Federated learning achieves joint training of deep models by connecting decentralized data sources, which can significantly mitigate the risk of privacy leakage. However, in a more general case, the distributions of labels among clients are different, called "label distribution skew". Directly applying conventional federated learning without consideration of label distribution skew issue significantly hurts the performance of the global model. To this end, we propose a novel federated learning method, named FedMGD, to alleviate the performance degradation caused by the label distribution skew issue. It introduces a global Generative Adversarial Network to model the global data distribution without access to local datasets, so the global model can be trained using the global information of data distribution without privacy leakage. The experimental results demonstrate that our proposed method significantly outperforms the state-of-the-art on several public benchmarks.
conda create -n fedmgd python=3.7
pip install -r requirements.txt
- Download dataset (EMNIST / FashionMNIST / SVHN / CIFAR10), and divide data to the client.
For example:
cd ./data/EMNIST
python generate_niid_dirichlet.py
- Collect distillation data.
pyhton upload_0.05_data.py
- FedMGD
python train_fedmgd.py --dataroot your_data_root \
--name fedmgd \
--gpu_ids 0,1 \
--checkpoints_dir ./result \
--model fedmgd \
--input_nc 1 \
--n_class 26 \
--n_client 5 \
--rounds 100 \
--num_epochs 10 \
--lr 0.0002 \
--lr_G 0.0002 \
--lr_D 0.0002
- Other Methods (In the case of FedAvg, please change the parameter "model")
python train_federated.py --dataroot your_data_root \
--name fedavg \
--gpu_ids 0,1 \
--checkpoints_dir ./result \
--model fedavg \
--input_nc 1 \
--n_class 26 \
--n_client 5 \
--rounds 100 \
--num_epochs 10 \
--lr 0.0002 \
-
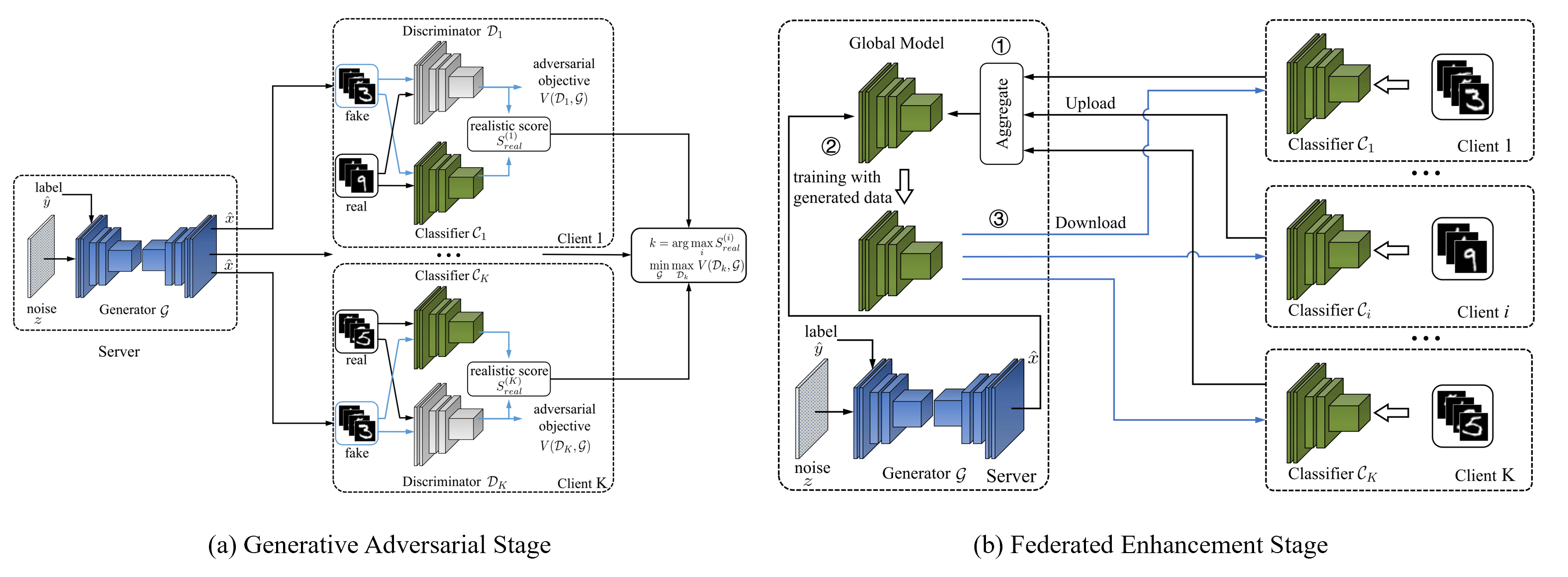
(1) Realistic Score in FedMGD.
-
FedDF(unlabeled real data)
python train_federated.py --model feddf --dataroot your_data_root -
FedDF(labeled real data)
python train_federated.py --model feddf_with_label --dataroot your_data_root -
FedMGD+FedDF(w/o real data)
python train_fedmgd.py --model fedmgd_feddf --dataroot your_data_root -
F2U+FedDF(unlabeled w/o real data)
python train_gan.py --model f2u --dataroot your_data_root python train_federated.py --model feddf --dataroot your_data_root --G_path f2u_model_path
-
-
(2) Compare with other distributed GANs.
python train_gan.py --model mdgan --dataroot your_data_root python train_gan.py --model fedgan --dataroot your_data_root python train_fedmgd.py --model fedmgd --dataroot your_data_root
| Dataset | α | Epoch | Acc(%) |
|---|---|---|---|
| EMNIST | 0.01 | 400+100 | 89.00±0.93 (↑2.44) |
| EMNIST | 0.05 | 400+100 | 91.15±0.35 (↑1.82) |
| EMNIST | 0.1 | 400+100 | 91.52±0.17 (↓0.13) |
| Dataset | α | Epoch | Acc(%) |
|---|---|---|---|
| SVHN | 0.01 | 400+100 | 84.14±0.91 (↑1.09) |
| SVHN | 0.05 | 400+100 | 88.62±0.39 (↑0.96) |
| SVHN | 0.1 | 400+100 | 90.47±0.37 (↑0.64) |
| Dataset | α | Epoch | Acc(%) |
|---|---|---|---|
| Cifar10 | 0.01 | 400+100 | 62.61±1.54 (↑8.15) |
| Cifar10 | 0.05 | 400+100 | 66.52±0.49 (↑2.24) |
| Cifar10 | 0.1 | 400+100 | 69.31±0.33 (↑1.94) |
| Dataset | α | Epoch | Acc(%) |
|---|---|---|---|
| FashionMNIST | 0.01 | 400+100 | 84.04±0.58 (↑13.02) |
| FashionMNIST | 0.05 | 400+100 | 87.57±0.40 (↑3.90) |
| FashionMNIST | 0.1 | 400+100 | 89.29±1.33 (↑1.01) |
@article{sheng2023modeling,
author = {Sheng, Tao and Shen, Chengchao and Liu, Yuan and Ou, Yeyu and Qu, Zhe and Wang, Jianxin},
title = {Modeling Global Distribution for Federated Learning with Label Distribution Skew},
journal = {Pattern Recognition},
volume = {143},
pages = {109724},
year = {2023}
}
We refer to the structure of CycleGAN and pix2pix to build the code.