Autor: Artur Kręgiel
Specjalne podziękowania za pomoc dla Marcina, jesteś koxem <3
Asembler wiele osób przeraża (tbh nie wiem czemu), jednak trzeba go trochę poznać, ponieważ na kierunku Informatyka techniczna na PWr (i na innych informatycznych kierunkach na innych uczelniach) ma się z nim styczność na zajęciach.
Na ITE trafisz na przedmiot Organizacja i architektura komputerów lub Wprowadzenie do wysokowydajnych komputerów (dawniej Architektura komputerów 2), na którym musisz pisać w asemblerze x86.
Ten tutorial niech będzie bootcampem, który pozwoli Ci - mam nadzieję - zdać laboratoria z tego przedmiotu. Jeśli chodzi o wykład to polecam książkę prof. Biernata albo prezentację z wykładów i modlitwę.
Nie zamierzam wchodzić w zbytnie szczegóły, a bardziej oswoić Cię z językiem asemblera i omówić podstawy.
Postaram się też podać przydatne źródła informacji z Internetu, z których sam korzystam oraz podrzucić kilka wskazówek, ale przygotuj się, że dużą część pracy musisz wykonać samodzielnie. Google będzie Twoim przyjacielem. Chat GPT oczywiście też, ale pamiętaj, że nie jest nieomylny.
Ten miniporadnik jest dość chaotyczny, więc przygotowałem spis treści.
Mam nadzieję, że poniższa lektura jakkolwiek ułatwi Ci otrzymanie zaliczenia.
Powodzenia <3
- Zrozumieć asemblera tutorial
- Wstęp
- Spis treści
- Co to jest asembler?
- Jakie asemblery na x86
- Składnie asemblera
- Zestaw instrukcji (ISA - Instruction Set Architecture)
- Rejestry
- Stos
- Tryby adresowania
- 1. Adresowanie natychmiastowe (immediate addressing)
- 2. Adresowanie rejestrowe (register addressing)
- 3. Adresowanie bezpośrednie (direct addressing)
- 4. Adresowanie pośrednie (indirect addressing)
- 5. Adresowanie bazowe (base addressing)
- 6. Adresowanie indeksowe (indexed addressing)
- 7. Adresowanie bazowe z indeksem i przesunięciem (base-indexed with displacement addressing)
- 8. Adresowanie względne (relative addressing)
- ABI - binarny interfejs aplikacji
- Jak właściwie wygląda program?
- Kompilacja i konsolidacja
- Pierwszy program
- Jak to uruchomić?
- Wywołania systemowe (System Calls)
- Skoki
- Wyrażenia warunkowe i pętle
- Funkcje
- Konwencje wywołania funkcji
- Ramka stosu
- Debugger (GDB)
- Łączenie C z asemblerem
- Operacje zmiennoprzecinkowe na FPU [x]
- SIMD [x]
- AVX [x]
- Przykładowe programy
- Szybka nauka asemblera - cheatcode
- Materiały do obczajenia
Asembler to niskopoziomowy język programowania, który bezpośrednio odpowiada instrukcjom procesora komputera. Programy napisane w asemblerze są przetwarzane przez program nazywany asemblerem (kto by się spodziewał), który tłumaczy kod asemblera na kod maszynowy - zestaw instrukcji, które procesor może wykonać bezpośrednio.
Każdy typ procesora (np. Intel x86, ARM, MIPS) ma swój własny zestaw instrukcji, który jest zrozumiały tylko dla tego konkretnego procesora. Dlatego kod asemblera napisany dla jednej architektury nie będzie działał na innej, ponieważ instrukcje i sposób adresowania różnią się między procesorami.
Na kierunku Informatyka techniczna na PWr (przynajmniej w momencie, w którym to piszę) spotkaliśmy się z dwoma różnymi asemblerami:
- x86 na przedmiotach Organizacja i architektura komputerów oraz Wprowadzenie do wysokowydajnych komputerów (czwarty semestr)
- Intel 8051 na przedmiocie Podstawy techniki mikroprocesorowej 1 (również czwarty semestr)
Kilka przykładowych asemblerów na x86:
-
NASM (Netwide Assembler):
- Bardzo popularny asembler dla x86.
- Obsługuje składnię Intel.
- Może generować różne formaty plików obiektowych, takie jak ELF, COFF, i binarne.
- Komenda do uruchomienia:
nasm.
-
MASM (Microsoft Macro Assembler):
- Asembler stworzony przez Microsoft, szeroko stosowany na platformach Windows.
- Obsługuje składnię Intel.
- Integruje się z Visual Studio.
- Komenda do uruchomienia:
ml.
-
GAS (GNU Assembler):
- Część pakietu GNU Binutils.
- Używa składni AT&T.
- Zintegrowany z GCC i używany w środowiskach GNU/Linux.
- Komenda do uruchomienia:
as.
-
FASM (Flat Assembler):
- Lekki i szybki asembler.
- Obsługuje składnię Intel.
- Może generować różne formaty plików obiektowych i binarne.
- Komenda do uruchomienia:
fasm.
-
YASM:
- Nowoczesny asembler inspirowany NASM.
- Obsługuje zarówno składnię Intel, jak i AT&T.
- Może generować różne formaty plików obiektowych.
- Komenda do uruchomienia:
yasm.
Ja osobiście korzystam z NASM, jednak na studiach bardziej preferowany jest GAS. Warto również wspomnieć, że pojawiające się w dalszej części tego samouczka będą pisane pod Linuksa i nie będą działać na Windowsie, dlatego jeśli nie korzystasz z Linuksa to lepiej zacznij warto, żebyś zaopatrzył(a) się w jakąś maszynę wirtualną bądź korzystał(a) z WSL-a.
Składnia asemblera x86 różni się głównie w zależności od używanego asemblera i preferencji dotyczących stylu zapisu kodu. Najczęściej używane składnie to składnia Intel i składnia AT&T. Oto kluczowe różnice między nimi:
- Intel: docelowy, źródłowy
- AT&T: źródłowy, docelowy
; Intel
mov eax, ebx ; Przenosi wartość z ebx do eax
; AT&T
movl %ebx, %eax ; Przenosi wartość z %ebx do %eax- Intel: rejestry bez prefiksu
- AT&T: rejestry z prefiksem
%
; Intel
mov eax, 5 ; Przenosi wartość 5 do rejestru eax
; AT&T
movl $5, %eax ; Przenosi wartość 5 do rejestru %eax- Intel: nawiasy kwadratowe do oznaczenia adresu pamięci
- AT&T: nawiasy okrągłe do oznaczenia adresu pamięci
; Intel
mov eax, [ebx] ; Przenosi wartość z adresu wskazywanego przez ebx do eax
; AT&T
movl (%ebx), %eax ; Przenosi wartość z adresu wskazywanego przez %ebx do %eax- Intel: stałe bez prefiksu
- AT&T: stałe z prefiksem
$
; Intel
mov eax, 10 ; Przenosi wartość 10 do rejestru eax
; AT&T
movl $10, %eax ; Przenosi wartość 10 do rejestru %eax- Intel: rozmiar operacji jest implicit (domyślnie zależny od operandów) lub explicity za pomocą słów kluczowych (
qword,dword,word,byte) - AT&T: rozmiar operacji jest explicity określony za pomocą sufiksów
b,w,l,q
; Intel
mov al, [ebx] ; Przenosi 8-bitową wartość z adresu wskazywanego przez ebx do al
mov eax, [ebx] ; Przenosi 32-bitową wartość z adresu wskazywanego przez ebx do eax
; AT&T
movb (%ebx), %al ; Przenosi 8-bitową wartość z adresu wskazywanego przez %ebx do %al
movl (%ebx), %eax ; Przenosi 32-bitową wartość z adresu wskazywanego przez %ebx do %eax- Intel:
base + index*scale + displacement - AT&T:
displacement(base, index, scale)
; Intel
mov eax, [ebx + ecx*4 + 8] ; Przenosi wartość z adresu (ebx + ecx*4 + 8) do eax
; AT&T
movl 8(%ebx, %ecx, 4), %eax ; Przenosi wartość z adresu (8 + %ebx + %ecx*4) do %eaxKażdy procesor ma swój unikalny zestaw instrukcji, które określają, jakie operacje może wykonywać. Zestaw instrukcji obejmuje operacje arytmetyczne, logiczne, kontrolne, pamięciowe i wiele innych. Zestaw instrukcji określa także format tych instrukcji, czyli jak wyglądają one w postaci binarnej.
Procesory mają różne układy rejestrów, które są małymi, szybkimi pamięciami wewnętrznymi używanymi do przechowywania danych i adresów. Na przykład procesor Intel x86 ma rejestry takie jak eax, ebx, ecx, edx, podczas gdy procesor ARM ma rejestry takie jak r0, r1, r2.
Ilość rejestrów ogólnego przeznaczenia zależy od trybu procesora. W trybie szesnastobitowym dostępne głowne rejestry ogólnego przeznaczenia to AX (Accumulator), BX (Base), CX (Counter), DX. Większość z nazw rejestrów ma znaczenie jedynie symboliczne, wynikające z zawiłości histori, choć należy pamiętać o pewnych specyficznych ograniczeniach z tychże wynikających. Mnożenie/dzielenie np. zapisuje swój wynik jedynie w rejestrach AX i DX (podobne ograiczenie obowiązuje różwnież w stosunku do arytmetyki o innej ilości bitów, mnożenie 32 bit zapisuje wynik tylko do EAX i EDX, mnożenie 64 bitowe tylko do RAX i RDX itd.).
Jak można zauważyć E jest prefiksem oznaczającym, że mamy na myśli rejestr 32-, a R, 64-bitowy. Zmiana "końcówki" X na L albo H w celu uzyskania rejestru 8-bitowego jest unikalna dla rejestrów AX, BX, CX, DX.
Oprócz tych czterech rejestrów, istnieją jeszcze rejestry DI (Destination Index) oraz SI (Source Index). Mają one swoje 32- i 64- bitowe odpowiedniki EDI, ESI oraz RDI, RSI.
Poniżej znajduje się tabela ilustrująca hierarchiczną strukturę rejestru w architekturze x86-64.
| a | Numer ostatniego bitu | ||||||||||
| a | 63 | 55 | 47 | 39 | 31 | 23 | 15 | 7 | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 64 bity | RxX | ||||||||||
| 32 bity | ExX | ||||||||||
| 16 bitów | xX | ||||||||||
| 8 bitów | xH | xL | |||||||||
Jak widać jeśli odwołamy się do rejestru AH, to odwołamy się również do bitów 8-15 rejestru RxX. Umożliwia to używanie operacji o niższej liczbie bitów, niż ma tryb, w którym obecnie działa procesor.
Struktura rejestrów DI i SI wygląda natomiast następująco:
| Numer ostatniego bitu | |||||||||||
| 63 | 55 | 47 | 39 | 31 | 23 | 15 | 7 | ||||
| 64 bity | RxI | ||||||||||
| 32 bity | ExI | ||||||||||
| 16 bitów | xI | ||||||||||
Tryb 64 bitowy dodaje również wiele nowych rejestrów ogólnego przeznaczenia. Są to rejestry od R8 do R15. Można odwołać się do ich niższych 16- i 32-bitowych częsci sufiksując nazwę rejestru odpowiednio w lub d.
Oprócz wyżej wymienionych rejestrów, istnieją jeszcze takie, z którymi trzeba postępować ostrożnie:
- Stack Pointer (SP)
- Base Pointer (BP)
Rejestr SP przechowuje adres wierzchołka stosu, zarządzając miejscem przechowywania ostatnich danych wprowadzonych na stos, co jest kluczowe dla zarządzania wywołaniami funkcji i danymi tymczasowymi.
Rejestr BP przechowuje adres podstawowy dla aktualnej ramki stosu, co ułatwia dostęp do parametrów funkcji i zmiennych lokalnych, będąc szczególnie użytecznym dla kompilatorów w organizacji pamięci funkcji.
Oto tabelka z rejestrami ogólnego przeznaczenia dla architektury x86-64:
| Rejestr | Opis | Uwagi |
|---|---|---|
| RAX | Accumulator | Wynik operacji arytmetycznych |
| RBX | Base | Wskaźnik bazowy danych |
| RCX | Counter | Licznik dla pętli i przesunięć |
| RDX | Data | Dane dla operacji we/wy |
| RSI | Source Index | Źródło danych dla operacji str |
| RDI | Destination Index | Cel danych dla operacji str |
| RBP | Base Pointer | Wskaźnik bazowy stosu |
| RSP | Stack Pointer | Wskaźnik wierzchołka stosu |
| R8 | Dodatkowy rejestr ogólnego przeznaczenia | |
| R9 | Dodatkowy rejestr ogólnego przeznaczenia | |
| R10 | Dodatkowy rejestr ogólnego przeznaczenia | |
| R11 | Dodatkowy rejestr ogólnego przeznaczenia | |
| R12 | Dodatkowy rejestr ogólnego przeznaczenia | |
| R13 | Dodatkowy rejestr ogólnego przeznaczenia | |
| R14 | Dodatkowy rejestr ogólnego przeznaczenia | |
| R15 | Dodatkowy rejestr ogólnego przeznaczenia |
Rejestr RFLAGS w architekturze x86-64 to 64-bitowy rejestr, który przechowuje różne flagi statusowe procesora. Te flagi informują o wyniku operacji arytmetycznych i logicznych, kontrolują przerwania oraz wpływają na działanie instrukcji warunkowych. RFLAGS jest używany do monitorowania i kontrolowania stanu procesora.
Podobnie jak w przypadku innych rejestrów, prefiks R jest używany w odniesieniu do trybu 64-bitowego, a E do trybu 32-bitowego
| Bit | Nazwa | Opis |
|---|---|---|
| 0 | CF (Carry Flag) | Flaga przeniesienia, ustawiana, gdy operacja arytmetyczna wygeneruje przeniesienie. |
| 1 | 1 | Zarezerwowane, zawsze ustawione na 1. |
| 2 | PF (Parity Flag) | Flaga parzystości, ustawiana, gdy liczba bitów ustawionych na 1 w wyniku operacji jest parzysta. |
| 3 | 0 | Zarezerwowane, zawsze ustawione na 0. |
| 4 | AF (Adjust Flag) | Flaga pomocnicza, ustawiana, gdy nastąpi przeniesienie z/do niskiego półbajtu. |
| 5 | 0 | Zarezerwowane, zawsze ustawione na 0. |
| 6 | ZF (Zero Flag) | Flaga zera, ustawiana, gdy wynik operacji jest równy zero. |
| 7 | SF (Sign Flag) | Flaga znaku, kopiowana z najstarszego bitu wyniku (MSB). |
| 8 | TF (Trap Flag) | Flaga pułapki, umożliwia działanie trybu krokowego (jednopoziomowe wykonanie). |
| 9 | IF (Interrupt Flag) | Flaga przerwania, pozwala na przerwania maskowalne, gdy jest ustawiona. |
| 10 | DF (Direction Flag) | Flaga kierunku, określa kierunek przetwarzania blokowego (0 = wzrost adresów, 1 = spadek adresów). |
| 11 | OF (Overflow Flag) | Flaga przepełnienia, ustawiana, gdy operacja arytmetyczna wygeneruje przepełnienie. |
| 12-13 | IOPL (I/O Privilege Level) | Poziom uprzywilejowania dostępu do operacji wejścia/wyjścia. |
| 14 | NT (Nested Task) | Flaga zagnieżdżonego zadania, używana do wsparcia mechanizmu zadań zagnieżdżonych. |
| 15 | 0 | Zarezerwowane, zawsze ustawione na 0. |
| 16 | RF (Resume Flag) | Flaga wznowienia, używana do kontroli debugowania. |
| 17 | VM (Virtual-8086 Mode) | Flaga trybu wirtualnego 8086, włącza tryb wirtualny 8086. |
| 18 | AC (Alignment Check) | Flaga sprawdzania wyrównania, włącza sprawdzanie wyrównania adresów pamięci. |
| 19 | VIF (Virtual Interrupt Flag) | Wirtualna flaga przerwania, używana w wirtualizacji. |
| 20 | VIP (Virtual Interrupt Pending) | Wirtualna flaga oczekiwania na przerwanie, używana w wirtualizacji. |
| 21 | ID (ID Flag) | Flaga identyfikacji, umożliwia programowi sprawdzenie obsługi instrukcji CPUID. |
| 22-63 | 0 | Zarezerwowane, zawsze ustawione na 0. |
Z powodu ograniczonej ilości rejestrów, nie jest możliwe przechowywanie wszystkich zmiennych programu w nich właśnie. Z tego powodu do przechowywania zmiennych lokalnych funckji korzysta się ze stosu. Stos jest zaimplementowany sprzętowo jako wskaźnik stosu (rejestr SP). Podstawowymi instruckjami do wykonywania operacji na stosie są instrukcje push i pop.
Stos jest również wykorzystywany przy wywoływaniu funkcji. To na stosie właśnie instrukcja call zapisuje adres powrotu. Według większości przyjętych konwencji, na stos umieszcza się również (choć niektóre) argumenty funkcji.
Rozmiary operacji na stosie bywają problematyczne. W trybie 64-bitowym dostępne są kodowania dla rejestrów 64-bitowych, w przypadku push - 8- i 16-bitowych wartości stałych oraz stałej 32-bitowej rozszerzanej ze znakiem do wartości 64-bitowej. W trybie 64-bitowym operacje 64-bitowe "zastępują" te 32-bitowe - kodowanie 32-bitowych wariantów instrukcji zastąpione zostało 64-bitowymi, czasem rozszerzając ze znakiem, jeśli było to konieczne.
Insturckja push dekrementuje (stos sprzętowy rośnie w dół pamięci) SP o rozmiar jej argumentu w bajtach. Do [SP] (pamięci o adresie wskazywanym przez tak zmieniony wskaźnik stosu) wpisywana jest wartość parametru.
Możliwymi typami paramtru dla tej instrukcji są rejestr, pamięć o adresie stałym, pamięć o adresie efektywnym lub wartość stała.
Przykład użycia push:
; `mov rsp, X` nie jest instrukcją używaną często w programach trybu użytkownika
; lecz na potrzeby prezentacji, będzie wykorzystywana w przykładach dotyczących stosu
; wpisujemy 64 do rejestru rsp
mov rsp, 64
; ponieważ pracujemy w trybie 64-bitowym, 0x4315 to tak naprawdę 0x0000000000004315 - wartość jest rozszerzana do 64 bitów
push 0x4315
; 1. najpierw zmniejszany o 8 (liczba 64-bitowa ma 8 bajtów) rejestr rsp
; zatem, rsp = 56
; 2. do adresu wskazywanego przez rsp, wpisywana jest nasza liczba
; po wykonaniu instrukcji rsp = 56, [56] = 0x0000000000004315Instruckja pop umieszcza w miejscu określonym przez jej argument [SP] inkrementuje (stos sprzętowy maleje w górę) SP o rozmiar jej argumentu w bajtach (należy tu zaznaczyć, że pop jest dużo bardziej restrykcyjne w kwestii dopuszczalnych rozmiarów parametrów niż push).
; inicjalizacja rejestru stosu
mov rsp, 56
; wczytaj QWORD (Quadriple WORD, 8 bajtów) do pamięci o adresie zawartości
; rejestru RBP zwiększonej o 8
pop QWORD [rbp+8]Tryby adresowania w architekturze x86 odnoszą się do metod, jakie procesor wykorzystuje do określenia miejsca, skąd pobiera dane lub gdzie zapisuje wyniki operacji. Poniżej przedstawiam najważniejsze sposoby adresowania w architekturze x86:
Wartość operandu jest bezpośrednio określona w instrukcji.
; Intel
mov eax, 5 ; przypisuje bezpośrednią wartość 5 do rejestru eax
; AT&T
movl $5, %eax ; przypisuje bezpośrednią wartość 5 do rejestru eaxOperand znajduje się w rejestrze.
; Intel
mov eax, ebx ; przenosi wartość z rejestru ebx do rejestru eax
; AT&T
movl %ebx, %eax ; przenosi wartość z rejestru ebx do rejestru eaxOperand znajduje się w określonym adresie pamięci.
; Intel
mov eax, [0x1000] ; przenosi wartość z adresu pamięci 0x1000 do rejestru eax
; AT&T
movl 0x1000,%eax ; przenosi wartość z adresu pamięci 0x1000 do rejestru eaxOperand znajduje się w adresie pamięci wskazywanym przez rejestr.
; Intel
mov eax, [ebx] ; przenosi wartość z adresu pamięci wskazywanego przez rejestr ebx do rejestru eax
; AT&T
movl (%ebx),%eax ; przenosi wartość z adresu pamięci wskazywanego przez rejestr ebx do rejestru eaxOperand znajduje się w pamięci w adresie określonym przez rejestr bazowy plus przesunięcie.
; Intel
mov eax, [ebx + 4] ; przenosi wartość z adresu pamięci (adres w ebx + 4) do rejestru eax
; AT&T
movl 4(%ebx), %eax ; przenosi wartość z adresu pamięci (adres w ebx + 4) do rejestru eaxOperand znajduje się w pamięci w adresie określonym przez rejestr indeksowy plus przesunięcie.
; Intel
mov eax, [ebx + ecx] ; przenosi wartość z adresu pamięci (adres w ebx + wartość w ecx) do rejestru eax
; AT&T
movl (%ebx,%ecx), %eax ; przenosi wartość z adresu pamięci (adres w ebx + wartość w ecx) do rejestru eaxOperand znajduje się w pamięci w adresie określonym przez rejestr bazowy, rejestr indeksowy i przesunięcie.
; Intel
mov eax, [ebx + ecx + 4] ; przenosi wartość z adresu pamięci (adres w ebx + wartość w ecx + 4) do rejestru eax
; AT&T
movl 4(%ebx,%ecx), %eax ; przenosi wartość z adresu pamięci (adres w ebx + wartość w ecx + 4) do rejestru eaxAdres jest określony jako przesunięcie względem aktualnej wartości licznika programowego (eip/rip).
jmp label ; skok do adresu określonego etykietą 'label' (relatywny do aktualnej wartości eip)Te sposoby adresowania pozwalają na różnorodne i elastyczne operacje na danych w programach asemblerowych, umożliwiając precyzyjne kontrolowanie przepływu danych i wykonywania programu.
Każda architektura procesora może używać różnych sposobów adresowania pamięci. Na przykład procesor x86 może używać trybu adresowania bezpośredniego, pośredniego, bazowego, z przesunięciem i wielu innych. Procesor ARM również posiada swoje specyficzne sposoby adresowania, które mogą się różnić od x86.
ABI, czyli Application Binary Interface (interfejs binarny aplikacji), to zestaw standardów i reguł określających sposób interakcji programów z systemem operacyjnym na poziomie binarnym. ABI definiuje:
- Format plików wykonywalnych i obiektowych.
- Konwencje wywoływania funkcji (jak argumenty są przekazywane, jak funkcje zwracają wartości).
- Zarządzanie pamięcią (stos, sterta).
- Układ i użycie rejestrów procesora.
ABI pozwala na współdziałanie skompilowanych programów i bibliotek różnych dostawców oraz zapewnia zgodność binarną.
System V ABI to standard ABI dla systemów operacyjnych UNIX, takich jak Linux i Solaris. Jest to najbardziej rozpowszechniony ABI na systemach Linux/x86-64. Zapewnia jednolite zasady, które umożliwiają współpracę aplikacji i bibliotek na poziomie binarnym w różnych systemach UNIX-owych.
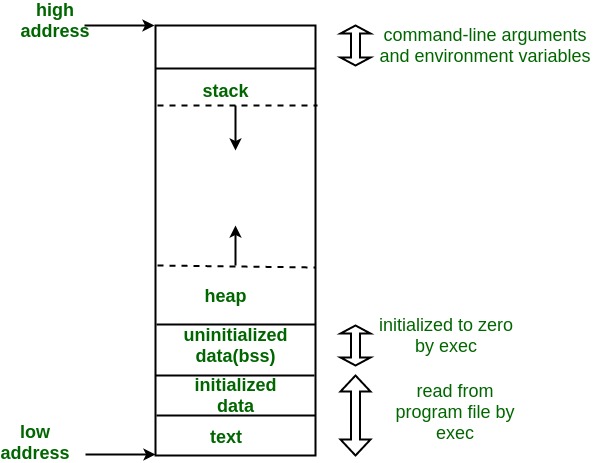
Program jest podzielony na kilka sekcji. Najważniejsze z nich to:
-
sekcja
text- Zawiera kod wykonywalny programu, czyli instrukcje maszynowe.
- Jest oznaczona jako tylko do odczytu i wykonywalna, aby zapobiec modyfikacjom kodu podczas jego wykonywania.
-
sekcja
data- Przechowuje dane inicjalizowane, takie jak zmienne globalne i statyczne, które mają zdefiniowane wartości początkowe.
- Jest zapisywalna, ponieważ wartości tych zmiennych mogą się zmieniać w trakcie działania programu.
-
sekcja
bss- Przechowuje dane niezainicjalizowane, takie jak zmienne globalne i statyczne, które są zadeklarowane, ale nie mają przypisanych wartości początkowych.
- Zajmuje miejsce w pamięci, ale nie jest zapisana w pliku wykonywalnym; jest wypełniana zerami w trakcie inicjalizacji programu.
-
sekcja
rodata- Przechowuje stałe dane tylko do odczytu, takie jak literały stringów, stałe liczby i inne wartości, które nie zmieniają się podczas wykonywania programu.
- Jest oznaczona jako tylko do odczytu, aby zapewnić, że dane te nie zostaną zmodyfikowane.
-
stos (ang. stack)
- Używany do przechowywania lokalnych zmiennych funkcji, adresów powrotu, oraz do zarządzania wywołaniami funkcji.
- stos rośnie w dół, czyli w kierunku niższych adresów pamięci. Jest zarządzany automatycznie przez procesor i kompilator w trakcie wykonywania programu.
-
sterta (ang. heap)
- Przechowuje dynamicznie alokowane dane, które są zarządzane ręcznie przez programistę za pomocą funkcji alokujących (np.
mallocw C) i dealokujących (np.free). - Sterta rośnie w górę, czyli w kierunku wyższych adresów pamięci.
- Umożliwia elastyczne zarządzanie pamięcią w trakcie działania programu, ale wymaga odpowiedniego zarządzania, aby unikać wycieków pamięci i fragmentacji.
- Programista musi sam zarządzać tą pamięcią, czyli tworzyć i usuwać dane, kiedy są potrzebne lub już nie są używane.
- Przechowuje dynamicznie alokowane dane, które są zarządzane ręcznie przez programistę za pomocą funkcji alokujących (np.
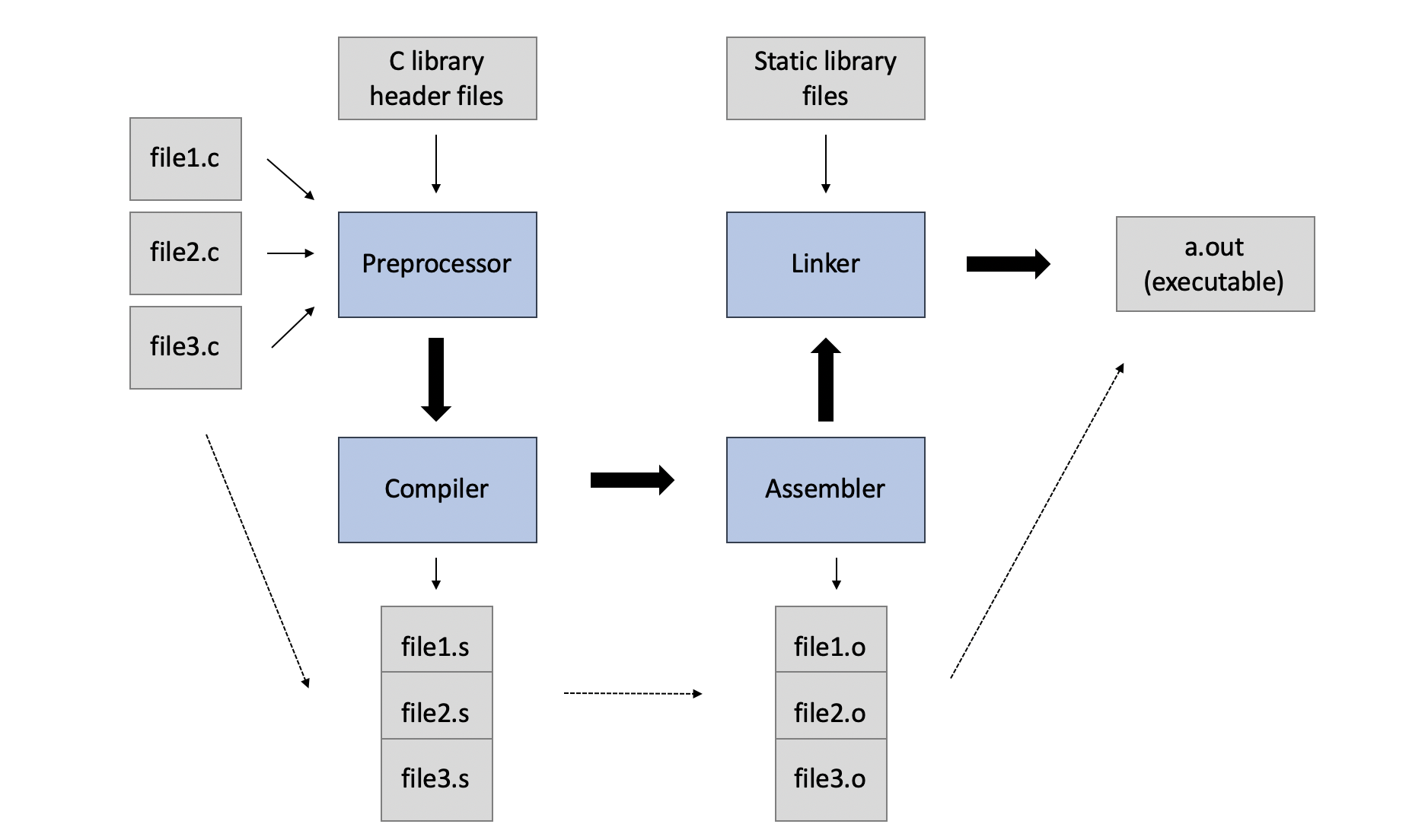
Kompilacja to proces przekształcania kodu źródłowego, napisanego w języku programowania wysokiego poziomu (jak C lub C++), na kod maszynowy, który może być bezpośrednio wykonany przez procesor. Proces kompilacji składa się z kilku etapów:
-
Preprocessing:
- Przed właściwą kompilacją, kod źródłowy przechodzi przez preprocesor. Preprocesor rozwija makra, wstawia pliki nagłówkowe (
#include), i usuwa komentarze. Wynik tego etapu to przetworzony kod źródłowy.
- Przed właściwą kompilacją, kod źródłowy przechodzi przez preprocesor. Preprocesor rozwija makra, wstawia pliki nagłówkowe (
-
Kompilacja:
- Przetworzony kod źródłowy jest przekształcany w kod asemblera. Kompilator analizuje kod źródłowy, sprawdza poprawność składni i semantyki, a następnie generuje kod asemblera.
-
Asemblacja:
- Kod asemblera jest przekształcany w kod maszynowy przez asembler. Wynikiem jest plik obiektowy, który zawiera binarną reprezentację kodu programu, gotową do wykonania przez procesor.
Konsolidacja (ang. linking) to proces łączenia jednego lub więcej plików obiektowych oraz bibliotek w jeden plik wykonywalny. Ten etap jest wykonywany przez linker (konsolidator) i składa się z następujących kroków:
-
Łączenie kodu:
- Linker zbiera wszystkie pliki obiektowe i biblioteki, które są wymagane przez program. Pliki obiektowe mogą pochodzić z różnych źródeł, na przykład z różnych modułów programu.
-
Rozwiązywanie referencji:
- Linker sprawdza wszystkie odniesienia do funkcji i zmiennych w plikach obiektowych, aby upewnić się, że wszystkie odwołania są poprawne. Jeśli funkcja zdefiniowana w jednym pliku obiektowym jest używana w innym pliku obiektowym, linker łączy te odwołania.
-
Generowanie pliku wykonywalnego:
- Po rozwiązaniu wszystkich referencji, linker generuje końcowy plik wykonywalny. Ten plik zawiera kod maszynowy, który może być bezpośrednio wykonany przez system operacyjny.
- Kompilacja: Przekształcenie kodu źródłowego (np. w języku C) na kod maszynowy poprzez etapy preprocessing, kompilacja i asemblacja.
- Konsolidacja (Linking): Łączenie plików obiektowych i bibliotek w jeden plik wykonywalny, gotowy do uruchomienia.
-
Kompilacja:
- Plik
example.cjest przetwarzany przez preprocesor, który rozwija makra i wstawia pliki nagłówkowe. - Kompilator przekształca przetworzony kod w kod asemblera.
- Asembler przekształca kod asemblera w plik obiektowy
example.o.
- Plik
-
Konsolidacja:
- Linker łączy
example.oz bibliotekami standardowymi, tworząc plik wykonywalnyexample.
- Linker łączy
gcc -o example example.cW powyższym poleceniu gcc (GNU Compiler Collection) wykonuje zarówno kompilację, jak i konsolidację, tworząc gotowy program example.
Tradycyjnie, rozpoczynając przygodę z nowym językiem, należy napisać Hello World!
Jest on w kilku wersjach:
x86 AT&T
# hello.s
.data
msg:
.asciz "hello, world!\n" # asciz - tekst ASCII zakończony 0
msg_len = (. - msg) # długość tekstu: bieżący adres - adres msg
.bss
.text
.global main
main:
mov $4, %eax # 4 - wywołanie write (w 32 bitowym)
mov $1, %ebx # 1 - STDOUT
mov $msg, %ecx # tekst
mov $msg_len, %edx # długość tekstu
int $0x80 # przerwanie z numerem 0x80 - syscall
# wyjście z programu
# (bez tego segfault)
mov $1, %eax # 1 - wywołanie exit (w 32 bitowym)
mov $0, %ebx # kod zakończenia
int $0x80 # syscallx86_64 AT&T
.data
msg: .asciz "Hello, World!\n"
msgLen = (. - msg)
.text
.global _start
_start:
mov $1, %rax
mov $1, %rdi
mov $msg, %rsi
mov $msgLen, %rdx
syscall
mov $0x3c, %rax
mov $0, %rdi
syscallx86 normalna składnia Intel (NASM)
global _start
section .text
_start:
mov eax, 0x4 ; use the write syscall
mov ebx, 1 ; use stdout fd
mov ecx, message ; use the message as the buffer
mov edx, message_length ; and supply the buffer length
int 0x80 ; invoke the syscall
; exit
mov eax, 0x1
mov ebx, 0
int 0x80
section .data
message: db "Hello World!", 0xA
message_length equ $-message ; length of the var messagex86_64 Intel (NASM)
BITS 64
section .data
_data db "Hello, World!", 10
section .text
global _start
_start:
mov rax, 1
mov rdi, 1
mov rsi, _data
mov rdx, 14
syscall
mov rax, 60
mov rdi, 0
syscallPo kolei. To jest jeszcze proste. To BITS 64 na początku w niektórych nasmowych przykładach to wskazówka dla asemblera, że będziemy pisać w trybie 64-bitowym, to nieistotne. Jest to potrzebne, jeśli assembler nie ma skąd wydedukować ilości bitów (czyli na przykład z flagą -f bin).
Warto też wspomnieć, że w GNU assembly komentarze rozpoczynają się od znaku #, a w NASM od ;.
W sekcji .data mamy zaalokowany nasz napis (db - define bytes (nasm), .asciz - napis ASCII z NULL na końcu (gnu)) jak również w niektórych przykładach jego długość. W nasm $ to bieżący adres czy coś takiego, więc $-msg oznacza bieżąca pozycja - pozycja msg, czyli po prostu długość msg - najważniejsze do zapamiętania. W GNU zamiast dolara jest ..
global _start oznacza, że ta funkcja (bo _start to funkcja, funkcje będą jeszcze później) będzie wyeksportowana i widoczna z zewnątrz - linker będzie ją widział oraz będzie to nasz punkt wejściowy do programu, czyli jak uruchomimy program, to wywoła się funkcja _start.
O tym dlaczego w jednym przykładzie jest
mainpowiem w sekcji poświęconej uruchamianiu programu, ale działa na tej samej zasadzie co_start.
No i tera się skup byczq
Przechodzimy do sekcji .text.
Systemy operacyjne mają coś takiego jak wywołania systemowe (syscall). Czyli taki zestaw funkcji, które coś tam robią. W tym przypadku chcemy skorzystać z wywołania systemowego czy tam funkcji systemowej write, która służy do wypisywania rzeczy - w naszym przypadku, bo nie tylko - na ekran.
Czyli w skrócie mówisz systemowi operacyjnemu e, we mi to zrób pliska i system mówi git.
No i tak się składa, że te wywołania systemowe mają swoje określone numery (do wygooglania linux syscalls albo coś w tym stylu, wierzę w cb <3). Na przykład w trybie 32-bitowym write ma numer
Wywołania systemowe oczekują jakichś argumentów (to się googla albo patrzy w manuala). Funkcja write oczekuje (w dokładnie tej kolejności):
- deskryptora pliku gdzie ma wypisać (wpisujemy 1 - STDOUT, nie zadawaj pytań)
- adresu tego czegoś co ma wypisać
- ile bajtów ma wypisać
Jak nie wierzysz to zerknij do manuala:
$ man 2 write
A tam o:
ssize_t write(int fd, const void buf[.count], size_t count);Ta, w C zamiast printf można użyć bezpośrednio write, a w asemblerze zamiast write można używać printf, ale do tego przejdziemy później, stay tuned.
$ man syscall
$ man syscalls
I teraz uwaga. W rejestrze eax (rax w 64-bitowym) umieszczamy numer naszego syscalla. Pozostałe argumenty będą przekazywane również przez rejestry, z tą różnicą, że inne rejestry są używane w trybie 32-bitowym i inne w 64-bitowym xD
Why? Because f**k you, that's why
(bo np. rcx jest sprzętowo zarezerwowany przez instrukcję syscall)
Ta kolejność też jest do wygooglania (jeśli nie będę aż tak leniwą paruwą czyli jak mi się zachce to wstawie jakieś linki).
W skrócie, w trybie 32-bitowym mamy:
ebx- pierwszy argument (STDOUT)ecx- drugi argument (msg)edx- trzeci argument (długość msg)
A w 64-bitowym:
rdi- pierwszy argument (STDOUT)rsi- drugi argument (msg)rdx- trzeci argument (długość msg)
No i jak mamy argumenty ustawione to wywołujemy funkcję systemową. W trybie 32-bitowym int 0x80 odpowiada za wywołanie syscalla (int od interrupt z nr 0x80), a w 64-bitowym mamy normalnie instrukcję syscall.
No i nam wypisuje, jesteśmy szczęśliwi. Czy to znaczy, że można już się rozejść? NIC BARDZIEJ MYLNEGO
Jeśli byśmy na tym etapie skończyli, to by się sromotnie wydupił (segmentation fault, przyzwyczajaj się). Dlaczego? A no dlatego, że po wypiasaniu Hello World program by leciał po prostu dalej, mimo że już więcej instrukcji mu nie daliśmy - czyli śmieci z pamięci by traktował jak instrukcje no a tak nie wolno.
Dlatego musimy program zakończyć poprawnie. Na nas spoczywa ta odpowiedzialność. Jesteśmy alfą i omegą. Sigmą jak chcesz. Generalnie trzeba wywołać exit - czyli no mówimy systemowi operacyjnemu dobra byq ja kończe naura.
Robimy to podobnie jak w przypadku write, czyli:
| 32-bitowy | 64-bitowy |
|---|---|
do eax dajemy nr syscalla - |
do rax dajemy nr syscalla - |
do ebx dajemy kod wyjścia z programu |
do rdi dajemy kod wyjścia z programu |
Jeśli jest gituwa, nie było jakiegoś błędu po drodze to dajemy
Jeśli pisałeś/pisałaś w C, to pewnie rzuciło Ci się w oczy kiedyś, że na końcu funkcji main jest często return 0 - jest to właśnie z tego powodu, który opisałem powyżej.
protip: na linuksie można sprawdzić kod wyjścia ostatniego uruchomionego (w terminalu oczywiście) programu w ten sposób:
$ echo $?
Przeczytaj to wszystko sobie jeszcze raz, na spokojnie, przeanalizuj te kody (będzie Ci potrzebny tylko jeden z nich, nie wiem w jakim asemblerze zamierzasz pisać) i postaraj się zrozumieć jak najwięcej. Te hello world to podstawowa struktura programu asemblera. Dalej postaram się operować raczej na konkretnych przykładach kodów, bo nie widzę sensu tłumaczenia każdej instrukcji. Ich jest w x86 od cholery, ale będzie ci potrzebne tylko kilkanaście. Na pewno przydadzą się podstawowe operacje arytmetyczne i logiczne:
add- dodawanie dwóch liczbsub- odejmuje jedną liczbę od drugiejmuliimul- mnożeniediviidiv- dzielenie oraz modulo (reszta z dzielenia)and- logiczne and (bitowe)or- logiczne or (bitowe)neg- negowanie liczby (bitów)xor- xorowanie liczbcmp- porównywanieinc- inkrementacja (+1)dec- dekrementacja (-1)shr/sar- przesunięcie bitowe w prawoshl/sal- przesunięcie bitowe w lewo
protip: zamiast robić mov rax, 0, można zrobić xor rax, rax i to da ten sam efekt - wyzeruje podany rejestr, ale jest szybsze i bardziej fancy.
Jeszcze fajna jest instrukcja lea (load effective address). Służy do obliczania adresów, ale dzięki niej można robić taką sztuczkę, że mnożymy 2 liczby, np. jeśli w rax mamy liczbę 3, możemy zrobić tak: lea rax, [0+rax*4] i wtedy będziemi w rax mieli liczbę 12 (a nie użyliśmy mul), ale to tak w ramach ciekawostki bardziej.
Generalnie ważna rzecz: jak chcesz dowiedzieć się, jak działa dana instrukcja - to to wygooglaj. Wszystko jest w internetach, także na chillku.
Mamy już kod, jesteśmy szczęśliwi - co teraz?
Teraz kod asemblera musimy przekształcić na plik object, a następnie zlinkować, aby dostać gotowy plik wykonywalny.
Nie będę się wdawać w szczegóły, ale musisz wykonać te dwie komendy:
- Dla 32-bitowego
$ as --32 -o hello.o hello.s
$ ld -m elf_i386 -o hello hello.o
- Dla 64-bitowego
$ as -o hello.o hello.s
$ ld -o hello hello.o
as (czyli asembler) wypluje nam tzw. plik object, czyli już plik powiedzmy binarny, ale jeszcze niezdatny do użytku.
ld to linker, który wypluje nam już gotowy plik wykonywalny, który można uruchomić.
A potem to już prościzna:
$ ./hello
Nie jestem pewien, czy w przypadku 32-bitowego nie trzeba dodawać jakichś jeszcze dodatkowych flag czy parametrów (nie korzystałem zbyt dużo z GNU assembly generalnie). Generalnie jest fajniejsza metoda asemblowania i linkowania programów, a mianowicie gcc.
gcc pewnie kojarzy ci się z kompilatorem języka C - i masz rację, ale tak naprawdę gcc ma w sobie kilka rzeczy:
- kompilator C, który zamienia C na asemblera (C to framework do asemblera w sumie)
as- czyli nasz asemblerld- czyli nasz linker
Dodatkowo gcc nam od razu doda bibliotekę standardową C, jeśli jej potrzebujemy - przyda się później.
Także można to zastąpić jedną komendą:
- Dla 64-bitowego programu
$ gcc -o hello hello.s -no-pie
- Dla 32-bitowego programu
$ gcc -o hello hello.s -no-pie -m32
Warunek korzystania z gcc jest taki, że generalnie nasza główna funkcja musi się nazywać main (tak jak w C), ponieważ gcc sobie domyślnie dodaje swoją funkcję _start, w której wywołuje main, więc będzie oczekiwał tej nazwy.
Tłumaczenie czym jest -no-pie jest poza zakresem tego bootcampu, nie musisz wiedzieć co to znaczy, nie wiem nawet czy trzeba to dawać w tych przykładach, ja dodawałem na wszelki wypadek. Generalnie jeśli chcielibyśmy robić programy na poważnie to ze względów bezpieczeństwa nie należy tego robić.
Z nasm jest podobnie jak w poprzednim przykładzie:
- Dla 32-bitowego
$ nasm -f elf32 hello.asm
$ ld -m elf_i386 -o hello hello.o
- Dla 64-bitowego
$ nasm -f elf64 hello.asm
$ ld -o hello hello.o
Flaga -f oznacza format pliku binarnego. Wykonywane pliki na linuksie są w formacie ELF. Jak wpiszesz polecenie nasm -h to dostaniesz listę dostępnych formatów.
Tutaj również można użyć gcc, ale już nie w jednej linii niestety:
$ nasm -f elf64 -g -F dwarf hello.asm
$ gcc -ggdb -no-pie hello.o -o hello
W tym przypadku gcc robi nam głównie za linker.
Flagi -g i -F oznaczają, że chcemy zostawić informacje do debuggowania, a dwarf to format debuggowania. Podobnie z flagą -ggdb. Na razie się tym nie przejmuj, ale to się przyda dalej.
Żeby nie wpisywać tego wszystkiego (zwłaszcza jak się pojawi więcej plików niż 1) można sobie stworzyć plik o nazwie makefile, który będzie zawierać informacje, jak to wszystko posklejać i przemielić.
- Dla GNU assembly
hello: hello.o
ld -o hello hello.o
hello.o: hello.asm
nasm -f elf64 -g -F dwarf hello.asmlub
hello: hello.s
gcc -o hello hello.s -no-pie -m32- Dla NASM
hello: hello.o
ld -o hello hello.o
hello.o: hello.asm
nasm -f elf64 -g -F dwarf hello.asm -l hello.lstJak chcemy użyć gcc to zamiast tej linijki z ld, dać komendę z gcc.
Mając gotowy plik makefile wystarczy wpisać:
$ make
i zrobi się samo.
To jak to działa: make przeczyta plik makefile i zobaczy regułkę hello, która wymaga pliku hello.o, więc poszuka regułki hello.o i zobaczy, że to wymaga pliku hello.asm. Plik hello.asm istnieje, więc wykona komendę, która wypluje hello.o. Następnie jak już ma plik hello.o, to wykona komendę, która nam da plik wykonywalny. Nie chcę się w to zbytnio zagłębiać, bo te pliki makefile, które będą potrzebne są krótkie i proste i można je robić na jedno kopyto czyli po prostu kopiować i odpowiednio pozmieniać nazwy plików.
Wszystko jest open source, jeśli potrafi się czytać assembly. Programy można zdeasemblować (ang. **), czyli z postaci binarnej dostać z powrotem kod asemblera. Można to uzyskać dzięki takim narzędziom jak objdump:
$ objdump -d ./hello64
./hello64: file format elf64-x86-64
Disassembly of section .text:
0000000000401000 <_start>:
401000: 48 c7 c0 01 00 00 00 mov $0x1,%rax
401007: 48 c7 c7 01 00 00 00 mov $0x1,%rdi
40100e: 48 c7 c6 00 20 40 00 mov $0x402000,%rsi
401015: 48 c7 c2 0f 00 00 00 mov $0xf,%rdx
40101c: 0f 05 syscall
40101e: 48 c7 c0 3c 00 00 00 mov $0x3c,%rax
401025: 48 c7 c7 00 00 00 00 mov $0x0,%rdi
40102c: 0f 05 syscall
Jeśli chcemy uzyskać kod w normalnej składni Intela, należy dodać flagę -Mintel:
Disassembly of section .text:
0000000000401000 <_start>:
401000: 48 c7 c0 01 00 00 00 mov rax,0x1
401007: 48 c7 c7 01 00 00 00 mov rdi,0x1
40100e: 48 c7 c6 00 20 40 00 mov rsi,0x402000
401015: 48 c7 c2 0f 00 00 00 mov rdx,0xf
40101c: 0f 05 syscall
40101e: 48 c7 c0 3c 00 00 00 mov rax,0x3c
401025: 48 c7 c7 00 00 00 00 mov rdi,0x0
40102c: 0f 05 syscall
Liczba 0x402000 to adres, gdzie znajduje się msg.
Tak wygląda mój alias na komendę objdump:
$ alias objdump
objdump='objdump -d -Mintel --disassembler-color=color --visualize-jumps=extended-color'
Wywołania systemowe to specjalne funkcje, które programy mogą wywoływać, aby skorzystać z usług oferowanych przez system operacyjny, takich jak odczyt i zapis plików, zarządzanie pamięcią, czy komunikacja sieciowa. Wywołania te umożliwiają programom interakcję z systemem operacyjnym na niskim poziomie.
Listę linuksowych numerów wywołań systemowych dla x86 można znaleźć tutaj, a dla x86_64 tutaj.
- Zgłoszenie żądania: Program zgłasza żądanie do systemu operacyjnego poprzez wywołanie systemowe.
- Przejście do trybu jądra: Procesor przełącza się w tryb jądra, który ma wyższe uprawnienia.
- Wykonanie funkcji jądra: System operacyjny wykonuje odpowiednią funkcję jądra.
- Powrót do trybu użytkownika: Procesor wraca do trybu użytkownika, kontynuując wykonanie programu.
Wywołania systemowe są realizowane przez ustawienie odpowiednich wartości w rejestrach i użycie instrukcji specjalnej, która przełącza procesor w tryb jądra. W zależności od architektury (x86 lub x86_64) i systemu operacyjnego, szczegóły mogą się różnić.
- Ustawienie numeru wywołania systemowego w rejestrze
eax. - Ustawienie argumentów wywołania w odpowiednich rejestrach (
ebx,ecx,edx,esi,edi). - Użycie instrukcji
int $0x80do przełączenia w tryb jądra i wykonania wywołania systemowego.
Przykład: Wywołanie systemowe write (numer 4) do zapisu tekstu na standardowe wyjście:
.section .data
msg:
.ascii "Hello, World!\n"
len = . - msg
.section .text
.global _start
_start:
movl $4, %eax # Numer wywołania systemowego (sys_write)
movl $1, %ebx # Deskryptor pliku (1 = stdout)
movl $msg, %ecx # Adres bufora
movl $len, %edx # Długość bufora
int $0x80 # Przełączenie do trybu jądra
movl $1, %eax # Numer wywołania systemowego (sys_exit)
xorl %ebx, %ebx # Kod wyjścia
int $0x80 # Przełączenie do trybu jądra- Ustawienie numeru wywołania systemowego w rejestrze
rax. - Ustawienie argumentów wywołania w odpowiednich rejestrach (
rdi,rsi,rdx,r10,r8,r9). - Użycie instrukcji
syscalldo przełączenia w tryb jądra i wykonania wywołania systemowego.
Przykład: Wywołanie systemowe write (numer 1) do zapisu tekstu na standardowe wyjście:
.section .data
msg:
.ascii "Hello, World!\n"
len = . - msg
.section .text
.global _start
_start:
mov $1, %rax # Numer wywołania systemowego (sys_write)
mov $1, %rdi # Deskryptor pliku (1 = stdout)
mov $msg, %rsi # Adres bufora
mov $len, %rdx # Długość bufora
syscall # Przełączenie do trybu jądra
mov $60, %rax # Numer wywołania systemowego (sys_exit)
xor %rdi, %rdi # Kod wyjścia
syscall # Przełączenie do trybu jądraSkok (ang. jump) to instrukcja w asemblerze, która zmienia przepływ wykonywania programu. Zamiast wykonywać kolejne instrukcje w liniowej kolejności, skok powoduje przejście do innej instrukcji w programie.
Skoki są podstawą do implementacji takich struktur programistycznych jak pętle, warunki (if-else) oraz wywołania funkcji. Skoki mogą być bezwarunkowe (zawsze się wykonują) lub warunkowe (wykonują się tylko, jeśli spełniony jest określony warunek).
Instrukcja skoku bezwarunkowego zawsze powoduje przejście do wskazanego adresu.
.section .text
.global _start
_start:
jmp end # Skok bezwarunkowy do etykiety "end"
middle:
# Ta instrukcja zostanie pominięta
nop
end:
# Instrukcje w tej części będą wykonane
nop # No Operation - instrukcja, która nic nie robiInstrukcje skoku warunkowego powodują przejście do wskazanego adresu tylko wtedy, gdy spełniony jest określony warunek.
je label(skok, jeśli równe)jne label(skok, jeśli nie równe)jg label(skok, jeśli większe)jl label(skok, jeśli mniejsze)
.section .text
.global _start
_start:
mov $5, %eax # Załaduj wartość 5 do rejestru %eax
cmp $5, %eax # Porównaj wartość 5 z zawartością rejestru %eax
je equal # Skocz do etykiety "equal", jeśli wartości są równe
# Instrukcje w tej części będą pominięte, jeśli %eax == 5
nop
equal:
# Instrukcje w tej części będą wykonane, jeśli %eax == 5
nop # No Operation - instrukcja, która nic nie robi
Instrukcja loop jest specjalną instrukcją w asemblerze, która służy do tworzenia pętli. Wykonuje się ją w połączeniu z rejestrem licznika pętli, czyli rejestrem ecx (dla 32-bitowych) lub rcx (dla 64-bitowych). Działanie instrukcji loop polega na zmniejszeniu wartości w rejestrze licznika i wykonaniu skoku do określonej etykiety, dopóki licznik nie osiągnie zera.
-
Zmniejszenie licznika:
- Instrukcja
loopzmniejsza wartość rejestruecx(32-bit) lubrcx(64-bit) o 1.
- Instrukcja
-
Sprawdzenie wartości licznika:
- Po zmniejszeniu wartości licznika, sprawdzana jest jego wartość.
-
Skok lub kontynuacja:
- Jeśli wartość licznika jest różna od zera, wykonywany jest skok do wskazanej etykiety.
- Jeśli wartość licznika wynosi zero, wykonywanie programu kontynuuje się od następnej instrukcji po
loop.
Przykład w składni AT&T dla x86 (32-bit):
.section .data
message:
.ascii "Hello, World!\n"
.section .text
.global _start
_start:
movl $5, %ecx # Ustaw licznik pętli na 5
movl $message, %ebx # Załaduj adres komunikatu do %ebx
loop_start:
# W tej części można umieścić dowolne instrukcje
movl $4, %eax # Numer wywołania systemowego (sys_write)
movl $1, %edi # Deskryptor pliku (1 = stdout)
movl $message, %esi # Adres bufora
movl $14, %edx # Długość bufora (14 znaków)
int $0x80 # Przełączenie do trybu jądra (wywołanie systemowe)
loop loop_start # Instrukcja pętli, skok do loop_start, jeśli %ecx != 0
# Po zakończeniu pętli wyjście z programu
movl $1, %eax # Numer wywołania systemowego (sys_exit)
xorl %ebx, %ebx # Kod wyjścia
int $0x80 # Przełączenie do trybu jądra (wywołanie systemowe)Wyrażenia warunkowe w asemblerze działają poprzez porównanie wartości i skok do określonej części kodu w zależności od wyniku porównania. Najczęściej używaną instrukcją do porównania jest cmp, a do skoków warunkowych je, jne, jg, jl, itp.
.section .data
val: .long 10
.section .text
.global _start
_start:
movl val, %eax # Załaduj wartość zmiennej 'val' do rejestru eax
cmpl $10, %eax # Porównaj wartość w eax z 10
je equal # Skocz do 'equal' jeśli eax == 10
not_equal:
# Kod wykonywany, jeśli eax != 10
nop
jmp end # Skocz do końca, aby pominąć sekcję 'equal'
equal:
# Kod wykonywany, jeśli eax == 10
nop
end:
# Wyjście z programu
movl $1, %eax # sys_exit
xorl %ebx, %ebx # Kod wyjścia 0
int $0x80Pętle w asemblerze mogą być realizowane na różne sposoby, na przykład przy użyciu instrukcji loop lub poprzez użycie skoków warunkowych.
.section .data
counter: .long 5
.section .text
.global _start
_start:
movl counter, %ecx # Załaduj wartość zmiennej 'counter' do rejestru ecx
loop_start:
# Kod wykonywany w pętli
nop
loop loop_start # Zmniejsz ecx i skocz do loop_start, jeśli ecx != 0
# Wyjście z programu
movl $1, %eax # sys_exit
xorl %ebx, %ebx # Kod wyjścia 0
int $0x80.section .data
val: .long 5
.section .text
.global _start
_start:
movl val, %eax # Załaduj wartość zmiennej 'val' do rejestru eax
while_start:
cmpl $0, %eax # Porównaj wartość eax z 0
jle while_end # Skocz do 'while_end', jeśli eax <= 0
# Kod wykonywany w pętli
nop
decl %eax # Zmniejsz wartość eax o 1
jmp while_start # Skocz do początku pętli
while_end:
# Wyjście z programu
movl $1, %eax # sys_exit
xorl %ebx, %ebx # Kod wyjścia 0
int $0x80W obu przypadkach, tworzenie wyrażeń warunkowych i pętli w asemblerze wymaga ręcznego zarządzania rejestrami i kontrolowania przepływu programu za pomocą skoków.
Funkcje to bloki kodu zajmujące pewien obszar pamięci. Wykonują ciągi instrukcji w celu rozwiązania jakiegoś zadania.
Przykład:
section .data
msg db "Hello",0
msgLen equ $-msg
section .text
global _start
_start:
call printText ; wywołanie funkcji
mov rax, 60
mov rdi, 0
syscall
; funkcja
printText:
mov rax, 1 ; write syscall
mov rdi, msg
mov rsi, msgLen
ret ; powrót z funkcjiFunkcje wywołujemy za pomocą instrukcji call wraz z nazwą funkcji (zwykły label, tak jak w przypadku _start czy pętli). Ta instrukcja powoduje wrzucenie na stos adresu, który będzie adresem powrotu z funkcji. Dzieje się tak dlatego, aby możliwy był w ogóle powrót z funkcji z powrotem tam, gdzie ją wywołaliśmy. Następnie wykonywany jest skok do obszaru pamięci, w którym znajduje się funkcja.
Powrót z funkcji odbywa się z użyciem instrukcji ret, która pobiera ze stosu adres powrotu i skacze w to miejsce - czyli tam, gdzie wywołano funkcje.
Dla porównania, przykład w C:
void funkcja()
{
return; // powrót z funkcji -> skok z powrotem
}
int main()
{
funkcja(); // wywołanie funkcji -> skaczemy w inne miejsce
return 0; // klasyk ;)
}A teraz pora omówić, jak przekazywać argumenty do funkcji i jak zwracać wartości.
Konwencje wywołania funkcji (calling conventions) to zestaw reguł określających sposób, w jaki funkcje w programowaniu przekazują argumenty, jak zwracają wartości oraz jak zarządzają stosami i rejestrami. Te reguły ustalają, które rejestry są używane do przekazywania argumentów, gdzie umieszczane są dodatkowe argumenty (np. na stosie), jak wartości są zwracane (w określonych rejestrach), oraz które rejestry muszą być zachowane (calle-saved) lub mogą być nadpisane (caller-saved). Konwencje wywołania są kluczowe dla zapewnienia kompatybilności między różnymi funkcjami i modułami, szczególnie gdy są kompilowane oddzielnie lub pochodzą od różnych dostawców. Przykładem takich konwencji jest System V ABI, używany w systemach UNIX-owych, w tym w systemach Linux na architekturach x86 i x86-64.
-
Przekazywanie argumentów:
- Argumenty są przekazywane na stosie w kolejności od prawej do lewej.
- Pierwszy argument jest umieszczany na górze stosu.
-
Zwracanie wartości:
- Wartości całkowite i wskaźniki są zwracane w rejestrze EAX.
- Wartości zmiennoprzecinkowe są zwracane w rejestrze ST0 (rejestr FPU).
-
Zarządzanie stosami:
- Wskaźnik stosu (ESP) jest używany do zarządzania stosami.
- Wywołujący (caller) jest odpowiedzialny za oczyszczenie stosu po wywołaniu funkcji (np. za pomocą instrukcji
add esp, X, gdzie X to liczba bajtów używanych przez argumenty).
-
Rejestry callee-saved (muszą być zachowane przez wywoływaną funkcję):
- EBX, ESI, EDI, EBP
-
Rejestry caller-saved (mogą być nadpisane przez wywoływaną funkcję):
- EAX, ECX, EDX
-
Przekazywanie argumentów:
- Pierwsze sześć argumentów całkowitych lub wskaźnikowych są przekazywane w rejestrach: RDI, RSI, RDX, RCX, R8, R9.
- Dodatkowe argumenty są przekazywane na stosie.
- Argumenty zmiennoprzecinkowe są przekazywane w rejestrach XMM0 - XMM7.
-
Zwracanie wartości:
- Wartości całkowite i wskaźniki są zwracane w rejestrach RAX i RDX (dla większych wartości).
- Wartości zmiennoprzecinkowe są zwracane w rejestrze XMM0.
-
Zarządzanie stosami:
- Stos musi być 16-bajtowo wyrównany przed wywołaniem funkcji (zwykle wyrównywany przez wywołującego).
- Wskaźnik stosu (RSP) jest używany do zarządzania stosami.
-
Rejestry callee-saved (muszą być zachowane przez wywoływaną funkcję):
- RBX, RBP, R12, R13, R14, R15
-
Rejestry caller-saved (mogą być nadpisane przez wywoływaną funkcję):
- RAX, RCX, RDX, RSI, RDI, R8, R9, R10, R11
Wywołanie funkcji int sum(int a, int b, int c)
.section .text
.globl _start
_start:
movl $1, %edi ; pierwszy argument a
movl $2, %esi ; drugi argument b
movl $3, %edx ; trzeci argument c
call sum
; Kod kończący program (syscall do exit)
movl $60, %eax ; syscall number for exit
xorl %edi, %edi ; status 0
syscall
sum:
pushq %rbp ; zachowaj rbp
movq %rsp, %rbp ; ustaw rbp na aktualną wartość rsp
movl %edi, %eax ; załaduj argument a do eax
addl %esi, %eax ; dodaj argument b
addl %edx, %eax ; dodaj argument c
popq %rbp ; przywróć rbp
ret ; zwróć wynik w eax
Wywołanie funkcji int sum(int a, int b, int c)
.section .text
.globl _start
_start:
pushl $3 ; trzeci argument c
pushl $2 ; drugi argument b
pushl $1 ; pierwszy argument a
call sum
addl $12, %esp ; wyczyść stos (3 argumenty * 4 bajty)
; Kod kończący program (syscall do exit)
movl $1, %eax ; syscall number for exit (Linux)
xorl %ebx, %ebx ; status 0
int $0x80
sum:
pushl %ebp ; zachowaj ebp
movl %esp, %ebp ; ustaw ebp na aktualną wartość esp
movl 8(%ebp), %eax ; załaduj argument a do eax
addl 12(%ebp), %eax ; dodaj argument b
addl 16(%ebp), %eax ; dodaj argument c
popl %ebp ; przywróć ebp
ret ; zwróć wynik w eaxTe przykłady ilustrują, jak różnią się konwencje wywoływania funkcji pomiędzy architekturami x86 i x86-64 zgodnie z System V ABI.
Ramka stosu (Stack Frame) to struktura danych utworzona na stosie przez każdą funkcję podczas jej wywołania. Zawiera informacje niezbędne do zarządzania funkcją, w tym:
- Adres powrotu: Adres w kodzie, do którego program powinien wrócić po zakończeniu funkcji.
- Argumenty funkcji: Przekazywane do funkcji podczas jej wywołania.
- Zmienne lokalne: Zmienne, które są deklarowane wewnątrz funkcji i używane tylko w jej zakresie.
- Rejestry: Wartości rejestrów, które muszą być zachowane i przywrócone po zakończeniu funkcji.
Ramka stosu jest kluczowa dla zarządzania wywołaniami funkcji i zapewnia poprawne działanie rekurencji oraz zagnieżdżonych wywołań funkcji.
Przykład:
.section .data
output_fmt_a: .asciz "Funkcja A: x = %d\n"
output_fmt_b: .asciz "Funkcja B: y = %d\n"
.section .text
.globl _start
# Prototypy funkcji
.type funkcjaA, @function
.type funkcjaB, @function
# Funkcja B
funkcjaB:
# prolog funkcji
pushl %ebp # Zapisz stary base pointer
movl %esp, %ebp # Ustaw nowy base pointer
subl $8, %esp # Alokacja miejsca na zmienne lokalne
movl 8(%ebp), %eax # Pobierz argument b (8) do %eax
addl $10, %eax # y = b + 10
movl %eax, -4(%ebp) # Zapisz y na stosie
# Wywołaj printf
pushl -4(%ebp) # Push y
pushl $output_fmt_b # Push format string
call printf
addl $8, %esp # Wyczyść stos
# epilog funkcji
leave # Przywróć %ebp i %esp
ret # Powrót
# Funkcja A
funkcjaA:
# prolog funkcji
pushl %ebp # Zapisz stary base pointer
movl %esp, %ebp # Ustaw nowy base pointer
subl $8, %esp # Alokacja miejsca na zmienne lokalne
movl 8(%ebp), %eax # Pobierz argument a (3) do %eax
addl $5, %eax # x = a + 5
movl %eax, -4(%ebp) # Zapisz x na stosie
# Wywołaj printf
pushl -4(%ebp) # Push x
pushl $output_fmt_a # Push format string
call printf
addl $8, %esp # Wyczyść stos
# Wywołaj funkcję B z argumentem x
pushl -4(%ebp) # Push x jako argument
call funkcjaB
addl $4, %esp # Wyczyść stos
# epilog funkcji
leave # Przywróć %ebp i %esp
ret # Powrót
# Główna funkcja
_start:
pushl $3 # Push z
call funkcjaA # Wywołaj funkcję A
addl $4, %esp # Wyczyść stos
# Wyjście z programu
movl $1, %eax # syscall: exit
xorl %ebx, %ebx # status: 0
int $0x80 # wykonaj syscallStruktura stosu podczas wykonania:
-
Wywołanie
_start:- Ramka stosu dla
_startzawiera argument dlafunkcjaA.
- Ramka stosu dla
-
Wywołanie
funkcjaA:- Tworzy swoją ramkę stosu, zawiera argument
ai zmienną lokalnąx. - Zapisuje stary base pointer (
ebp) i ustawia nowy.
- Tworzy swoją ramkę stosu, zawiera argument
-
Wywołanie
funkcjaB:- Tworzy swoją ramkę stosu, zawiera argument
bi zmienną lokalnąy. - Zapisuje stary base pointer (
ebp) i ustawia nowy.
- Tworzy swoją ramkę stosu, zawiera argument
Przebieg wykonania:
- Program startuje od
_start, deklaruje zmiennąz = 3, wywołujefunkcjaA(z). funkcjaAtworzy swoją ramkę stosu, zapisujea = 3, obliczax = 8, wywołujefunkcjaB(x).funkcjaBtworzy swoją ramkę stosu, zapisujeb = 8, obliczay = 18, drukuje wartośćy.funkcjaBkończy wykonanie, jej ramka stosu jest usuwana, sterowanie wraca dofunkcjaA.funkcjaAkończy wykonanie, jej ramka stosu jest usuwana, sterowanie wraca do_start._startkończy wykonanie programu.
Ten kod w asemblerze pokazuje, jak tworzone i zarządzane są ramki stosu podczas wywołań funkcji, z użyciem wskaźników SP i BP oraz stosu do przechowywania argumentów i zmiennych lokalnych.
Ramki stosu są tworzone i usuwane przy każdym wywołaniu funkcji, zarządzając pamięcią i kontrolą przepływu programu.
Być może przyszło Ci kiedyś korzystać z debuggera w Intellij IDEA, PyCharmie czy Visual Studio - zatęsknisz za tym w przypadku asemblera.
Debugger pozwala na uruchamianie programu linijka po linijce, instrukcja po instrukcji oraz podglądanie wartości poszczególnych zmiennych, a w przypadku asemblera - rejestrów.
Debugger jest Twoim przyjacielem, ponieważ bez tego ciężko może być określić, co i gdzie się schraniło w swoim programie. Błędy w Pythonie czy Javie powiedzą Ci, w której linii, w której funkcji i jaki wystąpił błąd. W przypadku programów pisanych w asemblerze (aczkolwiek w C też), jedyną wiadomością będzie po prostu Segmentation fault - i tyle. Dlatego warto zaznajomić się z asemblerem
Popularnym debuggerem jest GNU debugger (gdb).
Uruchomienie debuggera wygląda tak:
$ gdb ./program
Pierwszą rzeczą, którą należy zrobić jest ustawienie tzw. breakpointa, czyli miejsca, w którym wykonanie programu ma się zatrzymać i będzie można go uruchamiać krokowo, na przykład:
(gdb) b _start
Breakpoint 1 at 0x401000
Niekoniecznie to musi być _start, jeśli chcemy badać konkretną funkcję to możemy podać jej nazwę.Warto (oczywiście nie na produkcji) dodawać informacje debugowe przy kompilacji, ponieważ bez tego gdb może zachowywać się nie tak, jak byśmy chcieli.
Teraz program można uruchomić:
(gdb) run
Wykonanie programu zatrzyma się w pierwszym napotkanym breakpoincie.
Przydatne polecenia:
step- pojedynczy kroknext- kontynuuje do kolejnego momentu w tej samej ramce stosu - czyli jak mamy instruckcjęcallto nie wskoczymy do wnętrza wywoływanej funkcji, tylko ją przeskoczymycontinue- kontynuuje do momentu napotkania breakpointa lub zakończenia działania programuinfo registers- informacje o rejestrach w danym momencieprint- wypisuje wartość np. rejestru:print $raxx/s- examine string, np.x/s &hello- wypisze string pod adresem wskazywanym przez labelhello
Nie chce mi się omawiać każdego polecenia z osobna, dlatego znalazłem taki filmik i taką stronę oraz to
Łączenie C z asemblerem jest proste i przydatne. Po skompilowaniu, kod C i tak staje się kodem asemblera prawda? Ja np. lubię sobie użyć funkcji printf w asemblerze jak chcę coś wypisać.
Jak to zrobić? Trzeba powiedzieć linkerowi, gdzie ma szukać funkcji, ponieważ to właśnie on jest odpowiedzialny za ogarnianie gdzie co ma być.
Należy również pamiętać o konwencjach wywołania funkcji.
Przykład w nasm w trybie 64-bitowym:
section .data
printfFmt db "%d",10,0
section .text
extern printf ; mówimy asemblerowi, że ta funkcja znajduje się w innym pliku
global main:
push rbp
mov rbp, rsp
mov rax, 0 ; informujemy printf, że nie podajemy żadnych wartośći zmienno przecinkowych
mov rdi, printfFmt
mov rsi, 69 ; liczba do wstawienia w miejsce %d
call printf ; wywołanie printf
leave
retZdefiniowałem main zamiast _start, ponieważ do linkowania skorzystam z gcc, które dołączy mi bibliotekę standardową języka C i będzie szukał właśnie funkcji main (_start sobie doda sam):
$ nasm -f elf64 -g -F dwarf fibo.asm
$ gcc -ggdb -no-pie -o fibo fibo.o
I to wszystko! Podobnie sprawa wygląda z innymi funkcjami. Trzeba również pamiętać o konwencjach wywołania funkcji.
W pliku lib.c umieściłem następujące funkcje, które zamierzam wywołać z poziomu asemblera:
int addInt(int a, int b)
{
return a + b;
}
float mulFloat(float a, float b)
{
return a * b;
}
int findMin(int *a, int n)
{
int mini = *a;
for (int i = 1; i < n; i++)
{
if (*(a + i) < mini)
{
mini = *(a + i);
}
}
return mini;
}Plik lib.c
Natomiast kod asemblera prezentuje się następująco:
BITS 64
%define EXIT_NR 60
section .data
printfIntFmt db "%d",10,0
printfFloatFmt db "%.3f",10,0
arr dd 4, 3, 10, 2, 7, 5
arrLen dd 6
ai dd 4
bi dd 6
af dd 3.14
bf dd 4.2
section .bss
mulFloatRes resd 1
section .text
; funkcje, których nie zdefiniowaliśmy w tym pliku
; tak aby linker się nimi martwił, a nie asembler
extern printf
extern findMin
extern addInt
extern mulFloat
global main
main:
push rbp
mov rbp, rsp
xor rax, rax ; rax = 0
mov rdi, arr ; pierwszy argument funkcji (int *a)
mov rsi, [arrLen] ; drugi argument (int n)
call findMin ; wywołanie funkcji
mov rsi, rax ; wynik funkcji findMin (int mini)
mov rdi, printfIntFmt
xor rax, rax
call printf ; wypisanie wartości
xor rax, rax
mov rdi, [ai] ; int a
mov rsi, [bi] ; int b
call addInt
mov rsi, rax
mov rdi, printfIntFmt
xor rax, rax
call printf
; o rejestrach xmm będzie przy okazji omawiania SIMD
movsd xmm0, [af] ; float a
movsd xmm1, [bf] ; float b
mov rax, 2
call mulFloat
; o floatach za moment, na razie nie wnikaj co to jest xd
cvtps2pd xmm0, xmm0
mov rdi, printfFloatFmt
mov rax, 1
call printf
leave
mov rax, EXIT_NR
xor rdi, rdi
syscallPlik c_w_asm.asm
Jak to teraz skleić? Tak wygląda mój plik makefile:
c_w_asm.out: c_w_asm.o lib.o
gcc -no-pie -ggdb -o c_w_asm.out c_w_asm.o lib.o
c_w_asm.o: c_w_asm.asm
nasm -f elf64 -g -F dwarf c_w_asm.asm
lib.o: lib.c
gcc -ggdb -c -o lib.o lib.c
Plik makefile
Przeanalizujmy go od dołu do góry:
- Polecenie
gcc -ggdb -c -o lib.o lib.cwypluje mi plik object z pliku języka C, abym mógł go potem dokleić do kodu asemblera - Polecenie
nasm -f elf64 -g -F dwarf c_w_asm.asmpowinno być już znane - Polecenie
gcc -no-pie -ggdb -o c_w_asm.out c_w_asm.o lib.oskleja otrzymane wcześniej pliki object w finalny plik wykonywalny. Używamgcc, ponieważ korzystam z funkcjiprintf, natomiast jeśli nie korzystasz z biblioteki standardowej to zwykłeldpowinno wystarczyć
W przypadku GNU assembly różnica będzie tylko w przypadku pliku asemblera i poleceniu przekształcającym ów kod na plik object. Wydaje mi się, że nawet można te wszystkie polecenia zastąpić jednym:
gcc -no-pie -o c_w_asm lib.c c_w_asm.s
Teraz na odwrót. Mam swoją "bibliotekę" w asemblerze:
BITS 64
section .text
global mulInt
global addFloat
global sumFloat
mulInt:
push rbp
mov rbp, rsp
mov rax, rdi
mul rsi
leave
ret
addFloat:
push rbp
mov rbp, rsp
addss xmm0, xmm1
leave
ret
sumFloat:
push rbp
mov rbp, rsp
mov rcx, rsi
xorps xmm0, xmm0
.loop:
mov rax, rsi
sub rax, rcx
movss xmm1, [rdi + rax * 4]
addss xmm0, xmm1
loop .loop
leave
retPlik lib.asm
Natomiast jej wykorzystanie w C będzie wyglądać tak:
#include <stdio.h>
// tak aby kompilator nie krzyczał
extern int mulInt(int a, int b);
extern float addFloat(float a, float b);
extern float sumFloat(float *a, int n);
int main(int argc, char *argv[])
{
printf("%d\n", mulInt(2, 3));
printf("%.3f\n", addFloat(3.14, 4.20));
float af[4] = {21.37, 6.9, 4.20, 1.681};
printf("%.3f\n", sumFloat(af, 4));
return 0;
}Plik asm_w_c.c
Bardzo ważne jest pamiętanie o konwencjach wywołania funkcji, bo inaczej wszystko szlag trafi!
Sklejanie tego w program jest praktycznie takie samo jak wcześniej:
asm_w_c.out: lib.o asm_w_c.o
gcc -no-pie -ggdb -o asm_w_c.out lib.o asm_w_c.o
asm_w_c.o: asm_w_c.c
gcc -no-pie -c -o asm_w_c.o asm_w_c.c
lib.o: lib.asm
nasm -f elf64 -g -F dwarf lib.asmPonownie, w przypadku GNU assembly różnica będzie tylko w przypadku pliku asemblera i poleceniu przekształcającym ów kod na plik object. Wydaje mi się, że nawet można te wszystkie polecenia zastąpić jednym:
gcc -no-pie -o c_w_asm lib.s asm_w_c.c
Coming soon...
Coming soon...
Coming soon...
Coming soon...
Myślę, że najlepiej to będzie zrozumieć analizując jakieś programy - patrząc się na kod i uruchamiając pod debuggerem.
Dlatego wrzucę kilka programów, które miałem okazję napisać. Spora część z jest napisana w NASM, więc zalecam samodzielne przepisanie ich na GNU assembly, jeśli Twój prowadzący tego wymaga.
Różne programy znajdują się też w innych repozytoriach z OiAK oraz WdWK.
# NWD
.text
.global _start
_start:
# prolog funkcji
push %ebp
mov %esp, %ebp
push $16 # a
push $24 # b
call nwd
# epilog funkcji
mov %ebp, %esp
pop %ebp
mov %eax, %ebx
mov $1, %eax # exit
int $0x80
nwd:
# prolog funkcji
push %ebp
mov %esp, %ebp
while:
movl 12(%ebp), %eax # a
movl 8(%ebp), %ebx # b
cmp $0, %ebx
jz return # if b == 0: return a
mov %eax, %ecx
xor %edx, %edx
idiv %ebx
mov %ebx, %eax # a = b
mov %edx, %ebx # b = a % b
mov %eax, 12(%ebp)
mov %ebx, 8(%ebp)
jmp while
return:
# epilog funkcji
mov %ebp, %esp
pop %ebp
retBITS 64
section .data
text1 db "What's your name? "
text2 db "Hello, "
section .bss
name resb 32
section .text
global _start
_start:
call _printText1
call _getName
call _printText2
call _printName
mov rax, 60
mov rdi, 0
syscall
_getName:
mov rax, 0
mov rdi, 0
mov rsi, name
mov rdx, 32
syscall
ret
_printText1:
mov rax, 1
mov rdi, 1
mov rsi, text1
mov rdx, 18
syscall
ret
_printText2:
mov rax, 1
mov rdi, 1
mov rsi, text2
mov rdx, 7
syscall
ret
_printName:
mov rax, 1
mov rdi, 1
mov rsi, name
mov rdx, 32
syscall
retBITS 64
extern rand, srand, time, printf, scanf
section .text
global _start
_start:
mov rdi, 0x0
call time
add rsp, 8
mov rdi, rax
call srand
add rsp, 8
call rand
xor rdx, rdx
mov rcx, 100
div rcx
add rdx, 1
mov [answer], edx
.while_start:
mov rdi, formatHello
xor rax, rax
call printf
mov rdi, formatScanf
mov rsi, guess
xor rax, rax
call scanf
mov rax, [guess]
cmp eax, [answer]
je .while_end
jl .if_less
jg .if_greater
.if_less:
mov rdi, tooLowMsg
xor rax, rax
call printf
jmp .while_start
.if_greater:
mov rdi, tooHighMsg
xor rax, rax
call printf
jmp .while_start
.while_end:
xor rax, rax
mov rdi, formatWinMsg
mov rsi, [answer]
call printf
mov rdi, 0
mov rax, 0x3c
syscall
section .data
formatHello db "Try to guess a number between 1 and 100", 10, "> ", 0
formatScanf db "%d"
tooLowMsg db "Too low!", 10, 0
tooHighMsg db "Too high!", 10, 0
formatWinMsg db "Congrats! The number was: %d", 10, 0
section .bss
answer resd 1
guess resd 1
gcc nie musi wypluwać gotowego pliku binarnego. Jeśli użyjemy flagi -S to wypluje nam przetłumaczony kod z C na asemblera. Co prawda będzie ona zawierał różne pierdoły, które nas niekoniecznie będą interesować podczas nauki (zwłaszcza na studia), a labele będą miały mało mówiące nazwy typu .L69, ale zawsze coś.
Możemy napisać prosty kod w C, a potem porównać to co napisaliśmy z wygenerowanym przez gcc asemblerem i zobaczyć, jak to się przekłada jedno na drugie.
Przykładowo, Hello World będzie wyglądać w C tak:
#include <stdio.h>
int main()
{
printf("Hello, World!\n");
return 0;
}A po wpisaniu gcc -S hello.c dostaniemy takie coś:
.file "hello.c"
.text
.section .rodata
.LC0:
.string "Hello, World!"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
leaq .LC0(%rip), %rax
movq %rax, %rdi
call puts@PLT
movl $0, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Debian 12.3.0-5) 12.3.0"
.section .note.GNU-stack,"",@progbitsOsobiście zalecam też dodanie flagi -masm=intel, żeby dostać syntax Intela ;)
Powodzenia wariacie :3
(kolejność przypadkowa)
- Intel® 64 and IA-32 Architectures Software Developer Manuals
- Dokumentacja NASM
- (Książka) Programowanie w asemblerze x64. Od nowicjusza do znawcy AVX
- you can become a GIGACHAD assembly programmer in 10 minutes (try it RIGHT NOW)
- everything is open source if you can reverse engineer (try it RIGHT NOW!)
- You Can Learn Assembly in 10 Minutes (it’s easy)
- x86_64 Linux Assembly
- x64 Cheat Sheet
- x86 Assembly Guide
- Metody Realizacji Języków Programowania. Bardzo krótki kurs asemblera x86
- Calling Conventions
- (Książka, rozdział 6. Inżynieria wsteczna) Atak na sieć okiem hakera. Wykrywanie i eksploatacja luk w zabezpieczeniach sieci
- CPU Registers x86-64
- x86 Assembly/X86 Architecture
- x86 Registers