`_ 版本 7.5 以上的 GPU
+.. [#] GPU 利用率:这里指 GPU 计算能力被使用部分所占的百分比
.. [#] https://en.wikipedia.org/wiki/Thread_pool
.. [#] https://en.wikipedia.org/wiki/Data-flow_diagram
diff --git a/docs/advanced_guide/performance_improving/multinode_training_improving/gpu_training_with_low_bandwidth_dgc.md b/docs/advanced_guide/performance_improving/multinode_training_improving/gpu_training_with_low_bandwidth_dgc.md
index 7da97430c9e..16c36ab14a8 100644
--- a/docs/advanced_guide/performance_improving/multinode_training_improving/gpu_training_with_low_bandwidth_dgc.md
+++ b/docs/advanced_guide/performance_improving/multinode_training_improving/gpu_training_with_low_bandwidth_dgc.md
@@ -1,120 +1,120 @@
-# 低配网络的分布式GPU训练
+# 低配网络的分布式 GPU 训练
## 1. 背景
- 大规模分布式训练需要较高的网络带宽以便进行梯度的聚合更新,这限制了多节点训练时的可扩展性同时也需要昂贵的高带宽设备。在低带宽云网络等环境下进行分布式训练会变得更加糟糕。现有[Deep Gradient Compression](https://arxiv.org/abs/1712.01887)研究表明,分布式SGD中有99.9%的梯度交换都是冗余的,可以使用深度梯度压缩选择重要梯度进行通信来减少通信量,降低对通信带宽的依赖。Paddle目前实现了DGC的稀疏通信方式,可有效在低配网络下进行GPU分布式训练。下面将介绍DGC稀疏通信方式的使用方法、适用场景及基本原理。
+ 大规模分布式训练需要较高的网络带宽以便进行梯度的聚合更新,这限制了多节点训练时的可扩展性同时也需要昂贵的高带宽设备。在低带宽云网络等环境下进行分布式训练会变得更加糟糕。现有[Deep Gradient Compression](https://arxiv.org/abs/1712.01887)研究表明,分布式 SGD 中有 99.9%的梯度交换都是冗余的,可以使用深度梯度压缩选择重要梯度进行通信来减少通信量,降低对通信带宽的依赖。Paddle 目前实现了 DGC 的稀疏通信方式,可有效在低配网络下进行 GPU 分布式训练。下面将介绍 DGC 稀疏通信方式的使用方法、适用场景及基本原理。
## 2. 使用方法
-`注意:使用DGC请使用1.6.2及其之后版本,之前版本存在有若干bug。`
-DGC稀疏通信算法以DGCMomentumOptimizer接口的形式提供,目前只支持GPU多卡及GPU多机分布式,由于现有fuse策略会造成DGC失效,所以使用DGC时需设置`strategy.fuse_all_reduce_ops=False`关闭fuse。DGC只支持Momentum优化器,使用时把当前代码中的Momentum优化器替换为DGCMomentumOptimizer,并添加DGC所需参数即可。如下代码所示,其中rampup_begin_step表示从第几步开始使用DGC,更详细参数可见[api文档](https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/optimizer_cn/DGCMomentumOptimizer_cn.html#dgcmomentumoptimizer)。
+`注意:使用 DGC 请使用 1.6.2 及其之后版本,之前版本存在有若干 bug。`
+DGC 稀疏通信算法以 DGCMomentumOptimizer 接口的形式提供,目前只支持 GPU 多卡及 GPU 多机分布式,由于现有 fuse 策略会造成 DGC 失效,所以使用 DGC 时需设置`strategy.fuse_all_reduce_ops=False`关闭 fuse。DGC 只支持 Momentum 优化器,使用时把当前代码中的 Momentum 优化器替换为 DGCMomentumOptimizer,并添加 DGC 所需参数即可。如下代码所示,其中 rampup_begin_step 表示从第几步开始使用 DGC,更详细参数可见[api 文档](https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/optimizer_cn/DGCMomentumOptimizer_cn.html#dgcmomentumoptimizer)。
``` python
import paddle.fluid as fluid
# optimizer = fluid.optimizer.Momentum(learning_rate=0.001, momentum=0.9)
-# 替换Momentum优化器,添加DGC所需参数
+# 替换 Momentum 优化器,添加 DGC 所需参数
optimizer = fluid.optimizer.DGCMomentumOptimizer(
learning_rate=0.001, momentum=0.9, rampup_begin_step=0)
optimizer.minimize(cost)
```
-在fleet中我们提供了[DGC的示例](https://github.com/PaddlePaddle/FleetX/tree/old_develop/deprecated/examples/dgc_example)。示例中以数字手写体识别为例,将程序移植为分布式版本(注:DGC亦支持单机多卡),再加上DGC优化器。可参照此示例将单机单卡程序迁移到DGC。在单机单卡迁移到DGC过程中,一般需要先对齐多机Momentum的精度,再对齐DGC的精度。
+在 fleet 中我们提供了[DGC 的示例](https://github.com/PaddlePaddle/FleetX/tree/old_develop/deprecated/examples/dgc_example)。示例中以数字手写体识别为例,将程序移植为分布式版本(注:DGC 亦支持单机多卡),再加上 DGC 优化器。可参照此示例将单机单卡程序迁移到 DGC。在单机单卡迁移到 DGC 过程中,一般需要先对齐多机 Momentum 的精度,再对齐 DGC 的精度。
## 3. 调参&适用场景
### 3.1 预热调参
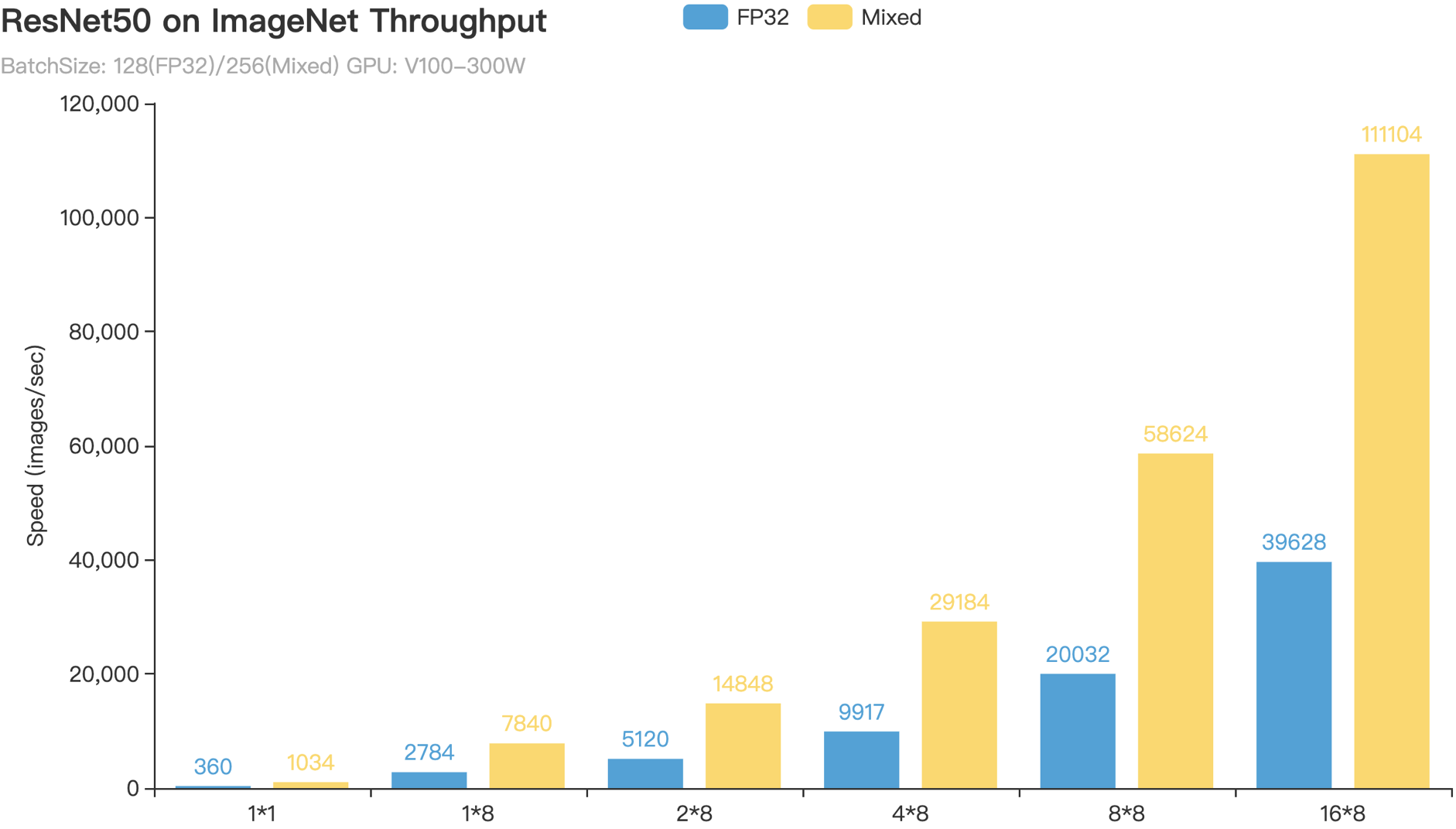
-对于正常的训练,使用DGC一般需进行预热训练,否则可能会有精度损失。如下图是ResNet50模型Imagenet数据集的训练结果,未进行预热训练的DGC最终损失了约0.3%的精度。
+对于正常的训练,使用 DGC 一般需进行预热训练,否则可能会有精度损失。如下图是 ResNet50 模型 Imagenet 数据集的训练结果,未进行预热训练的 DGC 最终损失了约 0.3%的精度。

-预热训练调参可参照论文的设置。对图像分类,论文在Cifar10和ImageNet数据集上共164和90个epochs的训练中都采用了4个epochs的预热训练。在语言模型PTB数据集上,在共40个epochs的训练中选择了1个epoch进行预热训练。在语音识别AN4数据集上,80个epochs中选择1个epoch进行预热训练。
-论文中使用了75%, 93.75%, 98.4375%, 99.6%, 99.9%稀疏度逐渐提升的策略。由于paddle稀疏梯度聚合通信使用了AllGather,通信量会随卡数增加而增长,所以在卡数较多时不推荐较低稀疏度的预热训练。如75%稀疏度时每张卡会选择25%的梯度进行通信,卡数为32时通信量是正常dense通信的32\*(1-0.75)=8倍,所以前几个epoch使用正常的dense通信为佳。可参照如下写法
+预热训练调参可参照论文的设置。对图像分类,论文在 Cifar10 和 ImageNet 数据集上共 164 和 90 个 epochs 的训练中都采用了 4 个 epochs 的预热训练。在语言模型 PTB 数据集上,在共 40 个 epochs 的训练中选择了 1 个 epoch 进行预热训练。在语音识别 AN4 数据集上,80 个 epochs 中选择 1 个 epoch 进行预热训练。
+论文中使用了 75%, 93.75%, 98.4375%, 99.6%, 99.9%稀疏度逐渐提升的策略。由于 paddle 稀疏梯度聚合通信使用了 AllGather,通信量会随卡数增加而增长,所以在卡数较多时不推荐较低稀疏度的预热训练。如 75%稀疏度时每张卡会选择 25%的梯度进行通信,卡数为 32 时通信量是正常 dense 通信的 32\*(1-0.75)=8 倍,所以前几个 epoch 使用正常的 dense 通信为佳。可参照如下写法
``` python
-# 1. 以1252个step为一个epoch,前2个epochs使用正常dense通信,后3个epochs逐步提升稀疏度为99.9%
+# 1. 以 1252 个 step 为一个 epoch,前 2 个 epochs 使用正常 dense 通信,后 3 个 epochs 逐步提升稀疏度为 99.9%
optimizer = fluid.optimizer.DGCMomentumOptimizer(
learning_rate=0.001, momentum=0.9, rampup_begin_step=1252*2,
rampup_step=1252*3, sparsity=[0.984375, 0.996, 0.999])
-# 2. 前面4个epochs都使用dense通信,之后默认0.999稀疏度运行
+# 2. 前面 4 个 epochs 都使用 dense 通信,之后默认 0.999 稀疏度运行
optimizer = fluid.optimizer.DGCMomentumOptimizer(
learning_rate=0.001, momentum=0.9, rampup_begin_step=1252*4)
```
-对于Fine-tuning训练,现测试可无需预热训练,从第0个epoch直接使用DGC即可。
+对于 Fine-tuning 训练,现测试可无需预热训练,从第 0 个 epoch 直接使用 DGC 即可。
``` python
-# 从第0步开始DGC稀疏通信
+# 从第 0 步开始 DGC 稀疏通信
optimizer = fluid.optimizer.DGCMomentumOptimizer(
learning_rate=0.001, momentum=0.9, rampup_begin_step=0)
```
### 3.2 适用场景
-DGC稀疏通信在低带宽通信瓶颈时会有较大的性能提升,但在单机多卡及RDMA网络通信并非瓶颈情况下,并不会带来性能上的提升。同时由于AllGather的通信量会随卡数的增多而增大,所以DGC的多机训练规模也不宜过大。故DGC适用于低配网络,同时节点规模不宜过大,如>128张卡。在云网络或高带宽网络设备昂贵时,DGC可有效降低训练成本。
+DGC 稀疏通信在低带宽通信瓶颈时会有较大的性能提升,但在单机多卡及 RDMA 网络通信并非瓶颈情况下,并不会带来性能上的提升。同时由于 AllGather 的通信量会随卡数的增多而增大,所以 DGC 的多机训练规模也不宜过大。故 DGC 适用于低配网络,同时节点规模不宜过大,如>128 张卡。在云网络或高带宽网络设备昂贵时,DGC 可有效降低训练成本。
## 4. 原理
本节原理部分基本来自[Deep Gradient Compression](https://arxiv.org/abs/1712.01887)论文,本文进行了部分理解翻译,英文较好者建议直接阅读论文。
### 4.1 梯度稀疏
-DGC的基本思路是通过只传送重要梯度,即只发送大于给定阈值的梯度来减少通信带宽的使用。为避免信息的丢失,DGC会将剩余梯度在局部累加起来,最终这些梯度会累加大到足以传输。
-换个角度,从理论依据上来看,局部梯度累加等同于随时间推移增加batch size,(DGC相当于每一个梯度有自己的batch size)。设定 $F(w)$ 为需要优化的loss函数,则有着N个训练节点的同步分布式SGD更新公式如下
+DGC 的基本思路是通过只传送重要梯度,即只发送大于给定阈值的梯度来减少通信带宽的使用。为避免信息的丢失,DGC 会将剩余梯度在局部累加起来,最终这些梯度会累加大到足以传输。
+换个角度,从理论依据上来看,局部梯度累加等同于随时间推移增加 batch size,(DGC 相当于每一个梯度有自己的 batch size)。设定 $F(w)$ 为需要优化的 loss 函数,则有着 N 个训练节点的同步分布式 SGD 更新公式如下
$$
F(w)=\\frac{1}{\|\\chi\|}\\sum\_{x\\in\\chi}f(x, w), \\qquad w\_{t+1}=w\_{t}-\\eta\\frac{1}{N b}\\sum\_{k=0}^{N}\\sum\_{x\\in\\mathcal{B}\_{k,t}}\\nabla f\\left(x, w\_{t}\\right) \\tag{1}
$$
-其中$\chi$是训练集,$w$是网络权值,$f(x, w)$是每个样本$x \in \chi$的loss,$\eta$是学习率,N是训练节点个数,$\mathcal{B}_{k, t}$代表第$k$个节点在第$t$个迭代时的minibatch,大小为b。
-考虑权重的第i个值,在T次迭代后,可获得
+其中$\chi$是训练集,$w$是网络权值,$f(x, w)$是每个样本$x \in \chi$的 loss,$\eta$是学习率,N 是训练节点个数,$\mathcal{B}_{k, t}$代表第$k$个节点在第$t$个迭代时的 minibatch,大小为 b。
+考虑权重的第 i 个值,在 T 次迭代后,可获得
$$
w\_{t+T}^{(i)}=w\_{t}^{(i)}-\\eta T \\cdot \\frac{1}{N b T} \\sum\_{k=1}^{N}\\left(\\sum\_{\\tau=0}^{T-1} \\sum\_{x \\in \\mathcal{B}\_{k, t+\\tau}} \\nabla^{(i)} f\\left(x, w\_{t+\\tau}\\right)\\right) \\tag{2}
$$
-等式2表明局部梯度累加可以被认为batch size从$Nb$增大为$NbT$,其中T是$w^{(i)}$两次更新的稀疏通信间隔。
+等式 2 表明局部梯度累加可以被认为 batch size 从$Nb$增大为$NbT$,其中 T 是$w^{(i)}$两次更新的稀疏通信间隔。
### 4.2 局部梯度累加改进
-正常情况,稀疏更新会严重影响收敛性。DGC中采用动量修正(Momentum Correction)和局部梯度裁减(local gradient clipping)来解决这个问题。
+正常情况,稀疏更新会严重影响收敛性。DGC 中采用动量修正(Momentum Correction)和局部梯度裁减(local gradient clipping)来解决这个问题。
#### 4.2.1 动量修正
-有着N个节点分布式训练中vanilla momentum SGD公式,
+有着 N 个节点分布式训练中 vanilla momentum SGD 公式,
$$
u\_{t}=m u\_{t-1}+\\sum\_{k=1}^{N}\\left(\\nabla\_{k, t}\\right), \\quad w\_{t+1}=w\_{t}-\\eta u\_{t} \\tag{3}
$$
其中$m$是动量因子,$N$是节点数,$\nabla_{k, t}=\frac{1}{N b} \sum_{x \in \mathcal{B}_{k, t}} \nabla f\left(x, w_{t}\right)$。
-考虑第i个权重$w^{(i)}$,在T次迭代后,权重更新公式如下,
+考虑第 i 个权重$w^{(i)}$,在 T 次迭代后,权重更新公式如下,
$$
w\_{t+T}^{(i)}=w\_{t}^{(i)}-\\eta\\left[\\cdots+\\left(\\sum\_{\\tau=0}^{T-2} m^{\\tau}\\right) \\nabla\_{k, t+1}^{(i)}+\\left(\\sum\_{\\tau=0}^{T-1} m^{\\tau}\\right) \\nabla\_{k, t}^{(i)}\\right] \\tag{4}
$$
-如果直接应用动量SGD到稀疏梯度更新中,则有公式,
+如果直接应用动量 SGD 到稀疏梯度更新中,则有公式,
$$
v_{k, t}=v_{k, t-1}+\\nabla_{k, t}, \\quad u_{t}=m u_{t-1}+\\sum_{k=1}^{N} \\operatorname{sparse}\\left(v_{k, t}\\right), \\quad w_{t+1}=w_{t}-\\eta u_{t} \\tag{5}
$$
-其中$v_k$是训练节点k上的局部梯度累加项,一旦$v_k$大于某一阈值,则会在第二项中压缩梯度进行动量更新,并使用sparse()函数获得mask清空大于阈值的梯度。
-$w^{(i)}$在T次稀疏更新后的权重为,
+其中$v_k$是训练节点 k 上的局部梯度累加项,一旦$v_k$大于某一阈值,则会在第二项中压缩梯度进行动量更新,并使用 sparse()函数获得 mask 清空大于阈值的梯度。
+$w^{(i)}$在 T 次稀疏更新后的权重为,
$$
w_{t+T}^{(i)}=w_{t}^{(i)}-\\eta\\left(\\cdots+\\nabla_{k, t+1}^{(i)}+\\nabla_{k, t}^{(i)}\\right) \\tag{6}
$$
-相比传统动量SGD,方程6缺失了累积衰减因子$\sum_{\tau=0}^{T-1} m^{\tau}$,会导致收敛精度的损失。如下图A,正常梯度更新从A点到B点,但是方程6则从A点到C点。当稀疏度很高时,会显著降低模型性能,所以需要在方程5基础上对梯度进行修正。
+相比传统动量 SGD,方程 6 缺失了累积衰减因子$\sum_{\tau=0}^{T-1} m^{\tau}$,会导致收敛精度的损失。如下图 A,正常梯度更新从 A 点到 B 点,但是方程 6 则从 A 点到 C 点。当稀疏度很高时,会显著降低模型性能,所以需要在方程 5 基础上对梯度进行修正。


-若将方程3中速度项$u_t$当作“梯度”,则方程3第二项可认为是在”梯度“$u_t$上应用传统SGD,前面已经证明了局部梯度累加在传统SGD上是有效的。因此,可以使用方程3局部累加速度项$u_t$而非累加真实的梯度$\nabla_{k, t}$来修正方程5,
+若将方程 3 中速度项$u_t$当作“梯度”,则方程 3 第二项可认为是在”梯度“$u_t$上应用传统 SGD,前面已经证明了局部梯度累加在传统 SGD 上是有效的。因此,可以使用方程 3 局部累加速度项$u_t$而非累加真实的梯度$\nabla_{k, t}$来修正方程 5,
$$
u_{k, t}=m u_{k, t-1}+\\nabla_{k, t}, \\quad v_{k, t}=v_{k, t-1}+u_{k, t}, \\quad w_{t+1}=w_{t}-\\eta \\sum_{k=1}^{N} \\operatorname{sparse}\\left(v_{k, t}\\right) \\tag{7}
$$
-修正后,如上图(b),方程可正常从A点到B点。除了传统动量方程修正,论文还给出了Nesterov动量SGD的修正方程。
+修正后,如上图(b),方程可正常从 A 点到 B 点。除了传统动量方程修正,论文还给出了 Nesterov 动量 SGD 的修正方程。
#### 4.2.2 局部梯度修剪
-梯度修剪是防止梯度爆炸的常用方法。这方法由Pascanu等人在2013年提出,当梯度的l2-norms和大于给定阈值时,就对梯度rescale。正常梯度修剪在梯度聚合后使用,而DGC因为每个节点独立的进行局部梯度累加,所以DGC在使用$G_t$累加前对其进行局部梯度修剪。阈值缩放为原来的$N^{-1/2}$
+梯度修剪是防止梯度爆炸的常用方法。这方法由 Pascanu 等人在 2013 年提出,当梯度的 l2-norms 和大于给定阈值时,就对梯度 rescale。正常梯度修剪在梯度聚合后使用,而 DGC 因为每个节点独立的进行局部梯度累加,所以 DGC 在使用$G_t$累加前对其进行局部梯度修剪。阈值缩放为原来的$N^{-1/2}$
$$
thr_{G^{k}}=N^{-1 / 2} \\cdot thr_{G} \\tag{8}
$$
### 4.3 克服迟滞效应
-因为推迟了较小梯度更新权重的时间,所以会有权重陈旧性问题。稀疏度为99.9%时大部分参数需600到1000步更新一次。迟滞效应会减缓收敛并降低模型精度。DGC中采用动量因子掩藏和预热训练来解决这问题。
+因为推迟了较小梯度更新权重的时间,所以会有权重陈旧性问题。稀疏度为 99.9%时大部分参数需 600 到 1000 步更新一次。迟滞效应会减缓收敛并降低模型精度。DGC 中采用动量因子掩藏和预热训练来解决这问题。
#### 4.3.1 动量因子掩藏
-DGC中使用下面方程来掩藏动量因子减缓陈旧性问题。
+DGC 中使用下面方程来掩藏动量因子减缓陈旧性问题。
$$
Mask \\leftarrow\\left|v_{k, t}\\right|>t h r, \\quad v_{k, t} \\leftarrow v_{k, t} \\odot \\neg Mask, \\quad u_{k, t} \\leftarrow u_{k, t} \\odot \\neg Mask \\tag{9}
$$
此掩码可以停止延迟梯度产生的动量,防止陈旧梯度把权重引入错误的方向。
#### 4.3.2 预热训练
-在训练初期,梯度变动剧烈,需要及时更新权重,此时迟滞效应影响会很大。为此DGC采用预热训练的方法,在预热期间使用更小的学习率来减缓网络的变化速度,并使用较小的稀疏度来减少需推迟更新的梯度数量。预热期间会线性增大学习率,指数型增加稀疏度到最终值。
+在训练初期,梯度变动剧烈,需要及时更新权重,此时迟滞效应影响会很大。为此 DGC 采用预热训练的方法,在预热期间使用更小的学习率来减缓网络的变化速度,并使用较小的稀疏度来减少需推迟更新的梯度数量。预热期间会线性增大学习率,指数型增加稀疏度到最终值。
### 4.4 正则化(Weight Decay)项修正
-Paddle框架以Weight Decay的形式实现正则化。以L2Decay为例,公式(3)中传统momentum添加weight decay后公式为
+Paddle 框架以 Weight Decay 的形式实现正则化。以 L2Decay 为例,公式(3)中传统 momentum 添加 weight decay 后公式为
$$
G_{t}=\\sum_{k=1}^{N}\\left(\\nabla_{k, t}\\right)+\\lambda w_{t}, \\quad u_{t}=m u_{t-1}+G_{t}, \\quad w_{t+1}=w_{t}-\\eta u_{t} \\tag{10}
$$
-其中$\lambda$为Weight Decay系数,$G_{t}$为添加L2Decay项之后的聚合梯度。由于在公式7中进行了局部动量修正,所以按照相同思路在局部梯度上运用修正的Weight Decay项。如下公式在局部梯度上添加局部Weight Decay项即可。
+其中$\lambda$为 Weight Decay 系数,$G_{t}$为添加 L2Decay 项之后的聚合梯度。由于在公式 7 中进行了局部动量修正,所以按照相同思路在局部梯度上运用修正的 Weight Decay 项。如下公式在局部梯度上添加局部 Weight Decay 项即可。
$$
\\nabla_{k, t}=\\nabla_{k, t}+\\frac{\\lambda}{N} w_{t} \\tag{11}
$$
-在模型实际训练中,通常会设置weight decay的系数$\lambda=10^{-4}$,在卡数较多如4机32卡的情况下局部weight decay系数为$\frac{\lambda}{N}=\frac{10^{-4}}{32}=3.125*10^{-6}$,在数值精度上偏低,测试训练时会损失一定精度。为此还需对局部weight decay项进行数值修正。如下公式,
+在模型实际训练中,通常会设置 weight decay 的系数$\lambda=10^{-4}$,在卡数较多如 4 机 32 卡的情况下局部 weight decay 系数为$\frac{\lambda}{N}=\frac{10^{-4}}{32}=3.125*10^{-6}$,在数值精度上偏低,测试训练时会损失一定精度。为此还需对局部 weight decay 项进行数值修正。如下公式,
$$
\\nabla_{k, t}^{'}=N \\nabla_{k, t}+\\lambda w_{t}, \\quad
G_{t}^{'}=\\sum_{k=1}^{N}\\left(\\nabla_{k, t}^{'}\\right)=N\\sum_{k=1}^{N}\\left(\\nabla_{k, t}\\right)+N\\lambda w_{t}, \\quad
diff --git a/docs/advanced_guide/performance_improving/multinode_training_improving/gpu_training_with_recompute.rst b/docs/advanced_guide/performance_improving/multinode_training_improving/gpu_training_with_recompute.rst
index b8e7ec5b2a4..8841973c398 100644
--- a/docs/advanced_guide/performance_improving/multinode_training_improving/gpu_training_with_recompute.rst
+++ b/docs/advanced_guide/performance_improving/multinode_training_improving/gpu_training_with_recompute.rst
@@ -1,11 +1,11 @@
-重计算:大Batch训练特性
+重计算:大 Batch 训练特性
=============
背景
---------
-
-随着训练数据规模的逐渐增加,训练更大、更深的深度学习模型成为一个主流趋势。目前的深度学习模型训练,通常要求保留前向计算的隐层结果,并且需要保存结果的数量会随着模型层数的增加线性增加,这对于目前能够使用的AI芯片的内存大小是个挑战。Forward Recomputation Backpropagation(FRB)可以在额外增加少量计算的情况下,显著增加模型的层数和宽度,同时也可以显著提升模型训练的batch大小。
+
+随着训练数据规模的逐渐增加,训练更大、更深的深度学习模型成为一个主流趋势。目前的深度学习模型训练,通常要求保留前向计算的隐层结果,并且需要保存结果的数量会随着模型层数的增加线性增加,这对于目前能够使用的 AI 芯片的内存大小是个挑战。Forward Recomputation Backpropagation(FRB)可以在额外增加少量计算的情况下,显著增加模型的层数和宽度,同时也可以显著提升模型训练的 batch 大小。
原理
---------
@@ -16,13 +16,13 @@
- **反向计算**:运行反向算子来计算参数(Parameter)的梯度
- **优化**:应用优化算法以更新参数值
-在前向计算过程中,前向算子会输出大量的中间计算结果,在Paddle中,使用
-Variable来存储这些隐层的中间结果。当模型层数加深时,其数量可达成千上万个,
-占据大量的内存。Paddle的 `显存回收机制 `_
+在前向计算过程中,前向算子会输出大量的中间计算结果,在 Paddle 中,使用
+Variable 来存储这些隐层的中间结果。当模型层数加深时,其数量可达成千上万个,
+占据大量的内存。Paddle 的 `显存回收机制 `_
会及时清除无用的中间结果,以节省存储。
-然而,有些中间结果是反向算子的输入,这些Variable必须存储在内存中,直到相应的反向算子计算完毕。
+然而,有些中间结果是反向算子的输入,这些 Variable 必须存储在内存中,直到相应的反向算子计算完毕。
-举个简单的例子, 我们定义一个由mul算子构成的网络,其前向计算为:
+举个简单的例子, 我们定义一个由 mul 算子构成的网络,其前向计算为:
.. math::
@@ -33,48 +33,48 @@ Variable来存储这些隐层的中间结果。当模型层数加深时,其数
其中 :math:`x, y, z` 为向量, :math:`W_1, W_2` 为矩阵。容易知道,求 :math:`W_2` 梯度的反向计算为:
.. math::
- W_{2}^{'} = z^{'} / y
+ W_{2}^{'} = z^{'} / y
可以看到反向计算中用到了前向计算生成的变量 :math:`y` ,因此变量 :math:`y` 必须存储在内存中,直到这个反向算子计算完毕。当模型加深时,我们会有大量的“ :math:`y` ”,占据了大量的内存。
-Forward Recomputation Backpropagation(FRB)的思想是将深度学习网络切分为k个部分(segments)。对每个segment而言:前向计算时,除了小部分必须存储在内存中的Variable外(我们后续会讨论这些特殊Variable),其他中间结果都将被删除;在反向计算中,首先重新计算一遍前向算子,以获得中间结果,再运行反向算子。简而言之,FRB和普通的网络迭代相比,多计算了一遍前向算子。
+Forward Recomputation Backpropagation(FRB)的思想是将深度学习网络切分为 k 个部分(segments)。对每个 segment 而言:前向计算时,除了小部分必须存储在内存中的 Variable 外(我们后续会讨论这些特殊 Variable),其他中间结果都将被删除;在反向计算中,首先重新计算一遍前向算子,以获得中间结果,再运行反向算子。简而言之,FRB 和普通的网络迭代相比,多计算了一遍前向算子。
-我们把切分网络的变量叫做checkpoints。
-那么问题来了,如何选择checkpoints呢?自从FRB方法提出以来 \ :sup:`[1], [2]`,大量学者在研究这一关键问题。
-我们知道深度学习网络通常是由一个个模块串联得到的,比如ResNet-50由16个block串联而成,
-Bert-Large由24个transformer串联而成,以两个子模块中间的变量作为切分点就是一个很好的选择。
-对于非串联的网络(比如含有大量shortcut结构的网络),FRB也支持对其做切分,
-只是可能多耗费一点内存(用于存储shortcut的Variable)。
+我们把切分网络的变量叫做 checkpoints。
+那么问题来了,如何选择 checkpoints 呢?自从 FRB 方法提出以来 \ :sup:`[1], [2]`,大量学者在研究这一关键问题。
+我们知道深度学习网络通常是由一个个模块串联得到的,比如 ResNet-50 由 16 个 block 串联而成,
+Bert-Large 由 24 个 transformer 串联而成,以两个子模块中间的变量作为切分点就是一个很好的选择。
+对于非串联的网络(比如含有大量 shortcut 结构的网络),FRB 也支持对其做切分,
+只是可能多耗费一点内存(用于存储 shortcut 的 Variable)。
Mitsuru Kusumoto \ :sup:`[3]` 等提出了一种基于动态规划的算法,
-可以根据指定的内存自动搜索合适的checkpoints,支持各种各样的网络结构。
+可以根据指定的内存自动搜索合适的 checkpoints,支持各种各样的网络结构。
-下图是由4个fc Layer、3个relu Layer、1个sigmoid Layer和1个log-loss Layer串联而成的一个网络:最左侧为其前向计算流程、中间是普通的前向计算和反向计算流程、最右侧为添加FRB后的前向计算和反向计算流程。其中方框代表算子(Operator),红点代表前向计算的中间结果、蓝点代表checkpoints。
+下图是由 4 个 fc Layer、3 个 relu Layer、1 个 sigmoid Layer 和 1 个 log-loss Layer 串联而成的一个网络:最左侧为其前向计算流程、中间是普通的前向计算和反向计算流程、最右侧为添加 FRB 后的前向计算和反向计算流程。其中方框代表算子(Operator),红点代表前向计算的中间结果、蓝点代表 checkpoints。
.. image:: images/recompute.png
注:该例子完整代码位于 `source `_
-添加FRB后,前向计算中需要存储的中间Variable从4个(红点)变为2个(蓝点),
+添加 FRB 后,前向计算中需要存储的中间 Variable 从 4 个(红点)变为 2 个(蓝点),
从而节省了这部分内存。当然了,重计算的部分也产生了新的中间变量,
这就需要根据实际情况来做权衡了。这个例子里的网络比较浅,通常来讲,
-对层数较深的网络,FRB节省的内存要远多于新增加的内存。
+对层数较深的网络,FRB 节省的内存要远多于新增加的内存。
使用方法
---------
-我们实现了基于Paddle的FRB算法,叫做RecomputeOptimizer,
+我们实现了基于 Paddle 的 FRB 算法,叫做 RecomputeOptimizer,
您可以根据其 `源码 `_
与
`文档 `_
-更深入地了解这一算法。我们为用户提供了两个使用RecomputeOptimizer的方法:
-直接调用与Fleet API中使用。在单机单卡或者CPU训练中建议您直接调用RecomputeOptimizer,
-在多卡训练或者多机训练任务上建议您在Fleet API中使用Recompute。
+更深入地了解这一算法。我们为用户提供了两个使用 RecomputeOptimizer 的方法:
+直接调用与 Fleet API 中使用。在单机单卡或者 CPU 训练中建议您直接调用 RecomputeOptimizer,
+在多卡训练或者多机训练任务上建议您在 Fleet API 中使用 Recompute。
**1. 直接调用**
-
-直接调用RecomputeOptimizer非常简单,首先要定义一个经典的Optimizer,比如Adam;
-然后在外面包一层RecomputeOptimizer;最后设置checkpoints即可。
-
+
+直接调用 RecomputeOptimizer 非常简单,首先要定义一个经典的 Optimizer,比如 Adam;
+然后在外面包一层 RecomputeOptimizer;最后设置 checkpoints 即可。
+
.. code-block:: python
import paddle.fluid as fluid
@@ -89,25 +89,25 @@ Mitsuru Kusumoto \ :sup:`[3]` 等提出了一种基于动态规划的算法,
input_x = fluid.layers.data(name="x", shape=[32], dtype='float32')
input_y = fluid.layers.data(name="y", shape=[1], dtype='int64')
cost, fc_1, pred = mlp(input_x, input_y)
- # 定义RecomputeOptimizer
+ # 定义 RecomputeOptimizer
sgd = fluid.optimizer.Adam(learning_rate=0.01)
sgd = fluid.optimizer.RecomputeOptimizer(sgd)
- # 设置checkpoints
+ # 设置 checkpoints
sgd._set_checkpoints([fc_1, pred])
# 运行优化算法
sgd.minimize(cost)
-Recompute原则上适用于所有Optimizer。
+Recompute 原则上适用于所有 Optimizer。
-**2. 在Fleet API中使用Recompute**
+**2. 在 Fleet API 中使用 Recompute**
-`Fleet API `_
-是基于Fluid的分布式计算高层API。在Fleet API中添加RecomputeOptimizer
-仅需要2步:
+`Fleet API `_
+是基于 Fluid 的分布式计算高层 API。在 Fleet API 中添加 RecomputeOptimizer
+仅需要 2 步:
-- 设置dist_strategy.forward_recompute为True;
+- 设置 dist_strategy.forward_recompute 为 True;
-- 设置dist_strategy.recompute_checkpoints。
+- 设置 dist_strategy.recompute_checkpoints。
.. code-block:: python
@@ -118,43 +118,43 @@ Recompute原则上适用于所有Optimizer。
optimizer = fleet.distributed_optimizer(optimizer, strategy=dist_strategy)
optimizer.minimize(loss)
-为了帮助您快速地用Fleet API使用Recompute任务,我们提供了一些例子,
+为了帮助您快速地用 Fleet API 使用 Recompute 任务,我们提供了一些例子,
并且给出了这些例子的计算速度、效果和显存节省情况:
-- 用Recompute做Bert Fine-tuning: `source `_
+- 用 Recompute 做 Bert Fine-tuning: `source `_
-- 用Recompute做目标检测:开发中.
+- 用 Recompute 做目标检测:开发中.
Q&A
-------
-- **是否支持带有随机性的Op?**
+- **是否支持带有随机性的 Op?**
- 目前Paddle中带随机性的Op有:dropout,Recompute支持
+ 目前 Paddle 中带随机性的 Op 有:dropout,Recompute 支持
dropout Operator,可以保证重计算与初次计算结果保持一致。
-- **有没有更多Recompute的官方例子?**
+- **有没有更多 Recompute 的官方例子?**
- 更多Recompute的例子将更新在 `examples `_
+ 更多 Recompute 的例子将更新在 `examples `_
和 `Fleet `_ 库下,欢迎关注。
-
-- **有没有添加checkpoints的建议?**
- 我们建议将子网络连接部分的变量添加为checkpoints,即:
- 如果一个变量能将网络完全分为前后两部分,那么建议将其加入checkpoints。
- checkpoints的数目会影响内存的消耗:如果checkpoints很少,
- 那么Recompute起的作用有限;如果checkpoints数量过多,
- 那么checkpoints本身占用的内存量就较大,内存消耗可能不降反升。
+- **有没有添加 checkpoints 的建议?**
+
+ 我们建议将子网络连接部分的变量添加为 checkpoints,即:
+ 如果一个变量能将网络完全分为前后两部分,那么建议将其加入 checkpoints。
+ checkpoints 的数目会影响内存的消耗:如果 checkpoints 很少,
+ 那么 Recompute 起的作用有限;如果 checkpoints 数量过多,
+ 那么 checkpoints 本身占用的内存量就较大,内存消耗可能不降反升。
我们后续会添加一个估算内存用量的工具,
- 可以对每个Operator运算前后的显存用量做可视化,
+ 可以对每个 Operator 运算前后的显存用量做可视化,
帮助用户定位问题。
[1] Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin . Training deep nets with sublinear memory cost.
-arXiv preprint, arXiv:1604.06174, 2016.
+arXiv preprint, arXiv:1604.06174, 2016.
[2] Audrunas Gruslys , Rémi Munos , Ivo Danihelka , Marc Lanctot , and Alex Graves. Memory efficient
backpropagation through time. In Advances in Neural Information Processing Systems (NIPS), pages 4125 4133,
2016.
-[3] Kusumoto, Mitsuru, et al. "A Graph Theoretic Framework of Recomputation Algorithms for Memory-Efficient Backpropagation." arXiv preprint arXiv:1905.11722 (2019).
+[3] Kusumoto, Mitsuru, et al. "A Graph Theoretic Framework of Recomputation Algorithms for Memory-Efficient Backpropagation." arXiv preprint arXiv:1905.11722 (2019).
diff --git a/docs/advanced_guide/performance_improving/multinode_training_improving/gpu_training_with_recompute_en.rst b/docs/advanced_guide/performance_improving/multinode_training_improving/gpu_training_with_recompute_en.rst
index b1431756f44..c20b390e010 100644
--- a/docs/advanced_guide/performance_improving/multinode_training_improving/gpu_training_with_recompute_en.rst
+++ b/docs/advanced_guide/performance_improving/multinode_training_improving/gpu_training_with_recompute_en.rst
@@ -10,7 +10,7 @@ and the number of outputs increases linearly with
the increase of the number of model layers,
which becomes a challenge of the memory size
for common devices.
-
+
Theory
---------
@@ -19,11 +19,11 @@ As we know, a training process of a deep-learning network contains 3 steps:
- **Forward Propagation**:Running forward operators and generate temporary variables as output
- **Backward Propagation**:Running backward operators to compute gradients of parameters
-- **Optimization**:Applying optimization algorithm to update parameters
+- **Optimization**:Applying optimization algorithm to update parameters
When the model becomes deeper, the number of temporary variables
generated in the forward propagation process can reach tens
-of thousands, occupying a large amount of memory.
+of thousands, occupying a large amount of memory.
The `Garbage Collection mechanism `_
in Paddle can delete useless variables for the sake of saving memory.
However, some variables serve as inputs of backward operators,
@@ -41,17 +41,17 @@ the forward propagation works as follows:
where :math:`x, y, z` are vectors, :math:`W_1, W_2` are matrix。It is easy to conduct that the gradient of :math:`W_2` is:
.. math::
- W_{2}^{'} = z^{'} / y
+ W_{2}^{'} = z^{'} / y
-We can see that :math:`y` is used in the backward propagation process,
+We can see that :math:`y` is used in the backward propagation process,
thus it must be kept in the memory during the whole forward propagation.
When network grows deeper, more 'y's need to be stored,
adding more requirements to the memory.
Forward Recomputation Backpropagation(FRB) splits a deep network to k segments.
-For each segment, in forward propagation,
-most of the temporary variables are erased in time,
-except for some special variables (we will talk about that later);
+For each segment, in forward propagation,
+most of the temporary variables are erased in time,
+except for some special variables (we will talk about that later);
in backward propagation, the forward operators will be recomputed
to get these temporary variables before running backward operators.
In short, FBR runs forward operators twice.
@@ -59,13 +59,13 @@ In short, FBR runs forward operators twice.
But how to split the network? A deep learning network usually consists
of connecting modules in series:
ResNet-50 contains 16 blocks and Bert-Large contains 24 transformers.
-It is a good choice to treat such modules as segments.
+It is a good choice to treat such modules as segments.
The variables among segments are
called as checkpoints.
-The following picture is a network with 4 fc layers, 3 relu layers,
+The following picture is a network with 4 fc layers, 3 relu layers,
1 sigmoid layer and 1 log-loss layer in series.
-The left column is the forward propagation,
+The left column is the forward propagation,
the middle column is the normal backward propagation,
and the right column is the FRB.
Rectangular boxes represent the operators, red dots represent
@@ -132,10 +132,10 @@ In principle, recompute is for all kinds of optimizers in Paddle.
**2. Using Recompute in Fleet API**
-`Fleet API `_
+`Fleet API `_
is a high-level API for distributed training in Fluid. Adding
RecomputeOptimizer to Fluid takes two steps:
-
+
- set dist_strategy.forward_recompute to True
- set dist_strategy.recompute_checkpoints
@@ -176,7 +176,7 @@ raise issues if you get any problem with these examples.
- **How should I set checkpoints?**
-The position of checkpoints is important:
+The position of checkpoints is important:
we suggest setting the variable between the sub-model as checkpoints,
that is, set a variable as a checkpoint if it
can separate the network into two parts without short-cut connections.
diff --git a/docs/api/index_cn.rst b/docs/api/index_cn.rst
index d72492835c6..2d2a7a796b4 100644
--- a/docs/api/index_cn.rst
+++ b/docs/api/index_cn.rst
@@ -4,76 +4,76 @@ API 文档
欢迎使用飞桨框架(PaddlePaddle), PaddlePaddle 是一个易用、高效、灵活、可扩展的深度学习框架,致力于让深度学习技术的创新与应用更简单。
-在本版本中,飞桨框架对API做了许多优化,您可以参考下表来了解飞桨框架最新版的API目录结构与说明。更详细的说明,请参见 `版本说明 <../release_note_cn.html>`_ 。此外,您可参考PaddlePaddle的 `GitHub `_ 了解详情。
+在本版本中,飞桨框架对 API 做了许多优化,您可以参考下表来了解飞桨框架最新版的 API 目录结构与说明。更详细的说明,请参见 `版本说明 <../release_note_cn.html>`_ 。此外,您可参考 PaddlePaddle 的 `GitHub `_ 了解详情。
-**注: paddle.fluid.\*, paddle.dataset.\* 会在未来的版本中废弃,请您尽量不要使用这两个目录下的API。**
+**注: paddle.fluid.\*, paddle.dataset.\* 会在未来的版本中废弃,请您尽量不要使用这两个目录下的 API。**
+-------------------------------+-------------------------------------------------------+
-| 目录 | 功能和包含的API |
+| 目录 | 功能和包含的 API |
+===============================+=======================================================+
| paddle.\* | paddle |
-| | 根目录下保留了常用API的别名,包括:paddle.tensor, |
-| | paddle.framework, paddle.device 目录下的所有API |
+| | 根目录下保留了常用 API 的别名,包括:paddle.tensor, |
+| | paddle.framework, paddle.device 目录下的所有 API |
+-------------------------------+-------------------------------------------------------+
-| paddle.tensor | Tensor操作相关的API,包括 创建zeros, |
-| | 矩阵运算matmul, 变换concat, 计算add, 查找argmax等 |
+| paddle.tensor | Tensor 操作相关的 API,包括 创建 zeros, |
+| | 矩阵运算 matmul, 变换 concat, 计算 add, 查找 argmax 等 |
+-------------------------------+-------------------------------------------------------+
-| paddle.framework | 框架通用API和动态图模式的API,包括 no_grad 、 |
+| paddle.framework | 框架通用 API 和动态图模式的 API,包括 no_grad 、 |
| | save 、 load 等。 |
+-------------------------------+-------------------------------------------------------+
-| paddle.device | 设备管理相关API,包括 set_device, get_device 等。 |
+| paddle.device | 设备管理相关 API,包括 set_device, get_device 等。 |
+-------------------------------+-------------------------------------------------------+
-| paddle.linalg | 线性代数相关API,包括 det, svd 等。 |
+| paddle.linalg | 线性代数相关 API,包括 det, svd 等。 |
+-------------------------------+-------------------------------------------------------+
-| paddle.fft | 快速傅里叶变换的相关API,包括 fft, fft2 等。 |
+| paddle.fft | 快速傅里叶变换的相关 API,包括 fft, fft2 等。 |
+-------------------------------+-------------------------------------------------------+
| paddle.amp | 自动混合精度策略,包括 auto_cast 、 |
| | GradScaler 等。 |
+-------------------------------+-------------------------------------------------------+
-| paddle.autograd | 自动求导相关API,包括 backward、PyLayer 等。 |
+| paddle.autograd | 自动求导相关 API,包括 backward、PyLayer 等。 |
+-------------------------------+-------------------------------------------------------+
| paddle.callbacks | 日志回调类,包括 ModelCheckpoint 、 |
| | ProgBarLogger 等。 |
+-------------------------------+-------------------------------------------------------+
-| paddle.distributed | 分布式相关基础API。 |
+| paddle.distributed | 分布式相关基础 API。 |
+-------------------------------+-------------------------------------------------------+
-| paddle.distributed.fleet | 分布式相关高层API。 |
+| paddle.distributed.fleet | 分布式相关高层 API。 |
+-------------------------------+-------------------------------------------------------+
-| paddle.hub | 模型拓展相关的API,包括 list、load、help 等。 |
+| paddle.hub | 模型拓展相关的 API,包括 list、load、help 等。 |
+-------------------------------+-------------------------------------------------------+
-| paddle.io | 数据输入输出相关API,包括 Dataset, DataLoader 等。 |
+| paddle.io | 数据输入输出相关 API,包括 Dataset, DataLoader 等。 |
+-------------------------------+-------------------------------------------------------+
-| paddle.jit | 动态图转静态图相关API,包括 to_static、 |
+| paddle.jit | 动态图转静态图相关 API,包括 to_static、 |
| | ProgramTranslator、TracedLayer 等。 |
+-------------------------------+-------------------------------------------------------+
-| paddle.metric | 评估指标计算相关的API,包括 Accuracy, Auc等。 |
+| paddle.metric | 评估指标计算相关的 API,包括 Accuracy, Auc 等。 |
+-------------------------------+-------------------------------------------------------+
-| paddle.nn | 组网相关的API,包括 Linear 、卷积 Conv2D 、 |
+| paddle.nn | 组网相关的 API,包括 Linear 、卷积 Conv2D 、 |
| | 循环神经网络 RNN 、损失函数 CrossEntropyLoss 、 |
| | 激活函数 ReLU 等。 |
+-------------------------------+-------------------------------------------------------+
-| paddle.onnx | paddle转换为onnx协议相关API,包括 export 等。 |
+| paddle.onnx | paddle 转换为 onnx 协议相关 API,包括 export 等。 |
+-------------------------------+-------------------------------------------------------+
-| paddle.optimizer | 优化算法相关API,包括 SGD,Adagrad, Adam 等。 |
+| paddle.optimizer | 优化算法相关 API,包括 SGD,Adagrad, Adam 等。 |
+-------------------------------+-------------------------------------------------------+
-| paddle.optimizer.lr | 学习率衰减相关API,包括 NoamDecay 、 StepDecay 、 |
+| paddle.optimizer.lr | 学习率衰减相关 API,包括 NoamDecay 、 StepDecay 、 |
| | PiecewiseDecay 等。 |
+-------------------------------+-------------------------------------------------------+
-| paddle.regularizer | 正则化相关API,包括 L1Decay、L2Decay 等。 |
+| paddle.regularizer | 正则化相关 API,包括 L1Decay、L2Decay 等。 |
+-------------------------------+-------------------------------------------------------+
-| paddle.static | 静态图下基础框架相关API,包括 Variable, Program, |
-| | Executor等 |
+| paddle.static | 静态图下基础框架相关 API,包括 Variable, Program, |
+| | Executor 等 |
+-------------------------------+-------------------------------------------------------+
-| paddle.static.nn | 静态图下组网专用API,包括 全连接层 fc 、控制流 |
+| paddle.static.nn | 静态图下组网专用 API,包括 全连接层 fc 、控制流 |
| | while_loop/cond 。 |
+-------------------------------+-------------------------------------------------------+
-| paddle.text | NLP领域API,包括NLP领域相关的数据集, |
+| paddle.text | NLP 领域 API,包括 NLP 领域相关的数据集, |
| | 如 Imdb 、 Movielens 。 |
+-------------------------------+-------------------------------------------------------+
-| paddle.utils | 工具类相关API,包括 CppExtension、CUDAExtension 等。 |
+| paddle.utils | 工具类相关 API,包括 CppExtension、CUDAExtension 等。 |
+-------------------------------+-------------------------------------------------------+
-| paddle.vision | 视觉领域API,包括 数据集 Cifar10 、数据处理 |
+| paddle.vision | 视觉领域 API,包括 数据集 Cifar10 、数据处理 |
| | ColorJitter、常用基础网络结构 ResNet 等。 |
+-------------------------------+-------------------------------------------------------+
-| paddle.sparse | 稀疏领域的API。 |
+| paddle.sparse | 稀疏领域的 API。 |
+-------------------------------+-------------------------------------------------------+
diff --git a/docs/api/index_en.rst b/docs/api/index_en.rst
index fb0d778cce5..730ab8d4613 100644
--- a/docs/api/index_en.rst
+++ b/docs/api/index_en.rst
@@ -26,12 +26,12 @@ In this version, PaddlePaddle has made many optimizations to the APIs. You can r
| paddle.device | Device management related APIs, such as set_device, |
| | get_device, etc. |
+-------------------------------+-------------------------------------------------------+
-| paddle.linalg | Linear algebra related APIs, such as det, svd, etc. |
+| paddle.linalg | Linear algebra related APIs, such as det, svd, etc. |
+-------------------------------+-------------------------------------------------------+
| paddle.fft | Fast Fourier Transform related APIs, such as |
| | fft, fft2, etc. |
+-------------------------------+-------------------------------------------------------+
-| paddle.amp | Paddle automatic mixed precision strategy, including |
+| paddle.amp | Paddle automatic mixed precision strategy, including |
| | auto_cast, GradScaler, etc. |
+-------------------------------+-------------------------------------------------------+
| paddle.autograd | Auto grad API, including backward, PyLayer, etc. |
@@ -63,12 +63,12 @@ In this version, PaddlePaddle has made many optimizations to the APIs. You can r
| paddld.optimizer | APIs related to optimization algorithms such as SGD, |
| | Adagrad, and Adam |
+-------------------------------+-------------------------------------------------------+
-| paddle.optimizer.lr | APIs related to learning rate decay, such as |
+| paddle.optimizer.lr | APIs related to learning rate decay, such as |
| | NoamDecay, StepDecay, PiecewiseDecay, etc. |
+-------------------------------+-------------------------------------------------------+
| paddle.regularizer | Regularization APIs, including L1Decay, L2Decay, etc. |
+-------------------------------+-------------------------------------------------------+
-| paddle.static | Basic framework related APIs under static graph, |
+| paddle.static | Basic framework related APIs under static graph, |
| | such as Variable, Program, Executor, etc. |
+-------------------------------+-------------------------------------------------------+
| paddle.static.nn | Special APIs for networking under static graph such |
@@ -86,4 +86,3 @@ In this version, PaddlePaddle has made many optimizations to the APIs. You can r
+-------------------------------+-------------------------------------------------------+
| paddle.sparse | The Sparse domain API. |
+-------------------------------+-------------------------------------------------------+
-
diff --git a/docs/api/paddle/CUDAPlace_cn.rst b/docs/api/paddle/CUDAPlace_cn.rst
index db3a51d3929..077a4f1a24d 100644
--- a/docs/api/paddle/CUDAPlace_cn.rst
+++ b/docs/api/paddle/CUDAPlace_cn.rst
@@ -10,7 +10,7 @@ CUDAPlace
``CUDAPlace`` 是一个设备描述符,表示一个分配或将要分配 ``Tensor`` 或 ``LoDTensor`` 的 GPU 设备。
-每个 ``CUDAPlace`` 有一个 ``dev_id`` (设备id)来表明当前的 ``CUDAPlace`` 所代表的显卡编号,编号从 0 开始。
+每个 ``CUDAPlace`` 有一个 ``dev_id`` (设备 id)来表明当前的 ``CUDAPlace`` 所代表的显卡编号,编号从 0 开始。
``dev_id`` 不同的 ``CUDAPlace`` 所对应的内存不可相互访问。
这里编号指的是可见显卡的逻辑编号,而不是显卡实际的编号。
可以通过 ``CUDA_VISIBLE_DEVICES`` 环境变量限制程序能够使用的 GPU 设备,程序启动时会遍历当前的可见设备,并从 0 开始为这些设备编号。
@@ -19,7 +19,7 @@ CUDAPlace
参数
::::::::::::
- - **id** (int,可选) - GPU的设备ID。如果为 ``None``,则默认会使用 id 为 0 的设备。默认值为 ``None``。
+ - **id** (int,可选) - GPU 的设备 ID。如果为 ``None``,则默认会使用 id 为 0 的设备。默认值为 ``None``。
代码示例
::::::::::::
diff --git a/docs/api/paddle/DataParallel_cn.rst b/docs/api/paddle/DataParallel_cn.rst
index 1947069d4fa..d34cda1777d 100644
--- a/docs/api/paddle/DataParallel_cn.rst
+++ b/docs/api/paddle/DataParallel_cn.rst
@@ -26,11 +26,11 @@ DataParallel
::::::::::::
- **Layer** (Layer) - 需要通过数据并行方式执行的模型。
- - **strategy** (ParallelStrategy,可选) - (deprecated) 数据并行的策略,包括并行执行的环境配置。默认为None。
- - **comm_buffer_size** (int,可选) - 它是通信调用(如NCCLAllReduce)时,参数梯度聚合为一组的内存大小(MB)。默认值:25。
- - **last_comm_buffer_size** (float,可选)它限制通信调用中最后一个缓冲区的内存大小(MB)。减小最后一个通信缓冲区的大小有助于提高性能。默认值:1。默认值:1
- - **find_unused_parameters** (bool,可选) 是否在模型forward函数的返回值的所有张量中,遍历整个向后图。对于不包括在loss计算中的参数,其梯度将被预先标记为ready状态用于后续多卡间的规约操作。请注意,模型参数的所有正向输出必须参与loss的计算以及后续的梯度计算。否则,将发生严重错误。请注意,将find_unused_parameters设置为True会影响计算性能,因此,如果确定所有参数都参与了loss计算和自动反向图的构建,请将其设置为False。默认值:False。
-
+ - **strategy** (ParallelStrategy,可选) - (deprecated) 数据并行的策略,包括并行执行的环境配置。默认为 None。
+ - **comm_buffer_size** (int,可选) - 它是通信调用(如 NCCLAllReduce)时,参数梯度聚合为一组的内存大小(MB)。默认值:25。
+ - **last_comm_buffer_size** (float,可选)它限制通信调用中最后一个缓冲区的内存大小(MB)。减小最后一个通信缓冲区的大小有助于提高性能。默认值:1。默认值:1
+ - **find_unused_parameters** (bool,可选) 是否在模型 forward 函数的返回值的所有张量中,遍历整个向后图。对于不包括在 loss 计算中的参数,其梯度将被预先标记为 ready 状态用于后续多卡间的规约操作。请注意,模型参数的所有正向输出必须参与 loss 的计算以及后续的梯度计算。否则,将发生严重错误。请注意,将 find_unused_parameters 设置为 True 会影响计算性能,因此,如果确定所有参数都参与了 loss 计算和自动反向图的构建,请将其设置为 False。默认值:False。
+
返回
::::::::::::
支持数据并行的 ``Layer``。
@@ -40,7 +40,7 @@ DataParallel
COPY-FROM: paddle.DataParallel:dp-example
.. Note::
- 目前数据并行不支持PyLayer自定义算子。如有此类需求,推荐先使用no_sync接口暂停多卡通信,然后在优化器前手动实现梯度同步;具体实现过程可参考下述示例。
+ 目前数据并行不支持 PyLayer 自定义算子。如有此类需求,推荐先使用 no_sync 接口暂停多卡通信,然后在优化器前手动实现梯度同步;具体实现过程可参考下述示例。
代码示例
::::::::::::
@@ -48,7 +48,7 @@ COPY-FROM: paddle.DataParallel:dp-pylayer-example
.. py:function:: no_sync()
-用于暂停梯度同步的上下文管理器。在no_sync()中参数梯度只会在模型上累加;直到with之外的第一个forward-backward,梯度才会被同步。
+用于暂停梯度同步的上下文管理器。在 no_sync()中参数梯度只会在模型上累加;直到 with 之外的第一个 forward-backward,梯度才会被同步。
代码示例
::::::::::::
@@ -60,15 +60,15 @@ COPY-FROM: paddle.DataParallel.no_sync
state_dict(destination=None, include_sublayers=True)
'''''''''
-获取当前层及其子层的所有parameters和持久的buffers。并将所有parameters和buffers存放在dict结构中。
+获取当前层及其子层的所有 parameters 和持久的 buffers。并将所有 parameters 和 buffers 存放在 dict 结构中。
**参数**
- - **destination** (dict,可选) - 如果提供 ``destination``,则所有参数和持久的buffers都将存放在 ``destination`` 中。默认值:None。
- - **include_sublayers** (bool,可选) - 如果设置为True,则包括子层的参数和buffers。默认值:True。
+ - **destination** (dict,可选) - 如果提供 ``destination``,则所有参数和持久的 buffers 都将存放在 ``destination`` 中。默认值:None。
+ - **include_sublayers** (bool,可选) - 如果设置为 True,则包括子层的参数和 buffers。默认值:True。
**返回**
-dict,包含所有parameters和持久的buffers的dict。
+dict,包含所有 parameters 和持久的 buffers 的 dict。
**代码示例**
@@ -78,12 +78,12 @@ COPY-FROM: paddle.DataParallel.state_dict
set_state_dict(state_dict, use_structured_name=True)
'''''''''
-根据传入的 ``state_dict`` 设置parameters和持久的buffers。所有parameters和buffers将由 ``state_dict`` 中的 ``Tensor`` 设置。
+根据传入的 ``state_dict`` 设置 parameters 和持久的 buffers。所有 parameters 和 buffers 将由 ``state_dict`` 中的 ``Tensor`` 设置。
**参数**
- - **state_dict** (dict) - 包含所有parameters和可持久性buffers的dict。
- - **use_structured_name** (bool,可选) - 如果设置为True,将使用Layer的结构性变量名作为dict的key,否则将使用Parameter或者Buffer的变量名作为key。默认值:True。
+ - **state_dict** (dict) - 包含所有 parameters 和可持久性 buffers 的 dict。
+ - **use_structured_name** (bool,可选) - 如果设置为 True,将使用 Layer 的结构性变量名作为 dict 的 key,否则将使用 Parameter 或者 Buffer 的变量名作为 key。默认值:True。
**返回**
diff --git a/docs/api/paddle/Model_cn.rst b/docs/api/paddle/Model_cn.rst
index 71cab82b277..ce3ae79c04e 100644
--- a/docs/api/paddle/Model_cn.rst
+++ b/docs/api/paddle/Model_cn.rst
@@ -7,7 +7,7 @@ Model
``Model`` 对象是一个具备训练、测试、推理的神经网络。该对象同时支持静态图和动态图模式,飞桨框架默认为动态图模式,通过 ``paddle.enable_static()`` 来切换到静态图模式。需要注意的是,需要在实例化 ``Model`` 对象之前完成切换。
-在 GPU 上训练时,高层 API 支持自动混合精度(AMP)训练,并且在静态图下使用 Adam、AdamW、Momentum 优化器时还支持纯 float16 的训练。在使用纯 float16 训练之前,优化器初始化时 ``multi_precision`` 参数可以设置为 True,这样可以避免性能变差或是收敛变慢的问题。并且,在组网中可以使用 ``paddle.static.amp.fp16_guard`` 来限定使用纯float16训练的范围,否则需要把 ``use_fp16_guard`` 手动设置为False以开启全局纯 float16 训练。使用纯 float16 训练前,可能需要手动将 dtype 为 float32 的输入转成 float16 的输入。然而,使用自动混合精度训练(AMP)时,不支持限定混合精度训练的范围。
+在 GPU 上训练时,高层 API 支持自动混合精度(AMP)训练,并且在静态图下使用 Adam、AdamW、Momentum 优化器时还支持纯 float16 的训练。在使用纯 float16 训练之前,优化器初始化时 ``multi_precision`` 参数可以设置为 True,这样可以避免性能变差或是收敛变慢的问题。并且,在组网中可以使用 ``paddle.static.amp.fp16_guard`` 来限定使用纯 float16 训练的范围,否则需要把 ``use_fp16_guard`` 手动设置为 False 以开启全局纯 float16 训练。使用纯 float16 训练前,可能需要手动将 dtype 为 float32 的输入转成 float16 的输入。然而,使用自动混合精度训练(AMP)时,不支持限定混合精度训练的范围。
参数
:::::::::
@@ -15,7 +15,7 @@ Model
- **network** (paddle.nn.Layer) - 是 ``paddle.nn.Layer`` 的一个实例。
- **inputs** (InputSpec|list|tuple|dict|None,可选) - ``network`` 的输入,可以是 ``InputSpec`` 的实例,或者是一个 ``InputSpec`` 的 ``list``,或者是格式为 ``{name: InputSpec}`` 的 ``dict``,或者为 ``None``。默认值为 ``None``。
- **labels** (InputSpec|list|tuple|None,可选) - ``network`` 的标签,可以是 ``InputSpec`` 的实例,或者是一个 ``InputSpec`` 的 ``list``,或者为 ``None``。 默认值为 ``None``。
-
+
.. note::
在动态图中,``inputs`` 和 ``labels`` 都可以设置为 ``None``。但是,在静态图中,``input`` 不能设置为 ``None``。而如果损失函数需要标签(label)作为输入,则必须设置 ``labels``,否则,可以为 ``None``。
@@ -69,7 +69,7 @@ eval_batch(inputs, labels=None)
- **inputs** (numpy.ndarray|Tensor|list) - 一批次的输入数据。它可以是一个 numpy 数组或 paddle.Tensor,或者是它们的列表(在模型具有多输入的情况下)。
- **labels** (numpy.ndarray|Tensor|list,可选) - 一批次的标签。它可以是一个 numpy 数组或 paddle.Tensor,或者是它们的列表(在模型具有多输入的情况下)。如果无标签,请设置为 None。默认值:None。
-
+
**返回**
list,如果没有定义评估函数,则返回包含了预测损失函数的值的列表;如果定义了评估函数,则返回一个元组(损失函数的列表,评估指标的列表)。
@@ -89,7 +89,7 @@ predict_batch(inputs)
- **inputs** (numpy.ndarray|Tensor|list) - 一批次的输入数据。它可以是一个 numpy 数组或 paddle.Tensor,或者是它们的列表(在模型具有多输入的情况下)。
-
+
**返回**
一个列表,包含了模型的输出。
@@ -110,7 +110,7 @@ save(path, training=True)
- **path** (str) - 保存的文件名前缀。格式如 ``dirname/file_prefix`` 或者 ``file_prefix`` 。
- **training** (bool,可选) - 是否保存训练的状态,包括模型参数和优化器参数等。如果为 False,则只保存推理所需的参数与文件。默认值:True。
-
+
**返回**
无。
@@ -131,7 +131,7 @@ load(path, skip_mismatch=False, reset_optimizer=False)
- **path** (str) - 保存参数或优化器信息的文件前缀。格式如 ``path.pdparams`` 或者 ``path.pdopt`` ,后者是非必要的,如果不想恢复优化器信息。
- **skip_mismatch** (bool,可选) - 是否需要跳过保存的模型文件中形状或名称不匹配的参数,设置为 ``False`` 时,当遇到不匹配的参数会抛出一个错误。默认值:False。
- **reset_optimizer** (bool,可选) - 设置为 ``True`` 时,会忽略提供的优化器信息文件。否则会载入提供的优化器信息。默认值:False。
-
+
**返回**
无。
@@ -145,7 +145,7 @@ parameters(*args, **kwargs)
'''''''''
返回一个包含模型所有参数的列表。
-
+
**返回**
在静态图中返回一个包含 ``Parameter`` 的列表,在动态图中返回一个包含 ``ParamBase`` 的列表。
@@ -165,7 +165,7 @@ prepare(optimizer=None, loss=None, metrics=None, amp_configs=None)
- **optimizer** (OOptimizer|None,可选) - 当训练模型的,该参数必须被设定。当评估或测试的时候,该参数可以不设定。默认值:None。
- **loss** (Loss|Callable|None,可选) - 当训练模型的,该参数必须被设定。默认值:None。
- **metrics** (Metric|list[Metric]|None,可选) - 当该参数被设定时,所有给定的评估方法会在训练和测试时被运行,并返回对应的指标。默认值:None。
- - **amp_configs** (str|dict|None,可选) - 混合精度训练的配置,通常是个 dict,也可以是 str。当使用自动混合精度训练或者纯 float16 训练时,``amp_configs`` 的 key ``level`` 需要被设置为 O1 或者 O2,float32 训练时则默认为 O0。除了 ``level`` ,还可以传入更多的和混合精度API一致的参数,例如:``init_loss_scaling``、 ``incr_ratio`` 、 ``decr_ratio``、 ``incr_every_n_steps``、 ``decr_every_n_nan_or_inf``、 ``use_dynamic_loss_scaling``、 ``custom_white_list``、 ``custom_black_list`` ,在静态图下还支持传入 ``custom_black_varnames`` 和 ``use_fp16_guard`` 。详细使用方法可以参考参考混合精度 API 的文档 :ref:`auto_cast ` 和 :ref:`GradScaler ` 。为了方便起见,当不设置其他的配置参数时,也可以直接传入 ``'O1'`` 、``'O2'`` 。在使用 float32 训练时,该参数可以为 None。默认值:None。
+ - **amp_configs** (str|dict|None,可选) - 混合精度训练的配置,通常是个 dict,也可以是 str。当使用自动混合精度训练或者纯 float16 训练时,``amp_configs`` 的 key ``level`` 需要被设置为 O1 或者 O2,float32 训练时则默认为 O0。除了 ``level`` ,还可以传入更多的和混合精度 API 一致的参数,例如:``init_loss_scaling``、 ``incr_ratio`` 、 ``decr_ratio``、 ``incr_every_n_steps``、 ``decr_every_n_nan_or_inf``、 ``use_dynamic_loss_scaling``、 ``custom_white_list``、 ``custom_black_list`` ,在静态图下还支持传入 ``custom_black_varnames`` 和 ``use_fp16_guard`` 。详细使用方法可以参考参考混合精度 API 的文档 :ref:`auto_cast ` 和 :ref:`GradScaler ` 。为了方便起见,当不设置其他的配置参数时,也可以直接传入 ``'O1'`` 、``'O2'`` 。在使用 float32 训练时,该参数可以为 None。默认值:None。
fit(train_data=None, eval_data=None, batch_size=1, epochs=1, eval_freq=1, log_freq=10, save_dir=None, save_freq=1, verbose=2, drop_last=False, shuffle=True, num_workers=0, callbacks=None, accumulate_grad_batches=1, num_iters=None)
@@ -225,7 +225,7 @@ evaluate(eval_data, batch_size=1, log_freq=10, verbose=2, num_workers=0, callbac
**返回**
-dict, key是 ``prepare`` 时 Metric 的的名称,value 是该 Metric 的值。
+dict, key 是 ``prepare`` 时 Metric 的的名称,value 是该 Metric 的值。
**代码示例**
diff --git a/docs/api/paddle/NPUPlace_cn.rst b/docs/api/paddle/NPUPlace_cn.rst
index 182afc83c2e..cae5f890c8a 100644
--- a/docs/api/paddle/NPUPlace_cn.rst
+++ b/docs/api/paddle/NPUPlace_cn.rst
@@ -6,16 +6,16 @@ NPUPlace
.. py:class:: paddle.NPUPlace
``NPUPlace`` 是一个设备描述符,表示一个分配或将要分配 ``Tensor`` 或 ``LoDTensor`` 的 NPU 设备。
-每个 ``NPUPlace`` 有一个 ``dev_id`` (设备id)来表明当前的 ``NPUPlace`` 所代表的显卡编号,编号从 0 开始。
+每个 ``NPUPlace`` 有一个 ``dev_id`` (设备 id)来表明当前的 ``NPUPlace`` 所代表的显卡编号,编号从 0 开始。
``dev_id`` 不同的 ``NPUPlace`` 所对应的内存不可相互访问。
这里编号指的是显卡实际的编号,而不是显卡的逻辑编号。
参数
::::::::::::
- - **id** (int,可选) - NPU的设备ID。
+ - **id** (int,可选) - NPU 的设备 ID。
代码示例
::::::::::::
-COPY-FROM: paddle.NPUPlace
\ No newline at end of file
+COPY-FROM: paddle.NPUPlace
diff --git a/docs/api/paddle/Overview_cn.rst b/docs/api/paddle/Overview_cn.rst
index fe5dd774135..113f031234d 100755
--- a/docs/api/paddle/Overview_cn.rst
+++ b/docs/api/paddle/Overview_cn.rst
@@ -3,64 +3,64 @@
paddle
---------------------
-paddle 目录下包含tensor、device、framework相关API以及某些高层API。具体如下:
-
-- :ref:`tensor数学操作 `
-- :ref:`tensor逻辑操作 `
-- :ref:`tensor属性相关 `
-- :ref:`tensor创建相关 `
-- :ref:`tensor元素查找相关 `
-- :ref:`tensor初始化相关 `
-- :ref:`tensor random相关 `
-- :ref:`tensor线性代数相关 `
-- :ref:`tensor元素操作相关(如:转置,reshape等) `
+paddle 目录下包含 tensor、device、framework 相关 API 以及某些高层 API。具体如下:
+
+- :ref:`tensor 数学操作 `
+- :ref:`tensor 逻辑操作 `
+- :ref:`tensor 属性相关 `
+- :ref:`tensor 创建相关 `
+- :ref:`tensor 元素查找相关 `
+- :ref:`tensor 初始化相关 `
+- :ref:`tensor random 相关 `
+- :ref:`tensor 线性代数相关 `
+- :ref:`tensor 元素操作相关(如:转置,reshape 等) `
- :ref:`爱因斯坦求和 `
-- :ref:`framework相关 `
-- :ref:`device相关 `
-- :ref:`高层API相关 `
-- :ref:`稀疏API相关 `
+- :ref:`framework 相关 `
+- :ref:`device 相关 `
+- :ref:`高层 API 相关 `
+- :ref:`稀疏 API 相关 `
.. _tensor_math:
-tensor数学操作
+tensor 数学操作
::::::::::::::::::::
.. csv-table::
- :header: "API名称", "API功能"
+ :header: "API 名称", "API 功能"
:widths: 10, 30
" :ref:`paddle.abs ` ", "绝对值函数"
" :ref:`paddle.angle ` ", "相位角函数"
- " :ref:`paddle.acos ` ", "arccosine函数"
- " :ref:`paddle.add ` ", "Tensor逐元素相加"
- " :ref:`paddle.add_n ` ", "对输入的一至多个Tensor或LoDTensor求和"
- " :ref:`paddle.addmm ` ", "计算输入Tensor x和y的乘积,将结果乘以标量alpha,再加上input与beta的乘积,得到输出"
- " :ref:`paddle.all ` ", "对指定维度上的Tensor元素进行逻辑与运算"
- " :ref:`paddle.allclose ` ", "逐个检查输入Tensor x和y的所有元素是否均满足 ∣x−y∣≤atol+rtol×∣y∣"
- " :ref:`paddle.isclose ` ", "逐个检查输入Tensor x和y的所有元素是否满足 ∣x−y∣≤atol+rtol×∣y∣"
- " :ref:`paddle.any ` ", "对指定维度上的Tensor元素进行逻辑或运算"
- " :ref:`paddle.asin ` ", "arcsine函数"
- " :ref:`paddle.atan ` ", "arctangent函数"
- " :ref:`paddle.atan2 ` ", "arctangent2函数"
+ " :ref:`paddle.acos ` ", "arccosine 函数"
+ " :ref:`paddle.add ` ", "Tensor 逐元素相加"
+ " :ref:`paddle.add_n ` ", "对输入的一至多个 Tensor 或 LoDTensor 求和"
+ " :ref:`paddle.addmm ` ", "计算输入 Tensor x 和 y 的乘积,将结果乘以标量 alpha,再加上 input 与 beta 的乘积,得到输出"
+ " :ref:`paddle.all ` ", "对指定维度上的 Tensor 元素进行逻辑与运算"
+ " :ref:`paddle.allclose ` ", "逐个检查输入 Tensor x 和 y 的所有元素是否均满足 ∣x−y∣≤atol+rtol×∣y∣"
+ " :ref:`paddle.isclose ` ", "逐个检查输入 Tensor x 和 y 的所有元素是否满足 ∣x−y∣≤atol+rtol×∣y∣"
+ " :ref:`paddle.any ` ", "对指定维度上的 Tensor 元素进行逻辑或运算"
+ " :ref:`paddle.asin ` ", "arcsine 函数"
+ " :ref:`paddle.atan ` ", "arctangent 函数"
+ " :ref:`paddle.atan2 ` ", "arctangent2 函数"
" :ref:`paddle.ceil ` ", "向上取整运算函数"
" :ref:`paddle.clip ` ", "将输入的所有元素进行剪裁,使得输出元素限制在[min, max]内"
- " :ref:`paddle.conj ` ", "逐元素计算Tensor的共轭运算"
+ " :ref:`paddle.conj ` ", "逐元素计算 Tensor 的共轭运算"
" :ref:`paddle.cos ` ", "余弦函数"
" :ref:`paddle.cosh ` ", "双曲余弦函数"
" :ref:`paddle.count_nonzero ` ", "沿给定的轴 axis 统计非零元素的数量"
" :ref:`paddle.cumsum ` ", "沿给定 axis 计算张量 x 的累加和"
" :ref:`paddle.cumprod ` ", "沿给定 dim 计算张量 x 的累乘"
- " :ref:`paddle.digamma ` ", "逐元素计算输入x的digamma函数值"
+ " :ref:`paddle.digamma ` ", "逐元素计算输入 x 的 digamma 函数值"
" :ref:`paddle.divide ` ", "逐元素相除算子"
- " :ref:`paddle.equal ` ", "该OP返回 x==y 逐元素比较x和y是否相等,相同位置的元素相同则返回True,否则返回False"
- " :ref:`paddle.equal_all ` ", "如果所有相同位置的元素相同返回True,否则返回False"
- " :ref:`paddle.erf ` ", "逐元素计算 Erf 激活函数"
- " :ref:`paddle.exp ` ", "逐元素进行以自然数e为底指数运算"
- " :ref:`paddle.expm1 ` ", "逐元素进行exp(x)-1运算"
- " :ref:`paddle.floor ` ", "向下取整函数"
+ " :ref:`paddle.equal ` ", "该 OP 返回 x==y 逐元素比较 x 和 y 是否相等,相同位置的元素相同则返回 True,否则返回 False"
+ " :ref:`paddle.equal_all ` ", "如果所有相同位置的元素相同返回 True,否则返回 False"
+ " :ref:`paddle.erf ` ", "逐元素计算 Erf 激活函数"
+ " :ref:`paddle.exp ` ", "逐元素进行以自然数 e 为底指数运算"
+ " :ref:`paddle.expm1 ` ", "逐元素进行 exp(x)-1 运算"
+ " :ref:`paddle.floor ` ", "向下取整函数"
" :ref:`paddle.floor_divide ` ", "逐元素整除算子,输入 x 与输入 y 逐元素整除,并将各个位置的输出元素保存到返回结果中"
" :ref:`paddle.greater_equal ` ", "逐元素地返回 x>=y 的逻辑值"
" :ref:`paddle.greater_than ` ", "逐元素地返回 x>y 的逻辑值"
@@ -70,69 +70,69 @@ tensor数学操作
" :ref:`paddle.less_equal ` ", "逐元素地返回 x<=y 的逻辑值"
" :ref:`paddle.less_than ` ", "逐元素地返回 x` ", "计算输入 x 的 gamma 函数的自然对数并返回"
- " :ref:`paddle.log ` ", "Log激活函数(计算自然对数)"
- " :ref:`paddle.log10 ` ", "Log10激活函数(计算底为10的对数)"
- " :ref:`paddle.log2 ` ", "计算Log1p(加一的自然对数)结果"
+ " :ref:`paddle.log ` ", "Log 激活函数(计算自然对数)"
+ " :ref:`paddle.log10 ` ", "Log10 激活函数(计算底为 10 的对数)"
+ " :ref:`paddle.log2 ` ", "计算 Log1p(加一的自然对数)结果"
" :ref:`paddle.logcumsumexp ` ", "计算 x 的指数的前缀和的对数"
" :ref:`paddle.logical_and ` ", "逐元素的对 x 和 y 进行逻辑与运算"
- " :ref:`paddle.logical_not ` ", "逐元素的对 X Tensor进行逻辑非运算"
+ " :ref:`paddle.logical_not ` ", "逐元素的对 X Tensor 进行逻辑非运算"
" :ref:`paddle.logical_or ` ", "逐元素的对 X 和 Y 进行逻辑或运算"
" :ref:`paddle.logical_xor ` ", "逐元素的对 X 和 Y 进行逻辑异或运算"
- " :ref:`paddle.logit ` ", "计算logit结果"
+ " :ref:`paddle.logit ` ", "计算 logit 结果"
" :ref:`paddle.bitwise_and ` ", "逐元素的对 x 和 y 进行按位与运算"
- " :ref:`paddle.bitwise_not ` ", "逐元素的对 X Tensor进行按位取反运算"
+ " :ref:`paddle.bitwise_not ` ", "逐元素的对 X Tensor 进行按位取反运算"
" :ref:`paddle.bitwise_or ` ", "逐元素的对 X 和 Y 进行按位或运算"
" :ref:`paddle.bitwise_xor ` ", "逐元素的对 X 和 Y 进行按位异或运算"
- " :ref:`paddle.logsumexp ` ", "沿着 axis 计算 x 的以e为底的指数的和的自然对数"
- " :ref:`paddle.max ` ", "对指定维度上的Tensor元素求最大值运算"
- " :ref:`paddle.amax ` ", "对指定维度上的Tensor元素求最大值运算"
- " :ref:`paddle.maximum ` ", "逐元素对比输入的两个Tensor,并且把各个位置更大的元素保存到返回结果中"
+ " :ref:`paddle.logsumexp ` ", "沿着 axis 计算 x 的以 e 为底的指数的和的自然对数"
+ " :ref:`paddle.max ` ", "对指定维度上的 Tensor 元素求最大值运算"
+ " :ref:`paddle.amax ` ", "对指定维度上的 Tensor 元素求最大值运算"
+ " :ref:`paddle.maximum ` ", "逐元素对比输入的两个 Tensor,并且把各个位置更大的元素保存到返回结果中"
" :ref:`paddle.mean ` ", "沿 axis 计算 x 的平均值"
" :ref:`paddle.median ` ", "沿给定的轴 axis 计算 x 中元素的中位数"
- " :ref:`paddle.nanmedian ` ", "沿给定的轴 axis 忽略NAN元素计算 x 中元素的中位数"
- " :ref:`paddle.min ` ", "对指定维度上的Tensor元素求最小值运算"
- " :ref:`paddle.amin ` ", "对指定维度上的Tensor元素求最小值运算"
- " :ref:`paddle.minimum ` ", "逐元素对比输入的两个Tensor,并且把各个位置更小的元素保存到返回结果中"
+ " :ref:`paddle.nanmedian ` ", "沿给定的轴 axis 忽略 NAN 元素计算 x 中元素的中位数"
+ " :ref:`paddle.min ` ", "对指定维度上的 Tensor 元素求最小值运算"
+ " :ref:`paddle.amin ` ", "对指定维度上的 Tensor 元素求最小值运算"
+ " :ref:`paddle.minimum ` ", "逐元素对比输入的两个 Tensor,并且把各个位置更小的元素保存到返回结果中"
" :ref:`paddle.mm ` ", "用于两个输入矩阵的相乘"
" :ref:`paddle.inner ` ", "计算两个输入矩阵的内积"
" :ref:`paddle.outer ` ", "计算两个输入矩阵的外积"
- " :ref:`paddle.multiplex ` ", "从每个输入Tensor中选择特定行构造输出Tensor"
+ " :ref:`paddle.multiplex ` ", "从每个输入 Tensor 中选择特定行构造输出 Tensor"
" :ref:`paddle.multiply ` ", "逐元素相乘算子"
" :ref:`paddle.neg ` ", "计算输入 x 的相反数并返回"
- " :ref:`paddle.not_equal ` ", "逐元素地返回x!=y 的逻辑值"
- " :ref:`paddle.pow ` ", "指数算子,逐元素计算 x 的 y 次幂"
- " :ref:`paddle.prod ` ", "对指定维度上的Tensor元素进行求乘积运算"
- " :ref:`paddle.reciprocal ` ", "对输入Tensor取倒数"
+ " :ref:`paddle.not_equal ` ", "逐元素地返回 x!=y 的逻辑值"
+ " :ref:`paddle.pow ` ", "指数算子,逐元素计算 x 的 y 次幂"
+ " :ref:`paddle.prod ` ", "对指定维度上的 Tensor 元素进行求乘积运算"
+ " :ref:`paddle.reciprocal ` ", "对输入 Tensor 取倒数"
" :ref:`paddle.round ` ", "将输入中的数值四舍五入到最接近的整数数值"
- " :ref:`paddle.rsqrt ` ", "rsqrt激活函数"
+ " :ref:`paddle.rsqrt ` ", "rsqrt 激活函数"
" :ref:`paddle.scale ` ", "缩放算子"
- " :ref:`paddle.sign ` ", "对输入x中每个元素进行正负判断"
+ " :ref:`paddle.sign ` ", "对输入 x 中每个元素进行正负判断"
" :ref:`paddle.sin ` ", "计算输入的正弦值"
" :ref:`paddle.sinh ` ", "双曲正弦函数"
" :ref:`paddle.sqrt ` ", "计算输入的算数平方根"
- " :ref:`paddle.square ` ", "该OP执行逐元素取平方运算"
+ " :ref:`paddle.square ` ", "该 OP 执行逐元素取平方运算"
" :ref:`paddle.stanh ` ", "stanh 激活函数"
" :ref:`paddle.std ` ", "沿给定的轴 axis 计算 x 中元素的标准差"
" :ref:`paddle.subtract ` ", "逐元素相减算子"
- " :ref:`paddle.sum ` ", "对指定维度上的Tensor元素进行求和运算"
- " :ref:`paddle.tan ` ", "三角函数tangent"
- " :ref:`paddle.tanh ` ", "tanh激活函数"
+ " :ref:`paddle.sum ` ", "对指定维度上的 Tensor 元素进行求和运算"
+ " :ref:`paddle.tan ` ", "三角函数 tangent"
+ " :ref:`paddle.tanh ` ", "tanh 激活函数"
" :ref:`paddle.tanh_ ` ", "Inplace 版本的 tanh API,对输入 x 采用 Inplace 策略"
" :ref:`paddle.trace ` ", "计算输入 Tensor 在指定平面上的对角线元素之和"
" :ref:`paddle.var ` ", "沿给定的轴 axis 计算 x 中元素的方差"
" :ref:`paddle.diagonal ` ", "根据给定的轴 axis 返回输入 Tensor 的局部视图"
" :ref:`paddle.trunc ` ", "对输入 Tensor 每个元素的小数部分进行截断"
" :ref:`paddle.frac ` ", "得到输入 Tensor 每个元素的小数部分"
- " :ref:`paddle.log1p ` ", "该OP计算Log1p(加一的自然对数)结果"
- " :ref:`paddle.take_along_axis ` ", "根据axis和index获取输入 Tensor 的对应元素"
- " :ref:`paddle.put_along_axis ` ", "根据axis和index放置value值至输入 Tensor"
- " :ref:`paddle.lerp ` ", "该OP基于给定的 weight 计算 x 与 y 的线性插值"
- " :ref:`paddle.diff ` ", "沿着指定维度对输入Tensor计算n阶的前向差值"
+ " :ref:`paddle.log1p ` ", "该 OP 计算 Log1p(加一的自然对数)结果"
+ " :ref:`paddle.take_along_axis ` ", "根据 axis 和 index 获取输入 Tensor 的对应元素"
+ " :ref:`paddle.put_along_axis ` ", "根据 axis 和 index 放置 value 值至输入 Tensor"
+ " :ref:`paddle.lerp ` ", "该 OP 基于给定的 weight 计算 x 与 y 的线性插值"
+ " :ref:`paddle.diff ` ", "沿着指定维度对输入 Tensor 计算 n 阶的前向差值"
" :ref:`paddle.rad2deg ` ", "将元素从弧度的角度转换为度"
" :ref:`paddle.deg2rad ` ", "将元素从度的角度转换为弧度"
" :ref:`paddle.gcd ` ", "计算两个输入的按元素绝对值的最大公约数"
" :ref:`paddle.lcm ` ", "计算两个输入的按元素绝对值的最小公倍数"
- " :ref:`paddle.erfinv ` ", "计算输入Tensor的逆误差函数"
+ " :ref:`paddle.erfinv ` ", "计算输入 Tensor 的逆误差函数"
" :ref:`paddle.acosh ` ", "反双曲余弦函数"
" :ref:`paddle.asinh ` ", "反双曲正弦函数"
" :ref:`paddle.atanh ` ", "反双曲正切函数"
@@ -140,75 +140,75 @@ tensor数学操作
.. _tensor_logic:
-tensor逻辑操作
+tensor 逻辑操作
::::::::::::::::::::
.. csv-table::
- :header: "API名称", "API功能"
+ :header: "API 名称", "API 功能"
:widths: 10, 30
" :ref:`paddle.is_empty ` ", "测试变量是否为空"
- " :ref:`paddle.is_tensor ` ", "用来测试输入对象是否是paddle.Tensor"
- " :ref:`paddle.isfinite ` ", "返回输入tensor的每一个值是否为Finite(既非 +/-INF 也非 +/-NaN )"
- " :ref:`paddle.isinf ` ", "返回输入tensor的每一个值是否为 +/-INF"
- " :ref:`paddle.isnan ` ", "返回输入tensor的每一个值是否为 +/-NaN"
+ " :ref:`paddle.is_tensor ` ", "用来测试输入对象是否是 paddle.Tensor"
+ " :ref:`paddle.isfinite ` ", "返回输入 tensor 的每一个值是否为 Finite(既非 +/-INF 也非 +/-NaN )"
+ " :ref:`paddle.isinf ` ", "返回输入 tensor 的每一个值是否为 +/-INF"
+ " :ref:`paddle.isnan ` ", "返回输入 tensor 的每一个值是否为 +/-NaN"
.. _tensor_attribute:
-tensor属性相关
+tensor 属性相关
::::::::::::::::::::
.. csv-table::
- :header: "API名称", "API功能"
+ :header: "API 名称", "API 功能"
:widths: 10, 30
- " :ref:`paddle.imag ` ", "返回一个包含输入复数Tensor的虚部数值的新Tensor"
- " :ref:`paddle.real ` ", "返回一个包含输入复数Tensor的实部数值的新Tensor"
- " :ref:`paddle.shape ` ", "获得输入Tensor或SelectedRows的shape"
+ " :ref:`paddle.imag ` ", "返回一个包含输入复数 Tensor 的虚部数值的新 Tensor"
+ " :ref:`paddle.real ` ", "返回一个包含输入复数 Tensor 的实部数值的新 Tensor"
+ " :ref:`paddle.shape ` ", "获得输入 Tensor 或 SelectedRows 的 shape"
" :ref:`paddle.is_complex ` ", "判断输入 tensor 的数据类型是否为复数类型"
" :ref:`paddle.is_integer ` ", "判断输入 tensor 的数据类型是否为整数类型"
- " :ref:`paddle.broadcast_shape ` ", "返回对x_shape大小的张量和y_shape大小的张量做broadcast操作后得到的shape"
- " :ref:`paddle.is_floating_point ` ", "判断输入Tensor的数据类型是否为浮点类型"
+ " :ref:`paddle.broadcast_shape ` ", "返回对 x_shape 大小的张量和 y_shape 大小的张量做 broadcast 操作后得到的 shape"
+ " :ref:`paddle.is_floating_point ` ", "判断输入 Tensor 的数据类型是否为浮点类型"
.. _tensor_creation:
-tensor创建相关
+tensor 创建相关
::::::::::::::::::::
.. csv-table::
- :header: "API名称", "API功能"
+ :header: "API 名称", "API 功能"
:widths: 10, 30
- " :ref:`paddle.arange ` ", "返回以步长 step 均匀分隔给定数值区间[start, end)的1-D Tensor,数据类型为 dtype"
- " :ref:`paddle.diag ` ", "如果 x 是向量(1-D张量),则返回带有 x 元素作为对角线的2-D方阵;如果 x 是矩阵(2-D张量),则提取 x 的对角线元素,以1-D张量返回。"
+ " :ref:`paddle.arange ` ", "返回以步长 step 均匀分隔给定数值区间[start, end)的 1-D Tensor,数据类型为 dtype"
+ " :ref:`paddle.diag ` ", "如果 x 是向量(1-D 张量),则返回带有 x 元素作为对角线的 2-D 方阵;如果 x 是矩阵(2-D 张量),则提取 x 的对角线元素,以 1-D 张量返回。"
" :ref:`paddle.diagflat ` ", "如果 x 是一维张量,则返回带有 x 元素作为对角线的二维方阵;如果 x 是大于等于二维的张量,则返回一个二维张量,其对角线元素为 x 在连续维度展开得到的一维张量的元素。"
- " :ref:`paddle.empty ` ", "创建形状大小为shape并且数据类型为dtype的Tensor"
- " :ref:`paddle.empty_like ` ", "根据 x 的shape和数据类型 dtype 创建未初始化的Tensor"
- " :ref:`paddle.eye ` ", "构建二维Tensor(主对角线元素为1,其他元素为0)"
- " :ref:`paddle.full ` ", "创建形状大小为 shape 并且数据类型为 dtype 的Tensor"
- " :ref:`paddle.full_like ` ", "创建一个和 x 具有相同的形状并且数据类型为 dtype 的Tensor"
- " :ref:`paddle.linspace ` ", "返回一个Tensor,Tensor的值为在区间start和stop上均匀间隔的num个值,输出Tensor的长度为num"
+ " :ref:`paddle.empty ` ", "创建形状大小为 shape 并且数据类型为 dtype 的 Tensor"
+ " :ref:`paddle.empty_like ` ", "根据 x 的 shape 和数据类型 dtype 创建未初始化的 Tensor"
+ " :ref:`paddle.eye ` ", "构建二维 Tensor(主对角线元素为 1,其他元素为 0)"
+ " :ref:`paddle.full ` ", "创建形状大小为 shape 并且数据类型为 dtype 的 Tensor"
+ " :ref:`paddle.full_like ` ", "创建一个和 x 具有相同的形状并且数据类型为 dtype 的 Tensor"
+ " :ref:`paddle.linspace ` ", "返回一个 Tensor,Tensor 的值为在区间 start 和 stop 上均匀间隔的 num 个值,输出 Tensor 的长度为 num"
" :ref:`paddle.meshgrid ` ", "对每个张量做扩充操作"
- " :ref:`paddle.numel ` ", "返回一个长度为1并且元素值为输入 x 元素个数的Tensor"
- " :ref:`paddle.ones ` ", "创建形状为 shape 、数据类型为 dtype 且值全为1的Tensor"
- " :ref:`paddle.ones_like ` ", "返回一个和 x 具有相同形状的数值都为1的Tensor"
- " :ref:`paddle.Tensor ` ", "Paddle中最为基础的数据结构"
- " :ref:`paddle.to_tensor ` ", "通过已知的data来创建一个tensor"
- " :ref:`paddle.tolist 
 -
-  -
-