deployment monitoring and epic progress dashboard #4999
Comments
|
Interesting visualisations! Somewhat related to #3508 (at least the TrustChain deployment monitoring). e2e anonymous download is an excellent candidate for performance monitoring and should not take long to setup. I think @ichorid addressed this a while ago actually but it has not been actively monitored since then. In fact, making us (more) aware of failing tests/validation experiments is becoming a necessity as the number of different tests that run with fixed time intervals is growing. I think we have to address this issue rather sooner than later. The problem is that if we do not do it, we will have a proliferation of different tools. Currently, we have the TrustChain explorer, Tribler user statistics, the error reporter and all tests/monitors on Jenkins. There might be some opportunity to merge some tools, which eases maintenance.
This might be a dangerous one to monitor and could be a violation of ones privacy expectations of Tribler. |
|
Please look at FileCoin slipped roadmap. After Release 7.5 I'm considering that we work together on the first Jenkins dashboard for 2 weeks:
|


|
Can we decide on some software/library to use (or to make) to graph all of this data? All sorts of dashboard creation tools exist. For example: https://dzone.com/articles/build-beautiful-console-dashboards-with-sampler |
|
Most of this data can either be extracted from our existing Jenkins Job using the API, or from our running Trustchain explorer backend, also with API requests. One of the question we should also answer, is whether we want a dedicated website for this. Jenkins unfortunately does not provide the tools for such real-time data, and integration of this dashboard in Jenkins would just be a new job with succeed/fail status.
We should secure a prominent spot at the coffee machine ☕️ |
|
I propose starting with something "easy". Exposing GitHub events through
The idea is that we can reuse the resulting backend for another (bigger and better) dashboard and we'll have something to look at in the mean time. |
|
One way to get more insights into our user count is by analysing the crawled TrustChain data. The plot below is generated based on our current dataset, with over 80.000 users and 123 million records. The (major) releases of Tribler are annotated. Note how our 7.5.0 release resulted in an increase in new user count.
Parsing this 97GB database, however, is computationally intensive and could be done on a daily basis for example. A dashboard could include this static image. |

|
In 2006-2009 we had initial deployment monitoring. Included in Zeilemaker master thesis. |

|
Based on data we already have |

|
Yesterday I did a little research on this topic, and now I want to suggest a way to show anonymized performance statistics. It may be the following set of technologies:
The most popular tool for gathering and processing metrics is Prometheus. It has has a big community and is widely used for gathering server metrics. Prometheus if often compared with InfluxDB (see the comparison on official Prometheus doc). While Prometheus is more popular, in my opinion, InfluxDB is better suited to our needs for the following reasons:
Grafana is a very popular open-source tool for graph visualization, which can be used with Prometheus, InfluxDB, and multiple other data sources. It allows constructing powerful dashboards with different types of graphs and charts.
If we decide to use this set of tools, I think I can take on this task. I see the following sub-tasks here to be implemented:
Later we can use Grafana to display all graphs, not only user statistics but also server builds, etc. What do you think? |

Pitfall: everything we want with our self-organising research project is easier to do in a central server... Primarily use our crawlers as early warning infrastructure! (IPv8 is designed for network health monitoring) Then we need to emphasise crawler intelligence and stats aggregation. Are we not re-creating this from scratch? https://jenkins-ci.tribler.org/job/Test_BootstrapServers/lastSuccessfulBuild/artifact/walk_rtts.png First, anonymity is our existential feature. How to do this? (True anonymity might be impossible, OFF switch by default) This needs to be opt-in for production releases and can hopefully be opt-out for nightly builds and Beta versions. What about Release Candidates? InfluxDB: 34,082 commits, 19.5k of stars on Github. This is a general time-series database solution, we still need to make custom code for deployment monitoring? This seems quite complex tooling. Afraid of overengineering for the user community we have currently. However, deployment monitoring is something we really need to do more and get right. |
|
InfluxDB and Graphana are indeed good choices.
I have done some work on 1 and 2. I'm extending https://release.tribler.org/docs to receive anonymized data from the client. That can be the entry point to further processing using InfluxDB and visualizing on Graphana. |
|
We probably can use InfluxDB Jenkins plugin to put deployment statistics into the InfluxDB: |
|
Change of plans:-) Our current methodology:
Tribler is a bottomless pit of problems. (stolen quote) |
I think a key metric is the stability of our unit tests. Currently, unstable unit tests (both on My suggestion would be to continuously run all unit tests on a dedicated machine and include in the upcoming dashboard how stable they are (e.g., % of runs failing during the last day). |
|
Related work: https://stats.goerli.net/ |

|
Impressive progress! Our .yml and servers are getting in much better shape. We can even see in real time the upgrade speed. Learned something new: they upgrade quite fast. Previous years we never had this. |

|
Yeah! More pretty graphs, exit node peak: 121 GiB per second |

|
cool |
|
Example: https://data.syncthing.net/ |
|
@kozlovsky Could you please duplicate this specific https://data.syncthing.net/ graphs and wrap up the Grafana work? |
Mature network alerts and deployment monitoring. The mission is to put everything in one place. The big danger is to partially put everything together, but actually create the n+1 place called Grafana where data is fragmented. Full user experience pipeline:
A single page having graphs for the health of each step in our user journey would help to identify faults. We learned a lot from our recent "unknown user drop" incident. Like: |



|
When we have hired more developers we can re-visit this issue. We need to focus on putting everything inside application-tester and existing code. Example of IPFS people on DHT health. |
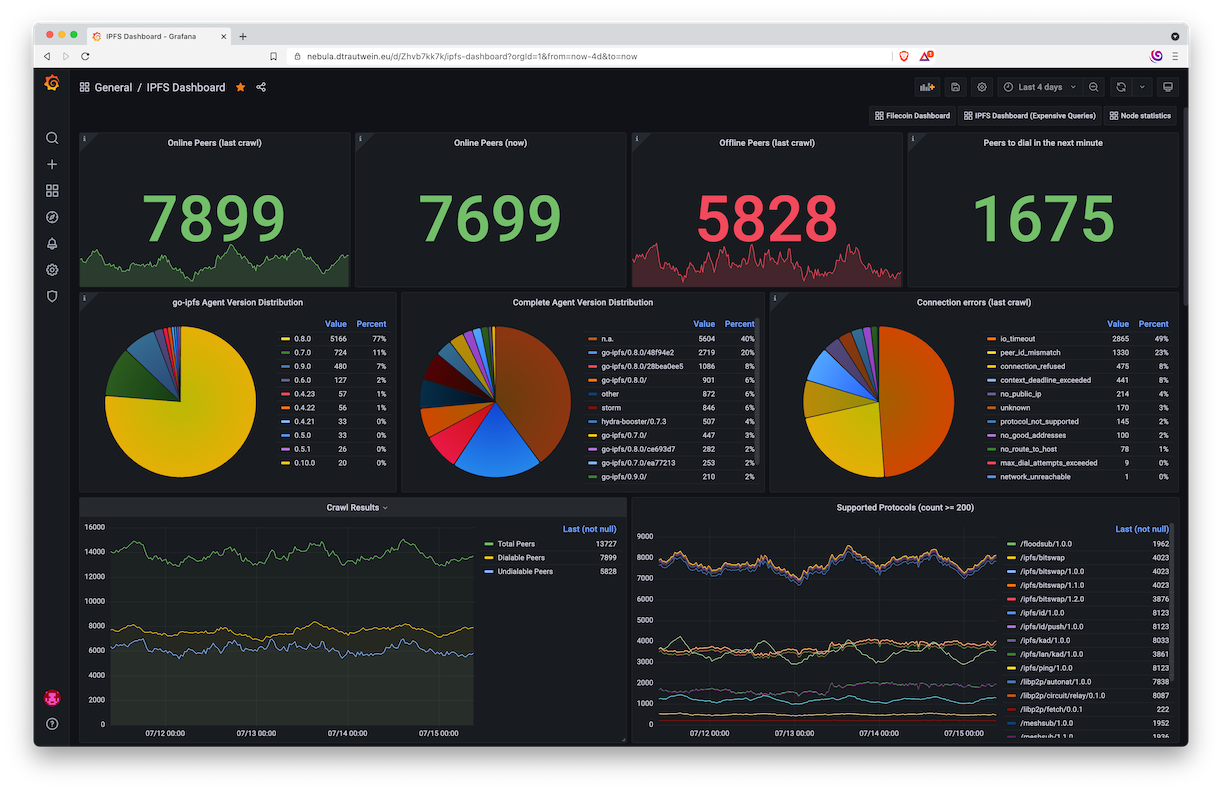
|
IPFS people have nice uptime monitoring script (DHT only level): Epic 2015 ticket with monitoring with Niels statistics. User community insight using an improved crawler |


|
We take screenshots, takes a few clicks to find (application tester on Jenkins) |


|
Complex monitoring. Numerous statistics systems, all connected together, and almost all down now 😿 The network was not functioning optimal these days. The Tor-like network was running out of capacity. Root cause of failure was a memory leak which went unnoticed. Grafana did not alert. No Slack alarm post. Testers did not alert. InfluxDB is not recording anymore. Prometheus-Grafana data feed is down. Dream of a single dashboard with health should have caught this. Another system brought live in a few hours: |

{kind=link}
{kind=link}
{kind=link}
|
This is yet another indication that choosing Grafana+Prometheus may not have been the best decision for our "new" dashboard. We already have ample sources of information, so adding another unique source doesn't seem optimal. What we really need is a singular place to integrate all existing information. From my perspective, here's what we should do (with a rough time estimation):
Our information sources:
(did I miss something?) |
|
I think that of all the services we use for dashboards and monitoring (Prometheus, InfluxDB, Grafana), Prometheus is the most reliable (and can display monitoring graphs without Grafana), while the most problematic was InfluxDB; most dashboard outages were caused by it. It may be worth spending time to set up Prometheus alerts, as it should cover most of the current problems. For persistent time series data, the most convenient data storage may be TimescaleDB, which can replace InfluxDB and fix most problems. But trying something simpler like Graphite is also possible. |
|
Since Grafana is currently used for deployment monitoring and as far as I understand there is no immediate priority to work on an alternative, I'm unassigning myself from this ticket. |
|
Indeed, we have a solution in place. This issue is - at the very least for now - resolved. If we have specific alternatives that we want to explore in the future, another issue can be opened. |
To better organise ourselves we need more critical information in 1 place.
The coming time we aim to close #1 finally. Our progress towards this goal and how stable we are should be captured in a Tribler-at-a-Glance dashboard. Example from Jenkins:
Tribler critical information candidates:
The text was updated successfully, but these errors were encountered: