很早之前,在开发过程实现通信协议就想深入学习编码相关的知识。在阅读 AFNetworking 源码的时候,看到下面这段代码,刚好借助"百分号编码"这个方法深入学习。
/**
Returns a percent-escaped string following RFC 3986 for a query string key or value.
RFC 3986 states that the following characters are "reserved" characters.
- General Delimiters: ":", "#", "[", "]", "@", "?", "/"
- Sub-Delimiters: "!", "$", "&", "'", "(", ")", "*", "+", ",", ";", "="
In RFC 3986 - Section 3.4, it states that the "?" and "/" characters should not be escaped to allow
query strings to include a URL. Therefore, all "reserved" characters with the exception of "?" and "/"
should be percent-escaped in the query string.
- parameter string: The string to be percent-escaped.
- returns: The percent-escaped string.
*/
NSString * AFPercentEscapedStringFromString(NSString *string) {
static NSString * const kAFCharactersGeneralDelimitersToEncode = @":#[]@"; // does not include "?" or "/" due to RFC 3986 - Section 3.4
static NSString * const kAFCharactersSubDelimitersToEncode = @"!$&'()*+,;=";
NSMutableCharacterSet * allowedCharacterSet = [[NSCharacterSet URLQueryAllowedCharacterSet] mutableCopy];
[allowedCharacterSet removeCharactersInString:[kAFCharactersGeneralDelimitersToEncode stringByAppendingString:kAFCharactersSubDelimitersToEncode]];
// FIXME: https://github.com/AFNetworking/AFNetworking/pull/3028
// return [string stringByAddingPercentEncodingWithAllowedCharacters:allowedCharacterSet];
static NSUInteger const batchSize = 50;
NSUInteger index = 0;
NSMutableString *escaped = @"".mutableCopy;
while (index < string.length) {
NSUInteger length = MIN(string.length - index, batchSize);
NSRange range = NSMakeRange(index, length);
// To avoid breaking up character sequences such as 👴🏻👮🏽
range = [string rangeOfComposedCharacterSequencesForRange:range];
NSString *substring = [string substringWithRange:range];
NSString *encoded = [substring stringByAddingPercentEncodingWithAllowedCharacters:allowedCharacterSet];
[escaped appendString:encoded];
index += range.length;
}
return escaped;
}URI = Universal Resource Identifier,统一资源标志符 URI 就是在某一规则下能把一个资源独一无二地标识出来。
URL = Universal Resource Locator,URL 是 URI 的一个子集,URL 的结构如下:
| scheme:// | host:port | path | ?query | #hash |
|---|---|---|---|---|
| 协议头 | 主机:端口 | 路径 | 查询,多个参数用&隔开,名和值用=隔开 | 锚点 |
百分号编码 用来对不符合规则的字符进行编码,一般是 query 中的字符(中文,保留字符,emoji等),如果有一个URL为 http://www.baidu.com?username=度娘, 这个链接就需要进行百分号编码.
根据 RFC3986协议规定
- 未保留字符:
A~Za~z0~9_-.~不处理 - 保留字符:
!*'();:@&=+$,/?#[]根据RFC3986 Section 4.3 除了!?之外,其他字符都进行 ASCII 编码 - 其他字符: 进行 UTF8 编码
例如: http://www.baidu.com?username=度娘 百分号编码之后为 http://www.baidu.com?username=%E5%BA%A6%E5%A8%98
字符编码,将字符集中的字符映射成二进制(即码点 < = > code point)的过程
下面会包含两种字符编码: ASCII 和 Unicode,其中后者是兼容前者的
ASCII 码字符集中一共有127个字符,通过 ASCII 能将这127个字符编码唯一的8位二进制(码点)
ASCII码的规定是最高位统一为0,只能表示128个字符编码
如下图的 ASCII cheat sheet:
S→0101 0011a→0110 0001

ASCII 只能编码 127 个字符,对于英语来说是足够的,但是根本无法满足其他语言(中文,日文,韩文等等)的编码。在 Unicode 出现之前,各个国家都是使用自己的编码标准,互相之间转换非常麻烦
Unicode 的出现让 "一个字符集可以代表世界上所有语言的字符 " 成为可能。 Unicode 字符集现在的规模大小可以容纳100万个符号, 21 位(从 U+000000 到 U+10FFFF)。每个符号的编码都不一样,并且有很好的扩展性,具体的符号对应表可以查询官方的 Code Charts 或者 OS X 里自带的字符显示程序(快捷键是 Control + Cmd + 空格键键)来查码点。

Unicode字符分为17组编排,每组称为平面(Plane),而每平面拥有65536(即216)个码点。然而目前只用了少数平面。

例如:
度→U+5EA6娘→U+5A18
Unicode 与 UTF8 的关系是什么呢?
这个回答 我感觉非常好:
"用通信理论的思路可以理解为: unicode是信源编码,对字符集数字化; utf8是信道编码,为更好的存储和传输。"
就像前面说的,Unicode 已经可以使用唯一的码点来映射世界上所有语言的字符了, 但是缺点在于:
- 浪费空间,一个 ASCII 码只需要 7 位,但是如果都用 16 位(UCS2) 来表示,浪费空间
- 由于 Unicode 编码单元使用了多个字节,如果不经过处理直接储存起来,在读取的时候计算机根本不知道如何识别/解码内容。比如:
度的Unicode码点为U+5EA6,如果直接储存,计算机不知道应该到底5E/A6算一个字符呢,还是5EA6算一个字符 - 存在
字节序的问题
为了解决这个问题,我们使用 UTF8/UTF16 对 Unicode 进行二次编码以方便 Unicode 的储存和传输。
下面主要介绍 UTF8 的编码方式:
UTF8 是 Unicode 最广泛被应用的一种实现方式,最大的特点就是 编码长度是变长的,使用 1~4 字节来编码一个字符。
下面引用自字符编码笔记:ASCII,Unicode 和 UTF-8, 这部分的叙述已经非常浅显易懂了
UTF-8 的编码规则很简单,只有二条:
- 对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
- 对于 n 字节的符号(n > 1),第一个字节的前 n 位都设为1,第 n + 1 位设为 0,后面字节的前两位一律设为 10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下表总结了编码规则,字母x表示可用编码的位。
| Unicode符号范围(十六进制) | UTF-8编码方式(二进制) |
|---|---|
| 0000 0000-0000 007F | 0xxxxxxx |
| 0000 0080-0000 07FF | 110xxxxx 10xxxxxx |
| 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
跟据上表,解读 UTF-8 编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
例如:
度→U+5EA6娘→U+5A18
度 的 Unicode 编码为U+5EA6
U+5EA6转换为二进制为:0101 1110 1010 0110- 根据上表得知,
U+5EA6落在0000 0800-0000 FFFF区间中,UTF-8编码方式为1110xxxx 10xxxxxx 10xxxxxx - 将
0101 1110 1001 0110的低位填到1110xxxx 10xxxxxx 10xxxxxx的低位中,不足的补零 - 即
11100101 10111010 10100110= E5 BA A6
在 Xcode 中我们看到如下的内存中的内容
E5 BA A6

娘的 Unicode 编码为U+5A18
U+5A18转换为二进制为:0101 1010 0001 1000- 根据上表得知,
U+5A18落在0000 0800-0000 FFFF区间中,UTF-8编码方式为1110xxxx 10xxxxxx 10xxxxxx - 将
0101 1010 0001 1000的低位填到1110xxxx 10xxxxxx 10xxxxxx的低位中,不足的补零 - 即
11100101 10101000 10011000= E5 A8 98
在 Xcode 中我们看到如下的内存中的内容
E5 A8 98

UTF8有两种:
-
带 BOM 的 UTF-8」: 微软制定的方法,BOM 头 Byte Order Mark 保存一个以 UTF-8 编码的文件时,会在文件开始的地方插入三个不可见的字符(0xEF 0xBB 0xBF,即BOM)
-
无 BOM 的 UTF-8」: iOS默认是使用这种
UTF16 编码单元为2个字节,编码结果长度为2个字节或者4个字节
基本多语言平面内,从 U+D800 到 U+DFFF 之间的码位区块是永久保留不映射到 Unicode 字符。UTF-16 就利用保留下来的0xD800-0xDFFF 区块的码位来对辅助平面的字符的码位进行编码。编码规则如下:
-
从
U+0000至U+D7FF以及从U+E000至U+FFFF的码点就代表了 UTF16编码的结果(2个字节) -
从
U+10000到U+10FFFF的码点 : 4个字节- 码点减去
0x10000,得到的值的范围为 20 比特长 - 高位的 10 比特的值加上
0xD800得到第一个码元或称作高位代理(high surrogate) - 低位的10比特的值(值的范围也是0..0x3FF)被加上0xDC00得到第二个码元或称作低位代理(low surrogate)
- 码点减去
例如:😍的 Unicode 编码为 U+1F60D
- 0x1F60D 减去 0x10000,结果为 0x0F60D,二进制为0000 1111 0110 0000 1101。
- 分割它的上10位值和下10位值(使用二进制):00001 11101 and 10000 01101。 添加0xD800到上值,以形成高位:0xD800 + 0x003D = 0xD83D。 添加0xDC00到下值,以形成低位:0xDC00 + 0x020D = 0xDE0D。
- 即结果为:
D8 3D DE 0D
NSData *dataEmoji = [@"😍" dataUsingEncoding:NSUTF16StringEncoding];
View Memory of "*_bytes":

FF FE 3D D8 0D DE 与 D8 3D DE 0D 不同, 为什么会这样, 为什么 UTF8 不存在这个问题?
字节序 是用来描述编码单元内多字节对象存储的规则
- 大端序 : 随着
储存地址的增大,最高有效位在最低有效位的前面 - 小端序 : 相反
对于不同的处理器,使用大小端的情况是不一样的 以Macintosh制作或存储的文字默认使用大端,iOS 默认存储使用小端
TCP/IP 定义的网络传输必须使用 大端,所以 iOS 在网络传输时需要将 小端 的数据转换成 大端的数据(可以使用htonl/htons用于本机序转换到网络序;ntohl/ntohs用于网络序转换到本机序。)
有一个数为 0xABCDEFGH,它以大端和小端存放的形式分别为:
大端
| 编码单元 | byte | byte + 1 | byte + 2 | byte + 3 |
|---|---|---|---|---|
| 8 | AB | CD | EF | GH |
| 16 | AB | CD | EF | GH |
小端
| 编码单元 | byte | byte + 1 | byte + 2 | byte + 3 |
|---|---|---|---|---|
| 8 | GH | EF | CD | AB |
| 16 | CD | AB | GH | EF |
FF FE 3D D8 0D DE与D8 3D DE 0D不同,为什么会这样?
对于 UTF16 来说,每个字符编码成 2/4 个字节, 储存的时候需要加上 Byte Order Mark, UTF-16 小端加上 FF FE 代表,UTF-16 大端加上FE FF
iOS 默认使用 小端 储存,所以加上 FFFE, 然后将 D8 3D DE 0D 转换成小端(编码单元为16)形式,即 FF FE 3D D8 0D DE
为什么 UTF 不存在这个问题?
UTF8 是单字节为编码单元,传输时,不存在字节序列问题。解码时,首字节记录有 UTF8 编码结果的总字节数,所以能正确解码。不需要加 Byte Order Mark
An NSString object encodes a Unicode-compliant text string, represented as a sequence of UTF–16 code units. All lengths, character indexes, and ranges are expressed in terms of 16-bit platform-endian values, with index values starting at 0.
根据 官方文档,NSString是一个由UTF16码元组成的数组(UTF16的码元长度是2个字节)
/* NSString primitives. A minimal subclass of NSString just needs to implement these two, along with an init method appropriate for that subclass. We also recommend overriding getCharacters:range: for performance.
*/
//返回的是 NSString 字符串包含的 UTF16 码元个数,而不是字符个数.
@property (readonly) NSUInteger length;
//返回的是在 index 上的码元
//unichar = unsigned short,在64位处理器上是16位,但是我们从前面可以知道:
//UTF16编码长度为2个字节或者是4个字节,一个 unichar 不够装,存在被截断的可能性
- (unichar)characterAtIndex:(NSUInteger)index;NSString 的相等性实际上就是 Unicode的相等性,Unicode的相等性有两种判断的标准:
-
标准等价(canonically equivalence):相同的外观和意义
例如: é(U+ 00E9) 与 e(U+0065) + ́(U+0301) 为标准等价
-
兼容等价(compatibility equivalence):相同的外观,但是意义不一样
例如: ff(U+FB00) 与 ff(U+0066U+0066)为兼容等价
NSString 提供了下面的方法让我们判断两个字符串是否等价
| normalization | 合成形式(é) | 分解形式(e + ´) |
|---|---|---|
| 标准等价 | precomposedStringWithCanonicalMapping | decomposedStringWithCanonicalMapping |
| 相容等价 | precomposedStringWithCompatibilityMapping | decomposedStringWithCompatibilityMapping |
-(void)testNSStringEquivalence{
NSString *s = @"\u00E9"; // é
NSString *t = @"e\u0301"; // e + ´
BOOL isEqual = [s isEqualToString:t];
NSLog(@"%@ is %@ to %@", s, isEqual ? @"equal" : @"not equal", t);
// => é is not equal to é
// Normalizing to form C
NSString *sNorm = [s precomposedStringWithCanonicalMapping];
NSString *tNorm = [t precomposedStringWithCanonicalMapping];
BOOL isEqualNorm = [sNorm isEqualToString:tNorm];
NSLog(@"%@ is %@ to %@", sNorm, isEqualNorm ? @"equal" : @"not equal", tNorm);
// => é is equal to é
//如果只想判断两个字符串是否是"兼容等价",可以使用 localizedCompare:
s = @"ff"; // ff
t = @"\uFB00"; // ff ligature
NSComparisonResult result = [s localizedCompare:t];
NSLog(@"%@ is %@ to %@", s, result == NSOrderedSame ? @"equal" : @"not equal", t);
// => ff is equal to ff
}从上面我们可以知道: NSString 的 length 方法返回的是字符串中包含的UTF16码元的个数,一般来说,可以认为一个字符长度就为1(因为一个码元就足够代表了);但是,我们知道 UTF16编码的结果是2/4字节,即1/2码元,如果字符串中包含 emoji,这个时候 length就不等于字符串字符个数了。并且调用 characterAtIndex传入 emoji的 index,得到的结果会被截断
NSString 为了解决这个问题,在 NSString.h头文件有详细的说明:
//1.解决被截断的问题: rangeOfComposedCharacterSequenceAtIndex 用于当定位于字符串的index位置时,返回在此位置的字符完整的range
NSString *substr = [string substringWithRange:[string rangeOfComposedCharacterSequenceAtIndex:index]];
NSString *str1 = @"A";
// => str.length = 1
str1 = @"度";
// => str.length = 1
str1 = @"😍";
// => str.length = 2
str1 = @"A度😍";
// => str.length = 4
unichar char2 =[str1 characterAtIndex:2];
// => 被截断 char2 U+d83d u
NSRange range = [str1 rangeOfComposedCharacterSequenceAtIndex:0];
// => {0,1}
range = [str1 rangeOfComposedCharacterSequenceAtIndex:1];
// => {1,1}
range = [str1 rangeOfComposedCharacterSequenceAtIndex:2];
// => {2,2}
range = [str1 rangeOfComposedCharacterSequencesForRange:NSMakeRange(2, 1)];
// => {2,2}
//2.解决 NSString 字符串长度的方法
[str1 enumerateSubstringsInRange:NSMakeRange(0, str1.length) // enumerate the whole range of the string
options:NSStringEnumerationByComposedCharacterSequences // by composed character sequences
usingBlock:^(NSString * substr, NSRange substrRange, NSRange enclosingRange, BOOL *stop) {
//这个的 substr 就是完整的字符
}];无论 NSData是如何被编码(UTF8/UTF16/UTF32),最终NSString 都是使用 UTF16码元 来表示
Base64 was originally devised as a way to allow binary data to be attached to emails as a part of the Multipurpose Internet Mail Extensions.
Base64 最开始的出现是用于 SMTP 协议中,使得邮件中可以有发送图片。
Base64可以让一串毫无规律的二进制转换成一串ASCII码字符串。(实际开发中,也可以用HEX字符串来表示,HEX也叫做BASE16,选择取决于通信协议的设计)
接触的最多的是 PEM中的公私钥格式,例如:一个2048的RSA PKCS#1-PEM 私钥
-----BEGIN RSA PRIVATE KEY-----
MIIEogIBAAKCAQBjYkZvNeIa+1shtXTSzOPmKbgnsaJDq0twWVwwvLLPDpm8dEv7
UgsZpnnXmxvG3phQkoGX1kiP1wvE9r5z6wmX7vlP55ogEshoN48nFnuvm6y+Ntik
E9EHg/ulnaNAUPxkkjbGWlWs4adCdiLBz790YsoU5xN3tJm080riONs2qvdh0k+O
e7gWLGV3xS/G1Ji9bc/9QilwRugRk9NNmt+GQHE0xTWFUSOHRuSe62Sgcp4eebCx
IZlQQ5TiZVFYa8iSjexPA2D9DssdBee/FpkFhaK87Zi5WtjjyxnHeZW37OTGQtN1
LDDXkiY6h8X5WcmZpHVe+KO80l+Lkdp727q/AgMBAAECggEAXwe3pdt2Kqqyh1cF
MBRuzsSRrJL0P5RpfDJWLtwgdlDVvBfQF65postGsl1EgDKUnmaYuGFT3QaZ4Gq3
zguujrMZfchN3eFX9B88KPocptxKn0++c5XnSDJxy/kiAvvtexU8fwod5kOXNbvU
nFJUFavo43fZa5srZpVEw2/uXSSBbhpibEL5+Mc3gg8CfS23CJnKbjHTnAD+PgB8
voCLICPVvpsRZ+XFTKlVqHuA1/Xe9tiaNvR32h2C8thDRB10BzOVaimb1e5zzF01
tdKYFQ8cU4238N91ezkqrEwNOPPwX+Au8Wi6BD5EW9HD700Jm8hzBqB6eclHfcTc
qEyhgQKBgQDFwZNl2GIFYtJst2Hq2dMQPzVsxFvvUBu5MJUN/pTD7d9GEz79nBtI
6QkAZt2JKFN080UtrSBhE/+/Nfh8wcw2b9TRo87j31hMTAjsZrpZOcpSuMwzPioI
FxLGzfiBKCpk89cmZY0p4tOa0MXFFW4iASbe5eXRBwJTgyHrDT273wKBgQCAp5/R
lwf73/LBT5H11A+s0zh/bRtC4omjkjsD9nHC3OypFR5TJ6z42LKaWAcm+SC5yc8K
Xdvi4tXh8aF6uMGCeon94K8Cs8zTbs01s45VYhfPoBW/ZJgWNjZX3u5zLX2mo8pZ
oKllyvwY35KyzWphZrmclo3Si7Q2t+8QOyndIQKBgAU2D6tMY3De5Mqmnnbw3IX+
FGtUVVPeGYzswdDHl6X+G7ceBLfsKC/orCsNiuL1ZBWd34HPoR3NyByC0JSBCt+Y
XNRVa7tHhG0mR8nq/xgg1LsPUZo8FiF2cjE49kZ5B3z3jADgBjNHXeojfEKwSOGu
hBa1mjPC6oXG29r0016jAoGAcETWvGlVuEC3cGXlc2Y4v5IazWgC0B0sCyeChHS8
1VVA2FPrgJkw4n8HbJTAuQvRuQ8Ys20wgw97oY3gYl1z0E7quDcnwe3xIdihDum/
nVbafH6wO7Km3Us1pPyPjMb3zUFFRW1kJcY6s+H1/D4xRQoFk1X2MPNkshNUdQ+L
+sECgYEAhdFYcmSrlDlk6O8tuVIed24UYHq+GymBCXq7TcF3u2AklAqq//5BSbgB
LYb5OL7rrO8iSNObOvEHffiGNlb5HcuT731u2NDJ0Fyu799n8JENKH4q/2Er5D1m
0faQeiBhRE7pcdNigkAx+mt+xhDuUK2WVomgC0ESWKbj6bzc6Rs=
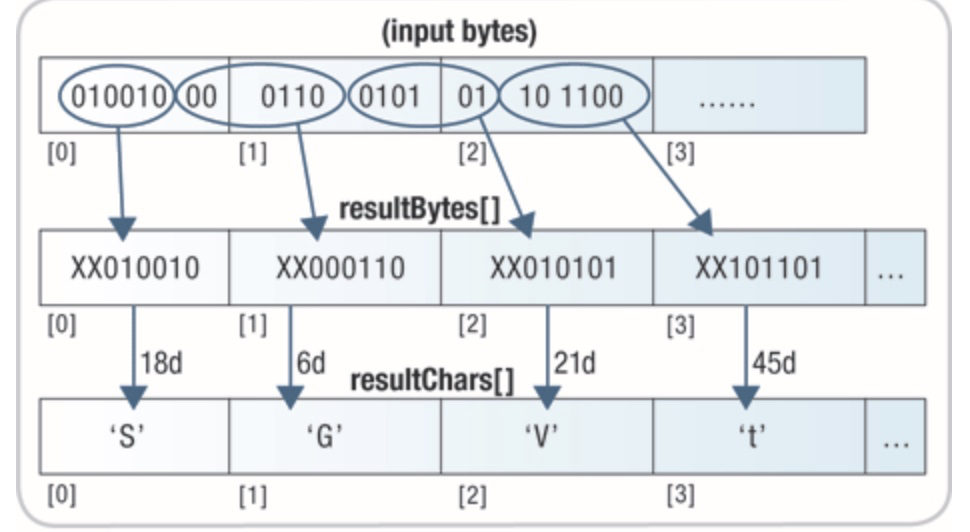
-----END RSA PRIVATE KEY-----Base64 将6比特编码成一个字符, 3字节长度的数据经过Base64编码之后会有4个字节的数据。
字符编码集:a~z,A~Z,0~9,+,/, 如果编码的数据不是3的倍数,那么在后面添加=作为后缀
字符编码表:
| 数值 | 字符 | 数值 | 字符 | 数值 | 字符 | 数值 | 字符 |
|---|---|---|---|---|---|---|---|
| 0 | A | 16 | Q | 32 | g | 48 | w |
| 1 | B | 17 | R | 33 | h | 49 | x |
| 2 | C | 18 | S | 34 | i | 50 | y |
| 3 | D | 19 | T | 35 | j | 51 | z |
| 4 | E | 20 | U | 36 | k | 52 | 0 |
| 5 | F | 21 | V | 37 | l | 53 | 1 |
| 6 | G | 22 | W | 38 | m | 54 | 2 |
| 7 | H | 23 | X | 39 | n | 55 | 3 |
| 8 | I | 24 | Y | 40 | o | 56 | 4 |
| 9 | J | 25 | Z | 41 | p | 57 | 5 |
| 10 | K | 26 | a | 42 | q | 58 | 6 |
| 11 | L | 27 | b | 43 | r | 59 | 7 |
| 12 | M | 28 | c | 44 | s | 60 | 8 |
| 13 | N | 29 | d | 45 | t | 61 | 9 |
| 14 | O | 30 | e | 46 | u | 62 | + |
| 15 | P | 31 | f | 47 | v | 63 | / |
typedef NS_OPTIONS(NSUInteger, NSDataBase64EncodingOptions) {
// Use zero or one of the following to control the maximum line length after which a line ending is inserted. No line endings are inserted by default.
NSDataBase64Encoding64CharacterLineLength = 1UL << 0,//每一行的长度为64时插入控制符
NSDataBase64Encoding76CharacterLineLength = 1UL << 1,//每一行的长度为76时插入控制符
// Use zero or more of the following to specify which kind of line ending is inserted. The default line ending is CR LF.
NSDataBase64EncodingEndLineWithCarriageReturn = 1UL << 4,//NSDataBase64EncodingXXCharacterLineLength设置时,插入回车
NSDataBase64EncodingEndLineWithLineFeed = 1UL << 5,////NSDataBase64EncodingXXCharacterLineLength设置时,插入换行
} API_AVAILABLE(macos(10.9), ios(7.0), watchos(2.0), tvos(9.0));
typedef NS_OPTIONS(NSUInteger, NSDataBase64DecodingOptions) {
// Use the following option to modify the decoding algorithm so that it ignores unknown non-Base64 bytes, including line ending characters.
NSDataBase64DecodingIgnoreUnknownCharacters = 1UL << 0
} API_AVAILABLE(macos(10.9), ios(7.0), watchos(2.0), tvos(9.0));
/* Create an NSData from a Base-64 encoded NSString using the given options. By default, returns nil when the input is not recognized as valid Base-64.
*/
- (nullable instancetype)initWithBase64EncodedString:(NSString *)base64String options:(NSDataBase64DecodingOptions)options API_AVAILABLE(macos(10.9), ios(7.0), watchos(2.0), tvos(9.0));
/* Create a Base-64 encoded NSString from the receiver's contents using the given options.
*/
- (NSString *)base64EncodedStringWithOptions:(NSDataBase64EncodingOptions)options API_AVAILABLE(macos(10.9), ios(7.0), watchos(2.0), tvos(9.0));
/* Create an NSData from a Base-64, UTF-8 encoded NSData. By default, returns nil when the input is not recognized as valid Base-64.
Base64
+-------+
001100 +--------> | M |
| |
+-------+
|
|
+-------+
| M |
0100 1100 <--------+ | |
+-------+
ASCII
*/
- (nullable instancetype)initWithBase64EncodedData:(NSData *)base64Data options:(NSDataBase64DecodingOptions)options API_AVAILABLE(macos(10.9), ios(7.0), watchos(2.0), tvos(9.0));
/* Create a Base-64, UTF-8 encoded NSData from the receiver's contents using the given options.
*/
- (NSData *)base64EncodedDataWithOptions:(NSDataBase64EncodingOptions)options API_AVAILABLE(macos(10.9), ios(7.0), watchos(2.0), tvos(9.0));-
把16进制字符串转换为base64字符串:
$ echo 6742c016888b50580934200002bf20002bf20040 | xxd -r -ps | openssl base64
#Z0LAFoiLUFgJNCAAAr8gACvyAEA=
-
把base64字符串转换为16进制字符串:
$ echo Z0LAFoiLUFgJNCAAAr8gACvyAEA= | openssl base64 -d | xxd -ps #6742c016888b50580934200002bf20002bf20040
-
另外,把16进制字符串转换为二进制文件方法为:
echo 68ce3c80 | xxd -r -ps > a.bin
-
BASE64编码命令
对字符串‘abc’进行base64编码: # echo abc | openssl base64 YWJjCg== (编码结果)
- 基本的 ASCII、Unicode、UTF8、UTF16 编码规则
- NSString 与 Unicode 的关系,再也不怕别人问起一个中文几个字节,这部分知识对做与文字处理的功能非常有用(社交应用)