ScrapeGraphAI 是一个网络爬虫 Python 库,使用大型语言模型和直接图逻辑为网站和本地文档(XML,HTML,JSON 等)创建爬取管道。
只需告诉库您想提取哪些信息,它将为您完成!
Scrapegraph-ai 的参考页面可以在 PyPI 的官方网站上找到: pypi。
pip install scrapegraphai注意: 建议在虚拟环境中安装该库,以避免与其他库发生冲突 🐱
官方 Streamlit 演示:
在 Google Colab 上直接尝试:
ScrapeGraphAI 的文档可以在这里找到。
还可以查看 Docusaurus 的版本。
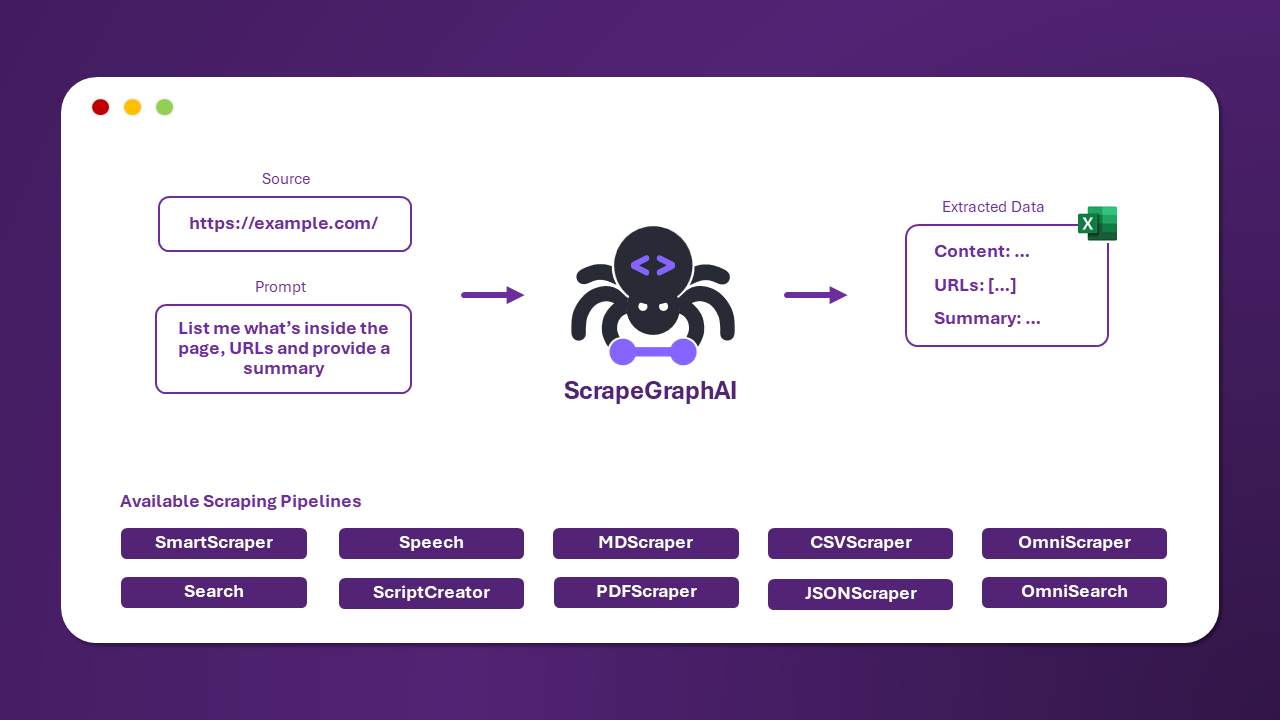
有三种主要的爬取管道可用于从网站(或本地文件)提取信息:
SmartScraperGraph: 单页爬虫,只需用户提示和输入源;SearchGraph: 多页爬虫,从搜索引擎的前 n 个搜索结果中提取信息;SpeechGraph: 单页爬虫,从网站提取信息并生成音频文件。SmartScraperMultiGraph: 多页爬虫,给定一个提示 可以通过 API 使用不同的 LLM,如 OpenAI,Groq,Azure 和 Gemini,或者使用 Ollama 的本地模型。
请确保已安装 Ollama 并使用 ollama pull 命令下载模型。
from scrapegraphai.graphs import SmartScraperGraph
graph_config = {
"llm": {
"model": "ollama/mistral",
"temperature": 0,
"format": "json", # Ollama 需要显式指定格式
"base_url": "http://localhost:11434", # 设置 Ollama URL
},
"embeddings": {
"model": "ollama/nomic-embed-text",
"base_url": "http://localhost:11434", # 设置 Ollama URL
},
"verbose": True,
}
smart_scraper_graph = SmartScraperGraph(
prompt="List me all the projects with their descriptions",
# 也接受已下载的 HTML 代码的字符串
source="https://perinim.github.io/projects",
config=graph_config
)
result = smart_scraper_graph.run()
print(result)输出将是一个包含项目及其描述的列表,如下所示:
{'projects': [{'title': 'Rotary Pendulum RL', 'description': 'Open Source project aimed at controlling a real life rotary pendulum using RL algorithms'}, {'title': 'DQN Implementation from scratch', 'description': 'Developed a Deep Q-Network algorithm to train a simple and double pendulum'}, ...]}我们使用 Groq 作为 LLM,使用 Ollama 作为嵌入模型。
from scrapegraphai.graphs import SearchGraph
# 定义图的配置
graph_config = {
"llm": {
"model": "groq/gemma-7b-it",
"api_key": "GROQ_API_KEY",
"temperature": 0
},
"embeddings": {
"model": "ollama/nomic-embed-text",
"base_url": "http://localhost:11434", # 任意设置 Ollama URL
},
"max_results": 5,
}
# 创建 SearchGraph 实例
search_graph = SearchGraph(
prompt="List me all the traditional recipes from Chioggia",
config=graph_config
)
# 运行图
result = search_graph.run()
print(result)输出将是一个食谱列表,如下所示:
{'recipes': [{'name': 'Sarde in Saòre'}, {'name': 'Bigoli in salsa'}, {'name': 'Seppie in umido'}, {'name': 'Moleche frite'}, {'name': 'Risotto alla pescatora'}, {'name': 'Broeto'}, {'name': 'Bibarasse in Cassopipa'}, {'name': 'Risi e bisi'}, {'name': 'Smegiassa Ciosota'}]}您只需传递 OpenAI API 密钥和模型名称。
from scrapegraphai.graphs import SpeechGraph
graph_config = {
"llm": {
"api_key": "OPENAI_API_KEY",
"model": "openai/gpt-3.5-turbo",
},
"tts_model": {
"api_key": "OPENAI_API_KEY",
"model": "tts-1",
"voice": "alloy"
},
"output_path": "audio_summary.mp3",
}
# ************************************************
# 创建 SpeechGraph 实例并运行
# ************************************************
speech_graph = SpeechGraph(
prompt="Make a detailed audio summary of the projects.",
source="https://perinim.github.io/projects/",
config=graph_config,
)
result = speech_graph.run()
print(result)输出将是一个包含页面上项目摘要的音频文件。

欢迎贡献并加入我们的 Discord 服务器与我们讨论改进和提出建议!
请参阅贡献指南。
在这里查看项目路线图! 🚀
想要以更互动的方式可视化路线图?请查看 markmap 通过将 markdown 内容复制粘贴到编辑器中进行可视化!
如果您将我们的库用于研究目的,请引用以下参考文献:
@misc{scrapegraph-ai,
author = {Marco Perini, Lorenzo Padoan, Marco Vinciguerra},
title = {Scrapegraph-ai},
year = {2024},
url = {https://github.com/VinciGit00/Scrapegraph-ai},
note = {一个利用大型语言模型进行爬取的 Python 库}
}
![]()
| Contact Info | |
|---|---|
| Marco Vinciguerra | |
| Marco Perini | |
| Lorenzo Padoan |
ScrapeGraphAI 采用 MIT 许可证。更多信息请查看 LICENSE 文件。
- 我们要感谢所有项目贡献者和开源社区的支持。
- ScrapeGraphAI 仅用于数据探索和研究目的。我们不对任何滥用该库的行为负责。