Imbalanced GPU memory with DDP, single machine multiple GPUs #6568
Replies: 4 comments 1 reply
-
|
This fixed the same problem in a setup using only pytorch (no pl): https://discuss.pytorch.org/t/extra-10gb-memory-on-gpu-0-in-ddp-tutorial/118113 |
Beta Was this translation helpful? Give feedback.
-
|
Did you manage to solve this issue in pytorch-lightning? I observe something similar where I am seeing that one GPU has max-ed out with the GPU memory while others not. I'm using ddp strategy. I didn't see anything to address this in their docs. |
Beta Was this translation helpful? Give feedback.
-
|
@ankurhanda I also have the same issue. I do not see where this could be coming from since I do not have any .cuda() calls in my code. |
Beta Was this translation helpful? Give feedback.
-
|
Is there any solution now? I am also troubled by this problem |
Beta Was this translation helpful? Give feedback.
-
Pass this to Dataloader constructor appears to work. |
Beta Was this translation helpful? Give feedback.
-
Hi all, Multi-GPU question here. I have an imbalance in memory usage between the GPUs, GPU0 mem usage is about 20% higher then the rest of my GPUs. this leads to an anoying bottleneck, while I have 20% x (num_gpus-1) unused memory, the peak of GPU0 blocks my ability to utilize it.
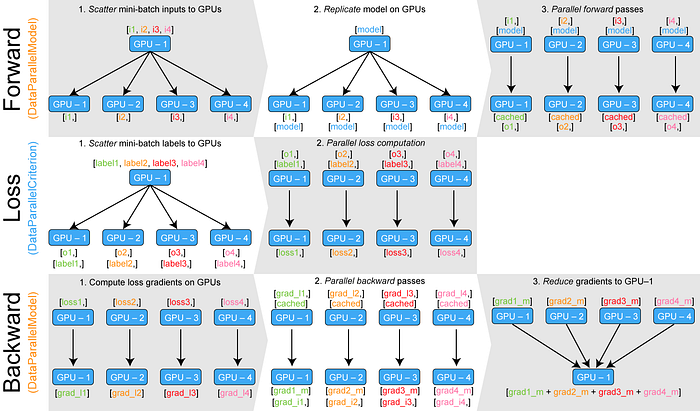
reading through this blog post that is aimed for general Pytorch, I see that this can happen when not using a ModelParallel equivalent model (attached image), I am trying to figure out how to do it using lightning especially steps 2-3 in the backward row described in the attached image.
from the lightning Multi-GPUs docs, I couldn't figure it out, the model parallelism that is described there seem to be different.
I have multiple gpus on a single machine and I'm training with ddp, and DDPPlugin(find_unused_parameters=True)).
any ideas \ resources \ solutions will be much appreciated
Beta Was this translation helpful? Give feedback.
All reactions