diff --git a/src/lightning/data/README.md b/src/lightning/data/README.md
index 5e7e9aa06bbe7..ef4fe08c437da 100644
--- a/src/lightning/data/README.md
+++ b/src/lightning/data/README.md
@@ -5,7 +5,7 @@
-## Blazing fast, distributed streaming of training data from cloud storage
+## Blazingly fast, distributed streaming of training data from cloud storage
@@ -13,15 +13,54 @@
We developed `StreamingDataset` to optimize training of large datasets stored on the cloud while prioritizing speed, affordability, and scalability.
-Specifically crafted for multi-node, distributed training with large models, it enhances accuracy, performance, and user-friendliness. Now, training efficiently is possible regardless of the data's location. Simply stream in the required data when needed.
+Specifically crafted for multi-gpu & multi-node (with [DDP](https://lightning.ai/docs/pytorch/stable/accelerators/gpu_intermediate.html), [FSDP](https://lightning.ai/docs/pytorch/stable/advanced/model_parallel/fsdp.html), etc...), distributed training with large models, it enhances accuracy, performance, and user-friendliness. Now, training efficiently is possible regardless of the data's location. Simply stream in the required data when needed.
-The `StreamingDataset` is compatible with any data type, including **images, text, video, and multimodal data** and it is a drop-in replacement for your PyTorch [IterableDataset](https://pytorch.org/docs/stable/data.html#torch.utils.data.IterableDataset) class. For example, it is used by [Lit-GPT](https://github.com/Lightning-AI/lit-gpt/blob/main/pretrain/tinyllama.py) to pretrain LLMs.
+The `StreamingDataset` is compatible with any data type, including **images, text, video, audio, geo-spatial, and multimodal data** and it is a drop-in replacement for your PyTorch [IterableDataset](https://pytorch.org/docs/stable/data.html#torch.utils.data.IterableDataset) class. For example, it is used by [Lit-GPT](https://github.com/Lightning-AI/lit-gpt/blob/main/pretrain/tinyllama.py) to pretrain LLMs.
-Finally, the `StreamingDataset` is fast! Check out our [benchmark](https://lightning.ai/lightning-ai/studios/benchmark-cloud-data-loading-libraries).
+# 🚀 Benchmarks
-Here is an illustration showing how the `StreamingDataset` works.
+[Imagenet-1.2M](https://www.image-net.org/) is a commonly used dataset to compare computer vision models. Its training dataset contains `1,281,167 images`.
-
+In this benchmark, we measured the streaming speed (`images per second`) loaded from [AWS S3](https://aws.amazon.com/s3/) for several frameworks.
+
+Find the reproducible [Studio Benchmark](https://lightning.ai/lightning-ai/studios/benchmark-cloud-data-loading-libraries).
+
+### Imagenet-1.2M Streaming from AWS S3
+
+| Framework | Images / sec 1st Epoch (float32) | Images / sec 2nd Epoch (float32) | Images / sec 1st Epoch (torch16) | Images / sec 2nd Epoch (torch16) |
+| ----------- | ------------------------------------- | ------------------------------------- | ------------------------------------- | ------------------------------------- |
+| PL Data | ${\\textbf{\\color{Fuchsia}5800.34}}$ | ${\\textbf{\\color{Fuchsia}6589.98}}$ | ${\\textbf{\\color{Fuchsia}6282.17}}$ | ${\\textbf{\\color{Fuchsia}7221.88}}$ |
+| Web Dataset | 3134.42 | 3924.95 | 3343.40 | 4424.62 |
+| Mosaic ML | 2898.61 | 5099.93 | 2809.69 | 5158.98 |
+
+Higher is better.
+
+### Imagenet-1.2M Conversion
+
+| Framework | Train Conversion Time | Val Conversion Time | Dataset Size | # Files |
+| ----------- | --------------------------------------- | --------------------------------------- | -------------------------------------- | ------- |
+| PL Data | ${\\textbf{\\color{Fuchsia}10:05 min}}$ | ${\\textbf{\\color{Fuchsia}00:30 min}}$ | ${\\textbf{\\color{Fuchsia}143.1 GB}}$ | 2.339 |
+| Web Dataset | 32:36 min | 01:22 min | 147.8 GB | 1.144 |
+| Mosaic ML | 49:49 min | 01:04 min | ${\\textbf{\\color{Fuchsia}143.1 GB}}$ | 2.298 |
+
+The dataset needs to be converted into an optimized format for cloud streaming. We measured how fast the 1.2 million images are converted.
+
+Faster is better.
+
+# 📚 Real World Examples
+
+We have built end-to-end free [Studios](https://lightning.ai) showing all the steps to prepare the following datasets:
+
+| Dataset | Data type | Studio |
+| -------------------------------------------------------------------------------------------------------------------------------------------- | :-----------------: | --------------------------------------------------------------------------------------------------------------------------------------: |
+| [LAION-400M](https://laion.ai/blog/laion-400-open-dataset/) | Image & description | [Use or explore LAION-400MILLION dataset](https://lightning.ai/lightning-ai/studios/use-or-explore-laion-400million-dataset) |
+| [Chesapeake Roads Spatial Context](https://github.com/isaaccorley/chesapeakersc) | Image & Mask | [Convert GeoSpatial data to Lightning Streaming](https://lightning.ai/lightning-ai/studios/convert-spatial-data-to-lightning-streaming) |
+| [Imagenet 1M](https://paperswithcode.com/sota/image-classification-on-imagenet?tag_filter=171) | Image & Label | [Benchmark cloud data-loading libraries](https://lightning.ai/lightning-ai/studios/benchmark-cloud-data-loading-libraries) |
+| [SlimPajama](https://huggingface.co/datasets/cerebras/SlimPajama-627B) & [StartCoder](https://huggingface.co/datasets/bigcode/starcoderdata) | Text | [Prepare the TinyLlama 1T token dataset](https://lightning.ai/lightning-ai/studios/prepare-the-tinyllama-1t-token-dataset) |
+| [English Wikepedia](https://huggingface.co/datasets/wikipedia) | Text | [Embed English Wikipedia under 5 dollars](https://lightning.ai/lightning-ai/studios/embed-english-wikipedia-under-5-dollars) |
+| Generated | Parquet Files | [Convert parquets to Lightning Streaming](https://lightning.ai/lightning-ai/studios/convert-parquets-to-lightning-streaming) |
+
+[Lightning Studios](https://lightning.ai) are fully reproducible cloud IDE with data, code, dependencies, etc...
# 🎬 Getting Started
@@ -32,7 +71,7 @@ Lightning Data can be installed with `pip`:
```bash
-pip install --no-cache-dir git+https://github.com/Lightning-AI/pytorch-lightning.git@master
+pip install --no-cache-dir git+https://github.com/Lightning-AI/lit-data.git@master
```
## 🏁 Quick Start
@@ -102,6 +141,10 @@ cls = sample['class']
dataloader = DataLoader(dataset)
```
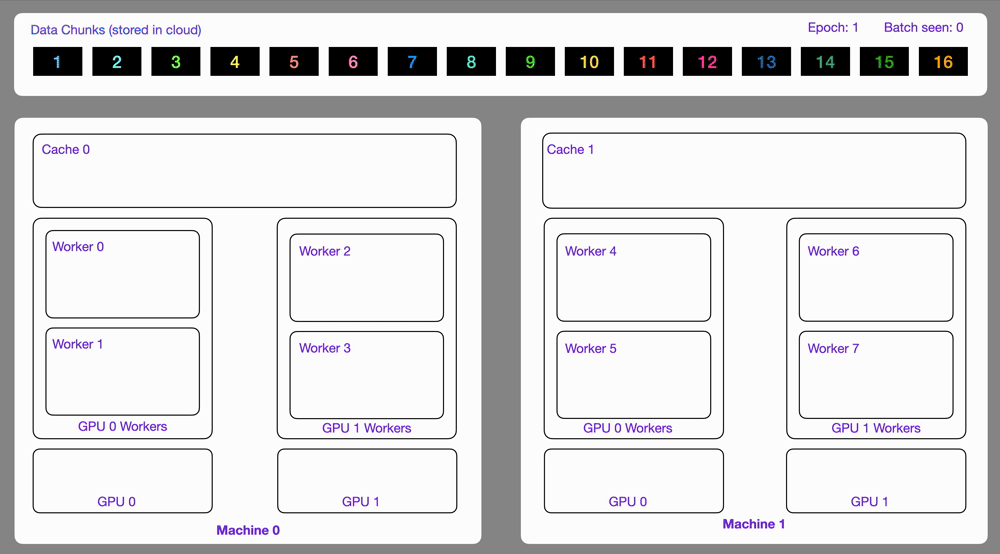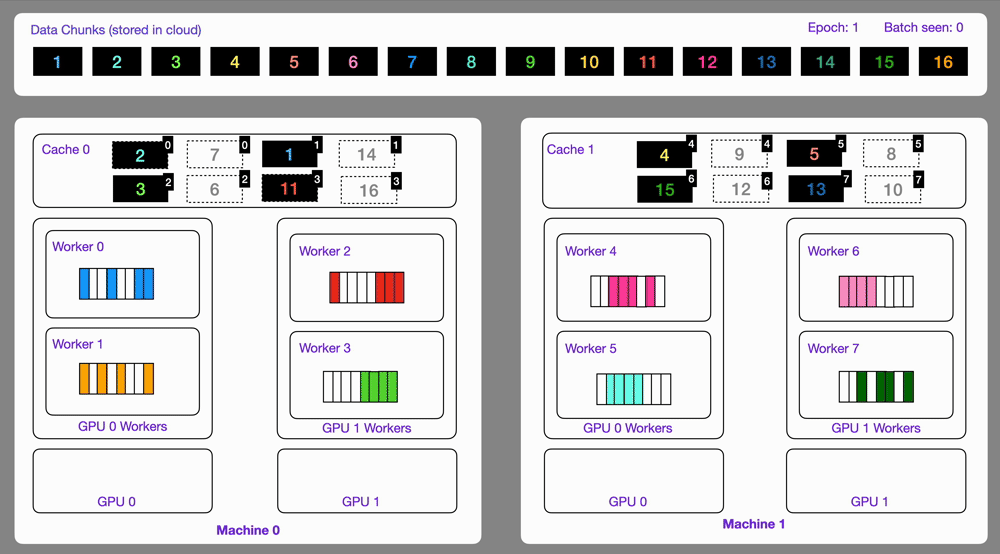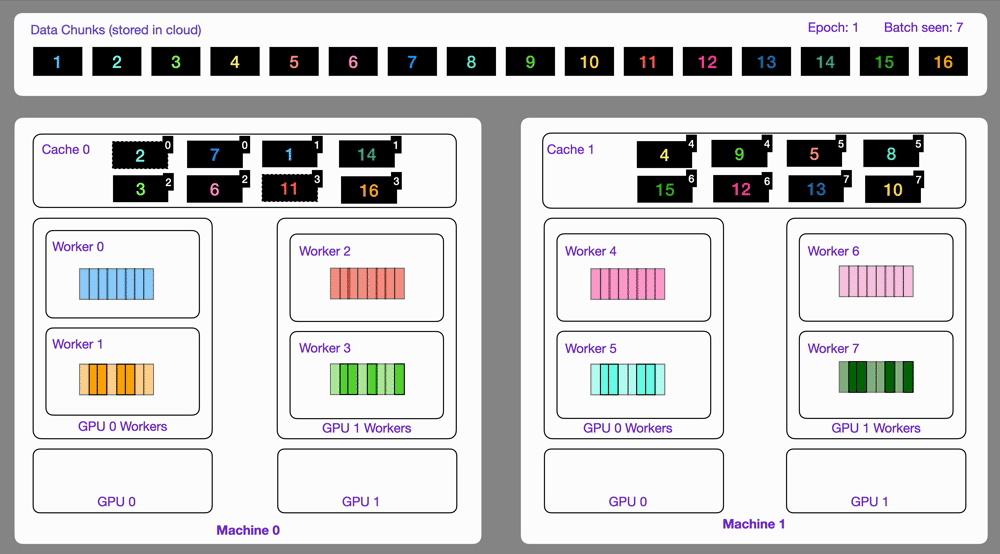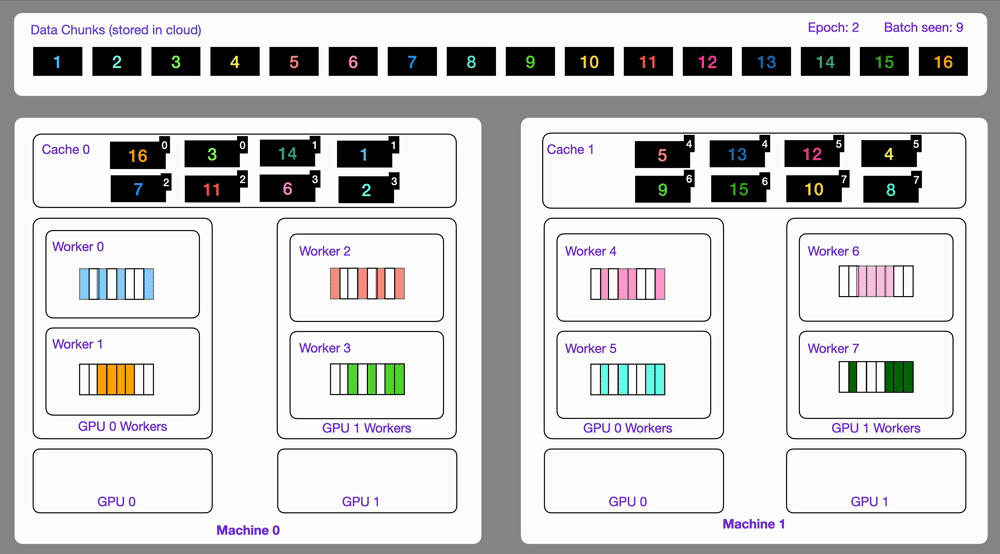
+Here is an illustration showing how the `StreamingDataset` works under the hood.
+
+
+
## Transform data
Similar to `optimize`, the `map` operator can be used to transform data by applying a function over a list of item and persist all the files written inside the output directory.
@@ -154,21 +197,6 @@ if __name__ == "__main__":
)
```
-# 📚 End-to-end Lightning Studio Templates
-
-We have end-to-end free [Studios](https://lightning.ai) showing all the steps to prepare the following datasets:
-
-| Dataset | Data type | Studio |
-| -------------------------------------------------------------------------------------------------------------------------------------------- | :-----------------: | --------------------------------------------------------------------------------------------------------------------------------------: |
-| [LAION-400M](https://laion.ai/blog/laion-400-open-dataset/) | Image & description | [Use or explore LAION-400MILLION dataset](https://lightning.ai/lightning-ai/studios/use-or-explore-laion-400million-dataset) |
-| [Chesapeake Roads Spatial Context](https://github.com/isaaccorley/chesapeakersc) | Image & Mask | [Convert GeoSpatial data to Lightning Streaming](https://lightning.ai/lightning-ai/studios/convert-spatial-data-to-lightning-streaming) |
-| [Imagenet 1M](https://paperswithcode.com/sota/image-classification-on-imagenet?tag_filter=171) | Image & Label | [Benchmark cloud data-loading libraries](https://lightning.ai/lightning-ai/studios/benchmark-cloud-data-loading-libraries) |
-| [SlimPajama](https://huggingface.co/datasets/cerebras/SlimPajama-627B) & [StartCoder](https://huggingface.co/datasets/bigcode/starcoderdata) | Text | [Prepare the TinyLlama 1T token dataset](https://lightning.ai/lightning-ai/studios/prepare-the-tinyllama-1t-token-dataset) |
-| [English Wikepedia](https://huggingface.co/datasets/wikipedia) | Text | [Embed English Wikipedia under 5 dollars](https://lightning.ai/lightning-ai/studios/embed-english-wikipedia-under-5-dollars) |
-| Generated | Parquet Files | [Convert parquets to Lightning Streaming](https://lightning.ai/lightning-ai/studios/convert-parquets-to-lightning-streaming) |
-
-[Lightning Studios](https://lightning.ai) are fully reproducible cloud IDE with data, code, dependencies, etc... Finally reproducible science.
-
# 📈 Easily scale data processing
To scale data processing, create a free account on [lightning.ai](https://lightning.ai/) platform. With the platform, the `optimize` and `map` can start multiple machines to make data processing drastically faster as follows:
diff --git a/src/lightning/data/__init__.py b/src/lightning/data/__init__.py
index 0b4816a1f9cc8..92431a2bc41db 100644
--- a/src/lightning/data/__init__.py
+++ b/src/lightning/data/__init__.py
@@ -1,9 +1,27 @@
+import sys
+
from lightning_utilities.core.imports import RequirementCache
-from lightning.data.processing.functions import map, optimize, walk
-from lightning.data.streaming.combined import CombinedStreamingDataset
-from lightning.data.streaming.dataloader import StreamingDataLoader
-from lightning.data.streaming.dataset import StreamingDataset
+_LIGHTNING_DATA_AVAILABLE = RequirementCache("lightning_data")
+_LIGHTNING_SDK_AVAILABLE = RequirementCache("lightning_sdk")
+
+if _LIGHTNING_DATA_AVAILABLE:
+ import lightning_data
+
+ # Enable resolution at least for lower data namespace
+ sys.modules["lightning.data"] = lightning_data
+
+ from lightning_data.processing.functions import map, optimize, walk
+ from lightning_data.streaming.combined import CombinedStreamingDataset
+ from lightning_data.streaming.dataloader import StreamingDataLoader
+ from lightning_data.streaming.dataset import StreamingDataset
+
+else:
+ # TODO: Delete all the code when everything is moved to lightning_data
+ from lightning.data.processing.functions import map, optimize, walk
+ from lightning.data.streaming.combined import CombinedStreamingDataset
+ from lightning.data.streaming.dataloader import StreamingDataLoader
+ from lightning.data.streaming.dataset import StreamingDataset
__all__ = [
"LightningDataset",
@@ -16,7 +34,8 @@
"walk",
]
-if RequirementCache("lightning_sdk"):
+# TODO: Move this to lightning_data
+if _LIGHTNING_SDK_AVAILABLE:
from lightning_sdk import Machine # noqa: F401
__all__.append("Machine")