This repository is a benchmarking suite for the pflua packet filtering library. It compares the following pflang implementations:
-
libpcap: The user-space Berkeley Packet Filter (BPF) interpreter from
libpcap. -
linux-bpf: The old Linux kernel-space BPF compiler from 2011. We have adapted this library to work as a loadable user-space module (source).
-
linux-ebpf: The new Linux kernel-space BPF compiler from 2014, also adapted to user-space (source).
-
bpf: BPF bytecodes, cross-compiled to Lua by pflua.
-
pflua: Pflang compiled directly to Lua by pflua.
-
pflua-native: Pflang compiled to x86 asm by pflua.
See https://github.com/Igalia/pflua for more on pflua's three execution engines, and for more resources on pflang and BPF.
To benchmark a pflang implementation, we use the implementation to run a set of pflang expressions over saved packet captures. The result is a corresponding set of benchmark scores measured in millions of packets per second (MPPS). The first set of results is thrown away as a warmup. After warmup, the run is repeated 50 times within the same process to get multiple result sets. Each run checks to see that the filter matches the the expected number of packets, to verify that each implementation does the same thing, and also to ensure that the loop is not dead.
In all cases the same Lua program is used to drive the benchmark. We have tested a native C loop when driving libpcap and gotten similar results, so we consider that the LuaJIT interface to C is not a performance bottleneck.
There are three test workloads:
-
A synthetic capture of about 1.1 GB of zeroes transferred between two machines over TCP port 5555; about 1.1M packets.
-
A synthetic capture of 64 MB of pings from one machine to another; about 1M packets. Here we test per-packet overhead for very small but similar packets.
-
A real-world capture of 37 MB of traffic to
wingolog.org, which mostly operates as a web server. About 20K packets.
Each packet is captured with the ethernet frame, and has 16 additional
bytes of overhead due to the libpcap savefile format.
Of course, we can't argue that any of these workloads reflect performance in real-world conditions, and this consideration applies to the benchmarking script itself as well.
The following measurements were made on a i7-3770 system, in x86-64 mode, under Debian GNU/Linux (3.14-2), on an otherwise unloaded machine.
In the following charts, the histograms on each bar show the distribution of the data, with the hairline marking the entire range. The bar itself marks the median.
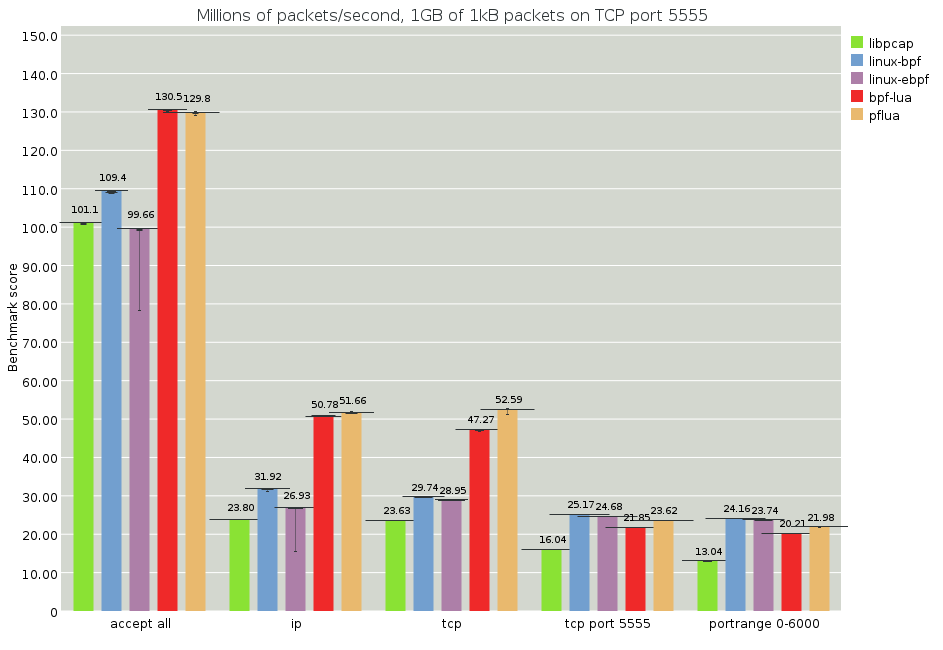
The throughput is ultimately bottlenecked by memory bandwidth, but this a useful test to check if filter overhead is significant when compared to memory bandwidth. Here we see some bizarre results: most tests have higher throughput when there is more work to do. Perhaps a filter that does a little bit of work causes better prefetching? At 20MPPS with 1KB packets, that's about 20GB/s, or 100 Gbit/s, which is near the limit of this machine's memory bandwidth. Some squirreliness is expected.
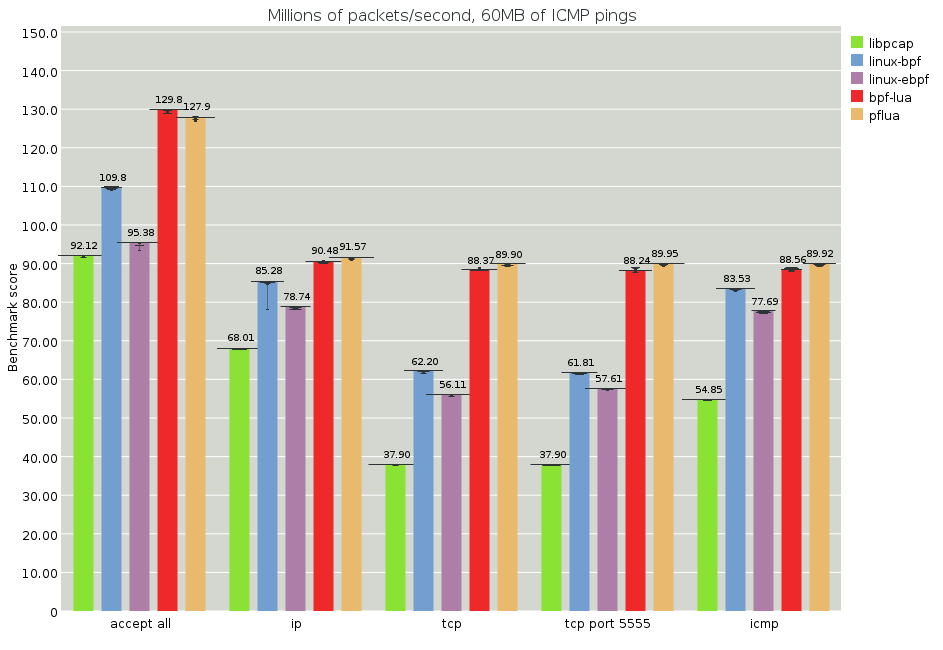
These results are great! To compare to the previous example, 180 MPPS for this file is also about 100 Gbit/s. Recall that this is a streaming memory bandwidth; we do not know how the memory access patterns in a networking switch would compare.
We actually don't know how fast this thing can go, because all results are faster than the "accept all" loop. However we can put an upper bound on the time for a simple pflua filter to run over a homogenous workload at about 6 nanoseconds per packet.
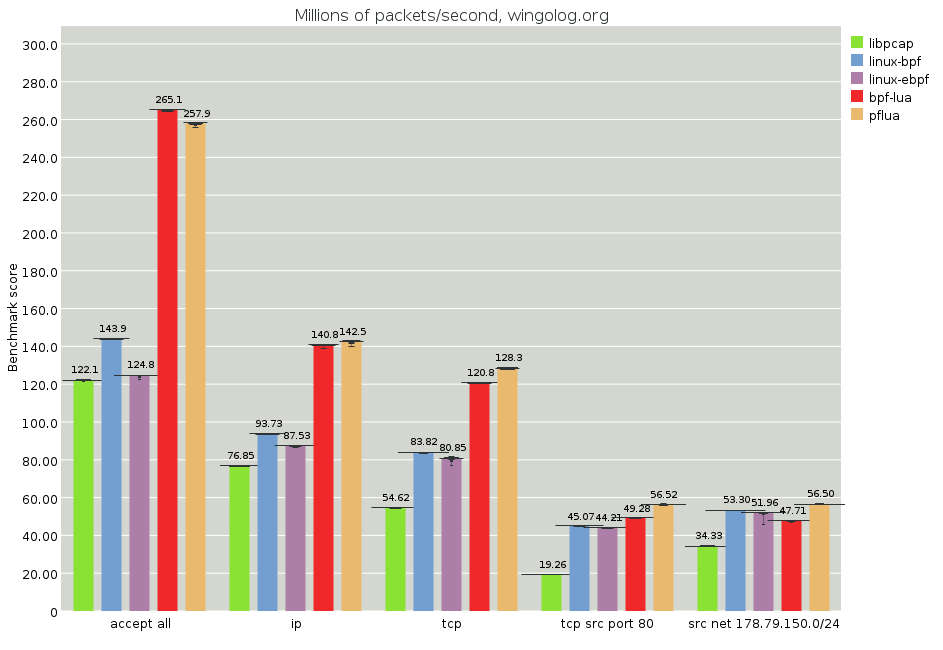
Here we have a more realistic scenario, as it's actual real-world traffic rather than a synthetic test. We see good results for pflua. We am not sure why the newer Linux JIT is performing worse than the older one, although they are not far apart.
The results above are the good results, but they're not great; in
particular, we don't see any reason for tcp src port 80 to be so slow.
It gets stranger, though:
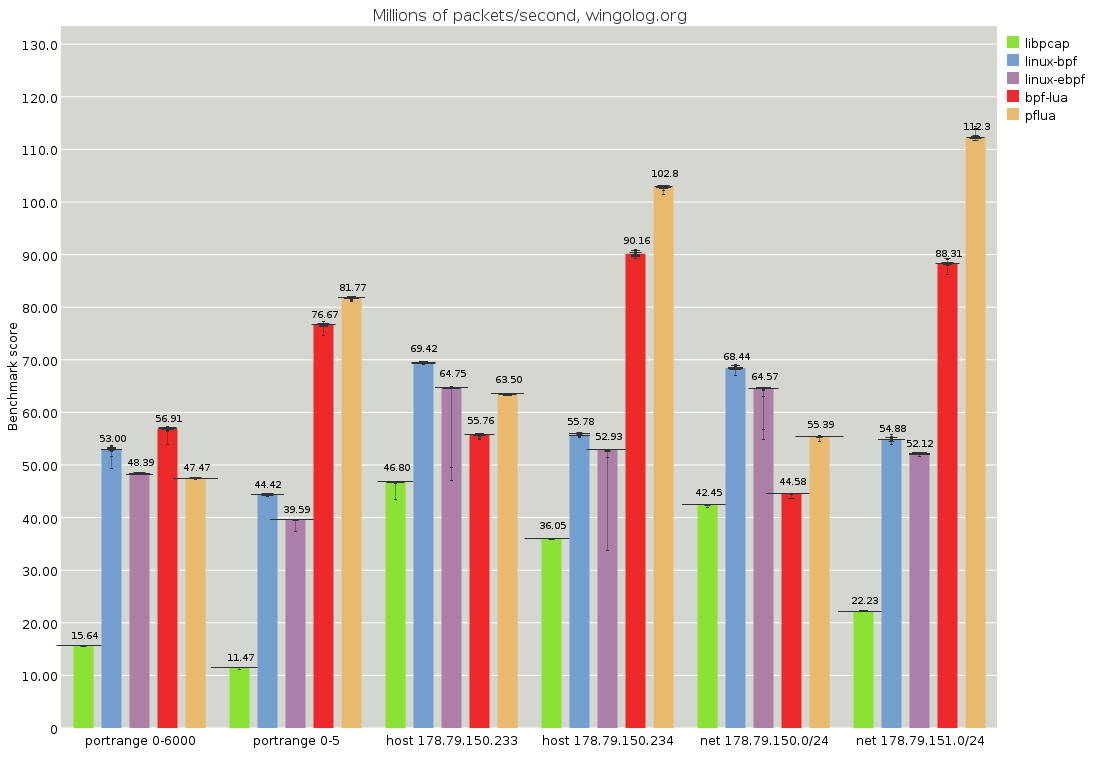
Here the tests are paired. The first test of a pair, for example the
leftmost portrange 0-6000, will match most packets. The second test
of a pair, for example the second-from-the-left portrange 0-5, will
reject all packets. The generated Lua code will be very similar, except
for some constants being different. See
https://github.com/Igalia/pflua/blob/master/doc/portrange-0-6000.md for
an example.
However the pflua performance of these filters is very different: the one that matches is slower than the one that doesn't, even though in most cases the non-matching filter will have to do more work. For example, a non-matching filter probably checks both src and dst ports, whereas a successful one might not need to check the dst.
It also hurts to see pflua's performance be less than the Linux JIT
compilers, and even less than libpcap at times. We can only think that
this is a LuaJIT issue. What we see from the -jv -jdump output is that
the first trace that goes through does end up residualizing a tight
loop, after hoisting a bunch of dynamic checks up before the loop (see
trace
66),
but that subsequent variations get compiled to traces that have a fairly
large state transfer penalty (trace
67)
and which don't jump to the top of the loop -- they jump to the top of
the trace with the loop, which then has to do a bunch of useless work.
This explains the good performance for the match-nothing case: the first trace that gets compiled residualizes the loop expecting that all tests fail, and so only matching cases or variations incur the trace transfer-and-re-loop cost.
It could be that the Lua code that pflua residualizes is in some way not idiomatic or not performant, but the state transfer costs are unexpected and they seem to me to be a current limitation of LuaJIT. In the end performance isn't terrible but it could be much better.
-
Pflua seems to be an acceptable implementation of pflang.
-
In many circumstances, pflua is the fastest pflang implementation out there, by a long shot.
-
In some cases, performance appears to be limited by state transfer costs in traces.
Finally, a plug: if you are interested in Lua, networking, JIT compilation, and all this kind of thing, let us know!.
First, check out this repo:
git clone https://github.com/Igalia/pflua-bench.git
cd pflua-bench
Then we need to check out the dependencies:
git submodule update --init # get pflua
cd deps/pflua
git submodule update --init # get luajit
make
cd ../..
Then compile the BPF C files:
cd linux-bpf-jit
make
cd ../linux-ebpf-jit
make
cd ..
You also need to have guile, guile-cairo, and guile-charting installed. On a Debian system, you can install the first two via apt:
sudo apt-get install guile-2.0 guile-cairo guile-2.0-dev guile-cairo-dev
and then guile-charting from git:
git clone https://gitorious.org/guile-charting/guile-charting.git
cd guile-charting
autoreconf -vif
./configure && make
cd ..
mkdir ~/src
mv guile-charting ~/src/
Finally, you can run the benchmark like this:
~/src/guile-charting/env make bench