resources\n\n[partintro]\n--\n\npreview::[]\n\nThe {es} Query Language ({esql}) is a query language that enables the iterative\nexploration of data.\n\nAn {esql} query consists of a series of commands, separated by pipes. Each query\nstarts with a <<esql-source-commands,source command>>. A source command produces\na table, typically with data from {es}.\n\nimage::images/esql/source-command.svg[A source command producing a table from {es},align=\"center\"]\n\nA source command can be followed by one or more\n<<esql-processing-commands,processing commands>>. Processing commands change an\ninput table by adding, removing, or changing rows and columns.\n\nimage::images/esql/processing-command.svg[A processing command changing an input table,align=\"center\"]\n\nYou can chain processing commands, separated by a pipe character: `|`. Each\nprocessing command works on the output table of the previous command.\n\nimage::images/esql/chaining-processing-commands.svg[Processing commands can be chained,align=\"center\"]\n\nThe result of a query is the table produced by the final processing command.\n\n[discrete]\n[[esql-console]]\n=== Run an {esql} query\n\n[discrete]\n==== The {esql} API\n\nUse the `_query` endpoint to run an {esql} query:\n\n[source,console]\n----\nPOST /_query\n{\n \"query\": \"\"\"\n FROM library\n | EVAL year = DATE_TRUNC(1 YEARS, release_date)\n | STATS MAX(page_count) BY year\n | SORT year\n | LIMIT 5\n \"\"\"\n}\n----\n// TEST[setup:library]\n\nThe results come back in rows:\n\n[source,console-result]\n----\n{\n \"columns\": [\n { \"name\": \"MAX(page_count)\", \"type\": \"integer\"},\n { \"name\": \"year\" , \"type\": \"date\"}\n ],\n \"values\": [\n [268, \"1932-01-01T00:00:00.000Z\"],\n [224, \"1951-01-01T00:00:00.000Z\"],\n [227, \"1953-01-01T00:00:00.000Z\"],\n [335, \"1959-01-01T00:00:00.000Z\"],\n [604, \"1965-01-01T00:00:00.000Z\"]\n ]\n}\n----\n\nBy default, results are returned as JSON. To return results formatted as text,\nCSV, or TSV, use the `format` parameter:\n\n[source,console]\n----\nPOST /_query?format=txt\n{\n \"query\": \"\"\"\n FROM library\n | EVAL year = DATE_TRUNC(1 YEARS, release_date)\n | STATS MAX(page_count) BY year\n | SORT year\n | LIMIT 5\n \"\"\"\n}\n----\n// TEST[setup:library]\n\n[discrete]\n==== {kib}\n\n{esql} can be used in Discover to explore a data set, and in Lens to visualize it.\nFirst, enable the `enableTextBased` setting in *Advanced Settings*. Next, in\nDiscover or Lens, from the data view dropdown, select *{esql}*.\n\nNOTE: {esql} queries in Discover and Lens are subject to the time range selected\nwith the time filter.\n\n[discrete]\n[[esql-limitations]]\n=== Limitations\n\n{esql} currently supports the following <<mapping-types,field types>>:\n\n- `alias`\n- `boolean`\n- `date`\n- `double` (`float`, `half_float`, `scaled_float` are represented as `double`)\n- `ip`\n- `keyword` family including `keyword`, `constant_keyword`, and `wildcard`\n- `int` (`short` and `byte` are represented as `int`)\n- `long`\n- `null`\n- `text`\n- `unsigned_long`\n- `version`\n--\n\ninclude::esql-get-started.asciidoc[]\n\ninclude::esql-syntax.asciidoc[]\n\ninclude::esql-source-commands.asciidoc[]\n\ninclude::esql-processing-commands.asciidoc[]\n\ninclude::esql-functions.asciidoc[]\n\ninclude::aggregation-functions.asciidoc[]\n\ninclude::multivalued-fields.asciidoc[]\n\ninclude::task-management.asciidoc[]\n\n:esql-tests!:\n:esql-specs!:\n\n\n[[esql-from]]\n=== `FROM`\n\nThe `FROM` source command returns a table with up to 10,000 documents from a\ndata stream, index, or alias. Each row in the resulting table represents a\ndocument. Each column corresponds to a field, and can be accessed by the name\nof that field.\n\n[source,esql]\n----\nFROM employees\n----\n\nYou can use <<api-date-math-index-names,date math>> to refer to indices, aliases\nand data streams. This can be useful for time series data, for example to access\ntoday's index:\n\n[source,esql]\n----\nFROM <logs-{now/d}>\n----\n\nUse comma-separated lists or wildcards to query multiple data streams, indices,\nor aliases:\n\n[source,esql]\n----\nFROM employees-00001,employees-*\n----\n\n\n[[esql-agg-count]]\n=== `COUNT`\nCounts field values.\n\n[source.merge.styled,esql]\n----\ninclude::{esql-specs}/stats.csv-spec[tag=count]\n----\n[%header.monospaced.styled,format=dsv,separator=|]\n|===\ninclude::{esql-specs}/stats.csv-spec[tag=count-result]\n|===\n\nCan take any field type as input and the result is always a `long` not matter\nthe input type.\n\nNOTE: There isn't yet a `COUNT(*)`. Please count a single valued field if you\n need a count of rows.\n\n\n[[esql-agg-count-distinct]]\n=== `COUNT_DISTINCT`\nThe approximate number of distinct values.\n\n[source.merge.styled,esql]\n----\ninclude::{esql-specs}/stats_count_distinct.csv-spec[tag=count-distinct]\n----\n[%header.monospaced.styled,format=dsv,separator=|]\n|===\ninclude::{esql-specs}/stats_count_distinct.csv-spec[tag=count-distinct-result]\n|===\n\nCan take any field type as input and the result is always a `long` not matter\nthe input type.\n\n==== Counts are approximate\n\nComputing exact counts requires loading values into a set and returning its\nsize. This doesn't scale when working on high-cardinality sets and/or large\nvalues as the required memory usage and the need to communicate those\nper-shard sets between nodes would utilize too many resources of the cluster.\n\nThis `COUNT_DISTINCT` function is based on the\nhttps://static.googleusercontent.com/media/research.google.com/fr//pubs/archive/40671.pdf[HyperLogLog++]\nalgorithm, which counts based on the hashes of the values with some interesting\nproperties:\n\ninclude::../../aggregations/metrics/cardinality-aggregation.asciidoc[tag=explanation]\n\n==== Precision is configurable\n\nThe `COUNT_DISTINCT` function takes an optional second parameter to configure the\nprecision discussed previously.\n\n[source.merge.styled,esql]\n----\ninclude::{esql-specs}/stats_count_distinct.csv-spec[tag=count-distinct-precision]\n----\n[%header.monospaced.styled,format=dsv,separator=|]\n|===\ninclude::{esql-specs}/stats_count_distinct.csv-spec[tag=count-distinct-precision-result]\n|===\n\n\n[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nFROM logs-*\n| WHERE NOT CIDR_MATCH(destination.ip, \"10.0.0.0/8\", \"172.16.0.0/12\", \"192.168.0.0/16\")\n| STATS destcount = COUNT(destination.ip) by user.name, host.name\n| ENRICH ldap_lookup_new ON user.name\n| WHERE group.name IS NOT NULL\n| EVAL follow_up = CASE(\n destcount >= 100, \"true\",\n \"false\")\n| SORT destcount desc\n| KEEP destcount, host.name, user.name, group.name, follow_up\n```\n\n\n[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nfrom logs-*\n| grok dns.question.name \"%{DATA}\\\\.%{GREEDYDATA:dns.question.registered_domain:string}\"\n| stats unique_queries = count_distinct(dns.question.name) by dns.question.registered_domain, process.name\n| where unique_queries > 5\n| sort unique_queries desc\n```\n\n\n[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nfrom logs-*\n| where event.code is not null\n| stats event_code_count = count(event.code) by event.code,host.name\n| enrich win_events on event.code with EVENT_DESCRIPTION\n| where EVENT_DESCRIPTION is not null and host.name is not null\n| rename EVENT_DESCRIPTION as event.description\n| sort event_code_count desc\n| keep event_code_count,event.code,host.name,event.description\n```\n\n\n[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nfrom logs-*\n| where event.category == \"file\" and event.action == \"creation\"\n| stats filecount = count(file.name) by process.name,host.name\n| dissect process.name \"%{process}.%{extension}\"\n| eval proclength = length(process.name)\n| where proclength > 10\n| sort filecount,proclength desc\n| limit 10\n| keep host.name,process.name,filecount,process,extension,fullproc,proclength\n```\n\n\n[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nfrom logs-*\n| where process.name == \"curl.exe\"\n| stats bytes = sum(destination.bytes) by destination.address\n| eval kb = bytes/1024\n| sort kb desc\n| limit 10\n| keep kb,destination.address\n```\n\n\n[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nFROM metrics-apm*\n| WHERE metricset.name == \"transaction\" AND metricset.interval == \"1m\"\n| EVAL bucket = AUTO_BUCKET(transaction.duration.histogram, 50, <start-date>, <end-date>)\n| STATS avg_duration = AVG(transaction.duration.histogram) BY bucket\n```\n\n\n[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nFROM packetbeat-*\n| STATS doc_count = COUNT(destination.domain) BY destination.domain\n| SORT doc_count DESC\n| LIMIT 10\n```\n\n\n[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nFROM employees\n| EVAL hire_date_formatted = DATE_FORMAT(hire_date, \"MMMM yyyy\")\n| SORT hire_date\n| KEEP emp_no, hire_date_formatted\n| LIMIT 5\n```\n\n\n[[esql-example-queries]]\n\nThe following is NOT an example of an ES|QL query:\n\n```\nPagination is not supported\n```\n\n\n[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nFROM logs-*\n| WHERE @timestamp >= NOW() - 15 minutes\n| EVAL bucket = DATE_TRUNC(1 minute, @timestamp)\n| STATS avg_cpu = AVG(system.cpu.total.norm.pct) BY bucket, host.name\n| LIMIT 10\n```\n\n\n[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nFROM traces-apm*\n| WHERE @timestamp >= NOW() - 24 hours\n| EVAL successful = CASE(event.outcome == \"success\", 1, 0),\n failed = CASE(event.outcome == \"failure\", 1, 0)\n| STATS success_rate = AVG(successful),\n avg_duration = AVG(transaction.duration),\n total_requests = COUNT(transaction.id) BY service.name\n```\n\n\n[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nFROM metricbeat*\n| EVAL cpu_pct_normalized = (system.cpu.user.pct + system.cpu.system.pct) / system.cpu.cores\n| STATS AVG(cpu_pct_normalized) BY host.name\n```\n\n\n[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nFROM postgres-logs\n| DISSECT message \"%{} duration: %{query_duration} ms\"\n| EVAL query_duration_num = TO_DOUBLE(query_duration)\n| STATS avg_duration = AVG(query_duration_num)\n```\n\n\n[[esql-example-queries]]\n\nThe following is an example ES|QL query:\n\n```\nFROM nyc_taxis\n| WHERE DATE_EXTRACT(drop_off_time, \"hour\") >= 6 AND DATE_EXTRACT(drop_off_time, \"hour\") < 10\n| LIMIT 10\n```\n"
}
// The `LLMChain` then generates a new prompt based on the `pageContent` and passes it to the `ActionsClientLlm`, so the LLM can produce the final answer:
[llm/start] [1:chain:AgentExecutor > 4:tool:ChainTool > 5:chain:RetrievalQAChain > 7:chain:StuffDocumentsChain > 8:chain:LLMChain > 9:llm:ActionsClientLlm] Entering LLM run with input: {
"prompts": [
"[{\"lc\":1,\"type\":\"constructor\",\"id\":[\"langchain\",\"schema\",\"SystemMessage\"],\"kwargs\":{\"content\":\"Use the following pieces of context to answer the users question. \\nIf you don't know the answer, just say that you don't know, don't try to make up an answer.\\n----------------\\n[[esql]]\\n= {esql}\\n\\n:esql-tests: {xes-repo-dir}/../../plugin/esql/qa\\n:esql-specs: {esql-tests}/testFixtures/src/main/resources\\n\\n[partintro]\\n--\\n\\npreview::[]\\n\\nThe {es} Query Language ({esql}) is a query language that enables the iterative\\nexploration of data.\\n\\nAn {esql} query consists of a series of commands, separated by pipes. Each query\\nstarts with a <<esql-source-commands,source command>>. A source command produces\\na table, typically with data from {es}.\\n\\nimage::images/esql/source-command.svg[A source command producing a table from {es},align=\\\"center\\\"]\\n\\nA source command can be followed by one or more\\n<<esql-processing-commands,processing commands>>. Processing commands change an\\ninput table by adding, removing, or changing rows and columns.\\n\\nimage::images/esql/processing-command.svg[A processing command changing an input table,align=\\\"center\\\"]\\n\\nYou can chain processing commands, separated by a pipe character: `|`. Each\\nprocessing command works on the output table of the previous command.\\n\\nimage::images/esql/chaining-processing-commands.svg[Processing commands can be chained,align=\\\"center\\\"]\\n\\nThe result of a query is the table produced by the final processing command.\\n\\n[discrete]\\n[[esql-console]]\\n=== Run an {esql} query\\n\\n[discrete]\\n==== The {esql} API\\n\\nUse the `_query` endpoint to run an {esql} query:\\n\\n[source,console]\\n----\\nPOST /_query\\n{\\n \\\"query\\\": \\\"\\\"\\\"\\n FROM library\\n | EVAL year = DATE_TRUNC(1 YEARS, release_date)\\n | STATS MAX(page_count) BY year\\n | SORT year\\n | LIMIT 5\\n \\\"\\\"\\\"\\n}\\n----\\n// TEST[setup:library]\\n\\nThe results come back in rows:\\n\\n[source,console-result]\\n----\\n{\\n \\\"columns\\\": [\\n { \\\"name\\\": \\\"MAX(page_count)\\\", \\\"type\\\": \\\"integer\\\"},\\n { \\\"name\\\": \\\"year\\\" , \\\"type\\\": \\\"date\\\"}\\n ],\\n \\\"values\\\": [\\n [268, \\\"1932-01-01T00:00:00.000Z\\\"],\\n [224, \\\"1951-01-01T00:00:00.000Z\\\"],\\n [227, \\\"1953-01-01T00:00:00.000Z\\\"],\\n [335, \\\"1959-01-01T00:00:00.000Z\\\"],\\n [604, \\\"1965-01-01T00:00:00.000Z\\\"]\\n ]\\n}\\n----\\n\\nBy default, results are returned as JSON. To return results formatted as text,\\nCSV, or TSV, use the `format` parameter:\\n\\n[source,console]\\n----\\nPOST /_query?format=txt\\n{\\n \\\"query\\\": \\\"\\\"\\\"\\n FROM library\\n | EVAL year = DATE_TRUNC(1 YEARS, release_date)\\n | STATS MAX(page_count) BY year\\n | SORT year\\n | LIMIT 5\\n \\\"\\\"\\\"\\n}\\n----\\n// TEST[setup:library]\\n\\n[discrete]\\n==== {kib}\\n\\n{esql} can be used in Discover to explore a data set, and in Lens to visualize it.\\nFirst, enable the `enableTextBased` setting in *Advanced Settings*. Next, in\\nDiscover or Lens, from the data view dropdown, select *{esql}*.\\n\\nNOTE: {esql} queries in Discover and Lens are subject to the time range selected\\nwith the time filter.\\n\\n[discrete]\\n[[esql-limitations]]\\n=== Limitations\\n\\n{esql} currently supports the following <<mapping-types,field types>>:\\n\\n- `alias`\\n- `boolean`\\n- `date`\\n- `double` (`float`, `half_f…
andrew-goldstein
pushed a commit
that referenced
this pull request
Dec 5, 2023
## Summary ### This PR enables user roles testing in FTR We use SAML authentication to get session cookie for user with the specific role. The cookie is cached on FTR service side so we only make SAML auth one time per user within FTR config run. For Kibana CI service relies on changes coming in elastic#170852 In order to run FTR tests locally against existing MKI project: - add `.ftr/role_users.json` in Kibana root dir ``` { "viewer": { "email": "...", "password": "..." }, "developer": { "email": "...", "password": "..." } } ``` - set Cloud hostname (!not project hostname!) with TEST_CLOUD_HOST_NAME, e.g. `export TEST_CLOUD_HOST_NAME=console.qa.cld.elstc.co` ### How to use: - functional tests: ``` const svlCommonPage = getPageObject('svlCommonPage'); before(async () => { // login with Viewer role await svlCommonPage.loginWithRole('viewer'); // you are logged in in browser and on project home page, start the test }); it('has project header', async () => { await svlCommonPage.assertProjectHeaderExists(); }); ``` - API integration tests: ``` const svlUserManager = getService('svlUserManager'); const supertestWithoutAuth = getService('supertestWithoutAuth'); let credentials: { Cookie: string }; before(async () => { // get auth header for Viewer role credentials = await svlUserManager.getApiCredentialsForRole('viewer'); }); it('returns full status payload for authenticated request', async () => { const { body } = await supertestWithoutAuth .get('/api/status') .set(credentials) .set('kbn-xsrf', 'kibana'); expect(body.name).to.be.a('string'); expect(body.uuid).to.be.a('string'); expect(body.version.number).to.be.a('string'); }); ``` Flaky-test-runner: #1 https://buildkite.com/elastic/kibana-flaky-test-suite-runner/builds/4081 #2 https://buildkite.com/elastic/kibana-flaky-test-suite-runner/builds/4114 --------- Co-authored-by: Robert Oskamp <[email protected]> Co-authored-by: kibanamachine <[email protected]> Co-authored-by: Aleh Zasypkin <[email protected]>
andrew-goldstein
pushed a commit
that referenced
this pull request
Dec 21, 2023
andrew-goldstein
pushed a commit
that referenced
this pull request
Jun 21, 2024
## Summary Set `security.session.cleanupInterval` to 5h for session concurrency test. ### **Prerequisites** - Task for session cleanup with [default schedule set to 1h](https://github.com/elastic/kibana/blob/main/x-pack/plugins/security/server/config.ts#L222). - Task polling interval is set to [3000ms](https://github.com/elastic/kibana/blob/main/x-pack/plugins/task_manager/server/config.ts#L13). - We override `scheduledAt` once we make a request in [runCleanupTaskSoon](https://github.com/elastic/kibana/blob/main/x-pack/test/security_api_integration/tests/session_concurrent_limit/cleanup.ts#L145). ### **Hypothesis** Taking into consideration that: - `session_cleanup` task is not the only one scheduled during test run. - There is sort of an exponential backoff implemented for task polling if there are too many retries. - Clock jitter. I had a hypothesis that if our whole test run exceeds 1h or polling interval gets adjusted because of retries we might end up executing the scheduled cleanup before we trigger `runCleanupTaskSoon` (this is there we drop 1 session already). ### **FTR runs (x55 each)** - `cleanupInterval` set to 5h: [#1](https://buildkite.com/elastic/kibana-flaky-test-suite-runner/builds/5986) :green_circle:, [#2](https://buildkite.com/elastic/kibana-flaky-test-suite-runner/builds/5987) :green_circle: - `cleanupInterval` set to default 1h: [#1](https://buildkite.com/elastic/kibana-flaky-test-suite-runner/builds/5983) :green_circle:, [#2](https://buildkite.com/elastic/kibana-flaky-test-suite-runner/builds/5982) :red_circle: (has 2 failures out of 55) ### Checklist - [x] [Flaky Test Runner](https://ci-stats.kibana.dev/trigger_flaky_test_runner/1) was used on any tests changed ### For maintainers - [x] This was checked for breaking API changes and was [labeled appropriately](https://www.elastic.co/guide/en/kibana/master/contributing.html#kibana-release-notes-process) __Fixes: https://github.com/elastic/kibana/issues/149091__
andrew-goldstein
pushed a commit
that referenced
this pull request
Aug 13, 2024
## Summary Resolves elastic#143905. This PR adds support for integration-level outputs. This means that different integrations within the same agent policy can now be configured to send data to different locations. This feature is gated behind `enterprise` level subscription. For each input, the agent policy will configure sending data to the following outputs in decreasing order of priority: 1. Output set specifically on the integration policy 2. Output set specifically on the integration's parent agent policy (including the case where an integration policy belongs to multiple agent policies) 3. Global default data output set via Fleet Settings Integration-level outputs will respect the same rules as agent policy-level outputs: - Certain integrations are disallowed from using certain output types, attempting to add them to each other via creation, updating, or "defaulting", will fail - `fleet-server`, `synthetics`, and `apm` can only use same-cluster Elasticsearch output - When an output is deleted, any integrations that were specifically using it will "clear" their output configuration and revert back to either `#2` or `#3` in the above list - When an output is edited, all agent policies across all spaces that use it will be bumped to a new revision, this includes: - Agent policies that have that output specifically set in their settings (existing behavior) - Agent policies that contain integrations which specifically has that output set (new behavior) - When a proxy is edited, the same new revision bump above will apply for any outputs using that proxy The final agent policy YAML that is generated will have: - `outputs` block that includes: - Data and monitoring outputs set at the agent policy level (existing behavior) - Any additional outputs set at the integration level, if they differ from the above - `outputs_permissions` block that includes permissions for each Elasticsearch output depending on which integrations and/or agent monitoring are assigned to it Integration policies table now includes `Output` column. If the output is defaulting to agent policy-level output, or global setting output, a tooltip is shown: <img width="1392" alt="image" src="https://github.com/user-attachments/assets/5534716b-49b5-402a-aa4a-4ba6533e0ca8"> Configuring an integration-level output is done under Advanced options in the policy editor. Setting to the blank value will "clear" the output configuration. The list of available outputs is filtered by what outputs are available for that integration (see above): <img width="799" alt="image" src="https://github.com/user-attachments/assets/617af6f4-e8f8-40b1-b476-848f8ac96e76"> An example of failure: ES output cannot be changed to Kafka while there is an integration <img width="1289" alt="image" src="https://github.com/user-attachments/assets/11847eb5-fd5d-4271-8464-983d7ab39218"> ## TODO - [x] Adjust side effects of editing/deleting output when policies use it across different spaces - [x] Add API integration tests - [x] Update OpenAPI spec - [x] Create doc issue ### Checklist Delete any items that are not applicable to this PR. - [x] Any text added follows [EUI's writing guidelines](https://elastic.github.io/eui/#/guidelines/writing), uses sentence case text and includes [i18n support](https://github.com/elastic/kibana/blob/main/packages/kbn-i18n/README.md) - [ ] [Documentation](https://www.elastic.co/guide/en/kibana/master/development-documentation.html) was added for features that require explanation or tutorials - [x] [Unit or functional tests](https://www.elastic.co/guide/en/kibana/master/development-tests.html) were updated or added to match the most common scenarios --------- Co-authored-by: kibanamachine <[email protected]>
elasticmachine
pushed a commit
that referenced
this pull request
Sep 19, 2024
…193441) ## Summary More files to be regenerated with a different shape since the js-yaml update: elastic#190678
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Summary
Summarize your PR. If it involves visual changes include a screenshot or gif.
Checklist
Delete any items that are not applicable to this PR.
Risk Matrix
Delete this section if it is not applicable to this PR.
Before closing this PR, invite QA, stakeholders, and other developers to identify risks that should be tested prior to the change/feature release.
When forming the risk matrix, consider some of the following examples and how they may potentially impact the change:
For maintainers