
 +
+
 +
+
 +
+
 +
+
 +
+
 +
+
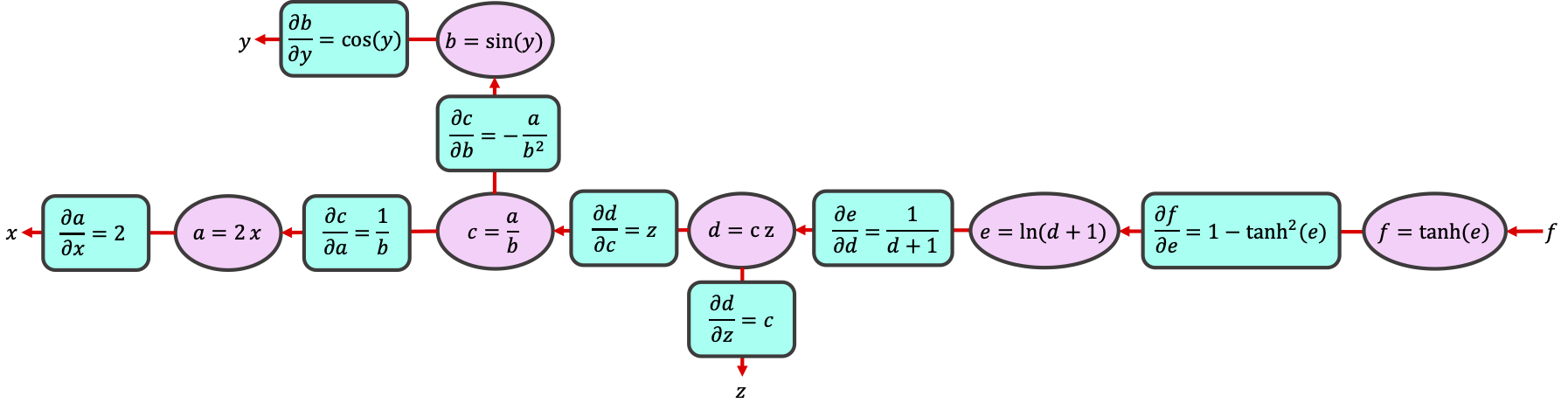
 +
+
 @@ -2594,7 +2594,7 @@
@@ -2594,7 +2594,7 @@  +
+ +
+ +
+ +
+ +
+ @@ -3012,7 +3012,7 @@
@@ -3012,7 +3012,7 @@  @@ -4863,7 +4863,7 @@
@@ -4863,7 +4863,7 @@  @@ -1746,8 +1746,8 @@
@@ -1746,8 +1746,8 @@ ![]()

![]()
Tutorial 2: Natural Language Processing and LLMs#
Week 3, Day 1: Time Series and Natural Language Processing
By Neuromatch Academy
-Content creators: Lyle Ungar, Jordan Matelsky, Konrad Kording, Shaonan Wang
+Content creators: Lyle Ungar, Jordan Matelsky, Konrad Kording, Shaonan Wang, Alish Dipani
Content reviewers: Shaonan Wang, Weizhe Yuan, Dalia Nasr, Stephen Kiilu, Alish Dipani, Dora Zhiyu Yang, Adrita Das
Content editors: Konrad Kording, Shaonan Wang
Production editors: Konrad Kording, Spiros Chavlis, Konstantine Tsafatinos
@@ -1048,7 +1046,7 @@Tutorial Objectives
-
+
@@ -1235,11 +1233,11 @@
Section 1: NLP architectures#
-
+
A core principle of Natural Language Processing is embedding words as vectors. In the relevant vector space, words with similar meanings are close to one another.
In classical transformer systems, a core principle is encoding and decoding. We can encode an input sequence as a vector (that implicitly codes what we just read). And we can then take this vector and decode it, e.g., as a new sentence. So a sequence-to-sequence (e.g., sentence translation) system may read a sentence (made out of words embedded in a relevant space) and encode it as an overall vector. It then takes the resulting encoding of the sentence and decodes it into a translated sentence.
-In modern transformer systems, such as GPT, all words are used in parallel. In that sense, the transformers generalize the encoding/decoding idea. Examples of this strategy include all the modern large language models (such as GPT).
+In modern transformer systems, such as GPT, all words are used parallelly. In that sense, the transformers generalize the encoding/decoding idea. Examples of this strategy include all the modern large language models (such as GPT).