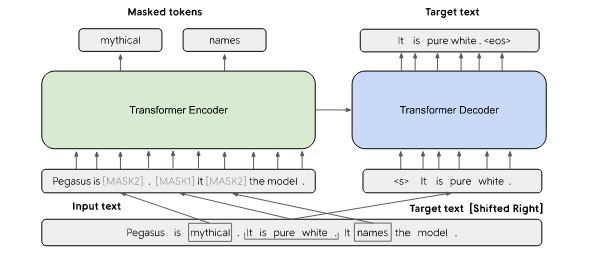
LongPegasus package is used for inducing longformer self attention over base pegasus abstractive summarization model to increase the token limit and performance.The Pegasus is a large Transformer-based encoder-decoder model with a new pre-training objective which is adapted to abstractive summarization. More specifically, the pre-training objective, called "Gap Sentence Generation (GSG)", consists of masking important sentences from a document and generating these gap-sentences.On the other hand, the Longformer is a Transformer which replaces the full-attention mechanism (quadratic dependency) with a novel attention mechanism which scale linearly with the input sequence length. Consequently, Longformer can process sequences up to 4,096 tokens long (8 times longer than BERT which is limited to 512 tokens).This package plugs Longformers attention mechanism to Pegasus in order to perform abstractive summarization on long documents. The base modules are built on Tensorflow platform.

The package can be installed from Pypi using the following code: The latest stable release is 0.3 which resolves an issue related to Keras base layer Issue#2
!pip install LongPegasus==0.3For an older version (0.1) similar syntax can be used with the proper version. The older version 0.1 does not support different pretrained pegasus summarization models from huggingface and resorts to the default pegasus pretrained model from google. The senteencepiece inbuilt package has also to be manually installed (for google colab) in the case of the previous version (0.1). The driver_test_long_model.py contains the steps to run this package which is described as follows:
- Importing the LongPegasus module from the package
from LongPegasus.LongPegasus import LongPegasus- Instantiating an object from that module class and calling the function create_long_model.
long_=LongPegasus()
model,tokenizer=long_.create_long_model(save_model="E:\\Pegasus\\", attention_window=512, max_pos=4096)-
This allows the model and the tokenizer to be stored in the 'save_model' folder. The arguements include the attention_window (extendable upto 4096) and the max_pos which is the defailt longformer encoder size (4096 tokens). For the version 0.1 , this only creates a long form of the pegasus-xsum model for summarization.
-
The model and tokenizer can be loaded and then used for inference as follows (either from the stored results in the folders or can be loaded with TFPegasusForConditionalGeneration):
ARTICLE_TO_SUMMARIZE = (
"PG&E stated it scheduled the blackouts in response to forecasts for high winds "
"amid dry conditions. The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were "
"scheduled to be affected by the shutoffs which were expected to last through at least midday tomorrow."
)
inputs = tokenizer([ARTICLE_TO_SUMMARIZE], max_length=4096, return_tensors='tf')
# Generate Summary
summary_ids = model.generate(inputs['input_ids'])
print([tokenizer.decode(g, skip_special_tokens=True, clean_up_tokenization_spaces=False) for g in summary_ids])The following is the output from the google xsum model for the input article:
['Thousands of people have been affected by wildfires across the US over the past few weeks.']- Sentencepiece is not installed by default in this version and requires a manuall installation via pip
!pip install sentencepiece- For inference, it is important to specify 'return_tensors' as tf since the module uses Tensorflow backend.
- The only difference is in the arguements of the create_long_model. There is an additional parameter called as 'model_name' which can be None or any model from the pretrained model list for Pegasus .If the model_name parameter is chosen as None , the the default 'google/pegasus-xsum' model is loaded as in version 0.1.The syntax for the create_long_model method is as follows:
model_name='human-centered-summarization/financial-summarization-pegasus'
model,tokenizer=l.create_long_model(save_model="E:\\Pegasus\\", attention_window=4096, max_pos=4096,model_name=model_name)Rest of the code segment mentioned in the previous version is the same. It is important to highlight that the model_name should be specified as either None or a valid pegasus model from the huggingface model hub.
-
For google colab,(possibly other notebook libraries), there is a requirement to install sentencepiece for transformers to function properly. This is done by default in the latest version (0.2) and no need to manually install it again.
-
For inference, it is important to specify 'return_tensors' as tf since the module uses Tensorflow backend.
-
Due to an issue in the keras base layer arguements, sometimes in Colab an issue arises for trainable arguement. This is resolved in the 0.3 stable version.A Colab notebook is present in the repository.
The models & tokenizers which get stored in the local drives/storages through this package is a longer version of pegasus and can be finetuned for different downstrea,m tasks as well. There will be follow up notebooks on that , and the huggingface site contains steps for finetuning the models.
More example notebooks would be shared from Kaggle/Colab. In the meantime, the package can be tried in Kaggle as well.A simple walkthrough has been provided in the colab link.
Pull requests are welcome. For major changes, please open an issue first to discuss what you would like to change.
MIT