# 基於共識的叢集系統(Clustering by Consensus by:Dustin J. Mitchell)
translated by<RanceJen>
Dustin is an open source software developer and release engineer at Mozilla. He has worked on projects as varied as a host configuration system in Puppet, a Flask-based web framework, unit tests for firewall configurations, and a continuous integration framework in Twisted Python. Find him as @djmitche on GitHub or at dustin@mozilla.com.
Dustin 是一個開源軟體開發者和 Mozilla 的佈署工程師,他曾在開發過各式各樣在 Puppet 中的端口配置系統、以 Flask 為基礎的網頁框架,防火牆設置的單元測試以及一個用 Twisted Python 開發的持續集合框架
譯註:上面沒翻出來的都是框架名,至於 Mozilla 我相信大家都認識就沒什麼好翻的了。
In this chapter, we'll explore implementation of a network protocol designed to support reliable distributed computation. Network protocols can be difficult to implement correctly, so we'll look at some techniques for minimizing bugs and for catching and fixing the remaining few. Building reliable software, too, requires some special development and debugging techniques.
在這個章節中,我們會探索如何實現一個網路協議,並使其支援有可靠性的分散式運算。要正確的實作網路協議是有其難度的,所以我們會使用一些技巧來最小化、排查並修復 bug,以建構一個可靠的軟體,這同時也會需要一些特定的開發和除錯技巧。
The focus of this chapter is on the protocol implementation, but as a motivating example let's consider a simple bank account management service. In this service, each account has a current balance and is identified with an account number. Users access the accounts by requesting operations like "deposit", "transfer", or "get-balance". The "transfer" operation operates on two accounts at once -- the source and destination accounts -- and must be rejected if the source account's balance is too low.
本章節的目標是一個協議的實現,先讓我們由一個案例開始,以一個簡單的銀行帳戶服務為例,在這個服務中,每個帳戶會有其額度並以及帳戶編號,用戶可以用請求「存款」、「轉帳」、「取得額度」來操作帳戶,「轉帳」操作在兩個帳戶之間同時運作,在來源帳戶跟目標帳戶上,並且在來源帳戶額度過低時應該被拒絕。
If the service is hosted on a single server, this is easy to implement: use a lock to make sure that transfer operations don't run in parallel, and verify the source account's balance in that method. However, a bank cannot rely on a single server for its critical account balances. Instead, the service is distributed over multiple servers, with each running a separate instance of exactly the same code. Users can then contact any server to perform an operation.
如果服務是建立在單一伺服器上,要實現的方式很簡單,用一個鎖來確保轉帳操作不會被平行的處理,並且在過程中驗證帳戶的額度。然而一個銀行重要的帳戶額度並不能只依賴單一伺服器處理。相對而言,服務應該要分散在多個伺服器中,每個都作為獨立個體執行相同的程式碼,使用者可以連接任何一個伺服器來處理操作。
In a naive implementation of distributed processing, each server would keep a local copy of every account's balance. It would handle any operations it received, and send updates for account balances to other servers. But this approach introduces a serious failure mode: if two servers process operations for the same account at the same time, which new account balance is correct? Even if the servers share operations with one another instead of balances, two simultaneous transfers out of an account might overdraw the account.
在比較粗淺的分散處理實作中,每個伺服器在本地保存一份所有帳號的額度,並處理任何收到的操作,再傳送帳號額度的更新給其他伺服器。但這種方法存在一種嚴重的錯誤狀態,如果兩個伺服器同時處理對同一個帳戶的操作,那新的帳號額度會正確嗎?就算伺服器之間只共享操作而非額度,對帳戶同時轉帳兩次也有可能透支該帳戶。
Fundamentally, these failures occur when servers use their local state to perform operations, without first ensuring that the local state matches the state on other servers. For example, imagine that server A receives a transfer operation from Account 101 to Account 202, when server B has already processed another transfer of Account 101's full balance to Account 202, but not yet informed server A. The local state on server A is different from that on server B, so server A incorrectly allows the transfer to complete, even though the result is an overdraft on Account 101.
從根本上來說,這個錯誤發生在當伺服器用它們本地的狀態來處理操作,卻沒先確認本地的狀態跟其他伺服器的狀態相符。舉例來說,想像當一個伺服器 A 收到一個轉帳操作從帳戶 101 轉帳到帳戶 202,此時伺服器 B 已經處理另外一個轉帳請求將帳戶 101 的全部額度都轉到帳戶 202 ,但還沒通知到伺服器 A 。這樣伺服器 A 跟 伺服器 B 的本地狀態各不相同。所以伺服器 A 就不正確的允許轉帳完成,即使這造成了帳戶 101 的透支。
The technique for avoiding such problems is called a "distributed state machine". The idea is that each server executes exactly the same deterministic state machine on exactly the same inputs. By the nature of state machines, then, each server will see exactly the same outputs. Operations such as "transfer" or "get-balance", together with their parameters (account numbers and amounts) represent the inputs to the state machine.
The state machine for this application is simple:
用來避免上敘問題的技術就叫做「分散式狀態機」,這個主意是透過相同的輸入讓每個伺服器都形成相等的狀態機,藉由狀態機與生俱來的特性,如此伺服器就都會給出相同的輸出。而操作像是「轉帳」或「取得額度」就同時帶著它們的參數(像是帳戶編號與帳戶額度)作為狀態機的輸入。
這個應用的狀態機非常簡單
def execute_operation(state, operation):
if operation.name == 'deposit':
if not verify_signature(operation.deposit_signature):
return state, False
state.accounts[operation.destination_account] += operation.amount
return state, True
elif operation.name == 'transfer':
if state.accounts[operation.source_account] < operation.amount:
return state, False
state.accounts[operation.source_account] -= operation.amount
state.accounts[operation.destination_account] += operation.amount
return state, True
elif operation.name == 'get-balance':
return state, state.accounts[operation.account]
Note that executing the "get-balance" operation does not modify the state, but is still implemented as a state transition. This guarantees that the returned balance is the latest information in the cluster of servers, and is not based on the (possibly stale) local state on a single server.
注意到執行「取得額度」操作並不會修改到狀態,但依然實作進狀態的轉換裡了,這保證回傳的額度一定是叢集中取出的最終額度,而非是某個伺服器的本地端備份。
This may look different than the typical state machine you'd learn about in a computer science course. Rather than a finite set of named states with labeled transitions, this machine's state is the collection of account balances, so there are infinite possible states. Still, the usual rules of deterministic state machines apply: starting with the same state and processing the same operations will always produce the same output.
這可能看起來跟在資工系上課時聽到的傳統狀態機不同,它不是帶有狀態轉換的有限狀態機,這個機器的狀態是帳號額度的總集,所以有無限多種可能的狀態,但常見在狀態機上的定律依然適用於其:從相同狀態開始後,對於相同的操作流程狀態機永遠會給出相同的輸出。
So, the distributed state machine technique ensures that the same operations occur on each host. But the problem remains of ensuring that every server agrees on the inputs to the state machine. This is a problem of consensus, and we'll address it with a derivative of the Paxos algorithm.
所以分散式狀態機的技術可以用來確保相同的操作發生在所有的端口上,但還是有疑慮就是要保證每個伺服器都要同意狀態機的輸入,這是一個共識的問題,我們會用 Paxos 演算法的延伸來解決它。
Paxos was described by Leslie Lamport in a fanciful paper, first submitted in 1990 and eventually published in 1998, entitled "The Part-Time Parliament"1. Lamport's paper has a great deal more detail than we will get into here, and is a fun read. The references at the end of the chapter describe some extensions of the algorithm that we have adapted in this implementation.
Paxos 是由 Leslie Lamport 在其奇妙的論文中提出,最初在 1990 提交並在 1998 年公佈,題目為"The Part-Time Parliament"(兼職議會),Lamport 的論文比我們這邊敘述的更詳細的多,讀起來也很有趣,在本文的最後有一些該演算法之延伸的參考文獻,我們會把它們應用到本次實作之中。
The simplest form of Paxos provides a way for a set of servers to agree on one value, for all time. Multi-Paxos builds on this foundation by agreeing on a numbered sequence of facts, one at a time. To implement a distributed state machine, we use Multi-Paxos to agree on each state-machine input, and execute them in sequence.
最簡單的 Paxos 形式為一組服務器提供了一種方式來持續同意一個值,Muliti paxos 則是建立在「逐一同意一系列的事實」為基礎。為了實作一個分散式狀態機,我們使用 Multi-Paxos 來同意每個狀態機的輸入,並以序列的形式執行他們。
The protocol operates in a series of ballots, each led by a single member of the cluster, called the proposer. Each ballot has a unique ballot number based on an integer and the proposer's identity. The proposer's goal is to get a majority of cluster members, acting as acceptors, to accept its value, but only if another value has not already been decided.
該協議由一系列的選票進行操作,每個都由叢集中的一個叫做「提案者」的成員提出,每個選票都有獨有的整數型態選票編號並由 proposer 來認證,提案者的目標是讓大多數叢集內的成員作為接收者同意其提出的價值,但前提是這個提案還沒被決定過。

A ballot begins with the proposer sending a
Preparemessage with the ballot number N to the acceptors and waiting to hear from a majority (Figure 3.1.)The
Preparemessage is a request for the accepted value (if any) with the highest ballot number less than N. Acceptors respond with aPromisecontaining any value they have already accepted, and promising not to accept any ballot numbered less than N in the future. If the acceptor has already made a promise for a larger ballot number, it includes that number in thePromise, indicating that the proposer has been pre-empted. In this case, the ballot is over, but the proposer is free to try again in another ballot (and with a larger ballot number).
一次表決會從提案者發出 Prepare 訊息而開始,表決會帶有一個編號 N 來給接受者,並等待他們大多數的回應。
Prepare 的訊息是請求其接受小於 N 的最大表決編號的數據,接受者會回應 Promise 並帶有所有其已接受的數據,並承諾它之後不會再接受任何小於 N 的表決編號。而此時若接受者已經對更大的表決編號做過承諾,則會將該編號帶在 Promise 中,藉此向提案者說明已經被捷足先登了。在這種情況下,這次的表決就直接結束,但提案者可以自由使用(更大的)表決編號再嘗試提出另一次表決。
When the proposer has heard back from a majority of the acceptors, it sends an
Acceptmessage, including the ballot number and value, to all acceptors. If the proposer did not receive any existing value from any acceptor, then it sends its own desired value. Otherwise, it sends the value from the highest-numbered promise.
當提案者收到大多數接受者的回應時,他會送出一個 Accept 訊息,包含表決編號和其數據給所有接受者。如果提案者沒有在接受者中收到任何現存的數據,則他送出自己預期的數據,否則他會送出來自最高表決編號之回應的數據。
Unless it would violate a promise, each acceptor records the value from the
Acceptmessage as accepted and replies with anAcceptedmessage. The ballot is complete and the value decided when the proposer has heard its ballot number from a majority of acceptors.
除非違反會先前的承諾,否則接受者就會紀錄下來自 Accept 的數據,並回應一個 Accepted 的訊息,當提案者收到大多數接受者回應這個提案編號時,就會定調其數據且完成此表決。
Returning to the example, initially no other value has been accepted, so the acceptors all send back a
Promisewith no value, and the proposer sends anAcceptcontaining its value, say:
回到範例上,再一開始沒有任何數據被同意過,所以接受者們都會先回傳一個不帶有任何數據的 Promise ,然後提案者再送出一個帶有自身數據的 Accept ,像是
operation(name='deposit', amount=100.00, destination_account='Mike DiBernardo')
If another proposer later initiates a ballot with a lower ballot number and a different operation (say, a transfer to acount
'Dustin J. Mitchell'), the acceptors will simply not accept it. If that ballot has a larger ballot number, then thePromisefrom the acceptors will inform the proposer about Michael's $100.00 deposit operation, and the proposer will send that value in theAcceptmessage instead of the transfer to Dustin. The new ballot will be accepted, but in favor of the same value as the first ballot.
如果有另外一個提案者後續才用較小的表決編號初始化的操作(像轉帳給 'Dustin J. Mitchell'),接受者則單純的不同意它,而如果該表決有更高的表決編號,則在接受者傳的 Promise 中則會告知提案者有關先前存款 100 元的操作。然後提案者會在 Accept 中傳送這個值而非轉帳給 Dustin,這個表決會被接受。但其實是贊成了與第一個表決同樣的數據。
In fact, the protocol will never allow two different values to be decided, even if the ballots overlap, messages are delayed, or a minority of acceptors fail.
When multiple proposers make a ballot at the same time, it is easy for neither ballot to be accepted. Both proposers then re-propose, and hopefully one wins, but the deadlock can continue indefinitely if the timing works out just right.
事實上,這個協議永遠不會允許兩種不同的數據被定義,即使有重複的表決,訊息延遲,或是小部份的接受者故障。 當多個提案者同時提出表決時,很容易發生沒有任何表決被接受,提案者們接著又重新提案,然後期待看有沒有一者能獲勝。不過如果時機就是恰到好處則這個死鎖可以無限的持續下去。
Consider the following sequence of events:
- Proposer A performs the
Prepare/Promisephase for ballot number 1.- Before Proposer A manages to get its proposal accepted, Proposer B performs a
Prepare/Promisephase for ballot number 2.- When Proposer A finally sends its
Acceptwith ballot number 1, the acceptors reject it because they have already promised ballot number 2.- Proposer A reacts by immediately sending a
Preparewith a higher ballot number (3), before Proposer B can send itsAcceptmessage.- Proposer B's subsequent
Acceptis rejected, and the process repeats.With unlucky timing -- more common over long-distance connections where the time between sending a message and getting a response is long -- this deadlock can continue for many rounds.
考慮下列的事件順序
- 提案者 A 執行了表決 1 的
Prepare/Promise步驟 - 在提案者 A 要接到 accepted 之前,提案者 B 執行了表決 2 的
Prepare/Promise步驟 - 在提案者 A 廣播表決 1 的
Accept時,接受者拒絕了因為他們已經承諾了表決 2(不接受更小表決) - 提案者 A 馬上傳送了一個新表決 3 的
Prepare,在提案者 B 可以廣播Accept之前。 - 提案者 B 隨後的
Accept也遭到拒絕,然後流程不斷循環。
只要發生時的運氣不好(這常見於長距離通訊中,因為在發送到取得回應之間的時間差較長),這個死鎖可以不斷重複很多次。
Reaching consensus on a single static value is not particularly useful on its own. Clustered systems such as the bank account service want to agree on a particular state (account balances) that changes over time. We use Paxos to agree on each operation, treated as a state machine transition.
對於單個靜態值達成共識並不是特別有用,叢集系統像是銀行帳戶服務希望能不斷的同意特定的狀態轉換(像帳戶額度),我們可以用 Paxos 來同意各個操作,就像狀態機轉換一樣處理他們。
Multi-Paxos is, in effect, a sequence of simple Paxos instances (slots), each numbered sequentially. Each state transition is given a "slot number", and each member of the cluster executes transitions in strict numeric order. To change the cluster's state (to process a transfer operation, for example), we try to achieve consensus on that operation in the next slot. In concrete terms, this means adding a slot number to each message, with all of the protocol state tracked on a per-slot basis.
Multi-Paxos 事實上是一個簡單 Paxos 實體的序列,每個先按順序編號,對於狀態的轉換會再給予一個插槽編號,並且每個成員執行以嚴格的數字順序進行傳輸。舉例來說要轉換叢集的狀態時(就是完成一個傳輸操作),我們會試著在下一個個插槽上達到共識,這代表對每個訊息加上插槽編號,並且每個協議都跟蹤插槽狀態
插槽就是一個陣列用來保存每次跟接下來的 transation
Running Paxos for every slot, with its minimum of two round trips, would be too slow. Multi-Paxos optimizes by using the same set of ballot numbers for all slots, and performing the
Prepare/Promisephase for all slots at once.
要在每個插槽上執行 Paxos,每次至少都必須執行兩次的來回也太慢了點,Multi-Paxos 藉由所有插槽使用同一組表決編號優化了這點,並一次執行所有插槽的 Prepare/Promise 。
Implementing Multi-Paxos in practical software is notoriously difficult, spawning a number of papers mocking Lamport's "Paxos Made Simple" with titles like "Paxos Made Practical".
在實際的軟體中實現 Multi-Paxos 是惡名昭彰的困難,更產生了一些論文用像 "Paxos Made Practical" 的標題來嘲弄 Lamport 的 "Paxos Made Simple"。
First, the multiple-proposers problem described above can become problematic in a busy environment, as each cluster member attempts to get its state machine operation decided in each slot. The fix is to elect a "leader" which is responsible for submitting ballots for each slot. All other cluster nodes then send new operations to the leader for execution. Thus, in normal operation with only one leader, ballot conflicts do not occur.
首先,前敘提到的多個提案者問題在繁忙的環境中越來越嚴重,因為每個叢集的成員都試圖讓其的狀態機操作在所有插槽中被決議。解決方法是選出一個 leader(領導者) 他負責提交所有插槽的表決。所有叢集中的其他結點都傳送它的新操作給領導者去執行,因此在只有單一領導者正常操作下,表決的衝突就不會再發生。
The
Prepare/Promisephase can function as a kind of leader election: whichever cluster member owns the most recently promised ballot number is considered the leader. The leader is then free to execute theAccept/Acceptedphase directly without repeating the first phase. As we'll see below, leader elections are actually quite complex.
Prepare 和 Promise 的階段可以作為選舉 leader 的一部分,擁有最靠前表決編號的叢集成為就被作為領導者,接著領導者就可以放心執行 Accept/Accepted 的階段而不用重複前敘的部份。我們接著可以在下面看到,領導者的選舉也是很複雜的。
Although simple Paxos guarantees that the cluster will not reach conflicting decisions, it cannot guarantee that any decision will be made. For example, if the initial
Preparemessage is lost and doesn't reach the acceptors, then the proposer will wait for aPromisemessage that will never arrive. Fixing this requires carefully orchestrated re-transmissions: enough to eventually make progress, but not so many that the cluster buries itself in a packet storm.
雖然 simple Paxos 保證了叢集內不會達成有衝突的決議,但它不保證會有決議被達成。舉個栗子,如果初始化的 Prepare 訊息丟失了沒有被傳給任何接收者,則提案者則會不斷等待永遠不會到達的 Promise 。要解決這個問題需要精心規劃的重送機制。要能重送到足夠繼續流程,但又不會讓整個叢集在封包風暴中炸掉。
瘋狂的重送給多個伺服器是真的可以炸掉整個叢集的,我們最近才炸了好幾次XDD
Another problem is the dissemination of decisions. A simple broadcast of a Decision message can take care of this for the normal case. If the message is lost, though, a node can remain permanently ignorant of the decision and unable to apply state machine transitions for later slots. So an implementation needs some mechanism for sharing information about decided proposals.
另外一個問題是該如何傳播決議,簡單的廣播出決議訊息就可以解決一般的狀況,但如果訊息丟失則節點可能永遠不知道該決議,並且無法為後續的插槽應用狀態機轉換。所以在實作中需要一些用來分享決議提案的機制。
Our use of a distributed state machine presents another interesting challenge: start-up. When a new node starts, it needs to catch up on the existing state of the cluster. Although it can do so by catching up on decisions for all slots since the first, in a mature cluster this may involve millions of slots. Furthermore, we need some way to initialize a new .
But enough talk of theory and algorithms -- let's have a look at the code.
我們使用的分散式狀態機還呈現了另外一個有趣的挑戰:「啟動」,當一個節點啟動時,他需要取得叢集中現存的狀態。雖然這可以用取得所有插槽所有從開始到現在的決議去解決,但這在一個足夠成熟的叢集中可能會涉及百萬個插槽,換句話說,我們需要一些用來初始化新叢集的方法。
討論了夠多理論跟演算法之後,讓我們開始看看程式碼吧。
The Cluster library in this chapter implements a simple form of Multi-Paxos. It is designed as a library to provide a consensus service to a larger application.
本章節中的叢集函式庫是 Multi-Paxos 的簡單實現,它被設計成一個函式庫來為大型應用提供取得共識的服務。
Users of this library will depend on its correctness, so it's important to structure the code so that we can see -- and test -- its correspondence to the specification. Complex protocols can exhibit complex failures, so we will build support for reproducing and debugging rare failures.
該函式庫的用戶會依賴其提供的正確性,所以將如何結構化程式碼讓我們可以觀察並且測試其規格的正確性是很重要的。複雜的協議會呈現出複雜的故障,所以我們的函式庫將會支援複雜問題的重現跟除錯。
The implementation in this chapter is proof-of-concept code: enough to demonstrate that the core concept is practical, but without all of the mundane equipment required for use in production. The code is structured so that such equipment can be added later with minimal changes to the core implementation.
Let's get started.
在本章節中的實作是驗證概念用的程式碼,足夠展示我們核心的概念是很實際的,但卻不需要用到正常產品環境中的設備。而且程式碼都是結構化過的,所以這些正常產品環境中的設備也可以在稍微修改實作的核心後被加入。
讓我們開始吧!
Cluster's protocol uses fifteen different message types, each defined as a Python
namedtuple.
叢集們會使用包含十五種不同訊息型態的協議,每一種各自用 Python 的 namedtuple 型態定義
Accepted = namedtuple('Accepted', ['slot', 'ballot_num'])
Accept = namedtuple('Accept', ['slot', 'ballot_num', 'proposal'])
Decision = namedtuple('Decision', ['slot', 'proposal'])
Invoked = namedtuple('Invoked', ['client_id', 'output'])
Invoke = namedtuple('Invoke', ['caller', 'client_id', 'input_value'])
Join = namedtuple('Join', [])
Active = namedtuple('Active', [])
Prepare = namedtuple('Prepare', ['ballot_num'])
Promise = namedtuple('Promise', ['ballot_num', 'accepted_proposals'])
Propose = namedtuple('Propose', ['slot', 'proposal'])
Welcome = namedtuple('Welcome', ['state', 'slot', 'decisions'])
Decided = namedtuple('Decided', ['slot'])
Preempted = namedtuple('Preempted', ['slot', 'preempted_by'])
Adopted = namedtuple('Adopted', ['ballot_num', 'accepted_proposals'])
Accepting = namedtuple('Accepting', ['leader'])
Using named tuples to describe each message type keeps the code clean and helps avoid some simple errors. The named tuple constructor will raise an exception if it is not given exactly the right attributes, making typos obvious. The tuples format themselves nicely in log messages, and as an added bonus don't use as much memory as a dictionary.
Creating a message reads naturally:
用 named tuples 去敘述各種訊息型態可以保持程式碼整潔並協助避免一些簡單的錯誤,named tuples 的建構子在沒有給定正確屬性的時候會丟出例外,讓手誤的部份變得相當明顯。 tuples 的格式在 log 中也很容易格式化,更加分的是它用的記憶體還沒有 dictionary 多。
可以很自然的閱讀創建 tuples 的訊息
msg = Accepted(slot=10, ballot_num=30)
And the fields of that message are accessible with a minimum of extra typing:
而且要存取該值域也很簡單
譯註:這句我意譯了,照字面翻很不直觀。
got_ballot_num = msg.ballot_num
We'll see what these messages mean in the sections that follow. The code also introduces a few constants, most of which define timeouts for various messages:
我們將在後續的部份看懂這些訊息的意思,這些程式碼引入了一些常數,它們大多是在定義各種訊息的超時。
JOIN_RETRANSMIT = 0.7
CATCHUP_INTERVAL = 0.6
ACCEPT_RETRANSMIT = 1.0
PREPARE_RETRANSMIT = 1.0
INVOKE_RETRANSMIT = 0.5
LEADER_TIMEOUT = 1.0
NULL_BALLOT = Ballot(-1, -1) # sorts before all real ballots
NOOP_PROPOSAL = Proposal(None, None, None) # no-op to fill otherwise empty slots
Finally, Cluster uses two data types named to correspond to the protocol description:
最終,叢集命名下面兩種資料型態來對應協議的敘述
譯註:這句有點拗口,意思是「協議本身是敘述傳輸的方式」,那我們用資料型態
namedtuple並命名為Proposal/Ballot來表達協議中的兩個敘述。
Proposal = namedtuple('Proposal', ['caller', 'client_id', 'input'])
Ballot = namedtuple('Ballot', ['n', 'leader'])
Humans are limited by what we can hold in our active memory. We can't reason about the entire Cluster implementation at once -- it's just too much, so it's easy to miss details. For similar reasons, large monolithic codebases are hard to test: test cases must manipulate many moving pieces and are brittle, failing on almost any change to the code.
人類受到我們在活躍記憶中能夠擁有的東西的限制,我們沒辦法一次就推測出整個叢集的實現,因為信息量太大了,所以很容易錯失細節。相同的,一整個大型獨立架構的程式碼也是很難測試的,測資必須模擬很多環節並且測試結果也很脆弱,只要有任何一點程式改動就有可能失敗。
To encourage testability and keep the code readable, we break Cluster down into a handful of classes corresponding to the roles described in the protocol. Each is a subclass of
Role.
為了增強其可測試性並且保持程式可讀性,我們將叢集拆分成數個類別,分別對應協議敘述的不同角色們,每一個都是整個「角色」類別本身的子類別。
由大往小分別是 網路 > 叢集 > 節點 > 角色
class Role(object):
def __init__(self, node):
self.node = node
self.node.register(self)
self.running = True
self.logger = node.logger.getChild(type(self).__name__)
def set_timer(self, seconds, callback):
return self.node.network.set_timer(self.node.address, seconds,
lambda: self.running and callback())
def stop(self):
self.running = False
self.node.unregister(self)
The roles that a cluster node has are glued together by the
Nodeclass, which represents a single node on the network. Roles are added to and removed from the node as execution proceeds. Messages that arrive on the node are relayed to all active roles, calling a method named after the message type with ado_prefix. Thesedo_methods receive the message's attributes as keyword arguments for easy access. TheNodeclass also provides asendmethod as a convenience, usingfunctools.partialto supply some arguments to the same methods of theNetworkclass.
一個叢集所擁有的全部角色是被用 Node 類別連結在一起的,它代表整個網路中的單一節點,角色可以隨著運行流程被加入或從節點中移除,到達一個節點的訊息則全部依賴於運行不同的角色去調用有 do_ 前綴的訊息類型。這些 do_ 方法會接收訊息的屬性當作參數可以輕鬆的使用。 Node 的類別也提供 send 的方法,內部利用 functools.partial 來轉送一些參數給 Network 的 send 方法。
譯註:這段是在說明 code ,所以配合下面的程式碼觀看比較容易理解。
class Node(object):
unique_ids = itertools.count()
def __init__(self, network, address):
self.network = network
self.address = address or 'N%d' % self.unique_ids.next()
self.logger = SimTimeLogger(
logging.getLogger(self.address), {'network': self.network})
self.logger.info('starting')
self.roles = []
self.send = functools.partial(self.network.send, self)
def register(self, roles):
self.roles.append(roles)
def unregister(self, roles):
self.roles.remove(roles)
def receive(self, sender, message):
handler_name = 'do_%s' % type(message).__name__
for comp in self.roles[:]:
if not hasattr(comp, handler_name):
continue
comp.logger.debug("received %s from %s", message, sender)
fn = getattr(comp, handler_name)
fn(sender=sender, **message._asdict())
The application creates and starts a
Memberobject on each cluster member, providing an application-specific state machine and a list of peers. The member object adds a bootstrap role to the node if it is joining an existing cluster, or seed if it is creating a new cluster. It then runs the protocol (viaNetwork.run) in a separate thread.
應用程式本身創建並為所有叢集成員各啟動一個 Member 物件,提供一個應用程式專用的狀態機及對照列表。如果節點本身是要加入一個現存的叢集則成員的物件會添加一個引導的角色給節點,或是當其實是要創造新的從即時添加 seed(一種 role) 給它,然後在不同的執行緒中執行該協議(透過 Network.run)
The application interacts with the cluster through the
invokemethod, which kicks off a proposal for a state transition. Once that proposal is decided and the state machine runs,invokereturns the machine's output. The method uses a simple synchronizedQueueto wait for the result from the protocol thread.
應用程式本身透過調用方法來跟叢集互動,同時也創造一個新的提案揭開狀態轉換的序幕,一旦這個提案被決議並則狀態機開始運行。 invoke 會回傳狀態機的輸出,這個方法用來和 Queue 做簡單的同步以等待協議的執行緒回傳結果。
譯註:這段一樣看 code 比較容易理解意思。
class Member(object):
def __init__(self, state_machine, network, peers, seed=None,
seed_cls=Seed, bootstrap_cls=Bootstrap):
self.network = network
self.node = network.new_node()
if seed is not None:
self.startup_role = seed_cls(self.node, initial_state=seed, peers=peers,
execute_fn=state_machine)
else:
self.startup_role = bootstrap_cls(self.node,
execute_fn=state_machine, peers=peers)
self.requester = None
def start(self):
self.startup_role.start()
self.thread = threading.Thread(target=self.network.run)
self.thread.start()
def invoke(self, input_value, request_cls=Requester):
assert self.requester is None
q = Queue.Queue()
self.requester = request_cls(self.node, input_value, q.put)
self.requester.start()
output = q.get()
self.requester = None
return output
Let's look at each of the role classes in the library one by one. 讓我們一一檢視函式庫內的角色類別。
The
Acceptorimplements the acceptor role in the protocol, so it must store the ballot number representing its most recent promise, along with the set of accepted proposals for each slot. It then responds toPrepareandAcceptmessages according to the protocol. The result is a short class that is easy to compare to the protocol.For acceptors, Multi-Paxos looks a lot like Simple Paxos, with the addition of slot numbers to the messages.
Acceptor 實現了協議中接受者這個角色,所以他必須保存能代表最新承諾的表決編號,以及每個插槽已接受的協議集合。然後他會根據協議回應 Prepare 和 Accept 的訊息,回應會是一個簡短的類別以至於可以輕易的跟協議本身做比較。
對於接受者來說 Multi-Paxos 跟簡單的 Paxos 看起來很相識,就是訊息會多了插槽的編號。
class Acceptor(Role):
def __init__(self, node):
super(Acceptor, self).__init__(node)
self.ballot_num = NULL_BALLOT
self.accepted_proposals = {} # {slot: (ballot_num, proposal)}
def do_Prepare(self, sender, ballot_num):
if ballot_num > self.ballot_num:
self.ballot_num = ballot_num
# we've heard from a scout, so it might be the next leader
self.node.send([self.node.address], Accepting(leader=sender))
self.node.send([sender], Promise(
ballot_num=self.ballot_num,
accepted_proposals=self.accepted_proposals
))
def do_Accept(self, sender, ballot_num, slot, proposal):
if ballot_num >= self.ballot_num:
self.ballot_num = ballot_num
acc = self.accepted_proposals
if slot not in acc or acc[slot][0] < ballot_num:
acc[slot] = (ballot_num, proposal)
self.node.send([sender], Accepted(
slot=slot, ballot_num=self.ballot_num))
The
Replicaclass is the most complicated role class, as it has a few closely related responsibilities:
- Making new proposals;
- Invoking the local state machine when proposals are decided;
- Tracking the current leader; and
- Adding newly started nodes to the cluster.
Replica 類別是最為複雜的角色類別,它有數個緊密相關的職責
- 發起一個新的提案
- 當提案被決議的時候調用本地的狀態機
- 追蹤現在的領導者是誰
- 為叢集加入新的節點
以下 Replica 翻成臨摹者
The replica creates new proposals in response to
Invokemessages from clients, selecting what it believes to be an unused slot and sending aProposemessage to the current leader (Figure 3.2.) Furthermore, if the consensus for the selected slot is for a different proposal, the replica must re-propose with a new slot.
臨摹者會為客戶端發起一個提案作為回應,選擇一個尚未使用的插槽並送訊息給當前的領導者。此外如果選擇插槽回應的共識是給其他提案的,則臨摹者需要重送提案給新的插槽。

Decisionmessages represent slots on which the cluster has come to consensus. Here, replicas store the new decision, then run the state machine until it reaches an undecided slot. Replicas distinguish decided slots, on which the cluster has agreed, from committed slots, which the local state machine has processed. When slots are decided out of order, the committed proposals may lag behind, waiting for the next slot to be decided. When a slot is committed, each replica sends anInvokedmessage back to the requester with the result of the operation.
Decision 訊息代表該叢集的插槽已達成共識,在這裡 replica 會先保存這個新的決定,然後運行狀態機直到他達到一個還沒決定的插槽。 replica 會從本地狀態機處理的順序來區分該叢集下已決議的插槽,如果插槽的決議是亂序的,那這個提案可能被向後順延,直到下一個插槽被決定為止。當插槽提交完成,每個 replica 都會傳送一個 Invoked 訊息帶操作的結果到 requester 。
In some circumstances, it's possible for a slot to have no active proposals and no decision. The state machine is required to execute slots one by one, so the cluster must reach a consensus on something to fill the slot. To protect against this possibility, replicas make a "no-op" proposal whenever they catch up on a slot. If such a proposal is eventually decided, then the state machine does nothing for that slot.
在某些情況下,有可能一個插槽並沒有提案要被決議。但狀態機仍需要一個一個的執行插槽,所以叢集必須達成某種共識來填滿這些空插槽。為了應對這種可能性,當臨摹者發現這種插槽它會製作一個 "no-op" 的提案,如果這種提案被決議了,然後狀態機並不會實際做任何事。
Likewise, it's possible for the same proposal to be decided twice. The replica skips invoking the state machine for any such duplicate proposals, performing no transition for that slot.
同樣的,有可能同一個提案被重複決議,對於任何重複的提案臨摹者會略過不調用狀態機,確保針對這個插槽沒有任何狀態轉換。
Replicas need to know which node is the active leader in order to send Propose messages to it. There is a surprising amount of subtlety required to get this right, as we'll see later. Each replica tracks the active leader using three sources of information.
臨摹者必須知道哪個節點是運行中的領導者才能發提案訊息給它。這需要一些極為精妙的操作才能達成,我們在後面就會看到,臨摹者用三種訊息做來源來追蹤現存的領導者。
When the leader role becomes active, it sends an
Adoptedmessage to the replica on the same node (Figure 3.3.)
當領導者這項角色被啟動時,他會送一個 Adopted 的訊息到相同節點上所有的臨摹者。(如下圖)

When the acceptor role sends a
Promiseto a new leader, it sends anAcceptingmessage to its local replica (Figure 3.4.)
而當接收者的角色發送一個 Promise 給新的領導者時,它會再送一個接受 Accepting 的訊息給本地的臨摹者。(如下圖)

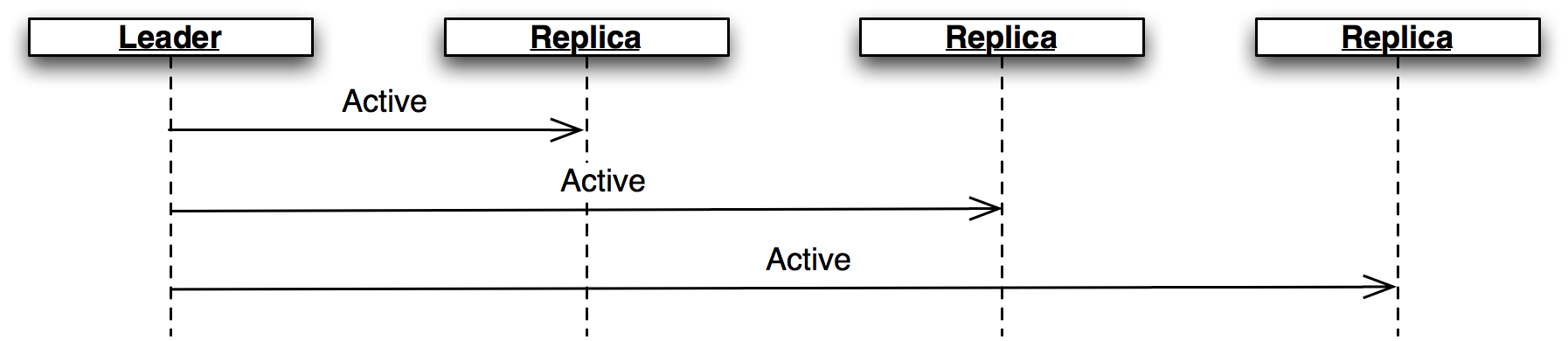
The active leader sends
Activemessages as a heartbeat (Figure 3.5.) If no such message arrives before theLEADER_TIMEOUTexpires, the replica assumes the leader is dead and moves on to the next leader. In this case, it's important that all replicas choose the same new leader, which we accomplish by sorting the members and selecting the next one in the list.
活動中的領導者會送出 Active 的訊息作為心跳包(如下圖),如果在 LEADER_TIMEOUT 超時之前一直都沒有收到這個訊息的話,臨摹者會認定領導者已經死了並選出下個領導者。在這種情況下,讓所有臨摹者都正確選擇相同的新領導者是很重要的,我們藉由排序並且選擇列表中的下一位成員來完成這件事。
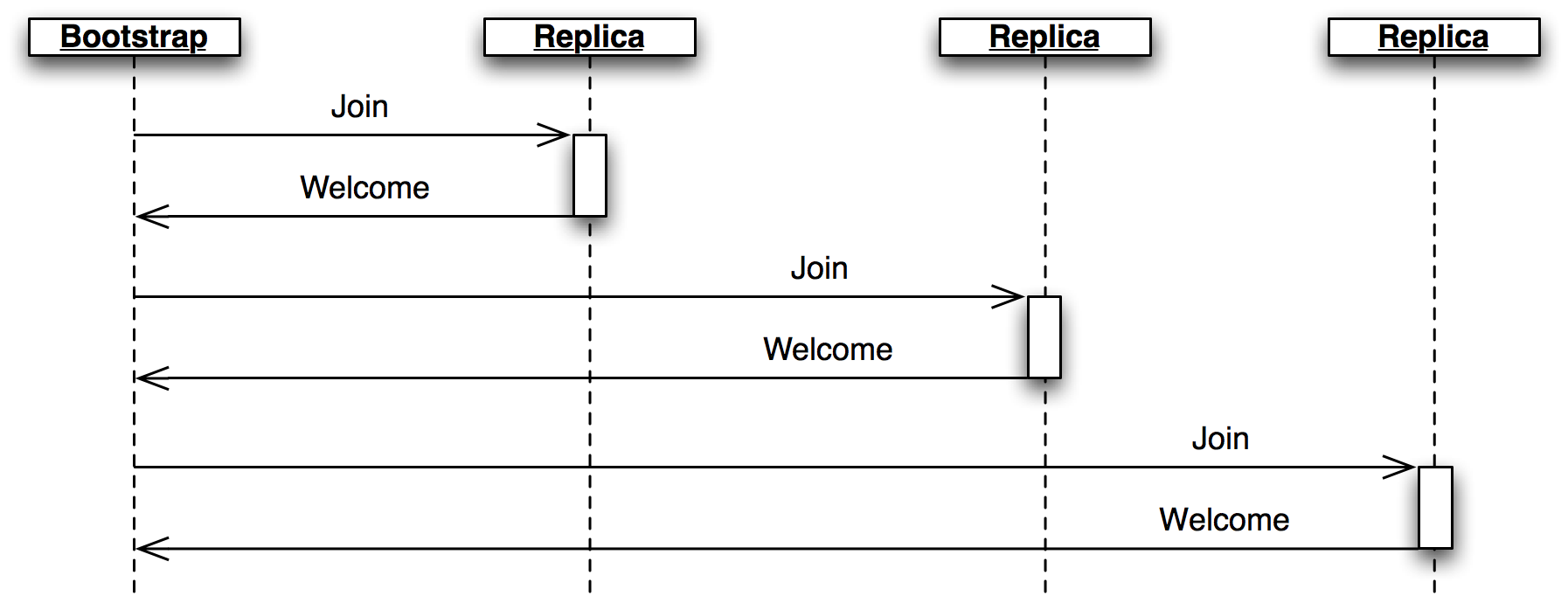
Finally, when a node joins the network, the bootstrap role sends a
Joinmessage (Figure 3.6.) The replica responds with aWelcomemessage containing its most recent state, allowing the new node to come up to speed quickly.
在最後,當一個節點加入整個網路時,引導者的角色會送出一個 Join 的訊息,而臨摹者則會回他一個帶有最新狀態的 Welcome 的訊息,讓新的節點可以盡快加入(如下圖)。
class Replica(Role):
def __init__(self, node, execute_fn, state, slot, decisions, peers):
super(Replica, self).__init__(node)
self.execute_fn = execute_fn
self.state = state
self.slot = slot
self.decisions = decisions
self.peers = peers
self.proposals = {}
# next slot num for a proposal (may lead slot)
self.next_slot = slot
self.latest_leader = None
self.latest_leader_timeout = None
# making proposals
def do_Invoke(self, sender, caller, client_id, input_value):
proposal = Proposal(caller, client_id, input_value)
slot = next((s for s, p in self.proposals.iteritems() if p == proposal), None)
# propose, or re-propose if this proposal already has a slot
self.propose(proposal, slot)
def propose(self, proposal, slot=None):
"""Send (or resend, if slot is specified) a proposal to the leader"""
if not slot:
slot, self.next_slot = self.next_slot, self.next_slot + 1
self.proposals[slot] = proposal
# find a leader we think is working - either the latest we know of, or
# ourselves (which may trigger a scout to make us the leader)
leader = self.latest_leader or self.node.address
self.logger.info(
"proposing %s at slot %d to leader %s" % (proposal, slot, leader))
self.node.send([leader], Propose(slot=slot, proposal=proposal))
# handling decided proposals
def do_Decision(self, sender, slot, proposal):
assert not self.decisions.get(self.slot, None), \
"next slot to commit is already decided"
if slot in self.decisions:
assert self.decisions[slot] == proposal, \
"slot %d already decided with %r!" % (slot, self.decisions[slot])
return
self.decisions[slot] = proposal
self.next_slot = max(self.next_slot, slot + 1)
# re-propose our proposal in a new slot if it lost its slot and wasn't a no-op
our_proposal = self.proposals.get(slot)
if (our_proposal is not None and
our_proposal != proposal and our_proposal.caller):
self.propose(our_proposal)
# execute any pending, decided proposals
while True:
commit_proposal = self.decisions.get(self.slot)
if not commit_proposal:
break # not decided yet
commit_slot, self.slot = self.slot, self.slot + 1
self.commit(commit_slot, commit_proposal)
def commit(self, slot, proposal):
"""Actually commit a proposal that is decided and in sequence"""
decided_proposals = [p for s, p in self.decisions.iteritems() if s < slot]
if proposal in decided_proposals:
self.logger.info(
"not committing duplicate proposal %r, slot %d", proposal, slot)
return # duplicate
self.logger.info("committing %r at slot %d" % (proposal, slot))
if proposal.caller is not None:
# perform a client operation
self.state, output = self.execute_fn(self.state, proposal.input)
self.node.send([proposal.caller],
Invoked(client_id=proposal.client_id, output=output))
# tracking the leader
def do_Adopted(self, sender, ballot_num, accepted_proposals):
self.latest_leader = self.node.address
self.leader_alive()
def do_Accepting(self, sender, leader):
self.latest_leader = leader
self.leader_alive()
def do_Active(self, sender):
if sender != self.latest_leader:
return
self.leader_alive()
def leader_alive(self):
if self.latest_leader_timeout:
self.latest_leader_timeout.cancel()
def reset_leader():
idx = self.peers.index(self.latest_leader)
self.latest_leader = self.peers[(idx + 1) % len(self.peers)]
self.logger.debug("leader timed out; tring the next one, %s",
self.latest_leader)
self.latest_leader_timeout = self.set_timer(LEADER_TIMEOUT, reset_leader)
# adding new cluster members
def do_Join(self, sender):
if sender in self.peers:
self.node.send([sender], Welcome(
state=self.state, slot=self.slot, decisions=self.decisions))
The leader's primary task is to take
Proposemessages requesting new ballots and produce decisions. A leader is "active" when it has successfully carried out thePrepare/Promiseportion of the protocol. An active leader can immediately send anAcceptmessage in response to aPropose.
領導者主要的任務就是接收 Propose 的提案請求並做出決定,當領導者成功處理協議的 Prepare/Promise 部份時,它就是個運作中的領導者。一個作用中的領導者可以立即的送出 Accept 來回應 Propose。
In keeping with the class-per-role model, the leader delegates to the scout and commander roles to carry out each portion of the protocol.
為了保持一個類別對應一個角色的模型,領導者會再分派指揮者跟偵查者去處理協議的各個部份。
class Leader(Role):
def __init__(self, node, peers, commander_cls=Commander, scout_cls=Scout):
super(Leader, self).__init__(node)
self.ballot_num = Ballot(0, node.address)
self.active = False
self.proposals = {}
self.commander_cls = commander_cls
self.scout_cls = scout_cls
self.scouting = False
self.peers = peers
def start(self):
# reminder others we're active before LEADER_TIMEOUT expires
def active():
if self.active:
self.node.send(self.peers, Active())
self.set_timer(LEADER_TIMEOUT / 2.0, active)
active()
def spawn_scout(self):
assert not self.scouting
self.scouting = True
self.scout_cls(self.node, self.ballot_num, self.peers).start()
def do_Adopted(self, sender, ballot_num, accepted_proposals):
self.scouting = False
self.proposals.update(accepted_proposals)
# note that we don't re-spawn commanders here; if there are undecided
# proposals, the replicas will re-propose
self.logger.info("leader becoming active")
self.active = True
def spawn_commander(self, ballot_num, slot):
proposal = self.proposals[slot]
self.commander_cls(self.node, ballot_num, slot, proposal, self.peers).start()
def do_Preempted(self, sender, slot, preempted_by):
if not slot: # from the scout
self.scouting = False
self.logger.info("leader preempted by %s", preempted_by.leader)
self.active = False
self.ballot_num = Ballot((preempted_by or self.ballot_num).n + 1,
self.ballot_num.leader)
def do_Propose(self, sender, slot, proposal):
if slot not in self.proposals:
if self.active:
self.proposals[slot] = proposal
self.logger.info("spawning commander for slot %d" % (slot,))
self.spawn_commander(self.ballot_num, slot)
else:
if not self.scouting:
self.logger.info("got PROPOSE when not active - scouting")
self.spawn_scout()
else:
self.logger.info("got PROPOSE while scouting; ignored")
else:
self.logger.info("got PROPOSE for a slot already being proposed")
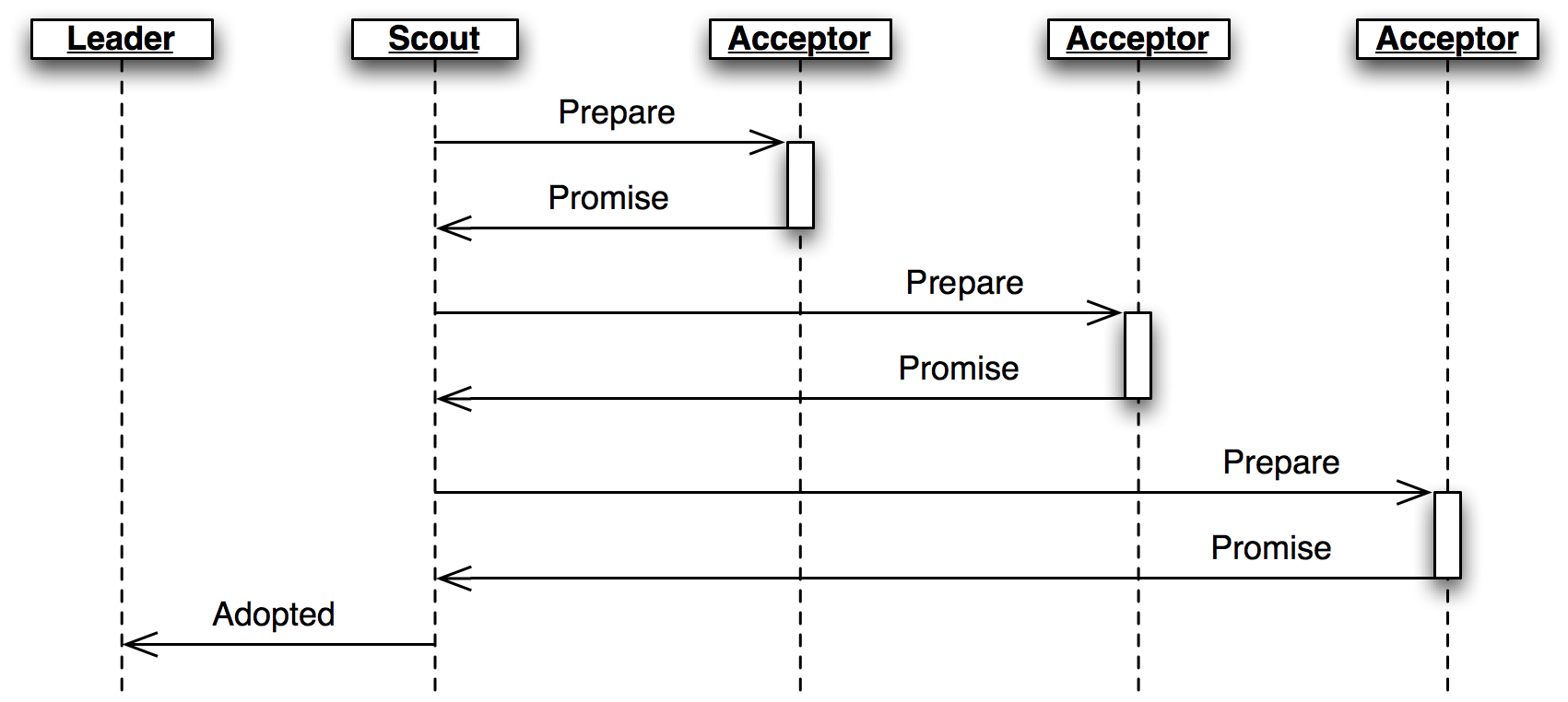
The leader creates a scout role when it wants to become active, in response to receiving a
Proposewhen it is inactive (Figure 3.7.) The scout sends (and re-sends, if necessary) aPreparemessage, and collectsPromiseresponses until it has heard from a majority of its peers or until it has been preempted. It communicates back to the leader withAdoptedorPreempted, respectively.
領導者在啟動時會創造偵查者的角色,用以在待機狀態下接收 Propose(如下圖)。 偵查者會送出(或重送)一個 Prepare 的訊息,並收集 Promise 的回應直到獲得同層級大多數的接受者的回應又或是收到這個這個提案號已經被搶佔為止。他會再用 Adopted 或 Preempted 去跟領導者回報。
class Scout(Role):
def __init__(self, node, ballot_num, peers):
super(Scout, self).__init__(node)
self.ballot_num = ballot_num
self.accepted_proposals = {}
self.acceptors = set([])
self.peers = peers
self.quorum = len(peers) / 2 + 1
self.retransmit_timer = None
def start(self):
self.logger.info("scout starting")
self.send_prepare()
def send_prepare(self):
self.node.send(self.peers, Prepare(ballot_num=self.ballot_num))
self.retransmit_timer = self.set_timer(PREPARE_RETRANSMIT, self.send_prepare)
def update_accepted(self, accepted_proposals):
acc = self.accepted_proposals
for slot, (ballot_num, proposal) in accepted_proposals.iteritems():
if slot not in acc or acc[slot][0] < ballot_num:
acc[slot] = (ballot_num, proposal)
def do_Promise(self, sender, ballot_num, accepted_proposals):
if ballot_num == self.ballot_num:
self.logger.info("got matching promise; need %d" % self.quorum)
self.update_accepted(accepted_proposals)
self.acceptors.add(sender)
if len(self.acceptors) >= self.quorum:
# strip the ballot numbers from self.accepted_proposals, now that it
# represents a majority
accepted_proposals = \
dict((s, p) for s, (b, p) in self.accepted_proposals.iteritems())
# We're adopted; note that this does *not* mean that no other
# leader is active. # Any such conflicts will be handled by the
# commanders.
self.node.send([self.node.address],
Adopted(ballot_num=ballot_num,
accepted_proposals=accepted_proposals))
self.stop()
else:
# this acceptor has promised another leader a higher ballot number,
# so we've lost
self.node.send([self.node.address],
Preempted(slot=None, preempted_by=ballot_num))
self.stop()
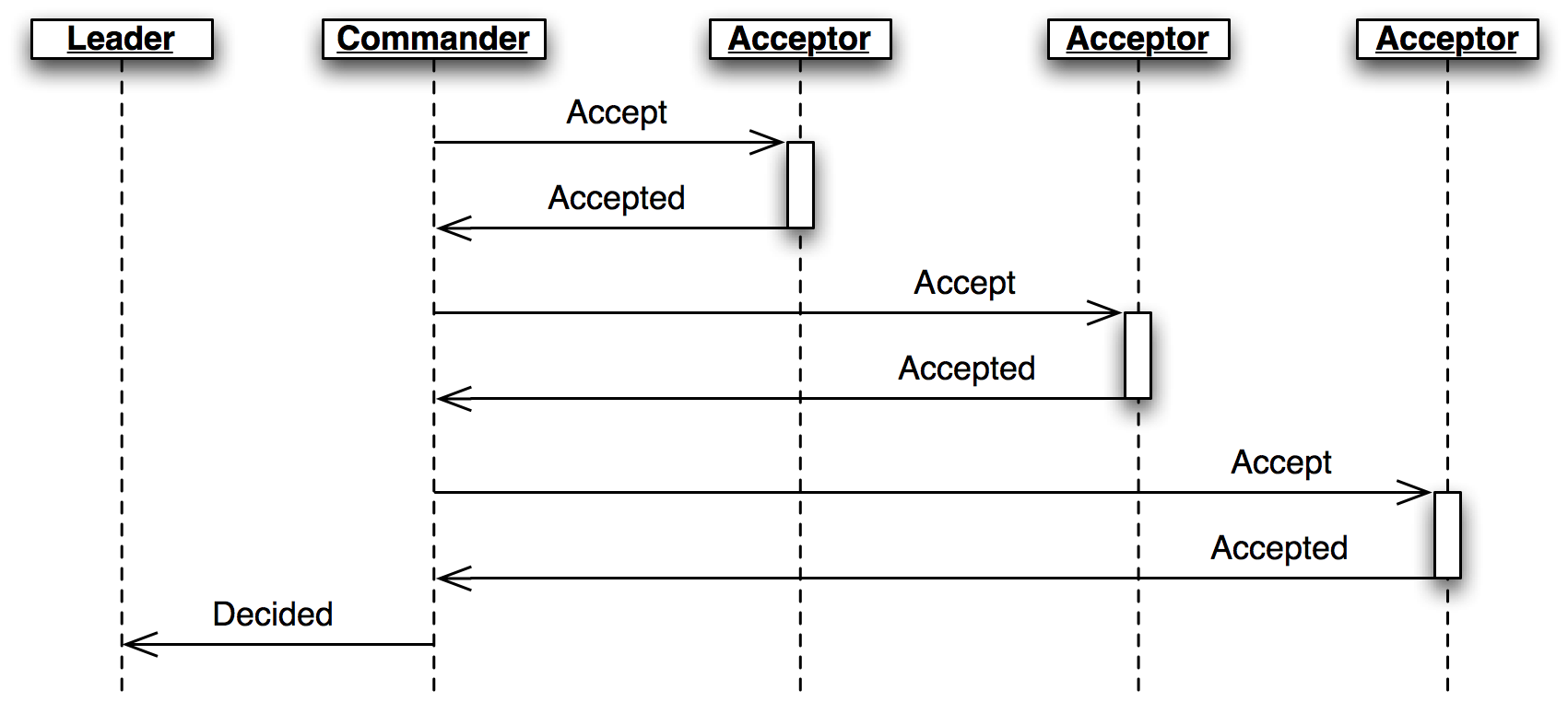
The leader creates a commander role for each slot where it has an active proposal (Figure 3.8.) Like a scout, a commander sends and re-sends
Acceptmessages and waits for a majority of acceptors to reply withAccepted, or for news of its preemption. When a proposal is accepted, the commander broadcasts aDecisionmessage to all nodes. It responds to the leader withDecidedorPreempted.
領導者為每個有活動中提案的插槽各創建一個指揮者的角色,就像指揮者一樣,指揮者送出或是重送一個 Accept 的訊習並等待大多數的接收者回覆一個 Accepted 或是已被搶佔的消息,當一個提案被通過時,指揮者廣播一個 Decision 的訊息給所有節點(包含自己喔!),並回應領導者 Decided 或 Preempted 的訊息。
class Commander(Role):
def __init__(self, node, ballot_num, slot, proposal, peers):
super(Commander, self).__init__(node)
self.ballot_num = ballot_num
self.slot = slot
self.proposal = proposal
self.acceptors = set([])
self.peers = peers
self.quorum = len(peers) / 2 + 1
def start(self):
self.node.send(set(self.peers) - self.acceptors, Accept(
slot=self.slot, ballot_num=self.ballot_num, proposal=self.proposal))
self.set_timer(ACCEPT_RETRANSMIT, self.start)
def finished(self, ballot_num, preempted):
if preempted:
self.node.send([self.node.address],
Preempted(slot=self.slot, preempted_by=ballot_num))
else:
self.node.send([self.node.address],
Decided(slot=self.slot))
self.stop()
def do_Accepted(self, sender, slot, ballot_num):
if slot != self.slot:
return
if ballot_num == self.ballot_num:
self.acceptors.add(sender)
if len(self.acceptors) < self.quorum:
return
self.node.send(self.peers, Decision(
slot=self.slot, proposal=self.proposal))
self.finished(ballot_num, False)
else:
self.finished(ballot_num, True)
As an aside, a surprisingly subtle bug appeared here during development. At the time, the network simulator introduced packet loss even on messages within a node. When all
Decisionmessages were lost, the protocol could not proceed. The replica continued to re-transmit Propose messages, but the leader ignored them as it already had a proposal for that slot. The replica's catch-up process could not find the result, as no replica had heard of the decision. The solution was to ensure that local messages are always delivered, as is the case for real network stacks.
補充個題外話,在開發時我發現一個令人訝異的微妙 bug ,在當時網路模擬器啟用了掉包的設定(就連在同一個節點上的訊息也掉),當所有的 Decision 都遺失時,協議無法繼續進行,臨摹者會重送提案的訊息,而領導者則會忽略這個訊息,因為在該插槽中已經有相同的提案。加上因為沒有任何臨摹者收到決議,所以臨摹者的進程搜尋不到任何結果。解決的方案是保證本地的訊息一定會被送到,就像現實中的網路一樣。
When a node joins the cluster, it must determine the current cluster state before it can participate. The bootstrap role handles this by sending
Joinmessages to each peer in turn until it receives aWelcome. Bootstrap's communication diagram is shown above in Replica.
當一個節點要加入叢集之前,必須先確定當前叢集的狀態。引導者的角色藉由送出 Join 給每一個同層級的直到收到 Welcome 為止來處理這件事情。引導者的通訊流程圖在Replica章節中有提及。
An early version of the implementation started each node with a full set of roles (replica, leader, and acceptor), each of which began in a "startup" phase, waiting for information from the
Welcomemessage. This spread the initialization logic around every role, requiring separate testing of each one. The final design has the bootstrap role adding each of the other roles to the node once startup is complete, passing the initial state to their constructors.
在早期的實作中透過運行全部的角色來啟動一個節點。每一個都由「啟動」的程序開始執行並等待 Welcome 的訊息。這樣就將初始化的邏輯分散到了每個角色上,必須要對每一個分別做測試。而在最後的設計中則由引導者在啟動完成後將不同的角色加入節點中。並傳遞初始的狀態給他們的建構子。
class Bootstrap(Role):
def __init__(self, node, peers, execute_fn,
replica_cls=Replica, acceptor_cls=Acceptor, leader_cls=Leader,
commander_cls=Commander, scout_cls=Scout):
super(Bootstrap, self).__init__(node)
self.execute_fn = execute_fn
self.peers = peers
self.peers_cycle = itertools.cycle(peers)
self.replica_cls = replica_cls
self.acceptor_cls = acceptor_cls
self.leader_cls = leader_cls
self.commander_cls = commander_cls
self.scout_cls = scout_cls
def start(self):
self.join()
def join(self):
self.node.send([next(self.peers_cycle)], Join())
self.set_timer(JOIN_RETRANSMIT, self.join)
def do_Welcome(self, sender, state, slot, decisions):
self.acceptor_cls(self.node)
self.replica_cls(self.node, execute_fn=self.execute_fn, peers=self.peers,
state=state, slot=slot, decisions=decisions)
self.leader_cls(self.node, peers=self.peers, commander_cls=self.commander_cls,
scout_cls=self.scout_cls).start()
self.stop()
In normal operation, when a node joins the cluster, it expects to find the cluster already running, with at least one node willing to respond to a
Joinmessage. But how does the cluster get started? One option is for the bootstrap role to determine, after attempting to contact every other node, that it is the first in the cluster. But this has two problems. First, for a large cluster it means a long wait while eachJointimes out. More importantly, in the event of a network partition, a new node might be unable to contact any others and start a new cluster.
在一般的操作中當一個節點要加入叢集時,它會預期能找到一個正在運行中的叢集,至少有一個節點會願意回應 Join 訊息,那叢集該如何啟動?其中一個選項就是有引導者得來決定,在嘗試聯繫所有其他的節點失敗後,則它就是叢集中的第一個。但這種做法有兩種問題:第一點是對於一個大型的叢集來說它可能必須要等待很久直到所有的 Join 請求都超時。還有更重要的一點是在網路分區中,一個新的節點可能因為沒辦法連接到任何其他的區段而錯誤開啟一個新的叢集。
Network partitions are the most challenging failure case for clustered applications. In a network partition, all cluster members remain alive, but communication fails between some members. For example, if the network link joining a cluster with nodes in Berlin and Taipei fails, the network is partitioned. If both parts of a cluster continue to operate during a partition, then re-joining the parts after the network link is restored can be challenging. In the Multi-Paxos case, the healed network would be hosting two clusters with different decisions for the same slot numbers.
對於叢集式的應用網路分區是最有挑戰性的失敗案例,在網路的各個分段中,所有叢集的成員都是存活的,但叢集之間的通訊卻不一定成功。舉個栗子如果柏林跟台北的叢集連結建立失敗,則網路就被分段了,如果兩邊各自繼續在自己的區段中運行,則在網路連接恢復要重新加入的部份會是很大的挑戰。在 Multi-Paxos 中這種情況則會導致恢復的網路中兩個叢集內相同的插槽編號卻個別包含不同的決議。
To avoid this outcome, creating a new cluster is a user-specified operation. Exactly one node in the cluster runs the seed role, with the others running bootstrap as usual. The seed waits until it has received
Joinmessages from a majority of its peers, then sends aWelcomewith an initial state for the state machine and an empty set of decisions. The seed role then stops itself and starts a bootstrap role to join the newly-seeded cluster.
因為避免這種結果,所以要建立一個叢集應該是使用者指定的操作。叢集中只有一個節點作為種子的角色,其他的則是擔任引導者。種子的角色會等待直到收到大多數同層級的 Join 訊息,然後送出 Welcome 及初始狀態跟空個決議集合。然後停止自己並啟動一個引導者的角色來加入這個新種出來的叢集。
Seed emulates the
Join/Welcomepart of thebootstrap/replicainteraction, so its communication diagram is the same as for the replica role
種子會模仿 bootstrap/replica 的 Join/Welcome 互動方式,所以通訊流程圖也是跟臨摹者的部份相同。
class Seed(Role):
def __init__(self, node, initial_state, execute_fn, peers,
bootstrap_cls=Bootstrap):
super(Seed, self).__init__(node)
self.initial_state = initial_state
self.execute_fn = execute_fn
self.peers = peers
self.bootstrap_cls = bootstrap_cls
self.seen_peers = set([])
self.exit_timer = None
def do_Join(self, sender):
self.seen_peers.add(sender)
if len(self.seen_peers) <= len(self.peers) / 2:
return
# cluster is ready - welcome everyone
self.node.send(list(self.seen_peers), Welcome(
state=self.initial_state, slot=1, decisions={}))
# stick around for long enough that we don't hear any new JOINs from
# the newly formed cluster
if self.exit_timer:
self.exit_timer.cancel()
self.exit_timer = self.set_timer(JOIN_RETRANSMIT * 2, self.finish)
def finish(self):
# bootstrap this node into the cluster we just seeded
bs = self.bootstrap_cls(self.node,
peers=self.peers, execute_fn=self.execute_fn)
bs.start()
self.stop()
The requester role manages a request to the distributed state machine. The role class simply sends
Invokemessages to the local replica until it receives a correspondingInvoked. See the "Replica" section, above, for this role's communication diagram.
提案者負責管理對於分散式狀態機的請求,這個角色類別單純的送出 Invoke 的訊息給本地的臨摹者並等待接收到對應的 Invoked。 通訊流程圖可見「臨摹者」 的段落。
class Requester(Role):
client_ids = itertools.count(start=100000)
def __init__(self, node, n, callback):
super(Requester, self).__init__(node)
self.client_id = self.client_ids.next()
self.n = n
self.output = None
self.callback = callback
def start(self):
self.node.send([self.node.address],
Invoke(caller=self.node.address,
client_id=self.client_id, input_value=self.n))
self.invoke_timer = self.set_timer(INVOKE_RETRANSMIT, self.start)
def do_Invoked(self, sender, client_id, output):
if client_id != self.client_id:
return
self.logger.debug("received output %r" % (output,))
self.invoke_timer.cancel()
self.callback(output)
self.stop()
To recap, cluster's roles are:
- Acceptor -- make promises and accept proposals
- Replica -- manage the distributed state machine: submitting proposals, committing decisions, and responding to requesters
- Leader -- lead rounds of the Multi-Paxos algorithm
- Scout -- perform the
Prepare/Promiseportion of the Multi-Paxos algorithm for a leader- Commander -- perform the
Accept/Acceptedportion of the Multi-Paxos algorithm for a leader- Bootstrap -- introduce a new node to an existing cluster
- Seed -- create a new cluster
- Requester -- request a distributed state machine operation
總結一下,叢集有以下角色:
- 接收者 -- 做出承諾並接受提案
- 臨摹者 -- 管理分散式狀態機像是:提交提案、決議並回應提案者
- 領導者 -- 引領整個 Multi-Paxos 的演算法執行
- 偵查者 -- 負責領導者事務中
Prepare/Promise的部份處理 - 指揮者 -- 負責領導者事務中
Accept/Accepted的部份處理 - 引導者 -- 引導一個新的節點到現有的叢集中
- 種子 -- 創建一個新的叢集
- 提案者 -- 請求一個分散式狀態機的操作
There is just one more piece of equipment required to make Cluster go: the network through which all of the nodes communicate.
只需要最後一個設備就能讓我們的叢集運作起來:就是透過網路讓所有的節點連結。
Any network protocol needs the ability to send and receive messages and a means of calling functions at a time in the future.
The
Networkclass provides a simple simulated network with these capabilities and also simulates packet loss and message propagation delays.
任何網路協議都需要有辦法傳送跟接收訊息,還有在後續調用函數的能力。
Network 這個類別提供模擬上敘功能的能力,並且可以模擬封包遺失跟訊息傳送延遲。
Timers are handled using Python's
heapqmodule, allowing efficient selection of the next event. Setting a timer involves pushing aTimerobject onto the heap. Since removing items from a heap is inefficient, cancelled timers are left in place but marked as cancelled.
我們使用 Python 的 heapq 來管理計時器,允許高效的檢索下一個事件。設定一個計時器只需要把 Timer 的物件推入 heap 中。此外由於從 heap 中移除物件是非常低效的,所以取消一個計時器時我們並不會移除他,只是標記為取消而已。
Message transmission uses the timer functionality to schedule a later delivery of the message at each node, using a random simulated delay. We again use
functools.partialto set up a future call to the destination node'sreceivemethod with appropriate arguments.
在訊息的傳輸上,我們使用計時器的函式來規劃每個節點的送達延遲,搭隨機的延遲時間來模擬。利用 functools.partial 的及適當的參數來設定到達節點的 receive 方法。
Running the simulation just involves popping timers from the heap and executing them if they have not been cancelled and if the destination node is still active.
運行模擬的流程只需要取得 heap 中被推出的計時器,並在沒有被取消以及目的地依然存活的情況下調用該計時器。
class Timer(object):
def __init__(self, expires, address, callback):
self.expires = expires
self.address = address
self.callback = callback
self.cancelled = False
def __cmp__(self, other):
return cmp(self.expires, other.expires)
def cancel(self):
self.cancelled = True
class Network(object):
PROP_DELAY = 0.03
PROP_JITTER = 0.02
DROP_PROB = 0.05
def __init__(self, seed):
self.nodes = {}
self.rnd = random.Random(seed)
self.timers = []
self.now = 1000.0
def new_node(self, address=None):
node = Node(self, address=address)
self.nodes[node.address] = node
return node
def run(self):
while self.timers:
next_timer = self.timers[0]
if next_timer.expires > self.now:
self.now = next_timer.expires
heapq.heappop(self.timers)
if next_timer.cancelled:
continue
if not next_timer.address or next_timer.address in self.nodes:
next_timer.callback()
def stop(self):
self.timers = []
def set_timer(self, address, seconds, callback):
timer = Timer(self.now + seconds, address, callback)
heapq.heappush(self.timers, timer)
return timer
def send(self, sender, destinations, message):
sender.logger.debug("sending %s to %s", message, destinations)
# avoid aliasing by making a closure containing distinct deep copy of
# message for each dest
def sendto(dest, message):
if dest == sender.address:
# reliably deliver local messages with no delay
self.set_timer(sender.address, 0,
lambda: sender.receive(sender.address, message))
elif self.rnd.uniform(0, 1.0) > self.DROP_PROB:
delay = self.PROP_DELAY + self.rnd.uniform(-self.PROP_JITTER,
self.PROP_JITTER)
self.set_timer(dest, delay,
functools.partial(self.nodes[dest].receive,
sender.address, message))
for dest in (d for d in destinations if d in self.nodes):
sendto(dest, copy.deepcopy(message))
While it's not included in this implementation, the component model allows us to swap in a real-world network implementation, communicating between actual servers on a real network, with no changes to the other components. Testing and debugging can take place using the simulated network, with production use of the library operating over real network hardware.
雖然該元件不算是此實作的一部分,這個模組允許我們替換掉真實的網路環境,模擬伺服器間的通訊。對於使用在真實網路硬體上的函式庫,在模擬的網路下測試跟除錯會更為簡單及便利。
When developing a complex system such as this, the bugs quickly transition from trivial, like a simple NameError, to obscure failures that only manifest after several minutes of (simulated) proocol operation. Chasing down bugs like this involves working backward from the point where the error became obvious. Interactive debuggers are useless here, as they can only step forward in time.
在開發這種複雜的系統時,由一些簡單的故障(像是名稱錯誤)常常在傳輸幾分鐘進行協議操作後變成模糊的故障。這樣的錯誤必須要從發生問題的地方一路向後追查,因此交互式除錯器在這裡用處不大,因為他們在時序上只能向前步進。
The most important debugging feature in Cluster is a deterministic simulator. Unlike a real network, it will behave exactly the same way on every run, given the same seed for the random number generator. This means that we can add additional debugging checks or output to the code and re-run the simulation to see the same failure in more detail.
在叢集上最重要的除錯功能就是具有確定性的模擬器,跟真實網路不一樣,在給定隨機生成器相同種子的情況下,他們每次都會用完全相同的方式運行(具有確定性)。這代表我們可以在程式碼上追加額外的除錯檢查或輸出並且重新模擬,輕易的重現相同錯誤。
Of course, much of that detail is in the messages exchanged by the nodes in the cluster, so those are automatically logged in their entirety. That logging includes the role class sending or receiving the message, as well as the simulated timestamp injected via the
SimTimeLoggerclass.
還有很大一部份的細節藏在節點跟叢集交換的訊息中,所以他們會自動的被紀錄在日誌中。該日誌紀錄時會包含(發送/接收)的角色,並透過 SimTimeLogger 類別注入相應的時間戳記。
lass SimTimeLogger(logging.LoggerAdapter):
def process(self, msg, kwargs):
return "T=%.3f %s" % (self.extra['network'].now, msg), kwargs
def getChild(self, name):
return self.__class__(self.logger.getChild(name),
{'network': self.extra['network']})
A resilient protocol such as this one can often run for a long time after a bug has been triggered. For example, during development, a data aliasing error caused all replicas to share the same decisions dictionary. This meant that once a decision was handled on one node, all other nodes saw it as already decided. Even with this serious bug, the cluster produced correct results for several transactions before deadlocking.
像本次我們實作這種有適應力的協議通常可以在 bug 被觸發之後還運作很長一段時間。舉個栗子,一個數據引用錯誤導致所有的臨摹者使用同一個決議的 dictionary (Python 的一種資料)。這代表一個決議還在處理時,其他的節點看過去就會認為這已經被決議好了。就像這種嚴重的 bug ,叢集也會在傳輸出數個正確的結果之後才進入死鎖。
Assertions are an important tool to catch this sort of error early. Assertions should include any invariants from the algorithm design, but when the code doesn't behave as we expect, asserting our expectations is a great way to see where things go astray.
Assertions(斷言) 是一個重要的工具可以來早期發現早期治療這種錯誤,斷言應該用來檢查在演算法層級具有不變性的設計。當程式並非按照這部份運行時,使用斷言來檢查我們期望的運作方向會是一個很好的方法來找出事情哪裡出錯了。
assert not self.decisions.get(self.slot, None), \
"next slot to commit is already decided"
if slot in self.decisions:
assert self.decisions[slot] == proposal, \
"slot %d already decided with %r!" % (slot, self.decisions[slot])
Identifying the right assumptions we make while reading code is a part of the art of debugging. In this code from
Replica.do_Decision, the problem was that theDecisionfor the next slot to commit was being ignored because it was already inself.decisions. The underlying assumption being violated was that the next slot to be committed was not yet decided. Asserting this at the beginning ofdo_Decisionidentified the flaw and led quickly to the fix. Similarly, other bugs led to cases where different proposals were decided in the same slot -- a serious error.
在閱讀程式碼時確定「正確的假設」是一種除錯的藝術,在這段來自 Replica.do_Decision 的程式碼,問題是來自下一個插槽要提交的 Decision 由於已經存在 self.decisions 而被無視了。其內含的假設「下一個要提交插槽內的必是還沒決議的」被迫壞了。對其在 do_Decision 的開頭做出斷言確認整體流程就可以讓我們快速的修復它,對於其他的 bug 像是不同的提案被決議在同個插槽這種嚴重錯誤也有同樣的效果。
Many other assertions were added during development of the protocol, but in the interests of space, only a few remain.
在開發階段還有加入很多其他的斷言,不過由於篇幅的限制,目前只留下了少數。
Some time in the last ten years, coding without tests finally became as crazy as driving without a seatbelt. Code without tests is probably incorrect, and modifying code is risky without a way to see if its behavior has changed.
從過去十年期間開始,在沒有測試的情況下進行程式設計終於變成像是開車不綁安全帶這種瘋狂的事了。沒有經過測試的程式碼有很大可能是作物的,而且在沒有驗證方式的情況下修改它們也有不知行為是否變更的風險。
Testing is most effective when the code is organized for testability. There are a few active schools of thought in this area, but the approach we've taken is to divide the code into small, minimally connected units that can be tested in isolation. This agrees nicely with the role model, where each role has a specific purpose and can operate in isolation from the others, resulting in a compact, self-sufficient class.
在程式碼是為了可測試性所架構時進行測試是最為高效的,在如何作到這點上也有很多不同的作法,我們所採取的是將程式碼劃分為小型元件,最小化各單位之間的連結,讓我們盡可能單獨對其進行測試。這很符合角色模型的作法,每個角色都可以獨立運行,是一個緊湊並且自給自足的類別。
Cluster is written to maximize that isolation: all communication between roles takes place via messages, with the exception of creating new roles. For the most part, then, roles can be tested by sending messages to them and observing their responses.
叢集就是被寫來最大化這種獨立性的,除了創建新角色以外,所有角色之間的通訊都透過訊息來進行。因此最棒的就是每個角色都可以透過傳送訊息以及觀察回應來進行測試。
The unit tests for Cluster are simple and short:
叢集的單元測試非常簡短。
class Tests(utils.ComponentTestCase):
def test_propose_active(self):
"""A PROPOSE received while active spawns a commander."""
self.activate_leader()
self.node.fake_message(Propose(slot=10, proposal=PROPOSAL1))
self.assertCommanderStarted(Ballot(0, 'F999'), 10, PROPOSAL1)
This method tests a single behavior (commander spawning) of a single unit (the Leader class). It follows the well-known "arrange, act, assert" pattern: set up an active leader, send it a message, and check the result.
這個方法用單元測試的方式來測試一個行為(領導者產生指揮者),它遵循「已知」的「安排、對應行為、斷言」的模式,來設置一個有效的領導者,傳送訊息,並檢查結果。
####Dependency Injection(依賴性注入)
We use a technique called "dependency injection" to handle creation of new roles. Each role class which adds other roles to the network takes a list of class objects as constructor arguments, defaulting to the actual classes. For example, the constructor for Leader looks like this
我們用「依賴性注入」的技術來處理新角色的創建,每個角色類別都將建構子參數作為建構的參數,默認則為實際的該類別,像是 Leader 的建構子看起來像這樣
class Leader(Role):
def __init__(self, node, peers, commander_cls=Commander, scout_cls=Scout):
super(Leader, self).__init__(node)
self.ballot_num = Ballot(0, node.address)
self.active = False
self.proposals = {}
self.commander_cls = commander_cls
self.scout_cls = scout_cls
self.scouting = False
self.peers = peers
The
spawn_scoutmethod (and similarly,spawn_commander) creates the new role object withself.scout_cls:
spawn_scout 這個方法用 self.scout_cls 來創建新的角色類別
譯註:注意
self.scout_cls的內容其實是我們剛剛建構時傳近來的參數,因此我們可以用建構時的參數來控制實際生成的物件)
class Leader(Role):
def spawn_scout(self):
assert not self.scouting
self.scouting = True
self.scout_cls(self.node, self.ballot_num, self.peers).start()
The magic of this technique is that, in testing,
Leadercan be given fake classes and thus tested separately fromScoutandCommander.
神奇之處就在這了,在測試時領導者可以被給予一個假的類別,因此測試本身就從實際的指揮者和偵查者類別拆開了。
One pitfall of a focus on small units is that it does not test the interfaces between units. For example, unit tests for the acceptor role verify the format of the
acceptedattribute of thePromisemessage, and the unit tests for the scout role supply well-formatted values for the attribute. Neither test checks that those formats match.
專住在小單元的測試上會有一個誤區,就是各單元之間的界面並沒有被測試到。舉個栗子來說,對接受者的角色進行單元測試可以測試 Promise 中的 accepted 格式是否正確。單元測試為偵查者的角色提供了格式正確的值,卻沒有測試兩者之間的傳輸的格式是互相匹配的。
One approach to fixing this issue is to make the interfaces self-enforcing. In Cluster, the use of named tuples and keyword arguments avoids any disagreement over messages' attributes. Because the only interaction between role classes is via messages, this covers a large part of the interface.
一個修正這個問題的作法是讓這個界面是有自我完成能力的。在叢集中,使用 named tuples 可以避免訊息屬性之間的不一致,因為角色類別之間的互動都只會透過訊息來完成,這就包含了大部分界面的大部分。
For specific issues such as the format of
accepted_proposals, both the real and test data can be verified using the same function, in this caseverifyPromiseAccepted. The tests for the acceptor use this method to verify each returnedPromise, and the tests for the scout use it to verify every fakePromise.
像這種像是 accepted_proposals 格式的問題,真實跟測試的資料都可以用同一個函式來驗證,在這個案例中為 verifyPromiseAccepted,對於接受者的測試我們用這個方法來驗證回傳的 Promise,至於對於偵查者我們則用此函式來製作假的 Promise
The final bulwark against interface problems and design errors is integration testing. An integration test assembles multiple units together and tests their combined effect. In our case, that means building a network of several nodes, injecting some requests into it, and verifying the results. If there are any interface issues not discovered in unit testing, they should cause the integration tests to fail quickly.
用來處理界面問題跟設計錯誤的最後一個防線則是集成測試,集成測試會組裝多個單元並測試他們組合後的效果,在我們的案例中就是建構具有數個節點的網路,注入一些請求,並檢驗結果。如果還有任何界面上的問題沒在單元測試中發現的,應該會很快的就導致集成測試失敗。
Because the protocol is intended to handle node failure gracefully, we test a few failure scenarios as well, including the untimely failure of the active leader.
由於一個協議有義務優雅的處理節點的錯誤,所以我們也會測試幾個失敗的場景,像是過早啟動 leader 的錯誤之類的。
Integration tests are harder to write than unit tests, because they are less well-isolated. For Cluster, this is clearest in testing the failed leader, as any node could be the active leader. Even with a deterministic network, a change in one message alters the random number generator's state and thus unpredictably changes later events. Rather than hard-coding the expected leader, the test code must dig into the internal state of each leader to find one that believes itself to be active.
集成測試比單元測試更難撰寫,因為測試之間的隔離性較差。對於一個叢集來說最為明顯的就是在測試領導者錯誤的時候。就算在具有確定性的網路之下,過程中一個訊息的變化就會導致隨機數產生器的狀態不同,因而導致後面的事件發生無法預測的改變。為了避免 hard-code 寫死指定的領導者這種作法,測試的程式碼需要深入到領導者的內部狀態,來找出認為自己是領導者的人。
It's very difficult to test resilient code: it is likely to be resilient to its own bugs, so integration tests may not detect even very serious bugs. It is also hard to imagine and construct tests for every possible failure mode.
越是彈性的代碼越南測試,他們的彈性可能會隱藏自己的 bug ,所以集成測試可能不會找出一些嚴重的 bug 。也很難去想像或建構針對所有可能發生錯誤的測試。
A common approach to this sort of problem is "fuzz testing": running the code repeatedly with randomly changing inputs until something breaks. When something does break, all of the debugging support becomes critical: if the failure can't be reproduced, and the logging information isn't sufficient to find the bug, then you can't fix it!
一個普通的解決方案是使用模糊測試,執行一段代碼會隨機的改變輸入直到任何錯誤發生,當錯誤發生時,除錯的支援就顯得重要。如果錯誤無法被重現,日誌又不足以讓我們找到 bug,那基本上就無法修復。
I performed some manual fuzz testing of cluster during development, but a full fuzz-testing infrastructure is beyond the scope of this project.
我在開發時有手動對叢集做了一些模糊測試,至於完整的模糊測試架構則超出了本專案的範圍了。
A cluster with many active leaders is a very noisy place, with scouts sending ever-increasing ballot numbers to acceptors, and no ballots being decided. A cluster with no active leader is quiet, but equally nonfunctional. Balancing the implementation so that a cluster almost always agrees on exactly one leader is remarkably difficult.
有多個領導者的叢集是非常吵雜的,偵查者會不斷增加提案編號並送給接收者,但卻並不會有提案被決定(因為提案會一直互蓋)。一個沒有任何領導者的叢集是寂靜的,但與前者同樣沒作用。在我們的實作中要取得平衡讓叢集總是只同意一個領導者是特別困難的
It's easy enough to avoid fighting leaders: when
preempted, a leader just accepts its new inactive status. However, this easily leads to a case where there are no active leaders, so an inactive leader will try to become active every time it gets aProposemessage.
要讓避免領導者角色的爭奪很簡單,當 preempted 發生時,領導者就接受它的新狀態為未啟用,但這很容易導致沒有任何領導者在運作的狀況。所以當一個未啟用的領導者接收到Propose 的訊息時就會嘗試去成為啟動狀態。
If the whole cluster doesn't agree on which member is the active leader, there's trouble: different replicas send
Proposemessages to different leaders, leading to battling scouts. So it's important that leader elections be decided quickly, and that all cluster members find out about the result as quickly as possible.
當整個叢集對於哪個成員是領導者沒有共識時就會有問題發生:不同的臨摹者傳送 Propose 訊息給不同的領導者,導致偵查者互相搶佔。所以誰是領導者必須盡可能快速的決議並通知其他成員。
Cluster handles this by detecting a leader change as quickly as possible: when an acceptor sends a
Promise, chances are good that the promised member will be the next leader. Failures are detected with a heartbeat protocol.
叢集必須盡可能的快速偵測誰轉為領導者,當一個接受者送出 Promise 時,有很大的可能性它承諾的對象就是新的領導者。至於失敗則用心跳包的協議來檢測。
Of course, there are plenty of ways we could extend and improve this implementation.
當然還有很多種方法可以繼續擴展跟改進這個實作。
In "pure" Multi-Paxos, nodes which fail to receive messages can be many slots behind the rest of the cluster. As long as the state of the distributed state machine is never accessed except via state machine transitions, this design is functional. To read from the state, the client requests a state-machine transition that does not actually alter the state, but which returns the desired value. This transition is executed cluster-wide, ensuring that it returns the same value everywhere, based on the state at the slot in which it is proposed.
在原始的 Multi-Paxos 中,一個節點可能因為接收訊息失敗而導致插槽內的操作數量落後於叢集內的其他成員。又由於分散式的狀態機只透過用訊息觸發狀態轉換來溝通,因此我們會把讀取狀態的操作也設計成一種狀態轉換,即使此操作並不會真的改變狀態,這是個很實用的設計。但這個狀態轉換必須在整個叢集跑過一遍,確保基於該插槽的提案的所有成員都回傳相同值。
Even in the optimal case, this is slow, requiring several round trips just to read a value. If a distributed object store made such a request for every object access, its performance would be dismal. But when the node receiving the request is lagging behind, the request delay is much greater as that node must catch up to the rest of the cluster before making a successful proposal.
即使在最好的狀態下這個操作也很低效,為了讀取一個值就需要在節點中跑好幾次,如果每次要存取分散式的物件都要提出這樣的請求,那效能會是非常令人沮喪的。還有當節點收到請求時是落後的,請求的延遲會更高,因為節點在成功做出提案之前還必須追上落後的部份。
A simple solution is to implement a gossip-style protocol, where each replica periodically contacts other replicas to share the highest slot it knows about and to request information on unknown slots. Then even when a
Decisionmessage was lost, the replica would quickly find out about the decision from one of its peers.
一個簡單的解決方案是實作一個八卦式(閒聊八卦的那個八卦)的協議,每個臨摹者定期聯絡其他的臨摹者來同步最新的插槽資訊,同時也請求未知插槽的資訊,這樣當一個 Decision 的訊息丟失時,臨摹者就會很快的從其他地方發現這件事。
A cluster-management library provides reliability in the presence of unreliable components. It shouldn't add unreliability of its own. Unfortunately, Cluster will not run for long without failing due to ever-growing memory use and message size.
一個管理叢集的函式庫需要為不可靠的部件提供可靠性,所以他本身不能是不可靠的。不幸的是我們實作的叢集會因為無限增加的內存使用跟封包大小而無法存活太久。
譯註:這個可靠性是指即使有部份發生錯誤也能正常運作的能力
In the protocol definition, acceptors and replicas form the "memory" of the protocol, so they need to remember everything. These classes never know when they will receive a request for an old slot, perhaps from a lagging replica or leader. To maintain correctness, then, they keep a list of every decision, ever, since the cluster was started. Worse, these decisions are transmitted between replicas in
Welcomemessages, making these messages enormous in a long-lived cluster.
在協議的定義,接受者跟臨摹者必須要記憶所有發生過得協議,因為這些類別永遠不知道會不會收到落後插槽的請求,所以為了保持正確性他們必須保留所有決策的列表。更遭的是這些決策還會隨著 Welcome 的操作傳遞,這些訊息會在長時間存活的叢集中變得非常龐大。
譯註:是因為
Welcome之後必須同步狀態,等於要把叢集從頭到尾超多的決議操作塞到一個訊息內。
One technique to address this issue is to periodically "checkpoint" each node's state, keeping information about some limited number of decisions on hand. Nodes which are so out of date that they have not committed all slots up to the checkpoint must "reset" themselves by leaving and re-joining the cluster.
一個解決方案是為節點設置「檢查點」,定期檢查每個節點的狀態並只保留有限的決策訊息,沒有提交所有插槽提案給檢查點的過時節點必須藉由離開再重新加入叢集來重置自己。
While it's OK for a minority of cluster members to fail, it's not OK for an acceptor to "forget" any of the values it has accepted or promises it has made.
雖然少數的叢集成員可以操作失敗,但接受者並不能忘記他已承諾的值,。
Unfortunately, this is exactly what happens when a cluster member fails and restarts: the newly initialized Acceptor instance has no record of the promises its predecessor made. The problem is that the newly-started instance takes the place of the old.
不幸的是這在叢集成員錯誤並重啟時有可能發生。新初始化的接受者實體並沒有重啟前承諾的紀錄,但它又確實取代了重啟前的位置。
There are two ways to solve this issue. The simpler solution involves writing acceptor state to disk and re-reading that state on startup. The more complex solution is to remove failed cluster members from the cluster, and require that new members be added to the cluster. This kind of dynamic adjustment of the cluster membership is called a "view change".
有兩個方式可以解決這個問題,簡單的解決方案會將接受者的狀態不斷寫入硬碟,並在重啟時讀取。複雜一點的解決方案則是從叢集中移除發生錯誤的舊成員,將重啟的視為新成員加入叢集中,這種成員資格的動態調整稱為「視圖更改」
Operations engineers need to be able to resize clusters to meet load and availability requirements. A simple test project might begin with a minimal cluster of three nodes, where any one can fail without impact. When that project goes "live", though, the additional load will require a larger cluster.
操作工程師需要能夠更改叢集的大小來符合負載跟可用性跟需求,一個簡單的測試專案含有最小的叢集會需要三個節點,而且其中任何一個可以錯誤卻不會影響叢集。但是當專案真正啟用時,額外的負載量會需要更大的叢集。
Cluster, as written, cannot change the set of peers in a cluster without restarting the entire cluster. Ideally, the cluster would be able to maintain a consensus about its membership, just as it does about state machine transitions. This means that the set of cluster members (the view) can be changed by special view-change proposals. But the Paxos algorithm depends on universal agreement about the members in the cluster, so we must define the view for each slot.
如上所敘,叢集無法在不重啟的情況下更改對應的方案規模,在理想情況下,叢集藉由維護成員的共識來運作,這代表叢集的成員(視圖)可以藉由特殊的更改視圖提案來改變,但 Paxos 的演算法是藉由成員的共同協議來溝通,所以我們需要為了每個插槽定義視圖。
譯註:意思是必須紀錄每個插槽(狀態)當下的成員視圖,這樣才知道決策時的成員有哪些,回朔的時候不會多送給當時不存在的成員之類的。
Lamport addresses this challenge in the final paragraph of "Paxos Made Simple":
We can allow a leader to get α commands ahead by letting the set of servers that execute instance i+α of the consensus algorithm be specified by the state after execution of the ith state machine command. (Lamport, 2001)
The idea is that each instance of Paxos (slot) uses the view from α slots earlier. This allows the cluster to work on, at most, α slots at any one time, so a very small value of α limits concurrency, while a very large value of α makes view changes slow to take effect.
Lamport 在 "Paxos Made Simple" 論文中紀錄了這個挑戰
我們可以讓領導者在執行 α 個命令後才加入第 i 個實體,這樣第 i 個實體就能提前獲得 α 個命令。
這個主意是每個插槽實際使用的是第 α 個之前的視圖,所以很小的 α 會限制併發性,而很大的 α 則會讓視圖的轉換很慢才生效。
上面的作法我不是很確定自己有沒有看懂,又沒付 code,可能要再研究一下
In early drafts of this implementation (dutifully preserved in the git history!), I implemented support for view changes (using α in place of 3). This seemingly simple change introduced a great deal of complexity:
- tracking the view for each of the last α
- committed slots and correctly sharing this with new nodes,
- ignoring proposals for which no slot is available,
- detecting failed nodes,
- properly serializing multiple competing view changes, and
- communicating view information between the leader and replica.
在早期的實作草稿中(git 歷史中有),我實現了對視圖更改的支援(α 帶入 3),這個簡單的改動帶來了巨大的複雜性改變。
- 要能跟蹤最後 α 個視圖
- 提交的插槽要能正確的跟新節點共享
- 忽略沒有可用插槽的提案
- 檢測失敗的節點
- 正確序列化對視圖更改的競爭
- 在領導者跟臨摹者之間傳遞視圖更改的訊息
The result was far too large for this book!
得到的結果對於這本書來說太龐大了。
In addition to the original Paxos paper and Lamport's follow-up "Paxos Made Simple"2, our implementation added extensions that were informed by several other resources. The role names were taken from "Paxos Made Moderately Complex"3. "Paxos Made Live"4 was helpful regarding snapshots in particular, and "Paxos Made Practical" described view changes (although not of the type described here.) Liskov's "From Viewstamped Replication to Byzantine Fault Tolerance"5 provided yet another perspective on view changes. Finally, a Stack Overflow discussion was helpful in learning how members are added and removed from the system.
除了最初的 Paxos 論文及 "Paxos Made Simple" 之外我們的實現還增加了幾種資源的擴展,角色名稱取自 "Paxos Made Moderately Complex","Paxos Made Live" 針對取得快照提供了幫助,"Paxos Made Practical" 敘述了視圖更改(儘管跟此處敘述的不太一樣),Liskov 的 "From Viewstamped Replication to Byzantine Fault Tolerance" 提供了另外一個對於視圖更改的視角,最後 Stack Overflow 的討論有助於了解如何在系統中新增或刪除成員。
-
L. Lamport, "The Part-Time Parliament," ACM Transactions on Computer Systems, 16(2):133–169, May 1998.↩
-
L. Lamport, "Paxos Made Simple," ACM SIGACT News (Distributed Computing Column) 32, 4 (Whole Number 121, December 2001) 51-58.↩
-
R. Van Renesse and D. Altinbuken, "Paxos Made Moderately Complex," ACM Comp. Survey 47, 3, Article 42 (Feb. 2015)↩
-
T. Chandra, R. Griesemer, and J. Redstone, "Paxos Made Live - An Engineering Perspective," Proceedings of the twenty-sixth annual ACM symposium on Principles of distributed computing (PODC '07). ACM, New York, NY, USA, 398-407.↩
-
B. Liskov, "From Viewstamped Replication to Byzantine Fault Tolerance," In Replication, Springer-Verlag, Berlin, Heidelberg 121-149 (2010)↩