In this repo, we show how to train a self-supervised model by using Global Contrastive Loss (GCL) on ImageNet. The original GCL was implementated in Tensorflow and run in TPUs here. This repo re-implements GCL in PyTorch based on moco's codebase. We recommend users to run this codebase on GPU-enabled environments, such as Google Cloud, AWS.
- 2023.03.05 Fixed
RuntimeErrorrelated to variableu - 2023.03.05 Fixed
AttributeErrorrelated tomargin
git clone https://github.com/Optimization-AI/SogCLR.gitBelow is an example for self-supervised pre-training of a ResNet-50 model on ImageNet on a 4-GPU server. By default, we use sqrt learning rate scaling, i.e.,
ImageNet1K
We use a batch size of 256 and pretrain ResNet-50 for 800 epochs. You can also increase the number of workers to accelerate the training speed.
CUDA_VISIBLE_DEVICES=0,1,2,3 python train.py \
--lr=.075 --epochs=800 --batch-size=256 \
--learning-rate-scaling=sqrt \
--loss_type dcl \
--gamma 0.9 \
--multiprocessing-distributed --world-size 1 --rank 0 --workers 32 \
--crop-min=.08 \
--wd=1e-6 \
--dist-url 'tcp://localhost:10001' \
--data_name imagenet1000 \
--data /your-data-path/imagenet1000/ \
--save_dir /your-data-path/saved_models/ \
--print-freq 1000ImageNet100
We also used a small version of ImageNet1K for experiments, i.e., ImageNet-100 is a subset with random selected 100 classes from original 1000 classes. To contrust the dataset, please follow these steps:
- Download the train and validation datasets from ImageNet1K website
- Run this script to create/move all validation images to each category (class) folder
- Copy images from train/val.txt to generate ImageNet-100
We use a batch size of 256 and pretrain ResNet-50 for 400 epochs.
CUDA_VISIBLE_DEVICES=0,1,2,3 python train.py \
--lr=.075 --epochs=400 --batch-size=256 \
--learning-rate-scaling=sqrt \
--loss_type dcl \
--gamma 0.9 \
--multiprocessing-distributed --world-size 1 --rank 0 --workers 32 \
--crop-min=.08 \
--wd=1e-6 \
--dist-url 'tcp://localhost:10001' \
--data_name imagenet100 \
--data /your-data-path/imagenet100/ \
--save_dir /your-data-path/saved_models/ \
--print-freq 1000By default, we use momentum-SGD without weight decay and a batch size of 1024 for linear evaluation on on frozen features/weights. In this stage, it runs 90 epochs for re-training the classifiers.
ImageNet
python lincls.py \
--dist-url 'tcp://localhost:10001' \
--multiprocessing-distributed --world-size 1 --rank 0 --workers 32 \
--pretrained /your-data-path/checkpoint_0799.pth.tar
--data_name imagenet1000 \
--data /your-data-path/imagenet1000/ \
--save_dir /your-data-path/saved_models/ \The following results are linear evaluation results on ImageNet1K validation set:
| Method | BatchSize | Epoch | Linear eval. |
|---|---|---|---|
| SimCLR (TF1) | 256 | 800 | 66.5 |
| SogCLR (PT2) | 256 | 800 | 69.0 |
| SogCLR (TF1) | 256 | 800 | 69.3 |
*SogCLR (PT2): pre-trained ResNet-50 checkpoint & linear evaluation training log can be downloaded here: [checkpoint_0799.pth.tar | linear_eval.txt]
The following results are linear evaluation results on ImageNet-100 validation set:
| Method | BatchSize | Epoch | Linear eval. |
|---|---|---|---|
| SimCLR (TF1) | 256 | 400 | 76.1 |
| SogCLR (PT2) | 256 | 400 | 80.0 |
| SogCLR (TF1) | 256 | 400 | 78.7 |
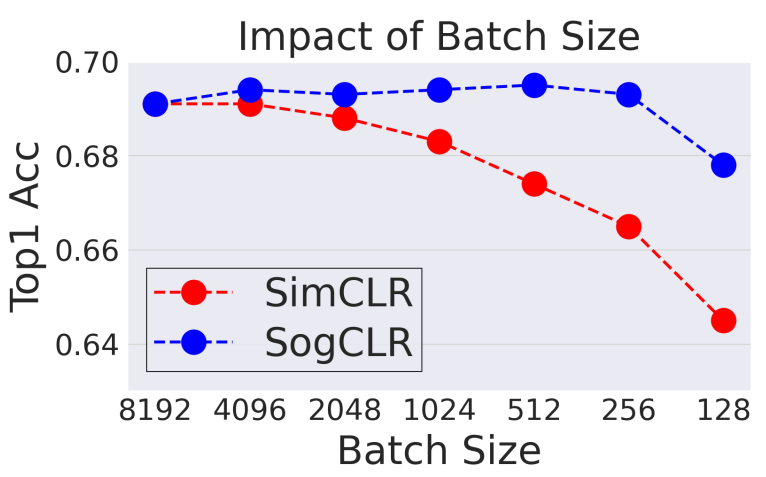
The following results are the comparsion of SogCLR and SimCLR using different batch sizes for 800-epoch pretraining on ImageNet-1K.
If you find this tutorial helpful, please cite our paper:
@inproceedings{yuan2022provable,
title={Provable stochastic optimization for global contrastive learning: Small batch does not harm performance},
author={Yuan, Zhuoning and Wu, Yuexin and Qiu, Zi-Hao and Du, Xianzhi and Zhang, Lijun and Zhou, Denny and Yang, Tianbao},
booktitle={International Conference on Machine Learning},
pages={25760--25782},
year={2022},
organization={PMLR}
}