
🎙️🤖Create, customize and talk to your AI Character/Companion in realtime🎙️🤖
Try our site at RealChar.ai
Not sure how to pronounce RealChar? Listen to this 👉 audip
Santa_tw.mp4
elon-edit-camera.mp4
raiden.mp4
Demo settings: Web, GPT4, ElevenLabs with voice clone, Chroma, Google Speech to Text
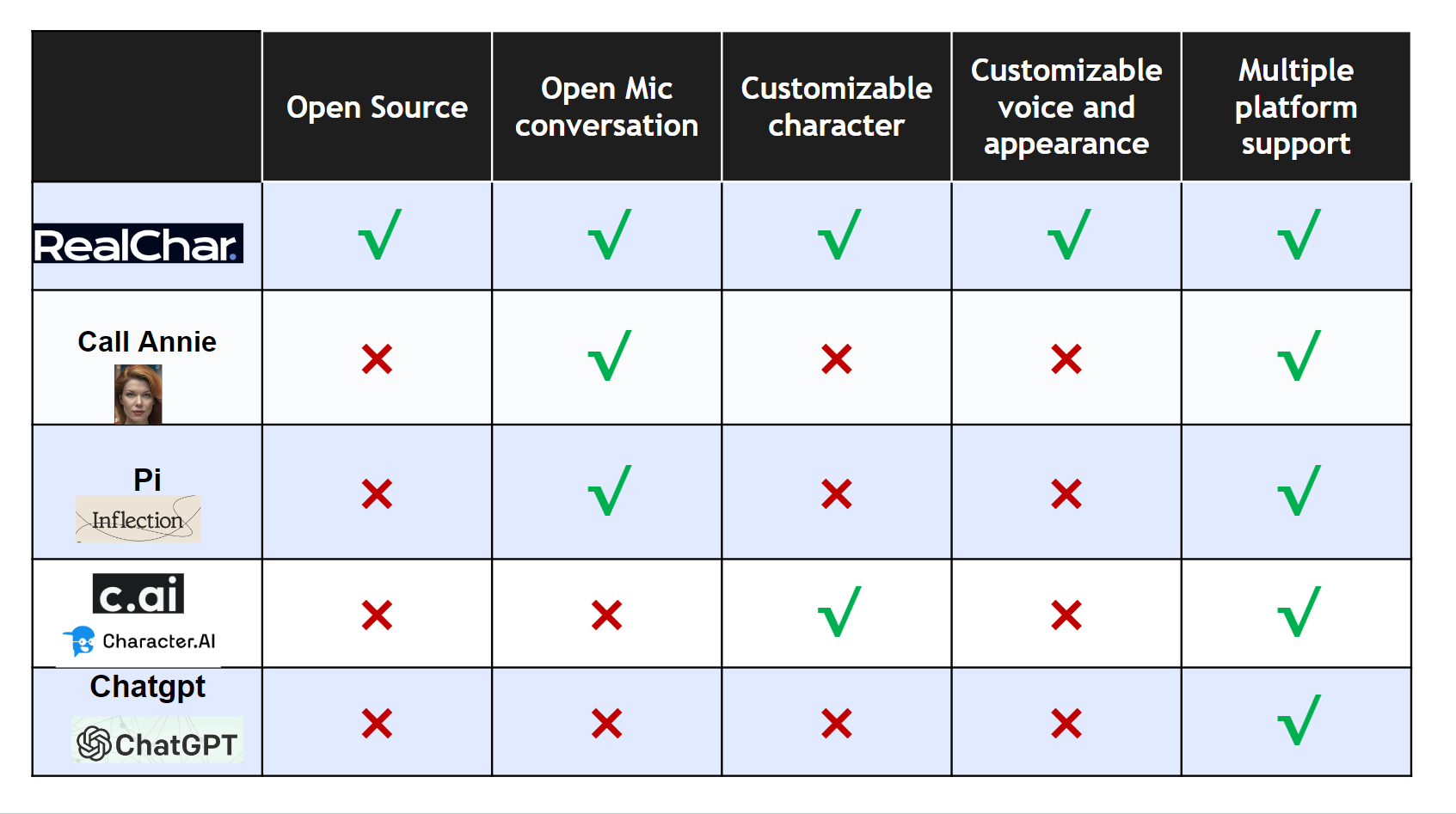
- Easy to use: No coding required to create your own AI character.
- Customizable: You can customize your AI character's personality, background, and even voice
- Realtime: Talk to or message your AI character in realtime
- Multi-Platform: You can talk to your AI character on web, terminal and mobile(Yes. we open source our mobile app)
- Most up-to-date AI: We use the most up-to-date AI technology to power your AI character, including OpenAI, Anthropic Claude 2, Chroma, Whisper, ElevenLabs, etc.
- Modular: You can easily swap out different modules to customize your flow. Less opinionated, more flexible. Great project to start your AI Engineering journey.
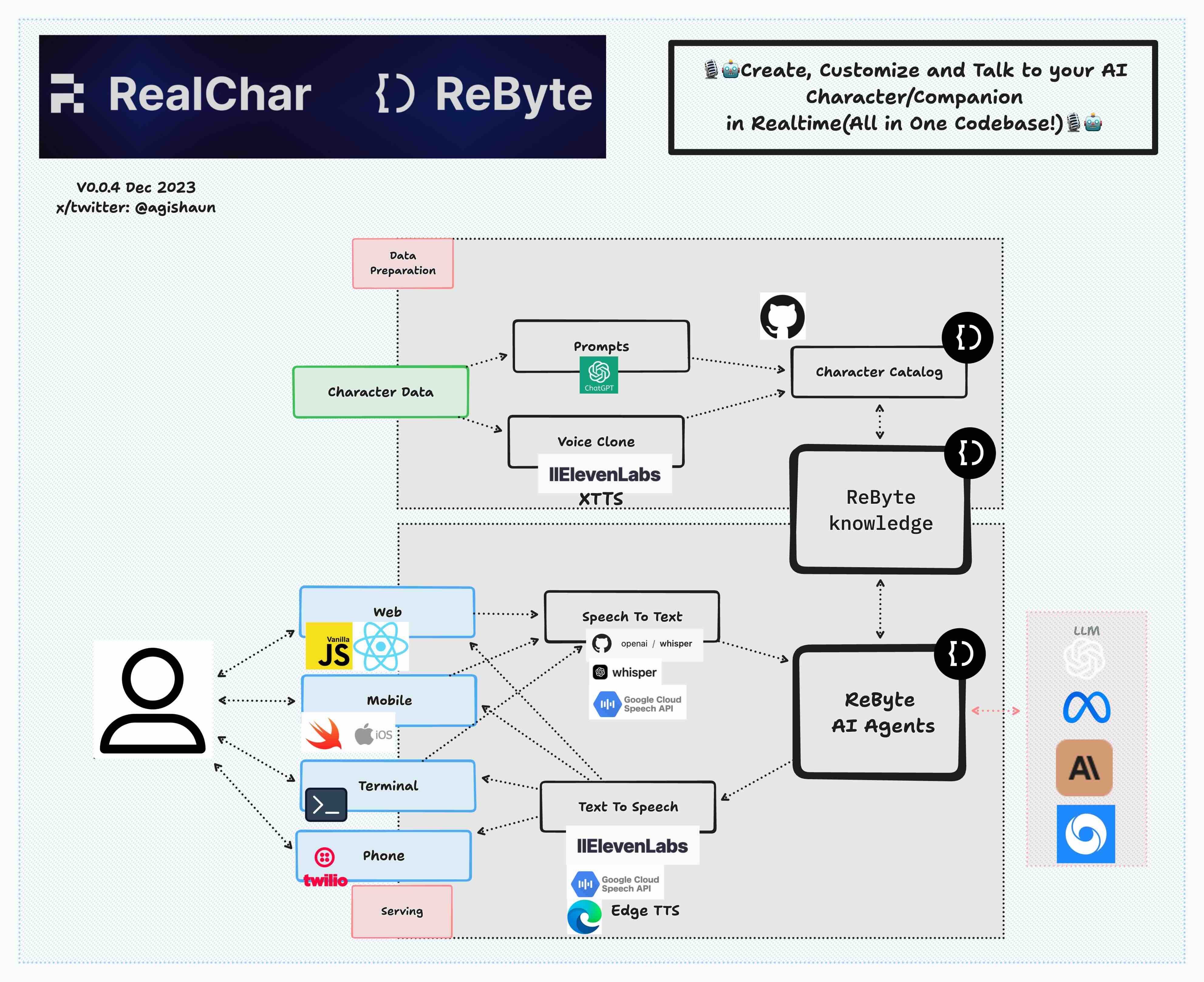
- ✅Web: React JS, Vanilla JS, WebSockets
- ✅Mobile: Swift, WebSockets
- ✅Backend: FastAPI, SQLite, Docker
- ✅Data Ingestion: LlamaIndex, Chroma
- ✅LLM Orchestration: LangChain, Chroma
- ✅LLM: ReByte, OpenAI GPT3.5/4, Anthropic Claude 2, Anyscale Llama2
- ✅Speech to Text: Local WhisperX, Local Whisper, OpenAI Whisper API, Google Speech to Text
- ✅Text to Speech: ElevenLabs, Edge TTS, Google Text to Speech
- ✅Voice Clone: ElevenLabs
-
Create a new
.envfilecp .env.example .env
Paste your API keys in
.envfile. A single ReByte or OpenAI API key is enough to get started.You can also configure other API keys if you have them.
-
Start the app with
docker-compose.yamldocker compose up
If you have issues with docker (especially on a non-Linux machine), please refer to https://docs.docker.com/get-docker/ (installation) and https://docs.docker.com/desktop/troubleshoot/overview/ (troubleshooting).
-
Open http://localhost:3000 and enjoy the app!
-
Step 1. Clone the repo
git clone https://github.com/Shaunwei/RealChar.git && cd RealChar
-
Step 2. Install requirements
Install portaudio and ffmpeg for audio
# for mac brew install portaudio brew install ffmpeg# for ubuntu sudo apt update sudo apt install portaudio19-dev sudo apt install ffmpegNote:
-
ffmpeg>=4.4is needed to work withtorchaudio>=2.1.0 -
Mac users may need to add ffmpeg library path to
DYLD_LIBRARY_PATHfor torchaudio to work:export DYLD_LIBRARY_PATH=/opt/homebrew/lib:$DYLD_LIBRARY_PATH
Then install all python requirements
pip install -r requirements.txt
If you need a faster local speech to text, install whisperX
pip install git+https://github.com/m-bain/whisperx.git
-
-
Step 3. Create an empty sqlite database if you have not done so before
sqlite3 test.db "VACUUM;" -
Step 4. Run db upgrade
alembic upgrade head
This ensures your database schema is up to date. Please run this after every time you pull the main branch.
-
Step 5. Setup
.env:cp .env.example .env
Update API keys and configs following the instructions in the
.envfile.Note that some features require a working login system. You can get your own OAuth2 login for free with Firebase if needed. To enable, set
USE_AUTHtotrueand fill in theFIREBASE_CONFIG_PATHfield. Also fill in Firebase configs inclient/next-web/.env. -
Step 6. Run backend server with
cli.pyor use uvicorn directlypython cli.py run-uvicorn # or uvicorn realtime_ai_character.main:app -
Step 7. Run frontend client:
-
web client:
Create an
.envfile underclient/next-web/cp client/next-web/.env.example client/next-web/.env
Adjust
.envaccording to the instruction inclient/next-web/README.md.Start the frontend server:
python cli.py next-web-dev # or cd client/next-web && npm run dev # or cd client/next-web && npm run build && npm run start
After running these commands, a local development server will start, and your default web browser will open a new tab/window pointing to this server (usually http://localhost:3000).
-
(Optional) Terminal client:
Run the following command in your terminal
python client/cli.py
-
(Optional) mobile client:
open
client/mobile/ios/rac/rac.xcodeproj/project.pbxprojin Xcode and run the app
-
-
Step 8. Select one character to talk to, then start talking. Use GPT4 for better conversation and Wear headphone for best audio(avoid echo)
Note if you want to remotely connect to a RealChar server, SSL set up is required to establish the audio connection.
To get your ReByte API key, follow these steps:
- Go to the ReByte website and sign up for an account if you haven't already.
- Once you're logged in, go to Settings > API Keys.
- Generate a new API key by clicking on the "Generate" button.
👇click me
This application utilizes the OpenAI API to access its powerful language model capabilities. In order to use the OpenAI API, you will need to obtain an API token.To get your OpenAI API token, follow these steps:
- Go to the OpenAI website and sign up for an account if you haven't already.
- Once you're logged in, navigate to the API keys page.
- Generate a new API key by clicking on the "Create API Key" button.
(Optional) To use Azure OpenAI API instead, refer to the following section:
- Set API type in your
.envfile:OPENAI_API_TYPE=azure
If you want to use the earlier version 2023-03-15-preview:
OPENAI_API_VERSION=2023-03-15-preview
- To set the base URL for your Azure OpenAI resource. You can find this in the Azure portal under your Azure OpenAI resource.
OPENAI_API_BASE=https://your-base-url.openai.azure.com
- To set the OpenAI model deployment name for your Azure OpenAI resource.
OPENAI_API_MODEL_DEPLOYMENT_NAME=gpt-35-turbo-16k
- To set the OpenAIEmbeddings model deployment name for your Azure OpenAI resource.
OPENAI_API_EMBEDDING_DEPLOYMENT_NAME=text-embedding-ada-002
👇click me
To get your Anthropic API token, follow these steps:
- Go to the Anthropic website and sign up for an account if you haven't already.
- Once you're logged in, navigate to the API keys page.
- Generate a new API key by clicking on the "Create Key" button.
👇click me
To get your Anyscale API token, follow these steps:
- Go to the Anyscale website and sign up for an account if you haven't already.
- Once you're logged in, navigate to the Credentials page.
- Generate a new API key by clicking on the "Generate credential" button.
We support faster-whisper and whisperX as the local speech to text engines. Work with CPU and NVIDIA GPU.
👇click me
To get your Google Cloud API credentials.json, follow these steps:
- Go to the GCP website and sign up for an account if you haven't already.
- Follow the guide to create a project and enable Speech to Text API
- Put
google_credentials.jsonin the root folder of this project. Check Create and delete service account keys - Change
SPEECH_TO_TEXT_USEto useGOOGLEin your.envfile
👇click me
Same as OpenAI API Token
Edge TTS is the default and is free to use.
👇click me
-
Creating an ElevenLabs Account
Visit ElevenLabs to create an account. You'll need this to access the text to speech and voice cloning features.
-
In your Profile Setting, you can get an API Key.
👇click me
To get your Google Cloud API credentials.json, follow these steps:
- Go to the GCP website and sign up for an account if you haven't already.
- Follow the guide to create a project and enable Text to Speech API
- Put
google_credentials.jsonin the root folder of this project. Check Create and delete service account keys
👇click me
👇click me
To use Twilio with RealChar, you need to set up a Twilio account. Then, fill in the following environment variables in your .env file:
TWILIO_ACCOUNT_SID=YOUR_TWILIO_ACCOUNT_SID
TWILIO_ACCESS_TOKEN=YOUR_TWILIO_ACCESS_TOKEN
DEFAULT_CALLOUT_NUMBER=YOUR_PHONE_NUMBERYou'll also need to install torch and torchaudio to use Twilio.
Now, you can receive phone calls from your characters by typing /call YOURNUMBER in the text box when chatting with your character.
Note: only US phone numbers and Elevenlabs voiced characters are supported at the moment.
👇click me
You can now use Anyscale Endpoint to serve Llama-2 models in your RealChar easily! Simply register an account with Anyscale Endpoint. Once you get the API key, set this environment variable in your .env file:
ANYSCALE_ENDPOINT_API_KEY=<your API Key>
By default, we show the largest servable Llama-2 model (70B) in the Web UI. You can change the model name (meta-llama/Llama-2-70b-chat-hf) to other models, e.g. 13b or 7b versions.
If you have access to LangSmith, you can edit these environment variables to enable:
LANGCHAIN_TRACING_V2=false # default off
LANGCHAIN_ENDPOINT=https://api.smith.langchain.com
LANGCHAIN_API_KEY=YOUR_LANGCHAIN_API_KEY
LANGCHAIN_PROJECT=YOUR_LANGCHAIN_PROJECT
And it should work out of the box.
- Launch v0.0.4
- Create a new character via web UI
- Lower conversation latency
- Support Twilio
- Support ReByte
- Persistent conversation*
- Session management*
- Support RAG*
- Support Agents/GPTs*
- Add additional TTS service*
Please check out our Contribution Guide!
- Join us on Discord